Unsupervised Raindrop Removal from a Single Image using Conditional Diffusion Models
Abstract
Raindrop removal is a challenging task in image processing. Removing raindrops while relying solely on a single image further increases the difficulty of the task. Common approaches include the detection of raindrop regions in the image, followed by performing a background restoration process conditioned on those regions. While various methods can be applied for the detection step, the most common architecture used for background restoration is the Generative Adversarial Network (GAN). Recent advances in the use of diffusion models have led to state-of-the-art image inpainting techniques. In this paper, we introduce a novel technique for raindrop removal from a single image using diffusion-based image inpainting.
Index Terms:
Deraining, diffusion model, image restoration, inpainting, refraction model.I Introduction
Rain is a weather condition that can adversely affect the quality of captured images. Due to rain, droplets and streaks of water can obscure the aforementioned images. Deraining is the act of removing these rain elements from an image or video, usually by machine and deep learning methods. Two types of rain elements are potentially present: (1) rain streaks, which are line-shaped in appearance [1], and (2) raindrops. In this paper, we focus on the task of raindrop removal from a single image. Hence, video restoration is beyond the scope of this study, and rain streaks are assumed to not be present in the images.

Raindrops occurring in an image are formed by rays of reflected light from a wider environment [2]. The circular regions produced by raindrops give a blurry effect to the image, which degrades the overall image quality. Raindrop removal on a single image is an image restoration task that was introduced by Qian et al. [2]. They released a novel raindrop removal dataset, known as the Raindrop dataset, for experimentation purposes (see Figure 1). Afterward, they applied an attentive Generative Adversarial Network (GAN) to this dataset. We utilize a diffusion model in this study instead of a GAN.
Diffusion models are generative models capable of producing high-quality images. They are latent variable models borrowing concepts from nonequilibrium thermodynamics [3]. Diffusion models have gained much traction in recent years as they have been shown to outperform GANs in image synthesis [4]. Notably, they were recently applied to image inpainting [5], an image restoration task that aims to artificially fill in missing sections within an image. Inpainting is closely related to raindrop removal, especially in regard to filling in the blurry circular regions left by the raindrops in order to reconstruct the background image.
To address the problem of raindrop removal from a single image, we propose DropWiper. DropWiper is a novel two-step architecture consisting of raindrop detection and background reconstruction. Although raindrop detection merely uses a convolutional neural network as the raindrop mask generator, the background reconstruction uses the aforementioned diffusion model that was used for inpainting. Two datasets are used for training and testing our model: the Raindrop dataset [2] and the Cityscapes dataset [6]. For training purposes, we also add synthetic raindrops onto the Cityscapes images via a non-parametric refraction model.
II Related Work
II-A Raindrop Removal
Raindrop removal has seen several applications, such as in unmanned aerial vehicle inspection [7] and coastal video enhancement [8]. Most approaches toward raindrop removal rely on GANs [9, 10, 11, 12, 13, 7]. Most recently, Xia et al. [9] devised a two-step GAN to maintain balance between raindrop removal and image inpainting. Their strategy is quite similar to our own but differs in the use of architecture. In contrast to GANs, we employ diffusion models to perform the inpainting. Recently, Özdenizci and Legenstein [14] designed TransWeather, a patch-based diffusion model for vision restoration in adverse weather conditions. Unlike this study, they approach multiple weather conditions at once, including rain, snow, and haze. Although we use a similar diffusion approach, we are strictly focused on raindrop-filled images.
II-B Diffusion Models
The theory of diffusion models is developed in detail by Ho et al. [15]. A diffusion model is essentially a Markov chain containing latent variables with respect to the original image data . The model consists of (1) a forward process, which gradually adds noise to and returns the latent variables in succession, and (2) a reverse process for denoising, which gradually removes noise from the latent variables to eventually reobtain . The forward process is represented as distributions , and the reverse process is represented as distributions . The illustrating diagram is provided in Figure 2.
For the forward process, the conditional probability of given can be calculated using the following formula:
| (1) |
where is a variance hyperparameter for the forward process. Let and . The conditional probability of given can be directly calculated using the following formula:
| (2) |
For the reverse process, the conditional probability of given can be calculated using the following formula:
| (3) |
Diffusion models have numerous applications to image synthesis [16, 17, 18], in which they have become the state-of-the-art approach. In addition, they have been applied to anomaly detection [19] and image restoration [14]. This indicates the versatility and effectiveness of diffusion models in the field of image processing.
III Methodology
This paper proposes a novel method to remove raindrops from a single image. We call our method DropWiper111Source code: https://github.com/lhfazry/DropWiper. For testing purposes, we use the Raindrop dataset from Qian et al. [2]. This dataset consists of pairs of images. Each pair consists of an image with raindrops and its corresponding ground-truth clean image. Unfortunately, the dataset does not contain ground-truth raindrop masks to identify areas containing raindrops in the image. These masks play an important role to ensure successful raindrop removal. To handle this issue, we divide our method into two steps: pseudo raindrop mask generation and background reconstruction.
In the first step, we create pseudo raindrop masks for the raindrop-filled images in the dataset. Using these pseudo-masks as guidance, we then try to recover the background using the Denoising Diffusion Probabilistic Model (DDPM) [15], which was recently used for image inpainting [5]. This image inpainting method does not expect a fine-grained level of masking since it can recover the background even when the masked regions are larger than expected. We design several approaches to generate the pseudo raindrop masks to see which one performs best.
III-A Pseudo Raindrop Mask Generation
A raindrop mask is a binary image that maps areas containing raindrops. This map separates the raindrop areas and the background areas of the image. If an area contains raindrops, then the pixels in the are set to (white). For the background areas that do not contain raindrops, pixels are set to (black).
We consider two approaches for generating a pseudo raindrop mask: residual mask generation and synthetic mask generation. In the first approach, we create a residual mask simply by subtracting the clean image from the corresponding image with raindrops. Then, we set a threshold to extract the raindrop regions from the resulting residual image. Residual pixels that lie above the threshold are categorized as part of the raindrop area, whereas those that do not are categorized as part of the background. Unfortunately, directly calculating the residual on images often results in poor masking due to the existence of extraneous variables. These variables include brightness, light intensity, other objects, etc. So, we employ several pre-processing techniques to minimize the influence of these variables, including histogram equalization and photometric distortion. In the second approach, we employ a more sophisticated method to generate synthetic masks. We then train a supervised raindrop detector by supplying it with a synthetic raindrop ground truth.
III-A1 Direct Thresholding on the Residual
Each data point in the Raindrop dataset [2] comes with a pair of images: an image with raindrops and its clean version. We are given two images taken from the dataset, where is an image with raindrops while is the corresponding clean image. The notations and represent the image’s height and weight respectively, while is the corresponding number of channels for RGB (Red, Green, and Blue) images. We compute the residual image from and via one of the following options:
-
a
Compute the residual image by subtracting from . The residual image is defined as follows:
(4) -
b
Compute the residual image by using the absolute difference between and as follows:
(5) -
c
Convert and into gray-scale images and then define the residual as follows:
(6) -
d
Convert and into gray-scale images and then compute the residual image by using the absolute difference between and as follows:
(7)
For options and , we convert the resulting residual into a gray-scale image. Afterward, for all options, we apply a threshold to categorize the pixels. We perform experiments with various threshold values to find the best one. The threshold values are set to , , , and .
III-A2 Raindrop Detection
During this step, we train a model to detect raindrops from an image. Given an image with raindrops, the model outputs a binary mask that segments the raindrops and the background. We use a lightweight Convolutional Neural Network (CNN) as the model. It only has k parameters in total.
The network has three main parts. The first part consists of two convolution blocks. Each block is a single 2D CNN with batch normalization [20] and LeakyReLU [21] as the non-linear activation function. Each CNN uses a kernel of size with stride . The feature dimension of the input image is increased from to (by the first block) and then to (by the second block) to ensure that the model learns richer features. Still in this first part, we add another 2D CNN to further increase the feature dimension to by a kernel with stride 2, but without the use of batch normalization nor non-linear activation.
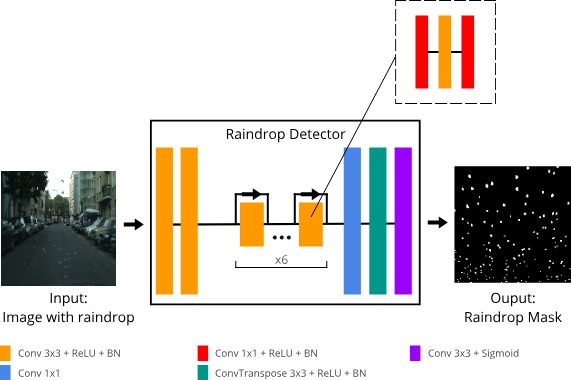
For the second part, we employ residual blocks. Each residual block contains layers of 2D CNNs equipped with batch normalization and LeakyReLU for non-linear activation. The first CNN takes as input a feature of dimension and uses a kernel of size . The output feature has dimension . In the second CNN, the output dimension continues to be , but we increase the kernel size to . The last CNN restores the feature dimension to using a kernel. In these residual blocks, we force the network to learn spatial patterns since the raindrops are spatially dependent. We stack blocks and employ a residual connection [22] in each block. A residual connection can be formally defined as . The aim of residual connections is to create a skip connection so that forward and backward operations can benefit from it. Residual connections have been proven to stabilize training even in very deep networks.
The final part of the raindrop detector consists of a convolution block, a convolution transpose block, and a single CNN. The convolution block used in this part is the same as the convolution block used in the first part. This block reduces the feature dimension from to . Then, the convolution transpose block increases the spatial resolution of the image to match the input resolution by up-sampling, and at the same time reduces the feature dimension to . In the very last layer, a CNN is used to further reduce the feature dimension to , denoting a gray-scale feature. The sigmoid function is then applied to obtain a probability value for every pixel. If the value is greater than , then the corresponding pixel is categorized as a raindrop. Otherwise, it is categorized as background. Figure 3 illustrates the model architecture.
The big question is how to train this model. The Raindrop dataset from Qian et al. does not contain ground-truth masks. Without raindrop masks, we cannot train the model. We overcome this issue by following the literature [23, 24, 25, 26, 27] to create synthetic raindrops using a refraction model. Under this model, the background of the raindrops can be seen as a contracted version of the full background. Figure 4 illustrates the refraction model. To generate synthetic raindrops, we need several parameters surrounding the camera, including the degree and distance between the camera and the screen. We generate these synthetic raindrops on the Cityscapes dataset [6] for two reasons. First, the Cityscapes dataset provides us with image data and the camera parameters we need. The camera parameters enable us to generate synthetic raindrops using the refraction model. Second, the images contained in the Cityscapes dataset and the Raindrop dataset are quite similar. The Cityscapes dataset contains images of roads, buildings, houses, etc. The Raindrop Dataset has similar venues, including roads, buildings, and campuses.
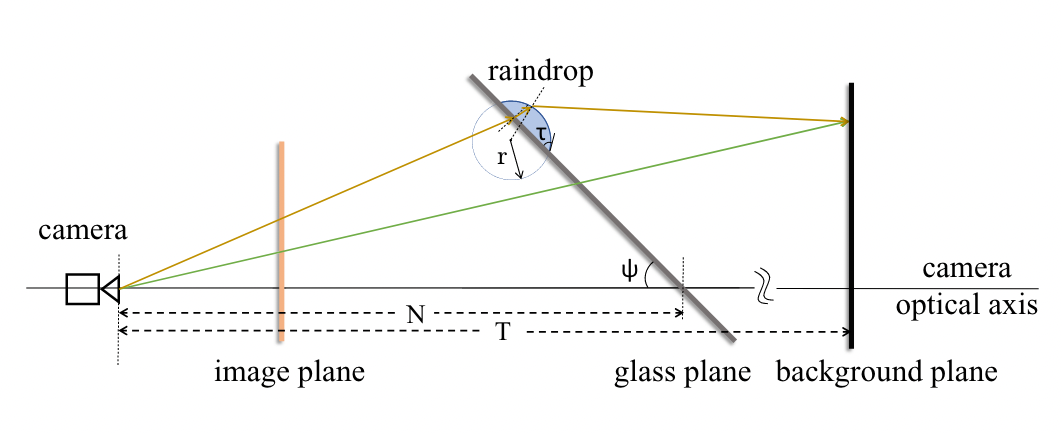
The refraction model is non-parametric. It is a single forward algorithm without the need for training. The model takes a single clean image as input and then returns two images: an image with synthetic raindrops and the corresponding raindrop mask. Both are then used to train our raindrop detector. The raindrop detector takes an image with synthetic raindrops as input and returns the raindrop mask prediction. The error between the model’s prediction and the ground-truth raindrop mask is used to backpropagate the model’s weights. After the detector model has been trained, it is applied to detect raindrops on the Raindrop dataset.
III-B Background Reconstruction
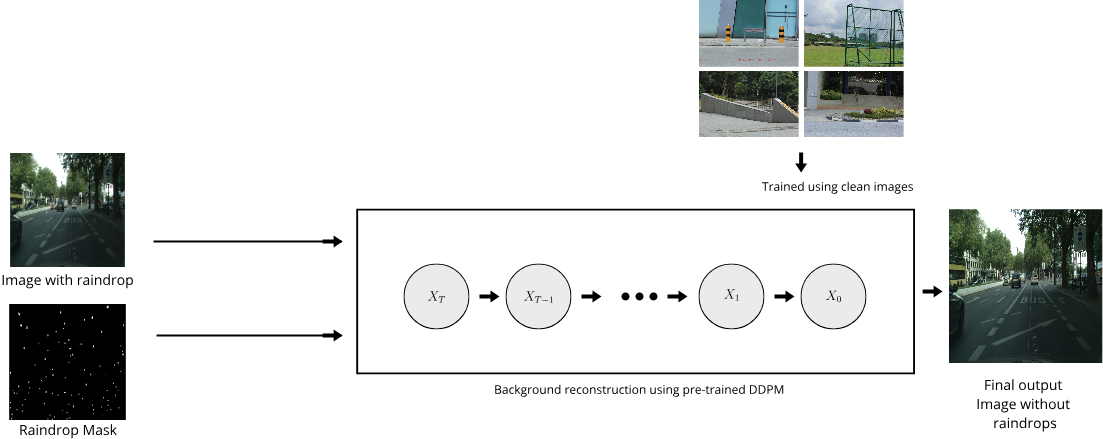
Given a pseudo-mask generated from the previous module, we aim to restore the background on the masked areas. In this module, we employ a pre-trained DDPM model [4] that has been trained on clean images of the Raindrop dataset. Specifically, we run the inference process using the pre-trained model to restore the background. We expect that the model can learn the distribution of clean images so it can generate novel images from that distribution. The intuition is simple. If the model can generate such novel images, then it can be used to reconstruct the background image when conditioned on the raindrop mask.
Background reconstruction based on a mask essentially consists of predicting the missing pixels due to raindrops conditioned on the mask. The Raindrop dataset comes with ground-truth clean images, so we can evaluate the result using these ground truths. First, we denote as the ground-truth image, as the missing pixels, and as the known pixels. The operator denotes element-wise multiplication.
Recall that from the DDPM perspective, model training is a forward diffusion process, while model inference is a reverse diffusion process. From Equation 3, we can see that in a single reverse step, we only need the variable to reconstruct . We can ensure that DDPM constructs only on the masked regions via a simple trick. After we obtain , we can alter the known pixels in using the corresponding pixels from that are obtained by forward diffusion. Fortunately, we can directly go to from for any by using Equation 2. So, we conduct the background restoration by combining two directions: forward and reverse. We use Equation 3 to obtain the unknown pixels and Equation 2 to obtain the known pixels. This technique can be formally defined as follows:
| (8) |
where and . Figure 5 illustrates the process of background restoration.
IV Experiments
IV-A Experimental Datasets
In the experiments, we use two datasets: the Raindrop dataset by Qian et al. [2] and the Cityscapes dataset [6]. The former dataset, Raindrop, contains images with raindrops and their corresponding clean images as ground truth. Our main goal is to detect and remove raindrops from these images and evaluate the results against clean images. This dataset consists of train data, validation data, and test data. Each image has a spatial resolution of with RGB channels. Most images in this dataset are photos taken around campus.
The latter dataset is the Cityscapes dataset. We use the gtFine_trainvaltest.zip package contained in this dataset. This package contains images, along with parameter settings on the camera that is used to take the photos. We employ this dataset to train our model. We generate synthetic raindrops on this dataset and then use the result to train the raindrop detector.
IV-B Experimental Settings
We use 1 GPU V100 for all experiments. We implement the raindrops synthetic generator using the C++ programming language, adapting the code from Hao et al. [27]. To better handle the image data using C++, we use OpenCV, an open-source C++ library that includes several hundreds of computer vision algorithms.
We implement the raindrop detector using the Python 3.8 programming language and the PyTorch 1.12 library to better create the model architecture. For easier model training and fine-tuning, we use the PyTorch Lightning framework [28]. We train the model for epochs with batch size . We also use the AdamW optimizer [29] with learning rate and weight decay . For the learning rate scheduler, we use StepLR with step_size . We train the model to minimize the binary cross entropy loss as the raindrop detector task is essentially a segmentation task utilizing per-pixel classification.
For the background reconstructor, we use the DDPM model implemented by Dhariwal et al. [4]. We train the model on the clean images of the Raindrop dataset for 1M iterations. We set the number of diffusion steps to . To save memory, we center-crop the images to size . We use the AdamW optimizer with learning rate without weight decay. The training process took 6 days in total.
IV-C Results and Discussion
IV-C1 Residual Masks
For this part, we conducted some experiments to generate residual masks based on different settings as explained in Subsection III-A1. Figure 6 shows the results from applying these settings.

It can be seen from Figure 6 that there is no significant difference between masks obtained from different residual settings. But, we found significant changes after applying different threshold settings since higher threshold values correlate with the increase of masked regions.
IV-C2 Synthetic Raindrops
Figure 7 shows samples of images obtained through synthetic raindrop generation.

IV-C3 Raindrop Detector
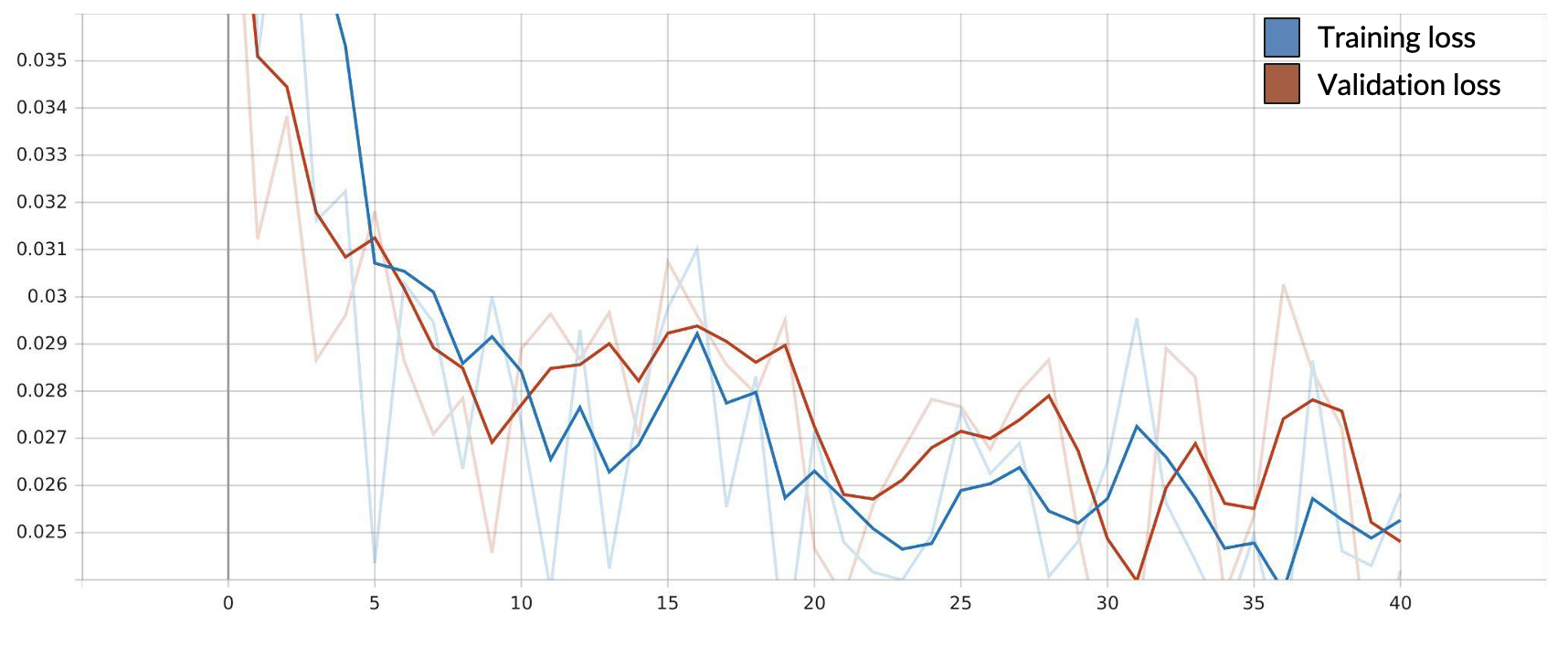
For this part of the experiment, we trained our raindrop detector. Figure 8 shows the plot of the training and validation losses. From this plot, we can see that the training and validation losses decrease in value as the number of epochs increases.
We then applied our raindrop detector to the Raindrop dataset. Figure 9 shows mask predictions obtained by the detector on five sample images. From this result, we can see that the mask quality is poor and does not represent the true areas containing raindrops. We analyzed the model’s behavior and found that this problem was caused by domain shifting due to the change of dataset from Cityscapes to Raindrop.

IV-C4 Background Reconstruction
After we trained the DDPM model on clean images of the Raindrop dataset, we test the inference capabilities of the model. Figure 10 shows samples of novel images generated by the models.

V Conclusion and Future Work
In this paper, we proposed a novel method to remove raindrops from a single image based on conditional diffusion models. Our method consists of raindrop detection and background reconstruction. From our experiments, we found that the residual mask generators provide more solid masks than the raindrop detection model. We argue that domain shifting (due to the change of dataset from Cityscapes to Raindrop) is the cause of this problem as it decreases model performance. Also, we are not able to perform an effective background reconstruction as a result of the lack of a proper mask. Forcing the background reconstruction to be performed on poor masks will lead to unstable reconstructions. In the future, we plan to explore more avenues of research in which we can generate better masks.
References
- [1] Yuhui Quan, Shijie Deng, Yixin Chen, and Hui Ji. Deep learning for seeing through window with raindrops. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2463–2471, 2019.
- [2] Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2482–2491, 2018.
- [3] Jascha Sohl-Dickstein, Eric A. Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep Unsupervised Learning using Nonequilibrium Thermodynamics, November 2015. arXiv:1503.03585 [cond-mat, q-bio, stat].
- [4] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in Neural Information Processing Systems, 34:8780–8794, 2021.
- [5] Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. RePaint: Inpainting using Denoising Diffusion Probabilistic Models. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11451–11461, New Orleans, LA, USA, June 2022. IEEE.
- [6] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proc. of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
- [7] Changbao Xu, Jipu Gao, Qi Wen, and Bo Wang. Generative adversarial network for image raindrop removal of transmission line based on unmanned aerial vehicle inspection. Wireless Communications and Mobile Computing, 2021, 2021.
- [8] Jinah Kim, Dong Huh, Taekyung Kim, Jaeil Kim, Jeseon Yoo, and Jae-Seol Shim. Raindrop-aware gan: Unsupervised learning for raindrop-contaminated coastal video enhancement. Remote Sensing, 12(20):3461, 2020.
- [9] Haiying Xia, Yang Lan, Shuxiang Song, and Haisheng Li. Raindrop removal from a single image using a two-step generative adversarial network. Signal, Image and Video Processing, 16(3):677–684, April 2022.
- [10] Duc Manh Nguyen and Sang-Woong Lee. Unfairgan: An enhanced generative adversarial network for raindrop removal from a single image. arXiv preprint arXiv:2110.05523, 2021.
- [11] Ülkü Uzun and Alptekin Temizel. Cycle-spinning gan for raindrop removal from images. In 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), pages 1–6. IEEE, 2019.
- [12] Hee-Deok Yang. Restoring raindrops using attentive generative adversarial networks. Applied Sciences, 11(15):7034, 2021.
- [13] Mingwen Shao, Le Li, Hong Wang, and Deyu Meng. Selective generative adversarial network for raindrop removal from a single image. Neurocomputing, 426:265–273, 2021.
- [14] Ozan Özdenizci and Robert Legenstein. Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models, November 2022. arXiv:2207.14626 [cs].
- [15] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in Neural Information Processing Systems, 33:6840–6851, 2020.
- [16] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- [17] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S Sara Mahdavi, Rapha Gontijo Lopes, et al. Photorealistic text-to-image diffusion models with deep language understanding. arXiv preprint arXiv:2205.11487, 2022.
- [18] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 2022.
- [19] Julian Wyatt, Adam Leach, Sebastian M Schmon, and Chris G Willcocks. Anoddpm: Anomaly detection with denoising diffusion probabilistic models using simplex noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 650–656, 2022.
- [20] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. ArXiv, abs/1502.03167, 2015.
- [21] Bing Xu, Naiyan Wang, Tianqi Chen, and Mu Li. Empirical evaluation of rectified activations in convolutional network. ArXiv, abs/1505.00853, 2015.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep Residual Learning for Image Recognition, December 2015. arXiv:1512.03385 [cs].
- [23] Jad C. Halimeh and Martin Roser. Raindrop detection on car windshields using geometric-photometric environment construction and intensity-based correlation. 2009 IEEE Intelligent Vehicles Symposium, pages 610–615, 2009.
- [24] Martin Roser, Julian Kurz, and Andreas Geiger. Realistic Modeling of Water Droplets for Monocular Adherent Raindrop Recognition Using Bézier Curves. In Reinhard Koch and Fay Huang, editors, Computer Vision – ACCV 2010 Workshops, volume 6469, pages 235–244. Springer Berlin Heidelberg, Berlin, Heidelberg, 2011. Series Title: Lecture Notes in Computer Science.
- [25] Alexander von Bernuth, Georg Volk, and Oliver Bringmann. Rendering Physically Correct Raindrops on Windshields for Robustness Verification of Camera-based Object Recognition. 2018 IEEE Intelligent Vehicles Symposium (IV), pages 922–927, 2018.
- [26] Shaodi You, Robby T. Tan, Rei Kawakami, Yasuhiro Mukaigawa, and Katsushi Ikeuchi. Waterdrop Stereo. ArXiv, abs/1604.00730, 2016.
- [27] Zhixiang Hao, Shaodi You, Yu Li, Kunming Li, and Feng Lu. Learning From Synthetic Photorealistic Raindrop for Single Image Raindrop Removal. In 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), pages 4340–4349, Seoul, Korea (South), October 2019. IEEE.
- [28] William Falcon and The PyTorch Lightning team. PyTorch Lightning, 3 2019.
- [29] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2017.