Unsupervised Learning of Rydberg Atom Array Phase Diagram with Siamese Neural Networks
Abstract
We introduce an unsupervised machine learning method based on Siamese Neural Networks (SNN) to detect phase boundaries. This method is applied to Monte-Carlo simulations of Ising-type systems and Rydberg atom arrays. In both cases the SNN reveals phase boundaries consistent with prior research. The combination of leveraging the power of feed-forward neural networks, unsupervised learning and the ability to learn about multiple phases without knowing about their existence provides a powerful method to explore new and unknown phases of matter.
Keywords: Artificial Neural Networks, Phase Transitions, Ising Model, Rydberg Array
1 Introduction
Machine learning (ML) algorithms enable computers to learn from experience and generalize their gained knowledge to previously unknown settings. It is perhaps the most transformative technology of the early 21th century. The ability to recognize objects in images [1] or translate languages [2] without being explicitly programmed for this task, highlights the enormous potential of machine learning.
In recent years the physical sciences have adopted machine learning based algorithms to explore complex questions. Many methods have been designed to solve problems beyond the scope of data science, and have now the potential to revolutionize physics. The most prominent examples of promising tasks that have been tackled include finding phase transitions [3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13], reconstructing or simulating quantum systems [14, 15, 16, 17, 18, 19, 20] and rediscovering physical concepts [21, 22, 23, 24, 25, 26, 27, 28, 29, 30]. All these advances are summarized in review articles directed at different audiences. A didactical review to the most modern techniques can be found in [31], a review article focused on the applications of machine learning to examine quantum matter [32] and a broad overview across different physical disciplines is summarized in [33].
The current manuscript contributes to the development of methods that automatize the calculation of phase diagrams with little to no human prior knowledge about the nature of the underlying phases. The subfield of automated phase recognition can be subdivided into two categories: supervised and unsupervised phase recognition.
In the first case, the operating scientists are aware of the of the possible phases and have a rough estimate of where these phases are positioned in the phase diagram; however, they are unsure about the exact location of the phases and the transitions between them. Supervised learning of phase transitions can be based on different machine learning algorithms. It was initially introduced using convolutional neural networks [3], which are to this day the most powerful and robust tools to learn accurate physical phase boundaries. There are hybrid methods that build upon purposely mislabelling phase classes [4], methods that are built upon support vector machines [24], and other powerful frameworks [7, 34, 35, 36, 37, 38, 39]. These methods have demonstrated success across a wide range of physical systems, from simple spin lattices, over strongly correlated quantum systems, up to lattice gauge theories [8, 10, 11, 13, 23, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50].
The second category contains unsupervised phase recognition algorithms. These algorithms are useful when the researcher who is employing these tools is unaware of the underlying phase structure, meaning they do not know about the existence or location of certain phases and thus cannot supply this information to the machine learning algorithm. The simplest unsupervised phase recognition scheme is based on principal component analysis [5] and the most widely used unsupervised scheme that leverages the power of artificial neural networks is based on variational autoencoders [6]. These methods have been examined, enhanced [9, 51, 52, 53] and successfully applied to many systems in physics and materials science [54, 55, 56, 26, 57, 58, 59, 60, 61, 62, 63]. Compared to supervised algorithms, unsupervised methods usually have the drawback of lacking accuracy in determining phase boundaries [6], or restricting the kinds of order parameters that can be learned [5].
We introduce an unsupervised machine learning method to discover phase transitions based on Siamese neural networks (SNN). Siamese networks were initially introduced for fingerprint and signature identification [64, 65]. Instead of predicting a certain class, Siamese networks predict if two inputs belong to the same class. Hence, these networks can be used for multi- or infinite class classification by comparison to anchor data points whose label is known. Although Siamese networks are very powerful, they have experienced little use in the physical sciences. So far Siamese networks have been employed to discover symmetry invariants and conserved quantities [25]. While Siamese neural networks are supervised machine learning algorithms, our proposed phase recognition method is unsupervised, in the sense that it does not require any phase information. This apparent contradiction is reconciled in Section 3.4.
While we initially present our phase recognition method using the example of two stacked Ising models exhibiting four different phases, we demonstrate the power of this method by examining the phase diagram of the Rydberg atom array. Rydberg atom arrays are a powerful platform for experimental realizations of quantum many-body phenomena [66, 67, 68]. Neutral atoms are typically arranged via optical tweezers to construct various physical lattices at varying interaction strengths which give rise to rich phase diagrams [69]. Such systems have already been examined with the help of machine learning algorithms. The phase diagram has been revealed by a combined effort of unsupervised and supervised methods [70]. Experimental states have been reconstructed using neural network based tomography [71]. Ground states have been calculated [72] and simulated measurement data has been used for pre-training variational wave functions [73].
The paper is structured in the following order: we first introduce the models we are examining with our new Siamese network based framework. These models include a stacked Ising model and the Rydberg atom array. Subsequently, we describe how we prepare the input data using Monte Carlo simulations. We describe how Siamese neural networks are constructed and trained, and develop our framework to do unsupervised learning of phase transitions. Then we apply our method to both models and present the results in the form of the predicted underlying phase structure. Finally, we summarize our findings and place our method into the broader context of machine learning tools for phase recognition.
2 Models
2.1 Stacked Ising Model
The Ising model on the square lattice is a simple, well studied, and exactly solvable model from statistical physics that exhibits a phase transition. Thus, it provides the ideal starting point for benchmarking the performance of a phase recognition algorithm. Its Hamiltonian is
| (1) |
a function of spin configurations . In the following, we focus on the ferromagnetic Ising model and set the external field .
SNN phase recognition is an algorithm that is able to detect multiple phases in an unsupervised manner. Hence, we trivially combine two Ising models by overlaying them on the same lattice where we can tune each temperature , or in other words the ratios and , independently. The combined Hamiltonian
| (2) |
acts on lattices containing two spins per site, . Since there is no interaction between them, phase transitions trivially occur at lines and in the phase diagram.
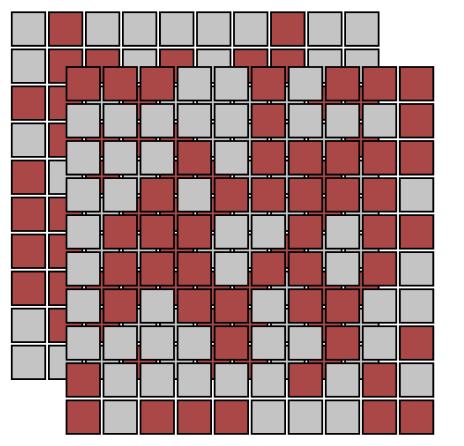
2.2 Rydberg Array
A common Hamiltonian that can be implemented by Rydberg arrays has a form similar to that of a Transverse Field Ising Model, meaning it is sign-problem free and thus amenable to simulation on classical computers. The Hamiltonian acts on a collection of atoms which individually act like 2-level systems, having a ground-state and an excited, so-called Rydberg state . The atoms are subject to a long-range interaction which is described by a van der Waals (vdW) interaction of the form that penalizes atoms that are simultaneously in the Rydberg state [74]. Additionally, the atoms are subject to coherent laser fields: a detuning which acts like a chemical potential, driving atoms into their Rydberg states, and a Rabi oscillation with frequency which excites ground-state atoms and de-excites atoms in Rydberg states.
| (3) |
where is the occupation/number operator, and . The interaction strength is typically parametrized in terms of a Rydberg blockade radius , which describes an effective radius within which two simultaneous Rydberg excitations are heavily penalized: [75, 76].
3 Methods
3.1 Monte-Carlo Simulation
The well-known single-spin-flip Metropolis algorithm is used to generate importance sampled Monte Carlo configurations of the Ising model on a square lattice of size with periodic boundary conditions [77]. After initializing a random lattice, we evolve the simulation for 7168 MC steps between drawing samples. It is important to note that neural networks can pick up on any residual correlations, thus relying on conventional auto-correlation measures to determine the independence of lattice configurations is not enough. We produce 92 independent configurations at each of 100 temperatures ranging from to . This naturally translates to samples for the stacked Ising model at each temperature pair .
For the Rydberg system, we make use of a recent Quantum Monte Carlo method [76] to generate occupation basis samples of the Rydberg Hamiltonian. The QMC simulation is based on a power-iteration scheme which projects out the ground-state of the Hamiltonian:
| (4) |
where is the positive eigenstate of , is the number of lattice sites, is a constant energy shift used to cure the sign-problem emerging from the diagonal part of the Hamiltonian, and is called the projection length. We perform our simulations on a square lattice with open boundaries at various parameter values. Unlike previous DMRG-based studies[75, 69] we do not impose a truncation on the vdW interaction. We take our projection length to be 100,000 which we found was more than enough to accurately converge to the ground-state over the parameter sets which were simulated. For our simulations we fixed and performed scans over and .
To generate the occupation basis data for the SNNs, we first perform 100,000 Monte Carlo update steps to allow the chain to reach equilibrium. We then record one sample every 10,000 steps in order to eliminate any possible autocorrelation between successive samples. Each Monte Carlo step consists of a diagonal update step, followed by a cluster update step in which all possible line-clusters are built deterministically and flipped independently according to a Metropolis condition; see [76] for further details. Additionally, at each point in parameter space we run 3 independent Markov chains. The chains are allowed to evolve until each has generated 400 samples, giving a total of 1200 independent samples for each parameter pair.
3.2 Siamese Neural Networks
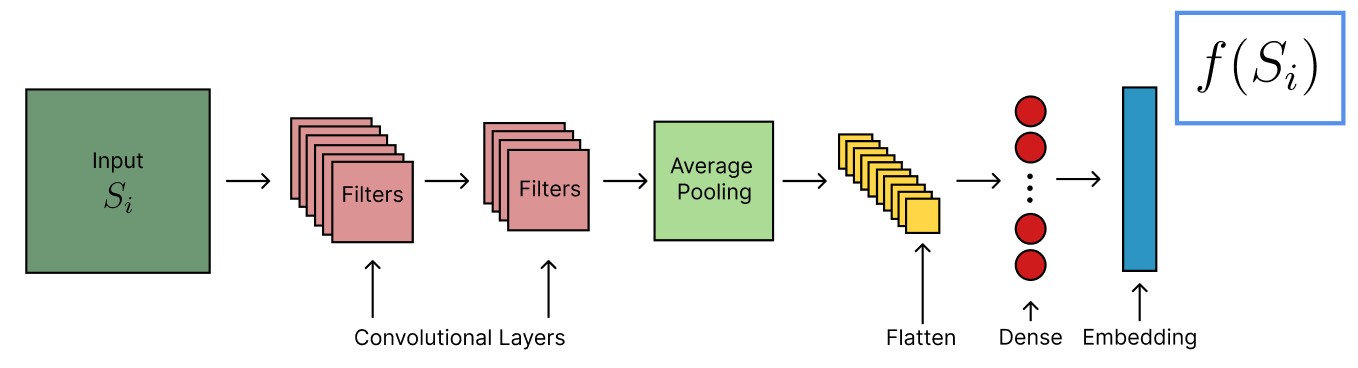
Artificial neural networks are directed graphs that have the ability to learn an approximation to any smooth function given sufficiently many parameters. A neural network is built by successively applying matrix multiplications characterized by weights that are offset by biases . ( are neuron indices in different layers ). Between subsequent matrix multiplications there is a non-linear activation function, common choices of which are sigmoid or rectified linear units. A neural network is trained by applying it to a data set and optimizing the network parameters to minimize a certain objective function using gradient descent.
Siamese neural networks (SNN) were introduced to solve an infinite class classification problem as it occurs in finger print recognition or signature verification [64, 65]. Instead of assigning a class label to a data instance, the SNN compares two data points and determines their similarity. A solution to the infinite class classification problem is obtained by calculating the predicted similarity between labelled anchor data points and a new unlabelled data instance.
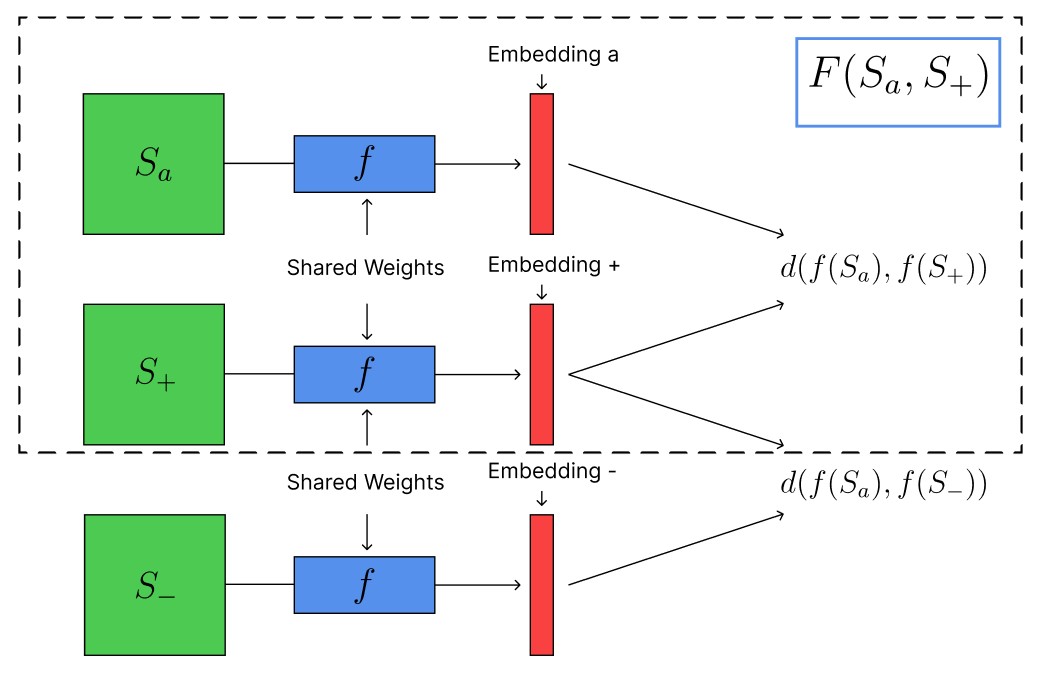
A SNN (Fig. 3) consists of two identical sub-networks (Fig. 2) which project an input pair into a latent embedding space. The similarity of two inputs is determined based on the distance in embedding space.
| (5) |
Possible distance metrics must be chosen according to the problem at hand, in our case we chose the average squared Euclidean distance on the unit sphere which is equivalent to the cosine distance.
| (6) |
Here denotes different components in an dimensional embedding space. Instead of training the SNN on paired training data, an effective way to train Siamese neural networks is through minimizing contrastive loss functions involving triplets of data points
| (7) |
where the hyperparameter is chosen such that the neural network is prevented from learning trivial embeddings. The intuition behind is its interpretation as a margin to encourage separation between the anchor and the negative embedding in the embedding space [78]. Minimizing requires minimizing the distance between the anchor and positive sample , while maximizing the distance between the anchor and negative sample . prevents the neural network from learning runaway embeddings .
3.3 Model Architecture
The explicit model architecture for Fig. 2 depends on the underlying data set. In the case of the Ising model, consists of two 2-D convolutional layers, both with stride , a kernel size of , and with 6 and 10 filters, respectively. Each layer is fed into a ReLU activation function. The resulting image dimensions are . This is followed by a average pooling layer. The output is flattened and fed to a dense layer with 10 neurons. Subsequently, we feed this output to the embedding layer, which also contains 10 neurons and a sigmoid activation function. The embedding is normalized to unit length under euclidean norm.
The model architecture for examining the Rydberg system is similar to the Ising model. In this case, we begin with two 2-D convolutional layers, both with stride (1, 1), a kernel size of (3, 3), and with 6 and 4 filters, respectively. The resulting image dimensions are (12, 12). As before, we subsequently apply an average pooling layer, but this time of dimension (12, 12). The remainder of the architecture is identical to before.
We use the Adam optimizer to train our neural network. Furthermore, our training procedure involves the early stopping callback. This technique involves training as long the loss is decreasing. If the loss is not decreasing for epochs, training is stopped. The value of is known as the patience. We set the maximum number of epochs to 150, which is enough to allow the callback to decide when to terminate the training process. We observe that small values of patience, around and are sufficient for training on the Ising model and the Rydberg system, respectively. Additionally, we use a learning rate of for the Ising model, and for the Rydberg system. Another hyperparameter is the margin for the contrastive loss, where we use . We employ the TensorFlow and Keras libraries to implement the network, training, and callbacks.
3.4 Phase Boundaries from Siamese Networks
3.4.1 Supervised Learning of Phase Transitions:
Since the proposal to use supervised machine learning algorithms for calculating phase diagrams, the most powerful method still remains using feed-forward neural networks for the binary classification of Monte-Carlo samples [3]. In this case a neural network is trained on configurations from known parts of the phase diagram labelled by their phase. By denoting the phases with binary labels , a neural network is trained to predict the phase of a configuration
| (10) |
After training, this neural network is then applied to samples from unknown parts of the phase diagram. Since these networks intrinsically learn the underlying physical features characterizing the phases like order parameters and other thermodynamic quantities [23], the predictions of the neural networks flip from one label to the other at the position of the phase transition.
The principle that guides us through the development of an unsupervised Siamese network-based scheme for phase recognition is to leverage the power of neural networks for phase classification in the supervised setting. This is done by reformulating the task of predicting phases by a neural network. A Siamese neural network takes a pair of input configurations and predicts if they are similar or different with respect to a metric imposed by the objective function during training.
| (13) |
In this formulation a SNN can be used as a supervised algorithm for multi-phase recognition. In order to do unsupervised learning of phases with SNNs the training data cannot be supplied with phase labels. In order to enable a SNN to learn from unlabelled data we need to understand how data affects the gradients while training neural networks.
3.4.2 Gradient Manipulation:
To develop an unsupervised framework, it is important to understand how gradients update the neural network. Let us discuss this at the example of a general neural network trained in a supervised setting to minimize the mean square error loss function on a labelled data set . The discussion can be extended to any network in this manuscript. The effect of a single training example on the loss function is
| (14) |
The neural network switches its prediction at the decision boundary
| (17) |
Neural networks are trained using backpropagation of gradients. Let us focus on the gradient signal on an example weight out of the millions of parameters characterizing a neural network. Let us further assume we have two identical training configurations with opposite labels labels . Each update step invloves the product of the learning rate and the inverse of the derivative of the loss function with respect to :
| (18) |
The update depends on the label :
| (21) |
Thus, by supplying the neural network with two similar training samples, but opposite labels in the same training step, their effect on the weights of the neural networks would approximately cancel each other out. While this combined training signal forces the neural network to be more uncertain , it will never change the prediction itself.
3.4.3 Unsupervised Learning of Phase Transitions:
In each update step the Siamese network is trained on triplets , where is called anchor, the positive comparison, and the negative comparison. In an unsupervised setting we do not have the true phase labels at hand. However, we know that two samples from the exact same point on the phase diagram must have the same phase. Thus, we create training batches where and are from the same coordinates in the phase diagram, while is sampled randomly from anywhere in the phase diagram.
Building on the discussion of gradient signals: If and stem from the same phase the training signals should approximately cancel each other out, such that the remaining noise is subleading compared to the signal that is obtained when and are from different phases. In a physical context, the noise might stem from thermal fluctuations, and the leading signal from relevant thermodynamical quantities.
Since there is still no comprehensive theory on neural network training dynamics, the above discussion lacks in mathematical rigor. Hence, in line with all other machine learning based phase recognition methods, the only way to convince ourselves of the capabilities of the proposed method is an empirical study by applying the method to physical systems.
4 Results
For the purpose of calculating phase diagrams, we train SNNs as outlined in the previous paragraphs for both the stacked Ising model and the Rydberg atom array. We create training triplets containing a randomly sampled anchor configuration , a positive configuration sampled from the same point in the phase diagram and a negative configuration sampled from any other point in the phase diagram. After having successfully trained a SNN it is employed to perform pairwise comparisons on configurations along a specified one-dimensional slice through the phase diagram.
4.1 Adjacency Comparisons
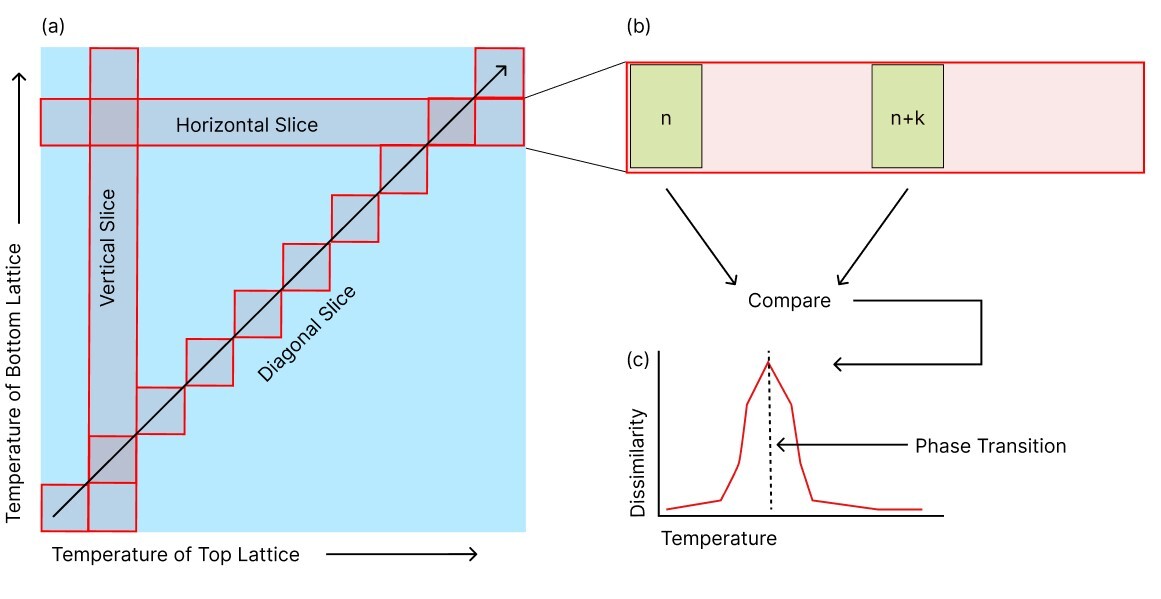
In this scheme, a configuration corresponding to a point in the phase diagram is compared to its neighbors within a certain distance. At the example of a single Ising model, this means a configuration from temperature is compared to a configuration at , where is the temperature list index and is a constant shift. The value of can be treated as a hyperparameter. A comparison between configurations at and is assigned a temperature of .
Our similarity measure of choice is the normalized cosine dissimilarity scaled to a range , where 1 corresponds to the empirically found maximal dissimilarity and 0 to the empirically determined minimal similarity. The cosine dissimilarity is related to the cosine distance via , where
| (22) |
The cosine distance is equivalent to the euclidean distance when acting on the SNN embedding space normalized to the unit sphere ():
| (23) |
Since the neural network is designed to output positive values , the cosine dissimilarity takes on its minimum for similar embeddings and its maximum if the embeddings are dissimilar.
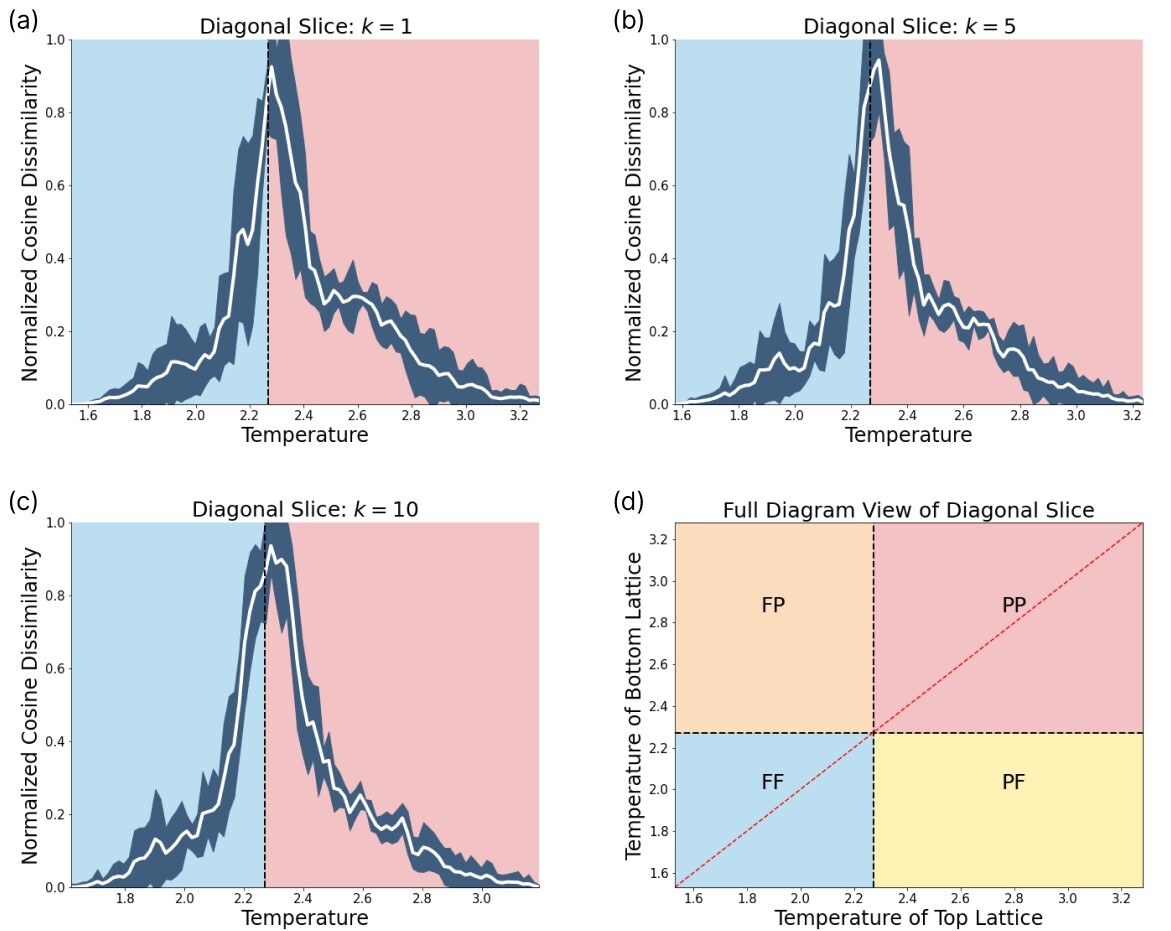
The result of scanning across a phase transition is depicted schematically in Fig. 4(c). The highest peak will indicate the SNN prediction of the phase transition.
4.2 Ising Model
We examine the results of applying SNN unsupervised phase recognition to the stacked Ising model. Analytically, the phase boundaries of the stacked Ising model in the thermodynamic limit are and . The phase transition temperature is prone to finite size effects as the lattice becomes smaller. If the phase transition would be calculated using the magnetization, finite size effects would distort the phase boundaries to and ; however, it is important to note that the quantities a neural network learns might differ from the magnetization and thus experience different finite size scalings [55].
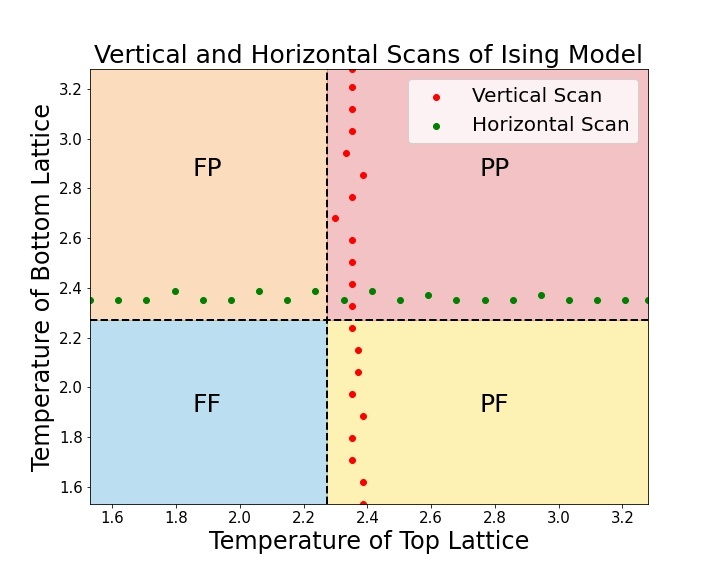
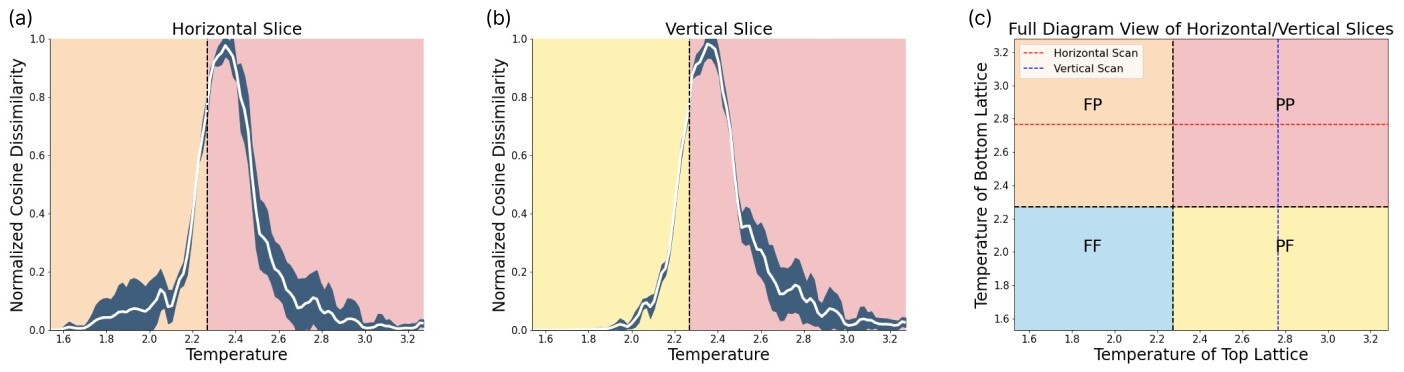
In order to calculate the stacked Ising model phase boundaries, we choose to perform vertical and horizontal scans across the phase diagram, where each scan is repeated five times and the standard deviation of this ensemble is displayed as uncertainty. Exemplarily, the results of two of these scans can be found in Fig. 5. The location of these scans is depicted in (c). (a) reveals the phase transition from (ferromagnetic, paramagnetic) to (paramagnetic, paramagnetic) (FP to PP), while (b) displays the phase transition from PF to PP. Collecting 21 vertical and 21 horizontal scans reveals the phase boundaries of the stacked Ising Model, as seen in Fig. 6. By comparing the horizontal (green dotted line) and vertical scans (red dotted line) with the Ising model phase boundaries in the thermodynamic limit (black dashed lines) one can observe a clear difference. The SNN predicts critical temperatures of , consistent with the finite size correction of the magnetization which indicates a phase transition at .
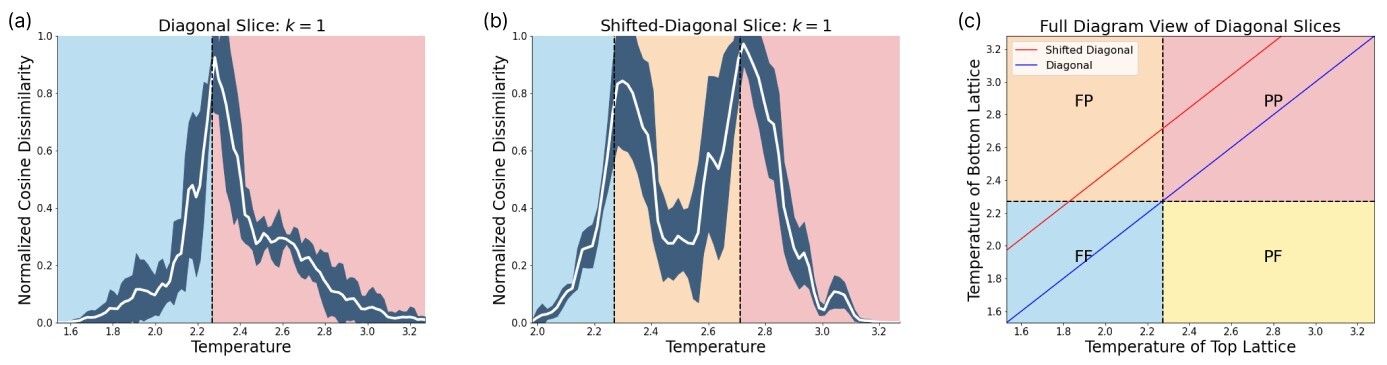
In order to reveal the power of our SNN based phase recognition scheme, we have to scan across diagonal slices within the phase diagram that contain more than one phase transition. For this purpose we scan diagonally across the phase diagram as depicted in Fig. 7. The two diagonal scans across the lattice reveal that this technique can identify more than one phase transition. The first diagonal scan is performed along a line through the center of the lattice. In this case, we see a single phase transition, as the network scans directly through the intersection of the vertical and horizontal phase lines. A closer examination of the effect of changing can be found in Fig. 20. The prediction yields a phase boundary at .
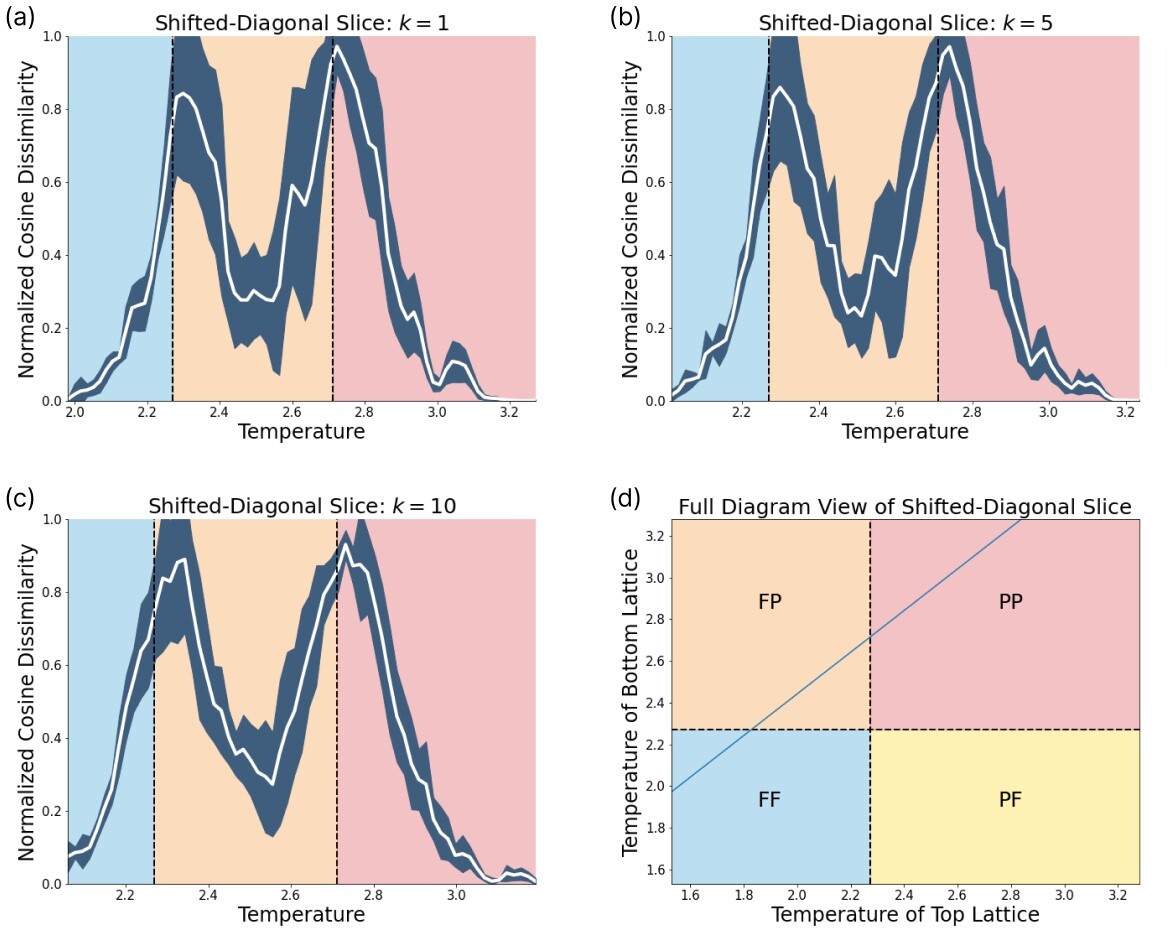
The second diagonal scan we perform is shifted, such that it crosses both the vertical and horizontal phase transition. In this case, the true phase boundaries are cut by the shifted diagonal slice at and . The network is able to capture both transitions at and . A closer examination is found in Fig. 21.
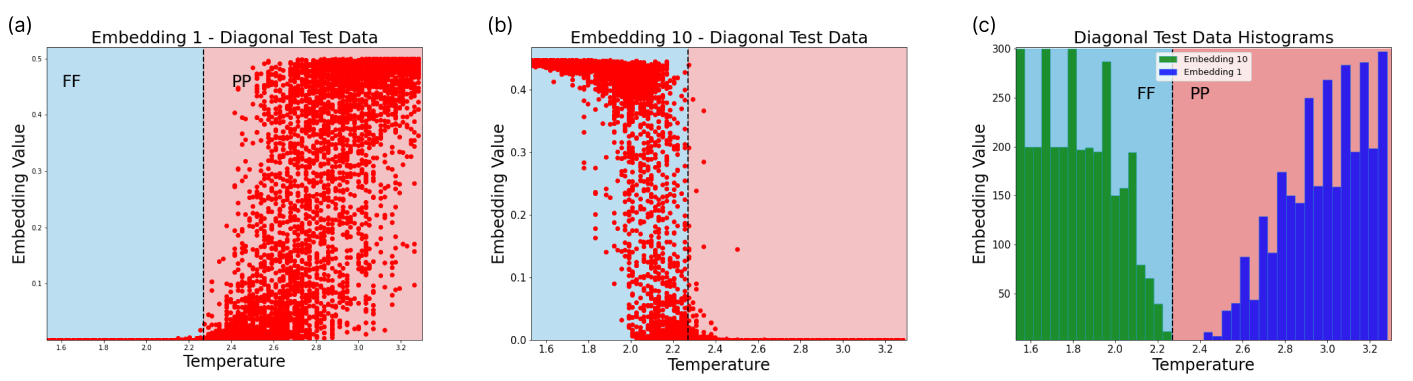
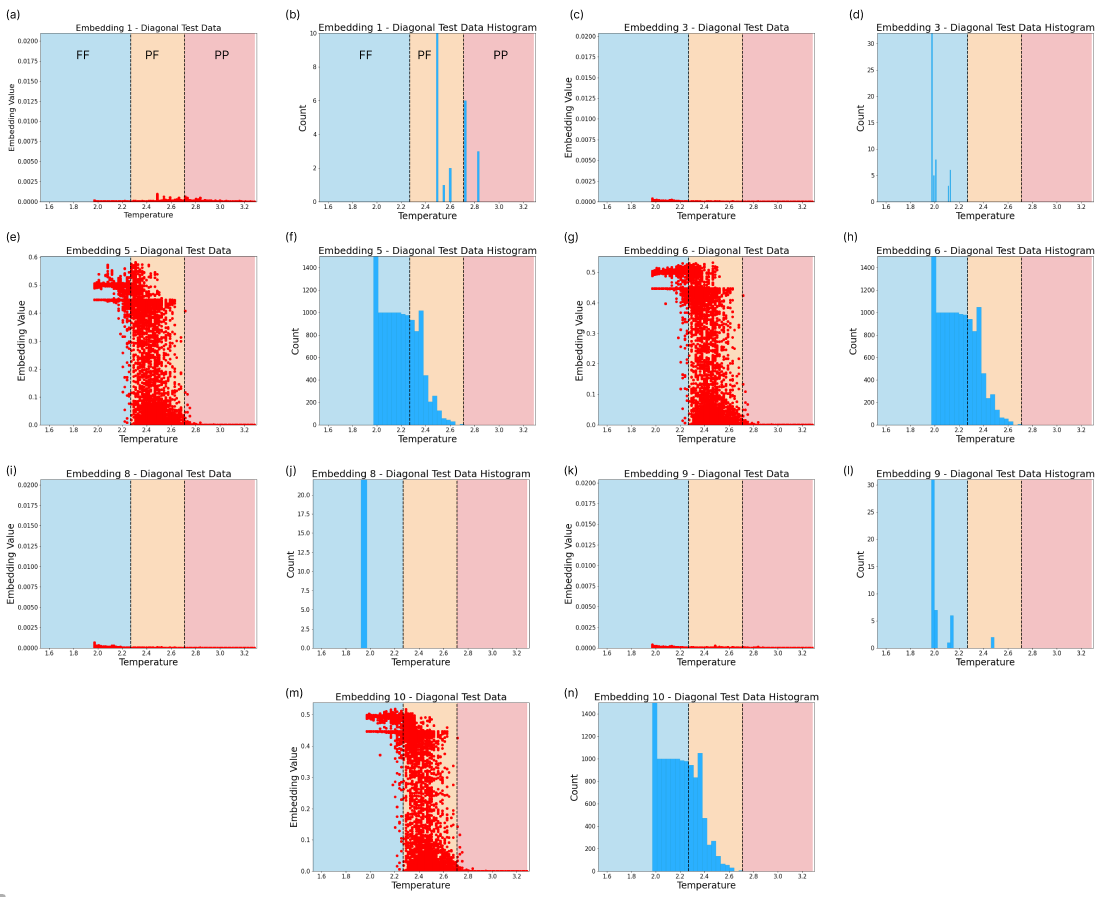
Furthermore, the embeddings shed some light on how the neural network encodes the aforesaid phase transitions. In Fig. 8 we see embeddings which encode phase information for the diagonal slice. These embeddings clearly separate between the two underlying phases. Embedding 1 only spikes in the PP phase, while embedding 10 activates at FF regimes. A switch between both embeddings occurs at the phase transition. Other embeddings can be found in Fig. 16. In the case of a single embedding, we may have noise contained in the same embedding neuron where the phase behaviour is captured. With additional embeddings, the noise may be relegated to other embedding neurons, isolating the phase transition information.
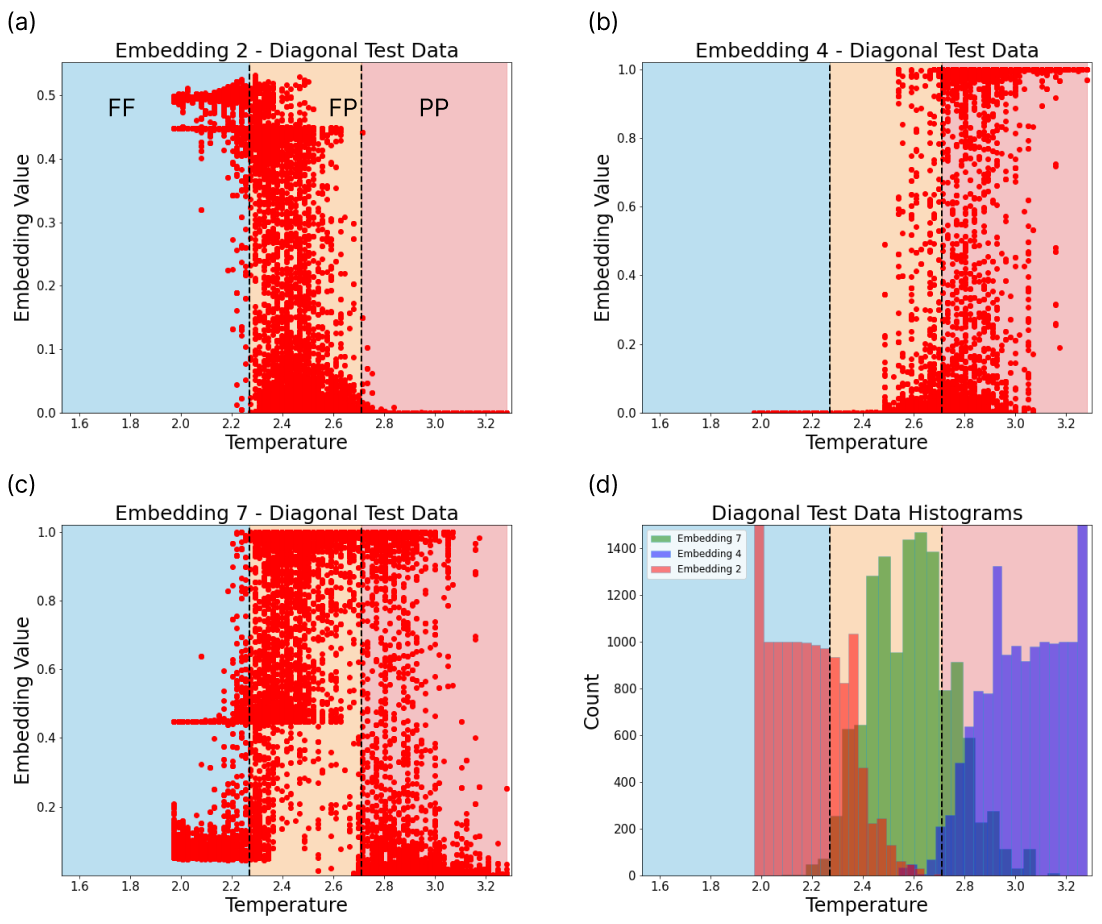
The embedding space of the shifted diagonal scan is depicted in Fig. 9. We observe three crucial behaviours in the embeddings. Each of the three histograms show maximum activity in three different regions. Embedding 2 encodes the FF phase, embedding 4 the PP phase, and embedding 7 encodes configurations from the FP phase.
4.3 Rydberg Array
The Rydberg atom array phase diagram is not as well studied as the Ising model, so we need to compare our SNN phase boundaries to recent papers [69, 75] and evaluate the order parameters on the QMC data ourselves.
In order to identify the approximate phase boundaries we compute predictors for the phases of interest. Each phase corresponds to various peaks in the absolute value of the Fourier transform (FT) of the one-point function:
| (24) |
where is the Rydberg occupation of the th site. Furthermore, we symmetrize the FT by averaging over permutations of the momentum axes:
| (25) |
The peaks occur for the checkerboard phase at , for the striated phase at and , and for the star phase at , and [75]. We compute, for each point in parameter space , the symmetrized FT at these specific momenta averaged over the full 1200 sample data set given to the SNNs.
4.3.1 Testing
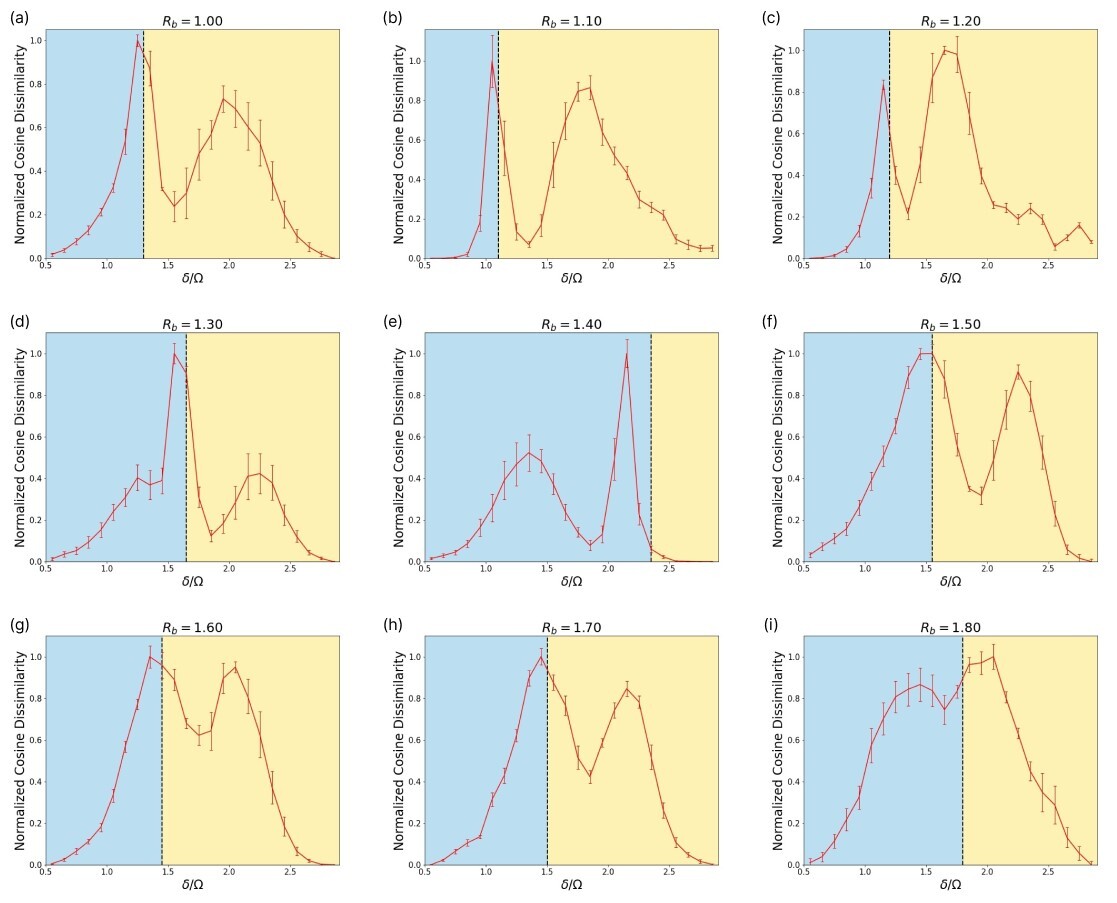
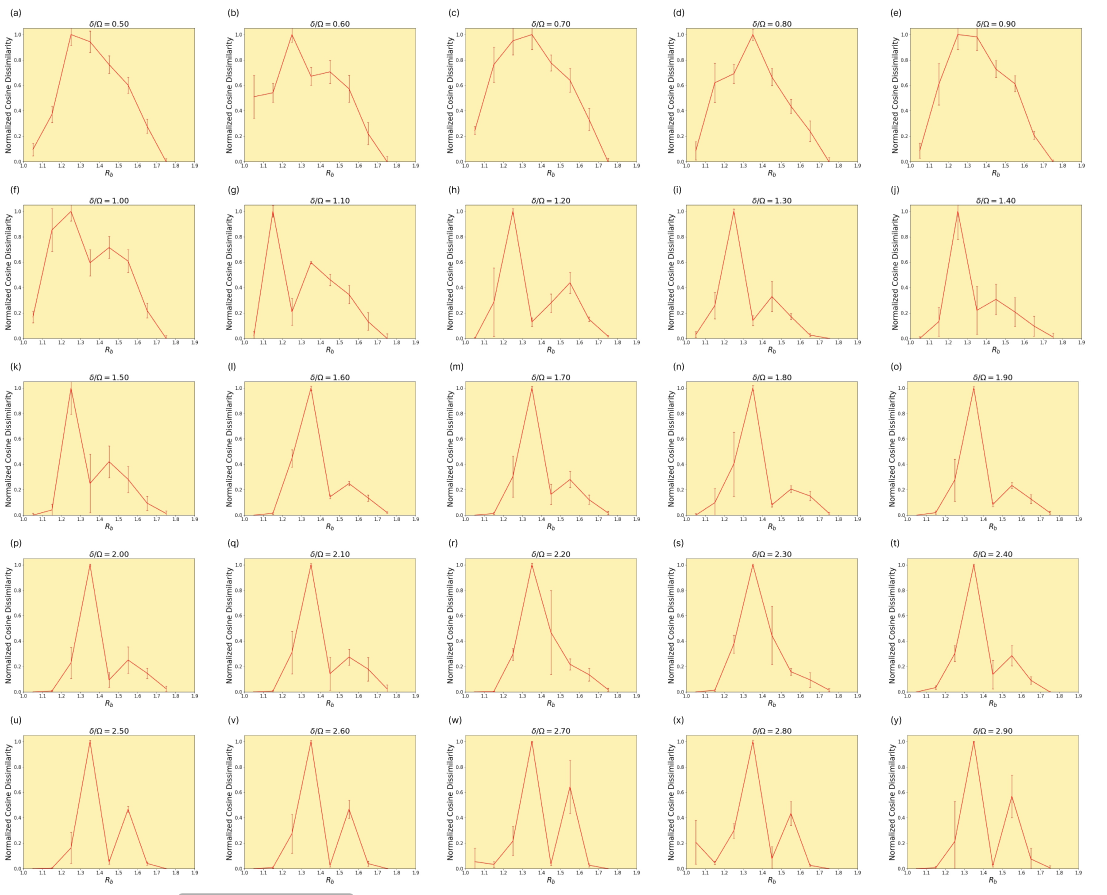
The Rydberg atom array phase diagram is examined in regimes where the checkerboard, striated and star phases are present. Thus, guided by [69] we focus the region and . The training of the SNN on Rydberg QMC data is performed similar to the Ising model on each horizontal and vertical slice. Inference is performed by adjacency comparisons with step-size . Because the Rydberg phase diagram is coarser than the Ising model phase diagram (25 points between to for the Rydberg array, compared to 100 points between and for the Ising model), there is no reason to use .
All horizontal and vertical scans depicted in Fig. 10 and Fig. 19, respectively, are the result of an ensemble average over 5 different runs per slice. The error bars represent the standard deviation between runs. The vertical lines in each plot in Fig. 10 represent the approximate phase transition at each based on [75]. Our observations differ from their result in the sense that we consistently observe two phase transitions in all slices (although some of these phase transition peaks are weak, as shown in Fig. 10). However, we also confirm that in all cases the SNN predicts a phase transition that coincides with the results from [75]. There is only a slight deviation at in the horizontal scanning direction. Furthermore, the results in Fig. 19 reveal the striated phase in between the star and checkerboard phases, which is also consistent with [75].
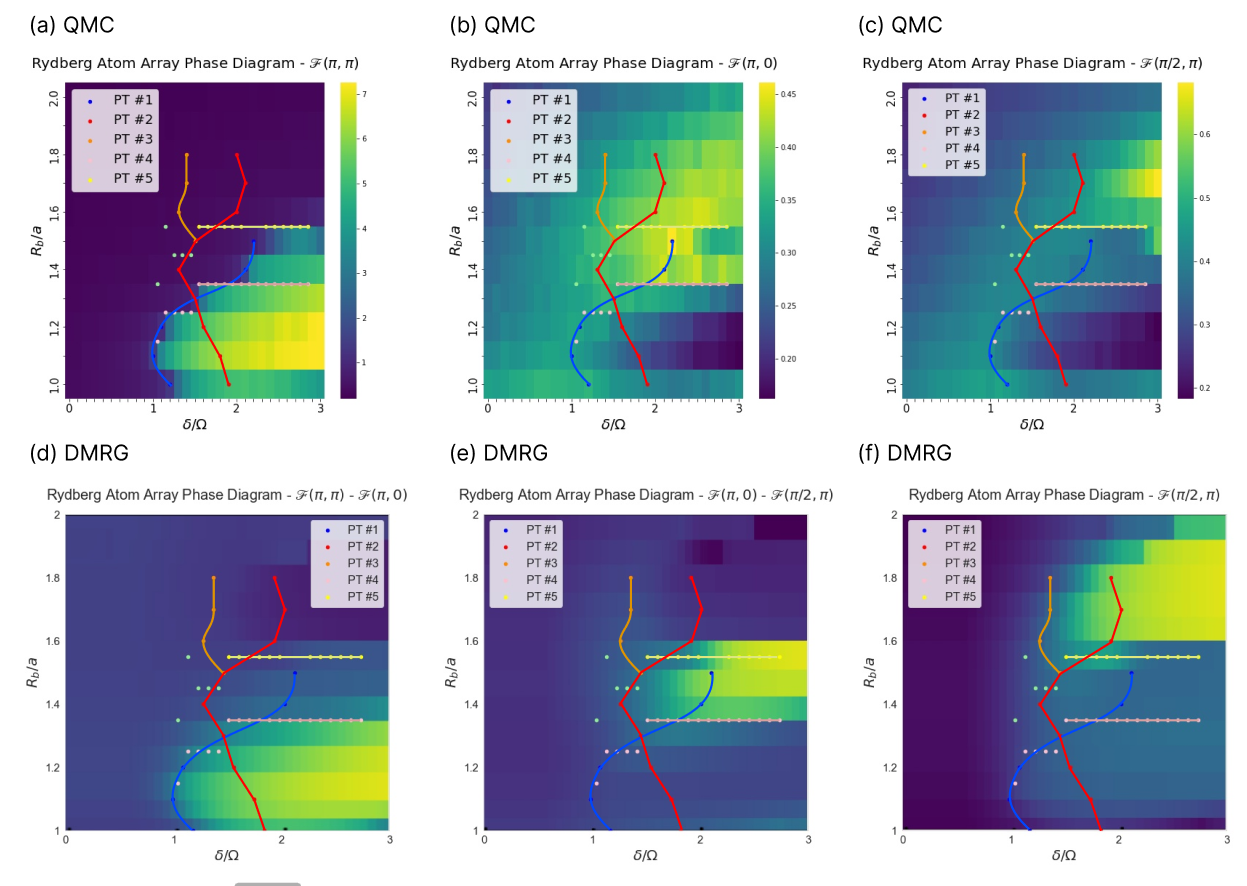
In figures Fig. 11 (a)-(c) we compare the SNN predictions with the results from evaluating order parameters on our QMC data. For each the checkerboard phase, the star phase, and the striated phase we create separate plots. The QMC data is chosen as the background, while in the foreground we connect phase transition signals from the SNN in the smoothest way possible in the form of blue, red, orange, pink and yellow lines. We first observe a perfect agreement of the checkerboard phase transitions seen in (a). The striated and star phase in figures (b) and (c) are very elusive; however, the SNN tends to capture clearer phase information than what is suggested by the evaluation of the order parameters. The red line captures the striated phase for . There are two distinct differences between SNN and QMC order parameter results: There is no QMC order parameter signal to explain the orange line. Further, the red line continues well within the checkerboard phase, where none of the three order parameters signal a phase transition.
We also compare our results to those obtained by [69] in Fig. 11 (d)-(f). Again the SNN prediction of the checkerboard phase transition is in good agreement with the DMRG results. Further, the red line for is similar to their striated phase boundary. The pink and yellow lines also bound the striated phase. In addition, our orange line corresponds very well to the DMRG star phase. The DMRG star phase is much larger than the QMC star phase. However, the SNN results should mimic what is present in the QMC data. This contradiction might be resolved by two different explanations: 1) the neural network is able to extract features which are a stronger indicator for the star phase than Fourier modes. 2) there is another phase present in the QMC data that is responsible for the orange phase boundary, [75] suggests possible candidates in form of rhombic, banded or staggered order.
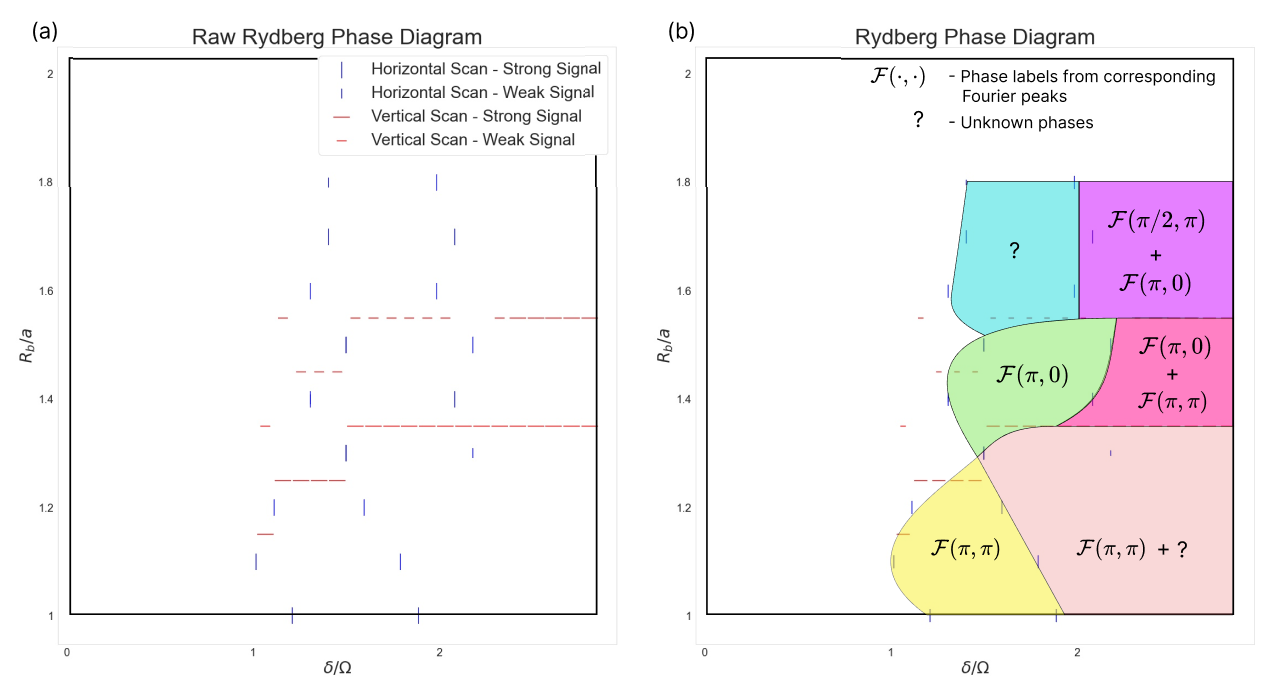
The full independent SNN prediction of the Rydberg Array phase diagram is constructed in Fig. 12, where (a) depicts the raw peaks of the horizontal and vertical scans in Fig. 10 and Fig. 19, respectively. The vertical scan slices between do not reveal any explicit phase transition, as expected, and are therefore not included in the phase diagram. Fig. 12(b) is constructed by connecting markers as smoothly as possible. This results in 7 phase regions, labelled according to Fig. 11.
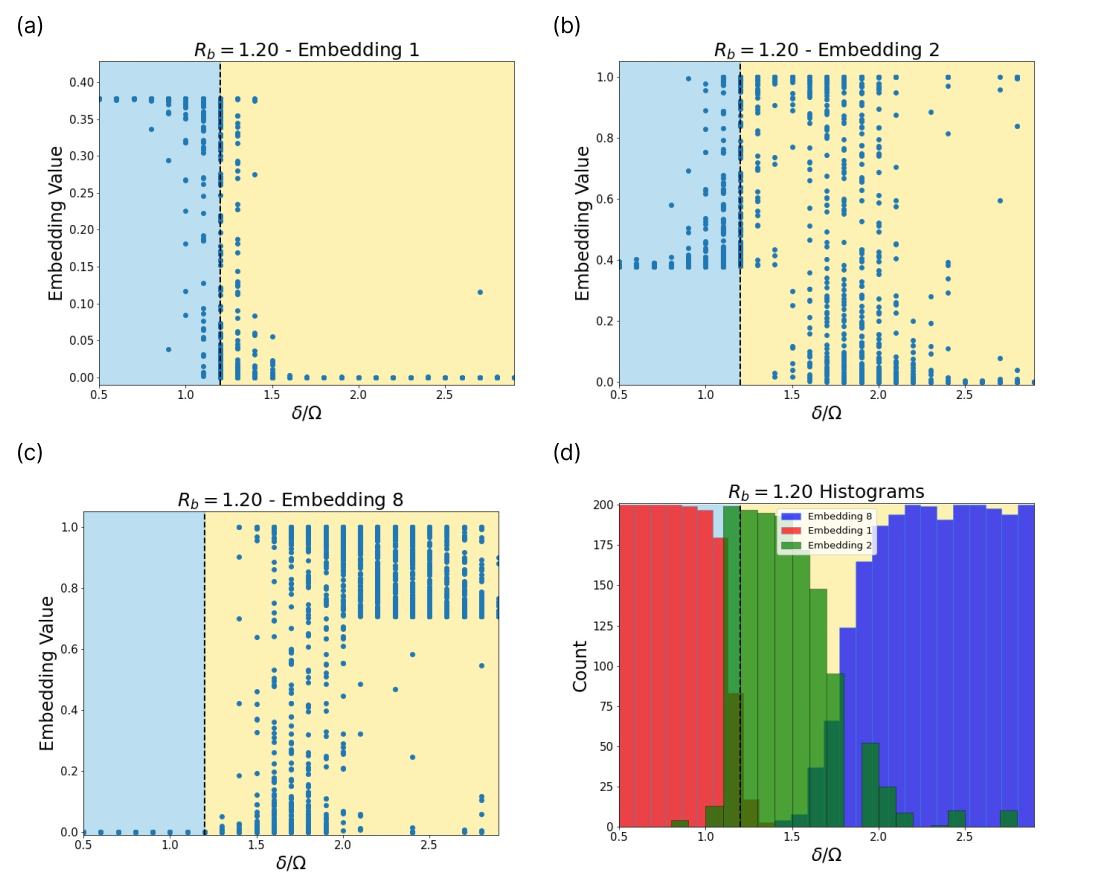
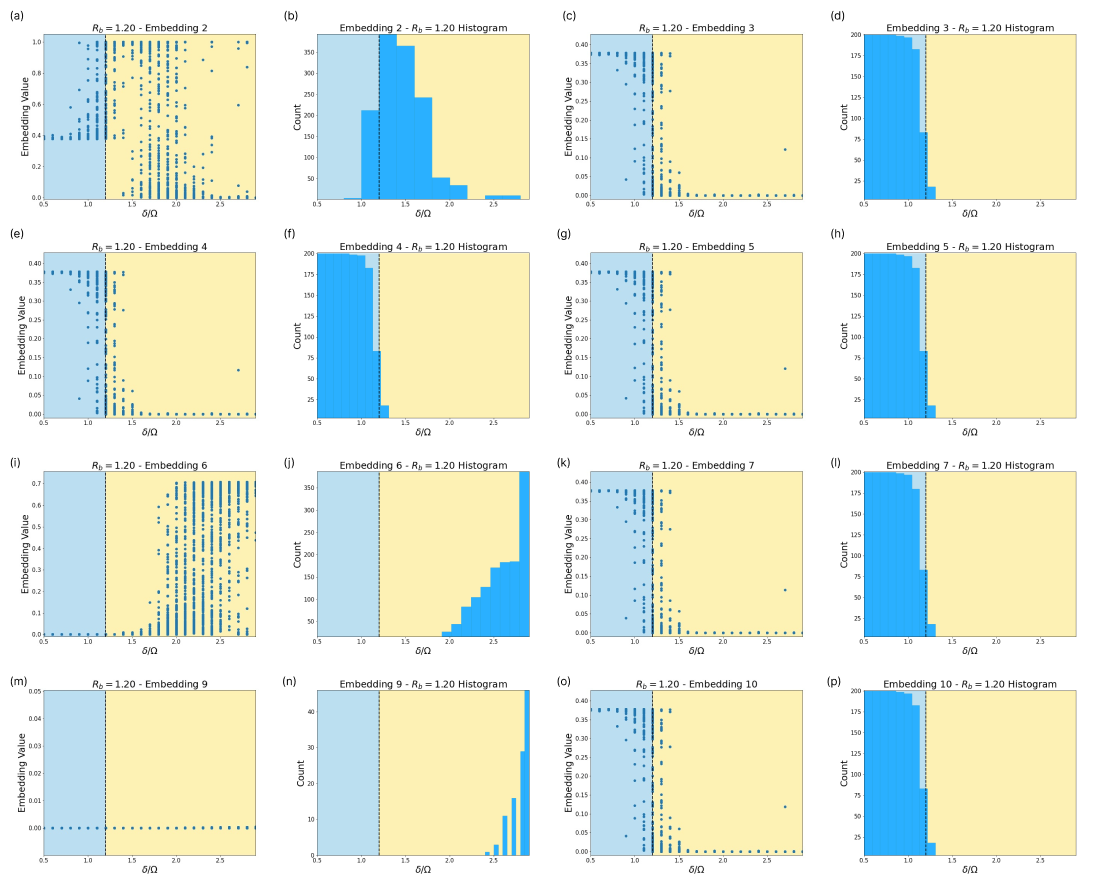
Fig. 13 provides insight into how the SNN encodes the phase information in the Rydberg system. Certain embeddings correspond to very specific regions in the phase diagram. Embeddings 1 and 2 separate in the vicinity of the first phase transition, and where embeddings 2 and 8 separate, the SNN indicates a second phase transition.
It is surprising that the SNN is able to reveal clearer phase information from the QMC data than what a direct evaluation of order parameters might indicate. The reason for this might be that the neural network is able to calculate other thermodynamic quantities which are relevant to describe the underlying physics, such as energies or susceptibilities. Further, the neural network might be able to deal better with domain boundaries. This observation encourages us to predict that neural networks might be able to reveal phases where conventional order parameter evaluations on MC configurations have trouble doing so. In that sense the SNN predicts the occurrence of 2 phases that are not evident in the QMC order parameter analysis, the blue and orange regions in Fig. 12. These findings guide us to examine these regions closer with a keen eye on revealing previously unknown physics.
5 Conclusion
We have introduced a Siamese neural network (SNN) based method to detect phase boundaries in an unsupervised manner. This method does not require any physical knowledge about the nature or existence of the underlying phases. SNN based phase detection shares the power of a) feed forward neural networks, which have been the most powerful machine learning algorithm to be applied to reveal physical phases, and b) certain unsupervised methods which can learn multiple phases without knowing about their existence. This method is shown to reproduce phase diagrams when trained on Monte-Carlo configurations of the corresponding physical system. In our case we introduced the method at the example of a model consisting of two stacked Ising Models exhibiting a phase diagram of four phases. Further, we used this method to calculate the phase diagram of a Rydberg atom array which is to the most extent consistent with prior results, and shows additional signatures of unknown and coexistence phases. Futher, in some regimes the SNN tends to be better at picking up phase information than order parameters applied to QMC data. As typical for neural network based phase recognition schemes, we do not have insight on what features a neural network is learning in order to calculate the phase boundaries. These quantities have been shown to be related to order parameters and other physically relevant quantities. Explicitly revealing them is difficult, but possible using methods like [23, 79].
With this work we have contributed to the zoo of machine learning methods for phase diagrams. While it remains to be seen if one of these methods will reveal a completely new unknown phase, we believe SNN based phase detection has the features of a top contender with its ability to detect multiple phases in an unsupervised manner.
6 Acknowledgements
We thank Roger Melko for helpful discussions. We thank the National Research Council of Canada for their partnership with Perimeter on the PIQuIL. Research at Perimeter Institute is supported in part by the Government of Canada through the Department of Innovation, Science and Economic Development Canada and by the Province of Ontario through the Ministry of Colleges and Universities.
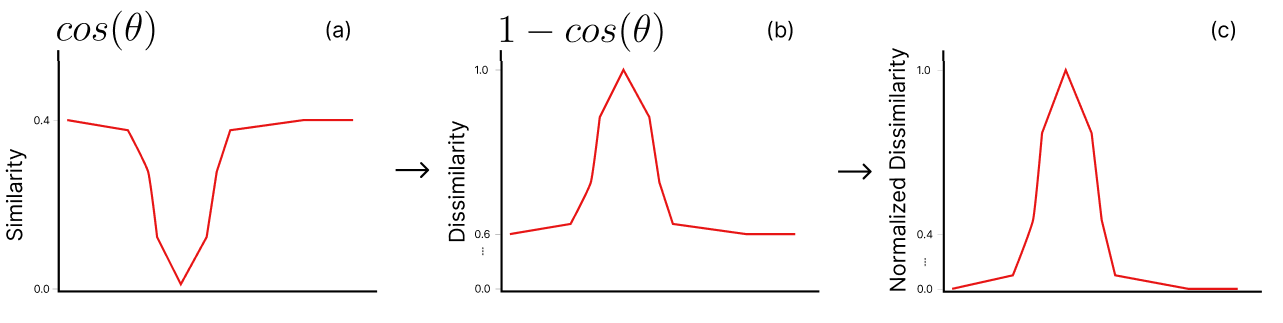
Appendix A Normalized Cosine Dissimilarity
In this section we display the calculation of the cosine dissimilarity in Fig. 14.
Appendix B Training
B.1 General Training Dynamics
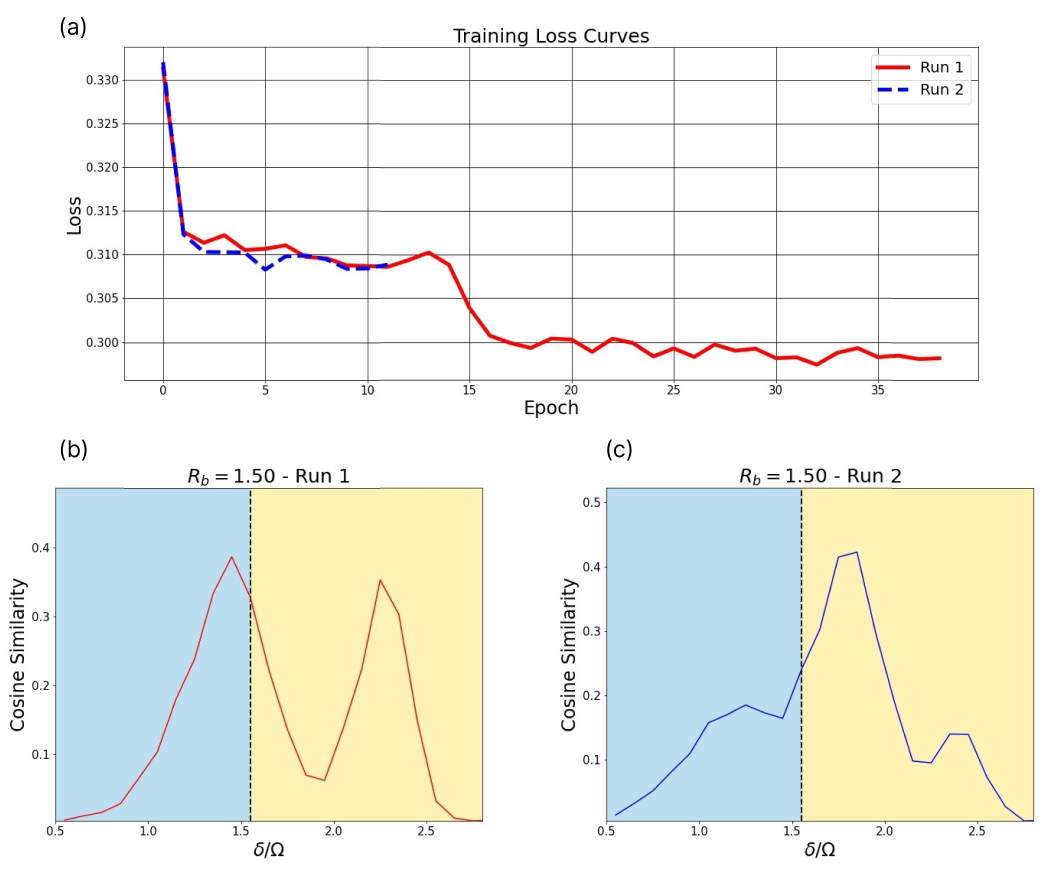
We observe that training is prone to getting stuck in local minima. For this reason, we may rerun the training phase several times for certain slices. In particular, the diagonal slices (both the shifted diagonal and the direct diagonal) are rerun if their adjacency comparisons exhibit unexpected/sub-optimal behaviour. One may use the loss curve to identify such instances. For instance, one run may exhibit a single phase transition, while the other may exhibit 2. We opt to keep the result with the lower loss. This scenario is depicted in Fig. 15. The single peak result in (c) corresponds to a higher loss. We identify this as a local minimum. The red curve in (a) corresponds to the plot (b). While this run also gets stuck in a local minimum, it is able to escape upon further training. As such, we keep (b) as our result.
B.2 Ising Model - Training on the Diagonal Slice
The diagonal slice is shown in Fig. 4(a) and Fig. 7(c). Of the 92 Ising configurations produced at each temperature, 50 are used in the training set, and 42 in the testing set. Then, we use these to produce 100 stacked configurations at random for both the training and testing sets. For example, we choose two random configurations out of the set of 50 for the training set, and overlay them to produce a single stacked configuration.
B.3 Ising Model - Training on the Shifted Diagonal Slice
The shifted diagonal slice is shown in Fig. 7(c). Here, we shift the slice by 25 temperature points vertically in order to cross two phase transitions. Of the 92 Ising configurations produced at each temperature, 70 are used in the training set, and 22 in the testing set. Once again, we use these to produce stacked configurations at random for both the training and testing sets. However, this time we produce 3500 stacked configurations for the training set, and 500 for the testing set. Because the diagonal slice does not contain many points from any of the three phases it crosses, we increase the amount of training data to compensate.
B.4 Ising Model - Training on the Horizontal/Vertical Slices
Of the 92 Ising configurations produced at each temperature, 42 are used in the training set, and 50 in the testing set. As with the diagonal slice, we then use these to produce 100 stacked configurations at random for both the training and testing sets.
B.5 Training the Rydberg System
Training on the Rydberg system is performed similar to the Ising model, i.e. slice-wise. We train over and , with 1000 configurations per -step. 800 are used for training, and the remaining 200 for testing.
Appendix C Additional Embeddings
This section presents the remaining embeddings for the Ising Model’s diagonal and shifted-diagonal scans, as well as the horizontal scan.
C.1 Ising Model - Diagonal Embeddings
C.2 Ising Model - Shifted Diagonal Embeddings
C.3 Rydberg System
Appendix D Additional Adjacency Comparisons
This section contains further examines the effect of the hyperparameter on the adjacency comparison.
References
- [1] Krizhevsky A, Sutskever I and Hinton G E 2012 Advances in neural information processing systems 25
- [2] Goldberg Y 2016 Journal of Artificial Intelligence Research 57 345–420
- [3] Carrasquilla J and Melko R G 2017 Nature Physics 13 431–434
- [4] van Nieuwenburg E P L, Liu Y H and Huber S D 2017 Nature Physics 13 435–439
- [5] Wang L 2016 Physical Review B 94
- [6] Wetzel S J 2017 Physical Review E 96
- [7] Zhang Y and Kim E A 2017 Physical Review Letters 118
- [8] Schindler F, Regnault N and Neupert T 2017 Physical Review B 95
- [9] Hu W, Singh R R P and Scalettar R T 2017 Physical Review E 95
- [10] Ohtsuki T and Ohtsuki T 2017 Journal of the Physical Society of Japan 86 044708
- [11] Broecker P, Carrasquilla J, Melko R G and Trebst S 2017 Scientific Reports 7
- [12] Deng D L, Li X and Sarma S D 2017 Physical Review B 96
- [13] Ch’ng K, Carrasquilla J, Melko R G and Khatami E 2017 Physical Review X 7
- [14] Torlai G and Melko R G 2016 Physical Review B 94
- [15] Carleo G and Troyer M 2017 Science 355 602–606
- [16] Inack E M, Santoro G E, Dell’Anna L and Pilati S 2018 Phys. Rev. B 98(23) 235145 URL https://link.aps.org/doi/10.1103/PhysRevB.98.235145
- [17] Hibat-Allah M, Ganahl M, Hayward L E, Melko R G and Carrasquilla J 2020 (Preprint http://arxiv.org/abs/2002.02973v2)
- [18] Carrasquilla J, Luo D, Pérez F, Milsted A, Clark B K, Volkovs M and Aolita L 2019 (Preprint http://arxiv.org/abs/1912.11052v1)
- [19] Ferrari F, Becca F and Carrasquilla J 2019 Physical Review B 100
- [20] Sharir O, Levine Y, Wies N, Carleo G and Shashua A 2020 Physical Review Letters 124
- [21] Schmidt M and Lipson H 2009 Science 324 81–85
- [22] Iten R, Metger T, Wilming H, del Rio L and Renner R 2020 Physical Review Letters 124
- [23] Wetzel S J and Scherzer M 2017 Physical Review B 96
- [24] Ponte P and Melko R G 2017 Physical Review B 96
- [25] Wetzel S J, Melko R G, Scott J, Panju M and Ganesh V 2020 Physical Review Research 2 033499
- [26] Greitemann J, Liu K and Pollet L 2019 Phys. Rev. B 99(6) 060404 URL https://link.aps.org/doi/10.1103/PhysRevB.99.060404
- [27] ichi Mototake Y 2019 (Preprint http://arxiv.org/abs/2001.00111v1)
- [28] Udrescu S M and Tegmark M 2019 (Preprint http://arxiv.org/abs/1905.11481v1)
- [29] Krenn M, Hochrainer A, Lahiri M and Zeilinger A 2017 Physical review letters 118 080401
- [30] Krenn M, Pollice R, Guo S Y, Aldeghi M, Cervera-Lierta A, Friederich P, Gomes G d P, Häse F, Jinich A, Nigam A et al. 2022 arXiv preprint arXiv:2204.01467
- [31] Dawid A, Arnold J, Requena B, Gresch A, Płodzień M, Donatella K, Nicoli K, Stornati P, Koch R, Büttner M et al. 2022 arXiv preprint arXiv:2204.04198
- [32] Carrasquilla J 2020 Advances in Physics: X 5 1797528
- [33] Carleo G, Cirac I, Cranmer K, Daudet L, Schuld M, Tishby N, Vogt-Maranto L and Zdeborová L 2019 Reviews of Modern Physics 91 045002
- [34] Huembeli P, Dauphin A and Wittek P 2018 Physical Review B 97 134109
- [35] Arnold J and Schäfer F 2022 arXiv preprint arXiv:2203.06084
- [36] van Nieuwenburg E, Bairey E and Refael G 2018 Physical Review B 98 060301
- [37] Hsu Y T, Li X, Deng D L and Sarma S D 2018 Physical Review Letters 121 245701
- [38] Vargas-Hernández R A, Sous J, Berciu M and Krems R V 2018 Physical review letters 121 255702
- [39] Bachtis D, Aarts G and Lucini B 2020 Physical Review E 102 033303
- [40] Beach M J, Golubeva A and Melko R G 2018 Physical Review B 97 045207
- [41] Zhang W, Liu J and Wei T C 2019 Physical Review E 99 032142
- [42] Suchsland P and Wessel S 2018 Phys. Rev. B 97(17) 174435 URL https://link.aps.org/doi/10.1103/PhysRevB.97.174435
- [43] Kim D and Kim D H 2018 Physical Review E 98 022138
- [44] Lian W, Wang S T, Lu S, Huang Y, Wang F, Yuan X, Zhang W, Ouyang X, Wang X, Huang X et al. 2019 Physical review letters 122 210503
- [45] Dong X Y, Pollmann F, Zhang X F et al. 2019 Physical Review B 99 121104
- [46] Giannetti C, Lucini B and Vadacchino D 2019 Nuclear Physics B 944 114639
- [47] Ohtsuki T and Mano T 2020 Journal of the Physical Society of Japan 89 022001
- [48] Casert C, Vieijra T, Nys J and Ryckebusch J 2019 Physical Review E 99 023304
- [49] Zhang R, Wei B, Zhang D, Zhu J J and Chang K 2019 Physical Review B 99 094427
- [50] Singh V K and Han J H 2019 Physical Review B 99 174426
- [51] Arnold J, Schäfer F, Žonda M and Lode A U 2021 Physical Review Research 3 033052
- [52] Liu Y H and Van Nieuwenburg E P 2018 Physical review letters 120 176401
- [53] Huembeli P, Dauphin A, Wittek P and Gogolin C 2019 Physical review B 99 104106
- [54] Käming N, Dawid A, Kottmann K, Lewenstein M, Sengstock K, Dauphin A and Weitenberg C 2021 Machine Learning: Science and Technology 2 035037
- [55] Alexandrou C, Athenodorou A, Chrysostomou C and Paul S 2020 The European Physical Journal B 93 1–15
- [56] Yin J, Pei Z and Gao M C 2021 Nature Computational Science 1 686–693
- [57] Greplova E, Valenti A, Boschung G, Schäfer F, Lörch N and Huber S D 2020 New Journal of Physics 22 045003
- [58] Kharkov Y A, Sotskov V, Karazeev A, Kiktenko E O and Fedorov A K 2020 Physical Review B 101 064406
- [59] Ch’ng K, Vazquez N and Khatami E 2018 Physical Review E 97 013306
- [60] Wang C and Zhai H 2017 Physical Review B 96 144432
- [61] Kottmann K, Huembeli P, Lewenstein M and Acín A 2020 Physical Review Letters 125 170603
- [62] Jadrich R, Lindquist B and Truskett T 2018 The Journal of chemical physics 149 194109
- [63] Che Y, Gneiting C, Liu T and Nori F 2020 Physical Review B 102 134213
- [64] Bromley J, Guyon I, LeCun Y, Säckinger E and Shah R 1993 Advances in neural information processing systems 6 737–744
- [65] Baldi P and Chauvin Y 1993 neural computation 5 402–418
- [66] Henriet L, Beguin L, Signoles A, Lahaye T, Browaeys A, Reymond G O and Jurczak C 2020 Quantum 4 327 ISSN 2521-327X URL https://doi.org/10.22331/q-2020-09-21-327
- [67] Browaeys A and Lahaye T 2020 Nature Physics 16 132–142 URL https://doi.org/10.1038/s41567-019-0733-z
- [68] Kalinowski M, Samajdar R, Melko R G, Lukin M D, Sachdev S and Choi S 2021 arXiv preprint arXiv:2112.10790
- [69] Ebadi S, Wang T T, Levine H, Keesling A, Semeghini G, Omran A, Bluvstein D, Samajdar R, Pichler H, Ho W W, Choi S, Sachdev S, Greiner M, Vuletić V and Lukin M D 2021 Nature 595 227–232 ISSN 1476-4687 URL http://dx.doi.org/10.1038/s41586-021-03582-4
- [70] Miles C, Samajdar R, Ebadi S, Wang T T, Pichler H, Sachdev S, Lukin M D, Greiner M, Weinberger K Q and Kim E A 2021 arXiv preprint arXiv:2112.10789
- [71] Torlai G, Timar B, Van Nieuwenburg E P, Levine H, Omran A, Keesling A, Bernien H, Greiner M, Vuletić V, Lukin M D et al. 2019 Physical review letters 123 230504
- [72] Carrasquilla J and Torlai G 2021 PRX Quantum 2 040201
- [73] Czischek S, Moss M S, Radzihovsky M, Merali E and Melko R G 2022 arXiv preprint arXiv:2203.04988
- [74] Browaeys A, Barredo D and Lahaye T 2016 Journal of Physics B: Atomic, Molecular and Optical Physics 49 152001 URL https://doi.org/10.1088/0953-4075/49/15/152001
- [75] Samajdar R, Ho W W, Pichler H, Lukin M D and Sachdev S 2020 Physical Review Letters 124 ISSN 1079-7114 URL http://dx.doi.org/10.1103/physrevlett.124.103601
- [76] Merali E, De Vlugt I J and Melko R G 2021 arXiv preprint arXiv:2107.00766
- [77] Newman M E J and Barkema G T 1999 Monte Carlo methods in statistical physics (Clarendon Press)
- [78] Schroff F, Kalenichenko D and Philbin J 2015 CoRR abs/1503.03832 (Preprint 1503.03832) URL http://arxiv.org/abs/1503.03832
- [79] Miles C, Bohrdt A, Wu R, Chiu C, Xu M, Ji G, Greiner M, Weinberger K Q, Demler E and Kim E A 2021 Nature Communications 12 1–7