Unified High-binding Watermark for Unconditional Image Generation Models
Abstract
Deep learning techniques have implemented many unconditional image generation (UIG) models, such as GAN, Diffusion model, etc. The extremely realistic images (also known as AI-Generated Content, AIGC for short) produced by these models bring urgent needs for intellectual property protection such as data traceability and copyright certification. An attacker can steal the output images of the target model and use them as part of the training data to train a private surrogate UIG model. The implementation mechanisms of UIG models are diverse and complex, and there is no unified and effective protection and verification method at present. To address these issues, we propose a two-stage unified watermark verification mechanism with high-binding effects for such models. In the first stage, we use an encoder to invisibly write the watermark image into the output images of the original AIGC tool, and reversely extract the watermark image through the corresponding decoder. In the second stage, we design the decoder fine-tuning process, and the fine-tuned decoder can make correct judgments on whether the suspicious model steals the original AIGC tool data. Experiments demonstrate our method can complete the verification work with almost zero false positive rate under the condition of only using the model output images. Moreover, the proposed method can achieve data steal verification across different types of UIG models, which further increases the practicality of the method.
Introduction
In the past two years, AIGC (Cao et al. 2023; Wu et al. 2023) has become the hottest research direction in the field of deep learning, and has achieved impressive progress. AIGC tools represented by ChatGPT, Stable diffusion, and Gen-2 can assist users in creating highly creative and realistic images, videos, audios and other works of art with or without generating conditional information. The remarkable capabilities of AIGC tools benefit from the amount of training data and model size far exceeding traditional deep learning tasks. On the one hand, each AIGC tool owner needs to have the ability to trace the legal responsibilities and the source of the content generated by the tool; on the other hand, these high-quality generated contents are valuable intellectual property (IP) for the tool owner. At present, several AIGC tool publishers have paid attention to the potential data security issues of AIGC and released corresponding statements. For example, the legal provisions of ChatGPT clearly stipulate that it is strictly forbidden to use its output results as training data to train other models.
UIG models refer to a class of models that generate new samples which conform to the same distribution as the training data without conditional generation information, such as Denoising Diffusion Probabilistic Models (DDPM) (Ho, Jain, and Abbeel 2020), Generative Adversarial Network (GAN) (Karras et al. 2020) and Variational Autoencoder (VAE) (Razavi, van den Oord, and Vinyals 2019). The diversity and authenticity of AI-generated images are the goals pursued by UIG models. State-of-the-art (SOTA) models can generate images so convincingly that it is difficult for humans to distinguish real images from AI-generated ones. Therefore, some AIGC tool manufacturers are very likely to use the output images of existing tools as training data to train their own model. Once such a thing happens, the interests of the original tool owner will be seriously violated. Effective supervision of such phenomena is a prerequisite for the healthy development of AIGC tools.
Recently, some research works starts paying attention to the IP protection of neural network. Frequently, they incorporate a regularization term into the loss function (Lukas et al. 2022; Li et al. 2020) or employ the forecasts of a specific group of indicator images(Qiao et al. 2023; Adi et al. 2018) as the watermark. However, due to the uncertainty and diversity of AIGC, traceability and copyright protection of AIGC is still a seriously under-researched field. Different from image processing models (Zhang et al. 2020), the input and output of UIG models belong to completely different image domains, usually using random noise as input to output high-quality images. The noise-image mapping functions formed by different UIG models under the same generation task may result in different output images for the same input noise. Therefore, such randomness makes previous model watermarking methods difficult to apply to current unconditional image generation tasks. Although some works have improved model watermarking for specific UIG models (Wei, Wang, and Zhang 2020; Qiao et al. 2023; Wei et al. 2022), these methods are not unified, that is, they are not applicable to all types of UIG models.
Motivated by this, we hope to protect the output images of UIG models, and in particular provide methods to protect the attribution and usage of such images. In a more general scenario, in order to expand the scale of training data so that the model can produce better image generation effects, data stealers may combine their existing image resources and the output images of the target AIGC tool to jointly obtain a private surrogate UIG model even package it as a commercial AIGC tool. In order to make the method more practical, the proposed watermark verification mechanism should be able to make a correct judgment on whether it has embezzled the data of the target AIGC tool only according to the output images of the suspicious AIGC tool. Furthermore, since it is not clear what type of models the data stealers use to implement their private AIGC tool, the proposed method should be applicable to different types of UIG models.
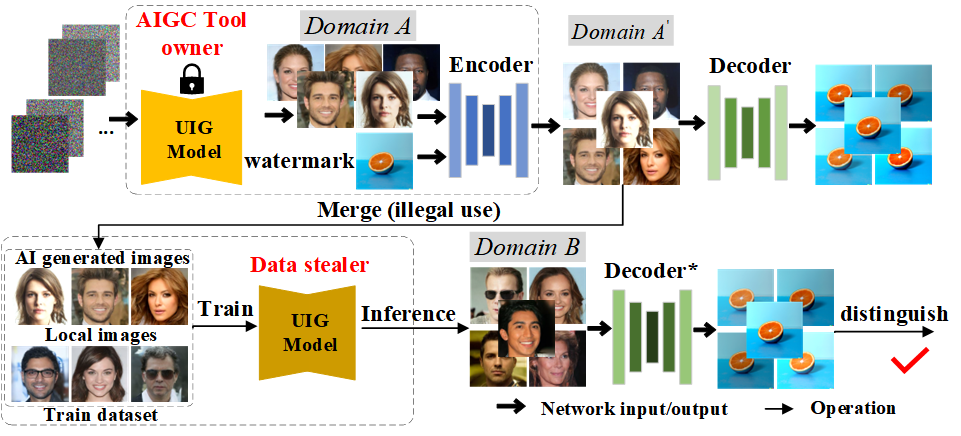
In this paper, we propose a unified high-binding watermark verification mechanism for UIG models to solve the AIGC data attribution problem existing in such models, as shown in Figure 1. Given a target model as the built-in model in the original AIGC tool, we denote its original output images distribution as domain . In the first stage, also known as the preparation stage, the owner of the tool can use an encoder to embed a custom watermark image into the built-in model output images in a spatially invisible way. We define the distribution of the watermarked image as domain . Assume that the data stealer combines his local images and the images collected from domain as total training dataset, and then uses it to train a surrogate UIG model with similar generation ability. We define the output image distribution of this surrogate UIG model as domain . In the second stage, also known as the verification stage, when the original AIGC tool owner discovers that there is a suspicious model, he can verify whether there exists data steal based on whether the watermark image can be extracted from the output of the suspicious model. In particular, we use multiple losses in the first stage to embed the watermark more covertly into the image, and design a decoder fine-tuning strategy in the second stage to greatly improve the decoder’s watermark extraction ability.
We conduct experiments using a variety of UIG models implemented by different mechanisms to demonstrate that our watermarking verification mechanism is applicable when different models are used as surrogate models. Experimental results show that our method can maintain a false positive rate close to 0% while having a high watermark extraction rate, which shows that our method has very good practical usability.
Our contributions can be summarized as the following:
-
•
We are the first to introduce AIGC copyright protection problem for uncondational image generation tasks. We hope it can draw more attention to this research field and inspire greater works.
-
•
We propose a high-binding unified watermark verification mechanism for UIG models. The framework can accurately judge whether the suspicious UIG model abuses the original model output images only according to its output images.
-
•
Extensive experiments demonstrate our method is task-agnostic and plug-and-play for arbitrary UIG models. Furthermore, our method is capable of cross-model validation under different data theft situations.
Related work
Image Watermarking Technology
Watermarking technology represented by steganography is one of the most important ways to protect the copyright of images. It can be roughly categorized into two types: visible watermarks like logos, and invisible watermarks. Obviously, the way of invisible watermark is more covert than the way of adding visible watermark to images and does not affect the use of them. Invisible watermark can be further divided into transform domain watermark and spatial domain watermark. The transform domain watermark method writes watermark into the coefficients that are not significant in the transform domain such as Discrete Fourier Transform (DFT) domain (Mersereau and Alturki 2001) and Discrete Wavelet Transform (DWT) domain (Kumar and Kumar 2018) of the images. Spatial watermark (Luo et al. 2023; Liu et al. 2022b; Ma et al. 2023) mainly uses deep neural network to complete watermark embedding and extraction. The image watermarking method is easier to implement than the model watermarking method (Adi et al. 2018; Lukas et al. 2022; Guo et al. 2021), but it is not suitable for verifying whether the surrogate model has data steal.
Unconditional Image Generation Models
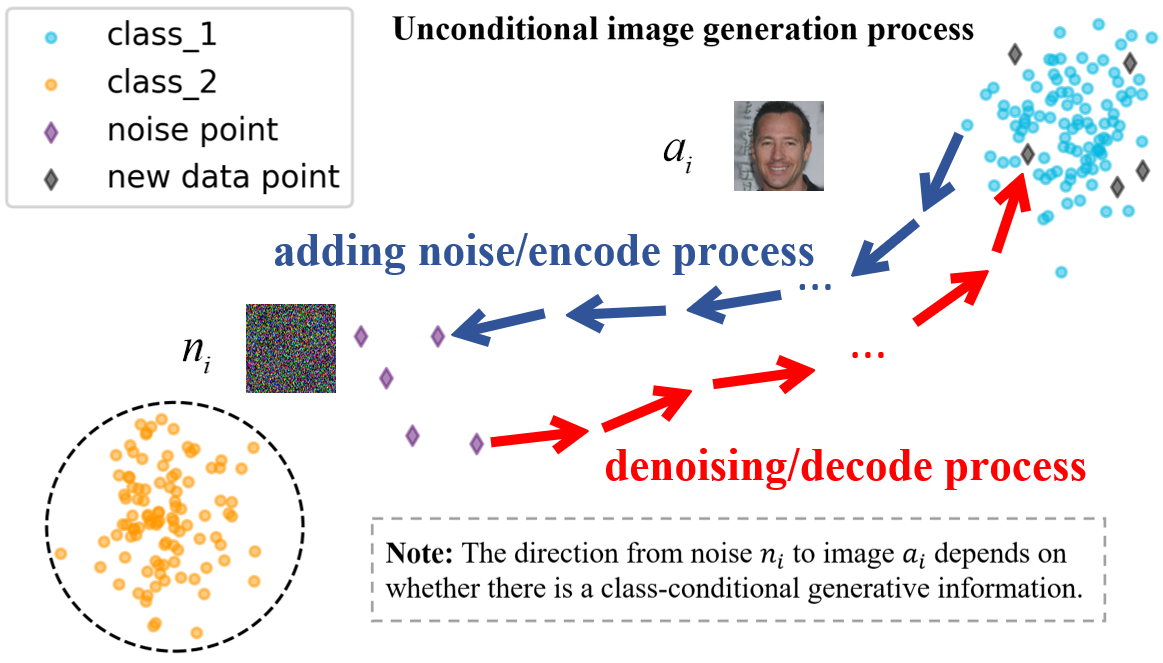
UIG models can create novel, original images that are not based on existing images without any specific input conditional information. As shown in Figure 2, this type of model learns the mapping functions from random noise to images through the training process, and then the inference stage uses sampling noise as a starting point to generate new images. This can be used in a variety of applications, such as improving image recognition algorithms(Zhang et al. 2022) or generating realistic images to augment dataset. Variational Autoencoder (VAE) (Chadebec et al. 2023; Razavi, van den Oord, and Vinyals 2019) and Generative Adversarial Network (GAN) (Goodfellow et al. 2014; Karras et al. 2020) are two typical UIG models that appeared earlier, they realize the conversion between noise and images in a single step during training and inference. Diffusion models (Ho, Jain, and Abbeel 2020; Song, Meng, and Ermon 2021; Liu et al. 2022a) draw inspiration from the principles of non-equilibrium thermodynamics. They establish a Markov chain of diffusion steps that gradually introduce random noise into image, and subsequently acquire the ability to invert the diffusion process to generate desired image samples from the noise. Although these UIG models achieve the same purpose, their different and complex implementation mechanisms bring difficulties to the formation of an unified watermark verification mechanism.
Watermark for AIGC
Though AIGC Watermarking Technology is still seriously under-studied, there are some initiatives and works that start paying attention to it. The famous AIGC tool DALLE marks the generated content by adding a spatially visible watermark in the lower right corner of the image. Stable Diffusion modifies specific Fourier frequency in the generated image (Wen et al. 2023) to watermark output images. (Huang et al. 2022) proposes an universal adversarial watermark to protect images from being abused by Deepfake technology. (Liu et al. 2022b) proposes a non-embedded watermark method, so that the newly generated image naturally contains potential watermark information. Existing work mainly focuses on the direct traceability of AIGC, and very few works (Yu et al. 2021; Zhao et al. 2023) study how to effectively verify AIGC data after it has been abused. At present, there is no unified watermark verification mechanism that can realize AIGC copyright protection across UIG models.
Method
In this section, we first introduce a formal problem definition, and then elaborate on the roles and implementation details of each stage of the proposed unified two-stage watermark verification mechanism.
Problem Definition
For an UIG model, we denote its output images as domain according to the image distribution, and domain follows the same distribution as the model training data. The goal of the UIG model is to approximately fit the mapping function from random noise to the target image distribution through one or several neural networks. Suppose we obtain an UIG model trained on a private dataset . Given a random noise , can output an image in domain that has never actually appeared in , i.e.,
| (1) |
Since UIG models use random noise as the starting point to generate new images, the attacker only needs to collect the output images of the target model instead of the input-output image pairs to train the corresponding surrogate model , which greatly reduces the difficulty for the attacker to steal. In addition, according to the image distribution, the output images of belong to another image domain with similar but different distribution to domain . In practical scenarios, AIGC tools formed from such models are usually presented in a black-box manner, and users can only obtain their output images. Therefore, our goal is to design a unified watermark verification mechanism with high-binding effect across data domains and even across model architectures, which can verify whether it steals generated images for training only through the outputs of the suspicious model.
Watermark Embedding Process
This is the first stage in our proposed unified watermark verification mechanism, which can also be called the preparation stage. For data stealers, they can only get the output images of the target AIGC tool instead of the built-in UIG model. For the suspicious UIG model that we mentioned above, the publisher of the original AIGC tool can only verify whether there is data steal based on its output images. As can be seen, the model output images are the only medium between the original AIGC tool owner and the suspect model. Therefore, we hope that the watermark image used as the basis for verification can be completely embedded in the output images of the above two types of models. In particular, the watermark image should be embedded in an invisible way so as not to affect the use of the model output image.
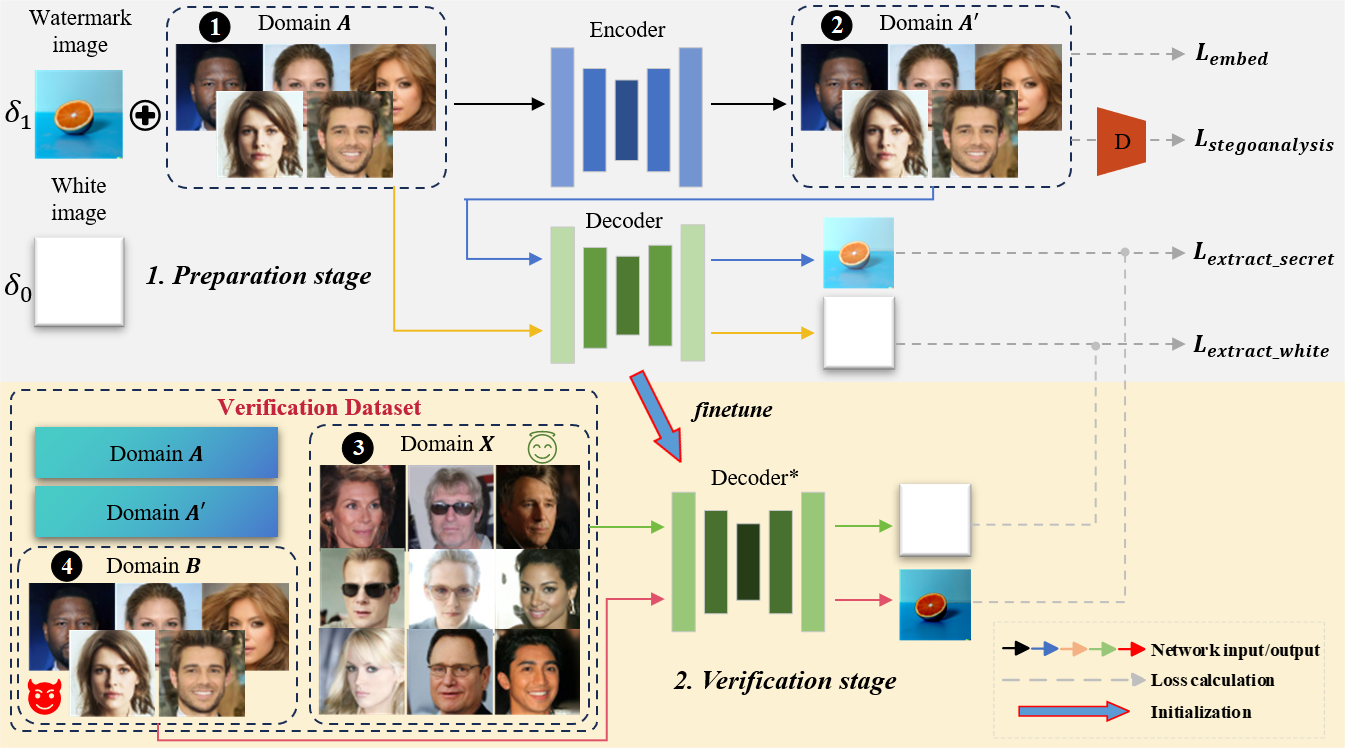
In the preparation stage, we first ensure that the output images of the original UIG model is embedded with a custom watermark image . As shown in the upper part of Figure 3, we select a neural network as an encoder to embed into the output images of the protected UIG model (i.e., domain ) in spatial invisible way, and denote the distribution of watermarked images as domain . Obviously, the distributions of domain and domain are similar, the subtle difference between the two distributions is caused by the potential watermark information. At the same time, we choose another neural network as the decoder to reversely extract from images in domain .
The difference between the corresponding image pair in domain and domain is extremely small (i.e., spatial invisible), the watermark image is injected into the images of domain mainly by changing the high-frequency information. In order to improve the ability of to recover the specified watermark image and to avoid the overfitting phenomenon that can be extracted from all images no matter whether is really written or not, we simultaneously add images from domain to the dataset for training . We force to extract a constant blank images from these non-watermarked images. To further narrow the data distribution difference between domain and domain , we add a steganalysis network as a discriminator after , and improve image quality in domain through adversarial training.
After the preparation stage, the publisher of the original AIGC tool can use to embed in the original output image of the model and then output it. In this way, what the data stealers get is the output images with the watermark information. The corresponding can be used to directly trace the source of the released images.
Network Structures.
In our method, for the encoder , the input and output image domains are highly similar, so we choose U2-Net (Qin et al. 2020) as the default network structure. For the decoder , we choose CEILNet (Fan et al. 2017) as the network structure to cope with image translation across image domains. As for the discriminator , we choose the steganalysis network SRNet (Tan et al. 2021) to ensure that the concealment of watermark embedding is increased while improving the image quality. To verify the generalization ability of the proposed method across UIG models, we choose UIG models with the same or different model structure as the original AIGC tool built-in model to obtain .
Loss Functions.
The objective loss function of watermark embedding stage consists of two parts: the embedding loss and the extracting loss , i.e.,
| (2) |
The purpose of embedding loss is to ensure that the visual quality of the image is not affected after the watermark image is embedded into the output images of the original UIG model, two different types of visual consistency loss are considered: the basic embed loss and steganalysis adversarial loss , i.e.,
| (3) |
where and are hyperparameters to balance these two loss terms. is used to calculate Mean-Squared Loss (MSE) for the image from domain and the corresponding image from domain , i.e.,
| (4) |
will let discriminator cannot differentiate the output images of from the images in domain , which makes the watermark embedding process more covert.
| (5) |
The purpose of the extracting loss is to enable to reversely extract the specified watermark image from the output images of and extract the constant blank image from the original image without watermark embedded, i.e.,
| (6) |
Decoder Fine-tuning Strategy
This is the second stage of our proposed unified watermark verification mechanism, which can also be called the verification stage. After this stage, we hope that the fine-tuned can also extract from the output images of .
As shown in the lower part of Figure 3, as the verifier, the publisher of the original AIGC tool needs to prepare a verification dataset containing four parts of the images, i.e., images from domain , , , and respectively. According to the above, the images in domain and domain are naturally exist after the preparation stage, especially the images of domain are private to the AIGC tool owner. The images in domain are collected from the output of the suspicious model to be verified. The images of domain come from the same task UIG models (preferably with different model architectures), which are trained on images without embedded watermarked images. It should be noted that these UIG models for the same task can be easily prepared by the AIGC tool owner based on the images of domain , so they are also private.
After the validation dataset is ready, we finetune the decoder using the decoder fine-tuning strategy. It consists of two parts the watermark extraction loss and the constant blank image extraction loss , i.e.,
| (7) |
| (8) |
Data Theft Verification.
With the above two-stage training process, we obtain the fine-tuned decoder . The verifier uses to extract the watermark image from the output images of the target , if the similarity between the output image of and the original real watermark image is greater than the preset threshold, it can be determined that the has data steal.
Experiment
In this section, we will frst describe our datasets and implementation details. Following, we introduce our evaluation metrics. Then, we show the experimental results of the proposed two-stage unified watermark verification mechanism for UIG models. Moreover, we systemically conduct an ablation study.
Datasets and Implementation Details
In our experiments, we use CelebA (Liu et al. 2015) trainset as the main dataset, which is more challenging, has higher resolution and contains more texture details in the images. It contains 202599 facial images. These images are split into two parts: 50,000 images are owned by the data stealer, others are used to train the original UIG models. All images in CelebA are processed into 128*128. In addition, we also verified the effectiveness of the method in another Oxford 102 Flower dataset (Nilsback and Zisserman 2008). It contains 8189 real flower images, we set 2000 as private images for data stealer, others are used to train original UIG models. All images in Oxford 102 Flower are processed into 64*64.
The original UIG models we select in our experiments are VQ-VAE-2 (Razavi, van den Oord, and Vinyals 2019), StyleGAN2 (Karras et al. 2020), DDPM (Ho, Jain, and Abbeel 2020) and PNDM (Liu et al. 2022a). The selected models are typical models of various UIG models under different implementation mechanisms. For the diffusion model that generates new samples through multiple steps, We choose DDPM and PNDM to consider the impact that different noise sampling strategies may have on the performance of the proposed method.
For the validation dataset involved in the second stage of our method, we always keep each part of the dataset to contain 1000 images when using the CeleA dataset, and we always keep each part of the dataset to contain 100 images when using the Oxford 102 Flower dataset. In all experiments, we fine-tune the decoder using the validation dataset until convergence is confirmed. We use new images outside the validation dataset to evaluate watermark extraction. By default, and equal to 1.
Evaluation Metrics
To evaluate the visual quality, PSNR and SSIM are used by default. In order to judge whether the watermark image is extracted from the image, we define that the extraction is successful when the SSIM between the extraction result and the real watermark image is bigger than 0.9, which means that there is a large similarity between them. Based on it, the extraction rate (ER) is further defined as the ratio of successfully extracting watermark image from model output images. The false positive rate (FPR) is defined as the ratio of successfully extracting watermark image from model output images without data steal. Furthermore, we define the data theft rate (DTR) as the ratio of output images from the original AIGC tool in the surrogate model training data.
The Results of Our Method
Invisible Watermark Embedding.
This experiment is to demonstrate the effect of watermark embedding in the first stage of our method. In order to prove that our method has the ability to embed large-capacity watermark image, we choose three-channel color images with more information as the watermark image (for single-channel grayscale images, our method is still applicable). We use the trained encoder to invisibly embed the watermark image into the output images of the UIG model, and then use the trained decoder to inversely extract the watermark image, two visual examples are shown in Figure 4. For the quantitative results, we randomly selected 1000 original face generation UIG model output images for testing (because of the high resolution). The average SSIM between the watermarked image and the original image is 0.95, and the average PSNR is 38.66. The average SSIM of the extracted watermark image and the original watermark image is 0.98, and the average PSNR is 42.32. This shows that through our watermark embedding process, it does not affect the use of the original images.

Robustness to Different Structures of Surrogate Models.
Since the data stealers may not know what model structure the original AIGC tool built-in model adopts, after collecting its output images, the data stealers may use other different network structures to build their private UIG model. To demonstrate the cross-model capability of our watermark verification mechanism, i.e. its generalizability to different structure UIG models, we employ many surrogate models to imitate real-world scenarios, and assume each model has partially private training data.
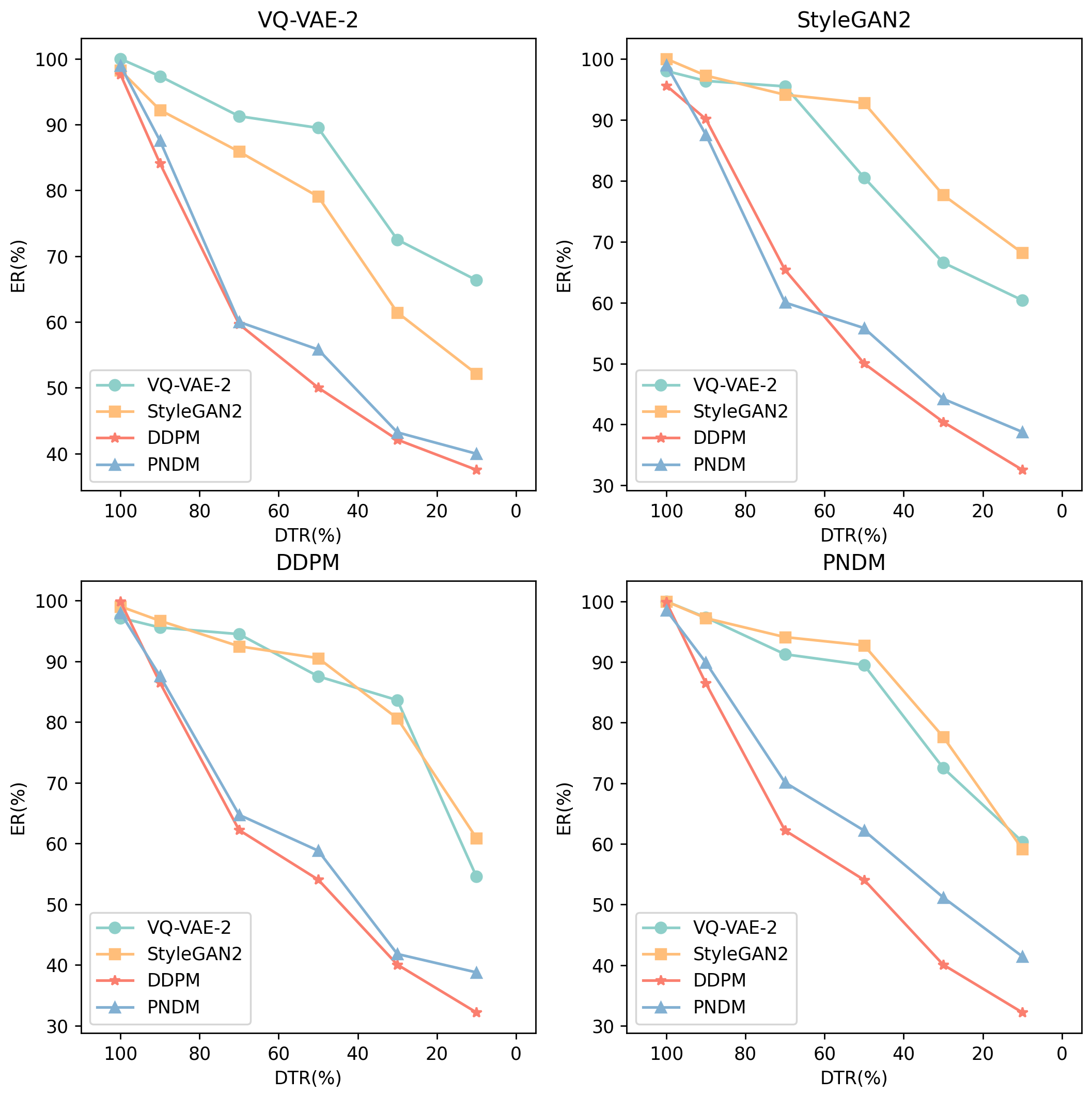
First, we choose a model as the original face generation UIG model and collect the images generated by it. Then, we jointly combine the collected images and private images into a training dataset for the surrogate model according to different DTRs. Next, we use these dataset to train different surrogate models and collect the output images of the surrogate models, which are used to form the validation dataset under the second stage of our method. After fine-tuning the decoder using the validation dataset, we perform ER calculations on the corresponding surrogate models using . As shown in Figure 5, although ER decreases with the decrease of DTR, the obtained by our proposed method always maintains a high ER at any time, even when the DTR is only 10%, the ER still exceeds 30%. It is noteworthy that our method works better when DTR is larger. In practice, data stealers usually steal the images generated by AIGC tools because real images are difficult to collect. Therefore, the phenomenon of data steal in reality usually corresponds to the situation when the DTR is large in our experiment.
Experimental results show that our method has good cross-model capability, and it is a unified watermark verification mechanism for unconditional image generation models. The inherent multi-step iterative mechanism of the diffusion model makes it more difficult to learn the potential watermark features in the image. Therefore, with the decrease of DTR, the corresponding ER attenuation is more obvious.
Ablation Study
The Importance of Decoder Fine-tuning Stratege.
In order to improve the ability of the decoder to extract the target watermark image from the output images of the surrogate model, we use a fine-tuning strategy on decoder to obtain . To demonstrate its necessity, we conducted experiments when the surrogate model used the same structure model as the original UIG model. With and without decoder fine-tuning (i.e., the second stage), we tested the watermark ER of the decoder on corresponding surrogate model under different DTRs, and the results are shown in Table 1. It can be seen that with the DTR gradually decreases, the ER of on the corresponding surrogate model gradually decreases. When the DTR is 10%, completely loses its verification ability. However, the fine-tuned can recover the extraction ability substantially under various DTRs. We also train surrogate models on unwatermarked images, which we call . It should be noted that in this experiment, the FPR of all decoders before and after fine-tuning for is 0%. The visualization of the decoder extraction results before and after fine-tuning is shown in Figure 6. The important role of the decoder fine-tuning strategy is clear at a glance.
ER 100% 50% 10% Stage1 Stage2 Stage1 Stage2 Stage1 Stage2 VQ-VAE-2 72.65% 100.00% 30.66% 89.50% 0.00% 66.36% StyleGAN2 60.33% 100.00% 10.26% 92.75% 0.00% 68.15% DDPM 49.12% 99.87% 18.39% 54.05% 0.66% 32.18% PNDM 56.46% 98.55% 22.92% 62.19% 1.45% 41.43%

The Importance of Steganalysis Adversarial Loss.
In order to make the embedding of watermark information more concealed, we added a steganalysis adversarial loss . The most intuitive benefit it brings is the improvement of the visual quality of the image after embedding the watermark image. Form CeleA, the average SSIM and PSNR between the original model output image and the watermarked image increased from 0.94, 36.68 to 0.95, 38.66, respectively. For Oxford 102 Flower, the corresponding metrics improved from 0.92, 33.15 to 0.96, 39.72.
Furthermore, we visualized the difference between the watermarked image obtained with and without and the original image. As shown in Figure 7, after using , the embedded watermark information is more focused on changing the pixels at key positions in the image, such as the face detail area in the image. We then analyze why our proposed method has high-binding effect. For UIG models, taking the face generation task as an example, the spatial face features in the training data are the main focus of the model’s learning. Therefore, we concentrate the watermark information on key positions in the image, which is the key reason why the watermark image can be extracted from the output images of the surrogate model. This is also the reason why cross-model validation can be achieved.

The Importance of Constant Blank Image Extraction Loss.
In order to reduce the overfitting phenomenon in the process of decoder fine-tuning. We add to the decoder fine-tuning strategy to reduce the FPR of on surrogate models. We conduct experiments when the surrogate model has the same structure as the original model and the DTR is equal to 70%, the results are shown in Table 2. We use a total of 400 images from domain and domain that did not appear in the validation dataset to count FPR. It can be seen that under different circumstances, with the help of , the FPR of is reduced to almost 0%.
FPR VQ-VAE-2 StyleGAN2 DDPM PNDM CeleA 14.25% 12.75% 8.25% 9.00% 0.00% 0.5% 0.00% 0.25% Oxford 102 Flower 22.50% 18.00% 11.25% 17.50% 0.25% 0.00% 0.00% 0.00%
Conclusion
In this work, we propose a high-binding unified watermark verification framework for unconditional image generation models. This is the first time that the AIGC copyright protection problem is introduced for the task of unconditional image generation. We use a two-stage process including spatially invisible watermark embedding and decoder fine-tuning to effectively address the verification of data steal. Extensive experiments prove that our method is task-agnostic and plug-and-play for arbitrary unconditional image generative models. We hope our work can draw more attention to this research field and inspire greater works.
References
- Adi et al. (2018) Adi, Y.; Baum, C.; Cissé, M.; Pinkas, B.; and Keshet, J. 2018. Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring. In USENIX Security Symposium, 1615–1631. USENIX Association.
- Cao et al. (2023) Cao, Y.; Li, S.; Liu, Y.; Yan, Z.; Dai, Y.; Yu, P. S.; and Sun, L. 2023. A Comprehensive Survey of AI-Generated Content (AIGC): A History of Generative AI from GAN to ChatGPT. CoRR, abs/2303.04226.
- Chadebec et al. (2023) Chadebec, C.; Thibeau-Sutre, E.; Burgos, N.; and Allassonnière, S. 2023. Data Augmentation in High Dimensional Low Sample Size Setting Using a Geometry-Based Variational Autoencoder. IEEE Trans. Pattern Anal. Mach. Intell., 45(3): 2879–2896.
- Fan et al. (2017) Fan, Q.; Yang, J.; Hua, G.; Chen, B.; and Wipf, D. P. 2017. A Generic Deep Architecture for Single Image Reflection Removal and Image Smoothing. In ICCV, 3258–3267. IEEE Computer Society.
- Goodfellow et al. (2014) Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; and Bengio, Y. 2014. Generative adversarial nets. In NeurIPS.
- Guo et al. (2021) Guo, S.; Zhang, T.; Qiu, H.; Zeng, Y.; Xiang, T.; and Liu, Y. 2021. Fine-tuning Is Not Enough: A Simple yet Effective Watermark Removal Attack for DNN Models. In IJCAI, 3635–3641. ijcai.org.
- Ho, Jain, and Abbeel (2020) Ho, J.; Jain, A.; and Abbeel, P. 2020. Denoising Diffusion Probabilistic Models. In NeurIPS.
- Huang et al. (2022) Huang, H.; Wang, Y.; Chen, Z.; Zhang, Y.; Li, Y.; Tang, Z.; Chu, W.; Chen, J.; Lin, W.; and Ma, K. 2022. CMUA-Watermark: A Cross-Model Universal Adversarial Watermark for Combating Deepfakes. In AAAI, 989–997. AAAI Press.
- Karras et al. (2020) Karras, T.; Laine, S.; Aittala, M.; Hellsten, J.; Lehtinen, J.; and Aila, T. 2020. Analyzing and Improving the Image Quality of StyleGAN. In CVPR, 8107–8116. Computer Vision Foundation / IEEE.
- Kumar and Kumar (2018) Kumar, V.; and Kumar, D. 2018. A modified DWT-based image steganography technique. Multim. Tools Appl., 77(11): 13279–13308.
- Li et al. (2020) Li, M.; Zhong, Q.; Zhang, L. Y.; Du, Y.; Zhang, J.; and Xiang, Y. 2020. Protecting the Intellectual Property of Deep Neural Networks with Watermarking: The Frequency Domain Approach. In TrustCom, 402–409. IEEE.
- Liu et al. (2022a) Liu, L.; Ren, Y.; Lin, Z.; and Zhao, Z. 2022a. Pseudo Numerical Methods for Diffusion Models on Manifolds. In ICLR. OpenReview.net.
- Liu et al. (2022b) Liu, X.; Ma, Z.; Ma, J.; Zhang, J.; Schaefer, G.; and Fang, H. 2022b. Image Disentanglement Autoencoder for Steganography without Embedding. In CVPR, 2293–2302. IEEE.
- Liu et al. (2015) Liu, Z.; Luo, P.; Wang, X.; and Tang, X. 2015. Deep Learning Face Attributes in the Wild. In ICCV, 3730–3738. IEEE Computer Society.
- Lukas et al. (2022) Lukas, N.; Jiang, E.; Li, X.; and Kerschbaum, F. 2022. SoK: How Robust is Image Classification Deep Neural Network Watermarking? In IEEE Symposium on Security and Privacy, 787–804. IEEE.
- Luo et al. (2023) Luo, Y.; Zhou, T.; Liu, F.; and Cai, Z. 2023. IRWArt: Levering Watermarking Performance for Protecting High-quality Artwork Images. In WWW, 2340–2348. ACM.
- Ma et al. (2023) Ma, Z.; Zhu, Y.; Luo, G.; Liu, X.; Schaefer, G.; and Fang, H. 2023. Robust Steganography without Embedding Based on Secure Container Synthesis and Iterative Message Recovery. In IJCAI, 4838–4846. ijcai.org.
- Mersereau and Alturki (2001) Mersereau, R. M.; and Alturki, F. 2001. Secure blind image steganographic technique using discrete Fourier transformation. In ICIP (2), 542–545. IEEE.
- Nilsback and Zisserman (2008) Nilsback, M.; and Zisserman, A. 2008. Automated Flower Classification over a Large Number of Classes. In ICVGIP, 722–729. IEEE Computer Society.
- Qiao et al. (2023) Qiao, T.; Ma, Y.; Zheng, N.; Wu, H.; Chen, Y.; Xu, M.; and Luo, X. 2023. A novel model watermarking for protecting generative adversarial network. Comput. Secur., 127: 103102.
- Qin et al. (2020) Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaïane, O. R.; and Jägersand, M. 2020. U-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit., 106: 107404.
- Razavi, van den Oord, and Vinyals (2019) Razavi, A.; van den Oord, A.; and Vinyals, O. 2019. Generating Diverse High-Fidelity Images with VQ-VAE-2. In NeurIPS, 14837–14847.
- Song, Meng, and Ermon (2021) Song, J.; Meng, C.; and Ermon, S. 2021. Denoising Diffusion Implicit Models. In ICLR. OpenReview.net.
- Tan et al. (2021) Tan, S.; Wu, W.; Shao, Z.; Li, Q.; Li, B.; and Huang, J. 2021. CALPA-NET: Channel-Pruning-Assisted Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur., 16: 131–146.
- Wei et al. (2022) Wei, P.; Li, S.; Zhang, X.; Luo, G.; Qian, Z.; and Zhou, Q. 2022. Generative Steganography Network. In ACM Multimedia, 1621–1629. ACM.
- Wei, Wang, and Zhang (2020) Wei, Q.; Wang, H.; and Zhang, G. 2020. A Robust Image Watermarking Approach Using Cycle Variational Autoencoder. Secur. Commun. Networks, 2020: 8869096:1–8869096:9.
- Wen et al. (2023) Wen, Y.; Kirchenbauer, J.; Geiping, J.; and Goldstein, T. 2023. Tree-Ring Watermarks: Fingerprints for Diffusion Images that are Invisible and Robust. CoRR, abs/2305.20030.
- Wu et al. (2023) Wu, J.; Gan, W.; Chen, Z.; Wan, S.; and Lin, H. 2023. AI-Generated Content (AIGC): A Survey. CoRR, abs/2304.06632.
- Yu et al. (2021) Yu, N.; Skripniuk, V.; Abdelnabi, S.; and Fritz, M. 2021. Artificial Fingerprinting for Generative Models: Rooting Deepfake Attribution in Training Data. In ICCV, 14428–14437. IEEE.
- Zhang et al. (2022) Zhang, B.; Li, S.; Feng, G.; Qian, Z.; and Zhang, X. 2022. Patch Diffusion: A General Module for Face Manipulation Detection. In AAAI, 3243–3251. AAAI Press.
- Zhang et al. (2020) Zhang, J.; Chen, D.; Liao, J.; Fang, H.; Zhang, W.; Zhou, W.; Cui, H.; and Yu, N. 2020. Model Watermarking for Image Processing Networks. In AAAI, 12805–12812. AAAI Press.
- Zhao et al. (2023) Zhao, Y.; Pang, T.; Du, C.; Yang, X.; Cheung, N.; and Lin, M. 2023. A Recipe for Watermarking Diffusion Models. CoRR, abs/2303.10137.