1.4pt
Unsupervised physics-informed neural network in reaction-diffusion biology models (Ulcerative colitis and Crohn’s disease cases) A preliminary study
Abstract
We propose to explore the potential of physics-informed neural networks (PINNs) in solving a class of partial differential equations (PDEs) used to model the propagation of chronic inflammatory bowel diseases, such as Crohn’s disease and ulcerative colitis. An unsupervised approach was privileged during the deep neural network training. Given the complexity of the underlying biological system, characterized by intricate feedback loops and limited availability of high-quality data, the aim of this study is to explore the potential of PINNs in solving PDEs. In addition to providing this exploratory assessment, we also aim to emphasize the principles of reproducibility and transparency in our approach, with a specific focus on ensuring the robustness and generalizability through the use of artificial intelligence. We will quantify the relevance of the PINN method with several linear and non-linear PDEs in relation to biology. However, it is important to note that the final solution is dependent on the initial conditions, chosen boundary conditions, and neural network architectures. 111This work was carried out under the scientific direction of the mathematician Pr. Hatem Zaag. 222Corresponding author: Ahmed Rebai, ahmed.rebai@value.com.tn
Keywords: Unsupervised PINN, Deep Neural Networks, Coupled Nonlinear PDEs, IBD (Inflammatory Bowel Diseases), Ulcerative Colitis, Crohn’s Disease, Computer Vision, Machine Learning Classification, AI Reproducibility.
1 Introduction
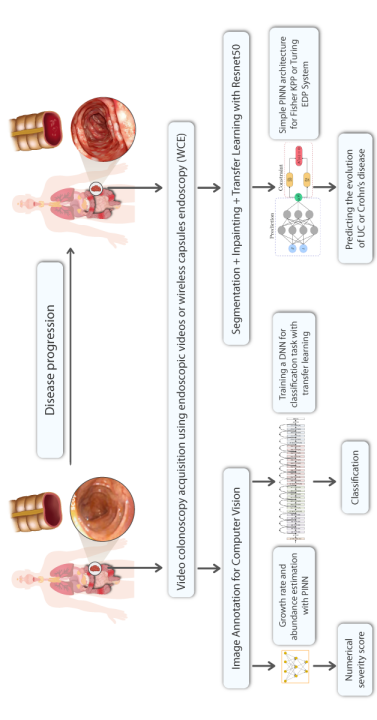
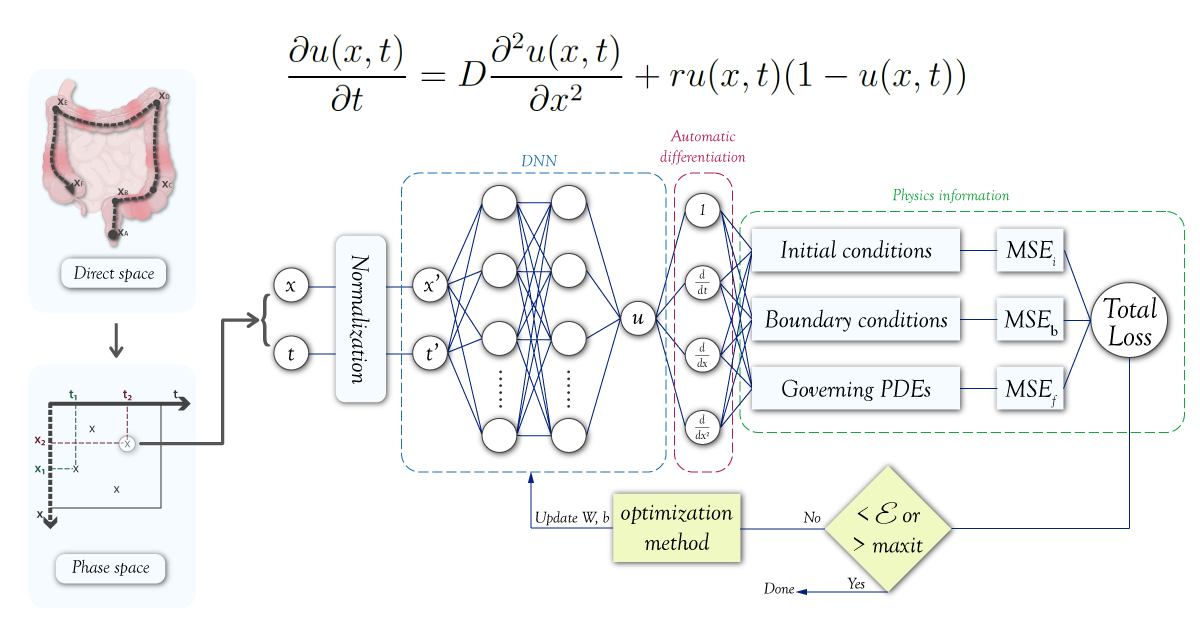
The current work focuses on a new multidisciplinary field at the intersection of three disciplines: artificial intelligence (AI) via deep learning, applied mathematics via partial differential equations, and the biology of the inflammatory bowel diseases (as illustrated in Figure 1). While writing this paper, we encountered several difficulties due to the unique nature of this multidisciplinary subject, which is both innovative and AI hyped, resulting in a genuine debate in the community between partisans who are optimistic about the potential of this new technique [1, 2] and non-partisans who point out its limitations [3, 4]. For this, we believe it is best to begin with a brief overview of each discipline before discussing progress at the various intersections between these disciplines, followed by a discussion of the resulting controversy.
2 PINN in biology: crossroads of several disciplines
2.1 Artificial intelligence
In its general definition, artificial intelligence allows computers to partially or totally perform intelligent tasks usually associated with human intelligence. Nowadays, artificial intelligence learns and generalizes patterns in high-dimensional and highly non-linear spaces without being specifically guided [6, 7]. This learning processes is based on various types of data (tabular data, image data, sound data, text data…) and is leading to success in various fields such as nuclear energy where AI has been used recently to control a fusion reactor [8] and Earth science where AI allowed to predict the weather in short-term within the "nowcasting" project with a deep reinforcement learning algorithm [9]. Continuing with this progress, in this paper we will see how neural networks could also learn the dynamics of a complex biological system from the structure of the partial differential equations describing these dynamics.
2.2 Partial differential equations
Many engineering fields use partial differential equations as models, including combustion theory, weather prediction, financial markets and industrial machine design. A partial differential equation or a system of partial differential equations can be solved analytically [10], numerically [11, 12] and now with artificial intelligence using techniques such as deep neural networks (DNNs) [1, 13]. In practice, the analytical method works for some simple equations, but its application is difficult in most cases of coupled and nonlinear PDE systems. The numerical resolution technique is preferred for this and often requires the use of expensive commercial numerical solvers such as finite element method (FEM) or finite difference method (FDM). It can be summarized in five steps: modeling, meshing, discretizing, numerical computing and post-processing:
-
•
Modeling: Mathematical modeling of physical or chemical or biological processes.
-
•
Mesh: The creation of a mesh or a grid called also computational domain which consists of equivalent system of multiple sub-domains (finite differences or elements or volumes). Given the mesh, the basis functions are predetermined. This step is characterized by its great temporal complexity. At this level, the PINN method could offer a solution to reduce the execution time since it only requires faster random sampling of the working domain.
-
•
Discretization: Discretize the governing equations by turning it into a system of equations simply by approximating the derivatives. The used functions are linear (i.e polynomial functions) which sometimes does not capture the non-linear character of the underlying phenomena. Given the non-linear nature of neural networks, they could help overcome this deficiency.
-
•
Solution: Solving the set of linear equations by numerical computing using extensive parallel IT ressources like CPUs, GPUs and large RAMs.
-
•
Postprocess: Finding the desired quantities like position or velocity by analyzing the obtained data. The use of machine learning models can make this analysis more refined and robust.
As previously stated, numerical methods have some drawbacks such as high time consumption, repetitiveness and lack of autonomy. In fact, creating a mesh to simulate an airplane turbo-reactor can take months in some industrial cases. Also, numerical solving is repetitive because the 5 steps must be reproduced each time the domain is changed. Furthermore, unlike AI models, this procedure does not learn from previous trials even if we keep the same domain or the same grid. However, the basis functions do not always allow for the reflection of non-linear phenomena that cause real or artificial blow-up phenomena such as numerical explosion [14]. Finally, when we consider how difficult it is to reduce human intervention, it is clear that this technique lacks the autonomy sought during the normal use of artificial intelligence. As a result, several unanswered questions may arise, such as: Is it possible for solvers to learn the basis functions from partial differential equations automatically? Is it feasible to develop autonomous flow solvers for fluid mechanics?
2.3 Biology of the inflammatory bowel diseases
Now let’s move to biology which is the science of living organisms extending from the molecular level to the mesoscopic ecosystems. In this paper, we focus on the modelling of the inflammatory process hitting the bowel. Crohn’s disease and ulcerative colitis are both inflammatory bowel diseases but they are different indeed [15, 16]. Ulcerative colitis (UC) is a chronic inflammatory bowel disease resulting from an overreaction of the natural defenses of the digestive immune system, with an estimated prevalence of 1 in 1500 people with an annual incidence of 6 to 8 new cases per 100,000 inhabitants in Australia [17], Western Europe and the United States. In Tunisia, the incidence is estimated at 2.11 per 100,000 inhabitants per year [18, 19]. UC is not a rare disease in tunisian adults, but in children. It is characterized by smooth ulceration of the inner lining of the colon. The inflammation begins in the lower region of the colon, just above the anus, and progresses upward at varying distances. One of the most important indicators of the severity of this disease is the spatial distribution of the intestinal lesions associated with an introduced gastro-enterologist’s severity score. While individuals with moderate to high severity scores have a concentration of lesions around the rectum, those with low severity scores frequently have a homogeneous spatial distribution of colonic lesions. UC appears in lesions such as bleeding rectal and colon ulcers. It is a currently incurable disease characterized by varying intensities of inflammatory relapse with interspersed remission periods. This puts the patient at higher risk of colon cancer than the general population thus the potential removal of the organ (colectomy). Currently available treatments aim to control pain, reduce the frequency and duration of relapses, and thereby relieve symptoms. Crohn’s disease is a type of painful inflammatory bowel disease (IBD) that is not well understood. In Tunisia, this serious disease affects both children over 10 and adults [18]. It consists of the appearance of several asymmetrical segments of deep lesions separated by intact areas. In the worst cases, these areas can turn into fissures or even holes in the wall of the intestine. Unlike other IBDs, it affects any part of the gastrointestinal tract, from top (the mouth) to bottom (the anus), in contiguous or isolated parts. The inflammation can affect the inner lining and even go beyond the entire thickness of the intestinal wall; It is manifested by a blood vessels dilation and tissues fluid loss. It is usually present in the lower part of the small intestine that connects to the colon. The inflamed portion of the intestine affects the deep panniculus and is not adjacent to it, but rather is distributed throughout the gastrointestinal tract, with an erratic inflammation pattern. The diagnosis of this disease requires advanced technological tools which present difficulties in the collection of data to predict the spread. For that, the mathematical modeling has been increasingly utilized as a tool to understand the complex and dynamic processes involved in both diseases as shown in [5, 20].
In the evaluation and management of both Crohn’s disease and ulcerative colitis, doctors typically use a combination of biological, clinical, and spatial indicators to assess a patient’s condition, predict its progression, and determine the most appropriate treatment. Clinical indicators may include a physician’s examination and questioning of the patient, as well as video examination of the colon through colonoscopy. Biopsy samples taken during colonoscopy can also provide valuable histological images. In addition, biological or chemical indicators such as the measurement of calprotectin levels in stool (as an indicator of inflammation) and analysis of the intestinal microbiota through DNA and RNA analysis can provide important insights into the disease. Additionally, analysis of RNA expression in the intestine can also be used as an indicator.
| Data type | Data requirements | Tasks |
|---|---|---|
| Clinical data | Doctor’s questionnaires | Classification |
| Biological data | Physico-clinical analysis | Scoring and Classification |
| Images and videos data | Computer vision treatment | Classification and PDE |
2.4 The importance of spatial information
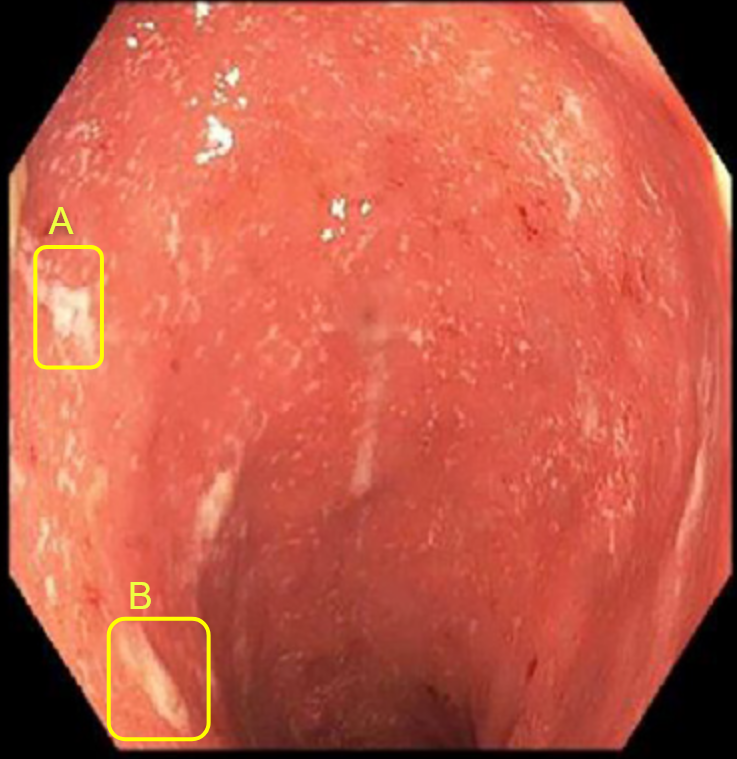
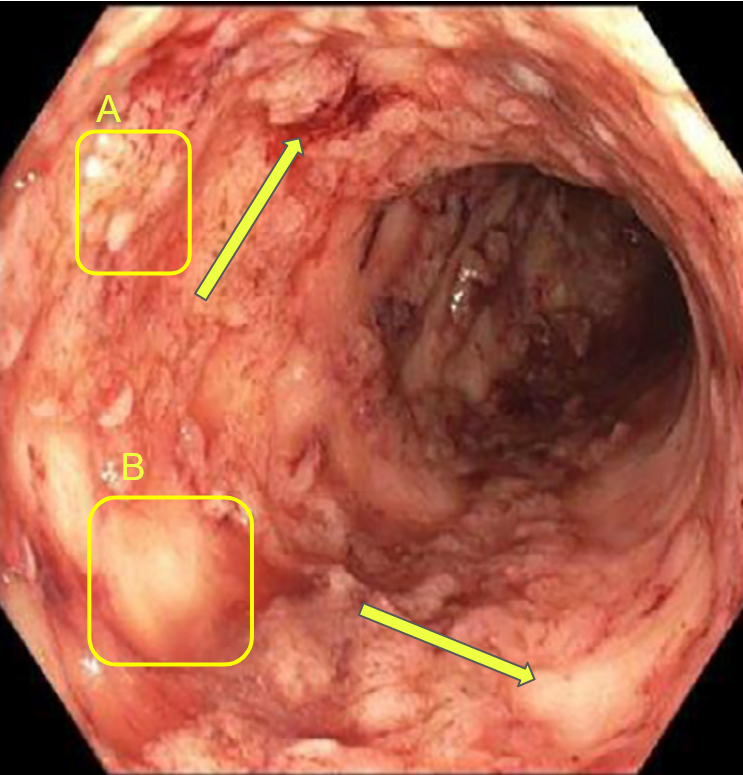
Gastro-enterologists and surgeons are hindered from having spatial information on anatomical sites since these indicators are not spatial, and the provided information is never localized in a specific position. The diagnosis of these diseases is based on the analysis of colonoscopy videos. Thus, physicians assess the severity of the disease according to the presence of inflammation, bleeding or ulcers on the intestinal wall which requires an advanced level of expertise. In the same way, the extent of the lesions is currently ignored in medical practice, for lack of a validated method for analyzing this information. This same remark applies to other indicators like numerical score of severity [21], the speed of inflammation propagation, the choice of treatment [22]. Gastroenterologists recognize the significance of spatial information in the development of complications such as esophageal and colon cancer in patients with Crohn’s disease and ulcerative colitis. However, current guidelines fail to fully consider the quantity and distribution of lesions, often focusing solely on the most severe lesion identified. This is due to the scarcity of software tools and scientific literature. Additionally, the intricate feedback loops and technical challenges in collecting high-quality data for the calibration of numerical and mathematical models (see figure 2) further highlights the need for innovative methods. This necessity is the driving force behind our current study, which aims to address the limitations in current approaches and provide a more comprehensive understanding of the disease.
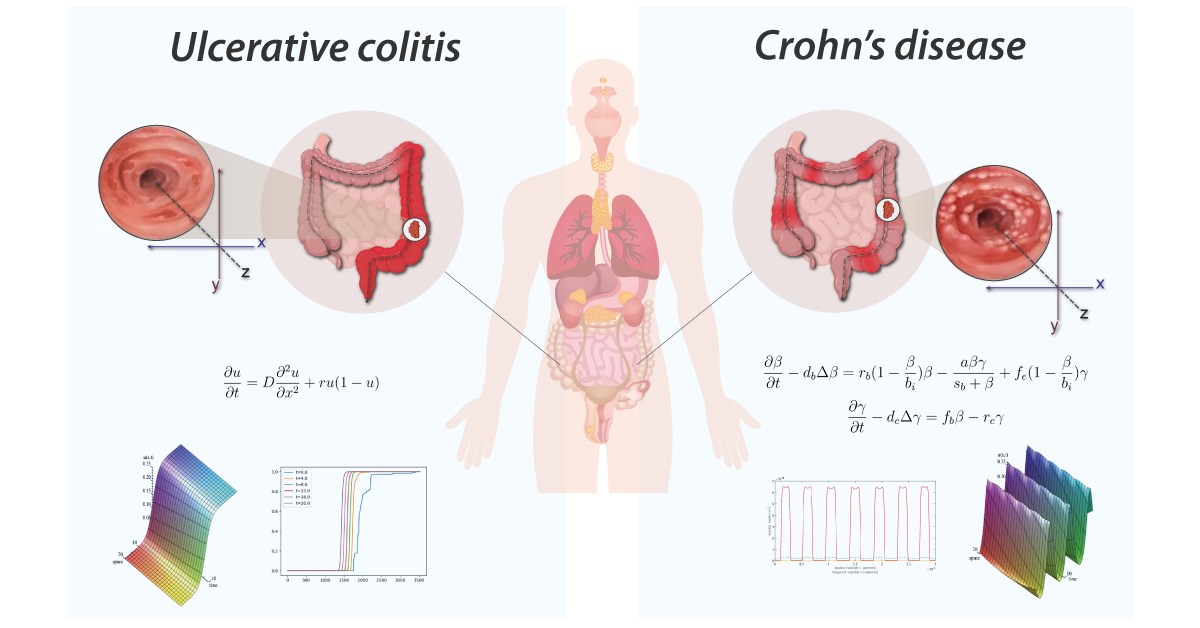
Endoscopic video analysis [24] plays a crucial role in evaluating the severity of ulcerative colitis and monitoring the progression of the disease. Colonoscopy is widely used as the reference examination to assess the intensity of the disease and the extent of intestinal lesions. During this routine procedure, a gastroenterologist inserts a camera-equipped endoscope into the colon to visualize the inner lining and take biopsies if necessary. It should be noted that this technique has a very strong impact on the quality of life of the patients.
Wireless capsule endoscopy (WCE) [24] is another commonly used technique in which patients swallow a small, intelligent capsule that contains a camera and a light source. The capsule sends images of the intestinal mucosa to a wearable sensor, making it a less invasive alternative to colonoscopy. This method is especially useful for accessing regions of the small intestine that are difficult to reach with endoscopy. However, it is more expensive as the capsule can only be used once. Unfortunately, this technique has been abandoned in Tunisian hospitals due to its cost being considered expensive.
Both colonoscopy and WCE allow for the detection of important lesions in the videos, such as: Loss of visibility of the vascular framework, which is indicated by the disappearance of blood vessels and the formation of fibrous tissue that impedes nutrient absorption and inflammation and bleeding, which appear as red areas on the intestinal wall and ulcers and indentations in the wall that appear white or gray. The precise collection and examination of the endoscopic video data is essential not only for identifying the disease presence and advancement, but also for categorizing the different types of IBDs and classifying the subtypes within the same disease.
2.5 PIML: A new and growing discipline with challenges
Physics-Informed Machine Learning (PIML), also known as Physics-Informed Neural Networks (PINN), is an emerging discipline that merges the concepts of physics with the advanced techniques of machine learning and neural networks. The objective of PIML is to harness the laws of physics to increase the precision of machine learning models, particularly in cases where the systems being modeled are governed by partial differential equations. In PIML, the governing equations of a physical system are integrated into the training process of a machine learning model, resulting in predictions that are not only accurate, but also physically meaningful and interpretable. Overfitting is prevented through this approach. PIML has been successfully applied in diverse fields such as fluid dynamics, structural mechanics, quantum mechanics, cosmology and quantitative finance. With many advancements and applications yet to be discovered, PIML is a rapidly growing field that promises exciting new possibilities. According to the Gartner AI Hype Cycle diagrams for 2021 [25] and 2022 [26], PINN and PIML are currently in the innovation trigger phase, gaining increasing attention and applications in the scientific community. With continued growth and development, these technologies are expected to reach the peak of inflated expectations before settling into a plateau of productivity. As PINN and PIML become more widely adopted, we can expect to see their use in solving real-world problems in biology and medicine (see the figure 3).
The establishment of neural networks in mathematics can be traced back to the seminal work of Cybenko in 1989 [27]. In this paper, Cybenko presented the concept of universal approximation, which demonstrated that a single hidden layer feedforward neural network with a sigmoid activation function is capable of approximating any continuous bounded function with a sufficient number of hidden units. This foundational work was further advanced by the studies of Hornik and Barron [28, 29], which provided additional insights into the concept of universal approximation. Various architectures have been developed, starting with original PINN and followed by DeepFNet, DeepONet, DeepM&MNet.
-
•
DeepFNet [30] is a neural network architecture that is well-suited for functional approximation tasks because it is flexible, able to model complex relationships, and scalable. Its hierarchical structure allows it to learn and represent multi-scale features in the data, improving its ability to generalize and make accurate predictions on unseen data. Generally, it requires significantly fewer neurons than shallow networks to achieve a given degree of function approximation.
-
•
DeepONet [31]: uses a deep learning approach to learn nonlinear operators. The advantage is that it can capture complex relationships between variables that are not easily modeled using linear techniques. DeepONet uses seq2seq and fractional algorithms. Seq2seq (or "sequence-to-sequence") is a type of algorithm that is used to map input sequences to output sequences. Data with long-range relationships are analyzed using fractional (or "fractionally-differentiated") approaches.
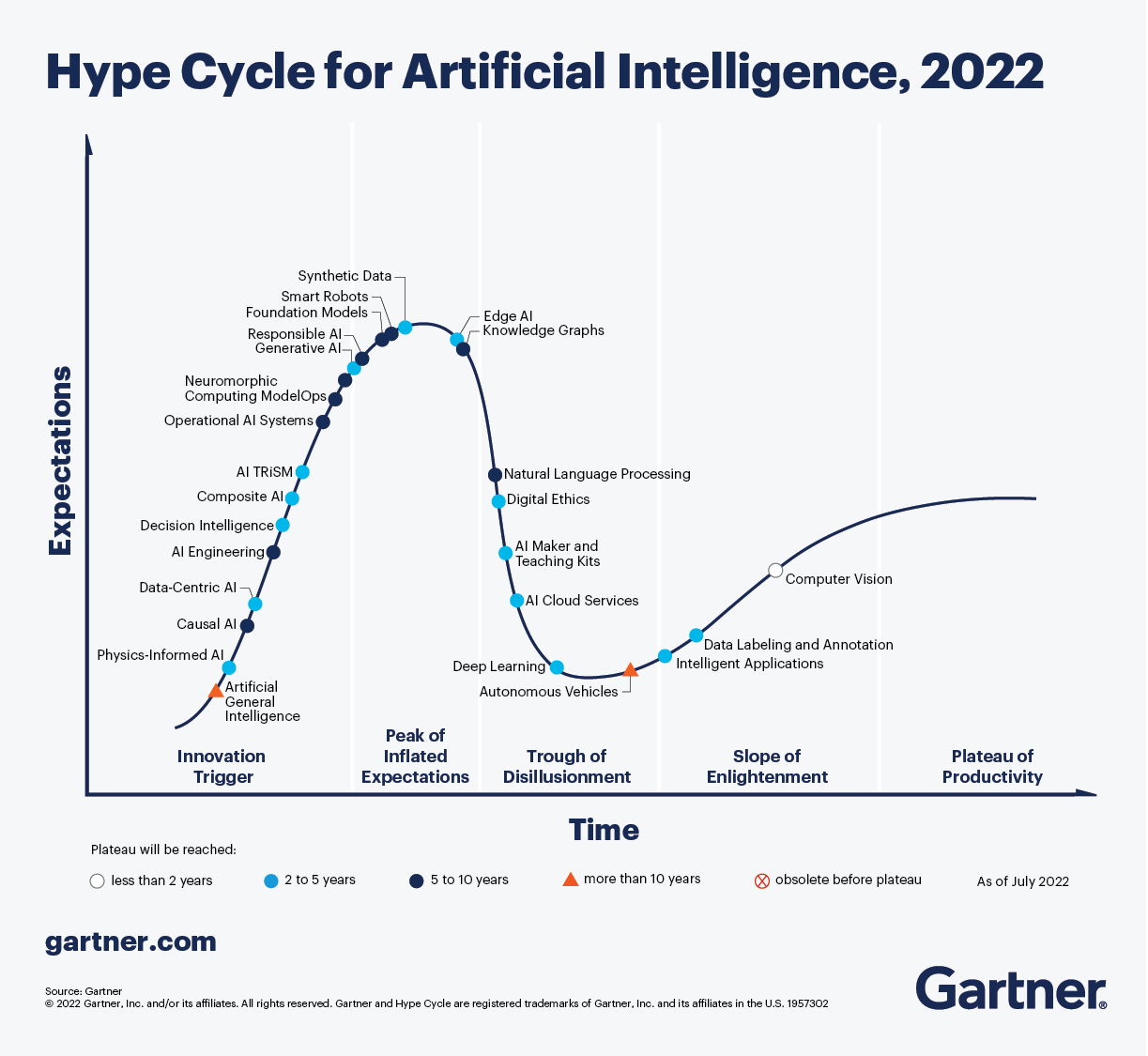
Figure 3: For the second consecutive year, the 2022 Gartner’s hype cycle for artificial intelligence evokes the physics-informed AI. We notice that the PIML is actually in the innovation trigger regime with an improved outlook because the plateau of productivity will be reached between 2 to 5 years instead of 5 to 10 years. -
•
DeepM&MNet [32, 33] is a neural network framework for simulating complex, multiphysics systems. It uses pre-trained neural networks to make predictions about the different fields in a coupled system, such as the flow, electric and concentration fields. The framework is designed to be fast and efficient, and can be used to build models with very little data. DeepM and MNet are versatile algorithms for modeling complex, multiphysics and multiscale dynamic systems. DeepM uses a multilayer perceptron architecture, while MNet uses a combination of convolutional and long short-term memory networks. Both algorithms are able to capture intricate patterns and trends in time series data.
However, the best approach for using PINN in a particular biological system depends on the available data and knowledge of the physics of the system. We will explore three possible scenarios in which PINN can be applied in biology.
-
•
First scenario: In this case, a Physics-Informed Neural Network (PINN) is used to make predictions about a system based on both data and known physics information. The neural network is trained on the data and also incorporates the known physics through the use of constraints or regularization terms in the loss function. This allows the network to make predictions that are consistent with the known physics and improve accuracy by utilizing the available data. Fluid dynamics represents a classic example where the neural network is trained on experimental or numerical data of the fluid flow and incorporates the governing equations of fluid dynamics as constraints or regularization terms in the loss function.
-
•
Second scenario: In this scenario, there is a large amount of data available, but there is no physical model to describe the dynamics. For example, consider the physics of jets produced by terrestrial accelerators in heavy ion experiments such as ALICE at the LHC-CERN accelerator. The lack of a physical model can make it difficult to understand the underlying dynamics of the system. This is a good use case for traditional machine learning techniques, as there is no physics information to incorporate into the model.
-
•
Third scenario: In this case, data is limited and the system is described by several physical models. The limited data and the presence of multiple physical models can make it challenging to determine which model is most appropriate for describing the system. In this case, it may be necessary to use a combination of approaches, such as combining physical models with machine learning techniques, to gain a more complete understanding of the system. It is also important to carefully validate the results and ensure that the chosen model is able to accurately describe the observed behavior. This is the case considered in this article, in which we attempt to model a biological phenomenon caused by loops of reactions and counter-reactions between bacteria and immune cells.
Having discussed the various techniques and scenarios involved in PINNs, it is now important to evaluate and quantify the performance of the model. From a general point of view, the neural network performance can be characterized into three main types:
-
1.
Approximation error to ground truth function.
-
2.
Generalization to unseen data.
-
3.
Trainability of the model.
In fact, the universal function approximation theorem only considers the approximation error of a neural network to the ground truth function. However, it does not consider other important factors, such as the generalization error and the model trainability. This generalization measures a model’s ability to make accurate predictions on new, unseen data. Meanwhile, the model trainability is determined by factors such as its size, complexity, amount and quality of training data. These factors can influence the model’s ability to be effectively trained, as larger and more complex models may require more resources and may be harder to converge. For that this theorm could not ensure the generalization and the trainability in complex biological process [34] or in the modeling of nonlinear two-phase transport in porous media [4]. These limitations include the availability and quality of data and the potential for the models to fail to capture the full range of possible behaviors or phenomena. In the following points, we aim to shed light on the challenges faced in our modeling efforts.
-
•
Complexity of underlying processes: Biological processes are often characterized by complex interactions and dynamics, making it challenging to accurately model them using traditional mathematical or physical approaches. The non-linear nature of the differential equations involved, including the presence of non-linear terms such as square or cubic terms, only adds to the difficulty. These non-linear terms can even lead to blow-up phenomena, a common challenge for mathematicians working with PDEs [5]. This can also make it challenging for PINNs to learn and represent the underlying patterns and relationships in the data.
-
•
Data availability and quality: The data used to train PINNs may be limited in quantity or quality, or may not be representative of the full range of behaviors or phenomena. This can affect the model’s ability to learn and generalize, and can reduce its accuracy and reliability. Spatial data requires exhaustive examination, which can be expensive, and hospitals are often reluctant to share their data. Our attempts to contact digestive disease institutes for data resulted in a refusal to collaborate. However, we were able to find a more accessible data set called Kvasir that we plan to use for our study [35].
-
•
Limited range of behaviors : PINNs may not be able to capture the full range of behaviors and phenomena that can occur in biological systems. This is because the models are typically trained on a limited set of data and are not able to capture the full range of possible behaviors or situations that can arise.
-
•
Necessity for simple and parsimonious PINN models: The complexity of the PINN model itself can also be a limitation. These models can be computationally expensive to train and may require a large amount of data and computational resources. This can make their use challenging in certain contexts, such as when data is limited or when computational resources are constrained, as in the case of automatic lesion detection techniques where the gastroenterologist manipulates the patient using the colonoscope and works on the software in real-time [36, 37].
2.6 Our approach
The discussion above have provided the necessary foundation for our main work. We are attempting to predict the evolution of two bowel diseases with poor quality data collected only on the edges of the domain and by integrating physical constraints from nonlinear PDE with the simplest deep neural networks. We are inspired by the first work in PINN done by M. Raissi et al. [38]. In this paper, the authors dealt with 4 equations:
-
•
Two-dimensional Navier-Stokes equation system
-
•
Shrödinger equation
-
•
Korteweg-De Vries equation
-
•
Burgers’ equation
Then, we will start with the simplest PDE equations and gradually add more complexity, including nonlinear terms. By following this progression, we hope to build a comprehensive model for predicting the evolution of these diseases. Therefore, we will apply this approch in these equations:
-
•
Simple partial differential equation (a Toy model)
-
•
Diffusion equation or heat equation in 2D domain
-
•
Fisher-KPP equation in 1D domain
-
•
Korteweg-De Vries equations
-
•
Traditional Turing System: nonlinear coupled system for Reaction Diffusion Equations
-
•
Turing mechanism System for Crohn’s disease presented in this paper [5].
3 Benchmarking our approach with some chosen PDEs
This benchmarking refers to the process of evaluating the performance and accuracy of the DNN against a series of PDEs with a minimum of data. We begin by testing the DNN on a simple PDE and observe that it is able to accurately solve it with a high degree of accuracy. We will see in the next section that this resolution relates to the determination of the severity score for IBDs, incorporating the crucial aspect of spatial information distribution. Next, we apply the DNN to the Burger’s equation, which is a more complex nonlinear PDE. The DNN is still able to solve this equation with a good level of accuracy. We then move on to the heat equation, which is a linear PDE and therefore relatively easier to solve. Finally, we test the DNN on a nonlinear system of Korteweg-De Vries equations.
3.1 Neural networks architecture
Choosing the hyperparameters of a DNN is an important step in its design and training. These parameters are the values that control the overall behaviour of the DNN, such as the number of layers, the number of neurons per layer, the learning rate and the regularization strength. Then, it is important to consider the nature of the problem being solved and the available data. For example, if the data is limited or noisy, it may be necessary to use a smaller or simpler network to avoid overfitting. The choice of optimization algorithm is another important factor in the training of the network. There are many different optimization algorithms available, each with its own strengths and weaknesses. Two commonly used optimization algorithms are L-BFGS and Adam.
We can control overfitting using the dropout concept which works by randomly "dropping out" a fraction of the neurons during training, then a proportion of neurons are temporarily excluded from the network and do not contribute to the forward or backward passes. This has the effect of reducing the complexity of the DNN and forcing the remaining neurons to learn more robust and generalizable features. The notion of parsimony is important in deep learning because it helps to ensure that the models we build are as simple as possible while still being able to effectively capture the underlying patterns in the data. By using parsimony, we can avoid overfitting and build models that are more likely to perform well on new, unseen data.
3.1.1 Adam vs LBFGS
Stochastic gradient descent (SGD) is an optimization algorithm for finding model parameters that minimize the loss function, which measures the difference between the expected and actual output of a model [39]. There are many variations of SGD, including Adagrad, RMSprop, and Adam. Adam optimization is a stochastic gradient descent method that adaptively estimates first-order and second-order moments [40].
In Adam optimization, the parameter update is given by:
where are the model parameters, is the loss function, is the current training iteration, and are the forgetting factors for gradients and second-order gradient moments, respectively.
On the other hand, the BFGS algorithm is a Quasi-Newton method for optimization, which approximates the Hessian matrix using a series of updates [41, 42]. One of the most widely used Quasi-Newton methods is L-BFGS (Limited-memory BFGS [43, 44]), which is more memory efficient than BFGS, as it only stores a few vectors representing the approximation of the Hessian matrix instead of the full matrix. L-BFGS is more computationally demanding than Adam, but can be faster in situations where the second-order moments are known analytically. Instead of storing the full n x n estimation of the inverse Hessian, L-BFGS stores only a few vectors that represent the approximation implicitly which make it more practical for usage in ML settings with small-mid sized datasets. This method is computationally more demanding. However when the second order is known analytically the optimization method moves faster towards the minimum. The reason lies in the fact that methods based on the first order approximate the error function at a point with a tangent hyperplane, while methods of the second order, with a quadratic hypersurface: this allows us to move closer to the error surface when we update the weights at each iteration.
The L-BFGS algorithm is as follows:
where are the model parameters, is the loss function, is an approximation of the Hessian matrix, and and are the differences between the current and previous values of and , respectively. The L-BFGS and ADAM optimization algorithms are both commonly used in the context of training neural networks, including PINN. Here is a comparison of some key features of these algorithms:
-
•
Convergence rate: L-BFGS typically has a faster convergence rate than ADAM. However, ADAM can still be effective in practice and may be preferred in some cases due to its simplicity and ability to adapt to changing data [40].
-
•
Memory requirements: L-BFGS requires storing a set of past gradients in memory, which can be costly for large datasets or networks. ADAM, on the other hand, only requires storing the average of the past gradients, which is typically much cheaper in terms of memory usage [41].
- •
-
•
Robustness: L-BFGS can be sensitive to the initialization of the parameters, and may require a good initial guess to find the optimal solution. ADAM can be more robust to the initialization, but may be less sensitive to the true global minimum as shown in [42].
Both L-BFGS and ADAM can be effective in training PINN models, and it may be useful to try both algorithms and compare their performance to determine which is the best fit for a particular problem. In our study, we found that the ADAM give best results.
| Optimization algorithms | |
|---|---|
| L-BFGS | ADAM |
3.1.2 Root Mean Square Error(RMSE) Loss
In the context of a biology process where the values are continuous and expected to be situated in a small range, using the mean squared error (MSE) or root mean squared error (RMSE) loss function can help ensure that the model is able to accurately predict the values within that range. Both MSE and RMSE measure the difference between the predicted values and the true values, but MSE is simply the average squared difference while RMSE is the square root of the average squared difference. Both of these loss functions penalize large errors more heavily than small errors, which can be useful for preventing the DNN model from making large errors in its predictions.
With: = the observed value, = the predicted value and n is the number of available observations.
3.1.3 RELU vs Sigmoid vs Tanh
In the context of tuning a DNN, the choice of activation function can significantly impact the performance. The Rectified Linear Unit (ReLU) activation function is widely used due to its simplicity and ability to converge faster than other activation functions. It is defined as and is generally used in the hidden layers of the network. One disadvantage of ReLU is that it can suffer from the "dying ReLU" problem, where the weights of the neurons become very small and the activation function becomes inactive. The Sigmoid activation function is defined as and is often used in the output layer of binary classification problems. However, it has a slow convergence rate and can suffer from vanishing gradients, where the gradients of the weights become very small, hindering the model’s ability to learn. The Hyperbolic Tangent (Tanh) activation function is defined as , where is the Sigmoid function. It is often used in the hidden layers of the network and can perform well in certain tasks, but it can also suffer from the vanishing gradients problem. The activation function choice can also depend on the range of the values being predicted, especially in a biology context. For example, if the predicted values are expected to be within a small range, such as between 0 and 1, the Sigmoid or Tanh activation functions may be more appropriate. However, if the predicted values are expected to have a larger range, the ReLU activation function may be more suitable. It is important to keep in mind that the choice of activation function is just one of many hyperparameters that can impact the performance of the model and should be tuned accordingly. In this work, we experimented with three activation functions: RELU, Sigmoid and Hyperbolic tangent. Our models converged for Sigmoid and Hyperbolic tangent but we couldn’t obtain satisfying result with RELU.
3.2 Toy model: simple partial differential equation
Let’s consider this first-order partial differential equation:
and let’s fix the values of the constants a, b, and c to be a = 1, b = -2, and c = -1. The modified equation becomes:
defined for the temporal interval and the spatial interval . The initial condition is given by:
and the PDE boundary conditions are given by:
(Note that during the numerical and PINN resolutions, we will choose and ).
To solve this partial differential equation analytically, the method of separation of variables is used. Start by separating the variables x and t and this involves writing the solution in the form:
Substituting this expression into the PDE gives:
with is an arbitrary constant.
Solving for X(x) and T(t) separately gives:
Let’s solve the left member,
The integration gives:
The right member is written
The integration gives:
The general solution is then given by:
Using the initial condition at :
Then and
Therefore, the solution is:
Analytical solution
Numerical schema
Now, we are interested in numerically solving the previous PDE by using the centered finite difference method. We need to discretize the spatial and temporal domains and approximate the derivatives using finite differences. Here is an outline of the steps involved in the numerical scheme:
-
•
Choose a spatial discretization step size , and a temporal discretization step size .
-
•
Define the grid points and as follows:
Substitute the initial condition to find .
Substitute the boundary conditions and to find and , where is the number of grid points in the spatial domain.
PINN approach
In the case of numerical methods, the approach is to convert the PDE into numerical schemes, ensuring properties such as numerical convergence, consistency, and numerical stability. In the PINN approach, the problem is reformulated as a numerical optimization problem the goal is to end up with a loss function that contains most of the system’s dynamic information. To achieve this, the equation is first rearranged such that all its terms are gathered on one side, which forms the first term of the cost function. The remaining two terms of the loss function consist of the initial and boundary conditions, respectively. Then, the function is the sum of three positive terms that must be minimized through an optimization algorithm. Secondly, the data is generated randomly sampled from the phase space, with points located at the boundary, within the interior of the domain, and subject to the initial conditions.
Let us define as :
In this case, will be approximated by a neural network. The latter has as an objective to minimize the following loss :
where
denotes the initial data at , denotes to the boundary data and corresponds to collocation points on .
Comparison between PINN, analytical solutions and finite difference method
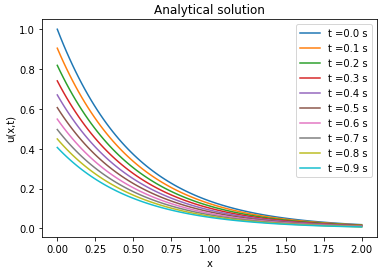
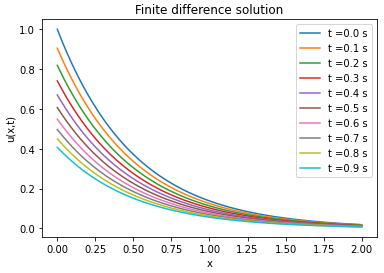
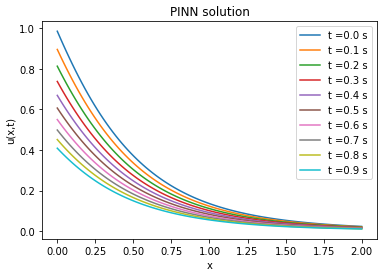
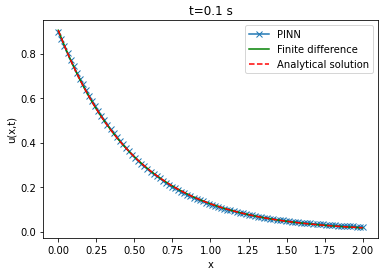
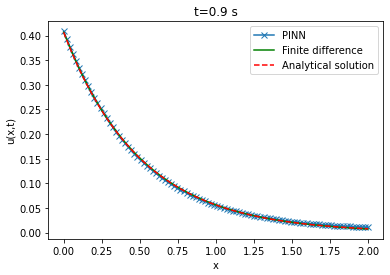
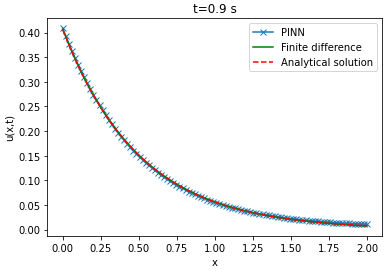
| Analytical solution | Finite difference solution | ||||||
|---|---|---|---|---|---|---|---|
| 8 | 16 | 32 | 8 | 16 | 32 | ||
| Layers | 2 | 0.000472 | 0.000416 | 0.000746 | 0.000702 | 0.000332 | 0.000572 |
| 4 | 0.000366 | 0.000465 | 0.000412 | 0.000614 | 0.000710 | 0.000644 | |
| 8 | 0.000790 | 0.001780 | 0.001695 | 0.000979 | 0.001777 | 0.001548 | |
| Neurons | ||||
|---|---|---|---|---|
| 8 | 16 | 32 | ||
| Layers | 2 | 2:05 | 2:02 | 2:55 |
| 4 | 3:58 | 3:46 | 3:43 | |
| 8 | 4:44 | 5:16 | 5:26 | |
3.3 Burger’s equation
The Burger’s equation is a nonlinear PDE that is often used to model a variety of physical, biological, and chemical phenomena, including incompressible fluid flow, population dynamics, and chemical reactions. It expresses the balance between the fluid convective transport and the diffusive transport due to viscosity. Solving the Burger’s equation allows to determine the fluid velocity field at a given time and spatial location. This equation has several applications in biology like modeling blood flow in the cardiovascular system [45], modeling pattern formation biological systems and modeling population dynamics [46]. Two types of Burgers equations are considered, those without viscosity term which can be obtained by considering the particles non-interaction and whose solution can be realized with the help of the finite method, including the derivatives approximation means of Taylor developments based on the discretization of the phase space with viscosity term. The solution of the nonlinear viscosity problem based on the Cole-Hopf transform. Concerning numerical resolution done here either by a finite difference method. The first limitation of the Burgers equation is that it is a simplified model that makes certain assumptions about the system being studied. For example, it may assume that the fluid is incompressible or that the reaction rate is constant, which may not hold true in all cases. As a result, the Burgers equation may not be able to accurately capture the full complexity of a heterogeneous system. The second limitation is that the equation is a deterministic model, not take into account the inherent randomness that is often present in biological systems.
Equation
The Burger’s equation is the following:
with the initial condition:
and the boundary conditions:
where = 1 is the coefficient of kinematic viscosity
Using the Hopf-Cole transformation
The burger’s equation transforms to the linear heat equation:
with the initial condition
and the boundary conditions
Analytical solution
The Fourier solution to the burger’s equation is given by
with
Numerical schema
The solution domain (x, t) :, is discretized into cells described by the node set in which =ih, =jk (i = 0,1,…,N; j = 0,1,…,J, Nh= 1 and Jk = 0.1) h= is a spatial mesh size, k= is the time step.
A standard explicit finite difference approximation of the heat equation is
Using the Hopf-Cole transformation
PINN approach
Let us define as :
In this case, will be approximated by a neural network. The latter has as an objective to minimize the following loss :
where
denotes the initial data at , denotes to the boundary data and corresponds to collocation points on .
Comparison between PINN, analytical solution and finite difference method
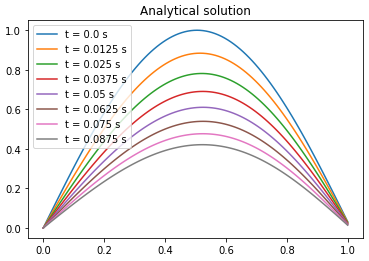
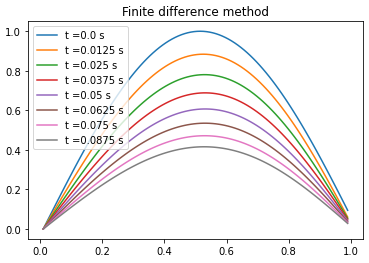
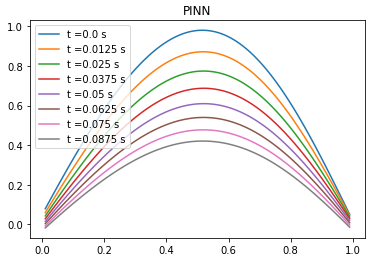
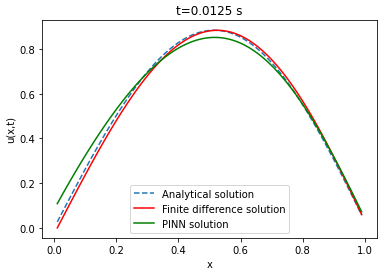
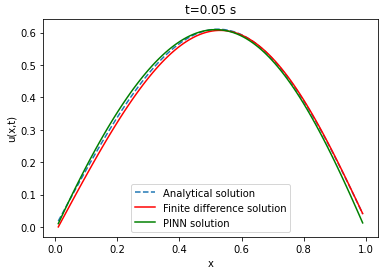
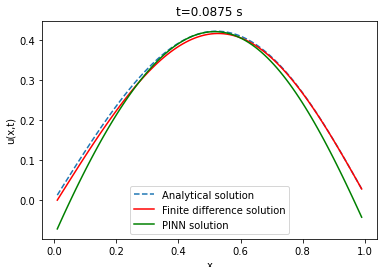
| Analytical solution | Finite difference | ||||||
|---|---|---|---|---|---|---|---|
| 8 | 16 | 32 | 8 | 16 | 32 | ||
| Layers | 2 | 0.020769 | 0.014624 | 0.011578 | 0.202538 | 0.021090 | 0.018698 |
| 4 | 0.010308 | 0.029504 | 0.033058 | 0.018142 | 0.034560 | 0.036699 | |
| 8 | 0.212536 | 0.212404 | 0.009440 | 0.209136 | 0.209136 | 0.018677 | |
| Neurons | ||||
|---|---|---|---|---|
| 8 | 16 | 32 | ||
| Layers | 2 | 2:00 | 2:03 | 2:38 |
| 4 | 2:37 | 4:32 | 5:02 | |
| 8 | 4:39 | 8:04 | 9:52 | |
3.4 Heat equation: good for diffusion but poor for spatial heterogeneity
In order to compare between the three resolution approaches: the analytical approach, the numerical approach with finite differences and the PINN; we propose to start by the analytical method. We solve the heat equation by considering a constant parameter.
with the initial condition
and the boundary conditions
We take .
Analytical solution
The analytical solution is
With the following Fourier transform applied:
Numerical schema
The solution domain is discretized into cells described by the node set in which , , (i = 0,1,…,I; i = 0,1,…,J ; n = 0,1,…,N) and are a spatial mesh size, is the time step and
PINN approach
Let us define as :
In this case, will be approximated by a neural network. The latter has as an objective to minimize the following loss :
where
denotes the initial data at , denotes to the boundary data and corresponds to collocation points on .
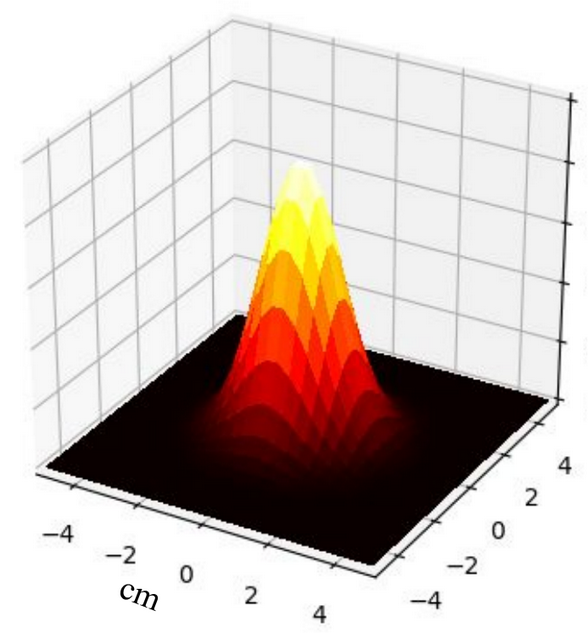
Comparison between PINN, analytical solution and finite difference method
| Analytical method | Finite difference | ||||||
|---|---|---|---|---|---|---|---|
| Number of neurons | |||||||
| 8 | 16 | 32 | 8 | 16 | 32 | ||
| Layers | 2 | 0.01104 | 0.02231 | 0.00507 | 0.01102 | 0.02230 | 0.00506 |
| 4 | 0.00289 | 0.02391 | 0.00601 | 0.00289 | 0.02391 | 0.00599 | |
| 8 | 0.04588 | 0.04613 | 0.04307 | 0.04586 | 0.04612 | 0.04308 | |
| Time of execution | ||||
|---|---|---|---|---|
| Layers | ||||
| 2 | 4 | 8 | ||
| Neurons | 8 | 1:56 | 3:22 | 5:40 |
| 16 | 1:39 | 3:19 | 5:58 | |
| 32 | 1:34 | 2:17 | 9:48 | |
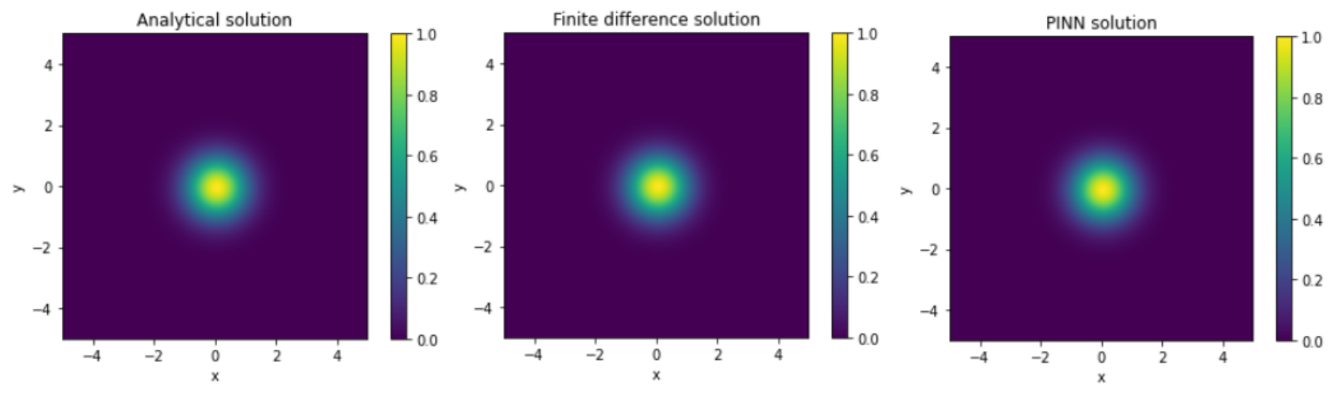
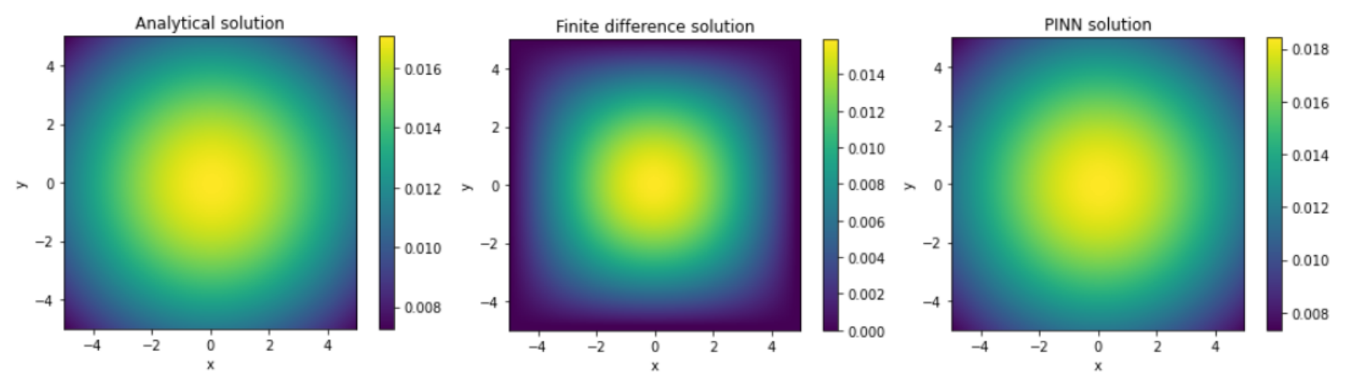
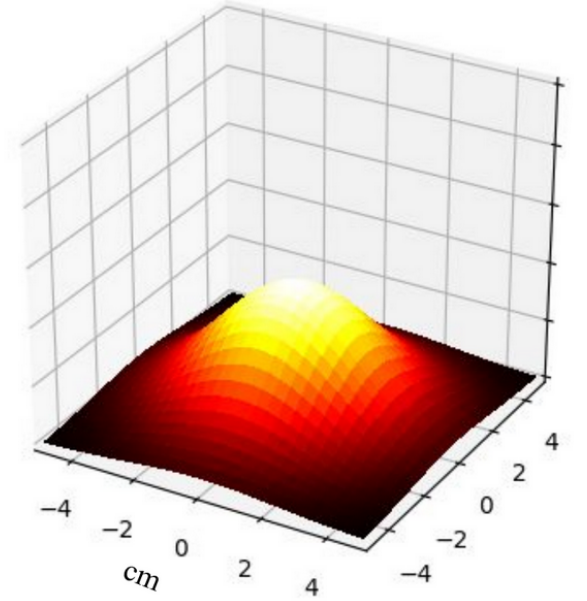
The RMSE between the analytical solution and the solution obtained from the PINN is found to be on average of the order of . This indicates that the PINN method is able to approximate the analytical solution with a certain level of accuracy. Furthermore, the RMSE between the finite difference solution and the PINN solution is also found to be of the same order. However, a direct correlation between the RMSE and the increase in the number of layers and neurons per layer in the PINN is not observed. Nevertheless, some configurations of the PINN are able to approximate the analytical solution as well as the finite difference, demonstrating the effectiveness of this method for solving the heat equation.
3.5 System of Korteweg-De Vries Equations
The Korteweg-de Vries (KDV) equation is a non-linear partial differential equation that describes solitary waves, also known as solitons, and arises from the Navier-Stokes equation, by neglecting the dispersion term. Solitons, are responsible for tsunamis and tidal bores, which can cause significant damage and threaten marine safety. To prevent such disasters, geophysicists study the production process and formation conditions of these waves. Solitary waves are rare maritime occurrences that were first observed by John Scott Russell in 1834. They are exceedingly dangerous due to their unexpected nature and amplitude, which far exceeds the height of swell waves. Characterizing the propagation mode of solitons can help identify them, as they propagate while preserving nearly all of the initial energy. Solitons can be explained using nonlinear models, as they do not conform to linear approaches like the Airy model. The speed of a solitary wave is proportional to its amplitude, a phenomenon known as wave front stiffening, which causes its nonlinear action. The Korteweg de Vries equation is derived from the assumption that the non-linear effect is added to the linear effect reflecting the wave’s dispersion, and the soliton is the compensation of the two effects. Soliton solutions can be obtained using numerical analysis, such as the finite difference method or the Lax-Wendrof approach, which can solve the KDV and Burger’s equations. Solitons can be found in various fields of physics, including solid mechanics and optics, and have real-world applications such as data transmission in telecommunications. PINN approach can be used to solve such equations [48].
Equation
The coupled Korteweg-De Vries Equations are given by
with the initial conditions:
and the boundary conditions:
Analytical solution
The analytical solution of the equation is the couple (u,v) with
where:
In this paper, we take , b=-3,
Numerical schema
The solution domain is discretized into cells described by the node set in which , (i = 0,1,…,I; n = 0,1,…,N) is a spatial mesh size, is the time step and
Comparison beetween PINN, analytical solution and finite difference method
| Analytical | Finite difference | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Layers | Layers | ||||||||||||
| 2 | 4 | 8 | 2 | 4 | 8 | ||||||||
| u | v | u | v | u | v | u | v | u | v | u | v | ||
| N | 8 | 0.007 | 0.002 | 0.008 | 0.0037 | 0.036 | 0.012 | 0.01 | 0.006 | 0.0101 | 0.005 | 0.01 | 0.009 |
| 16 | 0.005 | 0.0019 | 0.0028 | 0.007 | 0.036 | 0.012 | 0.009 | 0.006 | 0.0102 | 0.006 | 0.033 | 0.009 | |
| 32 | 0.005 | 0.0063 | 0.0029 | 0.0012 | 0.037 | 0.0065 | 0.01 | 0.006 | 0.0107 | 0.006 | 0.033 | 0.009 | |
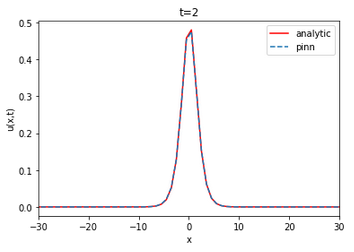
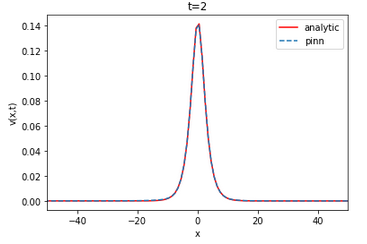
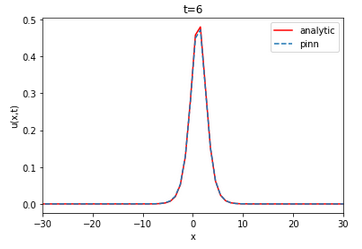
The value of the RMSE between the analytical solution and the finite difference is approximately 0.022733 and 0.011562 for u and v, respectively. The RMSE in relation to the number of layers and neurons is on average of the order of for u and v. The neural network is able to approximate the finite difference solution of the coupled KDV equation. The RMSE value does not vary linearly with the increase or decrease of the number of layers and neurons per layer.
4 PINN framework for the IBDs spread modeling by PDEs
In this section, we will discuss the combination of the concepts from image analysis and mathematical modeling. Using the PINN method, both of these areas are treated. Indeed, The figure 15 shows a global approach that unifies the mathematical models which exploit the spatial information of the two diseases.
-
•
The estimation of a score of the disease severity with the use of first-order ODE for spatial distribution. PINN is used to solve these equations and to estimate the score.
-
•
A transfer learning model for the classification of the visual appearance of the different type of lesions. The deep learning model can use an image dataset annotated by gastroenterologists.
-
•
Based on the spatial information extracted from images, PINN is used to predict the evolution and the spread of the two diseases.
-
•
PINN is used to predict the lesions distributions along the colon.
4.1 First-order ODE for spatial distribution
In this part, an ordinary differential equation (ODE) has been used to describe the spatial distribution of colonic lesions in individuals with ulcerative colitis. This model is found effective in describing the disease state and there parameters were correlated with severity assessments provided by gastroenterologists [49, 50]. Our contribution consists in finding an PINN architecture allowing to solve this equation by finding the two parameters the growth rate and the abundance for the following first-order ODE model:
with
then the analytical solution is
4.2 A possible explanation of the Crohn’s disease with a Turing mechanism
4.2.1 A first Turing mechanism presented in [5]
Crohn’s disease is a chronic inflammatory bowel disease characterized by patchy inflammation throughout the gastrointestinal tract. In this study [5], the authors propose a reaction-diffusion system that uses bacteria and phagocytic cells to model the dysfunctional immune responses that cause IBD. They demonstrate that, under specific conditions, the system can generate activator-inhibitor dynamics that lead to the formation of spatially periodic and time-indelible Turing patterns. This is the first time Turing patterns have been applied to an inflammation model, and the study compares the model parameters with realistic parameters from the literature.
The model represents the intestine as an interval on the real axis, taking into account only two components: external bacteria (microbiota, pathogens, or antigens) and immune cells (phagocytes). In a healthy gut, the immune response controls the inflammatory response, while in disease states, the intestinal immune system becomes unbalanced, resulting in excessive migration of immune cells to damaged areas and increased epithelial barrier permeability. These changes allow for further infiltration of the microbiota, which can exacerbate inflammation. A complex network of interactions between these factors initiates the inflammatory cascade that leads to the Crohn’s disease.
With the following initial conditions
and
In our study, the boundary conditions of Neumann have been considered. In the paper, a periodic boundary conditions have been considered instead.
| parameter | description | value |
|---|---|---|
| The bacteria reproduction rate per minute | ||
| The phagocytes intrinsic death rate per minute | ||
| The bacteria diffusion rate per minute | ||
| The phagocytes diffusion rate per minute | ||
| The bacteria density in the lumen | ||
| The rate of the immune response par minute | ||
| the product between and | ||
| a cofficient of proportionality between and | ||
| The rate per minute of the epithelium porosity |
4.2.2 A second Turing mechanism with cubic term
Let’s discuss another activator-inhibitor dynamic in a Turing system, where the diffusion rate of the activator is much slower than that of the inhibitor. In this system, the inhibitor suppresses the production of both components, while the activator component must increase its own production. The system is subject to small perturbations that encourage the emergence of large-scale patterns, according to the Turing model.
The system is described by two coupled non-linear partial differential equations. The first equation describes the time evolution of the activator component, u, as a function of time t and two spatial dimensions x and y. The left-hand side of the equation represents the rate of change of u with respect to time (irreversible over time), while the right-hand side consists of four terms. The first term represents the diffusion of u with a diffusion coefficient a, while the second term represents the self-enhancement of u (a non-linear term with a cubic dependency). The third term represents the inhibition of u by v, and the fourth term is a constant offset, c. The second equation describes the time evolution of the inhibitor component, v, with an additional time constant, . The left-hand side of the equation represents the rate of change of v with respect to time, while the right-hand side consists of three terms. The first term represents the diffusion of v with a diffusion coefficient b, while the second term represents the production of v by u. The third term represents the inhibition of v by itself. The coupling of the two equations via the inhibition term of the activator and the production term of the inhibitor results in the formation of spatial patterns in the system.


| Finite difference solution | |||||||
| Neurons | |||||||
| 8 | 16 | 32 | |||||
| U | V | U | V | U | V | ||
| Layers | 2 | 0.987 | 1.233 | 0.994 | 1.165 | 0.857 | 1.137 |
| 4 | 0.993 | 1.195 | 0.993 | 1.092 | 1.115 | 1.238 | |
| 8 | 0.989 | 1.132 | 1.003 | 1.120 | 1.238 | 1.125 | |
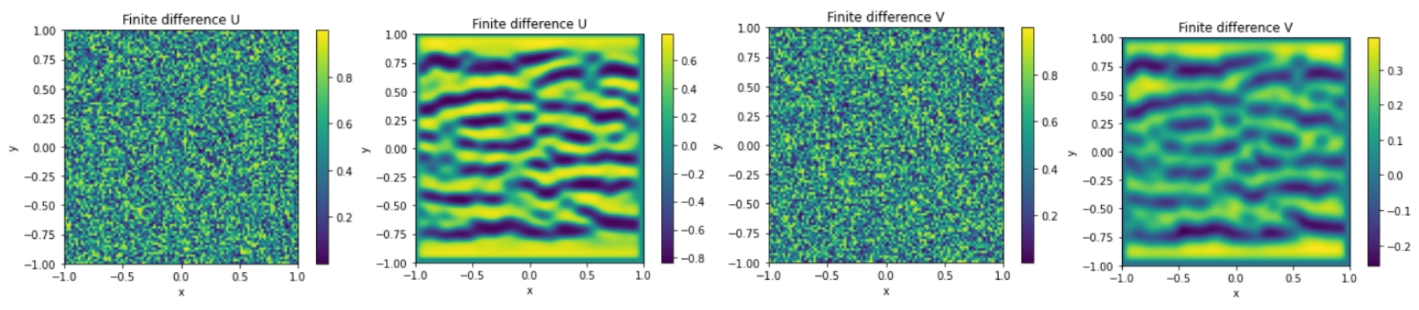
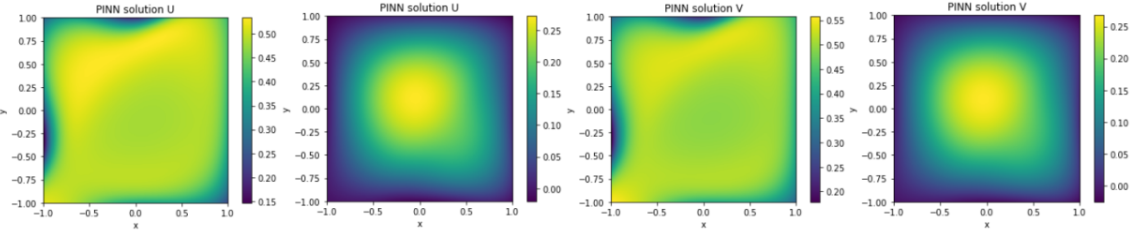
The root mean squared error (RMSE) between the solution obtained by using the physics-informed neural network (PINN) and the finite difference solution tends towards 1 for u and v. At first glance, this low RMSE might indicate that the neural network has converged to a solution. However, as evidenced in figure 19, this is not the case in practice. This equation models the formation of patterns as a result of interaction between different pigments, but the two solutions do not show the same patterns. Therefore, in this case, the PINN diverges and fails to approximate the numerical solution. Continued research aims to uncover the root causes behind the inability of PINNs to adequately capture the intricate explosion phenomena in IBDs.
4.3 Fisher-KPP equation: modeling the bacteria/phagocytes couple with one PDE
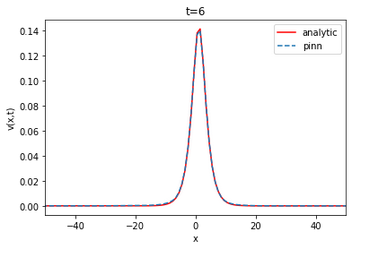
The Fisher [52] Kolmogorov-Petrovsky-Piskunov [53] equation is a reaction-diffusion equation that plays a significant role in describing various chemical, physical and biological phenomena. It is often used to model the propagation of a single wave, such as the spread of a disease or the front of a chemical reaction. In the case of ulcerative colitis and Crohn’s disease, the Fisher KPP equation can be used to model the spread of these intestinal diseases through the incorporation of factors such as the concentration of bacteria and the presence of phagocytes. One advantage of using the Fisher-KPP equation to model the IBDSs spread is that it is a relatively simple equation that can be solved analytically or numerically. This makes it a good choice for modeling the spread of these diseases, especially in cases where there is limited data available [34].
Fisher-KPP Equation
And the boundary conditions u(-50,t)=1 and u(50,t)=0 with D=1 and r=1. The diffusion term: represents the rate at which bacteria in the medium migrate through a linear diffusion process with diffusivity D. The reaction term: represents the bacteria proliferation rate in the medium, which is assumed to be proportional to the , and the remaining carrying capacity of the environment, . The parameter r represents the growth rate and the quantity models the bacteria logistic growth. The term represents the limiting factor, which means that the growth rate decreases as both bacteria and phagocytes approaches the carrying capacity of the biological medium.
Numerical schema
The solution domain is discretized into cells described by the node set in which , (i = 0,1,…,I; n = 0,1,…,N) is a spatial mesh size, is the time step and
Comparison
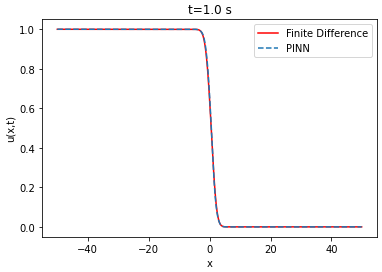
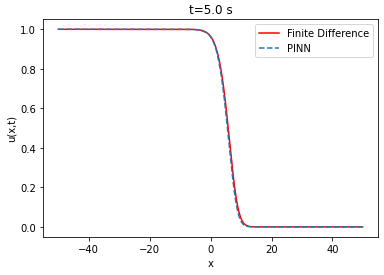
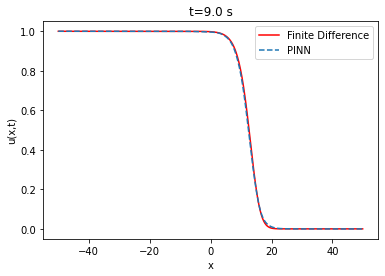
| Analytical solution | ||||
|---|---|---|---|---|
| 8 | 16 | 32 | ||
| Layers | 2 | 0.028321 | 0.074042 | 0.040836 |
| 4 | 0.037587 | 0.009196 | 0.027296 | |
| 8 | 0.043136 | 0.022766 | 0.013606 | |
| Neurons | ||||
|---|---|---|---|---|
| 8 | 16 | 32 | ||
| Layers | 2 | 1:39 | 1:43 | 2:06 |
| 4 | 2:41 | 2:39 | 4:02 | |
| 8 | 4:24 | 4:48 | 8:00 | |
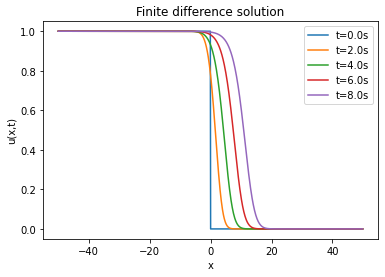
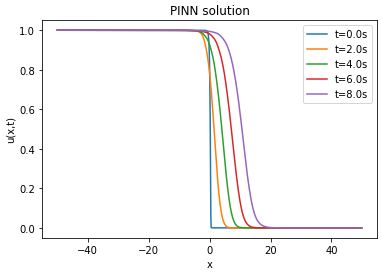
The lower the RMSE, the better the approximation. In our case, the RMSE in relation to the number of layers and neurons is on average of the order of . Thus, the PINN is able to approximate the finite difference solution of the Fisher-KPP equation. Note that increasing or decreasing the number of layers and neurons does not systematically improve the RMSE.
| Phenomenon | Modelling | Remarks |
| unidimensional modelling | First order differential equation |
Simplistic approach allows to have a score using a low quality data |
| Diffusion Modelling | Heat equation |
Unique/ works well without data/Does not take into consideration the pigmentation |
| Modelling of viscous diffusion | Burgers equation | Works well without data |
| Front wave transport Modelling | Fisher KPP | Works well without data |
|
M |
Kordweg de Vries | Works well without data |
|
Turing pattern Modelling |
Turing equation |
Numerical instability problem |
5 Spatial distribution extraction by computer vision
The extraction of the spatial distribution of ulcerative colitis and Crohn’s disease using computer vision can be very useful for our study. By using image processing algorithms, it is possible to accurately map out the areas affected by the two diseases. This can help doctors better understand the progression of the disease and adjust treatment accordingly. In addition, it can also allows for faster and more accurate evaluation of treatment response, which can be particularly useful in the context of testing new medications. The traditional detection methods based on the expertise of gastroenterologists are time and resource intensive. As a result, early detection and treatment of these diseases can reduce casualties and improve the patient’s quality of life later on. With recent advances in Deep Learning, powerful approaches for both detection and classification that can handle complex environments have been developed. In this paper, we propose a deep learning based architecture for object classification in the context of Crohn disease. The goal is to assist the PINN framework developed above with input data for the PDEs initial conditions and boundary conditions. The proposed solution combines deep learning and tweaked transfer learning models for object classification and detection with balanced data for each image class. It can operate in a more complex environment and takes into consideration the state of the input. Its aim is to automatically detect damages, locate them and classify the disease type.
5.1 Transfer learning for image transformation
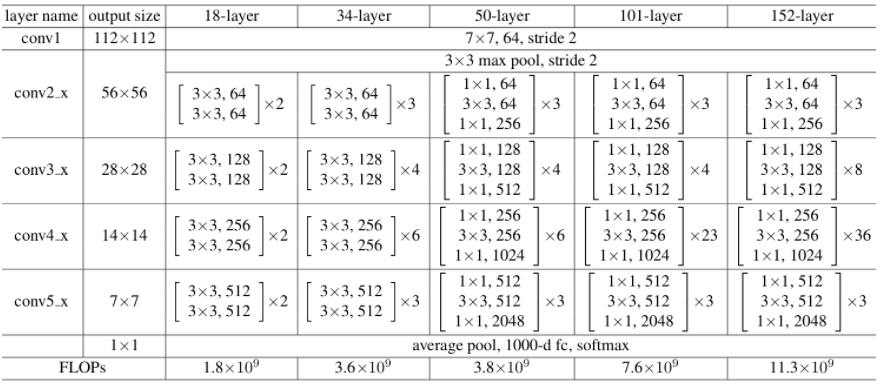
Transfer learning is a deep learning technique that allows the use of pre-trained models to perform image transformation tasks. The pre-trained models have already learned general features from a large dataset, making them suitable for transfer learning to related tasks. In the context of spatial distribution extraction, transfer learning can be used to improve the accuracy of feature extraction for specific image classes. The residual network ResNet [54] has been used for this transfer learning taks. Its architecture is available in many different forms, each with a different number of layers, a variant with 50 layers of neural networks is referred known as Resnet50. The Resnet50 and Resnet34 architectures differ significantly in one key area. In this case, the building block was changed into a bottleneck design due to worries about the amount of time needed to train the layers. In order to create the Resnet 50 architecture, each of the Resnet34’s 2-layer bottleneck blocks was changed to a 3-layer bottleneck block. Comparing this model to the 34-layer ResNet model, the accuracy of this model is noticeably higher (as shown in the figure 24).
On the other hand, the discrete gradient algorithm known as inpainting and the clustering techniques can then be used to fill in missing data and group similar data, respectively. Principal component analysis (PCA) can also be applied to reduce the dimensionality of the extracted features, enabling more efficient processing of the data. Ultimately, these image transformation techniques enable accurate and efficient computer vision solutions for analyzing complex biological images.
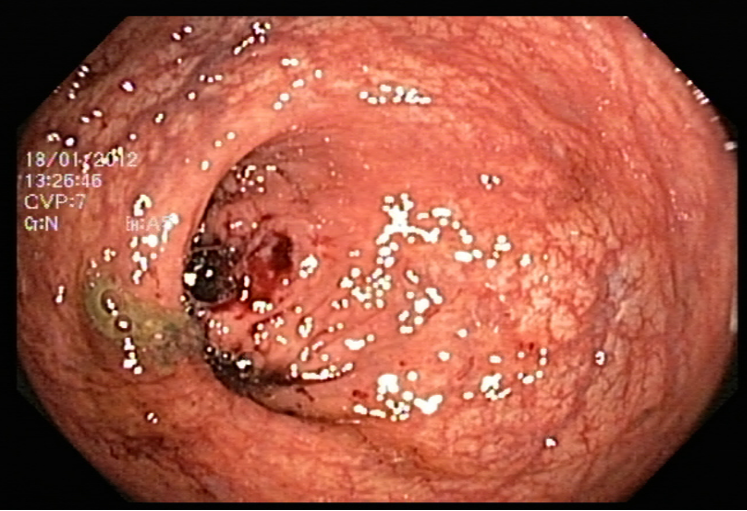
The data used to test this approach is the Kvasir dataset [35] which is a collection of annotated medical images of the gastrointestinal (GI) tract, designed for the purpose of computer-aided disease detection. The dataset is important for research in the medical domain of detection and retrieval, especially for single- and multi-disease computer aided detection. It contains images classified into three important anatomical landmarks and three clinically significant findings, as well as two categories of images related to endoscopic polyp removal. The sorting and annotation of the dataset are done by medical doctors. The Kvasir dataset may improve medical practice and refine health care systems globally since it includes sufficient numbers of images to be used for different tasks such as machine learning, deep learning, image retrieval, and transfer learning. The Kvasir dataset is collected using endoscopic equipment at Vestre Viken Hospital Trust in Norway and is carefully annotated by medical experts from VV and the Cancer Registry of Norway (CRN). The CRN is responsible for the national cancer screening programmes with the goal to prevent cancer death by discovering cancers or pre-cancerous lesions as early as possible. The Kvasir dataset is containing 8 classes of 2000 images per class. As a first step we opted to work with binary classification by feeding the model with both the normal images and the images having the disease.
5.2 Inpainting and clustering
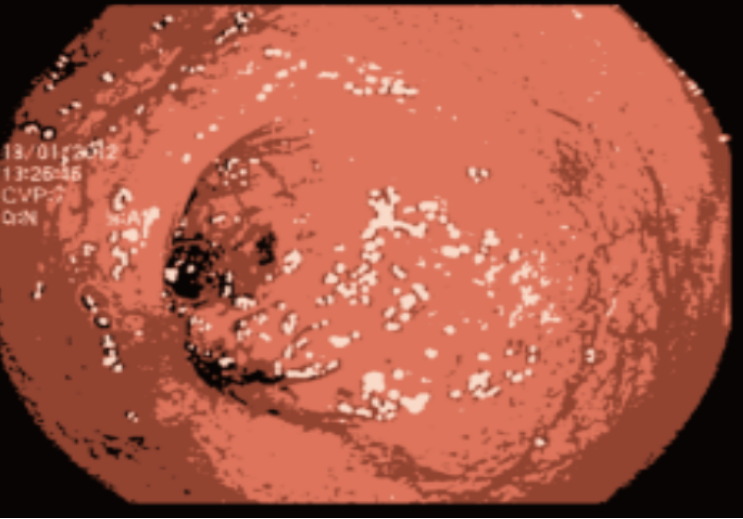
One major issue our data had is the the endoscopic camera’s light in work. In order to tackle this problem we tried firstly to inpaint the images. We have considered the areas with light on them as having missing values, so the inpainting idea, which is the task of reconstructing missing regions in an image, comes into play. It is an important problem in computer vision and an essential functionality in many imaging and graphics applications, e.g. object removal, image restoration, manipulation, re-targeting, compositing, and image-based rendering. The technique consisted of finding the white pixels in the images and dilute the surrounding pixels using a certain threshold on the pixels’ values by working with a mask between 221 and 255, in order to conserve the maximum amount of information. After inpainting the images, we noticed that they still contain some noise in them. So in order to tackle this problem, we tried kmeans [55] for clustering. Clustering algorithms are unsupervised algorithms, meaning they don’t use labelled data. They are used to assign data points from a population to different groups where data points belonging to the same group have similar traits. In our instance, clustering the image enabled us to blend the several image segments together in order to lessen the noise that persisted even after the inpainting.
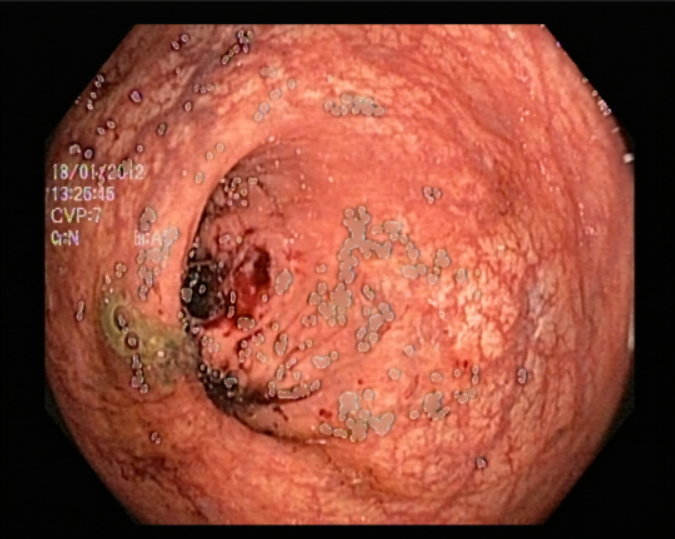
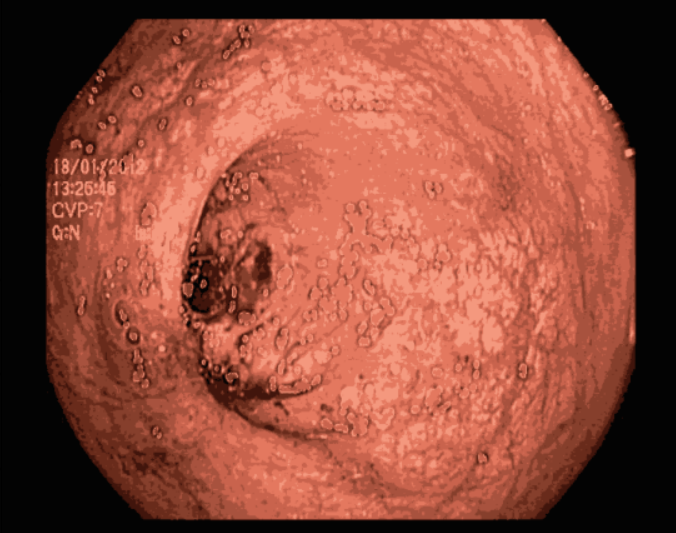
5.3 Image classification with PCA
Image classification using principal component analysis (PCA) was performed in this study to explore an unconventional approach to solving computer vision problems. While deep learning is commonly used to address these challenges, we opted to apply gradient boosting. Initially, we extracted the palettes of each image to obtain a correspondence table of selected colors in the RGB color space. We extracted the first five dominant color sets and transformed the images into vectors, which were arranged in a dataframe. However, before proceeding with the classification process, we applied PCA to reduce the dimensionality of the data and ensure that our points were represented optimally, thus increasing the chances of successful classification.
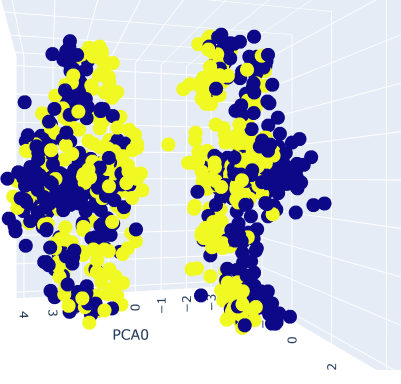
To identify the optimal number of palettes for the images, we plotted the accuracy of the model against the number of palettes used. Based on the results, we selected the optimal number of palettes for further tests. We then evaluated our gradient boosting method, specifically XGBoost [56], a distributed tree boosting algorithm that utilizes the gradient boosting framework to create efficient, flexible, and portable machine learning algorithms. Overall, this study demonstrates the potential of using gradient boosting and PCA to solve computer vision problems and offers new insights into the classification of image data. This table shows the confusion matrix of our results.
| P/A | Positive | Negative |
|---|---|---|
| Positive | 66 | 10 |
| Negative | 6 | 68 |

5.4 Computer vision solution perspectives
In this part, we are discussing how the previous subsections are going to introduce the complete architecture of the solution. While the partial differential equations gives us a solution depending on time, classification models only provide the current state of the disease. The proposed solution would be a tailored deep learning architecture having both the regression and the classification tasks in order to get the full picture on the evolution of the disease. The regression part of the solution consists of a convolutional long short term memory (ConvLSTM). This network is provided a sequence of images depending on time and its output is the next sequence of the disease meaning the next state. With this architecture we get both the current state and its evolution both on time and surface.
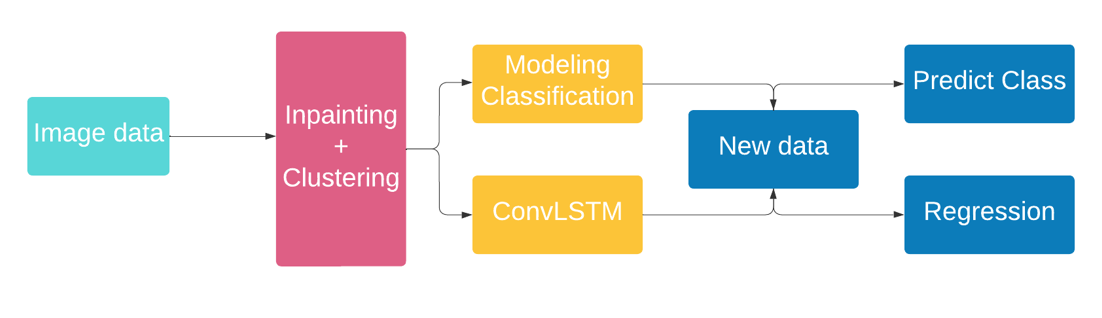
While the previous propositions might seem a bit shallow, we propose another approach which is image segmentation. This could be treated also as a regression problem. We apply an image segmentation model on our images that would return the surface that has the disease on it. The information we get is later treated as a tabular data and with sufficient data we could apply a state of the art regression model in order to determine the evolution of the surface. Keep in mind that the information provided by the segmentation model should be treated carefully because of the amount of disturbance that could be provided by the mask on the detected object.
6 Conclusion
This study was carried out with the ultimate goal of being producible and usable by the scientific community in a challenging Tunisian context. Digestive cancers are a significant public health concern due to their high mortality rates. Besides, the mortality depends on the stage at the time of diagnosis: high mortality for late stage detection vs survival rate for pre-cancerous stage detection. Ulcerative Colitis and Crohn’s disease may indicate a potential evolution towards cancer. However, the current diagnostic methods for these diseases are complicated: requires expert gastroenterologists, expensive equipments, and has a major impact on the quality of life of patients (invasive) making early detection challenging. Which brings us to try to answer several open questions: Can we improve on current methods, make it less expensive and with less heavy intervention then improving the patient’s life quality?
This paper aimed to demonstrate the potential of AI in providing a more cost-effective and less invasive solution for detection by solving partial differential equations that model the propagation of these diseases. Our findings provide open-source data and codes, promoting transparency and encouraging further research. Our preliminary study used unsupervised learning to model ulcerative colitis and Crohn’s disease due to the lack of good quality data. Further investigations may be necessary to better understand the modeling of these diseases and the potential to combine computer vision techniques and regression models. We have shown that is possible to solve the Fisher-KPPk equation with low quality data and with a deep neural network. The difficulty was noticed rather in comparison with the Turing non-linear and coupled PDEs system. For that, an investigation is necessary to understand the phenomenon of explosion badly modeled. Finally, we believe that this work was an opportunity to bring together three communities: gastro-enterologists, mathematicians, and AI specialists through our proposed experimental framework 15.
References
- [1] S. Cuomo, V.S. Di Cola, F. Giampaolo, et al. Scientific machine learning through physics–informed neural networks: Where we are and what’s next. J Sci Comput, 92:88, 2022.
- [2] Kevrekidis I.G. Lu L. Perdikaris P. Karniadakis, G.E. et al. Physics-informed machine learning. Nature Reviews Physics, 3(6):422–440, 2021.
- [3] Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, et al. Characterizing possible failure modes in physics-informed neural networks. Advances in Neural Information Processing Systems, 34:26548–26560, 2021.
- [4] Tchelepi H.A. Fuks O. Limitations of physics informed machine learning for nonlinear two-phase transport in porous media. Journal of Machine Learning for Modeling and Computing, 1(1):19–37, 2020.
- [5] Grégoire Nadin, Eric Ogier-Denis, Ana I. Toledo, and Hatem Zaag. A turing mechanism in order to explain the patchy nature of crohn’s disease. Journal of Mathematical Biology, 83(2):12, 2021.
- [6] Yann LeCun, Yoshua Bengio, and Geoffrey Hinton. Deep learning. Nature, 521(7553):436–444, 2015.
- [7] Hao-nan Wang, Ning Liu, Yi-yun Zhang, Da-wei Feng, Feng Huang, Dong-sheng Li, and Yi-ming Zhang. Deep reinforcement learning: a survey. Frontiers of Information Technology & Electronic Engineering, 21(12):1726–1744, 2020.
- [8] Jonas Degrave, Federico Felici, Jonas Buchli, et al. Magnetic control of tokamak plasmas through deep reinforcement learning. Nature, 602(7897):414–419, 2022.
- [9] Suman Ravuri, Karel Lenc, Matthew Willson, et al. Skilful precipitation nowcasting using deep generative models of radar. Nature, 597(7878):672–677, 09 2021.
- [10] L.C. Evans. Partial Differential Equations, volume 19 of Graduate Studies in Mathematics. AMS, 2nd edition, 2010.
- [11] Jean-Pierre Demailly. Analyse numérique et équations différentielles : nouvelle édition avec exercices corrigés. Grenoble Sciences. EDP Sciences, 05 2016.
- [12] Sören Bartels. Numerical Methods for Nonlinear Partial Differential Equations. Springer Series in Computational Mathematics. Springer Cham, 1 edition, 2015.
- [13] Jan Blechschmidt and Oliver G. Ernst. Three ways to solve partial differential equations with neural networks — a review. Gamm, 44(2):e202100006, 06 2021. "Special Issue: Scientific Machine Learning - Part II".
- [14] Frank Merle and Hatem Zaag. On degenerate blow-up profiles for the subcritical semilinear heat equation. arXiv, 2021.
- [15] Catherine Le Berre, Ashwin N Ananthakrishnan, Silvio Danese, et al. Ulcerative colitis and crohn’s disease have similar burden and goals for treatment. Clin Gastroenterol Hepatol, 18(1):14–23, Jan 2020.
- [16] Johan Burisch. Crohn’s disease and ulcerative colitis. occurrence, course and prognosis during the first year of disease in a european population-based inception cohort. Danish medical journal, 61(1):B4778, Jan 2014.
- [17] Doreen Busingye et al. Prevalence of inflammatory bowel disease in the australian general practice population: A cross-sectional study. PloS one, 16(5):e0252458, 2021.
- [18] M. Mosli, S. Alawadhi, F. Hasan, et al. Incidence, prevalence, and clinical epidemiology of inflammatory bowel disease in the arab world: A systematic review and meta-analysis. Inflamm Intest Dis, 6(3):123–131, 2021.
- [19] Sami Karoui and et al. Frequence et facteurs predictifs de colectomie et de coloproctectomie au cours de la rectocolite hemorragique. La tunisie Medicale, 87(02):115–119, 2009.
- [20] Maxime Collard. Les mathématiques au secours de la biologie. Société Nationale Française de Colo-Proctologie (SNFCP), Nov 2021.
- [21] S Kraszewski, W Szczurek, J Szymczak, et al. Machine learning prediction model for inflammatory bowel disease based on laboratory markers. working model in a discovery cohort study. J Clin Med, 10(20):4745, Oct 16 2021.
- [22] R. Makkar and S. Bo. Colonoscopic perforation in inflammatory bowel disease. Gastroenterol Hepatol (N Y), 9(9):573–83, 2013.
- [23] Ana Isis Toledo Marrero. Reaction-diffusion equations and applications to biological control of dengue and inflammation. PhD thesis, Université Paris-Nord - Paris XIII, 2021.
- [24] Safaa Al Ali. Mathematical modelling of chronic inflammatory bowel diseases. PhD thesis, Université Paris-Nord - Paris XIII, 2021.
- [25] Gartner. Gartner hype cycle for artificial intelligence, 2021.
- [26] Gartner. Gartner hype cycle for artificial intelligence, 2022.
- [27] G. Cybenko. Approximation by superpositions of a sigmoidal function. Mathematics of Control, Signals and Systems, 2(4):303–314, 1989.
- [28] Kurt Hornik, Maxwell Stinchcombe, and Halbert White. Multilayer feedforward networks are universal approximators. Neural Networks, 2(5):359–366, 1989.
- [29] Andrew R. Barron. Approximation and estimation bounds for artificial neural networks. Machine Learning, 14(1):115–133, January 1994.
- [30] Shiyu Liang and R. Srikant. Why deep neural networks for function approximation? In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- [31] Lu Lu, Pengzhan Jin, Guofei Pang, et al. Learning nonlinear operators via deeponet based on the universal approximation theorem of operators. Nature Machine Intelligence, 3(3):218–229, 2021.
- [32] Zhiping Mao, Lu Lu, Olaf Marxen, et al. Deepm mnet for hypersonics: Predicting the coupled flow and finite-rate chemistry behind a normal shock using neural-network approximation of operators. Journal of Computational Physics, 447:110698, 2021.
- [33] Shengze Cai, Zhicheng Wang, Lu Lu, et al. Deepm mnet: Inferring the electroconvection multiphysics fields based on operator approximation by neural networks. Journal of Computational Physics, 436:110296, 2021.
- [34] John H. Lagergren, John T. Nardini, Michael Lavigne G., Erica M. Rutter, and Kevin B. Flores. Learning partial differential equations for biological transport models from noisy spatio-temporal data. Proc. R. Soc. A., 476(20190800), 2020.
- [35] Konstantin Pogorelov, Kristin Ranheim Randel, Carsten Griwodz, et al. Kvasir: A multi-class image dataset for computer aided gastrointestinal disease detection. In Proceedings of the 8th ACM on Multimedia Systems Conference, MMSys’17, pages 164–169, New York, NY, USA, 2017. ACM.
- [36] J. Y. Lee, J. Jeong, E. M. Song, et al. Real-time detection of colon polyps during colonoscopy using deep learning: systematic validation with four independent datasets. Scientific Reports, 10:8379, 2020.
- [37] Marco Chierici, Nicolae Puica, Matteo Pozzi, et al. Automatically detecting crohn’s disease and ulcerative colitis from endoscopic imaging. BMC Medical Informatics and Decision Making, 22(6):300, 2022.
- [38] M. Raissi, P. Perdikaris, and G.E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019.
- [39] L. Bottou. Online Algorithms and Stochastic Approximations. Cambridge University Press, Cambridge, UK, 1998.
- [40] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- [41] Jorge Nocedal and Stephen J. Wright. Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer New York, NY, 2 edition, July 2006.
- [42] James Martens. Deep learning via hessian-free optimization. In International Conference on Machine Learning, 2010.
- [43] Dong C. Liu and Jorge Nocedal. On the limited memory bfgs method for large scale optimization. Mathematical Programming, 45(1):503–528, August 1989.
- [44] John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(61):2121–2159, 2011.
- [45] Tony Lyons. The 2-component dispersionless burgers equation arising in the modelling of blood flow. Communications on Pure and Applied Analysis, 11(4):1563–1576, 2012.
- [46] Matylda Jabłońska, Robert Sitarz, and Andrzej Kraslawski. Forecasting research trends using population dynamics model with burgers’ type interaction. 32:619–624, 2013.
- [47] Mahesh Gajendran, Priyadarshini Loganathan, Guillermo Jimenez, et al. A comprehensive review and update on ulcerative colitis,. Disease-a-Month, 65(12):100851, 2019. A Comprehensive Review and Update on Ulcerative Colitis.
- [48] Chaohao Xiao, Xiaoqian Zhu, Fukang Yin, and Xiaoqun Cao. Physics-informed neural network for solving coupled korteweg-de vries equations. Journal of Physics: Conference Series, 2031:012056, 2021.
- [49] Safaa Al-Ali, John Chaussard, Sébastien Li-Thiao-Té, et al. Automatic bleeding and ulcer detection from limited quality annotations in ulcerative colitis. Inflammatory Bowel Diseases, 28(Supplement 1):S19 S20, 01 2022.
- [50] Safaa Al-Ali, Sébastien Li-Thiao-Té, John Chaussard, and Hatem Zaag. Mathematical modeling of the spatial distribution of lesions in inflammatory bowel disease. feb 2020.
- [51] Cyrille Rossant. IPython Interactive Computing and Visualization Cookbook, Second Edition. Packt Publishing, 2018.
- [52] R. A. FISHER. The wave of advance of advantageous genes. Annals of Eugenics, 7(4):355–369, 1937.
- [53] A.N. Kolmogorov, I.G. Petrovsky, and N.S. Piskunov. Investigation of the equation of diffusion combined with increasing of the substance and its application to a biology problem. Bulletin of Moscow State University Series A: Mathematics and Mechanics, 1:1–25, 1937.
- [54] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016.
- [55] David Arthur and Sergei Vassilvitskii. k-means++: the advantages of careful seeding. In Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA ’07), pages 1027–1035. Society for Industrial and Applied Mathematics, 01 2007.
- [56] Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ’16), pages 785–794. ACM, 08 2016.