Vector Field-Guided Learning Predictive Control for Motion Planning of Mobile Robots with Uncertain Dynamics
Abstract
In obstacle-dense scenarios, providing safe guidance for mobile robots is critical to improve the safe maneuvering capability. However, the guidance provided by standard guiding vector fields (GVFs) may limit the motion capability due to the improper curvature of the integral curve when traversing obstacles. On the other hand, robotic system dynamics are often time-varying, uncertain, and even unknown during the motion planning process. Therefore, many existing kinodynamic motion planning methods could not achieve satisfactory reliability in guaranteeing safety. To address these challenges, we propose a two-level Vector Field-guided Learning Predictive Control (VF-LPC) approach that improves safe maneuverability. The first level, the guiding level, generates safe desired trajectories using the designed kinodynamic GVF, enabling safe motion in obstacle-dense environments. The second level, the Integrated Motion Planning and Control (IMPC) level, first uses a deep Koopman operator to learn a nominal dynamics model offline and then updates the model uncertainties online using sparse Gaussian processes (GPs). The learned dynamics and a game-based safe barrier function are then incorporated into the LPC framework to generate near-optimal planning solutions. Extensive simulations and real-world experiments were conducted on quadrotor unmanned aerial vehicles and unmanned ground vehicles, demonstrating that VF-LPC enables robots to maneuver safely.
Index Terms:
Collision avoidance, integrated planning and control, planning under uncertainty, reinforcement learning.I Introduction
Prior information or desired paths are often required to guide robots’ motion. As an effective and efficient method, guiding vector field (GVF) techniques have been recently studied to realize path-following or obstacle-avoidance tasks successfully for robots like fixed-wing airplanes[1], unicycle-type vehicles[2], unmanned aerial vehicles[3], etc. The GVF typically addresses motion planning and control tasks in the following manner[4]: (1) simple kinematic models of robots are considered (such as single or double integrator models); (2) GVF provides guidance signals to be tracked by the inner-loop dynamic controller). Therefore, the guidance level (i.e., the design of the GVF) and the control level can be separately designed. However, the proposed GVFs such as[5] may generate guidance signals with drastic variations when crossing static obstacles, posing a challenge to the robot’s maneuvering capabilities. On the other hand, robot dynamics and safety constraints (e.g., avoidance of suddenly appearing obstacles) are critical in improving the robots’ maneuvering capabilities. When considering the robotic dynamics constraint separately at planning and control levels, the issues of consistency and optimality have to be carefully addressed for real-world applications. Therefore, it is crucial to introduce an Integrated Motion Planning and Control (IMPC) approach to generate solutions transmitted to robot dynamics directly. In light of the above two aspects, designing adaptive IMPC approaches that leverage the improved GVF as guidance for real-world robots with uncertain/unknown dynamics is promising, particularly in obstacle-dense scenarios; An illustration diagram is presented in Fig. 1.
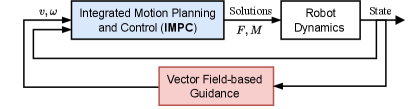
Optimization-based motion planning methods have recently been studied for realizing IMPC [6, 7]. It is crucial to estimate model uncertainties in real-time to address the challenge of uncertain robotic dynamics impacting model predictive control (MPC) methods. This can be achieved through online estimation techniques, while solving nonlinear or non-convex optimization problems online may pose reliability and computational intensity issues. Reinforcement learning (RL) and adaptive dynamic programming (ADP) are promising in solving optimal planning and control problems[8],[9],[10]. Recent works on realizing RL-based IMPC have been studied[9, 10]. They generally design proper reward functions based on priori information or desired paths to learn optimal policies. With the desired paths, existing endeavors primarily realize safe tracking control by designing reward functions encompassing state errors, control inputs, and safety terms. However, in obstacle-dense scenarios, obtaining the desired safe paths is not easy. When the desired path is constituted by a straight line from the starting point to the endpoint, it may traverse many obstacles in obstacle-dense environments. Furthermore, the desired speed or angular velocity for these paths needs to be computed separately. The two aspects increase the complexity of designing RL-based IMPC algorithms, posing challenges to achieving near-optimal performance. Therefore, providing guidance for them is very important. Despite the above difficulties, current RL-based IMPC has shown effectiveness and efficiency for robots with nonlinear system dynamics[8],[9],[10]. Letting RL-based IMPC approaches work as the IMPC structure in Fig. 1 is still promising if the above-discussed challenges can be well addressed. Namely, a GVF provides kinematic guidance (e.g. linear and angular velocities) for RL-based IMPC approaches.
There exist two main categories of RL-based IMPC studies; i.e., model-based and model-free ones. Obtaining a precise dynamic model is nontrivial due to internal factors such as system nonlinearity, and external factors such as uneven terrain, and slippery surfaces. The advantage of model-free RL methods lies in their independence from precise models. However, they still lack generalization ability to the unseen scenarios and data-efficiency of policy learning. Efficient model-based RL (MBRL) approaches have shown their effectiveness in real-world applications[9, 10]. Since real-world robot dynamics are often uncertain and even unknown, MBRL approaches struggle to achieve satisfactory reliability. This is due to: (1) The online adaptability of current data-driven modeling methods is insufficient; (2) The safety terms in the reward function may lead to policy divergence of RL-based motion planning algorithms. Motivated by the two challenges, we propose compensating for the data-driven model online and adopting a receding-horizon actor-critic framework (also called Learning Predictive Control[11], LPC) to ensure the convergence of planning policies in the prediction horizons.
To realize motion planning of mobile robots with uncertain/unknown dynamics in obstacle-dense scenarios, we propose a Vector Field-guided Learning Predictive Control (VF-LPC) approach. Specifically, the guiding level plans preliminary trajectories fast to avoid dense static obstacles. The optimal performance under the uncertain/unknown system dynamics and the safety constraints from (suddenly appearing) moving obstacles are optimized by solving the Hamilton–Jacobi–Bellman (HJB) equation online in prediction horizons. In particular, we introduce a sparsification technique in the model compensation and finite-horizon actor-critic learning processes to improve online efficiency and IMPC performance. The contributions of this paper are summarized as follows:
-
1)
The VF-LPC approach can achieve near-optimal motion planning for mobile robots with uncertain/unknown dynamics in obstacle-dense environments. The approach achieves higher computational efficiency and obtains more reliable solutions than advanced model predictive control (MPC) and RL methods in solving nonlinear optimization problems (see Sections IV-D and VI).
- 2)
-
3)
The VF-LPC approach can update online the uncertain dynamics of a fully data-driven model trained by the deep Koopman operator. It reduces the differences between the real and learned system dynamics models when the environment is time-varying or the system dynamics are learned inaccurately. Therefore, it improves the planning performance and guarantees safety (see Section IV-B).
-
4)
By adding virtual obstacles, the modified and improved discrete-time composite vector field adopted by our VF-LPC approach can satisfy robot kinodynamic constraints. In addition, the modified vector field does not suffer from the deadlock problem, which usually exists in traditional composite vector fields. Moreover, VF-LPC can deal with (suddenly appearing) moving obstacles by introducing a game-based barrier function (see Sections IV-A, IV-C).
The remainder of this paper is organized as follows. Section II reviews the related works. Then Section III provides the preliminaries and problem formulation. The VF-LPC is introduced in Section IV. Then, Section V presents the convergence results of VF-LPC. Section VI elaborates on the simulation and experimental validation. Finally, the conclusion is drawn in Section VII.
Notation: The notation represents , where is a positive (semi-)definite matrix, and . The field of real numbers is denoted by . A diagonal matrix is denoted by , where are entries on the diagonal. Throughout this paper, we use the notation to denote the identity matrix of suitable dimensions. The notations and denote the Kronnecker and Hadamard products, respectively.
II Related Work
We first discuss several modeling methods and then present a literature review on MPC and learning-based approaches for motion planning of robots with uncertain dynamics.
Data-driven modeling. Current advanced data-driven modeling methods include least-squares[12], recurrent neural networks (NNs)[13], multi-layer perception (MLP)[14], neural networks[15], etc. As a linear operator, the Koopman operator-based modeling methods[16],[17],[18] can establish linear time-invariant system dynamics. Impressed by such a property, dynamic mode decomposition (DMD)[16], extended DMD (EDMD)[17], and kernel-based DMD[18] have received much attention in recent years. However, the modeling performance of the Koopman operator relies heavily on the observable function design. Consequently, approaches using NNs for automated observable function construction [19, 20] were proposed and have been validated to be effective through numerical simulations. To improve the modeling accuracy, Xiao et al. [21] proposed a deep direct Koopman (DDK) method for identifying linear time-invariant vehicle dynamic models. Unlike these, we further consider improving the online adaptability of offline-trained dynamics models by learning the uncertain dynamics of the offline-trained Koopman model.
Sampling-based and optimization-based motion planning algorithms for robots with uncertain dynamics. Several studies have integrated chance constraints with sampling-based Rapidly-exploring Random Trees (CC-RRT) methods, presenting efficient path planning capability in densely cluttered obstacle environments [22, 23]. Gaussian processes (GPs) were employed for determining dynamically feasible paths and CC-RRT for establishing probabilistically feasible paths[23]. These approaches fail to guarantee optimality due to the lack of consideration of the robot’s motion dynamics.
Under uncertain dynamics, optimization-based motion planning methods typically involve objective functions incorporating Conditional Value-at-Risk (CVaR) measures[24],[25]. Nakka et. al. handle the motion planning problem of chance-constrained nonlinear stochastic systems by deriving a surrogate problem with convex constraints[6]. Zhu et. al. designed a chance-constrained nonlinear MPC method to solve collision avoidance problems of multi-robots under various uncertainties like motion disturbance[26]. To realize real-time optimization, they developed a tight bound for the approximation of collision probability. In[27], Lew et. al. proposed a robust trajectory optimization method for nonlinear systems with model uncertainty and disturbances. Especially, it is capable of processing non-convex obstacle constraints. In [28], Kalman filtering was utilized for state estimation, and risk-aware safety constraints arising from estimation errors were introduced into stochastic optimal motion planning problems. Many of the above studies process various uncertainties like sensing, obstacle motion, robot dynamics, etc. According to [29], two major ideas are considered in the area of feedback motion planning, i.e., probabilistic guarantees on safety and bounded models of uncertainties. In this paper, the unknown system dynamics are modeled with the previous deep Koopman operator[21]. We consider the bounded uncertainty of data-driven system dynamics and compensate online for it.
Learning-based motion planning for robots with uncertain dynamics. As discussed in[30], RL-based approaches to addressing obstacle avoidance problems under uncertainties typically fall into two categories: one involves the endeavor to construct stochastic models of the uncertain dynamics inherent in robotic systems, leveraging the resultant probabilistic models for planning or policy learning; the other entails devising plans that account for worst-case scenarios. Regarding the first category, a Gaussian process model was used in the policy search framework of PILCO, thereby capturing the system dynamics and estimating the probability of safe constraints violation[31]. During the policy learning process, the candidate policies are optimized toward the safer directions with low risks. In [32], the Monte Carlo motion planning method was proposed to sample feasible trajectories under uncertainties, thereby fulfilling probabilistic collision avoidance constraints. Model-based motion planning under uncertain dynamics can be found in [9],[10]. Regarding the second category, Snyder et. al. proposed a trust-region-based online learning algorithm with provable regret bounds by minimizing worst-case regret[30]. To realize kinodynamic motion planning and control, we design an IMPC framework leveraging the guidance from the vector field and further consider the uncertainties of the data-driven model in obstacle-dense environments.
III Preliminaries and Problem Formulation
This section presents a detailed preliminary for the composite vector field, which will be developed later in this paper for generating preliminary kinodynamic trajectories. Then, we review a data-driven deep Koopman-based system modeling method. The previously developed sparse GP can efficiently identify model uncertainties online, which is also reviewed here to identify the model uncertainties of the nominal model. Note that for one thing, GP can be used to identify the full system dynamics individually, but the long-horizon modeling accuracy is difficult to guarantee. To enhance the accuracy, one has to use flawless samples and fine-tune the hyperparameters, which can be computationally demanding. For another, the Koopman model may not accurately characterize the exact model, so estimating the uncertainty of model learning is essential. Therefore, to improve the accuracy, we propose to combine the Koopman model learning and the sparse GP. In particular, we employ online sparse GP to compensate for the inaccuracy and uncertainty associated with the offline-trained Koopman model, which will be introduced later in our methodology. Finally, we present the problem formulation for optimal motion planning under the fully data-driven system model containing uncertain dynamics.
III-A Composite Vector Field
Consider the following ordinary differential equation
with the initial state , where is continuously differentiable concerning , and it is designed to be a guiding vector field for path following [5].
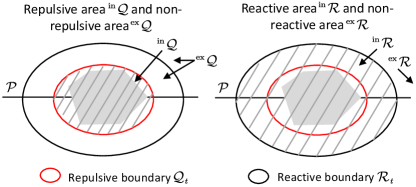
In Fig. 2, the elements of the composite vector field are illustrated in detail. A reference path is provided initially and may be occluded by obstacles, and it is defined by
where is twice continuously differentiable. For example, a circle path can be described by choosing , where is the circle radius. To avoid collisions, Yao et al. [5] proposed a composite vector field for processing obstacle constraints. It involves a reactive boundary and a repulsive boundary , i.e.,
where is twice continuously differentiable, , is the total number of obstacles, and . The repulsive boundary is the boundary that tightly encloses the -th obstacle at time and a robot is forbidden to cross this boundary to avoid collision with the obstacle. The reactive boundary is larger than and encloses the repulsive boundary, and its interior is a region where a robot can detect an obstacle and become reactive. We use prescripts and to denote the exterior and interior regions of a boundary, respectively. For example, represents the exterior region of the repulsive boundary (see Fig. 2). An example of moving circular reactive and repulsive boundaries can be characterized by choosing and letting . In this case, the reactive and repulsive boundaries are large and small concentric circles moving along the -axis as increases, respectively.
We denote the path-following vector field by and the repulsive vector field by , and they are defined below:
where is the rotation matrix of , , , determines the moving direction (clockwise or counterclockwise), and are positive coefficients. The composite vector field is as follows[5]:
| (1) |
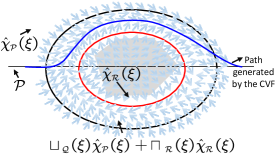
where is the normalization notation (i.e., for a nonzero vector , ), are smooth bump functions, where if and if , if and if , and are coefficients for changing the decaying or increasing rate. Note that for simplicity, the subscripts of related symbols have been omitted above. These smooth bump functions blend parts of different vector fields and create a composite vector field for path following and collision avoidance; for more details, see [5]. To understand the composite vector field intuitively, we illustrate the composite vector field (1) in Fig. 3. For in (1), it is equal to , , and within the three regions , , and , respectively.
The singular sets of and , denoted by and , respectively, are defined below:
The elements of singular sets are called singular points, where vector fields vanish. Due to the possible presence of singular points, special designs are required to solve the deadlock problem. When we employ the guiding vector field as high-level guiding signals, neglecting the kinodynamic constraints usually deteriorates the control performance. Therefore, in the subsequent sections, we will consider the kinodynamic constraints.
III-B Offline Deep Koopman Operator-based System Modeling
Consider the following continuous-time nonlinear system
| (2) |
where denotes the system state, is the system transition function, denotes the control input, and is the control constraint set. Note that the explicit dependence on time is dropped unless needed for clarity. We assume that is locally Lipschitz continuous.
The discrete-time Koopman operator of (2) can be described as follows:
| (3) |
where is an infinite-dimensional linear Koopman operator in a Hilbert space , and is the observable function. In [21], is approximated by -order system dynamics by using deep neural networks, i.e.,
| (4) |
where and are latent system matrices, where denotes the encoder module.
III-C Sparse GP Regression for Online Compensation
Next, we will review a sparse GP regression method called FITC [33], which reduces computational complexity by selecting inducing samples and introduces a low-rank approximation of the covariance matrix, transforming the original GP model into an efficient one. It is briefly introduced in the following.
III-C1 The formulation of full GP Regression
An independent training set is composed of state vectors, i.e., and the corresponding output vectors . In [34], the mean and variance functions of each output dimension at a test point are computed by
| (5) | ||||
where is the variance, is a Gram matrix containing variances of the training samples. Correspondingly, denotes the variance between a test sample and training samples, and represents the covariance, is the squared exponential kernel function and is defined as follows:
| (6) |
where is the signal variance and . Here and are hyperparameters of the covariance function.
III-C2 Sparse GP Regression
Given an inducing dictionary set with samples from , the prior hyper-parameters can be optimized by maximizing the marginal log-likelihood of the observed samples. In [33], the mean and variance functions of a full GP are approximated by using inducing targets , inputs , i.e.,
| (7) | ||||
where is diagonal and the notation . Several matrices in (7) do not depend on and can be precomputed, such that they only need to be updated when updating or itself.
Finally, a multivariate GP is established by
| (8) |
where , and .
III-D Problem Formulation
III-D1 Composite Vector Field with Kinodynamic Constraints
The composite vector field acts as a local path planner and should satisfy the kinodynamic constraint, leading to the problem of Vector-Field-guided Trajectory Planning with Kinodynamic Constraint (VF-TPKC), which is formulated in Definition 1. This problem is decomposed into two components. In the presence of obstacles obstructing the desired path, the planning method should ensure the safety of paths, i.e., avoiding collision with obstacles. Then, the issue of satisfying dynamic constraints arises, involving improvements upon the path planning method established in the first step.
Remark 1.
The term “kinodynamic constraint” refers to the requirement that a robot will not collide with obstacles at different speeds. To address this issue, we have transformed it into the fulfillment of the maximum lateral acceleration.
Definition 1.
(VF-TPKC) Design a continuously differentiable vector field for such that:
-
1)
It achieves path-following and collision avoidance. In addition, the path-following error is bounded, and no deadlocks exist.
-
2)
Given the robot’s velocities , , and the maximum centripetal acceleration , it holds that for and is the curvature at time t. .
A guiding vector field is designed to generate a continuously differentiable reference path, which is obtained by
Subsequently, we employ a learning-based predictive control approach to track the desired trajectories and avoid dynamic obstacles at the same time.
III-D2 Optimal Motion Planning to Avoid Moving Obstacles
Given the offline learned system (4), it is feasible to use it to design optimal IMPC. However, the interaction environments may be time-varying, causing the system dynamics to be uncertain. We can rewrite the exact system dynamics as a data-driven Koopman model adding an uncertain part by
| (9) |
where the above model consists of a known nominal part and an additive term , which lies within the subspace spanned by [35]. We assume that the process noise is independent and identically distributed (i.i.d.), with spatially uncorrelated properties, i.e., , where denotes the dimension of .
Assuming that the desired trajectory can be denoted by
| (10) |
the subtraction of Eq. (10) from Eq. (9) yields the following error model, i.e.,
| (11) |
where is the error state, is the reference state, and is the control input.
We formally define the Optimal Motion Planning (OMP) problem, which consists of two subproblems. The first subproblem is the tracking control problem. To formulate this subproblem, we first define the value function as the cumulative discounted sum of the infinite-horizon costs:
| (12) |
where , is the cost function, is positive semi-definite, and is positive definite. The second subproblem is how the robot can avoid moving obstacles. Combining the two subproblems, we formulate the optimal OMP as below:
Problem 1.
(OMP) Design an optimal IMPC for the robot with uncertain system dynamics such that it
-
C.1:
Starts at and tracks the reference path by minimizing the value function .
-
C.2:
Avoids collisions with all obstacles , where denotes the workspace.
IV Vector Field Guided Receding Horizon Reinforcement Learning for Mobile Robots with Uncertain System Dynamics
It is essential to generate local collision-free trajectories for guiding robots’ motion in obstacle-dense scenarios, which could improve safety and simplify the design of RL-based IMPC. Motivated by this aspect, we design a guiding vector field that considers dynamic constraints and excludes the deadlock problem (i.e., singular points). This part is illustrated by the safety guiding module in Fig. 4. Considering safety when robots track the desired trajectory, we must deal with the movements of (suddenly appearing) moving obstacles and the uncertainties of the nominal deep Koopman model. To this end, we develop an online receding-horizon reinforcement learning (RHRL) approach that employs a game-based exponential barrier function and a fast model compensation scheme. This part is illustrated by the learning predictive control module of Fig. 4. The details of each module and its sub-modules will be illustrated in the following subsections.
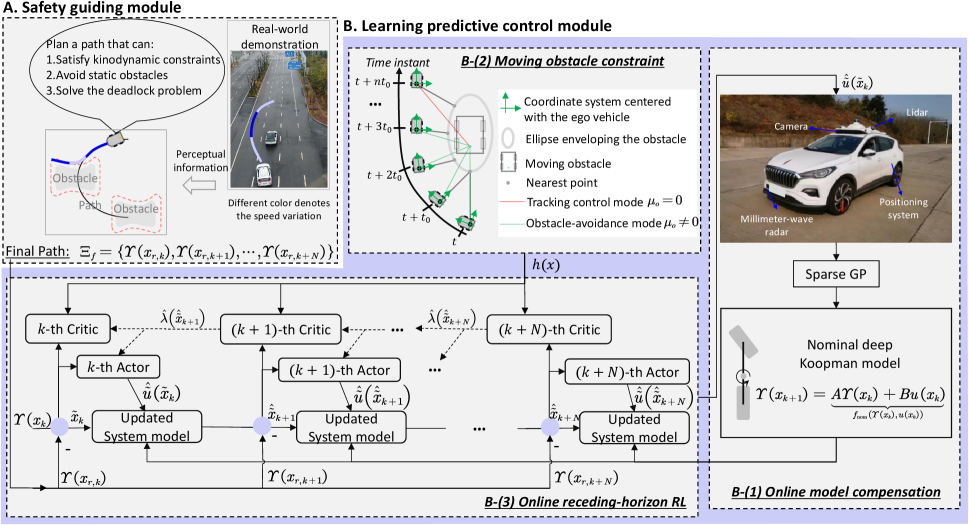
IV-A Discrete-time Kinodynamic Composite Vector Field
In this subsection, we present a discrete-time kinodynamic composite vector field to generate locally feasible trajectories, corresponding to module A of Fig. 4.
IV-A1 Composite Vector Field with Kinodynamic Constraints
The first objective in Definition 1 can be achieved by the composite vector field (1). To accomplish the second objective in Definition 1, we first design the following kinodynamic composite vector field based on (1):
|
|
(13) |
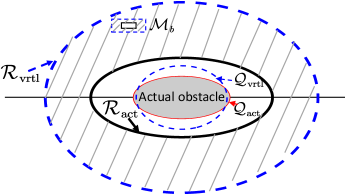
where is a set containing the index numbers of manually added virtual obstacles, and is a function to be designed later. The path generated by the original composite vector field in (1) would often require the robot to make large turns within a limited distance for collision avoidance. The role of virtual obstacles here is to proactively modify the vector field such that the curvature of the robot trajectory is less than the maximum allowable value as the robot enters the sandwiched region
| (14) |
(i.e., the area sandwiched between the repulsive and the reactive boundaries; see the white annulus region in Fig. 5), thereby satisfying the dynamic constraints. The definitions of the reactive and repulsive boundaries are expressed through the function . For example, the reactive boundary corresponding to a virtual obstacle is described by in Fig. 5, and its repulsive boundary is described by . When the robot’s position enters the virtual reactive region , it will be attracted towards the virtual repulsive boundary . This provides a direction change before enters the actual reactive region corresponding to the actual obstacle, and the virtual obstacle will not affect its motion after enters the actual reactive region . Based on the above analyses, within/outside the buffer region (i.e., the shaded area in Fig. 5)
| (15) |
the function is designed to be
| (16) |
where the adjustable coefficient is used to change the convergence rate to , and denotes the exponential function. Thus, in this design, if ; , otherwise.
Remark 2.
The placed virtual obstacle is assumed to satisfy . The assumption is used for letting exit the sandwiched region from , but not converging to when robots are in .
Remark 3.
Virtual obstacles cease to exert their influence if enter again from . This setting stops robots from returning to , but enables them to move towards the desired path to complete an obstacle avoidance process.
Now, the guidance path generated by the vector field can avoid rapidly increasing curvature. To satisfy the maximum centripetal acceleration , speed planning is further performed for the path under a given desired speed , where determines the time duration. The maximum allowable speed is . We can perform speed planning by the following strategy: If , then set the speed at to ; otherwise, set the speed at to .
IV-A2 Analysis of the Composite Vector Field
The composite vector field (13) gives an idea of how to accommodate the kinodynamic constraint. By redesigning the characterizing functions , , the bump functions, and the coefficients , the first condition of Definition 1 can be met in practice[5]. The second condition can be satisfied by selecting proper positive coefficient . These two conditions are satisfied in simulations and experiments in this paper.
IV-A3 Discrete-time Kinodynamic Guiding Vector Field
With defined in (13), the desired path is computed by its discrete-time form, i.e.,
| (17) |
where is the initial robot position and is the step length, and , where the set is the grid map consisting of a finite number of chosen points in a selected region. In terms of computational efficiency, it is advisable to precompute on a mesh grid map. This makes it possible to quickly identify the nearest vector on the mesh grip map based on the current position . Finally, we can obtain the planned trajectory. Note that a vector with nearly zero norms is not selected as the current vector but rather inherits the vector from the previous state to avoid suffering from the singularity issue. Namely, if , then , where is a small positive number. This allows us to plan guiding trajectories directly without causing the deadlock problem from singular points.
IV-B Online Compensation to Update the Offline Trained Deep Koopman Model
In this subsection, we present an online compensation method to update the offline trained deep Koopman model since model uncertainties exist. This subsection corresponds to module B-(1) of Fig. 4.
To construct the “input-output” form of a GP, Eq. (9) is rewritten as
| (18) |
where is the Moore–Penrose pseudoinverse of .
Remark 4.
Due to the necessity for efficient computation in the online compensation of vehicle dynamic models, we further apply the approximate linear dependence (ALD) strategy[9] to quantize the online updated dictionary for obtaining the training dataset . Note that is obtained in the same way as [36]. Subsequently, we employ the Sparse GP-based algorithm FITC [33] for online estimation to enhance computational efficiency. This approach aligns with our previous work, and additional details can be found in[9].
With the optimized parameters, GP models compensate for model uncertainties. Therefore, we define the learned model of (9) as
| (19) |
where is the estimation error. The reference trajectory can be expressed as .
We can obtain the Jacobian matrix of (19) at a reference state , i.e.,
| (20) |
where , . Note that and are then used for the training process of model-based RL in Section IV-D. To obtain and , one should compute first, which is equivalent to calculating , i.e.,
| (21) |
where and denotes the input and output of the training samples , respectively, denotes an -dimensional row vector consisting entirely of . Ultimately, this yields matrices and . Then an error model derived from (11) is given below by assuming that the estimation error is sufficiently small, i.e.,
| (22) |
IV-C Exponential Barrier Function Incorporated Cost Function to Avoid Moving Obstacles
In this subsection, we design a cost function incorporated with an exponential barrier function to deal with the moving obstacle constraint, corresponding to module B-(2) of Fig. 4.
Note that C.2 in the OMP Problem can cause safety issues due to the obstacles’ movements. Consistent with [9], an implementable barrier function used for safety is designed as
| (23) |
where is the penalty coefficient, is the nearest reactive boundary coordinate from the nearest obstacle, and maps and to the distance error. With , the robot keeps a safe distance from obstacles.
Due to the adoption of rule-based switching between tracking control and obstacle-avoiding modes in [9], without considering obstacle velocities, it does not guarantee the safety of mobile robots under extreme conditions such as the hazardous driving behavior of opposing vehicles. Our idea stems from the work[37] in completing suicidal game tasks, where the “evader” aspires to avoid being caught by the “pursuer” by computing safe actions. Similarly, when moving obstacles obstruct the road ahead, our strategy is to keep a safe distance from obstacles and track the desired trajectory if the ego robot cannot be caught. Integrating [9] and [37], the exponential barrier function comes into effect if the nearest surrounding obstacle would collide with the robot, where the judgment is generated by the method in [37], as elaborated below.
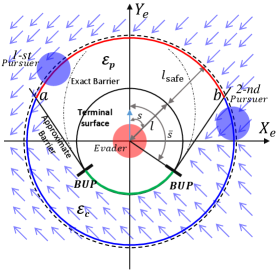
As shown in Fig. 6, a Cartesian coordinate system is established with the direction of the evader’s velocity as the -axis, to facilitate the design of the safety-guaranteed switching mechanism. In this figure, denotes the preset maximum safety margin, and depends on the maximum tracking error of a controller, and is the safety distance defined by the physical constraints of the robot and obstacles. The terminal circle is divided into the usable part (the black line) and the nonusable part (the green line), separated by the boundary of the usable part (BUP). In [37], the solution of BUP is determined by , where and are the speeds of the pursuer and the evader, respectively. The barrier implies that the optimal play by both agents starting from any point will generate a path that does not penetrate this surface. The BUP connects the barrier and meets the terminal surface at the BUP tangentially. Therefore, as shown in Fig. 6, we consider the plane formed by points , , and the points at BUP as a conservative barrier to ensure safety. Fig. 6 shows that the coordinate plane is divided into two regions: and , where and are defined below:
with
The switching mechanism is elucidated more clearly below: In the area , in (23) is set to keep a safe distance from the obstacle, while in the region , we let to track the planned preliminary path. To satisfy the conditions C.1 and C.2 in the OMP Problem, the step cost function at the -th stage is re-designed as
| (24) |
Equipped with the autonomous switching mechanism, the cost function is designed to learn motion planning policies.
IV-D Online Receding-horizon Reinforcement Learning with a Game-based Exponential Barrier Function Design
In this subsection, we design a receding-horizon reinforcement learning with a game-based exponential barrier function, corresponding to module B-(3) of Fig. 4. In the previous subsection, the game-based exponential barrier function has been incorporated into the cost function to establish a constraint-free optimization problem, which is to be solved online in this subsection by the Receding-Horizon Reinforcement Learning (RHRL) approach. For this reason, we call it Exponential barrier function-based RHRL (Eb-RHRL).
To minimize the infinite-horizon value function , we first present the definitions of the optimal solution (control) and value functions commonly used in infinite-horizon ADP and RL. As a class of ADP methods, the dual heuristic programming (DHP) approach aims to minimize the derivative of the value function with respect to the state. Consistent with the DHP-based framework, we re-define the value function as
| (25) |
Definition 2.
The optimal value function corresponding to the infinite-horizon optimization objective is defined by taking (12) into (25), i.e,
| (26) |
Then, the optimal solution is defined by the following equation:
| (27) |
where is the discount factor.
Note that the optimal solution and value function can be solved under the iterative learning framework[9]. However, the online convergence property is subject to learning efficiency. Motivated by the concept of receding-horizon from MPC, as discussed in [11], we divide into multiple sub-problems within the prediction horizon , where is the prediction horizon length. The value function in the prediction horizon is expressed by
| (28) |
where denotes the expectation value, and is the terminal cost function, defined by , where is the terminal penalty matrix, which can be determined in the same way as [11].
The value function in Eq. (28) is written by
| (29) |
According to the Bellman’s optimality principle, the optimal policy minimizes in the prediction horizons; i.e.,
|
|
(30) |
Definition 3.
For the critic network, the optimal value function in the finite horizon is re-defined by , i.e,
|
|
(31) |
With the optimal value function , one can compute the optimal solution by setting . Then, for the actor network, the optimal solution in the finite horizon is defined by
| (32) |
Remark 5.
At the -th iteration, the two optimal policies of the actor and critic networks are approximated by two kernel-based-network structures, i.e.,
| (33a) | ||||
| (33b) | ||||
where and are the weights of the actor and critic networks, respectively, and denotes the dimension of the RL training dictionary, which is obtained by employing the ALD strategy[9] to select representative samples from the robot’s state space. For the current state , the basis function in Eq. (33) is constructed by
where are elements in the RL training dictionary and is the Gaussian kernel function.
With the estimated value function in (33b) and consistent with (32), we can obtain the target optimal solution at the -th iteration and the -th horizon by
| (34) |
Correspondingly, for , the value function in Eq. (28) is written by
| (35) |
Note that is obtained by the identified system dynamics (22). Substituting Eq. (33b) into Eq. (31), the target value function becomes
|
|
(36) |
The critic network aims at minimizing the error function between the target and the approximate value functions, i.e.,
| (37) |
For the actor network, it minimizes the error function between the target and the approximate solutions, which is defined by the following equation:
| (38) |
Therefore, one can derive the following update rules for the critic network and the actor network, respectively:
| (39a) | ||||
| (39b) | ||||
where are the step coefficients of the gradients.
The overall algorithm of VF-LPC is shown in Algorithm. 1. Also, the convergence theorem of the Eb-RHRL algorithm is given below and its proof is presented in Section V. In the following, expressions similar to and denote the sequences in the prediction horizon of the -th time instant; i.e.,
and
Theorem 1.
V Theoretic Analysis
This section presents the theoretical analyses regarding Theorem 1. Building upon the proofs in [38, 39, 11], we prove that the Eb-RHRL algorithm, integrating the game-based barrier function, converges to the optimal value function and solution, thereby solving the OMP problem.
Lemma 1.
Proof.
The sequence is used to minimize , while all elements in are random. Under the condition of , holds, for all .
Lemma 2.
Proof.
To begin with, is assumed to be an admissible policy. Let , where
We define an upper bound
| (40) | ||||
with the dynamic model (22) and . When propagating from current stage to , two cases exist and analyzed below.
Case 1 ():
| (41) | ||||
Since , by applying an admissible control to the system, we can obtain
| (42) |
where . With Eqs. (41) and (42), we have
|
|
(43) |
Case 2 ():
|
|
(44) |
Proof.
The proof is given in[38].
VI Simulation and Experimental Results
In this section, we present the simulation and experimental results to validate our proposed VF-LPC approach. The algorithm was deployed on a computer running Windows 11 with an Intel Core i7-11800H @2.30GHZ CPU. We first compared VF-LPC with advanced IMPC methods in CarSim software. Then the effectiveness of the online model compensating strategy is verified through a tracking control task. The simulation results on a quadrotor UAV were performed. We also tested the VF-LPC approach on an actual ground vehicle of Hongqi EHS-3. The platform is shown in the right part of Fig. 4.
VI-A Path planning in an Obstacle-Dense Environment
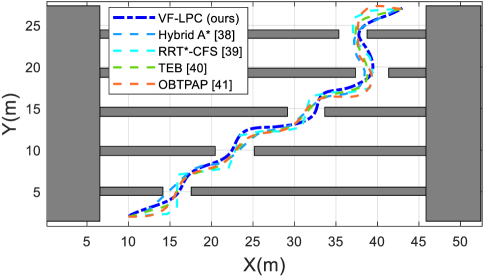
To evaluate the effectiveness of the VF-LPC approach, we compare it with advanced planning approaches in a scenario containing static obstacles; see Fig. 7. We compare VF-LPC with the commonly used planning approaches, such as Hybrid A*[40], RRT*-CFS[41], Timed Elastic Bands (TEB)[42] and OBTPAP[43] which iteratively solves the time-optimal motion planning problem. In these tests, we use the analytic kinematic vehicle model with the state variable , representing the -, -coordinates and the heading, respectively. All the approaches are performed in MATLAB 2023a.
VI-A1 Evaluation metrics
To evaluate the planning methods, we employ various performance metrics. The first metric is the trajectory length from the initial point to the destination, denoted as ; i.e., , where is the number of trajectory points. The second metric is the of trajectory planning. The third metric pertains to , serving to quantify whether the planned trajectories have a safe distance from obstacles.
VI-A2 Analyses of the results
As shown from TABLE I, the paths planned by methods VF-LPC and TEB exhibit similar lengths, albeit shorter than OBTPAP. Though the trajectory length of Hybrid A* is the shortest, it is deemed unsafe due to the lack of maintaining a safe distance while avoiding the first obstacle. Regarding computational efficiency, VF-LPC demonstrates the best performance among the methods.
VI-B Collision-Avoidance Simulation in High-Fidelity CarSim
Tracking a desired path while avoiding static and moving obstacles is a fundamental task. To demonstrate the superiority of VF-LPC, we compare it with MPC-CBF[44], LMPCC[45], RHRL-KDP[10], and CFS[46] under different metrics.
VI-B1 Simulation settings
All the comparison methods utilize the system dynamics model (45) and solve the nonlinear optimization problem using the IPOPT solver[47] within the CasADi framework[48], which describes the vehicle dynamics as follows:
|
|
(45) |
where is the state vector, are the global horizontal and vertical coordinates of the vehicle, respectively, is the yaw angle, denote the longitudinal and lateral velocities, respectively, denotes the yaw rate, and are the distances from the center of gravity (CoG) to the front and rear wheels, respectively; represent the cornering stiffnesses of the front and rear wheels, respectively; denotes the yaw moment of inertia; is the vehicle’s mass. Their values can be found in TABLE II. In this model, the acceleration and the steering angle are two variables of the control vector , i.e., . The reference state is .
For VF-LPC, we employed the approach outlined in [21] to conduct system identification by collecting vehicle motion data from the CarSim solver. Finally, a linear time-invariant system model (4) is generated for the VF-LPC algorithm, where and . To construct an error model for facilitating subsequent algorithm design, we subtract the desired state from the current state, i.e, and the desired control from system control, i.e., .
VI-B2 Evaluation metrics
The desired speed of all the methods is set to km/h. To evaluate the VF-LPC approach, we compare it with other IMPC algorithms under several metrics, which are Aver. S.T. (average solution time of each time step), (cost of the lateral error), (cost of the heading error), and (control cost). Specifically, they are defined by , , and , where and is definite. We define a weighted average cost to evaluate the overall performance, which is
where is the number of waypoints of the driving trajectory. The other quantitative metrics are route length , completion time , and calculation time .
VI-B3 Analyses of the results
The testing scenario requires the vehicle to track a reference path (black line in Fig. 8) while avoiding collisions with static and moving obstacles.
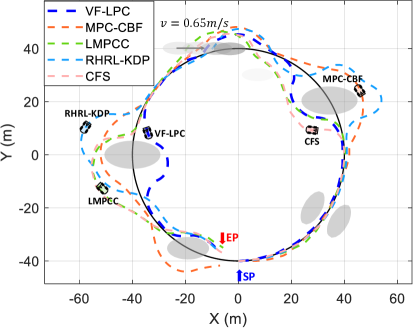
As seen in TABLE III, VF-LPC has the lowest motion control cost . The computational cost of VF-LPC is lower than that of MPC-CBF, LMPCC, RHRL-KDP, and CFS, and it generates the shortest trajectory and has the least completion time. As VF-LPC employs a linear time-invariant Koopman-based vehicle dynamic model to optimize the nonlinear optimal motion planning problem based on the scheme of Eb-RHRL, the computational time is the least. However, the MPC-based methods and RHRL-KDP require online solving of nonlinear optimization problems, resulting in a computational burden.
VI-C Model Uncertainties Learning
As mentioned in previous sections, the offline trained deep Koopman model probably does not perfectly reflect the exact system dynamics when deployed online due to external uncertainties. As a result, this could cause performance degradation both in planning and control and even safety issues. In this section, we will demonstrate the sparse GP-based learning model uncertainties for the deep Koopman model.
The uncertainty in the dynamics of a system negatively affects the planning and control performance of robots. To eliminate the influence, a quantified sparse GP [9] is utilized to compensate for the difference between the offline-trained deep Koopman model and the exact vehicle model. The simulated dynamical model (45), reveals that the vehicle states and are primarily affected by dynamic parameters. Therefore, we further derive , and .
The algorithm was simulated in a racing track road and the desired speed is set to be . Note that we collect motion data of the real vehicle (right half of Fig. 4) to train for an offline nominal deep Koopman model with and . The exact vehicle parameters are: , , , and . The iid process noise with zero mean and variance is added to the vehicle dynamics. Specifically, maps to .
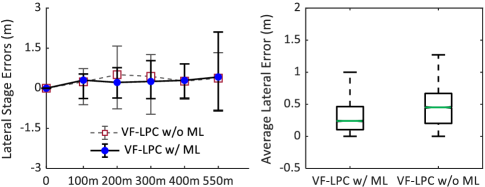
To evaluate the effectiveness of our algorithm on learning model uncertainties, VF-LPC with and without model learning, abbreviated as VF-LPC (w/ ML) and VF-LPC (w/o ML), are separately tested on the racing road. At the initial stage, i.e., the first , we update the dictionary online, and it is then sparsified with Approximate Linear Dependence (ALD) similarly to[9]. With the sparsified dictionary, we train it to update the Jacobian matrices (20) and compensate for (4) during the remaining miles.
From the simulation results in Fig. 9, notable improvement can be observed in the lateral stage error of VF-LPC (w/ ML) compared to VF-LPC (w/o ML). Ultimately, the average lateral error throughout the entire testing process for VF-LPC (w/ ML) is lower than that of VF-LPC (w/o ML). These results validate the capability of VF-LPC to process model uncertainty and enhance control performance.
VI-D Validation on Unmanned Aerial Vehicles
In this subsection, we demonstrate the effectiveness of VF-LPC on motion planning tasks of a different class of mobile robots, i.e., quadrotor UAVs, which have intricate dynamics. We use a widely-used model [50] to simulate the dynamics.
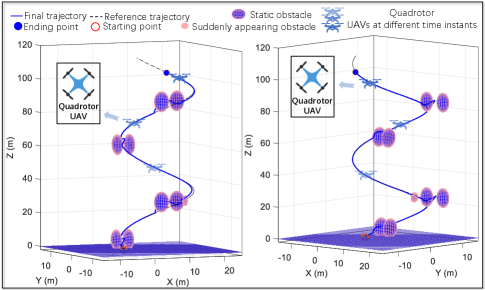
Firstly, we conduct data-driven modeling of the quadrotor UAV using deep Koopman operators[21], followed by employing the VF-LPC to generate the robot’s maneuvers in a 3D environment, as illustrated in Fig. 10. The state variables of the training data consist of the XYZ coordinates and velocities () of the quadrotor UAV, with control variables of acceleration in the XYZ directions. A total of data, each comprising approximately samples, were collected randomly in the state and control space for training and model validation purposes. The -dimensional state vector was processed through an encode layer, resulting in a final system model of state variables and control variables (i.e., ). Then the obtained model is incorporated into VF-LPC, which focuses on planning 3-axis accelerations for attitude control. Not only the VF-LPC approach can avoid multiple static obstacles. Under suddenly appearing obstacles (see Fig. 10), the VF-LPC approach is also capable of handling them, and the average speed of the vehicle reaches .
The results show that the VF-LPC approach can achieve near-optimal motion planning for robots with offline-trained data-driven dynamics.
VI-E Real-World Experiments
To further validate the effectiveness of VF-LPC, real-world vehicular experiments were conducted on the Hongqi E-HS3 platform, which is shown in module B-(1) of Fig. 4.
At each time instance within the predictive horizon, the desired trajectory and obstacles are initially transformed into the vehicle body’s local coordinate system. Then, we employ polynomial curves to fit the desired path points, obtaining the desired path with (13). Subsequently, the safe trajectory generated by the kinodynamic composite vector field is transformed back into the global coordinate system.
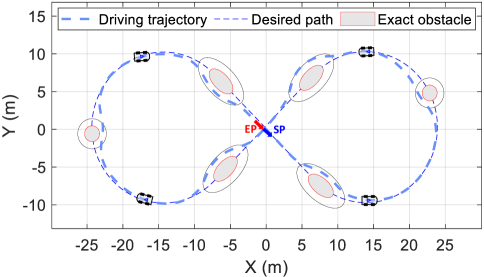
VI-E1 Multiple Static Obstacles Avoidance
In this scenario, we evaluate the obstacle avoidance capability of the VF-LPC approach. As illustrated in Fig. 11, the black dash line denotes the desired path. Due to the vehicle’s long wheelbase of meters, the turning radius is large. However, the desired path is constrained and small in size, posing a significant challenge for the algorithm in terms of safe obstacle avoidance and tracking. We set the speed to , and it can be observed that the vehicle successfully reaches the destination while avoiding multiple obstacles. VF-LPC can plan a smooth trajectory for guiding finite-horizon actor-critic learning processes. This also reflects the effectiveness and advantages of the kinodynamic guiding vector field which satisfies the kinodynamic constraint.
VI-E2 Moving Obstacles Avoidance
As shown in Fig. 12, a human driver first drove the intelligent vehicle to generate the desired path in this scenario. We have the following settings for testing our algorithm: The moving obstacles start to move at different preset velocities when the distance between them and the intelligent vehicle is less than , thereby validating its emergency collision avoidance capability. Using a gradient of gray, we label the obstacles’ positions at different moments during their motion processes, where the darkest color represents the initial moment.
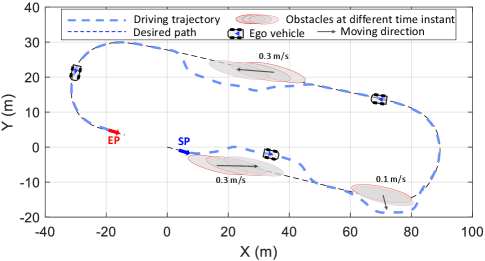
From the overall tracking results in Fig. 12, the intelligent vehicle keeps safe distances from obstacles all the time and returns to the desired path smoothly. In addition, our method exhibits small lateral tracking errors and longitudinal velocity deviation Moreover, the maximum vehicle’s speed reaches . Finally, it arrives at the ending point successfully and completes the motion planning and control task.
VII Conclusion and Future Work
This paper presents the Vector Field-guided Learning Predictive Control (VF-LPC) approach for mobile robots with safety guarantees, which offers a framework for the Integrated Motion Planning and Control (IMPC) of robots. VF-LPC designs kinodynamic guiding vector field for safe robot maneuvering. This is a notable improvement over the existing composite vector fields. Also, the learned deep Koopman model is updated online by sparse GP to improve safety and control performance. It is then incorporated into LPC to solve nonlinear IMPC problems. Rigorous theoretical analysis is provided to witness the online learning convergence.
VF-LPC is evaluated against motion planning methods that employ MPC and RL in high-fidelity CarSim software. The results show that VF-LPC outperforms them under metrics of completion time, route length, and average solution time. To further show the effectiveness and generalization of our proposed approach, we carried out path-tracking control tests of a mobile vehicle on a racing road to validate the model uncertainties learning capability, and we also successfully implemented the approach on quadrotor UAVs. Finally, we conducted real-world experiments on a Hongqi E-HS3 vehicle.
Our work has several possible future directions. 1) With an additional prediction module, VF-LPC could be promising even in higher-speed tasks. 2) In unknown environments, one can construct safer barrier functions in real-time using the information perceived by onboard sensors.
References
- [1] W. Yao, H. G. de Marina, B. Lin, and M. Cao, “Singularity-free guiding vector field for robot navigation,” IEEE Transactions on Robotics, vol. 37, no. 4, pp. 1206–1221, 2021.
- [2] D. Panagou, “Motion planning and collision avoidance using navigation vector fields,” in 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 2513–2518.
- [3] A. Marchidan and E. Bakolas, “Collision avoidance for an unmanned aerial vehicle in the presence of static and moving obstacles,” Journal of Guidance, Control, and Dynamics, vol. 43, no. 1, pp. 96–110, 2020.
- [4] Y. A. Kapitanyuk, A. V. Proskurnikov, and M. Cao, “A guiding vector-field algorithm for path-following control of nonholonomic mobile robots,” IEEE Transactions on Control Systems Technology, vol. 26, no. 4, pp. 1372–1385, 2018.
- [5] W. Yao, B. Lin, B. D. Anderson, and M. Cao, “Guiding vector fields for following occluded paths,” IEEE Transactions on Automatic Control, vol. 67, no. 8, pp. 4091–4106, 2022.
- [6] Y. K. Nakka and S.-J. Chung, “Trajectory optimization of chance-constrained nonlinear stochastic systems for motion planning under uncertainty,” IEEE Transactions on Robotics, vol. 39, no. 1, pp. 203–222, 2022.
- [7] C. Pek and M. Althoff, “Fail-safe motion planning for online verification of autonomous vehicles using convex optimization,” IEEE Transactions on Robotics, vol. 37, no. 3, pp. 798–814, 2020.
- [8] P. Deptula, H.-Y. Chen, R. A. Licitra, J. A. Rosenfeld, and W. E. Dixon, “Approximate optimal motion planning to avoid unknown moving avoidance regions,” IEEE Transactions on Robotics, vol. 36, no. 2, pp. 414–430, 2019.
- [9] Y. Lu, X. Zhang, X. Xu, and W. Yao, “Learning-based near-optimal motion planning for intelligent vehicles with uncertain dynamics,” IEEE Robotics and Automation Letters, vol. 9, no. 2, pp. 1532–1539, 2024.
- [10] X. Zhang, Y. Jiang, Y. Lu, and X. Xu, “Receding-horizon reinforcement learning approach for kinodynamic motion planning of autonomous vehicles,” IEEE Transactions on Intelligent Vehicles, vol. 7, no. 3, pp. 556–568, 2022.
- [11] X. Xu, H. Chen, C. Lian, and D. Li, “Learning-based predictive control for discrete-time nonlinear systems with stochastic disturbances,” IEEE Transactions on Neural Networks and Learning Systems, vol. 29, no. 12, pp. 6202–6213, 2018.
- [12] B. A. H. Vicente, S. S. James, and S. R. Anderson, “Linear system identification versus physical modeling of lateral–longitudinal vehicle dynamics,” IEEE Transactions on Control Systems Technology, vol. 29, no. 3, pp. 1380–1387, 2020.
- [13] T. Gräber, S. Lupberger, M. Unterreiner, and D. Schramm, “A hybrid approach to side-slip angle estimation with recurrent neural networks and kinematic vehicle models,” IEEE Transactions on Intelligent Vehicles, vol. 4, no. 1, pp. 39–47, 2019.
- [14] N. A. Spielberg, M. Brown, N. R. Kapania, J. C. Kegelman, and J. C. Gerdes, “Neural network vehicle models for high-performance automated driving,” Science Robotics, vol. 4, no. 28, p. eaaw1975, 2019.
- [15] M. Da Lio, D. Bortoluzzi, and G. P. Rosati Papini, “Modelling longitudinal vehicle dynamics with neural networks,” Vehicle System Dynamics, vol. 58, no. 11, pp. 1675–1693, 2020.
- [16] P. J. Schmid, “Dynamic mode decomposition of numerical and experimental data,” Journal of Fluid Mechanics, vol. 656, pp. 5–28, 2010.
- [17] M. O. Williams, I. G. Kevrekidis, and C. W. Rowley, “A data–driven approximation of the koopman operator: Extending dynamic mode decomposition,” Journal of Nonlinear Science, vol. 25, pp. 1307–1346, 2015.
- [18] I. Kevrekidis, C. W. Rowley, and M. Williams, “A kernel-based method for data-driven koopman spectral analysis,” Journal of Computational Dynamics, vol. 2, no. 2, pp. 247–265, 2016.
- [19] B. Lusch, J. N. Kutz, and S. L. Brunton, “Deep learning for universal linear embeddings of nonlinear dynamics,” Nature Communications, vol. 9, no. 1, p. 4950, 2018.
- [20] S. E. Otto and C. W. Rowley, “Linearly recurrent autoencoder networks for learning dynamics,” SIAM Journal on Applied Dynamical Systems, vol. 18, no. 1, pp. 558–593, 2019.
- [21] Y. Xiao, X. Zhang, X. Xu, Y. Lu, and J. Li, “DDK: A deep koopman approach for longitudinal and lateral control of autonomous ground vehicles,” in 2023 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2023, pp. 975–981.
- [22] B. Luders, M. Kothari, and J. How, “Chance constrained RRT for probabilistic robustness to environmental uncertainty,” in AIAA Guidance, Navigation, and Control Conference, 2010, p. 8160.
- [23] G. S. Aoude, B. D. Luders, J. M. Joseph, N. Roy, and J. P. How, “Probabilistically safe motion planning to avoid dynamic obstacles with uncertain motion patterns,” Autonomous Robots, vol. 35, pp. 51–76, 2013.
- [24] A. Hakobyan and I. Yang, “Distributionally robust risk map for learning-based motion planning and control: A semidefinite programming approach,” IEEE Transactions on Robotics, vol. 39, no. 1, pp. 718–737, 2022.
- [25] A. Dixit, M. Ahmadi, and J. W. Burdick, “Risk-averse receding horizon motion planning for obstacle avoidance using coherent risk measures,” Artificial Intelligence, vol. 325, p. 104018, 2023.
- [26] H. Zhu and J. Alonso-Mora, “Chance-constrained collision avoidance for MAVs in dynamic environments,” IEEE Robotics and Automation Letters, vol. 4, no. 2, pp. 776–783, 2019.
- [27] T. Lew, R. Bonalli, and M. Pavone, “Chance-constrained sequential convex programming for robust trajectory optimization,” in 2020 European Control Conference (ECC). IEEE, 2020, pp. 1871–1878.
- [28] L. Lindemann, M. Cleaveland, Y. Kantaros, and G. J. Pappas, “Robust motion planning in the presence of estimation uncertainty,” in 2021 60th IEEE Conference on Decision and Control (CDC). IEEE, 2021, pp. 5205–5212.
- [29] S. Singh, B. Landry, A. Majumdar, J.-J. Slotine, and M. Pavone, “Robust feedback motion planning via contraction theory,” The International Journal of Robotics Research, vol. 42, no. 9, pp. 655–688, 2023.
- [30] D. Snyder, M. Booker, N. Simon, W. Xia, D. Suo, E. Hazan, and A. Majumdar, “Online learning for obstacle avoidance,” in Conference on Robot Learning. PMLR, 2023, pp. 2926–2954.
- [31] K. Polymenakos, A. Abate, and S. Roberts, “Safe policy search using gaussian process models,” in Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems, 2019, pp. 1565–1573.
- [32] L. Janson, E. Schmerling, and M. Pavone, “Monte carlo motion planning for robot trajectory optimization under uncertainty,” in Robotics Research: Volume 2. Springer, 2018, pp. 343–361.
- [33] E. Snelson and Z. Ghahramani, “Sparse Gaussian processes using pseudo-inputs,” Advances in Neural Information Processing Systems, vol. 18, 2005.
- [34] C. E. Rasmussen, “Gaussian processes in machine learning,” in Summer School on Machine Learning. Springer, 2003, pp. 63–71.
- [35] L. Hewing, J. Kabzan, and M. N. Zeilinger, “Cautious model predictive control using Gaussian process regression,” IEEE Transactions on Control Systems Technology, vol. 28, no. 6, pp. 2736–2743, 2019.
- [36] J. Kabzan, L. Hewing, A. Liniger, and M. N. Zeilinger, “Learning-based model predictive control for autonomous racing,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3363–3370, 2019.
- [37] I. Exarchos, P. Tsiotras, and M. Pachter, “On the suicidal pedestrian differential game,” Dynamic Games and Applications, vol. 5, pp. 297–317, 2015.
- [38] A. Heydari and S. N. Balakrishnan, “Finite-horizon control-constrained nonlinear optimal control using single network adaptive critics,” IEEE Transactions on Neural Networks and Learning Systems, vol. 24, no. 1, pp. 145–157, 2012.
- [39] A. Al-Tamimi, F. L. Lewis, and M. Abu-Khalaf, “Discrete-time nonlinear HJB solution using approximate dynamic programming: Convergence proof,” IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), vol. 38, no. 4, pp. 943–949, 2008.
- [40] D. Dolgov, S. Thrun, M. Montemerlo, and J. Diebel, “Path planning for autonomous vehicles in unknown semi-structured environments,” The International Journal of Robotics Research, vol. 29, no. 5, pp. 485–501, 2010.
- [41] J. Leu, G. Zhang, L. Sun, and M. Tomizuka, “Efficient robot motion planning via sampling and optimization,” in 2021 American Control Conference (ACC). IEEE, 2021, pp. 4196–4202.
- [42] C. Rösmann, F. Hoffmann, and T. Bertram, “Kinodynamic trajectory optimization and control for car-like robots,” in 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 5681–5686.
- [43] B. Li, T. Acarman, Y. Zhang, Y. Ouyang, C. Yaman, Q. Kong, X. Zhong, and X. Peng, “Optimization-based trajectory planning for autonomous parking with irregularly placed obstacles: A lightweight iterative framework,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 11 970–11 981, 2022.
- [44] J. Zeng, B. Zhang, and K. Sreenath, “Safety-critical model predictive control with discrete-time control barrier function,” in American Control Conference (ACC), 2021, pp. 3882–3889.
- [45] B. Brito, B. Floor, L. Ferranti, and J. Alonso-Mora, “Model predictive contouring control for collision avoidance in unstructured dynamic environments,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4459–4466, 2019.
- [46] C. Liu, C.-Y. Lin, and M. Tomizuka, “The convex feasible set algorithm for real time optimization in motion planning,” SIAM Journal on Control and Optimization, vol. 56, no. 4, pp. 2712–2733, 2018.
- [47] A. Wächter and L. T. Biegler, “On the implementation of an interior-point filter line-search algorithm for large-scale nonlinear programming,” Mathematical Programming, vol. 106, no. 1, pp. 25–57, 2006.
- [48] J. A. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl, “CasADi: a software framework for nonlinear optimization and optimal control,” Mathematical Programming Computation, vol. 11, no. 1, pp. 1–36, 2019.
- [49] R. Rajamani, Vehicle dynamics and control. Springer Science & Business Media, 2011.
- [50] Y. Xu, W. Zheng, D. Luo, and H. Duan, “Dynamic affine formation control of networked under-actuated quad-rotor uavs with three-dimensional patterns,” Journal of Systems Engineering and Electronics, vol. 33, no. 6, pp. 1269–1285, 2022.