Value-Function-based Sequential Minimization for Bi-level Optimization
Abstract
Gradient-based Bi-Level Optimization (BLO) methods have been widely applied to handle modern learning tasks. However, most existing strategies are theoretically designed based on restrictive assumptions (e.g., convexity of the lower-level sub-problem), and computationally not applicable for high-dimensional tasks. Moreover, there are almost no gradient-based methods able to solve BLO in those challenging scenarios, such as BLO with functional constraints and pessimistic BLO. In this work, by reformulating BLO into approximated single-level problems, we provide a new algorithm, named Bi-level Value-Function-based Sequential Minimization (BVFSM), to address the above issues. Specifically, BVFSM constructs a series of value-function-based approximations, and thus avoids repeated calculations of recurrent gradient and Hessian inverse required by existing approaches, time-consuming especially for high-dimensional tasks. We also extend BVFSM to address BLO with additional functional constraints. More importantly, BVFSM can be used for the challenging pessimistic BLO, which has never been properly solved before. In theory, we prove the asymptotic convergence of BVFSM on these types of BLO, in which the restrictive lower-level convexity assumption is discarded. To our best knowledge, this is the first gradient-based algorithm that can solve different kinds of BLO (e.g., optimistic, pessimistic, and with constraints) with solid convergence guarantees. Extensive experiments verify the theoretical investigations and demonstrate our superiority on various real-world applications.
Index Terms:
Bi-level optimization, gradient-based method, value-function, sequential minimization, hyper-parameter optimization.1 Introduction
Currently, a number of important machine learning and deep learning tasks can be captured by hierarchical models, such as hyper-parameter optimization [1, 2, 3, 4], neural architecture search [5, 6, 7], meta learning [8, 9, 10], Generative Adversarial Networks (GAN) [11, 12], reinforcement learning [13], image processing [14, 15, 16, 17], and so on. In general, these hierarchical models can be formulated as the following Bi-Level Optimization (BLO) problem [18, 19, 20]:
| (1) |
where is the Upper-Level (UL) variable, is the Lower-Level (LL) variable, the UL objective and the LL objective , are continuously differentiable and jointly continuous functions, and the UL constraint is a compact set. Nevertheless, the model in Eq. (1) cannot be solved directly. Some existing works only consider the case that the LL solution set is a singleton. However, since this may not be satisfied and may not be unique, Eq. (1) is not a rigorous BLO model in mathematics, and thus we use the quotation marks around “min” to denote the slightly imprecise definition of the UL objective [18, 21].
Strictly, people usually focus on an extreme situation of the BLO model, i.e., the optimistic BLO [18]:
| (2) |
It can be found from the above expression that in optimistic BLO, and are in a cooperative relationship, aiming to minimize at the same time. Therefore, it can be applied to a variety of learning and vision tasks, such as hyper-parameter optimization, meta learning, and so on. Sometimes we also need to study BLO problems with inequality constraints on the UL or LL for capturing constraints in real tasks. Another situation one can consider is the pessimistic BLO, which changes the in Eq. (2) into [18]. In the pessimistic case, and are in an adversarial relationship, and hence solving pessimistic BLO can be applied to adversarial learning and GAN.
Actually, BLO is challenging to solve, because in the hierarchical structure, we need to solve governed by the fixed , and select an appropriate from to optimize the UL , making and intricately dependent of each other, especially when is not a singleton [22]. In classical optimization, KKT condition is utilized to characterize the problem, but this method is not applicable to machine learning tasks of large scale due to the use of too many multipliers [23, 24]. In the machine learning community, a class of mainstream and popular methods are gradient-based methods, divided into Explicit Gradient-Based Methods (EGBMs) [2, 8, 25, 26, 5] and Implicit Gradient-Based Methods (IGBMs) [27, 9, 28], according to divergent ideas of calculating the gradient needed for implementing gradient descent. EGBMs implement this process via unrolled differentiation, and IGBMs use the implicit function theorem to obtain the gradient. Both of them usually deal with the problem where the LL solution set is a singleton, which is a quite restrictive condition in real application tasks. In dealing with this, Liu et al. [29, 30] proposed Bi-level Descent Aggregation (BDA) as a new EGBM, which removes this assumption and solves the model from the perspective of optimistic BLO.
Nevertheless, there still exists a bottleneck hard to break through, that the LL problems in real learning tasks are usually too complex for EGBMs and IGBMs. In theory, all of the EGBMs and IGBMs require the convexity of the LL problem, or the Lower-Level Convexity, denoted as LLC for short, which is a strong condition and not satisfied in many complicated real-world tasks. For example, since the layer of chosen network is usually greater than one, LLC is not satisfied, so the convergence of these methods cannot be guaranteed. In computation, additionally, EGBMs using unrolled differentiation request large time and space complexity, while IGBMs need to approximate the inverse of a matrix, also with high computational cost, especially when the LL variable is of large scale, which means the dimension of is large, generating matrices and vectors of high dimension during the calculating procedure. Furthermore, it has been rarely discussed how to handle machine learning tasks by solving an optimization problem with functional constraints on the UL and LL, or by solving a pessimistic BLO. However, these problems are worth discussing, because pessimistic BLO can be used to capture min-max bi-level structures, which is suitable for GAN and so on, and optimization problems with constraints can be used to represent learning tasks more accurately. Unfortunately, existing methods including EGBMs and IGBMs, are not able to handle these problems.
To address the above limitations of existing methods, in this work, we propose a novel framework, named Bi-level Value-Function-based Sequential Minimization (BVFSM) 111A preliminary version of this work has been published in [1].. To be specific, we start with reformulating BLO into a simple bi-level optimization problem by the value-function [31, 32] of UL objective. After that, we further transform it into a single-level optimization problem with an inequality constraint through the value-function of LL objective. Then, by using the smoothing technique via regularization and adding the constraint into the objective by an auxiliary function of penalty or barrier, eventually the original problem can be transformed into a sequence of unconstrained differentiable single-level problems, which can be solved by gradient descent. Thanks to the re-characterization via the value-function of LL problem, our computational cost is the least to implement the algorithm, and simultaneously, BVFSM can be applied under more relaxed conditions.
Specifically, BVFSM avoids solving an unrolled dynamic system by recurrent gradient or approximating the inverse of Hessian during each iteration like existing methods. Instead, we only need to calculate the first-order gradient in each iteration, reduces the computational complexity relative to the LL problem size by an order of magnitude compared to existing gradient-based BLO methods, and thus require less time and space complexity than EGBMs and IGBMs, especially for complex high-dimensional BLO. Besides, BVFSM enables to maintain the level of complexity when applying BLO to networks, thereby making it possible to use BLO in existing networks and expanding its range of applications significantly. We illustrate the efficiency of BVFSM over existing methods through complexity analysis in theory and various experimental results in reality. In addition, we consider the asymptotic convergence different from some previous gradient-based methods inspired from the perspective of sequential minimization, and prove that the solutions to the sequence of approximate sub-problems converge to the true solution of the original BLO without the restrictive LLC assumption as before. Also, BVFSM can be extended to more complicated and challenging scenarios, namely, BLO with functional constraints and pessimistic BLO problems. We regard pessimistic BLO as a new viewpoint to deal with learning tasks, which has not been solved by gradient-based methods before to our best knowledge. Specially, we use the experiment of GAN as an example to illustrate the application of our method for solving pessimistic BLO. We summarize our contributions as follows.
-
•
By reformulating the original BLO as an approximated single-level problem based on the value-function, BVFSM breaks the traditional mindset in gradient-based methods, and establishes a competently new sequential minimization algorithmic framework, which not only can be used to address optimistic BLO, but also has the ability to handle BLO in other more challenging scenarios (i.e., with functional constraints and pessimistic), which have seldom been discussed.
-
•
BVFSM significantly reduces the computational complexity by an order of magnitude compared to existing gradient-based BLO methods with the help of value-function-based reformulation which breaks the traditional mindset. Also, BVFSM avoids the repeated calculation of recurrent gradients and Hessian inverse, which are the core bottleneck for solving high-dimensional BLO problems in existing approaches. The superiority allows BVFSM to be applied to large-scale networks and frontier tasks effectively.
-
•
We rigorously analyze the asymptotic convergence behaviors of BVFSM on all types of BLO mentioned above. Our theoretical investigations successfully remove the restrictive LLC condition, required in most existing works but actually too ambitious to satisfy in real-world applications.
-
•
In terms of experiments, we conduct extensive experiments to verify our theoretical findings and demonstrate the superiority of BVFSM on various learning tasks. Especially, by formulating and solving GAN by BVFSM, we also show the application potential of our solution strategy on pessimistic BLO for complex learning problems.
2 Related Works
As aforementioned, BLO is challenging to solve due to its nested structures between UL and LL. Early methods can only handle models with not too many hyper-parameters. For example, to find appropriate parameters, the standard method is to use random search [33] through randomly sampling, or to use Bayesian optimization [34]. However, in real learning tasks, the dimension of hyper-parameters is very large, which early methods cannot deal with, so gradient-based methods are proposed. Here we first put forward a unified form of gradient-based methods, and then discuss the existing methods for further comparing them with our proposed method.
Existing gradient-based methods mainly focus on the optimistic BLO only, so we use the optimistic scenario to illustrate our algorithmic framework clearly, while in Section 3.4, we will discuss how to use our method to solve pessimistic BLO. For optimistic BLO, it can be found from Eq. (2) that the UL variable and LL variable will effect each other in a nested relationship. To address this issue, one can transform it into the following form, where is the value-function of the sub-problem,
| (3) |
For a fixed , this sub-problem for solving is an inner simple BLO task, as it is only about one variable , with as a parameter. Then, we hope to minimize through gradient descent. However, as a value-function, is non-smooth, non-convex, even with jumps, and thus ill-conditioned, so we use a smooth function to approximate and approach . Existing methods can be classified into two categories according to divergent ways to calculate [20], i.e., Explicit Gradient-Based Methods (EGBMs), which derives the gradient by Automatic Differentiation (AD), and Implicit Gradient-Based Methods (IGBMs), which apply implicit function theorem to deal with the optimality conditions of LL problems.
Note that both EGBMs and IGBMs require to be unique (except BDA), denoted as , while for BDA, by integrating information from both the UL and LL sub-problem, is obtained by iterations to approach the appropriate . Hence, , and therefore by the chain rule, the approximated is split into direct and indirect gradients of ,
| (4) |
where is the direct gradient and is the indirect gradient, . Then we need to compute , in other words, the value of .
Explicit Gradient-Based Methods (EGBMs). Maclaurin et al. [25] and Franceschi et al. [2, 8] first proposed Reverse Hyper-Gradient (RHG) and Forward Hyper-Gradient (FHG) respectively, to implement a dynamic system, under the LLC assumption. Given an initial point , denote the iteration process to approach as where is a smooth mapping performed to solve and is the number of iterations. In particular, for example, if the process is gradient descent, where is the corresponding step size. Then in Eq. (3) can be approximated by . As increases, approaches generally, and a sequence of unconstrained minimization problems is obtained. Thus, gradient-based methods can be regarded as a kind of sequential-minimization-type scheme [35]. From the chain rule, we have and can be obtained from this unrolled procedure. However, FHG and RHG require calculating the gradient of composed of the first-order condition of LL problem by AD during the entire trajectory, so the computational cost owing to the time and space complexity is very high. In dealing with this, Shaban et al. [26] proposed Truncated Reverse Hyper-Gradient (TRHG) to truncate the iteration, and thus TRHG only needs to store the last iterations, reducing the computational load. Nevertheless, it additionally requires to be strongly convex, and the truncated path length is hard to determine. Another method Liu et al. [5] tried is to use the difference of vectors to approximate the gradient, but the accuracy of using the difference is not promised and there is no theoretical guarantee for this method. On the other hand, from the viewpoint of theory, for more relaxed conditions, Liu et al. [29, 30] proposed Bi-level Descent Aggregation (BDA) to remove the assumption that the LL solution set is a singleton, which is a simplification of real-world problems. Specifically, BDA uses information from both the UL and the LL problem as an aggregation during iterations. However, the obstacle of LLC and computational cost still exists.
Implicit Gradient-Based Methods (IGBMs). IGBMs or implicit differentiation [27, 9, 28], can be applied to obtain under the LLC assumption. If is assumed to be invertible in advance as an additional condition, by using the implicit function theorem on the optimality condition , the LL problem is replaced with an implicit equation, and then Unlike EGBMs relying on the first-order condition during the entire trajectory, IGBMs only depends on the first-order condition once, which decouples the computational burden from the solution trajectory of the LL problem, but this leads to repeated computation of the inverse of Hessian matrix, which is still a heavy burden. In dealing with this, to avoid direct inverse calculation, the Conjugate Gradient (CG) method [27, 9] changes it into solving a linear system, and Neumann method [28] uses the Neumann series to calculate the Hessian inverse. However, after using these methods, the computational requirements are reduced but still large, because the burden of computing the inverse of matrix changes into computing Hessian-vector products. Additionally, the accuracy of solving a linear system highly depends on its condition number [36], and the ill condition may result in numerical instabilities. A large quadratic term is added on the LL objective to eliminate the ill-condition in [9], but this approach may change the solution set greatly.
As discussed above, EGBMs and IGBMs need repeated calculations of recurrent gradient or Hessian inverse, leading to high time and space complexity in numerical computation, and require the LLC assumption in theory. Actually, when the dimension of is very large, which happens in practical problems usually, the computational burden of massively computing the products of matrices and vectors might be too heavy to carry. In addition, the LLC assumption is also not suitable for most complex real-world tasks.
3 The Proposed Algorithm
In this section, we illustrate our algorithmic framework, named Bi-level Value-Function-based Sequential Minimization (BVFSM). Our method also follows the idea of constructing a sequence of unconstrained minimization problems to approximate the original bi-level problem, but different from existing methods, BVFSM uses the re-characterization via the value-function of the LL problem. Thanks to this strategy, our algorithm is able to handle problems with complicated non-convex high-dimensional LL, which existing methods are not able to deal with.
3.1 Value-Function-based Single-level Reformulation
BVFSM designs a sequence of single-level unconstrained minimization problems to approximate the original problem through a value-function-based reformulation. We first present this procedure under the optimistic BLO case.
Recall the original optimistic BLO in Eq. (2) has been transformed into Eq. (3), and we hope to compute in Eq. (4). Note that the difficulty of computing comes from the ill-condition of , owing to the nested structure of the bi-level sub-problem for solving . Hence, we introduce the value-function of the LL problem to transform it into a single-level problem. Then the problem can be reformulated as
| (5) |
However, the inequality constraint is still ill-posed, because it does not satisfy any standard regularity condition and is non-smooth. In dealing with such difficulty, we approximate with regularization:
| (6) |
where () is the regularization term.
We further add an auxiliary function of the inequality constraints to the objective, and obtain
| (7) |
where , is the regularization term, and (where ) is the selected auxiliary function for the sequential unconstrained minimization method with parameter , which will be defined in Eq. (8) and discussed in detail next. This reformulation changes the constrained problem Eq. (5) into a sequence of unconstrained problems Eq. (7) under different parameters. The regularization terms in Eq. 6 and Eq. 7 are to guarantee the uniqueness of solution to these two problems, which is essential for the differentiability of , and will be discussed in Remark 1 of Section 3.2. Experiments in Section 5.1.1 also demonstrate that introducing the regularization terms for differentiability to avoid possible jumps matters to improve the computational stability.
The sequential unconstrained minimization method is mainly used for solving constrained nonlinear programming by changing the problem into a sequence of unconstrained minimization problems [35, 37, 38]. To be specific, we add to the objective a selected auxiliary function of the constraints with a sequence of parameters, and obtain a series of unconstrained problems. The convergence of parameters makes the sequential unconstrained problems converge to the original constrained problem, leading to the convergence of the solution. Based on the property of auxiliary functions, they are divided mainly into two types, barrier functions and penalty functions [39, 40], whose definitions are provided here.
Definition 1
A continuous, differentiable, and non-decreasing function is called a standard barrier function if satisfies and , when ; and when . It is called a standard penalty function if it satisfies when ; and and when . Here is the barrier or penalty parameter. In addition, if is a standard barrier function, then is called a modified barrier function .
For the simplicity of expression later, we denote the function in Eq. (7) to be
| (8) |
Here for a modified barrier function, is to guarantee that in Eq. (7), , and the barrier function is well-defined.
Classical examples of auxiliary functions are the quadratic penalty function, inverse barrier function and log barrier function [41, 40]. There are also some other popular examples, such as the polynomial penalty function [39] and truncated log barrier function [42]. These examples of standard penalty and barrier functions are listed in Table I. Note that we need the smoothness of , and will calculate the gradient of afterwards, so we choose smooth auxiliary functions rather than non-smooth exact penalty functions. Note that when is a modified barrier function, of in Eq. (8) has two components and , and the specific form of comes from substituting and for and in Table I.
| Penalty functions | |
|---|---|
| Quadratic | , where |
| Polynomial | , where is a positive integer |
| chosen such that is differentiable | |
| Barrier functions | |
| Inverse | |
| Truncated Log | |
| where , are chosen | |
| such that and is twice differentiable | |
3.2 Sequential Minimization Strategy
From the discussion above, we then hope to solve
| (9) |
with in Eq. (7). First denote
| (10) |
| (11) |
The following proposition gives the smoothness of and the formula for computing or , which serves as the ground for our algorithm.
Proposition 1 (Calculation of )
Suppose and are bounded below and continuously differentiable. Given and , when and are unique, then is differentiable and
| (12) |
where and
Proof.
We first prove that for any , is level-bounded in locally uniformly in (see [29, Definition 3]). That means for any , there exist and a bounded set , such that for all , where denotes the open ball with center at and radius , i.e., . Assume by contradiction that the above does not hold. Then there exist sequences and satisfying and , such that As is bounded below, then implies , which contradicts with and .
Hence, from the arbitrariness of , we have is level-bounded in locally uniformly in , and then the inf-compactness condition in [43, Theorem 4.13] holds for . Since is a singleton, it follows from [43, Theorem 4.13, Remark 4.14] that
Next, from definitions of penalty and barrier functions (Definition 1), we have for any , so holds. Then, since is assumed to be bounded below, similar to , the inf-compactness condition in [43, Theorem 4.13] also holds for . Combining with the fact that
is a singleton, [43, Theorem 4.13, Remark 4.14] shows that
Therefore, the conclusion in Eq. (12) follows immediately. ∎
Remark 1
In Proposition 1 we require the uniqueness of and to guarantee the differentiability of . This can be achieved by conditions much weaker than convexity, such as the convexity only on a level set. We start with the uniqueness of . For any given , consider a function satisfying that there exists a constant such that is convex in on the level set . Suppose is a minimum of . Then for a sufficiently small . Thus, locates inside the level set on which is convex. Hence, is strictly convex on , and the uniqueness of follows.
As for the uniqueness of , suppose given , there exist constants and such that and are convex in on the set . If we select a non-decreasing and convex auxiliary function (such as those in Table I), then is convex in on the set (see [44] Proposition 1.54). Or simply if there exists such that is convex on the set , then it derives the strict convexity of in on the set similarly, and the uniqueness of follows.
Proposition 1 serves as the foundation for our algorithmic framework. Denote . Next, we will illustrate the implementation at the -th step of the outer loop and the -th step of the inner loop, that is, to calculate , as a guide.
We first calculate in Eq. (10) through steps of gradient descent, and denote the output as , regarded as an approximation of . After that, we calculate in Eq. (11) through steps of gradient descent, and denote the output as . Note that if the objective function is convex, running some number of steps of the method would lead to an approximation of the minimizer. Meanwhile, the convexity of objective functions for approximating and can be guaranteed if and are convex in as discussed in Remark 1. Also, if the objective function is not convex but all of its stationary points are minimizers, which is a weaker condition than convexity, gradient descent would still help to converge to minimizers.
Then, according to Proposition 1, we can obtain
| (13) |
with where As a summary, the algorithm for solving Eq. (9) is shown in Algorithms 1 and 2.
3.3 Extension for BLO with Functional Constraints
We consider the BLO with functional constraints on UL and LL problems in this subsection, which is a more general setting, and the above discussion without constraints can be extended to the case with inequality constraints.
The optimistic BLO problems in Eq. (2) with functional constraints are then
where the UL constraints and the LL constraints are continuously differentiable functions. This is equivalent to where , the value-function of the sub-problem in Eq. (3), is adapted correspondingly to be
Also, the counterpart for value-function of the LL problem is , and following the technique within Eq. (5) to transform the LL problem into an inequality constraint, the problem can be reformulated as
| (14) | ||||
After that, using the same idea of sequential minimization method, inspired by the regularized smoothing method in [45], the value-function can be approximated with a barrier function (different from Eq. (6) due to the LL constraints) and a regularization term:
where is the selected standard barrier function for the LL constraint as defined in Eq. (8), with as the barrier parameter. Note that here we define as a standard barrier function but not a modified barrier function. As for the approximation of , Eq. (7) is transferred into where are the selected auxiliary functions of penalty or modified barrier with parameters , and , and .
Then corresponding to Eq. (10) and Eq. (11), by denoting
we have the next proposition, which follows the same idea from Proposition 1.
Proposition 2
Suppose and are bounded below and continuously differentiable. Given and , when and are unique, then is differentiable and where
The proof is similar to Proposition 1, obtained by applying [43, Theorem 4.13, Remark 4.14]. The algorithm is then based on Proposition 2 and similar to Algorithm 1 and 2. Note that in Section 4.1, our convergence analysis is carried out under this constrained setting, because problems without constraints can be regarded as its special case.
Remark 2
In terms of the uniqueness of and , if we select convex auxiliary functions , , , , and suppose and in the constraints are convex in the level set, then the uniqueness follows similarly as in Remark 1.
3.4 Extension for Pessimistic BLO
In this part, we consider the pessimistic BLO, which has been rarely discussed for handling learning tasks to our best knowledge. For brevity, we focus on problems without constraints on UL and LL, and this can be extended to the case with constraints easily. As what we have discussed about pessimistic BLO at the very beginning, its form is
| (15) |
Similar to the optimistic case, this problem can be transformed into where the value-function in Eq. (3) is redefined as Considering the value-function , we have the same regularized to the optimistic case in Eq. (6). As for the approximation of , thanks to the value-function-based sequential minimization, different from Eq. (7), we have
where is defined in Eq. (8). Same as before, our goal is to solve
Denote to be the same as in Eq. (10), and Eq. (11) is changed into
Then Proposition 1 in the optimistic case is changed into the following in the pessimistic case.
Proposition 3
Suppose and are bounded below and continuously differentiable. Given and , when and are unique, then is differentiable and
with where and
The proof is similar to Proposition 1, obtained by applying [43, Theorem 4.13, Remark 4.14]. The algorithm in the pessimistic case can then be derived similar to the optimistic case, but when calculating , gradient ascent is performed instead of gradient descent. In addition, the convergence of BVFSM for pessimistic BLO will be discussed in detail in Section 4.1.
Remark 3
The uniqueness of can be guaranteed same to the analysis in Remark 1. Similarly, suppose given , there exist constants and such that is concave and is convex in on the set , and we select a non-decreasing and convex auxiliary function . Or simply suppose there exists such that is concave on the set . Then the uniqueness of follows.
4 Theoretical Analysis
This section brings out the convergence analysis and complexity analysis of the proposed BVFSM.
4.1 Convergence Analysis
Here we show the convergence analysis of the proposed method. As BLO without constraints can be seen as a special case of BLO with constraints by regarding constraints as and , we prove the more general constrained case. Also, for brevity, we first prove in the optimistic BLO case, and the pessimistic case will be analyzed later in Corollary 1.
Note that for sequential-minimization-type scheme, including EGBMs and BVFSM, the convergence analysis can be classified into asymptotic and non-asymptotic convergence [46, 47]. This work considers asymptotic convergence and focuses on the approximation quality. That is, whether the solutions to approximate problems converge to the original solution, which comes from the sequential approximated sub-problems converging to the original bi-level problem. We prove the asymptotic convergence from the aspect of global solution, and start by recalling the equivalent definition of epiconvergence given in [43, pp. 41].
Definition 2
if and only if for all , the following two conditions hold:
-
(1)
for any sequence converging to ,
(16) -
(2)
there is a sequence converging to such that
(17)
The convergence results are given under the following statements as our blanket assumption.
Assumption 1 (Assumptions for the problem)
-
(1)
is nonempty for .
-
(2)
Both and are jointly continuous and continuously differentiable. Both , and , are continuously differentiable.
-
(3)
is level-bounded in locally uniformly in (see [29, Definition 3]).
-
(4)
For constrained BLO, is not a local optimal value of w.r.t. for all .
For the simplicity of symbols, here we let , meaning that there is one constraint on the UL and LL problem respectively, and denote them as and . When or , the proofs parallel actually. In addition, denote , , and defined in Eq. (8). Also, are defined similarly. Note that is the standard barrier function, while , , are penalty or modified barrier functions. Then
To begin with, we present the following lemma on the properties of penalty and modified barrier functions, as the preparation for further discussion and proofs222Proofs of the four lemmas are provided in Appendix A, available at https://arxiv.org/abs/2110.04974..
Lemma 1
Let in be a positive sequence such that . Additionally assume that when is a modified barrier function. Then we have
-
(1)
is continuous, differentiable and non-decreasing, and satisfies .
-
(2)
For any , .
-
(3)
For any sequence , implies that .
We will use these properties in later proofs, so we hold these requirements on parameters in Lemma 1 from now on. To prove the convergence result, we verify the two conditions given in Definition 2, and show that , where denotes the indicator function of the set , i.e., if and if . To begin with, we propose the following three lemmas to verify the two condition in Eq. (16) and Eq. (17) in Definition 2.
Lemma 2
Let be a positive sequence such that , also satisfying the same setting as in Lemma 1. Then for any sequence converging to ,
Lemma 3
Let be a positive sequence such that , and satisfy the same setting as in Lemma 1. Given , then for any sequence converging to , we have
Lemma 4
Let be a positive sequence such that , and satisfy the same setting as in Lemma 1. Then for any ,
| Category | Method | Convergence Results | Required Conditions | w/o LLC | Constraints | Pessimistic |
| EGBMs | FHG/RHG | Asymptotic | and are . | ✗ | ✗ | ✗ |
| is a singleton. | ||||||
| TRHG | Non-asymptotic | is and bounded below. | ✗ | ✗ | ✗ | |
| is , -smooth and strongly convex. | ||||||
| BDA | Asymptotic | is -smooth, convex, bounded below. | ✗ | ✗ | ✗ | |
| is -smooth. is a singleton. | ||||||
| IGBMs | CG/Neumann | Non-asymptotic | and are . | ✗ | ✗ | ✗ |
| is invertible. is a singleton. | ||||||
| Ours | BVFSM | Asymptotic | and are | ✔ | ✔ | ✔ |
| and level-bounded. |
-
1
denotes continuously differentiable. (or )-smooth means the gradient of (or ) is Lipschitz continuous with Lipschitz constant (or ). “Level-bounded” is short for “level-bounded in locally uniformly in ”.
-
2
denotes the stationary point.
| Category | Method | Key point for calculating | Time | Space | |
|---|---|---|---|---|---|
| EGBMs | FHG | ||||
| RHG | |||||
| TRHG | |||||
| BDA | Same as RHG, but replace with | ||||
| IGBMs | CG | ||||
| Neumann | |||||
| Ours | BVFSM | ||||
Now, by combining the above results, we can obtain the desired epiconvergence result, which also indicates the convergence of our method. Note that this is another type of the convergence of algorithm iterates in asymptotic convergence different from non-asymptotic convergence.
Theorem 1 (Convergence for Optimistic BLO)
Let be a positive sequence such that , also satisfying the same setting as in Lemma 1.
-
(1)
The epiconvergence holds:
-
(2)
We have the following inequality:
In addition, if for some subsequence , and converges to , then and
Proof.
Next, we consider the convergence for pessimistic BLO. To begin with, for pessimistic BLO without functional constraints, we denote similarly to the optimistic case:
where Then we have the following corollary. Note that this convergence result can also be extended to pessimistic BLO with constraints easily.
Corollary 1 (Convergence for Pessimistic BLO)
Let be a positive sequence such that , also satisfying the same setting as in Lemma 1. Then we have the following inequality:
In addition, if for some subsequence , and converges to , then we have and
Proof.
Based on the proof of Theorem 1, we first need to prove by Lemma 1, 2, 3, and 4. Lemma 1 and 2 are unrelated to whether it is the optimistic or pessimistic case, and thus holds naturally. The corresponding results for Lemma 3 and 4 can be derived simply by replacing in their proof with . Then the conclusion can be obtained by the process same to Theorem 1. ∎
In Table II, we present the comparison among existing methods and our BVFSM. It can be seen that under mild assumptions, BVFSM is able to achieve asymptotic convergence without the LLC restriction, and be applied in BLO with constraints and pessimistic BLO, which is not available by other methods. In addition, as shown in Theorem 1, our asymptotic convergence is obtained from the epiconvergence property, which is a stronger result than solely asymptotic convergence.
4.2 Complexity Analysis
In this part, we compare the time and space complexity of Algorithms 2 with EGBMs (i.e., FHG, RHG, TRHG and BDA) and IGBMs (i.e., CG and Neumann) for computing or , i.e., the direction for updating variable . Table III summarizes the complexity results. Our complexity analysis follows the assumptions in [5]. Note that BVFSM has an order of magnitude lower time complexity with respect to the LL dimension compared to existing methods. For all existing methods, we assume solving the optimal solution of the LL problem, also the transition function in EGBMs for obtaining , is the process of a -step gradient descent.
EGBMs. As discussed in [2, 26], after implementing steps of gradient descent with time and space complexity of to solve the LL problem, FHG for forward calculation of Hessian-matrix product can be evaluated in time and space , and RHG for reverse calculation of Hessian- and Jacobian-vector products can be evaluated in time and space . TRHG truncates the length of back-propagation trajectory to after a -step gradient descent, and thus reduces the time and space complexity to and space . BDA uses the same idea to RHG, except that it combines UL and LL objectives during back propagation, so the order of complexity of time and space is the same to RHG. The time complexity for EGBMs to calculate the UL gradient is proportional to , the number of iterations of the LL problem, and thus EGBMs take a large amount of time to ensure convergence.
IGBMs. After implementing a -step gradient descent for the LL problem, IGBMs approximate the inverse of Hessian matrix by conjugate gradient (CG), which solves a linear system of steps, or by Neumann series. Note that each step of CG and Neumann method includes Hessian-vector products, requiring time and space, so IGBMs run in time and space . IGBMs decouple the complexity of calculating the UL gradient from being proportional to , but the iteration number always relies on the properties of the Hessian matrix, and in some cases, can be much larger than .
BVFSM. In our algorithm, it takes time and space to calculate steps of gradient descent on Eq. (10) for the solution of LL problem . Then steps of gradient descent on Eq. (11) are used to calculate , which requires time and space . After that, the direction can be obtained according to the formula given in Eq. (13) by several computations of the gradient and without any intermediate update, which requires time and space . Therefore, BVFSM runs in time and space for each iteration.
It can be observed from Table III that BVFSM needs less space than EGBMs, and it takes much less time than EGBMs and IGBMs, especially when is large, meaning the LL problem is high-dimensional, such as in application tasks with a large-scale network. Overall, this is because BVFSM does not need any computation of Hessian- or Jacobian-vector products for solving the unrolled dynamic system by recurrent iteration or approximating the inverse of Hessian. Its complexity only comes from calculating the gradients of and , which is much easier than calculating Hessian- and Jacobian-vector products (even by AD). Besides, although BVFSM has the same order of space complexity to IGBMs, it is indeed smaller, because the memory is saved by eliminating the need to save the computational graph used for calculating Hessian. We will further verify these advantages through numerical results in Section 5.
5 Experimental Results
In this section, we quantitatively demonstrate the performance of our BVFSM333Code is available at https://github.com/vis-opt-group/BVFSM., especially when dealing with complicated and high-dimensional problems. We start with investigating the convergence performance, computational efficiency, and effect of hyper-parameters on numerical examples in Section 5.1. In Section 5.2, we apply BVFSM in the hyper-parameter optimization for the data hyper-cleaning task under different settings including the type of auxiliary functions, contamination rates, and various network structures. To further validate the generality of our method, we conduct experiments on other tasks such as few-shot learning in Section 5.3 and GAN in Section 5.4. The experiments were conducted on a PC with Intel Core i7-9700K CPU (4.2 GHz), 32GB RAM and an NVIDIA GeForce RTX 2060S GPU with 8GB VRAM, and the algorithm was implemented using PyTorch 1.6. We use the implementation in [48, 36] for the existing methods, and use MB (MegaByte) and S (Second) as the evaluation units of space and time complexity, respectively. Regarding the selection of coefficients and hyper-parameters, we evaluate them in numerical experiments and use the same method to select them in later tasks. Furthermore, we set , to initialize each step of the sub-problems. In view of the optimizer, we use SGD for solving LL and UL sub-problems in numerical experiments. In some applications, we change the UL optimizer to Adam to speed up the convergence.
5.1 Numerical Evaluations
5.1.1 Optimistic BLO
We start with the optimistic BLO, and use the numerical example with a non-convex LL which can adjust various dimensions to validate the effectiveness of BVFSM over existing methods. In particular, consider
| (18) | ||||
where denotes the -th component of , while and are adjustable parameters. Note that here is a one-dimensional real number, but we still use the bold letter to represent this scalar to maintain the context consistency. The solution of such problem is where and the optimal value is 444 Derivation of the closed-form solution is provided in Appendix B, available at https://arxiv.org/abs/2110.04974.. This example satisfies all the assumptions of BVFSM, but does not meet the LLC assumption in [27, 9, 28], which makes it a good example to validate the advantages of BVFSM. In the following experiments we set and .
We compare BVFSM with several gradient-based optimization methods, including RHG, BDA, CG and Neumann. Note that they all assume the solution of the LL problem is unique except BDA, so for these methods we directly regard the obtained local optimal solutions of LL problems as the unique solutions. We set for RHG and BDA, , for CG and Neumann, the aggregation parameters equal to in BDA, and , , step size , , , and in BVFSM.
| RHG | BDA | CG | Neumann | BVFSM | |
|---|---|---|---|---|---|
| 50 | 2.296 | 2.336 | 2.058 | 2.260 | 0.117 |
| 100 | 2.253 | 2.294 | 2.073 | 2.236 | 0.159 |
| 150 | 2.213 | 2.253 | 2.032 | 2.202 | 0.190 |
| 200 | 2.187 | 2.227 | 1.972 | 2.178 | 0.209 |
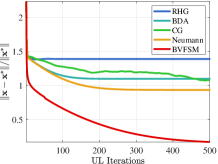
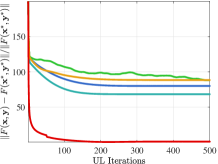
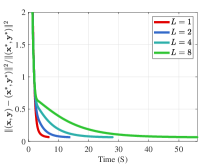
Convergence performance. Figure 1 compares the convergence curves of UL variable and objective in the 2-dimensional case (). Here the optimal solution is . In order to show the impact of initial points, we also set different initial points. From Figure 1(a), when the initial point is , existing methods show the trend of convergence at the beginning of iteration, but they soon stop further converging due to falling into a local optimal solution. Furthermore, when the initial point is in Figure 1(b), existing methods show a trend that the distance to the optimal solution even increases during the whole iterative process because they incorrectly converge to the local solution away from the global solution. On the contrary, our method can converge to the optimal solution under different initial points. Table IV further verifies the convergence performance for larger-scale problems of various LL dimension . It shows that our method can still maintain good convergence performance with high-dimensional LL, while existing methods fail because they cannot solve the non-convex LL with convergence guarantee.

| RHG | BDA | CG | Neumann | BVFSM | |
|---|---|---|---|---|---|
| 13089 | 12871 | 15093 | 18118 | 283200 |
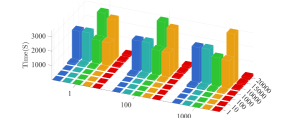
Computational efficiency for large-scale problems. Figure 2 compares the computation time for problems under various scales and . Note that the scale-up of UL dimension can be achieved by converting the one-dimensional to the mean of multi-dimensional . As we can see, our method costs the least computation time for problems of all scales, and the LL dimension has much more influence than the UL dimension . Table V shows the largest LL dimension within the 3600-second time limit. This allows us to apply BVFSM to more complex LL problems, which existing methods cannot deal with. We attribute these superior results to our novel way of the re-characterization via value-function. We further explore our performance on problems with complex network structures in Section 5.2.
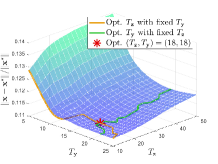
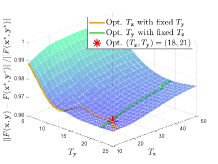
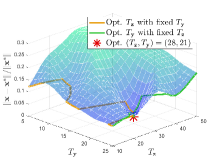
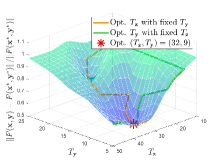
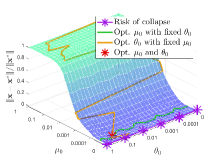
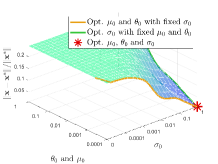
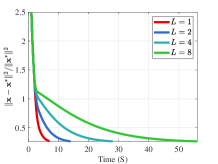
Effect of hyper-parameters. We next evaluate the effect of various hyper-parameters in the 2-dimensional case (). In Figure 3, we compare the errors under different settings of , , and . In Figure 3(a), with larger regularization coefficients and , the regularized problems are away from the original problems. Figure 3(b) shows that smaller and may not completely overcome the ill condition of the LL problem, which means the small coefficients cause the approximate problem to remain a little ill-conditioned, resulting in the instability of the surfaces. Hence, it is not an easy task to determine the regularization coefficients. Since the selection of such parameters is often highly related to the specific problem, in order to maintain the fairness for comparing the computational burden with other methods, we set in all experiments (because we need to calculate the gradient of two functions and for the -step gradient descent). Figure 4 shows the effect of , , and on the convergence results. Figure 4(a) reveals the effect of regularization coefficients and . We find that when , the collapse may occur (with the collapse rate at around ), which indicates the necessity of adding the regularization term to avoid collapse and improve the computational stability. Figure 4(b) shows that it is a good choice to use smaller and larger with a suitable decay factor to avoid the offset of solution and achieve better convergence. Figure 5 further analyzes the effect of , the number of inner-loop iterations, on the convergence speed. It can be seen that the smaller is, the higher convergence speed can be obtained, so we set in all experiments.
5.1.2 BLO with Constraints
To show the performance of BVFSM for problems with constraints discussed in Section 3.3, we use the following constrained example with non-convex LL: where and are any fixed given constant and vector satisfying . The optimal solution is and the optimal value is . Derivation of the closed-form solution is provided in Appendix B. We conduct experiments under the 2-dimensional case () and set and . The constraint is carried out via , for each component of , which is equivalent to .
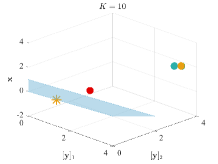
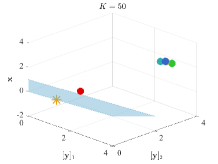
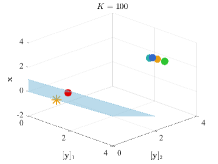
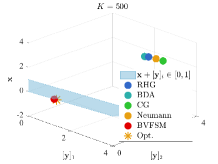
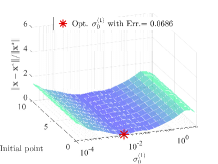
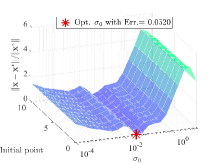
Figure 6 displays the solutions after iterations. It can be seen that when dealing with constrained LL problems, only BVFSM can effectively deal with the constraint. Hence, our method has broader application space, and we will show the experiment in real learning tasks in Section 5.2, which solves problems with UL constraints.

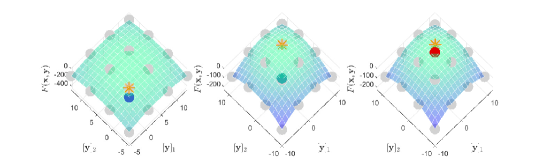
| Method | MNIST | FashionMNIST | CIFAR10 | ||||||
| Accuracy | F1 score | Time (S) | Accuracy | F1 score | Time (S) | Accuracy | F1 score | Time (S) | |
| RHG | 87.900.27 | 89.360.11 | 0.4131 | 81.910.18 | 87.120.19 | 0.4589 | 34.950.47 | 68.270.72 | 1.3374 |
| TRHG | 88.570.18 | 89.770.29 | 0.2623 | 81.850.17 | 86.760.14 | 0.2840 | 35.420.49 | 68.060.55 | 0.8409 |
| BDA | 87.150.82 | 90.380.76 | 0.6694 | 79.970.71 | 88.240.58 | 0.8571 | 36.410.23 | 67.330.31 | 1.4869 |
| CG | 89.190.35 | 85.960.48 | 0.1799 | 83.150.24 | 85.130.27 | 0.2041 | 34.160.75 | 69.100.93 | 0.4796 |
| Neumann | 87.540.13 | 89.580.34 | 0.1723 | 81.370.18 | 87.280.19 | 0.1958 | 33.450.16 | 68.870.11 | 0.4694 |
| BVFSM | 90.410.32 | 91.190.25 | 0.1480 | 84.310.27 | 88.350.13 | 0.1612 | 38.190.62 | 69.550.42 | 0.4092 |
| BVFSM-C | 90.940.32 | 91.830.30 | 0.1566 | 83.230.34 | 89.740.24 | 0.1514 | 37.330.33 | 69.730.51 | 0.4374 |
To compare the performance of different auxiliary functions, we try barrier and penalty functions for and , which can be selected arbitrarily and separately indeed, but here are chosen the same to be compared more directly. Since all of these auxiliary functions can guarantee the convergence theoretically, we mainly focus on the robustness of them under different settings. From Figure 7, it can be seen that using a penalty function can converge only under certain settings within a small region, while using a barrier function has greater robustness, so we use barrier functions in other experiments. In Section 5.2, we further show investigations on penalty and barrier functions on complex networks.
5.1.3 Pessimistic BLO
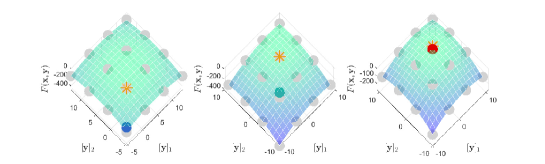
To study the performance of pessimistic BLO, we use the example similar to optimistic BLO by changing Eq. (18) from to and from to . Here we consider the 2-dimensional case (LL dimension ), and set and . In this case, the optimal solution is and the optimal value is Derivation of the exact solution is provided in Appendix B. We select RHG and BDA respectively as the representatives of gradient-based methods with or without unique LL solution. We make no adaptive modifications to these methods which do not consider the pessimistic BLO situation.
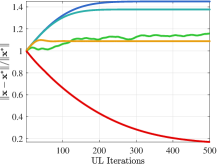
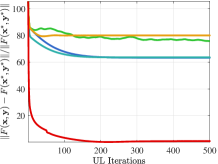
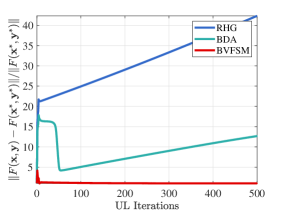
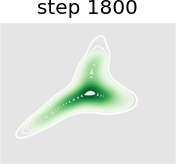
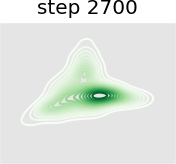
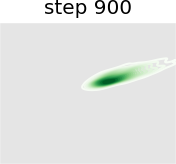
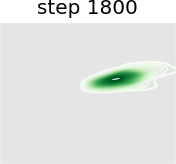
Figure 8 shows the convergence curves of UL objective and how various methods choose when is not a singleton. From Figure 8(a), our method has significantly better convergence in the pessimistic case, while RHG and BDA cannot converge at all. Their distances to the optimal solution even increase because they fail to select the optimal LL solution from multiple LL solutions , which is intuitively demonstrated in Figure 8(b) and 8(c).
| Contamination rate | 0.6 | 0.7 | 0.8 | 0.9 | ||||
| Method | Accuracy | F1 score | Accuracy | F1 score | Accuracy | F1 score | Accuracy | F1 score |
| RHG | 77.39±0.61 | 68.18±0.94 | 75.62±0.94 | 56.72±0.72 | 68.91±0.71 | 46.81±0.78 | 59.83±0.91 | 29.39±0.38 |
| TRHG | 77.37±0.52 | 76.76±0.13 | 75.60±0.84 | 65.30±0.10 | 68.89±0.30 | 55.39±0.97 | 59.81±0.38 | 37.97±0.48 |
| BDA | 75.44±0.44 | 78.24±0.34 | 73.67±0.59 | 66.78±0.82 | 66.96±0.69 | 56.87±0.79 | 57.88±0.87 | 39.45±0.08 |
| CG | 78.64±0.52 | 75.17±0.79 | 76.87±0.06 | 63.71±0.41 | 70.16±0.80 | 53.80±0.09 | 61.08±0.63 | 36.38±0.03 |
| Neumann | 76.85±0.95 | 77.29±0.29 | 75.08±0.15 | 65.83±0.22 | 68.37±0.40 | 55.92±0.46 | 59.29±0.26 | 38.50±0.63 |
| BVFSM | 81.49±0.22 | 85.51±0.70 | 81.34±0.42 | 82.55±0.33 | 80.06±0.97 | 73.51±0.83 | 79.73±0.20 | 55.97±0.73 |

5.2 Hyper-parameter Optimization
In this subsection, we use a specific task of hyper-parameter optimization, called data hyper-cleaning, to evaluate the performance of BVFSM when the LL problem is non-convex. Assuming that some of the labels in our dataset are contaminated, the goal of data hyper-cleaning is to reduce the impact of incorrect samples by adding hyper-parameters to them. In this experiment, we set as the parameter of a non-convex 2-layer linear network classifier where is the dimension of data, and as the weight of each sample in the training set. Therefore, the LL problem is to learn a classifier by cross-entropy loss weighted with given :
where are the training samples, and is the sigmoid function to constrain the weights into the range of . The UL problem is to find a weight to reduce the cross-entropy loss of on a cleanly labeled validation set:
In addition, we also consider adding explicit constraints directly on (as discussed in Section 3.3) instead of using the sigmoid function as indirect constraints. The constraint is carried out via , for each component of , such that .
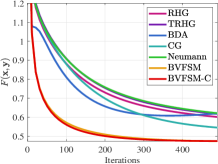
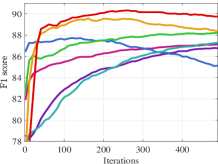
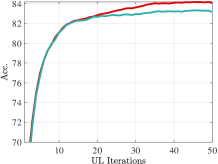
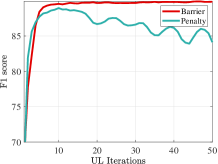
Overall performance. Table VI shows the accuracy, F1 score and computation time on three different datasets. For each dataset, we randomly select 5000 samples as the training set , 5000 samples as the validation set , and 10000 samples as the test set . After that, we contaminate half of the labels in . From the result, BVFSM achieves the most competitive performance on all datasets. Furthermore, BVFSM is faster than EGBMs and IGBMs, and this advantage is more evident on CIFAR10 with larger LL dimension, consistent with the complexity analysis in Section 4.2. The UL objective value and F1 score during iterations on FashionMNIST are also plotted in Figure 9.
As for the performance of BLO with constraints, we can find from Table VI that BVFSM with constraints (denoted as BVFSM-C in the table) has slightly lower accuracy but higher F1 score than BVFSM using sigmoid function without explicit constraints. This is because for BVFSM without constraints, the compound of sigmoid function in the LL objective decreases the gradient of , and thus the UL variable with small change rate contributes to its slower convergence. Accuracy more reflects the convergence of LL variable , while F1 score more reflects the convergence of UL variable . Therefore, BVFSM with constraints performs slightly worse in accuracy but better in F1 score than BVFSM without constraint but with the sigmoid function.
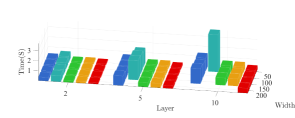
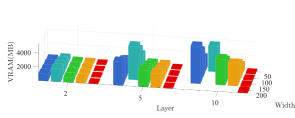
Evaluations on the auxiliary functions, robustness, and network structures. Figure 10 compares the performance of different auxiliary functions. Consistent with the numerical experiment in Figure 7, the barrier function works better with higher stability without the need for too much fine tuning of parameters. Table VII compares the robustness under various data contamination rates. Figure 11 further shows the impact of network structures in depth and width. For the LL variable we use fully connected networks of various layers and widths. It is worth noting that the computational burden is overall not quite sensitive to the network width, but very sensitive to the network depth. With the deepening of networks, other methods experience varying degrees of collapse due to occupying too much memory, while BVFSM can always keep the computation stable. Since there is no need to retain the LL iteration trajectory, our storage burden is much less than that of EGBMs (RHG and BDA). Thanks to the fact that BVFSM does not need to calculate the Jacobian- and Hessian-vector products (realized by saving an additional calculation graph in AD), our burden is also significantly lower than that of IGBMs (CG and Neumann).
| Conv. | (B,K) | RHG | CG | Neumann | BVFSM |
|---|---|---|---|---|---|
| 2 | (1,7) | 7515 | 4730 | 3225 | 2252 |
| 2 | (128,20) | N/A | N/A | 415.4 | 60.81 |
| 13 | (128,100) | N/A | N/A | 472.9 | 171.9 |
| 13 | (512,100) | N/A | N/A | N/A | 121.8 |

Computational efficiency for large-scale networks. Next, we verify our computational burden on large-scale networks closer to real applications such as VGG16 on CIFAR10 dataset. Because VGG16 has too much computational burden on existing methods, in order to make the comparison available, we change the experimental settings as follows. For each dataset, we randomly select 4096 samples as the training set , 4096 samples as the validation set , and 512 samples as the test set . Because the original network is too computationally intensive for EGBMs, we perform an additional experiment on some sufficiently small batch size and iteration number . We also simplify the convolution layers from 13 layers in VGG16 to only the first two layers, and retain the last 3 linear layers. As shown in Table VIII, BVFSM always has the highest speed under various settings, and still works well with a large and batch size.
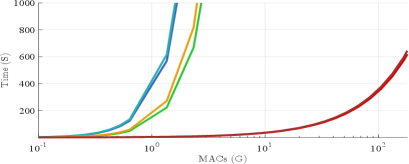
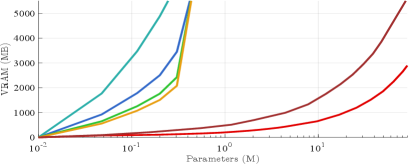
Additionally, we visualize how BVFSM can be applied to large-scale networks by expanding the width of 5-layer network, and compare the computational efficiency when the Multiply–Accumulate Operations (MACs) and parameters are increased. For the same-size network, the fully-connected layer typically has more parameters, while the convolutional layer has more MACs, so we use the fully-connected and convolutional layer respectively to simulate the scale-up of parameters and MACs. From Figure 12, other methods are computationally inefficient and can only handle small-scale networks, while BVFSM with much higher efficiency is applicable to larger-scale networks in frontier tasks. Moreover, considering the effect of number of layers on efficiency as shown in Figure 11, we also use a more challenging 50-layer network for BVFSM to further demonstrate its high efficiency. Specifically, existing methods usually cannot work under MobileNet with around 1 GMACs, while BVFSM is available under StyleGAN with around 100 GMACs.
| Method | 5-way | 20-way | 30-way | 40-way | ||||
| 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | 1-shot | 5-shot | |
| MAML | 98.700.40 | 99.910.10 | 95.800.30 | 98.900.20 | 86.860.49 | 96.860.19 | 85.980.45 | 94.460.43 |
| Meta-SGD | 97.970.70 | 98.960.20 | 93.980.43 | 98.420.11 | 89.910.04 | 96.210.15 | 87.390.43 | 95.100.15 |
| Reptile | 97.680.04 | 99.480.06 | 89.430.14 | 97.120.32 | 85.400.30 | 95.280.30 | 82.500.30 | 92.790.33 |
| iMAML | 99.160.35 | 99.670.12 | 94.460.42 | 98.690.10 | 89.520.20 | 96.510.08 | 87.280.21 | 95.270.08 |
| RHG | 98.640.21 | 99.580.12 | 96.130.20 | 99.090.08 | 93.920.18 | 98.430.08 | 90.780.20 | 96.790.10 |
| TRHG | 98.740.21 | 99.710.07 | 95.820.20 | 98.950.07 | 94.020.18 | 98.390.07 | 90.730.20 | 96.790.10 |
| BDA | 99.040.18 | 99.740.05 | 96.500.16 | 99.190.07 | 94.370.18 | 98.530.07 | 92.490.18 | 97.120.09 |
| BVFSM | 98.850.12 | 99.210.18 | 96.730.30 | 98.950.20 | 94.650.20 | 98.560.17 | 92.730.12 | 97.610.47 |




5.3 Few-shot Learning
We then conduct experiments on the few-shot learning task. Few-shot learning is one of the most popular applications in meta-learning, whose goal is to learn an algorithm that can also handle new tasks well. Specifically, each task is an -way classification and it aims to learn the hyper-parameter so that each task can be solved by only training samples (i.e., -way -shot). Similar to works in [8, 29, 30], we model the network with two parts: a four-layer convolution network as a common feature extraction layer among tasks, and a logical regression layer as the separated classifier for each task. We also set dataset as , where for the -th task. By setting the loss function of the -th task to be cross-entropy for the LL problem, the LL objective can be defined as
As for the UL objective, we also utilize the cross-entropy function but define it based on as
Our experiment is performed on the widely used benchmark dataset: Omniglot [49], which contains examples of 1623 handwritten characters from 50 alphabets.
We compare our BVFSM with several approaches, such as MAML, Meta-SGD, Reptile, iMAML, RHG, TRHG and BDA [29, 30]. From Table IX, BVFSM achieves slightly poorer performance than existing methods in the 5-way task, because when dealing with small-scale LLC problems, the strength of regularization term by BVFSM to accelerate the convergence cannot fully counteract its impact on the offset of solution. However, for larger-scale LL problems (such as 20-way, 30-way and 40-way), thanks to the regularization term, BVFSM reveals significant advantages over other methods.
5.4 Generative Adversarial Networks
Next we perform intuitive experiments on GAN to illustrate the application of BVFSM for pessimistic BLO. GAN is a network used for unsupervised machine learning to build a min-max game between two players, i.e., the generator with the network parameter , and the discriminator with the network parameter . We denote the standard Gaussian distribution as and the real data distribution as . The generator tries to fool the discriminator by producing data from random latent vector , while the discriminator distinguishes between real data and generated data by outputting the probability that the samples are real. The goal of GAN is to [50].
However, this traditional modeling method regards and as equal status, and does not characterize the leader-follower relationship that first generates data and after that judges the data, which can be modeled by Stackelberg game and captured through BLO problems. Specifically, from this perspective, generative adversarial learning corresponds to a pessimistic BLO problem: the UL objective of tries to generate adversarial samples, and the LL objective of aims to learn a robust classifier which can maximize the UL objective. Therefore, we reformulate GAN into the form in Eq. (15) discussed in Section 3.4 to model this relationship, and call it bi-level GAN. Concretely, for the follower , the LL objective is consistent with the original GAN:
As for UL, considering the antagonistic goals of and , we model the UL problem as
Note that the popular WGAN [51] is a variation of the most classic vanilla GAN [50] (or simply GAN), while unrolled GAN [11] and the GAN generated by our BVFSM belong to bi-level GAN, modeling from a BLO perspective. Our method has the following two advantages over other types of GAN. On the one hand, compared with vanilla GAN and WGAN, bi-level GAN can effectively model the leader-follower relationship between the generator and discriminator, rather than regard them as the same status. On the other hand, in bi-level GAN, our method considers the situation that the objective has multiple solutions, from the viewpoint of pessimistic BLO, with theoretical convergence guarantee, which unrolled GAN cannot achieve.
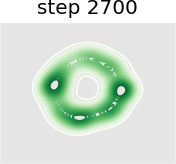
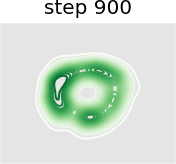
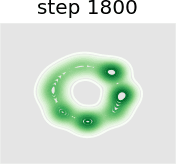
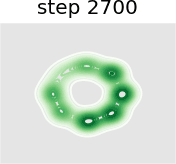
In this experiment we train a simple GAN architecture on a 2D mixture of 8 Gaussians arranged on a circle. The dataset is sampled from a mixture of 8 Gaussians with standard deviation 0.02. The 8 points are the means of data and are equally spaced around a circle with radius 2. The generator consists of a fully-connected network with 2 hidden layers of size 128 with ReLU activation followed by a linear projection to 2 dimensions. The discriminator first scales its input down by a factor of 4 (to roughly scale it to ), and is followed by a 1-layer fully-connected network from ReLU activation to a linear layer of size 1 to act as the logit. As shown in Figure 13, we present a visual comparison of sample generation among GAN, WGAN, unrolled GAN, and our method. It can be seen that vanilla GAN can capture only one distribution rather than all Gaussian distributions at a time, because it ignores the leader-follower structure. WGAN benefits from the improvement of distance function and uses one distribution to approximate all Gaussian distributions at the same time, but it fails to display satisfying performance. Unrolled GAN shows the ability to capture all distributions simultaneously thanks to the leader-follower modeling by BLO, but it lacks further details of the distribution. However, the desirable treatment of non-convex problems by BVFSM brings about its ability to fit all distributions well with details. In addition, we show the KL divergence between the generated and target image in Table X. It can be seen that the traditional alternately optimized GAN and WGAN yield larger KL divergence, while unrolled GAN and our method, which consider GAN as a BLO model, produce smaller KL divergence, and our method further achieves the best result.
Figure 14 further validates the performance of BVFSM to be adaptive in large-scale GAN on real datasets. Specifically, we add BVFSM as a training strategy based on StyleGAN2 [52] on the AFHQ dataset. It can be seen that our approach is effective in improving the generation quality and performance metrics Inception Score (IS) and Frechet Inception Distance (FID).
| GAN | WGAN | Unrolled GAN | BVFSM | |
| KL Divergence | 2.56 | 2.48 | 0.26 | 0.15 |


6 Conclusions
In this paper, we propose a novel bi-level algorithm BVFSM to provide an accessible path for large-scale problems with high dimensions from complex real-world tasks. With the help of value-function which breaks the traditional mindset in gradient-based methods, BVFSM can remove the LLC condition required by earlier works, and improve the efficiency of gradient-based methods, to overcome the bottleneck caused by high-dimensional non-convex LL problems. By transforming the regularized LL problem into UL objective by the value-function-based sequential minimization method, we obtain a sequence of single-level unconstrained differentiable problems to approximate the original problem. We prove the asymptotic convergence without LLC, and present our numerical superiority through complexity analysis and numerical evaluations for a variety of applications. We also extend our method to BLO problems with constraints, and pessimistic BLO problems.
Acknowledgments
This work is partially supported by the National Natural Science Foundation of China (Nos. U22B2052, 61922019, 12222106), the National Key R&D Program of China (2020YFB1313503, 2022YFA1004101), Shenzhen Science and Technology Program (No. RCYX20200714114700072), the Guangdong Basic and Applied Basic Research Foundation (No. 2022B1515020082), and Pacific Institute for the Mathematical Sciences (PIMS).
References
- [1] R. Liu, X. Liu, X. Yuan, S. Zeng, and J. Zhang, “A value-function-based interior-point method for non-convex bi-level optimization,” in ICML, 2021.
- [2] L. Franceschi, M. Donini, P. Frasconi, and M. Pontil, “Forward and reverse gradient-based hyperparameter optimization,” in ICML, 2017.
- [3] T. Okuno, A. Takeda, A. Kawana, and M. Watanabe, “On lp-hyperparameter learning via bilevel nonsmooth optimization,” JMLR, vol. 22, no. 245, pp. 1–47, 2021.
- [4] M. Mackay, P. Vicol, J. Lorraine, D. Duvenaud, and R. Grosse, “Self-tuning networks: Bilevel optimization of hyperparameters using structured best-response functions,” in ICLR, 2018.
- [5] H. Liu, K. Simonyan, and Y. Yang, “DARTS: differentiable architecture search,” in ICLR, 2019.
- [6] H. Liang, S. Zhang, J. Sun, X. He, W. Huang, K. Zhuang, and Z. Li, “Darts+: Improved differentiable architecture search with early stopping,” arXiv preprint arXiv:1909.06035, 2019.
- [7] X. Chen, L. Xie, J. Wu, and Q. Tian, “Progressive differentiable architecture search: Bridging the depth gap between search and evaluation,” in ICCV, 2019.
- [8] L. Franceschi, P. Frasconi, S. Salzo, R. Grazzi, and M. Pontil, “Bilevel programming for hyperparameter optimization and meta-learning,” in ICML, 2018.
- [9] A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine, “Meta-learning with implicit gradients,” in NeurIPS, 2019.
- [10] D. Zügner and S. Günnemann, “Adversarial attacks on graph neural networks via meta learning,” in ICLR, 2019.
- [11] L. Metz, B. Poole, D. Pfau, and J. Sohl-Dickstein, “Unrolled generative adversarial networks,” arXiv preprint arXiv:1611.02163, 2016.
- [12] D. Pfau and O. Vinyals, “Connecting generative adversarial networks and actor-critic methods,” arXiv preprint arXiv:1610.01945, 2016.
- [13] Z. Yang, Y. Chen, M. Hong, and Z. Wang, “Provably global convergence of actor-critic: A case for linear quadratic regulator with ergodic cost,” in NeurIPS, 2019.
- [14] R. Liu, S. Cheng, Y. He, X. Fan, Z. Lin, and Z. Luo, “On the convergence of learning-based iterative methods for nonconvex inverse problems,” IEEE TPAMI, 2019.
- [15] R. Liu, Z. Li, Y. Zhang, X. Fan, and Z. Luo, “Bi-level probabilistic feature learning for deformable image registration,” in IJCAI, 2020.
- [16] R. Liu, J. Liu, Z. Jiang, X. Fan, and Z. Luo, “A bilevel integrated model with data-driven layer ensemble for multi-modality image fusion,” IEEE TIP, 2020.
- [17] R. Liu, P. Mu, J. Chen, X. Fan, and Z. Luo, “Investigating task-driven latent feasibility for nonconvex image modeling,” IEEE TIP, 2020.
- [18] S. Dempe, N. Gadhi, and L. Lafhim, “Optimality conditions for pessimistic bilevel problems using convexificator,” Positivity, pp. 1–19, 2020.
- [19] S. Dempe, Bilevel optimization: theory, algorithms and applications. TU Bergakademie Freiberg, Fakultät für Mathematik und Informatik, 2018.
- [20] R. Liu, J. Gao, J. Zhang, D. Meng, and Z. Lin, “Investigating bi-level optimization for learning and vision from a unified perspective: A survey and beyond,” IEEE TPAMI, vol. 44, no. 12, pp. 10 045–10 067, 2021.
- [21] M. J. Alves, C. H. Antunes, and J. P. Costa, “New concepts and an algorithm for multiobjective bilevel programming: optimistic, pessimistic and moderate solutions,” Operational Research, pp. 1–34, 2019.
- [22] R. G. Jeroslow, “The polynomial hierarchy and a simple model for competitive analysis,” Mathematical programming, 1985.
- [23] J. F. Bard and J. E. Falk, “An explicit solution to the multi-level programming problem,” Computers & Opeations Research, vol. 9, no. 1, pp. 77–100, 1982.
- [24] Z.-Q. Luo, J.-S. Pang, and D. Ralph, Mathematical programs with equilibrium constraints. Cambridge University Press, 1996.
- [25] D. Maclaurin, D. Duvenaud, and R. P. Adams, “Gradient-based hyperparameter optimization through reversible learning,” in ICML, ser. JMLR Workshop and Conference Proceedings, 2015.
- [26] A. Shaban, C. Cheng, N. Hatch, and B. Boots, “Truncated back-propagation for bilevel optimization,” in AISTATS, 2019.
- [27] F. Pedregosa, “Hyperparameter optimization with approximate gradient,” in ICML, 2016.
- [28] J. Lorraine, P. Vicol, and D. Duvenaud, “Optimizing millions of hyperparameters by implicit differentiation,” in AISTATS, 2020.
- [29] R. Liu, P. Mu, X. Yuan, S. Zeng, and J. Zhang, “A generic first-order algorithmic framework for bi-level programming beyond lower-level singleton,” in ICML, 2020.
- [30] ——, “A general descent aggregation framework for gradient-based bi-level optimization,” IEEE TPAMI, vol. 45, no. 1, pp. 38–57, 2022.
- [31] J. V. Outrata, “On the numerical solution of a class of stackelberg problems,” ZOR-Methods and Models of Operations Research, 1990.
- [32] J. J. Ye and D. L. Zhu, “Optimality conditions for bilevel programming problems,” Optimization, 1995.
- [33] J. Bergstra and Y. Bengio, “Random search for hyper-parameter optimization,” JMLR, vol. 13, pp. 281–305, 2012.
- [34] F. Hutter, H. H. Hoos, and K. Leyton-Brown, “Sequential model-based optimization for general algorithm configuration,” in International conference on learning and intelligent optimization, 2011.
- [35] A. V. Fiacco and G. P. McCormick, Nonlinear programming: sequential unconstrained minimization techniques. SIAM, 1990.
- [36] R. Grazzi, L. Franceschi, M. Pontil, and S. Salzo, “On the iteration complexity of hypergradient computation,” in ICML, 2020.
- [37] L. S. Lasdon, “An efficient algorithm for minimizing barrier and penalty functions,” Mathematical Programming, vol. 2, no. 1, pp. 65–106, 1972.
- [38] C. L. Byrne, “Alternating minimization as sequential unconstrained minimization: a survey,” Journal of Optimization Theory and Applications, vol. 156, no. 3, pp. 554–566, 2013.
- [39] R. M. Freund, “Penalty and barrier methods for constrained optimization,” Lecture Notes, Massachusetts Institute of Technology, 2004.
- [40] D. G. Luenberger, Y. Ye et al., Linear and nonlinear programming. Springer, 1984, vol. 2.
- [41] D. Boukari and A. Fiacco, “Survey of penalty, exact-penalty and multiplier methods from 1968 to 1993,” Optimization, vol. 32, no. 4, pp. 301–334, 1995.
- [42] A. Auslender, “Penalty and barrier methods: a unified framework,” SIAM Journal on Optimization, vol. 10, no. 1, pp. 211–230, 1999.
- [43] J. F. Bonnans and A. Shapiro, Perturbation analysis of optimization problems. Springer Science & Business Media, 2013.
- [44] B. S. Mordukhovich and N. M. Nam, “An easy path to convex analysis and applications,” Synthesis Lectures on Mathematics and Statistics, vol. 6, no. 2, pp. 1–218, 2013.
- [45] P. Borges, C. Sagastizábal, and M. Solodov, “A regularized smoothing method for fully parameterized convex problems with applications to convex and nonconvex two-stage stochastic programming,” Mathematical Programming, 2020.
- [46] R. Liu, Y. Liu, W. Yao, S. Zeng, and J. Zhang, “Averaged method of multipliers for bi-level optimization without lower-level strong convexity,” arXiv preprint arXiv:2302.03407, 2023.
- [47] K. Ji and Y. Liang, “Lower bounds and accelerated algorithms for bilevel optimization,” JMLR, vol. 23, pp. 1–56, 2022.
- [48] E. Grefenstette, B. Amos, D. Yarats, P. M. Htut, A. Molchanov, F. Meier, D. Kiela, K. Cho, and S. Chintala, “Generalized inner loop meta-learning,” arXiv preprint arXiv:1910.01727, 2019.
- [49] B. M. Lake, R. Salakhutdinov, and J. B. Tenenbaum, “Human-level concept learning through probabilistic program induction,” Science, 2015.
- [50] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014.
- [51] M. Arjovsky, S. Chintala, and L. Bottou, “Wasserstein gan,” 2017.
- [52] T. Karras, S. Laine, and T. Aila, “A style-based generator architecture for generative adversarial networks,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 4401–4410.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/52e16187-18e9-4345-9bb2-de7c09d262f3/RishengLiu.png) |
Risheng Liu received the B.Sc. and Ph.D. degrees in mathematics from Dalian University of Technology in 2007 and 2012, respectively. He was a Visiting Scholar with the Robotics Institute, Carnegie Mellon University, from 2010 to 2012. He served as a Hong Kong Scholar Research Fellow at the Hong Kong Polytechnic University from 2016 to 2017. He is currently a Professor with the DUT-RU International School of Information Science & Engineering, Dalian University of Technology. His research interests include machine learning, optimization, computer vision, and multimedia. He is a member of the ACM, and was a co-recipient of the IEEE ICME Best Student Paper Award in 2014 and 2015. Two papers were also selected as a Finalist of the Best Paper Award in ICME 2017. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/52e16187-18e9-4345-9bb2-de7c09d262f3/XuanLiu.png) |
Xuan Liu received the B.Sc. degree in mathematics from Dalian University of Technology in 2020. He is currently an M.Phil. student in the Department of Software Engineering at Dalian University of Technology. His research interests include computer vision, machine learning, and control and optimization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/52e16187-18e9-4345-9bb2-de7c09d262f3/ShangzhiZeng.jpg) |
Shangzhi Zeng received the B.Sc. degree in Mathematics and Applied Mathematics from Wuhan University in 2015, the M.Phil. degree from Hong Kong Baptist University in 2017, and the Ph.D. degree from the University of Hong Kong in 2021. He is currently a PIMS postdoctoral fellow in the Department of Mathematics and Statistics at University of Victoria. His current research interests include variational analysis and bilevel optimization. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/52e16187-18e9-4345-9bb2-de7c09d262f3/x35.png) |
Jin Zhang received the B.A. degree in journalism and the M.Phil. degree in mathematics and operational research and cybernetics from Dalian University of Technology in 2007 and 2010, respectively, and the Ph.D. degree in applied mathematics from University of Victoria, Canada, in 2015. After working with Hong Kong Baptist University for three years, he joined Southern University of Science and Technology as a tenure-track Assistant Professor with the Department of Mathematics and promoted to an Associate Professor in 2022. His broad research area is comprised of optimization, variational analysis and their applications in economics, engineering, and data science. |
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/52e16187-18e9-4345-9bb2-de7c09d262f3/YixuanZhang.jpg) |
Yixuan Zhang received the B.Sc. degree in Mathematics and Applied Mathematics from Beijing Normal University in 2020, and the M.Phil. degree from Southern University of Science and Technology in 2022. She is currently a Ph.D. student in the Department of Applied Mathematics at the Hong Kong Polytechnic University. Her current research interests include optimization and machine learning. |
Appendix A Proofs of Lemmas in Section 4.1
A.1 Lemma 1
Let in be a positive sequence such that . Additionally assume that when is a modified barrier function. Then we have
-
(1)
is continuous, differentiable and non-decreasing, and satisfies .
-
(2)
For any , .
-
(3)
For any sequence , implies that .
Proof.
From the definitions of penalty and barrier functions (see, e.g., Definition 1), the statement (1) follows immediately.
When is a penalty function, is equal to for and for . Hence, as , , and we have , for . For any sequence , if , there exists a subsequence of and such that for all . Then, it follows from the monotonicity of that . Thus, implies that .
If is a modified barrier function, since is non-creasing, we have when . The assumption implies when . Hence, as , we have , , and , for . For any sequence , if , then it follows from the definition of modified barrier function that and (3) follows immediately from .
∎
A.2 Lemma 2
Let be a positive sequence such that , also satisfying the same setting as in Lemma 1. Then for any sequence converging to ,
Proof.
Given any , there exists such that , and . If , by Assumption 1.(4), the minimum of w.r.t. in any neighbourhood of is smaller than 0, so we can find a close enough to such that , and for some . If , such exists obviously.
As converges to , combining with the continuity of implies the existence of such that for all . Since the barrier function is non-decreasing, it follows that . Then yields
Next, as converges to , it follows from the continuity of and that there exists , such that for any ,
By letting , we obtain
and taking to the above yields the conclusion. ∎
A.3 Lemma 3
Let be a positive sequence such that , and satisfy the same setting as in Lemma 1. Given , then for any sequence converging to , we have
Proof.
We assume by contradiction that there exists and a sequence , satisfying as with the following inequality
Then, there exist and a sequence satisfying
| (19) | ||||
Since is level-bounded in locally uniformly in , we have that is bounded. Take a subsequence of which satisfies there exists , such that .
The inequality Eq. (19) yields that
Taking then . From Lemma 1, we have , and hence by the continuity of ,
Then, by the continuity of and Lemma 2, we have
By using similar arguments and the continuity of and , one can show and Thus, we have and is a feasible point to problem Eq. (14) with . Then Eq. (19) yields
which implies a contradiction. Thus we get the conclusion. ∎
A.4 Lemma 4
Let be a positive sequence such that , and satisfy the same setting as in Lemma 1. Then for any ,
Proof.
Given any , for any , there exists satisfying , , , and .
By the definition of , we have
| (20) | ||||
From Lemma 1, as , we have , and . As we choose the standard barrier function for in the definition of , thus is always larger than for any and feasible to the LL problem, and hence . Then we have . Then it follows from the monotonicity of and Lemma 1 that .
Therefore, as , by taking in inequality Eq. (20), we have
Then, we get the conclusion by letting . ∎
Appendix B Closed-form Solution in Section 5.1
Here we provide the detailed derivation of the closed-form solutions for the numerical examples in Section 5.1.
B.1 Optimistic BLO in Section 5.1.1
We consider the following optimistic BLO:
where denotes the -th component of , while and are adjustable parameters. Note that here in the numerical example, is a one-dimensional real number, and we still use the bold letter to represent the scalar in order to maintain the consistency of the context. The solution of such problem is
where
and the optimal value is . Derivation of the optimal solution and optimal value is as follows.
From the LL problem
we have . Then the problem is to find the and to minimize
For a given , denote , then
which is strongly convex and quadratic w.r.t. . Thus, it is easy to obtain , and
Hence, by denoting
we have the optimal value , and the corresponding solution
B.2 BLO with constraints in Section 5.1.2
We consider the following constrained BLO problem with non-convex LL:
where and are any fixed given constant and vector satisfying . The optimal solution is
and the optimal value is . Derivation of the optimal solution and optimal value is as follows.
From along with it is easy to obtain
Hence, is increasing w.r.t. under the constraints for all . Thus, from the LL problem we have , i.e., Then the problem is to find the to minimize
Therefore, the optimal solution , , and by substituting into , we have the optimal value .
B.3 Pessimistic BLO in Section 5.1.3
For the pessimistic BLO we use the following example:
| (21) | ||||
where denotes the -th component of , while and are adjustable parameters. In our experiment, we set and , and consider the 2-dimensional case (LL dimension ). The optimal solution to this problem is
and the optimal value is
Derivation of the optimal solution and optimal value is as follows.
From the LL problem
we have . Then the problem is transferred to
Denote . For a given , suppose
Then to maximize w.r.t. is to minimize w.r.t. , and
Thus, the problem is transformed into
i.e.,
where
It is easy to obtain that is continuous on (on interval endpoints ), and
when .
Because we set and , then if ,
Hence,
Therefore,
-
(1)
if , then
and is decreasing. In this case, , and .
-
(2)
if , then
and is increasing. In this case, , and .
-
(3)
when , the corresponding , and
Thus, when , , and is increasing; when , , and is decreasing.
To sum up, is increasing on and , and decreasing on and . Therefore, the optimal occurs at either or . Since at these two local minimizers,
we have , and
For , it means and , so or , i.e., or . Thus,
or
for . Hence,