Use of Excess Power Method and Convolutional Neural Network in All-Sky Search for Continuous Gravitational Waves
Abstract
The signal of continuous gravitational waves has a longer duration than the observation period. Even if the waveform in the source frame is monochromatic, we will observe the waveform with modulated frequencies due to the motion of the detector. If the source location is unknown, a lot of templates having different sky positions are required to demodulate the frequency, and the required huge computational cost restricts the applicable parameter region of coherent search. In this work, we propose and examine a new method to select candidates, which reduces the cost of coherent search by following-up only the selected candidates. As a first step, we consider an idealized situation in which only a single-detector having 100% duty cycle is available and its detector noise is approximated by the stationary Gaussian noise. Also, we assume the signal has no spindown and the polarization angle, the inclination angle, and the initial phase are fixed to be , , and , and they are treated as known parameters. We combine several methods: 1) the short-time Fourier transform with the re-sampled data such that the Earth motion for the source is canceled in some reference direction, 2) the excess power search in the Fourier transform of the time series obtained by picking up the amplitude in a particular frequency bin from the short-time Fourier transform data, and 3) the deep learning method to further constrain the source sky position. The computational cost and the detection probability are estimated. The injection test is carried out to check the validity of the detection probability. We find that our method is worthy of further study for analyzing sec strain data.
I Introduction
Advanced LIGO and Advanced Virgo detected the first event of gravitational waves from a binary black hole merger in 2015 Abbott et al. (2016). After the three observation runs, a lot of binary coalescence events are found Abbott et al. (2019a, 2020a). In addition to Advanced LIGO and Advanced Virgo, KAGRA Aso et al. (2013) and LIGO India Bala et al. (2011) are planning to join the gravitational wave detector network Abbott et al. (2020b). The gravitational wave astronomy is expected to get fruitful results for improving our understanding of the astronomical properties of compact objects Abbott et al. (2019b, 2020c, 2020d), the true nature of gravity Will (2014); Abbott et al. (2019c, 2020e), the origin of the Universe Maggiore (2000) and so on (see Sathyaprakash and Schutz (2009) for a review).
All gravitational wave signals which are detected so far have duration sec, which is much shorter than the observation period. By contrast, we also expect gravitational waves which last longer than the observation period. Such long-lived gravitational waves are called continuous gravitational waves (see Maggiore (2007); Creighton and Anderson (2011) as textbooks). Continuous gravitational waves are defined by the following three properties: 1) small change rate of the amplitude, 2) almost constant fundamental frequency, and 3) duration longer than the observation period. Rotating anisotropic neutron stars are typical candidate sources of continuous gravitational waves. In addition, there are several exotic objects proposed as possible candidates of the sources of continuous gravitational waves (Zhu et al. (2020); Arvanitaki et al. (2015); Brito et al. (2017)).
Continuous gravitational waves are modeled by simpler waveforms than those of coalescing binaries. The parameters characterizing a typical waveform are the amplitude, the initial frequency, and the frequency derivatives with time. Although the waveform generated by the source is analytically simple, the effect of the detector’s motion makes the data analysis for continuous gravitational waves challenging. The detector’s motion causes the modulation in the frequency, and resulting in the dispersion of the power in the frequency domain. If the source location is a priori known by electromagnetic observations, the modulation can be removed precisely enough. By contrast, for the unknown target search, we need to correlate the data with a tremendous amount of templates to cover the unknown source location on the sky. This severely restricts the applicability of the all-sky coherent search to strain data of long durations. Therefore, semi-coherent methods, in which the strain data is divided into a set of segments and statistics calculated for respective segments are summed up appropriately, are often used. Various semi-coherent methods (e.g. Time-Domain -statistic Jaranowski et al. (1998), SkyHough Krishnan et al. (2004), FrequencyHough Astone et al. (2014)) were proposed so far, and they are actually used to analyze LIGO and Virgo’s data. Despite tremendous efforts, up to now no continuous gravitational wave event is detected Abbott et al. (2017, 2018, 2019d).
As another trend of the research, the deep learning method is introduced to the field of gravitational wave data analysis. After the pioneering work done by George & Huerta George and Huerta (2018), there are many proposals to use deep learning for wide purposes, e.g., parameter estimation for binary coalescence Gabbard et al. (2019); Chua and Vallisneri (2020); Nakano et al. (2019); Yamamoto and Tanaka (2020), noise classification George et al. (2018) and waveform modeling Chua et al. (2020). As for applications to the search for continuous gravitational waves, several groups already proposed deep learning methods. Dreissigacker et al. Dreissigacker et al. (2019); Dreissigacker and Prix (2020) applied neural networks to all-sky searches of signals with the duration sec and sec. They used Fourier transformed strain as inputs. Their methods can be applied to the signal located in broad frequency bands and to the case of multiple detectors and realistic noise. Also, it is shown that the synergies between the deep learning and standard methods or other machine learning techniques are also powerful Morawski et al. (2019); Beheshtipour and Papa (2020).
In this paper, we propose a new method designed for detecting monochromatic waves, combining several transformations and the deep learning method. In Sec. II, the waveform model and some assumptions are introduced. The coherent matched filtering and the time resampling technique are briefly reviewed in Sec. III. In Sec. IV, we explain our strategy that combines several traditional methods such as the resampling, the short-time Fourier transform, and the excess power search with the deep learning method. We show the results of the assessment of the performance of our new method in Sec. V. Sec. VI is devoted to the conclusion.
II Waveform model
We consider a monochromatic gravitational wave. We denote by its frequency constant in time. With the assumption that the source is at rest with respect to the solar system barycenter (SSB), a complex-valued gravitational waveform in the source frame will be simply written as
| (1) |
where is called SSB time, and are the amplitude and the initial phase, respectively. In this work, for simplicity, we assume that
| (2) |
and regard it as a known parameter. The phase of a gravitational wave is modulated due to the detector motion and the modulation depends on the source location. The normal vector pointing from the Earth’s center to the sky position specified by a right ascension and a declination angle is defined by
| (3) |
with the tilt angle between the Earth’s rotation axis and the orbital angular momentum . Here, we work in the SSB frame, in which the -axis is along the Earth’s orbital angular momentum and the -axis points towards the vernal equinox. Defining the detector time so as to satisfy
| (4) |
we obtain the waveform in the detector frame
| (5) |
with
| (6) |
A subscript “s” indicates the quantity related to the gravitational wave source. Namely, means the sky position of the source. In the following, we use the notation .
For the modeling of the detector motion, we adopt a little simplification, which we believe will not affect our main result. We assume that the position vector of the detector can be written by a sum of the Earth’s rotation part , and the Earth’s orbital motion part . The Earth is assumed to take a circular orbit on -plane. Then, we can write as
| (7) |
where , and are the distance between the Earth and the Sun, the angular velocity of the orbital motion and the initial phase, respectively. The detector motion due to the Earth’s rotation can be described as
| (8) |
where , , and are the radius of the Earth, the latitude of the detector, the angular velocity of the Earth’s rotation and the initial phase, respectively. The modulated phase can be decomposed into
| (9) |
where
| (10) | ||||
| (11) |
Finally, we take into account the amplitude modulation due to the detector’s motion, which can be described by the antenna pattern function. In this work, the polarization angle and the inclination angle are, respectively, assumed to be
| (12) |
and, similarly to , they are treated as known parameters. Then, the gravitational wave to be observed by a detector can be written as
| (13) |
with
| (14) |
The definitions of and are the same as those used in Jaranowski et al., Jaranowski et al. (1998). In this work, the antenna pattern function of LIGO Hanford is employed. The strain data is written as
| (15) |
where is the detector noise. We assume that the strain data from the detector has no gaps in time and the detector noise is stationary and Gaussian.
III Coherent search method
Before explaining our method, we briefly review the coherent search method and the time resampling technique Jaranowski et al. (1998).
If the expected waveforms can be modeled precisely and the noise is Gaussian, the matched filtering is the optimal method for the detection and the parameter estimation, besides the computational cost. The noise weighted inner product is defined by
| (16) |
where is the power spectral density of the detector noise. A signal-to-noise ratio (SNR) can be calculated with the inner product between a strain and a template as
| (17) |
Theoretically predicted waveforms have various parameters characterizing the source properties and the geometrical information. A set of waveforms having different parameters is called a template bank. For each template in a template bank, we can assign the value of SNR calculated by Eq. (17). If the maximum value of SNR in the template set exceeds a threshold value, it is a sign that an actual signal may exist and the parameter inference is also obtained from the distribution of SNR.
Due to a long duration and a narrow frequency band of continuous gravitational waves, the inner product (16) can be recast into the time-domain expression as
| (18) |
where is the observation time. For a monochromatic source, the waveform can be modeled by Eq. (1). The modulation due to the detector motion is only in the phase of the waveform. The time resampling technique nullifies the phase modulation by redefining the time coordinate. If the position of the source is a priori known, the exact relation (4) can be obtained. Therefore, the phase modulation can be completely removed and the monochromatic waveform is applicable to the time-domain matched filtering (18). Calculation of the inner product (18) between the resampled signal and a monochromatic waveform is equivalent to the Fourier transform. Thus, the fast algorithm (i.e., Fast Fourier transform) can be employed to rapidly search the gravitational wave frequency, .
When the source location is unknown, we need to search all-sky by placing a set of grid points to keep the maximum loss of SNR within the acceptable range. For each grid point, we carry out the Fourier transform after the transformation
| (19) |
Here, we omit the superscript , for brevity. The necessary number of grid points can be estimated by the angular resolution of gravitational wave sources. The angular resolution of gravitational wave sources can be roughly given by the ratio between the wavelength of the gravitational wave and the diameter of the Earth’s orbit, i.e.,
| (20) |
Here, we adopt 100Hz as the fiducial value for . Thus, the required number of grid points is, at least,
| (21) |
The time resampling and the Fourier transform are applied to each grid point. The number of floating point operations required for carrying out FFT is per grid point, with the signal of a duration sec and a sampling frequency 1024 Hz. Even if we have a 1PFlops machine, the computational time becomes sec, which is longer than the signal duration. For this reason, the coherent all-sky search is not realistic even for monochromatic sources yet.
IV Our Method
IV.1 Subtracting the effect due to the Earth’s rotation
As stated in Sec. III, the time resampling technique can demodulate the phase, but complete demodulation is not available because of the limitation of computational resources. In our work, the time resampling technique is employed to eliminate only the effect caused by the Earth’s diurnal rotation, . Assuming a representative grid point , we can rewrite the phase (6) as
| (22) |
where
| (23) | ||||
| (24) |
and . Since the residual phase varies with time, we will place grid points so that the amplitude of the residual phase in the worst case, i.e.,
becomes smaller than a threshold for any source direction within the area covered by the grid point . To optimize the grid placement, we employ the method proposed in Ref. Nakano et al. (2003). The residual phase is expanded up to the first order of and . Then, we get
| (25) |
Here, the constant term is neglected because it degenerates with the initial phase . The maximum value of the residual phase is
| (26) |
The grid points are to be determined to satisfy for any source direction.
Because the residual phase (26) is symmetric under the transformation , the placement of grids on the negative side can be generated by inverting the sign of the grids on the positive side. Therefore, we focus on the case with .
Since the residual phase depends only on at , a single template can cover the neighbor of . In fact, at , Eq. (26) becomes
| (27) |
Therefore, the condition gives the lower bound of such that the region can be covered by a signle patch represented by , to find
| (28) |
Plural patches are necessary to cover the strip of a constant in the other range. We introduce a 2-dimensional metric corresponding to the residual phase (26),
| (29) |
In general, a metric in a 2-dimensional manifold can be transformed into a conformally flat metric by an appropriate coordinate transformation. When the space is conformally flat, the curve of a small constant distance measured from an arbitrary chosen point can be approximated by a circle. Therefore, a template spacing in the 2-dimensional parameter space becomes relatively easy. By defining new variables and , the metric can be transformed into
| (30) |
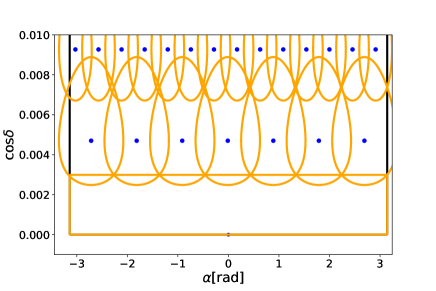
Along with Nakano et al. (2003), we can construct the sky patches covering the half-sky region with . Figure 1 shows a part of grid points constructed under the condition
| (31) |
which we adopt throughout this paper. The total number of grid points to cover the whole sky is
| (32) |
for = 100Hz.
IV.2 Modeling the effect due to the Earth’s orbital motion
As we choose to be sufficiently small, we neglect in the following discussion. Then, after subtracting the phase modulation due to the Earth’s rotation, the phase of the gravitational wave (22) becomes
| (33) |
We apply the short-time Fourier transform (STFT) to the time-resampled strain,
| (34) |
In the rest of the paper, we treat only the time-resampled data. Therefore, without confusion, the time-resampled data in Eq. (34) can be denoted by the same character as the original one. The strain is divided into segments having the duration and their start times are denoted by . is not necessary to be equal to . The output of STFT with the window function is defined by
| (35) |
where
| (36) |
| (37) |
and is the frequency of the -th element of STFT. Let us focus on the positive frequency modes, i.e., . Then, the second term of Eq. (13) can be neglected and Eq. (36) can be approximated by
| (38) |
with . In the expression of , the SSB time appears only through the combination . The difference between and is negligiblly small. Therefore, in Eq. (38), can be replaced by . The duration is chosen so that can be approximated by a constant in each segment. With this choice of , the factor also can be seen as a constant in each segment because it varies slower than the antenna pattern function. Therefore, Eq. (38) can be approximated by
| (39) |
where
| (40) |
In this work, we use the tukey window,
| (41) |
We set the parameter to 0.125. With , Eq. (40) can be calculated as
| (42) |
Using the Jacobi-Anger expansion, we can expand the factor that appears in Eq. (39) as
| (43) |
where is the Bessel function of the first kind and
| (44) | |||
| (45) |
Therefore, Eq. (39) can be expressed as
| (46) |
The Fourier transform of with a fixed integer is defined by
| (47) |
We refer to as the -domain signal. To understand the pattern hidden in , we set aside the factor for a while. Then, Eq. (47) can be estimated as
| (48) |
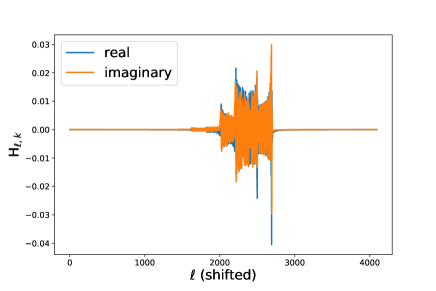
with . Because of the fact that for and for Hz, the signal is localized within the region where only few thousand bins in the -domain. Putting back the antenna pattern , we expect that -domain signals lose their amplitude and their localizations become worse than those for the idealized cases. Figure 2 shows an example of the -domain signal.
IV.3 Excess power method for finding candidates
By the method shown in the previous subsection, for every grid point and every frequency bin , we obtain an -domain strain defined by
| (49) |
with
| (50) |
There are data points in a single -domain strain and we know that the signal in -domain will be localized within a small region . Thus, the excess power method Anderson et al. (2001) is useful for selecting the candidates with a minimal computational cost. We here divide an -domain signal into short chunks so that each chunk has the length and neighbored segments have an overlap by , which is one of the simplest choices but not the optimal one. Then, we obtain chunks from one -domain signal. The excess power statistic for the grid point , the frequency bin , and the -th chunk () is defined by
| (51) |
where
| (52) |
The variance of noise in -domain, , is estimated as
| (53) |
where is the factor coming from the window function and defined by
| (54) |
We define the SNR of the excess power by
| (55) |
where
| (56) |
and
| (57) |
are, respectively, the expectation value and the standard deviation of when only noise exists. We select the candidate set of parameter values , when
is satisfied with a threshold value . Strictly speaking, since the excess power statistic is the sum of squared Gaussian random variables with the variance , follows a chi square distribution with the degree of freedom . However, since here we choose to be large, the distribution of can be approximated by a Gaussian distribution with the average and the standard deviation . Therefore, in the absence of gravitational wave signal, the probability distribution of is a Gaussian distribution with zero mean and unit variance.
Also in the presence of some signal, the excess power statistics is given by a sum of many statistical variables. Thus, the statistical distribution of can be approximated by the Gaussian distribution whose mean and standard deviation are calculated as
| (58) |
and
| (59) |
Here, we define
| (60) |
and we define as a set of parameters . The false alarm rate and the detection efficiency will be assessed with this Gaussian approximation.
IV.4 Neural network for localizing
IV.4.1 fundamentals
Deep learning is one of the approaches for finding features being hidden in the data (see Goodfellow et al. (2016) as a textbook). Artificial neural networks (ANNs) are the architectures playing the central roll in deep learning. An ANN consists of consecutive layers and each layer is formed by a lot of units (neurons). Each layer takes inputs from the previous layer and processed data is passed to the next layer. As a simple example, the process occurring in each layer can be written as the combination of affine transformation and a non-linear transformation, i.e.,
| (61) |
where is a set of input data on the -th layer and is a nonlinear function, which is called an activation function. We use a ReLU function Jarrett et al. (2009), defined by
| (62) |
The parameters and are, respectively, called weights and biases. They are tunable parameters and optimized to capture the features of data. The process to optimize weights and biases is called training. Frequently, the affine transformation and the non-linear transformation are divided into two layers, called a linear layer and a non-linear transformation layer, respectively.
In addition to the layers as given by Eq. (61), many variants are proposed so far. In this work, we use also one-dimensional convolutional layers LeCun and Bengio (1998) and max-pooling layers Zhou and Chellappa (1988). The input of a convolutional layer, denoted by , is a set of vectors. For example, in the case of color images, each pixel has three channels corresponding to three primary colors of light. Therefore, the input data is a set of three two-dimensional arrays. The discrete convolution, which is represented as
| (63) |
is calculated in a convolutional layer. Here, is the input and is the output data of the layer. and are, respectively, the number of channels and the width of the kernel. Each pixel of the data is specified by an index . The parameters and are optimized during the training. A max pooling layer, whose operation can be written as
| (64) |
with the kernel size and the stride , reduces the length of the data and hence the computational cost.
In supervised learning, a given dataset consists of many pairs of input data and target values. An ANN learns the relation between input data and target values from the dataset and predicts values corresponding to newly given input data. In order to train an ANN, the deviation between the predicted values and the target value is quantified by a loss function. For a regression problem, the mean square loss,
| (65) |
is often employed. Here, and are a set of predicted values and that of target values, respectively, and they are expressed as -dimensional vectors. The prediction depends on the weights of the neural network, which are denoted by a single symbol . An ANN is optimized so as to minimize the loss function for a given dataset, which is the sum of the loss functions for all data contained in the training dataset. Because the complete minimization using all dataset cannot be done, the iterative method is used. The weight is updated by the replacement algorithm given by
| (66) |
where is the number of data contained in the dataset and is called learning rate and characterizes the strength of each update. The algorithm shown in Eq. (66) is called gradient descent, which is the simplest procedure to update the weights, and many variants (e.g., momentum Polyak (1964), RMS prop Hinton (2012), Adam Kingma and Ba (2017)) are proposed so far. Regardless of the choice of the update algorithm, the gradients of a loss function is required and they can be quickly calculated by the backpropagation scheme Rumelhart et al. (1986). In Eq. (66), all data in the dataset are used for each iteration. In practice, the loss function for a subset of the dataset is calculated. The subset is called a batch and chosen randomly in every iteration. This procedure is called a mini-batch training.
In the training process, we optimize a neural network so that the loss function is minimized for a dataset. However, this strategy cannot be straightforwardly applied to practical situations. First, the trained neural network may fall in overfitting. Then, the neural network does not have an expected ability to correctly predict the label for a newly given input data which is not used for training. Second, we have to optimize the neural network model and the update procedure, too. For this purpose, we have to appropriately select the hyperparameters, such as the number of neurons of the -th layer () and the learning rate (). They are not automatically tuned during the training process.
To solve these problems, we prepare a validation dataset which is independent from the training dataset. The weights of the neural network are optimized so that the loss function for the training dataset is minimized. The validation data is used for monitoring the training process and assessing which model is better for the problem that the user wants to solve. To prevent the overfitting, the training should be stopped when the loss for the validation dataset tend to deviate from that for the training dataset (early stopping). To optimize the hyperparameters, many neural network models having various structures are trained with different training schemes. Among them, we choose the one performing with the smallest loss for the validation dataset.
IV.4.2 setup in our analysis
The whole architecture of the neural network we used is shown in Table 1. The input data of the neural network is the complex valued numbers taken from a short chunk of the -domain signal, and the output is the predicted sky position. The -domain waveform is determined mainly by the residual phase , which depends on the sky position through the vector . Because , only and components of affect . Therefore, we label each waveform with the values of and , which are the targets of the prediction of the neural network. The outputs of the neural network are inverted to the predicted values which are denoted by . We apply the neural network to each candidate, selected by the excess power method, in order to narrow down the possible area in which the source is likely to be located. For simplicity, the -plane is regarded as a two-dimensional Euclidean space, and the shape of the predicted region is assumed to be a disk on the -plane. For each candidate, the origin of the disk is set to the predicted point. The radius of the disk, denoted by , is fixed to a constant value. In the follow-up stage, the finer grids are placed to cover whole region of the disk.
| Layer | Input | output |
|---|---|---|
| 1-d convolution | (2, 2048) | (64, 2033) |
| ReLU | (64, 2033) | (64, 2033) |
| 1-d convolution | (64, 2033) | (64, 2018) |
| ReLU | (64, 2018) | (64, 2018) |
| max pooling | (64, 2018) | (64, 504) |
| 1-d convolution | (64, 504) | (128, 497) |
| ReLU | (128, 497) | (128, 497) |
| 1-d convolution | (128, 497) | (128, 490) |
| ReLU | (128, 490) | (128, 490) |
| max pooling | (128, 490) | (128, 122) |
| 1-d convolution | (128, 122) | (256, 119) |
| ReLU | (256, 119) | (256, 119) |
| 1-d convolution | (256, 119) | (256, 116) |
| ReLU | (256, 116) | (256, 116) |
| max pooling | (256, 116) | (256, 29) |
| Dense | 25629 | 64 |
| ReLU | 64 | 64 |
| Dense | 64 | 64 |
| ReLU | 64 | 64 |
| Dense | 64 | 2 |
In order to train the neural network, we need to prepare the training dataset and the validation dataset. We use Eq. (47) as the model waveform and pick up only a short chunk containing the signal. The length of chunk is . We prepare 200,000 waveforms for the training and ten thousand waveforms for validation. At that time, we set . We assume that we use only a single detector and use the geometry information (e.g., the latitude of the detector) of LIGO Hanford in calculating the antenna pattern function as an example. In this work, we focus on one sky patch covered by a single grid point and a frequency bin fixed at Hz since the scaling to the search over the whole sky and the wider frequency band is straightforward. The sources are randomly distributed within the sky patch. The parameters are randomly sampled from a uniform distribution on . The original strain has the duration sec and the sampling frequency Hz. We introduce the normalized gravitational wave amplitude by
| (67) |
Here, we set . At each training step, the amplitude whose logarism is randomly chosen from the uniform distribution on is multiplied to the waveforms, and they are injected into the simulated noise. The different realizations of noise are sampled for every iterations. The real part and the imaginary part of the noise data mimicking are generated from a Gaussian distribution with a zero mean and a variance
| (68) |
We employ the mini-batch training. We set the batch size to 256. The Adam Kingma and Ba (2017) is used for the update algorithm. We implement with the Python library PyTorch Paszke et al. (2019) and use a GPU GeForce 1080Ti. The parameter values we used are listed in Table 2.
| Symbol | Parameters | Value |
|---|---|---|
| Observation period | sec | |
| Sampling frequency | 1024 Hz | |
| # of grids | 352436 | |
| # of frequency bins of STFT | 3200 | |
| Duration of a STFT segment | 32 sec | |
| Dilation of STFT segment | 32 sec | |
| Length of chunk | 2048 | |
| Dilation of chunk | 128 | |
| Fixed frequency bin | 100 Hz | |
| Right ascension of grid | -0.158649 rad | |
| Declination of grid | 1.02631 rad |
IV.5 Follow-up analysis by coherent matched filtering
After selecting candidates and narrowing down the possible area at which the source is likely to be located, we apply the coherent matched filtering for the follow-up analysis. The grid points with the resolution shown in Eq. (20) are placed to cover the selected area. Assuming a grid point, we can carry out the demodulation of the phase by using the time resampling technique. If the deviation between the directions of the grid point and the source is smaller than the resolution, the residual phase remaining after the time resampling is sufficiently small to avoid the loss of SNR.
In this operation, heterodyning and downsampling can significantly reduce the data length and hence the computational cost Dupuis and Woan (2005). Let us assume that we have a candidate labeled with . If the candidate is the true event, the gravitational wave frequency should take the value in the narrow frequency band indicated by
| (69) |
By multiplying the factor to the resampled strain, we can convert the gravitational wave signal frequency to near DC components (heterodyning). After that, the gravitational wave signal has a lower frequency than Hz. Therefore, downsampling by appropriately averaging the resampled strain data with a sampling frequency reduces the number of data points without loss of the significance of the gravitational wave signal.
The coherent matched filtering follows the heterodyning and the downsampling processes. As stated in Eqs. (2) and (12), we fix , , and and treat them as known parameters. Also, we assume that the signal waveform and the template completely match. The definition of a match is already given in Eq. (17). The gravitational waveform is written as
| (70) |
Among these parameters, the amplitude can be analytically marginalized to maximize the likelihood. Then, we obtain the signal-to-noise ratio in Eq. (17) and use it as the detection statistic. When only the detector noise dominates the strain data, follows the standard normal distribution. On the other hand, if the signal exists, the SNR follows a Gaussian distribution with a mean
| (71) |
and a unit variance.
V Results
V.1 Computational cost
Our procedure is characterized by three parameters , i.e.,
-
•
, false alarm probability for each chunk,
-
•
, the radius of the predicted region to which the follow-up analysis is applied,
-
•
, the threshold of the SNR of the coherent matched filtering.
denotes the computational cost of the excess power method. multiplications and additions of real numbers are required to calculate the excess powers for all chunks in one -domain signal. The computational cost for calculating the excess powers for all chunks can be estimated as
| (72) |
in the unit of the number of floating point operations. As we see in the following, this cost can be neglected. Next, we check the computational time of the neural network analysis. We estimate the computational time of the neural network by measuring the elapsed time for analyzing ten thousand data. Because the elapsed time is 1.4sec, the total computational time of the neural network is estimated as
| (73) |
where is the number of candidates which are selected by the excess power method and is estimated as
| (74) |
Substituting it, we obtain
| (75) |
Therefore, we focus on the case . The computational cost of our analysis is dominated mainly by the preprocessing of the observed strain data and the follow-up analysis. The computational cost of the entire analysis is denoted by and is approximately calculated by
| (76) |
where and are the computational cost of the preprocessing and the follow-up analysis, respectively. In this work, we fix the STFT segment duration and the length of the chunk. Thus, the computational cost of the preprocessing is a constant.
| (77) |
The computational cost of the STFT is
| (78) |
and the computational cost of FFT is
| (79) |
With sec, sec, Hz, and , the computational cost of the preprocess is estimated as
| (80) |
On the other hand, the computational cost of the follow-up analysis is determined by the combination of and . The computational cost of the follow-up analysis is
| (81) |
Here, is the typical area of region where each grid point of the coherent analysis covers (see Eq. (20)). The computational cost of taking match is dominated by the Fourier transform and calculated as
| (82) |
where Hz. Therefore, we estimate the computational cost of the follow-up analysis as
| (83) |
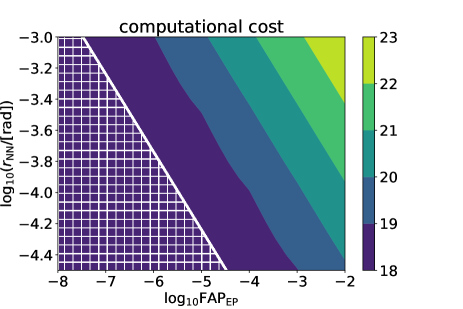
Substituting Eqs. (80) and (83) into Eq. (76), we can assess the computational cost of the entire analysis as a function of and . Figure. 3 shows the computational cost for various combinations of and . One can read a feasible combination of and depending on one’s available computational resources.
V.2 False alarm probability
The false alarm probability of the entire process (see Wette (2012); Dreissigacker et al. (2018)) is
| (84) |
where is the number of required templates for the coherent search. It can be estimated by
| (85) |
where is the number of the frequency bins of the coherent search. Using the value listed in Table. 2, we obtain
| (86) |
Because the false alarm probability of the follow-up stage determines that of the entire process, we can approximate it as
| (87) |
Furthermore, because , we can approximate
| (88) |
In this work, the threshold is chosen so that the false alarm probability of the entire process is 0.01. As shown in Eq. (86), the number of templates depends on , and the same is true for .
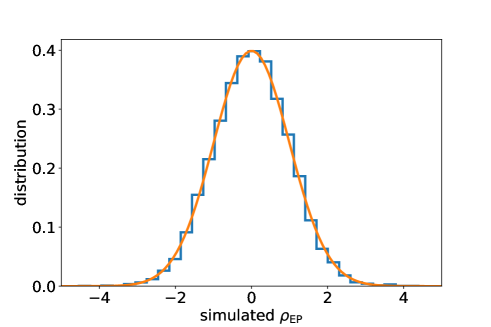
The false alarm probability of the matched filtering has already been studied in the literature. Therefore, in this work, we check only the validity of the statistical properties of the excess power method. It is computationally difficult to treat a whole signal of a duration sec. Therefore, we generate short noise data of a duration assuming . After applying a window function, FFT is carried out to each short strain. We pick up a FFT of -th frequency bin from each FFT data and regard them as . We obtain by taking the Fourier transform of and divide it into chunks. After repeating above procedures for 80 times, 10,240 chunks are generated. For each chunk, the excess power statistics and SNRs are calculated. The histogram of the simulated values of is shown in Fig. 4. It seems to match the standard normal distribution. Additionally, we carry out the Kolmogorov-Smirnov test and obtain a p-value of 0.753254. It is numerically confirmed that the SNR of noise data follows the standard normal distribution.
V.3 Detection probability
The detection probability of the signal with an amplitude can be estimated by
| (89) |
where
| (90) |
is the average over the source parameters with the probability density function . As explained in Sec. IV.4, the neural network is trained with the waveforms sampled only from the vicinity of the reference grid point and the narrow frequency band. It is envisaged that the trained neural network does not work well for signals outside of the reference patch and the frequency band. Therefore, we only test for the limited parameter region. Correspondingly, the average operation is also taken over such narrow parameter space. To quantify the detection power, the amplitude parameter is defined by
| (91) |
and correspondingly,
| (92) |
The parameters, and , are optimized so that takes the smallest value under the condition of the computational power.
To explorer the parameter space of (), we place the regular grid on from to by a step of 1, and the regular grid on from -4.5 to -3.0 by a step of 0.05. For every pair of and , we calculate by the following procedure. First, we place a regular grid on from -2.3 to -1.0 by a step of 0.05. For one sample of the amplitude, the parameters are randomly sampled. The sampled parameters are denoted by . The waveforms are generated with the sampled parameters. Each waveform is injected into different noise data in the same manner as the method explained in Sec. IV.4. The fraction of the events detected is employed as the estimator of the detection probability of the signal with parameter . Repeating these procedure for every sampled parameters , we obtain the set of the estimated detection probabilities. Then, the detection probability is estimated by
| (93) |
Changing the value of the amplitude , we get the estimated detection probability as a function of for a certain values of and . If the estimated detection probability exceeds 95% for one or more samples of the amplitude, the obtained detection probabilities are fitted by a sigmoid-like function,
| (94) |
where
| (95) |
is called the sensitivity depth, and the parameters of a sigmoid function is to be optimized. Using the optimized parameters , the estimated value of can be obtained as
| (96) |
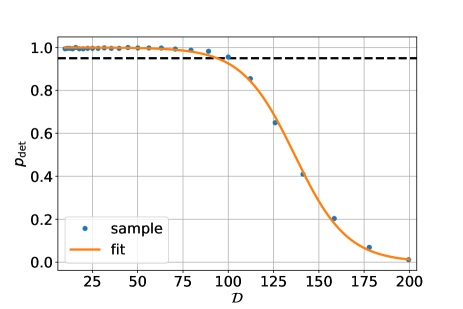
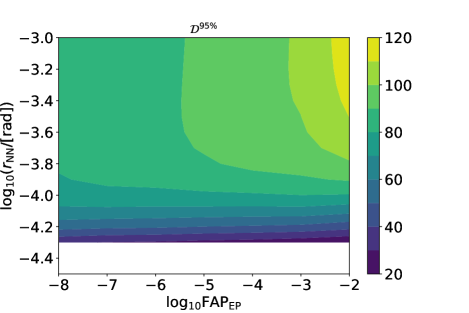
which is the inverse of . In this work, we set and the number of noise realization for each parameter set to be 512. Figure. 5 shows an example of the fitting. The estimated values of is shown in Fig. 6.
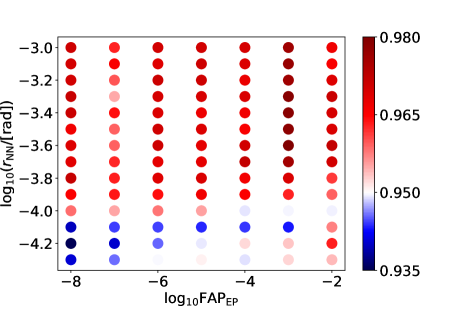
To confirm that the signals with the amplitude are detected with 95% detection probability, we perform the injection test. To save the computational cost, we skip the follow-up stage and assume that the detection probability is determined by the excess power selection and the neural network analysis. We only use a short chunk centered at the support of the signal as an injection waveform. Ten thousand chunks with various signal parameters are prepared and injected into Gaussian noise data. The waveform model and the noise property are the same as those of the training dataset of the neural network. The excess power is calculated for each chunk, and the neural network analysis is carried out if a chunk is selected as a candidate. Counting the number of detected events, we obtain the recovered value of the detection probability. The procedure shown above is repeated for each combination of . Figure. 7 shows the result of the injection test. For all combinations of , the detection probabilities are close to 95%. Therefore, our estimation of the detectable amplitude is convincing.
VI Conclusion
We proposed a new method of an all-sky search for continuous gravitational waves, combining the excess power and the deep learning methods. The time resampling and the STFT are used for localizing the signal into a relatively small number of elements in the whole data. Then, the excess power method selects the candidates of the grid point in the sky and the frequency bins where the signal likely exists. The deep neural network narrows down the region to be explored by the follow-up search by two orders of magnitude than the original area of the sky patch. Before the follow-up coherent search, the heterodyning and the downsampling can reduce the computational cost. We calculated the computational cost of our method. Most of the computational costs are spent by preprocessing the strain data and the follow-up coherent matched filtering search. The computational costs of the excess power method are negligibly small, and the computational time of the neural network can be suppressed to an acceptable level by setting . We estimated the detection abilities of our method with the limited setup where the polarization angle, the inclination angle, and the initial phase are fixed and assumed as known parameters. The dataset for training the neural network and testing is generated from a very narrow parameter space of . With a reasonable computational power, the sensitivity depth can be achieved .
Our training data, which is used for training the neural network, span the restricted parameter region. Namely, the gravitational wave frequencies of the training data are distributed within the small frequency band centered at 100 Hz of width and the source locations are sampled from very narrow regions around the fixed grid point. Nevertheless, we can expect our method can be applied to the all-sky search and the frequency band below 100 Hz. If the gravitational wave frequency becomes lower than 100Hz, the strength of the phase modulation becomes weaker (see Eq. (6)). Therefore, even if Hz, the signal power in -domain would still be concentrated in a narrow region, and it can be expected that the efficiency of the excess power method is maintained. We can employ a similar discussion also for the dependency on the source location. The power concentration in -domain is still valid even if we take into account the dependency of the source location, while it causes the variation of the signal amplitude. From the above discussion, only slight modifications of the construction of the training data and our neural network structure are enough to apply our strategies to an all-sky search of monochromatic sources having a frequency lower than Hz.
In addition to the above points, there are several rooms for improving our method. We fixed various parameters such as the width of the STFT and the length of each chunk in a little hand-waving manner. Surveying and optimizing these parameters may improve the detection efficiency of our method. Especially, the sampling frequency when downsampling might reduce the computational cost significantly. As can be seen from Eq. (48), the deviation causes the translation of the signal in the -domain. It is expected that we can further constrain the gravitational wave frequency than . Considering this effect, we can set the sampling frequencies of downsampled strains to a lower value than our current choice. This optimization would result in the further reduction of the computational time of the follow-up coherent search.
In the present paper, we assumed that the stationary Gaussian detector noise and 100% duty cycle. We also simplified the waveform model, e.g., the frequency change is not incorporated. In spite of these simplifications, the obtained results can be regarded as a proof-of-principle and are enough to convince that our method has the potential for improving the all-sky search for continuous gravitational waves with the duration of sec. Relaxing these assumptions is beyond the scope of this paper and left as future work.
Acknowledgements.
We thank Yousuke Itoh for fruitful discussions. This work was supported by JSPS KAKENHI Grant Number JP17H06358 (and also JP17H06357), A01: Testing gravity theories using gravitational waves, as a part of the innovative research area, “Gravitational wave physics and astronomy: Genesis”, and JP20K03928. Some part of calculation has been performed by using a GeForce 1080Ti GPU at Nagaoka University of Technology.Appendix A Noise statistics in -domain
In general, the power spectral density of a stochastic process is defined by
| (97) |
where the Fourier transform of is defined by
| (98) |
while we define the STFT by Eq. (37). Ignoring the effect of the window function, the variance of can be approximated by
| (99) |
Here, we assume that different STFT bins are statistically independent. The variance of is
| (100) |
Therefore, we get
| (101) |
References
- Abbott et al. (2016) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. Lett. 116, 131103 (2016), eprint 1602.03838.
- Abbott et al. (2019a) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. X 9, 031040 (2019a), eprint 1811.12907.
- Abbott et al. (2020a) R. Abbott et al. (LIGO Scientific, Virgo) (2020a), eprint 2010.14527.
- Aso et al. (2013) Y. Aso, Y. Michimura, K. Somiya, M. Ando, O. Miyakawa, T. Sekiguchi, D. Tatsumi, and H. Yamamoto (KAGRA), Phys. Rev. D 88, 043007 (2013), eprint 1306.6747.
- Bala et al. (2011) I. Bala, S. Tarun, U. CS, D. Sanjeev, R. Sendhil, and S. Anand (2011), URL https://dcc.ligo.org/LIGO-M1100296/public.
- Abbott et al. (2020b) B. P. Abbott et al. (KAGRA, LIGO Scientific, Virgo), Living Rev. Rel. 23, 3 (2020b).
- Abbott et al. (2019b) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. X 9, 011001 (2019b), eprint 1805.11579.
- Abbott et al. (2020c) R. Abbott et al. (LIGO Scientific, Virgo), Astrophys. J. Lett. 900, L13 (2020c), eprint 2009.01190.
- Abbott et al. (2020d) R. Abbott et al. (LIGO Scientific, Virgo), Population Properties of Compact Objects from the Second LIGO-Virgo Gravitational-Wave Transient Catalog (2020d), eprint 2010.14533.
- Will (2014) C. M. Will, Living Rev. Rel. 17, 4 (2014), eprint 1403.7377.
- Abbott et al. (2019c) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. D 100, 104036 (2019c), eprint 1903.04467.
- Abbott et al. (2020e) R. Abbott et al. (LIGO Scientific, Virgo) (2020e), eprint 2010.14529.
- Maggiore (2000) M. Maggiore, Phys. Rept. 331, 283 (2000), eprint gr-qc/9909001.
- Sathyaprakash and Schutz (2009) B. S. Sathyaprakash and B. F. Schutz, Living Rev. Rel. 12, 2 (2009), eprint 0903.0338.
- Maggiore (2007) M. Maggiore, Gravitational Waves. Vol. 1: Theory and Experiments, Oxford Master Series in Physics (Oxford University Press, 2007), ISBN 978-0-19-857074-5, 978-0-19-852074-0.
- Creighton and Anderson (2011) J. D. E. Creighton and W. G. Anderson, Gravitational-wave physics and astronomy: An introduction to theory, experiment and data analysis (2011).
- Zhu et al. (2020) S. J. Zhu, M. Baryakhtar, M. A. Papa, D. Tsuna, N. Kawanaka, and H.-B. Eggenstein, Phys. Rev. D 102, 063020 (2020), eprint 2003.03359.
- Arvanitaki et al. (2015) A. Arvanitaki, M. Baryakhtar, and X. Huang, Phys. Rev. D 91, 084011 (2015), eprint 1411.2263.
- Brito et al. (2017) R. Brito, S. Ghosh, E. Barausse, E. Berti, V. Cardoso, I. Dvorkin, A. Klein, and P. Pani, Phys. Rev. D 96, 064050 (2017), eprint 1706.06311.
- Jaranowski et al. (1998) P. Jaranowski, A. Krolak, and B. F. Schutz, Phys. Rev. D 58, 063001 (1998), eprint gr-qc/9804014.
- Krishnan et al. (2004) B. Krishnan, A. M. Sintes, M. A. Papa, B. F. Schutz, S. Frasca, and C. Palomba, Phys. Rev. D 70, 082001 (2004), eprint gr-qc/0407001.
- Astone et al. (2014) P. Astone, A. Colla, S. D’Antonio, S. Frasca, and C. Palomba, Phys. Rev. D 90, 042002 (2014), eprint 1407.8333.
- Abbott et al. (2017) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. D 96, 062002 (2017), eprint 1707.02667.
- Abbott et al. (2018) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. D 97, 102003 (2018), eprint 1802.05241.
- Abbott et al. (2019d) B. P. Abbott et al. (LIGO Scientific, Virgo), Phys. Rev. D 100, 024004 (2019d), eprint 1903.01901.
- George and Huerta (2018) D. George and E. A. Huerta, Phys. Rev. D 97, 044039 (2018), eprint 1701.00008.
- Gabbard et al. (2019) H. Gabbard, C. Messenger, I. S. Heng, F. Tonolini, and R. Murray-Smith (2019), eprint 1909.06296.
- Chua and Vallisneri (2020) A. J. K. Chua and M. Vallisneri, Phys. Rev. Lett. 124, 041102 (2020), eprint 1909.05966.
- Nakano et al. (2019) H. Nakano, T. Narikawa, K.-i. Oohara, K. Sakai, H.-a. Shinkai, H. Takahashi, T. Tanaka, N. Uchikata, S. Yamamoto, and T. S. Yamamoto, Phys. Rev. D 99, 124032 (2019), eprint 1811.06443.
- Yamamoto and Tanaka (2020) T. S. Yamamoto and T. Tanaka (2020), eprint 2002.12095.
- George et al. (2018) D. George, H. Shen, and E. A. Huerta, Phys. Rev. D 97, 101501(R) (2018).
- Chua et al. (2020) A. J. K. Chua, M. L. Katz, N. Warburton, and S. A. Hughes (2020), eprint 2008.06071.
- Dreissigacker et al. (2019) C. Dreissigacker, R. Sharma, C. Messenger, R. Zhao, and R. Prix, Phys. Rev. D 100, 044009 (2019), eprint 1904.13291.
- Dreissigacker and Prix (2020) C. Dreissigacker and R. Prix, Phys. Rev. D 102, 022005 (2020), eprint 2005.04140.
- Morawski et al. (2019) F. Morawski, M. Bejger, and P. Ciecieląg (2019), eprint 1907.06917.
- Beheshtipour and Papa (2020) B. Beheshtipour and M. A. Papa, Phys. Rev. D 101, 064009 (2020), eprint 2001.03116.
- Nakano et al. (2003) H. Nakano, H. Takahashi, H. Tagoshi, and M. Sasaki, Phys. Rev. D 68, 102003 (2003), eprint gr-qc/0306082.
- Anderson et al. (2001) W. G. Anderson, P. R. Brady, J. D. E. Creighton, and E. E. Flanagan, Phys. Rev. D 63, 042003 (2001), eprint gr-qc/0008066.
- Goodfellow et al. (2016) I. Goodfellow, Y. Bengio, and A. Courville, Deep Learning (MIT Press, 2016), http://www.deeplearningbook.org.
- Jarrett et al. (2009) K. Jarrett, K. Kavukcuoglu, M. Ranzato, and Y. LeCun, in 2009 IEEE 12th International Conference on Computer Vision (ICCV) (IEEE Computer Society, Los Alamitos, CA, USA, 2009), pp. 2146–2153, ISSN 1550-5499, URL https://doi.ieeecomputersociety.org/10.1109/ICCV.2009.5459469.
- LeCun and Bengio (1998) Y. LeCun and Y. Bengio, in The Handbook of Brain Theory and Neural Networks (MIT Press, Cambridge, MA, USA, 1998), p. 255–258, ISBN 0262511029.
- Zhou and Chellappa (1988) Y. Zhou and R. Chellappa, in IEEE 1988 International Conference on Neural Networks (1988), pp. 71–78.
- Polyak (1964) B. T. Polyak, USSR Computational Mathematics and Mathematical Physics 4, 1 (1964), ISSN 0041-5553, URL http://www.sciencedirect.com/science/article/pii/0041555364901375.
- Hinton (2012) G. Hinton, Neural networks for machine learning (2012).
- Kingma and Ba (2017) D. P. Kingma and J. Ba (2017), eprint 1412.6980.
- Rumelhart et al. (1986) D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Nature 323, 533 (1986), ISSN 1476-4687, URL https://doi.org/10.1038/323533a0.
- Paszke et al. (2019) A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, et al., in Advances in Neural Information Processing Systems 32, edited by H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019), pp. 8024–8035.
- Dupuis and Woan (2005) R. J. Dupuis and G. Woan, Phys. Rev. D 72, 102002 (2005), eprint gr-qc/0508096.
- Wette (2012) K. Wette, Phys. Rev. D 85, 042003 (2012), eprint 1111.5650.
- Dreissigacker et al. (2018) C. Dreissigacker, R. Prix, and K. Wette, Phys. Rev. D 98, 084058 (2018), eprint 1808.02459.