Unmasking Transformers: A Theoretical Approach to Data Recovery via Attention Weights
In the realm of deep learning, transformers have emerged as a dominant architecture, particularly in natural language processing tasks. However, with their widespread adoption, concerns regarding the security and privacy of the data processed by these models have arisen. In this paper, we address a pivotal question: Can the data fed into transformers be recovered using their attention weights and outputs? We introduce a theoretical framework to tackle this problem. Specifically, we present an algorithm that aims to recover the input data from given attention weights and output by minimizing the loss function . This loss function captures the discrepancy between the expected output and the actual output of the transformer. Our findings have significant implications for the Localized Layer-wise Mechanism (LLM), suggesting potential vulnerabilities in the model’s design from a security and privacy perspective. This work underscores the importance of understanding and safeguarding the internal workings of transformers to ensure the confidentiality of processed data.
1 Introduction
In the intricate and constantly evolving domain of deep learning, the transformer architecture has emerged as a game-changing innovation [98]. This novel architecture has propelled the state-of-the-art performance in a myriad of tasks, and its potency lies in the underlying mechanism known as the “attention mechanism.” The essence of this mechanism can be distilled into its unique interaction between three distinct matrices: the Query (), the Key (), and the Value (), where the Query matrix () represents the questions or the aspects we’re interested in, the Key matrix () denotes the elements against which these questions are compared or matched, and the he Value matrix () encapsulates the information we want to retrieve based on the comparisons. These matrices are not just mere multidimensional arrays; they play vital roles in encoding, comparing, and extracting pertinent information from the data.
Given this context, the attention mechanism can be mathematically captured as follows:
Definition 1.1 (Attention matrix computation).
Let be two matrices that respectively represent the query and key. Similarly, for a matrix denoting the value, the attention matrix is defined as
In this equation, two matrices are introduced: and , defined as:
Here, the matrix represents the relationship scores between the query and key, and ensures normalization, ensuring that the attention weights sum to one. The computation hence, deftly combines these relationships with the value matrix to output the final attended representation.
In practical large-scale language models [16, 72], there might be multi-levels of the attention computation. For those multi-level architecture, the feed-forward can be represented as
where is the input of -th layer, and is the output of -th layer, and are the attention weights in -th layer.
This architecture has particularly played a pivotal role in driving progress across various sub-disciplines of natural language processing (NLP). It has profoundly influenced sectors such as machine translation [32, 13], sentiment analysis [96, 71], language modeling [65], and even the generation of creative text [16, 72]. This trajectory of influence is most prominently embodied by the creation and widespread adoption of Large Language Models (LLMs) like GPT [81] and BERT [25]. These models, along with their successive versions, e.g., GPT-2 [83], GPT-3 [10], PaLM [21], OPT [115], are hallmarks in the field due to their staggering number of parameters and complex architectural designs. These LLMs have achieved unparalleled performance levels, setting new standards in machine understanding and automated text generation [16, 72]. Moreover, their emergence has acted as a catalyst for rethinking what algorithms are capable of, spurring new lines of inquiry and scrutiny within both academic and industrial circles [79]. As these LLMs find broader application across an array of sectors, gaining a thorough understanding of their intricate internal mechanisms is evolving from a topic of scholarly interest into a crucial requirement for their effective and responsible deployment.
Yet, the very complexity and architectural sophistication that propel the success of transformers come with a host of consequential challenges, making their effective and responsible usage nontrivial. Prominent among these challenges is the overarching imperative of ensuring data security and privacy [77, 9, 55]. Within the corridors of the research community, an increasingly pertinent question is emerging regarding the inherent vulnerabilities of these architectures. Specifically,
is it possible to know the input data by analyzing the attention weights and model outputs?
To put it in mathematical terms, given a language model represented as , if one has access to the output and the attention weights , is it possible to mathematically invert the model to obtain the original input data ?
Addressing this line of inquiry extends far beyond the realm of academic speculation; it has direct and significant implications for practical, real-world applications. This is especially true when these transformer models interact with data that is either sensitive in nature, like personal health records [20], or proprietary, as in the financial sector [99]. With the broader deployment of Large Language Models (LLMs) into environments that adhere to stringent data confidentiality regulations, the mandate for achieving absolute data security becomes unequivocally critical. In this work, we aim to delve deeply into this paramount issue, striving to offer a nuanced understanding of these potential vulnerabilities while suggesting pathways for ensuring safety in the development, training, and utilization of transformer technologies.
In this study, we address a distinct problem that differs from the conventional task of finding optimal weights for a given input and output. Specifically, we assume that the weights are already known, and our objective is to invert the input to recover the original data. The key focus of our investigation lies in identifying the conditions under which successful inversion of the original input is feasible. This problem holds significant relevance in the context of addressing security concerns associated with attention networks.
To provide a formal definition of our training objective for data recovery, we aim to optimize a specific criterion that enables effective inversion of the input. By formulating and solving this objective, we aim to gain valuable insights into the security implications and vulnerabilities of attention networks.
Definition 1.2 (Regression model).
Given the attention weights , and output , the goal is find such that
where
-
•
In order to establish an understanding of attacking on the above model, we present our main result in the following section.
1.1 Our Result
We state our result as follows:
Theorem 1.3 (Informal version of Theorem J.1).
Given a model with several layers of attention. For each layer, we have parameters . We denote . Given a desired output , then we can denote the training data input
Next, we choose a good initial point that is close enough to . Assume that there exists a scalar such that , , where denotes the -th entry of for all .
Then, for any accuracy parameter and a failure probability , an algorithm based on the Newton method can be employed to recover the initial data. The result of this algorithm guarantee within executions, it outputs a matrix satisfying with a probability of at least .
Roadmap.
We arrange the rest of our paper as follows. In Section 2 we present some works related our topic. In Section 3 we provide a preliminary for our work. In Section 4, we state an overview of our techniques, summarizing the method we use to recover data via attention weights. We conclude our work and propose some future directions in Section 5.
2 Related Works
Attention Computation Theory.
Following the rise of LLM, numerous studies have emerged on attention computation [53, 94, 18, 107, 95, 84, 75, 109, 3, 93, 27, 102, 54]. LSH techniques approximate attention, and based on them, the KDEformer offers a notable dot-product attention approximation [107]. Recent works [6, 12, 28] explored diverse attention computation methods and strategies to enhance model efficiency. On the optimization front, [110] highlighted that adaptive methods excel over SGD due to heavy-tailed noise distributions. Other insights include the emergence of the KTIW property [91] and various regression problems inspired by attention computation [33, 63, 59], revealing deeper nuances of attention models.
Security concerns about LLM.
Amid LLM advancements, concerns about misuse have arisen [77, 9, 55, 52, 97, 23, 103, 38, 52, 47, 48, 39, 88]. [77] assesses the privacy risks of capturing sensitive data with eight models and introduces defensive strategies, balancing performance and privacy. [9] asserts that current methods fall short in guaranteeing comprehensive privacy for language models, recommending training on publicly intended text. [55] reveals that the vulnerability of large language models to privacy attacks is significantly tied to data duplication in training sets, emphasizing that deduplicating this data greatly boosts their resistance to such breaches. [52] devised a way to watermark LLM output without compromising quality or accessing LLM internals. Meanwhile, [97] introduced near access-freeness (NAF), ensuring generative models, like transformers and image diffusion models, don’t closely mimic copyrighted content by over -bits.
Inverting the neural network.
Originating from the explosion of deep learning, there have been a series of works focused on inverting the neural network [49, 56, 69, 24, 108]. [49] surveys various techniques for neural network inversion, which involves finding input values that produce desired outputs, and highlights its applications in query-based learning, sonar performance analysis, power system security assessment, control, and codebook vector generation. [56] presents a method for inverting trained neural networks by formulating the problem as a mathematical programming task, enabling various network inversions and enhancing generalization performance.. [69] explores the reconstruction of image representations, including CNNs, to assess the extent to which it’s possible to recreate the original image, revealing that certain layers in CNNs retain accurate visual information with varying degrees of geometric and photometric invariance. [108] presents a novel generative model-inversion attack method that can effectively reverse deep neural networks, particularly in the context of face image reconstruction, and explores the connection between a model’s predictive ability and vulnerability to such attacks while noting limitations in using differential privacy for defense.
Attacking the Neural Networks.
During the development of artificial intelligence, there have been many works on attaching the neural networks [111, 100, 80, 46, 104, 43, 36]. Several studies [111, 100, 80, 104] have warned that local training data can be compromised using only exchanged gradient information. These methods start with dummy data and gradients, and through gradient descent, they empirically show that the original data can be fully reconstructed. A follow-up study [112] specifically focuses on classification tasks and finds that the real labels can also be accurately recovered. Other types of attacks include membership and property inference [86, 67], the use of Generative Adversarial Networks (GANs) [42, 34], and additional machine-learning techniques [68, 74]. A recent paper [101] uses tensor decomposition for gradient leakage attacks but is limited by its inefficiency and focus on over-parametrized networks.
Theoretical Approaches to Understanding LLMs.
Recent strides have been made in understanding and optimizing regression models using various activation functions. Research on over-parameterized neural networks has examined exponential and hyperbolic activation functions for their convergence properties and computational efficiency [33, 63, 27, 38, 61, 40, 90, 87, 23, 22, 85]. Modifications such as regularization terms and algorithmic innovations, like a convergent approximation Newton method, have been introduced to enhance their performance [63, 29]. Studies have also leveraged tensor tricks to vectorize regression models, allowing for advanced Lipschitz and time-complexity analyses [37, 26]. Simultaneously, the field is seeing innovations in optimization algorithms tailored for LLMs. Techniques like block gradient estimators have been employed for huge-scale optimization problems, significantly reducing computational complexity [17]. Unique approaches like Direct Preference Optimization bypass the need for reward models, fine-tuning LLMs based on human preference data [82]. Additionally, advancements in second-order optimizers have relaxed the conventional Lipschitz Hessian assumptions, providing more flexibility in convergence proofs [58]. Also, there is a series of work on understanding fine-tuning [64, 70, 76]. Collectively, these theoretical contributions are refining our understanding and optimization of LLMs, even as they introduce new techniques to address challenges such as non-guaranteed Hessian Lipschitz conditions.
Optimization and Convergence of Deep Neural Networks.
Prior research [57, 31, 7, 8, 1, 2, 89, 15, 113, 14, 105, 73, 51, 60, 45, 114, 11, 109, 92, 4, 66, 106, 33, 63, 78] on the optimization and convergence of deep neural networks has been crucial in understanding their exceptional performance across various tasks. These studies have also contributed to enhancing the safety and efficiency of AI systems. In [33] they define a neural function using an exponential activation function and apply the gradient descent algorithm to find optimal weights. In [63], they focus on the exponential regression problem inspired by the attention mechanism in large language models. They address the non-convex nature of standard exponential regression by considering a regularization version that is convex. They propose an algorithm that leverages input sparsity to achieve efficient computation. The algorithm has a logarithmic number of iterations and requires nearly linear time per iteration, making use of the sparsity of the input matrix.
3 Preliminary
In this section, we present the preliminary concepts and introductions to the background of our research that form the foundation of our paper. We begin by introducing the notations we utilize in Section 3.1. In Section 3.2, we introduce a solid method to attack neural networks by inverting their weights and outputs. In Section 3.3, we use a regression form to simplify the training process when transformer implements back-propagation.
3.1 Notations
We used to denote real numbers. We use to denote an size matrix where each entry is a real number. For any positive integer , we use to denote . For a matrix , we use to denote the an entry of which is in -th row and -th column of , for each , . We use to denote a matrix such that all of its entries equal to except for . We use to denote a length- vector where all the entries are ones. For a vector , we use denote a diagonal matrix where and all other off-diagonal entries are zero. Let be a diagonal matrix, we use to denote a diagonal matrix where -th entry on diagonal is and all the off-diagonal entries are zero. Given two vectors , we use to denote the length- vector where -th entry is . For a matrix , we use to denote the transpose of matrix . For a vector , we use to denote a length- vector where for all . For a matrix , we use to denote matrix where . For any matrix , we define . For a vector , we use to denote .
3.2 Model Inversion Attack
A model inversion attack is a type of adversarial attack in which a malicious user attempts to recover the private dataset used to train a supervised machine learning model . The goal of a model inversion attack is to generate realistic and diverse samples that accurately describe each class in the private dataset.
The attacker typically has access to the trained model and can use it to make predictions on input data . By carefully crafting input data and observing the model’s predictions, the attacker can infer information about the training data.
Model inversion attacks can be a significant privacy concern, as they can potentially reveal sensitive information about individuals or organizations. These attacks exploit vulnerabilities in the model’s behavior and can be used to extract information that was not intended to be disclosed.
Model inversion attacks can be formulated as an optimization problem. Given the output , the model function with parameters , and the loss function , the objective of a model inversion attack is to find an input data that minimizes the loss between the model’s prediction and the target output . Mathematically, this can be expressed as:
Since the loss function is convex with respect to optimizing , we can employ a specific method for model inversion attack, which involves the following steps:
-
1.
Initialize an input data .
-
2.
Compute the gradient .
-
3.
Optimize using a learning rate by updating .
This iterative process aims to find an input that minimizes the loss between the model’s prediction and the target output. By updating in the direction opposite to the gradient, the attack can potentially converge to an input that generates a prediction close to the desired output, thereby inverting the model. In this work, we focus our effort on the Attention models (which is natural due to the explosive development of LLMs). In this case, the parameters in our model are considered to consist of . During the script, to avoid the abuse of notations, we use to denote the ground truth label.
3.3 Regression Problem Inspired by Attention Computation
In this paper, we extend the prior work of [37] and focus on the training process of the attention mechanism in the context of the Transformer model. We decompose the training procedure into a regression form based on the insights provided by [27].
Specifically, we investigate the training process for a specific layer, denoted as the -th layer, and consider the case of single-headed attention. In this setting, we have an input matrix represented as and a target matrix denoted as . Given as the trained weights of attention architecture. The objective of the training process in the Transformer model is to minimize the loss function by utilizing back-propagation.
The loss function, denoted as , is defined as follows:
where and each row of corresponds to a softmax function.
The goal of minimizing this loss function is to align the predicted output, obtained by applying the attention mechanism, with the target matrix .
4 Recovering Data via Attention Weights
In this section, we propose our theoretical method to recover the training data from trained transformer weights and outputs. Besides, we solve our method by proving hessian of our training objective is Lipschitz-continuous and positive definite. In Section 4.1, we provide a detailed description of our approach. In Section 4.3, we show our result that proving hessian of training objective is Lipschitz-continuous. In Section 4.4, we show our result that the hessian of training objective is positive definite.
4.1 Training Objective of Attention Inversion Attack
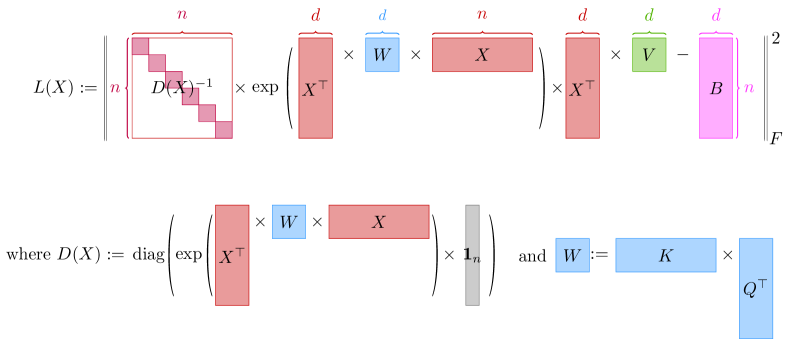
In this study, we propose a novel technique for inverting the attention weights of a transformer model using Hessian decomposition. Our aim is to find the input that minimizes the Frobenius norm of the difference between and , where represents the attention weights, is the desired output, and is a diagonal matrix.
To achieve this, we introduce an algorithm that minimizes the loss function , defined as follows:
| (1) |
where is a matrix of values, and captures any additional regularization terms. This loss function quantifies the discrepancy between the expected output and the actual output of the transformer.
In our approach, we leverage Hessian decomposition to efficiently compute the Hessian matrix and apply a second-order method to approximate the optimal input . By utilizing the Hessian, we can gain insights into the curvature of the loss function and improve the efficiency of optimization. This approach enables us to efficiently find an approximate solution for the input that minimizes the loss function, thereby inverting the attention weights of the transformer model.
By integrating Hessian decomposition and second-order optimization techniques ([5, 62, 19, 50, 44, 35, 41]), our proposed algorithm provides a promising approach for addressing the challenging task of inverting attention weights in transformer models.
Due to the complexity of the loss function (Eq. (1)), directly computing its Hessian is challenging or even impossible. To simplify the computation, we introduce several notations (See Figure 2 for visualization):
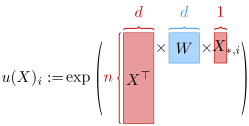
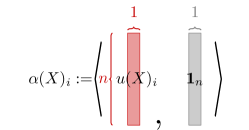
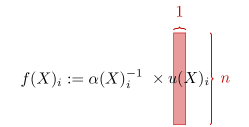
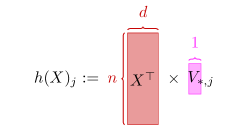
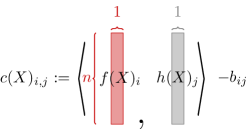
Using these terms, we can express the loss function as the sum over all elements:
This allows us to break down the computation into several steps. Specifically, we start by computing the gradients of the predefined terms. Given two integers and , we define as a matrix where all entries are zero except for the entry . Additionally, we denote and as two other integers, and use to represent the entry in corresponding to the -th row and -th column.
We can now express (the gradient of ) in two cases:
-
•
Case 1: The situation when .
-
•
Case 2: The situation when .
By decomposing the Hessian into several cases (See Section F for details), we can calculate the final Hessian. Similar to the approach used when computing the gradients, we introduce two additional integers and . The Hessian can then be expressed as . We can further break down the computation into four cases to handle different scenarios:
-
•
Case 1: The situation when .
-
•
Case 2: The situation when .
-
•
Case 3: The situation when , and .
-
•
Case 4: The situation when , and .
It is worth mentioning that there is a case that , , is equivalent to the case that . By considering these four cases, we can calculate the Hessian for each element in . This allows us to gain further insights into the curvature of the loss function and optimize the parameters more effectively.
4.2 Hessian Decomposition
By considering different conditions of Hessian, we have the following decomposition.
Definition 4.1 (Hessian of functions of matrix).
We define the Hessian of by considering its Hessian with respect to . This means that, is a matrix with its -th entry being .
Definition 4.2 (Hessian split).
We split the hessian of into following cases
-
•
:
-
•
, :
-
•
, :
-
•
, , :
-
•
, , :
In above, is a matrix with its -th entry being .
Utilizing above definitions, we split the Hessian to a partition with its -th component being .
Definition 4.3.
We define to be as following
4.3 Hessian of is Lipschitz- continuous
We present our findings that establish the Lipschitz continuity property of the Hessian of , which is a highly desirable characteristic in optimization. This property signifies that the second derivatives of exhibit smooth changes within a defined range. Leveraging this Lipschitz property enables us to employ gradient-based methods with guaranteed convergence rates and enhanced stability. Consequently, our results validate the feasibility of utilizing the proposed training objective to achieve convergence in the model inversion attack. This finding holds significant promise for the development of efficient and effective optimization strategies in this context.
4.4 Hessian of is Positive Definite
After computing the Hessian of , we now show our result that can confirm it is positive definite under proper regularization. Therefore, we can apply a modified Newton’s method to approach the optimal solution.
Lemma 4.5 (PSD bounds for ).
Therefore, we define the regulatization term as follows to have the PSD guarantee.
Definition 4.6 (Regularization).
Let , we define
With above properties of the loss function, we have the convergence result in Theorem 1.3.
5 Conclusion and Future Discussion
In this study, we have presented a theoretical approach for inverting input data using weights and outputs. Our investigation delved into the mathematical frameworks that underpin the attention mechanism, with the aim of determining whether knowledge of attention weights and model outputs could enable the reconstruction of sensitive information from the input data. The insights gained from this research are intended to deepen our understanding and facilitate the development of more secure and robust transformer models. By doing so, we strive to foster responsible and ethical advancements in the field of deep learning.
This work lays the groundwork for future research and development aimed at fortifying transformer technologies against potential threats and vulnerabilities. Our ultimate goal is to enhance the safety and effectiveness of these groundbreaking models across a wide range of applications. By addressing potential risks and ensuring the integrity of sensitive information, we aim to create a more secure and trustworthy environment for the deployment of transformer models.
Roadmap.
We arrange the appendix as follows. In Section A, we provide several preliminary notations. In Section B we provide details of computing the gradients. In Section C and Section D we provide detail of computing Hessian for two cases. In Section E we show how to split the Hessian matrix. In Section F we combine the results before and compute the Hessian for the loss function. In Section G we bound the basic functions to be used later. In Section H we provide proof for the Lipschitz property of the loss function. We provide our final result in Section J.
Appendix A Notations
We used to denote real numbers. We use to denote an size matrix where each entry is a real number. For any positive integer , we use to denote . For a matrix , we use to denote the an entry of which is in -th row and -th column of , for each , . We use to denote a matrix such that all of its entries equal to except for . We use to denote a length- vector where all the entries are ones. For a vector , we use denote a diagonal matrix where and all other off-diagonal entries are zero. Let be a diagonal matrix, we use to denote a diagonal matrix where -th entry on diagonal is and all the off-diagonal entries are zero. Given two vectors , we use to denote the length- vector where -th entry is . For a matrix , we use to denote the transpose of matrix . For a vector , we use to denote a length- vector where for all . For a matrix , we use to denote matrix where . For any matrix , we define . For a vector , we use to denote .
Appendix B Gradients
Here in this section, we provide analysis for the gradient computation. In Section B.1 we state some facts to be used. In Section B.2 we provide some definitions. In Sections B.3, B.4, B.5, B.6, B.7, B.8 and B.9 we compute the gradient for the terms defined respectively. Finally in Section B.10 we compute the gradient for .
B.1 Facts
Fact B.1 (Basic algebra).
We have
-
•
.
-
•
-
•
Fact B.2 (Basic calculus rule).
We have
-
•
(here can be any variable)
-
•
-
•
-
•
where is a vector that only -th entry is and zero everywhere else.
-
•
Let , let be independent of , we have .
-
•
Let , we have
-
•
Let ,
-
•
Let , we have
B.2 Definitions
Definition B.3 (Simplified notations).
We have following definitions
-
•
We use to denote the -th entry of .
-
•
We use to denote the -th entry of .
-
•
We define to denote the -th row of . (In the proof, we treat as a column vector).
-
•
We define to denote the -th column of .
-
•
We define to denote the scalar equals to the entry in -th row, -th column of .
-
•
We define to denote the -th column of .
-
•
We define to denote the scalar equals to the entry in -th row, -th column of .
-
•
We define to denote the -th column of .
-
•
We define to denote the scalar equals to the entry in -th column, -th row of .
Definition B.4 (Exponential function ).
If the following conditions hold
-
•
Let
-
•
Let
For each , we define as follows
Definition B.5 (Sum function of softmax ).
If the following conditions hold
-
•
Let
-
•
Let be defined as Definition B.4
We define for all as follows
Definition B.6 (Softmax probability function ).
Definition B.7 (Value function ).
If the following conditions hold
-
•
Let
-
•
Let
We define for each as follows
Definition B.8 (One-unit loss function ).
Definition B.9 (Overall function ).
B.3 Gradient for each column of
Lemma B.10.
We have
-
•
Part 1. Let ,
-
•
Part 2 Let ,
Proof.
Proof of Part 1.
where the 1st step follows from Fact B.2, the 2nd step follows from simple derivative rule, the 3rd is simple algebra, the 4th step ie because .
Proof of Part 2
where the 1st step follows from Fact B.2, the 2nd step follows from simple derivative rule, the 3rd is simple algebra. ∎
B.4 Gradient for
Lemma B.11.
Under following conditions
-
•
Let be defined as Definition B.4
We have
-
•
Part 1. For each ,
-
•
Part 2 For each ,
Proof.
Proof of Part 1
where the 1st step and the 3rd step follow from Definition of (see Definition B.4), the 2nd step follows from Fact B.2, the 4th step follows by Lemma B.10.
Proof of Part 2
where the 1st step and the 3rd step follow from Definition of (see Definition B.4), the 2nd step follows from Fact B.2, the 4th step follows by Lemma B.10.
∎
B.5 Gradient Computation for
Lemma B.12 (A generalization of Lemma 5.6 in [27]).
If the following conditions hold
-
•
Let be defined as Definition B.5
Then, we have
-
•
Part 1. For each ,
-
•
Part 2. For each ,
Proof.
Proof of Part 1.
where the 1st step follows from the definition of (see Definition B.5), the 2nd step follows from Fact B.2, the 3rd step follows from Lemma B.11, the 4th step is rearrangement, the 5th step is derived by Fact B.1, the last step is by the definition of .
Proof of Part 2.
where the 1st step follows from the definition of (see Definition B.5), the 2nd step follows from Fact B.2, the 3rd step follows from Lemma B.11, the 4th step is rearrangement, the 5th step is derived by Fact B.1.
∎
B.6 Gradient Computation for
B.7 Gradient for
Lemma B.14.
If the following conditions hold
-
•
Let be defined as Definition B.6
Then, we have
-
•
Part 1. For all ,
-
•
Part 2. For all ,
B.8 Gradient for
Lemma B.15.
Proof.
where the first step is by definition of (see Definition B.7), the 2nd and the 3rd step are by differentiation rules, the 4th step is by simple algebra. ∎
B.9 Gradient for
Lemma B.16.
If the following conditions hold
-
•
Let be defined as Definition B.8
-
•
Let
Then, we have
-
•
Part 1. For all ,
where we have definitions:
-
–
-
–
-
–
-
–
-
–
-
–
-
•
Part 2. For all ,
where we have definitions:
-
–
-
*
This is corresponding to
-
*
-
–
-
*
This is corresponding to
-
*
-
–
-
*
This is corresponding to
-
*
-
–
Proof.
Proof of Part 1
where the first step is by definition of (see Definition B.8), the 2nd step is because is independent of , the 3rd step is by Fact B.2, the 4th step uses Lemma B.15, the 5th step uses Lemma B.14, the 6th and 8th step are rearrangement of terms, the 7th step holds by the definition of (see Definition B.6).
B.10 Gradient for
Lemma B.17.
Proof.
The result directly follows by chain rule. ∎
Appendix C Hessian case 1:
Here in this section, we provide Hessian analysis for the first case. In Sections C.1, C.2, C.3, C.4, C.5, C.6 and C.8, we calculate the derivative for several important terms. In Section C.9, C.10, C.11, C.12 and C.13 we calculate derivative for and respectively. Finally in Section C.14 we calculate derivative of .
Now, we list some simplified notations which will be used in following sections.
Definition C.1.
We have following definitions to simplify the expression.
-
•
-
•
-
•
-
•
-
•
C.1 Derivative of Scalar Function
Lemma C.2.
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
C.2 Derivative of Vector Function
Lemma C.3.
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
C.3 Derivative of Scalar Function
Lemma C.4.
C.4 Derivative of Scalar Function
Lemma C.5.
C.5 Derivative of Scalar Function
Lemma C.6.
If the following holds:
-
•
Let be defined as Definition B.6
-
•
Let
-
•
Let
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
C.6 Derivative of Scalar Function
Lemma C.7.
C.7 Derivative of Scalar Function
Lemma C.8.
C.8 Derivative of Vector Function
Lemma C.9.
C.9 Derivative of
| ID | Term | Symmetric? | Table Name |
|---|---|---|---|
| 1 | Yes | N/A | |
| 2 | Yes | N/A | |
| 3 | No | Table 4: 1 | |
| 4 | No | Table 5: 1 | |
| 5 | Yes | N/A | |
| 6 | No | Table 2: 7 | |
| 7 | No | Table 2: 9 | |
| 8 | No | Table 2: 1 |
Lemma C.10.
If the following holds:
-
•
Let be defined as in Lemma B.16
-
•
Let
-
•
Let
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
C.10 Derivative of
| ID | Term | Symmetric Terms | Table Name |
|---|---|---|---|
| 1 | No | Table 1: 9 | |
| 2 | Yes | N/A | |
| 3 | No | Table 3: 3 | |
| 4 | No | Table 4: 2 | |
| 5 | No | Table 5: 2 | |
| 6 | Yes | N/A | |
| 7 | No | Table 1: 6 | |
| 8 | Yes | N/A | |
| 9 | No | Table 1: 7 |
Lemma C.11.
If the following holds:
-
•
Let be defined as in Lemma B.16
-
•
We define .
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
C.11 Derivative of
| ID | Term | Symmetric Terms | Table Name |
|---|---|---|---|
| 1 | Yes | N/A | |
| 2 | Yes | N/A | |
| 3 | No | Table 2: 3 | |
| 4 | No | Table 4: 3 | |
| 5 | No | Table 5: 3 | |
| 6 | No | Table 4: 5 |
Lemma C.12.
Proof.
Proof of Part 1
where the first step is by definition of (see Lemma B.16), the 2nd step is by Fact B.2, the 3rd step is by Lemma C.2, the 4th step is because Lemma C.7, the 5th step is a rearrangement.
Proof of Part 2
where the first step is by definition of (see Lemma B.16), the 2nd step is by Fact B.2, the 3rd step is by Lemma C.2, the 4th step is because Lemma C.7, the 5th step is a rearrangement.
∎
C.12 Derivative of
| ID | Term | Symmetric? | Table Name |
|---|---|---|---|
| 1 | No | Table 1: 3 | |
| 2 | No | Table 2: 4 | |
| 3 | No | Table 3: 4 | |
| 4 | Yes | N/A | |
| 5 | No | Table 3: 6 | |
| 6 | No | Table 5:4 |
Lemma C.13.
Proof.
Proof of Part 1
where the first step is by definition of (see Lemma B.16), the 2nd step is by Fact B.2, the 3rd step is by Lemma B.15, the 4th step is because Lemma C.9, the 5th step is a rearrangement.
Proof of Part 2
where the first step is by definition of (see Lemma B.16), the 2nd step is by Fact B.2, the 3rd step is by Lemma B.15, the 4th step is because Lemma C.9, the 5th step is a rearrangement.
∎
C.13 Derivative of
Lemma C.14.
C.14 Derivative of
Lemma C.15.
If the following holds:
-
•
Let be defined as in Definition B.8
We have
-
•
Part 1 For ,
where we have following definitions
-
•
Part 2 For ,
where we have following definitions
Proof.
The proof is a combination of derivatives of in this section.
Notice that the symmetricity for Part 1 is verified by tables in this section. ∎
Appendix D Hessian case 2:
In this section, we focus on the second case of Hessian. In Sections D.1, D.2, D.3, D.4 and D.5, we calculated derivative of some important terms. In Sections D.6, D.7 and D.8 we calculate derivative of , and respectively. And in Section D.9 we calculate the derivative of .
D.1 Derivative of scalar function
Lemma D.1.
If the following holds:
-
•
Let be defined as Definition B.6
-
•
For ,
We have
-
•
Part 1. For ,
-
•
Part 2. For ,
D.2 Derivative of scalar function
Lemma D.2.
If the following holds:
-
•
Let be defined as Definition B.7
-
•
For ,
We have
-
•
Part 1. For ,
-
•
Part 2. For ,
D.3 Derivative of scalar function
Lemma D.3.
D.4 Derivative of scalar function
Lemma D.4.
If the following holds:
-
•
Let be defined as Definition B.6
-
•
For ,
We have
-
•
Part 1. For ,
-
•
Part 2. For ,
Proof.
Proof of Part 1
where the first step follows from simple differential rule, the second step follows from Lemma D.1, the third step follows from , the last step follows from simple algebra.
Proof of Part 2
where the first step follows from simple differential rule, the second step follows from Lemma D.1, the third step follows from , the last step follows from simple algebra. ∎
D.5 Derivative of scalar function
Lemma D.5.
D.6 Derivative of
Lemma D.6.
If the following holds:
-
•
Let be defined as in Lemma B.16
-
•
For ,
We have
-
•
Part 1 For ,
-
•
Part 2 For ,
D.7 Derivative of
Lemma D.7.
D.8 Derivative of
Lemma D.8.
If the following holds:
-
•
Let be defined as in Lemma B.16
-
•
For ,
We have
-
•
Part 1. For ,
-
•
Part 2. For ,
D.9 Derivative of
Lemma D.9.
Proof.
Proof of Part 1.
where the first step follows from Lemma B.16, the second step follows from previous results in this section, the last step is a rearrangement.
Proof of Part 2.
where the first step follows from Lemma B.16, the second step follows from Lemma D.6, the third step follows from Part 2 of Lemma D.7, the last step follows from Lemma D.8.
Notice that, by our construction, Part 1 should be symmetric w.r.t. , Part 2 should be symmetric w.r.t. , which are all satisfied. ∎
Appendix E Hessian Reformulation
In this section, we provide a reformulation of Hessian formula, which simplifies our calculation and analysis. In Section E.1 we show the way we split the Hessian. In Section E.2 we show the decomposition when .
E.1 Hessian split
Definition E.1 (Hessian of functions of matrix).
We define the Hessian of by considering its Hessian with respect to . This means that, is a matrix with its -th entry being
Definition E.2 (Hessian split).
We split the hessian of into following cases
-
•
Part 1: :
-
•
Part 2: , :
-
•
Part 3: , :
-
•
Part 4: , , :
-
•
Part 5: , , :
In above, is a matrix with its -th entry being
Utilizing above definitions, we split the Hessian to a partition with its -th component being based on above definition.
Definition E.3.
We define to be as following
E.2 Decomposition Hessian : Part 1
Lemma E.4 (Helpful lemma).
Under following conditions
-
•
Let
-
•
Let
we have
-
•
Part 1:
-
•
Part 2:
Proof.
Proof of Part 1
where the first step is by the definition of the 2nd and 3rd step are from linear algebra facts, the 4th step is by the definition of .
Proof of Part 2
where the first step is by the definition of the 2nd, 3rd, and the 4th step are from linear algebra facts, the 5th step is by the definition of . ∎
Lemma E.5.
Proof.
This lemma is followed by Lemma E.4 and linear algebra facts. ∎
Based on above auxiliary lemma, we have following definition.
Definition E.6.
Under following conditions
-
•
Let
-
•
Let
We present the Case 1 component of Hessian to be
where we have
E.3 Decomposition Hessian: Part 2 and Part 3
Lemma E.7.
Proof.
This lemma is followed by Lemma E.4 and linear algebra facts. ∎
Based on above auxiliary lemma, we have following definition.
Definition E.8.
Under following conditions
-
•
Let
-
•
Let
We present the Case 2 component of Hessian to be
where we have
Next, we define the third case by the symmetricity of Hessian.
Definition E.9.
We present the Case 3 component of Hessian to be
E.4 Decomposition Hessian : Part 4
Lemma E.10.
Proof.
This lemma is followed by Lemma E.4 and linear algebra facts. ∎
Based on above auxiliary lemma, we have following definition.
Definition E.11.
Under following conditions
-
•
Let
-
•
Let
We present the Case 4 component of Hessian to be
where we have
E.5 Decomposition Hessian : Part 5
Lemma E.12.
Proof.
This lemma is followed by Lemma E.4 and linear algebra facts. ∎
Based on above auxiliary lemma, we have following definition.
Definition E.13.
Under following conditions
-
•
Let
-
•
Let
We present the Case 5 component of Hessian to be
where we have
Appendix F Hessian of loss function
In this section, we provide the Hessian of our loss function.
Lemma F.1 (A single entry).
Proof.
Proof of Part 1:
where the first step is given by chain rule, and the 2nd step are given by product rule. ∎
Lemma F.2 (Matrix Representation of Hessian).
Proof.
This is directly given by the single-entry representation in Lemma F.1. ∎
Appendix G Bounds for basic functions
In this section, we prove the upper bound for each function, with following assumption about the domain of parameters. In Section G.1 we bound the basic terms. In Section G.2 we bound the gradient of . In Section G.3 we bound the gradient of
Assumption G.1 (Bounded parameters).
Let be defined as in Section B.2,
-
•
Let be some fixed constant satisfies
-
•
We have , , where is the matrix spectral norm
-
•
We have
G.1 Bounds for basic functions
Lemma G.2.
Under Assumption G.1, for all , we have following bounds:
-
•
Part 1
-
•
Part 2
-
•
Part 3
-
•
Part 4
-
•
Part 5
-
•
Part 6
-
•
Part 7
Proof.
Proof of Part 1
The proof is similar to [30], and hence is omitted here.
Proof of Part 2
where the first step is by Definition B.7, the 2nd step is by basic algebra, the 3rd follows by Assumption G.1.
Proof of Part 3
where the first step is by Definition B.8, the 2nd step uses triangle inequality, the 3rd step uses Cauchy-Schwartz inequality, the 4th step is by Assumption G.1 and Part 2.
Proof of Part 5
where the first step is by the definition of , the 2nd step is Cauchy-Schwartz inequality, the 3rd step is by Assumption G.1.
Proof of Part 6
where the first step is by the definition of , the 2nd step is Cauchy-Schwartz inequality, the 3rd step is by Assumption G.1.
Proof of Part 7
where the first step is by the definition of , the 2nd step is Cauchy-Schwartz inequality, the 3rd step is by Part 1 and Part 2. ∎
G.2 Bounds for gradient of
Lemma G.3.
G.3 Bounds for gradient of
Lemma G.4.
G.4 Bounds for Hessian of
Lemma G.5.
Proof.
The proof is similar to Lemma G.4 and hence omit. ∎
Appendix H Lipschitz of Hessian
In Section H.1 we provide tools and facts. In Sections H.2, H.3, H.4, H.7, H.6, H.7 and H.8 we provide proof of lipschitz property of several important terms. And finally in Section H.9 we provide proof for Lipschitz property of Hessian of .
H.1 Facts and Tools
In this section, we introduce 2 tools for effectively calculate the Lipschitz for Hessian.
Fact H.1 (Mean value theorem for vector function, Fact 34 in [30]).
Under following conditions,
-
•
Let where is an open convex domain
-
•
Let be a differentiable vector function on
-
•
Let for all , where denotes a matrix which its -th term is
then we have
Fact H.2 (Lipschitz for product of functions).
Under following conditions
-
•
Let be a sequence of function with same domain and range
-
•
For each we have
-
–
is bounded: with
-
–
is Lipschitz continuous:
-
–
Then we have
Proof.
We prove it by mathematical induction. The case that obviously.
Now assume the case holds for . Consider , we have.
where the first step is by triangle inequality, the 2nd step is by property of norm, the 3rd step is by upper bound of functions, the 4th step is by induction hypothesis, the 5th step is by Lipschitz of , the 6th step is by , the 7th step is a rearrangement.
Since the claim holds for , we prove the desired result. ∎
H.2 Lipschitz for
Definition H.3 (Notation of norm).
For writing efficiency, we use to denote , which is equivalent to .
Lemma H.4.
H.3 Lipschitz for
Lemma H.5.
H.4 Lipschitz for
Lemma H.6.
H.5 Lipschitz for
Lemma H.7.
H.6 Lipschitz for
Lemma H.8.
H.7 Lipschitz for first order derivative of
Lemma H.9.
H.8 Lipschitz for second order derivative of
Lemma H.10.
H.9 Lipschitz for Hessian of
Lemma H.11.
Proof.
Recall that
For the first item , we have
where the 2nd step is by triangle inequality, the 3rd step is by Lemma G.4, the 4th step uses Lemma H.9.
For the 2nd item , we have
where the 2nd step is by triangle inequality, the 3rd step uses Lemma G.2, the 4th step uses Lemma H.5, the 5th step uses Lemma H.10, the last step uses Lemma G.5.
Combining the above 2 items, we have
Then, we have
where the 1st step is by matrix calculus, the 2nd is by the lipschitz for each entry of . ∎
Appendix I Strongly Convexity
In this section, we provide proof for PSD bounds for the Hessian of Loss function.
I.1 PSD bounds for Hessian of
Lemma I.1 (PSD bounds for ).
Proof.
We prove this statement by the definition of PSD. Let be a vector. Let , we use to denote the vector formed by the -th term to the -th term of vector .
I.2 PSD bounds for Hessian of loss
Lemma I.2 (PSD bound for ).
Appendix J Final Result
Theorem J.1 (Formal of Theorem 1.3, Main Result).
We assume our model satisfies the following conditions
-
•
Bounded parameters: there exists such that
-
–
,
-
–
-
–
where denotes the -th entry of
-
–
-
•
Regularization: we consider the following problem:
-
•
Good initial point: We choose an initial point such that , where
Then, for any accuracy parameter and a failure probability , an algorithm based on the Newton method can be employed to recover the initial data. The result of this algorithm guarantee within executions, it outputs a matrix satisfying with a probability of at least . The execution time for each iteration is .
References
- [1] Sanjeev Arora, Simon Du, Wei Hu, Zhiyuan Li, and Ruosong Wang. Fine-grained analysis of optimization and generalization for overparameterized two-layer neural networks. In International Conference on Machine Learning, pages 322–332. PMLR, 2019.
- [2] Sanjeev Arora, Simon S Du, Wei Hu, Zhiyuan Li, Russ R Salakhutdinov, and Ruosong Wang. On exact computation with an infinitely wide neural net. Advances in neural information processing systems, 32, 2019.
- AG [23] Sanjeev Arora and Anirudh Goyal. A theory for emergence of complex skills in language models. arXiv preprint arXiv:2307.15936, 2023.
- ALS+ [23] Josh Alman, Jiehao Liang, Zhao Song, Ruizhe Zhang, and Danyang Zhuo. Bypass exponential time preprocessing: Fast neural network training via weight-data correlation preprocessing. In NeurIPS. arXiv preprint arXiv:2211.14227, 2023.
- Ans [00] Kurt M Anstreicher. The volumetric barrier for semidefinite programming. Mathematics of Operations Research, 2000.
- AS [23] Josh Alman and Zhao Song. Fast attention requires bounded entries. In NeurIPS. arXiv preprint arXiv:2302.13214, 2023.
- [7] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. A convergence theory for deep learning via over-parameterization. In International conference on machine learning, pages 242–252. PMLR, 2019.
- [8] Zeyuan Allen-Zhu, Yuanzhi Li, and Zhao Song. On the convergence rate of training recurrent neural networks. Advances in neural information processing systems, 32, 2019.
- BLM+ [22] Hannah Brown, Katherine Lee, Fatemehsadat Mireshghallah, Reza Shokri, and Florian Tramèr. What does it mean for a language model to preserve privacy? In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, pages 2280–2292, 2022.
- BMR+ [20] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- BPSW [20] Jan van den Brand, Binghui Peng, Zhao Song, and Omri Weinstein. Training (overparametrized) neural networks in near-linear time. arXiv preprint arXiv:2006.11648, 2020.
- BSZ [23] Jan van den Brand, Zhao Song, and Tianyi Zhou. Algorithm and hardness for dynamic attention maintenance in large language models. arXiv preprint arXiv:2304.02207, 2023.
- CCB [18] Heeyoul Choi, Kyunghyun Cho, and Yoshua Bengio. Fine-grained attention mechanism for neural machine translation. Neurocomputing, 284:171–176, 2018.
- CG [19] Yuan Cao and Quanquan Gu. Generalization bounds of stochastic gradient descent for wide and deep neural networks. Advances in neural information processing systems, 32, 2019.
- CGH+ [19] Tianle Cai, Ruiqi Gao, Jikai Hou, Siyu Chen, Dong Wang, Di He, Zhihua Zhang, and Liwei Wang. Gram-gauss-newton method: Learning overparameterized neural networks for regression problems. arXiv preprint arXiv:1905.11675, 2019.
- Cha [22] ChatGPT. Optimizing language models for dialogue. OpenAI Blog, November 2022.
- CLMY [21] HanQin Cai, Yuchen Lou, Daniel Mckenzie, and Wotao Yin. A zeroth-order block coordinate descent algorithm for huge-scale black-box optimization. arXiv preprint arXiv:2102.10707, 2021.
- CLP+ [21] Beidi Chen, Zichang Liu, Binghui Peng, Zhaozhuo Xu, Jonathan Lingjie Li, Tri Dao, Zhao Song, Anshumali Shrivastava, and Christopher Re. Mongoose: A learnable lsh framework for efficient neural network training. In International Conference on Learning Representations, 2021.
- CLS [19] Michael B Cohen, Yin Tat Lee, and Zhao Song. Solving linear programs in the current matrix multiplication time. In STOC, 2019.
- CMBB [23] Marco Cascella, Jonathan Montomoli, Valentina Bellini, and Elena Bignami. Evaluating the feasibility of chatgpt in healthcare: an analysis of multiple clinical and research scenarios. Journal of Medical Systems, 47(1):33, 2023.
- CND+ [22] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311, 2022.
- [22] Timothy Chu, Zhao Song, and Chiwun Yang. Fine-tune language models to approximate unbiased in-context learning. arXiv preprint arXiv:2310.03331, 2023.
- [23] Timothy Chu, Zhao Song, and Chiwun Yang. How to protect copyright data in optimization of large language models? arXiv preprint arXiv:2308.12247, 2023.
- DB [16] Alexey Dosovitskiy and Thomas Brox. Inverting visual representations with convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4829–4837, 2016.
- DCLT [18] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- DLMS [23] Yichuan Deng, Zhihang Li, Sridhar Mahadevan, and Zhao Song. Zero-th order algorithm for softmax attention optimization. arXiv preprint arXiv:2307.08352, 2023.
- DLS [23] Yichuan Deng, Zhihang Li, and Zhao Song. Attention scheme inspired softmax regression. arXiv preprint arXiv:2304.10411, 2023.
- DMS [23] Yichuan Deng, Sridhar Mahadevan, and Zhao Song. Randomized and deterministic attention sparsification algorithms for over-parameterized feature dimension. arxiv preprint: arxiv 2304.03426, 2023.
- DSW [22] Yichuan Deng, Zhao Song, and Omri Weinstein. Discrepancy minimization in input sparsity time. arXiv preprint arXiv:2210.12468, 2022.
- DSX [23] Yichuan Deng, Zhao Song, and Shenghao Xie. Convergence of two-layer regression with nonlinear units. arXiv preprint arXiv:2308.08358, 2023.
- DZPS [18] Simon S Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over-parameterized neural networks. arXiv preprint arXiv:1810.02054, 2018.
- FCB [16] Orhan Firat, Kyunghyun Cho, and Yoshua Bengio. Multi-way, multilingual neural machine translation with a shared attention mechanism. arXiv preprint arXiv:1601.01073, 2016.
- GMS [23] Yeqi Gao, Sridhar Mahadevan, and Zhao Song. An over-parameterized exponential regression. arXiv preprint arXiv:2303.16504, 2023.
- GPAM+ [14] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. Advances in neural information processing systems, 27, 2014.
- GS [22] Yuzhou Gu and Zhao Song. A faster small treewidth sdp solver. arXiv preprint arXiv:2211.06033, 2022.
- [36] Yeqi Gao, Zhao Song, and Shenghao Xie. In-context learning for attention scheme: from single softmax regression to multiple softmax regression via a tensor trick. arXiv preprint arXiv:2307.02419, 2023.
- [37] Yeqi Gao, Zhao Song, and Shenghao Xie. In-context learning for attention scheme: from single softmax regression to multiple softmax regression via a tensor trick. arXiv preprint arXiv:2307.02419, 2023.
- [38] Yeqi Gao, Zhao Song, and Xin Yang. Differentially private attention computation. arXiv preprint arXiv:2305.04701, 2023.
- [39] Yeqi Gao, Zhao Song, and Junze Yin. Gradientcoin: A peer-to-peer decentralized large language models. arXiv preprint arXiv:2308.10502, 2023.
- GSYZ [23] Yeqi Gao, Zhao Song, Xin Yang, and Ruizhe Zhang. Fast quantum algorithm for attention computation. arXiv preprint arXiv:2307.08045, 2023.
- GSZ [23] Yuzhou Gu, Zhao Song, and Lichen Zhang. A nearly-linear time algorithm for structured support vector machines. arXiv preprint arXiv:2307.07735, 2023.
- HAPC [17] Briland Hitaj, Giuseppe Ateniese, and Fernando Perez-Cruz. Deep models under the gan: information leakage from collaborative deep learning. In Proceedings of the 2017 ACM SIGSAC conference on computer and communications security, pages 603–618, 2017.
- HGS+ [21] Yangsibo Huang, Samyak Gupta, Zhao Song, Kai Li, and Sanjeev Arora. Evaluating gradient inversion attacks and defenses in federated learning. Advances in Neural Information Processing Systems, 34:7232–7241, 2021.
- HJS+ [22] Baihe Huang, Shunhua Jiang, Zhao Song, Runzhou Tao, and Ruizhe Zhang. Solving sdp faster: A robust ipm framework and efficient implementation. In 2022 IEEE 63rd Annual Symposium on Foundations of Computer Science (FOCS), pages 233–244. IEEE, 2022.
- HLSY [21] Baihe Huang, Xiaoxiao Li, Zhao Song, and Xin Yang. Fl-ntk: A neural tangent kernel-based framework for federated learning analysis. In International Conference on Machine Learning, pages 4423–4434. PMLR, 2021.
- HSLA [20] Yangsibo Huang, Zhao Song, Kai Li, and Sanjeev Arora. Instahide: Instance-hiding schemes for private distributed learning. In International conference on machine learning, pages 4507–4518. PMLR, 2020.
- HXL+ [22] Xuanli He, Qiongkai Xu, Lingjuan Lyu, Fangzhao Wu, and Chenguang Wang. Protecting intellectual property of language generation apis with lexical watermark. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 10758–10766, 2022.
- HXZ+ [22] Xuanli He, Qiongkai Xu, Yi Zeng, Lingjuan Lyu, Fangzhao Wu, Jiwei Li, and Ruoxi Jia. Cater: Intellectual property protection on text generation apis via conditional watermarks. Advances in Neural Information Processing Systems, 35:5431–5445, 2022.
- JRM+ [99] Craig A Jensen, Russell D Reed, Robert Jackson Marks, Mohamed A El-Sharkawi, Jae-Byung Jung, Robert T Miyamoto, Gregory M Anderson, and Christian J Eggen. Inversion of feedforward neural networks: algorithms and applications. Proceedings of the IEEE, 87(9):1536–1549, 1999.
- JSWZ [21] Shunhua Jiang, Zhao Song, Omri Weinstein, and Hengjie Zhang. Faster dynamic matrix inverse for faster lps. In STOC, 2021.
- JT [19] Ziwei Ji and Matus Telgarsky. Polylogarithmic width suffices for gradient descent to achieve arbitrarily small test error with shallow relu networks. arXiv preprint arXiv:1909.12292, 2019.
- KGW+ [23] John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, and Tom Goldstein. A watermark for large language models. arXiv preprint arXiv:2301.10226, 2023.
- KKL [20] Nikita Kitaev, Łukasz Kaiser, and Anselm Levskaya. Reformer: The efficient transformer. arXiv preprint arXiv:2001.04451, 2020.
- KMZ [23] Praneeth Kacham, Vahab Mirrokni, and Peilin Zhong. Polysketchformer: Fast transformers via sketches for polynomial kernels. arXiv preprint arXiv:2310.01655, 2023.
- KWR [22] Nikhil Kandpal, Eric Wallace, and Colin Raffel. Deduplicating training data mitigates privacy risks in language models. In International Conference on Machine Learning, pages 10697–10707. PMLR, 2022.
- LKN [99] Bao-Liang Lu, Hajime Kita, and Yoshikazu Nishikawa. Inverting feedforward neural networks using linear and nonlinear programming. IEEE Transactions on Neural networks, 10(6):1271–1290, 1999.
- LL [18] Yuanzhi Li and Yingyu Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. Advances in neural information processing systems, 31, 2018.
- LLH+ [23] Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. Sophia: A scalable stochastic second-order optimizer for language model pre-training. arXiv preprint arXiv:2305.14342, 2023.
- LLR [23] Yuchen Li, Yuanzhi Li, and Andrej Risteski. How do transformers learn topic structure: Towards a mechanistic understanding. arXiv preprint arXiv:2303.04245, 2023.
- LSS+ [20] Jason D Lee, Ruoqi Shen, Zhao Song, Mengdi Wang, et al. Generalized leverage score sampling for neural networks. Advances in Neural Information Processing Systems, 33:10775–10787, 2020.
- LSX+ [23] Shuai Li, Zhao Song, Yu Xia, Tong Yu, and Tianyi Zhou. The closeness of in-context learning and weight shifting for softmax regression. arXiv preprint arXiv:2304.13276, 2023.
- LSZ [19] Yin Tat Lee, Zhao Song, and Qiuyi Zhang. Solving empirical risk minimization in the current matrix multiplication time. In Conference on Learning Theory (COLT), pages 2140–2157. PMLR, 2019.
- LSZ [23] Zhihang Li, Zhao Song, and Tianyi Zhou. Solving regularized exp, cosh and sinh regression problems. arXiv preprint, 2303.15725, 2023.
- MGN+ [23] Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes. arXiv preprint arXiv:2305.17333, 2023.
- MMS+ [19] Louis Martin, Benjamin Muller, Pedro Javier Ortiz Suarez, Yoann Dupont, Laurent Romary, Eric Villemonte de La Clergerie, Djame Seddah, and Benoit Sagot. Camembert: a tasty french language model. arXiv preprint arXiv:1911.03894, 2019.
- MOSW [22] Alexander Munteanu, Simon Omlor, Zhao Song, and David Woodruff. Bounding the width of neural networks via coupled initialization a worst case analysis. In International Conference on Machine Learning, pages 16083–16122. PMLR, 2022.
- MSDCS [19] Luca Melis, Congzheng Song, Emiliano De Cristofaro, and Vitaly Shmatikov. Exploiting unintended feature leakage in collaborative learning. In 2019 IEEE symposium on security and privacy (SP), pages 691–706. IEEE, 2019.
- MSS [16] Richard McPherson, Reza Shokri, and Vitaly Shmatikov. Defeating image obfuscation with deep learning. arXiv preprint arXiv:1609.00408, 2016.
- MV [15] Aravindh Mahendran and Andrea Vedaldi. Understanding deep image representations by inverting them. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5188–5196, 2015.
- MWY+ [23] Sadhika Malladi, Alexander Wettig, Dingli Yu, Danqi Chen, and Sanjeev Arora. A kernel-based view of language model fine-tuning. In International Conference on Machine Learning, pages 23610–23641. PMLR, 2023.
- NRMI [20] Usman Naseem, Imran Razzak, Katarzyna Musial, and Muhammad Imran. Transformer based deep intelligent contextual embedding for twitter sentiment analysis. Future Generation Computer Systems, 113:58–69, 2020.
- Ope [23] OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- OS [20] Samet Oymak and Mahdi Soltanolkotabi. Toward moderate overparameterization: Global convergence guarantees for training shallow neural networks. IEEE Journal on Selected Areas in Information Theory, 1(1):84–105, 2020.
- PMJ+ [16] Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik, and Ananthram Swami. The limitations of deep learning in adversarial settings. In 2016 IEEE European symposium on security and privacy (EuroS&P), pages 372–387. IEEE, 2016.
- PMXA [23] Abhishek Panigrahi, Sadhika Malladi, Mengzhou Xia, and Sanjeev Arora. Trainable transformer in transformer. arXiv preprint arXiv:2307.01189, 2023.
- PSZA [23] Abhishek Panigrahi, Nikunj Saunshi, Haoyu Zhao, and Sanjeev Arora. Task-specific skill localization in fine-tuned language models. arXiv preprint arXiv:2302.06600, 2023.
- PZJY [20] Xudong Pan, Mi Zhang, Shouling Ji, and Min Yang. Privacy risks of general-purpose language models. In 2020 IEEE Symposium on Security and Privacy (SP), pages 1314–1331. IEEE, 2020.
- QSY [23] Lianke Qin, Zhao Song, and Yuanyuan Yang. Efficient sgd neural network training via sublinear activated neuron identification. arXiv preprint arXiv:2307.06565, 2023.
- Ray [23] Partha Pratim Ray. Chatgpt: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet of Things and Cyber-Physical Systems, 2023.
- RG [20] Maria Rigaki and Sebastian Garcia. A survey of privacy attacks in machine learning. ACM Computing Surveys, 2020.
- RNS+ [18] Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. ., 2018.
- RSM+ [23] Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D.Manning, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290, 2023.
- RWC+ [19] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- SHT [23] Clayton Sanford, Daniel Hsu, and Matus Telgarsky. Representational strengths and limitations of transformers. arXiv preprint arXiv:2306.02896, 2023.
- SMK [23] Lingfeng Shen, Aayush Mishra, and Daniel Khashabi. Do pretrained transformers really learn in-context by gradient descent? arXiv preprint arXiv:2310.08540, 2023.
- SSSS [17] Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3–18. IEEE, 2017.
- SSZ [23] Ritwik Sinha, Zhao Song, and Tianyi Zhou. A mathematical abstraction for balancing the trade-off between creativity and reality in large language models. arXiv preprint arXiv:2306.02295, 2023.
- SWX+ [23] Hanpu Shen, Cheng-Long Wang, Zihang Xiang, Yiming Ying, and Di Wang. Differentially private non-convex learning for multi-layer neural networks. arXiv preprint arXiv:2310.08425, 2023.
- SY [19] Zhao Song and Xin Yang. Quadratic suffices for over-parametrization via matrix chernoff bound. arXiv preprint arXiv:1906.03593, 2019.
- SYZ [23] Zhao Song, Junze Yin, and Lichen Zhang. Solving attention kernel regression problem via pre-conditioner. arXiv preprint arXiv:2308.14304, 2023.
- SZKS [21] Charlie Snell, Ruiqi Zhong, Dan Klein, and Jacob Steinhardt. Approximating how single head attention learns. arXiv preprint arXiv:2103.07601, 2021.
- SZZ [21] Zhao Song, Lichen Zhang, and Ruizhe Zhang. Training multi-layer over-parametrized neural network in subquadratic time. arXiv preprint arXiv:2112.07628, 2021.
- TBM+ [21] Yi Tay, Dara Bahri, Donald Metzler, Da-Cheng Juan, Zhe Zhao, and Che Zheng. Synthesizer: Rethinking self-attention for transformer models. In International conference on machine learning, pages 10183–10192. PMLR, 2021.
- TDA+ [20] Yi Tay, Mostafa Dehghani, Samira Abnar, Yikang Shen, Dara Bahri, Philip Pham, Jinfeng Rao, Liu Yang, Sebastian Ruder, and Donald Metzler. Long range arena: A benchmark for efficient transformers. arXiv preprint arXiv:2011.04006, 2020.
- TLTO [23] Davoud Ataee Tarzanagh, Yingcong Li, Christos Thrampoulidis, and Samet Oymak. Transformers as support vector machines. arXiv preprint arXiv:2308.16898, 2023.
- UAS+ [20] Mohd Usama, Belal Ahmad, Enmin Song, M Shamim Hossain, Mubarak Alrashoud, and Ghulam Muhammad. Attention-based sentiment analysis using convolutional and recurrent neural network. Future Generation Computer Systems, 113:571–578, 2020.
- VKB [23] Nikhil Vyas, Sham Kakade, and Boaz Barak. Provable copyright protection for generative models. arXiv preprint arXiv:2302.10870, 2023.
- VSP+ [17] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- WIL+ [23] Shijie Wu, Ozan Irsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg, and Gideon Mann. Bloomberggpt: A large language model for finance. arXiv preprint arXiv:2303.17564, 2023.
- WLL+ [20] Wenqi Wei, Ling Liu, Margaret Loper, Ka-Ho Chow, Mehmet Emre Gursoy, Stacey Truex, and Yanzhao Wu. A framework for evaluating gradient leakage attacks in federated learning. arXiv preprint arXiv:2004.10397, 2020.
- WLL [23] Zihan Wang, Jason Lee, and Qi Lei. Reconstructing training data from model gradient, provably. In International Conference on Artificial Intelligence and Statistics, pages 6595–6612. PMLR, 2023.
- XGZC [23] Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, and Danqi Chen. Sheared llama: Accelerating language model pre-training via structured pruning. arXiv preprint arXiv:2310.06694, 2023.
- XZA+ [23] Zheng Xu, Yanxiang Zhang, Galen Andrew, Christopher A Choquette-Choo, Peter Kairouz, H Brendan McMahan, Jesse Rosenstock, and Yuanbo Zhang. Federated learning of gboard language models with differential privacy. arXiv preprint arXiv:2305.18465, 2023.
- YMV+ [21] Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M Alvarez, Jan Kautz, and Pavlo Molchanov. See through gradients: Image batch recovery via gradinversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16337–16346, 2021.
- ZG [19] Difan Zou and Quanquan Gu. An improved analysis of training over-parameterized deep neural networks. Advances in neural information processing systems, 32, 2019.
- Zha [22] Lichen Zhang. Speeding up optimizations via data structures: Faster search, sample and maintenance. PhD thesis, Master’s thesis, Carnegie Mellon University, 2022.
- ZHDK [23] Amir Zandieh, Insu Han, Majid Daliri, and Amin Karbasi. Kdeformer: Accelerating transformers via kernel density estimation. arXiv preprint arXiv:2302.02451, 2023.
- ZJP+ [20] Yuheng Zhang, Ruoxi Jia, Hengzhi Pei, Wenxiao Wang, Bo Li, and Dawn Song. The secret revealer: Generative model-inversion attacks against deep neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 253–261, 2020.
- [109] Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33:15383–15393, 2020.
- [110] Jingzhao Zhang, Sai Praneeth Karimireddy, Andreas Veit, Seungyeon Kim, Sashank Reddi, Sanjiv Kumar, and Suvrit Sra. Why are adaptive methods good for attention models? Advances in Neural Information Processing Systems, 33:15383–15393, 2020.
- ZLH [19] Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. Advances in neural information processing systems, 32, 2019.
- ZMB [20] Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. idlg: Improved deep leakage from gradients. arXiv preprint arXiv:2001.02610, 2020.
- ZMG [19] Guodong Zhang, James Martens, and Roger B Grosse. Fast convergence of natural gradient descent for over-parameterized neural networks. Advances in Neural Information Processing Systems, 32, 2019.
- ZPD+ [20] Yi Zhang, Orestis Plevrakis, Simon S Du, Xingguo Li, Zhao Song, and Sanjeev Arora. Over-parameterized adversarial training: An analysis overcoming the curse of dimensionality. Advances in Neural Information Processing Systems, 33:679–688, 2020.
- ZRG+ [22] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068, 2022.