Unit Selection with Nonbinary Treatment and Effect
Abstract
The unit selection problem aims to identify a set of individuals who are most likely to exhibit a desired mode of behavior, for example, selecting individuals who would respond one way if encouraged and a different way if not encouraged. Using a combination of experimental and observational data, Li and Pearl derived tight bounds on the “benefit function”, which is the payoff/cost associated with selecting an individual with given characteristics. This paper extends the benefit function to the general form such that the treatment and effect are not restricted to binary. We propose an algorithm to test the identifiability of the nonbinary benefit function and an algorithm to compute the bounds of the nonbinary benefit function using experimental and observational data.
Introduction
Several areas of industry, marketing, and health science face the unit selection dilemma. For example, in customer relationship management (Berson, Smith, and Thearling 1999; Lejeune 2001; Hung, Yen, and Wang 2006; Tsai and Lu 2009), it is useful to determine the customers who are going to leave but might reconsider if encouraged to stay. Due to the high expense of such initiatives, management is forced to limit inducement to customers who are most likely to exhibit the behavior of interest. As another example, companies are interested in identifying users who would click on an advertisement if and only if it is highlighted in online advertising (Yan et al. 2009; Bottou et al. 2013; Li et al. 2014; Sun et al. 2015). The challenge in identifying these users stems from the fact that the desired response pattern is not observed directly but rather is defined counterfactually in terms of what the individual would do under hypothetical unrealized conditions. For example, when we observe that a user has clicked on a highlighted advertisement, we do not know whether they would click on that same advertisement if it were not highlighted.
The binary benefit function for the unit selection problem was defined by Li and Pearl (Li and Pearl 2019) (we will call this Li-Pearl’s model), and it properly captures the nature of the desired behavior. Using a combination of experimental and observational data, Li and Pearl derived tight bounds of the benefit function. The only assumption is that the treatment has no effect on the population-specific characteristics. Inspired by the idea of Mueller, Li, and Pearl (Mueller, Li, and Pearl 2021) and Dawid et al. (Dawid, Musio, and Murtas 2017) that the bounds of probabilities of causation could be narrowed using covariates information, Li and Pearl (Li and Pearl 2022c) narrowed the bounds of the benefit function using covariates information and their causal structure. However, the abovementioned studies are based on binary treatment and effect. Recently, researchers have shown interest in developing bounds for probabilities of causation with nonbinary treatment and effect. Zhang, Tian, and Bareinboim (Zhang, Tian, and Bareinboim 2022), as well as Li and Pearl (Li and Pearl 2022a), proposed nonlinear programming-based solutions to compute the bounds of nonbinary probabilities of causation numerically. Li and Pearl (Li and Pearl 2022b) provided the theoretical bounds of nonbinary probabilities of causation. The benefit function is a linear combination of probabilities of causation; therefore, in this paper, we focus on discovering the bounds of any benefit function without restricting them to binary treatment and effect.
Consider the following motivating scenario: a clinical study is conducted to test the effectiveness of a vaccine. The treatments include vaccinated and unvaccinated. The outcomes include uninfected, asymptomatic infected, and infected in a severe condition. The benefited individuals include the following: the individual who would be infected in a severe condition if unvaccinated and would be asymptomatic infected if vaccinated, the individual who would be infected in a severe condition if unvaccinated and would be uninfected if vaccinated, and the individual who would be asymptomatic infected if unvaccinated and would be uninfected if vaccinated. The harmed individuals include the following: the individual who would be asymptomatic infected if unvaccinated and would be infected in a severe condition if vaccinated, the individual who would be uninfected if unvaccinated and would be infected in a severe condition if vaccinated, and the individual who would be uninfected if unvaccinated and would be asymptomatic infected if vaccinated. All others are unaffected individuals. The researcher performing the clinical study has collected both experimental and observational data. The researcher then wants to know the expected difference between benefited and harmed individuals to emphasize the effectiveness of the vaccine.
We cannot apply Li-Pearl’s model because we have two treatments and three outcomes. In this paper, we extend Li-Pearl’s benefit function to general form without restricting them to binary treatment and effect. We will provide an algorithm to test the identifiability of the nonbinary benefit function and an algorithm to compute the bounds of the nonbinary benefit function using experimental and observational data.
Preliminaries
In this section, we review Li and Pearl’s binary benefit function of the unit selection problem (Li and Pearl 2019), and the theoretical bounds of the probabilities of causation recently proposed by Li and Pearl (Li and Pearl 2022b).
In this paper we use the language of counterfactuals in structural model semantics, as given in (Galles and Pearl 1998; Halpern 2000). we use to denote the counterfactual sentence “Variable would have the value , had been ”. For simplicity purposes, in the rest of the paper, we use to denote the event , to denote the event , to denote the event , and to denote the event . we assume that experimental data will be summarized in the form of the causal efects such as and observational data will be summarized in the form of the joint probability function such as . If not specified, the variable stands for treatment and the variable stands for effect.
Individual behavior was classified into four response types: labeled complier, always-taker, never-taker, and defier. Suppose the benefit of selecting one individual in each category are respectively (i.e., the benefit vector is ). Li and Pearl defined the objective function of the unit selection problem as the average benefit gained per individual. Suppose and are binary treatments, and are binary outcomes, and are population-specific characteristics, the objective function (i.e., benefit function) is following (If the goal is to evaluate the average benefit gained per individual for a specific population , can be dropped.):
Using a combination of experimental and observational data, Li and Pearl established the most general tight bounds on this benefit function (which we refer to as Li-Pearl’s Theorem in the rest of the paper). The only constraint is that the population-specific characteristics are not a descendant of the treatment.
Li and Pearl (Li and Pearl 2022b) provided eight theorems to compute bounds for any type of probabilities of causation with nonbinary treatment and effect. Suppose variable has values and has values, the following probabilities of causation are bounded. Besides, if the probabilities of causation are conditioned on a population-specific variable that is not affected by , then all the theorems still hold (we provided the extended theorems from Li and Pearl in the appendix).
The benefit function is a linear combination of the probabilities of causation; therefore, we define the general benefit function for the unit selection problem based on Li and Pearl’s results.
Counterfactual Formulation of the Unit Selection Problem
Based on Li and Pearl (Li and Pearl 2019), the objective is to find a set of characteristics that maximizes the benefit associated with the resulting mixture of different response types of individuals. Let denotes the treatment with values and denotes the effect with values. Therefore, we have different response types (i.e., one response type means assigning one effect to each of the treatments). Suppose the benefit of selecting an individual are (we call as benefit vector). Our objective, then, should be to find that maximizes the following expression (If the goal is to evaluate the average benefit gained per individual for a specific population , can be dropped):
Note that can be interpreted as the population-specific variable, the only assumption is that the treatment has no effect on the population-specific variable. Recall from Li and Pearl’s paper (Li and Pearl 2019), the benefit vector is provided by the decision-maker who uses the model.
In the next section, we will provide an algorithm that could check whether a given benefit function with the benefit vector is identifiable with purely experimental data (i.e., we can find the exact value of the benefit function rather than bounds). If it is not identifiable we will then provide an algorithm that computes the bounds of the benefit function given the benefit vector using experimental and observational data.
Main Results
Identifiability of Benefit Function
Recall that in binary case, the conditions of identifiable are gain equality (i.e., ) or monotonicity (i.e., ) (Li and Pearl 2019). Here, it is complicated in nonbinary cases, therefore; we provide an algorithm to test whether a given benefit function with the benefit vector is identifiable with purely experimental data.
Theorem 1.
Suppose variables has values and has values . Then the benefit function is identifiable if Algorithm 1 returns (True, res), and res is the value of the benefit function.
Input: , the benefit function,where is a tuple that stands for ith term in the benefit function. If the ith term is , then
, the experimental data, where .
, the adjusted value of the benefit function.
The initial call of the algorithm is , where corresponding to the original benefit function.
All lists in this algorithm start with index .
Output: (identifiable, value), a tuple, where identifiable True if the given benefit function is identifiable and value is the value of the benefit function.
Function :
The correctness of the algorithm simply follow the fact that . Therefore, if there exist such terms in the benefit function, then we can obtain an equivalent benefit function by replacing one of the terms with experimental data . We exhausted all equivalent benefit functions to check if we could replace all the counterfactual terms with experimental data (i.e., identifiable).
For example, consider and the benefit function:
Bounds of Benefit Function
If Algorithm 1 returns false, we then need to compute the bounds of the benefit function using experimental and observational data. We first obtain the bounds of the probabilities of causation, , …, , …, , …, , by Li and Pearl’s theorems (Li and Pearl 2022b). We then have the following theorem.
Theorem 2.
Suppose variables has values and has values . Then the bounds of the benefit function is obtained by Algorithm 2.
Input: , the benefit function,where is a tuple that stands for ith term in the benefit function. If the ith term is , then
, the lower bound of all possible terms obtained from Li-Pearl’s theorems, where is the lower bound of .
, the upper bound of all possible terms obtained from Li-Pearl’s theorems, where is the upper bound of .
, the adjusted value of the benefit function.
The initial call of the algorithm is , where corresponding to the original benefit function.
All lists in this algorithm start with index .
Output: (lo, up), lower and upper bound of the benefit function.
Function :
Again, the correctness of the algorithm simply follow the fact that . We exhausted all equivalent benefit functions and take the maximum of all the lower bounds and take the minimum of all the upper bounds of equivalent benefit functions.
Example: Effectiveness of a Vaccine
Recall the motivating example at the beginning, a clinical study is conducted to test the effectiveness of a vaccine. The treatments include vaccinated and unvaccinated. The outcomes include uninfected, asymptomatic infected, and infected in a severe condition. The researcher of the clinical study has collected both experimental and observational data.
Task 1
The researcher wants to know the expected difference between benefited and harmed individuals to emphasize the effectiveness of the vaccine.
Let denotes vaccination with being vaccinated and being unvaccinated and denotes outcome, where denotes uninfected, denotes asymptomatic infected, and denotes infected in a severe condition. The experimental and observational data of the clinical study are summarized in Tables 1 and 2.
| Vaccinated | Unvaccinated | |||||
|---|---|---|---|---|---|---|
| Uninfected |
|
|
||||
| Asymptomatic |
|
|
||||
| Severe Condition |
|
|
||||
| Overall |
|
|
| Vaccinated | Unvaccinated | |||||
|---|---|---|---|---|---|---|
| Uninfected |
|
|
||||
| Asymptomatic |
|
|
||||
| Severe Condition |
|
|
||||
| Overall |
|
|
Based on the clinical study, the researcher of the vaccine claimed that the vaccine is effective in controlling the severe condition, the number of severe condition patients dropped from to only .
Now consider the expected difference between benefited and harmed individuals. Recall the benefited individuals include the individual who would be infected in a severe condition if unvaccinated and would be asymptomatic infected if vaccinated, the individual who would be infected in a severe condition if unvaccinated and would be uninfected if vaccinated, and the individual who would be asymptomatic infected if unvaccinated and would be uninfected if vaccinated. The harmed individuals include the individual who would be asymptomatic infected if unvaccinated and would be infected in a severe condition if vaccinated, the individual who would be uninfected if unvaccinated and would be infected in a severe condition if vaccinated, and the individual who would be uninfected if unvaccinated and would be asymptomatic infected if vaccinated. All others are unaffected individuals. In order to maximize the difference between benefited and harmed individuals; therefore, we assign to benefited individuals, assign to harmed individuals, and to all others in the benefit vector. The objective function (i.e., benefit function) is then
The experimental data in Table 1 provide the following estimates:
The observational data Table 2 provide the following estimates:
We plug the estimates and the benefit function into Theorem 1, the Algorithm 1 returns false (i.e., not identifiable by experimental data). We then plug the estimates and the benefit function into Theorem 2 to obtain the bounds
Thus, the expected difference between benefited and harmed individuals is at most per individual. We can conclude that the vaccine is ineffective for the virus.
Task 2
The researcher of the clinic study claimed that the individual who would be infected in a severe condition if unvaccinated and would be uninfected if vaccinated and the individual who would be uninfected if unvaccinated and would be infected in a severe condition if vaccinated should be twice important than other individuals. Based on the clinical study, the number of severe condition patients dropped from to only ; therefore, the vaccine should be effective for the virus.
Now consider the expected difference between benefited and harmed individuals. The benefit vector should be the same except assigning to the individual who would be infected in a severe condition if unvaccinated and would be uninfected if vaccinated and assigning to the individual who would be uninfected if unvaccinated and would be infected in a severe condition if vaccinated.
The objective function (i.e., benefit function) is then
We plug the estimates and the benefit function into Theorem 1, the Algorithm 1 returns true (i.e., identifiable by experimental data) with value . The benefit function can be simplified as follow:
Thus, the expected difference between benefited and harmed individuals is exactly per individual. We can conclude that the vaccine is still ineffective for the virus.
Simulated Results
In this section, we show the quality of the bounds of the benefit function obtained by Theorem 2 using four common benefit vectors.
First, we set (i.e., has two values) and (i.e., has three values). We set the benefit vector to one of the most common ones, , which is to evaluate the expected difference between benefited and harmed individuals. We randomly generated populations where each population consists of different fractions of nine response types of individuals. For each population, we then generated sample distributions (observational data and experimental data) compatible with the fractions of response types (see the appendix for the generating algorithm). The advantage of this generating process is that we have the real benefit value (because we know the fractions of the response types) for comparison. Each sample population represents a different instantiate of the population-specific characteristics in the model. The generating algorithm ensures that the experimental data and observational data satisfy the general relation (i.e., ). For a sample population , let be the bounds of the benefit function from the proposed theorem. We summarized the following criteria for each population as illustrated in Figure 1:
-
•
lower bound : ;
-
•
upper bound : ;
-
•
midpoint : ;
-
•
real benefit : dot product of the benefit vector and the fractions of response types;
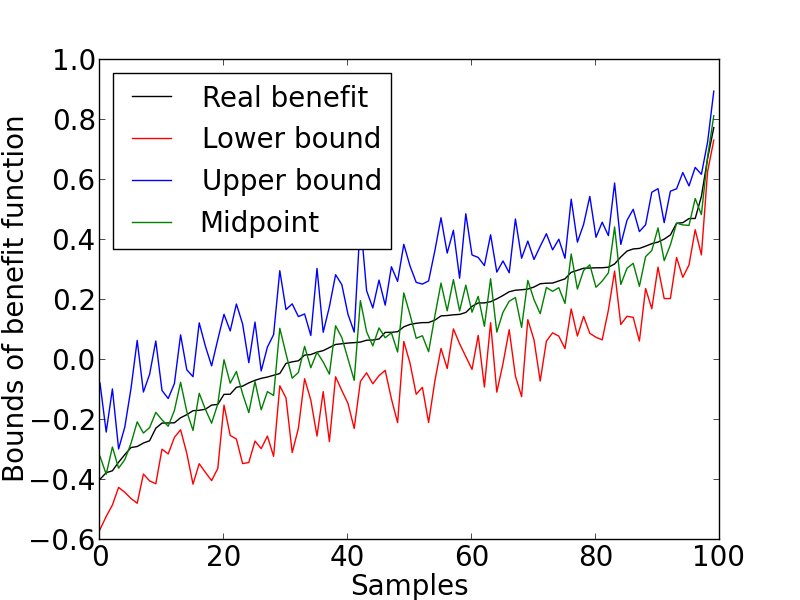
From Figure 1, it is clear that the proposed bounds obtained from Theorem 2 are a good estimation of the real benefit. The lower and upper bounds are closely around the real benefit and the midpoints are almost identified with the real benefit. Besides, the average gap of the bounds, , is , which is also small compared to the largest possible gap of .
Second, we set the benefit vector to another common one, , which is to evaluate the expected difference between benefited and unbenefited (i.e., unaffected and harmed) individuals. We again randomly generated populations where each population consists of different fractions of nine response types. The data generating process and all other factors remain the same. We summarized the same criteria for each population as illustrated in Figure 2.
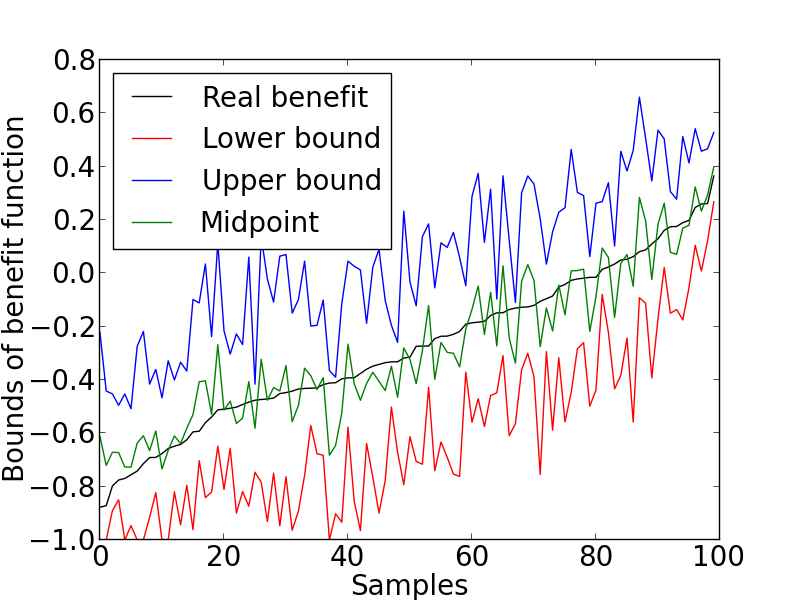
From Figure 2, it is clear that the proposed bounds obtained from Theorem 2 are a good estimation of the real benefit. The lower and upper bounds are closely around the real benefit and the midpoints are almost identified with the real benefit. Besides, the average gap of the bounds, , is , which is also small compared to the largest possible gap of .
Third, we set the benefit vector to another common one, , which is to evaluate the expected benefited individuals. We again randomly generated populations where each population consists of different fractions of nine response types. The data generating process and all other factors still remain the same. We summarized the same criteria for each population as illustrated in Figure 3.
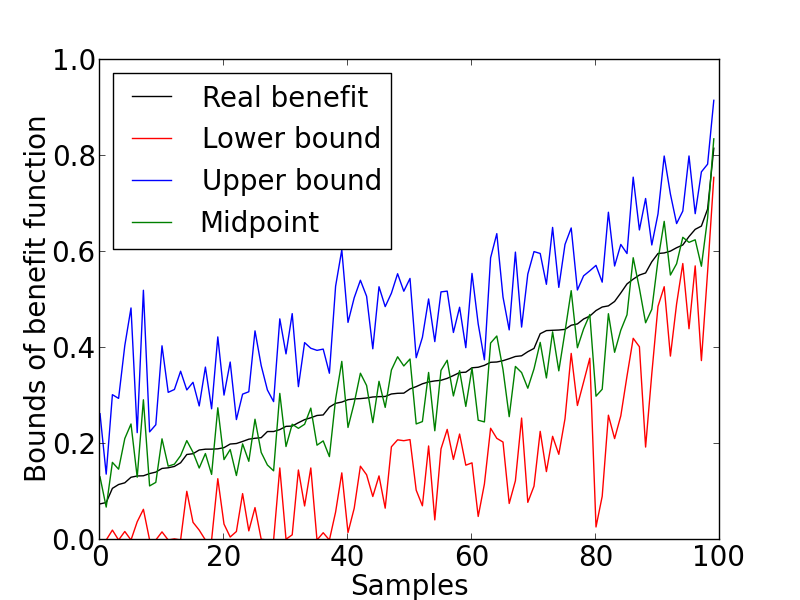
From Figure 3, it is clear that the proposed bounds obtained from Theorem 2 are a good estimation of the real benefit. The lower and upper bounds are closely around the real benefit and the midpoints are almost identified with the real benefit. Besides, the average gap of the bounds, , is , which is also small compared to the largest possible gap of .
Lastly, we set the benefit vector to the last common one, , which is to evaluate the expected harmed individuals (we set the benefit vector to because we want to minimize the harmed individuals). We again randomly generated populations where each population consists of different fractions of nine response types. The data generating process and all other factors still remain the same. We summarized the same criteria for each population as illustrated in Figure 4.
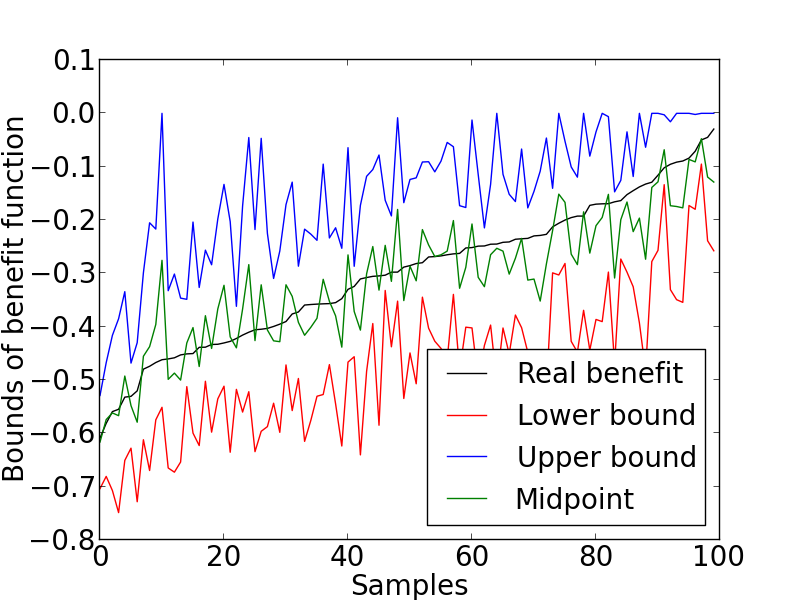
From Figure 4, it is clear that the proposed bounds obtained from Theorem 2 are a good estimation of the real benefit. The lower and upper bounds are closely around the real benefit and the midpoints are almost identified with the real benefit. Besides, the average gap of the bounds, , is , which is also small compared to the largest possible gap of .
Discussion
We have shown that the proposed theorems are a good estimation of the non-binary benefit function using examples and simulated studies. One may concern about the computation complexity of Algorithms 1 and 2. They are for sure in exponential time. However, the and (i.e., values of and ) are usually small constant, therefore, we do not need to worry about too much.
Conclusion and Future Work
We demonstrated the formalization of the general benefit function with nonbinary treatment and effect. We provided the algorithm to compute the bounds of the general benefit function and the algorithm to check whether the benefit function is identifiable with purely experimental data. Examples and simulation results are provided to support the proposed theorems.
Future studies could assess the statistical properties of the proposed bounds. How tight would the bounds be? Does it sufficient to make decisions? Which data, experimental or observational, would affect the bounds more? How would the number of values in treatment and effect affect the quality of the bounds?
Another future direction could be to improve the bounds using covariate information as Li and Pearl (Li and Pearl 2019) did for the binary benefit function.
Acknowledgements
This research was supported in parts by grants from the National Science Foundation [#IIS-2106908], Office of Naval Research [#N00014-17-S-12091 and #N00014-21-1-2351], and Toyota Research Institute of North America [#PO-000897].
References
- Berson, Smith, and Thearling (1999) Berson, A.; Smith, S.; and Thearling, K. 1999. Building data mining applications for CRM. McGraw-Hill Professional.
- Bottou et al. (2013) Bottou, L.; Peters, J.; Quiñonero-Candela, J.; Charles, D. X.; Chickering, D. M.; Portugaly, E.; Ray, D.; Simard, P.; and Snelson, E. 2013. Counterfactual reasoning and learning systems: The example of computational advertising. The Journal of Machine Learning Research, 14(1): 3207–3260.
- Dawid, Musio, and Murtas (2017) Dawid, P.; Musio, M.; and Murtas, R. 2017. The Probability of Causation. Law, Probability and Risk, (16): 163–179.
- Galles and Pearl (1998) Galles, D.; and Pearl, J. 1998. An axiomatic characterization of causal counterfactuals. Foundations of Science, 3(1): 151–182.
- Halpern (2000) Halpern, J. Y. 2000. Axiomatizing causal reasoning. Journal of Artificial Intelligence Research, 12: 317–337.
- Hung, Yen, and Wang (2006) Hung, S.-Y.; Yen, D. C.; and Wang, H.-Y. 2006. Applying data mining to telecom churn management. Expert Systems with Applications, 31(3): 515–524.
- Lejeune (2001) Lejeune, M. A. 2001. Measuring the impact of data mining on churn management. Internet Research, 11(5): 375–387.
- Li and Pearl (2019) Li, A.; and Pearl, J. 2019. Unit Selection Based on Counterfactual Logic. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19, 1793–1799. International Joint Conferences on Artificial Intelligence Organization.
- Li and Pearl (2022a) Li, A.; and Pearl, J. 2022a. Bounds on causal effects and application to high dimensional data. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 5773–5780.
- Li and Pearl (2022b) Li, A.; and Pearl, J. 2022b. Probabilities of Causation with Non-binary Treatment and Effect. Technical Report R-516, Department of Computer Science, University of California, Los Angeles, CA.
- Li and Pearl (2022c) Li, A.; and Pearl, J. 2022c. Unit selection with causal diagram. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 5765–5772.
- Li et al. (2014) Li, L.; Chen, S.; Kleban, J.; and Gupta, A. 2014. Counterfactual estimation and optimization of click metrics for search engines. arXiv preprint arXiv:1403.1891.
- Mueller, Li, and Pearl (2021) Mueller, S.; Li, A.; and Pearl, J. 2021. Causes of effects: Learning individual responses from population data. Technical Report R-505, http://ftp.cs.ucla.edu/pub/stat_ser/r505.pdf, Department of Computer Science, University of California, Los Angeles, CA. Forthcoming, Proceedings of IJCAI-2022.
- Sun et al. (2015) Sun, W.; Wang, P.; Yin, D.; Yang, J.; and Chang, Y. 2015. Causal inference via sparse additive models with application to online advertising. In AAAI, 297–303.
- Tsai and Lu (2009) Tsai, C.-F.; and Lu, Y.-H. 2009. Customer churn prediction by hybrid neural networks. Expert Systems with Applications, 36(10): 12547–12553.
- Yan et al. (2009) Yan, J.; Liu, N.; Wang, G.; Zhang, W.; Jiang, Y.; and Chen, Z. 2009. How much can behavioral targeting help online advertising? In Proceedings of the 18th international conference on World Wide Web, 261–270. ACM.
- Zhang, Tian, and Bareinboim (2022) Zhang, J.; Tian, J.; and Bareinboim, E. 2022. Partial counterfactual identification from observational and experimental data. In International Conference on Machine Learning, 26548–26558. PMLR.
Appendix A Appendix
Proof of Theorems
Theorem 1.
Suppose variables has values and has values . Then the benefit function is identifiable if Algorithm 1 returns (True, res), and res is the value of the benefit function.
Proof.
The proof is simple.
Lines to in Algorithm 1 simply check whether the given benefit function (encoded as in the algorithm) is identifiable.
On line of the algorithm, we recursively call on another benefit function (encoded as in the algorithm).
Now lets consider how we obtain .
if there exist terms in and , s.t., , these terms are , and the sum of these terms is equal to .
We obtain by eliminating kth of the terms in , replacing kth term by other terms and their sum .
Therefore, where .
Thus, is identifiable if and only if is identifiable and .
∎
Theorem 2.
Suppose variables has values and has values . Then the bounds of the benefit function is obtained by Algorithm 2.
Proof.
Similarly to Theorem 1,
lines to in Algorithm 2 simply compute the bounds of the given benefit function (encoded as in the algorithm).
On line of the algorithm, we recursively call on another benefit function (encoded as in the algorithm).
Now lets consider how we obtain .
if there exist terms in and , s.t., , these terms are , and the sum of these terms is equal to .
We obtain by eliminating kth of the terms in , replacing kth term by other terms and their sum .
Therefore, where .
Thus, the bounds of is the bounds of .
∎
Li-Pearl’s Bounds of Probabilities of Causation
The input, , in Algorithm 2 depends on the bounds of probabilities of causation. The bounds of probabilities of causation recently proposed by Li and Pearl (Li and Pearl 2022b) is not conditional . However, nothing is changed if conditioning on a variable that is not affected by . We listed the conditional version of the eight theorems proposed by Li and Pearl. The proof of eight theorems is exactly the same, except every probability should be conditioned on .
Theorem 3.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
Theorem 4.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
Theorem 5.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
Theorem 6.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
Theorem 7.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
where,
LB denotes the lower bound of a function and UB denotes the upper bound of a function . The bounds of are given by Theorem 6 or 10, the bounds of are given by Theorem 5 or 8, and the bounds of are given by Theorem 7 or experimental data if .
Theorem 8.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
where,
LB denotes the lower bound of a function and UB denotes the upper bound of a function . The bounds of are given by Theorem 7 or experimental data if and the bounds of are given by Theorem 5.
Theorem 9.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
where,
LB denotes the lower bound of a function and UB denotes the upper bound of a function . The bounds of , are given by Theorem 6 or 10, the bounds of are given by Theorem 7 or experimental data if , and the bounds of are given by Theorem 3 or 4.
Theorem 10.
Suppose variable has values and has values , and variable is not affected by , then the probability of causation , where , is bounded as following:
where,
LB denotes the lower bound of a function and UB denotes the upper bound of a function . The bounds of are given by Theorem 7 or experimental data if and the bounds of are given by Theorem 6.
Calculation in the Example
Task 1
Task 2
By Algorithm 1, the result came from the following steps,
Distribution Generating Algorithm
Here, the sample distribution generating algorithm in the simulated studies is presented. It generated both experimental and observational data compatible with the fractions of response types of individuals. The data satisfy the general relation between experimental and observational data. Note that all four simulated studies shared the same distribution generating algorithm but with different benefit vectors.
Input: , number of samples needed.
Output: sample distributions (observational data and experimental data).