Undesirable Memorization in Large Language Models: A Survey
Abstract
While recent research increasingly showcases the remarkable capabilities of Large Language Models (LLMs), it is equally crucial to examine their associated risks. Among these, privacy and security vulnerabilities are particularly concerning, posing significant ethical and legal challenges. At the heart of these vulnerabilities stands memorization, which refers to a model’s tendency to store and reproduce phrases from its training data. This phenomenon has been shown to be a fundamental source to various privacy and security attacks against LLMs.
In this paper, we provide a taxonomy of the literature on LLM memorization, exploring it across three dimensions: granularity, retrievability, and desirability. Next, we discuss the metrics and methods used to quantify memorization, followed by an analysis of the causes and factors that contribute to memorization phenomenon. We then explore strategies that are used so far to mitigate the undesirable aspects of this phenomenon. We conclude our survey by identifying potential research topics for the near future, including methods to balance privacy and performance, and the analysis of memorization in specific LLM contexts such as conversational agents, retrieval-augmented generation, and diffusion language models.
Given the rapid research pace in this field, we also maintain a dedicated repository of the references discussed in this survey111https://github.com/alistvt/undesirable-llm-memorization, which will be regularly updated to reflect the latest developments.
Index Terms:
Memorization, Large Language Models, Privacy in LLMsI Introduction
In recent years, large language models (LLMs) have demonstrated remarkable advancements, driven by the scaling of model parameters, large amounts of data, and extensive training paradigms [1, 2, 3, 4]. State-of-the-art models have exhibited capabilities across a broad spectrum of natural language processing (NLP) tasks, consistently pushing the envelope in areas such as text generation, code synthesis, machine translation, question answering, and summarization [5, 6]. These models are trained on massive datasets, enabling them to perform competitively or even surpass human-level performance in specific tasks [7, 8].
Despite these impressive advancements of LLMs, researchers have shown that there are certain problems with these models, including hallucination [9], bias [10], and privacy and security vulnerabilities [11]. In the context of data privacy, memorization is one of the core sources of concern. Memorization in LLM refers to the model’s tendency to store and reproduce exact phrases or passages from the training data rather than generating novel or generalized outputs. While memorization can be advantageous in knowledge-intensive benchmarks, such as factual recall tasks or domain-specific question answering [12], it also introduces ethical and legal challenges: models may inadvertently reveal sensitive or private information included in their training data, posing significant privacy and security risks [13, 14]. In addition, the ability of LLMs to repeat verbatim copyrighted or proprietary text from their training data raises issues related to intellectual property infringement [15, 16].
These challenges motivate the need to further explore memorization in LLMs to effectively tackle the associated challenges. In this paper, we provide an overview of aspects related to memorization, emphasizing the need for further exploration of this topic, thereby balancing model performance with the risks of privacy breaches and ethical concerns.
I-A Related surveys
Before recent advances in LLMs, memorization has been explored extensively as a topic in machine learning and deep learning mostly with a focus on security and privacy. Usynin et al. [17] explore memorization in machine learning. They propose a framework to quantify the influence of individual data samples and detect memorization in various learning settings. Wei et al. [18] provides a systematic framework for understanding memorization in deep neural networks, discussing LLM memorization from the view of deep neural networks. Survey papers on the privacy and safety of LLMs often address memorization as a core phenomenon, framing it as both a privacy issue and a foundational factor that supports other non-security/privacy-related challenges they explore [19, 20]. Hartmann et al. [21] provide an overview of memorization in general-purpose LLMs. They aggregate memorization-related topics from the copyright, privacy, security, and model performance perspectives. In our survey, we not only incorporate more recent work but also specifically focus on memorization as an undesirable phenomenon, examining it with the aspects of granularity, retrievability, and desirability. Our work is not only relevant for privacy but also for (un)safety and bias as undesirable properties of LLMs when memorization takes place. In addition, we provide an extensive and concrete research agenda for the near future. Table I provides a comparison of the scope of our survey with that of previous surveys.
| Paper | Focus | Differences With our Study |
|---|---|---|
| Usynin et al. [17] | Memorization in machine learning | We focus on LLMs |
| Wei et al. [18] | Memorization in deep neural networks | We focus on LLMs |
| Neel and Chang [19] | Privacy Problems in LLMs | Memorization is treated as one of the sources of privacy-related problems rather than being the focus. |
| Smith et al. [20] | Privacy Problems in LLMs | Memorization is treated as one of the sources of privacy-related problems rather than being the focus. |
| Hartmann et al. [21] | Memorization in general-purpose LLMs | We focus on undesirable memorization in LLMs, and propose concrete directions for future work. |
I-B Data selection
The selection of works included in this survey was guided by the goal of capturing a comprehensive view of the literature surrounding memorization in LLMs, with a particular focus on its undesirable aspects. However, to provide a well-rounded taxonomy and to contextualize these challenges, we also consider works that explore the desirable aspects of memorization, such as generalization and knowledge retention, as they offer complementary insights into the mechanisms at play.
Selection process
The process of identifying relevant papers was iterative, beginning with the most widely cited early studies by recognized researchers in the field (14 papers). These foundational and influential works were selected as they represent key milestones that have shaped current understandings of memorization in LLMs. Then we included the papers drawn from keyword searches in article repositories. We used Google Scholar222https://https://scholar.google.com/ and arXiv333https://arxiv.org/, as they are predominantly used by researchers in the computer science and computational linguistics domains [22]. For Google Scholar we restricted our keyword search to the papers that include the term “Memorization” in their title and include “Language Model” in their body (memorization is also used as a term in biology). For the scanning of arXiv, we collected the papers that included both of the words “Memorization” and “Privacy” in their abstract. For inclusion, we selected articles published before January 2025.
Additionally, given the broad scope of the topic, our survey draws from adjacent areas, including studies on data extraction, membership inference, and other forms of data leakage, which intersect with the broader concept of memorization. These works were identified through reference chaining, utilizing bibliographies of key papers, and consulting sections of existing survey articles. We believe this approach allows the survey to address the complexities and nuances of memorization in LLMs.
Rejection criteria
After obtaining the initial repository of papers, we manually iterated through the collection and removed non-relevant papers (e.g., out of scope for “undesirable memorization”, focus on deep learning) and the papers that were neither published at a scientific venue nor had any citations. This process and the obtained statistics are summarized in Figure 1.

I-C Paper organization
This survey is organized to capture the body of literature around undesirable memorization and offers an extensive view of this phenomenon from different perspectives. Our contribution is driven and structured around the following research questions:
-
RQ1.
How is memorization defined in the context of LLMs?
-
RQ2.
What are the methods used to measure memorization of LLMs?
-
RQ3.
What are the factors contributing to memorization?
-
RQ4.
What methods are used to prevent or mitigate undesirable memorization?
-
RQ5.
What are the important aspects of memorization that are still unexplored or require more research?
In the following sections of this paper, we provide a comprehensive exploration of memorization in LLMs around the mentioned research questions, structured into five main sections. We begin with the Spectrum of memorization (section II), where we examine the concept from multiple perspectives including desirability, retrievability, and granularity, offering a deep understanding of how memorization occurs. Next, in Measuring memorization (section III), we review various methodologies that have been used in previous studies to quantify and assess memorization within LLMs. We then explore the Influencing factors and dynamics of memorization (section III), identifying key factors and conditions that contribute to this phenomenon. Next, in the Mitigating memorization section (section V), we discuss strategies and techniques employed to minimize or control memorization in LLMs, addressing concerns related to privacy and generalization. Finally, we conclude with Future directions and open challenges (section VI), outlining potential areas for further research and unresolved questions, before summarizing our findings in the Conclusion (section VII). Figure 2 shows a visual overview of our survey scope.
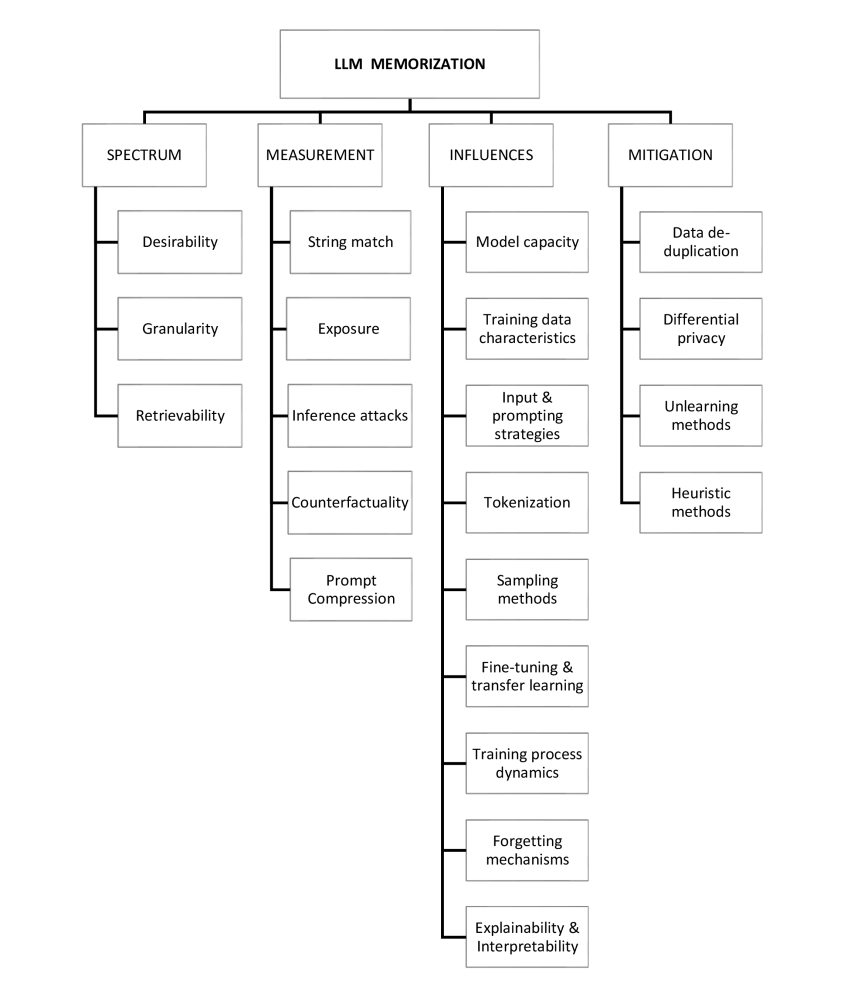
II Spectrum of Memorization
In this section, we provide an overview of the available definitions for memorization in various dimensions and categorize the existing work according to these dimensions. The overall summary of our findings is presented in Table III along with the other aspects.
II-A Granularity of memorization
While memorization in LLMs is widely discussed in the literature, there is no universally accepted definition for it. The definition of memorization can vary based on factors such as the level of detail required, the context in which the information is recalled, and the specific task or application at hand. This section discusses different levels of granularity of recall that are explored in the literature evolving around memorization in LLMs.
Perfect memorization
Perfect memorization refers to a setting where a model can generate only from the training data. Kandpal et al. [23] define perfect memorization as follows:
Definition.
[Perfect memorization] A model is said to perfectly memorize its training data if the generation frequencies of sequences are the same as their appearances in the training data. Sampling outputs from a perfect memorization model is identical to sampling from the training data.
Perfect memorization could be viewed as an upper bound for the level of memorization a language model can exhibit. It acts as an imaginary language model to help compare the extent of memorization in practical scenarios.
Verbatim memorization
Verbatim memorization is defined as a form of memorization that involves the exact reproduction of strings from the training data. It captures instances where the model outputs a training sample without any alterations. This type of memorization is straightforward to identify and is often the primary focus in discussions about memorization in language models [24, 13] (Table III).
Carlini et al. [13] define verbatim memorization under the term eidetic memorization as follows:
Definition.
[Verbatim memorization] Let denote the output of a language model when prompted with . A string from the training set is defined as verbatim memorized if there exists a prompt such that .
Due to its intuitiveness, various variants of verbatim memorization has been put forward. Tirumala et al. [25] define another version of verbatim memorization as Exact memorization with a focus on the context and sampling method:
Definition.
[Exact memorization] Let be a context where is incomplete block that is completed by the sequence . The context from the training set is considered to be exactly memorized by the language model if .
This definition is more strict and does not capture the memorization under different forms of sampling methods. It rather considers only the greedy sampling [see Section IV-E].
It should be noted that these definitions do not impose any restrictions on the length of the prompt or the generated output . However, if the generated text is too short, it may not be appropriate to classify it as memorization. Typically, a certain number of tokens is considered when assessing memorization; 50 tokens length prefix and suffix is used predominantly by the researchers (different employed prompt lengths and generation lengths are summarized in table III).
Throughout the rest of this paper, we use the word memorization interchangeably with the verbatim memorization, as it is the one that is mostly associated with the undesirable aspects of memorization.444discussed in section II-C
Approximate memorization
Approximate memorization extends beyond verbatim memorization to include instances where the output is similar but not identical to the training data. Verbatim memorization does not capture the subtler forms of memorization, as it is too confined. For example, if two sentences differ by a minor detail, such as punctuation, a misspelled word, or a stylistic variation (e.g., American English vs. British English), these instances would fall outside the strict boundaries of verbatim memorization. However, human judges would likely consider these variations as memorized examples.
Ippolito et al. [26] define Approximate memorization when the generation BLEU similarity score 555a metric used to compare the similarity of texts based on n-grams overlaps [27] with respect to the training data surpasses the 0.75 threshold, which was chosen based on qualitative analyses of the samples. By adopting this definition of memorization, they show that the measurement of memorization can increase by a factor of two compared to only considering verbatim memorization. Similarly, Duan et al. [28] use token-wise Levenshtein as an approximation distance function to experiment with the dynamics of memorized sequences.
Definition.
[Approximate memorization] A suffix for prefix is labeled as approximately memorized if for generation , ; where is a textual similarity metric.
As discussed by Ippolito et al. [26], this definition can lead to both false positives and false negatives when compared to human judgment, indicating a potential direction for future investigations. Since detecting approximate memorization could be resource intensive, Peng et al. [29] introduce a Mini-hash algorithm to efficiently detect approximately memorized content by the LLMs based on the Jaccard similarity metric.
Entity-level memorization
When considering privacy, the relationships between entities and their connections are often more critical than their exact phrasing in a sentence. This means that even approximate memorization might fail to capture certain privacy risks. For example, suppose the sentence “John Smith’s phone number is 012345678.” was included in the training set. If an adversary manages to prompt the language model to generate the following sentence: “I called John Smith yesterday and entered this number into my phone: 012345678,” the model would still be revealing sensitive information. However, this case would not be detected by the memorization granularities discussed earlier. Despite the lack of verbatim memorization, the model is still violating privacy by exposing the association between John Smith and their phone number. Zhou et al. [30] define the entity-level memorization as a phenomenon when the model recalls (generates) an entity when prompted with several other entities, when all of these entities have been linked to each other in the training phase.
Definition.
[Entity memorization] Let be a training sample containing a set of entities . A prompt can be constructed to include a strict subset of the entities . Model is said to show entity memorization if, when prompted with , outputs a response containing some entities in .
Zhou et al. [30] conduct various experiments and show that entity-level memorization happens in different scales affected by model size, context length, and repetitions of the entities in the pretraining data. Similarly, Kim et al. [31] target the personally identifiable information (PII) leakage in the OPT models [32] and show that different types of PII can be extracted if the attackers feed intelligently crafted prompts to the model. They also show that the susceptibility of this leakage is influenced by the type of PII; emails and phone numbers show higher extraction rates compared to addresses.
Content memorization
Beyond the categories described thus far, several broader notions of memorization involve reproducing or inferring general content from the training data, rather than focusing on exact strings (verbatim memorization) or specific entities. This can include, for instance, reproducing factual knowledge in different words than originally presented (often called factual memorization), or recalling underlying concepts without necessarily matching the original phrasing (conceptual memorization or knowledge memorization) [12, 33, 34, 35].
While these types of memorization can be beneficial for tasks requiring reasoning or knowledge application, they also raise distinct concerns. For example, when a model memorizes factual knowledge or concepts, the source of that information becomes critical [36, 37]. If the training data contains inaccuracies, biases, or falsehoods, these errors might be presented in the model outputs as well, leading to trustworthiness issues. Additionally, facts or knowledge could be outdated, further compounding the problem. This is particularly problematic in applications where factual accuracy is paramount, such as educational tools or decision-making systems. Bender et al. [38] highlight how language models can sustain misinformation when trained on unverified or noisy datasets, emphasizing the risks tied to the provenance of memorized knowledge.
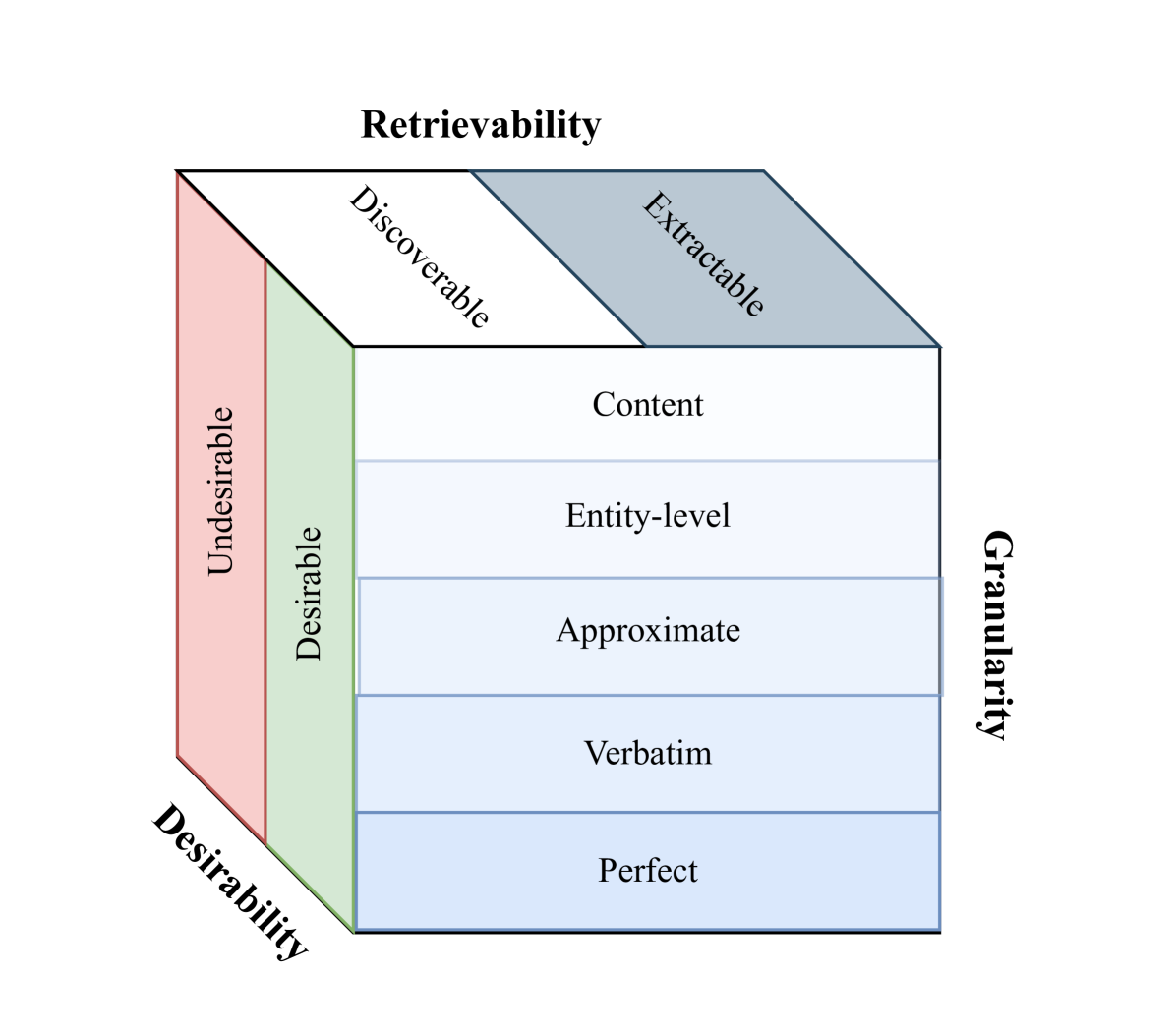
II-B Retrievability
A common way to analyze memorization in LLMs is through sampling. This involves selecting tokens probabilistically from the model’s predicted distribution at each step, to see if a sequence of probabilistically generated tokens can be traced back to the training data. Since the LLM’s input and output domains are both discrete, it is important to note that it might not be possible to extract all of the memorized content, given a finite number of generation trials through sampling. Based on how an LLM can be prompted to output the training data, memorization can be classified into extractable and discoverable in terms of retrievability.
Extractable memorization
Extractable memorization refers to the ability to retrieve specific information from a model’s training data without direct access to that data. Carlini et al. [39] defines extractable memorization as follows:
Definition.
(Extractable Memorization) Let denote the output of a language model when prompted with . An example from the training set is extractably memorized if an adversary (without access to ) can construct a prompt that makes the model produce (that is, ).
Analyzing extractable memorization usually involves two main challenges: designing prompts that best elicit memorization in a model and verifying if the model output is indeed from the training data.
Research in this area has employed various strategies. Carlini et al. [13] recover training examples from GPT-2 by prompting it with short strings from the public Internet and manually verifying the outputs via Google search. This method confirmed the memorization of about 0.00001% of GPT-2’s training data due to the labor-intensive verification process. Nasr et al. [40] conduct extensive analysis on Pythia, RedPajama, and GPT-Neo models [41]. They query these models with millions of 5-token blocks from Wikipedia and count for unique 50-grams that the model generates whether they exist in a combined dataset of the models’ training data. Their method was more successful, showing that 0.1% to 1% of the models’ outputs are memorized, with a strong correlation between model size and memorization abilities.
Discoverable memorization
Discoverable memorization measures the extent to which models can reproduce their training data when explicitly prompted with data from their training set. Nasr et al. [40] suggests the following definition for discoverable memorization:
Definition.
(Discoverable memorization) Let denote the output of a language model when prompted with . For a context from the training set , we say that is discoverably memorized if .
A more specific form of this is k-discoverable memorization666Biderman et al. [42] mention this as K-extractable, however, to avoid confusion with the definition of extractability (Definition Definition) we opt to use this terminology for this definition. which adds a criterion to the number of prefix tokens:
Definition.
(k-discoverable memorization) For an example from the training set, string is said to be k-discoverable if is discoverable and is consisted of tokens [42].
Considering the limited knowledge of the adversary in the extractable memorization definition, Nasr et al. [40] assume that discoverable memorization provides an upper bound for data extraction. Ideally, discoverable memorization requires querying the model with all of the possible substrings from its entire training set, which is computationally intractable. Also, noteworthy is that discoverable memorization differs from extractable memorization in that the prompt is known to be from the training set.
Carlini et al. [39] investigate the upper bounds of data extraction in GPT-Neo models through discoverable memorization. They find that (a) LLMs discoverably memorize roughly 1% of their training datasets; (b) there is a log-linear correlation between data extraction and model size, repetition of data, and prefix context length. Other studies on different models (PaLM, MADLAD-400) corroborate the 1% memorization rate when prompting with about 50 tokens of context [43, 44].
Discoverable and extractable Memorization
Nasr et al. [40] compare their extractable memorization results with the discoverable memorizations from Carlini et al. [39] for the GPT-Neo 6B parameter model. This comparison revealed that (1) some sequences are both discoverably and extractably memorized; (2) some sequences are discoverably memorized but not extractably memorized, and vice versa; (3) the overlap between these two types of memorization provides insights into the model’s information retention and retrieval mechanisms. This comparison highlights the complementary nature of these two approaches in understanding a model’s memorization capabilities and the retrievability of information from its training data.
Remark.
Based on the definitions presented here, one might perceive extractable/discoverable memorization and other concepts within the granularity dimension (section II-A) as equivalent. However, it is important to distinguish them. Extractable and discoverable memorization emphasize the methods used to retrieve memorized samples. In the case of granularity of memorization, the retrieval method is irrelevant; the primary concern is what granularity of the data has been memorized, irrespective of how it is produced by the model. Thus, each of the levels of the granularity, can be encompass both extractable and discoverable memorization.
II-C Desirability
Although memorization of factual information can be helpful for the model to perform more accurately on benchmark tasks such as question answering, other data might be retained without any clear purpose, and this might cause issues with privacy and copyright. In this regard, memorization could be categorized into desirable and undesirable subcategories. [45, 39, 46].
Undesirable memorization
Memorization has been demonstrated to be partly an undesirable phenomenon, often resulting in a range of issues, including:
-
•
Privacy risks: LLMs might inadvertently memorize and potentially reveal sensitive personal information present in the training data [16].
- •
- •
-
•
Bias and fairness: Based on the distribution of the data, memorization could introduce bias issues in the model output.
-
•
Transparency and auditing: Memorization poses challenges for transparency and auditing by making it difficult to decide whether specific outputs stem from generalization or memorized content, leading to accountability and interpretability issues in LLM systems.
- •
Desirable memorization
Ranaldi et al. [54] in their experiments show that memorization is could be beneficial for model performance. Moreover, as discussed above, even though unintended, memorization sometimes allows models to store and utilize vast amounts of knowledge, acting as a desirable phenomenon. Key aspects of desirable memorization include:
- •
-
•
Language generation: Deliberate memorization of linguistic patterns, grammar rules, and vocabulary is crucial for the model’s ability to generate coherent and contextually appropriate text.
-
•
Alignment goals: Deliberate memorization can be utilized in the AI alignment phase to inject desired behaviors and values into the model [57].
III Measuring memorization
Measuring memorization in generative language models was originally performed using the exact match metric [47]. However, as we will discuss in Section III-A this has its own limits and issues, therefore we discuss different methods that can be used to provide an approximation of the memorization of a specific model through so-called white-box attacks.
III-A String match
Measuring verbatim memorization (Section Definition) with the methods discussed in the retrievability section (Section II-B), requires exhaustively interacting with the model by inputting different prompts and comparing the model output to the training data. Then the attack success rate is measured by dividing the portion of memorized text by the size of the training data. Since there are infinite combinations of tokens that one can feed the model, this method usually falls short in providing the accurate amount of memorization, rather it can provide a good approximation on memorization lower bound. Since this is directly linked to the memorization risks, it is predominantly used by the researchers [47, 40]. As the exact match metric is too sensitive to small perturbations in the generation, approximate match (Section Definition) has been introduced [26] to capture more memorized samples by bypassing negligible changes in the outputs.
III-B Exposure metric
Introduced by Carlini et al. [24], exposure provides a quantitative measure of how much a model has memorized specific sequences from its training data. This metric is particularly useful for assessing the memorization of rare or unique information.
Exposure is computed based on the negative log-rank of the generation of a sequence according to a language model. To practically apply the exposure metric, researchers often use the “canary extraction test” [24]. This involves inserting known secret numbers as ‘canary’ sequences into the training data and then measuring their exposure in the trained model.
Definition (Exposure).
Given a canary , a model with parameters , and the randomness space R, the exposure of is [47]:
| (1) |
Helali et al. [58] propose the so-called “d-exposure” metric as a measure of memorization for discriminative tasks such as text classification, since in those situations we don’t have access to the perplexity of a given text.
III-C Inference attacks
Inference attacks are another approach to measuring memorization, focusing on the model’s ability to reveal information about its training data. These attacks typically perform under the assumption that when a model displays high confidence in its outputs, those outputs are likely to be from the training data, which means the model has memorized them. These attacks can be categorized into two main types:
Membership Inference Attacks (MIA)
These attacks aim to determine whether a specific data point was part of the model’s training set. Shokri et al. [59] introduced this concept for machine learning models, and it has since been adapted for language models. Doing MIA on LLMs typically involves determining the model’s confidence in a given text and using it as an indicator of whether the text was part of the training data. This is often done by computing the perplexity of the sequence [60, 61, 62, 63, 64, 65, 66].
Extraction Attacks
These attacks attempt to extract specific pieces of information from the model that were present in its training data. Different works have demonstrated the feasibility of such attacks on language models, showing that private information could be extracted through prompting with different strategies [67, 40, 68, 47, 69, 66].
The effectiveness of inference attacks can serve as a proxy measure for memorization. Models that are more susceptible to these attacks are generally considered to have higher levels of memorization.
III-D Counterfactuality
Previous work analyzed the memorization of large language models on sensitive information (e.g. phone numbers) in the training data [13] or synthetically injected ‘canaries’ [24, 70]. However, not all the memorized texts are equally interesting. Zhang et al. [71] propose another measure of memorization which is counterfactual memorization. The idea is to see how the presence or absence of a sample of the dataset, affects the performance of the model on the same sample. This measure has similarities with the definition of differential privacy.777Differential privacy as a mitigation strategy will be discussed in Section V-B.
In their experiments, the authors create different subsets of a bigger dataset and then they fine-tune the LM on each of these. Then they consider an item (e.g. a document from Wikipedia as the dataset) from the datasets and based on the presence or absence of in the subsets, they divide the subsets into two groups: IN and OUT. Then they test and report the performance on the IN and OUT group of models by averaging. Their experiments on 400 trained models show the counterfactually memorized data, are generally unconventional texts such as all-caps, structured formats (i.e. tables or bullet lists), and multilingual texts. In conclusion, counterfactuality could be used as a metric for measuring memorization, however, the interplay between this metric and the different types of memorization is unexplored and worth more research in the future.
III-E Prompt Compression
Schwarzschild et al. [72] introduce the Adversarial Compression Ratio (ACR) as a novel metric to assess memorization in large language models (LLMs). ACR evaluates whether a string from the training data is memorized by determining if it can be elicited with a significantly shorter adversarial prompt. The method uses the GCG algorithm [73] to find the most compressed prompt. This approach aligns conceptually with Kolmogorov complexity888Kolmogorov complexity measures the shortest possible set of instructions (or program) needed for a computer (Turing machine) to generate a specific output., as it measures the minimum description length of a string but adapts the concept for practical use in LLMs by focusing on adversarial prompts. ACR provides a flexible and compute-efficient framework to evaluate memorization for arbitrary strings, particularly in scenarios like monitoring unlearning and ensuring compliance with data usage policies. This metric offers practical and legal insights into potential misuse of training data, addressing critical concerns in LLM development.
IV Influencing factors and dynamics of memorization
Understanding the factors that influence memorization in LLMs is crucial for developing more efficient, secure, and privacy-preserving systems. This section explores various aspects that affect memorization, from model architecture to training processes.
IV-A Model capacity
The first significant factor influencing memorization is model size. Carlini et al. [39], Tirumala et al. [25], Kiyomaru et al. [74], demonstrated that larger models are more prone to memorization and do so more rapidly. This trend persists across different architectures and datasets. Carlini et al. [39] find that the relationship between model size and memorization grows consistently on a log-linear scale, with larger models memorizing a greater portion of the data.
Tirumala et al. [25] further highlight that larger models not only memorize more but do so faster in the training process. Interestingly, while memorization increases with model size, it does not necessarily correlate with improved performance. This was shown by Carlini et al. [39] by comparison of models with similar capacities but differing performance levels because of their architectures.
In the same line, several works analyze the memorization capacity of Transformers from a theoretical perspective. Mahdavi et al. [75] explore the memorization abilities of multi-head attention mechanisms, showing that the number of memorized sequences scales with the number of heads and context size under specific assumptions about input data. Similarly, Kim et al. [76] quantify the theoretical lower bound of memorization capacity of Transformers on sequence-to-sequence mappings and examine this capacity across classification and language modeling tasks with empirical validation.
Overall, the findings suggest that the ability of LLMs to memorize is strongly linked to their size, potentially due to the high capacity of these models to store detailed information from training data.
IV-B Training data characteristics
The nature of the training data heavily influences memorization. Lee et al. [77] develop tools to deduplicate training data and show that models trained on deduplicated data would produce memorized text ten times less frequently. Kandpal et al. [23] show that a sequence appearing 10 times in the training data is, on average, generated approximately 1000 times more frequently than a sequence that appears only once. A study done by Tirumala et al. [25] on memorization of different parts of speech, reveals that nouns and numbers are memorized significantly faster than other parts of speech, likely because they serve as unique identifiers for specific samples. Prashanth et al. [78] categorize memorization into recitation (memorization of highly duplicated sequences), reconstruction (generation using learned templates or patterns), and recollection (memorization of rare, non-template sequences). They argue that memorization is a multi-faceted phenomenon influenced by duplication, template patterns, and rarity, requiring nuanced analysis.
As simple sequences, such as repeated patterns or numbers, are easily memorized by models but often lack substantive content or sensitive information, distinguishing the memorization of these trivial sequences from more complex and meaningful ones would be essential. Duan et al. [28] observed that data with lower z-complexity999Z-complexity is a way to measure how much temporary memory (workspace) a computer needs to generate a specific output using the shortest possible instructions. Unlike Kolmogorov complexity, which only looks at the length of the instructions, Z-complexity also considers the memory used during the process. leads to faster decreases in training loss, as more compressible patterns are memorized more quickly. They further demonstrated that strings of varying complexity exhibit distinct memorization curves, with lower-complexity strings being memorized more easily even for smaller repeats, following a log-linear relationship in memorization probability.
IV-C Input and prompting strategies
Carlini et al. [13], McCoy et al. [79], Kandpal et al. [23] show that longer prompts increase the likelihood of triggering memorized sequences, making it easier for language models to regurgitate training data. Moreover, methods like prefix tuning [80] and prompt engineering have been employed to maximize memorization. Ozdayi et al. [81] introduce a novel approach using prompt tuning to control memorized content extraction rates in LLMs. Wang et al. [82] introduce a dynamic, prefix-dependent soft prompt approach to elicit more memorization. By generating soft prompts based on input variations, this method outperforms previous techniques in extracting memorized content across both text and code generation tasks. Kassem et al. [83] investigate how instruction-tuning influences memorization in LLMs, showing that instruction-tuned models can reveal as much or more training data as base models. They propose a black-box prompt optimization method where an attacker LLM generates instruction-based prompts, achieving higher memorization levels than direct prompting approaches. Weller et al. [84] propose ‘according-to’ prompting, a technique that directs LLMs to ground responses in previously observed text.
IV-D Tokenization
Kharitonov et al. [85] explore the impact of the tokenizer on memorization. They experiment with the size of the sub-word vocabulary learned through Byte-Pair Encoding (BPE) and demonstrate that increasing the sub-word vocabulary significantly affects the model’s ability and inclination to memorize training data. Furthermore, models with larger vocabularies are more likely to reproduce training data when given specific prompts. The authors suggest that this effect stems from the reduction in sequence lengths as BPE vocabulary size increases.
IV-E Decoding methods
While memorization phenomenon stems from the model internals, decoding methods have an important role in arousing it. In their experiments, Carlini et al. [13] initially opt for greedy decoding to maximize the regeneration of training data. One limitation is that this decoding scheme generates low-diversity outputs; thus, they also experiment with the decaying temperature and Top-n decoding methods, the latter of which shows to be more successful. Yu et al. [86] experiment with different decoding schemes, including decaying temperature, top-n, nucleus-, and typical- decoding [87, 88, 89] and use an auto-tuning method on these to find the optimal decoding method that yields to the maximization of training data reproduction. As could be drawn from table III, most of the previous works use greedy decoding to heighten memorized content generation, suggesting it could serve as a standard approach for future researchers as well.
IV-F Fine-tuning and transfer learning
Mireshghallah et al. [90] evaluate how different fine-tuning methods—full model, model head, and adapter fine-tuning—vary in terms of memorization and vulnerability to privacy attacks. Their research, using membership inference and extraction attacks, finds that head fine-tuning is most susceptible to attacks, whereas adapter fine-tuning is less prone. Zeng et al. [91] conduct a comprehensive analysis of fine-tuning T5 models [92] across various tasks, including summarization, dialogue, question answering, and machine translation, finding that fine-tuned memorization varies significantly depending on the task. Additionally, they identify a strong link between attention score distributions and memorization, and propose that multi-task fine-tuning can mitigate memorization risks more effectively than single-task fine-tuning.
IV-G Training process dynamics
Zhang et al. [71], Kandpal et al. [23] show that memorization grows consistently with the number of training epochs, which makes sense, as more epochs push the model to potential overfitting. Jagielski et al. [93] demonstrate that examples seen during the earlier stages of training are less prone to memorization and rather they are forgotten over time. These findings indicate that memorization increases with more training, while early-seen examples being more likely to be forgotten. Leybzon and Kervadec [94] show higher memorization rates happens early and late in training, with lower rates mid-training. Therefore, suggesting that placing sensitive data in the middle stages of training could reduce its vulnerability to extraction attacks.
IV-H Forgetting mechanisms
In machine learning, forgetting mechanisms are the processes through which models lose or discard previously learned information [95]. These mechanisms can occur unintentionally as part of the natural training dynamics or be purposefully induced to meet specific objectives, such as improving model generalization or addressing privacy concerns [96, 97, 98]. Blanco-Justicia et al. [99] provide a recent, detailed overview of forgetting in LLMs.
Kirkpatrick et al. [100] initially introduced “catastrophic forgetting” in the context of neural networks and continual learning. They propose a method to protect important model weights to retain knowledge. This approach has been effective in maintaining performance on older tasks, even after long periods of non-use. Tirumala et al. [25] observe the forgetting mechanisms of a special batch through the learning process and show that it follows an exponential degradation, reaching a constant value baseline. They show that the mentioned baseline scales with the model size. Jagielski et al. [93] address the dual phenomena of memorization and forgetting in LLMs through stronger privacy attacks and several strategies for measuring the worst-case forgetting of the training examples. The study introduces a method to measure to what extent models forget specific training data, highlighting that standard image, speech, and language models do indeed forget examples over time, though non-convex models might retain data indefinitely in the worst case. The findings suggest that examples from early training phases, such as those used in pre-training large models, might enjoy privacy benefits but could disadvantage examples encountered later in training.
IV-I Explainability and interpretability
Huang et al. [101] study verbatim memorization in LLMs using controlled pre-training with injected sequences. They find that memorization requires significant repetition, increases in later checkpoints, and is tied to distributed model states and general language modeling capabilities. Their stress tests show unlearning methods often fail to remove memorized information without degrading model performance, highlighting the difficulty of isolating memorization. Haviv et al. [102] propose a framework to probe how memorized sequences are recalled in transformers, showing that memory recall follows a two-step process: early layers promote the correct token in the output distribution, while upper layers amplify confidence. They find that memorized information is primarily stored and retrieved in early layers. Similarly, Dankers and Titov [103] investigate where memorization occurs across model layers, demonstrating that memorization is a gradual and task-dependent process rather than localized to specific layers. Using centroid analysis, they show that deeper layers contribute more to memorization when models generalize well to new data. Stoehr et al. [104] show that memorization in LLMs, while distributed across layers, is driven by distinct gradients in lower layers and influenced by a low-layer attention head focusing on rare tokens. Perturbation analysis reveals that distinctive tokens in a prefix can corrupt entire continuations, and memorized sequences are harder to unlearn and more robust to corruption than non-memorized ones. Chen et al. [105] reveal interpretability insights into memorization by identifying clustering of sentences with different memorization scores in the embedding space and observing an inverse boundary effect in entropy distributions for memorized and unmemorized sequences. They also demonstrate that hidden states of LLMs can be used to predict unmemorized tokens, shedding light on the dynamics of memorization within the model. These findings offer insights into the mechanisms of memorization, enhancing interpretability and guiding future research.
| Factor from Section IV | Key findings | Representative Works |
|---|---|---|
| Model capacity | Larger models memorize more | [39, 25] |
| Training data | Duplicated data amplifies memorization | [77, 23, 25] |
| Input and prompting | Longer prompts and prompt tuning can facilitate recall of the memorized suffix. | [13, 79, 23, 80, 81, 84] |
| Tokenization | Bigger tokenizer vocabulary leads to more memorization | [85] |
| Decoding methods | Greedy decoding is dominantly employed to extract memorized data. | [13, 86] |
| Fine-tuning | The amount of memorization after fine-tuning significantly varies depending on the task. | [106, 91] |
| Training process | Earlier phases of training are less prone to memorization | [71, 23, 93] |
| Forgetting mechanisms | Forgetting follows an exponentially decaying curve | [25, 93] |
| Work | Retrievability | Granularity | Model | Dataset | Decoding | Prompt Len | Match Len |
|---|---|---|---|---|---|---|---|
| Carlini et al. [39] | discoverable | verbatim | GPT-Neo | PILE | 50 - 450 | 50 | |
| Tirumala et al. [25] | discoverable | verbatim | roberta | wikitext-103 | greedy | ||
| Borec et al. [107] | discoverable | verbatim | GPT-Neo | OpenMemText [107] | nucleus | 50 | 50 - 450 |
| Zhou et al. [30] | extractable | entity | GPT-Neo , GPT-J | PILE | |||
| Wang et al. [82] | discoverable | verbatim | GPT-Neo, GPT-J, Pythia, StarCoderBase | PILE, the-stacksmol | greedy | ||
| Kassem et al. [83] | extractable | approximate | Alpaca, Vicuna, Tulu | RedPajama, RefinedWeb, Dolma | 66 , 100, 166 | 133, 200, 366 | |
| Leybzon and Kervadec [94] | discoverable | verbatim | OLMo | Dolma | 32 | 32 | |
| Duan et al. [28] | discoverable | approximate | Pythia-1b, Amber-7b | PILE | 32 | 64 | |
| Kiyomaru et al. [74] | discoverable | approximate, verbatim | Pythia, LLM-jp | PILE, Japanese Wikipedia | greedy | 100 - 1000 | 50 |
| Stoehr et al. [104] | discoverable | verbatim | GPT-Neo-125M | PILE | greedy | 50 | 50 |
| Chen et al. [105] | discoverable | verbatim | Pythia[dedup] | PILE | greedy | 32,48,64,96 | 32,48,64,96 |
| Huang et al. [101] | discoverable | verbatim | Pythia[dedup] | PILE | greedy | 8, 16, 32, 64 | 32 |
| Prashanth et al. [78] | discoverable | verbatim | Pythia[dedup] | Memorized set of PILE | greedy | 32 | 32 |
| Carlini et al. [13] | extractable | verbatim | GPT-2 | model generations | greedy, temperature | 256 | |
| Nasr et al. [40] | extractable | verbatim | Pythia, LLaMA, InstructGPT, ChatGPT | AuxDataset [40] | greedy | 50 | |
| Shao et al. [108] | extractable | entity | GPT-Neo, GPT-J | Enron, LAMA [12] | greedy | ||
| Huang et al. [109] | extractable | entity | GPT-Neo | Enron | greedy | ||
| Yu et al. [86] | discoverable | verbatim | GPT-Neo-1.3B | lm-extraction-benchmark | greedy, top-p, top-k, nucleus | 50 | 100 |
| Biderman et al. [42] | discoverable | verbatim | Pythia | PILE | greedy | 32 | 64 |
| Ippolito et al. [26] | discoverable | approximate | GPT-3, PaLM | PILE | greedy | 50 | 50 |
| Lee et al. [77] | extractable discoverable | verbatim | T5 [trained again] | C4 (variants) | top-k | >50 | |
| Kandpal et al. [23] | extractable | verbatim | Mistral project | OpenWebText, C4 | top-k, temprature | 100 - 700 (char) | |
| Lukas et al. [69] | extractable | entity | GPT-2 | ECHR, Enron | greedy, beam | ||
| Kim et al. [31] | extractable | entity | OPT | PILE | beam search | ||
| Zhang et al. [110] | extractable | entity | GPT-Neo-1.3B | PILE | greedy, top-p, top-k, beam | ||
| Ozdayi et al. [81] | discoverable | verbatim | GPT-Neo | lm-extraction-benchmark | beam | 50 | 50 |
V Mitigating memorization: strategies and techniques
As discussed in earlier sections, memorization is influenced by a range of factors and it is sometimes necessary for the learning process [111, 112]. However, in scenarios where memorization could lead to privacy concerns or security vulnerabilities, some methods could be employed to mitigate its impact. In these cases, specific strategies are utilized to limit the retention of sensitive information, ensuring that potential risks related to data exposure or misuse are minimized.
V-A Data de-duplication
Lee et al. [77] run exact matching and approximate matching (MiniHash) de-duplication algorithms on the C4 [113], RealNews [114], LM1B [115], and Wiki40B [116] datasets and show that these datasets contain up to 13.6% near duplicates and up to 19.4% exact duplicates.
To investigate the impact of data de-duplication on a language model’s memorization, they train a 1.5B parameter GPT-2 [117] model from scratch on three different settings: C4-Original, C4-NearDup, and C4-ExactSubstr, each for two epochs. Then they evaluate the memorization in no-prompt and prompted settings and measure the 50-token exact match (Section III-A). The no-prompt experiment generations show less memorization in de-duplicated trained models. On the other hand, in the prompted experiment, when the prompt comes from the duplicate examples, the model trained on C4-Original generates the true exact continuation over 40% of the time. The other two models also generate the ground truth more often when the prompt is sampled from the duplicate examples, suggesting that more harsh de-duplication algorithms are needed to prevent memorization.
V-B Differential privacy
Differential privacy is a data privacy method that ensures the results of any analysis over a dataset reveals minimal information about any individual’s data, protecting against privacy breaches [118]. This method is adopted in some techniques in machine learning to protect individual data points by adding noise, minimizing the impact of any single data point on the model’s output. DP-SGD (Differentially Private Stochastic Gradient Descent) is an adaptation of the standard SGD algorithm, designed to fine-tune language models while maintaining privacy [119]. Carlini et al. [24] demonstrate that by adjusting the privacy budget parameter in DP-SGD training, the exposure of memorized data can be reduced to a level that makes it indistinguishable from any other data. However, this comes at the cost of reduced model utility and a slower training process.
To address these utility issues, some studies propose selective differential privacy approaches [120, 121, 122, 123]. For instance, Kerrigan et al. [120] propose training a non-private base model on a public dataset and then fine-tuning it on a private dataset using DP-SGD. This approach aims to balance privacy with model performance.
Li et al. [121] show that with carefully chosen hyperparameters and downstream task objectives, fine-tuning pretrained language models with DP-SGD can yield strong performance on a variety of NLP tasks at privacy levels. Remarkably, some of their fine-tuned models even outperform non-private baselines and models trained under heuristic privacy approaches.
While adopting the DP method in data privacy is mathematically proven to protect individuals’ privacy, it is crucial to select hyperparameters wisely when used in training LLMs as a technique; otherwise, the model may not withstand stronger privacy attacks, potentially compromising its effectiveness as shown in Lukas et al. [69].
V-C Unlearning methods
As memorization could lead to privacy risks and copyright issues, unlearning methods could be necessary in some situations. Methods like knowledge unlearning aim to selectively remove specific information from trained models without retraining them from scratch. Bourtoule et al. [124] introduce the “SISA” framework for efficient machine unlearning, which divides the training data into shards (shards partition the data into disjoint segments) and trains sub-models that can be easily retrained if data needs to be removed. For LLMs specifically, Chen and Yang [125] introduce lightweight unlearning layers into transformers, allowing for selective data removal without full model retraining. Pawelczyk et al. [126] introduce “In-Context Unlearning,” which involves providing specific training instances with flipped labels and additional correctly labeled instances as inputs during inference, effectively removing the targeted information without updating model parameters. Kassem et al. [127] propose “DeMem,” a novel unlearning approach leveraging a reinforcement learning feedback loop with proximal policy optimization to reduce memorization. By fine-tuning the model with a negative similarity score as a reward signal, the approach encourages the LLM to paraphrase and unlearn pre-training data while maintaining performance.
Additionally, knowledge unlearning techniques have been categorized into parameter optimization, parameter merging, and in-context learning, each offering unique advantages in efficiently removing harmful or undesirable knowledge from LLMs [128]. These methods not only enhance privacy and security but also ensure that the overall performance of the models remains intact, making them scalable and practical for real-world applications [129].
Unlearning methods offer effective strategies to mitigate memorization by selectively removing specific information from trained models without the need for full retraining. However, these methods are generally designed to target specific pieces of information, which means they rely on the ability to identify what the model has memorized beforehand. This reliance poses a challenge, as determining the exact content a model has memorized can be difficult and may limit the applicability of unlearning techniques for general mitigation against memorization.
V-D Heuristic Methods
Liu et al. [130] propose the alternating teaching method, a teacher-student framework where multiple teachers trained on disjoint datasets supervise a student model in an alternating fashion to reduce unintended memorization. This approach demonstrates superior privacy-preserving results on the LibriSpeech dataset [131] while maintaining minimal utility loss when sufficient training data is available. Ippolito et al. [26] propose “MemFree Decoding,” a novel sampling strategy to reduce memorization during text generation by avoiding the emission of token sequences matching the training data. They demonstrate its effectiveness across multiple models, including GPT-Neo [132] and Copilot [133], significantly lowering generation similarity with the training data. However, they also reveal that a simple style transfer in prompts can bypass this defense, highlighting its limitations. Similarly, Borec et al. [107] investigate the impact of nucleus sampling on memorization, showing that while increasing the nucleus size slightly reduces memorization, it only provides modest protection. They also highlight the distinction between “hard” memorization, involving verbatim reproduction, and “soft” memorization measured by the ROUGE similarity metric [134], where generated outputs echo the training data without exact replication. Hans et al. [135] introduce the “goldfish loss,” a subtle modification to the next-token training objective where randomly sampled subsets of tokens are excluded from the loss computation. This prevents models from memorizing complete token sequences, significantly reducing extractable memorization while maintaining downstream performance.
VI Future directions and open challenges
Based on the discussion of the existing literature to date on memorization in LLMs, we make suggestions for research topics to be addressed in the near future.
VI-A Balancing performance and privacy in LLMs
As discussed earlier, memorization in LLMs can also have beneficial uses, such as improving factual recall and enhancing performance in specific tasks such as question answering. Privacy and copyright issues are some of the major concerns here [19, 20, 11]. Privacy-enhancing technologies such as multi-party computing, homomorphic encryption, and differential privacy, which can be employed to mitigate memorization risks and prevent sensitive data exposure, often come at the cost of reduced model performance, as they limit the model’s ability to retain precise information or perturb the model’s output. To fully harness the benefits of memorization while safeguarding against privacy breaches, future research needs to focus on strategies that balance these competing goals. This includes developing techniques that protect sensitive data and intellectual property without significantly degrading the model’s accuracy and utility. Such efforts will be key to ensuring both legal compliance and high-performance outcomes in LLMs.
VI-A1 Memorization and Differential Privacy
As discussed in Section III-D, counterfactual memorization shares some conceptual similarities with differential privacy. Counterfactual memorization evaluates the difference in a model’s behavior on a specific data point when the data point is included in or excluded from the training dataset. In contrast, a model is considered differentially private for a given example if the outputs of two models trained on neighboring datasets—differing by only that example—are indistinguishable.
In the context of text data, the definition of a “data point” can vary significantly. It might refer to named entities, individual sentences, complete documents, or even the entire text corpora. Both of these points underscore the need for further research to examine the interplay and dynamics between memorization and differential privacy at different data granularities.
VI-B Reducing verbatim memorization in favor of content memorization
The interplay between factual and content memorization is relevant in LLM development, because there is a trade-off between the correctness of information, and undesirable recall of training data: Although verbatim memorization can provide more precise information recall, it also presents higher risks in terms of privacy and data protection. Content memorization, on the other hand, contributes to the model’s ability to generalize and apply knowledge flexibly, but it may also present more challenges for audit and control. For example, when using LLMs for question answering, literal reproduction of facts is desired; this includes names and numbers (e.g., “Who was the first person to fly across the ocean and when did this take place?”). It is straightforward to evaluate LLMs to generate the (correct) facts. If content memorization is preferred over verbatim memorization in LLMs, a higher rate of hallucinations should be accepted because the model generates text more freely based on its parametric knowledge.
Future research in this area should therefore focus on developing techniques to balance these two types of memorization, enhancing the benefits of each while mitigating their undesired consequences. This could involve methods to selectively encourage content memorization while limiting unnecessary factual memorization, particularly of sensitive information, depending on the type of task at hand.
VI-C The boundary between memorization and understanding
It is relatively straightforward to design experiments that demonstrate a model’s ability to generate fluent and human-like text, such as generating novel content or adapting to new contexts. However, verifying that these capabilities are not simply the result of memorization rather than the abstraction/generalization over the information processed during training is much more challenging, as both can produce similar outcomes. Distinguishing between these requires carefully designed experiments, and further research is needed to clarify when a model makes abstractions over learned concepts versus merely memorizing and reproducing them.
VI-D Memorization in specific contexts
Several application domains are currently understudied with respect to the effect of memorization. We identified four contexts specifically where more research is needed.
Conversational Agents
LLMs that have been fine-tuned for conversations can be used as conversational agents (chatbots), e.g., to assist customers of online services [136, 137]. Nasr et al. [40] introduce their so-called “divergence attack” to extract memorized samples from conversation-aligned LLMs. As they also discuss, these attacks are not powerful enough to stimulate training data reproduction. However, this does not mean that the conversation-aligned LLMs are not vulnerable to attacks or manipulation. It also means This makes us conclude that attacking conversation-aligned language models requires more advanced methods. Since most of the production language models are only available in a conversational settings, addressing memorization in conversational agents and conducting novel attacking methods to alleviate training data extraction in these models would be a prominent research direction.
Retrieval-Augmented Generation (RAG)
In RAG frameworks, LLMs are helped with a retrieval component that first selects the most relevant documents from a collection and feeds them to the prompt [138, 139]. The LLM then generates an answer based on the provided sources. This has advantages such as the reduction of hallucination [140], the transparency of sources, and the potential of generating answers related to proprietary or novel sources that were not in the LLM training data. Although very popular, RAG is not yet thoroughly analyzed regarding memorization. This is important, because a reduction of hallucination when using RAG in LLMs could also have an increase in memorization as a side effect: less hallucination means that the LLM stays closer to the original content. Recently, Zeng et al. [141] analyzed privacy aspects in RAG. They show that RAG systems are vulnerable to leaking private information. On the other hand, they also found that RAG can mitigate the reproduction of the LLM training data. A broader study focusing on memorization in RAG-based LLMs that compares different proposed retrieval architectures is an important future research direction.
Multilingual Large Language Models (xLM)
xLMs are trained to interpret and generate text in multiple languages. Trained on extensive datasets that include various languages, these models develop language-agnostic representations [142]. Despite their potential, xLMs often face challenges related to data scarcity for low-resource languages, leading to performance disparities [143]. This necessitates ongoing research to enhance their efficacy and fairness across all languages. In line with the significant effect of training data on memorization (discussed in section IV-B), for future work, we propose to investigate whether a low-resource language setting is more prone to memorization by comparing it to English scenarios. Addressing this research direction is essential not only for understanding the privacy implications associated with LLMs and data leakage in low-resource settings but also for ensuring AI safety in societies using LLMs with languages that have fewer resources.
Diffusion Language Models (DLM)
Since DLMs show remarkable performance in the vision domain, researchers have started to adopt the diffusion models (DM) idea to the text domain and utilize their generative capabilities [144]. Carlini et al. [145] have conducted data extraction analysis on the image diffusion models, showing that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training. Gu et al. [146] also show that according to the training objective of the diffusion models, a memorization behavior is theoretically expected and then they quantify the impact of the influential factors on the memorization behaviors in DMs. However, research focusing on the memorization issues related to DLMs for text remains unexplored. Even though the idea of diffusion language models is the same as the vision domain, they are inherently different, because of the discrete nature of the text domain. Therefore, an analysis of the general vision diffusion models may not be applicable to the diffusion language models, making an independent research on memorization against DLMs a prominent future direction.
VII Conclusion
In this paper, we organized, summarized, and discussed the existing scientific work related to undesirable memorization in LLMs. Undesirable memorization might lead to privacy risks and other ethical consequences. We found that there exists a large body of research on memorization in LLMs, given the young age of the technology: Transformer models were first developed in 2017 [147], and the first generative large language model with emergent abilities was released in 2022 [1, 5]. The majority of papers on the topic were therefore published in recent years. This indicates that the field is working fast to analyze memorization and developing methods to mitigate undesirable memorization.
Despite the fast-growing body of literature on the topic, we argue that there are important areas that require more attention in research in the coming years. We have pointed out four specific contexts in which memorization needs to be studied and, when needed and possible, mitigated: LLM-based conversational agents, retrieval-augmented generation, multilingual LLMs, and diffusion language models. These areas all are of high importance, not only from the academic perspective, but maybe even more from the application and industry perspective. In particular, conversational agents and retrieval-augmented generation are actively being developed in the commercial context. When applied to proprietary databases or in interaction with customer information, these applications are particularly vulnerable to privacy and security risks.
Limitations
The main limitation of a survey paper on a highly active research topic is the fast pace at which the field is evolving. A survey paper written in 2025 risks becoming outdated by 2026. Although we acknowledge this, we argue that the topic of memorization is too important to overlook, especially given the added value we provide through our concrete suggestions for future directions. To mitigate this issue, we maintain a dedicated GitHub repository101010https://github.com/alistvt/undesirable-llm-memorization that catalogs the references discussed in this survey and will be regularly updated to reflect the latest developments in the field.
Acknowledgment
This publication is part of the project LESSEN111111https://lessen-project.nl with project number NWA.1389.20.183 of the research program NWA ORC 2020/21 which is (partly) financed by the Dutch Research Council (NWO).
References
- Brown et al. [2020] T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33. Curran Associates, Inc., 2020, pp. 1877–1901.
- Touvron et al. [2023] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom, “Llama 2: Open foundation and fine-tuned chat models,” 2023.
- OpenAI [2023] OpenAI, “Chatgpt,” 2023. [Online]. Available: https://chat.openai.com
- Ouyang et al. [2022a] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. F. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback,” in Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, Eds., vol. 35. Curran Associates, Inc., 2022, pp. 27 730–27 744.
- Wei et al. [2022] J. Wei, Y. Tay, R. Bommasani, C. Raffel, B. Zoph, S. Borgeaud, D. Yogatama, M. Bosma, D. Zhou, D. Metzler, E. H. Chi, T. Hashimoto, O. Vinyals, P. Liang, J. Dean, and W. Fedus, “Emergent abilities of large language models,” Transactions on Machine Learning Research, 2022, survey Certification.
- Xu et al. [2022] F. F. Xu, U. Alon, G. Neubig, and V. J. Hellendoorn, “A systematic evaluation of large language models of code,” in Proceedings of the 6th ACM SIGPLAN International Symposium on Machine Programming, ser. MAPS 2022. New York, NY, USA: Association for Computing Machinery, 2022, p. 1–10.
- Guo et al. [2023] Z. Guo, R. Jin, C. Liu, Y. Huang, D. Shi, L. Yu, Y. Liu, J. Li, B. Xiong, D. Xiong et al., “Evaluating large language models: A comprehensive survey,” arXiv preprint arXiv:2310.19736, 2023.
- Chang et al. [2023] Y.-C. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang, W. Ye, Y. Zhang, Y. Chang, P. S. Yu, Q. Yang, and X. Xie, “A survey on evaluation of large language models,” ArXiv, vol. abs/2307.03109, 2023.
- Huang et al. [2023] L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, B. Qin et al., “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” arXiv preprint arXiv:2311.05232, 2023.
- Tjuatja et al. [2024] L. Tjuatja, V. Chen, T. Wu, A. Talwalkwar, and G. Neubig, “Do llms exhibit human-like response biases? a case study in survey design,” Transactions of the Association for Computational Linguistics, vol. 12, pp. 1011–1026, 2024.
- Yao et al. [2024a] Y. Yao, J. Duan, K. Xu, Y. Cai, Z. Sun, and Y. Zhang, “A survey on large language model (llm) security and privacy: The good, the bad, and the ugly,” High-Confidence Computing, p. 100211, 2024.
- Petroni et al. [2019] F. Petroni, T. Rocktäschel, S. Riedel, P. Lewis, A. Bakhtin, Y. Wu, and A. Miller, “Language models as knowledge bases?” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Hong Kong, China: Association for Computational Linguistics, Nov. 2019, pp. 2463–2473.
- Carlini et al. [2021] N. Carlini, F. Tramer, E. Wallace, M. Jagielski, A. Herbert-Voss, K. Lee, A. Roberts, T. Brown, D. Song, U. Erlingsson et al., “Extracting training data from large language models,” in 30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 2633–2650.
- Song et al. [2023] B. Song, M. Deng, S. Pokhrel, Q. Lan, R. Doss, and G. Li, “Digital privacy under attack: Challenges and enablers,” 02 2023.
- Bender et al. [2021a] E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” in Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, 2021, pp. 610–623.
- Henderson et al. [2023] P. Henderson, X. Li, D. Jurafsky, T. Hashimoto, M. A. Lemley, and P. Liang, “Foundation models and fair use,” Journal of Machine Learning Research, vol. 24, no. 400, pp. 1–79, 2023.
- Usynin et al. [2024] D. Usynin, M. Knolle, and G. Kaissis, “Memorisation in machine learning: A survey of results,” Transactions on Machine Learning Research, 2024.
- Wei et al. [2024] J. Wei, Y. Zhang, L. Y. Zhang, M. Ding, C. Chen, K.-L. Ong, J. Zhang, and Y. Xiang, “Memorization in deep learning: A survey,” arXiv preprint arXiv:2406.03880, 2024.
- Neel and Chang [2023] S. Neel and P. Chang, “Privacy issues in large language models: A survey,” arXiv preprint arXiv:2312.06717, 2023.
- Smith et al. [2023] V. Smith, A. S. Shamsabadi, C. Ashurst, and A. Weller, “Identifying and mitigating privacy risks stemming from language models: A survey,” arXiv preprint arXiv:2310.01424, 2023.
- Hartmann et al. [2023] V. Hartmann, A. Suri, V. Bindschaedler, D. Evans, S. Tople, and R. West, “Sok: Memorization in general-purpose large language models,” 2023. [Online]. Available: https://arxiv.org/abs/2310.18362
- Sutton and Gong [2017] C. Sutton and L. Gong, “Popularity of arxiv.org within computer science,” 2017.
- Kandpal et al. [2022] N. Kandpal, E. Wallace, and C. Raffel, “Deduplicating training data mitigates privacy risks in language models,” in International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, ser. Proceedings of Machine Learning Research, vol. 162. PMLR, 2022, pp. 10 697–10 707.
- Carlini et al. [2019a] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, “The secret sharer: Evaluating and testing unintended memorization in neural networks,” in Proceedings of the 28th USENIX Conference on Security Symposium, ser. SEC’19. USA: USENIX Association, 2019, p. 267–284.
- Tirumala et al. [2022] K. Tirumala, A. H. Markosyan, L. Zettlemoyer, and A. Aghajanyan, “Memorization without overfitting: Analyzing the training dynamics of large language models,” in Advances in Neural Information Processing Systems, A. H. Oh, A. Agarwal, D. Belgrave, and K. Cho, Eds., 2022.
- Ippolito et al. [2023] D. Ippolito, F. Tramer, M. Nasr, C. Zhang, M. Jagielski, K. Lee, C. Choquette Choo, and N. Carlini, “Preventing generation of verbatim memorization in language models gives a false sense of privacy,” in Proceedings of the 16th International Natural Language Generation Conference, C. M. Keet, H.-Y. Lee, and S. Zarrieß, Eds. Prague, Czechia: Association for Computational Linguistics, Sep. 2023, pp. 28–53.
- Papineni et al. [2002] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, P. Isabelle, E. Charniak, and D. Lin, Eds. Philadelphia, Pennsylvania, USA: Association for Computational Linguistics, Jul. 2002, pp. 311–318.
- Duan et al. [2024] S. Duan, M. Khona, A. Iyer, R. Schaeffer, and I. R. Fiete, “Uncovering latent memories: Assessing data leakage and memorization patterns in large language models,” in ICML 2024 Workshop on Mechanistic Interpretability, 2024. [Online]. Available: https://openreview.net/forum?id=7PZgCems9w
- Peng et al. [2023] Z. Peng, Z. Wang, and D. Deng, “Near-duplicate sequence search at scale for large language model memorization evaluation,” Proc. ACM Manag. Data, vol. 1, no. 2, Jun. 2023.
- Zhou et al. [2023] Z. Zhou, J. Xiang, C. Chen, and S. Su, “Quantifying and analyzing entity-level memorization in large language models,” 2023.
- Kim et al. [2023a] S. Kim, S. Yun, H. Lee, M. Gubri, S. Yoon, and S. J. Oh, “ProPILE: Probing privacy leakage in large language models,” in Thirty-seventh Conference on Neural Information Processing Systems, 2023.
- Zhang et al. [2022] S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin et al., “Opt: Open pre-trained transformer language models,” arXiv preprint arXiv:2205.01068, 2022.
- Jiang et al. [2020] Z. Jiang, F. F. Xu, J. Araki, and G. Neubig, “How can we know what language models know?” Transactions of the Association for Computational Linguistics, vol. 8, pp. 423–438, 2020.
- AlKhamissi et al. [2022] B. AlKhamissi, M. Li, A. Celikyilmaz, M. Diab, and M. Ghazvininejad, “A review on language models as knowledge bases,” 2022.
- Luo et al. [2023] L. Luo, T.-T. Vu, D. Q. Phung, and G. Haffari, “Systematic assessment of factual knowledge in large language models,” pp. 13 272–13 286, 2023.
- Lin et al. [2022] S. Lin, J. Hilton, and O. Evans, “TruthfulQA: Measuring how models mimic human falsehoods,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 3214–3252.
- Min et al. [2024] S. Min, S. Gururangan, E. Wallace, W. Shi, H. Hajishirzi, N. A. Smith, and L. Zettlemoyer, “Silo language models: Isolating legal risk in a nonparametric datastore,” 2024.
- Bender et al. [2021b] E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” in Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, ser. FAccT ’21. New York, NY, USA: Association for Computing Machinery, 2021, p. 610–623.
- Carlini et al. [2023a] N. Carlini, D. Ippolito, M. Jagielski, K. Lee, F. Tramer, and C. Zhang, “Quantifying memorization across neural language models,” in The Eleventh International Conference on Learning Representations, 2023.
- Nasr et al. [2023] M. Nasr, N. Carlini, J. Hayase, M. Jagielski, A. F. Cooper, D. Ippolito, C. A. Choquette-Choo, E. Wallace, F. Tramèr, and K. Lee, “Scalable extraction of training data from (production) language models,” 2023.
- Biderman et al. [2023a] S. Biderman, H. Schoelkopf, Q. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. Van Der Wal, “Pythia: a suite for analyzing large language models across training and scaling,” in Proceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023.
- Biderman et al. [2023b] S. Biderman, U. S. Prashanth, L. Sutawika, H. Schoelkopf, Q. Anthony, S. Purohit, and E. Raff, “Emergent and predictable memorization in large language models,” 2023.
- Anil et al. [2023] R. Anil, A. M. Dai, O. Firat, M. Johnson et al., “Palm 2 technical report,” 2023.
- Kudugunta et al. [2023] S. Kudugunta, I. Caswell, B. Zhang, X. Garcia, C. A. Choquette-Choo, K. Lee, D. Xin, A. Kusupati, R. Stella, A. Bapna, and O. Firat, “Madlad-400: A multilingual and document-level large audited dataset,” 2023.
- Peris et al. [2023] C. Peris, C. Dupuy, J. Majmudar, R. Parikh, S. Smaili, R. Zemel, and R. Gupta, “Privacy in the time of language models,” in Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, ser. WSDM ’23. New York, NY, USA: Association for Computing Machinery, 2023, p. 1291–1292.
- Huang et al. [2022a] W. R. Huang, S. Chien, O. Thakkar, and R. Mathews, “Detecting unintended memorization in language-model-fused asr,” pp. 2808–2812, 2022.
- Carlini et al. [2019b] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, “The secret sharer: Evaluating and testing unintended memorization in neural networks,” ser. SEC’19. USA: USENIX Association, 2019, p. 267–284.
- Ramaswamy et al. [2020] S. Ramaswamy, O. Thakkar, R. Mathews, G. Andrew, H. B. McMahan, and F. Beaufays, “Training production language models without memorizing user data,” 2020.
- Huang et al. [2024a] Y. Huang, Y. Li, W. Wu, J. Zhang, and M. R. Lyu, “Your code secret belongs to me: Neural code completion tools can memorize hard-coded credentials,” Proc. ACM Softw. Eng., vol. 1, no. FSE, Jul. 2024.
- Mueller et al. [2024] F. B. Mueller, R. Görge, A. K. Bernzen, J. C. Pirk, and M. Poretschkin, “Llms and memorization: On quality and specificity of copyright compliance,” 2024. [Online]. Available: https://arxiv.org/abs/2405.18492
- Freeman et al. [2024] J. Freeman, C. Rippe, E. Debenedetti, and M. Andriushchenko, “Exploring memorization and copyright violation in frontier LLMs: A study of the new york times v. openAI 2023 lawsuit,” in Neurips Safe Generative AI Workshop 2024, 2024. [Online]. Available: https://openreview.net/forum?id=C66DBl9At8
- Elangovan et al. [2021] A. Elangovan, J. He, and K. Verspoor, “Memorization vs. generalization : Quantifying data leakage in NLP performance evaluation,” in Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, P. Merlo, J. Tiedemann, and R. Tsarfaty, Eds. Online: Association for Computational Linguistics, Apr. 2021, pp. 1325–1335.
- Bordt et al. [2024] S. Bordt, H. Nori, V. C. R. Vasconcelos, B. Nushi, and R. Caruana, “Elephants never forget: Memorization and learning of tabular data in large language models,” in First Conference on Language Modeling, 2024. [Online]. Available: https://openreview.net/forum?id=HLoWN6m4fS
- Ranaldi et al. [2023] L. Ranaldi, E. S. Ruzzetti, and F. M. Zanzotto, “PreCog: Exploring the relation between memorization and performance in pre-trained language models,” in Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing, R. Mitkov and G. Angelova, Eds. Varna, Bulgaria: INCOMA Ltd., Shoumen, Bulgaria, Sep. 2023, pp. 961–967.
- Chen et al. [2023] L. Chen, Y. Deng, Y. Bian, Z. Qin, B. Wu, T.-S. Chua, and K.-F. Wong, “Beyond factuality: A comprehensive evaluation of large language models as knowledge generators,” pp. 6325–6341, 2023.
- Lu et al. [2024] X. Lu, X. Li, Q. Cheng, K. Ding, X. Huang, and X. Qiu, “Scaling laws for fact memorization of large language models,” in Findings of the Association for Computational Linguistics: EMNLP 2024, Y. Al-Onaizan, M. Bansal, and Y.-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 11 263–11 282.
- Ouyang et al. [2022b] L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022.
- Helali et al. [2020] M. Helali, T. Kleinbauer, and D. Klakow, “Assessing unintended memorization in neural discriminative sequence models,” in Text, Speech, and Dialogue, P. Sojka, I. Kopeček, K. Pala, and A. Horák, Eds. Cham: Springer International Publishing, 2020, pp. 265–272.
- Shokri et al. [2017] R. Shokri, M. Stronati, C. Song, and V. Shmatikov, “Membership inference attacks against machine learning models,” in 2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 3–18.
- Mattern et al. [2023] J. Mattern, F. Mireshghallah, Z. Jin, B. Schoelkopf, M. Sachan, and T. Berg-Kirkpatrick, “Membership inference attacks against language models via neighbourhood comparison,” in Findings of the Association for Computational Linguistics: ACL 2023, A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 11 330–11 343.
- Shachor et al. [2024] S. Shachor, N. Razinkov, and A. Goldsteen, “Improved membership inference attacks against language classification models,” 2024.
- Shejwalkar et al. [2021] V. Shejwalkar, H. A. Inan, A. Houmansadr, and R. Sim, “Membership inference attacks against NLP classification models,” in NeurIPS 2021 Workshop Privacy in Machine Learning, 2021.
- Jagannatha et al. [2021] A. N. Jagannatha, B. P. S. Rawat, and H. Yu, “Membership inference attack susceptibility of clinical language models,” ArXiv, vol. abs/2104.08305, 2021.
- Wang et al. [2022] Y. Wang, N. Xu, S. Huang, K. Mahmood, D. Guo, C. Ding, W. Wen, and S. Rajasekaran, “Analyzing and defending against membership inference attacks in natural language processing classification,” in 2022 IEEE International Conference on Big Data (Big Data), 2022, pp. 5823–5832.
- Song and Shmatikov [2019] C. Song and V. Shmatikov, “Auditing data provenance in text-generation models,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 196–206.
- Wang et al. [2024a] J. G. Wang, J. Wang, M. Li, and S. Neel, “Pandora’s white-box: Increased training data leakage in open llms,” arXiv preprint arXiv:2402.17012, 2024.
- Ishihara [2023] S. Ishihara, “Training data extraction from pre-trained language models: A survey,” in Proceedings of the 3rd Workshop on Trustworthy Natural Language Processing (TrustNLP 2023), A. Ovalle, K.-W. Chang, N. Mehrabi, Y. Pruksachatkun, A. Galystan, J. Dhamala, A. Verma, T. Cao, A. Kumar, and R. Gupta, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 260–275.
- Parikh et al. [2022] R. Parikh, C. Dupuy, and R. Gupta, “Canary extraction in natural language understanding models,” pp. 552–560, 2022.
- Lukas et al. [2023] N. Lukas, A. Salem, R. Sim, S. Tople, L. Wutschitz, and S. Zanella-Beguelin, “Analyzing leakage of personally identifiable information in language models,” in 2023 IEEE Symposium on Security and Privacy (SP). Los Alamitos, CA, USA: IEEE Computer Society, may 2023, pp. 346–363.
- Henderson et al. [2018] P. Henderson, K. Sinha, N. Angelard-Gontier, N. R. Ke, G. Fried, R. Lowe, and J. Pineau, “Ethical challenges in data-driven dialogue systems,” in Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, ser. AIES ’18. New York, NY, USA: Association for Computing Machinery, 2018, p. 123–129.
- Zhang et al. [2023a] C. Zhang, D. Ippolito, K. Lee, M. Jagielski, F. Tramer, and N. Carlini, “Counterfactual memorization in neural language models,” 2023.
- Schwarzschild et al. [2024] A. Schwarzschild, Z. Feng, P. Maini, Z. C. Lipton, and J. Z. Kolter, “Rethinking LLM memorization through the lens of adversarial compression,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024.
- Zou et al. [2023a] A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models,” 2023.
- Kiyomaru et al. [2024] H. Kiyomaru, I. Sugiura, D. Kawahara, and S. Kurohashi, “A comprehensive analysis of memorization in large language models,” in Proceedings of the 17th International Natural Language Generation Conference, S. Mahamood, N. L. Minh, and D. Ippolito, Eds. Tokyo, Japan: Association for Computational Linguistics, Sep. 2024, pp. 584–596.
- Mahdavi et al. [2024] S. Mahdavi, R. Liao, and C. Thrampoulidis, “Memorization capacity of multi-head attention in transformers,” in The Twelfth International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=MrR3rMxqqv
- Kim et al. [2023b] J. Kim, M. Kim, and B. Mozafari, “Provable memorization capacity of transformers,” in The Eleventh International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=8JCg5xJCTPR
- Lee et al. [2022] K. Lee, D. Ippolito, A. Nystrom, C. Zhang, D. Eck, C. Callison-Burch, and N. Carlini, “Deduplicating training data makes language models better,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), S. Muresan, P. Nakov, and A. Villavicencio, Eds. Dublin, Ireland: Association for Computational Linguistics, May 2022, pp. 8424–8445.
- Prashanth et al. [2024] U. S. Prashanth, A. Deng, K. O’Brien, J. S. V, M. A. Khan, J. Borkar, C. A. Choquette-Choo, J. R. Fuehne, S. Biderman, T. Ke, K. Lee, and N. Saphra, “Recite, reconstruct, recollect: Memorization in lms as a multifaceted phenomenon,” 2024.
- McCoy et al. [2023] R. T. McCoy, P. Smolensky, T. Linzen, J. Gao, and A. Celikyilmaz, “How much do language models copy from their training data? evaluating linguistic novelty in text generation using RAVEN,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 652–670, 2023.
- Li and Liang [2021] X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), C. Zong, F. Xia, W. Li, and R. Navigli, Eds. Online: Association for Computational Linguistics, Aug. 2021, pp. 4582–4597.
- Ozdayi et al. [2023] M. Ozdayi, C. Peris, J. FitzGerald, C. Dupuy, J. Majmudar, H. Khan, R. Parikh, and R. Gupta, “Controlling the extraction of memorized data from large language models via prompt-tuning,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 1512–1521.
- Wang et al. [2024b] Z. Wang, R. Bao, Y. Wu, J. Taylor, C. Xiao, F. Zheng, W. Jiang, S. Gao, and Y. Zhang, “Unlocking memorization in large language models with dynamic soft prompting,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y. Al-Onaizan, M. Bansal, and Y.-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 9782–9796.
- Kassem et al. [2024] A. M. Kassem, O. Mahmoud, N. Mireshghallah, H. Kim, Y. Tsvetkov, Y. Choi, S. Saad, and S. Rana, “Alpaca against vicuna: Using llms to uncover memorization of llms,” 2024.
- Weller et al. [2024] O. Weller, M. Marone, N. Weir, D. Lawrie, D. Khashabi, and B. Van Durme, ““according to . . . ”: Prompting language models improves quoting from pre-training data,” in Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), Y. Graham and M. Purver, Eds. St. Julian’s, Malta: Association for Computational Linguistics, Mar. 2024, pp. 2288–2301.
- Kharitonov et al. [2022] E. Kharitonov, M. Baroni, and D. Hupkes, “How BPE affects memorization in transformers,” 2022.
- Yu et al. [2023] W. Yu, T. Pang, Q. Liu, C. Du, B. Kang, Y. Huang, M. Lin, and S. Yan, “Bag of tricks for training data extraction from language models,” in Proceedings of the 40th International Conference on Machine Learning, ser. ICML’23. JMLR.org, 2023.
- Fan et al. [2018] A. Fan, M. Lewis, and Y. Dauphin, “Hierarchical neural story generation,” arXiv preprint arXiv:1805.04833, 2018.
- Holtzman et al. [2019] A. Holtzman, J. Buys, L. Du, M. Forbes, and Y. Choi, “The curious case of neural text degeneration,” arXiv preprint arXiv:1904.09751, 2019.
- Meister et al. [2023] C. Meister, T. Pimentel, G. Wiher, and R. Cotterell, “Locally typical sampling,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 102–121, 2023.
- Mireshghallah et al. [2022a] F. Mireshghallah, A. Uniyal, T. Wang, D. Evans, and T. Berg-Kirkpatrick, “An empirical analysis of memorization in fine-tuned autoregressive language models,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 1816–1826.
- Zeng et al. [2024a] S. Zeng, Y. Li, J. Ren, Y. Liu, H. Xu, P. He, Y. Xing, J. Tang, and D. Yin, “Exploring memorization in fine-tuned language models,” 2024.
- Raffel et al. [2020] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,” Journal of machine learning research, vol. 21, no. 140, pp. 1–67, 2020.
- Jagielski et al. [2023] M. Jagielski, O. Thakkar, F. Tramer, D. Ippolito, K. Lee, N. Carlini, E. Wallace, S. Song, A. G. Thakurta, N. Papernot, and C. Zhang, “Measuring forgetting of memorized training examples,” in The Eleventh International Conference on Learning Representations, 2023.
- Leybzon and Kervadec [2024] D. D. Leybzon and C. Kervadec, “Learning, forgetting, remembering: Insights from tracking LLM memorization during training,” in Proceedings of the 7th BlackboxNLP Workshop: Analyzing and Interpreting Neural Networks for NLP, Y. Belinkov, N. Kim, J. Jumelet, H. Mohebbi, A. Mueller, and H. Chen, Eds. Miami, Florida, US: Association for Computational Linguistics, Nov. 2024, pp. 43–57.
- De Lange et al. [2021] M. De Lange, R. Aljundi, M. Masana, S. Parisot, X. Jia, A. Leonardis, G. Slabaugh, and T. Tuytelaars, “A continual learning survey: Defying forgetting in classification tasks,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 7, pp. 3366–3385, 2021.
- Timm et al. [2018] I. J. Timm, S. Staab, M. Siebers, C. Schon, U. Schmid, K. Sauerwald, L. Reuter, M. Ragni, C. Niederée, H. Maus et al., “Intentional forgetting in artificial intelligence systems: Perspectives and challenges,” in KI 2018: Advances in Artificial Intelligence: 41st German Conference on AI, Berlin, Germany, September 24–28, 2018, Proceedings 41. Springer, 2018, pp. 357–365.
- Beierle and Timm [2019] C. Beierle and I. J. Timm, “Intentional forgetting: An emerging field in ai and beyond,” pp. 5–8, 2019.
- Nguyen et al. [2022] T. T. Nguyen, T. T. Huynh, P. L. Nguyen, A. W.-C. Liew, H. Yin, and Q. V. H. Nguyen, “A survey of machine unlearning,” arXiv preprint arXiv:2209.02299, 2022.
- Blanco-Justicia et al. [2024] A. Blanco-Justicia, N. Jebreel, B. Manzanares, D. Sánchez, J. Domingo-Ferrer, G. Collell, and K. E. Tan, “Digital forgetting in large language models: A survey of unlearning methods,” arXiv preprint arXiv:2404.02062, 2024.
- Kirkpatrick et al. [2017] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- Huang et al. [2024b] J. Huang, D. Yang, and C. Potts, “Demystifying verbatim memorization in large language models,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y. Al-Onaizan, M. Bansal, and Y.-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 10 711–10 732.
- Haviv et al. [2023] A. Haviv, I. Cohen, J. Gidron, R. Schuster, Y. Goldberg, and M. Geva, “Understanding transformer memorization recall through idioms,” in Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, A. Vlachos and I. Augenstein, Eds. Dubrovnik, Croatia: Association for Computational Linguistics, May 2023, pp. 248–264.
- Dankers and Titov [2024] V. Dankers and I. Titov, “Generalisation first, memorisation second? memorisation localisation for natural language classification tasks,” in Findings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V. Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 14 348–14 366.
- Stoehr et al. [2024] N. Stoehr, M. Gordon, C. Zhang, and O. Lewis, “Localizing paragraph memorization in language models,” 2024.
- Chen et al. [2024] B. Chen, N. Han, and Y. Miyao, “A multi-perspective analysis of memorization in large language models,” in Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y. Al-Onaizan, M. Bansal, and Y.-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 11 190–11 209.
- Mireshghallah et al. [2022b] F. Mireshghallah, K. Goyal, A. Uniyal, T. Berg-Kirkpatrick, and R. Shokri, “Quantifying privacy risks of masked language models using membership inference attacks,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 8332–8347.
- Borec et al. [2024] L. Borec, P. Sadler, and D. Schlangen, “The unreasonable ineffectiveness of nucleus sampling on mitigating text memorization,” in Proceedings of the 17th International Natural Language Generation Conference, S. Mahamood, N. L. Minh, and D. Ippolito, Eds. Tokyo, Japan: Association for Computational Linguistics, Sep. 2024, pp. 358–370.
- Shao et al. [2023] H. Shao, J. Huang, S. Zheng, and K. C.-C. Chang, “Quantifying Association Capabilities of Large Language Models and Its Implications on Privacy Leakage,” 2023, publisher: arXiv Version Number: 1.
- Huang et al. [2022b] J. Huang, H. Shao, and K. C.-C. Chang, “Are Large Pre-Trained Language Models Leaking Your Personal Information?” Oct. 2022.
- Zhang et al. [2023b] Z. Zhang, J. Wen, and M. Huang, “ETHICIST: Targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A. Rogers, J. Boyd-Graber, and N. Okazaki, Eds. Toronto, Canada: Association for Computational Linguistics, Jul. 2023, pp. 12 674–12 687.
- Feldman [2020] V. Feldman, “Does learning require memorization? a short tale about a long tail,” in Proceedings of the 52nd Annual ACM SIGACT Symposium on Theory of Computing, ser. STOC 2020. New York, NY, USA: Association for Computing Machinery, 2020, p. 954–959.
- Brown et al. [2021] G. Brown, M. Bun, V. Feldman, A. Smith, and K. Talwar, “When is memorization of irrelevant training data necessary for high-accuracy learning?” in Proceedings of the 53rd annual ACM SIGACT symposium on theory of computing, 2021, pp. 123–132.
- Dodge et al. [2021] J. Dodge, M. Sap, A. Marasovic, W. Agnew, G. Ilharco, D. Groeneveld, and M. Gardner, “Documenting the english colossal clean crawled corpus,” CoRR, vol. abs/2104.08758, 2021.
- Zellers et al. [2019] R. Zellers, A. Holtzman, H. Rashkin, Y. Bisk, A. Farhadi, F. Roesner, and Y. Choi, “Defending against neural fake news,” Advances in neural information processing systems, vol. 32, 2019.
- Chelba et al. [2013] C. Chelba, T. Mikolov, M. Schuster, Q. Ge, T. Brants, P. Koehn, and T. Robinson, “One billion word benchmark for measuring progress in statistical language modeling,” arXiv preprint arXiv:1312.3005, 2013.
- Guo et al. [2020] M. Guo, Z. Dai, D. Vrandečić, and R. Al-Rfou, “Wiki-40B: Multilingual language model dataset,” in Proceedings of the Twelfth Language Resources and Evaluation Conference, N. Calzolari, F. Béchet, P. Blache, K. Choukri, C. Cieri, T. Declerck, S. Goggi, H. Isahara, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, and S. Piperidis, Eds. Marseille, France: European Language Resources Association, May 2020, pp. 2440–2452.
- Radford et al. [2019] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, I. Sutskever et al., “Language models are unsupervised multitask learners,” OpenAI blog, vol. 1, no. 8, p. 9, 2019.
- Dwork et al. [2006] C. Dwork, F. McSherry, K. Nissim, and A. Smith, “Calibrating noise to sensitivity in private data analysis,” in Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, March 4-7, 2006. Proceedings 3. Springer, 2006, pp. 265–284.
- Abadi et al. [2016] M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS’16. ACM, Oct. 2016.
- Kerrigan et al. [2020] G. Kerrigan, D. Slack, and J. Tuyls, “Differentially private language models benefit from public pre-training,” in Proceedings of the Second Workshop on Privacy in NLP, O. Feyisetan, S. Ghanavati, S. Malmasi, and P. Thaine, Eds. Online: Association for Computational Linguistics, Nov. 2020, pp. 39–45.
- Li et al. [2022] X. Li, F. Tramer, P. Liang, and T. Hashimoto, “Large language models can be strong differentially private learners,” in International Conference on Learning Representations, 2022.
- Shi et al. [2022a] W. Shi, R. Shea, S. Chen, C. Zhang, R. Jia, and Z. Yu, “Just fine-tune twice: Selective differential privacy for large language models,” in Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Abu Dhabi, United Arab Emirates: Association for Computational Linguistics, Dec. 2022, pp. 6327–6340.
- Shi et al. [2022b] W. Shi, A. Cui, E. Li, R. Jia, and Z. Yu, “Selective differential privacy for language modeling,” in Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, M. Carpuat, M.-C. de Marneffe, and I. V. Meza Ruiz, Eds. Seattle, United States: Association for Computational Linguistics, Jul. 2022, pp. 2848–2859.
- Bourtoule et al. [2021] L. Bourtoule, V. Chandrasekaran, C. A. Choquette-Choo, H. Jia, A. Travers, B. Zhang, D. Lie, and N. Papernot, “Machine unlearning,” in 2021 IEEE Symposium on Security and Privacy (SP). IEEE, 2021, pp. 141–159.
- Chen and Yang [2023] J. Chen and D. Yang, “Unlearn what you want to forget: Efficient unlearning for LLMs,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 12 041–12 052.
- Pawelczyk et al. [2024] M. Pawelczyk, S. Neel, and H. Lakkaraju, “In-context unlearning: Language models as few shot unlearners,” 2024.
- Kassem et al. [2023] A. Kassem, O. Mahmoud, and S. Saad, “Preserving privacy through dememorization: An unlearning technique for mitigating memorization risks in language models,” in Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 4360–4379.
- Si et al. [2023] N. Si, H. Zhang, H. Chang, W. Zhang, D. Qu, and W. Zhang, “Knowledge unlearning for llms: Tasks, methods, and challenges,” ArXiv, vol. abs/2311.15766, 2023.
- Yao et al. [2024b] Y. Yao, X. Xu, and Y. Liu, “Large language model unlearning,” 2024.
- Liu et al. [2023] Z. Liu, X. Zhang, and F. Peng, “Mitigating unintended memorization in language models via alternating teaching,” in ICASSP 2023 - 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2023, pp. 1–5.
- Panayotov et al. [2015] V. Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Librispeech: an asr corpus based on public domain audio books,” in 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210.
- Black et al. [2021] S. Black, L. Gao, P. Wang, C. Leahy, and S. Biderman, “GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow,” Mar. 2021, If you use this software, please cite it using these metadata.
- GitHub Copilot [2024] GitHub Copilot, “GitHub Copilot: AI-Powered Code Completion,” 2024, accessed: 2025-03-13. [Online]. Available: https://github.com/features/copilot
- Lin [2004] C.-Y. Lin, “ROUGE: A package for automatic evaluation of summaries,” in Text Summarization Branches Out. Barcelona, Spain: Association for Computational Linguistics, Jul. 2004, pp. 74–81. [Online]. Available: https://aclanthology.org/W04-1013/
- Hans et al. [2024] A. Hans, J. Kirchenbauer, Y. Wen, N. Jain, H. Kazemi, P. Singhania, S. Singh, G. Somepalli, J. Geiping, A. Bhatele, and T. Goldstein, “Be like a goldfish, don’t memorize! mitigating memorization in generative LLMs,” in The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=DylSyAfmWs
- Xi et al. [2023] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou et al., “The rise and potential of large language model based agents: A survey,” arXiv preprint arXiv:2309.07864, 2023.
- Deng et al. [2023] Y. Deng, W. Lei, M. Huang, and T.-S. Chua, “Rethinking conversational agents in the era of llms: Proactivity, non-collaborativity, and beyond,” in Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, 2023, pp. 298–301.
- Lewis et al. [2020] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020.
- Gao et al. [2023] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” arXiv preprint arXiv:2312.10997, 2023.
- Shuster et al. [2021] K. Shuster, S. Poff, M. Chen, D. Kiela, and J. Weston, “Retrieval augmentation reduces hallucination in conversation,” in Findings of the Association for Computational Linguistics: EMNLP 2021, 2021, pp. 3784–3803.
- Zeng et al. [2024b] S. Zeng, J. Zhang, P. He, Y. Xing, Y. Liu, H. Xu, J. Ren, S. Wang, D. Yin, Y. Chang, and J. Tang, “The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag),” 2024.
- Qin et al. [2024] L. Qin, Q. Chen, Y. Zhou, Z. Chen, Y. Li, L. Liao, M. Li, W. Che, and P. S. Yu, “Multilingual large language model: A survey of resources, taxonomy and frontiers,” 2024.
- Xu et al. [2024] Y. Xu, L. Hu, J. Zhao, Z. Qiu, Y. Ye, and H. Gu, “A survey on multilingual large language models: Corpora, alignment, and bias,” arXiv preprint arXiv:2404.00929, 2024.
- Zou et al. [2023b] H. Zou, Z. M. Kim, and D. Kang, “A survey of diffusion models in natural language processing,” 2023.
- Carlini et al. [2023b] N. Carlini, J. Hayes, M. Nasr, M. Jagielski, V. Sehwag, F. Tramer, B. Balle, D. Ippolito, and E. Wallace, “Extracting training data from diffusion models,” in 32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 5253–5270.
- Gu et al. [2024] X. Gu, C. Du, T. Pang, C. Li, M. Lin, and Y. Wang, “On memorization in diffusion models,” 2024.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.