Unsupervised Ensemble Methods for Anomaly Detection in PLC-based Process Control
Abstract
Programmable logic controller (PLC) based industrial control systems (ICS) are used to monitor and control critical infrastructure. Integration of communication networks and an Internet of Things approach in ICS has increased ICS vulnerability to cyber-attacks. This work proposes novel unsupervised machine learning ensemble methods for anomaly detection in PLC-based ICS. The work presents two broad approaches to anomaly detection: a weighted voting ensemble approach with a learning algorithm based on coefficient of determination and a stacking-based ensemble approach using isolation forest meta-detector. The two ensemble methods were analyzed via an open-source PLC-based ICS subjected to multiple attack scenarios as a case study. The work considers four different learning models for the weighted voting ensemble method. Comparative performance analyses of five ensemble methods driven diverse base detectors are presented. Results show that stacking-based ensemble method using isolation forest meta-detector achieves superior performance to previous work on all performance metrics. Results also suggest that effective unsupervised ensemble methods, such as stacking-based ensemble having isolation forest meta-detector, can robustly detect anomalies in arbitrary ICS datasets. Finally, the presented results were validated by using statistical hypothesis tests.
Index Terms:
Ensemble learning; cyber-physical systems; weighted voting; Programmable Logic Controllers (PLCs); attack detection; unsupervised machine learning; cybersecurity.I Introduction
Integrating physical control processes, computing, and communication through Internet of Things technology (IoT) improves industrial control systems (ICSs) production efficiency, flexibility, and reliability. Unfortunately, the prevalence of Internet of Things technology and networked sensors in many ICSs opens up opportunities for cybercriminals to leverage ICS vulnerabilities towards initiating cyber-attacks [1, 2]. There has been an increase in cyber-attack awareness of critical infrastructure [3, 4, 5, 6]. Programmable Logic Controllers (PLCs) are industrial computers that play a significant role in ICS. PLCs are a family of embedded devices critical to ICS network operation. PLCs collect input data from field devices such as sensors and send output commands to actuating devices to control ICS operations [7, 8]. ICS plays a vital role in monitoring and controlling critical infrastructures such as electricity supply, nuclear plants, petrochemical industries, and water management. PLCs, which serve as the heart of ICS, are vulnerable to attacks like other embedded devices. Because PLCs are broadly used to control the physical processes of critical infrastructure in societies, PLC malfunctions or attacks can cause physical and economic damages as well as compromise the safety of ICS service personnel [9].
Traditionally, PLCs use proprietary hardware and software in physically secure locations with no external connection to the internet [10, 11]. As a result, attacks on PLCs were limited to insider intrusion, physical damage, and tampering with PLC devices [12]. In recent times, PLCs have adopted corporate networks and common information technologies with integrated smart sensors and wireless networks for performance enhancement, and efficiency improvement [13, 14]. Applying traditional techniques and contemporary tools for detecting PLC anomalous behavior is difficult due to their unique architecture and proprietary operating systems. Therefore, it is crucial to protect PLCs against any forms of attack or anomalies such as hardware malfunction, accidental actions by insiders, and malicious intruders [15].
Machine learning techniques have been applied for anomaly detection in embedded devices and for identifying anomalies in several computing applications [16, 17, 18, 19, 20, 21]. Recently, work has been done that utilizes ICS data to develop unsupervised anomaly detection models which exhibit the ICS system’s normal behavior and identify all different behaviors as anomalies [22, 23, 24]. These algorithms learn a single hypothesis from training dataset in order to make generalizations about unseen events. Moreover, different anomaly detection algorithms make different assumptions about the dataset, which may not be accurate. As a result, different anomaly detection algorithms perform well on some subsets of a dataset and perform poorly on other subsets [25]. Anomaly detection algorithms’ unique assumptions about datasets make it challenging to generalize their performance to an arbitrary dataset.
Ensemble methods refer to the approach by which multiple models are strategically developed and combined for improved performance. In supervised machine learning classification domain, ensemble methods broadly include bagging, boosting, stacking [26, 27]. However, in unsupervised outlier analysis domain, there are two primary types of ensembles, namely sequential ensembles and independent ensembles [25]. In sequential ensembles, a given algorithm or set of algorithms are applied sequentially such that previous applications influence future applications of the algorithm. In contrast, different anomaly detection algorithms are applied to either the complete dataset or portions of the dataset in independent ensembles. In [25], Aggarwal claims that ensemble combinations of multiple anomaly detection algorithms are often able to perform more robustly on arbitrary datasets due to their ability to combine the strengths of multiple detection algorithms. The work in [22] suggests that ensemble learning techniques may improve anomaly detection in ICS based on the performances of several anomaly detection algorithms. Several studies have focused on improving supervised classification performance using homogeneous classifiers [28, 29], heterogeneous classifiers [30], or a combination of both [31, 32]. However, there is not sufficient study concerning unsupervised ensemble machine learning techniques for anomaly detection in PLCs and ICSs.
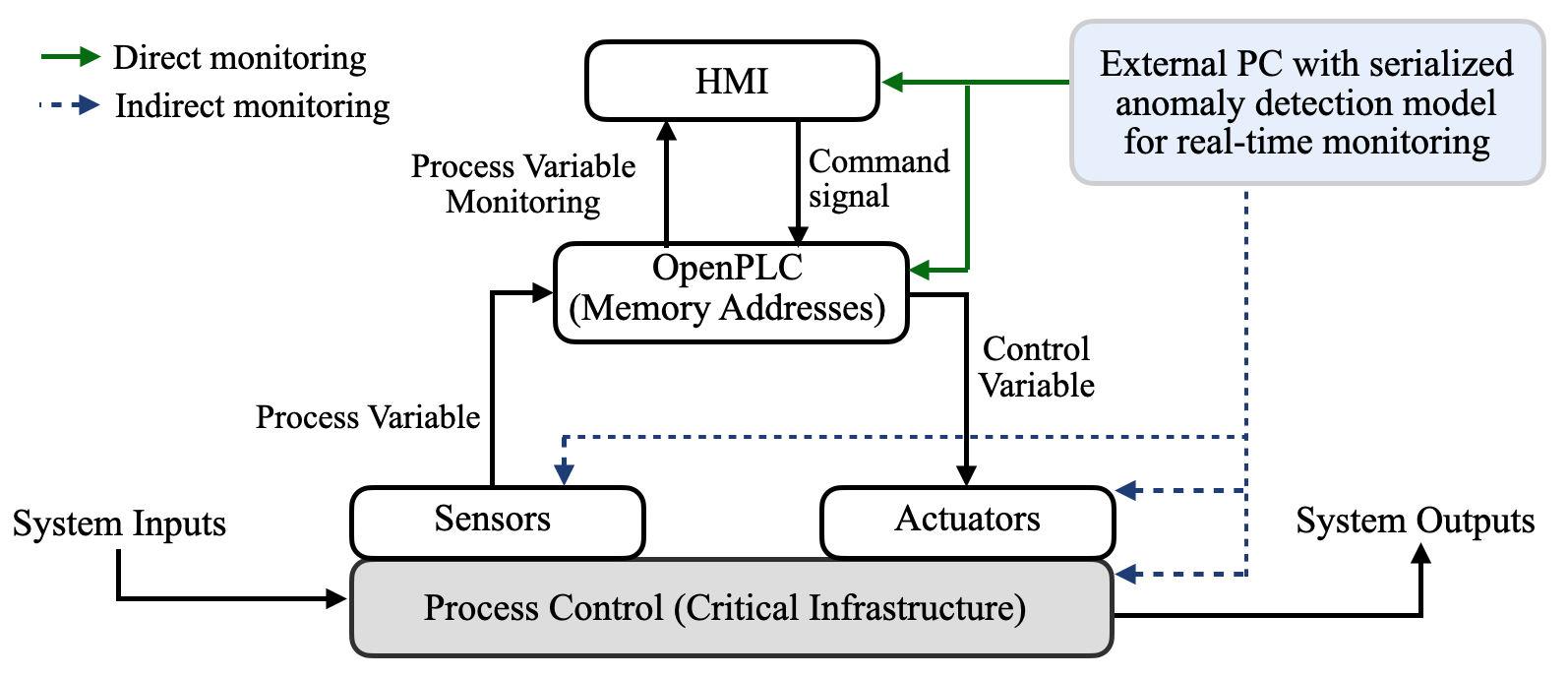
This work proposes five generalized unsupervised ensemble techniques for ICS anomaly detection: majority voting, maximum-score, soft voting, weighted voting, and stacking-based anomaly detection approaches. The weighted voting ensemble method introduces a new approach for assigning weights to base detectors based on their coefficient of determination. The stacking-based approach is a new ensemble approach based on IF meta-learner. The proposed methods broadly fall under independent ensembles in outlier analysis. For each ensemble method, this work adopts the same base detectors, namely; OCSVM, OCNN, and IF, that learn new representations from the training dataset. Then, output representations from the base detectors are concatenated and passed to a voting strategy algorithm to detect attacks from the newly merged representations. The trained models are intended to run on a dedicated or separate computer to monitor operations at the PLC memory addresses through real-time HMI historian logs. Experimental results show that the proposed ensemble techniques in this work outperform existing approaches with acceptable statistical significance.
In summary, the main contributions of this work are listed as follows:
-
1.
Propose first known ensemble anomaly detection methods using OCSVM, OCNN, and IF base detectors;
-
2.
Introduce a weighted voting ensemble technique with a learning algorithm for assigning weights to base detectors based on their coefficient of determination; and
-
3.
Introduce a stacking-based anomaly detection framework with isolation forest meta-detector for robust performance.
The remainder of the paper is organized as follows. Section 2 reviews related works. Section 3 presents details of the experiment setup and data collection approach. Section 4 presents the proposed methods, followed by section 5, which presents results and analysis. Section 6 presents the conclusions and recommendations for future work.
II Related Work
II-A Unsupervised Ensemble Methods
Sun et al. [33] employed an unsupervised ensemble outliers detection framework based on IF algorithms to detect insider threats in an industry. They modified the isolation trees in the IF to support categorical data. Although they achieved significant detection recall values, a drawback of the approach in [33] is that the ensemble method consisted only of isolation trees. As a result, the isolation trees made the same assumptions about the dataset.
Haider et al. [34] proposed an ensemble method based on OCSVM and IF on data clusters. They employed human domain experts to identify false-positive results, which were used to update the ensemble algorithm progressively. They executed a k-means algorithm for class decomposition on top of the base detectors. Finally, they tuned the ensemble algorithm by oversampling the false-positive results to create an accurate decision boundary. Although this algorithm presents an interesting idea for unsupervised anomaly detection, it requires human intervention to achieve optimal performance.
In [35], the authors proposed an ensemble learning framework that combines an unsupervised learning method with a graph-based anomaly detection technique. The base detectors consisted of OCSVM and minimum description length (MDL)[36]. They also proposed a detection model solely based on multiple OCSVM and a streaming data mining approach to account for concept drift. Reported performance was was, suggesting that choice and number of base detectors in an ensemble algorithm are crucial to obtain the best results.
Yuan et al. [37] proposed an ensemble of deep learning algorithms consisting of long short-term memory and a convolutional neural network to identify anomalies in multiple scenarios. They achieved an area under the curve of . Although their method worked well, their approach requires significant computational resources like graphical processing units during training and testing.
II-B Base Detectors for Ensemble Methods
Inoue et al. utilized unsupervised ML algorithms for anomaly detection in water treatment systems [38]. They compared a deep neural network consisting of feedforward layers with multiple inputs and outputs with a One-class Support Vector Machine (OCSVM). The authors claimed that the deep neural network model produced fewer false positives than the OCSVM, although the OCSVM could detect more anomalies. The authors achieved recall values of less than 0.7 for both deep neural network and OCSVM.
In [39], the authors employed a fully connected neural network and an autoencoder to detect anomalies in IoT computer network traffic. Their results showed a higher detection rate and lowered false positive rate when compared with eight other modern anomaly detection techniques. Potluri et al. [40] proposed using artificial neural networks for identifying false data injection attacks in ICS. The classification report obtained in [40] shows a promising detection accuracy with artificial neural networks.
Ahmed et al. [41] presented an unsupervised learning IF approach to detect hidden data integrity assault on a smart grid communication network. They reported an average accuracy of 93%,using simulated experimental data. While the simulated data may not depict ICS accurately, The work in [41] suggests that IF has the potential for high performance in anomaly detection.
Although both supervised and unsupervised ML techniques have been applied in PLC anomaly detection [22, 24, 42], it is usually difficult to rely on a supervised learning approach as real-world ICS contain numerous sensor data that are tedious to label. An unsupervised ML technique called OCSVM was employed to detect anomalies in PLCs successfully [22]. In [22], the authors employed OCSVM, OCNN, and IF for PLC anomaly detection. Their experiment simulated a traffic light control system using a PLC. They captured relevant PLC memory addresses into a log file for real-time data recording of system operations. The captured data was normalized and used to train and evaluate their models. Aboah et al. concluded that IF outperforms OCNN and OCSVM on the TLIGHT system dataset.
While OCSVM, OCNN, and IF have been used as effective unsupervised techniques for anomaly detection, OCSVM performance is unsatisfactory on complex, high-dimensional datasets [43, 44, 45]. Although OCNN has been used for anomaly detection in a complex dataset [43, 22], the work in [22] shows that OCNN performs at par with OCSVM on several test cases of their TLIGHT dataset because OCNN and OCSVM are formulated from a similar optimization problem. The work in [22] also shows that some anomalous data points are detected by either OCSVM or OCNN, but IF fails to detect them. Therefore, this work hypothesizes that some base anomaly detectors will perform well on a particular subset of a dataset, whereas other base detectors will perform better on other subsets. This work proposes five unsupervised ensemble techniques based on OCSVM, OCNN, and IF to improve anomaly detection performance.
III Experiment Setup
This section provides the details of the experimental setup for simulating the behavior of the traffic light (TLIGHT) system in [22, 46] for the purposes of data collection. The details of the experimental setup is provided in [22].
The experimental setup is based on Siemen’s open-source TLIGHT program described in [22, 46]. OpenPLC is an open-source PLC simulation platform for home and industrial automation systems development [47]. OpenPLC editor was used to simulate and test the TLIGHT system logic to ensure that the program was error-free and accurately depicted the TLIGHT system description in [22, 46]. The ladder logic was converted to a structured text format and uploaded to OpenPLC runtime for execution. ScadaBR [48], an open-source Supervisory Control and Data Acquisition (SCADA) system, was employed as the HMI to monitor and control the PLC runtime. HMI application runs independently of the PLC. The PLC input and output memory addresses were mapped to corresponding Modbus input and output addresses in the HMI. At the end of every HMI cycle time (100 ms), ScadaBR logs available data at the input and output Modbus addresses to a log file. Finally, TLIGHT system operations are exported from the HMI as comma-separated-values files for preprocessing and machine learning model training.
IV Proposed Method
The proposed unsupervised ensemble methods use the normal process data from the TLIGHT system’s input and output signals. This section presents the details about the data collection, anomalies, and theoretical background of the algorithms used in the proposed methods. Figure 1 shows the general anomaly detection framework of the proposed methods. The anomaly detection framework in Figure 1 represents a real-world scenario whereby the trained ensemble models in this work are serialized onto a separate personal computer (PC) for real-time PLC monitoring and anomaly detection. The trained ensemble models receive the process control’s real-time data through the HMI and the OpenPLC memory addresses in order to determine whether the received signals violate the process control’s normal operations.
In order to evaluate and compare the proposed unsupervised ensemble methods performance in this work, five different test sets are generated. Each test set contains normal and anomalous TLIGHT system events. Anomalous system events for the five test sets are derived from seven scenarios. The attack scenarios considered in the experiment could represent real-world anomalies resulting from malfunctioning sensors and actuators, such as physical obstruction, natural disaster, or malicious attacks by cyber threat actors. The five test cases were considered based on combinations of the anomalous scenarios. The total training dataset samples and test sets 1–5 are identical with the setup used in [22]. Test sets 4 and 5 consist mainly of timing bits anomalies. Table I summarizes the number of records and proportion of anomalies in the training and test sets.
| Dataset | No. of Records | % Anomalies |
|---|---|---|
| Training set | 41580 | n/a |
| Test Set 1 | 5000 | 10 |
| Test Set 2 | 7000 | 10 |
| Test Set 3 | 13130 | 20 |
| Test Set 4 | 15000 | 30 |
| Test Set 5 | 18270 | 50 |
IV-A Base Detectors
Base detectors refer to the individual components of an ensemble technique. The base detectors are strategically combined to make ensemble techniques’ output robust. The base detectors could consist of different kinds of learning algorithms of any number depending on the problem and adopted strategy [49, 50]. The base detectors adopted for all ensemble methods in this work are OCSVM, OCNN, and IF. OCSVM is an unsupervised anomaly detection technique that learns a decision function for separating the normal class from anomalies in a dataset. OCSVM has been employed for ICS anomaly detection in [51, 52, 22]. OCNN is an unsupervised machine learning algorithm for anomaly detection formulated on the foundation of OCSVM [22]. OCNN has been employed for anomaly detection in [43], although its application in ICS is very limited [24, 22]. IF is also an unsupervised machine learning technique that builds an ensemble of binary trees for a given dataset for anomaly detection [53, 54]. IF has been utilized to successfully detect anomalies in ICS [23, 55, 22]. The ensemble methods proposed in this work use different voting strategies for combining OCSVM, OCNN, and IF outputs.
IV-B Ensemble-Based Detection Approach
Ensemble learning is a technique for combining the outputs of multiple algorithms to create an improved output. The three different anomaly detection techniques mentioned in the subsection above make independent assumptions about the nature of the dataset, which may not be the case for every dataset. Ensemble learning techniques have been successfully employed in various data mining and supervised machine learning applications such as classification and recommender systems [56, 57, 58]. However, unsupervised ensemble analysis is a recent field in anomaly detection, especially in ICS, with little work on combining anomaly detection algorithms [25]. This work seeks to extend the knowledge of ensemble-based detection approaches for anomaly detection in ICS. This section discusses five proposed ensemble-based anomaly detection techniques that combine the outputs of the three base detectors, namely, OCSVM, OCNN, and IF.
Ensemble learning is generally challenging in the context of anomaly detection because of the unsupervised nature or labeled data unavailability [25]. Another challenge is the coherent combination of base detectors’ decision scores, as base detectors may have different objective and scoring functions. Figure 2 shows a general representation of the proposed ensemble approach. Algorithm 1 and Algorithm 2 summarize the general approach to training and testing the proposed ensemble methods in this work. The major changes in each method relate to combining the scores of the base detectors and making final predictions, as described in the following subsections.
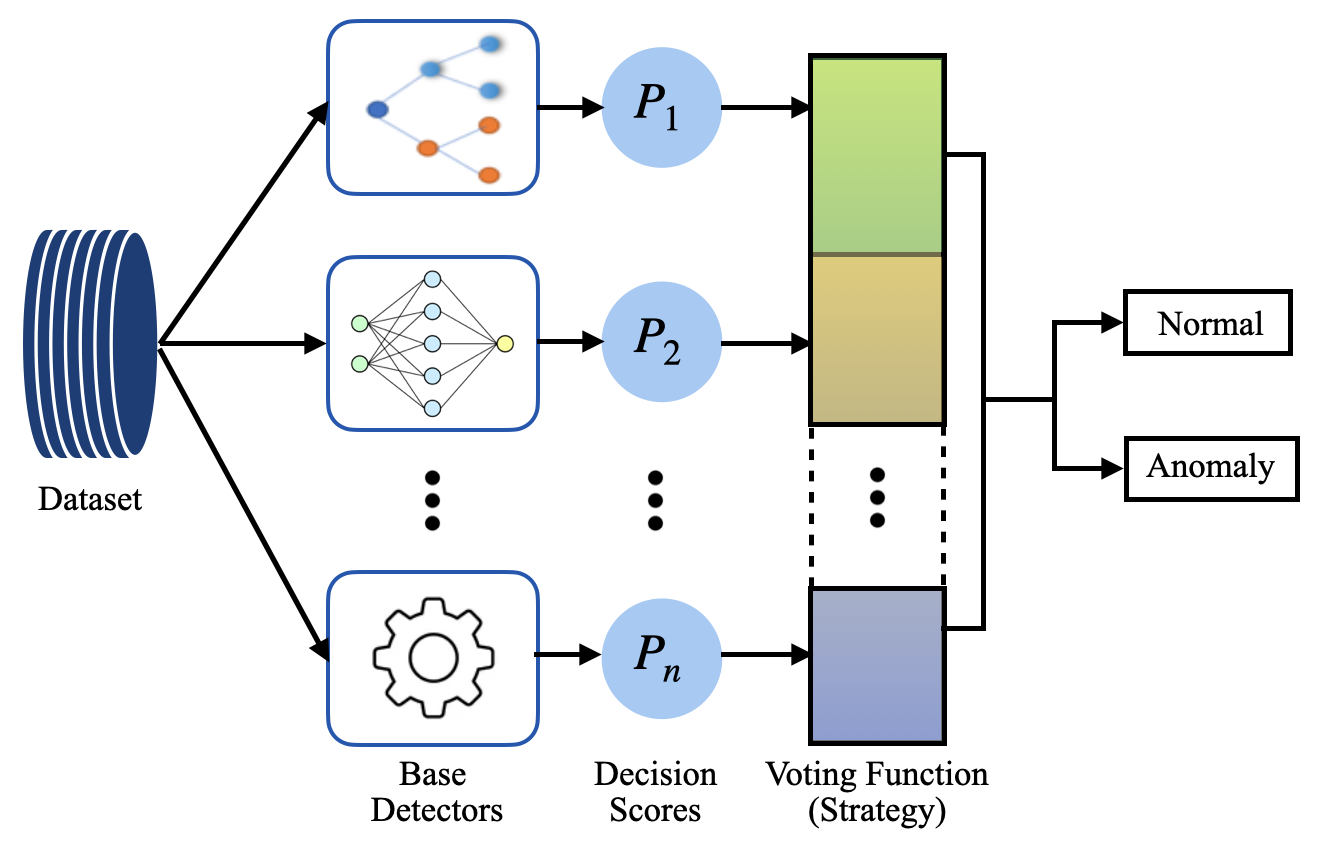
IV-B1 Majority-Vote Ensemble Method
This hard voting strategy is a majority-vote ensemble that selects the mode of the base detectors’ predictions. The majority vote ensemble techniques for supervised machine learning classifiers have been widely studied in the literature [25, 59, 60]. The approach in this work adopts a similar strategy in [25] with an additional normalization mechanism for purposes of unsupervised anomaly detection. The base detectors provide decision scores for each data point in the training set during training. The decision scores are converted into binary predictions of either normal or anomaly based on the scoring function in (1). Ultimately, the majority prediction by the base detectors becomes the final output of the observations in the training set. Similarly, during testing, each trained base detector predicts the new observation. The mode of the predictions becomes the new observation’s final class (either normal or anomaly). This method follows Algorithm 1 and Algorithm 2 for training and testing by using the following voting function for , where is the final ensemble prediction and is the normalized positive and negative decision scores
| (1) |
The majority vote ensemble detection method often achieves a higher anomaly detection rate than the best base detector in the ensemble [25]. In situations where the base detectors are weak detectors, this ensemble technique can still provide good performance [25]. The majority vote ensemble method is a naive approach with several challenges. In some cases where the majority of the base detectors have related objective functions, there is a high likelihood that this ensemble technique will make biased decisions. This ensemble technique’s high bias in prediction is evident in results achieved in this work, as discussed in section 5. In order to minimize the majority vote ensemble’s bias effect, the next subsection introduces an ensemble anomaly detection technique based on the maximum score over all base detectors.
IV-B2 Maximum-score Ensemble Method
In the case of the maximum-score ensemble method, the final anomaly score of a data point is its maximum decision score over all base detectors. Lal et al. [61] employed a maximum-score based ensemble method for online fraud detection. However, in this work, the maximum decision score over all base detectors is
| (2) |
where is the anomaly score of a base detector . During training, the scores of each base detector are normalized between the range of and the normalization parameters (feature range) are saved. The base detector with the highest normalized score gets to decide the final anomaly score of the ensemble based on (2). During testing phase, the base detectors predictions on new data points are normalized based on the training data normalization feature range. Subsequently, the base detector with the highest normalized score becomes the ensemble detector’s final anomaly score. Maximum-score ensemble approach follows Algorithm 1 and Algorithm 2 for training and testing by using a voting function of (2).
The effect of maximum-score ensemble learning is more complex because it can often improve bias but increase variance. This challenge makes the overall effect unpredictable [25]. In order to combat the high variance effect of this technique, the next section introduces a soft voting ensemble technique for anomaly detection.
IV-B3 Soft Voting Ensemble Anomaly Detection Technique
The soft voting ensemble anomaly detection technique reports the average decision scores of all base detectors as data points final scores. Soft voting ensemble methods based on scores averaging have been widely studied in the literature [25, 60, 62]. The approach adopted in this work follows a similar technique in [25], in order to compare its performance to other novel unsupervised methods proposed in this work. In this work, positive and negative decision scores of the base detectors are normalized during training, and the anomaly score of the data point is computed as
| (3) |
During testing phase, base detectors’ decision scores are normalized using the maximum and minimum normalization feature values of the training dataset, and the average is computed as the final score. If the average score is negative, the data point is an anomaly; otherwise, the data point is a normal instant. The soft voting ensemble approach follows Algorithm 1 and Algorithm 2 for training and testing by using a voting function of (3). The intent of averaging the normalized scores is to reduce the variance of the scores and thereby improve accuracy.
IV-B4 Weighted Voting Ensemble Technique
The proposed weighted voting technique is an ensemble technique that produces a combined output prediction based on weights applied to the scores of the base detectors. The challenge of the soft voting technique for combining base detectors outputs is the appropriate weight assignment to each base detector. The work in [25, 63] show that uncorrelated features with all other features in a dataset are less relevant. Hence, uncorrelated scores violate the model of normal data dependencies. This work introduces a new generalized method of assigning weights to the base detectors based on statistical coefficient of determination (R-squared).
Each base detector is trained on the training set to produce an anomaly score for each data point in the training set. The decision scores for each base detector are normalized according to Algorithm 1, and concatenated to form features of a new training set. In this approach, the voting function in Algorithm 1 is replaced by a linear regression model. The linear regression model is used to predict each of the features from the other features and computes the root-mean-squared error of predicting the feature from the other features. The weighted voting ensemble method can take an arbitrary learning model other than linear regression model such as decision tree regressor [64], K-nearest neighbor [65] and ridge regression [66]. Irrelevant features will produce larger [25, 63], and hence larger leads to lower associated feature weight. Next, each feature weight of the new training set is given by . The weights of each feature are multiplied by the respective feature set to produce a weighted score for each feature. Finally, the maximum of the weighted features becomes the final anomaly score. Similarly, during prediction on a new data point after training, outputs of the base detectors are normalized and multiplied by the weights, obtained during training before the maximum score is selected as the new instance’s final decision score.
The challenge with using is that it works on the assumption that predicted scores of each base detector are normalized, making it difficult to scale or generalize to any arbitrary base detector. This work further proposes the use of R-squared (coefficient of determination) value , as the weight of each feature instead of . The -value measures the level of explainability of predicting each feature from other features. It is easy and intuitive to calculate the -value, and most importantly, it produces result in the range between 0 and 1 regardless of the input data scale. Higher -value is better. -value has a direct relationship with as
where
and
where represents the total sum of squares (outcome response variance), is the target (ground truth scores), represents the dependent variables which are the features in this case, and is average of . The proposed approach for assigning weights to the output scores of the base detectors is summarized in Algorithm 3. Substituting the voting function in Algorithm 1 with Algorithm 3 provides a complete Algorithm for the proposed weighted voting ensemble technique. The proposed weighted voting ensemble technique is a flexible algorithm because, instead of using the maximum of the weighted features as the final anomaly score in this work, the average of the weighted features could be used as the final anomaly score.
IV-B5 Stacking-based Anomaly Detection Approach
This work proposes a new stacking-based anomaly detection architecture to identify ICS anomalies. The approach adopted here uses a meta-detector, often called blender, to best learn how to combine the output scores of the base detectors to produce robust, stable, and accurate results. First, each base detector is trained independently on the training dataset. The base detectors have different scoring functions; hence their outputs are normalized as described in Algorithm 1. The normalized outputs of the base detectors are used as input (training data) to the meta-detector to learn the best way to combine the normalized scores to produce a robust anomaly detection model.
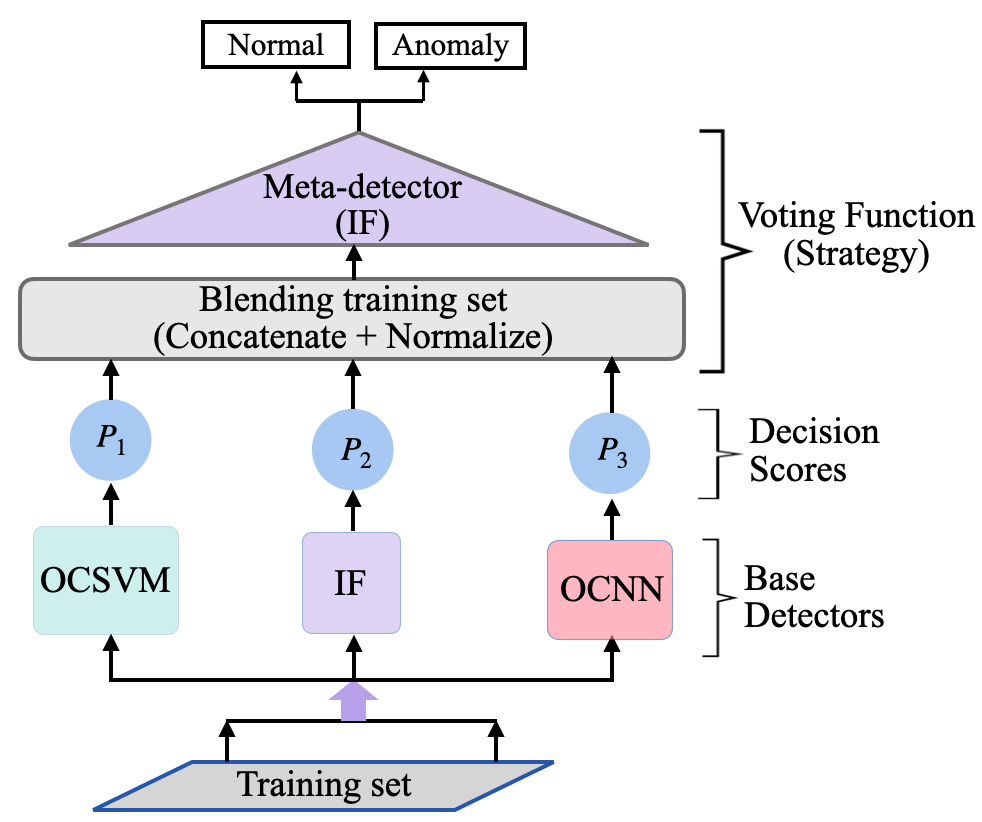
IF is used as the meta-detector for learning the new training set because the detection problem is still unsupervised, so labeled classes of the training data are assumed to be unavailable. Again, IF is a robust and fast anomaly detection algorithm that builds a homogeneous binary tree ensemble for a given dataset [22]. Figure 3 shows the architecture of the proposed stacking-based anomaly detection approach. Replacing the voting function in Algorithm 1 with a layer of IF meta-detector described in this section results in the complete algorithm for this proposed technique. Each base detector provides an independent normalized score for the new data point during model prediction after training, which serves as input to the meta-detector. Finally, the meta-detector provides a combined score for the new data point to determine whether it is a normal data point or an anomaly. Table II shows optimal hyperparameters used to develop the IF meta-detector.
| Parameter | Description | value |
| Number of base estimators in the forest ensemble | 100 | |
| Number of training samples to draw to train each estimator | 256 | |
| contamination | Proportion of outliers in the data set | 0.007 |
V Results and Discussions
The evaluation is based on performance metrics, results from predictions on the test data, and comparison with prior work trained on a similar dataset. Google’s Tensorflow [67], an open-source deep learning library, is used for training and performing inference on the base detectors. Evaluation results and performance metrics calculations are performed by using the Scikit-learn library [68]. The dataset used to develop the proposed methods in this work is the HMI historian log of operations at PLC memory addresses. The data is obtained through Modbus communication protocol between the PLC and HMI.
The performance metrics for evaluating the proposed anomaly detection models are derived from the confusion matrix. Four evaluation outcomes are derived from the confusion matrix: true positive (TN), true negative (TN), false positive (FP), and false negative (FN). These outcomes are used for calculating the accuracy, precision, recall, and F1-score of anomaly detection models as described in [22].
The results presented in this section use the visualization approach proposed in [22, 69] to better understand ensemble algorithms’ performance. The histogram-based visualization approach normalizes the histogram frequency (y-axis) to a range between and , whereas the x-axis represents the normalized decision scores indicating the prediction confidence. After investigating various hyperparameter ranges, the three base detectors, OSCVM, OCNN, and IF, are trained with optimal hyperparameters. The optimal hyperparameters for the base detectors are presented in [22].
V-A Performance of Majority-Vote Ensemble Method
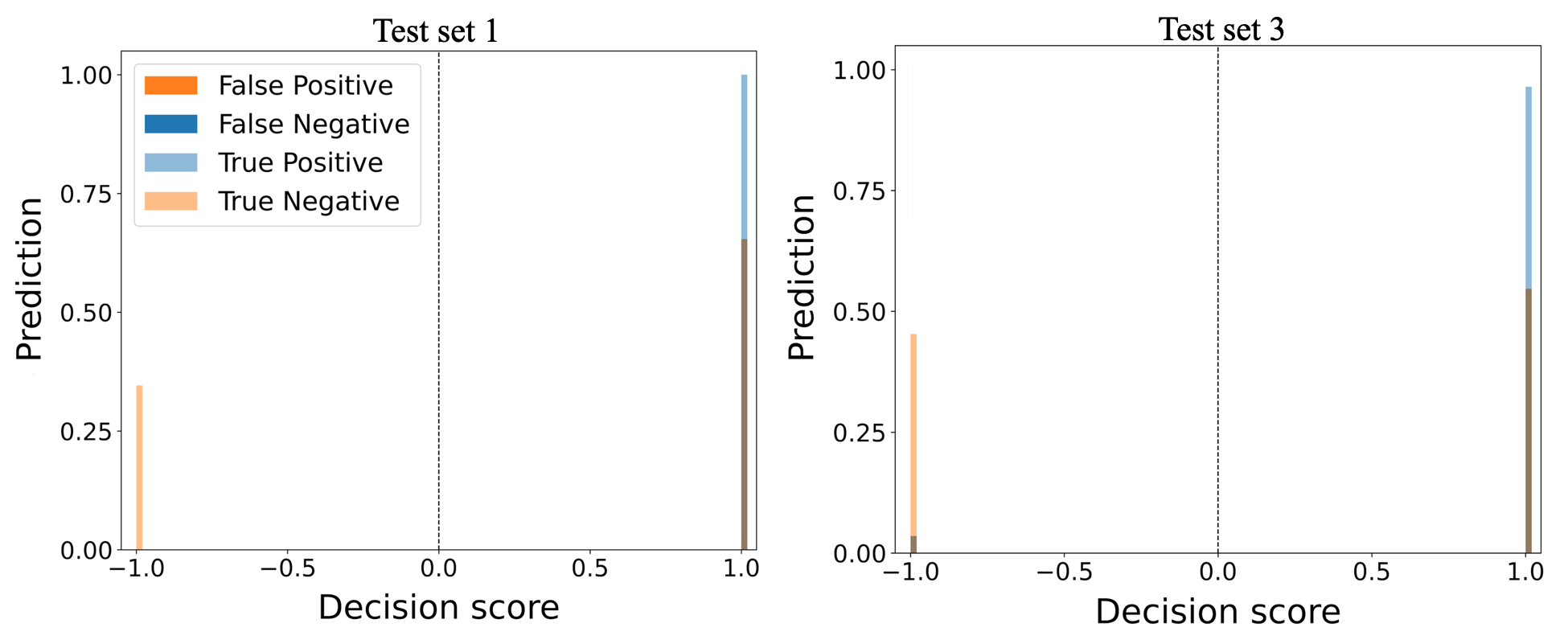
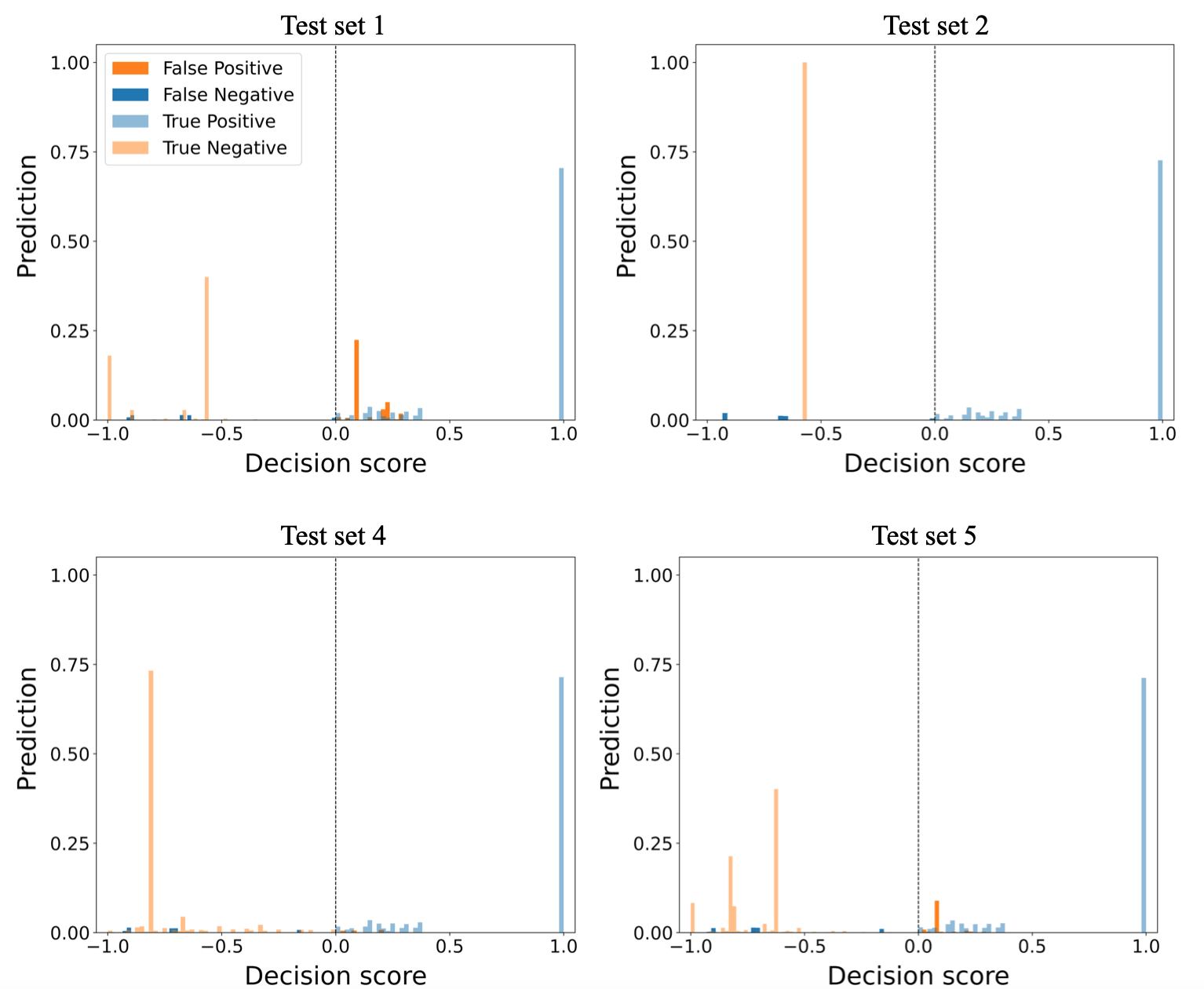
The majority-vote ensemble method performed well on test set 1 by having precision, recall, and F1-score of , , and respectively. The algorithm achieved a recall and F1-score of and respectively on test set 2, which are similar to the recall and F1-score values of test set 3. However, the algorithm’s high recall and F1-score rate on test set 2 resulted from its high anomaly detection rate on the normal data points at the expense of high false positive rate. The algorithm finds it challenging to detect anomalies involving anomalous scenarios 1 and 3. Performance of the algorithm decreases on test sets 4 and 5 as the recall values decreased to and respectively. Figure 4 shows the majority-vote ensemble method results of the normalized TP, TN, FP, and FN values on test sets 1 and 3.
Because of the algorithm’s binary prediction outcome, it is impossible to visualize and assess prediction confidence levels, unlike other ensemble approaches proposed in this work. Figure 4 shows that although the algorithm’s TN predictions are less than , the levels of FN predictions are low at values below . However, the algorithm has high levels of FP in the range above for test sets 1 and 2. The visualization of the algorithm performance on test sets 3-5 is similar to Figure 4.
V-B Performance of Maximum-score Ensemble Method
Maximum-score ensemble method performance on test sets 1 and 2 are high with F1-scores of and respectively. This method has the same precision, and recall values as the majority-vote method on test set 1. However, this method significantly performs well on test set 2 as compared to the majority-vote method by having precision and recall values of and respectively. The algorithm’s performance on test sets 3 and 5 is similar to majority-vote method. F1-scores for test sets 3 and 5 are and , respectively. This method has its worst performance on test set 4, with recall and F1-scores of and respectively. In effect, the maximum-score ensemble method has low detection performance on TLIGHT system anomalies involving timing bits manipulation. Figure 5 shows the maximum-score ensemble method results of the normalized TP, TN, FP, and FN values on test sets 1-4.
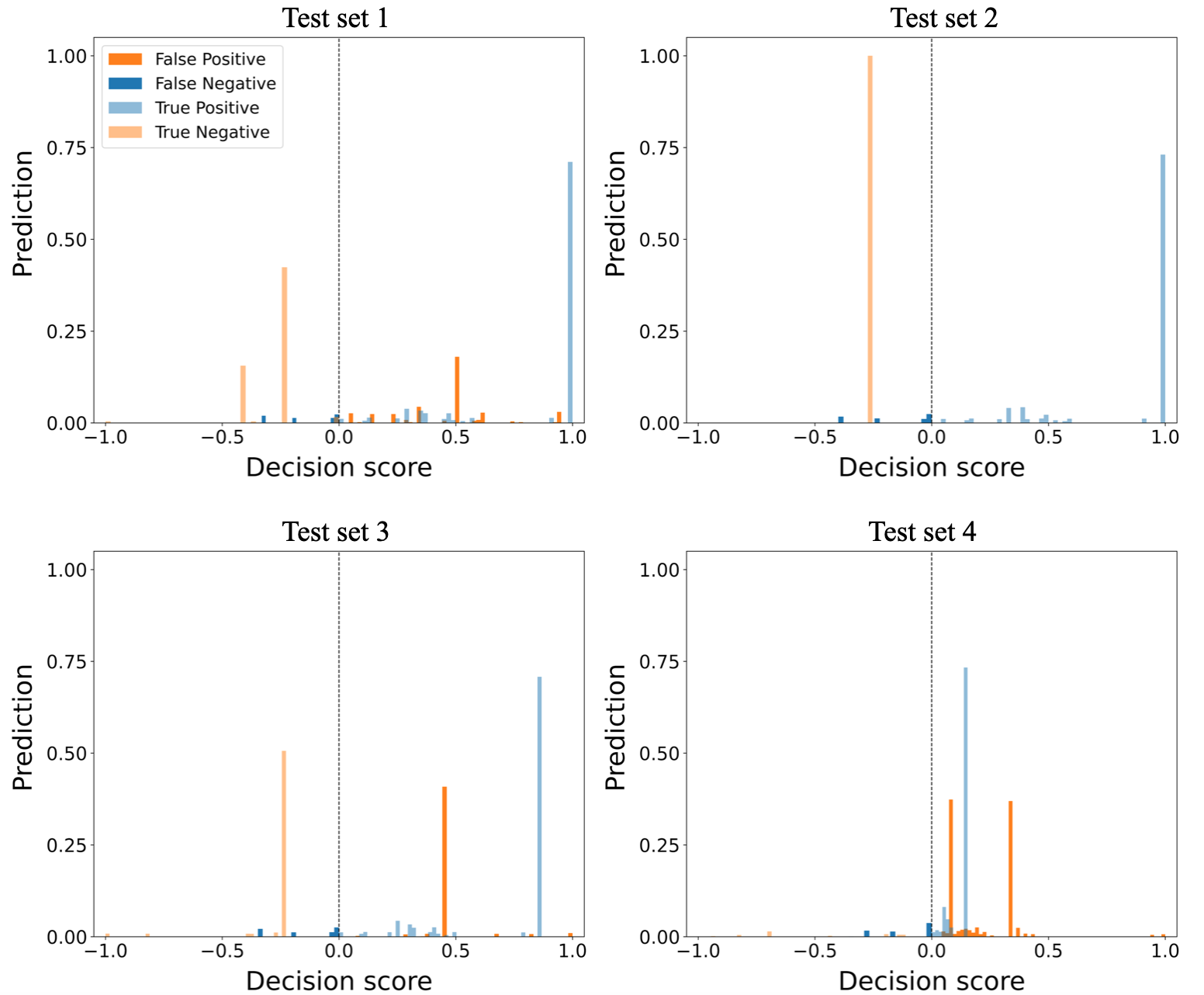
Maximum-score ensemble method has TP values above in test sets 1-4 and high TP scores confidence in test sets 1-3. The method detected all anomalies in test set 2 by having a TN value of , which explains its high performance on test set 2. Figure 5 shows that the method misclassified over of test set 4 anomalies as normal instances, which resulted in high FP and low TN values. The visualization of the algorithm performance on test set 5 is similar to test set 4, and therefore it is not shown here.
V-C Performance of Soft Voting Ensemble Method
Soft voting ensemble method achieved high performance on test set 1 with a precision, recall, and F1-score of , , and respectively. The method’s performance on test sets 1 and 2 are similar, with F1-scores of and respectively. However, the method has low performance on test sets 4 and 5, with F1-scores in both cases below . The method’s low performance on test sets 4 and 5 signifies its inability to detect timing bits anomalies. Figure 6 shows the soft voting ensemble method results of the normalized TP, TN, FP, and FN values on test sets 1, 2, 3, and 5.
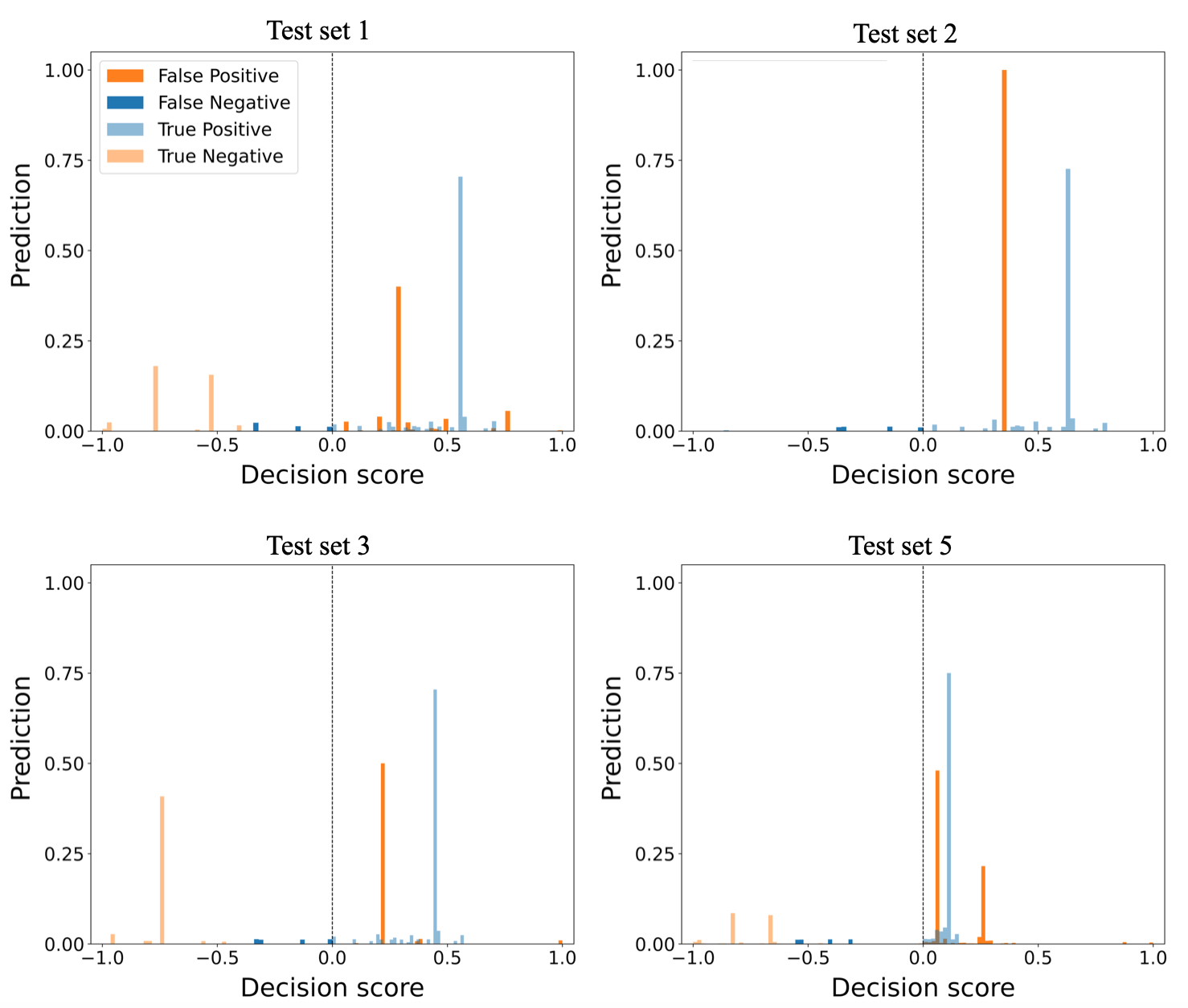
Soft voting ensemble method has a TP prediction confidence over on test sets 1 and 2. Again, the method correctly predicted the TLIGHT system’s normal behavior in all test cases by having TP predictions over . However, the method misclassified all anomalies in test set 2 as normal instances leading to a high FP rate of , which explains the low performance of the algorithm on test set 2. The method’s confidence levels of TP and FP predictions on test set 5 are below . Also, over of anomalies in test set 5 are misclassified as normal instances leading to high FP rate. The visualization of the algorithm performance on test set 4 is similar to test set 5, and therefore it is not shown here.
V-D Performance of Weighted Voting Ensemble Method
The weighted voting ensemble method uses an ordinary least squares regression model for assigning weights to the base detectors. The weighted voting with ordinary least squares regression model WV-OLS has a similar performance to soft voting ensemble method on all datasets. The method achieved its highest performance on test set 1 with precision, recall, and F1-score of . The method’s performance on test set 2 and 3 are similar, with F1-scores of and respectively. This method has its lowest performance on test sets 4 and 5, with F1-scores below . The method’s low performance on test sets 4 and 5 signifies its inability to detect anomalies in timing bits. Figure 7 shows the WV-OLS ensemble method results of the normalized TP, TN, FP, and FN values on test sets 3 and 4.
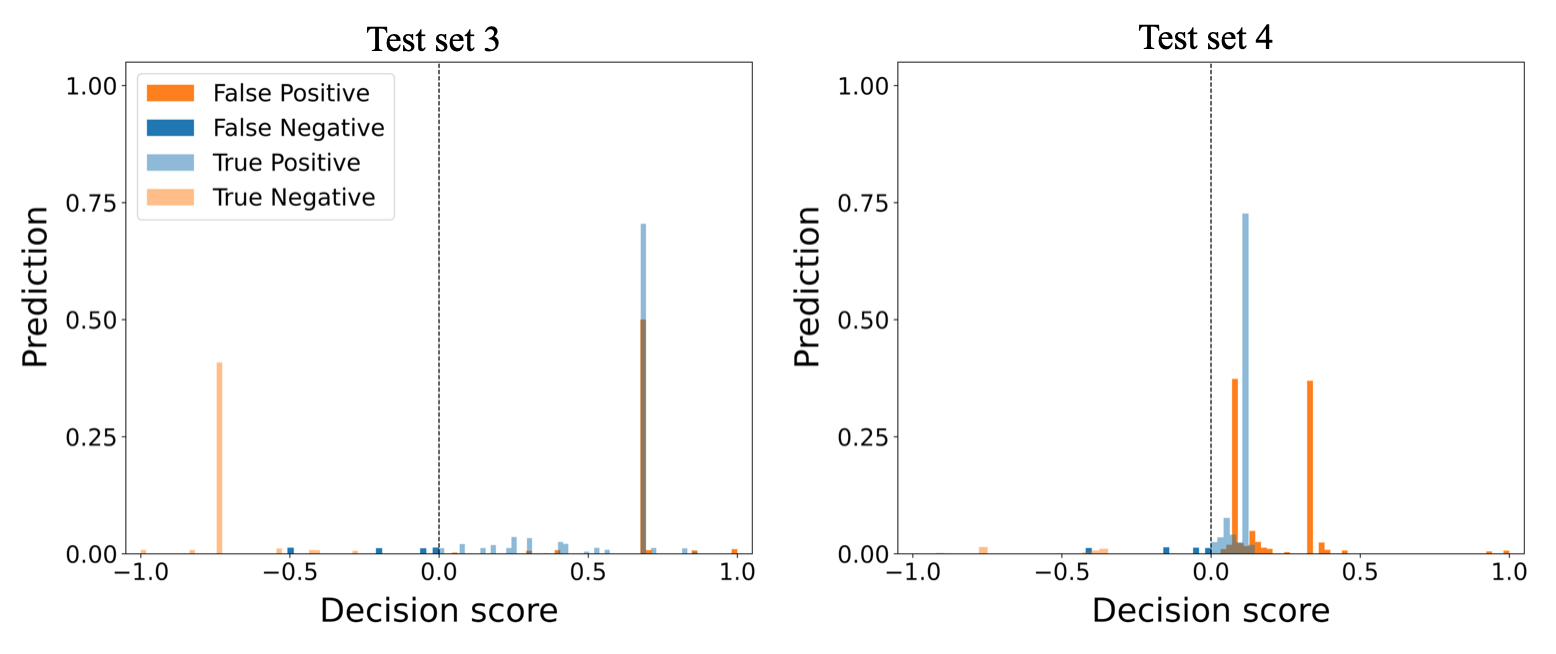
The WV-OLS method correctly predicted the TLIGHT system’s normal behavior in all test sets with a TP score over 60%. The method’s confidence of TP and FP predictions on test set 3 is over , whereas the confidence of the TP and FP predictions on test set 4 is below . The visualization of the algorithm performance on test sets 1 and 2 are similar to test set 3, whereas the visualization of the algorithm performance on test sets 5 is similar to test set 4, and therefore they are not shown here. The method misclassified over of anomalies as normal in test set 4 leading to high FP. The method’s high FP value on test set 4 explains its low performance on test set 4.
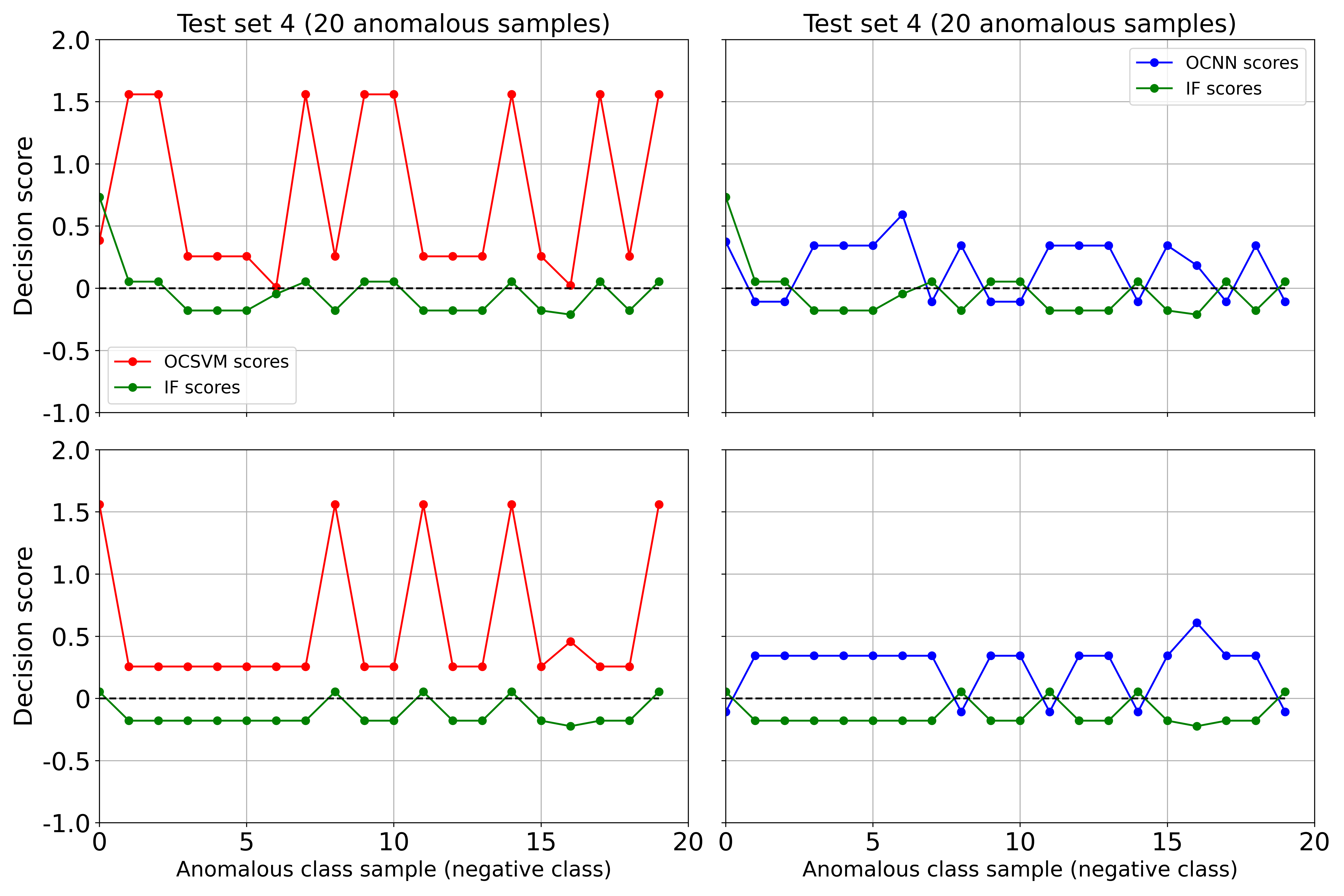
WV-OLS ensemble method performance is lower than maximum score ensemble method. The WV-OLS ensemble method’s low performance results from the similarities between OCSVM and OCNN objective functions which makes their errors correlated. OCNN is formulated based on the foundation of OCSVM optimization problem [22]; hence WV-OLS method’s assigned weights are biased towards OCSVM and OCNN. Figure 8 shows the decision scores of WV-OLS base dectectors on 20 anomalous samples of test set 4. In each of the 20 anomalous samples, a negative score is desired to signify correct prediction. However, the OCSVM base detector misclassifies the anomalous test samples by producing positive scores for all 20 anomalous test samples. The OCNN base detector misclassifies more than 50% of the anomalous test samples. On the contrary, the IF base detector correctly detects more than 60% of the anomalous test samples. Similar misclassifications of anomalous test samples by the OCSVM and OCNN base detectors were observed across all test sets, explaining the low performance of the WV-OLS approach to weighted voting.
In an attempt to control the WV-OLS method’s high bias, the ordinary least squares linear regression model for assigning weights in Algorithm 3 can be replaced by a ridge regression model [64] or K-nearest neighbor model [65]. The resulting weighted voting approaches using these learning models are denoted WV-Ridge and WV-KNN, respectively. The proposed weighted voting method using different linear regression models are compared with the weighted voting approach found in [25]. WV-[25] uses RMSE for assigning weights to the base detectors. Table III shows accuracy, precision, recall, and F1-score for the four weighted voting approaches. The WV-OLS approach shows no significant improvement over WV-Ridge and weighted voting method in previous work [25]. WV-OLS, WV-Ridge, and WV-[25] all use linear models for assigning weights to base detectors’ output; therefore, the same fundamental limitation associated with the bias of OCSVM and OCNN base detectors holds. However, WV-KNN outperforms WV-[25], WV-OLS, and WV-Ridge on test sets 1, 2, and 5 across all performance metrics. WV-KNN achieved over 7% improvement in accuracy, precision, recall, and F1-score on test set 2 as compared to WV-[25], WV-OLS, and WV-Ridge. WV-KNN achieved high performance because it relies on distance in the feature space instead of making a linear assumption about the dataset.
| Dataset | WV Method | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|---|
| Test | WV-[25] | 0.89 | 0.88 | 0.89 | 0.89 |
| Set | WV-OLS | 0.89 | 0.89 | 0.89 | 0.89 |
| 1 | WV-Ridge | 0.89 | 0.89 | 0.89 | 0.89 |
| WV-KNN | 0.90 | 0.91 | 0.90 | 0.90 | |
| Test | WV-[25] | 0.85 | 0.81 | 0.85 | 0.83 |
| Set | WV-OLS | 0.86 | 0.81 | 0.86 | 0.83 |
| 2 | WV-Ridge | 0.86 | 0.81 | 0.86 | 0.83 |
| WV-KNN | 0.94 | 0.96 | 0.94 | 0.95 | |
| Test | WV-[25] | 0.85 | 0.83 | 0.85 | 0.84 |
| Set | WV-OLS | 0.85 | 0.84 | 0.85 | 0.84 |
| 3 | WV-Ridge | 0.85 | 0.84 | 0.85 | 0.84 |
| WV-KNN | 0.85 | 0.85 | 0.85 | 0.85 | |
| Test | WV-[25] | 0.67 | 0.56 | 0.67 | 0.58 |
| Set | WV-OLS | 0.67 | 0.56 | 0.67 | 0.58 |
| 4 | WV-Ridge | 0.67 | 0.56 | 0.67 | 0.58 |
| WV-KNN | 0.66 | 0.55 | 0.66 | 0.58 | |
| Test | WV-[25] | 0.58 | 0.67 | 0.58 | 0.51 |
| Set | WV-OLS | 0.57 | 0.67 | 0.57 | 0.50 |
| 5 | WV-Ridge | 0.57 | 0.67 | 0.57 | 0.50 |
| WV-KNN | 0.73 | 0.77 | 0.73 | 0.71 |
Figure 9 shows WV-KNN ensemble method results of the normalized TP, TN, FP, and FN values on test sets 2 and 5. WV-KNN correctly detects all anomalies in test set set with over 25% prediction confidence. Also, WV-KNN correctly detects over 70% of normal data points with 100% prediction confidence leading to high TP value in test set 2. WV-KNN’s high anomaly detection on test set 2 explains why it achieves over 90% accuracy, precision, recall, and F1-score. WV-[25], WV-OLS, and WV-Ridge are unable to detect more than 20% of anomalies in test set 5. However, WV-KNN detects over 50% of anomalies in test set 5 which explains why WV-KNN has over 10% improved accuracy, precison, recall, and F1-score as compared to WV-[25], WV-OLS, and WV-Ridge. The visualization of WV-KNN performance on test 1 and 3 are similar to WV-OLS visualization on test set 3 in Figure 7. The visualization of WV-KNN performance on test set 4 is similar to the WV-OLS visualization on test set 4 in Figure 7, and therefore it is not shown here. Lastly, WV-[25] and WV-Ridge performance visualizations across all test sets are similar to those of WV-OLS in Figure 7, and therefore they are not shown here.
V-E Performance of Stacking-based Ensemble Method
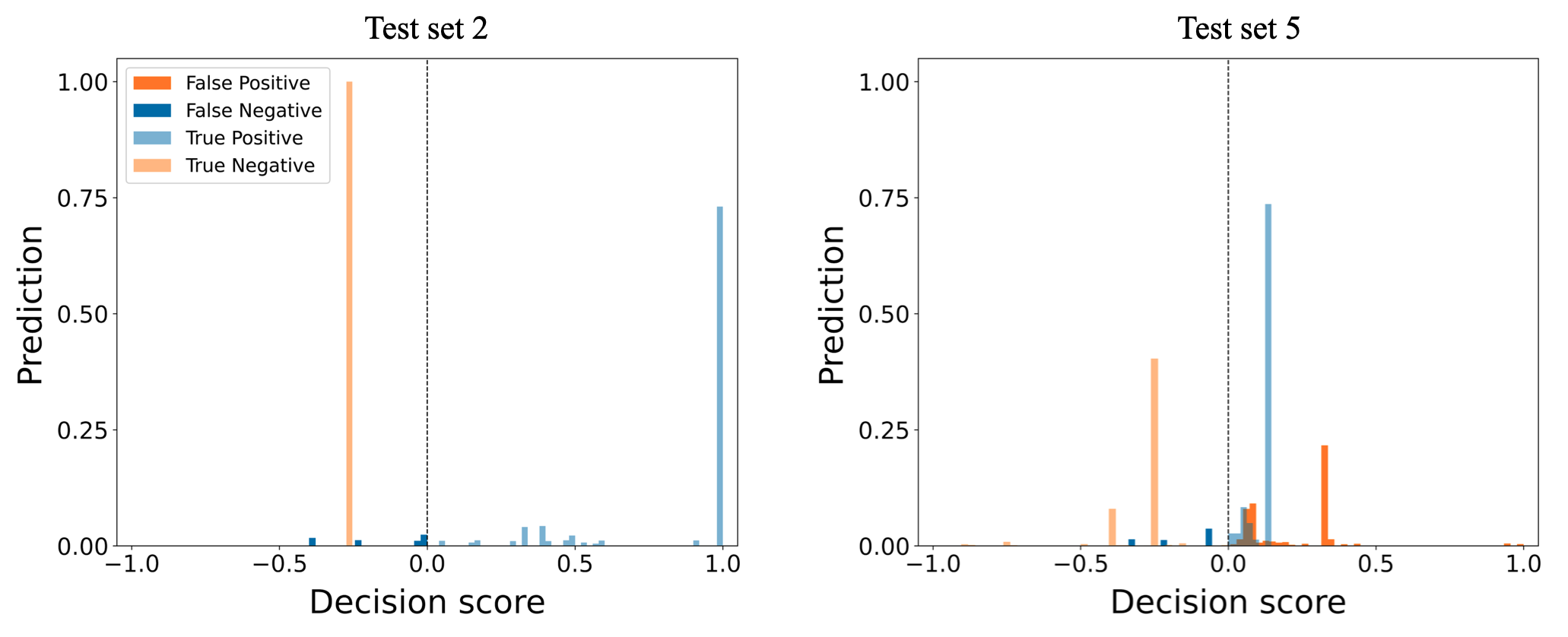
Stacking based ensemble method uses an IF meta-detector to consider the results of the base detectors. This method has excellent performance on all test sets. It achieved its highest performance on test sets 2 and 4 by having the same precision, recall, and F1-score of , , and , respectively. Unlike other ensemble methods described in previous sections, the stacking-based ensemble has high performance on test sets 4 and 5 with recall values of and respectively. The method’s performance shows its ability to detect TLIGHT signals anomalies and its robustness in detecting timing bits anomalies. The method had its worst performance on test set 3 with a recall and F1-score of and respectively. The high performance of the stacking-based ensemble method is due to the IF meta-detector’s ability to extract significant information from the base detectors in an unsupervised learning manner. Figure 10 shows the stacking-based ensemble method results of the normalized TP, TN, FP, and FN values on test sets 1, 2, 4, and 5.
This method correctly predicted all anomalies in test 2 with high prediction confidence and TN value of , which explains why it attained an F1-score of . This method correctly predicted TLIGHT system normal behavior with TP value over at prediction confidence in all test sets. Again, in all test sets, over of TN predictions have prediction confidence over . A closer assessment of Figure 10 confirms that not only is the stacking-based method excellent at detecting anomalies, but in all test cases, the method is confident about its decisions. The visualization of the algorithm performance on test sets 3 is similar to test set 1, and therefore it is not shown here.
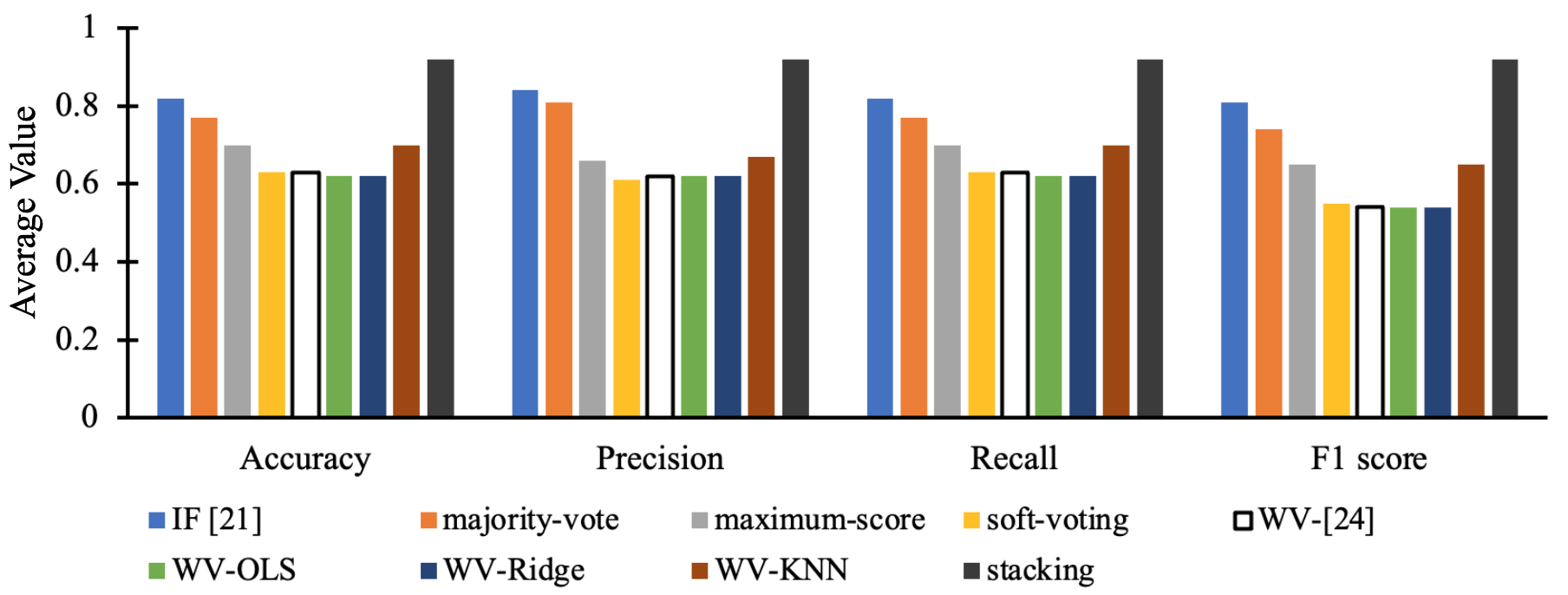
Figure 11 shows the average performance of the ensemble methods with their respective standard deviations on the five test sets. Stacking-based ensemble and IF [22] have the least standard deviations 0.07 on all performance metrics across all test sets. WV [26], WV-OLS, WV-Ridge, and soft-voting methods have the high standard deviations 0.1 as a result of their poor performance on test sets 4 and 5. Table IV provides a performance summary of all ensemble methods explored in this work. It is evident from Table IV that stacking-based ensemble method has superior performance over all test sets.
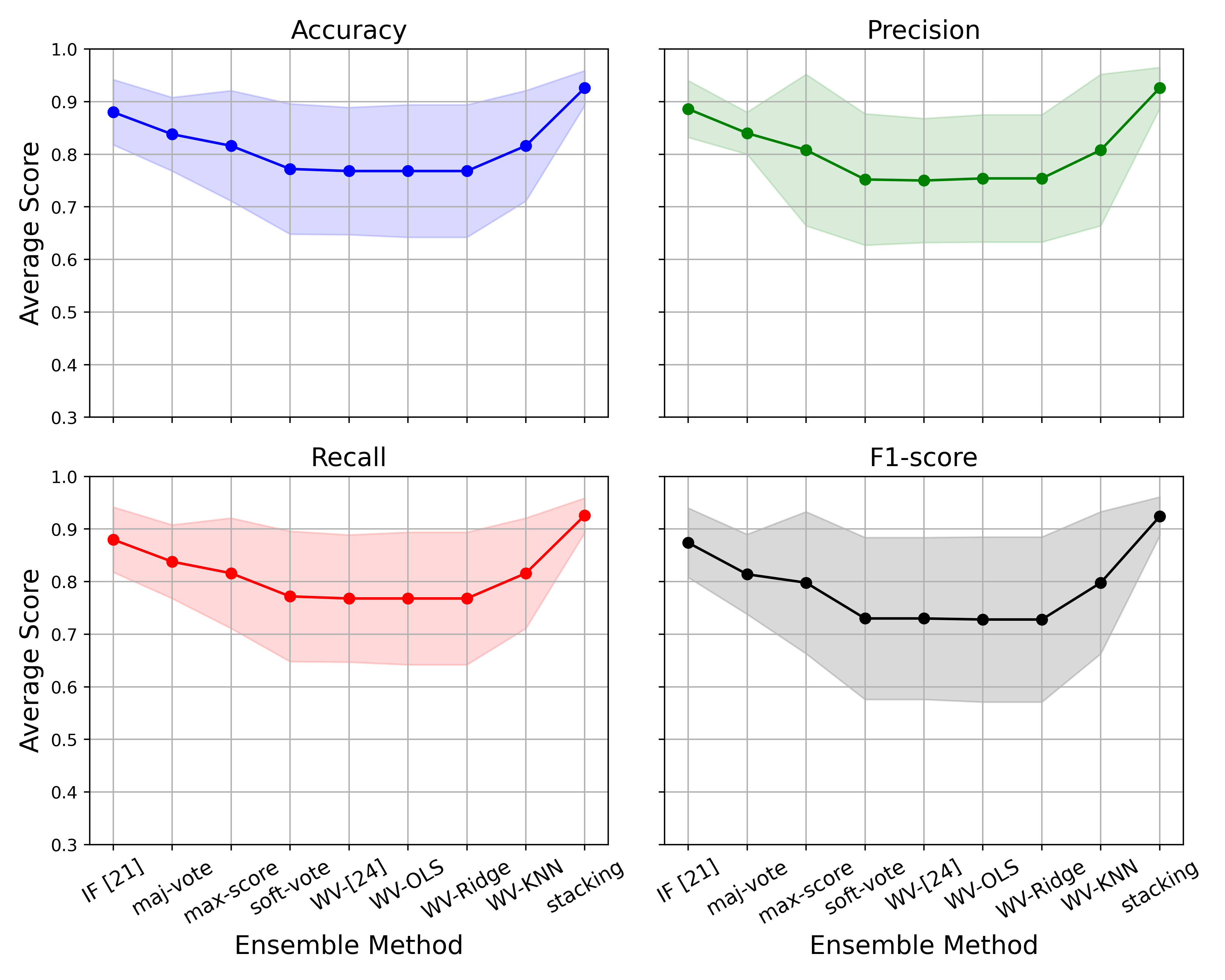
| Accuracy | Precision | Recall | F1-score | |||||
| Technique | Mean | std | Mean | std | Mean | std | Mean | std |
| IF [22] | 0.880 | 0.062 | 0.886 | 0.054 | 0.880 | 0.062 | 0.874 | 0.066 |
| Majority-vote | 0.838 | 0.070 | 0.840 | 0.040 | 0.838 | 0.070 | 0.814 | 0.076 |
| Maximum-score | 0.816 | 0.105 | 0.808 | 0.144 | 0.816 | 0.105 | 0.798 | 0.135 |
| Soft-voting | 0.772 | 0.124 | 0.752 | 0.125 | 0.772 | 0.124 | 0.730 | 0.154 |
| WV-[25] | 0.768 | 0.121 | 0.750 | 0.118 | 0.768 | 0.121 | 0.730 | 0.154 |
| WV-OLS | 0.768 | 0.126 | 0.754 | 0.121 | 0.768 | 0.126 | 0.728 | 0.157 |
| WV-Ridge | 0.768 | 0.126 | 0.754 | 0.121 | 0.768 | 0.126 | 0.728 | 0.157 |
| WV-KNN | 0.816 | 0.105 | 0.808 | 0.144 | 0.816 | 0.105 | 0.798 | 0.135 |
| Stacking | 0.926 | 0.033 | 0.926 | 0.039 | 0.926 | 0.033 | 0.924 | 0.037 |
V-F Comparison with Previous Work
An anomaly detection performance comparison between individual unsupervised machine learning detectors using the same dataset is presented in [22]. The unsupervised ensemble methods proposed here strategically aggregates the decision scores of the three methods examined in [22]. This section compares the average performance of the proposed unsupervised ensemble techniques with the reported results of the highest performing algorithm in [22] across all test sets.
First, the comparison is performed across test sets 1-3, which consisted of TLIGHT system signal anomalies, excluding timing bits anomalies. Figure 12 shows the average test sets 1–3 performance proposed ensemble methods in this work and the reported results of IF in [22]. Soft-voting, WV-OLS, WV-Ridge and WV-[25] methods have similar average accuracy, precision, recall, and F1-score. Majority vote and WV-KNN have similar average accuracy, precision, recall, and F1-score. The stacking ensemble method and IF [22] algorithm achieve the same average accuracy, precision, recall, and F1-score of . Therefore, the stacking approach and IF [22] have similar detection performance on TLIGHT system anomalies, excluding timing bit anomalies. Stacking ensemble and IF [22] have superior performance to all other ensemble techniques.
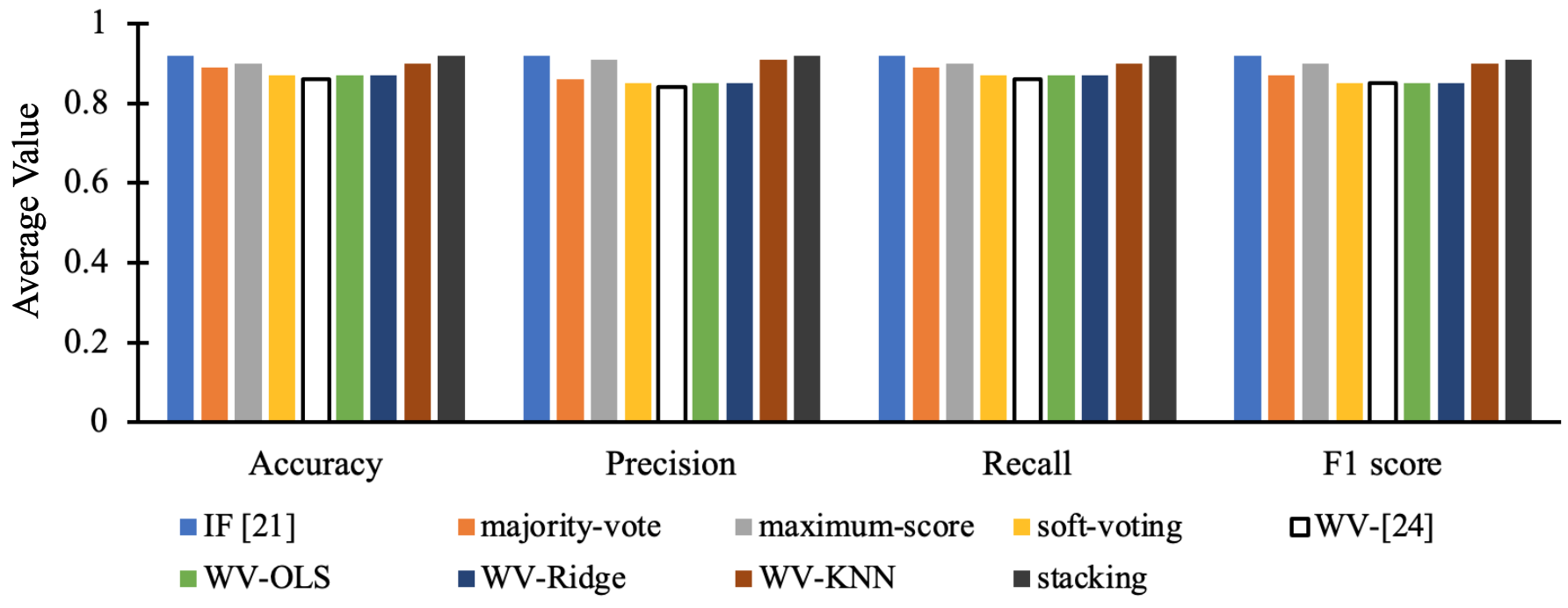
Test sets 4–5 consist of timing bits anomalies unique to [22] and this work. Figure 13 shows the average performance comparison between the ensemble methods presented in this work and the reported results of IF algorithm in [22] on test sets 4–5. Soft-voting maximum-score, WV-[25], WV-OLS, and WV-Ridge methods have relatively similar average accuracy, and precision on test sets 4–5 which were inferior to WV-KNN and maximum vote ensemble methods. Stacking-based ensemble achieves the same average accuracy, precision, recall, and F1-score of , whereas IF [22] achieves the same average accuracy, precision, recall, and F1-score of . Overall, stacking-based ensemble method achieves outstanding performance on all evaluation metrics on test sets 4–5. The stacking-based ensemble method’s high performance on all test sets compared to previous work [22] upholds the motivation of this work: effective unsupervised ensembling of anomaly detection algorithms could result in a robust detection model capable of identifying anomalies in arbitrary datasets.
Stacking-based ensemble methods for classification purposes using supervised machine learning meta-detectors were examined in [70, 71, 72, 73, 74, 75]. However, a direct comparison between the proposed stacking-based ensemble method in this work and the works in [70, 71, 72, 73, 74, 75] is unrealistic because of the unsupervised ensemble approach adopted in this work for anomaly detection purposes.
In order to validate the results for the best performing algorithm, stacking-based ensemble method is compared with previous work trained and evaluated on the same TLIGHT system dataset by using statistical hypothesis test. Statistical hypothesis testing is employed to validate and ensure fair comparison between the stacking ensemble method and previous work. Table III compares the average performance of the best algorithm in [22] with the proposed stacking algorithm in this work. Statistical evidence about the best-performing technique is conducted using one-way analysis of variance (ANOVA) in order to determine if there is any significant difference between the average performance of the method in this work and that of previous work [22]. F1-score is selected as an evaluation metric in the hypothesis test because it measures the balance between precision and recall. The following assumptions are made about the ICS dataset
-
•
data points in each test sample identically distributed and independent; and
-
•
data points in each test sample are normally distributed.
Additionally, the hypotheses for the statistical test are
-
•
null hypothesis : The mean F1-scores of all anomaly detection models are equal; and
-
•
alternate hypothesis : One or more of the mean F1-score of the anomaly detection models are unequal.
Anomaly detection performance of the stacking-based ensemble in this work and the IF in [22] are evaluated on twenty different test samples of the exact sizes as test sets 1-5. Furthermore, each model’s F1-score is computed on the twenty different samples of each test set. Results from one-way ANOVA test shows an of 42.54, and a p-value 0.001. Since the p-value is below 0.05, one-way ANOVA provides significant evidence to reject the null hypothesis. Rejecting the null hypothesis means there is a significant difference between IF [22] and stacking-based ensemble with confidence level. Because performance comparison is between two algorithms, one-way ANOVA results are sufficient to conclude that the stacking-based ensemble method outperforms IF [22].
V-G Practical Considerations and Limitations
The unsupervised ensemble methods presented in this work can be implemented in real-world PLC-based ICS infrastructure. One way is to adapt the experimental approach in this work, or the approach in [22] by serializing the trained ensemble models onto a separate computer with a data pipeline to the HMI historian and PLC memory addresses to receive data and perform real-time anomaly detection. Alternatively, the proposed methods can be implemented on both legacy and embedded PLCs by adapting a similar process outlined in [22]. That is, the trained ensemble models can be compiled to C code using open-source compilers [76, 77]. The resulting C code should be readily portable to dedicated embedded or general-purpose processors [78] for real-time anomaly detection.
Although this work proposes robust unsupervised ensemble techniques for anomaly detection in ICS, some limitations are associated with the proposed methods. First, ensembling OCSVM, OCNN, and IF base detectors make the proposed methods in this work expensive in terms of time and storage. That large amount of memory is required to store outputs of the base detectors and their ensemble output during training and testing. Moreover, the high time complexities of the proposed methods result from the effective summation of the base models’ time complexities and the time required for the voting function in each method to compute the final anomaly score. Despite the stacking-based method’s superior performance in all test cases, its IF meta-detector still requires hyperparameter tuning to achieve such robust performance. Lastly, the proposed WV-OLS has a fundamental limitation of high bias in situations where two or more base detectors have similar objective functions. The high bias effect is reduced by using a KNN learning algorithm for assigning the weights. In practice, a learning algorithm for the weighted voting method should be selected based on its ability to handle non-linear features and has low bias.
VI Conclusion
This work proposes five unsupervised ensemble anomaly detection techniques: majority-vote, maximum-score, soft voting, weighted voting, and stacking-based ensemble methods, specifically for anomaly detection in ICS. The proposed techniques incorporate OCSVM, OCNN, and IF base detectors for learning representations from the input dataset and voting strategy algorithms for combining the representations into final prediction scores. Dataset from a previously studied TLIGHT ICS system is used to train and evaluate the proposed algorithms. Majority-vote and maximum-score ensembles outperform soft-voting and WV-OLS with higher average accuracy, precision, and recall on all test datasets. The WV-OLS ensemble method’s lower performance relative to majority vote and maximum score methods is because of OCSVM and OCNN’s similar objective functions. As a result, the WV-OLS method’s assigned weights are biased towards OCSVM and OCNN, leading to a biased outcome. Changing the weighted-voting learning algorithm to KNN results in an improved performance which was at par with majority-vote ensemble method. Stacking-based ensemble outperform all other ensemble methods with higher average accuracy, precision, recall, and F1-score on all test datasets. Unlike other ensemble methods, which struggle to detect timing bits anomalies, stacking-based ensemble has excellent detection performance on timing bits anomalies. Not only does stacking-based ensemble produce high anomaly detection performance, but the approach is confident about all predictions. A hypothesis test involving analysis of variance is used to compare stacking-based ensemble method with previous work. The hypothesis test indicates that stacking-based ensemble outperforms previous work trained on the same dataset. The high performance of the stacking-based ensemble method on all evaluation metrics compared to previous work justifies the motivation of this work: effective unsupervised ensembling of anomaly detection algorithms could result in a robust detection model capable of identifying anomalies in arbitrary ICS datasets.
Future work would be as follows:
-
•
optimizing the weighted voting ensemble learning algorithm to mitigate its fundamental limitation of high bias in situations where two or more base detectors have similar objective functions and have correlated errors; and
-
•
extending the proposed ensemble methods to detecting anomalies in ICS network layer.
References
- [1] J. Sakhnini, H. Karimipour, A. Dehghantanha, R. M. Parizi, and G. Srivastava, “Security aspects of internet of things aided smart grids: A bibliometric survey,” Internet of things, vol. 14, p. 100111, 2021.
- [2] H. HaddadPajouh, A. Dehghantanha, R. M. Parizi, M. Aledhari, and H. Karimipour, “A survey on internet of things security: Requirements, challenges, and solutions,” Internet of Things, vol. 14, p. 100129, 2021.
- [3] L. Kello, The virtual weapon and international order. Yale University Press, 2019.
- [4] J.-P. A. Yaacoub, O. Salman, H. N. Noura, N. Kaaniche, A. Chehab, and M. Malli, “Cyber-physical systems security: Limitations, issues and future trends,” Microprocessors and Microsystems, vol. 77, p. 103201, 2020.
- [5] K. Thakur, M. L. Ali, N. Jiang, and M. Qiu, “Impact of cyber-attacks on critical infrastructure,” in 2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS). IEEE, 2016, pp. 183–186.
- [6] T. Plėta, M. Tvaronavičienė, S. D. Casa, and K. Agafonov, “Cyber-attacks to critical energy infrastructure and management issues: Overview of selected cases,” 2020.
- [7] H. Wardak, S. Zhioua, and A. Almulhem, “Plc access control: a security analysis,” in 2016 World Congress on Industrial Control Systems Security (WCICSS). IEEE, 2016, pp. 1–6.
- [8] A. Abbasi, T. Holz, E. Zambon, and S. Etalle, “Ecfi: Asynchronous control flow integrity for programmable logic controllers,” in Proceedings of the 33rd Annual Computer Security Applications Conference, 2017, pp. 437–448.
- [9] A. Abbasi, “Ghost in the plc: stealth on-the-fly manipulation of programmable logic controllers’ i/o,” Proceedings of the Black Hat EU, London, UK, pp. 1–4, 2016.
- [10] K. Yau and K.-P. Chow, “Plc forensics based on control program logic change detection,” Journal of Digital Forensics, Security and Law, vol. 10, no. 4, p. 5, 2015.
- [11] R. Langmann and M. Stiller, “The plc as a smart service in industry 4.0 production systems,” Applied Sciences, vol. 9, no. 18, p. 3815, 2019.
- [12] K. Tsiknas, D. Taketzis, K. Demertzis, and C. Skianis, “Cyber threats to industrial iot: A survey on attacks and countermeasures,” IoT, vol. 2, no. 1, pp. 163–188, 2021.
- [13] T. Spyridopoulos, T. Tryfonas, and J. May, “Incident analysis & digital forensics in scada and industrial control systems,” 2013.
- [14] C. Hwang and T. Lee, “E-sfd: Explainable sensor fault detection in the ics anomaly detection system,” IEEE Access, vol. 9, pp. 140 470–140 486, 2021.
- [15] K. Boeckl, K. Boeckl, M. Fagan, W. Fisher, N. Lefkovitz, K. N. Megas, E. Nadeau, D. G. O’Rourke, B. Piccarreta, and K. Scarfone, Considerations for managing Internet of Things (IoT) cybersecurity and privacy risks. US Department of Commerce, National Institute of Standards and Technology, 2019.
- [16] Y. Chen and W. Wu, “Application of one-class support vector machine to quickly identify multivariate anomalies from geochemical exploration data,” Geochemistry: Exploration, Environment, Analysis, vol. 17, no. 3, pp. 231–238, 2017.
- [17] T. Welborn, “One-class support vector machines approach for trust-aware recommendation systems,” 2021.
- [18] K. Hiranai, A. Kuramoto, and A. Seo, “Detection of anomalies in working posture during obstacle avoidance tasks using one-class support vector machine,” Journal of Japan Industrial Management Association, vol. 72, no. 2E, pp. 125–133, 2021.
- [19] S. Shitharth et al., “An enhanced optimization based algorithm for intrusion detection in scada network,” Computers & Security, vol. 70, pp. 16–26, 2017.
- [20] C. Yin, Y. Zhu, J. Fei, and X. He, “A deep learning approach for intrusion detection using recurrent neural networks,” Ieee Access, vol. 5, pp. 21 954–21 961, 2017.
- [21] B. E. Aboah, J. W. Bruce, and D. A. Talbert, “Anomaly detection for a water treatment system based on one-class neural network,” IEEE Access, vol. 10, pp. 115 179–115 191, 2022.
- [22] B. E. Aboah and J. Bruce, “Unsupervised machine learning techniques for detecting plc process control anomalies,” Journal of Cybersecurity and Privacy, vol. 2, no. 2, pp. 220–244, 2022.
- [23] M. Elnour, N. Meskin, and K. M. Khan, “Hybrid attack detection framework for industrial control systems using 1d-convolutional neural network and isolation forest,” in 2020 IEEE Conference on Control Technology and Applications (CCTA). IEEE, 2020, pp. 877–884.
- [24] B. E. Aboah and J. W. Bruce, “Anomaly detection for industrial control systems based on neural networks with one-class objective function,” in Proceedings of Student Research and Creative Inquiry Day, vol. 5. Tennessee Technological University, 2021.
- [25] C. C. Aggarwal, “An introduction to outlier analysis,” in Outlier analysis. Springer, 2017, pp. 1–34.
- [26] C. C. Aggarwal and C. R. D. Clustering, “Algorithms and applications,” 2014.
- [27] C. C. Aggarwal et al., Data mining: the textbook. Springer, 2015, vol. 1.
- [28] J. B. Cabrera, C. Gutiérrez, and R. K. Mehra, “Ensemble methods for anomaly detection and distributed intrusion detection in mobile ad-hoc networks,” Information fusion, vol. 9, no. 1, pp. 96–119, 2008.
- [29] G. Folino, F. S. Pisani, and P. Sabatino, “A distributed intrusion detection framework based on evolved specialized ensembles of classifiers,” in European Conference on the Applications of Evolutionary Computation. Springer, 2016, pp. 315–331.
- [30] Z. Zhao, K. G. Mehrotra, and C. K. Mohan, “Ensemble algorithms for unsupervised anomaly detection,” in International Conference on Industrial, Engineering and Other Applications of Applied Intelligent Systems. Springer, 2015, pp. 514–525.
- [31] M. Amozegar and K. Khorasani, “An ensemble of dynamic neural network identifiers for fault detection and isolation of gas turbine engines,” Neural Networks, vol. 76, pp. 106–121, 2016.
- [32] A. A. Aburomman and M. B. I. Reaz, “A novel svm-knn-pso ensemble method for intrusion detection system,” Applied Soft Computing, vol. 38, pp. 360–372, 2016.
- [33] L. Sun, S. Versteeg, S. Boztas, and A. Rao, “Detecting anomalous user behavior using an extended isolation forest algorithm: an enterprise case study,” arXiv preprint arXiv:1609.06676, 2016.
- [34] D. Haidar and M. M. Gaber, “Adaptive one-class ensemble-based anomaly detection: an application to insider threats,” in 2018 International Joint Conference on Neural Networks (IJCNN). IEEE, 2018, pp. 1–9.
- [35] P. Parveen, N. Mcdaniel, Z. Weger, J. Evans, B. Thuraisingham, K. Hamlen, and L. Khan, “Evolving insider threat detection stream mining perspective,” International Journal on Artificial Intelligence Tools, vol. 22, no. 05, p. 1360013, 2013.
- [36] A. Diop, N. Emad, T. Winter, and M. Hilia, “Design of an ensemble learning behavior anomaly detection framework,” International Journal of Computer and Information Engineering, vol. 13, no. 10, pp. 547–555, 2019.
- [37] F. Yuan, Y. Cao, Y. Shang, Y. Liu, J. Tan, and B. Fang, “Insider threat detection with deep neural network,” in International Conference on Computational Science. Springer, 2018, pp. 43–54.
- [38] J. Inoue, Y. Yamagata, Y. Chen, C. M. Poskitt, and J. Sun, “Anomaly detection for a water treatment system using unsupervised machine learning,” in 2017 IEEE International Conference on Data Mining Workshops (ICDMW). IEEE, 2017, pp. 1058–1065.
- [39] A.-H. Muna, N. Moustafa, and E. Sitnikova, “Identification of malicious activities in industrial internet of things based on deep learning models,” Journal of Information security and applications, vol. 41, pp. 1–11, 2018.
- [40] S. Potluri, C. Diedrich, and G. K. R. Sangala, “Identifying false data injection attacks in industrial control systems using artificial neural networks,” in 2017 22nd IEEE International Conference on Emerging Technologies and Factory Automation (ETFA). IEEE, 2017, pp. 1–8.
- [41] S. Ahmed, Y. Lee, S.-H. Hyun, and I. Koo, “Unsupervised machine learning-based detection of covert data integrity assault in smart grid networks utilizing isolation forest,” IEEE Transactions on Information Forensics and Security, vol. 14, no. 10, pp. 2765–2777, 2019.
- [42] I. Ahmad, S. Shahabuddin, H. Malik, E. Harjula, T. Leppänen, L. Loven, A. Anttonen, A. H. Sodhro, M. M. Alam, M. Juntti et al., “Machine learning meets communication networks: Current trends and future challenges,” IEEE Access, vol. 8, pp. 223 418–223 460, 2020.
- [43] R. Chalapathy, A. K. Menon, and S. Chawla, “Anomaly detection using one-class neural networks,” arXiv preprint arXiv:1802.06360, 2018.
- [44] Y. Bengio, Y. LeCun et al., “Scaling learning algorithms towards ai,” Large-scale kernel machines, vol. 34, no. 5, pp. 1–41, 2007.
- [45] T. Fawcett and N. Mishra, Proceedings of the Twentieth International Conference on International Conference on Machine Learning. AAAI Press, 2003.
- [46] S. Siemens, “S7-300 programmable controller quick start, primer, preface,” C79000-G7076-C500-01, Nuremberg, Germany, Tech. Rep., 1996.
- [47] T. R. Alves, M. Buratto, F. M. De Souza, and T. V. Rodrigues, “Openplc: An open source alternative to automation,” in IEEE Global Humanitarian Technology Conference (GHTC 2014). IEEE, 2014, pp. 585–589.
- [48] P. Mazurkiewicz, “An open source scada application in a small automation system,” Measurement Automation Monitoring, vol. 62, 2016.
- [49] D. C. Le and N. Zincir-Heywood, “Anomaly detection for insider threats using unsupervised ensembles,” IEEE Transactions on Network and Service Management, vol. 18, no. 2, pp. 1152–1164, 2021.
- [50] M. Ganaie, M. Hu et al., “Ensemble deep learning: A review,” arXiv preprint arXiv:2104.02395, 2021.
- [51] C. Raghuraman, “Detecting anomalies in programmable logic controllers through parameter modeling,” Master’s thesis, University of Twente, 2021.
- [52] R. Zhang, L. Xia, and Y. Lu, “Anomaly detection of ics based on eb-ocsvm,” in Journal of Physics: Conference Series, vol. 1267, no. 1. IOP Publishing, 2019, p. 012054.
- [53] F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation forest,” in 2008 eighth ieee international conference on data mining. IEEE, 2008, pp. 413–422.
- [54] S. Hariri, M. C. Kind, and R. J. Brunner, “Extended isolation forest,” IEEE Transactions on Knowledge and Data Engineering, 2019.
- [55] M. U. Togbe, M. Barry, A. Boly, Y. Chabchoub, R. Chiky, J. Montiel, and V.-T. Tran, “Anomaly detection for data streams based on isolation forest using scikit-multiflow,” in International Conference on Computational Science and Its Applications. Springer, 2020, pp. 15–30.
- [56] H. Sayadi, N. Patel, S. M. PD, A. Sasan, S. Rafatirad, and H. Homayoun, “Ensemble learning for effective run-time hardware-based malware detection: A comprehensive analysis and classification,” in 2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC). IEEE, 2018, pp. 1–6.
- [57] X. Dong, Z. Yu, W. Cao, Y. Shi, and Q. Ma, “A survey on ensemble learning,” Frontiers of Computer Science, vol. 14, no. 2, pp. 241–258, 2020.
- [58] S. Forouzandeh, K. Berahmand, and M. Rostami, “Presentation of a recommender system with ensemble learning and graph embedding: a case on movielens,” Multimedia Tools and Applications, vol. 80, no. 5, pp. 7805–7832, 2021.
- [59] G. Brown and L. I. Kuncheva, ““good” and “bad” diversity in majority vote ensembles,” in International workshop on multiple classifier systems. Springer, 2010, pp. 124–133.
- [60] A. Géron, “Hands-on machine learning with scikit-learn and tensorflow: Concepts,” Tools, and Techniques to build intelligent systems, 2017.
- [61] S. Lal, R. Jiaswal, N. Sardana, A. Verma, A. Kaur, and R. Mourya, “Orfdetector: ensemble learning based online recruitment fraud detection,” in 2019 Twelfth International Conference on Contemporary Computing (IC3). IEEE, 2019, pp. 1–5.
- [62] M. Fathi, M. Azadi, G. Kamali, and A. H. Meshkatee, “Improving precipitation forecasts over iran using a weighted average ensemble technique,” Journal of Earth System Science, vol. 128, no. 5, pp. 1–17, 2019.
- [63] H. Paulheim and R. Meusel, “A decomposition of the outlier detection problem into a set of supervised learning problems,” Machine Learning, vol. 100, no. 2, pp. 509–531, 2015.
- [64] L. Rokach and O. Maimon, “Decision trees,” in Data mining and knowledge discovery handbook. Springer, 2005, pp. 165–192.
- [65] L. E. Peterson, “K-nearest neighbor,” Scholarpedia, vol. 4, no. 2, p. 1883, 2009.
- [66] G. C. McDonald, “Ridge regression,” Wiley Interdisciplinary Reviews: Computational Statistics, vol. 1, no. 1, pp. 93–100, 2009.
- [67] M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mané, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Viégas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu, and X. Zheng, “TensorFlow: Large-scale machine learning on heterogeneous systems,” 2015, software available from tensorflow.org. [Online]. Available: https://www.tensorflow.org/
- [68] F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay, “Scikit-learn: Machine learning in Python,” Journal of Machine Learning Research, vol. 12, pp. 2825–2830, 2011.
- [69] B. E. Aboah and J. Bruce, “A new histogram-based visualization tool for analyzing anomaly detection algorithm performance,” Proceedings of Student Research and Creative Inquiry Day, vol. 6, 2022.
- [70] Y. Xia, C. Liu, B. Da, and F. Xie, “A novel heterogeneous ensemble credit scoring model based on bstacking approach,” Expert Systems with Applications, vol. 93, pp. 182–199, 2018.
- [71] S. A. El-Shorbagy, W. M. El-Gammal, and W. M. Abdelmoez, “Using smote and heterogeneous stacking in ensemble learning for software defect prediction,” in Proceedings of the 7th International Conference on Software and Information Engineering, 2018, pp. 44–47.
- [72] F. Akhtar, J. Li, Y. Pei, A. Imran, A. Rajput, M. Azeem, and Q. Wang, “Diagnosis and prediction of large-for-gestational-age fetus using the stacked generalization method,” Applied Sciences, vol. 9, no. 20, p. 4317, 2019.
- [73] S. L. Javan, M. M. Sepehri, M. L. Javan, and T. Khatibi, “An intelligent warning model for early prediction of cardiac arrest in sepsis patients,” Computer methods and programs in biomedicine, vol. 178, pp. 47–58, 2019.
- [74] M. Ahmed, H. Afzal, I. Siddiqi, M. F. Amjad, and K. Khurshid, “Exploring nested ensemble learners using overproduction and choose approach for churn prediction in telecom industry,” Neural Computing and Applications, vol. 32, no. 8, pp. 3237–3251, 2020.
- [75] M. L. Williams, W. P. James, and M. T. Rose, “Variable segmentation and ensemble classifiers for predicting dairy cow behaviour,” biosystems engineering, vol. 178, pp. 156–167, 2019.
- [76] H. Unlu, “Efficient neural network deployment for microcontroller,” arXiv preprint arXiv:2007.01348, 2020.
- [77] “NNCG: Neural Network Code Generator, howpublished = https://github.com/iml130/nncg, note = Accessed: 2022-03-03.”
- [78] O. Urbann, S. Camphausen, A. Moos, I. Schwarz, S. Kerner, and M. Otten, “Ac code generator for fast inference and simple deployment of convolutional neural networks on resource constrained systems,” in 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS). IEEE, 2020, pp. 1–7.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c231b852-7c78-464e-a268-92963dcdeb43/em.png) |
Emmanuel Aboah Boateng (Member, IEEE) received the BSc. degree in Electrical and Electronic Engineering from the University of Mines and Technology, Tarkwa, Ghana, in 2017 and the M.S degree in Electronics Engineering from Norfolk State University, Norfolk, VA, USA, in 2019. He is currently pursuing the Ph.D. degree in Electrical and Computer Engineering at Tennessee Technological University, USA, as a Carnegie Classification Scholar, where he specializes in developing artificial intelligence and data provenance analysis techniques to detect anomalies in hardware/embedded devices and cyber-physical systems. His research interests include machine learning, anomaly detection, cyber-physical systems security, signal processing, and fault diagnosis in hardware/embedded devices. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/c231b852-7c78-464e-a268-92963dcdeb43/jwb_small.jpg) |
J.W. Bruce (Senior Member, 2003; Member, 1994, Student Member, 1988) Dr. Bruce received the B.S.E. from the University of Alabama in Huntsville in 1991, the M.S.E.E. from the Georgia Institute of Technology in 1993, and the Ph.D. from the University of Nevada Las Vegas in 2000, all in electrical engineering. Dr. Bruce was a graduate research fellow of the Audio Engineering Society from 1998-2000. In 2018, Dr. Bruce joined the faculty in the Department of Electrical & Computer Engineering at Tennessee Technological University in Cookeville, TN. From 2000-2018, Dr. Bruce served in the Department of Electrical and Computer Engineering at Mississippi State University. Dr. Bruce has contributed to the research areas of embedded systems design, engineering education, UAVs, and data converter architecture design. Dr. Bruce’s research has resulted in more than 50 technical publications, one book chapter, and two books. |