unsupervised machine learning for physical concepts
Abstract
In recent years, machine learning methods have been used to assist scientists in scientific research. Human scientific theories are based on a series of concepts. How machine learns the concepts from experimental data will be an important first step. We propose a hybrid method to extract interpretable physical concepts through unsupervised machine learning. This method consists of two stages. At first, we need to find the Betti numbers of experimental data. Secondly, given the Betti numbers, we use a variational autoencoder network to extract meaningful physical variables. We test our protocol on toy models and show how it works.
I introduction
Physics is built on many different concepts, such as force, entropy, and Hamiltonian. Scientists derive meaningful concepts from observations by their ingenuity and then use formulas to connect them, constituting the theory. As a principle, this theory is always as simple as possible. Since the beginning of the 21st century, machine learning has developed rapidly Liu et al. (2018) and has been widely used in various fields Teichert et al. (2019); Bourilkov (2019); Mishra et al. (2016), including machine-assisted scientific research Vamathevan et al. (2019); Valletta et al. (2017); Schmidt et al. (2019); Carleo et al. (2019). A natural question arises: can machines propose scientific theories by themselves? It is undoubtedly a fundamental and challenging goal. Many works have studied this from different aspects Ha and Jeong (2021); Zhang and Lin (2018); Boullé et al. (2021); Zobeiry and Humfeld (2019); Farina et al. (2020); Wu and Tegmark (2019); Zheng et al. (2018); D’Agnolo and Wulzer (2019). In general, the establishment of the theory can be divided into two steps: identify the critical variables from observations and connect them by formula. A technique known as symbolic regression has been developed for the second step Udrescu and Tegmark (2020); Udrescu et al. (2020). The authors propose a network named AI Feymann to automatically find the formula the system obeys. To increase the success rate of symbolic regression, the critical variables identified by the first step should be as few as possible.
In this work, we focus on the first step of establishing a theory. We suggest using both Topological Data Analysis(TDA)Wasserman (2018); chazal2017introduction; Murugan and Robertson (2019) and variational autoencoder(VAE) Kingma and Welling (2019, 2013); An and Cho (2015); Khobahi and Soltanalian (2019); Rezende et al. (2014); Higgins et al. (2016); Burgess et al. (2018) to extract meaningful variables from extensive observations. TDA is a recent and fast-growing tool to analyze and exploit the complex topological and geometric structures underlying data. This tool is necessary for our protocol if specific structures such as circles and sphere are in experimental data. VAE is a deep learning technique for learning latent representations. This technique has been widely used in many problemsLuchnikov et al. (2019); Cerri et al. (2019) as a generative model. It can also be seen as a manifold learning network for dimensionality reduction and unsupervised learning tasks.
Our protocol has two stages. Firstly, we use TDA to infer relevant topological features for experimental data. In the simplest case, where the manifold has a low dimension, an essential feature for us is the Betti numbers, topology invariants. Once we get the topological features, we can design the proper architecture and loss function of VAE. As we will show later, the latent variables of VAE need to form a manifold homeomorphic to the manifold composed of observations. After the training of the VAE network, the latent variables represent the key variables discovered by this machine. Thanks to the structure of the VAE network, the latent variables, and the observations are in one-to-one correspondence. Using the trained VAE network, one can calculate the latent variables and the observations from each other. That means the formula derived by symbolic regression connecting the latent variables can predict the experimental phenomena.
We test our protocol on three toy models. They have different topological features. The first is a classical coupled harmonic oscillator, where the observations constitute a circle embedded in three-dimensional Euclidean space. Another example is two balls rotating around the same center, with different radius and angular velocities. With the other ball as the reference system, the observations are the Cartesian coordinates of the ball. The observations constitute a lemniscate curve. The third is a two-level system, and the observations are the expected value of some physical quantity,i.e., some hermitian matrices. The observations constitute a sphere.
This paper is organized as follows. In section II, we describe the works been done before and the problem we want to solve in more detail. In section III, we introduce the architecture of neuron networks and argue why we need the manifold of latent variants should be homeomorphic to that of observations. In section IV, we show the performance of this protocol on three toy models. We compare the observations and latent variables to show the relation between them.
II Related work and our goal
Data-driven scientific discoveries are not new ideas. It follows from the revolutionary work of Johannes Kepler and Sir Isaac Newton Roscher et al. (2020). Unlike the 17th century, we now have higher quality data and better calculation tools. People have done a lot of research on how to make machines help people make scientific discoveries in different contexts Carleo et al. (2019); Cichos et al. (2020); Karpatne et al. (2018); Wetzel (2017); Rodriguez-Nieva and Scheurer (2019); Wu and Tegmark (2019). In the early days, people paid more attention to the symbolic regression Kim et al. (2020); Udrescu and Tegmark (2020); Udrescu et al. (2020); Lample and Charton (2019). Another challenging direction is to let the machine design experiments. In Melnikov et al. (2018); Krenn et al. (2016); Fösel et al. (2018); Bukov et al. (2018), authors designed automated search techniques and a reinforcement-learning-based network to generate new experimental setups. In condensed physics, machine learning has been used to characterize phase transitions Van Nieuwenburg et al. (2017); Uvarov et al. (2020); Carrasquilla and Melko (2017); Wang (2016); Ch’Ng et al. (2017); Yu and Deng (2021).
In recent years, some works have contributed to letting the machine search for key physical concepts. They used the different networks to extract key physical parameters from the experimental data Iten et al. (2020); Zheng et al. (2018); Lu et al. (2020). In Zheng et al. (2018), authors propose an unsupervised method to extract physical parameters by interaction networks Battaglia et al. (2016). Another helpful tool is the VAE network, which has been widely used for similar goal Lu et al. (2020); Iten et al. (2020).
VAE network is a powerful tool, by which one can minimize the numbers of extracted variables by making the variables independent of each other Higgins et al. (2016); Burgess et al. (2018). To do this, one can choose the prior distribution as latent variables . However, this method fails when the manifold of observations have some topological features. This paper aims to solve this problem.
Here we describe this goal in more detail. Suppose we have an experimental system . In this system , some physical variables change as the experiment progresses. We use to denote the set consists of the value of these physical variables. We use to represent the value of these variables in time . From the system we can derive an experimental data set . Every data point is a vector where denotes the data point belongs to time . From the perspective of physics, the change of experimental data must be attributed to the change of key physical variables. Therefore there is a function such that for any . In this paper we aim to find the function and such that where constitute a set . We call the effective physical variables. We remark that is not necessary to equal to , but their dimensions should be the same. Effective physical variables are enough to describe the experimental system. In fact, one can redefine the physical quantity can get a theory that looks very different but the predicted results are completely consistent with existing theories.
The problem arise if we try to use neuron network to find proper function and . All the functions neuron network can simulate is continuousLABEL:, so and must be continuous. In a real physical system, and don’t have to be like this. Therefore, in some cases, we can never find a which has the same dimension with . For example, suppose we have a ball rotating around a center. The observable data is the location of the ball, denoted by Cartesian coordinates , which form a circle, and the simplest physical variable is the angle . In this case, is continuous while is not, which cannot be approximated by neural network. This is because is a periodic function of . More generally, as long as the manifold composed of has holes with any dimension, this problem arises. We call these physical variables topological physical variables(TPVs). Back to the last example, we can find the Betti numbers of the ball’s location is , where the second means that it has one TPVs. Due to this reason, we suggest using TDA to identify the topological features firstly. After knowing the numbers of TPVs, we can design proper latent variables and the corresponding loss function . For the case we have two PPVs, we need two latent variables, named and , and we add the topological term to to restrict them.
In at least two cases, the manifold will have holes. One is the of a conversed system,e.g., the classical harmonic oscillator. Another situation stems from the limits of the physical quantity itself, such as the single-qubit state, which forms a sphere. In addition to these two categories, sometimes the choice of observations and references also affects their topological properties.
III architecture of neuron network
As shown in figure 2, This network consists of two parts. The left is called encoder, and the right is called decoder. The encoder part is used to encode high-dimensional data into low-dimensional space, while the decoder part is used to recover the data, i.e., the input from low-dimensional data. The latent variables are low-dimensional data, and we hope they contain all the information needed to recover the input data. So that we require the output is as close as possible to input . Therefore, we can train this neuron network without supervision.
In general, the encoder and decoder can simulate arbitrary continuous function and . That imposes restrictions on latent variables:
Theorem 1.
The manifold composed of latent variables must be homeomorphic to that of input .
This limitation means that the Betti numbers should keep the same. Suppose the inputs form a circle, as shown in 1, the easiest quantity to describe these data is the angle. According to 1, this neuron network can never find such a quantity because the angle will form a line segment that is not homeomorphic to a circle. On the other hand, VAE network can’t even find the Cartesian coordinate because and are not irrelevant. To handle this case, we suggest analyzing the Betti numbers as a priori knowledge of input and tell the neuron network.
The general loss function is wirtten as Higgins et al. (2016):
| (1) |
Here are the parameters of decoder and encoder networks, respectively. is the prior distribution about the latent variables . and denote the conditional probability. means the KL divergence of two distributions.
| (2) |
To calculate the loss function for a given output , one needs to set up a prior , and parameterize the distribution and . In traditional VAE, the distributions , and are often supposed to be multidimensional Gaussian distribution. The mean of is zero the and variance is . The mean and variance of and is the output of encoder network.
In our cases, we choose the prior as . Where denotes the GPVs, and denotes the TPVs. With the same as traditional VAE, in order to minimize the number of GPVs, a convenient way is to choose as Gaussion distribution . According to the topological features, we choose a proper topological term . We choose the as . Here is a constant. The variance can be asorpted into the hyperparameters in loss function.
For the conditional distribution we choose as s , with constantly variance and means determined by the encoder network. has the same expression . In this assumption, the KL divergence can be written as
| (3) |
Thus the loss function can be written as a simplier expression:
| (4) |
where are hyperparameters and is the topological term depending on the Betti numbers. For example, when the Betti numbers are , can be written as . When the Betti numbers are , can be written as , which is known as a Lemniscate. Here we use to denote the latent variables. is the distribution of . We need to choose some latent variables as TPVs, and others as general physical variables(GPVs). In general, we know how many TPVs we need from the Betti numbers, but we usually don’t know how many GPVs we need. One solution is to set up as many GPVs as possible, and the redundant GPVs will be zero.
IV Numerical Simulation


We test this neuron network by numerical simulation. Three toy models whose manifolds are different are considered here.
We use pytorch to implement neural networks. Our code can be found here. We use the same structure in the encoding and decoding network. They have two hidden layers, each with 20 neurons. In encoder network, we choose Tanh as the active function, while in decoder network, we choose ReLU as the active function. In numerical simulation, we first generate a database of , where m is the dimension of the observations. We then use the TDA tools to analyze the Betti numbers of the manifold constituted by observations and set up the latent neurons. We used the Adam optimizer and set the learning rate to . At each training session, we randomly select 100 sets of data from the database as a batch, then calculate the average of its loss and reverse propagate it. All training can be done on the desktop in less than 6 hours.
IV.1 classical Harmonic oscillator
One type of vital importance is the system with some conserved quantity. In classical mechanics, we study these systems by their phase space, constituted by all possible states. Generalized coordinates and generalized momentum are usually not independent of each other, but it is not possible to uniquely determine the other when only one is known. This is caused by the topological nature of the phase space. In some cases, the experimenter may only be able to make observations and cannot exert influence on the observation object. At this time, the observations may constitute a compact manifold, and the traditional VAE network cannot accurately reduce the dimension of the parameter space.
The most common conversed system is the harmonic oscillator, which is a conservative system. We first consider a ball connected with two springs, as shown in Fig 4. We can write the energy as
| (5) |
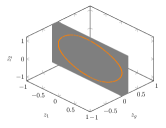
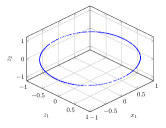
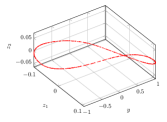
Here we make and . The unit is not important. In loss function 4 we make . In this system, the underlying changing physical variables are or . The observations one can choose here are where and denote the distance from the ball to the bottom of two springs, respectively, and denote the speed of the ball. We specify that the direction of speed is positive to the right and negative to the left. We generate the observations by randomly sampling from the evolution of the system. According to classical mechanics, we know that the manifold should be a circle embedded in 3-d Euclid space. Programme shows that the Betti numbers are . It means that we need 2 latent variables and the topological term in loss function (4) is . Besides, we set up one general physical variable, whose prior is a Gaussian distribution.
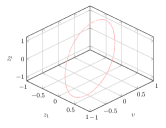
After the train is finished, we calculate the latent variables corresponding to the observations in by encoder network. As is shown in Fig 3(a), the latent variables constitute a circle again. Fig 3(a) shows that the GPV is always zero for different observations. This means that the effective physical variables are .
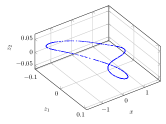
We compared the new physical variables with observations , as shown in Fig LABEL:fig:os_x and 3(c). Given effective physical variables , we can uniquely determine while the mapping is continuous. They are one-to-one correspondence, so can be used to build a theory.
IV.2 Orbit
In classical physics and special relativity, the inertial reference system plays an important role. The physical laws in an inertial reference frame are usually simpler than those in a non-inertial reference frame. In fact, there was no concept of an inertial reference frame at the beginning. Due to the existence of gravity, there is no truly perfect inertial reference frame. When observing some simple motions in a non-inertial frame, the observations may constitute some complex manifolds.
Consider a scenario where two balls, labeled by and , rotate around a fixed point, as shown in Fig 5. Both balls do a constant-speed circular motion. We assume that the distance between it and the fixed point is . Establishing the Cartesian coordinate system with a fixed point as the origin, starts at and starts at .They have the same radius of rotation, but they are on different planes. moves in the plane and moves in the plane. has the angular speed of and has the angular speed of . Unit is not important. Observations is the three-dimensional coordinates of measured by as the reference system.
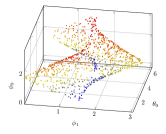
We generate the observations by random sampling from the trajectory With TDA we know the betti numbers of are so the topological term is , and again We set up one GPV. The hyperparameters of loss function 4 is .
After training, the latent variables corresponding to the observations are plotted, as shown in fig 3(d). The GPV is always zero for different observations, which means the effective physical variables is , like the first example. Fig 3(e) and 3(f) shows the comparison between the effective physical variables and observations. The results show that and observational measurements are still one-to-one, so is an effective representation.
IV.3 Quantum state
Both of the previously introduced situations come from the limitations of experimental conditions. If we can modify the conserved quantities of conservative systems through experiments, or find some approximate inertial reference frames, such as the earth or distant stars, then it is possible to turn it into a situation that can be solved by traditional VAE networks. Unlike these, the topological properties of some observations are derived from the laws of physics. If this physical quantity can only take partial values in a certain experimental system, then the VAE network may work at this time. But if we want to establish a physical theory, you need to have a comprehensive understanding of the key parameters, and then you need a VAE network based on topological properties.
In quantum mechanics, quantum state is described by wave function, i.e. a vector in Hilbert space. Here we consider a two-level system, which according to quantum mechanics can be described as , where . The machine don’t know how to describe this system, but it will learn some efficient variables. Suppose we can get five observations in experiments,i.e. . In experiments, is due to the experimental setup. In our numerical simulation, we calculate observations by , where is the pauli matrix and the combination of pauli matrix:
| (6) |
We need many different states, so the coefficient and of the wave function are the physical variables that change as the experiment progresses. In this model, consists of wave functions we use and . The first step is to characterize the topological feature of . By TDA, we can find that the Betti numbers of the data set are , which means that the manifold of is homeomorphic to a sphere. This can be understood because we can use the point on the Bloch sphere to represent the state of a two-level system. So that we know the number of TVs is . However, we don’t know how many GVs are. Different from TVs, we can assume GVs are independent of each other. In general, we do this by assuming in (4) is independent Gaussian distribution. In this case, we only introduce one GV.
As shown in Fig 3(g), after training, TVs form a sphere. At the same time GV stabilizes near 0(not drawn in the figure). That means the five observations can be reduced to three variables continuously. We call these three variables as equivalent density matrix, denoted by . Only two of them are independent. We can construct two independent angles by transforming Cartesian coordinates to polar coordinates. In figure 3(h) we compare and corresponding to the equivalent density matrix. We can see that these two representations have a one-to-one correspondence. Unlike before, the mapping here is discontinuous.
V Conclusion
In this work, we discuss the defect of the traditional VAE network and propose a simple solution. We can extract the minimum effective physical variables from the experimental data with the improved method by classifying the latent variables. We test our approach on three models. They represent three different situations that may arise that traditional VAE cannot handle. Some of them come from experimental restrictions, and some come from physical laws. We think the latter situation is more essential. However, in the more complex case, the Betti numbers are not the only useful topological features. Two manifolds may have the same Betti numbers but not Homeomorphic. In such a case, more topological features are needed to design reasonable restrictions on latent variables. When the manifold dimension is higher, it may be hard for TDA to calculate the Betti numbers. One efficient way is to firstly reduce the dimensions by traditional autoencoder, and then calculate the Betti numbers of latent variables. Another important question is how to ensure that the relation between meaningful variables and observations is simple. We leave it for the future work.
Appendix A persistent homology and betti numbers
Persistent homology is a useful tool for analyzing topological data. The first step is to generate a simplicial complex from the observations. Vietoris–Rips complex is a way of forming a topological space from distances in a set of points. This method uses a generalisation of an neighbouring graph and the final complex is
| (7) |
Here denotes the simplex and are two data points. is the Euclidean metric. A -simplex is expressed as , where denotes the point in the space. Given a set of -simplex , one -chain is defined by
| (8) |
Here the coefficients take values in some field. For the simplicial complex , we denote the set of all -chains by . We can introduce the addition between two -chain. For and , the addition is . Furthermore, the set of all -chains form a abelian group .
For different , a natural group homomorphism is the boundary operator
| (9) |
Boundary operator is linear, and it can be defined by the simplex
| (10) |
One important subgroup of is the kernel of the boundary operator , namely -cycles. There is also an important subgroups of , denoted by , which is the imagine .
Both and are normal, so we can define the quotient group , called the -th homology group. The rank of is called the -th Betti number.
Appendix B Comparison with other work
As we point in the paper, the topological feature of latent space will influence the construction of the output. In the field of machine learning, this phenomenon is called manifold mismatch de Haan and Falorsi (2018); Davidson et al. (2018); Rey et al. (2019); Gong and Cheng (2019), which will lead to poor representations.
Let’s consider what happens when manifold mismatch occurs. Recall the first example, suppose we have a latent structure as , i.e., a circle. While in normal VAE, the prior distribution will limit the latent structure to be , where is the number of latent variables. This prior will make the hidden variables independent of each other. Like before, here we set . One parameter can describe this system, e.g. the angle . Thus we get a network which maps the coordinate to a parameter and then maps the to the coordinate . In practice, our data set is finite, and the finally network will only be effective for an arc on the circle, instead of the total circle. This problem can be worse when the manifold dimension is higher.
In the earlier works, some methods have been developed for capturing the topological features of date set. However, to our understanding, these methods are not suitable for our goal because they usually derive a set of entangled latent vatiables.
References
- Liu et al. (2018) J. Liu, X. Kong, F. Xia, X. Bai, L. Wang, Q. Qing, and I. Lee, IEEE Access 6, 34403 (2018).
- Teichert et al. (2019) G. H. Teichert, A. Natarajan, A. Van der Ven, and K. Garikipati, Computer Methods in Applied Mechanics and Engineering 353, 201 (2019).
- Bourilkov (2019) D. Bourilkov, International Journal of Modern Physics A 34, 1930019 (2019).
- Mishra et al. (2016) S. Mishra, D. Mishra, and G. H. Santra, Indian Journal of Science and Technology 9, 1 (2016).
- Vamathevan et al. (2019) J. Vamathevan, D. Clark, P. Czodrowski, I. Dunham, E. Ferran, G. Lee, B. Li, A. Madabhushi, P. Shah, M. Spitzer, et al., Nature Reviews Drug Discovery 18, 463 (2019).
- Valletta et al. (2017) J. J. Valletta, C. Torney, M. Kings, A. Thornton, and J. Madden, Animal Behaviour 124, 203 (2017).
- Schmidt et al. (2019) J. Schmidt, M. R. Marques, S. Botti, and M. A. Marques, npj Computational Materials 5, 1 (2019).
- Carleo et al. (2019) G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová, Reviews of Modern Physics 91, 045002 (2019).
- Ha and Jeong (2021) S. Ha and H. Jeong, arXiv preprint arXiv:2102.04008 (2021).
- Zhang and Lin (2018) S. Zhang and G. Lin, Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 474, 20180305 (2018).
- Boullé et al. (2021) N. Boullé, C. J. Earls, and A. Townsend, arXiv preprint arXiv:2105.00266 (2021).
- Zobeiry and Humfeld (2019) N. Zobeiry and K. D. Humfeld, arXiv preprint arXiv:1909.13718 (2019).
- Farina et al. (2020) M. Farina, Y. Nakai, and D. Shih, Physical Review D 101, 075021 (2020).
- Wu and Tegmark (2019) T. Wu and M. Tegmark, Physical Review E 100, 033311 (2019).
- Zheng et al. (2018) D. Zheng, V. Luo, J. Wu, and J. B. Tenenbaum, arXiv preprint arXiv:1807.09244 (2018).
- D’Agnolo and Wulzer (2019) R. T. D’Agnolo and A. Wulzer, Physical Review D 99, 015014 (2019).
- Udrescu and Tegmark (2020) S.-M. Udrescu and M. Tegmark, Science Advances 6, eaay2631 (2020).
- Udrescu et al. (2020) S.-M. Udrescu, A. Tan, J. Feng, O. Neto, T. Wu, and M. Tegmark, arXiv preprint arXiv:2006.10782 (2020).
- Wasserman (2018) L. Wasserman, Annual Review of Statistics and Its Application 5, 501 (2018).
- Murugan and Robertson (2019) J. Murugan and D. Robertson, arXiv preprint arXiv:1904.11044 (2019).
- Kingma and Welling (2019) D. P. Kingma and M. Welling, arXiv preprint arXiv:1906.02691 (2019).
- Kingma and Welling (2013) D. P. Kingma and M. Welling, arXiv preprint arXiv:1312.6114 (2013).
- An and Cho (2015) J. An and S. Cho, Special Lecture on IE 2, 1 (2015).
- Khobahi and Soltanalian (2019) S. Khobahi and M. Soltanalian, arXiv preprint arXiv:1911.12410 (2019).
- Rezende et al. (2014) D. J. Rezende, S. Mohamed, and D. Wierstra, in International conference on machine learning (PMLR, 2014) pp. 1278–1286.
- Higgins et al. (2016) I. Higgins, L. Matthey, A. Pal, C. Burgess, X. Glorot, M. Botvinick, S. Mohamed, and A. Lerchner, (2016).
- Burgess et al. (2018) C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, and A. Lerchner, arXiv preprint arXiv:1804.03599 (2018).
- Luchnikov et al. (2019) I. A. Luchnikov, A. Ryzhov, P.-J. Stas, S. N. Filippov, and H. Ouerdane, Entropy 21, 1091 (2019).
- Cerri et al. (2019) O. Cerri, T. Q. Nguyen, M. Pierini, M. Spiropulu, and J.-R. Vlimant, Journal of High Energy Physics 2019, 1 (2019).
- Roscher et al. (2020) R. Roscher, B. Bohn, M. F. Duarte, and J. Garcke, Ieee Access 8, 42200 (2020).
- Cichos et al. (2020) F. Cichos, K. Gustavsson, B. Mehlig, and G. Volpe, Nature Machine Intelligence 2, 94 (2020).
- Karpatne et al. (2018) A. Karpatne, I. Ebert-Uphoff, S. Ravela, H. A. Babaie, and V. Kumar, IEEE Transactions on Knowledge and Data Engineering 31, 1544 (2018).
- Wetzel (2017) S. J. Wetzel, Physical Review E 96, 022140 (2017).
- Rodriguez-Nieva and Scheurer (2019) J. F. Rodriguez-Nieva and M. S. Scheurer, Nature Physics 15, 790 (2019).
- Kim et al. (2020) S. Kim, P. Y. Lu, S. Mukherjee, M. Gilbert, L. Jing, V. Čeperić, and M. Soljačić, IEEE Transactions on Neural Networks and Learning Systems (2020).
- Lample and Charton (2019) G. Lample and F. Charton, arXiv preprint arXiv:1912.01412 (2019).
- Melnikov et al. (2018) A. A. Melnikov, H. P. Nautrup, M. Krenn, V. Dunjko, M. Tiersch, A. Zeilinger, and H. J. Briegel, Proceedings of the National Academy of Sciences 115, 1221 (2018).
- Krenn et al. (2016) M. Krenn, M. Malik, R. Fickler, R. Lapkiewicz, and A. Zeilinger, Physical review letters 116, 090405 (2016).
- Fösel et al. (2018) T. Fösel, P. Tighineanu, T. Weiss, and F. Marquardt, Physical Review X 8, 031084 (2018).
- Bukov et al. (2018) M. Bukov, A. G. Day, D. Sels, P. Weinberg, A. Polkovnikov, and P. Mehta, Physical Review X 8, 031086 (2018).
- Van Nieuwenburg et al. (2017) E. P. Van Nieuwenburg, Y.-H. Liu, and S. D. Huber, Nature Physics 13, 435 (2017).
- Uvarov et al. (2020) A. Uvarov, A. Kardashin, and J. D. Biamonte, Physical Review A 102, 012415 (2020).
- Carrasquilla and Melko (2017) J. Carrasquilla and R. G. Melko, Nature Physics 13, 431 (2017).
- Wang (2016) L. Wang, Physical Review B 94, 195105 (2016).
- Ch’Ng et al. (2017) K. Ch’Ng, J. Carrasquilla, R. G. Melko, and E. Khatami, Physical Review X 7, 031038 (2017).
- Yu and Deng (2021) L.-W. Yu and D.-L. Deng, Physical Review Letters 126, 240402 (2021).
- Iten et al. (2020) R. Iten, T. Metger, H. Wilming, L. Del Rio, and R. Renner, Physical review letters 124, 010508 (2020).
- Lu et al. (2020) P. Y. Lu, S. Kim, and M. Soljačić, Physical Review X 10, 031056 (2020).
- Battaglia et al. (2016) P. W. Battaglia, R. Pascanu, M. Lai, D. Rezende, and K. Kavukcuoglu, arXiv preprint arXiv:1612.00222 (2016).
- de Haan and Falorsi (2018) P. de Haan and L. Falorsi, arXiv preprint arXiv:1812.10783 (2018).
- Davidson et al. (2018) T. R. Davidson, L. Falorsi, N. De Cao, T. Kipf, and J. M. Tomczak, arXiv preprint arXiv:1804.00891 (2018).
- Rey et al. (2019) L. A. P. Rey, V. Menkovski, and J. W. Portegies, arXiv preprint arXiv:1901.08991 (2019).
- Gong and Cheng (2019) L. Gong and Q. Cheng, arXiv preprint arXiv:1901.09970 (2019).