Universal kernel-type estimation of random fields ††thanks: The study was supported by the program for fundamental scientific research of the Siberian Branch of the Russian Academy of Sciences, project FWNF-2022-0015.
Abstract
Consistent weighted least square estimators are proposed for a wide class of nonparametric regression models with random regression function, where this real-valued random function of arguments is assumed to be continuous with probability 1. We obtain explicit upper bounds for the rate of uniform convergence in probability of the new estimators to the unobservable random regression function for both fixed or random designs. In contrast to the predecessors’ results, the bounds for the convergence are insensitive to the correlation structure of the -variate design points. As an application, we study the problem of estimating the mean and covariance functions of random fields with additive noise under dense data conditions. The theoretical results of the study are illustrated by simulation examples which show that the new estimators are more accurate in some cases than the Nadaraya–Watson ones. An example of processing real data on earthquakes in Japan in 2012–2021 is included.
Key words and phrases: nonparametric regression, uniform consistency, kernel-type estimator.
AMS subject classification: 62G08.
1. Introduction
We study the following regression model:
| (1) |
where , , , is an unknown real-valued random function (a random field). We assume that is a compact set, the random field is continuous on with probability 1, and the design consists of a collection of observed random vectors with unknown (generally speaking) distributions, not necessarily independent or identically distributed. The random design points may depend on , i.e., a triangular array scheme for the design can be considered within this model. In particular, this scheme includes regression models with fixed design. Moreover, we do not require that the random field be independent of the design .
Next, we will assume that the unobservable random errors (a noise) form a martingale difference sequence, with
| (2) |
We also assume that are independent of the collection and the random field . The noise may depend on .
Our goal is to construct consistent in estimators for the random regression field by the observations under minimal restrictions on the design points , where denotes the space of all continuous functions on with the uniform norm.
In the classical case of nonrandom , the most popular estimating procedures are based on kernel-type estimators. We emphasize among them the Nadaraya–Watson, the Priestley-Chao, the Gasser-Müller estimators, the local polynomial estimators, and some of their modifications (see Härdle, 1990; Wand and Jones, 1995; Fan and Gijbels, 1996; Fan and Yao, 2003; Loader, 1999; Young, 2017; Müller, 1988). We do not aspire for providing a comprehensive review of this actively developing (especially in the last two decades) area of nonparametric estimation, and will focus only on publications representing certain methodological areas. We are primarily interested in conditions on the design elements. In this regard, a large number of publications in this area may be tentatively divided into the two groups: the studies dealing with fixed design or with random one. In papers dealing with a random design, as a rule, the design consists of independent identically distributed random variables or stationary observations satisfying known forms of dependence, e.g., various types of mixing conditions, association, Markov or martingale properties, etc. Not attempting to present a comprehensive review, we may note the papers by Kulik and Lorek (2011), Kulik and Wichelhaus (2011), Roussas (1990, 1991), Györfi et. al. (2002), Masry (2005), Hansen (2008), Honda (2010), Laib and Louani (2010), Li et al. (2016), Hong and Linton (2016), Shen and Xie (2013), Jiang and Mack (2002), Linton and Jacho-Chavez (2010), Chu and Deng (2003) (see also the references in the papers). Besides, in the recent studies by Gao et al. (2015), Wang and Chan (2014), Chan and Wang (2014), Linton and Wang (2016), Wang and Phillips (2009a,b), Karlsen et al. (2007), the authors considered nonstationary design sequences under special forms of dependence (Markov chains, autoregressions, sums of moving averages, and so on).
In the case of fixed design, the vast majority of papers make certain assumptions on the regularity of design (see Zhou and Zhu, 2020; Benelmadani et al., 2020; Tang et al., 2018; Gu et al., 2007; Benhenni et al., 2010; Müller and Prewitt, 1993; Ahmad and Lin, 1984; Georgiev, 1988, 1990). In univariate models, the nonrandom design points are most often restricted by the formula with a function of bounded variation, where the error term is uniform in . If is linear, then the design is equidistant. Another regularity condition in the univariate case is the relation , where the design elements are arranged in increasing order. In a number of recent studies, a more general condition can be found (e.g., see Yang and Yang, 2016; He, 2019; Wu et al., 2020). In several works, including those dealing with the so-called weighted estimators, certain conditions are imposed on the behavior of functions of design elements, but meaningful corresponding examples are limited to cases of regular design (e.g., see Zhang et al., 2019 ; Zhang et al., 2018; Liang and Jing, 2005; Roussas et al., 1992; Georgiev, 1988).
The problem of uniform approximation of the kernel-type estimators has been studied by many authors (e.g., see Einmahl and Mason, 2005; Hansen, 2008; Gu et al., 2007; Shen and Xie, 2013; Li et al., 2016; Liang and Jing, 2005; Wang and Chan, 2014; Chan and Wang, 2014; Gao et al., 2015 and the references therein).
In this paper, we study a class of kernel-type estimators, asymptotic properties of which do not depend on the design correlation structure. The design may be fixed (and not necessarily regularly spaced) or random (with not necessarily weakly dependent components). We present weighted least square estimators where the weights are chosen as the Lebesgue measures of the elements of a finite random partition of the regression function domain such that every partition element corresponds to one design point. As a result, the proposed kernel estimators for the regression function are transformation of sums of weighted observations in a certain way with the structure of multiple Riemann integral sums, so that conceptually our approach is close to the methods of Priestley and Chao (1972) and of Mack and Müller (1988), who considered the cases of univariate fixed design and i.i.d. random design, respectively. Explicit upper bounds are obtained for the rate of uniform convergence of these estimators to the random regression field.
In contrast to the predecessors’ results, we do not impose any restrictions on the design correlation structure. We will consider the maximum cell diameter of the above-mentioned partition of generated by the design elements, as the main characteristic of the design. Sufficient conditions for the consistency of the new estimators, as well as the windows’ widths will be derived in terms of that characteristic. The advantage of that characteristic over the classical weak dependence conditions is that the characteristic is insensitive to forms of correlation of the design elements. The main condition will be that the maximum cell diameter tends to zero in probability as the sample size grows. Note that such requirement is, in fact, necessary, since only when the design densely fills the regression function domain, it is possible to reconstruct the function more or less precisely.
Univariate versions of this estimation problem were studied in Borisov et al. (2021) and Linke et al. (2022) where the asymptotic analysis and simulations showed that the proposed estimators perform better than the Nadaraya–Watson ones in several cases. Note that the univariate case in Borisov et al. (2021) does not allow direct generalization to a multivariate case, since the weights were defined there as the spacings of the variational series generated by the design elements. Note also that the estimator in Borisov et al. (2021) is a particular univariate case of the estimators proposed in this paper, but not the only one. One of the univariate estimators studied here may be more accurate than the estimator in Borisov et al. (2021) (see Remark 3 below). Conditions on the design elements similar to those of this paper were used Linke and Borisov (2022), and in Linke (2023). The conditions provide uniform consistency of the estimators, but guarantee only pointwise consistency of the Nadarya–Watson ones. Besides, similar restrictions on the design elements were used before in Linke and Borisov (2017, 2018), and Linke (2019) in estimation of the parameters of several nonlinear regression models.
In this paper, we will assume that the unknown random regression function , , is continuous with probability 1. Considering the general case of random regression function allows us to obtain results on estimating the mean function of a random regression process. In regard to estimating random regression functions, we may note the papers by Li and Hsing (2010), Hall et al. (2006), Zhou et al. (2018), Zhang and Wang (2016, 2018), Yao et al. (2005), Zhang and Chen (2007), Yao (2007), Lin and Wang (2022). In those papers, the mean and covariance functions of the random regression process were estimated when, for independent noisy copies of the random process, each of the trajectories was observed in a certain subset of design elements (nonuniform random time grid). Estimation of mean and covariance of random processes is an actively developing area of nonparametric estimation, especially in the last couple of decades, is of independent interest, and plays an important role in subsequent analyses (e.g., see Hsing and Eubank, 2015; Li and Hsing, 2010; Zhang and Wang, 2016; Wang et al., 2016).
Estimation of random regression functions usually deals with either random or deterministic design. In the case of random design, it is usually assumed that the design elements are independent identically distributed (e.g., see Hall et al., 2006; Li and Hsing, 2010; Zhou et al., 2018; Yao , 2007; Yao et al., 2005; Zhang and Chen, 2007; Zhang and Wang, 2016, 2018; Lin and Wang, 2022). Some authors emphasized that their results can be extended to weakly dependent design (e.g., see Hall et al., 2006). For deterministic time grids, regularity conditions are often required (e.g., see Song et al., 2014; Hall et al., 2006). In regard to denseness of filling the regression function domain, the two types of design are distinguished in the literature: either the design is “sparse”, e.g., the number of design elements in each series is uniformly limited (Hall et al., 2006; Zhou et al., 2018; Li and Hsing, 2010), or the design is “dense” and the number of elements in a series increases with the sequential number of the series (Zhou et al., 2018; Li and Hsing, 2010). Uniform consistency of several estimators of the mean of random regression function was considered, for example, by Yao et al. (2005), Zhou et al. (2018), Li and Hsing (2010), Hsing and Eubank (2015), Zhang and Wang (2016).
In this paper, we consider one of the variants of estimation of the mean of a random regression function as an application of the main result. In the case of dense design, uniformly consistent estimators are constructed for the mean function, when the series-to-series-independent design is arbitrarily correlated inside each series. We require only that, in each series, the design elements form a refining partition of the domain of the random regression function. Our settings also include a general deterministic design situation, but we do not impose traditionally used regularity conditions. Thus, in the problem of estimating the mean function, as well as in the problem of estimating the function in model (1), we weaken traditional conditions on the design elements. Note that methodologies used for estimating the mean function for dense and for sparse data usually differ (e.g., see Wang et al., 2016). In the case of growing number of observations in each series, it is natural to preliminarily evaluate the trajectory of the random regression function in each series and then average the estimates over all series (e.g., see Hall et al., 2006). That is what we will do in this paper following this generally accepted approach. Universal estimates both for the mean and covariance functions of a random process in the case of sparse data, insensitive to the nature of the dependence of design elements, are proposed in Linke and Borisov (2024).
This paper has the following structure. Section 2 contains the main results on the rate of uniform convergence of the new estimators to the random regression function. In Section 3, we consider an application of the main results to the problem of estimating the mean and covariance function of a random regression field. In Section 4, the asymptotic normality of the new estimators is discussed. Section 5 contains several simulation examples. In Section 6, we discuss an example of assessing real data on earthquakes in Japan in 2012–2021. In Section 7, we summarize the main results of the paper. The proofs of the theorems and lemmas from Sections 2–4 are contained in Section 8.
2. Main assumptions and results
Without loss of generality we will assume that , where
is the diameter of a set and is the supnorm in . In what follows, unless otherwise stated, all the limits will be taken as .
Our approach recalls a construction of multivariate Riemann integrals. To this end, we need the following condition on the design .
For each , there exists a random partition of the set into Borel-measurable subsets such that in probability.
Condition (D) means that, for every , the set forms a -net in the compact set . In particular, Condition (D) is satisfied if the design points are pairwise distinct, for all , and in probability.
In the case , a regularly spaced design satisfies Condition (D). Moreover, if is a stationary sequence satisfying an -mixing condition and is the support of the distribution of , then Condition is fulfilled (see Remark 3 in Linke and Borisov, 2017). It is not hard to verify that, for i.i.d. design points with the probability density function of bounded away from zero on , one can have with probability 1. Notice that the dependence of random variables in Condition may be much stronger than that in these examples (see Linke and Borisov, 2017, 2018 and the example below).
Example. Let a sequence of bivariate random variables is defined by the relation
| (3) |
where the random vectors and are independent and uniformly distributed on the rectangles and , respectively, while the sequence does not depend on and and consists of Bernoulli random variables with success probability , i.e., the distribution of is the equi-weighted mixture of the two above-mentioned uniform distributions. The dependence between the random variables is defined by the equalities and . In this case, the random variables in (3) form a stationary sequence of random variables uniformly distributed on the unit square , but, say, all known mixing conditions are not satisfied here because, for all natural and ,
On the other hand, it is easy to check that the stationary sequence satisfies the Glivenko–Cantelli theorem. This means that, for any fixed ,
almost surely uniformly in , where denotes the standard counting measure. In other words, the sequence satisfies Condition .
It is clear that, according to the scheme of this example, one can construct various sequences of dependent random variables uniformly distributed on , based on the choice of different sequences of the Bernoulli switches with the conditions and for infinitely many indices and , respectively. In this case, Condition will also be satisfied. But the corresponding sequence (not necessarily stationary) may not satisfy the strong law of large numbers. For example, a similar situation occurs when for and for , where (i.e., we randomly choose one of the two rectangles and , into which we randomly throw the first point, and then alternate the selection of one of the two rectangles by the following numbers of elements of the sequence: , , , , etc.). Indeed, we can introduce the notation , , , with , and note that, for all outcomes consisting the event , one has
| (4) |
where , ; and are the collections of indices for which the observations lie in the rectangles or , respectively. It is easy to see that and . Hence, almost surely as due to the strong law of large numbers for the sequences and . On the other hand, for all elementary outcomes in the event , as , we have with probability 1
| (5) |
where and are the collections of indices for which the observations lie the rectangles or , respectively. In proving the convergence in (5) we took into account that , , i.e., .
Similar arguments are valid for elementary outcomes consisting the event .
In what follows, by , , we will denote the kernel function. We assume that the kernel function is zero outside and is a centrally symmetric probability density function, i.e., , for all , and . For example, we may consider product-kernels of the form
where is a univariate symmetric probability density function with support . We also assume that the function satisfies the Lipschitz condition with constant :
for all and , and put for all such that . Notice that, under these restrictions, .
Put
By we denote a random vector with the density , which is independent of the random variables .
Let denote the Lebesgue measure in . Introduce the following notation:
| (6) |
where by definition;
| (7) |
Now, notice that
i.e., the estimators of the form (6) belong to the class of weighted least square estimators. Estimators (6) are also called local constant ones.
Finally, we will assume that there exist constants and such that
| (8) |
So, some cases (for example, if contains isolated points) are excluded from the scheme under consideration.
R e m a r k 1.
Notice that if the set can be represented as the union of hyperrectangles with the edges of lengths greater than and kernel is a product-kernel, then we have the lower bound .
The main result of this paper is as follows.
Theorem 1. Let the conditions and hold. Then, for any fixed ,
| (9) |
with probability , where is a positive random variable such that
| (10) | |||||
where
In what follows, we will denote by some univariate random variables such that, for all ,
where is a sequence of positive nonrandom numbers, , and the function does not depend on .
R e m a r k 2.
For example, let the function be nonrandom. In (10), put
Applying the power Markov’s inequality with exponent for the second summand in (10), we obtain that, under the conditions of the theorem,
and there exists a solution to the equation
| (11) |
It is clear that this solution vanishes as . In fact, the value minimizes in the order of smallness for the right-hand side of (9). Notice that and in view of (11).
Taking Remark 1 into account one can obtain the following two assertions as consequences of Theorem .
Corollary 1. Let be a set of nonrandom equicontinuous functions from the function space for example, a precompact subset of . Then, under Condition ,
where is a solution to equation in which the modulus of continuity is replaced with the universal modulus . In this case, .
Corollary 2. If the modulus of continuity of the regression random field , , in Model meets the condition a.s., where is a proper random variable and is a positive continuous nonrandom function, with as , then, under Condition ,
| (12) |
where is a solution to equation in which the modulus of continuity is replaced with .
Example 2. Let , , with , and , , where is a proper random variable. Then and
In particular, in the one-dimensional case, if is a Wiener process on , and the i.i.d. random variables are centered Gaussian, then by Lévy’s modulus of continuity theorem, for any arbitrarily small , we have
Here we put , , and , with arbitrarily small positive and .
R e m a r k 3.
Let , . Denote by the ordered sample . Put
Denote by the response variable corresponding to in (1). Then we can write down estimator (6) for the function as
| (13) |
where
This estimator was proposed and studied in detail in Borisov et al. (2021).
But, instead of , we can consider Voronoi cells
and write down the corresponding estimator:
| (14) |
where
Repeating, for the last estimator, the corresponding proofs in Borisov et al. (2021) originally applied to estimator (13), we can easily see that all properties of estimator (13) are retained for (14), except the constant factor in the asymptotic variance. Namely, let the regression function be twice continuously differentiable and nonrandom, let the errors be independent identically distributed, centered with finite second moment , and independent of the design , whose elements be independent identically distributed. In addition, let have a strictly positive density which is continuously differentiable. Then
| (15) |
The former asymptotic relation was established in Lemma 3 by Borisov et al. (2021). The latter relation can be proved by repeating the proof of that lemma with obvious changes. Hence, in the case of independent and identically distributed design points, the asymptotic variance of the estimator can be reduced by choosing an appropriate partition.
3. Application to estimating the mean and covariance functions
of a random regression function
In this section, as an application of Theorem 1, we will construct a consistent estimator for the mean function of the random regression function in Model . We consider the following multivariate statement of the problem of estimating the mean function of an a.s. continuous random regression stochastic process. Consider independent copies of Model :
| (16) |
where , , are i.i.d. unknown a.s. continuous stochastic processes, and, for every , the collection satisfies condition (2). Here and in what follows, the subscript denotes the sequential number of such a copy. Introduce the notation
Theorem 2. Let Condition for Model be fulfilled and
| (17) |
Besides, let a sequences and a sequence of naturals satisfy the conditions
| (18) |
Then
| (19) |
R e m a r k 4.
If condition (17) is replaced with a slightly stronger condition
then, under the restrictions (18), one can prove the uniform consistency of the estimator
for the unknown mixed second-moment function , where and are defined in (18). The proof is based on the same arguments as those in proving Theorem 2, and therefore is omitted. In other words, under the above-mentioned conditions, the estimator
is uniformly consistent for the covariance function of the random regression field .
4. Asymptotic normality
In this section, we discuss sufficient conditions for asymptotic normality of the estimators . Denote by the trivial -field, and by the -field generated by the collection , by the design points, and by the regression random field.
Theorem 3. Let the design do not depend on . Under Condition , assume that, for some and a sequence ,
| (20) |
Then
where is a centered Gaussian random variable with variance ,
The theorem is a direct consequence of Corollary 3.1 in Hall and Heyde (1980).
5. Simulation examples
In this section, we present simulations comparing the estimator defined in (6) with the Nadaraya–Watson estimator
in the 2-dimensional case. For this estimator, we will assume , like that was done for the estimator .
The elements of the design space will be denoted by . The following two algorithms were used to partition the space into the sets .
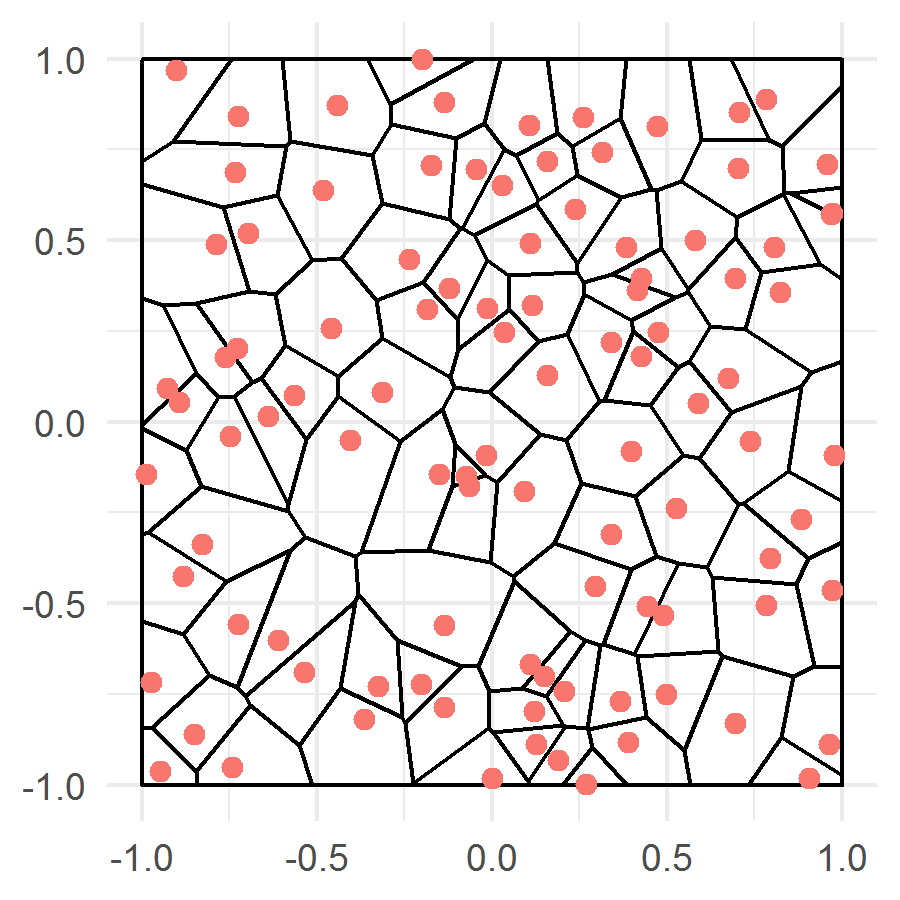
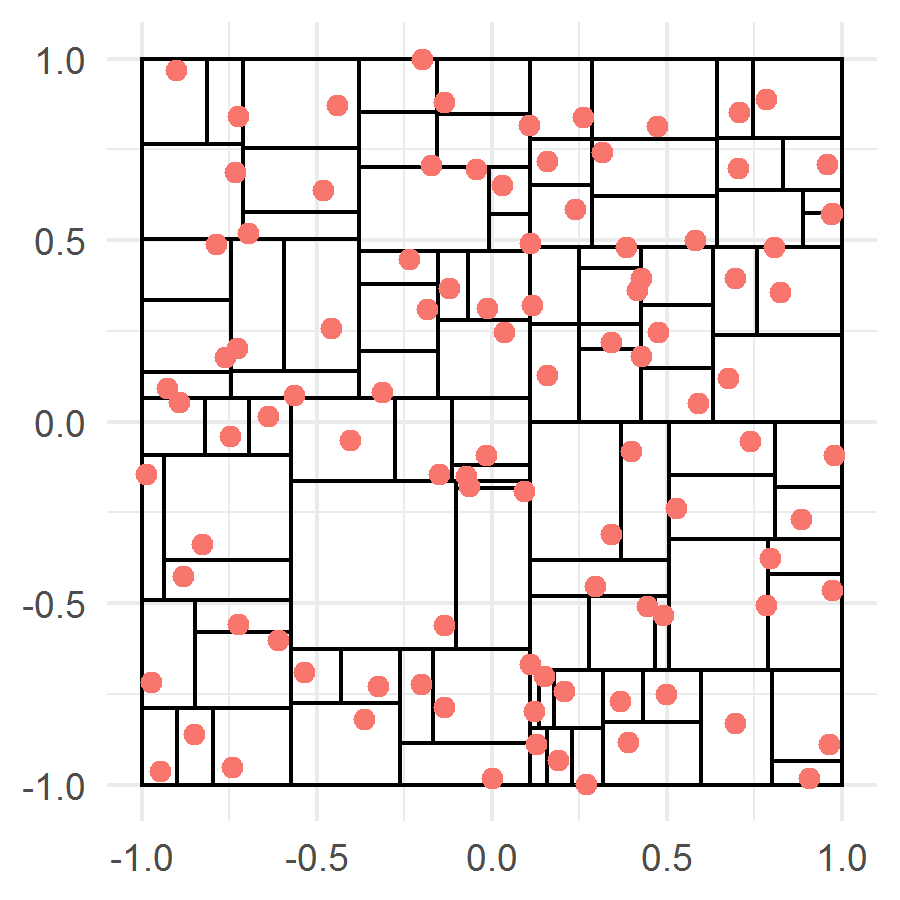
The first algorithm is the Voronoi partitioning. For each , the set is the Voronoi cell corresponding to , i.e. the set of all points of that lie closer to than to any other design point. The deldir R package was employed for calculation of the squares of the cells.
The second algorithm is recursive partitioning by coordinate-wise medians. First, we divide into the two rectangles by the line where the median is the midpoint of the interval when all the points are sorted in increasing order with respect to the first coordinate. Then each of the two rectangles is divided recursively. If, at some step, a rectangle contains two or more design points then it is divided into the two parts: If the rectangle’s width is greater than its height, then the rectangle is divided by the line where is the set of indices of the design points falling into the rectangle; otherwise it is divided by the line . As soon as there is only one design point in a rectangle, the rectangle is put to be .
Results of partitioning into cells for a collection of 100 points by the both algorithms are displayed in Fig. 1.
In the simulation examples below, we used the tricubic kernel
In each example, 1000 simulation runs were performed. In each of the simulation runs, 5000 design points were generated and randomly divided into the training (80%) and validation (20%) sets. For the design points , the observations were generated with i.i.d. Gaussian noise with standard deviation . For each of the tested algorithms, on the training set, the optimal was calculated by 10-fold cross-validation minimizing the average of mean-square errors. The was selected from 20 values located on the logarithmic grid from 0.01 to 0.5. The random partitioning for the cross-validation was the same for all the tested algorithms.
Then, for each of the algorithms, the model, trained on the training set with the chosen , was used to compute the mean-square error (MSE) for the observations of the validation set:
where the sum is taken over the validation set, and is the size of the set. Besides, that model was employed to compute the maximal absolute error (MaxE) for the true values of the target function on the uniform lattice on :
where the maximum is computed for the elements of the lattice covering .
The algorithms that were compared will be denoted by NW (Nadaraya-Watson), ULCV (Universal Local Constant estimator (6) with Voronoi partitioning), and ULCM (Universal Local Constant estimator (6) with coordinate-wise Medians partitioning).
The results of the simulation runs are presented as median (1-st quartile, 3-rd quartile) and are compared between the estimators with the paired Wilcoxon test.
In the examples below, we intentionally chose the densities of the design points with high nonuniformity in order to demonstrate possible advantages of the new estimator.
5.1. Example 1
In this example, we approximate the nonrandom regression function
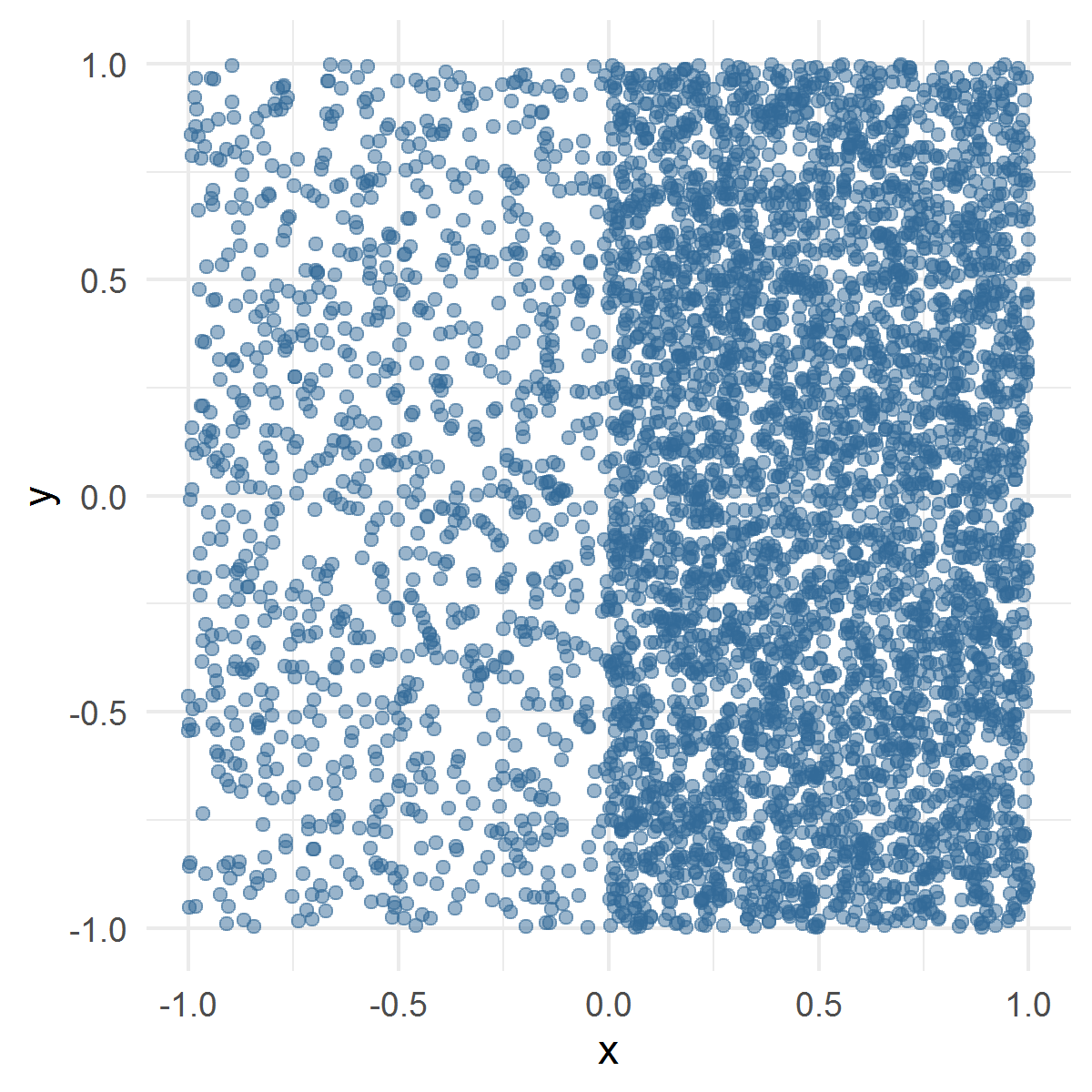
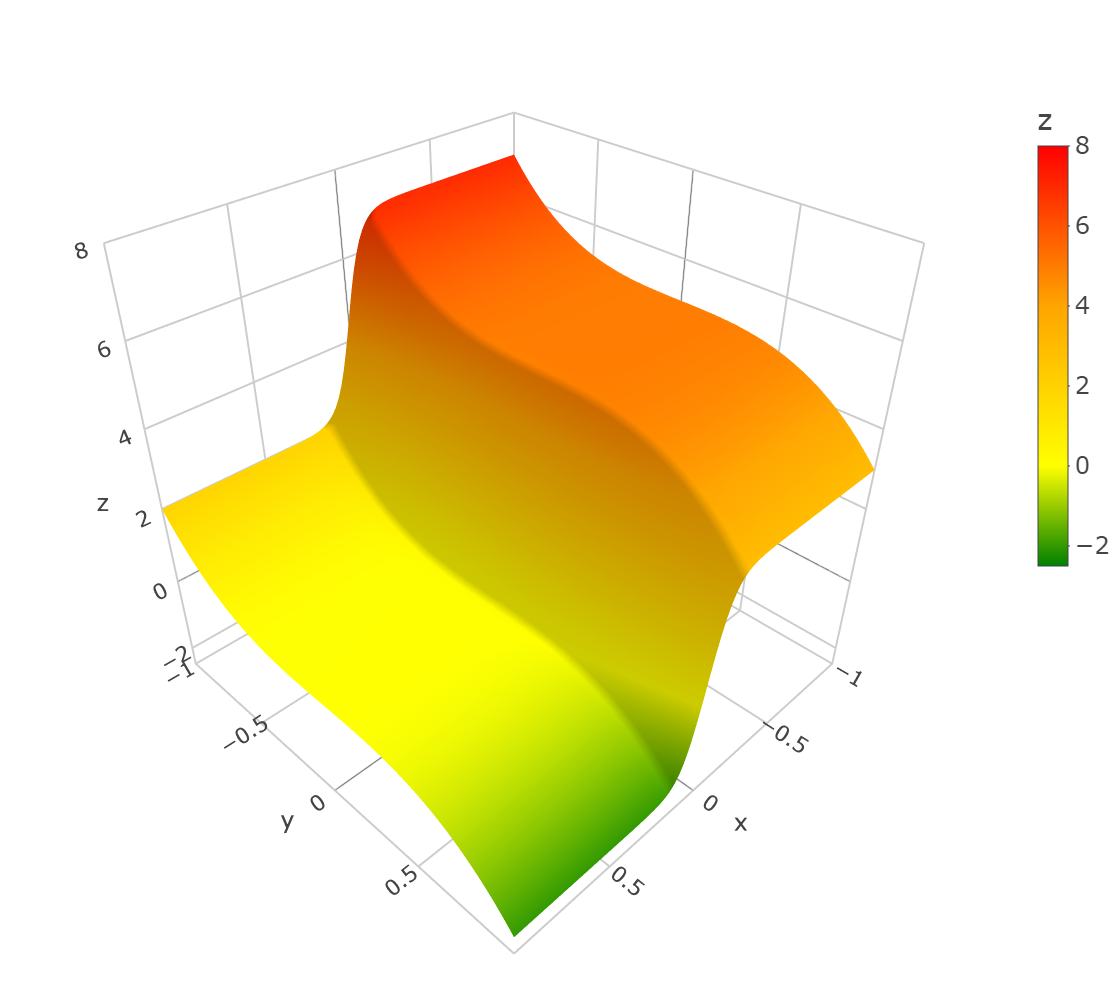
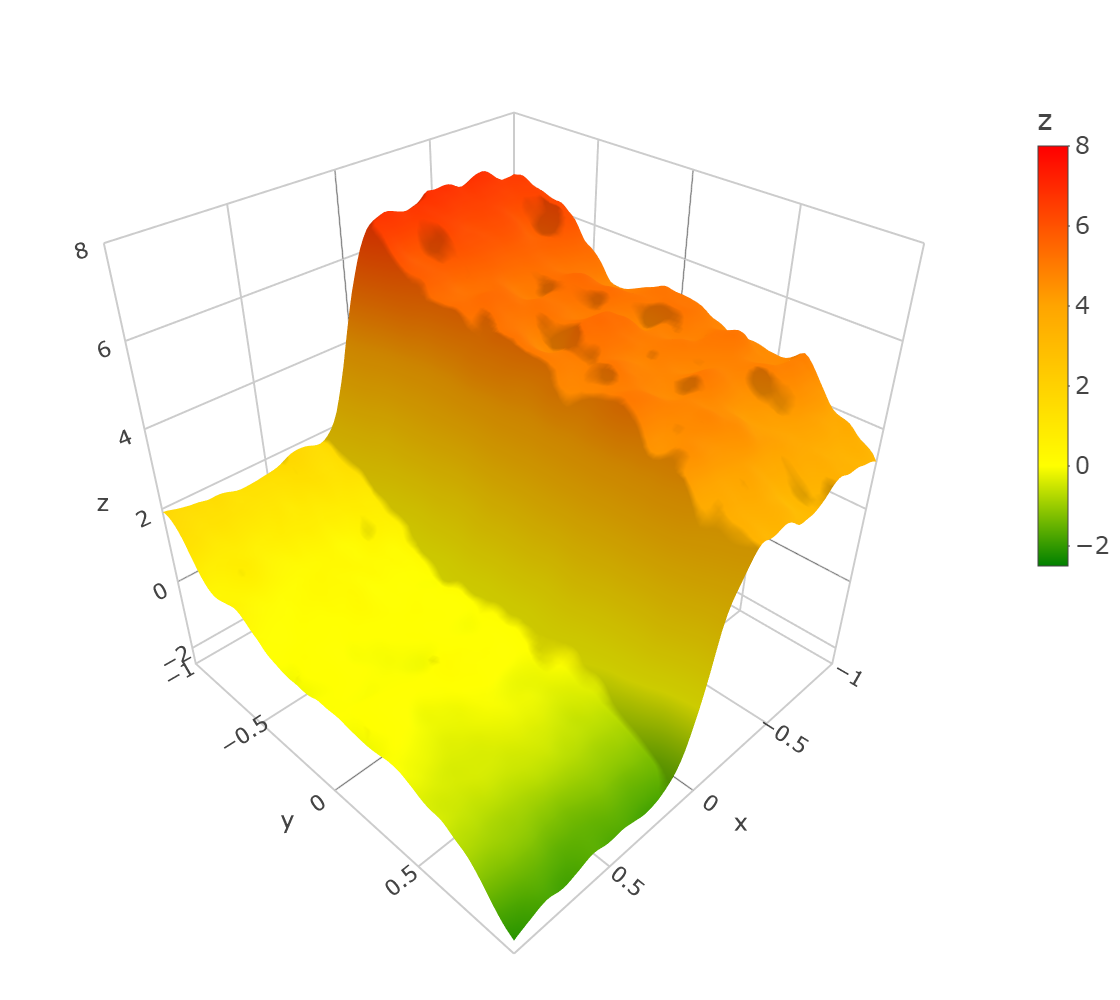
The design points were generated in a way similar to that in Example in Sec. 1. First, we choose the left rectangle or the right rectangle with equal probabilities and draw uniformly distributed in the chosen rectangle. Then we draw design points uniformly distributed in the other rectangle. Then we draw design points uniformly distributed in the rectangle where lies. Then we draw design points uniformly distributed in the rectangle where lies, and so on. In other words, we alternate the rectangle after , , , , … draws. One draw of the design points is depicted in Fig. 2. The estimated function and a computed ULCV estimate are depicted in Fig. 3.
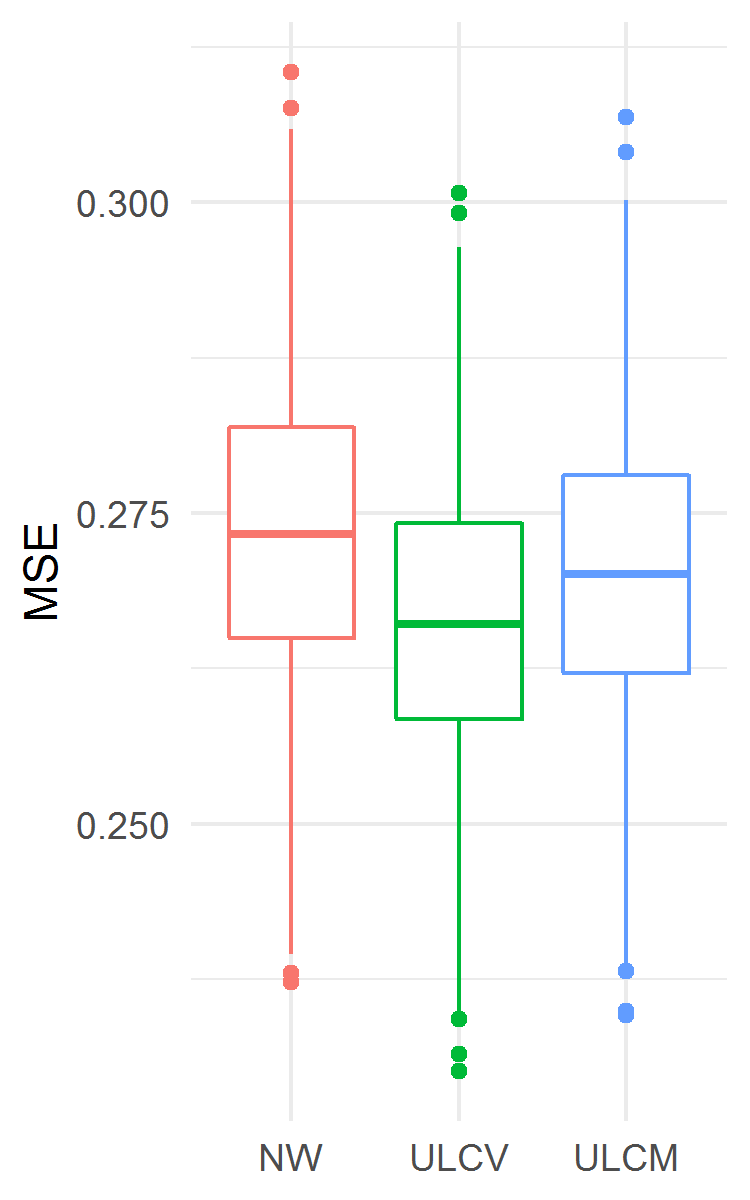
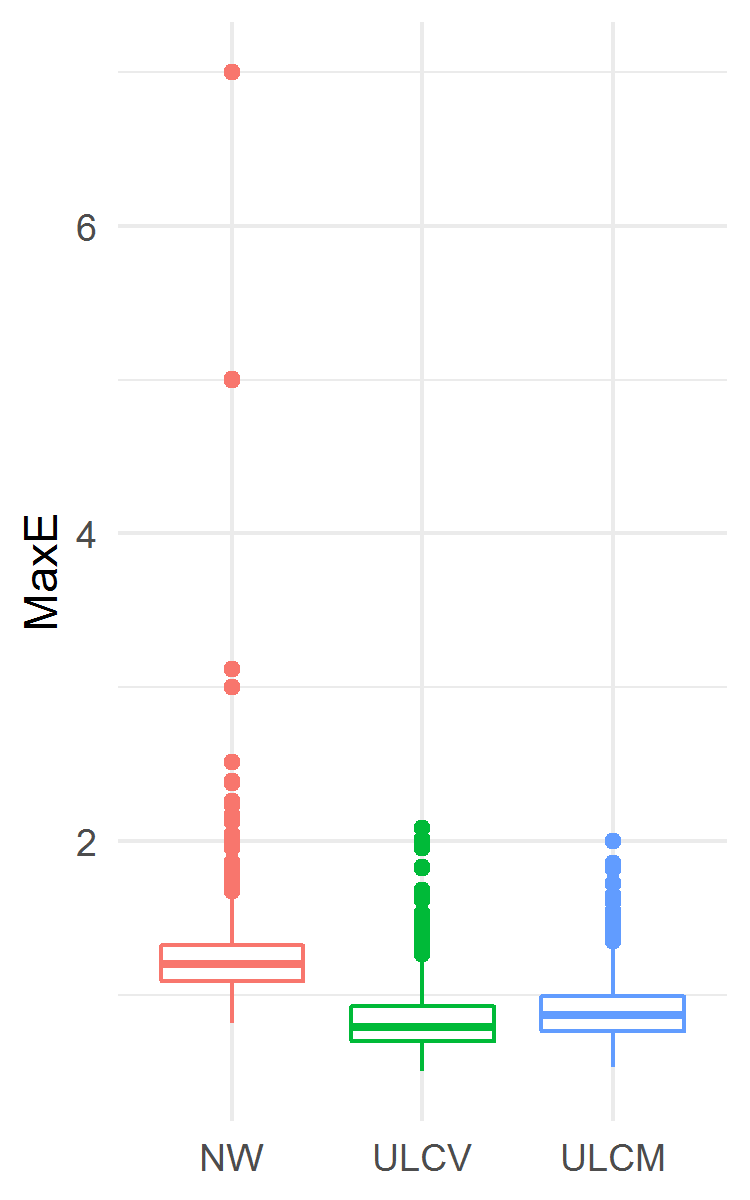
The results are presented in Fig. 2. The ULCV estimator appeared to perform best among the three considered ones both for MSE and MaxE accuracy measures. In particular, the ULCV estimator was better than the NW one: MSE 0.2661 (0.2584, 0.2742) vs. 0.2734 (0.2650, 0.2819), ; MaxE 0.7878 (0.7013, 0.9230) vs. 1.1998 (1.0911, 1.3250), . In this example, the ULCM estimator was better than the NW one as well.
5.2. Example 2
In this example, we approximate the nonrandom regression function
| (21) |
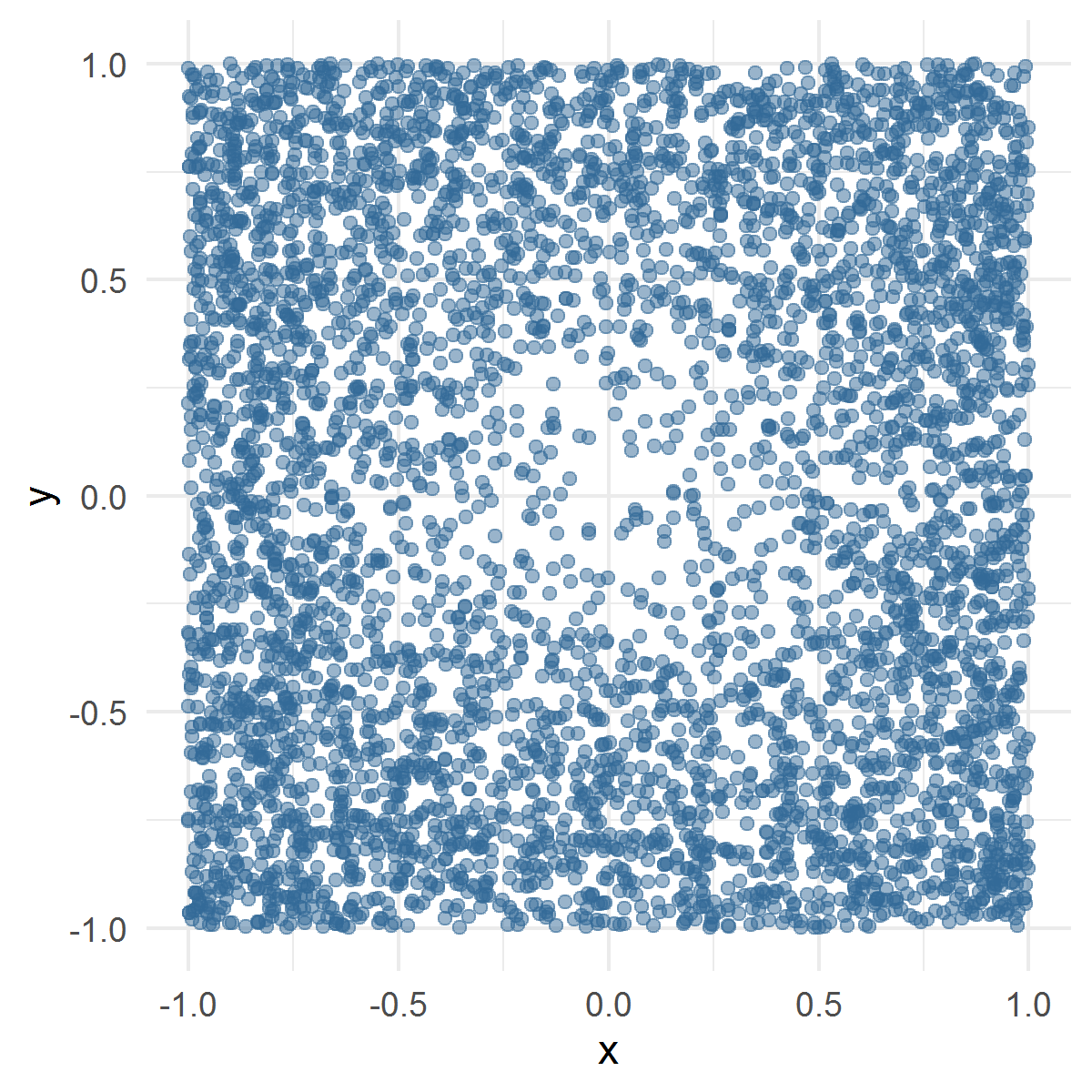
The i.i.d. design points were generated with independent polar coordinates , where was drawn with the density proportional to , , and was uniformly distributed on . The distribution of the design points was restricted on , i.e., the design points that did not fall into were excluded, keeping the total number of collected points equal to 5000, as in the other simulation examples. One draw of the design points is depicted in Fig. 4. The estimated function and a computed ULCV estimate are depicted in Fig. 5.
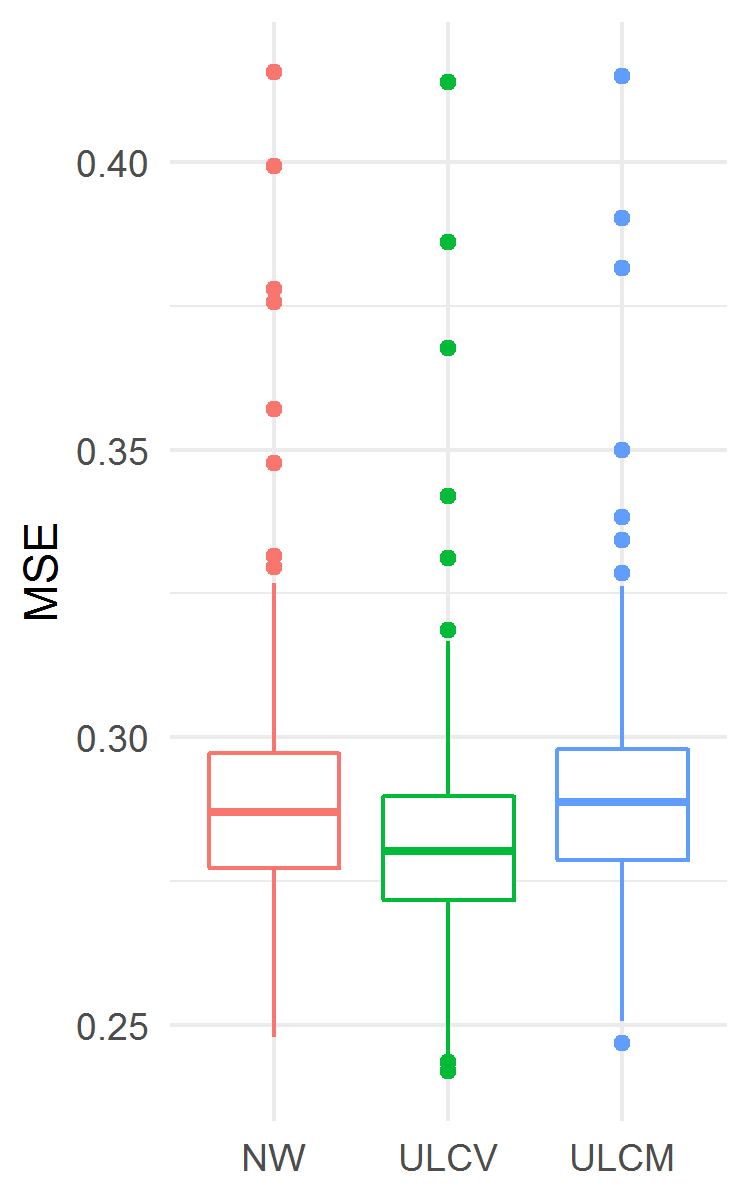
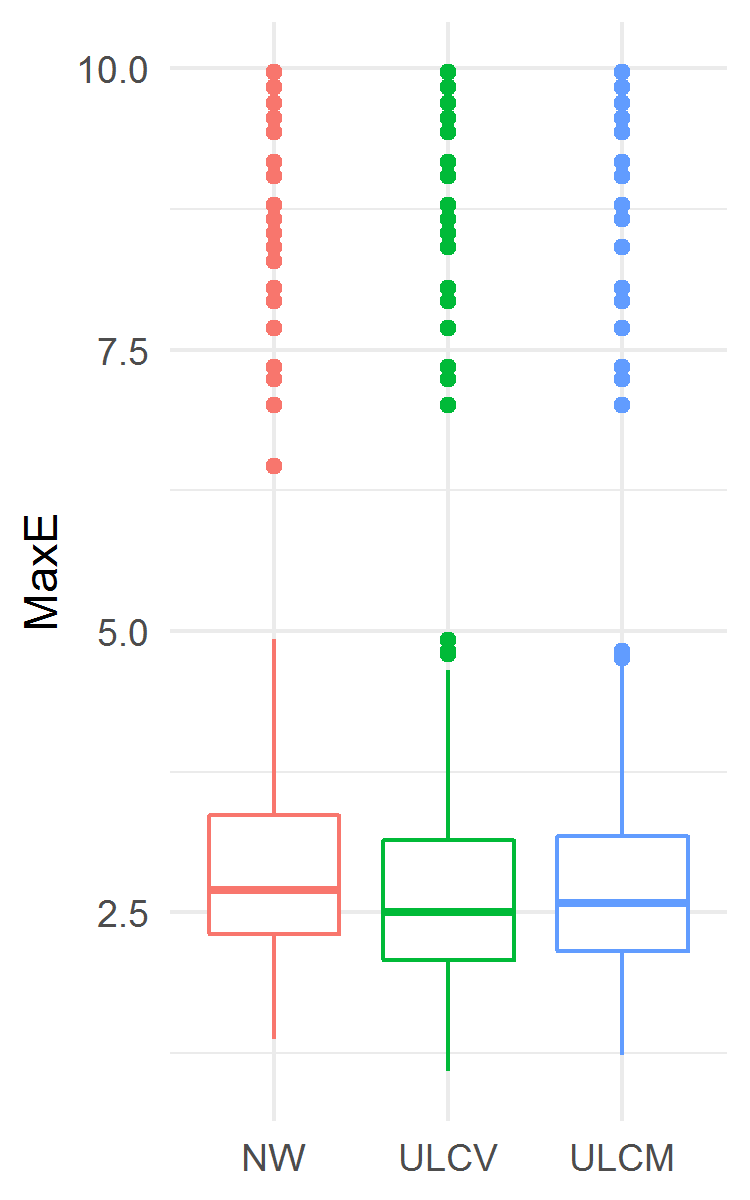
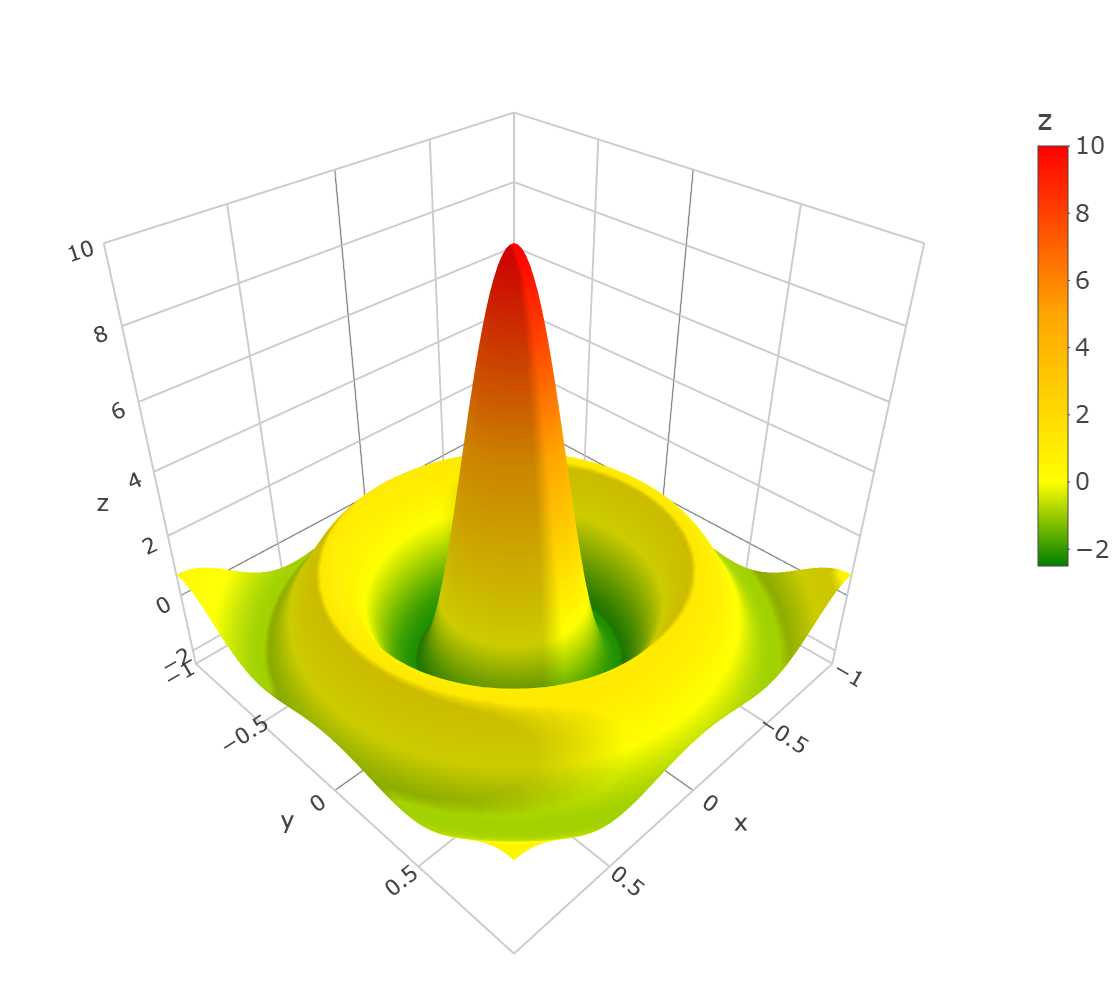
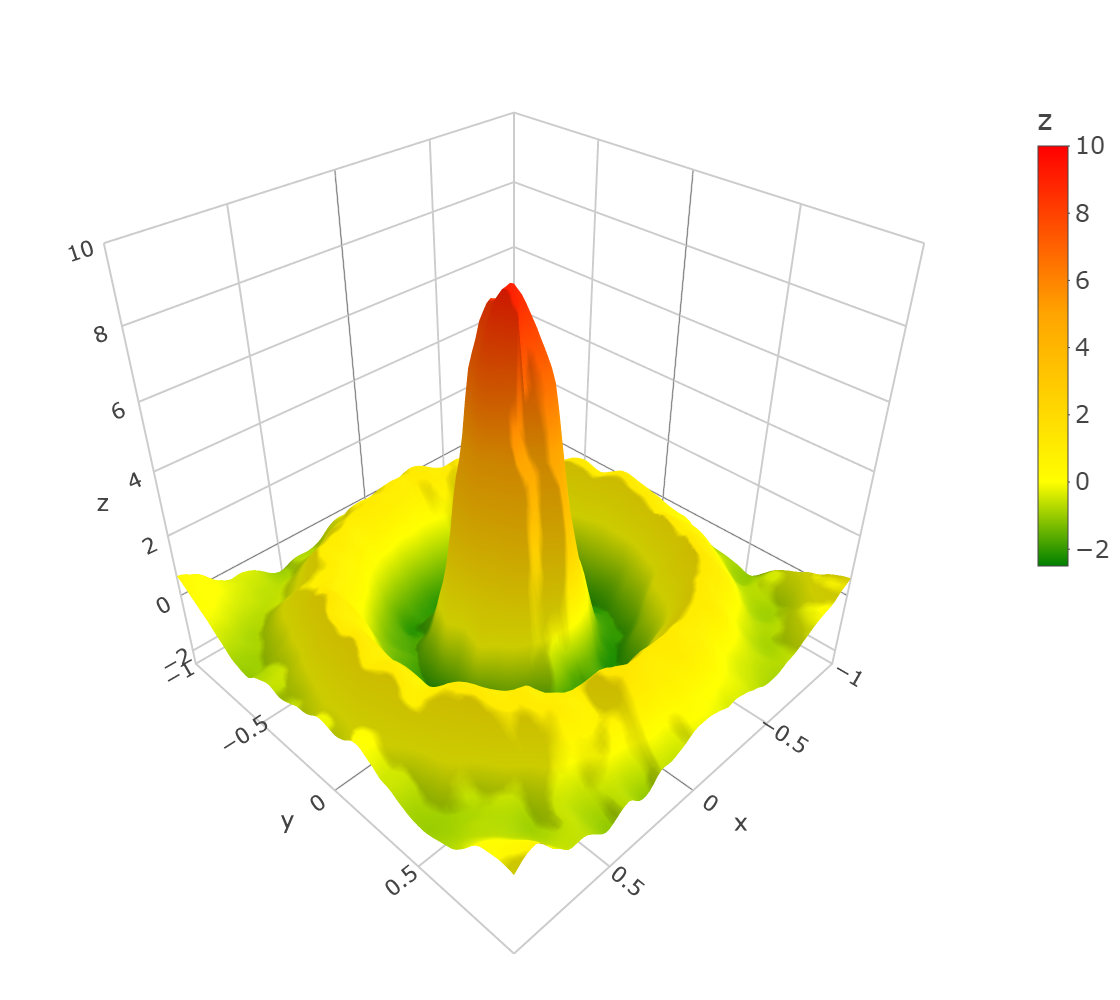
The results are presented in Fig. 4. The ULCV estimator was the best among the three considered ones both for MSE and MaxE accuracy measures. In particular, the ULCV estimator was better than the NW one: MSE 0.2803 (0.2718, 0.2898) vs. 0.2870 (0.2774, 0.2974), ; MaxE 2.505 (2.072, 3.140) vs. 2.695 (2.303, 3.361), . In this example, the ULCM estimator had lower MaxE and higher MSE than the NW estimator did.
5.3. Example 3
In this example, we approximate the same nonrandom regression function (21) as in Example 2. The only difference of this example from Example 2 is that here the coordinates of the design points were generated as independent normal random variables with mean 0 and standard deviation 1/2. As above, the distribution of the design points was restricted on . One draw of the design points is depicted in Fig. 6.
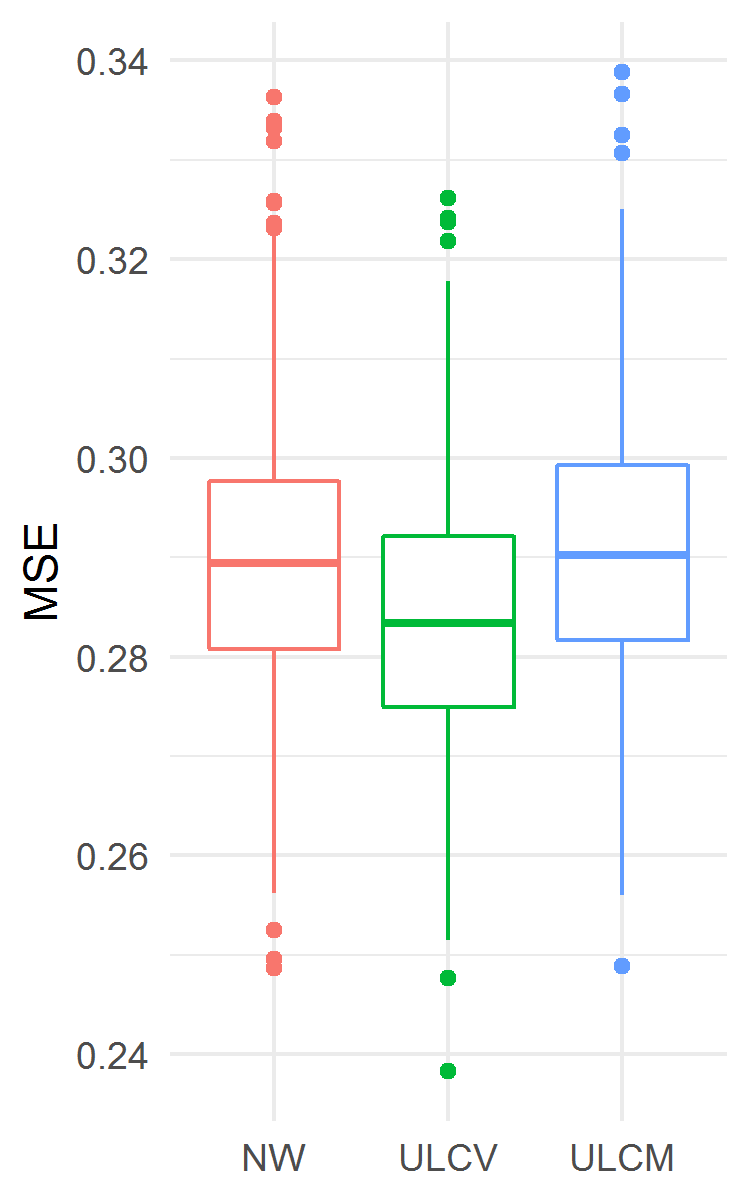
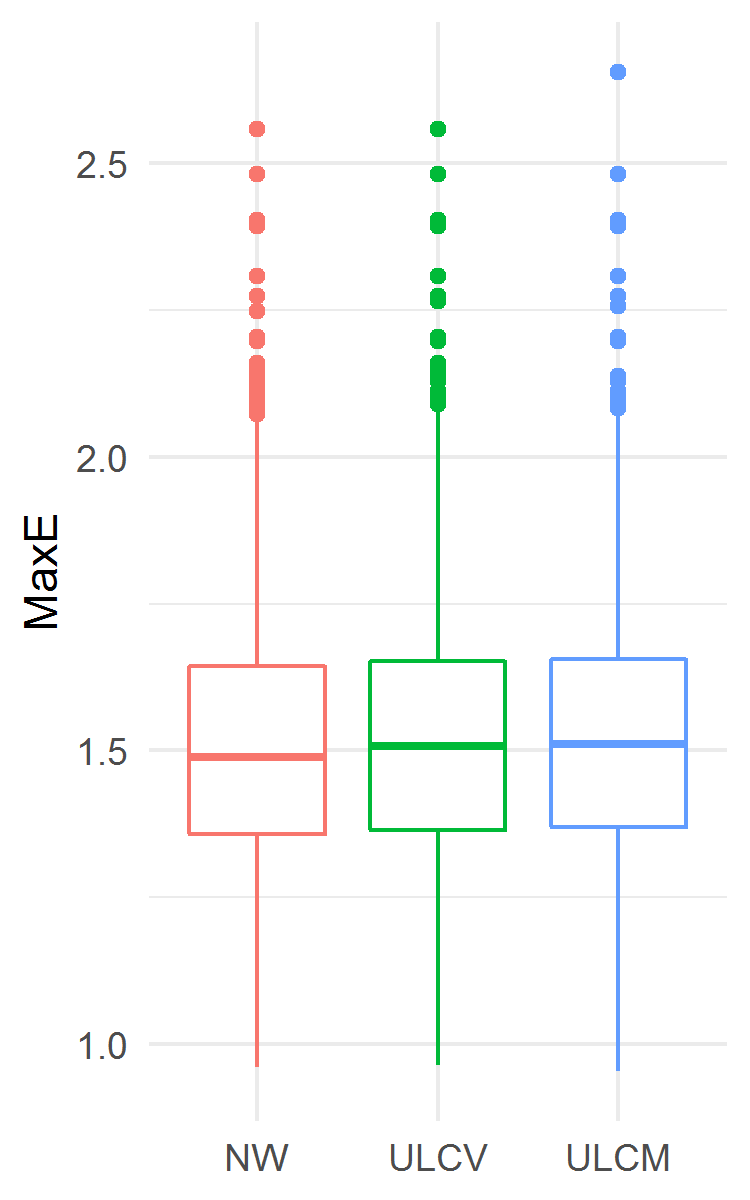
The results are presented in Fig. 6. The ULCV estimator was the best one in terms of MSE, in particular, it was better than NW: MSE 0.2834 (0.2750, 0.2922) vs. 0.2895 (0.2808, 0.2977), . But ULCV was worse than NW in terms of MaxE: 1.507 (1.364, 1.653) vs. 1.488 (1.357, 1.643), . In this example, the ULCM estimator was the worst one both for MSE and MaxE. However, from a practical point of view, the three estimators demonstrated similar accuracy in terms of MaxE.
6. Real data application
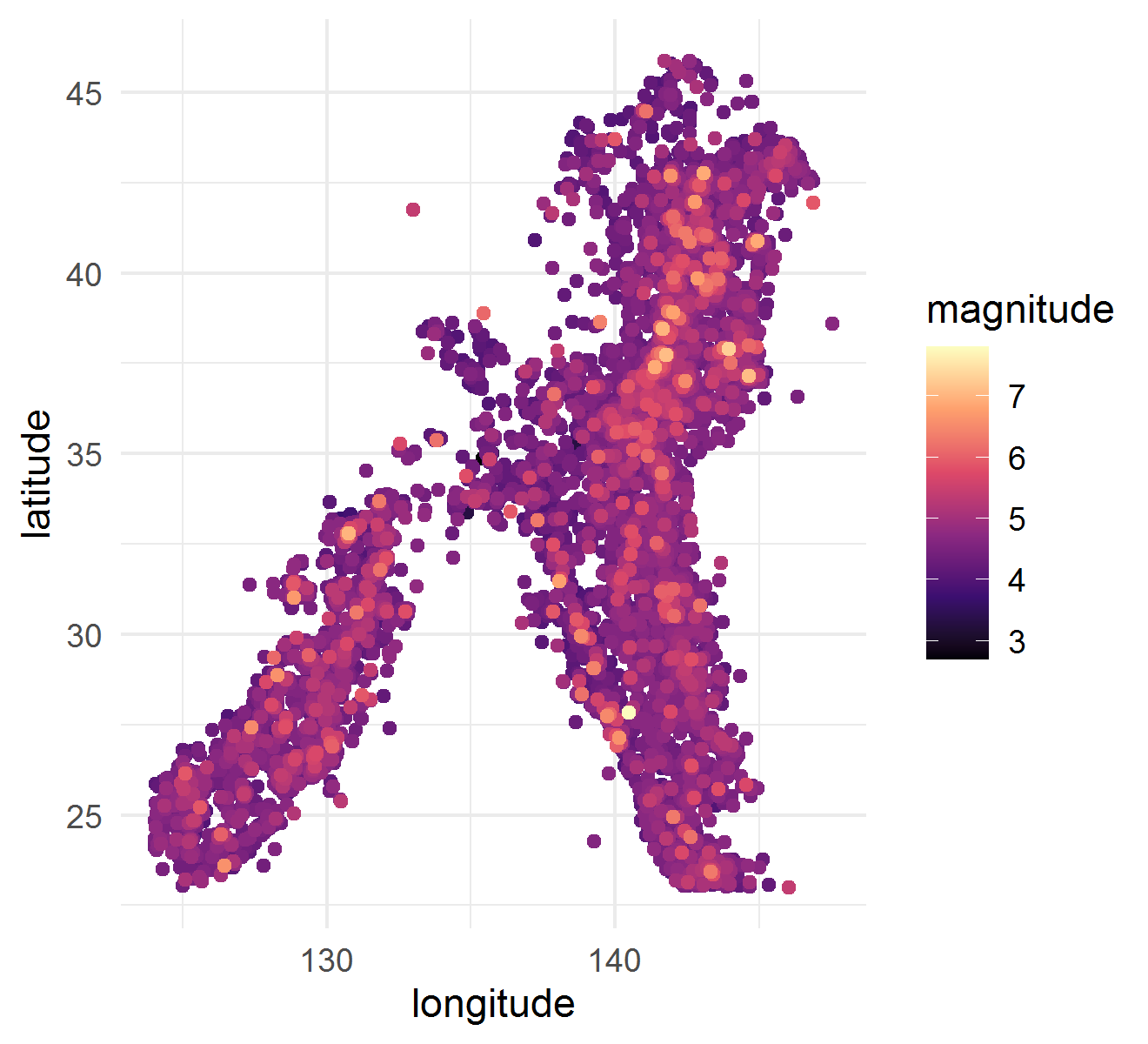

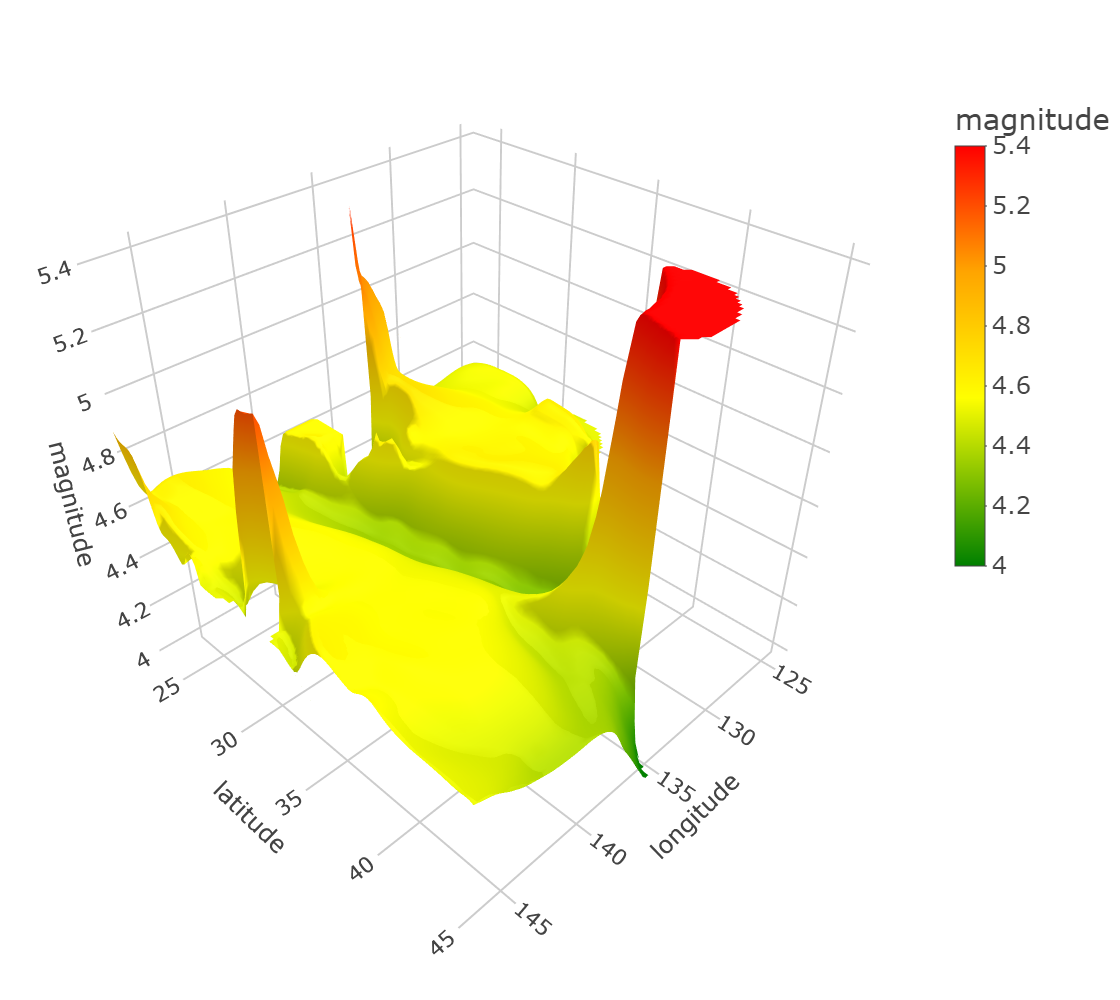
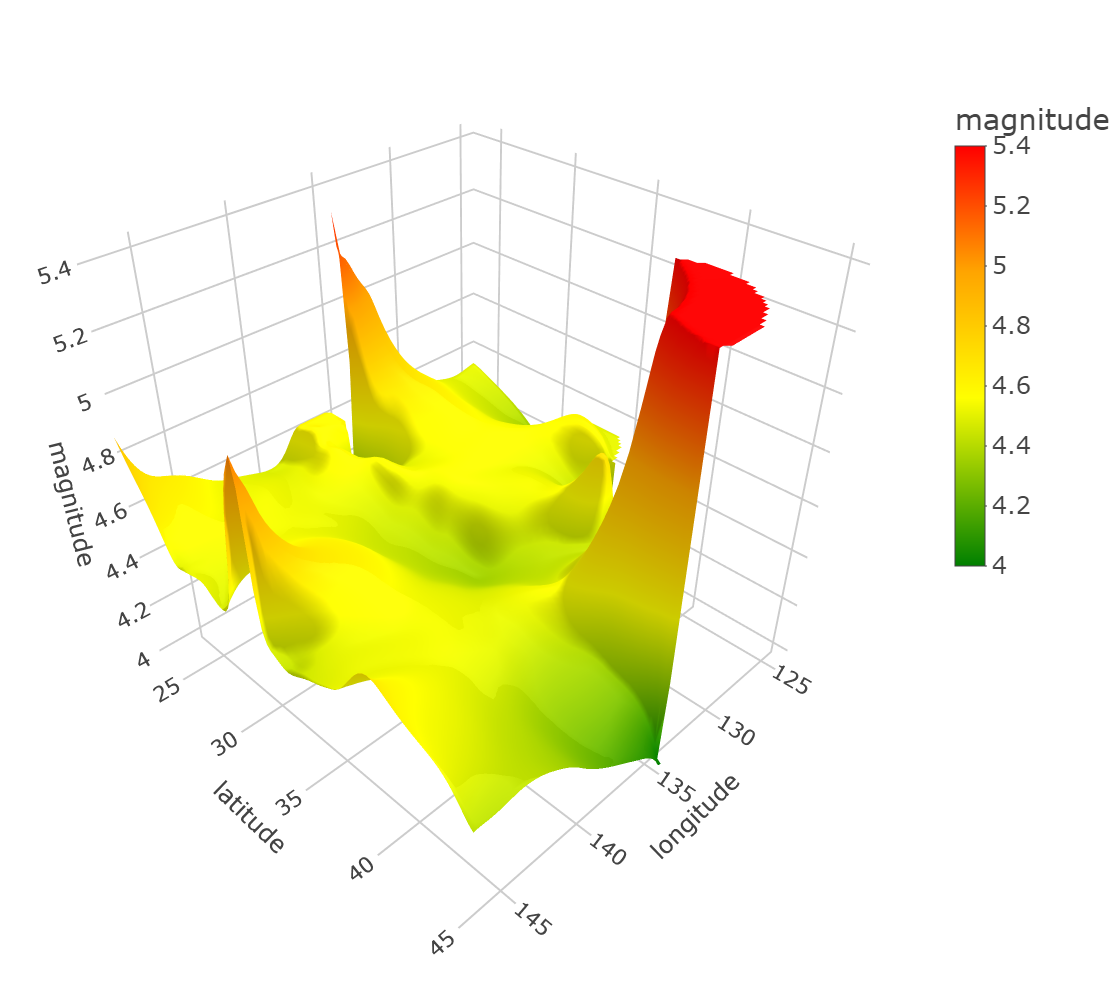
In this section, we compared the new ULCV and ULCM estimators with the NW one in the application to the data on earthquakes in Japan that happened in 2012–2021 (data retrieved from ANSS Comprehensive Earthquake Catalog, 2022). Each of the 10184 collected earthquake events was described by its coordinates (longitude and latitude) and its magnitude (ranging from 2.7 to 7.8). The collected events are presented in Fig. 7. The goal of the application of the estimators was to accurately estimate the mean magnitude depending on the coordinates. As in the simulation examples above, we did 1000 runs, in each of which the data were randomly divided into the training (80%) and validation (20%) sets. For each of the tested algorithms, on the training set, the optimal was calculated by 10-fold cross-validation minimizing the average of mean-square errors. The was selected from 20 values located on the logarithmic grid from 1 to 10. The random partitioning for the cross-validation was the same for all the tested algorithms. The difference of the computations of this section with those of Sec. 5 was that we did not know the true value of the estimated function, therefore, we had to estimate the maximal error (MaxE) on the validation set in each run, not on true values of the estimated function. Besides, since the domain of the coordinates of the events is nonrectangular while the epmloyed domain partitioning algorithms (Voronoi cells algorithm and coordinate-wise medians algorithm) calculated the squares of the cells for a rectangular domain, we bounded the squares of the cells from above by 1 in order to avoid overweighting of the corresponding observations. The resulting estimates of the NW and ULCV estimators are depicted in Fig. 8, where, for each estimator, the value of was chosen as the median of those chosen in the 1000 runs.
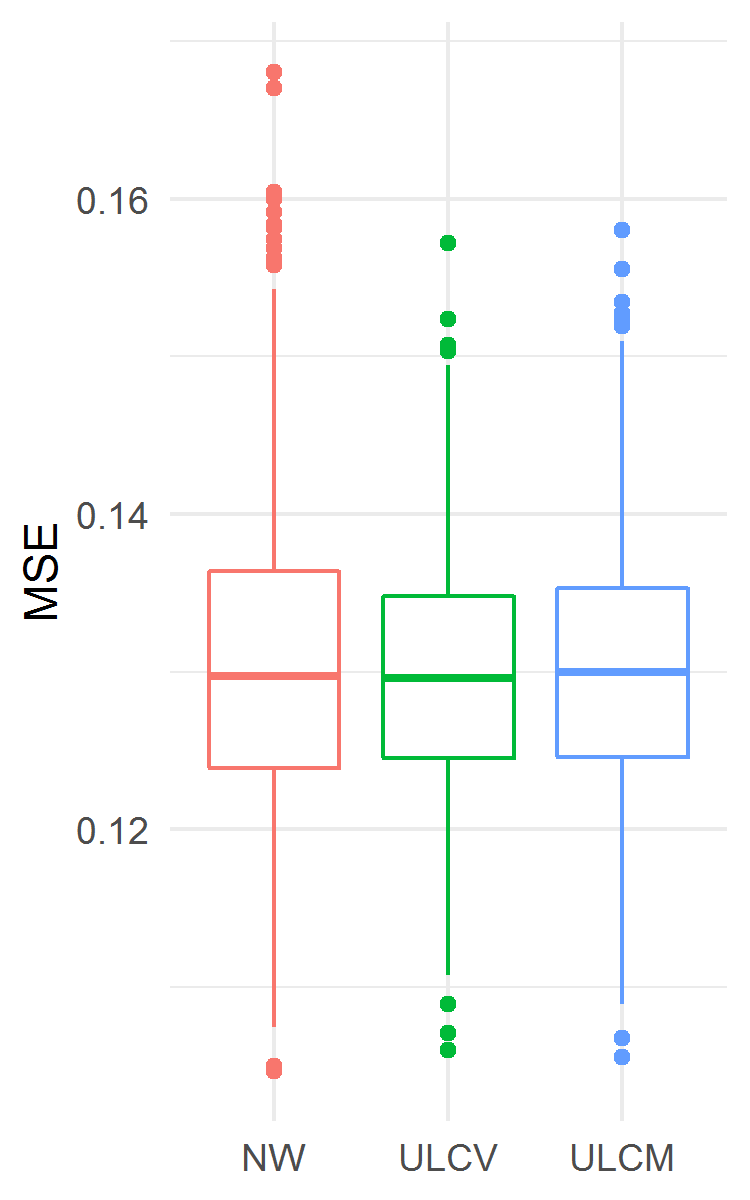
The results are presented in Fig. 7. The ULCV estimator was the best among the three considered ones both for MSE and MaxE accuracy measures. In particular, the ULCV estimator was better than the NW one: MSE 0.1296 (0.1245, 0.1348) vs. 0.1297 (0.1239, 0.1364), ; MaxE 2.573 (2.464, 2.785) vs. 2.736 (2.442, 3.346), . In this example, the ULCM estimator yielded lower MaxE and higher MSE than the NW estimator did. However, from a practical point of view, the three estimators displayed similar median MSE.
7. Conclusion
In this paper, for a wide class of nonparametric regression models with a multivariate random design, universal uniformly consistent kernel estimators are proposed for the unknown random regression functions (random fields) of the corresponding multivariate argument. These estimators belong to the class of local constant kernel estimators. But in contrast to the vast majority of previously known results, traditional correlation conditions of design elements are not needed for the consistency of the new estimators. The design can be either fixed and not necessarily regular, or random and not necessarily consisting of independent or weakly dependent random variables. With regard to design elements, the only condition that is required is the dense filling of the regression function domain with the design points.
Explicit upper bounds are found for the rate of uniform convergence in probability of the new estimators to an unknown random regression function. The only characteristic explicitly included in these estimators is the maximum diameter of the cells of partition generated by the design elements, and only convergence to zero in probability is required for the characteristic. The advantage of this condition over the classical ones is that it is insensitive to the forms of dependence of the design observations. Note that this condition is, in fact, necessary, since only when the design densely fills the regression function domain, it is possible to reconstruct the regression function with a certain accuracy. As a corollary of the main result, we obtain a consistent estimator for the mean function of a continuous random process.
In the simulation examples of Section 5, the new estimators were compared with Nadaraya–Watson estimators. In some of the examples, the new estimators proved to be most accurate. In Section 6, as an application of the new estimators, we studied the real data on the magnitudes of earthquakes in Japan, and the accuracy of the new estimators was comparable to that of the Nadaraya-Watson ones.
8. Proofs
Proof of Theorem . Taking the relation (1) into account, one can obtain the following identity:
where
Notice that, by virtue of the properties of , the range of summation in the three sums above is equal to . This is the principal argument in the calculations below.
Lemma 1. The following estimate is valid:
| (22) |
The proof is immediate from the identity
Lemma 2. If then, for any , the following relation is valid
The lemma is proved.
Lemma 3. For every and , on the subset of elementary events defined by the relation , the following upper bound is valid
| (24) |
where the symbol denotes the conditional probability given the -field generated by the design and the paths of the random field ; here
Proof. Under the condition , by virtue of Lemma 2 the simple inequality is valid, where
The distribution tail of will be estimated by Kolmogorov’s dyadic chaining which has been used to estimate the tail probability of the sup-norm of a stochastic processes having continuous paths with probability 1.
Without loss of generality we will assume that . We first note that the set under the supremum sign above can be replaced with the subset of dyadic rational points , where
Thus,
where is some natural number that will be chosen later, and is the -dimensional vector with the -th component 1 and other components 0.
Hence,
where is a sequence of positive numbers such that .
In order to estimate the probability , we use Rio’s martingale inequality (Rio 2009, Theorem 2.1)
| (26) |
where is a martingale-difference sequence with finite moments of order .
Now let us estimate . In order to do it we use (26) with
We have
Thus
Again, under the restriction , the last inequality and (26) imply
| (28) |
where
Combining (Universal kernel-type estimation of random fields ††thanks: The study was supported by the program for fundamental scientific research of the Siberian Branch of the Russian Academy of Sciences, project FWNF-2022-0015. ), (27), and (28), we obtain
The optimal sequence minimizing the right-hand side of this inequality is as follows: and for , where the coefficient is defined by the relation . For this sequence, we get
Now, put , where is the minimal integer greater than or equal to . Then
This yields the statement of the lemma with
Lemma 3 is proved.
The statement of Theorem 1 follows from Lemmas 1–3.
Proof of Theorem 2. First of all, notice that condition (17) and Lebesgue’s dominated convergence theorem imply the relation
| (29) |
It is clear that the relation (29) implies the uniform law of large numbers for independent copies of the a.s. continuous random process , i.e.,
as , where . Put
| (30) |
So, to prove (19) we need only to verify the following version of the law of large numbers for independent copies of the residuals defined in (30):
but only for the sequences and chosen in (18).
Introduce the following events:
where the sequence meets (18). (It is evident that such a sequence exists.) For any positive we have
| (31) |
Next, from Theorem 1 we obtain
where and . It remains to apply Markov’s inequality for the first probability on the right-hand side of (31) and use the limit relations (18) and the last estimate. Theorem 2 is proved.
Acknowledgments
The authors are deeply grateful to Professor I.A. Ibragimov for his useful remarks. In addition, the authors thank the anonymous referee whose comments contributed to a better presentation of this study.
Data availability statement. The data required to reproduce the above findings are available to download from https://earthquake.usgs.gov/data/comcat/ (ANSS Comprehensive Earthquake Catalog, 2022).
References
Ahmad, I. A. and Lin, P.-E. (1984), ‘Fitting a multiple regression function’, J. Statist. Plann. Infer. 9, 163–176.
ANSS Comprehensive Earthquake Catalog, 2022. In: U.S. Geological Survey, Earthquake Hazards Program, 2017, Advanced National Seismic System (ANSS) Comprehensive Catalog of Earthquake Events and Products: Various, https://doi.org/10.5066/F7MS3QZH. Data retrieved September 4, 2022 from https://earthquake.usgs.gov/data/comcat/
Benhenni, K., Hedli-Griche, S., and Rachdi, M. (2010), ‘Estimation of the regression operator from functional fixed-design with correlated errors’, J. Multivar. Anal. 101, 476–490.
Benelmadani, D., Benhenni, K., and Louhichi, S. (2020), ‘Trapezoidal rule and sampling designs for the nonparametric estimation of the regression function in models with correlated errors’, Statistics 54, 59–96.
Borisov, I.S., Linke, Yu.Yu., and Ruzankin P.S. (2021), ‘Universal weighted kernel-type estimators for some class of regression models’, Metrika 84, 141–166.
Brown, L.D. and Levine, M. (2007), ‘Variance estimation in nonparametric regression via the difference sequence method’, Ann. Statist. 35, 2219–2232.
Chan, N. and Wang, Q. (2014), ‘Uniform convergence for Nadaraya-Watson estimators with nonstationary data’, Econometric Theory 30, 1110–1133.
Chu, C. K. and Deng, W.-S. (2003), ‘An interpolation method for adapting to sparse design in multivariate nonparametric regression’, J. Statist. Plann. Inference 116, 91–111.
Einmahl, U. and Mason, D.M. (2005), ‘Uniform in bandwidth consistency of kernel-type function estimators’, Ann. Statist. 33, 1380–1403.
Fan, J. and Gijbels, I. (1996), Local Polynomial Modelling and its Applications, London: Chapman and Hall.
Fan, J. and Yao, Q. (2003), Nonlinear time series nonparametric and parametric methods, Springer.
Gao, J., Kanaya, S., Li, D., and Tjostheim, D. (2015), ‘Uniform consistency for nonparametric estimators in null recurrent time series’, Econometric Theory 31, 911–952.
Gasser, T. and Engel, J. (1990), ‘The choice of weghts in kernel regression estimation’, Biometrica 77, 277-381.
Georgiev, A. A. (1988), ‘Consistent nonparametric multiple regression: The fixed design case’, J. Multivariate Anal. 25, 100–110.
Georgiev, A. A. (1990), ‘Nonparametric multiple function fitting’, Stat. Probab. Lett. 10, 203–211.
Georgiev, A. A. (1989), ‘Asymptotic properties of the multivariate Nadaraya-Watson regression function estimate: The fixed design case’, Stat. Probab. Lett. 7, 35–40.
Gu, W., Roussas, G. G., and Tran, L. T. (2007), ‘On the convergence rate of fixed design regression estimators for negatively associated random variables’, Stat. Probab. Lett. 77, 1214–1224.
Györfi, L., Kohler, M., Krzyzak, A., and Walk, H. (2002), A Distribution-Free Theory of Nonparametric Regression, New York: Springer.
Hall, P. and Heyde, C. C., (1980), Martingale limit theory and its application. Academic Press.
Hall, P., Müller, H.-G., and Wang, J.-L. (2006), ‘Properties of principal component methods for functional and longitudinal data analysis’, Ann. Statist. 34, 1493–1517.
Hansen, B.E. (2008), ‘Uniform convergence rates for kernel estimation with dependent data’, Econometric Theory 24, 726–748.
Härdle, W. (1990), Applied Nonparametric Regression, New York: Cambridge University Press.
He, Q. (2019), ‘Consistency of the Priestley–Chao estimator in nonparametric regression model with widely orthant dependent errors’, J. Inequal. Appl. 64, 2–13.
Hsing, T. and Eubank, R. (2015), Theoretical foundations of functional data analysis, with an introduction to linear operators, Wiley.
Honda, T. (2010), ‘Nonparametric regression for dependent data in the errors-in-variables problem‘, Global COE Hi-Stat Discussion Paper Series, Institute of Economic Research, Hitotsubashi University.
Hong, S. Y. and Linton, O. B. (2016), ‘Asymptotic properties of a Nadaraya-Watson type estimator for regression functions of infinite order’, SSRN Electronic Journal.
Jennen-Steinmetz, C. and Gasser, T. (1989), ‘A unifying approach for nonparametric regression estimation’, J. Americ. Stat. Assoc. 83, 1084–1089.
Jiang, J. and Mack, Y.P. (2001), ‘Robust local polynomial regression for dependent data’, Statistica Sinica 11, 705–722.
Jones, M.C., Davies, S.J., and Park, B.U. (1994), ‘Versions of kernel-type regression estimators’, J. Americ. Stat. Assoc. 89, 825–832.
Karlsen, H.A., Myklebust, T., and Tjostheim, D. (2007), ‘Nonparametric estimation in a nonlinear cointegration type model’, Ann. Statist. 35, 252–299.
Kulik, R. and Lorek, P. (2011), ‘Some results on random design regression with long memory errors and predictors’, J. Statist. Plann. Infer. 141, 508–523.
Kulik, R. and Wichelhaus C. (2011), ‘Nonparametric conditional variance and error density estimation in regrssion models with dependent errors and predictors’, Electr. J. Statist. 5, 856–898.
Laib, N. and Louani, D. (2010), ‘Nonparametric kernel regression estimation for stationary ergodic data: Asymptotic properties’, J. Multivar. Anal. 101, 2266–2281.
Liang, H.-Y. and Jing, B.-Y. (2005), ‘Asymptotic properties for estimates of nonparametric regression models based on negatively associated sequences’, J. Multivariate Anal. 95, 227–245.
Li, Y. and Hsing, T. (2010), ‘Uniform convergence rates for nonparametric regression and principal component analysis in functional/longitudinal data’, Ann. Statist. 38, 3321–3351.
Li, X., Yang, W., and Hu, S. (2016), ‘Uniform convergence of estimator for nonparametric regression with dependent data’, J. Inequal. Appl., 142.
Lin, Z. and Wang, J.-L. (2022), ‘Mean and covariance estimation for functional snippets’, J. Amer. Statist. Assoc. 117, 348–360.
Linton, O. and Wang, Q. (2016), ‘Nonparametric transformation regression with nonstationary data’, Econometric Theory 32, 1–29.
Linke, Yu.Yu. and Borisov, I.S. (2017), ‘Constructing initial estimators in one-step estimation procedures of nonlinear regression’, Stat. Probab. Lett. 120, 87–94.
Linke, Yu.Yu. and Borisov, I.S. (2018), ‘Constructing explicit estimators in nonlinear regression problems’, Theory Probab. Appl. 63, 22–44.
Linke, Yu.Yu. (2019), ‘Asymptotic properties of one-step M-estimators’, Commun. Stat. Theory Methods 48, 4096–4118.
Linke, Yu.Yu. (2023), ‘Towards insensitivity of Nadaraya–Watson estimators to design correlation’, Theory Probab. Appl. 68 (to appear).
Linke, Yu.Yu. and Borisov, I.S. (2022), ‘Insensitivity of Nadaraya–Watson estimators to design correlation’, Commun. Stat. Theory Methods 51, 6909–6918.
Linton, O. B. and Jacho-Chavez, D. T. (2010), ‘On internally corrected and symmetrized kernel estimators for nonparametric regression’, TEST 19, 166–186.
Loader, C. (1999), Local regression and likelihood, Springer.
Mack, Y.P. and Müller, H.-G. (1988), ‘Convolution type estimators for nonparametric regression’, Stat. Prob. Lett. 7, 229–239.
Masry, E. (2005), ‘Nonparametric regression estimation for dependent functional data’, Stoch. Proc. Their Appl. 115, 155–177.
Müller, H.-G. (1988), Nonparametric Regression Analysis of Longitudinal Data, New York: Springer.
Müller, H. G. and Prewitt, K. A. (1993), ‘Multiparameter bandwidth processes and adaptive surface smoothing’, J. Multivariate Anal. 47, 1–21.
Priestley, M.B. and Chao, M.T. (1972), ‘Non-Parametric Function Fitting’, J. Royal Statist. Soc., Series B, 34, 385–392.
Rio, E. (2009), ‘Moment Inequalities for Sums of Dependent Random Variables under Projective Conditions’, J. Theor. Probab. 22: 146–163.
Roussas, G.G. (1990), ‘Nonparametric regression estimation under mixing conditions’, Stach. Proc. Appl., 36, 107-116.
Roussas, G.G. (1991), ‘Kernel estimates under association: Strong uniform consistency’, Stat. Probab. Lett. 12, 393-403.
Roussas, G. G., Tran, L. T., and Ioannides, D. A. (1992), ‘Fixed design regression for time series: asymptotic normality’, J. Multivariate Anal. 40, 262–291.
Shen, J. and Xie, Y. (2013), ‘Strong consistency of the internal estimator of nonparametric regression with dependent data’, Stat. Probab. Lett. 83, 1915–1925.
Song, Q., Liu, R., Shao, Q., and Yang, L. (2014), ‘A simultaneous confidence band for dense longitudinal regression’, Commun. Stat. Theory Methods 43, 5195–5210.
Tang, X., Xi, M., Wu, Y., and Wang, X. (2018), ‘Asymptotic normality of a wavelet estimator for asymptotically negatively associated errors’, Stat. Probab. Lett. 140, 191–201.
Wand, M.P. and Jones, M.C. (1995), Kernel Smoothing, London: Chapman and Hall.
Wang, J.-L., Chiou, J.-M., and Müller, H.-G. (2016), ‘Review of functional data analysis’, Annu. Rev. Statist. 3, 257–295.
Wang, Q. and Chan, N. (2014), ‘Uniform convergence rates for a class of martingales with application in non-linear cointegrating regression’, Bernoulli 20, 207–230.
Wang, Q.Y. and Phillips, P.C.B. (2009a), ‘Asymptotic theory for local time density estimation and nonparametric cointegrating regression’, Econometric Theory 25, 710–738.
Wang, Q. and Phillips, P.C.B. (2009b), ‘Structural nonparametric cointegrating regression’, Econometrica 77, 1901–1948.
Wu, J.S. and Chu, C.K. (1994), ‘Nonparametric estimation of a regression function with dependent observations’, Stoch. Proc. Their Appl., 50, 149-160.
Wu, Y., Wang, X., and Balakrishnan, N. (2020), ‘On the consistency of the P–C estimator in a nonparametric regression model’, Stat. Papers 61, 899–915.
Yang, X. and Yang, S. (2016), ‘Strong consistency of non parametric kernel regression estimator for strong mixing samples’, Commun. Stat. Theory Methods 46, 10537–10548.
Yao, F. (2007), ‘Asymptotic distributions of nonparametric regression estimators for longitudinal or functional data’, J. Multivariate Anal. 98, 40–56.
Yao, F., Müller, H.-G., and Wang, J.-L. (2005), ‘Functional data analysis for sparse longitudinal data’, J. Amer. Statist. Assoc. 100, 577–590.
Young, D.S. (2017), Handbook of regression methods, Chapman and Hall.
Zhang, X. and Wang, J.-L. (2016), ‘From sparse to dense functional data and beyond’, Ann. Statist. 44, 2281–2321.
Zhang, J.-T. and Chen, J. (2007), ‘Statistical inferences for functional data’, Ann. Statist. 35, 1052–1079.
Zhang, X. and Wang, J.-L. (2018), ‘Optimal weighting schemes for longitudinal and functional data’, Stat. Prob. Lett. 138, 165–170.
Zhang, S., Miao, Y., Xu, X., and Gao, Q. (2018), ‘Limit behaviors of the estimator of nonparametric regression model based on martingale difference errors’, J. Korean Stat. Soc. 47, 537–547.
Zhang, S., Hou, T., and Qu, C. (2019), ‘Complete consistency for the estimator of nonparametric regression model based on martingale difference errors’, Commun. Stat. Theory Methods 50, 358–370.
Zhou, X. and Zhu, F. (2020), ‘Asymptotics for L1-wavelet method for nonparametric regression’, J. Inequal. Appl. 216.