Variance reduction techniques for stochastic proximal point algorithms
Abstract
In the context of finite sums minimization, variance reduction techniques are widely used to improve the performance of state-of-the-art stochastic gradient methods. Their practical impact is clear, as well as their theoretical properties. Stochastic proximal point algorithms have been studied as an alternative to stochastic gradient algorithms since they are more stable with respect to the choice of the step size. However, their variance-reduced versions are not as well studied as the gradient ones. In this work, we propose the first unified study of variance reduction techniques for stochastic proximal point algorithms. We introduce a generic stochastic proximal-based algorithm that can be specified to give the proximal version of SVRG, SAGA, and some of their variants. For this algorithm, in the smooth setting, we provide several convergence rates for the iterates and the objective function values, which are faster than those of the vanilla stochastic proximal point algorithm. More specifically, for convex functions, we prove a sublinear convergence rate of . In addition, under the Polyak-Łojasiewicz (PL) condition, we obtain linear convergence rates. Finally, our numerical experiments demonstrate the advantages of the proximal variance reduction methods over their gradient counterparts in terms of the stability with respect to the choice of the step size in most cases, especially for difficult problems.
Keywords. Stochastic optimization, proximal point algorithm, variance reduction techniques, SVRG, SAGA.
AMS Mathematics Subject Classification: 65K05, 90C25, 90C06, 49M27
1 Introduction
The objective of the paper is to solve the following finite-sum optimization problem
| (1.1) |
where is a separable Hilbert space and for all , .
Several problems can be expressed as in (1.1). The most popular example is the Empirical Risk Minimization (ERM) problem in machine learning [41, Section 2.2]. In that setting, is the number of data points, includes the parameters of a machine learning model (linear functions, neural networks, etc.), and the function is the loss of the model at the -th data point. Due to the large scale of data points used in machine learning/deep learning, leveraging gradient descent (GD) for the problem (1.1) can be excessively costly both in terms of computational power and storage. To overcome these issues, several stochastic variants of gradient descent have been proposed in recent years.
Stochastic Gradient Descent.
The most common version of stochastic approximation [37] applied to (1.1) is that where at each step the full gradient is replaced by , the gradient of a function , with sampled uniformly among . This procedure yields stochastic gradient descent (SGD), often referred to as incremental SGD. In its vanilla version or modified ones (AdaGrad [16], ADAM [27], etc.), SGD is ubiquitous in modern machine learning and deep learning. Stochastic approximation [37] provides the appropriate framework to study the theoretical properties of the SGD algorithm, which are nowadays well understood [10, 11, 31, 25]. Theoretical analysis shows that SGD has a worse convergence rate compared to its deterministic counterpart GD. Indeed, GD exhibits a convergence rate for the function values ranging from for convex functions to for -strongly convex functions, while for SGD the convergence rates of the function values vary from to . In addition, convergence of SGD is guaranteed if the step size sequence is square summable, but not summable. In practice, this requirement is not really meaningful, and the appropriate choice of the step size is one of the major issues in SGD implementations. In particular, if the initial step size is too large, the SGD blows up even if the sequence of step sizes satisfies the suitable decrease requirement; see, e.g., [31]. Therefore, the step size needs to be tuned by hand, and for solving problem (1.1), this is typically time consuming.
Stochastic Proximal Point Algorithm.
Whenever the computation of the proximity operator of , (for a definition see notation paragraph 2.1), is tractable, an alternative to SGD is the stochastic proximal point algorithm (SPPA). Instead of the gradient , the proximity operator of a , chosen randomly, is used in each iteration. Recent works, in particular [38, 3, 26], showed that SPPA is more robust to the choice of step size with respect to SGD. In addition, the convergence rates are the same as those of SGD, in various settings [6, 34, 3], possibly including a momentum term [26, 44, 42, 43].
Variance reduction methods.
As observed above, the convergence rates for SGD are worse than those of their deterministic counterparts. This is due to the non-vanishing variance of the stochastic estimator of the true gradient. In order to circumvent this issue, starting from SVRG [22, 1], a new wave of SGD algorithms was developed with the aim of reducing the variance and recovering standard GD rates with constant step size. Different methods were developed and all share a and a convergence rate for function values for convex and -strongly convex objective functions, respectively. In the convex case, the convergence is ergodic. Apart from SVRG, the other methods share the idea of reducing the variance by aggregating different stochastic estimates of the gradient. Among them we mention SAG [39] and SAGA [14]. In subsequent years, a plethora of papers have appeared on variance reduction techniques; see, for example, [28, 17, 45, 33]. The paper [20] provided a unified study of variance reduction techniques for SGD that encompasses many of them. The latter work [20] has inspired our unified study of variance reduction for SPPA.
Variance-reduced Stochastic Proximal Point Algorithms.
The application of variance reduction techniques to SPPA is very recent and limited: the existing methods are Point-SAGA in [13], the proximal version of L-SVRG [28], and SNSPP proposed in [30]. All existing convergence results are provided in the smooth case, except for Point-SAGA in [13], where an ergodic and sublinear convergence rate with a constant step size is provided for nonsmooth strongly convex functions.
Contributions.
Our contribution can be summarized as follows:
-
•
Assuming that the functions are smooth, we propose a unified variance reduction technique for stochastic proximal point algorithm (SPPA). We devise a unified analysis that extends several variance reduction techniques used for SGD to SPPA, as listed in Section 4, with improved rates over SPPA. In particular, we prove a sublinear convergence rate of the function values for convex functions. The analysis in the convex case is new in the literature. Assuming additionally that the objective function satisfies the Polyak-Łojasiewicz (PL) condition, we prove linear convergence rate both for the iterates and the function values. The PL condition on is less strong than the strong convexity of or even used in the related previous work. Finally, we show that these results are achieved for constant step sizes.
- •
-
•
The experiments show that, in most cases and especially for difficult problems, the proposed methods are more robust to the step sizes and converge with larger step sizes, while retaining at least the same speed of convergence as their gradient counterparts. This generalizes the advantages of SPPA over SGD (see [3, 26]) to variance reduction settings.
Organization.
The rest of the paper is organized as follows: In Section 2, we present our generic algorithm and the assumptions we will need in subsequent sections. In Section 3, we show the results pertaining to that algorithm. Then, in Section 4, we specialize the general results to particular variance reduction algorithms. Section 5 collects our numerical experiments. Proofs of auxiliary results can be found in Appendix A.
2 Algorithm and assumptions
2.1 Notation
We first introduce the notation and recall a few basic notions that will be needed throughout the paper. We denote by the set of natural numbers (including zero) and by the set of positive real numbers. For every integer , we define . is a Hilbert space endowed with scalar product and induced norm . If is convex and closed and , we set . The projection of onto is denoted by .
Bold default font is used for random variables taking values in , while bold sans serif font is used for their realizations or deterministic variables in . The probability space underlying random variables is denoted by . For every random variable , denotes its expectation, while if is a sub -algebra we denote by the conditional expectation of given . Also, represents the -algebra generated by the random variable .
Let be a function. The set of minimizers of is . If is finite, it is represented by . When is differentiable denotes the gradient of . We recall that the proximity operator of is defined as .
In this work, represents the space of sequences which norms are summable and the space of sequences which norms are square summable.
2.2 Algorithm
In this paragraph, we describe a generic method for solving problem (1.1), based on the stochastic proximal point algorithm.
Algorithm 2.1.
Let be a sequence of random vectors in and let be a sequence of i.i.d. random variables uniformly distributed on , so that is independent of , …, . Let and set the initial point . Then define
Algorithm 2.1 is a stochastic proximal point method including an additional term , that will be suitably chosen to reduce the variance. As we shall see in Section 4, depending on the specific algorithm (SPPA, SVRP, L-SVRP, SAPA), may be defined in various ways. Note that is a random vector depending on , and . By definition of the proximal operator, we derive from Algorithm 2.1
By the optimality condition and assuming is differentiable, we have
| (2.1) |
Let . Thanks to (2.1), the update in Algorithm 2.1 can be rewritten as
| (2.2) |
Keeping in mind that actually depends on , Equation (2.2) shows that Algorithm 2.1 can be seen as an implicit stochastic gradient method, in contrast to an explicit one, where is replaced by
| (2.3) |
This point of view has been exploited in [20, Appendix A], to provide a unified theory for variance reduction techniques for SGD.
Remark 2.2.
Due to the dependence of on , in general and , making the analysis of Algorithm 2.1 tricky. We circumvent that problem using as an auxiliary variable; see (A.3). This is helpful since is independent of . Therefore, even though does not appear explicitly in Algorithm 2.1, it is still relevant in the associated analysis of the convergence bounds, and, for those derivations, some assumptions will be required on .
Remark 2.3.
Variance reduction techniques have been already connected to the proximal gradient algorithm to solve structured problems of the form , where are assumed to be smooth and is just prox friendly. Indeed, this is the model corresponding to regularized empirical risk minimization [41]. For this objective functions the stochastic proximal gradient algorithm is as follows
As can be seen from the definition, no sum structure is assumed on the function which is the one activated through the proximity operator. On the contrary, stochasticity arises from the computation of the gradient of and variance reduction techniques can be exploited at this level. In this paper we tackle the same problem, in the special case where , but we analyze a different algorithm, where the functions ’s are activated through their proximity operator instead of their gradient. The addition of a regularizer can be considered, but at the moment differentiability is needed for our analysis.
2.3 Assumptions
The first assumptions are made on the functions , , as well as on the objective function .
Assumptions 2.4.
-
(A.i)
.
-
(A.ii)
For all , is convex and -smooth, i.e., differentiable and such that
for some . As a consequence, is convex and -smooth.
-
(A.iii)
satisfies the PL condition with constant , i.e.,
(2.4) which is equivalent to the following quadratic growth condition when is convex
(2.5)
(A.i) and (A.ii) constitute the common assumptions that we use for all the convergence results presented in Sections 3 and 4. Assumption (A.iii) is often called Polyak-Łojasiewicz condition and was introduced in [29] (see also [35]) and is closely connected with the quadratic growth condition (2.5) (they are equivalent in the convex setting, see e.g. [9]). Conditions (2.4) and (2.5) are both relaxations of the strong convexity property and are powerful key tools in establishing linear convergence for many iterative schemes, both in the convex [23, 9, 18, 15] and the non-convex setting [35, 36, 8, 5, 2].
In the same fashion, in this work, Assumption (A.iii) will be used in order to deduce linear convergence rates in terms of objective function values for the sequence generated by Algorithm 2.1.
Assumptions 2.5.
Let, for all , . Then there exist non-negative real numbers and , and a non-positive real-valued random variable such that, for every ,
-
(B.i)
a.s.,
-
(B.ii)
a.s.,
-
(B.iii)
,
where is a real-valued random variable, is a sequence of -algebras such that, , , and are -measurables, and is independent of .
Assumption (B.i) ensures that , so that the direction is an unbiased estimator of the full gradient of at , which is a standard assumption in the related literature. Assumption (B.ii) on is the equivalent of what is called, in the literature [25, 20], the condition on with and constant (see also [20]). Assumption (B.iii) is justified by the fact that it is needed for the theoretical study and it is satisfied by many examples of variance reduction techniques. For additional discussion on these assumptions, especially Assumption (B.iii), see [20].
3 Main results
In the rest of the paper, we will always suppose that Assumption (A.i) holds.
Before stating the main results of this work, we start with a technical proposition that constitutes the cornerstone of our analysis. The proof can be found in Appendix A.1
Proposition 3.1.
We now state two theorems that can be derived from the previous proposition. The first theorem deals with cases where the function is only convex.
Theorem 3.2.
Proof.
Since and , it follows from Proposition 3.1 that
Summing from up to and dividing both sides by , we obtain
Finally, by convexity of , we get
The next theorem shows that, when additionally satisfies the PL property (2.4), the sequence generated by algorithm 2.1 exhibits a linear convergence rate both in terms of the distance to a minimizer and also of the values of the objective function.
Theorem 3.3.
Proof.
Since , we obtain thanks to Assumption (A.iii) and Proposition 3.1
| (3.1) |
Since and , we obtain from (3) that
Since , it is clear that . Iterating down on , we obtain
| (3.2) |
Let . As is -Lipschitz smooth, from the Descent Lemma [32, Lemma 1.2.3], we have
In particular,
| (3.3) |
Using (3.3) with in (3.2), we get
Remark 3.4.
-
(i)
The convergence rate of order for the general variance reduction scheme 2.1, with constant step size, as stated in Theorem 3.2, is an improved extension of the one found for the vanilla stochastic proximal gradient method (see e.g. [3, Proposition ]). It is important to mention that the convergence with a constant step size is no longer true when in Assumption (B.ii) is positive. As we shall see in Section 4 several choices for the variance term in Algorithm 2.1 can be beneficial regarding this issue, provided Assumption (B.ii) with .
-
(ii)
The linear rates as stated in Theorem 3.3 have some similarity with the ones found in [20, Theorem ], where the authors present a unified study for variance-reduced stochastic (explicit) gradient methods. However we note that the Polyak-Łojasiewicz condition (2.4) on used here is slightly weaker than the quasi-strong convexity used in [20, Assumption ].
4 Derivation of stochastic proximal point type algorithms
In this section, we provide and analyze several instances of the general scheme 2.1, corresponding to different choices of the variance reduction term . In particular in the next paragraphs we describe four different schemes, namely Stochastic Proximal Point Algorithm (SPPA), Stochastic Variance-reduced Proximal (SVRP) algorithm, Loopless SVRP (L-SVRP) and Stochastic Average Proximal Algorithm (SAPA).
4.1 Stochastic Proximal Point Algorithm
We start by presenting the classic vanilla stochastic proximal method (SPPA), see e.g. [6, 7, 34]. We suppose that Assumptions (A.i) and (A.ii) hold and that for all
| (4.1) |
Algorithm 4.1 (SPPA).
Let be a sequence of i.i.d. random variables uniformly distributed on . Let for all and set the initial point . Define
| (4.2) |
Algorithm 4.1 can be directly identified with the general scheme 2.1, by setting and . The following lemma provides a bound in expectation on the sequence and can be found in the related literature; see, e.g. [40, Lemma 1].
Lemma 4.2.
From Lemma 4.2, we immediately notice that Assumptions 2.5 are verified with , and . In this setting, we are able to recover the following convergence result (see also [3, Lemma and Proposition ]).
Theorem 4.3.
4.2 Stochastic Variance-Reduced Proximal point algorithm
In this paragraph, we present a Stochastic Proximal Point Algorithm coupled with a variance reduction term, in the spirit of the Stochastic Variance Reduction Gradient (SVRG) method introduced in [22]. It is coined Stochastic Variance-Reduced Proximal point algorithm (SVRP).
The SVRP method involves two levels of iterative procedure: outer iterations and inner iterations. We shall stress out that the framework presented in the previous section covers only the inner iteration procedure and thus the convergence analysis for SVRP demands an additional care. In contrast to the subsequent schemes, Theorems 3.2 and 3.3 do not apply directly to SVRP. In particular, as it can be noted below, in the case of SVRP, the constant appearing in (B.iii) in Assumption 2.5, is null. Nevertheless, it is worth mentioning that the convergence analysis still uses Proposition 3.1.
Algorithm 4.4 (SVRP).
Let , with , and , be two independent sequences of i.i.d. random variables uniformly distributed on and respectively. Let and set the initial point . Then
where is the Kronecker symbol. In the case of the first option, one iterate is randomly selected among the inner iterates , losing possibly a lot of information computed in the inner loop. For the second option, those inner iterates are averaged and most of the information are used.
Let . In this case, for all , setting , the inner iteration procedure of Algorithm 4.4 can be identified with the general scheme 2.1, by setting . In addition let us define
| (4.4) |
where is such that . Moreover, setting , we have that , and are -measurables and is independent of . The following result is proved in Appendix A.2.
Lemma 4.5.
As an immediate consequence, of Proposition 3.1, we have the following corollary regarding the inner iteration procedure of Algorithm 4.4.
Corollary 4.6.
Proof.
The next theorem shows that, under some additional assumptions on the choice of the step size and the number of inner iterations , Algorithm 4.4 yields a linear convergence rate in terms of the expectation of the objective function values of the outer iterates (.
Theorem 4.7.
Remark 4.8.
-
(i)
Conditions (4.7) is used in this form if is set first and is chosen after. They are needed to ensure that . Indeed, it is clear that is needed to have . If not, cannot be less than . Then we need once is fixed.
-
(ii)
Conditions (4.7) can be equivalently stated as follows
The above formulas can be useful if one prefers to set the parameter first and set the step size afterwards.
-
(iii)
The convergence rate in Theorem 4.7 establishes the improvement from the outer step to . Of course, it depends on the number of inner iterations . As expected, and as we can see from Equation 4.8, increasing improve the bound on the rate, and since is not bounded from above, the best choice would be to let go to . In practice, there is no best choice of , but empirically a balance between the number of inner and outer iterations should be found. Consequently, there is also no optimal choice for either.
-
(iv)
It is worth mentioning that the linear convergence factor in (4.8) is better (smaller) than the one provided in [22, Theorem ] for the SVRG method for strongly convex functions. There, it is . The linear convergence factor in (4.8) is also better than the one in [46, Proposition ], and also [19, Theorem ], dealing with a proximal version of SVRG for functions satisfying the PL condition (2.4). In both papers, it is . However, we note that this improvement can also be obtained for the aforementioned SVRG methods using a similar analysis.
- (v)
Remark 4.9.
In [30] a variant of Algorithm 4.4 (SVRP) in this paper, called SNSPP, has been also proposed and analyzed. The SNSPP algorithm includes a subroutine to compute the proximity operator. This can be useful in practice when a closed form solution of the proximity operator is not available. Contingent on some additional conditions on the conjugate of and assuming semismoothness of the proximity mapping, [30] provides a linear convergence rate for SNSPP for Lipschitz smooth and strongly convex. An ergodic sublinear convergence rate is also proved for weakly convex functions.
Proof of Theorem 4.7.
We consider a fixed stage and is defined as in Algorithm 4.4. By summing inequality (4.6) in Corollary 4.6 over and taking the total expectation, we obtain
| (4.9) | ||||
In the first inequality, we used the fact that
Notice that relation (4.9) is still valid by choosing , in Algorithm 4.4, and using Jensen inequality to lower bound by .
4.3 Loopless SVRP
In this paragraph, we propose a single-loop variant of the SVRP algorithm presented previously, by removing the burden of choosing the number of inner iterations. This idea is inspired by the Loopless Stochastic Variance-Reduced Gradient (L-SVRG) method, as proposed in [28, 21] (see also [20]) and here, we present the stochastic proximal method variant that we call L-SVRP.
Algorithm 4.10 (L-SVRP).
Let be a sequence of i.i.d. random variables uniformly distributed on and let be a sequence of i.i.d Bernoulli random variables such that . Let and set the initial points . Then
Here we note that Algorithm 4.10 can be identified with the general scheme 2.1, by setting . In addition, we define
| (4.10) |
with such that . Moreover, setting , we have that , and are -measurable, and are independent of .
Lemma 4.11.
Lemma 4.11 whose proof can be found in Appendix A.2 ensures that Assumptions 2.5 hold true with constants , and . Then the following corollaries can be obtained by applying respectively Theorem 3.2 and 3.3 on Algorithm 4.10.
Corollary 4.12.
Corollary 4.13.
Remark 4.14.
The proximal version of L-SVRG [28] has been concurrently proposed in [24]. Linear convergence holds in the smooth strongly convex setting. In [24], an approximation of the proximity operator at each iteration is used. Also, Lipschitz continuity of the gradient is replaced by the weaker “second-order similarity”, namely
In [24] the convex case is not analyzed.
4.4 Stochastic Average Proximal Algorithm
In this paragraph, we propose a new stochastic proximal point method in analogy to SAGA [14], called Stochastic Aggregated Proximal Algorithm (SAPA).
Algorithm 4.15 (SAPA).
Let be a sequence of i.i.d. random variables uniformly distributed on . Let and set, for every , . Then
where is the Kronecker symbol.
Remark 4.16.
As for the previous cases, SAPA can be identified with Algorithm 2.1, by setting for all . In addition, let
| (4.13) |
with such that . Setting , we have that and are -measurables and is independent of .
Lemma 4.17.
Suppose that Assumption (A.ii) holds. Let be the sequence generated by Algorithm 4.15, with and as defined in (4.13). Then, for all , it holds
and
| (4.14) |
From the above lemma, we know that Assumptions 2.5 are verified with , and . These allow us to state the next corollaries obtained by applying respectively Theorem 3.2 and 3.3 on Algorithm 4.15.
Corollary 4.18.
Corollary 4.19.
Remark 4.20.
Now, we compare our results with those in [13] for Point-SAGA. In the smooth case, Point-SAGA converges linearly when is differentiable with Lipschitz gradient and strongly convex for every , whereas we require convexity of and only the PL condition to be satisfied by . The work [13] does not provide any rate for convex functions but instead does provide an ergodic sublinear convergence rate for nonsmooth and strongly convex functions. While the rate is ergodic and sublinear for strongly convex functions, the algorithm converges with a constant step size.
5 Experiments
In this section, we perform some experiments on synthetic data to compare the schemes presented and analyzed in Section 4. We compare the variance-reduced algorithms SAPA (Algorithm 4.15) and SVRP (Algorithm 4.4) with their vanilla counterpart SPPA (Algorithm 4.1) and their explicit gradient counterparts: SAGA [14] and SVRG [22]. The plots presented in the section are averaged of 10 or 5 runs, depending on the computational demand of the problem. The deviation from the average is also plotted. All the codes are available on GitHub111https://github.com/cheiktraore/Variance-reduction-for-SPPA.
5.1 Comparing SAPA and SVRP to SPPA
The cost of each iteration of SVRP is different from that of SPPA. More precisely, SVRP consists of two nested iterations, where each outer iteration requires a full explicit gradient and stochastic gradient computations. We will consider the minimization of the sum of functions; therefore, we run SPPA for iterations, with , where is the maximum number of outer iterations and is that of inner iterations as defined in Algorithm 4.4. Let be the outer iterations counter. As for , it is set at like in [22]. Then the step size in SVRP is fixed at . For SAPA, we run it for iterations because there is a full gradient computation at the beginning of the algorithm. The SAPA step size is set to . Finally, the SPPA step size is is chosen to be .
For all three algorithms, we normalize the abscissa so to present the convergence with respect to the outer iterates as in Theorem 4.7.
The algorithms are run for , fixed at and , the condition number of , at .
5.1.1 Logistic regression
First, we consider experiments on the logistic loss:
| (5.1) |
where is the row of a matrix and for all . If we set for all , then . The matrix is generated randomly. We first generate a matrix according to the standard normal distribution. A singular value decomposition gives . We set the smallest singular value to zero and rescale the rest of the vector of singular values so that the biggest singular value is equal to a given condition number and the second smallest to one. We obtain a new diagonal matrix . Then is given by . In this problem, we have . We compute the proximity operator of the logistic function according to the formula and the subroutine code available in [12] and considering the rule of calculus of the proximity operator of a function composed with a linear map [4, Corollary 24.15].
Even though we don’t have any theoretical result for SVRP in the convex case, we perform some experiments in this case as well. As it can readily be seen in Figure 1, both SAPA and SVRP are better than SPPA.
5.1.2 Ordinary least squares (OLS)
To analyze the practical behavior of the proposed methods when the PL condition holds, we test all the algorithms on an ordinary least squares problem:
| (5.2) |
where is the row of the matrix and for all . In this setting, we have with for all .
Here, the matrix was generated as in Section 5.1.1. The proximity operator is computed with the following closed form solution:
Like in the logistic case, SVRP and SAPA exhibit faster convergence compared to SPPA. See Figure 2.
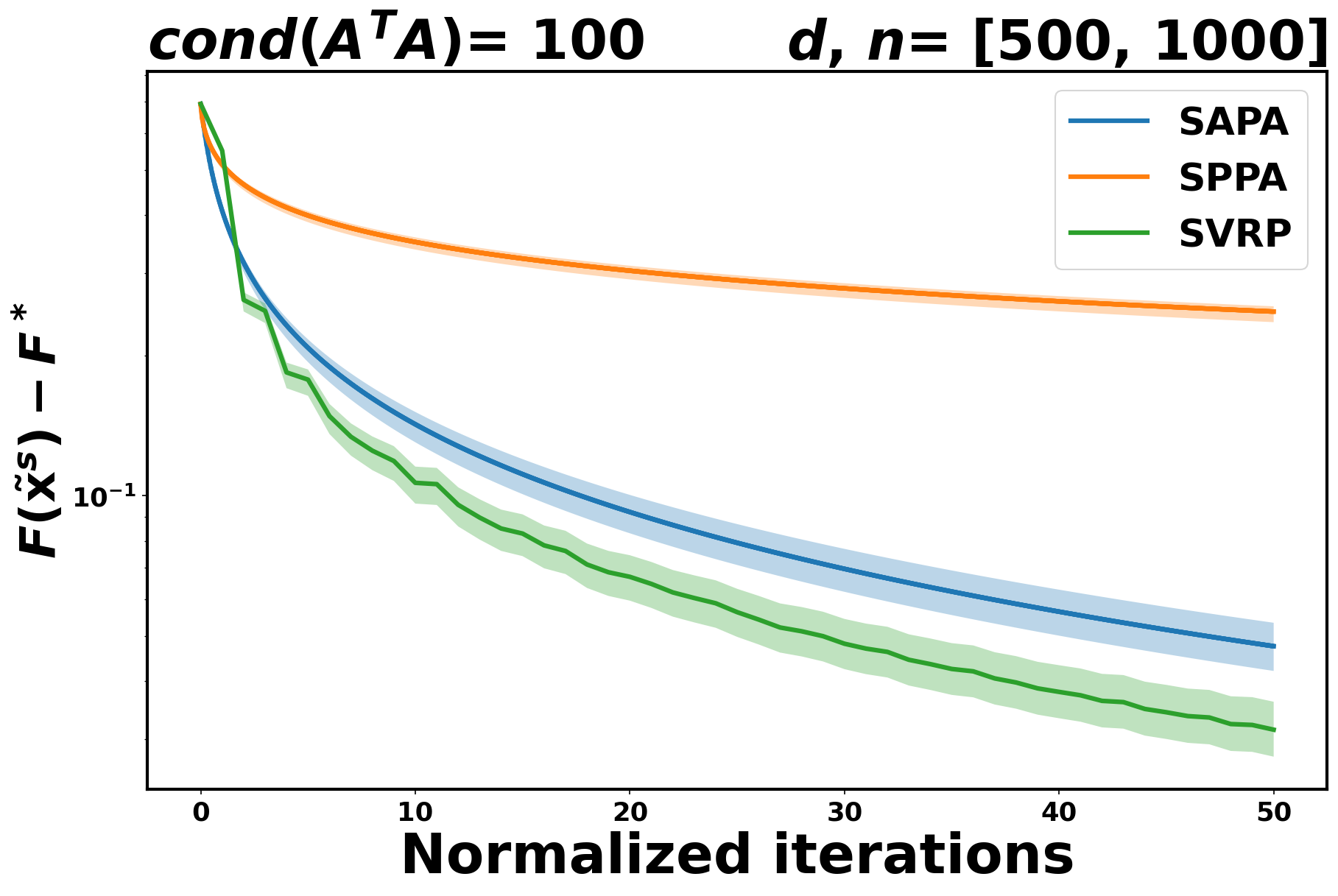
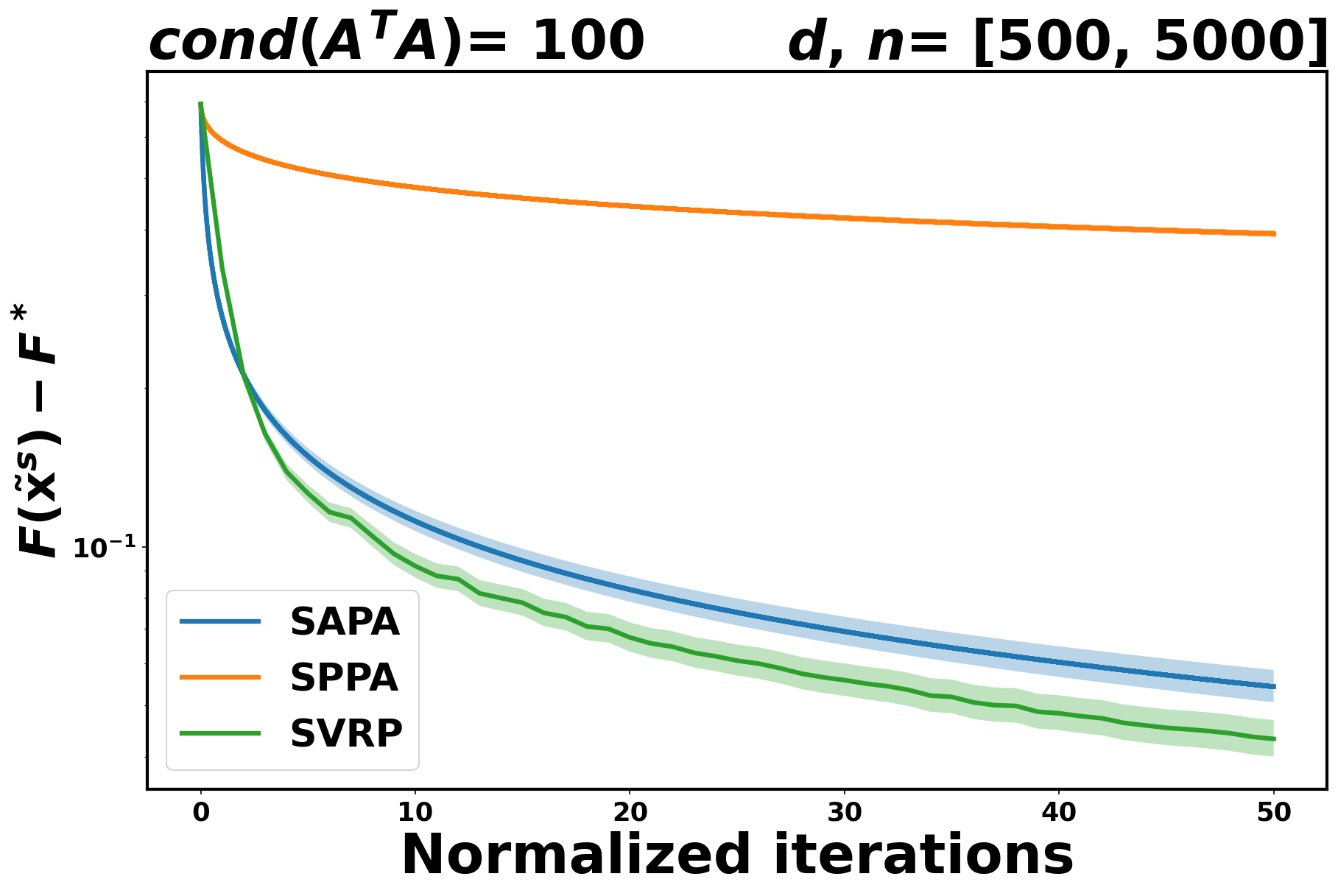
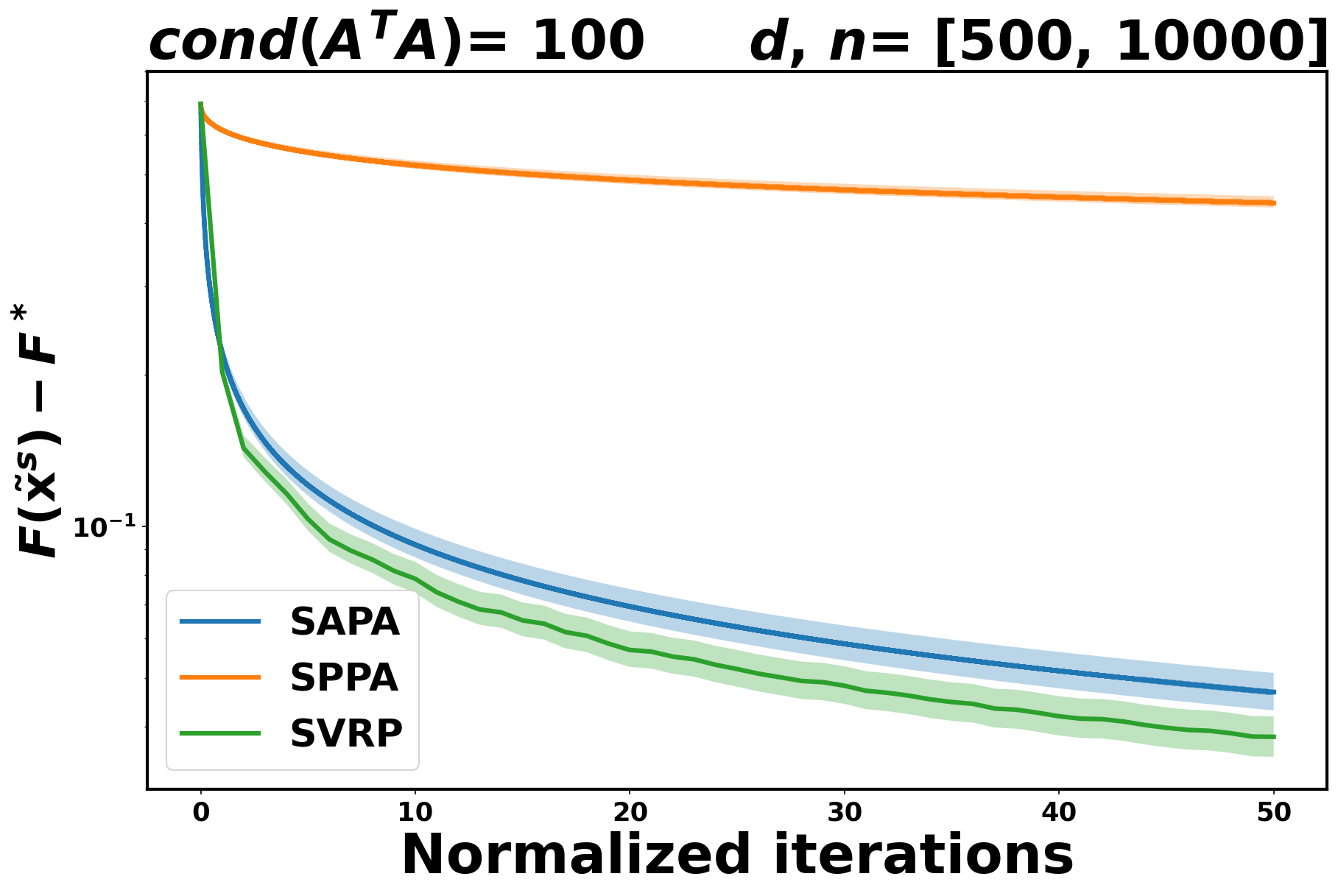
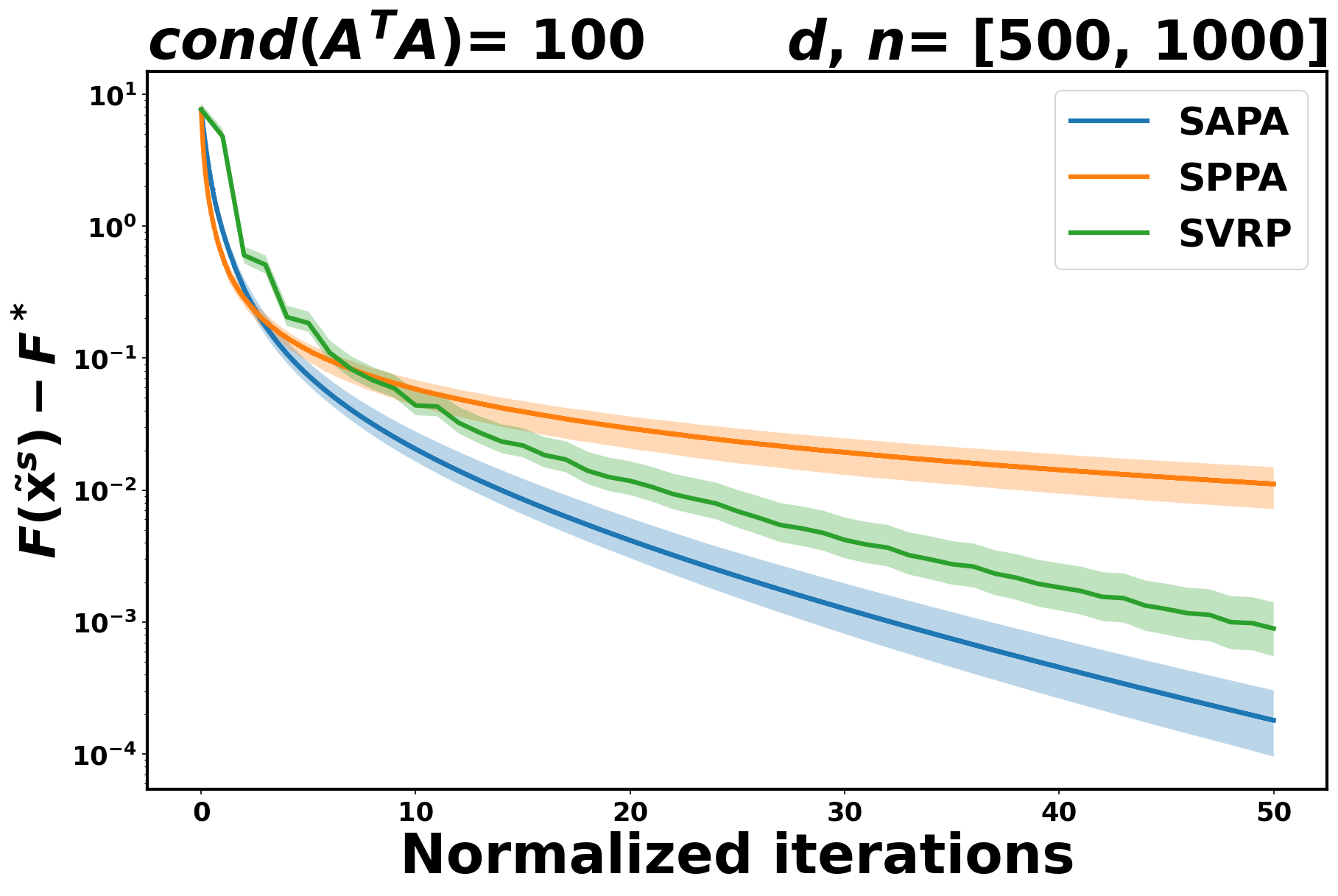
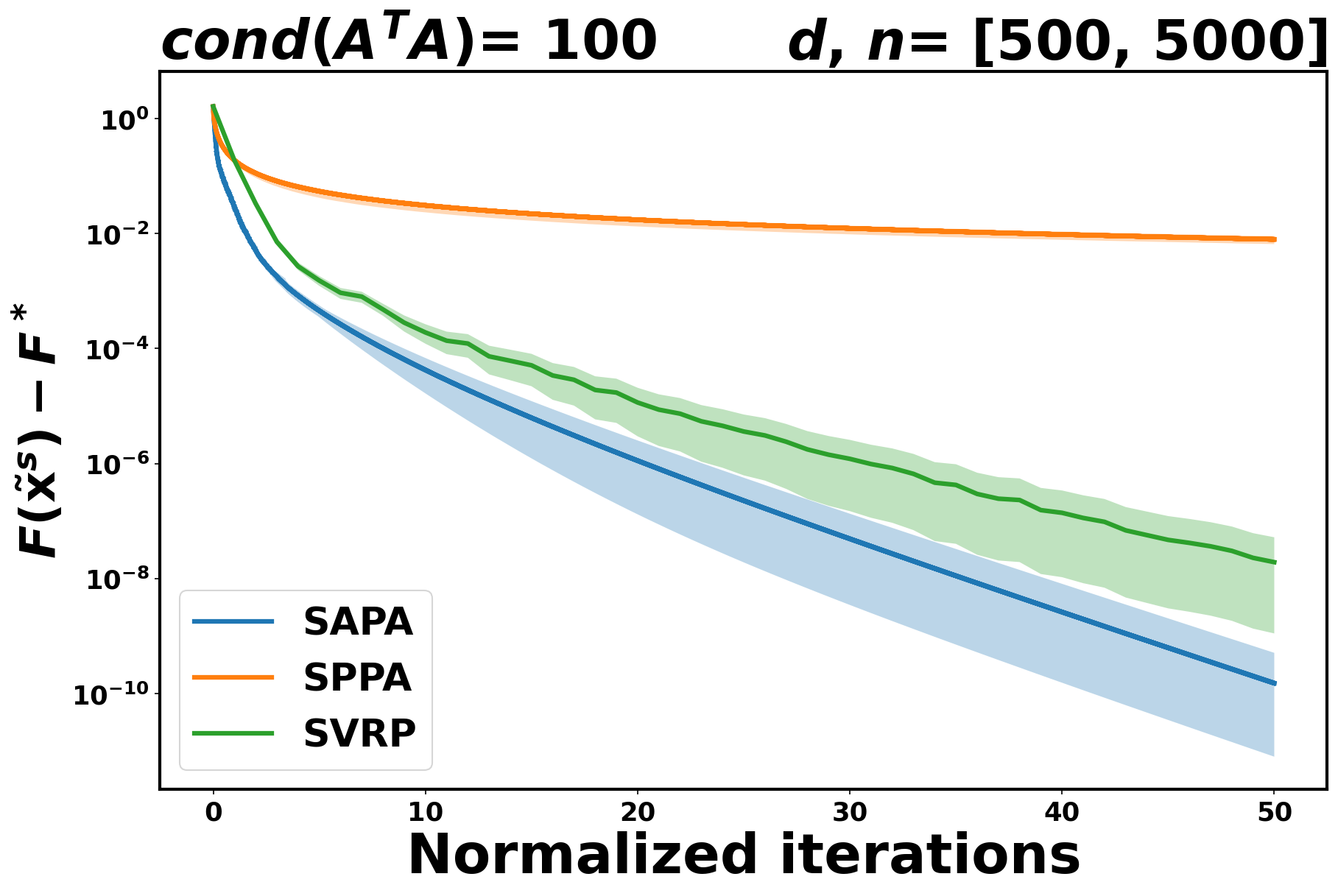
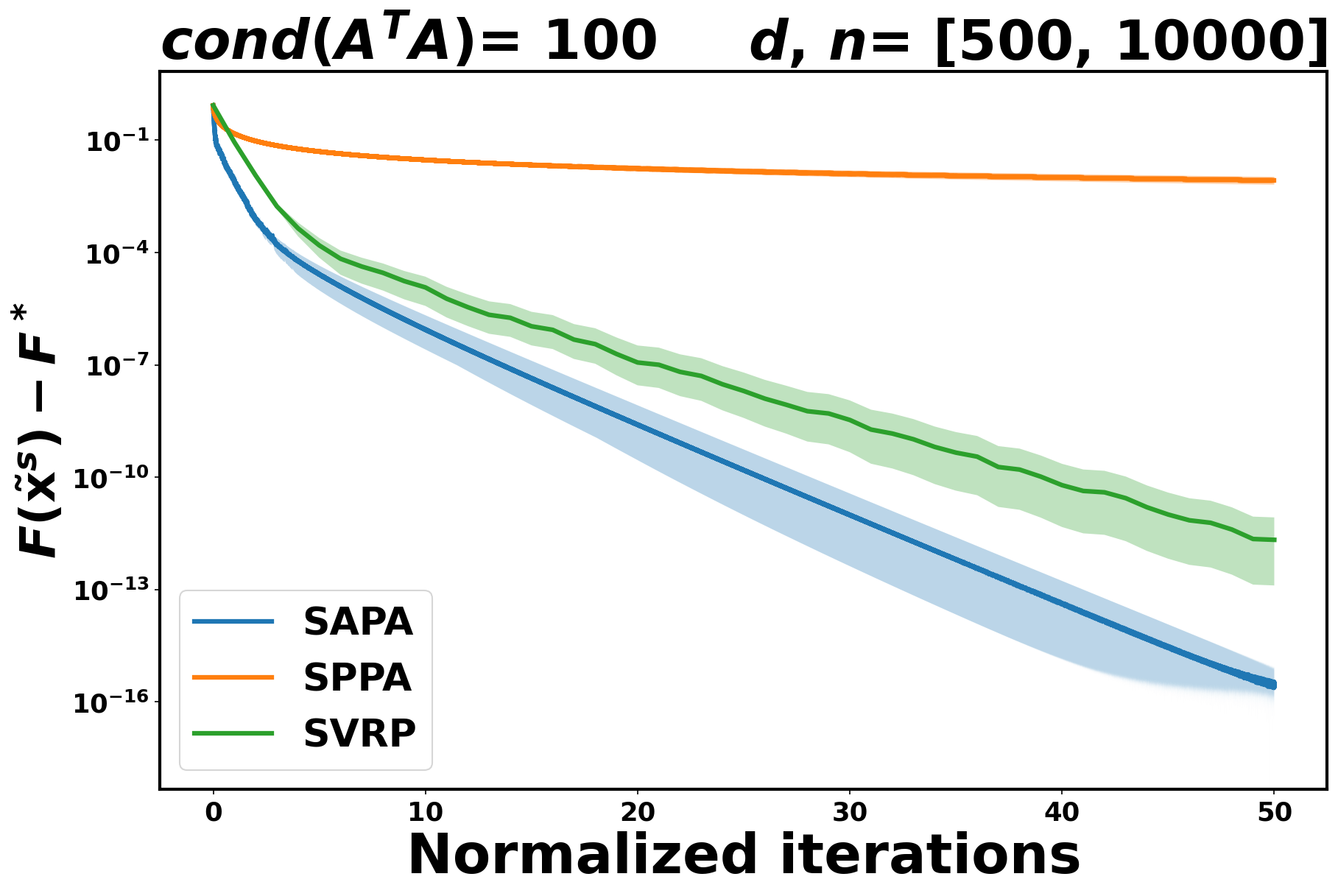
5.2 Comparing SAPA to SAGA
In the next experiments, we implement SAPA and SAGA to solve the least-squares problem (5.2) and logistic problem (5.1). The data are exactly as in Section 5.1.2 and the matrix is generated as explained in Section 5.1.1.
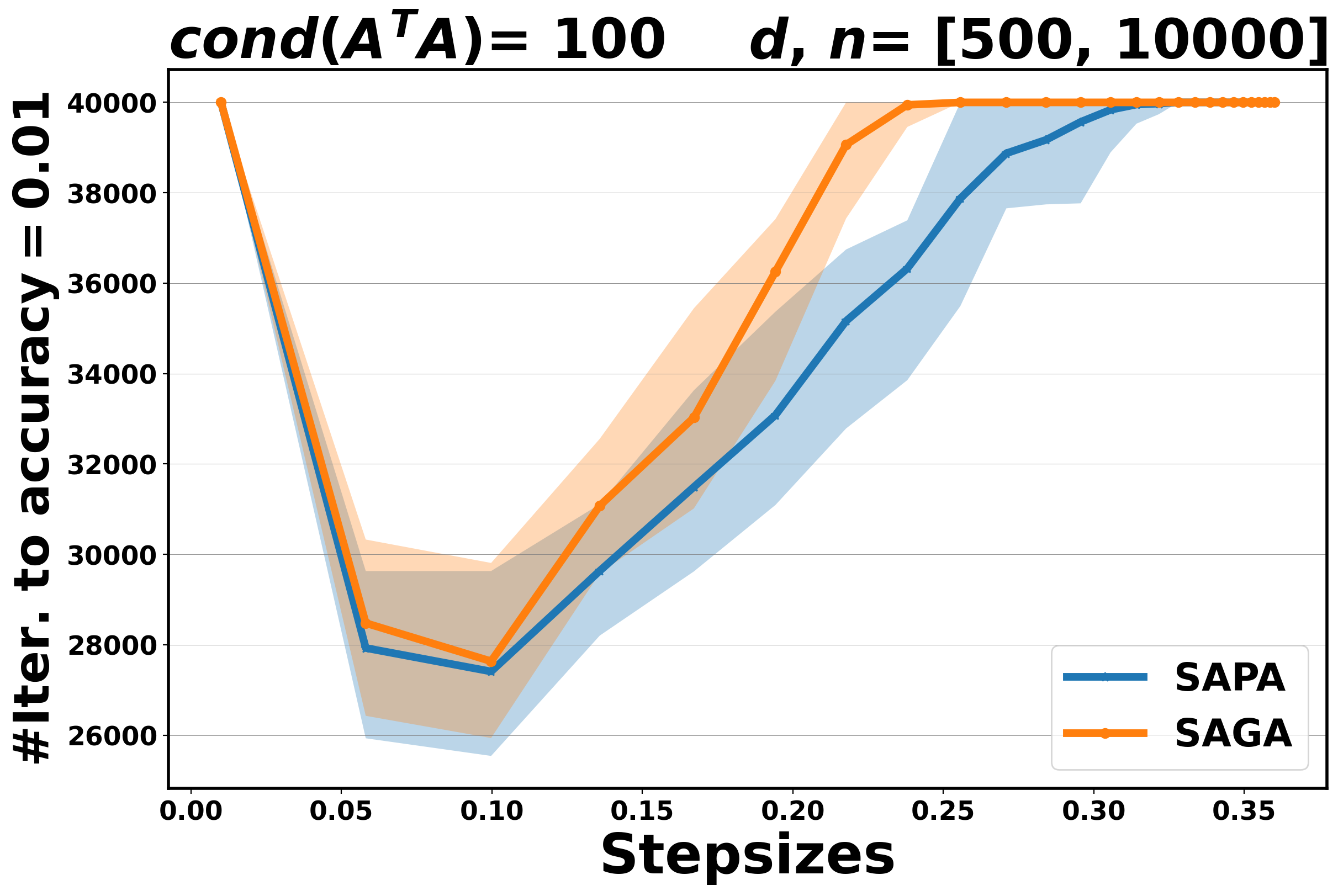
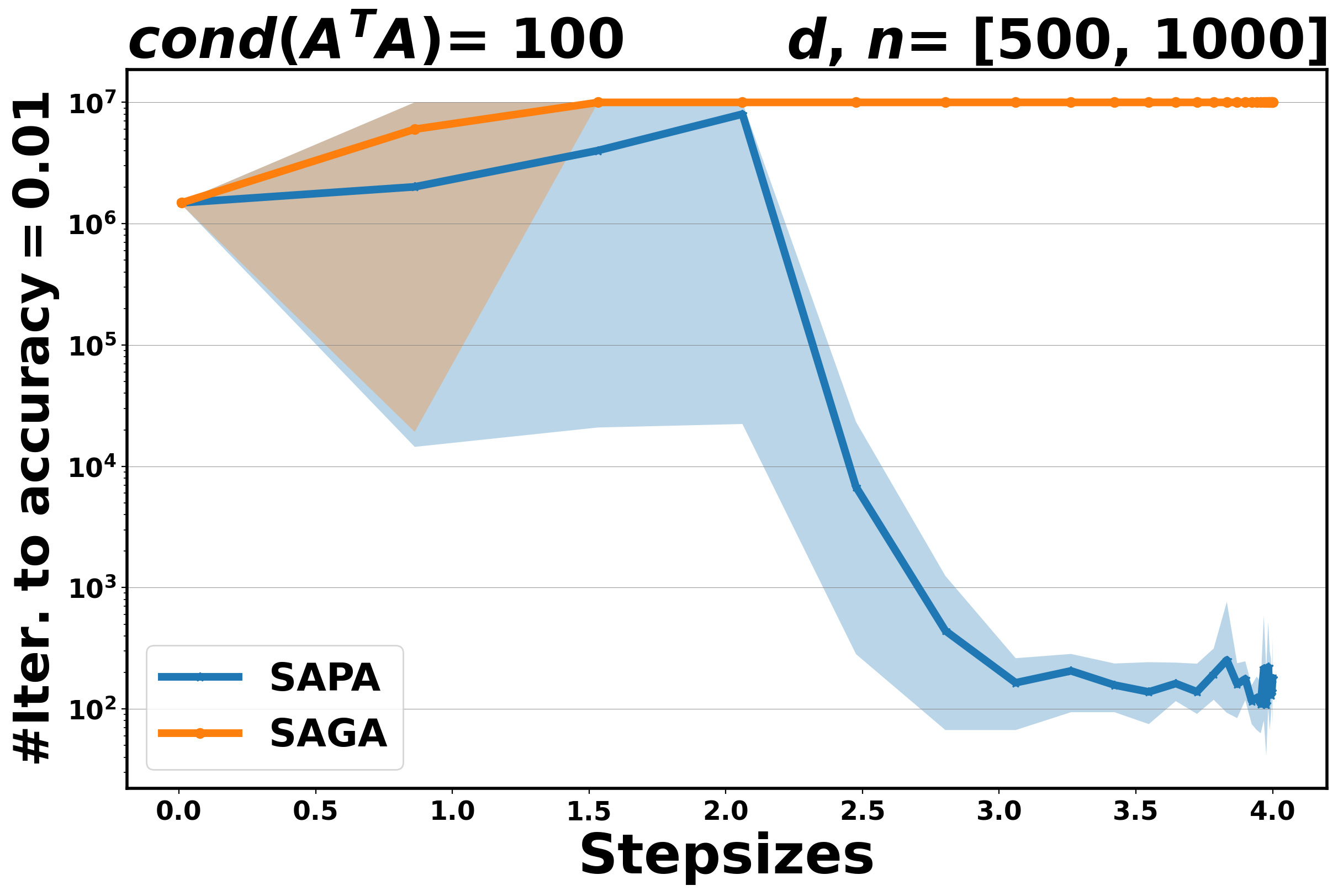
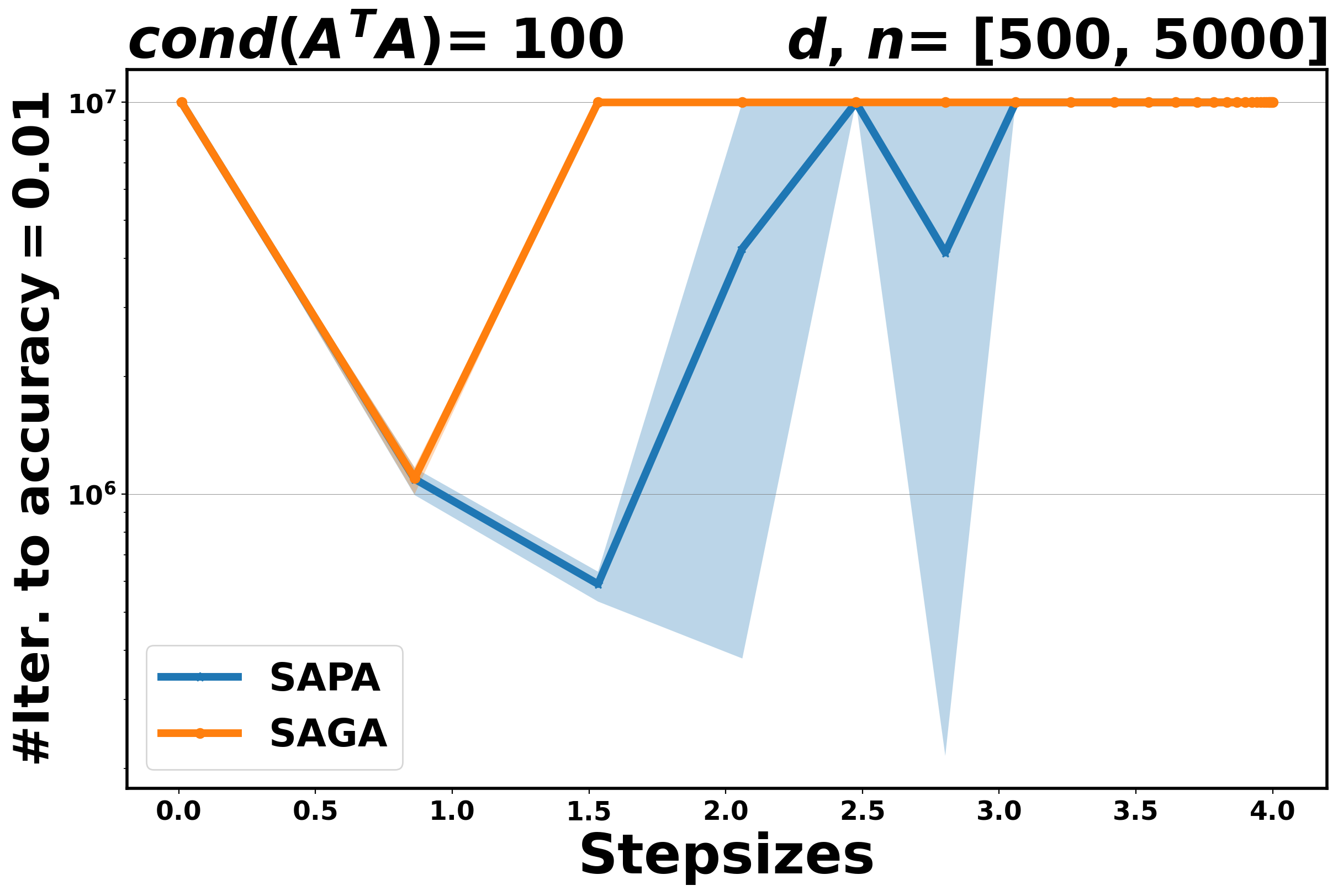
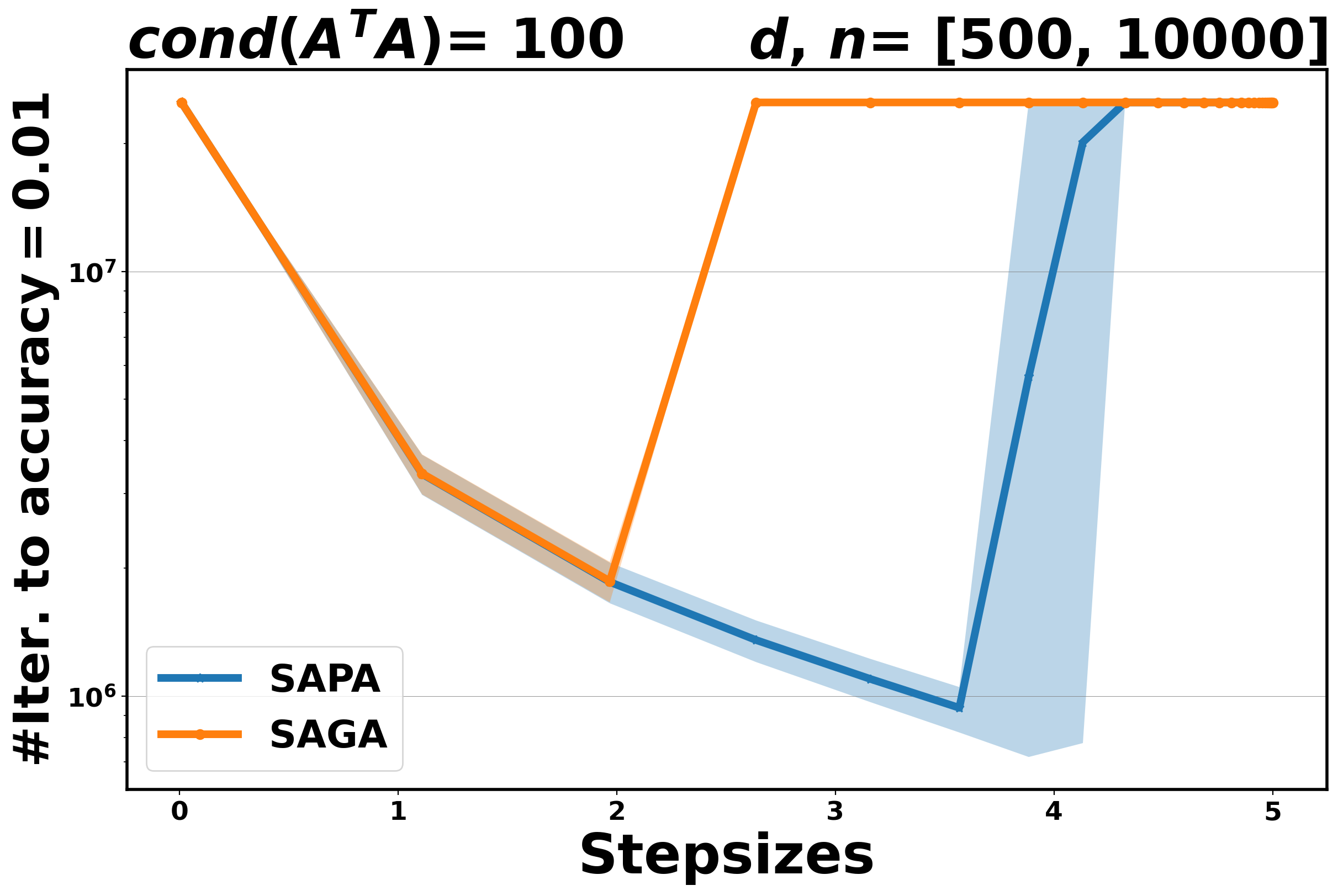
The aim of these experiments is twofold: on the one hand, we aim to establish the practical performance of the proposed method in terms of convergence rate and to compare it with the corresponding variance reduction gradient algorithm, on the other hand, we want to assess the stability of SAPA with respect to the step size selection. Indeed, SPPA has been shown to be more robust and stable with respect to the choice of the step size than the stochastic gradient algorithms, see [3, 37, 26]. In Figure 3 for OLS and Figure 4 for logistic, we plot the number of iterations that are needed for SAPA and SAGA to achieve an accuracy at least , along a fixed range of step sizes. The algorithms run for , fixed at and at .
Our experimental results show that if the step size is small enough, SAPA and SAGA behave very similarly for both problems, see Figure 3 and Figure 4. This behavior is in agreement with the theoretical results that establish convergence rates for SAPA that are similar to those of SAGA. By increasing the step sizes, we observe that SAPA is more stable than SAGA: the range of step sizes for which SAPA converges is wider than that for SAGA.
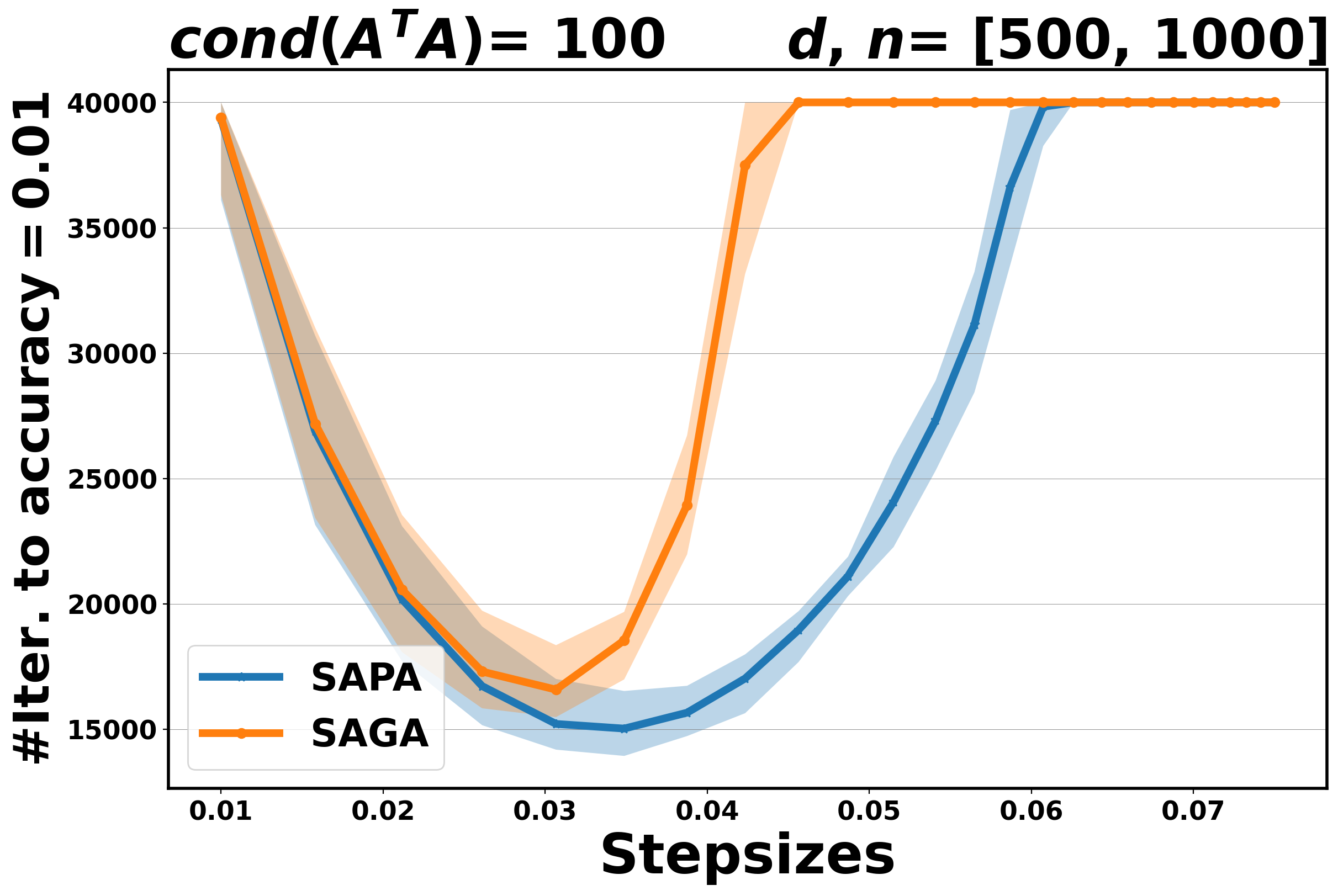
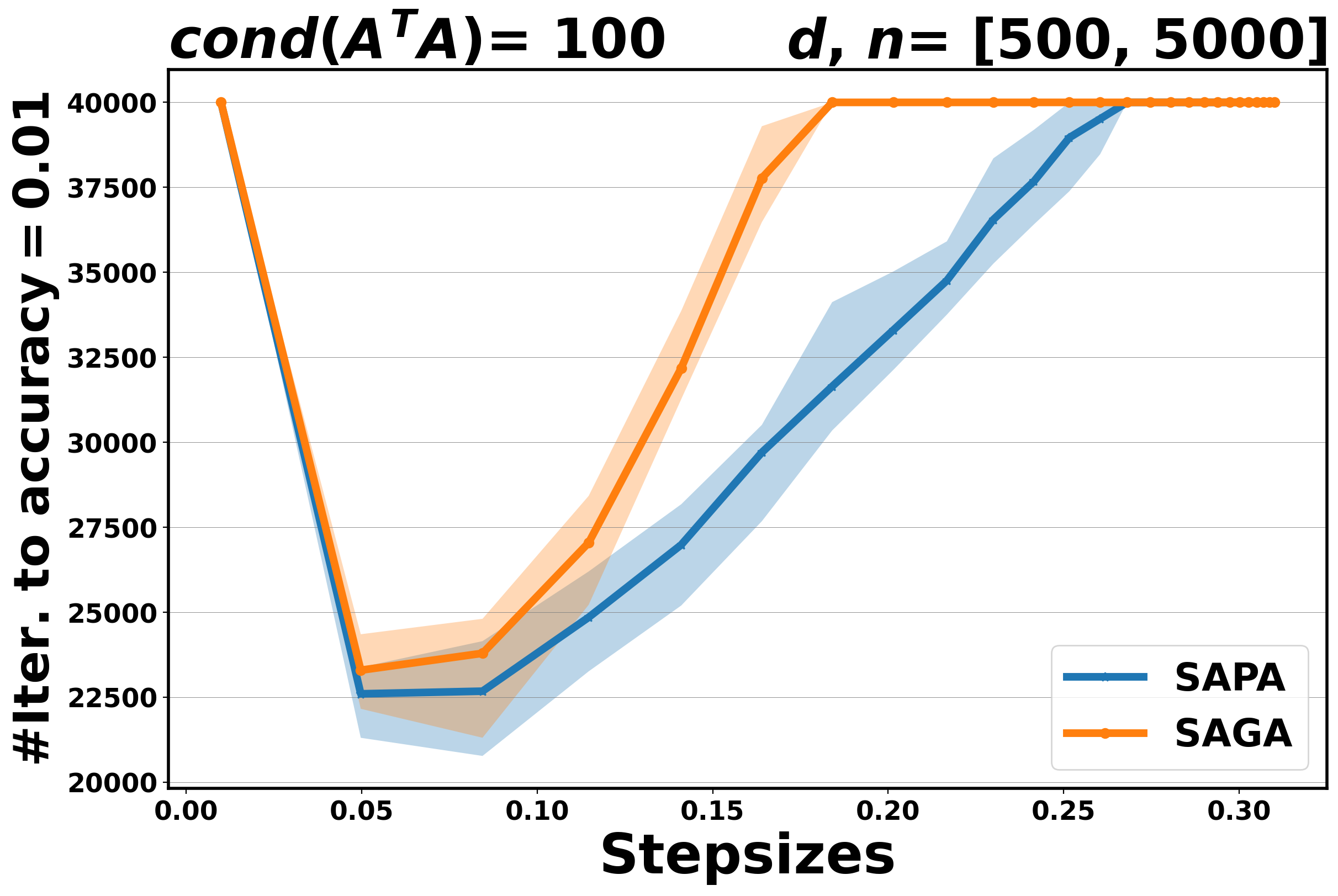
5.3 Comparing SVRP to SVRG
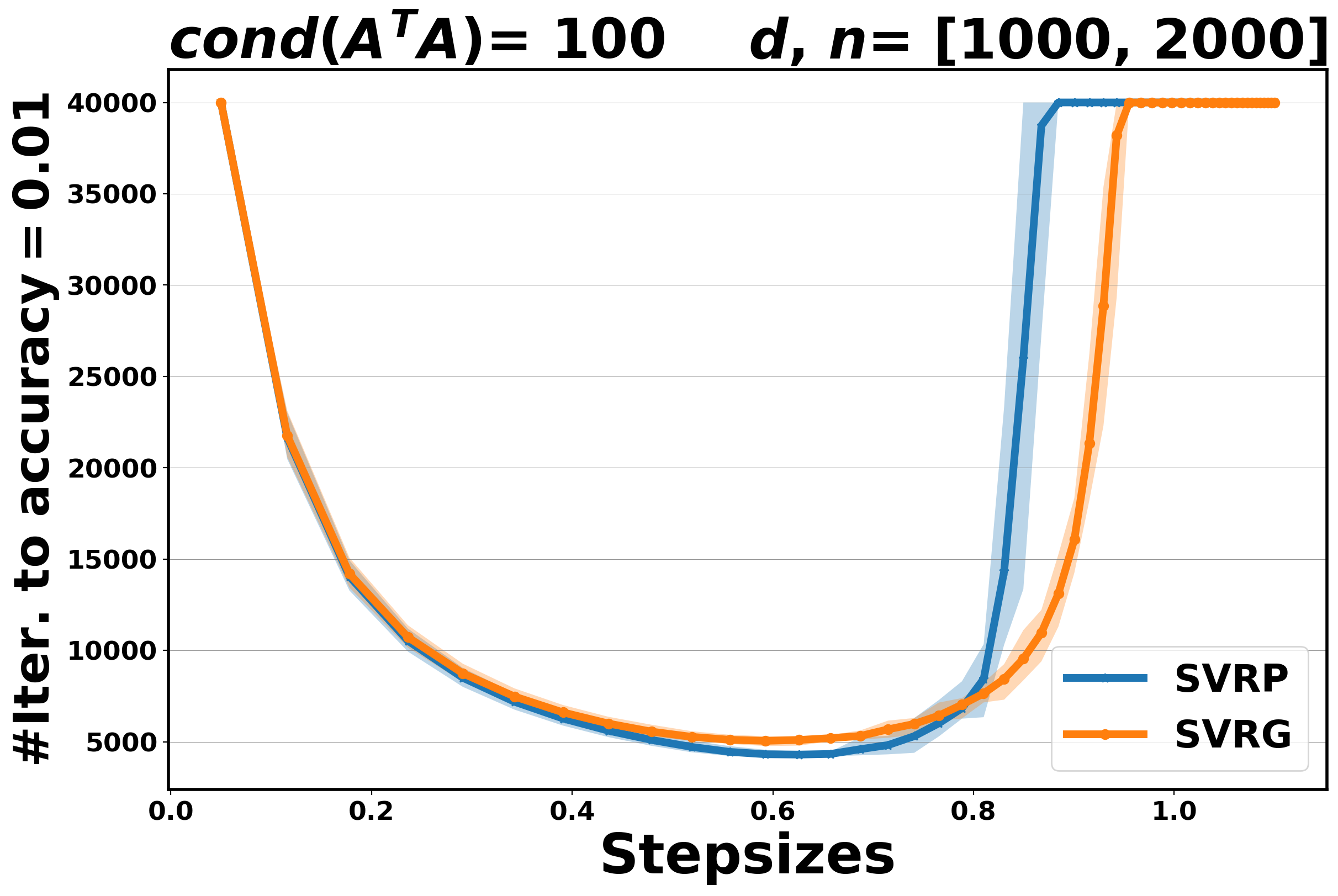
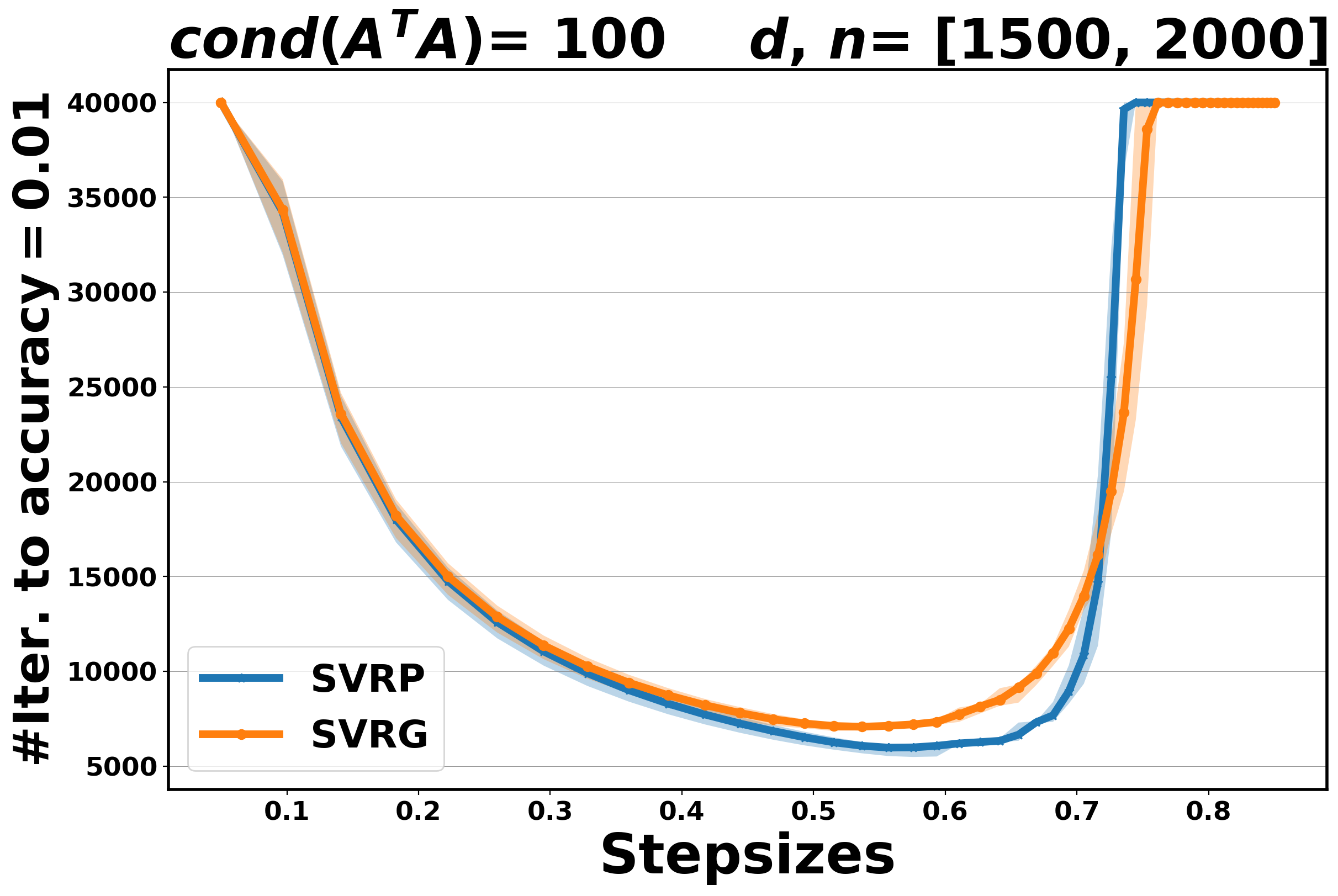
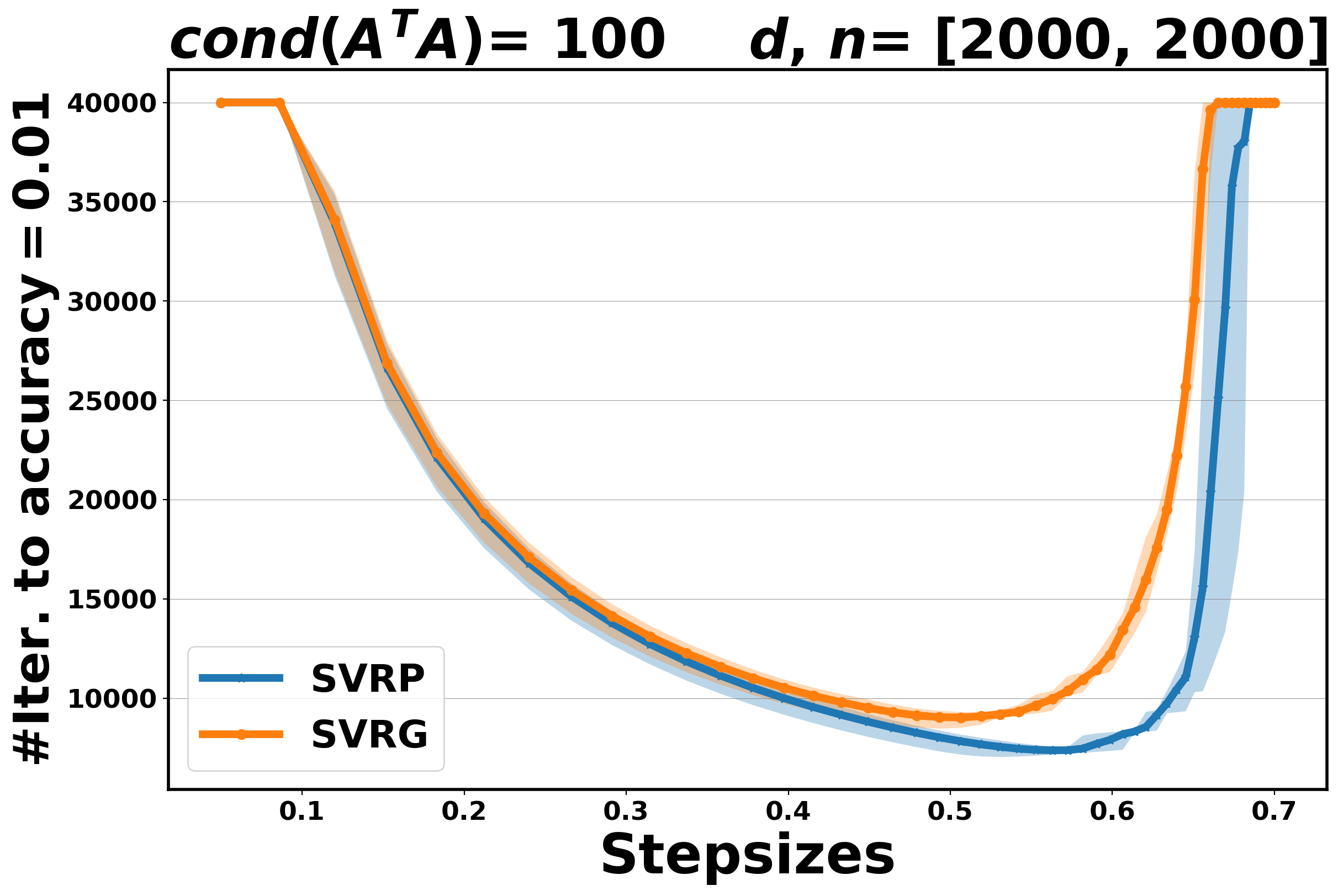
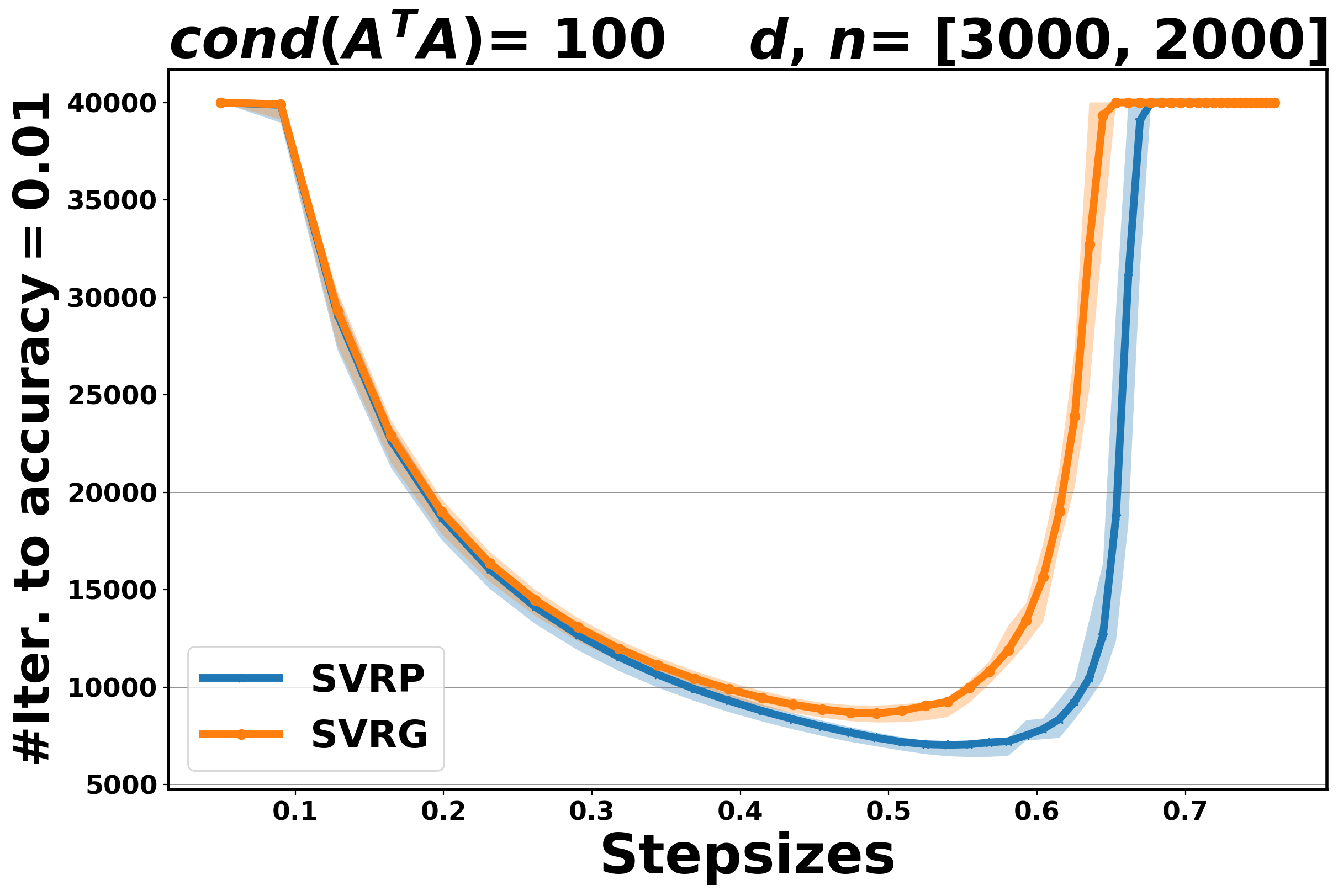
In this section, we compare the performance of Algorithm 4.4 (SVRP) with SVRG [22] for the least-squares problem (5.2), in terms of number of inner iterations (oracle calls) to achieve an accuracy at least , along a fixed range of step sizes. In this experiment, the condition number is set , and the dimension of the objective variable varies in . The number of outer and inner iterations is set to and , respectively, and the maximum number of iterations (oracle calls) is set to .
Two main observations can be made. First, we note that when the step size is optimally tuned, SVRP performs always better than SVRG (overall, it requires fewer iterations to achieve accuracy). Secondly, regarding the stability of the two methods with respect to the choice of the step size, while SVRG seems to be a bit more stable for easy problems (), the situation is reversed for harder problems (e.g., ), where SVRP is more robust. The results are reported in Figure 5.
6 Conclusion and future work
In this work, we proposed a general scheme of variance reduction, based on the stochastic proximal point algorithm (SPPA). In particular, we introduced some new variants of SPPA coupled with various variance reduction strategies, namely SVRP, SAPA and L-SVRP (see Section 4) for which we provide improved convergence results compared to the vanilla version. As the experiments suggest, the convergence behavior of these stochastic proximal variance-reduced methods is more stable with respect to the step size, rendering them advantageous over their explicit-gradient counterparts.
Since in this paper, differentiability of the summands is required, an interesting line of future research includes the extension of these results to the nonsmooth case and the model-based framework, as well as the consideration of inertial (accelerated) variants leading, hopefully, to faster rates. Appendices
Appendix A Additional proofs
In this appendix we provide the proofs of some auxiliary lemmas used in Sections 3 and 4 in the main core of the paper.
A.1 Proofs of Section
Let . The function is convex and continuously differentiable with
By convexity of , we have:
| (A.1) | ||||
Since , from (A.1), it follows:
By using the identity in the previous inequality, we find
| (A.2) |
Recalling the definition of in (2.3), we can lower bound the left hand term as follows:
| (A.3) |
where in the first inequality, we used the convexity of , for all . Since
From (A.3), it follows
| (A.4) |
By using (A.1) in (A.1), we obtain
| (A.5) |
Now, define , where is defined in Assumptions 2.5 and is such that is -measurable and is independent of . Thus, taking the conditional expectation of inequality A.5 and rearranging the terms, we have
Replacing by , with such that and using Assumption (B.ii), we get
| (A.6) |
By taking the total expectation in (A.1) and using (B.iii), for all we have
Since , the statement follows.
∎
A.2 Proofs of Section
Proof of Lemma 4.5. Given any , since is convex and -Lipschitz smooth, it is a standard fact (see [32, Equation 2.1.7]) that
By summing the above inequality over , we have
and hence if we suppose that , then we obtain
| (A.7) |
Now, let and and set, for the sake of brevity, . Defining and , and recalling that
we obtain
where in the last inequality, we used (A.7) with .
∎
Proof of Lemma 4.11 The proof of equation (4.11) is equal to that of (4.5) in Lemma 4.5 using instead of and with , which ensures that and are -measurables, and and are independent of . Concerning (4.12), we note that
Therefore, we have
where in the last inequality we used (A.7) with .
∎
Proof of Lemma 4.17 We recall that, by definition,
Now, set with , so that and are -measurable and is independent of . By definition of , and using the fact that and inequality (A.7), we have
For the second part (4.14), we proceed as follows
where in the last inequality we used inequality (A.7) with .
∎
References
- [1] Z. Allen-Zhu and Y. Yuan. Improved svrg for non-strongly-convex or sum-of-non-convex objectives. In M. F. Balcan and K. Q. Weinberger, editors, Proceedings of The 33rd International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 1080–1089, New York, New York, USA, 20–22 Jun 2016. PMLR.
- [2] V. Apidopoulos, N. Ginatta, and S. Villa. Convergence rates for the heavy-ball continuous dynamics for non-convex optimization, under Polyak–Łojasiewicz condition. Journal of Global Optimization, 84(3):563–589, 2022.
- [3] H. Asi and J. C. Duchi. Stochastic (approximate) proximal point methods: convergence, optimality, and adaptivity. SIAM Journal on Optimization, 29(3):2257–2290, 2019.
- [4] H. H. Bauschke and P. L. Combettes. Convex Analysis and Monotone Operator Theory in Hilbert Spaces. Springer New York, NY, 2017.
- [5] P. Bégout, J. Bolte, and M. A. Jendoubi. On damped second-order gradient systems. Journal of Differential Equations, 259(7):3115–3143, 2015.
- [6] D. P. Bertsekas. Incremental proximal methods for large scale convex optimization. Mathematical programming, 129(2):163–195, 2011.
- [7] P. Bianchi. Ergodic convergence of a stochastic proximal point algorithm. SIAM Journal on Optimization, 26(4):2235–2260, 2016.
- [8] J. Bolte, A. Daniilidis, and A. Lewis. The Łojasiewicz inequality for nonsmooth subanalytic functions with applications to subgradient dynamical systems. SIAM Journal on Optimization, 17(4):1205–1223, 2007.
- [9] J. Bolte, T. P. Nguyen, J. Peypouquet, and B. W. Suter. From error bounds to the complexity of first-order descent methods for convex functions. Mathematical Programming, 165(2):471–507, 2017.
- [10] L. Bottou. On-line Learning and Stochastic Approximations, page 9–42. Publications of the Newton Institute. Cambridge University Press, 1999.
- [11] L. Bottou. Large-scale machine learning with stochastic gradient descent. In Y. Lechevallier and G. Saporta, editors, Proceedings of COMPSTAT’2010, pages 177–186, Heidelberg, 2010. Physica-Verlag HD.
- [12] G. Chierchia, E. Chouzenoux, P. L. Combettes, and J.-C. Pesquet. The proximity operator repository. user’s guide. http://proximity-operator. net/download/guide.pdf, 6, 2020.
- [13] A. Defazio. A simple practical accelerated method for finite sums. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016.
- [14] A. Defazio, F. Bach, and S. Lacoste-Julien. Saga: A fast incremental gradient method with support for non-strongly convex composite objectives. Advances in neural information processing systems, 27:1646–1654, 2014.
- [15] D. Drusvyatskiy and A. S. Lewis. Error bounds, quadratic growth, and linear convergence of proximal methods. Mathematics of Operations Research, 43(3):919–948, 2018.
- [16] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradient methods for online learning and stochastic optimization. Journal of Machine Learning Research, 12(61):2121–2159, 2011.
- [17] C. Fang, C. J. Li, Z. Lin, and T. Zhang. Spider: Near-optimal non-convex optimization via stochastic path-integrated differential estimator. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 31, pages 689–699. Curran Associates, Inc., 2018.
- [18] G. Garrigos, L. Rosasco, and S. Villa. Convergence of the forward-backward algorithm: beyond the worst-case with the help of geometry. Mathematical Programming, 198:937–996, 2023.
- [19] P. Gong and J. Ye. Linear convergence of variance-reduced stochastic gradient without strong convexity. arXiv preprint arXiv:1406.1102, 2014.
- [20] E. Gorbunov, F. Hanzely, and P. Richtarik. A unified theory of sgd: Variance reduction, sampling, quantization and coordinate descent. In S. Chiappa and R. Calandra, editors, Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 of Proceedings of Machine Learning Research, pages 680–690. PMLR, 26–28 Aug 2020.
- [21] T. Hofmann, A. Lucchi, S. Lacoste-Julien, and B. McWilliams. Variance reduced stochastic gradient descent with neighbors. In C. Cortes, N. Lawrence, D. Lee, M. Sugiyama, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 28, pages 2305–2313. Curran Associates, Inc., 2015.
- [22] R. Johnson and T. Zhang. Accelerating stochastic gradient descent using predictive variance reduction. In C. Burges, L. Bottou, M. Welling, Z. Ghahramani, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 26, pages 315–323. Curran Associates, Inc., 2013.
- [23] H. Karimi, J. Nutini, and M. Schmidt. Linear convergence of gradient and proximal-gradient methods under the polyak-łojasiewicz condition. In P. Frasconi, N. Landwehr, G. Manco, and J. Vreeken, editors, Machine Learning and Knowledge Discovery in Databases, pages 795–811, Cham, 2016. Springer International Publishing.
- [24] A. Khaled and C. Jin. Faster federated optimization under second-order similarity. In The Eleventh International Conference on Learning Representations, 2023.
- [25] A. Khaled and P. Richtárik. Better theory for SGD in the nonconvex world. Transactions on Machine Learning Research, 2023. Survey Certification.
- [26] J. L. Kim, P. Toulis, and A. Kyrillidis. Convergence and stability of the stochastic proximal point algorithm with momentum. In R. Firoozi, N. Mehr, E. Yel, R. Antonova, J. Bohg, M. Schwager, and M. Kochenderfer, editors, Proceedings of The 4th Annual Learning for Dynamics and Control Conference, volume 168 of Proceedings of Machine Learning Research, pages 1034–1047. PMLR, 23–24 Jun 2022.
- [27] D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [28] D. Kovalev, S. Horváth, and P. Richtárik. Don’t jump through hoops and remove those loops: Svrg and katyusha are better without the outer loop. In A. Kontorovich and G. Neu, editors, Proceedings of the 31st International Conference on Algorithmic Learning Theory, volume 117 of Proceedings of Machine Learning Research, pages 451–467. PMLR, 08 Feb–11 Feb 2020.
- [29] S. Łojasiewicz. Une propriété topologique des sous-ensembles analytiques réels. Les équations aux dérivées partielles, 117:87–89, 1963.
- [30] A. Milzarek, F. Schaipp, and M. Ulbrich. A semismooth newton stochastic proximal point algorithm with variance reduction. SIAM Journal on Optimization, 34(1):1157–1185, 2024.
- [31] E. Moulines and F. Bach. Non-asymptotic analysis of stochastic approximation algorithms for machine learning. In J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger, editors, Advances in Neural Information Processing Systems, volume 24, pages 451–459. Curran Associates, Inc., 2011.
- [32] Y. Nesterov. Introductory lectures on convex optimization: A basic course, volume 87. Springer Science & Business Media, 2003.
- [33] L. M. Nguyen, J. Liu, K. Scheinberg, and M. Takáč. SARAH: A novel method for machine learning problems using stochastic recursive gradient. In D. Precup and Y. W. Teh, editors, Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 2613–2621. PMLR, 06–11 Aug 2017.
- [34] A. Patrascu and I. Necoara. Nonasymptotic convergence of stochastic proximal point methods for constrained convex optimization. The Journal of Machine Learning Research, 18(1):7204–7245, 2017.
- [35] B. T. Polyak. Gradient methods for the minimisation of functionals. USSR Computational Mathematics and Mathematical Physics, 3(4):864–878, 1963.
- [36] B. T. Polyak. Some methods of speeding up the convergence of iteration methods. Ussr computational mathematics and mathematical physics, 4(5):1–17, 1964.
- [37] H. Robbins and S. Monro. A stochastic approximation method. The annals of mathematical statistics, 22(3):400–407, 1951.
- [38] E. K. Ryu and S. Boyd. Stochastic proximal iteration: a non-asymptotic improvement upon stochastic gradient descent. Author website, early draft, 2014.
- [39] M. Schmidt, N. Le Roux, and F. Bach. Minimizing finite sums with the stochastic average gradient. Mathematical Programming, 162(1):83–112, 2017.
- [40] O. Sebbouh, R. M. Gower, and A. Defazio. Almost sure convergence rates for stochastic gradient descent and stochastic heavy ball. In M. Belkin and S. Kpotufe, editors, Proceedings of Thirty Fourth Conference on Learning Theory, volume 134 of Proceedings of Machine Learning Research, pages 3935–3971. PMLR, 15–19 Aug 2021.
- [41] S. Shalev-Shwartz and S. Ben-David. Understanding machine learning: From theory to algorithms. Cambridge university press, 2014.
- [42] P. Toulis and E. M. Airoldi. Asymptotic and finite-sample properties of estimators based on stochastic gradients. The Annals of Statistics, 45(4):1694–1727, 2017.
- [43] P. Toulis, T. Horel, and E. M. Airoldi. The proximal robbins–monro method. Journal of the Royal Statistical Society Series B: Statistical Methodology, 83(1):188–212, 2021.
- [44] P. Toulis, D. Tran, and E. Airoldi. Towards stability and optimality in stochastic gradient descent. In A. Gretton and C. C. Robert, editors, Proceedings of the 19th International Conference on Artificial Intelligence and Statistics, volume 51 of Proceedings of Machine Learning Research, pages 1290–1298, Cadiz, Spain, 09–11 May 2016. PMLR.
- [45] Z. Wang, K. Ji, Y. Zhou, Y. Liang, and V. Tarokh. Spiderboost and momentum: Faster variance reduction algorithms. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32, pages 2406–2416. Curran Associates, Inc., 2019.
- [46] J. Zhang and X. Zhu. Linear convergence of prox-svrg method for separable non-smooth convex optimization problems under bounded metric subregularity. Journal of Optimization Theory and Applications, 192(2):564–597, 2022.