Unified Chinese License Plate Detection and Recognition with High Efficiency
Abstract
Recently, deep learning-based methods have reached an excellent performance on License Plate (LP) detection and recognition tasks. However, it is still challenging to build a robust model for Chinese LPs since there are not enough large and representative datasets. In this work, we propose a new dataset named Chinese Road Plate Dataset (CRPD) that contains multi-objective Chinese LP images as a supplement to the existing public benchmarks. The images are mainly captured with electronic monitoring systems with detailed annotations. To our knowledge, CRPD is the largest public multi-objective Chinese LP dataset with annotations of vertices. With CRPD, a unified detection and recognition network with high efficiency is presented as the baseline. The network is end-to-end trainable with totally real-time inference efficiency (30 fps with 640p). The experiments on several public benchmarks demonstrate that our method has reached competitive performance. The code and dataset will be publicly available at https://github.com/yxgong0/CRPD.
keywords:
Chinese license plate dataset; License plate detection and recognition; End-to-end; Real-time1 Introduction
License Plate (LP) detection and recognition are the key parts of intelligent transportation systems because it is the unique identification of vehicles. The relevant methods are widely used on electronic toll payment, parking managing, and traffic monitoring systems. In order to achieve effective detection and recognition, researchers proposed a variety of techniques that are capable of handling the task in most conditions. Before the deep learning era, most of the methods were on the basis of artificial designs [1, 2, 3]. They utilized hand-crafted features such as colors, shadows and textures, and integrated them by a cascaded strategy with license plate detection, segmentation, and recognition. Although they reached promising performance, the robustness may not be enough for some uncontrolled circumstances like weather, illumination, and rotation since the scheme relies on manually designed features. Then with the explosion of deep learning methods in recent years, most researchers turned their attention to this framework that is able to learn features automatically. The convenient and efficient technique quickly became popular, and networks for detection and recognition also sprung up [4, 5, 6]. In these works, great successes have been achieved. However, for Chinese LPs, the problem of data scarcity gradually emerges. Existing annotated Chinese LP data that is representative of most scenarios cannot meet the huge demands. Thus, to alleviate the issue, we present our Chinese Road Plate Dataset (CRPD).
Admittedly, there are already some excellent public datasets with LPs [4, 7, 8, 9, 10, 11, 12, 13, 14, 15]. These public benchmarks lay the foundation of various LP processing methods, and our CRPD is an effective supplement to existing Chinese LP datasets, which is more challenging. Images of CRPD are collected from electronic monitoring systems in most provinces of mainland China in different periods and weather conditions. The images contain cars with different statuses and types, and quite a part of the data contains more than one LP in one image. Each image has annotations of (i) LP content. (ii) Locations of four vertices. (iii) LP type. More details will be introduced in Section 3.
As for detection and recognition tasks, most prestigious methods designed the two branches separately. Zhou et al. [4] proposed a scheme for LP detection with Principal Visual Word (PVW) generation and applied bag-of-words in partial-duplicate image search. Chen et al. [5] put forward a method to detect the vehicles and the LPs simultaneously, where the results can be used for further recognition. The two-stage framework is effective, but the error accumulation problems hinder further progresses. Therefore, end-to-end frameworks are increasingly prevalent. In this paper, we propose an end-to-end trainable Chinese LP detection and recognition network with both high efficiency and satisfactory performance as the baseline of our CRPD. Our method is a unified network that consists of two branches. The branch for detection is based on STELA [16], which is a learned anchor-based detector. It only associates one reference box at each spatial position, which highly reduces the computation to reach a fast running speed. In the recognition branch, we abandon the recognition by segmentation pipeline and utilize a sequence-to-sequence method to accomplish the recognition task. The region-wise features are extracted by the RRoIAlign [17] operator and then will be fed into components for recognition. This scheme blurs the line between detection and recognition, which strongly alleviates the error accumulation issues.
In summary, there are three main contributions in this work:
-
1.
We publish a new Chinese LP dataset with more than 30k images, which covers more scenes and administrative regions of mainland China. We argue that this new dataset is more difficult than existing datasets and is also a supplement to the Chinese LP research field.
-
2.
We propose an end-to-end trainable network for Chinese LP detection and recognition, which almost reaches a trade-off between accuracy and efficiency as a baseline. Through utilizing the common feature extraction branch and the RRoIAlign [17] operator, end-to-end training is achieved, and the error accumulation problems are alleviated with a real-time efficiency kept.
-
3.
Our code and dataset will be publicly available soon. To facilitate the reference of researchers and get more progress, we will upload related materials.
2 Related Work
2.1 LP Datasets
Due to the importance of LP detection and recognition, researchers built and published a number of LP datasets. ReId [7] is a dataset for license plate recognition with 76k images gathered from surveillance cameras on highway toll gates. Caltech [8] and Zemris [9] collected over 600 images from the road and freeways with high-resolution cameras. Hsu et al. [11] presented a dataset for applications of access control, traffic law enforcement and road patrol. Gonçalves et al. [12] proposed Sense SegPlate Database to evaluate license plate character segmentation problem. Laroca et al. [13] provided a dataset that includes 4,500 fully annotated images from 150 vehicles in real-world scenarios. These datasets strongly support the researches of LP detection and recognition methods.
However, LPs in different countries and regions are usually not the same. The mentioned datasets mostly contain LPs that only include alphanumeric characters. In some countries or regions, such as Chinese mainland regions, Japan and South Korea, the LPs contain some special characters. Therefore, it is still significant to build new datasets for these LPs. Among them, mainland Chinese LP detection and recognition are one of the important tasks which require a large amount of data. To meet the demand, Chinese LP datasets were proposed. Zhou et al. [4] collected 220 LP images where the LPs were of little affine distortion. Yuan et al. [14] presented a dataset that contains vehicle images captured from various scenes under diverse conditions. Zhang et al. [15] proposed a dataset that contains 1,200 LP images from all 31 provinces in mainland China. CCPD [10] is a large and comprehensive dataset with about 290k images that contain plates with various angles, distances, and illuminations. Though they made important contributions to the progress of detection and recognition methods, there are still not enough large and representative datasets.
2.2 LP Detection and Recognition
Owing to the successes of text detection and recognition, LP processing is also well developed. There are methods with end-to-end frameworks, which achieved excellent performance. Zhang et al. [18] integrated LP detection, tracking, and recognition into a unified framework via deep learning. Silva et al. [19] proposed to identify the vehicle and the LP region using two passes on the same CNN and then to recognize the characters using a second CNN. Kessentini et al. [20] presented a two-stage network to achieve the detection and recognition of LPs. In [21], a light CNN was proposed for detection and recognition, which achieved real-time efficiency.
As for Chinese LPs, there are also excellent end-to-end frameworks. Laroca et al. [22] proposed a unified approach for LP detection and layout classification to improve the recognition results. Qin et al. [23] proposed a unified method that can recognize both single-line and double-line LPs in an end-to-end way without line segmentation and character segmentation. However, Chinese LP processing is still challenging due to the large number of categories of Chinese characters. Meanwhile, LP processing under unconstrained scenarios also faces many problems. Therefore, it is still valuable to propose a new end-to-end framework for Chinese LP detection and recognition.
3 CRPD Overview
3.1 Constitution of Data
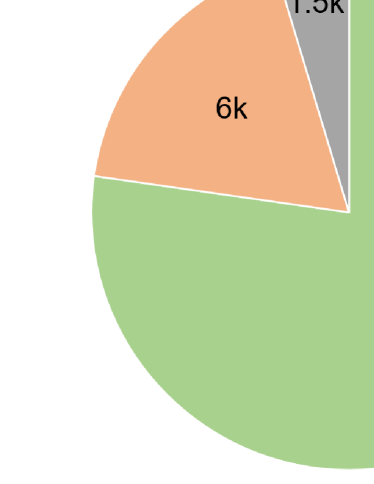
Because CRPD is presented as a supplement for existing datasets, special attention is paid to the diversity of data. The images are mainly captured on electronic monitoring systems, including vehicles that are running, turning, parked, or far away which may cause blur and rotation. The scene includes day and night and different weathers. Quite a part of the images contains more than one LP from different provinces and cities, and there are LPs of special vehicles involved, such as coach cars, police cars, and trailers, whose LPs will contain some special characters. The dataset includes three sub-datasets according to the numbers of LPs: CRPD-single, CRPD-double, and CRPD-multi, as shown in Figure 1. CRPD-single contains images with only one LP, CRPD-double contains images with two LPs, and CRPD-multi contains images with three or more LPs.
There are totally about 25k images for training, 6.25k for validating, and 2.3k for testing. In CRPD-single, there are 20k images for training, 5k for validating, and 1k for testing. In CRPD-double, there are 4k images for training, 1k for validating, and 1k for testing. In CRPD-multi, there are 1k images for training, 0.25k for validating, and 0.3k for testing.
The annotations consist of three parts. The first is LP content which includes numbers, Chinese and English characters. There are some LPs that are too small or seriously blurred whose content is unidentifiable, and they are also annotated while the unrecognizable characters are replaced with a special one. The second is the coordinate of four vertices of the LPs. The last is the LP type, including blue (small cars), yellow and single line (front of large cars), yellow and double lines (back of large cars), and white (police cars).
3.2 Data Analysis
CRPD provides more than 30k LP images with annotations. Though it is not the largest dataset in current frequently used Chinese datasets, some characteristics of CRPD will be helpful for training a robust model. Existing datasets mostly contain single and focused LP in one image, as shown in Figure 2. In some cases, such as electronic toll payment or parking managing systems, the data is highly effective. But when dealing with data for traffic monitoring systems, suspect car tracking, or vehicle flow measuring, images with more LPs will be required. CRPD aims to fill up this deficiency, so we paid special attention to the number of LPs, as shown in Figure 3.

Also, CRPD has some other advantages for building a robust model. To illustrate them, we compare with CCPD [10], EasyPR [24], ChineseLP [4] and CLPD [15] in some aspects, which are shown in Tables 1, 2 and 3.
The first is the number of LPs. Images in CCPD [10] and CLPD [15] contain one LP, which can better indicate the detection Precision of a network. But as noted above, this may restrict the scenarios where it can be used. In comparison, EasyPR [24], ChineseLP [4] and our CRPD have better compatibility in this aspect.
The second is the status of vehicles. CCPD [10] contains images captured from parking lots, and they are more interested in LPs in various circumstances with different illumination, rotation, and blur. Therefore, the vehicle status is not focused. Our CRPD concentrates on the capability to deal with a variety of vehicles, so there is better coverage on vehicle status.

| LP Number | CCPD | EasyPR | ChineseLP | CLPD | CRPD |
|---|---|---|---|---|---|
| 224001 | 225 | 392 | 1200 | 26659 | |
| 0 | 21 | 16 | 0 | 6242 | |
| 0 | 10 | 1 | 0 | 1232 | |
| 0 | 0 | 2 | 0 | 371 |
| Status of Vehicles | CCPD | EasyPR | ChineseLP | CLPD | CRPD |
|---|---|---|---|---|---|
| Parked | ✔ | ✔ | ✔ | ✔ | ✔ |
| Running | ✗ | ✔ | ✔ | ✔ | ✔ |
| Turning | ✗ | ✔ | ✔ | ✔ | ✔ |
| Far away | ✗ | ✗ | ✗ | ✔ | ✔ |
The last is the vehicle types. Though there are not a number of special vehicles on the road, the detection and recognition of them are still of great importance. Thus, we paid attention to the LPs of special vehicles to ensure the capability of the network trained by CRPD to deal with these LPs. Some images of them are shown in Figure 4. Altogether, our CRPD covers most a variety of common scenes. It is a strong supplement to Chinese LP datasets either used as training or evaluating data.
| Type of Vehicles | CCPD | EasyPR | ChineseLP | CLPD | CRPD |
|---|---|---|---|---|---|
| Coach Vehicles | ✗ | ✔ | ✗ | ✔ | ✔ |
| Police Vehicles | ✗ | ✗ | ✗ | ✔ | ✔ |
| Trailers | ✗ | ✗ | ✗ | ✗ | ✔ |

However, there are also some limitations of CRPD. First, the location of each LP character is not annotated, which restricts the applications of object detection and data augmentation. Meanwhile, it is also difficult to detect each character because it is very small in the perspective of electronic monitoring systems. Second, the LPs are all on the vehicles. The actual LPs can be held in hand or placed on the ground in some circumstances, and the detection and recognition of these LPs are also useful.
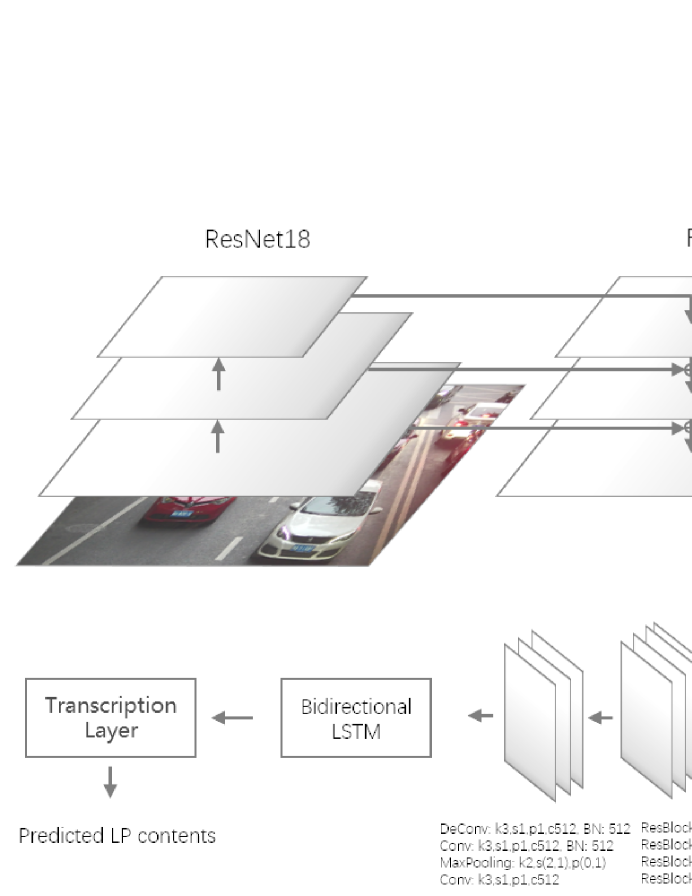
4 Methodology
In this section, we will describe the proposed method in detail, and the pipeline is shown in Figure 5.
4.1 Detection Branch
The first stage is the LP detection step. As noted above, there are some obstacles for LP detection networks to reach a balance between accuracy and efficiency. Considering the trade-off, we utilize our previous STELA [16], a totally real-time detector, as the basis of our detection branch. The detection network is implemented on RetinaNet [25] and utilizes Feature Pyramid Network (FPN) [26] to construct a rich, multi-scale feature pyramid from a single resolution input image. It consists of three portions: anchor classification, rotated bounding box regression, and anchor refining.
4.1.1 Anchor Classification
As we do not generate region proposals, class imbalance problems still exist in our scheme. That means there are only a few anchors that are annotated as positive (the object), while the others are negative. Therefore, Focal Loss [25] are utilized to calculate the loss of classification, as it is designed to deal with the problem. Firstly, we define with
| (1) |
where is the predicted probability and specifies the ground-truth class. Then the loss is defined as
| (2) |
is a balanced weighting factor and is a focusing parameter. They are set to 0.25 and 2.0 respectively, which is the same as the original Focal Loss [25].

4.1.2 Rotated Bounding Box Regression
For the detection of tilted LP, we utilize rotated bounding boxes to match the instances. The box can be represented by a five tuple , in which and are the coordinate of the center point, and are the width and height of the box, and is the angle to horizontal, as shown in Figure 6. For the regression operation, the distance vector is defined as
| (3) |
| (4) |
| (5) |
where and represent a bounding box and the corresponding target groundtruth respectively. The loss of the regression can be calculated by
| (6) |
where is the smooth L1 loss [27], is the target and is the predicted tuple.
4.1.3 Learned Anchor
As depicted in [16], the most important part of the proposed scheme in two-stage is that the selected proposals are chosen by learning. The manually-defined original anchors with fixed scales and aspect ratios may not be the optimal designs, so an extra regression branch for anchor refining is added. The final classification and regression task will be reached on the learned anchors, which brings an improvement in accuracy with a little increment of computation. The original anchor, learned anchor, and output boxes are illustrated in Figure 7. It is obvious that the center should be well aligned with the pixel in feature maps. Thus, the offsets are only regressed within , which means that only the shapes are adjusted. The loss can be calculated with
| (7) |
in which is the target and is the predicted tuple. And finally, the total loss is
| (8) |
in which and are the weights which are set to 0.5, 0.5, and 1 which have been proven to be effective.

4.2 Recognition Branch
The recognition step is the second stage of the LP processing tasks. Because most of the networks for recognition achieved high efficiency, we simply utilize modules based on CRNN [28] to achieve the recognition. There are three parts in the modules: the convolutional layers, the recurrent layers, and the transcription layer.
In consideration that the backbone of our network has already extracted critical features of the input images, to avoid redundant computation, we utilize the processed feature maps as the input of the recognition branch. In order to effectively deal with rotated plates, RRoIAlign [17] that can crop the feature map with a rotated box, is applied to crop the maps according to the groundtruth boxes of LPs, and the cropped size is . While training, we consider that the feature maps may not be processed well when the predicted boxes are not accurate, so the feature maps will also be cropped with both groundtruth boxes and predicted boxes with a score higher than 0.9.
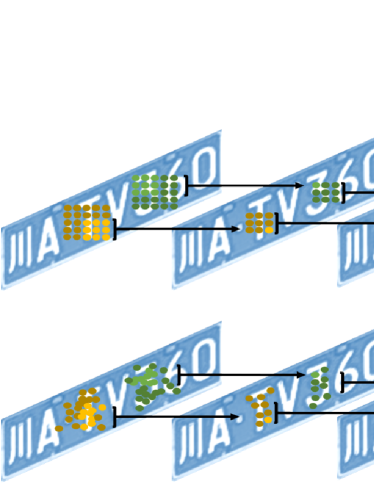
And because the input is feature maps, we remove the first three convolutions of the original convolutional layers of CRNN [28] to avoid the over-fitting problems. And in order to reach better accuracy, we refer to our another previous work [29], and replace two convolution layers with deformable convolution layers and add four residual blocks in this branch. The deformable convolution layers have an adaptive receptive field that can better cover the text area, as shown in Figure 8.
The architecture of the convolutional layers is shown in Figure 5. The recurrent layers are based on bidirectional LSTM [30], and the transcription component is based on CTCLoss [31]. The total loss function is a weighted loss
| (9) |
where and are constants that indicate the strength of the detection and recognition modules. And in our training, the value of is one-magnitude-order larger than , so to keep a balance, we set them to 1 and 0.1, respectively.
5 Experiments
5.1 Training Details
The training and testing datasets are from CCPD [10], EasyPR [24], and our CRPD. The input images are resized to with three channels. In the training stage, the optimizer of the network is Adam [18], the batch size is set to 32, and the learning rate is 1e-4. The network is trained for 35000 iterations which consume about 10 hours. The proposed method is implemented by PyTorch [32]. The experiments are carried on a platform with Intel Xeon(R) E5-2630 v3 CPU and a single NVIDIA TITAN RTX GPU.
5.2 Evaluation Metrics
To demonstrate the effectiveness of the methods, we utilize the protocols described in [10] to evaluate the models. The detection will be considered as a match if it overlaps a ground truth bounding box by more than 60% and the words match exactly. Then Recall, Precision, and F-score are calculated with
| (10) |
| (11) |
| (12) |
where represents the number of positive objects that are predicted as positive and the words match, represents the number of negative objects that are predicted as positive, and represents the number of negative objects that are predicted as negative.
5.3 Ablations
To demonstrate that the unified architecture brings some improvements and our scheme reaches the best performance, we evaluate the proposed components. Firstly, we test the effectiveness of our unified network. As comparisons, cascaded STELA [16] and CRNN [28] models are utilized. The two networks are trained respectively, and the CRNN [28] model will process the original images cropped in the light of the boxes predicted by STELA [16]. All the models are trained on CRPD and evaluated on CCPD [10], EasyPR [24], and CRPD. From Table 4, we see that our network achieves a few improvements. A better result is reached on CRPD because the training and testing data have the same distribution. The LPs in CCPD [10] have a larger size, so the model trained on our CRPD, which contains LPs with small sizes, is not able to reach the best performance.
| Dataset | STELA+CRNN | Our Method | |||||
|---|---|---|---|---|---|---|---|
| R | P | F | R | P | F | ||
| CCPD | 79.1 | 67.8 | 73.0 | 75.6 | 72.1 | 73.8 | |
| EasyPR | 90.2 | 72.8 | 80.6 | 89.9 | 73.0 | 80.6 | |
| CRPD | 88.3 | 82.9 | 85.5 | 95.4 | 84.1 | 89.4 | |
-
1.
R: Recall; P: Precision; F: F-score
Then as we utilize the predicted boxes of the detection modules to crop the feature maps in the training stage, we evaluate the effectiveness of them with different scores. In Table 5, it is obvious that utilizing predicted boxes will bring an improvement on the Recall because more incomplete LPs will be detected, with a little descend on Precision. Considering the recognition branch will also become more robust with this mechanism, it will make the network able to better deal with inaccurate boxes. But because Chinese LPs usually have seven characters, a box with a score lower than 0.86 may cut a whole character off. Thus, there must be a deterioration of the performance when using boxes with scores only higher than 0.85. And the number of boxes with scores higher than 0.95 is less, which causes a smaller batch size for recognition modules, so we choose 0.9 as the threshold finally.
| Threshold | Recall | Precision | F-score |
|---|---|---|---|
| None | 91.2 | 85.4 | 88.2 |
| >0.95 | 91.7 | 84.6 | 88.0 |
| >0.90 | 95.4 | 84.1 | 89.4 |
| >0.85 | 94.5 | 82.5 | 88.1 |
The way to crop the feature maps may also bring different results of the recognition modules. We compare RoIPool [27], RoIAlign [33], and RRoIAlign [17], and the results are shown in Table 6. There is no obvious difference between the first two methods, and we think the reason is that LPs are not small objects, so some slight errors will not influence much. RRoIAlign [17] can better handle the work because the recognition branch will have great progress with consideration of the rotation degrees.
| Approach | Recall | Precision | F-score |
|---|---|---|---|
| RoIPooling | 95.0 | 80.2 | 87.0 |
| RoIAlign | 95.7 | 80.1 | 87.2 |
| RRoIAlign | 95.4 | 84.1 | 89.4 |
In the recognition branch, we crop the feature maps yield by different layers of the FPN [26] components to explain why we utilize those from the third layer. Though it seems to utilize the feature maps from the third layer is optimal in Table 7, but we consider it is because most of the LPs in the images of CRPD have sizes which match the anchors in the third layer. In the fifth or deeper layers, the anchors are mappings of some huge boxes in the original images, but most of the LPs have a small size.
| Feature Map Layer | Recall | Precision | F-score |
|---|---|---|---|
| P3 | 95.4 | 84.1 | 89.4 |
| P4 | 82.4 | 70.1 | 75.8 |
| P5 | 2.6 | 2.9 | 2.7 |
| Deformable Conv | Recall | Precision | F-score |
|---|---|---|---|
| ✗ | 93.0 | 83.7 | 88.1 |
| ✔ | 95.4 | 84.1 | 89.4 |
Finally, to demonstrate that the deformable layers and residual blocks in the recognition branch are effective, ablations are involved, as shown in Table 8. In our metrics, only when the content matches exactly, the result will be regarded as correct. Therefore, deformable convolution brings an improvement in recognition, and the Recall and Precision are both improved.
5.4 Comparisons
| Method | CRPD-all | CRPD-single | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Recall | Precision | F-score | FPS | Recall | Precision | F-score | FPS | ||
| EasyPR | 2.0 | 1.3 | 1.6 | 6 | 2.3 | 1.3 | 1.7 | 6 | |
| SSD512 + CRNN | 97.8 | 27.2 | 42.6 | 66 | 98.9 | 28.7 | 44.4 | 71 | |
| YOLOv3 + CRNN | 73.0 | 61.0 | 66.5 | 18 | 73.7 | 59.4 | 65.8 | 18 | |
| YOLOv4 + CRNN | 84.4 | 60.5 | 70.5 | 40 | 87.3 | 68.4 | 76.7 | 40 | |
| SYOLOv4 + CRNN | 86.8 | 71.0 | 78.2 | 35 | 90.1 | 72.4 | 80.3 | 35 | |
| Faster-RCNN + CRNN | 79.9 | 73.7 | 76.7 | 19 | 81.4 | 71.7 | 76.3 | 20 | |
| STELA + CRNN | 88.3 | 82.9 | 85.5 | 36 | 83.1 | 73.3 | 77.9 | 36 | |
| Ours | 95.4 | 84.1 | 89.4 | 30 | 96.3 | 83.6 | 89.5 | 35 | |
| Method | CRPD-double | CRPD-multi | |||||||
| Recall | Precision | F-score | FPS | Recall | Precision | F-score | FPS | ||
| EasyPR | 1.5 | 1.2 | 1.3 | 6 | 1.8 | 1.7 | 1.8 | 6 | |
| SSD512 + CRNN | 97.5 | 27.5 | 42.9 | 66 | 93.5 | 21.1 | 34.5 | 63 | |
| YOLOv3 + CRNN | 74.6 | 64.4 | 69.1 | 17 | 66.2 | 61.3 | 63.6 | 17 | |
| YOLOv4 + CRNN | 90.4 | 41.2 | 56.6 | 40 | 88.9 | 36.8 | 52.0 | 39 | |
| SYOLOv4 + CRNN | 91.5 | 75.9 | 83.0 | 35 | 91.5 | 75.2 | 82.5 | 35 | |
| Faster-RCNN + CRNN | 81.1 | 77.9 | 79.5 | 19 | 69.3 | 75.2 | 72.1 | 17 | |
| STELA + CRNN | 84.0 | 80.6 | 82.3 | 34 | 77.6 | 82.8 | 80.1 | 33 | |
| Ours | 95.8 | 84.5 | 89.8 | 30 | 90.8 | 85.0 | 87.7 | 26 | |
-
1.
SYOLOv4: Scaled YOLOv4
To demonstrate that our method has reached a satisfactory performance, we make some comparisons with other methods. We involve EasyPR [24], SSD [34], YOLO-v3 [35], YOLO-v4 [36], Scaled YOLO-v4 [37] and Faster-RCNN [38]. A CRNN [28] model is appended to achieve recognition. We utilize cascaded STELA [16] and CRNN [28] as our baseline in experiments. From Table 9, it can be observed that EasyPR [24] cannot treat LPs in CRPD well because it depends on manually designed features. SSD [34], YOLOv3 [35], YOLO-v4 [36], Scaled YOLO-v4 [37] and Faster-RCNN [38] are not specially designed for LPs or text, but the results are still competitive. Our method reaches the best on all the sub-datasets, which proves the effectiveness.
Because Xu et al. [10] evaluated their method on different circumstances, for fair comparisons, experiments of our method on these datasets are also utilized. And as the other methods are trained on CCPD [10], we also utilize it as the training data of our method in this comparison. Because images in CCPD [10] only contain one LP in one image, only Precision is involved when the Recall is not considered. Following the experiments of Xu et al. [10], Cascade classifier [39], SSD300 [34], YOLO9000 [40], Faster-RCNN [38] are involved as the detector with Holistic-CNN [7] as the recognition model. And end-to-end methods TE2E [41] and RPNet [10] are utilized for comparisons. We also involve YOLO-v4 [36] and Scaled YOLO-v4 [37] with CRNN [28] to report more results. Our baseline which consists of STELA [16] and CRNN [28] are also involved. From Table 10, it can be observed that our method has reached the best in most circumstances, and the efficiency is also competitive.
| Method | Size | AP | Base | DB | FN | Rotate | Tilt | Weather | Challenge | FPS |
|---|---|---|---|---|---|---|---|---|---|---|
| Cascade classifier + HC | 480 | 58.9 | 69.7 | 67.2 | 69.7 | 0.1 | 3.1 | 52.3 | 30.9 | 29 |
| SSD300 + HC | 300 | 95.2 | 98.3 | 96.6 | 95.9 | 88.4 | 91.5 | 87.3 | 83.8 | 35 |
| YOLO9000 + HC | 480 | 93.7 | 98.1 | 96.0 | 88.2 | 84.5 | 88.5 | 87.0 | 80.5 | 36 |
| YOLOv4 + CRNN | 512 | 94.7 | 97.8 | 94.6 | 87.3 | 82.9 | 89.9 | 83.3 | 75.7 | 40 |
| SYOLOv4 + CRNN | 640 | 95.3 | 97.8 | 95.0 | 88.9 | 84.9 | 91.5 | 90.4 | 77.1 | 34 |
| Faster-RCNN + HC | 600 | 92.8 | 97.2 | 94.4 | 90.9 | 82.9 | 87.3 | 85.5 | 76.3 | 13 |
| TE2E | 600 | 94.4 | 97.8 | 94.8 | 94.5 | 87.9 | 92.1 | 86.8 | 81.2 | 3 |
| RPNet | 480 | 95.5 | 98.5 | 96.9 | 94.3 | 90.8 | 92.5 | 87.9 | 85.1 | 61 |
| STELA + CRNN | 640 | 97.8 | 97.9 | 98.3 | 94.5 | 90.1 | 91.3 | 89.5 | 83.6 | 41 |
| Ours | 640 | 97.9 | 98.3 | 98.0 | 97.2 | 92.5 | 93.7 | 90.7 | 87.9 | 30 |
-
1.
SYOLOv4: Scaled YOLOv4; HC: Holistic-CNN; AP: average percent of all the circumstances
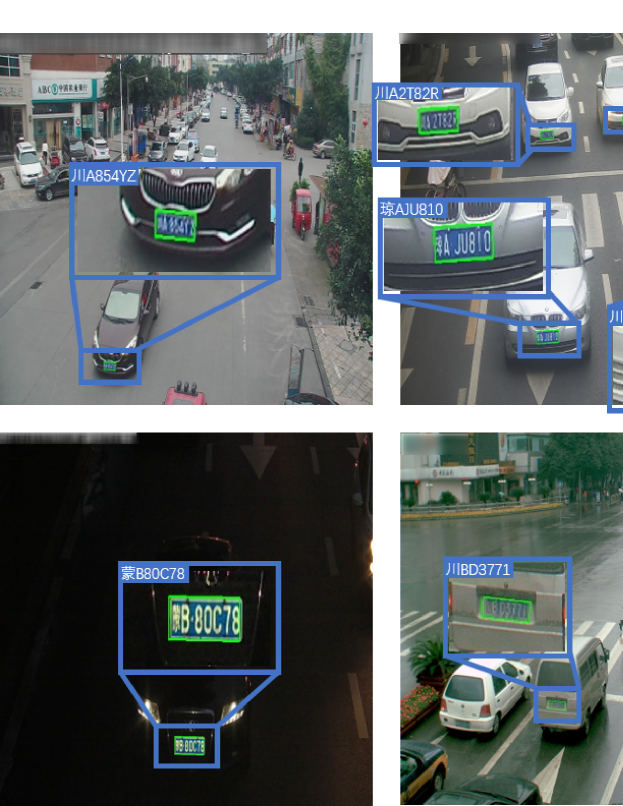
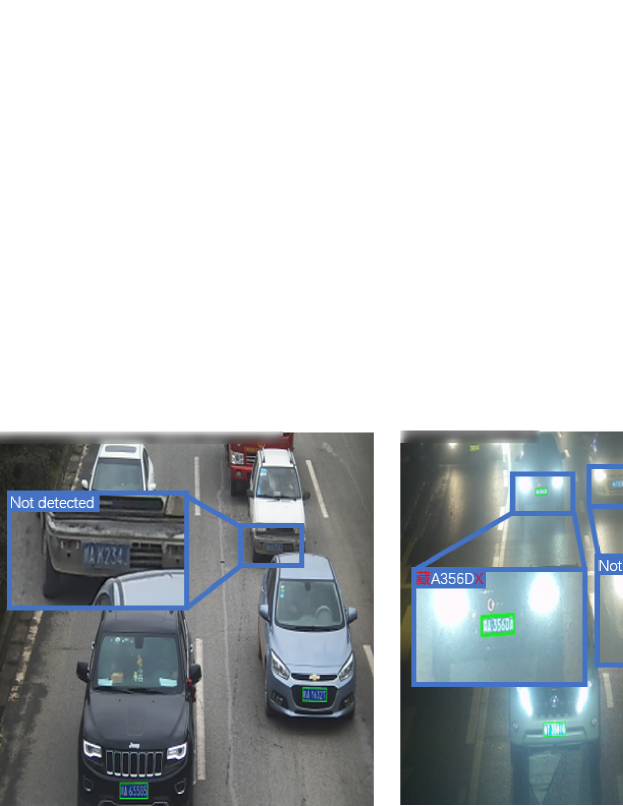
Finally, some detection and recognition results on CRPD are shown in Figure 9 and 10. In the illustrations, we see that most LPs that are recognized incorrectly are also hard to distinguish by humans. Our proposed method is still effective in most cases, and the performance is competitive.
6 Discussion and Conclusion
In this paper, we present a dataset with Chinese LP images, which is named CRPD. As a supplement to multi-LP datasets, CRPD includes three sub-datasets, CRPD-single, CRPD-double, and CRPD-multi, which are able to deal with a variety of application scenarios. And CRPD covers many kinds of vehicles and a number of environments that will be helpful to build a robust model. We also propose an end-to-end trainable network to detect and recognize LPs with high efficiency as the baseline of the dataset. The experiments demonstrate the effectiveness of our proposed components, and the performance of the network is satisfactory. In the future, we hope CRPD will become a new benchmark on multi-LP detection and recognition tasks. We also consider utilizing the network for end-to-end scene text spotting and integrating more advanced techniques to achieve better portability and adaptation capability.
Acknowledgments
This work was partly supported by the National Key Research and Development Program of China with ID 2018AAA0103203.
References
- [1] S. Zhu, S. A. Dianat, L. K. Mestha, End-to-end system of license plate localization and recognition, Journal of Electronic Imaging 24 (2) (2015) 1 – 18.
- [2] Y. Wen, Y. Lu, J. Yan, Z. Zhou, K. M. von Deneen, P. Shi, An algorithm for license plate recognition applied to intelligent transportation system, IEEE Transactions on Intelligent Transportation Systems 12 (3) (2011) 830–845.
- [3] S. Du, M. Ibrahim, M. Shehata, W. Badawy, Automatic license plate recognition (alpr): A state-of-the-art review, IEEE Transactions on Circuits and Systems for Video Technology 23 (2) (2012) 311–325.
- [4] W. Zhou, H. Li, Y. Lu, Q. Tian, Principal visual word discovery for automatic license plate detection, IEEE Transactions on Image Processing 21 (9) (2012) 4269–4279.
- [5] S.-L. Chen, C. Yang, J.-W. Ma, F. Chen, X.-C. Yin, Simultaneous end-to-end vehicle and license plate detection with multi-branch attention neural network, IEEE Transactions on Intelligent Transportation Systems 21 (9) (2020) 3686–3695.
- [6] S. C. Barreto, J. A. Lambert, F. de Barros Vidal, Using synthetic images for deep learning recognition process on automatic license plate recognition, in: Mexican Conference on Pattern Recognition (MCPR), 2019, pp. 115–126.
- [7] J. Špaňhel, J. Sochor, R. Juránek, A. Herout, L. Maršík, P. Zemčík, Holistic recognition of low quality license plates by cnn using track annotated data, in: 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), 2017, pp. 1–6.
- [8] Caltech, Caltech license plate dataset, http://www.vision.caltech.edu/html-files/archive.html (2005).
- [9] Zemris, Zemris license plate dataset, http://www.zemris.fer.hr/projects/LicensePlates/hrvatski/rezultati.shtml (2003).
- [10] Z. Xu, W. Yang, A. Meng, N. Lu, H. Huang, C. Ying, L. Huang, Towards end-to-end license plate detection and recognition: A large dataset and baseline, in: Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 255–271.
- [11] G.-S. Hsu, J.-C. Chen, Y.-Z. Chung, Application-oriented license plate recognition, IEEE Transactions on Vehicular Technology 62 (2) (2012) 552–561.
- [12] G. R. Gonçalves, S. P. G. da Silva, D. Menotti, W. R. Schwartz, Benchmark for license plate character segmentation, Journal of Electronic Imaging 25 (5) (2016) 053034.
- [13] R. Laroca, E. Severo, L. A. Zanlorensi, L. S. Oliveira, G. R. Gonçalves, W. R. Schwartz, D. Menotti, A robust real-time automatic license plate recognition based on the yolo detector, in: 2018 International Joint Conference on Neural Networks (IJCNN), 2018, pp. 1–10.
- [14] Y. Yuan, W. Zou, Y. Zhao, X. Wang, X. Hu, N. Komodakis, A robust and efficient approach to license plate detection, IEEE Transactions on Image Processing 26 (3) (2017) 1102–1114.
- [15] L. Zhang, P. Wang, H. Li, Z. Li, C. Shen, Y. Zhang, A robust attentional framework for license plate recognition in the wild, IEEE Transactions on Intelligent Transportation Systems 22 (11) (2021) 6967–6976.
- [16] L. Deng, Y. Gong, X. Lu, Y. Lin, Z. Ma, M. Xie, Stela: A real-time scene text detector with learned anchor, IEEE Access 7 (2019) 153400–153407.
- [17] X. Liu, D. Liang, S. Yan, D. Chen, Y. Qiao, J. Yan, Fots: Fast oriented text spotting with a unified network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 5676–5685.
- [18] C. Zhang, Q. Wang, X. Li, V-lpdr: Towards a unified framework for license plate detection, tracking, and recognition in real-world traffic videos, Neurocomputing 449 (2021) 189–206.
- [19] S. M. Silva, C. R. Jung, Real-time license plate detection and recognition using deep convolutional neural networks, Journal of Visual Communication and Image Representation 71 (2020) 102773.
- [20] Y. Kessentini, M. D. Besbes, S. Ammar, A. Chabbouh, A two-stage deep neural network for multi-norm license plate detection and recognition, Expert Systems with Applications 136 (2019) 159–170.
- [21] W. Wang, J. Yang, M. Chen, P. Wang, A light cnn for end-to-end car license plates detection and recognition, IEEE Access 7 (2019) 173875–173883.
- [22] R. Laroca, L. A. Zanlorensi, G. R. Gonçalves, E. Todt, W. R. Schwartz, D. Menotti, An efficient and layout-independent automatic license plate recognition system based on the yolo detector, IET Intelligent Transport Systems 15 (4) (2021) 483–503.
- [23] S. Qin, S. Liu, Efficient and unified license plate recognition via lightweight deep neural network, IET Image Processing 14 (16) (2020) 4102–4109.
- [24] R. Liu, M. Li, Easypr, https://github.com/liuruoze/EasyPR (2014).
- [25] T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2980–2988.
- [26] T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, S. Belongie, Feature pyramid networks for object detection, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 2117–2125.
- [27] R. Girshick, Fast r-cnn, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 1440–1448.
- [28] B. Shi, X. Bai, C. Yao, An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition, IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (11) (2016) 2298–2304.
- [29] L. Deng, Y. Gong, X. Lu, X. Yi, Z. Ma, M. Xie, Focus-enhanced scene text recognition with deformable convolutions, in: IEEE 5th International Conference on Computer and Communications (ICCC), 2019, pp. 1685–1689.
- [30] S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Computation 9 (8) (1997) 1735–1780.
- [31] A. Graves, S. Fernández, F. Gomez, J. Schmidhuber, Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks, in: Proceedings of the 23rd International Conference on Machine Learning (ICML), 2006, pp. 369–376.
- [32] A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., Pytorch: An imperative style, high-performance deep learning library, Advances in Neural Information Processing Systems (NIPS) 32 (2019) 8026–8037.
- [33] K. He, G. Gkioxari, P. Dollár, R. Girshick, Mask r-cnn, in: Proceedings of the IEEE International Conference on Computer Vision (ICCV), 2017, pp. 2961–2969.
- [34] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A. C. Berg, Ssd: Single shot multibox detector, in: European Conference on Computer Vision (ECCV), 2016, pp. 21–37.
- [35] J. Redmon, A. Farhadi, Yolov3: An incremental improvement, arXiv preprint arXiv:1804.02767.
- [36] A. Bochkovskiy, C.-Y. Wang, H.-Y. M. Liao, Yolov4: Optimal speed and accuracy of object detection, arXiv preprint arXiv:2004.10934.
- [37] C.-Y. Wang, A. Bochkovskiy, H.-Y. M. Liao, Scaled-yolov4: Scaling cross stage partial network, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021, pp. 13029–13038.
- [38] S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: Towards real-time object detection with region proposal networks, in: Advances in Neural Information Processing Systems (NIPS), 2015, pp. 91–99.
- [39] S.-Z. Wang, H.-J. Lee, A cascade framework for a real-time statistical plate recognition system, IEEE Transactions on Information Forensics and Security 2 (2) (2007) 267–282.
- [40] J. Redmon, A. Farhadi, Yolo9000: Better, faster, stronger, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017, pp. 7263–7271.
- [41] H. Li, P. Wang, C. Shen, Toward end-to-end car license plate detection and recognition with deep neural networks, IEEE Transactions on Intelligent Transportation Systems 20 (3) (2019) 1126–1136.