Uncertainty Quantification of Hyperspectral Image Denoising Frameworks based on Sliding-Window Low-Rank Matrix Approximation
Abstract
Sliding-window based low-rank matrix approximation (LRMA) is a technique widely used in hyperspectral images (HSIs) denoising or completion. However, the uncertainty quantification of the restored HSI has not been addressed to date. Accurate uncertainty quantification of the denoised HSI facilitates applications such as multi-source or multi-scale data fusion, data assimilation, and product uncertainty quantification since these applications require an accurate approach to describe the statistical distributions of the input data. Therefore, we propose a prior-free closed-form element-wise uncertainty quantification method for LRMA-based HSI restoration. Our closed-form algorithm overcomes the difficulty of handling uncertainty in HSI patch mixing caused by the sliding-window strategy used in the conventional LRMA process. The proposed approach only requires the uncertainty of the observed HSI and provides the uncertainty result relatively rapidly and with similar computational complexity as the LRMA technique. We conduct extensive experiments to validate the estimation accuracy of the proposed closed-form uncertainty approach. The method is robust to at least random impulse noise at the cost of of additional processing time compared to the LRMA. The experiments indicate that the proposed closed-form uncertainty quantification method is more applicable to real-world applications than the baseline Monte Carlo test, which is computationally expensive.
Index Terms:
Low-rank matrix approximation, hyperspectral images, uncertainty quantification.I INTRODUCTION
Data uncertainty, which refers to the lack of sureness about the data [1], is an essential factor to consider when utilizing data and derived products [2]. When the data uncertainty is known, users can determine whether a product is suitable for specific applications or can balance the contributions of different data sources. For example, in [3], the minimum detectable deformation can be estimated based on the uncertainty measures in a point cloud so that engineers can develop appropriate project plans, including sensor selection and set-up schemes [4]. In multiple data fusion tasks, the label uncertainties of hyperspectral images (HSIs) and point clouds are often considered to achieve high fusion accuracy [5].
In theory, uncertainty can be classified as aleatoric uncertainty, and epistemic uncertainty [6]. Aleatoric uncertainty is caused by noise in the data and the processing steps. In contrast, epistemic uncertainty is introduced into the observation models, and data post-processing steps [2, 7, 4, 8, 1]. In the absence of ground truth data to measure the model performance, the epistemic uncertainty is ignored, and the output uncertainty is defined as the aleatoric uncertainty due to the propagation of an arbitrary model. Most studies have defined the probabilistic density function of the noise as a mixture of the normal distribution and the random distribution. Assuming that random noise is significantly low, the uncertainty can be described by the Gaussian distribution. In HSI restoration, symmetric uncertainty based on mutual information was proposed in [9] and was used in HSI classifications. In HSI unmixing, the end member uncertainty of unmixing methods based on the normal compositional model is defined as the covariance matrix, which is used to predict the unmixing errors without knowing the ground truth [10]. Uncertainty has been described differently in different studies. [1] proposed an entropy-based uncertainty measure for evaluating the classification results of multi-spectral remote sensing images. The calculated entropy, which was defined as the pixel-wise classification uncertainty, had a linear relation with the accuracy of the classification results. In [11], the uncertainty of 3D point clouds was defined as the measurement repeatability, which was represented by the median and the two percentiles (5% and 95%) related to repeated measurements.
This paper focuses on the uncertainty quantification in HSI denoising. HSIs consisting of hundreds or thousands of spectral bands have been widely used in various applications (e.g., land cover mapping, pollution monitoring, and crop yield estimation) due to their rich spectral information compared to the spatial information. In HSI data processing, image denoising is regarded as an important preprocessing step for advanced applications and has been researched intensively in the past decades [12]. According to [13], existing HSI denoising methods can be categorized into three groups: filter-based methods, model optimization methods, and deep learning methods. Filter-based methods try to remove noise using various filters. Classical methods in this category are based on nonlocal filters [14, 15, 16, 17]. Model optimization methods can be further divided into total variation methods [18], sparse representation-based [19], and sliding-window low-rank matrix-based methods [20]. The major advantages of this group of denoising methods are utilizing image priors and considering spatial and spectral features simultaneously. These methods are often combined to achieve better performance [21, 22]. The last group is based on deep learning frameworks, which have attracted increasing attention in the past three years [23]. A recent deep learning-based framework was proposed in [13] to remove hybrid noise in a spatial-spectral framework.
HSI denoising based on the sliding-window low-rank matrix approximation (LRMA) framework has become a state-of-the-art technique in the community [20, 24]. These methods are model optimization methods aimed at exploiting the low-dimensional structure in the high-dimensional data space. LRMA-based studies [25, 20, 21] assume that the noise-free HSI can be represented by a low-rank matrix. Thus, HSI denoising can be regarded as a classical sliding-window low-rank matrix recovery problem. A representative HSI denoising framework based on LRMA is described in [20], where a clean image, impulse noise, and Gaussian noise were formulated separately in the objective function, which was minimized under a low-rank assumption. Many variants of LRMA-based HSI denoising methods have been proposed in the past five years [24, 26, 21, 27, 28]. For example, [24] proposed an LRMA-based framework containing a total-variation regularization term to preserve spatial information. The spatial-spectral structure in HSI denoising was also exploited by replacing the sliding-window low-rank matrix analysis with low-rank tensor approximation [28]. In general, LRMA-based HSI denoising methods are state-of-the-art frameworks that have been widely used in this area.
Despite the progress in LRMA-based HSI denoising, no studies investigated the uncertainty quantification of denoised HSI to date. Some works aimed to determine the noise of the raw observations [29, 30], but the uncertainty of denoised HSI has not yet been addressed, although it is critical in subsequent applications, as discussed above. However, the quantification of uncertainties of denoised HSIs based on LRMA is difficult due to the nonlinear discontinuous functions in LRMA models (e.g., nuclear norm), which hinders the deduction of the closed-form uncertainty propagation formulations. Recently, [31] proposed an optimal uncertainty quantification and inference method for noisy matrix completion. Inspired by this work, we expect that it is possible to quantify the uncertainties of outputs from LRMA-based HSI denoising frameworks.
A sliding-window strategy is always used in HSI denoising to handle the extensive data volume of HSI [24, 20]; the denoised element values are obtained by averaging the values from several traversed patches. The mixed values from multiple patches pose difficulty in quantifying the uncertainty of the estimations. Unlike the conventional perspective of multiple observations, which obey the same independent and identical distribution (i.i.d.), multiple overlapping sliding windows are inter-connected statistically. Thus, the covariance of the overlapping window should also be addressed. To tackle these problems, we introduce and improve the method described in [32] to quantify the uncertainty of the low-rank-based HSI approach. Note that we assume the input HSI is a mixture of Gaussian noise and random noise. Previous studies [30, 16, 21] already proved that the Poisson noise was the primary concern in real HSI data but could be approximated by additive Gaussian noise. Based on these results, Gaussian noise with mean and covariance is suitable to establish the uncertainty propagation model.
This research does not aim at providing a new LRMA formulation. Instead, we propose a general uncertainty quantification method for the existing LRMA approach. The main contributions of this paper are threefold,
-
1.
To the best of our knowledge, the uncertainty quantification of the denoised HSI based on LRMA is presented for the first time in this paper. We provide a closed-form time-efficient uncertainty propagation model to predict the element-wise uncertainty of the denoised HSI without any ground truth data.
-
2.
To solve the “uncertainty mixing” problem caused by the sliding-window strategy, we deduce a weighted average uncertainty formulation, which proves effective based on extensive experiments.
-
3.
The proposed uncertainty estimation approach is independent of the choice of the LRMA algorithm. It is based on the global minimum assumption of the LRMA solver; thus, a more accurate solver leads to better uncertainty description.
The rest of this paper is organized as follows. In Section II, we briefly summarize the canonical formulation of LRMA-based HSI denoising. Section III presents the proposed algorithm for the uncertainty propagation in a classical LRMA-based HSI denoising framework. Section IV shows experiments on both simulated and real HSI data. The discussion of the parameter settings and limitations is also presented in Section IV. Section V summarizes this paper.
II LRMA algorithm for LRMA HSI denoising
We cite [20] as a typical LRMA approach and discuss the uncertainty evaluation based on the LRMA approach. Section II is a brief formulation of the routine LRMA method [20]. The results provided in Section II have been strictly tested and validated in different LRMA studies. Section III describes the proposed uncertainty estimation method for an LRMA approach, as described in [20]. We emphasize that this work DOES NOT aim at proposing another LRMA formulation. The goal of this approach is to quantify the uncertainty of LRMA denoised images in a closed-form manner.
II-A Revisiting the general HSI restoration process
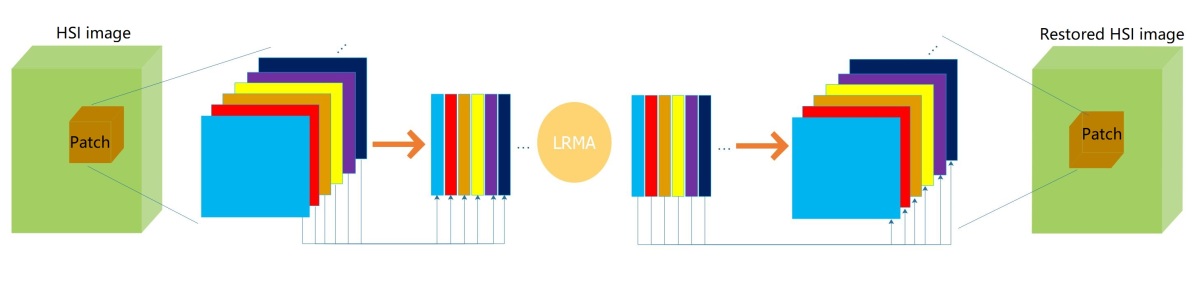
Fig. 1 demonstrates the routine process of the LMRA-based HSI restoration. The HSI is processed with a 3D sliding window to reduce the computational burden. For each 3D patch in the window, all the bands are vectorized and stacked into the 2D matrix. The permutated 2D matrix goes through the routine LMRA process, and the result is re-permutated to recover the 3D denoised patch. Finally, all the patches are summarized and averaged to create the restored HSI.
An HSI acquired by a sensor is typically modeled as a 3D image composed of Gaussian noise and random noise:
| (1) |
where is the image acquired from the hyperspectral sensor with the size and channels, is the noise-free image denoted as the ground truth, is the element-wise i.i.d. Gaussian noise and is the sparse and random noise (impulse signal). The random noise is normally considered negligible with regard to , and the data quality quantification process is inferring the statistical distribution of . In practice, the ground truth HSI cannot be obtained. Thus, we denote as the estimated denoised HSI calculated from studies based on the low-rank assumption [21, 22].
The goal of HSI denoising is to recover the denoised with the 3D HSI noisy observation and the exact rank prior. Assuming that the random noise is negligible and the residual follows the i.i.d. zero-mean Gaussian distribution, the restored image is recovered with the following formulation:
| (2) |
where is the hyperparameter balancing the two terms. constraints the rank of the input matrix to be no greater than the given rank. is the Frobenius norm that minimizes the residuals in Gaussian distribution. permutates the 3D HSI to a 2D matrix by vectorizing and concatenating to a general 2D matrix (Fig. 1). The low-rank formulation was originally proposed by [33] and was called “robust principal component analysis” (RPCA). The work in [20] introduced RPCA into LRMA scenario.
II-B The sliding-window in the HSI restoration process
HSI restoration differs greatly from conventional image processing due to the data size. The extremely large permutated 2D matrix hinders the iterative regular singular value decomposition (SVD) process, which is essential in solving Eq. (2). The HSI is segmented into small patches (denoted as the overlapped sliding window) and solved in parallel to overcome the heavy computational burden in minimizing the objective function due to the huge HSI size. Previous studies regarded the sliding-window strategy as an engineering compromise and ignored the formal mathematical presentation. However, we realize that the unique sliding-window structure significantly impairs the uncertainty quantification. By following [20], we obtain a sliding-window version that minimizes all patches in Eq. (2):
| (3) |
where the matrices , and are the patch indexed in with regard to , and . is the size of the permutated matrix. is the number of patches in the HSI. After all the patches are optimized, the optimal is restored by averaging the overlapped patches element-wisely. By ignoring the random noise, we obtain the observation corrupted with the element-wise Gaussian noise:
| (4) |
where is the variance of the noise obtained from the image or estimated by algorithms such as described in [25]. is the Gaussian noise in patch . In previous studies, the choice of rank was often estimated by manual-tuning strategies based on the differences between the reconstructed signal and the original one [21].
The idea of Eq. (LABEL:Eq_image_recovery) is to convert the 3D patch into a typical 2D small-size matrix so that the conventional low-rank factorization algorithm can be executed with limited computational resources. The equation is often solved with a Lagrange multiplier or an augmented Lagrange multiplier (ALM); off-the-shelf low-rank solvers can be used. In this work, we choose the GoDec algorithm proposed by [34] to be consistent with the LRMA method [20]. However, it should be emphasized that the proposed uncertainty quantification method is independent of the solver since it only assumes that the estimation of the LRMA is close to the minimum. The better the performance of the LRMA solver, the more accurate the confidence interval of our method describes.
After all small overlapped patches have gone through the process of Eq. (LABEL:Eq_image_recovery), the optimized denoised patches are summed to restore the HSI:
| (5) |
where is the padding function to convert the patch to the same size of by padding the rest of the elements with 0. The matrix counts the number of the patches valid on each voxel. is the Hadamard division operator.
III Uncertainty quantification method for LRMA-based HSI denoising
Based on the above-mentioned formulation, we propose a closed-form element-wise uncertainty quantification method that can handle the sliding-window LRMA-based HSI denoising.
III-A The general framework
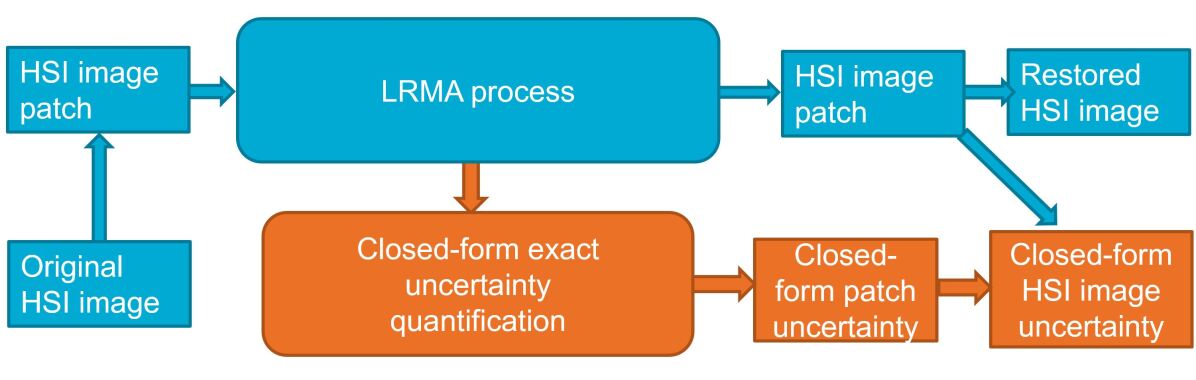
Fig. 2 illustrates the general framework and the relationship with the routine LRMA approach. In the LRMA process, the temporary variable, i.e., the 2D sliding-window patch, is utilized to provide the uncertainty to the HSI patch based on our closed-form formulation. After the HSI patch and its associated closed-form uncertainty have been generated, the routine LRMA approach averages them to yield the restored HSI. We also provide a closed-form uncertainty propagation to quantify the final restored HSI. As shown in Fig. 2, in all processes, the proposed approach is independent of the choice of the low-rank solver. The method can also be easily integrated into the derivations of the LRMA process. In addition, since our method is a closed-form solution and only utilizes temporary variables, the processing time is relatively short compared to the routine LRMA process.
One major contribution of this work is that it provides an element-wise closed-form solution to quantify the uncertainty in a time-efficient manner. For the restored HSI , one straightforward approach of the element-wise uncertainty quantification is conducting the Monte Carlo test with the given statistical distribution of the observation . However, the size of HSIs is notoriously large, resulting in a heavy computational burden to conduct numerous Monte Carlo tests. Roughly, a one-time process in [20] on a HSI requires 20 minutes with a typical commercial desktop computer. Since a robust uncertainty quantification requires a reasonable number of trials, the Monte Carlo test is inefficient for use in the element-wise HSI uncertainty quantification.
Another benefit of this research is that it solves the uncertainty propagation of the sliding-window process. The uniqueness of HSIs is that the permutated 2D matrix after dimensionality reduction is still relatively large. The solution cannot be achieved with a one-time LRMA process. Instead, researchers have adopted the sliding-window strategy to segment the HSI into many small patches and process them parallel. The different statistical properties of each overlapped patch make it challenging to quantify the uncertainty of the final restored HSI. We solve this problem and present a closed-form solution in the proposed sliding-window element-wise closed-form HSI uncertainty quantification.
III-B Uncertainty quantification for the exact low-rank factorization
This section focuses on solving the uncertainty quantification of the patch-wise low-rank factorization process (Eq. (LABEL:Eq_image_recovery)). We follow the example of [31] and draw a similar conclusion for the uncertainty quantification of the exact low-rank patch factorization. A concise and clear proof is also provided. HSI patch-based averaging (Eq. (5)) will be discussed in the next subsection. A recent study [31] proposed an uncertainty quantification method for the exact low-rank 2D matrix. This element-wise algorithm can quantify the confidence interval for a common low-rank based 2D matrix denoising algorithm. Synthetic and real-world tests validate the efficiency of this method. We introduce this approach and modify it to enable the quantification of the uncertainty of each estimated 3D HSI patch using Eq. (LABEL:Eq_image_recovery). We also provide concise proof different from [31].
In the patch optimization process shown in Eq. (LABEL:Eq_image_recovery), we first aim to quantify the uncertainty of the temporary 2D square matrix ( and it can be any patch in ). We denote the ground truth of and as and . For the sake of conciseness, the rank-r SVD decomposition is . For conciseness, we simplify by ignoring the patch index and rewrite it as . Two matrices are defined as the product of the unitary matrix and the squared singular matrix is: , . The following rules apply:
| (6) |
Following the above definition, the ground truth 2D temporary matrix is . Similarly, we define the estimated version where and are the estimated matrices regarding and . We also obtain the estimated version of as :
| (7) |
It should be noticed that the factorization of is not unique. For each pair of estimated auxiliary matrices (), there are infinite unitary matrices that satisfy:
| (8) |
Among the unitary matrices, there is a rectification matrix that minimizes the distance between the auxilliary matrices () and the ground truth ():
| (9) |
Theorem 1.
On condition that each pixel of the observed image only has i.i.d. Gaussian noise ( in Eq. (LABEL:Eq_Wsharp_noise)) and the low-rank solver achieves the global minimum, the differences between the rectified auxiliary matrices estimations and and the ground truth and are:
| (10) |
where the unitary matrix () is the rectification matrix to rectify (, ) to (, ). are the negligible residuals. The rows of the error matrix (resp. ) are independent and obey:
| (11) |
where is the basis vector.
We provide the proof of theorem 1 in Section A. This proof is specifically designed for the full HSI patch denoising scenario and is clearer and more concise than the one in [31].
In theorem 1, we make two assumptions, i.e., the Gaussian noise distribution and the global minimum obtained from the low-rank solver. The former ensures the correctness of the error propagation equations. The latter ensures that the residual noises and are negligible compared to and , and Eq. (10) is approximated to:
| (12) |
Assuming that the first-order expansion is reasonably tight and omitting the high order expansion, the element-wise error between the estimation and the ground truth at the position is:
| (13) | ||||
where the bases localize the elements involved in calculating the element in position . After some manipulation, we have the element-wise variance of the error as:
| (14) | ||||
where (i) is derived from theorem 1 since and are nearly independent. (ii) is obtained from Eq. (10). (iii) and are the /th row of and . For conciseness, we define , and is the variance.
In practice, the rows of the ground truth and are impossible to obtain. Assuming that the solver achieves a solution close to the global minimum, we approximate them with the estimated version and , which are the /th row of the estimations and . Thus the element-wise variance can be approximated as:
| (15) |
where can be regarded as the estimated version of . Due to the relationship of and , the corresponding variance of is Eq. (16) and provides a closed-form variance describing the confidence of . The variance of is:
| (16) |
where is the inverse permutation function of . is the corresponding 3D index of the 2D at patch .
III-C Uncertainty estimation of the sliding-window
Another unique characteristic of the uncertainty quantification in the LRMA technique is the “uncertainty mixing” caused by the sliding-window strategy. The sliding window approach is seldom used in the 2D image domain, and recent work [31] did not address this issue. Thus we propose a method to solve the “uncertainty mixing” issue in HSI denoising due to the sliding-window strategy. Unlike averaging all patches to generate the final restored HSI (Eq. (2)), the uncertainty of the product does not follow the typical error propagation, such as estimating the uncertainty of multiple observations [35]. In the scenario of uncertainty estimation for i.i.d. observations, if the variance of each observation is and we conduct times observation, the variance of the averaged observation is . This shows that the accuracy of the average observation is times more accurate than every single observation. However, in the LRMA process, we only make one observation. If we can process the entire HSI using one-time LRMA and the accuracy is , the sliding-window strategy in LRMA should not exceed because no new information has been introduced. In other words, is not the correct uncertainty. The difference between multiple i.i.d. observations and the single processing scenarios is that the former has i.i.d. observations for all events, whereas the observations in the latter are correlated. In other words, the covariance between the overlapped patches in the LRMA is not null. For two related events and , the ratio is often used to describe the relationship:
| (17) |
where defines the covariance of the two events. If is 0, the events and are i.i.d. If is 1, the events and are linearly correlated, having the highest correlation.
We provide a toy example as the weighted average of events and as . Assuming the variance of and are and , the propagated uncertainty of is :
| (18) |
where is the variance ratio defining the relation between events and .
For convenience, we rewrite Eq. (5) to the element-wise form:
| (19) | ||||
where defines the index of the patches covering the position and is the number of those patches. Similar to the permutation function , converts the 3D index of to the 2D premutated version . By denoting the element-wise variance of each is , based on the uncertainty propagation theory, we obtain the variance that describes as:
| (20) | ||||
where each is different from . defines the relation between the element in patch and patch . Readers may be aware that this is an extended multiple event version of the toy example in Eq. (18).
We provide a practical solution to estimate the optimal ratio . Similar to theorem 1, we assume that the adopted low-rank solver (GoDec algorithm in this paper, but it could be any solver) achieves the global minimum, the information on the denoised element in the patch is determined by the sum of the information embedded in all the elements in the patch . The mutual information encoded in two overlapping patches is linearly related to the number of elements shared by the overlapping patches [36]. Thus the mutual information of the element from two patches is linearly related to the number of shared elements in the two patches. Therefore, the optimal ratio between the two patches is close to:
| (21) |
where defines the number of shared elements in patch and patch . means slightly below . The ratio on the left is close to but smaller than that of the right term. The result is attributed to the assumption of a global minimum. If the global minimum is guaranteed, we have the information in each patch fully exploited; thus, the ratio is linearly related to the overlap. Thus, the mutual information and number of elements are not strictly linearly related. Extreme case is the full overlap () and no overlap (). Otherwise, if and are not ignored, or the low-rank solver does not converge adequately, the variance based on the local minimum is not accurate and behaves more randomly; thus, the ratio is less than the expected right term. In the extreme case when the low-rank solver fails and converges randomly either due to bad performance of the algorithm or heavy random noise, the should be 0. All other things being equal, a smaller ratio will lead to a smaller variance and slight over-confidence. However, a quantitative assessment of the approximation of Eq. (21) is difficult because the performance of the low-rank solver remains difficult to quantify.
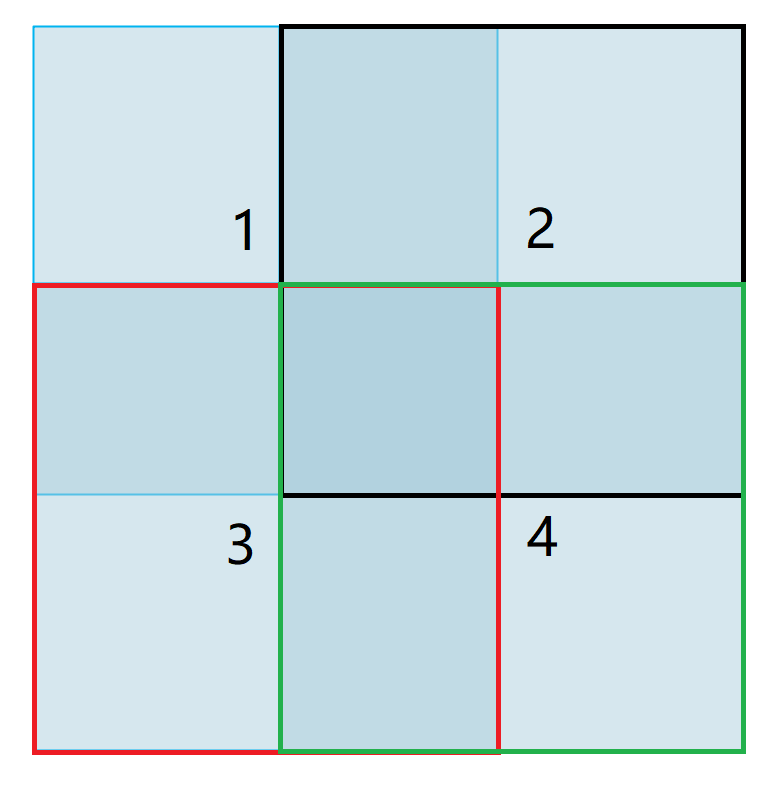
Fig. 3 presents an example of Eq. (21). Each neighboring block pair has overlap. Based on the statistics of the number of overlapping elements, the of the pairs , , and is 0.5, whereas the of pairs and is 0.25.
III-D The impact of random noise
The result of Eq. (16) is based on the assumption that the noises and are significantly smaller than the variables and with a normal distribution. If and are not ignored, the conclusion does not hold. Therefore, it remains challenging to quantify the impact of random noise versus Gaussian noise. However, as [33] pointed out, the RPCA-like formulation (Eq. (LABEL:Eq_image_recovery).) is robust against random noise since the low-rank solver will adjust the use of the norm-1 or norm-2 to regularize the state matrix. Correspondingly, elements not corrupted by random noise are unaffected, whereas the impulse noise can be identified. Therefore, regarding the impact of random noise, the robustness of our approach is closely related to the choice of the LRMA algorithm. It should be noted that most existing HSI denoising studies have focused on modeling Gaussian noise [21, 25]. A few LRMA-based methods have addressed non-Gaussian noise [24]. These approaches utilize a total-variance related term to filter out non-Gaussian noise in the HSI to maintain good boundaries after filtering. Similarly, the proposed uncertainty estimation method can also be integrated with the method in [24] since the total-variance term is only a constraint.



IV Results and discussion
Our work aims at providing an uncertainty quantification approach and does not consider convergence analysis, hyperparameter definition, denoised image visualization, or comparison of HSI denoising methods. For clarifications on the methods described in Section II, we refer the reader to [20, 24, 26, 21, 27, 28]. This work is NOT a new LRMA formulation. We only demonstrate that the proposed closed-form uncertainty estimation approach (Section III) quantifies the denoised HSI accurately, efficiently, and robustly. Since previous works have not provided any uncertainty quantification methods, we only show that our proposed approach can statistically describe the uncertainty based on the Monte Carlo tests.
To the best of our knowledge, a Monte Carlo test is the only appropriate method to validate the efficiency of the proposed method. The complexity of the LRMA formulation hinders the closed-form retrieval of the posterior distribution of the denoised image. This problem motivated us to provide the closed-form estimation of the variance. Therefore, we could not design an experiment providing the ground truth information on both the noisy image and the denoised image. Moreover, regarding the Monte Carlo tests, we should emphasize that the noise of the original image follows identical Gaussian distribution while noise of the denoised image is non-identical. The noise of any pixel in original observations follows . However, as Eq. (16) indicates, the noise of the denoised image depends on the ratio . Thus, the pixels of the denoised image do not maintain the same noise level. The simulated identical noise can only be enforced on the original image. The Monte Carlo test is the optimal method to obtain the posterior distribution of the denoised image. Theoretically, the Monte Carlo test can generate the ground truth variance when the number of trials is large enough.
We validate the proposed method on the Indian Pines dataset (simulation dataset) 111https://engineering.purdue.edu/ biehl/MultiSpec/hyperspectral.html, the University of Pavia dataset (real dataset) 222http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral
_Remote_Sensing_Scenes, and the Washington, D.C. mall dataset 333https://engineering.purdue.edu/ biehl/MultiSpec/hyperspectral.html (real dataset). The Indian Pines dataset is a subset of the data acquired by the AVIRIS sensor. It consists of pixels and 224 spectral reflectance bands in the wavelength range of meters and covers the Indian Pines test site in northwestern Indiana, USA. The Indian Pines scene consists of two-thirds agricultural land and one-third forest or other natural perennial vegetation. We use the ground truth of the Indian Pines dataset and simulate arbitrary Gaussian noise. The University of Pavia dataset was acquired by the ROSIS sensor and covers Pavia in northern Italy. It consists of pixels with 103 spectral bands; however, some of the samples in the images contained no information and were discarded before the analysis. The geometric resolution is 1.3 meters. We select a subset of in the experiments. In the Washington, D.C. mall dataset, the image contains 191 spectral bands with a size of . We clip the image to a size of in our experiment. Fig. 4 shows the false-color images of the three datasets.
We strictly follow the parameter and noise setting of the selected LRMA method to provide a convincing validation [20]. The size of the sliding window is , where is the number of bands in the dataset. The step size is 4, and the rank is 7. In the image restoration process, all images are normalized to the range . The zero-mean Gaussian noise is uniformly applied to all pixels in the datasets with different levels of noise. Since the two real datasets do not have ground truth, we use the output of [20] as the ground truth. The impact of impulse noise is further tested on the datasets. It should be noted that this research is based on the known raw HSI noise, which can be retrieved using previously described methods [29, 30].
| Indian | University of Pavia | Washington, D.C. | ||||
|---|---|---|---|---|---|---|
| Mean | Std | Mean | Std | Mean | Std | |
| 0.025 | 0.9514 | 0.0483 | 0.9573 | 0.0515 | 0.9411 | 0.0583 |
| 0.050 | 0.9579 | 0.0371 | 0.9476 | 0.0292 | 0.9368 | 0.0348 |
| 0.075 | 0.9576 | 0.0383 | 0.9556 | 0.0263 | 0.9501 | 0.0311 |
| 0.100 | 0.9643 | 0.0319 | 0.9652 | 0.0233 | 0.9626 | 0.0266 |
| 0.125 | 0.9704 | 0.0273 | 0.9735 | 0.0205 | 0.9712 | 0.0297 |
IV-A The validation of the uncertainty description
The accuracy of the proposed closed-form uncertainty quantification method is extensively validated with numerical Monte Carlo tests. We apply different levels of Gaussian noises to the HSI. The numerical experiments provide sufficient samples to test if the statistical distributions of the samples are described accurately with the output confidence interval. Specifically, Monte Carlo tests are performed on the input of the same noise . We should emphasize that the 100 trials are chosen due to limited computational resources. Due to the large volume of the HSIs, 100 Monte Carlo trials are sufficient to obtain a statistic assessment of the efficiency of the proposed method. The code is provided for readers to conduct more tests. For each element of the estimated HSI in trial at position as , we define its deviation from the corresponding times mean value as . The deviation from the mean is defined as:
| (22) |
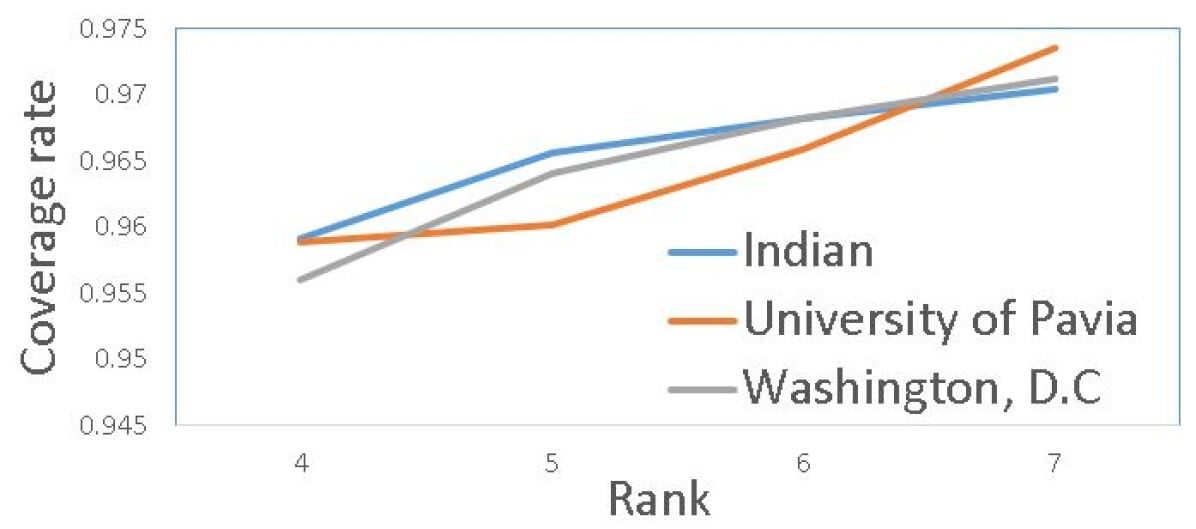
If the closed-form solution describes the statistical distribution of the estimation well, of should fall within the range of . Following Eq. (22), we define the ratio of falling within the bound as the element-wise coverage rate. The average coverage rate of all elements is the average coverage rate. Table I presents the average and standard deviation of the coverage rate. The result indicates that the uncertainty approach robustly and accurately describes the element-wise denoised HSI when the level of noise is low ( less than ) 444https://JingweiSong@bitbucket.org/JingweiSong/uncertainty-estimation-for-hyper-spectral-image-denoising.git.. In the case , we notice an under-confident of the prediction. We hypothesize that the accuracy is related to the level of noise and the choice of the optimal rank. When the noise level increases, the fixed rank LRMA does not accurately filter the noise while retaining useful information. A lower rank is needed to ensure that the residual follows the assumption of the normal distribution of the noise. As depicted in Table I, we strictly follow [20] by setting . To determine the reason, we conduct an experiment by choosing different . The results are shown in Fig. (6), indicating that the performance (uncertainty quantification) of our approach improves by decreasing the arbitrary rank. This implies that the Monte Carlo experiment provides a method to validate the correct choice of the rank. Further studies are needed to determine the rank at high noise level.
IV-B The validation of the normal distribution of the restored HSI
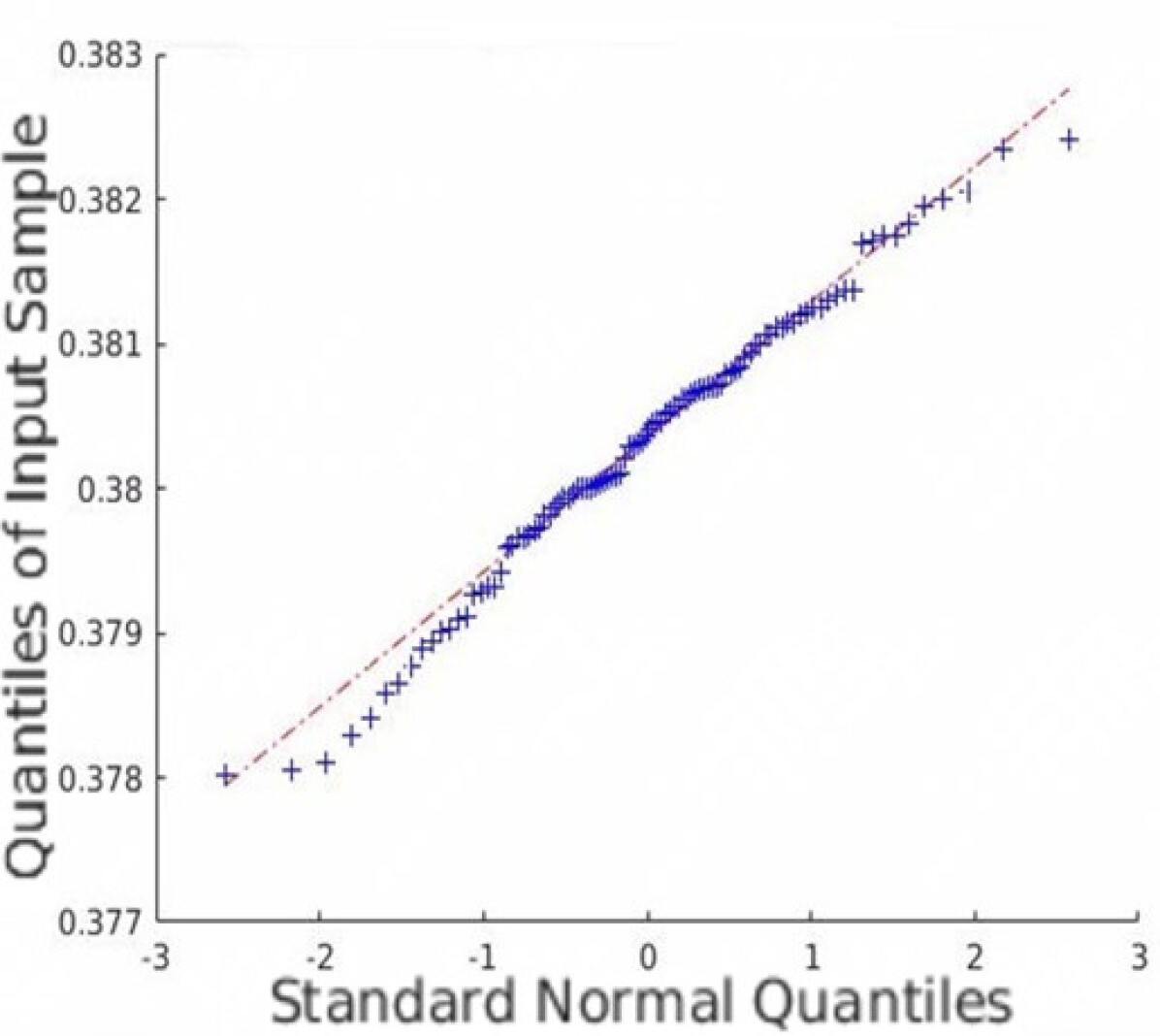
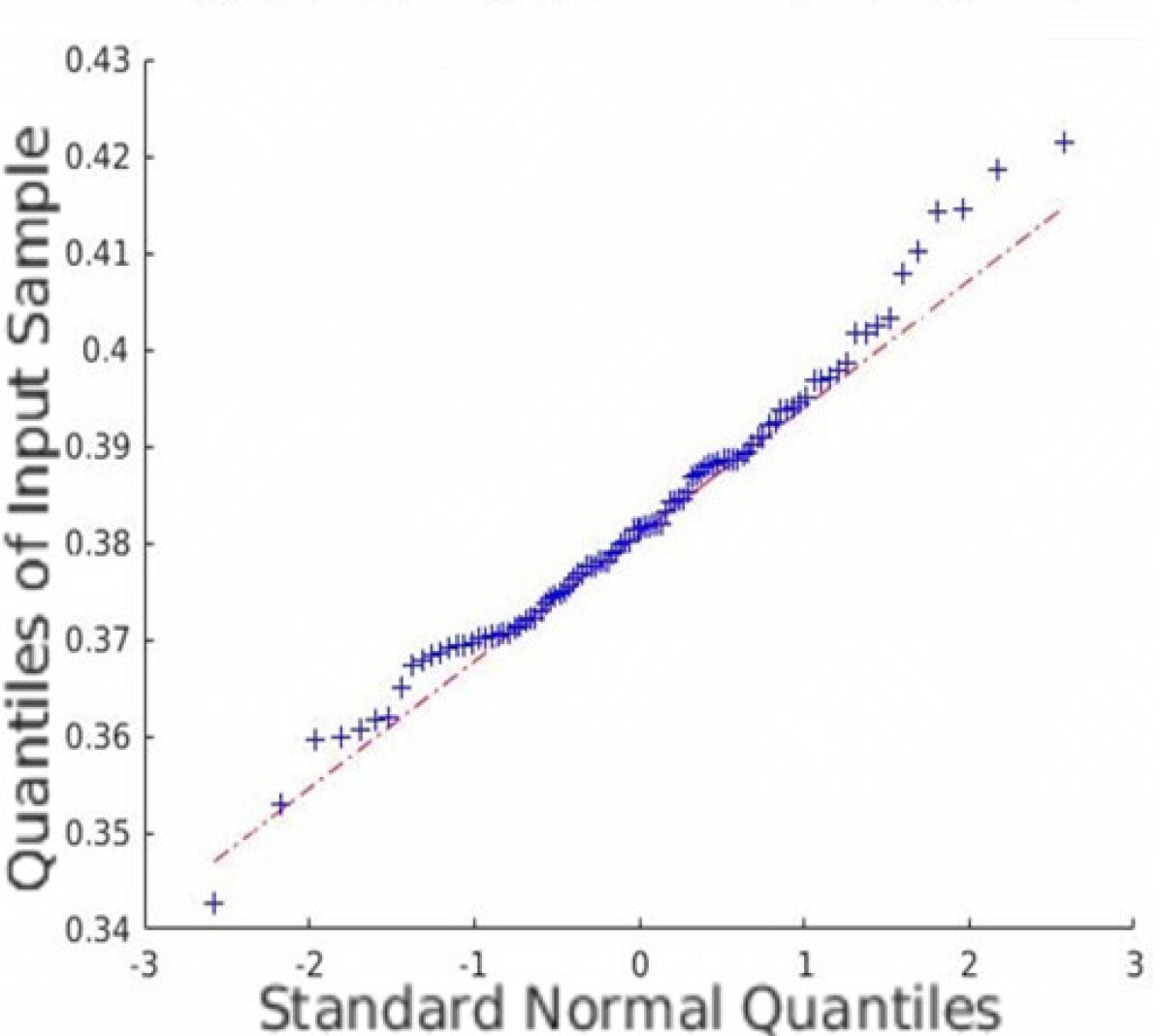
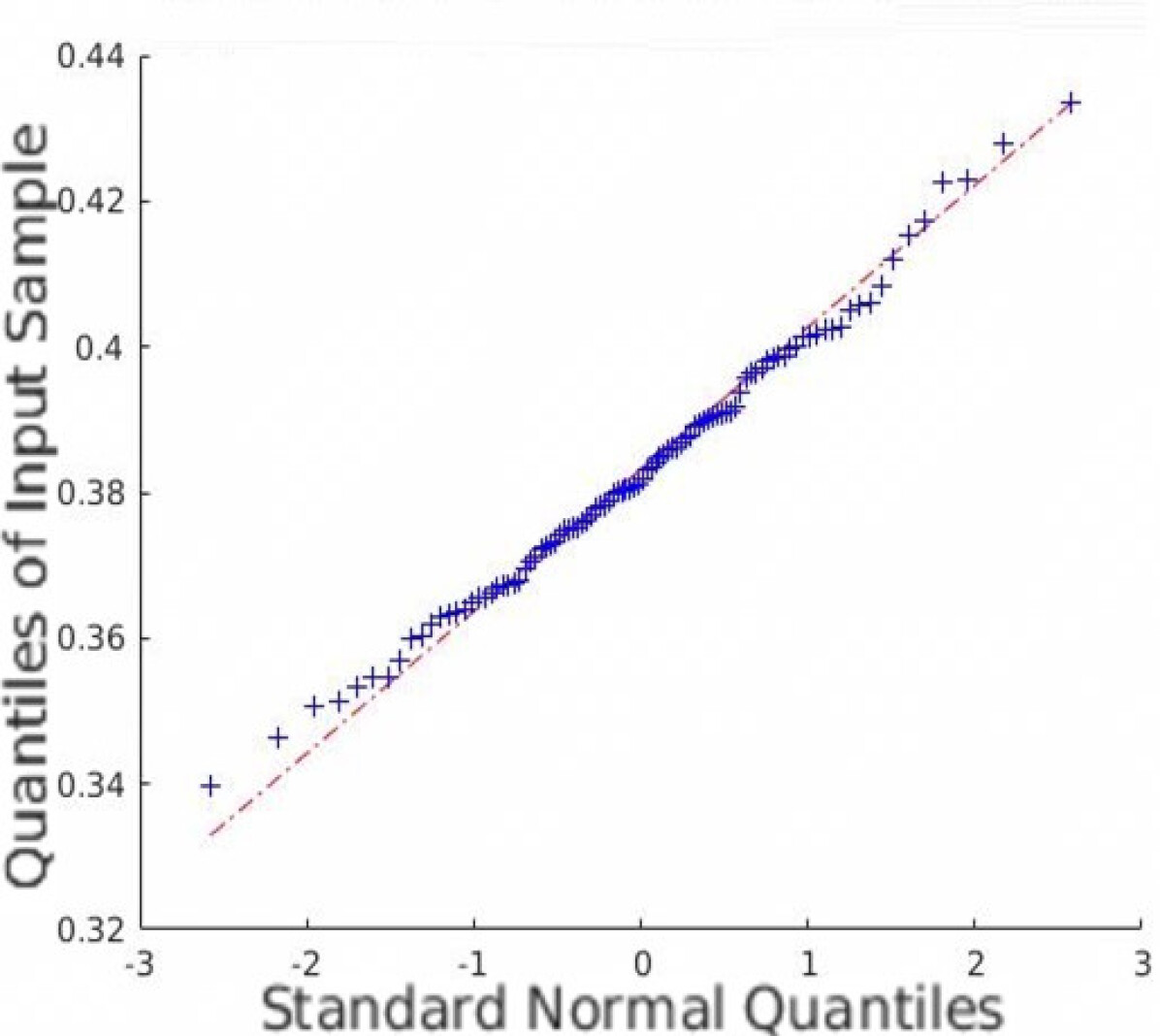
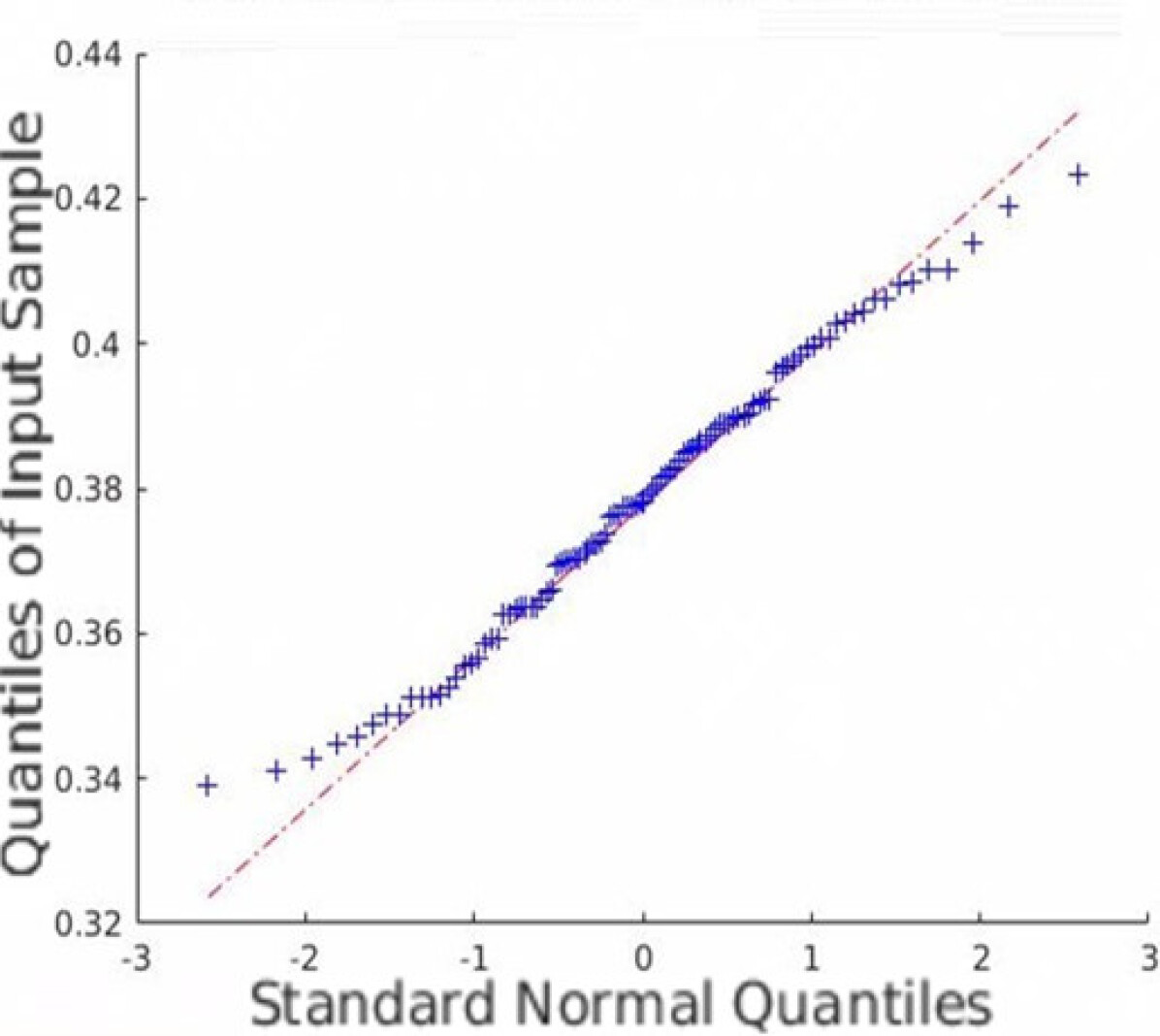
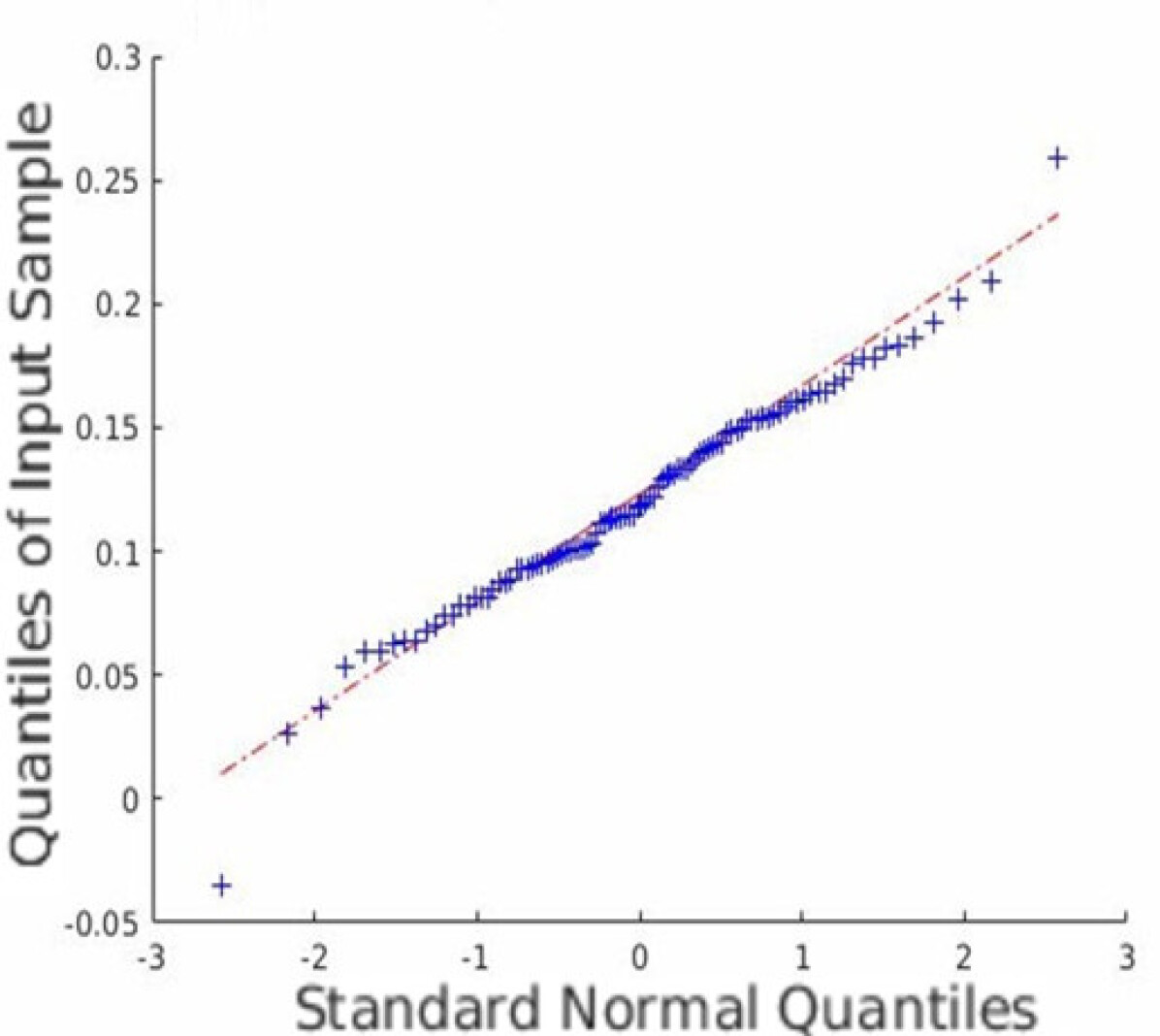
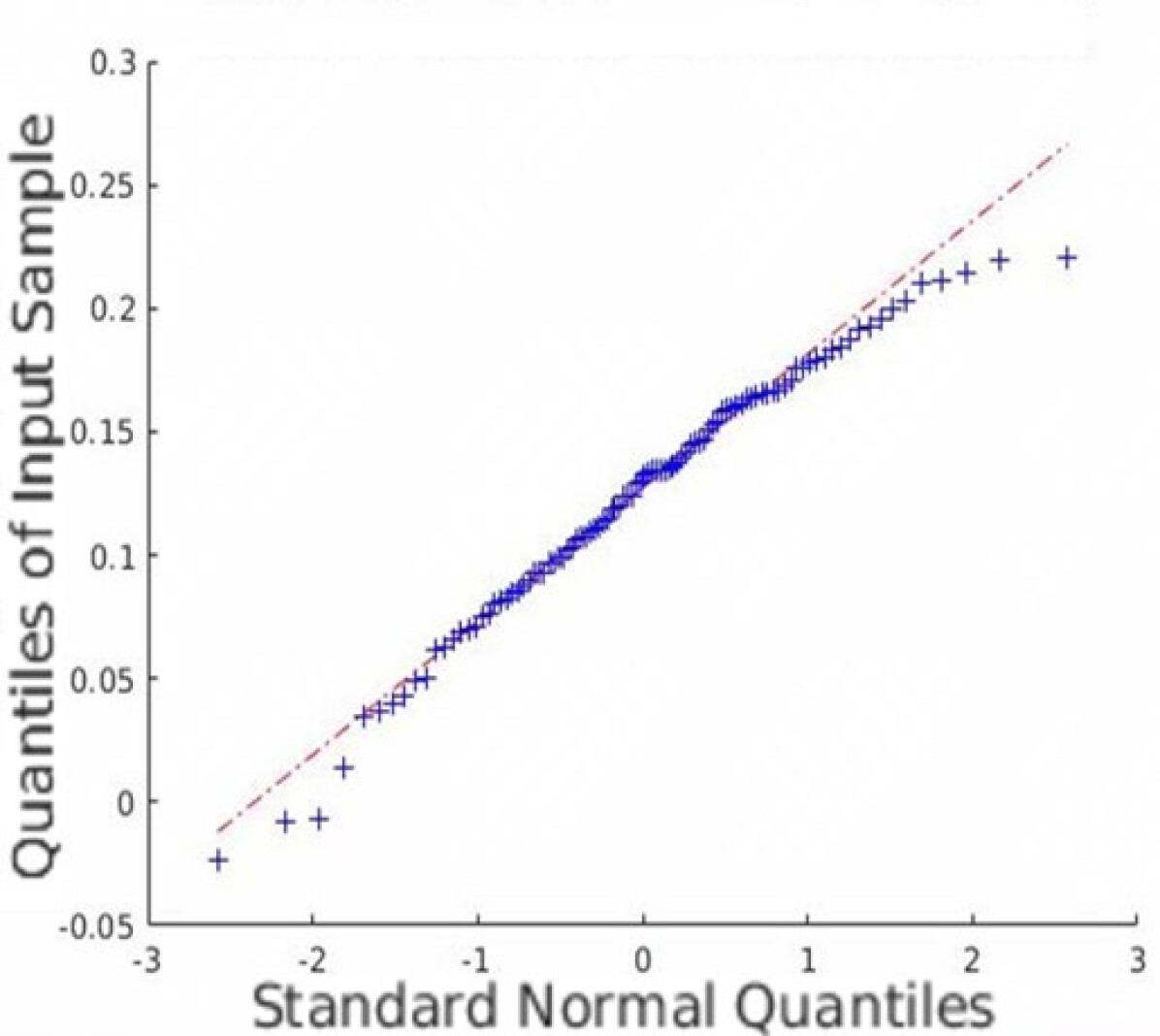
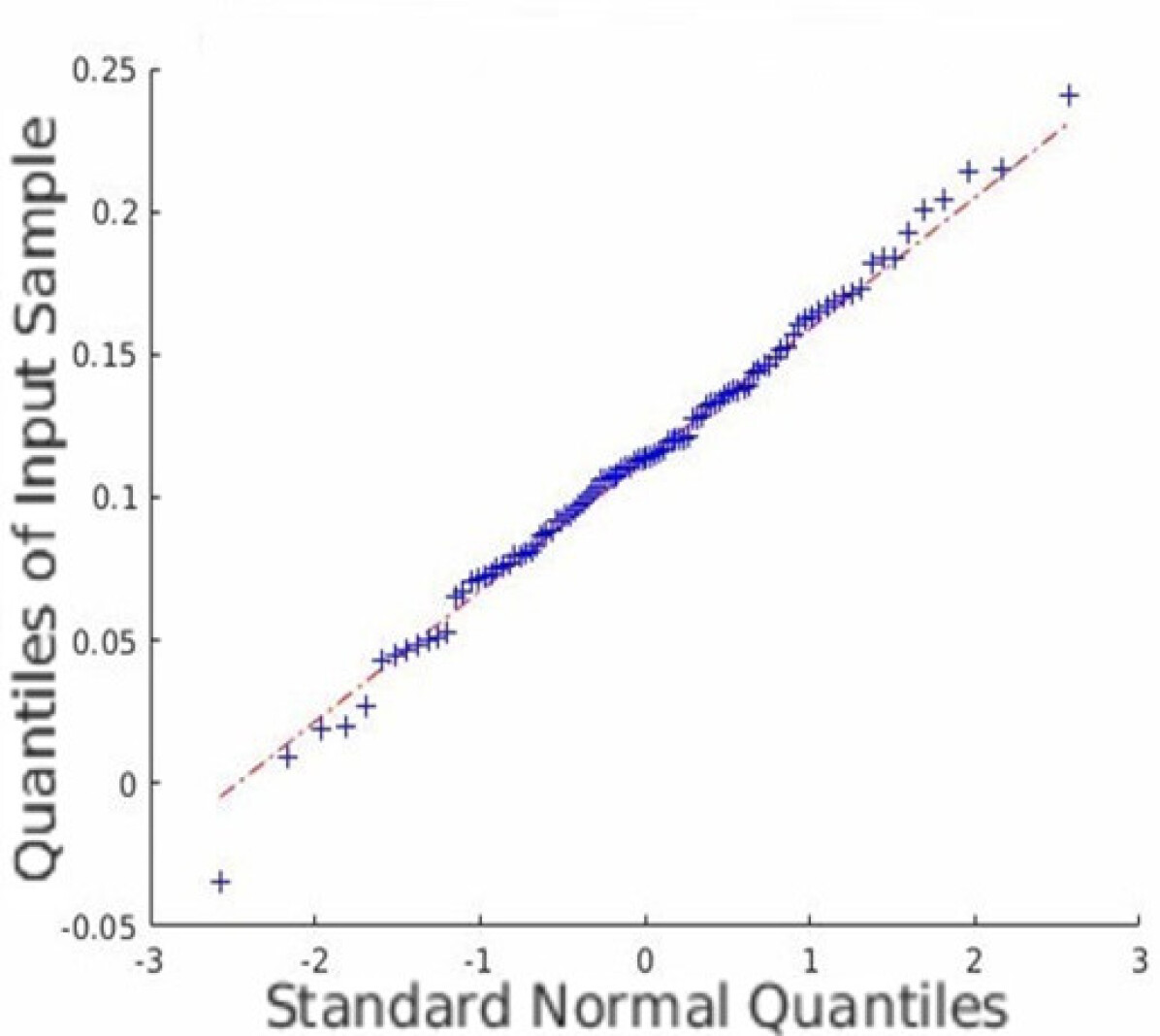
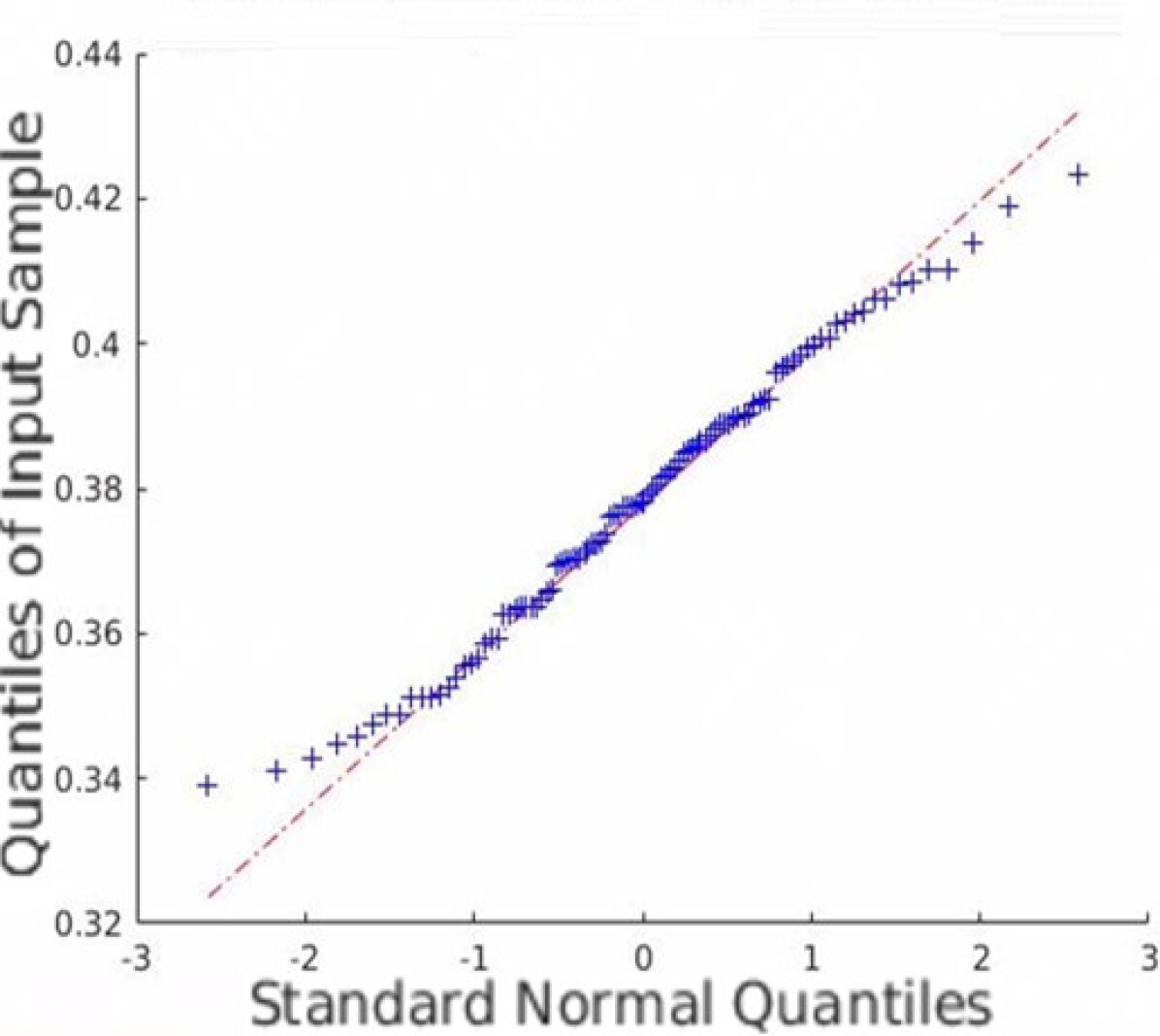
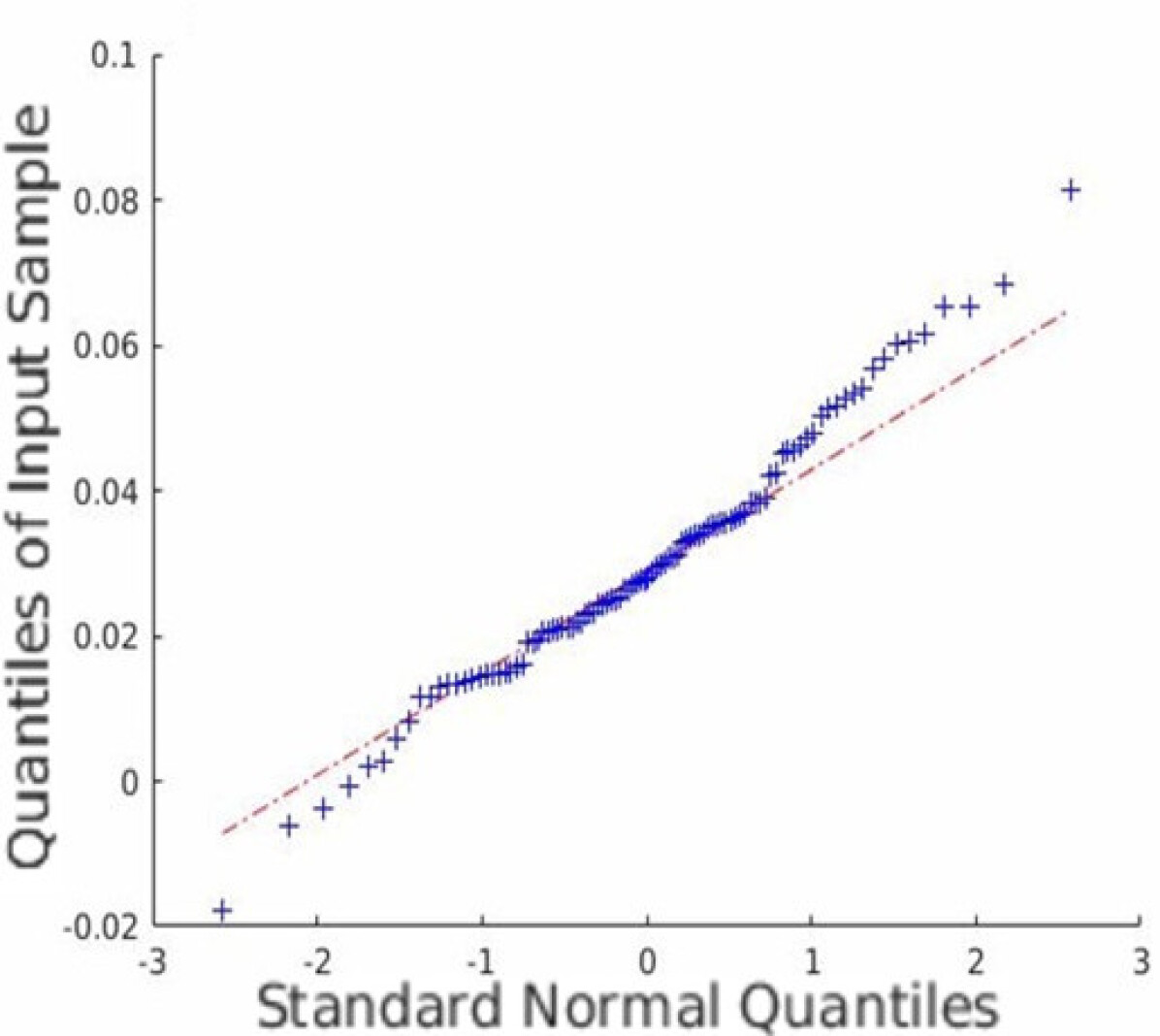
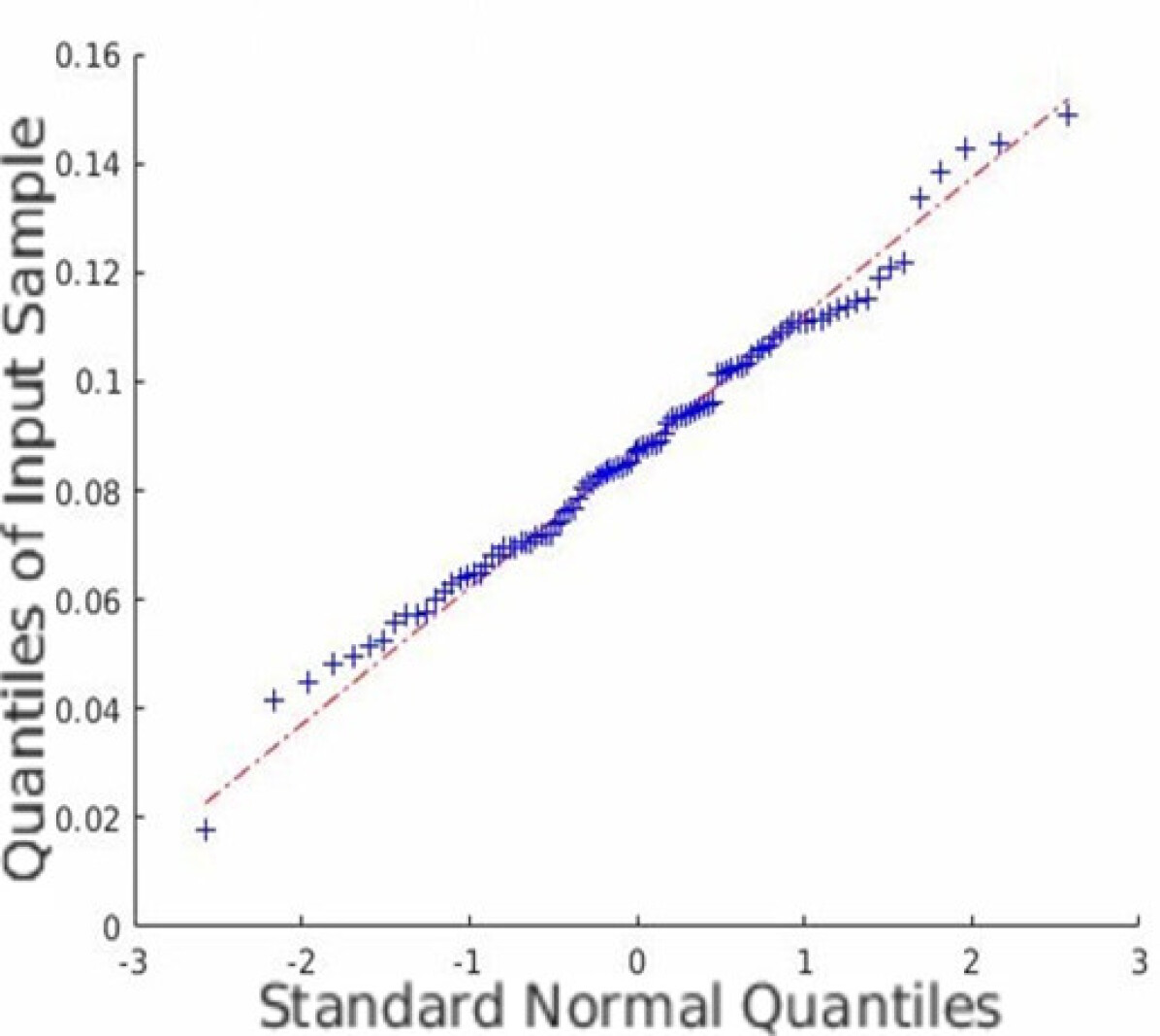
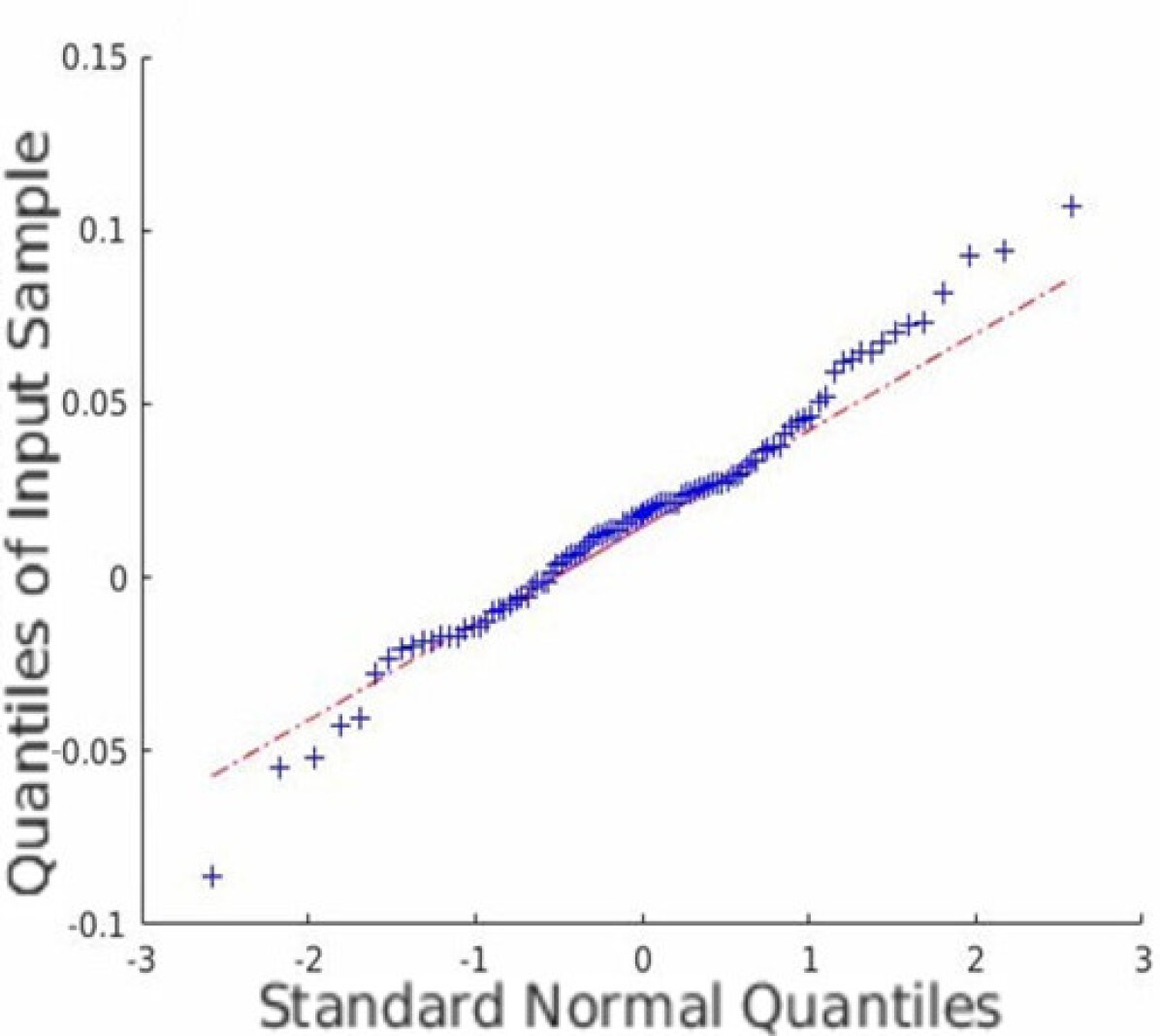
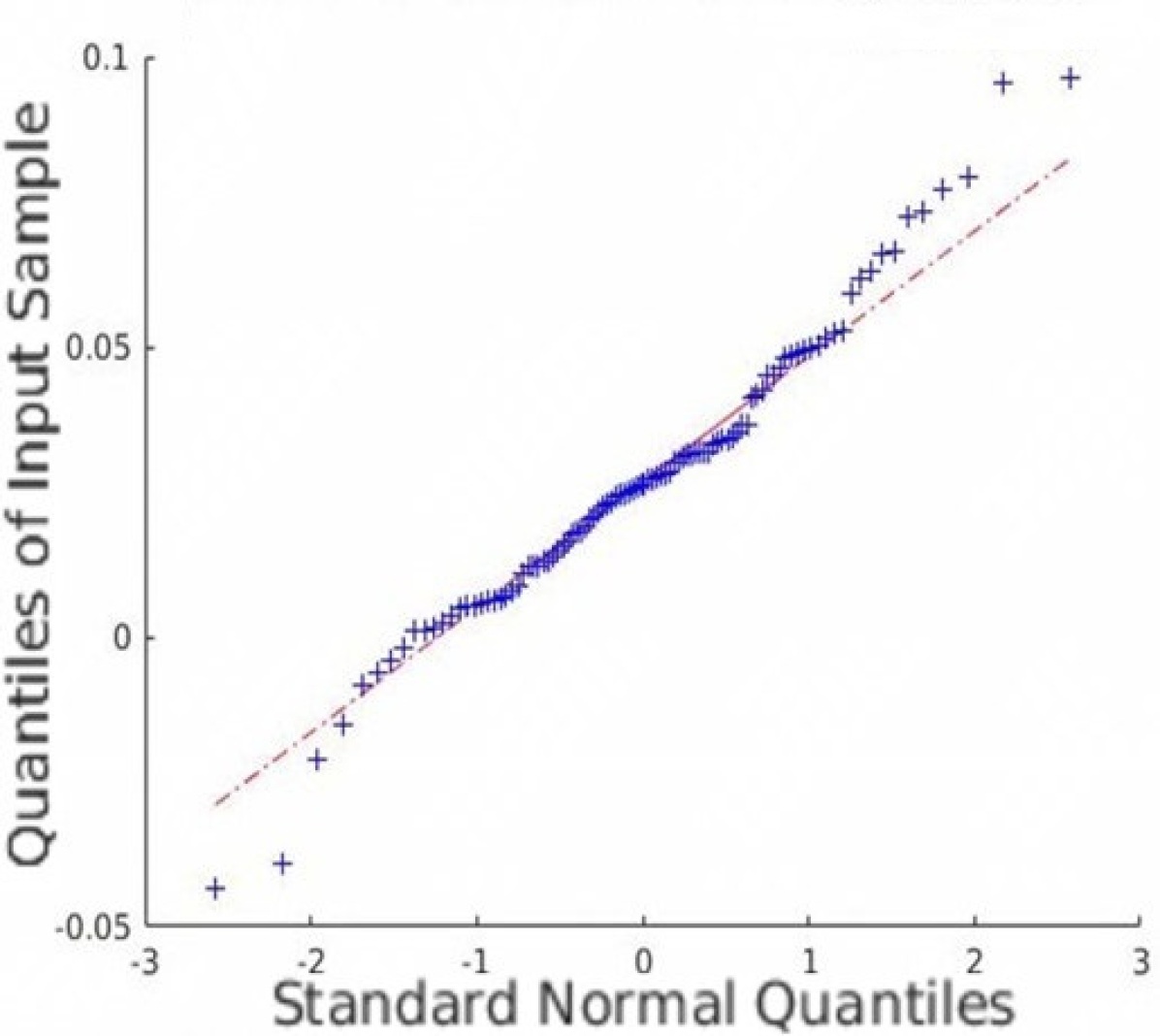
In addition to the average coverage rate, we also adopt the Monte Carlo experiments to prove that the restored HSI has an innate Gaussian distribution. Quantile-Quantile (Q-Q) plots are created, and Shapiro-Wilk tests are conducted to validate the proposed approach. Fig. 5 shows the Q-Q plots of all the datasets. Note that we randomly plot one element in each dataset as an example, but all other elements are similar since the observation is isotropic. Fig. 5 indicates that the Monte Carlo estimation of all the trials is close to a line; thus, the sample follows the Gaussian distribution.
In the Shapiro-Wilk tests, it is not possible to present all the elements. Thus, we randomly choose several elements from the three datasets with different levels of Gaussian noise. The results are presented in Table II. The -values indicate that all samples follow the normal distribution (). Since all pixels are acquired under the same conditions, and their statistics should be consistent (either obey or reject the normal distribution assumption), we can conclude that the restored HSI still follows the Gaussian distribution.
| Dataset | Indian | University of Pavia | Washington, D.C. |
|---|---|---|---|
| 0.050 | 0.4239 | 0.1531 | 0.2046 |
| 0.075 | 0.1103 | 0.1924 | 0.0585 |
| 0.100 | 0.8498 | 0.7537 | 0.6977 |
| 0.125 | 0.4346 | 0.1531 | 0.5331 |
IV-C Time consumption comparison
In addition to the accuracy tests, we determine the time consumption. We find that the closed-form uncertainty estimation method has similar time consumption as the LRMA and far less time consumption than the Monte Carlo numerical tests. We use the LRMA code used in [20] and add the uncertainty estimation module. The proposed algorithm, the LRMA, and the Monte Carlo tests are all implemented in Matlab 2019a. In the Monte Carlo tests, we utilize the Parallel Computing Toolbox of Matlab to speed up the steps. The hardware set is Intel Xeon E5-2687wv3 and 64 GB DDR4-Ram. In the Monte Carlo experiments, all 20 CPU threads are utilized. Note that in the Monte Carlo tests, each element is covered by several sliding windows. Since the memory is not sufficient to store all sliding windows, we calculate the result of the patch, store it on the hard disk, and reload it to calculate each element in the final step.
| Dataset | Monte Carlo | LRMA | LRMA+Uncertainty |
|---|---|---|---|
| Indian | 7862 | 653 | 864 |
| University of Pavia | 8393 | 815 | 930 |
| Washington, D.C. | 12437 | 1023 | 1590 |
Table III shows the time consumption of the Monte Carlo uncertainty estimation, the LRMA method [20], and the proposed method integrated into [20]. The 100 Monte Carlo trials are significantly speeded up because of the running in parallel using 20 CPU threads. The results indicate that the proposed closed-form estimation does not add a significant amount of time to the LRMA method, whereas the Monte Carlo test requires substantially more time. As indicated by Eq. (14), the proposed approach requires no more than one band-wise SVD decomposition of the given HSI in addition to the original LRMA solver.
IV-D The impact of random noise
| 5% | 10% | 20% | 30% | ||||||
| Dataset | Mean | Std | Mean | Std | Mean | Std | Mean | Std | |
| Indian | 0.050 | 0.9006 | 0.0619 | 0.8429 | 0.0770 | 0.7309 | 0.0924 | 0.6278 | 0.0952 |
| 0.075 | 0.9348 | 0.0476 | 0.9063 | 0.0578 | 0.8395 | 0.0745 | 0.7621 | 0.0860 | |
| 0.100 | 0.9516 | 0.0382 | 0.9340 | 0.0456 | 0.8888 | 0.0606 | 0.8293 | 0.0747 | |
| 0.125 | 0.9624 | 0.0318 | 0.9495 | 0.0379 | 0.9148 | 0.0516 | 0.8657 | 0.0663 | |
| University of Pavia | 0.050 | 0.9008 | 0.0438 | 0.8472 | 0.0558 | 0.7466 | 0.0711 | 0.6578 | 0.0783 |
| 0.075 | 0.9434 | 0.0343 | 0.9189 | 0.0432 | 0.8640 | 0.0591 | 0.8020 | 0.0715 | |
| 0.100 | 0.9649 | 0.0275 | 0.9519 | 0.0340 | 0.9195 | 0.0477 | 0.8778 | 0.0607 | |
| 0.125 | 0.9778 | 0.0220 | 0.9700 | 0.0270 | 0.9496 | 0.0382 | 0.9201 | 0.0503 | |
| Washington, D.C | 0.050 | 0.9010 | 0.0549 | 0.8536 | 0.0690 | 0.7649 | 0.0860 | 0.6840 | 0.0933 |
| 0.075 | 0.9456 | 0.0417 | 0.9250 | 0.0514 | 0.8781 | 0.0689 | 0.8248 | 0.0835 | |
| 0.100 | 0.9674 | 0.0319 | 0.9566 | 0.0388 | 0.9301 | 0.0534 | 0.8954 | 0.0688 | |
| 0.125 | 0.9798 | 0.0245 | 0.9735 | 0.0297 | 0.9566 | 0.0417 | 0.9330 | 0.0560 | |
In addition to the coverage rate tests, we assess if the proposed approach is robust to the random noise from the sensor. As Eq. (2) shows, our work ignores the random noise and only assumes that the residuals follow the Gaussian noise . As described in Section III-D, we expect that the proposed method is robust to random noise such as impulse noise, dead lines, and stripes [37, 38]. We conduct the tests by deliberately corrupting the original HSI with random noise and test the performance of the proposed uncertainty quantification method. We simulate different proportions of impulse noise on all datasets and determine the coverage rate of the Monte Carlo experiments.
Table IV shows the results of the Monte Carlo experiments for different coverage rates. The results indicate a relationship between the robustness of the proposed closed-form method and the coverage rate. When the noise is greater than , the uncertainty quantification approach is less sensitive to pulse noises. When the noise is less than , the proposed method is susceptible to random noise. Theoretically, the proposed approach is only effective for Gaussian noise, which is the low-rank prior to Eq. (2). Therefore, less Gaussian noise means less reliable of the assumption that is less than in Eq. (1). Thus, the results from the closed-form approach are less reliable. When the Gaussian noise level of the observation is low, the proposed approach tends to be over-confident of the result, and the result is lower than the coverage rate with a higher . A higher means that the distribution is closer to the impulse noise. Furthermore, since the solvers (either GoDec or ALM solver) are all based on SVD decomposition, our approach has the same computational complexity as the original LRMA methods.
V Conclusion
This is the first study that addresses the uncertainty quantification of LRMA-based HSI denoising techniques. We provide a time-efficient closed-form uncertainty propagation model to quantify the element-wise uncertainty of the denoised HSI without requiring any ground truth. We also propose a weighted average uncertainty formulation to tackle the “uncertainty mixing” problem caused by the sliding-window strategy in HSI denoising. Moreover, the proposed uncertainty estimation approach is independent of the choice of the LRMA solver. It is based on the global minimum assumption of LRMA; thus, a more accurate algorithm leads to a better performance of the uncertainty estimation. Extensive numerical experiments indicate that the proposed uncertainty quantification method is accurate and robust and describes the statistical behavior of the estimates obtained from the LRMA approach. The time consumption of the closed-form formulation is low; therefore, the method can be deployed in any state-of-the-art LRMA algorithm. The proposed uncertainty approach can also be used in applications that require multi-source or multi-scale data fusion, data assimilation, and remote sensing uncertainty estimation.
Future works may also focus on tackling the observable random noise, such as impulse noises, deadlines, and stripes. The percentage of the observable random noise can be utilized to adjust the proposed closed-form uncertainty method.
Appendix A Appendix
Proof of Theorem 1. If the selected LRMA solver provides the optimal solution to the objective function Eq. (LABEL:Eq_image_recovery), the optimizer , should satisfy the local minima of Eq. (LABEL:Eq_image_recovery). are denoted as:
| (23) | ||||
where is because is the permutation function and . Assuming the solver yields close to the global minimum . The first-order expansion of is close to the zero matrix defined as . By solving Eq. (1) and ignoring random noise, we define the patch function:
| (24) | ||||
where . The optimizer achieves local minima which is close to the global minima; thus, we obtain the partial derivatives equal to the zero matrix:
| (25) | ||||
| (26) | ||||
where (i) is the result of . (ii) is approximated by the fact that the rectified local minima (,) are close to the global minima (,). We manipulate Eq. (25) and Eq. (26) to:
| (27) | ||||
| (28) | ||||
where the matrix exchange in step (i) is enabled because and are diagonal matrices. We denote the rectified local minima (,) equal to (,) for a concise presentation.
The proof of step (ii): Each element of the Gaussian noise matrix . According to Eq. (7), is a diagonal matrix and the diagonal element at position equals to or where or is the th column of matrix or .
The proof of (i):
| (29) | ||||
Take the first element as an example:
| (30) | ||||
The same conclusion also applies to other elements.
Similarly, the proof of (ii):
| (31) | ||||
Take the first element as an example:
| (32) | ||||
The same conclusion also applies to other elements.
Following Eqs. (27) and (28), we strictly obtain the conclusion that the residual of Gaussian noise . Thus, are the negligible residuals due to numerical issues.
This concludes the proof of and and also the proof of theorem 1.
References
- [1] H. Dehghan and H. Ghassemian, “Measurement of uncertainty by the entropy: application to the classification of mss data,” International journal of remote sensing, vol. 27, no. 18, pp. 4005–4014, 2006.
- [2] G. M. Foody and P. M. Atkinson, Uncertainty in remote sensing and GIS. John Wiley & Sons, 2003.
- [3] W. Verhoef and H. Bach, “Coupled soil–leaf-canopy and atmosphere radiative transfer modeling to simulate hyperspectral multi-angular surface reflectance and toa radiance data,” Remote Sensing of Environment, vol. 109, no. 2, pp. 166–182, 2007.
- [4] X. Chen, K. Yu, and H. Wu, “Determination of minimum detectable deformation of terrestrial laser scanning based on error entropy model,” IEEE Transactions on Geoscience and Remote Sensing, vol. 56, no. 1, pp. 105–116, 2017.
- [5] X. Du and A. Zare, “Multiresolution multimodal sensor fusion for remote sensing data with label uncertainty,” IEEE Transactions on Geoscience and Remote Sensing, 2019.
- [6] R. Senge, S. Bösner, K. Dembczyński, J. Haasenritter, O. Hirsch, N. Donner-Banzhoff, and E. Hüllermeier, “Reliable classification: Learning classifiers that distinguish aleatoric and epistemic uncertainty,” Information Sciences, vol. 255, pp. 16–29, 2014.
- [7] A. Oxley, Uncertainties in GPS Positioning: A mathematical discourse. Academic Press, 2017.
- [8] L. Bastin, P. F. Fisher, and J. Wood, “Visualizing uncertainty in multi-spectral remotely sensed imagery,” Computers & Geosciences, vol. 28, no. 3, pp. 337–350, 2002.
- [9] E. Sarhrouni, A. Hammouch, and D. Aboutajdine, “Application of symmetric uncertainty and mutual information to dimensionality reduction of and classification hyperspectral images,” International Journal of Engineering and Technology (IJET), vol. 4, no. 5, pp. 268–276, 2012.
- [10] Y. Zhou, A. Rangarajan, and P. D. Gader, “A spatial compositional model for linear unmixing and endmember uncertainty estimation,” IEEE Transactions on Image Processing, vol. 25, no. 12, pp. 5987–6002, 2016.
- [11] M.-E. Polo, Á. M. Felicísimo, A. G. Villanueva, and J.-Á. Martinez-del Pozo, “Estimating the uncertainty of terrestrial laser scanner measurements,” IEEE transactions on geoscience and remote sensing, vol. 50, no. 11, pp. 4804–4808, 2012.
- [12] P. Ghamisi, N. Yokoya, J. Li, W. Liao, S. Liu, J. Plaza, B. Rasti, and A. Plaza, “Advances in hyperspectral image and signal processing: A comprehensive overview of the state of the art,” IEEE Geoscience and Remote Sensing Magazine, vol. 5, no. 4, pp. 37–78, 2017.
- [13] Q. Zhang, Q. Yuan, J. Li, X. Liu, H. Shen, and L. Zhang, “Hybrid noise removal in hyperspectral imagery with a spatial–spectral gradient network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 10, pp. 7317–7329, 2019.
- [14] A. Buades, B. Coll, and J.-M. Morel, “A non-local algorithm for image denoising,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), vol. 2. IEEE, 2005, pp. 60–65.
- [15] M. Maggioni, V. Katkovnik, K. Egiazarian, and A. Foi, “Nonlocal transform-domain filter for volumetric data denoising and reconstruction,” IEEE transactions on image processing, vol. 22, no. 1, pp. 119–133, 2012.
- [16] Y. Qian and M. Ye, “Hyperspectral imagery restoration using nonlocal spectral-spatial structured sparse representation with noise estimation,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 6, no. 2, pp. 499–515, 2012.
- [17] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian, “Image denoising by sparse 3-d transform-domain collaborative filtering,” IEEE Transactions on image processing, vol. 16, no. 8, pp. 2080–2095, 2007.
- [18] Q. Yuan, L. Zhang, and H. Shen, “Hyperspectral image denoising employing a spectral–spatial adaptive total variation model,” IEEE Transactions on Geoscience and Remote Sensing, vol. 50, no. 10, pp. 3660–3677, 2012.
- [19] J. Li, Q. Yuan, H. Shen, and L. Zhang, “Noise removal from hyperspectral image with joint spectral–spatial distributed sparse representation,” IEEE Transactions on Geoscience and Remote Sensing, vol. 54, no. 9, pp. 5425–5439, 2016.
- [20] H. Zhang, W. He, L. Zhang, H. Shen, and Q. Yuan, “Hyperspectral image restoration using low-rank matrix recovery,” IEEE Transactions on Geoscience and Remote Sensing, vol. 52, no. 8, pp. 4729–4743, 2013.
- [21] L. Zhuang and J. M. Bioucas-Dias, “Fast hyperspectral image denoising and inpainting based on low-rank and sparse representations,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 11, no. 3, pp. 730–742, 2018.
- [22] W. He, H. Zhang, L. Zhang, and H. Shen, “Hyperspectral image denoising via noise-adjusted iterative low-rank matrix approximation,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 8, no. 6, pp. 3050–3061, 2015.
- [23] Q. Yuan, Q. Zhang, J. Li, H. Shen, and L. Zhang, “Hyperspectral image denoising employing a spatial–spectral deep residual convolutional neural network,” IEEE Transactions on Geoscience and Remote Sensing, vol. 57, no. 2, pp. 1205–1218, 2018.
- [24] W. He, H. Zhang, L. Zhang, and H. Shen, “Total-variation-regularized low-rank matrix factorization for hyperspectral image restoration,” IEEE transactions on geoscience and remote sensing, vol. 54, no. 1, pp. 178–188, 2015.
- [25] J. M. Bioucas-Dias and J. M. Nascimento, “Hyperspectral subspace identification,” IEEE Transactions on Geoscience and Remote Sensing, vol. 46, no. 8, pp. 2435–2445, 2008.
- [26] Y. Chen, X. Cao, Q. Zhao, D. Meng, and Z. Xu, “Denoising hyperspectral image with non-iid noise structure,” IEEE transactions on cybernetics, vol. 48, no. 3, pp. 1054–1066, 2017.
- [27] H. Fan, C. Li, Y. Guo, G. Kuang, and J. Ma, “Spatial–spectral total variation regularized low-rank tensor decomposition for hyperspectral image denoising,” IEEE Transactions on Geoscience and Remote Sensing, vol. 56, no. 10, pp. 6196–6213, 2018.
- [28] Y. Chen, W. He, N. Yokoya, and T.-Z. Huang, “Hyperspectral image restoration using weighted group sparsity-regularized low-rank tensor decomposition,” IEEE transactions on cybernetics, 2019.
- [29] B. Aiazzi, L. Alparone, A. Barducci, S. Baronti, P. Marcoionni, I. Pippi, and M. Selva, “Noise modelling and estimation of hyperspectral data from airborne imaging spectrometers,” Annals of Geophysics, vol. 49, no. 1, 2006.
- [30] N. Acito, M. Diani, and G. Corsini, “Signal-dependent noise modeling and model parameter estimation in hyperspectral images,” IEEE Transactions on Geoscience and Remote Sensing, vol. 49, no. 8, pp. 2957–2971, 2011.
- [31] Y. Chen, J. Fan, C. Ma, and Y. Yan, “Inference and uncertainty quantification for noisy matrix completion,” Proceedings of the National Academy of Sciences, vol. 116, no. 46, pp. 22 931–22 937, 2019.
- [32] Y. Chen, Y. Chi, J. Fan, C. Ma, and Y. Yan, “Noisy matrix completion: Understanding statistical guarantees for convex relaxation via nonconvex optimization,” SIAM Journal on Optimization, vol. 30, no. 4, pp. 3098–3121, 2020.
- [33] J. Wright, A. Ganesh, S. Rao, Y. Peng, and Y. Ma, “Robust principal component analysis: Exact recovery of corrupted low-rank matrices via convex optimization,” in Advances in neural information processing systems, 2009, pp. 2080–2088.
- [34] T. Zhou and D. Tao, “Godec: Randomized low-rank & sparse matrix decomposition in noisy case,” in Proceedings of the 28th International Conference on Machine Learning, ICML 2011, 2011.
- [35] G. Casella and R. L. Berger, Statistical inference. Duxbury Pacific Grove, CA, 2002, vol. 2.
- [36] R. M. Gray, Entropy and information theory. Springer Science & Business Media, 2011.
- [37] G. Vane, R. O. Green, T. G. Chrien, H. T. Enmark, E. G. Hansen, and W. M. Porter, “The airborne visible/infrared imaging spectrometer (aviris),” Remote sensing of environment, vol. 44, no. 2-3, pp. 127–143, 1993.
- [38] R. O. Green, M. L. Eastwood, C. M. Sarture, T. G. Chrien, M. Aronsson, B. J. Chippendale, J. A. Faust, B. E. Pavri, C. J. Chovit, M. Solis et al., “Imaging spectroscopy and the airborne visible/infrared imaging spectrometer (aviris),” Remote sensing of environment, vol. 65, no. 3, pp. 227–248, 1998.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/798a0b67-4050-4066-a8bc-38a5a98a0692/author_JingweiSong.jpg) |
Jingwei Song obtained his doctoral degree in Center of Autonomous System, University of Technology Sydney in 2020. Before that, he received B.E. degree in Remote sensing science and technology from Wuhan University, Wuhan in 2012. He obtained a master’s degree in Cartography and Geographic Information System from Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences in 2015. He is a research associate at the Department of Naval Architecture and Marine Engineering, University of Michigan, Ann Arbor. His research interests include computer vision, simultaneous localization and mapping, and robotics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/798a0b67-4050-4066-a8bc-38a5a98a0692/author_ShaoboXia.jpg) |
Shaobo Xia received the bachelor’s degree in geodesy and geomatics from the School of Geodesy and Geomatics, Wuhan University, Wuhan, China, in 2013, the master’s degree in cartography and geographic information systems from the Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences, Beijing, China, in 2016, and the Ph.D. degree in geomatics from the University of Calgary, Calgary, AB, Canada, in 2020. He is an Assistant Professor with the College of Environmental and Resource Sciences, Zhejiang A&F University, Hangzhou, China. His research interests include mobile mapping and remote sensing. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/798a0b67-4050-4066-a8bc-38a5a98a0692/author_JunWang.jpg) |
Jun Wang received B.E. degree in Remote sensing science and technology from Wuhan University, Wuhan, China, in 2012 and is currently pursuing the Ph.D. degree in Remote sensing science from University of Chinese Academy of Sciences. He also got a joint Ph.D. program in Robotics from University of Technology, Sydney. His research interests include computer vision, simultaneous localization and mapping, robotics. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/798a0b67-4050-4066-a8bc-38a5a98a0692/author_MiteshPatel.jpg) |
Mitesh Patel received my Ph.D. in Robotics from Center of Autonomous Systems (CAS) at the University of Technology Sydney in 2014 where I focused on modeling a wide spectrum of high-level user activities (also known as activities of daily living) using different probabilistic techniques. Most recently, he was a senior research scientist at FX Palo Alto Laboratory Inc., where he worked on developing indoor localization system using variety of sensors such as RF, RGB, RGB-D images, LiDAR. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/798a0b67-4050-4066-a8bc-38a5a98a0692/author_DongChen.jpg) |
Dong Chen (Member, IEEE) received the bachelor’s degree in computer science from the Qingdao University of Science and Technology, Qingdao, China, in 2005, the master’s degree in cartography and geographical information engineering from the Xi’an University of Science and Technology, Xi’an, China, in 2009, and the Ph.D. degree in geographical information sciences from Beijing Normal University, Beijing, China, in 2013. He is an Associate Professor with Nanjing Forestry University, Nanjing, China. He is also a Post-Doctoral Fellow with the Department of Geomatics Engineering, University of Calgary, Calgary, AB, Canada. His research interests include image-and LiDAR-based segmentation and reconstruction, full-waveform LiDAR data processing, and related remote sensing applications in the field of forest ecosystems. |