V-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Abstract
Image inpainting is a key technique in image processing task to predict the missing regions and generate realistic images. Given the advancement of existing generative inpainting models with feature extraction, propagation and reconstruction capabilities, there is lack of high-quality feature extraction and transfer mechanisms in deeper layers to tackle persistent aberrations on the generated inpainted regions. Our method, V-LinkNet, develops high-level feature transference to deep level textural context of inpainted regions our work, proposes a novel technique of combining encoders learning through a recursive residual transition layer (RSTL). The RSTL layer easily adapts dual encoders by increasing the unique semantic information through direct communication. By collaborating the dual encoders structure with contextualised feature representation loss function, our system gains the ability to inpaint with high-level features. To reduce biases from random mask-image pairing, we introduce a standard protocol with paired mask-image on the testing set of CelebA-HQ, Paris Street View and Places2 datasets. Our results show V-LinkNet performed better on CelebA-HQ and Paris Street View using this standard protocol. We will share the standard protocol and our codes with the research community upon acceptance of this paper.
Index Terms:
Image inpainting, GAN, V-LinkNet, deep learning, standard protocol.I Introduction
Recent advances in deep learning approaches have begun to dominate the field of algorithmic research in image inpainting. The Generative Adversarial Network based (GAN-based) technique to generate realistic images is possibly the most promising field in image inpainting. Besides GAN-based inpainting techniques, traditional methods [1, 2, 3] that employ propagation by pixel interpolation are still being researched. Image inpainting has demonstrated in many applications, which include image restoration [4], facial image editing [5], facial wrinkle inpainting [6] and scene occlusion removal [7].
Image inpainting techniques has been classified into traditional methods and deep learning (learning-based) methods [8, 9]. Traditional image inpainting methods propagate features from background or boundary regions to fill-in missing contents of damaged (foreground) or neighbouring regions. Depending on the contents of propagation, Jam et al. [9] classified these methods into three categories, i.e., diffusion-based approaches, exemplar-based methods and hybrid methods.
The learning-based methods, popular known as deep generative neural networks, have become the state of the art, based on their ability to learn distribution with regards to context. These approaches [10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20] use convolutional neural network (CNN) within an encoder-decoder within a GAN-based network to generate realistic images. These algorithms with a large amount of parameters and alternative layer configurations learn to manage feature extraction, propagation, and regularisation. However, the failures in generating contextualised features has probed the increased design of models, specifically targeting feature extraction and propagation capabilities in image inpainting [21, 22] and other research domains [23, 24, 25].
However, we also notice a gap in the research focus, the performance is always judged over existing models by a series of image quality measures, which could not as significant as projected, due to vulnerabilities in the qualitative analyses. It is uncertain if these GAN-based inpainting algorithms can generalise well, if the same facial image is evaluated with different masks or if the same mask is applied to other facial images with varying contextual information can generate images that perform similarly. The general question is whether there has been genuine progress in this field of research using GAN-based methodologies. This could be attributed to a variety of factors:
-
•
Are the models reported using a standardised testing approach?
-
•
Are these models being tested against a baseline model with predefined parameters?
-
•
Are papers explicit enough to improve reproducibility when comparing results?
-
•
Is the baseline utilised for comparison in the same domain?

We observed that the datasets used for inpainting methods are often randomly split into training and testing sets. Also, the pairing of the masks are mostly random and lack a standard protocol. This is in vast contrast to other deep learning fields where training, validation and testing set are provided pre-split to ensure a robust and fair comparison. This is owing to the test set allowing an even split of cases under different conditions. Figure 1 illustrates the inpainting results of a mask on different faces using V-LinkNet. It is noted that the results are varied depending on the occluded regions. While most of the frontal and near to frontal faces achieved SSIM of 0.91 and above, the bottom right image achieved poor results with SSIM of 0.89, due to variation in lighting and facial expression. Figure 2 shows another issue when we inpaint a face occluded by different masks. With different masks, the inpainted results have significant discrepancies; demonstrating vulnerabilities in the assessment pipeline where certain images and masks can be used to demonstrate high results. Therefore, algorithms performances are dependent on datasets and assessment approaches. While there is a rising trend in image inpainting research publications and codes sharing, we observe that there is no universal guideline for repeatable baseline result. This is due to the lack of standard protocol in this domain.

In this paper, we address the research gap by proposing a cross-latent space reverse mapping GAN for image inpainting and a standard protocol to evaluate the performance of image inpainting. Our main contributions are:
-
•
We propose V-LinkNet, an end-to-end learning across latent space that uses feature information to encode fine details to complete the missing regions. We design a dual-encoder network approach and introduce a new learning strategy for both encoders to communicate with each other. This will improve networks internal collaboration allowing each encoder, to share features. Thus, distributing the task and focusing on unique high-level feature space representations.
-
•
We design a RSTL to capture high-level features in a similar manner as maxpooling units within convolutions with feature preservation, and transfer technique employed as a ResNet-like unit within the block. This will allow the networks to extract and use high-level feature space representations in the inpainting task. Allow for increased detail in image reconstruction.
-
•
We introduce a standard protocol by pairing testing set images with masks, which will be made available for the research community. This will facilitate a fair comparison of existing state-of-the-art image inpainting algorithms, and motivate reproducible research in the field of image inpainting.
We conduct an ablation study to validate the results of our proposed solution to image inpainting. We show that the results of the inpainting task can generate images with contextualised features.
II Related Work
Image inpainting is an open and ongoing problem with extensive prior work in existence. This section summarises previous work with key focuses on GAN-based methods. For full review in image inpainting, refer to Jam et al. [9].
II-A Traditional Methods
The main categories of traditional methods [9] are summarised as:
-
•
Diffusion-based approach [2]. It transmits structural information from boundary areas into the interior, are among the categories of traditional inpainting techniques [9]. Techniques in this category, on the other hand, produce blurry artefacts on large textured missing patches, which is undesirable.
-
•
Exemplar-based methods [1, 3]. It uses similar patch searching techniques to fill in missing regions. Methods in this category attempt to address the limitation of diffusion methods on large textured regions, but still fail to match exact content and sometimes suffer with misalignment due to patch overlap, such as PatchMatch [3]. In addition, they are usually computationally expensive and time consuming with unrealistic results for large image-to-hole ratio with an arbitrary mask.
-
•
Hybrid methods. It uses both diffusion and exemplar-based methods to address misalignment by adding blurry effect in the boundary areas of the target region. Despite the success in producing textural features for a missing region, there are still issues with computation and aberrations persist. Nonetheless, the failure to capture high-level image features and the inability to generate complex and non-repetitive structures [26, 27] continue to be problematic.
Reconstruction of complicated textural regions such as faces was also a challenge for traditional techniques. However, despite the reasonable results obtained with other natural scene images, the limited amount of high-level information accessible during computation has resulted in techniques in this category failing to produce high-quality features with believable semantic structures in natural scene images. Traditional inpainted images frequently exhibit broken or unconnected edges along border regions, blurry artefacts, and overlapping patches along seam regions. Additionally, the inpainting process for techniques in this category is rather computationally intensive.
II-B GAN-based Methods
GAN-based methods make use of large-scale data to facilitate hallucination and the extraction of high-fidelity features within CNN blocks for image inpainting. GAN models for image inpainting [21, 28, 29] have used multi-columns to encode and propagated features directly to the decoder or use a self-supervised Siamese style inference approach [22], where a style encoder is the supervisor of the generator, to improve feature extraction and learning. Other methods [30, 31, 19] observed that failures in feature extraction and propagation could be due to the irregular holes. To address the limitation, Liu et al. [12] proposed an independent mask updating with partial convolutions to specifically target missing regions. Yu et al. [31] proposed to use gated convolutions to gear the model towards learning soft mask of the irregular hole regions. More recently, Jam et al. [19] proposed a reverse mask mechanism to specifically target missing regions whilst preserving the visible ones using a spatial preserving operation.
Alternative approaches are two-stage models [32, 33], where a coarse version is generated at stage 1, and then used as the input to a refinement network at stage 2. The issue with this approach is inadequate information during reconstruction, due to larger target pixel region, hence a poor input for decoration at stage 2. It is still a challenge to reconstruct high-dimensional distribution from natural scenes than from aligned faces with no visible aberrations. A couple of reasons could be failures in feature propagation techniques or lack of refinement mechanisms in deeper layers to capture high-resolution feature maps. To address the aforementioned limitations, Pathak et al. [10] proposed a channel-wise convolution layer for feature propagation but the drawback is high computation and inefficient transfer of feature maps.
Attention-based inpainting in GANs The attention mechanism method is a frequently utilised tool in computer vision problems because of its ability to focus on key features. Improved segmentation, re-identification, captioning, and tracking performance have all been demonstrated to be beneficial [34]. Using a two-stage network with a contextual attention layer, Yu et al. [13] demonstrated that the attention layer assist the model in finding tiny texture details across patches within the masked regions in order to gather high-level features during inpainting. In other approach, Yu et al. [31] presents an attention layer and a soft gating approach as gated convolutions to learn soft mask from data in order to increase the performance even more. Sigmoid activation is used by the gating mechanism to convey realistic qualities by scaling features between [0,1] in order to achieve this.
Attention mechanisms [35, 13, 36, 26] have also been considered in deeper layers or as transition between the encoder and decoder. It is noted that a bottleneck [37, 38, 39] or a feature transfer mechanism like attention layers within deep layers of convolutions is often required when inpainting high-resolution images. Due to high-resolution images, convolutional outputs required large amount of GPU memory, thus resulting to an increase training time [10, 40, 41]. Additionally, when extracting features from high-resolution images, some features may be lost during the operation. However, more detailed information about low-level features, such as edges, is frequently captured within the first few layers of the convolution. As a result, failure to consider prior semantic distributions leads in unusual textures on the generated image. One limitation of attention mechanism is that it increases computational cost [13] and does not generalise well in feature propagation. Liu et al. [15] considered pixel consistency and proposed a module that searches previous patches to extract relevant features.
Thus feature extraction and propagation are important factors to consider at the design stages of the network. Although these are actively being considered, there are still gaps for new approaches. One reason is the limitation in information dissemination of high-level features caused by the design of attention layers.
Image gradients in GAN-based inpainting Image gradients are often used by different image processing techniques [42, 43]. This is due to the fact that the human vision is far more sensitive to gradients than it is to overall pixel intensity [44, 45, 46]. Because known and unknown areas are representations of the masked image in image inpainting, implementing a gradient method to identify occlusion boundaries might be beneficial. Image gradients draw attention to directional changes in images and can be utilised in edge detection algorithms [47]. Image gradients have been used in image inpainting [2, 48, 49] by utilising edge information, which has been shown to be effective. It is possible to utilise diffusion-based inpainting to spread information around the borders of a painting from known to unknown regions by utilising fluid dynamics and partial differential equations. Because edges are continuous, information travelling through isophote (a line linking locations with the same pixel level intensity) matches gradient vectors at the border between the missing pixels and the known pixels. The usage of edge information, on the other hand, varies depending on the hyperparameter and the edge detector used.
When it comes to image inpainting, the Sobel operator is not a new technique [50]. Because images include noise, which may induce a rapid change in pixel values [42], the Sobel algorithm [51] is capable of extracting occlusion boundaries. When employing the Sobel operator for edge detection, noise may be subdued without losing edges, edges can be improved by applying a high pass filter, and spurious edges, which are caused by noise, can be eliminated (edge localisation). Sadowski et al. [50] employed the Sobel operation to collect gradient information from generated and ground-truth images in order to construct a loss function. With the help of edge information, Zhang et al. [52] was able to obtain gradient features that were later fused with image features to obtain the final image. They used a masked gradient map and mask to enable the network to obtain gradient features, which were later fused with image features to obtain a final image. Several techniques have been developed in an attempt to apply structural restrictions to the inpainting tasks, such as two-stage networks, instance images, and matching completion images. Reconstructed images, not with standing their successes, fall short of capturing high-level feature information of the target regions. This problem continues to be difficult, and there is still much opportunity for progress in this field of research.
III Method
III-A Problem Formulation
Previous works [10, 11, 12, 35] in computer vision have shown that inpainting is a learning problem that can be solved by encoding high-level features. The reconstructed output is geared towards having a close similarity to the input. We consider the inpainting task to have an input source and a target image , where is a binary mask and is element-wise multiplication. The proposed V-LinkNet is a neural network generator with dual encoders of differing weights, a recursive residual transition layer (RSTL), and a decoder. It utilises a global and local Wasserstein discriminator to build a generative model. We have included descriptions of the proposed technique as shown on (Figure 3) with the RSTL for more clarity. Additionally, we explain the training procedure that occurs to optimise the training loss functions.
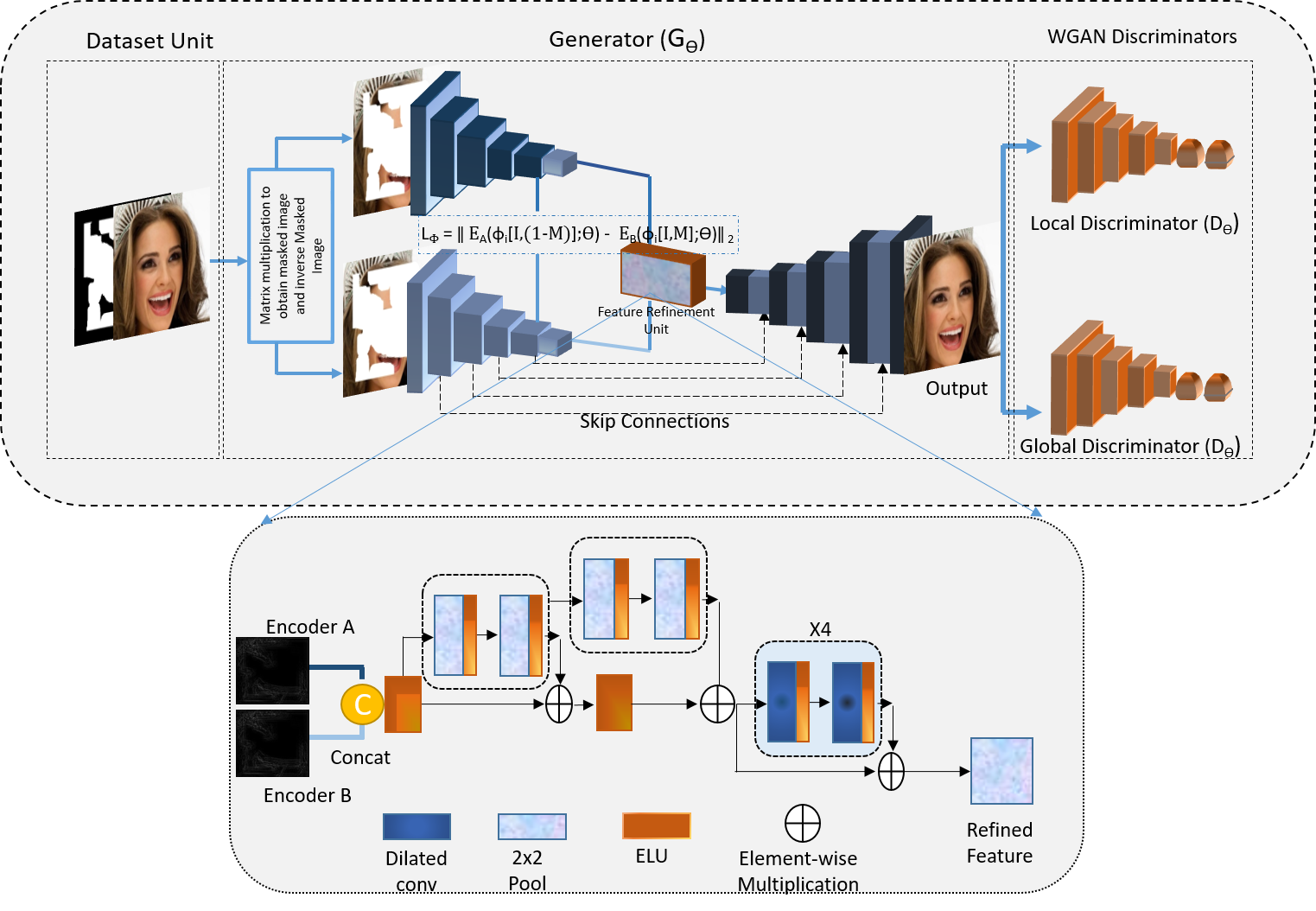
III-B V-LinkNet Architecture
Our proposed V-LinkNet is a generative model consisting of a generator, a global discriminator and a local discriminator as shown in Figure 3. The discriminators are included for adversarial training. Only the generator network is used during the testing phase.
The generator has dual encoder branches ( and ) and a decoder (). Within , encoder branch focuses on the capturing contextual information covered by the masked (unknown) regions. To ensure the reconstructed image is visually coherent with the structure and context of the ground-truth, we design to capture encoding with main focus on perceptual and structural information.
Both encoders and have eight convolution blocks, each with variations in spatial resolution and receptive fields at dilation rates of 2, 4, 8, 16. has dropout layers with value after each convolution block to reinforce learning. Blocks one to five, have batch normalization and Exponential Linear Unit (ELU) activation followed by maxpooling layer, while blocks six to eight has ELU and dropout. Within the decoder , are learnable upsampling layers using bilinear interpolation each with a convolution block that includes batch normalization and ELU activation layers. The final convolution block of the encoder-decoder (generator) has a Tanh activation layer with no batch normalization layer, which is deliberate so as to accelerate training and stabilize learning. The output of the final layer and the generator output as . The final output a generated image based on nonlinear weighted upsampling in latent space.
We train the V-LinkNet on the training set of and use high-level features within both encoders to minimise the error. Midway between the paired encoders, we modify the convolution block by increasing the dilation rate to 8 and 16. Both encoders and learn high-level features to obtain output features and , which are passed into a RSTL. The RSTL is designed to fuse the features from both encoders to exploit feature information at different scales. The V-LinkNet learns through latent space loss and adversarial loss to reconstruct images with similar pixel values of the target image. V-LinkNet consists of a training and inference (testing) phase. We use the traditional WGAN training, where the training sample are masks and ground-truth images. During training, the network learns with the main objective being to generate an image given the mask and the ground-truth. To minimise the error through back propagation, we design a new loss function that evaluates the training set to minimise the error in order to find high-level matching features between the paired encoders. The details of our proposed loss function will be discussed in Section 4. We project the corrupted input onto the latent space of the generator through iterative backpropagation. Therefore, we reuse the weights of both encoders to compute an objective function that will specifically target valid regions. At each stage of the network training, the weights will assist with fast updating during learning to guide the model.
III-C Recursive Residual Transition Layer
Residual learning has been well established in deep learning due to their ability to reduce training error in much deeper layers. A simple implementation of a residual block is a fast-forwarded activation layer within the neural network. By adding the activation layer of a previous layer, to a deeper layer within the network, a residual connection is achieved. In previous works [10, 53, 18], feature extraction and propagation often fail with large portions of the background due to low level capture and poor transition to the decoder. We consider maxpooling, an operation that highlights the most present feature of an image patch and calculates its maximum value. Because features encode spatial representation of visible patterns, it is more informative to consider the maximum presence of different features extracted from the image. Hence the reason why maxpooling is considered instead of average pooling in this work.
We design the RSTL, as illustrated in Figure 3, with the aim to capture high-level semantic information. There are two units in the RSTL: a maxpooling residual connected unit and a convolution residual connected unit. The RSTL is formed by residually connecting both units. The idea is to efficiently pool multiple window sizes, combine them using learnable weights and fast-forward to deeper layers to reduce the error during training. As a result, training gradients are obtained from the next connected layer within each layer, and these gradients are used to update the parameters in the current layer. This, in turn, influences the weights of the filters, causing the activation maps to increase or decrease, lowering the loss. We combine the residual connection of the activation maps with the output of the final pooling layer and the input of the residual layer to obtain the unit output feature map. To feed the RSTL, we concatenate the output feature maps of both encoders. The RSTL extracts high-level semantic information from the concatenated input to generate a feature map, which is then passed on to the decoder.
Our proposed connected pooling operation combined with residual connections reduces the error near the boundary regions of the hole regions, as it captures fine contextual information. This unit is designed to predict and delineate any mask residues as it highlights high-level semantic information by recursively performing pooling and convolution operations. The concatenated features when passed via pooling unit suppresses noise to project informative pixels. This is different from using the channel-wise attention which squeezes the spatial dimension of the feature map. The objective of this design is to extract meaningful pixels whilst suppressing uninformative ones before passing them to the decoder. First we concatenate features extracted from and and pass them through ELU activation and then perform pooling operation followed by a convolution and ELU unit as a gating layer. For more refined details we use a dilation rate of 16 within the convolution layer.
| (1) |
where is the ELU activation function, is the convolution layer. The final feature map is given by:
| (2) |
where is element-wise addition and lastly a dilated convolution layer to refine and transfer the feature to the decoder.
III-D Loss Function
To optimise the RSTL and dual encoders, we introduce a novel loss function that uses features of both encoders to assist the model during learning. To ensure high-level contextual features for missing regions, we introduce a loss between and . During training, the loss between both encoders ensures ongoing communication, in order to improve the models learning on contextual information. By employing this technique, the model can enhance visual consistency with contextualised features. The loss model is designed based on the Mean Squared Error (MSE) specifically to penalize large errors and provide fast learning.
Feature Losses More recent approaches [31, 54, 55, 41] use pre-trained VGG16 or VGG19 [56] to evaluate or enhance the perceptual quality of image inpainting results. These models [21, 31, 17, 55] have perceptual and style losses and these losses are still undisputed when it comes to evaluating or improving the overall performance of the generator. Inspired by perceptual losses in feature space, we propose a novel feature loss in latent space. Features are low-dimensional latent state representations captured in latent space. By reusing deeper-level features from both encoders in latent space, we design an objective learning loss model to capture rich features of the reversed regions covered by the mask. In addition, it is desirable for the inpainted regions to be as close to the counterpart regions of the ground-truth. Thus a head-start with faster update of parameters and weights to the generator is important in this task. The reasons for this is that both encoders will learn from each other. Another reason is that loss functions can become difficult in latent representations, thus reusing latent representations to compute error within layers give the network easy access to compute the gradients for better head-start. This, enables understanding of contextual features during learning from the reversed input regions for a reasonable prediction. Hence continuous training can potentially capture subtle or more refined features in space. However, using all layers to find a better gradient computation increases computational complexity hence why only two identical deep layers of both encoders are used for this experiment.
Latent space feature-aware gradient loss Utilising image gradients is a very common practice of various image processing algorithms [42, 43]. The Sobel operator [51] (filter) is a gradient operator that measures gradients on 2D images by capturing focused information. It works by directing attention to areas of high spatial frequency that correspond to the image’s edges.

In image inpainting, known and unknown regions are representations of the masked image, thus applying gradient algorithm to detect occlusion boundaries can prove useful. To determine the direction of filling priority, we target the image gradients of feature maps and use this information to construct a loss model.
We obtain feature gradients of the third convolutional layer of both encoders and compute the loss model. To re-enforce on outer edges and fidelity of the generated image, we utilize gradients of the generated and ground-truth images to assist in the final reconstruction. Note that the edge map based on the gradients are computed in x and y directions.
Generator Loss The generator loss evaluates the missing pixel region and the perceptual quality of the image. To maximise contextual and feature-wise learning, we extract high-level features from deeper layers of and corresponding features of .
| (3) |
| (4) |
where and are gradients computed by depth-wise convolution using the x and y components of the Sobel operator on an image .
| (5) |
| (6) |
| (7) |
| (8) |
where as coefficient to obtain . We use pixel space L1-norm, based on a range of pixel values with the input image and output image.
| (9) |
| (10) |
where, is a constant, is the element-wise multiplication, is the ground-truth image and is the predicted image. Further, we utilize the reversed mask loss () from [19] and compute a contextual loss. We want to keep the known pixel locations of the input image by penalizing the predictions thus creating similar pixels based on the reversed mask and masked regions.
| (11) | |||
| (12) |
| (13) |
The total loss () is a weighted sum of all the losses with highest weight applied to .
| (14) |
where are coefficients of the weights applied to the loss.
Discriminator Loss We utilise the Wasserstein distance loss similar to [21, 19] in both discriminators.
| (15) |
where real-data distribution is represented in the first term and generated-data distribution is the second term. The local discriminator uses the same loss term as the global discriminator , but only provides loss gradients for missing regions during training. The final objective loss for the discriminator is:
| (16) |
Finally, we combine the objective loss function of the model defined in Equation 17.
| (17) |
IV Experiments
In this section, we describe the implementation of V-LinkNet, the datasets and introduce a standard protocol to benchmark the performance of image inpainting algorithms.
IV-A Implementation
Implementation of the V-LinkNet is done using the Keras library with a Tensorflow backend, and the model is trained on a P6000 GPU computer. We resized our images to and align them with random masks during training and during testing aligned them with appropriate masks. We pretrain the network using a novel loss function that backpropagates gradients using features from both encoders. We use the RSMProp optimizer, with a 0.0005 learning rate. We updated the generator and discriminator networks following pretraining and utilised the Adam optimizer [57] with a learning rate of 1E-4 and a beta of 0.5. The network is trained with a batch size of 5 and for 100 epochs, which takes around three to five days depending on the amount of the training data. After obtaining a well-trained model, we use reverse mask loss and a decreased learning rate (1E-5) to fine-tune it while retaining the original network topology. The input is updated throughout completion using a contextual loss and a perceptual loss with coefficients of 0.4 and 0.6, respectively. Stochastic clipping is employed during back-propagation. We picked a modest value to ensure that contextual loss is prioritised during test-time optimization, and that the inpainted part of the generated image most closely resembles the input background context of the entire image. The generator and discriminator are fixed during back-propagation. We evaluate the performance of V-LinkNet on CelebA-HQ, Paris Street View, and Places2 datasets, which are the most widely used datasets by the state of the art.
A fully trained model can predict missing pixels for image-to-mask ratios ranging from [0.1 to 0.8] during testing. The inference time is between 0.192 seconds to 63 seconds depending on the mask size. During inference, we employ the network design with batch normalisation layers disabled.
IV-B Datasets
The images and the masks are two essential components to train and test the performance of inpainting methods. The following are the most commonly used datasets to evaluate the performance of image inpainting algorithms:
- •
-
•
Paris Street View [60]: This dataset contains 14,900 training images and a test set of 100 images collected from Paris street views. The main focus of the dataset is the buildings of the city and very important in geo-location task.
-
•
Places2 [61]: A dataset containing over 1 million images from 365 scenery from places. It is suitable for model learning and understanding of diverse complex natural scenery. The following scene categories were chosen: butte, canyon, field, synagogue, tundra, and valley (in that order) as proposed by Yan et al. [35]. In each category, there are 5,000 training images and 900 test images. Our model is trained on the training set and evaluated on the testing set.
Each training image for both Paris Street View and Places2 is resized to pixels, which is then used as an input to our model.
IV-C Standard Protocol Testing Dataset
To encourage full reproducibility of our work, we introduce a standard protocol for image inpainting testing datasets. The facial test set is labeled according to CelebA-HQ [58] dataset, which contains 3,000 high-resolution face images from CelebA [59]. The facial test set is split randomly according to [12]. These images are paired with 3,000 masks images from Quick-Draw Mask [62] and 3,000 masks images from the Nvidia Mask [12] test dataset, as illustrated in Figure 5. We will share the filenames of the paired image and mask test set in a comma-separated value (CSV) file. Note that our evaluation masks are set to 3,000 mask images and the images and masks used for training are not paired. The proposed standardised test dataset is curated with the facial image pose in mind. We evaluate the difficulty in inpainting task based on pose and variation in mask holes.
The Paris Street View [60, 10] were standardised by Pathak et al. [10], which is available upon request only from the authors. We adopted the Pathak et al.’s protocol for the Paris Street view dataset, which has 100 test images but used our own masks for testing. On the other hand, the Places2 [61] test dataset is extract from Places365-Standard. The categories used are butte, canyon, field, synagogue, tundra and valley. These are the same categories for training and testing. Each training set has 5,000 images, 900 test images and 100 validation images as per [35]. In total, there are a total of 5,400 test images. We paired each images with 5,400 masks and use it as a standard protocol for testing. For follow this due to longer training times and also based on the split by the state-of-the-art [35]. For Places2 and Paris Street View datasets, we run evaluations based on the mask difficulty on their standard test set.

V Results
This section presents a quantitative and qualitative evaluation of the proposed V-LinkNet in comparison to state-of-the-art methods.
V-A Baseline model Comparison
Without bias and dependent on codes availability, we used Pathak et al. [10] (CE), Liu et al. [12] (PC), Yu et al. [31] (GC), and Jam et al. (RMNet) [19] as baseline models. The following summarise the baseline models used as the benchmarks for our standard protocol:
-
•
Context encoder-decoder framework (CE) [10] introduced the channel-wise fully connected layer to solve the convolutional layer limitation associated with failures in direct connection of all locations within a specific feature map. The channel-wise fully connected layer is designed to directly link all activation; thus enabling propagation of information within the activation of a feature map.
-
•
Partial Convolution (PC) [12] proposed partial convolutions with mask updating to enforce learning in irregular hole regions during convolutions and ease feature transfer to subsequent layers, allowing convolution layers to target more of the missing regions as a result.
-
•
Gated Convolution (GC) The authors [31] proposed a gating mechanism that learns soft masks within convolutions to make the transfer of features within convolutions more convenient. This method differs from PC [12] in that the irregular mask is learnt rather than being updated in each step, whereas the former does not have this feature.
-
•
Reverse Masking Network (RMNet) [19] introduced reverse mask mechanism within the network. The reverse mask forces the convolutions to subtract visible regions through the reverse mask mechanism, thus ensuring the output prediction is on the missing regions only.
V-B Qualitative Results
The figures in this section depict the visual results of the V-LinkNet method. For comparison with the benchmarks and a variation of our model, we show the generated face images in Figure 6. It shows CE struggles with arbitrary hole-to-image mask regions and the generated image is blurry, while PC and GC leave a bit of artefacts (best viewed when zoomed) on the generated image. Focusing on the face and hair regions, our model performs better than the state of the art with no artefacts left on the inpainted regions. However, despite marginally comparable quantitative results on full inpainted images, our model completes and generates the facial image with no visible boundaries of the binary masks as seen on the generated images completed by the state of the art.

The visual comparison of Places2 and Paris Street View datasets best represent how our model can generalise to natural scene images. The generated images are shown on Figure 7 for Places2 [63] while Figure 8 shows the inpainted images generated from Paris Street View dataset [28].


V-C Quantitative Results
It is important to note that the visual and semantic understanding of the completed regions is critical to the audience when inpainting in the wild. This is because the visual quality of the blending between the inpainted regions and the original unmasked regions should be unnoticeable in real-world scenarios. However, in computer vision, we use quantitative evaluation to track model performance. Based on previous state-of-the-art research, we use the Mean Absolute Error (MAE), Frechet Inception Distance (FID), Peak Signal to Noise Ratio (PSNR), and SSIM to quantify performance against the state of the art ([10, 12, 31]). The high values obtained for MAE and FID show poor performance of the model whereas lower values for these metrics indicate better performance. For clarity, we have included in the table, where indicates lower is better and indicates higher is better.
Table I shows the quantitative evaluation for the inpainted images on CelebA-HQ testing set, with the best results in bold. Our proposed method achieved the best FID of 2.76 and SSIM of 0.96 when compared to the baseline models.
In addition, we perform quantitative measures on Places2 and Paris Street View datasets to test the ability of V-LinkNet in other image types. We compare the results to the state of the art [19] and present the findings in Table II. On the Paris Street View dataset, our proposed model outperformed the state of the art [19] with SSIM of 0.95, but achieved marginally comparable result on the Places2 dataset, with SSIM of 0.91. The best results in Table II are highlighted in bold.
VI Ablation Study
To understand the proposed method, an investigation is carried out to demonstrate the effectiveness of each component contributing to the image inpainting task. We carry out the ablation study V-LinkNet’s performance on the proposed standard protocol of CelebA-HQ testing set. First, we evaluate the model using the latent space feature loss combined with the edge-based (Sobel) gradient loss. For the purpose of space on the Figure 9, we name this model as VN1, and then the full model with features losses and RSTL denoted by VN2. The visual results are shown on Figure 9 and the quantitative evaluations on Table III.
VI-A Latent space feature loss combined with edge-based gradient loss (VN1)
We slight modify the RSTL by removing the pooling unit. The modified layer is a residual block with the concept of attention in our inpainting task. We perform convolutions on and output and concatenate the projected features maps. For dynamic feature selection, a softmax function is utilised on the concatenated feature map. Applying softmax after convolutions on each encoder output enables precise feature values, thus preserving local and detailed information.
During the experiment, we use , combined with pixel-wise reconstruction loss. We notice that using the loss combined with gets rid of checker-board artefacts on the generated image. We notice that Sobel aids noise reduction and enhances the image quality of the generated output.
VI-B Full model with feature losses and RSTL (VN2)
This section examines whether residual features from our recursive residual pooling unit has a positive effect on our model. The results in Table III demonstrate that residual refinement has a positive impact on the overall performance of our model. According to our findings, this improvement is attributable to the elimination of low-level information as a result of the pooling units being interconnected residually, which allows direct backpropagation of high-level information throughout the learning process.

| Performance Assessment | |||||
|---|---|---|---|---|---|
| Method | Losses | MAE | FID | PSNR | SSIM |
| (VN1) | VN1 | 37.81 | 3.91 | 35.54 | 0.92 |
| (VN2) | VN2 | 37.97 | 2.76 | 39.75 | 0.96 |
VI-C Quantitative evaluation of the standard protocol test set for facial images.
This protocol is designed to evaluate the performance on a set of mask and images. The mask ratios in the Masksets range from [0.01,0.6]. The different MaskDataset and ratios are: MaskDataset1 [0.1,0.6], MaskDataset2 [0.01,0.1], MaskDataset3 [0.1,0.3], MaskDataset4 [0.3,0.4], MaskDataset5 [0.5,0.6] and MaskDataset6 [0.1,0.4].
| Performance Assessment | |||||
|---|---|---|---|---|---|
| Dataset/Mask Ratio | Mask Type | MAE | FID | PSNR | SSIM |
| MaskDataset1 [0.01,0.6] | Irregular | 37.97 | 2.76 | 39.75 | 0.96 |
| MaskDataset2 [0.01,0.1] | Irregular | 21.35 | 3.36 | 39.04 | 0.94 |
| MaskDataset3 [0.1,0.3] | Irregular | 33.64 | 5.23 | 36.53 | 0.91 |
| MaskDataset4 [0.3,0.4] | Irregular | 64.15 | 12.06 | 33.72 | 0.89 |
| MaskDataset5 [0.5,0.6] | Irregular | 107.33 | 15.82 | 31.90 | 0.74 |
| MaskDataset6 [0.1,0.4] | Irregular | 25.75 | 4.19 | 37.7 | 0.93 |
The MaskDataset6 are selected irregular masks that are used as masking method for more than one image (i.e one mask to many). Each mask is evaluated on more than one image and the performance is different across the dataset. The overall results are shown in Table IV. The V-LinkNet has demonstrated overall best performance when presented with mask of various size ranges.
This study is conducted to identify biases for different masks on different images and propose a standard protocol that will propel research in image inpainting. The mask-to-area ratio was determined using OpenCV toolbox. Based on this study, we observed that the performance of an algorithm will very much depend on the mask type and the image type. There are some conditions on a facial image that can influence the performance such as pose, lighting, features and background. In the case of CelebA-HQ dataset, we observed that if the mask is on the skin region, the performance evaluation has better scores compared to when the mask is on the a difficult background with variations in lighting conditions. Furthermore, the mask applied to a face posed at an angle will influence the results as shown in Figure 1 second row, second set of images. Based on this finding, we proposed standardised test sets to support a fairer comparison in future research.
VII Conclusion
We proposed V-LinkNet, a novel image inpainting technique that uses two encoders to learn from each other, which advanced the field by outperformed previous methods. To tackle the irregular-holes inpainting problem, we presented a dual-encoder method that exploits semantic coherency across textural features through enforced collaboration. For each spatial location, each convolutional layer expects a certainty. V-LinkNet handles high-level feature propagation as a learned operation within a residual unit designed with maxpooling units and a residual convolution unit to create the full layer. The proposed solution is simple and efficient, and it acts as a bridge to the decoder.
We presented a RSTL that serves as a propagation module to optimise the projected textures from features of both encoders in a morphological manner. This module provides consistency and coherency by combining two features into one. The V-LinkNet model can propagate high-level features to the decoder using this unit. To validate its efficacy, we conducted an ablation study with various model components. The unmodified RSTL combined with the feature losses loss is found to be the best model combination. We contend that the combined recursive residual unit, which is linked to residual pooling and residual convolution, enables direct backpropagation within the bottleneck’s deeper layers. This forces the selection of high-level information during decoder layer propagation, resulting in high quality reconstruction of inpainted regions.
From the results, we observed that the model achieves learning of high-level features with propagation to decoding layers. Furthermore, the feature-wise loss model shared by both encoders aids the model during early learning, resulting in a better learning strategy shared by both encoders. The losses and Wasserstein discriminators improve the semantic consistency of our model, which ensures fine contextual information. Our approach successfully generate quality semantic structural and textural features that match the ground-truth image. Our research provides new insights on the need of a standard protocol, where we shared this protocol as a recommendation for performance evaluation.
Acknowledgment
This work was supported by The Royal Society UK (INF \PHD \180007 and IF160006). We gratefully acknowledge the support of NVIDIA Corporation with the donation of the Quadro P6000 used for this research.
References
- [1] A. A. Efros and T. K. Leung, “Texture synthesis by non-parametric sampling,” in iccv. IEEE, 1999, p. 1033.
- [2] M. Bertalmio, G. Sapiro, V. Caselles, and C. Ballester, “Image inpainting,” in Proceedings of the 27th annual conference on Computer graphics and interactive techniques. ACM Press/Addison-Wesley Publishing Co., 2000, pp. 417–424.
- [3] C. Barnes, E. Shechtman, A. Finkelstein, and D. B. Goldman, “Patchmatch: A randomized correspondence algorithm for structural image editing,” ACM Trans. Graph., vol. 28, no. 3, p. 24, 2009.
- [4] Z. Wan, B. Zhang, D. Chen, P. Zhang, D. Chen, J. Liao, and F. Wen, “Bringing old photos back to life,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2747–2757.
- [5] Y. Jo and J. Park, “Sc-fegan: Face editing generative adversarial network with user’s sketch and color,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1745–1753.
- [6] M. H. Yap, N. Batool, C.-C. Ng, M. Rogers, and K. Walker, “A survey on facial wrinkles detection and inpainting: Datasets, methods, and challenges,” IEEE Transactions on Emerging Topics in Computational Intelligence, vol. 5, no. 4, pp. 505–519, 2021.
- [7] X. Zhan, X. Pan, B. Dai, Z. Liu, D. Lin, and C. C. Loy, “Self-supervised scene de-occlusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 3784–3792.
- [8] O. Elharrouss, N. Almaadeed, S. Al-Maadeed, and Y. Akbari, “Image inpainting: A review,” Neural Processing Letters, pp. 1–22, 2019.
- [9] J. Jam, C. Kendrick, K. Walker, V. Drouard, J. G.-S. Hsu, and M. H. Yap, “A comprehensive review of past and present image inpainting methods,” Computer Vision and Image Understanding, p. 103147, 2020.
- [10] D. Pathak, P. Krahenbuhl, J. Donahue, T. Darrell, and A. A. Efros, “Context encoders: Feature learning by inpainting,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2536–2544.
- [11] S. Iizuka, E. Simo-Serra, and H. Ishikawa, “Globally and locally consistent image completion,” ACM Transactions on Graphics (TOG), vol. 36, no. 4, p. 107, 2017.
- [12] G. Liu, F. A. Reda, K. J. Shih, T.-C. Wang, A. Tao, and B. Catanzaro, “Image inpainting for irregular holes using partial convolutions,” arXiv preprint arXiv:1804.07723, 2018.
- [13] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Generative image inpainting with contextual attention,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 5505–5514.
- [14] J. Li, F. He, L. Zhang, B. Du, and D. Tao, “Progressive reconstruction of visual structure for image inpainting,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 5962–5971.
- [15] H. Liu, B. Jiang, Y. Xiao, and C. Yang, “Coherent semantic attention for image inpainting,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 4170–4179.
- [16] C. Zheng, T.-J. Cham, and J. Cai, “Pluralistic image completion,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2019, pp. 1438–1447.
- [17] L. Zhao, Q. Mo, S. Lin, Z. Wang, Z. Zuo, H. Chen, W. Xing, and D. Lu, “Uctgan: Diverse image inpainting based on unsupervised cross-space translation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 5741–5750.
- [18] J. Jam, C. Kendrick, V. Drouard, K. Walker, G.-S. Hsu, and M. H. Yap, “Symmetric skip connection wasserstein gan for high-resolution facial image inpainting,” arXiv preprint arXiv:2001.03725, 2020.
- [19] ——, “R-mnet: A perceptual adversarial network for image inpainting,” arXiv preprint arXiv:2008.04621, 2020.
- [20] J. Jam, C. Kendrick, V. Drouard, K. Walker, and M. H. Yap, “Foreground-guided facial inpainting with fidelity preservation,” arXiv preprint arXiv:2105.03342, 2021.
- [21] Y. Wang, X. Tao, X. Qi, X. Shen, and J. Jia, “Image inpainting via generative multi-column convolutional neural networks,” in Advances in neural information processing systems, 2018, pp. 331–340.
- [22] J. Xiao, L. Liao, Q. Liu, and R. Hu, “Cisi-net: Explicit latent content inference and imitated style rendering for image inpainting,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, 2019, pp. 354–362.
- [23] M. Chen, C. Li, K. Li, H. Zhang, and X. He, “Double encoder conditional gan for facial expression synthesis,” in 2018 37th Chinese Control Conference (CCC). IEEE, 2018, pp. 9286–9291.
- [24] P. Chakravarty, P. Narayanan, and T. Roussel, “Gen-slam: Generative modeling for monocular simultaneous localization and mapping,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 147–153.
- [25] Y. Chen, G. Wu, J. Zhou, and G. Qi, “Image generation via latent space learning using improved combination,” Neurocomputing, vol. 340, pp. 8–18, 2019.
- [26] Y. Zeng, J. Fu, H. Chao, and B. Guo, “Learning pyramid-context encoder network for high-quality image inpainting,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2019, pp. 1486–1494.
- [27] C. Xie, S. Liu, C. Li, M.-M. Cheng, W. Zuo, X. Liu, S. Wen, and E. Ding, “Image inpainting with learnable bidirectional attention maps,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 8858–8867.
- [28] H. Liu, B. Jiang, Y. Song, W. Huang, and C. Yang, “Rethinking image inpainting via a mutual encoder-decoder with feature equalizations,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16. Springer, 2020, pp. 725–741.
- [29] Y. Yang, Z. Cheng, H. Yu, Y. Zhang, X. Cheng, Z. Zhang, and G. Xie, “Mse-net: generative image inpainting with multi-scale encoder,” The Visual Computer, pp. 1–13, 2021.
- [30] Y. Lu, S. Wu, Y.-W. Tai, and C.-K. Tang, “Image generation from sketch constraint using contextual gan,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 205–220.
- [31] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang, “Free-form image inpainting with gated convolution,” in Proceedings of the IEEE International Conference on Computer Vision, 2019, pp. 4471–4480.
- [32] Y. Song, C. Yang, Y. Shen, P. Wang, Q. Huang, and C.-C. J. Kuo, “Spg-net: Segmentation prediction and guidance network for image inpainting,” arXiv preprint arXiv:1805.03356, 2018.
- [33] Y. Song, C. Yang, Z. Lin, X. Liu, Q. Huang, H. Li, and C.-C. J. Kuo, “Contextual-based image inpainting: Infer, match, and translate,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 3–19.
- [34] N. Wang, S. Ma, J. Li, Y. Zhang, and L. Zhang, “Multistage attention network for image inpainting,” Pattern Recognition, p. 107448, 2020.
- [35] Z. Yan, X. Li, M. Li, W. Zuo, and S. Shan, “Shift-net: Image inpainting via deep feature rearrangement,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 1–17.
- [36] N. Wang, J. Li, L. Zhang, and B. Du, “Musical: Multi-scale image contextual attention learning for inpainting.” in IJCAI, 2019, pp. 3748–3754.
- [37] H. Zhou, Z. Liu, X. Xu, P. Luo, and X. Wang, “Vision-infused deep audio inpainting,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 283–292.
- [38] Y. Yang, X. Guo, J. Ma, L. Ma, and H. Ling, “Lafin: Generative landmark guided face inpainting,” arXiv preprint arXiv:1911.11394, 2019.
- [39] H. Li and J. Huang, “Localization of deep inpainting using high-pass fully convolutional network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8301–8310.
- [40] G. Lin, A. Milan, C. Shen, and I. Reid, “Refinenet: Multi-path refinement networks for high-resolution semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 1925–1934.
- [41] Y. Zeng, J. Fu, H. Chao, and B. Guo, “Aggregated contextual transformations for high-resolution image inpainting,” arXiv preprint arXiv:2104.01431, 2021.
- [42] Y. Zhang and T. Funkhouser, “Deep depth completion of a single rgb-d image,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 175–185.
- [43] Y.-K. Huang, T.-H. Wu, Y.-C. Liu, and W. H. Hsu, “Indoor depth completion with boundary consistency and self-attention,” in Proceedings of the IEEE International Conference on Computer Vision Workshops, 2019, pp. 0–0.
- [44] R. Achanta and S. Süsstrunk, “Saliency detection for content-aware image resizing,” in 2009 16th IEEE international conference on image processing (ICIP). IEEE, 2009, pp. 1005–1008.
- [45] Q. Wu, G. Xu, Y. Cheng, W. Dong, L. Ma, and Z. Li, “Histogram of maximal point-edge orientation for multi-source image matching,” International Journal of Remote Sensing, vol. 41, no. 14, pp. 5166–5185, 2020.
- [46] E. A. Sekehravani, E. Babulak, and M. Masoodi, “Implementing canny edge detection algorithm for noisy image,” Bulletin of Electrical Engineering and Informatics, vol. 9, no. 4, pp. 1404–1410, 2020.
- [47] S. Xie and Z. Tu, “Holistically-nested edge detection,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 1395–1403.
- [48] A. Criminisi, P. Pérez, and K. Toyama, “Region filling and object removal by exemplar-based image inpainting,” IEEE Transactions on image processing, vol. 13, no. 9, pp. 1200–1212, 2004.
- [49] H. V. Vo, N. Q. Duong, and P. Perez, “Structural inpainting,” arXiv preprint arXiv:1803.10348, 2018.
- [50] M. Sadowski and A. Grzegorczyk, “Image inpainting with gradient attention,” Schedae Informaticae, vol. 27, 2018.
- [51] N. Kanopoulos, N. Vasanthavada, and R. L. Baker, “Design of an image edge detection filter using the sobel operator,” IEEE Journal of solid-state circuits, vol. 23, no. 2, pp. 358–367, 1988.
- [52] J. Zhang, L. Niu, D. Yang, L. Kang, Y. Li, W. Zhao, and L. Zhang, “Gain: Gradient augmented inpainting network for irregular holes,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1870–1878.
- [53] C. Yang, X. Lu, Z. Lin, E. Shechtman, O. Wang, and H. Li, “High-resolution image inpainting using multi-scale neural patch synthesis,” in The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, 2017, p. 3.
- [54] C. Lu and G. Dubbelman, “Semantic foreground inpainting from weak supervision,” IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 1334–1341, 2020.
- [55] Z. Yi, Q. Tang, S. Azizi, D. Jang, and Z. Xu, “Contextual residual aggregation for ultra high-resolution image inpainting,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 7508–7517.
- [56] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [57] D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” arXiv preprint arXiv:1412.6980, 2014.
- [58] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” in International Conference on Learning Representations, 2018.
- [59] Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of the IEEE international conference on computer vision, 2015, pp. 3730–3738.
- [60] C. Doersch, S. Singh, A. Gupta, J. Sivic, and A. Efros, “What makes paris look like paris?” ACM Transactions on Graphics, vol. 31, no. 4, 2012.
- [61] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2018.
- [62] K. Iskakov, “Semi-parametric image inpainting,” arXiv preprint arXiv:1807.02855, 2018.
- [63] B. Zhou, A. Lapedriza, A. Khosla, A. Oliva, and A. Torralba, “Places: A 10 million image database for scene recognition,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 6, pp. 1452–1464, 2017.
- [64] T. Karras, T. Aila, S. Laine, and J. Lehtinen, “Progressive growing of gans for improved quality, stability, and variation,” arXiv preprint arXiv:1710.10196, 2017.