Understanding Expressivity of GNN in Rule Learning
Abstract
Rule learning is critical to improving knowledge graph (KG) reasoning due to their ability to provide logical and interpretable explanations. Recently, Graph Neural Networks (GNNs) with tail entity scoring achieve the state-of-the-art performance on KG reasoning. However, the theoretical understandings for these GNNs are either lacking or focusing on single-relational graphs, leaving what the kind of rules these GNNs can learn an open problem. We propose to fill the above gap in this paper. Specifically, GNNs with tail entity scoring are unified into a common framework. Then, we analyze their expressivity by formally describing the rule structures they can learn and theoretically demonstrating their superiority. These results further inspire us to propose a novel labeling strategy to learn more rules in KG reasoning. Experimental results are consistent with our theoretical findings and verify the effectiveness of our proposed method. The code is publicly available at https://github.com/LARS-research/Rule-learning-expressivity.
1 Introduction
A knowledge graph (KG) (Battaglia et al., 2018; Ji et al., 2021) is a type of graph where edges represent multiple types of relationships between entities. These relationships can be of different types, such as friend, spouse, coworker, or parent-child, and each type of relationship is represented by a separate edge. By encapsulating the interactions among entities, KGs provide a way for machines to understand and process complex information. KG reasoning refers to the task of deducing new facts from the existing facts in KG. This task is important because it helps in many real-world applications, such as recommendation systems (Cao et al., 2019) and drug discovery (Mohamed et al., 2019).
With the success of graph neural networks (GNNs) in modeling graph-structured data, GNNs have been developed for KG reasoning in recent years. Classical methods such as R-GCN (Schlichtkrull et al., 2018) and CompGCN (Vashishth et al., 2020) are proposed for KG reasoning by aggregating the representations of two end entities of a triplet. And they are known to fail to distinguish the structural role of different neighbors. GraIL (Teru et al., 2020) and RED-GNN (Zhang & Yao, 2022) tackle this problem by encoding the subgraph around the target triplet. GraIL predicts a new triplet using the subgraph representations, while RED-GNN employs dynamic programming for efficient subgraph encoding. Motivated by the effectiveness of heuristic metrics over paths between a link, NBFNet (Zhu et al., 2021) proposes a neural network based on Bellman-Ford algorithm for KG reasoning. AdaProp (Zhang et al., 2023) and A⋆Net (Zhu et al., 2022) enhance the scalability of RED-GNN and NBFNet respectively by selecting crucial nodes and edges iteratively. Among these methods, NBFNet, RED-GNN and their variants score a triplet with its tail entity representation and achieve state-of-the-art (SOTA) performance on KG reasoning. However, these methods are motivated by different heuristics, e.g., Bellman-Ford algorithm and enclosing subgraph encoding, which make the understanding of their effectiveness for KG reasoning difficult.
In this paper, inspired by the importance of rule learning in KG reasoning, we propose to study expressivity of SOTA GNNs for KG reasoning by analyzing the kind of rules they can learn. First, we unify SOTA GNNs for KG reasoning into a common framework called QL-GNN, based on the observation that they score a triplet with its tail entity representation and essentially extract rule structures from subgraphs with same pattern. Then, we analyze the logical expressivity of QL-GNN to study its ability of learning rule structures. The analysis helps us reveal the underneath theoretical reasons that contribute to the empirical success of QL-GNN, elucidating their effectiveness over classical methods. Specifically, our analysis is based on the formal description of rule structures in graph, which differs from previous analysis that relies on graph isomorphism testing (Xu et al., 2019; Zhang et al., 2021) and focuses on the expressivity of distinguishing various rules. The new analysis tool allows us to understand the rules learned by QL-GNN and reveals the maximum expressivity that QL-GNN can generalize through training. Based on the new theory, we also uncover the deficiencies of QL-GNN in learning rule structures and we propose EL-GNN based on labeling trick as an improvement upon QL-GNN to improve its learning ability. In summary, our paper has the following contributions:
-
•
Our work unifies state-of-the-art GNNs for KG reasoning into a common framework named QL-GNN, and analyzes their logical expressivity to study their ability of learning rule structures, explaining their superior performance over classical methods.
-
•
The logical expressivity of QL-GNN demonstrates its capability in learning a particular class of rule structures. Consequently, based on further theoretical analysis, we introduce EL-GNN, a novel GNN designed to learn rule structures that are beyond the learning capacity of QL-GNN.
-
•
Synthetic datasets are generated to evaluate the expressivity of various GNNs, whose experimental results are consistent with our theory. Also, results of the proposed labeling method show improved performance on real datasets.
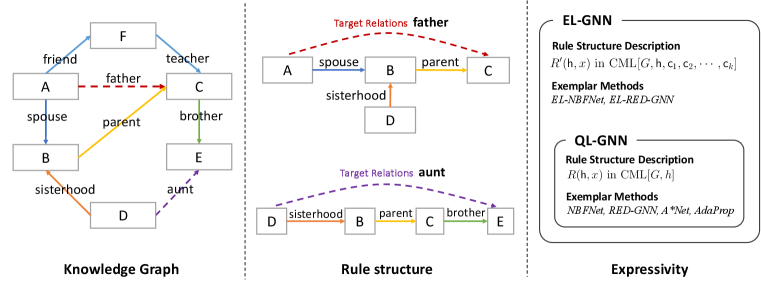
2 A common framework for the state-of-the-art methods
To study the state-of-the-art GNNs for KG reasoning, we find that they (e.g., RED-GNN and NBFNet) essentially learn rule structures from GNN’s tail entity representation which encodes subgraphs with the same pattern, i.e., a subgraph with the query entity as the source node and the tail entity as the sink node. Based on this observation, we are motivated to derive a common framework for these SOTA methods and analyze their ability of learning rule structures with the derived framework.
Given a query , the labeling trick of query entity ensures the SOTA methods to extract rules from a graph with the same pattern because it makes the query entity distinguishable among all entities in graph. Therefore, we unify NBFNet, RED-GNN and their variants to a common framework called Query Labeling (QL) GNN (see correspondence in Appdendix B). For a query , QL-GNN first applies labeling trick by assigning special initial representation to entity , which make the query entity distinguishable from other entities. Base on these initial features, QL-GNN aggregates entity representations with a -layer message passing neural network (MPNN) for each candidate . MPNN’s last layer representation of entity in QL-GNN is denoted as indicating its dependency on query entity . Finally, QL-GNN scores new facts with tail entity representation . For example, NBFNet uses the score function for new triplet where denotes a feed-forward neural network.
Even RED-GNN, NBFNet and their variant may take the different MPNNs to calculate , without loss of generality, their MPNNs can take the following form in QL-GNN (omit for simplicity):
| (1) |
where and are combination and aggregation functions respectively, is the message function encoding the relation and entity neighboring to , is a multiset, and is the neighboring entity set .
3 Expressivity of QL-GNN
In this section, we explore the logical expressivity of QL-GNN to analyze the types of rule structures QL-GNN can learn. First, we provide the logic to describe rules in KGs. Then, we analyze logical expressivity of QL-GNN using Theorem 3.2 and Corollary 3.3, formally demonstrating the kind of rule structures it can learn. Finally, we compare QL-GNN with classical methods and highlight its superior expressivity in KG reasoning.
3.1 Expressivity analysis with logic of rule structures
From previous works of rule mining on KG (Yang et al., 2017; Sadeghian et al., 2019), rule structures are usually described as a formula in first-order logic. We also follow this way to formally describe the rule structures in KG. Therefore, we have the following correspondence between the elements in rule structures and logic:
-
•
Variable: variables denoted with lowercase italic letters represent entities in a KG;
-
•
Unary predicate: unary predicate is corresponding to the entity property in a KG, e.g., denotes the color of an entity is red;
-
•
Binary predicate: binary predicate is corresponding to the relation in a KG, e.g., denotes is the father of ;
-
•
Constant: constant denoted with lowercase letters with serif typestyle is the unique identifier of some entity in a KG.
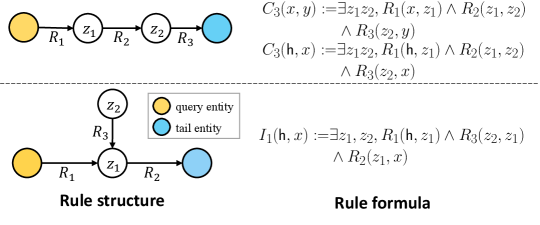
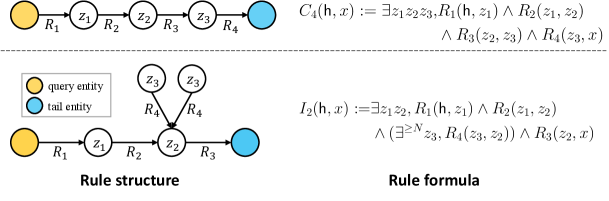
Except from the above elements, the quantifier expresses the existence of entities satisfying a condition, expresses universal quantification, and represents the existence of at least entities satisfying a condition. The logical connective denotes conjunction, denotes disjunction, and and represent true and false, respectively. Using these symbols, rule structures can be represented by describing their elements directly. For example, in Figure 2 describes a chain-like structure between and with three relations . Rule structures can be represented using the rule formula , and the existence of a rule structure for the triplet is equivalent to the satisfaction of the rule formula at the entity pair . In this paper, logical expressivity of GNN is a measurement of the ability of GNN to learn logical formulas and is defined as the set of logical formulas that GNN can learn. Therefore, since rule structures can be described by logical formulas, the logical expressivity of QL-GNN can determine their ability to learn rule structures in KG reasoning.
3.2 What kind of rule structures can QL-GNN learn?
In this section, we analyze the logical expressivity of QL-GNN regarding what kind of rule structure it can learn. Given a query , we first have the following proposition about the rule formula describing a rule structure.
Proposition 3.1.
The rule structure for query can be described with rule formula or rule formula 111The rule formula is equivalent to where denotes the assignment of constant to and is called constant predicate in our paper. where is the logical constant assigned to query entity .
QL-GNN applies labeling trick to the query entity , which can be equivalently seen as assigning constant to query entity 222The initial representation of an entity should be unique among all entities to be regarded as constant in logic. The initial representation assigned to query entity are indeed unique in NBFNet, RED-GNN and their variants..With Proposition 3.1 (proven in Appendix A), the logical expressivity of QL-GNN can be analyzed by the types of rule formula it can learn. In this case, the rule structure of triplet exists if and only if the logical formula is satisfied at entity .
3.2.1 Expressivity of QL-GNN
Before presenting the logical expressivity of QL-GNN, we start by explaining how QL-GNN learns the rule formula . Following the definition in Barceló et al. (2020), we treat as a binary classifier. When given a candidate tail entity , if the triplet exists in a KG, the binary classifier should output true; otherwise, it should output false. If QL-GNN can learn the rule formula , it implies that QL-GNN can estimate binary classifier . Consequently, if the rule formula is satisfied at entity , the representation is mapped to a high probability value, indicating the existence of triplet in KG. Conversely, when the rule formula is not satisfied at , is mapped to a low probability value, indicating the absence of the triplet.
The rule structures that QL-GNN can learn are described by a family of logic called graded modal logic (CML) (De Rijke, 2000; Otto, 2019). CML is defined by recursion with the base elements , all unary predicates , and the recursion rule: if are formulas in CML, are also formulas in CML. Since QL-GNN introduces a constant to the query entity , we use the notation to denote the CML recursively built from base elements in and constant (equivalent to constant predicate ). Then, the following theorem and corollary show the expressivity of QL-GNN for KG reasoning.
Theorem 3.2 (Logical expressivity of QL-GNN).
For KG reasoning, given a query , a rule formula is learned by QL-GNN if and only if is a formula in .
Corollary 3.3.
The rule structures learned by QL-GNN can be constructed with the recursion:
-
•
Base case: all unary predicates can be learned by QL-GNN; the constant predicate can be learned by QL-GNN;
-
•
Recursion rule: if the rule structures are learned by QL-GNN, , are learned by QL-GNN.
Theorem 3.2 (proved in Appendix C) provides the logical expressivity of QL-GNN with rule formula in , which shows that querying labeling transforms to and enable QL-GNN to learn the corresponding rule structure. To gain a concrete understanding of the rule structures learned by QL-GNN, Corollary 3.3 provides the recursive definition for these rule structures. Note that Theorem 3.2 cannot be directly applied to analyze the expressivity of QL-GNN when learning more than one rule structures. The ability of learning more than one rule structures relates to the capacity of QL-GNN, which we take as a future direction. Theorem 3.2 also reveals the maximum expressivity that QL-GNN can generalize through training, and its proof also provides some insights about the design QL-GNN with better generalization (more discussions are provided in Appendix F.1). Besides, our results in this section can be reduced to single relational-graph by restricting the relation type to a single relation type, and we give these results as corollaries in Appendix E.
3.2.2 Examples
We analyze several rule structures and their corresponding rule formulas in Figure 2 as illustrative examples, demonstrating the application of our theory in analyzing the rule structures that QL-GNN can learn. The real examples of these rule structures are shown in Figure 1. In Appdendix A, we have detailed analysis of rule structures discussed in the paper and present some rules from real datasets.
Chain-like rules, e.g., in Figure 2, are basic rule structures investigated in many previous works (Sadeghian et al., 2019; Teru et al., 2020; Zhu et al., 2021). QL-GNN assigns constant to query entity , thus triplets with relation can be predicted by learning the rule formula . are formulas in and can be recursively defined with rules in Corollary 3.3 (proven in Corollary A.2). Therefore, our theory gives a general proof of QL-GNN’s ability to learn chain-like structures.
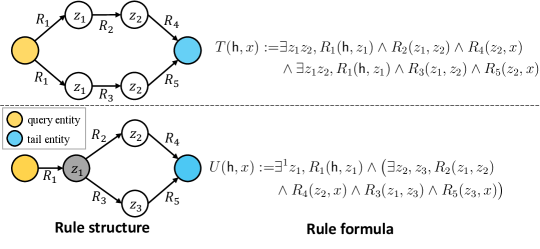
The second type of rule structure in Figure 2 is composed of a chain-like structure from query entity to tail entity along with additional entity connected to the chain. are formulas in and can be defined with recursive rules in Corollary 3.3 (proven in Corollary A.3), which indicates that can be learned by QL-GNN. These structures are important in KG reasoning because the entity connected to the chain can bring extra information about property of the entity it connected to (see examples of rule in Appendix A).
3.3 Comparison with classical methods
Classical methods such as R-GCN and CompGCN perform KG reasoning by first applying MPNN (1) to compute the entity representations and then scoring the triplet by with aggregation function . For simplicity, we take CompGCN as an example to analyze the expressivity of the classical methods on learning rule structures.
Since CompGCN scores a triplet using its query and tail entity representations without applying labeling trick, the rule structures learned by CompGCN should be in the form of . In CompGCN, the query and tail entities’ representations encode different subgraphs. However, the joint subgraph they represent may not necessarily be connected. This suggests that the rule structures learned by CompGCN are non-structural, indicating there is no path between its query and tail entities except for relation . This observation is proven with the following theorem.
Theorem 3.4 (Logical expressivity of CompGCN).
For KG reasoning, CompGCN can learn the rule formula where is a formula involving sub-formulas from and which are the sets of formulas in .
Remark.
Theorem 3.4 indicates that representations of two end entities encoding two formulas respectively, and these two formulas are independent. Thus, the rule structures learned by CompGCN should be two disconnected subgraphs surrounding the query and tail entities respectively.
Similar to Theorem 3.2, CompGCN learns rule formula by treating it as a binary classifier. In a KG, the binary classifier should output true if the triplet exists; otherwise, it should output false. If CompGCN can learn the rule formula , it implies that it can estimate the binary classifier . Consequently, if the rule formula is (not) satisfied at entity pair , the score is a high (low) value, indicating the existence (absence) of triplet .
Theorem 3.4 (proven in Appendix C) shows that CompGCN can only learn rule formula for non-structural rules. One important type of relation in this category is the similarity between two entities (experiments in Appendix D.2), like indicating entities with the same color. However, structural rules are more commonly observed in KG reasoning (Lavrac & Dzeroski, 1994; Sadeghian et al., 2019; Srinivasan & Ribeiro, 2020). Since Theorem 3.4 indicates CompGCN fails to learn connected rule structures that are not independent, the structural rules in Figure 2 cannot be learned by CompGCN. Such a comparison shows why QL-GNN is more efficient than classical methods, e.g., R-GCN and CompGCN, in real applications. Compared with previous work on single-relational graphs, Zhang et al. (2021) shows CompGCN cannot distinguish many non-isomorphic links, while our paper derives expressivity of CompGCN for learning rule structures.
4 Entity Labeling GNN based on rule formula transformation
QL-GNN is proven to be able to learn the class of rule structures defined in Corollary 3.3. For rule structures outside this class, we try to learn them with a novel labeling trick based on QL-GNN. Our general idea is to transform the rule structures outside this class into the rule structures in this class by adding constants to the graph. The following proposition and corollary show how to add constants to a rule structure so that it can be described by formulas in CML and how to apply labeling trick to make it learnable for QL-GNN.
Proposition 4.1.
Let describe a single-connected rule structure in . If we assign constants to all entities with out-degree larger than one in , the rule structure can be described with a new rule formula in .
Corollary 4.2.
Applying labeling trick with unique initial representations to entities assigned with constants in Proposition 4.1, the rule structure can be learned by QL-GNN.
For instance, in Figure 3, the rule structure cannot be distinguished from the rule structure by recursive definition in Corollary 3.3, thus cannot be learned by QL-GNN. In this example, Proposition 4.1 suggests assigning constant to the entity colored with gray in Figure 3, then a new rule formula
in (Corollary A.5) can describe the rule structure of . Therefore, the rule structure of can be learned with by QL-GNN with constant and cannot be learned by classical methods and vanilla QL-GNN.
Based on Corollary 4.2, we need apply labeling trick to entities other than the query entities in QL-GNN to learn the rule structures outside the scope of Corollary 3.3. The new method is called Entity-Labeling (EL) GNN shown in Algorithm 1 and is different from QL-GNN in assigning constants to all the entities with out-degree larger than . We choose the degree threshold as a hyperparameter because a small (such as ) will introduce too many constants to KG, which impedes the generalization of GNN (Abboud et al., 2021) (see an explanation from logical perspective in Appendix F.2). In fact, a smaller makes GNN learn the rule formulas with many constants and results bad generalization, while a larger may not be able to transform indistinguishable rules into formulas in CML. As a result, the degree threshold should be tuned to balance the expressivity and generalization of GNN. Same as the constant in QL-GNN, we add a unique initial representation for entities whose out-degree in steps 3-5. For the query entity , we assign it with a unique initial representation in step 7. In Algorithm 1, it can be seen that the additional time of EL-GNN comes from traversing all entities in the graph. The additional time complexity is linear with respect to the number of entities, which is negligible compared to QL-GNN. For convenience, GNN initialized with EL algorithm is denoted as EL-GNN (e.g., EL-NBFNet) in our paper.
Discussion
In Figure 1, we visually compare the expressivity of QL-GNN and EL-GNN. Classical methods, e.g., R-GCN and CompGCN, are not compared here because they can solely learn non-structural rules which are not commonly-seen in real applications. QL-GNN, e.g., NBFNet and RED-GNN, excels at learning rule structures described by formula in . The proposed EL-GNN, encompassing QL-GNN as a special case, can learn rule structures described by formula in which has a larger description scope than .
5 Related Works
5.1 Expressivity of Graph Neural Network (GNN)
GNN (Kipf & Welling, 2016; Gilmer et al., 2017) has shown good performance on a wide range of tasks involving graph-structured data, thus many existing works try to analyze the expressivity of GNNs. Most of these works analyze the expressivity of GNNs from the perspective of graph isomorphism testing. A well-known result (Xu et al., 2019) shows that the expressivity of vanilla GNN is limited to WL test and the result is extended to KG by Barcelo et al. (2022). To improve the expressivity of GNNs, most of the existing works either design GNNs motivated by high-order WL test (Morris et al., 2019; 2020; Barcelo et al., 2022) or apply special initial representations (Abboud et al., 2021; You et al., 2021; Sato et al., 2021; Zhang et al., 2021). Except for using graph isomorphism testing, Barceló et al. (2020) analyze the logical expressivity of GNNs and identify that the logical rules from graded modal logic can be learned by vanilla GNN. However, their analysis is limited to node classification on the single-relational graph. Except from the expressivity of vanilla GNN, Tena Cucala et al. (2022) propose monotonic GNN whose prediction can be explained by symbolical rules in Datalog and the expressivity of monotonic GNN is further analyzed in Cucala et al. (2023).
Regarding the expressivity of GNNs for link prediction, Srinivasan & Ribeiro (2020) demonstrate that GNNs’ structural node representations alone are insufficient for accurate link prediction. To overcome this limitation, they introduce a method that incorporates Monte Carlo samples of node embeddings obtained from network embedding techniques instead of relying solely on GNNs. However, Zhang et al. (2021) discovered that by leveraging the labeling trick in GNNs, it is indeed possible to learn structural link representations for effective link prediction. This finding provides reassurance regarding the viability of GNNs for this task. Nonetheless, their analysis is confined to single-relational graphs, and their conclusions are limited to the fact that the labeling trick enables distinct representations for some non-isomorphic links, which other approaches cannot achieve. In this paper, we delve into the analysis of GNNs’ logical expressivity to study their ability of learning rule structures. By doing so, we aim to gain a comprehensive understanding of the rule structures that SOTA GNNs can learn in graphs. Our analysis encompasses both single-relational graph and KGs, thus broadening the applicability of our findings.
A concurrent work by Huang et al. (2023) analyzes the expressivity of GNNs for NBFNet (a kind of QL-GNN in our paper) with conditional MPNN while our work unifies state-ot-the-art GNNs into QL-GNN and analyzes the expressivity from a different perspective focusing on the understanding of relationship between labeling trick and constants in logic.
5.2 Knowledge graph reasoning
KG reasoning is the task to predict new facts based on the known facts in a KG where are sets of entities, edges and relation types in the graph respectively. The facts (or edges, links) are typically expressed as triplets in the form of , where the head entity and tail entity are related with the relation type . KG reasoning can be modeled as the process of predicting the tail entity of a query in the form where is called the query entity in our paper. The head prediction can be transformed into tail prediction with inverse relation . Thus, we focus on tail prediction in this paper.
Embedding-based methods like TransE (Bordes et al., 2013), ComplEx (Trouillon et al., 2016), RotatE (Sun et al., 2019), and QuatE (Zhang et al., 2019) have been developed for KG reasoning. They learn embeddings for entities and relations, and predict facts by aggregating their representations. To capture local evidence within graphs, Neural LP (Yang et al., 2017) and DRUM (Sadeghian et al., 2019) learn logical rules based on predefined chain-like structures. However, apart from chain-like rules, these methods failed to learn more complex structures in KG (Hamilton et al., 2018; Ren et al., 2019). GNNs have also been used for KG reasoning, such as R-GCN (Schlichtkrull et al., 2018) and CompGCN (Vashishth et al., 2020), which aggregate entity and relation representations to calculate scores for new facts. However, these methods struggle to differentiate between the structural roles of different neighbors (Srinivasan & Ribeiro, 2020; Zhang et al., 2021). GraIL (Teru et al., 2020) addresses this by extracting enclosing subgraphs to predict new facts, while RED-GNN (Zhang & Yao, 2022) employs dynamic programming for efficient subgraph extraction and predicts new facts based on the tail entity representation. To extract relevant structures from graph, AdaProp (Zhang et al., 2023) improves RED-GNN by employing adaptive propagation to filter out irrelevant entities and retain promising targets. Motivated by the effectiveness of heuristic path-based metrics for link prediction, NBFNet (Zhu et al., 2021) proposes a neural network aligned with Bellman-Ford algorithm for KG reasoning. Zhu et al. (2022) propose A⋆Net to learn a priority function to select important nodes and edges at each iteration. Specifically, AdaProp and A⋆Net are variants of RED-GNN and NBFNet, respectively, designed to enhance their scalability. Among these methods, RED-GNN, NBFNet, AdaProp, and A⋆Net achieve state-of-the-art performance on KG reasoning.
6 Experiment
In this section, we validate our theoretical findings from Section 3 and showcase the efficacy of our proposed EL-GNN (Section 4) on synthetic and real datasets through experiments. All experiments were implemented in Python using PyTorch and executed on A100 GPUs with 80GB memory.
6.1 Experiments on synthetic datasets
We generate six KGs based on rule structures in Figure 2, 3, 6 to validate our theory on expressivity and verify the improved performance of EL-GNN. These rule structures are either analyzed in the previous sections, or representative for evaluating GNN’s ability for learning rule structures. We evaluate R-GCN, CompGCN, RED-GNN, NBFNet, EL-RED-GNN, and EL-NBFNet (using RED-GNN/NBFNet as backbone with Algorithm 1). Our evaluation metric is prediction Accuracy which measures how well a rule structure is learned. We report testing accuracy of classical methods, QL-GNN, and EL-GNN on six synthetic graphs. Hyperparameters for all methods are automatically tuned with Ray (Liaw et al., 2018) based on the validation accuracy.
| Method | Method | ||||||
| Classical | R-GCN | 0.016 | 0.031 | 0.044 | 0.024 | 0.067 | 0.014 |
| CompGCN | 0.016 | 0.021 | 0.053 | 0.039 | 0.067 | 0.027 | |
| QL-GNN | RED-GNN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.405 |
| NBFNet | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.541 | |
| EL-GNN | EL-RED-GNN | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.797 |
| EL-NBFNet | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.838 |
Dataset generation
Given a target relation, there are three steps to generate a dataset: (1) rule structure generation: generate specific rule structures according to their definition; (2) noisy triplets generation: generate noisy triplets to avoid GNN from learning naive rule structures; (3) missing triplets completion: generate missing triplets based on the target rule structure because the noisy triplets generation step could add triplets satisfying the target rule structure. We use triplets generated from rule structure and noisy triplets generation steps as known triplets in graph. Triplets with the target relation are separated into training, validation, and testing sets. Our experimental setting differs slightly from previous works as all GNNs in the experiments only perform message passing on the known triplets in the graph. This setup is reasonable and allows for evaluating the performance of GNNs in learning rule structures because the presence of a triplet can be determined based on the known triplets in the graph, following the rule structure generation process.
Results
Table 1 presents the testing accuracy of classical GNN methods, QL-GNN, and EL-GNN on six synthetic datasets (denoted as and ) generated from their corresponding rule structures. The experimental results support our theory. CompGCN performs poorly on all six datasets, as it fails to learn the underlying rule structures discussed in examples of Section 3 (refer to Section D.2 for experiments of CompGCN). QL-GNN achieves perfect predictions (100% accuracy) for triplets with relations and , successfully learning the corresponding rule formulas from . EL-GNN demonstrates improved expressivity, as evidenced by its performance on dataset , aligning with the analysis in Section 4. Furthermore, EL-GNN effectively learns rule formulas and , validating its expressivity.
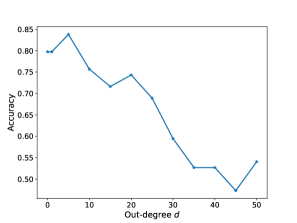
Furthermore, we demonstrate the impact of the degree threshold on EL-GNN with dataset . The testing accuracy in Figure 4 reveals that an excessively small or large out-degree hinders the performance of EL-GNN. Therefore, it is important to empirically fine-tune the hyperparameter . To test the robustness of QL-GNN and EL-GNN in learning rules with incomplete structures, we randomly remove triplets in the training set to evaluate the accuracy of learning rule structures. The results can be found in Appendix D.4.
6.2 Experiments on real datasets
In this section, we follow the standard setup as Zhu et al. (2021) to test EL-GNN’s effectiveness on four real datasets: Family (Kok & Domingos, 2007), Kinship (Hinton et al., 1986), UMLS (Kok & Domingos, 2007), WN18RR (Dettmers et al., 2017), and FB15k-237 (Toutanova & Chen, 2015). For a fair comparison, we evaluate EL-NBFNet and EL-RED-GNN (applying EL to NBFNet and RED-GNN) using the same hyperparameters as NBFNet and RED-GNN and handcrafted . We compare it with embedding-based methods (RotatE, QuatE), rule-based methods (Neural LP, DRUM), and GNN-based methods (CompGCN, NBFNet, RED-GNN). To evaluate performance, we provide testing accuracy and standard deviation obtained from three repetitions for thorough evaluation.
In Table 2, we present our experimental findings. The results first show that NBFNet and RED-GNN (QL-GNN) outperform CompGCN. Furthermore, the proposed EL algorithm improves the accuracy of RED-GNN and NBFNet on real datasets. However, the degree of improvement varies across datasets due to the number and variations of rule types, and the quality of missing triplets in training sets. More experimental results, e.g., time cost and more performance metrics, are in Appendix D.5.
| Method Class | Methods | Family | Kinship | UMLS | WN18RR | FB15k-237 |
| Embedding- based | RotatE | 0.865±0.004 | 0.704±0.002 | 0.860±0.003 | 0.427±0.003 | 0.240±0.001 |
| QuatE | 0.897±0.001 | 0.311±0.003 | 0.907±0.002 | 0.441±0.002 | 0.255±0.004 | |
| Rule-based | Neural LP | 0.872±0.002 | 0.481±0.006 | 0.630±0.001 | 0.369±0.003 | 0.190±0.002 |
| DRUM | 0.880±0.003 | 0.459±0.005 | 0.676±0.004 | 0.424±0.002 | 0.252±0.003 | |
| GNN-based | CompGCN | 0.883±0.001 | 0.751±0.003 | 0.867±0.002 | 0.443±0.001 | 0.265±0.001 |
| RED-GNN | 0.988±0.002 | 0.820±0.003 | 0.946±0.001 | 0.502±0.001 | 0.284±0.002 | |
| NBFNet | 0.977±0.001 | 0.819±0.002 | 0.946±0.002 | 0.496±0.002 | 0.320±0.001 | |
| EL-RED-GNN | 0.990±0.002 | 0.839±0.001 | 0.952±0.003 | 0.504±0.001 | 0.322±0.002 | |
| EL-NBFNet | 0.985±0.001 | 0.842±0.003 | 0.953±0.002 | 0.501±0.003 | 0.332±0.001 |
7 Conclusion
In this paper, we analyze the expressivity of the state-of-the-art GNNs for learning rules in KG reasoning, explaining their superior performance over classical methods. Our analysis sheds light on the rule structures that GNNs can learn. Additionally, our theory motivates an effective labeling method to improve GNN’s expressivity. Moving forward, we will extend our analysis to GNNs with general labeling trick and try to extract explainable rule structures from trained GNN. Limitations and impacts are discussed in Appendix G.
Acknowledgments
Q. Yao was in part supported by National Key Research and Development Program of China under Grant 2023YFB2903904 and NSFC (No. 92270106).
References
- Abboud et al. (2021) Ralph Abboud, Ismail Ilkan Ceylan, Martin Grohe, and Thomas Lukasiewicz. The surprising power of graph neural networks with random node initialization. In International Joint Conference on Artificial Intelligence, 2021.
- Arakelyan et al. (2021) Erik Arakelyan, Daniel Daza, Pasquale Minervini, and Michael Cochez. Complex query answering with neural link predictors. In International Conference on Learning Representations, 2021.
- Barceló et al. (2020) Pablo Barceló, Egor V Kostylev, Mikael Monet, Jorge Pérez, Juan Reutter, and Juan-Pablo Silva. The logical expressiveness of graph neural networks. In International Conference on Learning Representations, 2020.
- Barcelo et al. (2022) Pablo Barcelo, Mikhail Galkin, Christopher Morris, and Miguel Romero Orth. Weisfeiler and leman go relational. In The First Learning on Graphs Conference, 2022. URL https://openreview.net/forum?id=wY_IYhh6pqj.
- Battaglia et al. (2018) Peter W Battaglia, Jessica B Hamrick, Victor Bapst, Alvaro Sanchez-Gonzalez, Vinicius Zambaldi, Mateusz Malinowski, Andrea Tacchetti, David Raposo, Adam Santoro, Ryan Faulkner, et al. Relational inductive biases, deep learning, and graph networks. arXiv preprint arXiv:1806.01261, 2018.
- Bordes et al. (2013) Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. Translating embeddings for modeling multi-relational data. Advances in Neural Information Processing Systems, 2013.
- Cao et al. (2019) Yixin Cao, Xiang Wang, Xiangnan He, Zikun Hu, and Tat-Seng Chua. Unifying knowledge graph learning and recommendation: Towards a better understanding of user preferences. In International World Wide Web Conference, 2019.
- Cucala et al. (2023) David Tena Cucala, Bernardo Cuenca Grau, Boris Motik, and Egor V Kostylev. On the correspondence between monotonic max-sum gnns and datalog. arXiv preprint arXiv:2305.18015, 2023.
- De Rijke (2000) Maarten De Rijke. A note on graded modal logic. Studia Logica, 64(2):271–283, 2000.
- Dettmers et al. (2017) Tim Dettmers, Pasquale Minervini, Pontus Stenetorp, and Sebastian Riedel. Convolutional 2D knowledge graph embeddings. In AAAI conference on Artificial Intelligence, 2017.
- Gilmer et al. (2017) Justin Gilmer, Samuel S Schoenholz, Patrick F Riley, Oriol Vinyals, and George E Dahl. Neural message passing for quantum chemistry. In International Conference on Machine Learning, 2017.
- Hamilton et al. (2018) Will Hamilton, Payal Bajaj, Marinka Zitnik, Dan Jurafsky, and Jure Leskovec. Embedding logical queries on knowledge graphs. Advances in neural information processing systems, 31, 2018.
- Hinton et al. (1986) Geoffrey E Hinton et al. Learning distributed representations of concepts. In Annual Conference of the Cognitive Science Society, 1986.
- Huang et al. (2023) Xingyue Huang, Miguel Romero Orth, İsmail İlkan Ceylan, and Pablo Barceló. A theory of link prediction via relational weisfeiler-leman. arXiv preprint arXiv:2302.02209, 2023.
- Ji et al. (2021) Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Marttinen, and S Yu Philip. A survey on knowledge graphs: Representation, acquisition, and applications. IEEE transactions on neural networks and learning systems, 33(2):494–514, 2021.
- Kipf & Welling (2016) Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In International Conference on Learning Representations, 2016.
- Kok & Domingos (2007) Stanley Kok and Pedro Domingos. Statistical predicate invention. In International Conference on Machine Learning, 2007.
- Lavrac & Dzeroski (1994) Nada Lavrac and Saso Dzeroski. Inductive logic programming. In WLP, pp. 146–160. Springer, 1994.
- Liaw et al. (2018) Richard Liaw, Eric Liang, Robert Nishihara, Philipp Moritz, Joseph E Gonzalez, and Ion Stoica. Tune: A research platform for distributed model selection and training. arXiv preprint arXiv:1807.05118, 2018.
- Mohamed et al. (2019) Sameh K. Mohamed, Vít Novácek, and Aayah Nounu. Discovering protein drug targets using knowledge graph embeddings. Bioinformatics, 2019.
- Morris et al. (2019) Christopher Morris, Martin Ritzert, Matthias Fey, William L Hamilton, Jan Eric Lenssen, Gaurav Rattan, and Martin Grohe. Weisfeiler and leman go neural: Higher-order graph neural networks. In AAAI conference on Artificial Intelligence, 2019.
- Morris et al. (2020) Christopher Morris, Gaurav Rattan, and Petra Mutzel. Weisfeiler and leman go sparse: Towards scalable higher-order graph embeddings. Advances in Neural Information Processing Systems, 2020.
- Otto (2019) Martin Otto. Graded modal logic and counting bisimulation. arXiv preprint arXiv:1910.00039, 2019.
- Ren et al. (2019) Hongyu Ren, Weihua Hu, and Jure Leskovec. Query2box: Reasoning over knowledge graphs in vector space using box embeddings. In International Conference on Learning Representations, 2019.
- Sadeghian et al. (2019) Ali Sadeghian, Mohammadreza Armandpour, Patrick Ding, and Daisy Zhe Wang. Drum: End-to-end differentiable rule mining on knowledge graphs. Advances in Neural Information Processing Systems, 2019.
- Sato et al. (2021) Ryoma Sato, Makoto Yamada, and Hisashi Kashima. Random features strengthen graph neural networks. In SIAM International Conference on Data Mining, 2021.
- Schlichtkrull et al. (2018) Michael Schlichtkrull, Thomas N Kipf, Peter Bloem, Rianne van den Berg, Ivan Titov, and Max Welling. Modeling relational data with graph convolutional networks. In European Semantic Web Conference, 2018.
- Srinivasan & Ribeiro (2020) Balasubramaniam Srinivasan and Bruno Ribeiro. On the equivalence between positional node embeddings and structural graph representations. ICLR, 2020.
- Sun et al. (2019) Zhiqing Sun, Zhi-Hong Deng, Jian-Yun Nie, and Jian Tang. Rotate: Knowledge graph embedding by relational rotation in complex space. In International Conference on Learning Representations, 2019.
- Tena Cucala et al. (2022) DJ Tena Cucala, B Cuenca Grau, Egor V Kostylev, and Boris Motik. Explainable gnn-based models over knowledge graphs. 2022.
- Teru et al. (2020) Komal Teru, Etienne Denis, and Will Hamilton. Inductive relation prediction by subgraph reasoning. In International Conference on Machine Learning, 2020.
- Toutanova & Chen (2015) Kristina Toutanova and Danqi Chen. Observed versus latent features for knowledge base and text inference. In Alexandre Allauzen, Edward Grefenstette, Karl Moritz Hermann, Hugo Larochelle, and Scott Wen-tau Yih (eds.), Proceedings of the 3rd Workshop on Continuous Vector Space Models and their Compositionality, pp. 57–66, Beijing, China, July 2015. Association for Computational Linguistics. doi: 10.18653/v1/W15-4007. URL https://aclanthology.org/W15-4007.
- Trouillon et al. (2016) Théo Trouillon, Johannes Welbl, Sebastian Riedel, Éric Gaussier, and Guillaume Bouchard. Complex embeddings for simple link prediction. In International Conference on Machine Learning, 2016.
- Vashishth et al. (2020) Shikhar Vashishth, Soumya Sanyal, Vikram Nitin, and Partha Talukdar. Composition-based multi-relational graph convolutional networks. In International Conference on Learning Representations, 2020.
- Xu et al. (2019) Keyulu Xu, Weihua Hu, Jure Leskovec, and Stefanie Jegelka. How powerful are graph neural networks? In International Conference on Learning Representations, 2019.
- Yang et al. (2017) Fan Yang, Zhilin Yang, and William W Cohen. Differentiable learning of logical rules for knowledge base reasoning. Advances in Neural Information Processing Systems, 2017.
- You et al. (2021) Jiaxuan You, Jonathan M Gomes-Selman, Rex Ying, and Jure Leskovec. Identity-aware graph neural networks. In AAAI Conference on Artificial Intelligence, 2021.
- Zhang et al. (2021) Muhan Zhang, Pan Li, Yinglong Xia, Kai Wang, and Long Jin. Labeling trick: A theory of using graph neural networks for multi-node representation learning. Advances in Neural Information Processing Systems, 2021.
- Zhang et al. (2019) Shuai Zhang, Yi Tay, Lina Yao, and Qi Liu. Quaternion knowledge graph embeddings. Advances in Neural Information Processing Systems, 32, 2019.
- Zhang & Yao (2022) Yongqi Zhang and Quanming Yao. Knowledge graph reasoning with relational digraph. In International World Wide Web Conference, 2022.
- Zhang et al. (2023) Yongqi Zhang, Zhanke Zhou, Quanming Yao, Xiaowen Chu, and Bo Han. Adaprop: Learning adaptive propagation for graph neural network based knowledge graph reasoning. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pp. 3446–3457, 2023.
- Zhu et al. (2021) Zhaocheng Zhu, Zuobai Zhang, Louis-Pascal Xhonneux, and Jian Tang. Neural bellman-ford networks: A general graph neural network framework for link prediction. Advances in Neural Information Processing Systems, 2021.
- Zhu et al. (2022) Zhaocheng Zhu, Xinyu Yuan, Mikhail Galkin, Sophie Xhonneux, Ming Zhang, Maxime Gazeau, and Jian Tang. A*net: A scalable path-based reasoning approach for knowledge graphs. arXiv preprint arXiv:2206.04798, 2022.
Appendix A Rule analysis
We first give a simple proof for Proposition 3.1.
proof of Proposition 3.1.
Since is equivalent to , where is the constant predicate only satisfied at entity . Because can describe the rule structure of , can describe the rule structure of as well. ∎
We use the notation () to represent that the unary predicate is (not) satisfied at entity .
Definition A.1 (Definition of graded modal logic).
A formula in graded modal logic of KG is recursively defined as follows:
-
1.
If , if is an entity in KG;
-
2.
If , if and only if has the property or can be uniquely identified by constant ;
-
3.
If , if and only if and ;
-
4.
If , if and only if ;
-
5.
If , if and only if the set of entities has cardinality at least .
Corollary A.2.
are formulas in .
Proof.
is a formula in as it can be recursively defined as follows
∎
Corollary A.3.
is a formula in .
Proof.
is a formula in as it can be recursively defined as follows
∎
Corollary A.4.
is a formula in .
Proof.
By Corollary A.2, and are formulas in . Thus is a formula in . ∎
Corollary A.5.
is a formula in .
Proof.
is a formula in as it can be recursively defined as follows
where the constant ensures that there is only one entity satisfied for unary predicate . ∎
Example of rules
We can find some relations in reality corresponding to rules in Figure 2. Here are two examples of and :
-
•
Relation nationality (): ;
-
•
Relation father (): and .
Rule structures in real datasets
To show that the expressivity is meaningful in our paper, we select three rule structures from Family and FB15k-237 in Figure 5 to show the existence of rule structures in real datasets. With the definition of CML, the rule structure in Figure 5(a) is not a formula in CML and rule structures in Figure 5(b) and 5(c) are formulas in CML. The real rules shows that rules defined by CML is common in real-world datasets and the rules beyond CML also exist, which highlights the importance of our work.

Summary
Here we give Table 3 to illustrate the correspondence between GNNs for KG reasoning, rule structures, and theories presented in our paper.
| Rule formula | Theoretical result | Exemplar Methods | ||||
| Classical | ✗ | ✗ | ✗ | ✗ | Theorem 3.4 | R-GCN, CompGCN |
| QL-GNN | ✓ | ✓ | ✓ | ✗ | Theorem 3.2 | NBFNet, RED-GNN |
| EL-GNN | ✓ | ✓ | ✓ | ✓ | Proposition 4.1 | EL-NBFNet/RED-GNN |
Appendix B Relation between QL-GNN and NBFNet/RED-GNN
In this part, we show that NBFNet and RED-GNN are special cases of QL-GNN in Table 4 and 5 respectively.
| NBFNet | |
| Query representation | Relation embedding |
| Non-query representation | 0 |
| MPNN | |
| Triplet score | Feed-forward network |
| RED-GNN | |
| Query representation | 0 |
| Non-query representation | NULL |
| MPNN | |
| Triplet score | Linear transformation |
Appendix C Proof
We use the notation () to denote is (not) satisfied at .
C.1 Base theorem: what kind of logical formulas can MPNN backbone for KG learn?
In this section, we analyze the expressivity of MPNN backbone (1) for learning logical formulas in KG. This section is the extension of Barceló et al. (2020) to KG.
In a KG , MPNN with layers is a type of neural network that applies graph and initial entity representation to learn the representations . MPNN employs message-passing mechanisms (Gilmer et al., 2017) to propagate information between entities in graph. The -th layer of MPNN updates the entity representation via the following message-passing formula
where and are combination and aggregation functions respectively, is the message function encoding the relation and entity neighboring to , is a multiset, and is the neighboring entity set .
To understand how MPNN can learn logical formulas, we regard logical formula as a binary classifier indicating whether is satisfied at entity . Then, we commence with the following definition.
Definition C.1.
A MPNN captures a logical formula if and only if given any graph , the MPNN representation can be mapped to a binary value, where True indicates that satisfies on entity , while False does not satisfy.
According to the above definition, MPNN can learn logical formula in KG by encoding whether these logical formulas is satisfied in the representation of the corresponding entity. For example, if MPNN can learn a logical formula , it implies that can be mapped to a binary value True/False by a function indicating whether is satisfied at entity . Previous work (Barceló et al., 2020) has proven that vanilla GNN for single-relational graph can learn the logical formulas from graded modal logic (De Rijke, 2000; Otto, 2019) (a.k.a., Counting extension of Modal Logic, CML). In this section, we will present a similar theory of MPNN for KG.
The insight of MPNN’s ability to learn formulas in CML lies in the alignment between certain CML formulas and the message-passing mechanism, which also holds for KG. Specifically, is the formula aligned with MPNN’s message-passing mechanism and allows to check the property of neighbor of entity variable . We use notation to denote CML of a graph . Then, we give the following theorem to find out the kind of logical formula MPNN (1) can learn in KG.
Theorem C.2.
In a KG , a logical formula is learned by MPNN (1) from its representations if and only if is a formula in .
Our theorem can be viewed as an extension of Theorem 4.2 in Barceló et al. (2020) to KG and is the elementary tool for analyzing the expressivity of GNNs for KG reasoning. The proof of Theorem C.2 is in Appendix C and employs novel techniques that specifically account for relation types. Our theorem shows that CML of KG is the tightest subclass of logic that MPNN can learn. Similarly, our theorem is about the ability to implicitly learn logical formulas by MPNN rather than explicitly extracting them.
C.2 Proof of Theorem C.2
The backward direction of Theorem C.2 is proven by constructing a MPNN that can learn any formula in CML. The forward direction relies on the results from recent theoretical results in Otto (2019). Our theorem can be seen as an extension of Theorem 4.2 in Barceló et al. (2020) to KG.
We first prove the backward direction of Theorem C.2.
Lemma C.3.
Each formula in CML can be learned by MPNN (1) from its entity representations.
Proof.
Let be a formula in CML. We decompose into a series of sub-formulas where is a sub-formula of if and . Assume the MPNN representation . In this proof, the theoretical analysis will based on the following simple choice of (1)
| (2) |
with , and . The entries of the -th columns of , and depend on the sub-formulas of as follows:
-
•
Case 0. if where is a unary predicate, ;
-
•
Case 1. if , and ;
-
•
Case 2. if , and ;
-
•
Case 3. if , and .
with all the other values set to 0.
Before the proof, for every entity , the initial representation has if the sub-formula is satisfied at , and otherwise.
Let be a KG. We next prove that for every and every entity it holds that
for every .
Now, we prove this by induction of the number of formulas in .
Base case: One sub-formula in . In this case, the formula is an atomic predicate . Because and , we have if and otherwise. For , satisfies the same property.
Induction Hypothesis: sub-formulas in with . Assume if and otherwise for .
Proof: sub-formulas in . Let . Case 1-3 should be considered.
Case 1. Let . Then and . Then we have
By the induction hypothesis, if only if and otherwise. Similarly, if and only if and otherwise. Then we have if and only if , which means and . Then if and only if and , i.e., , and otherwise.
Case 2. Let . Because of and , we have
By the induction hypothesis, if and only if and otherwise. Then we have if and only if , which means . Because if and only if , we have if and only if , i.e., , and otherwise.
Case 3. Let . Because of and , we have
By the induction hypothesis, if and only if and otherwise. Let . Then we have if and only if , which means . Because , is connected to with relation , and , we have if and only if and otherwise.
To learn a logical formula , we only apply a linear classifier to to extract the component of corresponding to . If , the value of the corresponding extracted component is 1.
∎
Next, we prove the forward direction of Theorem C.2.
Theorem C.4.
A formula is learned by MPNN (1) if it can be expressed as a formula in CML.
Definition C.5 (Unraveling tree).
Let be a KG, be entity in , and . The unravelling of in at depth , denoted by , is a tree composed of
-
•
a node for each path in with ,
-
•
an edge between and when is a triplet in (assume is ), and
-
•
each node has the same properties as in .
Lemma C.6.
Let and be two KGs, and be two entities in and respectively. Then for every , the RWL test (Barcelo et al., 2022) assigns the same color/hash to and at round if and only if there is an isomorphism between and sending to .
Proof.
Base Case: When , the result is obvious.
Induction Hypothesis: Relational WL (RWL) test assigns the same color to and at round if and only if there is an isomorphism between and sending to .
Proof: In the -th round,
Prove “same color isomorphism”.
Because , we have , and there exists an entity pair that
Then we have . According to induction hypothesis, we have . Also, because the edge connecting entity pair and is , so there is an isomorphism between and sending to .
Prove “isomorphism same color”.
Because there exists an isomorphism between and sending to , assume is an bijective between the neighbors of and , e.g, and , the relation between entity pair and is .
Next we prove . Because and are isomorphism, and maps to , for the left tree with depth, i.e., and , can be the isomorphism mapping between and . According to induction hypothesis, we have . Because , we also have which means . After running RWL test, we have . ∎
Theorem C.7.
Let be a unary formula in the formal description of graph in Section 3.1. If is not equivalent to a formula in CML, there exist two KGs and and two entities in and in such that for every and such that but .
Proof.
The theorem follows directly from Theorem 2.2 in Otto (2019). Because and are equivalent with the definition of counting bisimulation (i.e., notation ). ∎
Lemma C.8.
If a formula is not equivalent to any formula in CML, there is no MPNN (1) that can learn .
Proof.
Assume for a contradiction that there exists a MPNN that can learn . Since is not equivalent to any formula in CML, with Theorem C.7, there exists two KGs and and two entities in and in such that for every and such that and . By Lemma C.6, because for every , we have . But this contradicts the assumption that MPNN is supposed to learn . ∎
The following two remarks intuitively explain why MPNN can learn formulas in CML.
Remark C.9.
Theorem C.2 applies to both and . The atomic unary predicate in CML of graph is learned by the initial representations , which can be achieved by assigning special vectors to . In particular, the constant predicate in is learned by assigning a unique vector (e.g., one-hot vector for different entities) as the initial representation of the entity with unique identifier . The other sub-formulas in Definition A.1 can be learned by continuous logical operations (Arakelyan et al., 2021) which are independent of message-passing mechanisms.
Remark C.10.
Assume the -th layer representations can learn the formula in CML, the -th layer representations of MPNN can learn with specific aggregation function in (1) because can aggregate the logical formulas in the one-hop neighbor representation (i.e., ) with message-passing mechanisms.
Remark C.11.
The positive results for our theorem (e.g., a MPNN variant can learn a logical formula) hold for MPNNs powerful than the MPNN we construct in (2), while our negative results (e.g., a MPNN variant cannot learn a logical formula) hold for any general MPNNs (1). Hence, the backward direction remains valid irrespective of the aggregate and combine operators under consideration. This limitation is inherent to the MPNN architecture represented by (1) and not specific to the chosen representation update functions. On the other hand, the forward direction holds for MPNNs that are more powerful than (2).
C.3 Proof of Theorem 3.2
Definition C.12.
QL-GNN learns a rule formula if and only if given any graph , the QL-GNN’s score of a new triplet can be mapped to a binary value, where True indicates that satisfies on entity , while False does not satisfy.
Proof.
We set the KG as and restrict the unary formulas in to the form of . This theorem is directly obtained by Theorem C.2 because constant can be equivalently transformed to constant predicate . ∎
Proof of Corollary 3.3.
Base case: Since the unary predicate can be encoded into the initial representation of the entity according to Section C.1. Then the base case is obvious.
Recursion rule: Since the rule structures are unary predicate and can be learned by QL-GNN, they are formulas in . According to recursive definition of CML, , are also formulas in , therefore can be learned by QL-GNN.
∎
C.4 Proof of Theorem 3.4
Definition C.13.
CompGCN learns a rule formula if and only if given any graph , the QL-GNN’s score of a new triplet can be mapped to a binary value, where True indicates that satisfies on entity pair , while False does not satisfy.
Proof.
According to Theorem C.2, the MPNN representation can represent the formulas in . Assume and can be represented by the MPNN representation and there exists two functions and that can extract the logical formulas from , i.e., if and if for . We show how the following two logical operators can be learned by for candidate triplet :
-
•
Conjunction: . The conjunction of can be learned with function .
-
•
Negation: . The negation of can be learned with function .
The disjunction can be obtained by . More complex formula involving sub-formulas from and can be learned by combining the score functions above. ∎
C.5 Proof of Proposition 4.1
Lemma C.14.
Assume describes a single-connected rule structure in a KG. If assign constant to entities with out-degree large than 1 in the KG, the structure can be described with formula in CML of KG with assigned constants.
Proof.
According to Theorem C.7, assume with assigned constants is not equivalent to a formula in CML, there should exist two rule structures in KG , and entity in and entity in such that for every and such that but .
Since each entity in () with out-degree larger than 1 is assigned with a constant, the rule structure () can be uniquely recovered from its unravelling tree () for sufficient large . Therefore, if for every , the corresponding rule structures and should be isomorphism too, which means and . Thus, must be a formula in CML. ∎
Appendix D Experiments
D.1 More rule structures in synthetic datasets
In Section 6.1, we also include the following rule structures in the synthetic datasets, i.e., and in Figure 6, for experiments. and are both formulas from . The proof of is similar to the proof of in Corollary A.2. The proof of is similar to that of and is in Corollary D.1.
Corollary D.1.
is a formula in .
Proof.
is a formula in as it can be recursively defined as follows
∎
D.2 Experiments for CompGCN
The classical framework of KG reasoning is inadequate for assessing the expressivity of CompGCN because the query assumes that certain logical formula are satisfied at the head entity by default. In order to validate the expressivity of CompGCN, it is necessary to predict all missing triplets directly based on entity representations without relying on the query . To accomplish this, we create a new dataset called that adheres to the rule formula , where the logical formula is defined as:
Here, is represented with parameter reusing (reusing and ) and is a formula in CML. Therefore, the formula takes the form of and can be learned by CompGCN, as indicated by Theorem 3.4. To validate our theorem, we generate a synthetic dataset using the same steps outlined in Section 6.1, following the rule . We then train CompGCN on dataset . The experimental results demonstrate that CompGCN effectively learns the rule formula with 100% accuracy. Comparing it with QL-GNN is unnecessary since the latter is specifically designed for KG reasoning setting involving the query .
D.3 Statistics of synthetic datasets
| Datasets | |||||||
| known triplets | 1514 | 2013 | 843 | 1546 | 2242 | 2840 | 320 |
| training | 1358 | 2265 | 304 | 674 | 83 | 396 | 583 |
| validation | 86 | 143 | 20 | 43 | 6 | 26 | 37 |
| testing | 254 | 424 | 57 | 126 | 15 | 183 | 109 |
D.4 Results on synthetic with missing triplets
We randomly remove 5%, 10%, and 20% edges from synthetic datasets to test the robustness of QL-GNN and EL-GNN for rule structures learning. The results of QL-GNN and EL-GNN are shown in Table 7 and 8 respectively. The results show that the completeness of rule structure correlates strongly with the performance of QL-GNN and EL-GNN.
| Triplet missing ratio | ||||||
| 5% | 0.899 | 0.866 | 0.760 | 0.783 | 0.556 | 0.329 |
| 10% | 0.837 | 0.718 | 0.667 | 0.685 | 0.133 | 0.279 |
| 20% | 0.523 | 0.465 | 0.532 | 0.468 | 0.111 | 0.162 |
| Triplet missing ratio | ||||||
| 5% | 0.878 | 0.807 | 0.842 | 0.857 | 0.244 | 0.5 |
| 10% | 0.766 | 0.674 | 0.725 | 0.661 | 0.222 | 0.347 |
| 20% | 0.499 | 0.405 | 0.637 | 0.458 | 0.111 | 0.257 |
D.5 More experimental details on real datasets
MRR and Hit@10
Here we supplement MRR and Hit@10 of NBFNet and EL-NBFNet on real datasets in Table 9. The improvement of EL-NBFNet on MRR and Hit@10 is not as significant as that on Accuracy because the EL-NBFNet is designed for exactly learning rule formulas and only Accuracy can be guaranteed to be improved.
| Family | Kinship | UMLS | WN18RR | FB15k-237 | ||||||
| MRR | Hit@10 | MRR | Hit@10 | MRR | Hit@10 | MRR | Hit@10 | MRR | Hit@10 | |
| NBFNet | 0.983 | 0.993 | 0.900 | 0.997 | 0.970 | 0.997 | 0.548 | 0.657 | 0.415 | 0.599 |
| EL-NBFNet | 0.990 | 0.991 | 0.905 | 0.996 | 0.975 | 0.993 | 0.562 | 0.669 | 0.424 | 0.607 |
Different hyperparameters of
We have observed that a larger or smaller does not necessarily lead to better performance in Figure 4. For real datasets, we also observed similar phenomenon in Table 10. For real datasets, we uses for Family, Kinship, UMLS, WN18RR, and FB15k-237, respectively.
| NBFNet | ||||
| 0.948 | 0.958 | 0.963 | 0.961 | 0.951 |
Time cost of EL-NBFNet
In Table 11, we show the time cost of EL-NBFNet and NBFNet on real datasets. The time cost is measured by seconds of testing phase. The results show that EL-NBFNet is slightly slower than NBFNet. The reason is that EL-NBFNet needs to traverse all entities on KG to assign constants to entities with out-degree larger than degree threshold .
| Methods | Family | Kinship | UMLS | WN18RR | FB15k-237 |
| EL-NBFNet | 270.3 | 14.0 | 6.7 | 35.6 | 20.1 |
| NBFNet | 269.6 | 13.5 | 6.4 | 34.3 | 19.8 |
Appendix E Theory of GNNs for single-relational link prediction
Our theory of KG reasoning can be easily extended to the single-relational link prediction. The following two corollaries are the extensions of Theorem 3.2 and Theorem 3.4 to the single-relational link prediction, respectively.
Corollary E.1 (Theorem 3.2 on single-relational link prediction).
For single-relational link prediction, given a query , a rule formula is learned by QL-GNN if and only if is a formula in .
Appendix F Understanding generalization based on expressivity
F.1 Understanding expressivity vs. generalization
In this section, we provide some insights on the relation between expressivity and generalization. Expressivity in deep learning pertains to a model’s capacity to accurately represent information, whereas the ability of a model to achieve this level of expressivity depends on its generalization. Considering generalization requires not only contemplating the model design but also assessing whether the training algorithm can enable the model to achieve its expressivity. The experiments in this paper can also show this relation about expressivity and generalization from two perspective: (1) The experimental results of QL-GNN shows that its expressivity can be achieved with classical deep learning training strategies; (2) In the development of deep learning, a consensus is that more expressivity often leads to better generalization. The experimental results of EL-GNN verify this consensus.
In addition, our theory can provide some insights on model design with better generalization. Based on the constructive proof of Lemma C.3, if QL-GNN can learn a rule formula with recursive definition, QL-GNN can learn with layers and hidden dimensions no less than . Assuming learning relations with QL-GNN and numbers of recursive definition for these relations are respectively, QL-GNN can learn these relations with layers no more than and hidden dimensions no more than . Since these bounds are nearly worst-case scenarios, both the dimensions and layers can be further optimized. Also, in the constructive proof of Lemma C.3, the aggregation function is summation, and it is difficult for mean and max/min aggregation function to capture sub-formula . From the perspective of rule learning, QL-GNN extracts structural information at each layer. Therefore, to learn rule structures, QL-GNN needs an activation function with compression capability for information extraction from inputs. Empirically, QL-GNN with identify activation function fails to learn with rules in synthetic dataset.
Moreover, because our theory cannot help understand generalization related to network training, the dependence to hyperparameters of network training, e.g., the number of training examples, graph size, number of entities, cannot be revealed from our theory.
F.2 Why assigning lots of constants hurts generalization?
We take the relation as an example to show why assigning lots of constants hurts generalization from logical perspective. We add two different constants and to the rule formula , which results two different rule formulas and . Predicting new triplets for relation can now be achieved by learning the rule formulas , or . Among these rule formulas, is the rule with the best generalization, while and require the rule structure to pass through the entities with identifiers of constants and , respectively. Thus, when adding constants, maintaining performance requires the network to learn both rule formulas simultaneously which may potentially require a network with larger capacity. Even EL-GNN is unnecessary to learn since is learnable, EL-GNN cannot avoid learning rules with more than one constant in it when the rules are out of CML.
Appendix G Limitations and Impacts
Our work offers a fresh perspective on understanding GNN’s expressivity in KG reasoning. Unlike most existing studies that focus on distinguishing ability, we analyze GNN’s expressivity based solely on its ability to learn rule structures. Our work has the potential to inspire further studies. For instance, our theory analyzes GNN’s ability to learn a single relation, but in practice, GNNs are often applied to learn multiple relations. Therefore, determining the number of relations that GNNs can effectively learn for KG reasoning remains an interesting problem that can help determine the size of GNNs. Furthermore, while our experiments are conducted on synthetic datasets without missing triplets, real datasets are incomplete (e.g., missing triplets in testing sets). Thus, understanding the expressivity of GNNs for KG reasoning on incomplete datasets remains an important challenge.