Versatile linkage: a family of space-conserving strategies for agglomerative hierarchical clustering
Abstract
Abstract: Agglomerative hierarchical clustering can be implemented with several strategies that differ in the way elements of a collection are grouped together to build a hierarchy of clusters. Here we introduce versatile linkage, a new infinite system of agglomerative hierarchical clustering strategies based on generalized means, which go from single linkage to complete linkage, passing through arithmetic average linkage and other clustering methods yet unexplored such as geometric linkage and harmonic linkage. We compare the different clustering strategies in terms of cophenetic correlation, mean absolute error, and also tree balance and space distortion, two new measures proposed to describe hierarchical trees. Unlike the -flexible clustering system, we show that the versatile linkage family is space-conserving.
1 Introduction
Agglomerative hierarchical clustering constitutes one of the most widely used methods for cluster analysis. Starting with a matrix of dissimilarities between a set of elements, each element is first assigned to its own cluster, and the algorithm sequentially merges the more similar clusters until a complete hierarchy of clusters is obtained [22, 10]. This method requires the definition of the dissimilarity (or distance) between clusters, using only the original distances between their constituent elements. The way these distances are defined leads to distinct strategies of agglomerative hierarchical clustering. To name just two such clustering strategies, single linkage usually leads to an elongate growth of clusters, while complete linkage generally leads to tight clusters that join others with difficulty. Average linkage clustering strategies were developed by Sokal and Michener to avoid the extreme cases produced by single linkage and complete linkage [23]. They require the calculation of some kind of average distance between clusters; average linkage, for instance, calculates the arithmetic average of all the distances between members of the clusters.
More than fifty years ago, Lance and Williams introduced a formula for integrating several agglomerative hierarchical clustering strategies into a single system [13]. Based on this formula they proposed -flexible clustering [14], a generalized clustering procedure that provides an infinite number of hierarchical clustering strategies just varying a parameter . Similarly, in this work we introduce versatile linkage, a new parameterized family of agglomerative hierarchical clustering strategies that go from single linkage to complete linkage, passing through arithmetic average linkage and other clustering strategies yet unexplored such as geometric linkage and harmonic linkage.
Both -flexible clustering and versatile linkage are presented here using variable-group methods [23, 7] that, unlike pair-group methods, admit any number of new members simultaneously into groups. In the case of pair-group methods the resulting hierarchical tree is called a dendrogram, which is built upon bifurcations, while in the case of variable-group methods the resulting hierarchical tree is called a multidendrogram [7], which consists of multifurcations, not necessarily binary ones. Here we use the variable-group algorithm introduced in [7] that solves the non-uniqueness problem, also called the ties in proximity problem, found in pair-group algorithms [22, 11, 5]. This problem arises when there are more than two clusters separated by the same minimum distance during the agglomerative process. Pair-group algorithms break ties between distances choosing a pair of clusters, usually at random. However, different output dendrograms are possible depending on the criterion used to break ties. Moreover, very frequently results depend on the order of the elements in the input data file, what is an undesired effect in hierarchical clustering except for the case of contiguity-constrained hierarchical clustering, which is used to obtain a hierarchical clustering that takes into account the ordering on the input elements. The variable-group algorithm used here always gives a uniquely determined solution grouping more than two clusters at the same time when ties occur, and when there are no ties it gives the same results as the pair-group algorithm.
Section 2 reviews the -flexible family of hierarchical clustering strategies, while Section 3 introduces the versatile linkage family. Four case studies are used in Section 4 to perform a descriptive analysis of different hierarchical clustering strategies in terms of cophenetic correlation, mean absolute error, and the proposed new measures of space distortion and tree balance. Finally, some concluding remarks are given in Section 5.
2 -Flexible Clustering
In any procedure implementing an agglomerative hierarchical clustering strategy, given a set of individuals , initially each individual forms a singleton cluster, , and the distances between singleton clusters are equal to the dissimilarities between individuals, . During the subsequent iterations of the procedure, the distances are computed between any two clusters and , each one of them made up of several subclusters and indexed by and , respectively. Lance and Williams introduced a formula for integrating several agglomerative hierarchical clustering strategies into a single system [13]. The variable-group generalization of Lance and Williams’ formula, compatible with the fusion of more than two clusters simultaneously, is:
| (1) | |||||
where the values of the parameters , and determine the nature of the clustering strategy [7]. This formula is combinatorial [14], i.e., the distance can be calculated from the distances , and obtained from the previous iteration and it is not necessary to keep the initial distance matrix during the whole clustering process.
Based on Equation 1, Lance and Williams [14] proposed an infinite system of agglomerative hierarchical clustering strategies defined by the constraint
| (2) |
where generates a whole system of hierarchical clustering strategies for the infinite possible values of . Given a value of , the value for can be assigned following a weighted approach as in the original -flexible clustering based on WPGMA (weighted pair-group method using arithmetic mean) and introduced by Lance and Williams [13], or it can be assigned following an unweighted approach as in the -flexible clustering based on UPGMA (unweighted pair-group method using arithmetic mean) and introduced by Belbin et al. [2]. The standard WPGMA and UPGMA strategies are obtained from weighted and unweighted -flexible clustering, respectively, when is set equal to . The difference between weighted and unweighted methods lies in the weights assigned to individuals and clusters during the agglomerative process: weighted methods assign equal weights to clusters, while unweighted methods assign equal weights to individuals. In unweighted -flexible clustering the value for is determined proportionally to :
| (3) |
where and are the number of individuals in subclusters and , respectively, and and are the number of individuals in clusters and , i.e., and . In a similar way, the value for is calculated proportionally to , and the value for proportionally to :
| (4) | |||||
| (5) |
The corresponding values for weighted -flexible clustering are:
| (6) | |||||
| (7) | |||||
| (8) |
where and are the number of subclusters contained in clusters and , respectively. These formulas derive from the unweighted ones when we take , , and , .
3 Versatile Linkage
Arithmetic average linkage clustering iteratively forms clusters made up of previously formed subclusters, based on the arithmetic mean distances between their member individuals; for simplicity and to avoid confusion, we will denote it arithmetic linkage instead of the standard term average linkage. Substituting the arithmetic means by generalized means, also known as power means, this clustering strategy can be extended to any finite power :
| (9) | |||||
We call this new system of agglomerative hierarchical clustering strategies as versatile linkage. As in the case of -flexible clustering, versatile linkage provides a way of obtaining an infinite number of clustering strategies from a single formula. The second equality in Equation 9 shows that versatile linkage can be calculated using a combinatorial formula, from the distances obtained during the previous iteration, in the same way as Lance and Williams’ recurrence formula given in Equation 1.
The decision of what power to use could be taken in agreement with the type of distance employed to measure the initial dissimilarities between individuals. For instance, if the initial dissimilarities were calculated using a generalized distance of order , then the natural agglomerative clustering strategy would be versatile linkage with the same power . However, this procedure does not guarantee that the dendrogram obtained is the best according to other criteria, e.g., cophenetic correlation, mean absolute error, space distortion or tree balance, see Section 4. A better approach consists in scanning the whole range of parameters , calculate the preferred descriptors of the corresponding dendrograms, and decide if it is better to substitute the natural parameter by another one. This is especially important when only the dissimilarities between individuals are available, without coordinates for the individuals, as is common in multidimensional scaling problems, or when the dissimilarities have not been calculated using generalized means.
3.1 Particular Cases
The generalized mean contains several well-known particular cases, depending on the value of the power , that deserve special attention. Some of them reduce versatile linkage to the most commonly used methods, while others emerge naturally as deserving further attention:
-
•
In the limit when , versatile linkage becomes single linkage (SL):
(10) -
•
In the limit when , versatile linkage becomes complete linkage (CL):
(11)
There are also three other particular cases that can be grouped together as Pythagorean linkages:
-
•
When , the generalized mean is equal to the arithmetic mean and arithmetic linkage (AL), i.e. the standard average linkage or UPGMA, is recovered.
-
•
When , the generalized mean is equal to the harmonic mean and, therefore, harmonic linkage (HL) is obtained.
-
•
In the limit when , the generalized mean tends to the geometric mean. Hence, the distance definition for geometric linkage (GL) is:
(12)
| Alice | Bob | Carol | Dave | |
|---|---|---|---|---|
| Alice | 0 | 7 | 16 | 28 |
| Bob | 0 | 9 | 21 | |
| Carol | 0 | 12 | ||
| Dave | 0 |
To show the effects of varying the power in versatile linkage clustering, we have built a small dataset with four individuals: Alice, Bob, Carol and Dave, which lay on a straight line, separated between them by distances equal to , and units, respectively. Table 1 gives the pairwise distances between the four individuals, and Figure LABEL:fig:versatile shows some multidendrograms obtained varying the power in versatile linkage clustering. Alice and Bob are always grouped together forming the first binary cluster, at a distance equal to . For values of the exponent , the Alice-Bob cluster is joined with Carol’s singleton cluster at distances that range between and . More precisely, this distance takes values for SL (), for HL () and when we approach GL (). For larger values of the exponent, , this distance becomes larger than , thus Carol joins instead in a cluster with Dave at their distance . The remaining cluster for , which joins the Alice-Bob-Carol cluster with Dave, happens at heights (SL), (HL) and (), respectively. For the range , the clusters Alice-Bob and Carol-Dave join at heights (), (AL) and (CL), respectively.
GL () lays between these two structurally different dendrograms, represented as “(((Alice,Bob),Carol),Dave)” and “((Alice,Bob),(Carol,Dave))”. Using pair-group agglomerative clustering methods, we would assign one of these two possible dendrograms to GL, thus breaking the tied pairs (Alice,Bob)-Carol and Carol-Dave (both at distance ) randomly; this is an example of the ties in proximity (non-uniqueness) problem mentioned above. With the variable-group approach [7], we join them at once forming the multidendrogram “((Alice,Bob),Carol,Dave)”, where the three clusters join at distance , with a band going up to distance to represent the heterogeneity of the new cluster, being the distance between the clusters (Alice,Bob) and Dave (see middle multidendrogram in Figure LABEL:fig:versatile). This simple example shows the ability of versatile linkage to cover structurally different hierarchical clustering structures, including at the same time the traditionally important methods of SL, AL and CL.
3.2 Weighted Versatile Linkage
Weighted clustering was introduced by Sokal and Michener [23] in an attempt to give merging branches in a hierarchical tree equal weight regardless of the number of individuals carried on each branch. Such a procedure weights the individuals unequally, contrasting with unweighted clustering that gives equal weight to each individual in the clusters.
In weighted versatile linkage strategies, the distance between two clusters and is calculated by taking the generalized mean of the pairwise distances, not between individuals in the initial distance matrix, but between component subclusters in the matrix used during the previous iteration of the procedure, thus Equation 9 being replaced by:
| (13) |
3.3 Absence of inversions
Versatile linkage strategies are monotonic, that is, they do not produce inversions. An inversion or reversal appears in a hierarchy when the hierarchy contains two clusters and for which but the height of cluster is higher than the height of cluster [18, 17]. Inversions make hierarchies difficult to interpret, specially if they occur during the last stages of the agglomeration process.
The monotonicity of versatile linkage strategies is explained by the Pythagorean means inequality,
| (14) |
where HM stands for the harmonic mean, GM for the geometric mean, and AM for the arithmetic mean. In the general case given by Equations 9 and 13, the generalized mean inequality holds:
| (15) |
and if, and only if, the initial distances are equal and . Supposing that at a certain step of the clustering procedure the minimum distance between any two subclusters still to be merged is equal to , then the distance between any two subclusters to be included in different clusters, and , will be necessarily greater than , otherwise subclusters and would be merged into the same cluster. In particular, . Therefore, taking into account the generalized mean inequality in Equation 15, and given that in the limit when we have , we can conclude that , , which proves the absence of inversions of versatile linkage strategies.
4 Descriptive Analysis of Hierarchical Trees
We have selected four case studies, drawn from the UCI Machine Learning Repository [15], for a descriptive analysis of several agglomerative hierarchical clustering strategies. Table 2 summarizes the main characteristics of these datasets. The values of the variables in these datasets show different orders of magnitude; therefore, all the variables have been scaled first, and then the corresponding dissimilarity matrices have been built using the Euclidean distance between all pairs of individuals.
| Dataset | Instances | Features |
|---|---|---|
| Breast tissue [12] | 106 | 9 |
| Iris [8] | 150 | 4 |
| Wine [1] | 178 | 13 |
| Parkinsons [16] | 195 | 22 |
For the comparison of the hierarchical clustering strategies, we have chosen the following methods: -flexible with , to avoid the completely flat hierarchical trees obtained with ; versatile linkage with , i.e., SL; centroid method; versatile linkage with , i.e., HL; versatile linkage with , i.e., GL; versatile linkage with , which is the same as -flexible with , i.e., AL; versatile linkage with , i.e., CL; Ward’s minimum variance method [25]; and -flexible with . This selection includes five variants of versatile linkage, three of them equivalent to traditional methods (SL, AL and CL) and the other two introduced in this work (HL and GL), and three variants of -flexible clustering, one of them equivalent to AL.
Weighted and unweighted versions of the hierarchical clustering strategies have been used. Although weighting has no effect on SL and CL, we have included both of them for visual convenience in all the figures depicted next. The software used to run these experiments is MultiDendrograms [9], which from version implements all the hierarchical clustering strategies analyzed here and it also computes the necessary descriptive measures.
4.1 Cophenetic Correlation
The cophenetic correlation coefficient (CCC) measures the similarity between the distances in the initial matrix and the distances in the final ultrametric matrix obtained as result of a hierarchical clustering procedure [24]. The ultrametric distance between two individuals is represented in a dendrogram by the height at which those two individuals are first joined. The CCC is calculated as the Pearson correlation coefficient between both matrices of distances; thus, the closer to , the largest their similarity.
In the analysis shown in Figure 1, the CCC is higher for Pythagorean linkages (i.e., HL, GL and AL), and also the unweighted clustering strategies generally perform better than the weighted ones, corroborating the empirical observation already stated by Sneath and Sokal [22]. In the case of the almost flat hierarchical trees obtained with -flexible clustering when , the CCC is very close to .
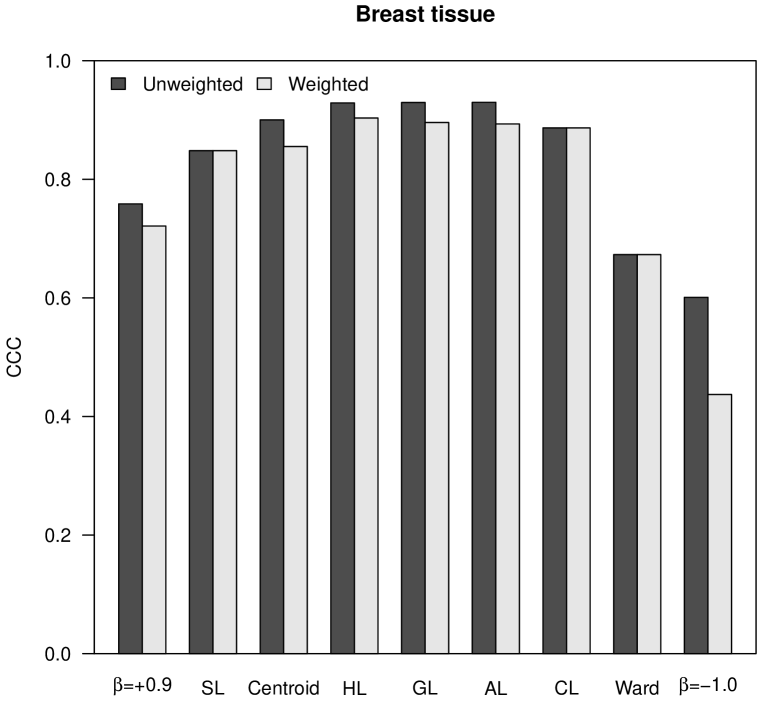 |
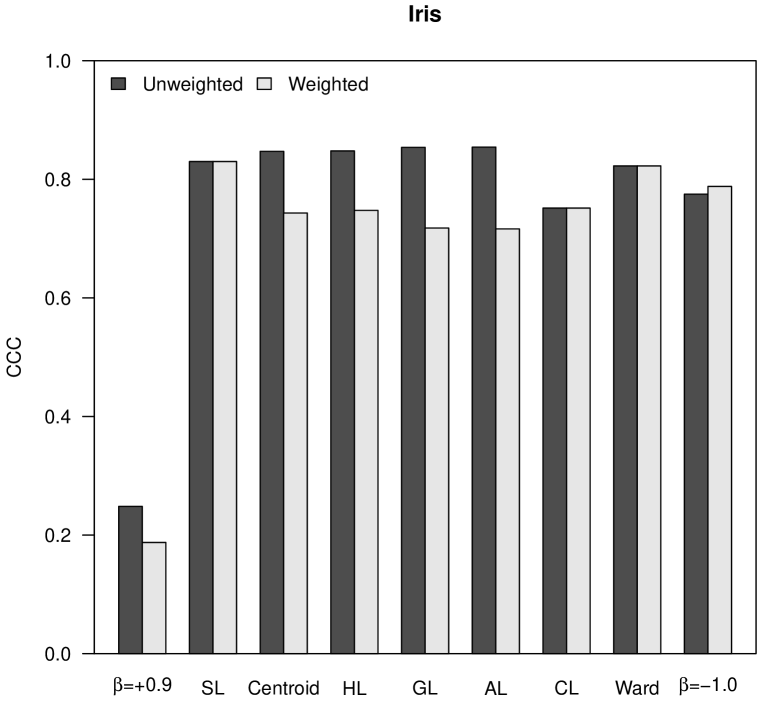 |
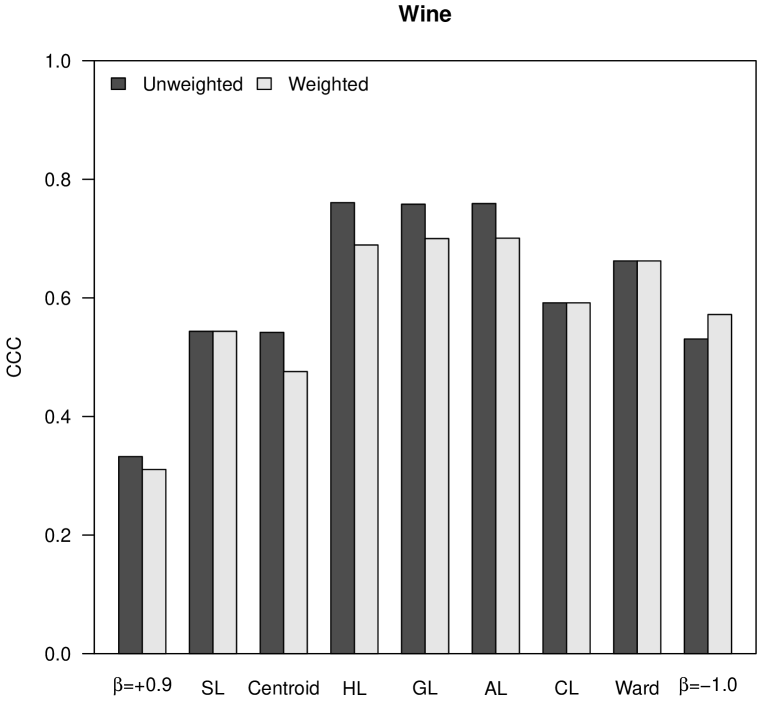 |
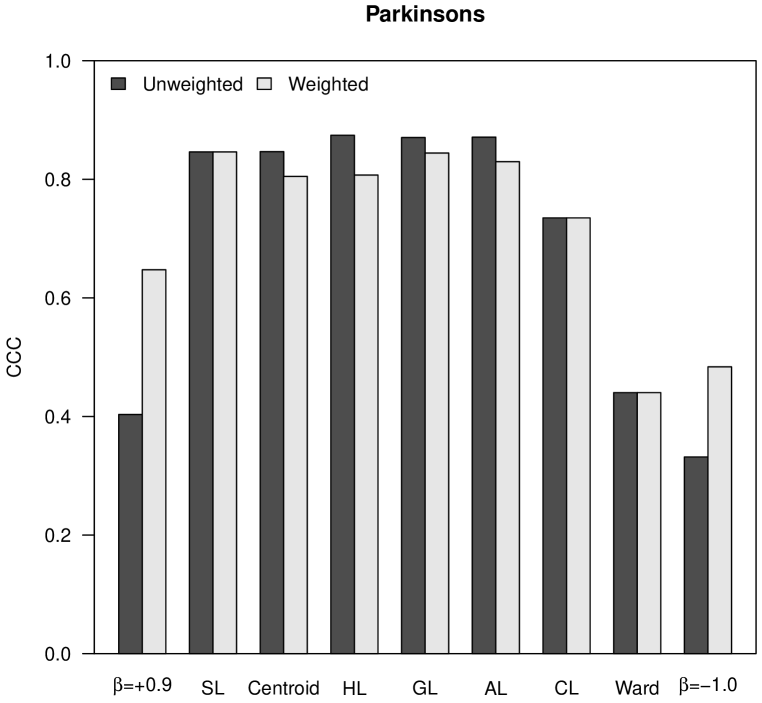 |
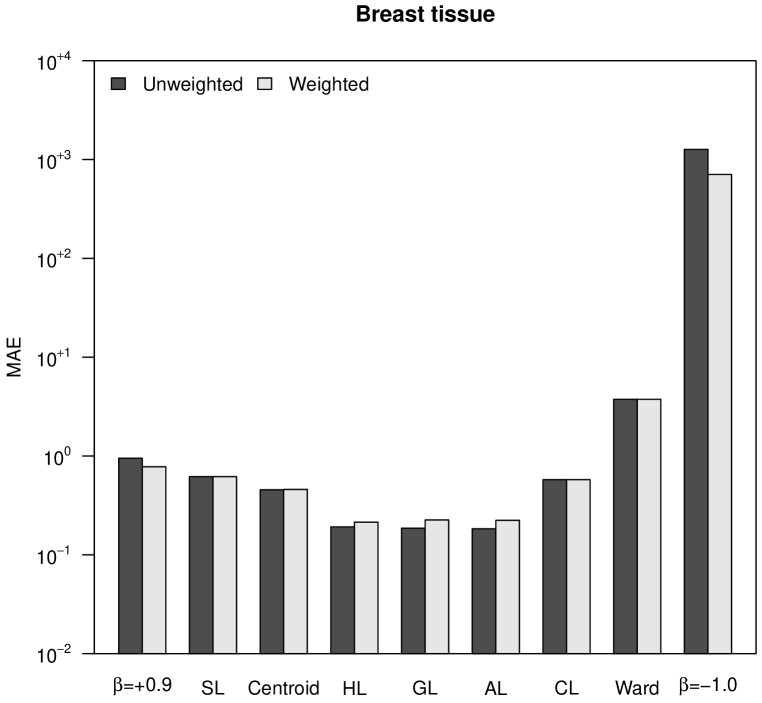
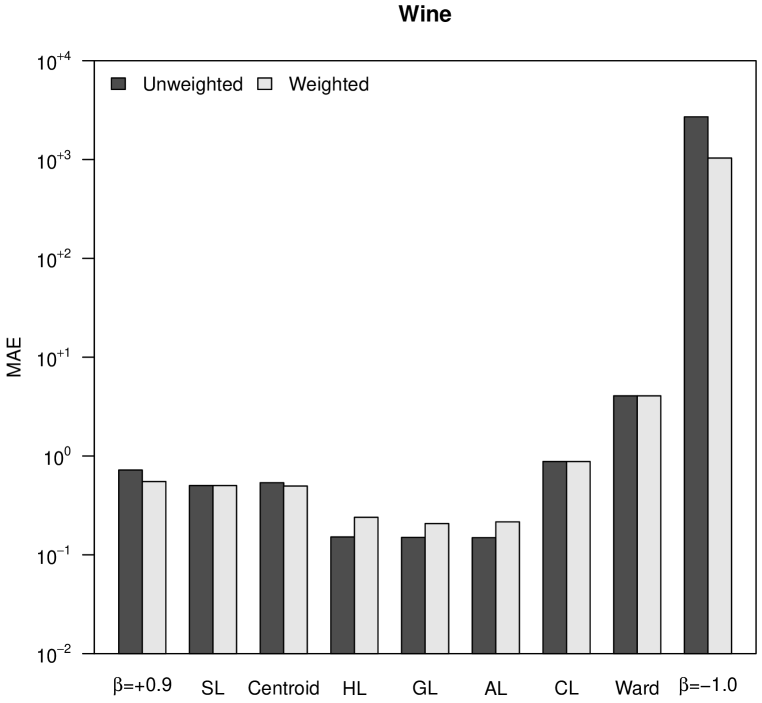
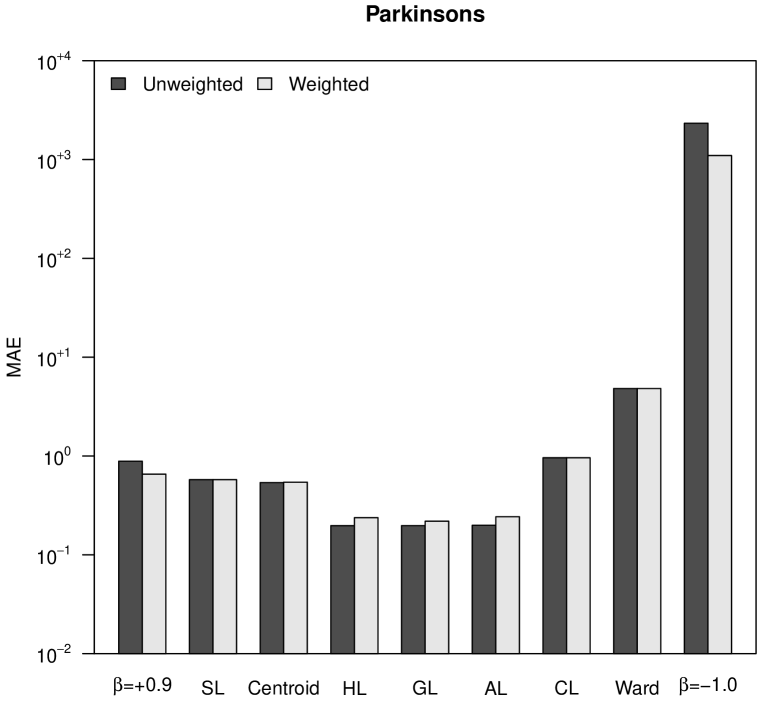
4.2 Mean Absolute Error
The CCC is a bounded measure that does not take into account how different the magnitudes of the distances in the initial matrix are from the distances in the final ultrametric matrix. For this reason, in Figure 2 we show the normalized mean absolute error (MAE), which takes into account this type of differences. Note that in the case of the Iris dataset, Ward’s method and -flexible clustering with showed a very good CCC in Figure 1, while their MAE observed in Figure 2 are the worst ones. As a matter of fact, -flexible clustering with yields results orders of magnitude worse than all the other methods, for the four datasets shown in Figure 2. The best results are obtained again with Pythagorean linkages, and also unweighted clustering strategies are slightly better than the weighted ones.
 |
 |
 |
 |
4.3 Space Distortion
For any agglomerative hierarchical clustering strategy, the initial distances between individuals may be regarded as defining a space with known properties [14]. When clusters begin to form, if the new distances between clusters are kept within the limits of the same space, then the original model remains unchanged and the clustering strategy is referred to as space-conserving. Otherwise, the clustering strategy is referred to as space-distorting. According to the formalization of the concept of space distortion [6], a clustering strategy is said to be space-conserving if
| (16) |
On the contrary, a clustering strategy is space-contracting if the left inequality, delimited by SL, is not satisfied; and a clustering strategy is space-dilating if the right inequality, delimited by CL, is not satisfied. For space-contracting clustering strategies, as clusters grow in size, they move closer to other clusters. This effect is called chaining and it refers to the successive addition of elements to an ever expanding single cluster [14]. Space-dilating clustering strategies produce the opposite effect, i.e., clusters moving further away from other clusters as they grow in size.
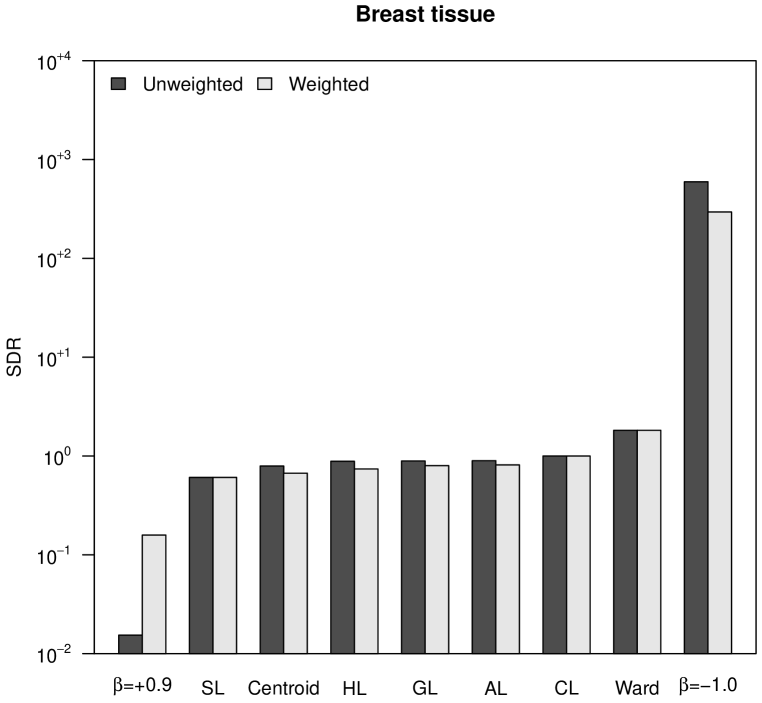
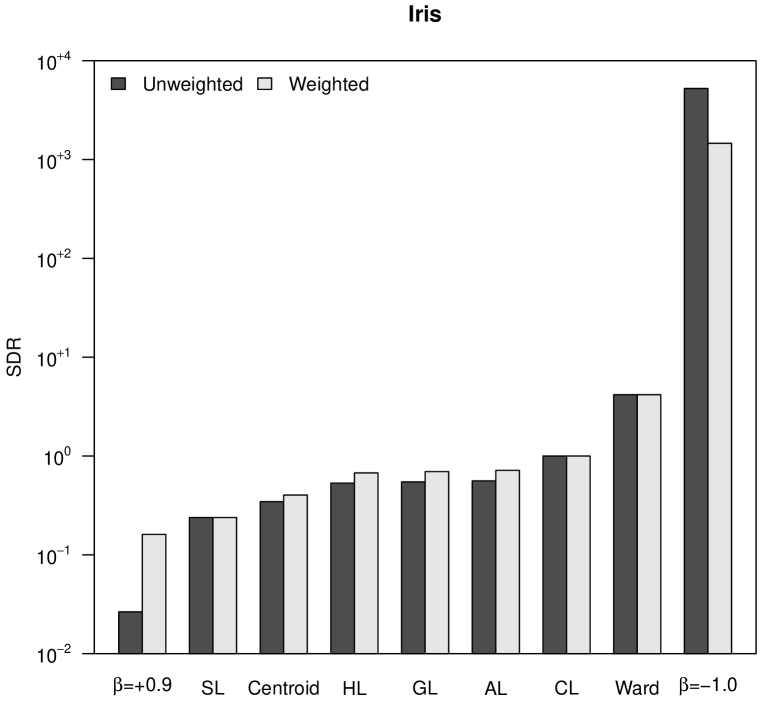
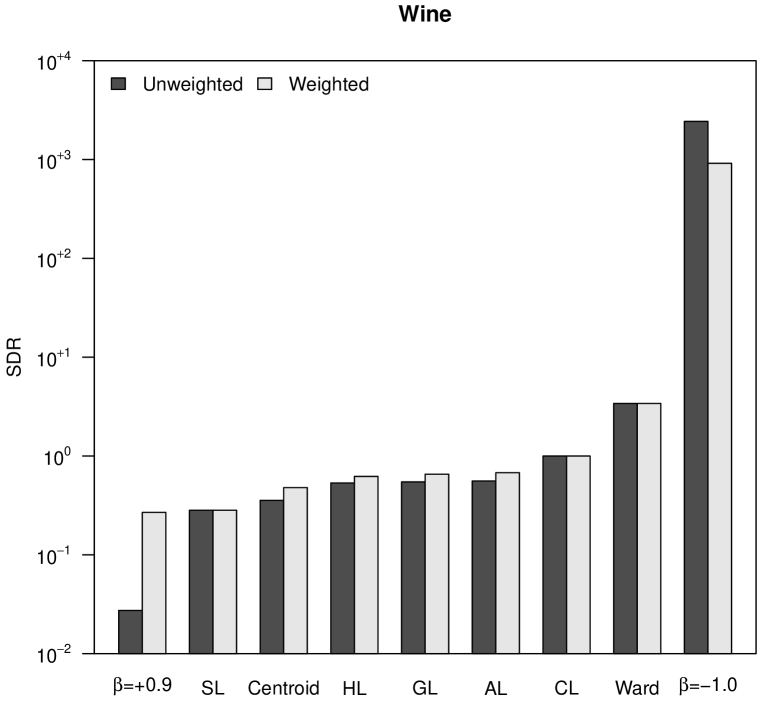
To numerically assess space distortion, we propose a space distortion ratio (SDR) measure, calculated as the quotient between the range of final ultrametric distances, , and the range of initial distances, :
| (17) |
The SDR is equal to for CL, thus this value separates space-conserving hierarchical trees from space-dilating ones. Figure 3 shows the SDR values corresponding to our four case studies. The outstanding differences between initial distances and ultrametric distances in the case of Ward’s method and -flexible clustering with , already observed in Figure 2, allow the classification of both hierarchical clustering methods as space-dilating. With regard to weighting, it cannot be stated that neither weighted nor unweighted clustering strategies produce more space distortion: it depends on the particular dataset.
 |
 |
 |
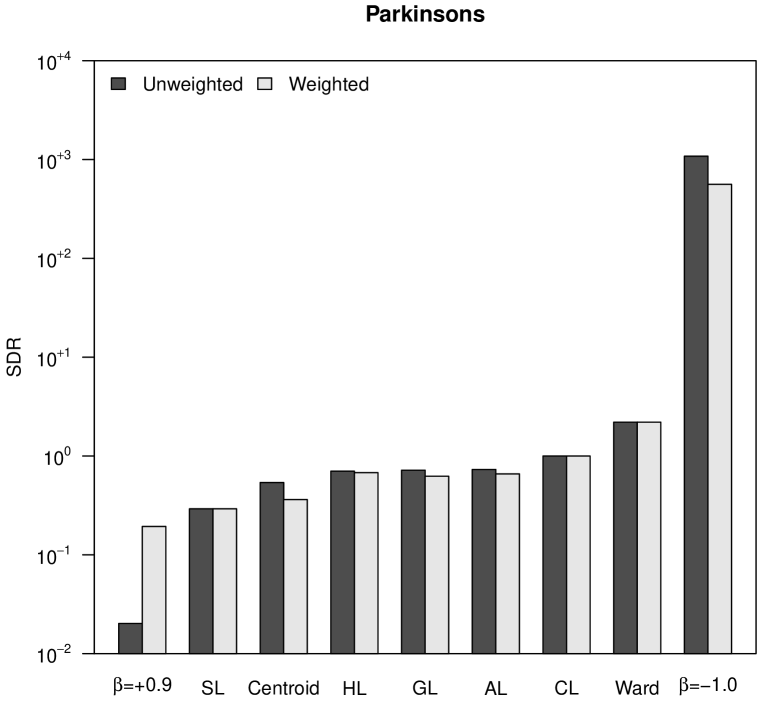 |
In Figure 3 it can also be observed the increasing space distortion when decreases in -flexible clustering, or when the power increases in versatile linkage clustering. Both parameters, and , work as cluster intensity coefficients in their respective clustering systems. In the case of versatile linkage, the increasing space distortion when the power increases is explained by the generalized mean inequality in Equation 15. Therefore, taking also into account that, according to Equation 16, space-conserving clustering strategies are lower bounded by SL () and upper bounded by CL (), we can state that versatile linkage defines an infinite system of space-conserving strategies for agglomerative hierarchical clustering.
4.4 Tree Balance
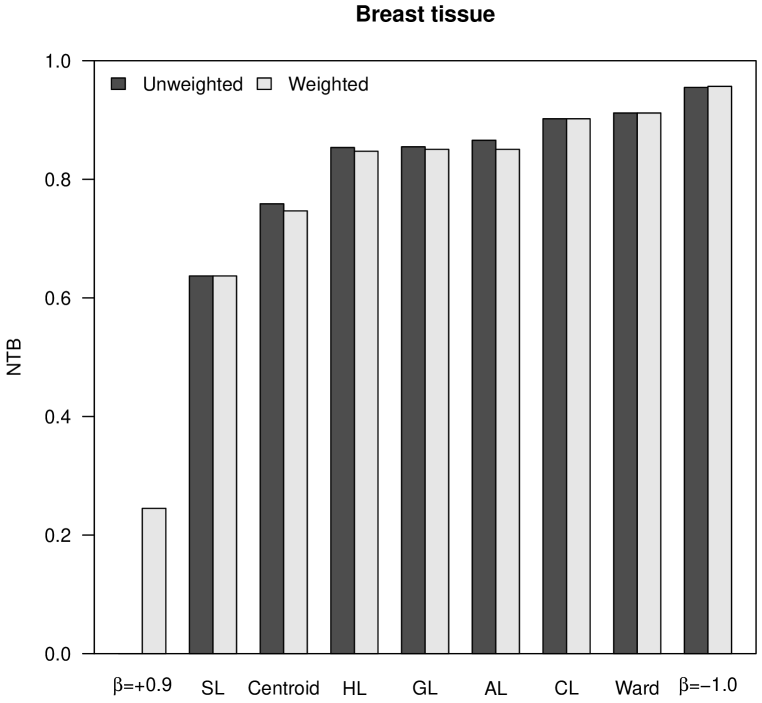
We use the concept of entropy from information theory, more concretely Shannon’s entropy [21], to introduce a new measure to assess the degree of homogeneity in size of the clusters in a hierarchical tree. Given a cluster , we define its entropy as
| (18) |
where is the proportion of individuals in cluster that are also members of subcluster . Next, we define the tree balance, , of a hierarchical tree as the average entropy of all its internal clusters. The maximum tree balance is equal to and it is obtained, for instance, for a completely flat hierarchical tree with a single cluster containing the individuals in the collection. Another example of hierarchical trees with maximum tree balance are the regular -way trees obtained when applying the Baire-based divisive hierarchical clustering algorithm on a collection of sequences with uniformly distributed prefixes [3, 4]. On the contrary, the minimum tree balance, , corresponds to a binary tree where individuals are chained one at a time:
| (19) |
Now, we can define the normalized tree balance (NTB) as
| (20) |
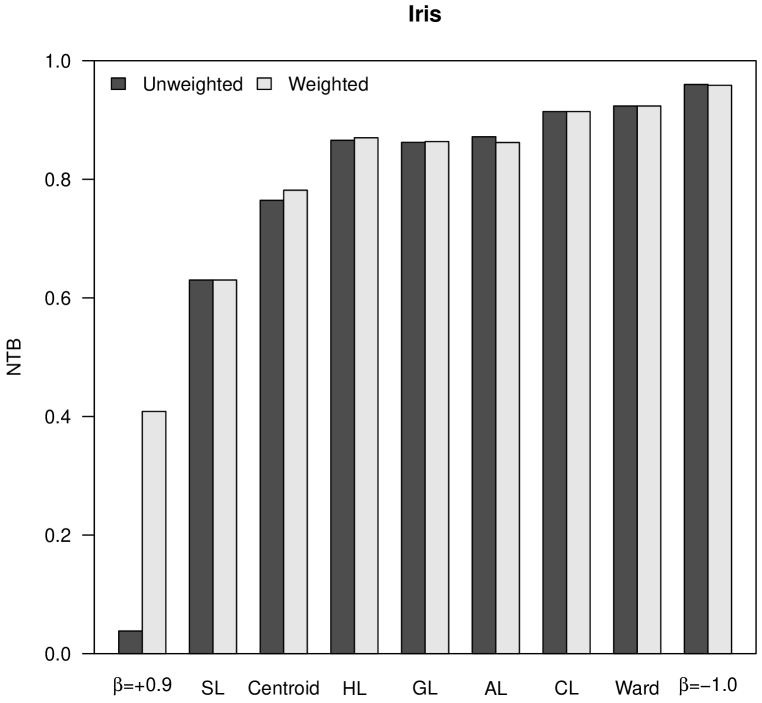
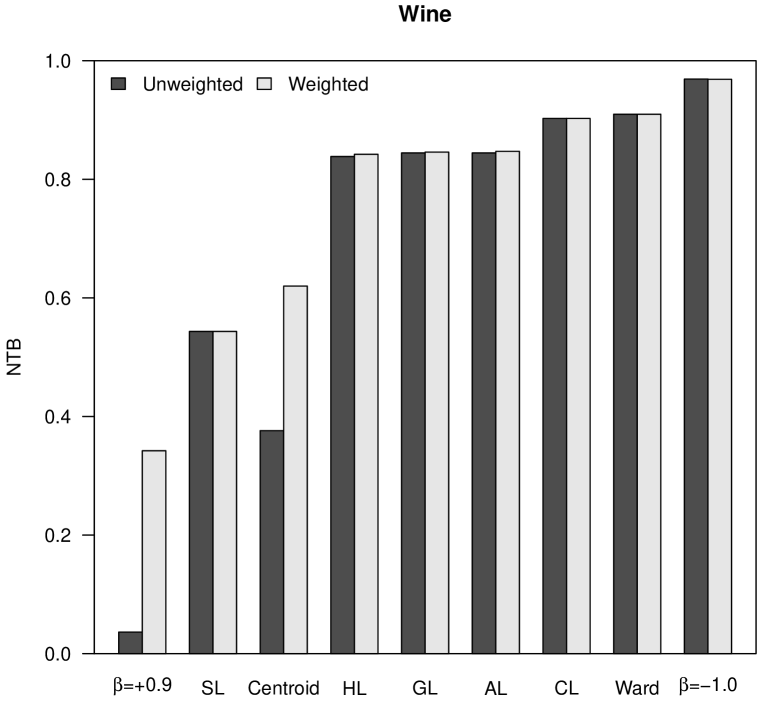
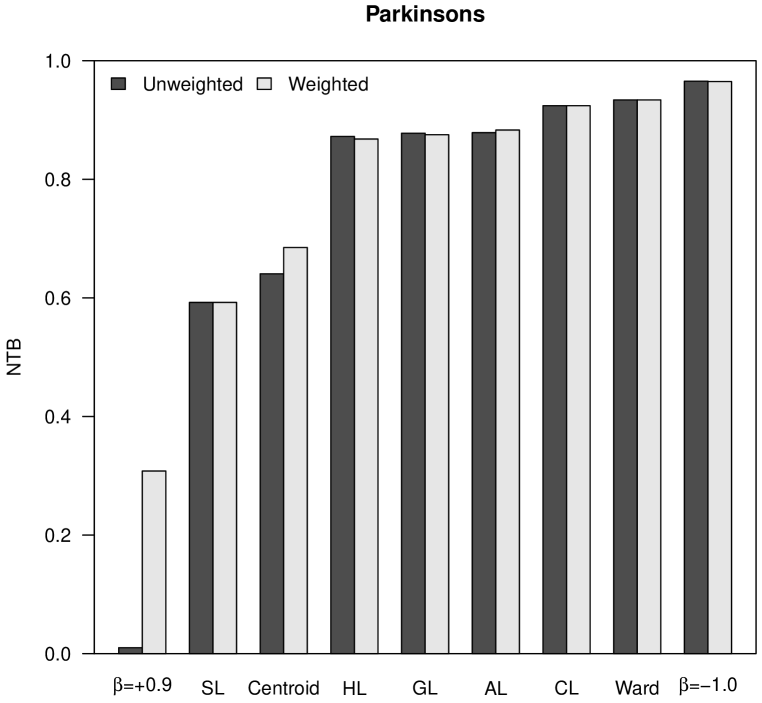
which becomes a measure with values between and . Figure 4 shows the NTB values obtained for our case studies. Similarly to space distortion, tree balance increases when decreases in -flexible clustering, or when the power increases in versatile linkage clustering. In the case of the almost flat hierarchical trees obtained with -flexible clustering when , the NTB is very close to . Finally, according to the values observed in Figure 4, it cannot be stated that neither weighted nor unweighted clustering strategies produce hierarchical trees that are more balanced.
 |
 |
 |
 |
5 Conclusions
Agglomerative hierarchical clustering methods have been continually evolving since their origins back in the 1950s, and historically they have been deployed in very diverse application domains, such as geosciences, biosciences, ecology, chemistry, text mining and information retrieval, among others [19]. Nowadays, with the advent of the big data revolution, hierarchical clustering methods have had to address the new challenges brought by more recent application domains that require the hierarchical clustering of thousands of observations [20].
In this work we have introduced versatile linkage, an infinite family of agglomerative hierarchical clustering strategies based on the definition of generalized mean. We have shown that the versatile linkage family contains as particular cases not only the traditionally important strategies of single linkage, complete linkage and arithmetic linkage, but also two new clustering strategies such as geometric linkage and harmonic linkage. In addition, we have given both weighted and unweighted versions of these hierarchical clustering strategies, and we have proved the monotonicity of versatile linkage strategies, which guarantees the absence of inversions in the hierarchy. Although we have built versatile linkage upon the multidendrograms variable-group methods to ensure the uniqueness of the clustering, it may also be used with the common pair-group approach just by breaking ties randomly.
We have shown that any descriptive analysis of hierarchical trees in terms of cophenetic correlation should be complemented with the use of other measures capable of describing the space distortion that different hierarchical clustering strategies cause. Under this point of view, we have shown that it is helpful to use other measures such as the mean absolute error or the space distortion ratio. The latter, in addition, provides a way to describe numerically the increase in space distortion observed all along a system of hierarchical clustering strategies such as versatile linkage.
Space distortion is inversely proportional to clustering intensity: space-contracting clustering strategies drive systems to cluster very weakly and produce a chaining effect, while space-dilating clustering strategies drive systems to cluster with high intensity and produce very compact clusters. These differences are described by the normalized tree balance measure introduced here, which is based on Shannon’s entropy. Tree balance and space distortion are two new descriptive measures meant to be helpful to analyze and understand any hierarchical tree.
The -flexible clustering also integrates an infinite number of agglomerative hierarchical clustering strategies into a single system, driven by a parameter that works as a cluster intensity coefficient. However, to the best of our knowledge, no one has rigorously defined yet a range of values of for which the corresponding -flexible clustering strategies can be regarded as space-conserving. Unlike the -flexible clustering system, we have shown that the versatile linkage family is space-conserving.
Acknowledgements
This work has been partially supported by MINECO through grant FIS2015-71582-C2-1 (S.G.), Generalitat de Catalunya project 2017-SGR-896 (S.G.), and Universitat Rovira i Virgili projects 2017PFR-URV-B2-29 (A.F.) and 2017PFR-URV-B2-41 (S.G.).
References
- [1] S. Aeberhard, D. Coomans, and O. De Vel. Comparison of classifiers in high dimensional settings. Dept. Math. Statist., James Cook Univ., North Queensland, Australia, Tech. Rep. no. 92-02, 1992.
- [2] L. Belbin, D.P. Faith, and G.W. Milligan. A comparison of two approaches to beta-flexible clustering. Multivariate Behavioral Research, 27(3):417–433, 1992.
- [3] P.E. Bradley. Mumford dendrograms. The Computer Journal, 53(4):393–404, 2010.
- [4] P. Contreras and F. Murtagh. Fast, linear time hierarchical clustering using the baire metric. Journal of Classification, 29(2):118–143, 2012.
- [5] W.H.E. Day and H. Edelsbrunner. Efficient algorithms for agglomerative hierarchical clustering methods. Journal of Classification, 1(1):7–24, 1984.
- [6] J.L. Dubien and W.D. Warde. A mathematical comparison of the members of an infinite family of agglomerative clustering algorithms. Canadian Journal of Statistics, 7:29–38, 1979.
- [7] A. Fernández and S. Gómez. Solving non-uniqueness in agglomerative hierarchical clustering using multidendrograms. Journal of Classification, 25(1):43–65, 2008.
- [8] R.A. Fisher. The use of multiple measurements in taxonomic problems. Annals of Eugenics, 7(2):179–188, 1936.
- [9] S. Gómez and A. Fernández. MultiDendrograms: A hierarchical clustering tool (Version 5.0), 2018. http://deim.urv.cat/~sergio.gomez/multidendrograms.php.
- [10] A.D. Gordon. Classification. Chapman & Hall/CRC, 2nd edition, 1999.
- [11] G. Hart. The occurrence of multiple UPGMA phenograms. In J. Felsenstein, editor, Numerical Taxonomy, pages 254–258. Springer Berlin Heidelberg, 1983.
- [12] J Jossinet. Variability of impedivity in normal and pathological breast tissue. Medical and Biological Engineering and Computing, 34(5):346–350, 1996.
- [13] G.N. Lance and W.T. Williams. A generalized sorting strategy for computer classifications. Nature, 212:218, 1966.
- [14] G.N. Lance and W.T. Williams. A general theory of classificatory sorting strategies: 1. Hierarchical systems. The Computer Journal, 9(4):373–380, 1967.
- [15] M. Lichman. UCI machine learning repository, 2013.
- [16] M.A. Little, P.E. McSharry, E.J. Hunter, J. Spielman, and L.O. Ramig. Suitability of dysphonia measurements for telemonitoring of Parkinson’s disease. IEEE Transactions on Biomedical Engineering, 56(4):1015–1022, 2009.
- [17] B.J.T. Morgan and A.P.G. Ray. Non-uniqueness and inversions in cluster analysis. Journal of the Royal Statistical Society: Series C (Applied Statistics), 44(1):117–134, 1995.
- [18] F. Murtagh. Multidimensional clustering algorithms. In Compstat Lectures. Physica-Verlag, Vienna, 1985.
- [19] F. Murtagh and P. Contreras. Algorithms for hierarchical clustering: An overview, ii. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 7(6):e1219, 2017.
- [20] F. Murtagh and P. Contreras. Clustering through high dimensional data scaling: Applications and implementations. Archives of Data Science, Series A, 2(1):1–16, 2017.
- [21] C.E. Shannon. A mathematical theory of communication. The Bell System Technical Journal, 27:379–423, 1948.
- [22] P.H.A. Sneath and R.R. Sokal. Numerical Taxonomy: The Principles and Practice of Numerical Classification. W. H. Freeman and Company, 1973.
- [23] R.R. Sokal and C.D. Michener. A statistical method for evaluating systematic relationships. The University of Kansas Science Bulletin, 38:1409–1438, 1958.
- [24] R.R. Sokal and F.J. Rohlf. The comparison of dendrograms by objective methods. Taxon, 11(2):33–40, 1962.
- [25] J.H. Ward Jr. Hierarchical grouping to optimize an objective function. Journal of the American Statistical Association, 58(301):236–244, 1963.