Vision-Language Navigation:
A Survey and Taxonomy
Abstract
Vision-Language Navigation (VLN) tasks require an agent to follow human language instructions to navigate in previously unseen environments. This challenging field involving problems in natural language processing, computer vision, robotics, etc., has spawn many excellent works focusing on various VLN tasks. This paper provides a comprehensive survey and an insightful taxonomy of these tasks based on the different characteristics of language instructions in these tasks. Depending on whether the navigation instructions are given for once or multiple times, this paper divides the tasks into two categories, i.e., single-turn and multi-turn tasks. For single-turn tasks, we further subdivide them into goal-oriented and route-oriented based on whether the instructions designate a single goal location or specify a sequence of multiple locations. For multi-turn tasks, we subdivide them into passive and interactive tasks based on whether the agent is allowed to question the instruction or not. These tasks require different capabilities of the agent and entail various model designs. We identify progress made on the tasks and look into the limitations of existing VLN models and task settings. Finally, we discuss several open issues of VLN and point out some opportunities in the future, i.e., incorporating knowledge with VLN models and implementing them in the real physical world.
Index Terms:
Vision-and-Language Navigation, Survey, Taxonomy.I Introduction
Artificial Intelligent systems should be able to sense the environment and make actions in order to perform specific tasks [1]. Computer Vision (CV) and Natural Language Processing (NLP) as the main technologies for agents to perceive the environment, have also received extensive attention from researchers. Significant progress have been made in CV and NLP fields largely due to the successful application of deep learning such as classification [2], object detection [3], segmentation [4], large-scale pre-trained language model [5, 6], etc. Deep learning has also achieved certain results in the field of robot control and decision-making, such as [7]. These tremendous advances have fueled the confidence of researchers for solving more complex tasks that involve language embedding, vision encoding and decision-making on actions. Vision-Language Navigation (VLN) is this type of task, which requires agent to follow human language instructions to navigate in previously unseen environments. VLN task is more in line with human expectations of artificial intelligence, and has inspired a series of subsequent work, such as manipulation using vision and language [8] and outdoor navigation [9]. As shown in Figure 1, a VLN agent typically takes visual observations and language instructions as inputs and output is either navigation actions, natural language, manipulation actions or identifying object locations.
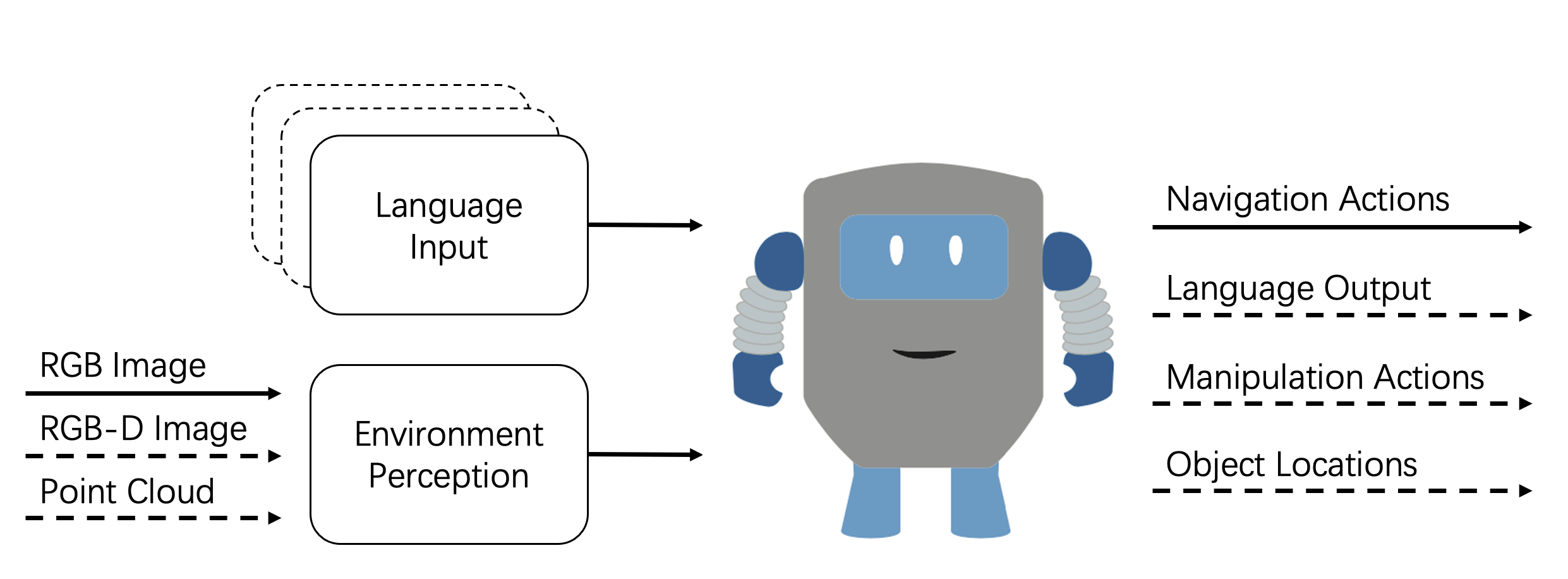
In this survey, we will comprehensively review existing vision-and-language literatures for different tasks, not only the task proposed by Anderson et al. [10] in 2018, but also other tasks that utilize both natural language and visual information for navigation. Futhermore, we try to find out the inherent differences among the VLN tasks. We found that the visual input of the same type of task is basically similar, i.e., environments for indoor tasks are mostly home, while for outdoor tasks are street scenes. There may also be different task settings in the same environment, so these tasks cannot be effectively classified by visual input. For example, REVERIE [11] task and Room-to-Room [10] task are based on the same environment simulator, but they have different task settings. In comparison, the language part leads these tasks completely different. Some tasks give specific instructions when the agent navigation starts, and the form of the instructions varies. Some tasks require agents to interact with humans to obtain information progressively, so as to complete the navigation task. Based on this observation, we introduce a new taxonomy to categorize existing different VLN tasks. Depending on navigation instruction is given for once or multiple times, the VLN tasks can be divided into two types: single-turn and multi-turn tasks.
For single-turn tasks, the agent receives a language instruction at start position and then navigates to the destination following the instruction. Depending on whether the specific route is described in the instructions, single-turn task can be subdivided into: Goal-oriented tasks and Route-oriented tasks.
-
•
Goal-oriented. The instructions contain one or more goals, but does not give detailed routes to reach these goals. The goals are often visible at the initial position, but there are also invisible situations, which require the agent to find in the environment by moving or interacting with the environment(e.g., “bring me a spoon”, spoon is in the drawer, only can be found by openning the drawer). After finding the target, the agent needs to plan the trajectory by itself to reach the target position.
-
•
Route-oriented. In this type of tasks, the language instruction describes the objects seen along the way and the agent’s route in detail. The agent may get lost if it does not strictly follow the route indicated in the instruction which is usually well-formed. Instructions can be decomposed into several meaningful pieces by some rules and each of them indicates an movement action. In this case, the agent can plan an action sequence, then carries out them.
For multi-turn tasks, instructions will be given by a guide to VLN agent in several turns, until the agent has reached the specified goal. According to whether the agent can question the instruction or not, we subdivided multi-turn tasks into: Passive and Interactive tasks. As different instructions can be given sequentially, an instruction in a single turn is mainly goal-oriented for easy execution, where the goal is usually visible when the agent is required to perform the instruction.
-
•
Passive. Instructions are given to the agent in stages, where the information contained in the instructions is often sufficient and unambiguous, so the agent only needs to understand the meanings and move to the target position. Order instructions for this type of task is different for this problem.
-
•
Interactive. In this task setting, the human guide and the agent are usually cooperative, and the agent can ask the person if it encounters a situation of information insufficiency or ambiguity. In this interactive manner, the agent can continuously acquire information to complete the navigation task.
Scope of the survey. Existing reviews related to VLN are mainly in Embodied AI [12, 13, 14] areas and multi-modal research in vision and language [15, 16]. Other related paper like [17] reviews previous works of traditional navigation model based on geometrical and topological approaches, and Guilherme and Avinash [18] reviews the robotic navigation literature. Review papers mentioned above are related to VLN approaches, but none of the reviews specifically studied the VLN task. Since VLN has now become a popular field, models and datasets are also being updated very quickly. Therefore, a comprehensive review of the progress and taxonomy of related tasks that enable researchers to better grasp the key point of a specific task and identify directions for future research is necessary. Due to limitations on space and our knowledge, we apologize to those authors whose works are not included in this paper.
| Task Type | Instruction | Name | Simulator | Outdoor | Compound |
|---|---|---|---|---|---|
| Single | Goal-Oriented | LANI [19] | - | - | |
| ALFRED [8] | AI2-THOR [20] | M | |||
| Talk2Car [21] | - | ✔ | M | ||
| XWORLD [22] | - | - | |||
| 3D Doom[23] | VizDoom [24] | - | |||
| Visual Semantic Navigation | AI2-THOR [20] | ||||
| EQA [25] | House3D [26] | Q | |||
| RoomNav [26] | House3D [26] | - | |||
| REVERIE [11] | Matterport3D [10] | L | |||
| Behavioral Robot Navigation[27] | - | - | |||
| Navigation Task Based on SUNCG[28] | - | - | |||
| Route-Oriented | Room-to-Room [10] | Matterport3D | - | ||
| Room-for-Room [29] | Matterport3D | - | |||
| Room-Cross-Room [30] | Matterport3D | - | |||
| R6R, R8R [31] | Matterport3D | - | |||
| Room-to-Room-CE [32] | Matterport3D | - | |||
| Cross lingual Room-to-Room [33] | Matterport3D | - | |||
| TouchDown [34] | Google Street View 1 | ✔ | L | ||
| RUN [35] | - | - | |||
| Street Nav [36] | Google Street View | ✔ | - | ||
| StreetLearn [37] | Google Street View | ✔ | - | ||
| ARRAMON [38] | - | M | |||
| Multi | Passive | CEREALBAR [39] | - | - | |
| VLNA [40] | Matterport3D | - | |||
| HANNA [41] | Matterport3D | - | |||
| Interactive | CVDN [42] | Matterport3D | - | ||
| Just Ask[43] | Matterport3D | - | |||
| Talk The Walk [44] | - | ✔ | - | ||
| RobotSlang [45] | Physical | - |
Contributions. First, to the best of our knowledge, this paper is the first work to give a comprehensive review of the existing vision-and-language tasks . Compared to recent works, this survey covers more recent papers, more tasks and datasets. Second, the taxonomy of VLN tasks is well-designed, it can help researchers better understand the task. Third, limitations of current approaches are fully described and discussed. We also proposed some possible solutions, which may provide inspiring ideas for researchers in this field.
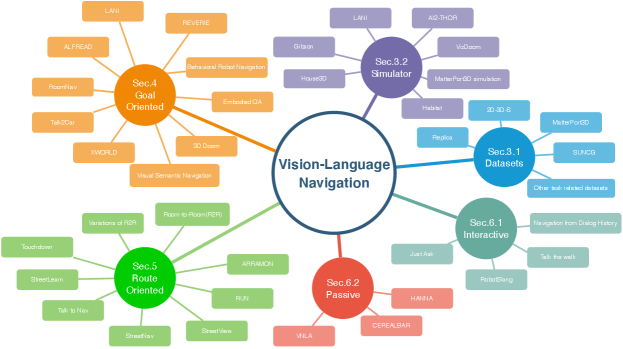
The remainder of this paper is organized as follows: In Section II, we briefly provide some technical background in CV, NLP and robot navigation field. Then, in Section III, different types of VLN dataset and simulator are described in detail. As shown in Tab. I, we summarize typical datasets and related simulators, the tasks will be illustrated in Section IV. Beyond navigation, some tasks may interleave with other actions, such as manipulate an object, answer an question, locate a target object. Note that our taxonomy only considers the navigation part if a task have multiple task settings. Finally, the conclusions are presented in Section V. A knowledge graph is summarized in Figure 2. This can help readers to quickly find content of interest.
II Preliminaries
In this section, we briefly provide technical background needed of VLN tasks. We review the effect of deep learning to computer vision, natural language processing, robot navigation and Visual-Linguistic Learning, which are preliminaries of VLN tasks.
II-A Computer Vision
The advent of deep learning [46] has tremendously changed the field of computer vision. The best way to represent images is by leveraging automatic feature extraction methods. Convolutional Neural Networks (CNNs) [47] have become the de facto standard for generating representations of images using end-to-end trainable models. Residual Networks He et al. [2] make the layer number of the network increase from a dozen to dozens, or even more than 100.
With these novel architecture, all task of computer vision, such as Image Classification, Object Localization, Object Detection, Object Segmentation, Object Identification, Instance segmentation and Panoptic segmentation, have made tremendous progress.
II-B Statistical Natural Language Processing
Language is usually represented either with bag-of-words or with sentence representations. Modern approaches use word vectors to capture or learn structure, such as Long Short-Term Memory units (LSTMs) [48] combined with Word2Vec [49] or Paragraph Vector [50]. These approaches learn a vector representation associated with either words or longer documents and then compute over an entire sentence to perform tasks such as shallow parsing, syntax parsing, semantic role labeling, named entity recognition, entity linking, co-reference resolution, etc.
II-C Robot Navigation
Navigation is a important ability for artificial agents to adapt to an environment and is the precondition for other advanced behaviors. Robot navigation task expects robot find optimal path to reach the destination, typical navigation tasks including standard vision-based navigation using only visual input [51, 52] and natural language instruction based navigation [53, 54]. Furthermore, combining vision and language information during navigation task is more challenging and realistic, because natural language navigation instruction should be interpreted based on visual input, just like humans.
II-D Visual-Linguistic Learning
The deep learning advances the development of both computer vision and natural language processing. Moreover, it unifies the visual and language data into a vector representation. This is the most important preliminary to combine vision with language and high-level reasoning. Visual Question Answering[55, 56, 57, 58] is a prime example of this trend. Others are image captioning [59, 60, 61], visual commonsense reasoning [62, 63] and so on.
III Datasets and Simulators
Considering of the scale, annotation and influence, we will introduce some typical datasets ans simulators. Other datasets or simulators will be briefly referred alone the introduction of related tasks.
| Simulator | Dataset | Observation | 2D/3D |
|---|---|---|---|
| AI2-THOR | - | photo-realistic | 3D |
| VizDoom | - | Virtual | 2.5D |
| Gibson | 2D-3D-S, Matterport3D | photo-realistic | 3D |
| LANI | - | Virtual | 3D |
| House3D | SUNCG | photo-realistic | 3D |
| Matterport3D Simulator | Matterport3D | photo-realistic | 3D |
| Habitat | Gibson, Matterport3D, Replica | photo-realistic | 3D |
III-A Datasets
SUNCG [64]111https://github.com/shurans/sscnet dataset contains 45,622 artificially designed 3D scenes, ranging from single chamber to multi-floor houses. These 3D scenes include a large number of objects, spatial layout and other elements, hoping to provide a good platform for 3D object recognition researchers. On average, there are 8.9 rooms and 1.3 floors per scene, and also many categories of rooms and objects in each scene. More than 20 types of room and 80 categories of object in SUNCG datasets, 404,508 room instances and 5,697,217 object instances.
People have annotated each scene in dataset with 3D coordinates and inside room and object types. At every time step an agent has access to the following signals: a) the visual RGB signal of its current first person view; b) semantic (instance) segmentation masks for all the objects visible in its current view; c) depth information. For different tasks, these signals might serve for different purposes, e.g., as a feature plane or an auxiliary target.
Matterport 3D [65]222https://github.com/niessner/Matterport is a recent mainstream dataset, which contains 90 scenes collected from reality and 194,400 RGB-D images in total. Dataset have been fully annotated with 3D reconstructions and 2D and 3D semantic segmentation.
The precise global alignment of the entire building and a comprehensive and diverse panoramic view set supports various supervised and self-supervised computer vision tasks, such as view overlap prediction, semantic segmentation, and region classification etc.
2D-3D-S [66]333http://3Dsemantics.stanford.edu/ is a indoor environment supporting 2D, 2.5D and 3D domains with multi-modal, 3D meshes and point clouds data. The dataset has over 70,000 RGB images, annotated with fully information such as depths, semantic annotations, and camera configurations.
Replica [67]444https://github.com/facebookresearch/Replica-Dataset is a photo-realistic 3D indoor environment with 18 different scenes rendered by high quality images. The scenes selected focus on the semantic diversity and scale of the environment. Each scene is composed of dense grids, high-resolution textures, original semantic classes, instance information, flat mirrors and glass reflectors.
III-B Simulators with Builtin Dataset
LANI [19] is a massive 3D navigation dataset with 6,000 language instructions in total, based on Unity 3D. The environment is a fenced, square, grass field. Each scene includes between 6–13 randomly placed landmarks, sampled from 63 unique landmarks. The agent has discrete actions: forward, stop, turnleft, and turnright. At each time step, the agent performs an action, observes a first person view of the surroundings as an image, and receives a scalar reward. The simulator provides a socket API to control the agent and the environment.
AI2-THOR [20]555http://ai2thor.allenai.org.is a large-scale near photo-realistic 3D indoor dataset, where agents can navigate in the scenes and interact with objects to perform tasks. AI2-THOR enables research in many different domains, such as deep reinforcement learning, planning, visual question answering, and object detection and segmentation etc.
VizDoom[24]666http://vizdoom.cs.put.edu.pl is modified on Doom, a first-person shooter video game. Aiming at providing convenience for researchers, ViZDoom is designed small-scale, efficient, and highly customizable for different domains of experiments. Besides, VizDoom supports different control modes, custom scenes, access to the depth buffer, and can run without a graphical interface, which improving the efficiency of algorithm execution.
Gibson [68]777http://gibson.vision/ is based on virtualized real spaces, with embodiment of agents and making them subject to constraints of complex semantic scenes. Gibson consists of 572 building scenes and 1,447 floors, and each scene is equipped with panoramic images and camera configurations. The base format of the dataset is similar to 2D-3D-S dataset [66], but is more diverse and has 2 orders of magnitude more spaces. The simulator of Gibson has also integrated 2D-3D-S dataset [66] and Matterport3D [65] for optional use.
III-C Simulators
House3D [26]888http://github.com/facebookresearch/House3D contains diverse room types and objects inside and support MacOS and Linux operating system. The 3D scenes are based on SUNCG dataset and annotated with rich information. To build a realistic 3D environment, House3D offers a OpenGL based renderer for the SUNCG scenes. Agents in this environment can move freely, receiving tasks for the different kinds of research.
Matterport3D Simulator [10]999https://github.com/peteanderson80/Matterport3DSimulator is a large-scale machine learning research platform based on the Matterport3D dataset [65] for the research and development of intelligent agents. Agents can virtually ‘move’ throughout a scene by adopting poses coinciding with panoramic viewpoints. Each scene has a corresponding weighted, undirected graph, so that the presence of an edge indicates a robot-navigable transition between the two viewpoints. The simulator does not define or place restrictions on the agent’s goal, reward function, or any additional context, so researchers can design this metrics according to their experimental settings.
Habitat [69]101010https://aihabitat.org is a platform for research in photo-realistic 3D environment, and integrates multiple commonly used VLN datasets. Specifically, the simulator supports Matterport3D [65], Gibson [68], and Replica [67] datasets. Besides, Habitat consists of a simulator Habitat-Sim and a modular library Habitat-API. Habitat-API aiming to help researchers verify and improve intelligent algorithms.
IV Goal-Oriented Tasks
In goal-oriented tasks, the language instruction only contain specific goals with no detailed route on it, so agents need to make plan by themselves. In this section, we will introduce several goal oriented tasks from task definition, evaluation metrics, related works and typical methods.
IV-A LANI
IV-A1 Task Definition
Misra et al. [19] collect a corpus of navigation instructions using crowd sourcing. They used LANI simulator to generate environments randomly and one reference path for each environment. The generated reference paths are near to their neighbor landmarks to elicit instructions. Then, they used Amazon Mechanical Turk to annotate. The experiment environment is simulated and relatively simple. Furthermore, Blukis et al. [70] propose a real-world learning framework, which is similar to LANI, so we will not describe details here.
IV-A2 Evaluation Metrics
The task performance is evaluated on a test set , where is an instruction, is the start state, and is the goal state. Task completion accuracy and the distance of the agent’s final state to are evaluated.
IV-A3 Related Task
Before LANI, Blukis et al. [71] propose a virtual environment navigation task based on Unreal Engine, which uses the AirSim plugin [72] to simulate realistic quadcopter dynamics. The agent is a quad-copter flying between landmarks. This work focus on the problem of mapping, planning and task execution. Language instructions for this task are generated from a pre-defined set of templates. For solving this problem, Blukis et al. [71] put instructions into a LSTM network to get language embedding at the task beginning. A custom residual network is used to represent the image features at every time step and project features in global reference frame for making actions.
IV-A4 Typical Methods
In Misra et al. [19]’s work, this instruction following task is decomposed into two submodules: goal prediction and action generation. They proposed a new language-conditioned image generation network architecture LINGUNET, to make a map from visual input to goals output.
Base on LANI, Blukis et al. [73] propose an approach for mapping natural language instructions and raw observations inputs to continuous control of a quadcopter drone, which used the quadcopter simulator environment from Blukis et al. [71]. For indicating where the agent should visit during navigation and where to stop, they built a model to predict the position-visitation distributions, and then actions are generated from the predicted distributions.
For combing the simulation and reality, Blukis et al. [70] propose a learning framework to map language instructions and images to low-level action outputs. In addition, Supervised Reinforcement Asynchronous Learning (SuReAL) is used in both simulation and reality without the need to fly in real world during training. SuReAL combines supervised learning for predicting next goal and reinforcement learning for continuous action outputs.
More recently, Blukis et al. [74] study the problem of extending to reason about new objects. Due to the lack of sufficient training data, they used a few-shot method trained from extra augmented reality data to ground language instructions to objects. This method can align the objects and their mentions in language instructions.
IV-B Action Learning From Realistic Environments and Directives
IV-B1 Task Definition
Action Learning From Realistic Environments and Directives [8](ALFRED) is a indoor task, agents in this task need to receive a language instruction about doing a household and first-person image observations, then generated a sequence of actions to finish it. ALFRED includes 25,743 English instructions, describing 8,055 expert demonstrations, each with an average of 50 steps, resulting in 428,322 image-action pairs.The expert demonstrations are together with both high-level and low-level language instructions in 120 indoor scenes based on AI2-THOR 2.0 simulator [20]. These demonstrations involve partial observability, a long range of actions, in a designated natural language, and irreversible actions.
IV-B2 Evaluation Metrics
ALFRED allows users to evaluate both full task and task goal-condition completion. In navigation-only tasks, the model performance can be measured by how far the agent is from the goal. Whether the target conditions of the task have been completed can also be evaluated in the ALFRED task. The evaluation metrics consist of Task Success, Goal-Condition Success and Path Weighted Metrics.
-
•
Task Success. If the object positions and state changes correspond correctly to the task goal-conditions at the end of the action sequence, the task success will be set to 1, and otherwise to 0.
-
•
Goal-Condition Success. This metric is the ratio of goal-conditions completed at the end of an episode to those necessary to have finished a task.
-
•
Path Weighted Metrics. Anderson et al. [75] find that PDDL solver can not find the optimal result, but usually efficient. The path weighted score for metric is given as
(1) where is the number of actions the model took in the episode, and is the number of actions in the expert demonstration. Obviously, a model receives half-credit for taking twice as long as the expert to accomplish a task.
IV-B3 Typical Methods
In [8], a Sequence-to-Sequence (Seq2Seq) Model with progress monitoring is introduced. Each visual observation was encoded with a froze ResNet-18 [2]. The step-by-step instructions is combined into a single input sequence with the token. Then the sequences are fed into a bi-directional LSTM encoder to produce an encoding sequence. The agent’s actions at each time step are based on the attention mechanism that can identify the related tokens in the language instruction. The agent interacts with the environment by choosing an action and producing dense pixel-wise binary mask to indicate specific objects in the frame.
In [76], during the navigation of the sub-goals, the agent’s field of view is enhanced through multiple perspectives, and the agent is trained to predict its relative spatial relationship with the target position at each time step.
Singh et al. [77] propose a Modular Object-Centric Approach (MOCA) to decouple ALFRED task into two sub-task, i.e., visual perception and action policy generation. The former aiming to predict an interaction mask for the object that the agent interacts with using object-centric mask prediction, while the latter makes a prediction of the current action of the agent.
IV-C Embodied Question Answering
IV-C1 Task Overview
Embodied Question Answering (EQA) tasks require an agent to ask a question (e.g. ‘What color is the cup?’). The agent usually situated at a random location in an environment (a house or building), and can observe the environment by first-person perspective images. The action space of the agent includes move forward, turn and strafe, etc. After understanding the question, the agent needs to gather useful information in the environment for answering it. Unlike the previous work [78], the agent does not receive any global or structured representation of the environment (map, location, rooms, objects), or of the task (the functional program that generated the question).
EQA is built upon House3D simulator and SUNCG datasets, more details about House3D please refer to section III. In order to ensure the quality of the dataset, the environment inside must be realistic and typical, and there must be no abnormal conditions. Scenes in this task have one kitchen, dining room, living room, and bedroom at least. The EQA v1 dataset contains more than 5000 questions in over 750 environments, involving a total of 45 unique objects in 7 unique room types. There are 1 to 22 related questions in each environment, with an average of 6. Preposition questions are less than other kinds of questions because many frequently occurring spatial relationships are too easy to solve without exploration and cannot be processed by entropy threshold.
IV-C2 Evaluation Metrics
The goal of an EQA agent is to answer questions precisely. However, it is important to disentangle success/failure at the intermediate task of navigation from the downstream task of question answering. The evaluation metrics of this task are as following:
-
•
Question Answering Accuracy. The mean rank of the ground-truth answer in the candidate answers list sorted by the model.
-
•
Navigation Accuracy. This metric consists of the distance to the target object at navigation termination , changes in distance to target from initial to final position , and the smallest distance to the target at any point in the episode . All these distances are measured in meters along the shortest path to the target.
-
•
The percentage of questions for which an agent either terminates in () or ever enters () the room containing the target objects.
-
•
The percentage of episodes in which agents choose to stop navigation and give a answer before reaching the maximum episode length ().
IV-C3 Typical Methods
Das et al. [25] give a baseline model, which has four modules, i.e., vision, language, navigation, answering and are trained in two stages. First, the navigation and answer module use imitation/supervised learning to independently train the automatically generated navigation expert demonstrations. Then, the navigation architecture uses policy gradients for fine-tuning. This model can map raw sensory input to navigation actions and answers generation.
Anand et al. [79] explore blindfold (question-only) model for EQA which neglects environmental and visual information. Intuitively, the blindfold model is a degraded solution, but it reaches state-of-the-art results on EQA except some rare initialization situations.
Das et al. [80] propose a modular approach of learning strategies for navigating within long-term planning from instructions. For increasing sample efficiency, imitation learning is used to warm-start policies at each level of the hierarchical policy on multiple timescales.
Parvaneh et al. [81] propose a new learning strategy that learns both from observations and generated counterfactual environments. Specifically, the algorithm generating counterfactual observations on the fly for navigation is introduced as the linear combinations of present environments. In addition, the agent’s actions are encouraged to remain stable between initial and counterfactual environments by training objective–effectively removing false features that could mislead the agent.
Furthermore, Wu et al. [82] introduce an easier and practical EQA setting called calibration. They designed a warm-up stage that the agent is asked a few rhetorical questions when it entered into a new environment. The goal is to adapt the agent policy to the new environments. Then they proposed a new model, which contains two modules, designed for the intermediate navigation task, called Navigation Module, and downstream question answering task, called Question Answering Module, respectively.
IV-C4 Task Variation
When using behavioral cloning method to train a recurrent model for navigation, the impact of a novel loss-weighting metric named inflection weighting has grown. Wijmans et al. [83] extend the EQA task in realistic environments from the Matterport3D dataset [65] and propose a model which can surpass the baseline by optimize the infection weighting metric. Moreover, they argue that point clouds can provide more information than traditional RGB images in photo-realistic environment, especially for tasks like embodied navigation and obstacle avoidance.
Yu et al. [84] extend the EQA to Multi-Target version, i.e., Multi-Target EQA. As the questions are more complex, the agent is supposed to navigate to multiple locations and performs some comparative reasoning steps before answering the question. A new model is designed to solve MT-EQA, which consists of four modules: the question-to-program generator, the navigator, the controller, and the VQA module.
IV-D RoomNav
IV-D1 Task Overview
While Wu et al. [26] propose the House3D simulator, a Concept-Driven Navigation benchmark task is also proposed (i.e., RoomNav). The goal is defined as ”Go to X”, where X represents a pre-defined room type or object type. This is a semantic concept, and the agent needs to be interpreted from a variety of scenes with different visual appearances. RoomNav consists of 270 houses divided into three splits, i.e., small, large and test with 20, 200, and 50 respectively.
Observation: Three different kinds of visual input signals are utilized for , including (1) raw pixel values; (2) semantic segmentation mask of the pixel input; (3) depth information, and different combinations of these three. Each concept (language instruction) is encoded as a one-hot vector representation.
Action Space: This task support continuous and discrete actions, such as agents can move in certain velocities or pre-defined movements.
IV-D2 Evaluation Metrics
The episode is regarded as successful if both of the following two criteria are satisfied: (1) the agent is located inside the target room; (2) the agent consecutively sees a designated object category associated with that target room type for at least 2 time steps. An agent sees an object if there are at least 4% of pixels in belonging to that object.
IV-D3 Typical Methods
In [26], a gated-attention architecture is introduced. Gated-CNN and Gated-LSTM network are used for controlling continuous and discrete actions respectively. The Gated-CNN policy is trained using the Deep Deterministic Policy Gradient (DDPG) [85], while the Gated-LSTM policy is trained using the asynchronous advantage actor-critic algorithm (A3C) [86].
Wu et al. [87] introduce a new memory architecture, Bayesian Relational Memory (BRM), taking the form of a probability relationship graph on semantic entities to improve the generalization ability in unseen environments. BRM supports obtaining some prior knowledge from the training environment, and at the same time, it can update the knowledge in memory after exploration. A BRM agent consists of a module for generating sub-goals and goal-conditioned locomotion module for control
IV-E Remote Embodied Visual referring Expression in Real Indoor Environments
IV-E1 Task Overview
Remote Embodied Visual referring Expression in Real Indoor Environments - REVERIE [11] task requires the intelligent agent to correctly locate the remote target object specified by the concise high-level natural language instructions (which cannot be observed at the starting position). Since the target object and the starting object are in different rooms, the agent needs to navigate to the target location first. Unlike other navigation tasks, agents in this task can execute detection action if agents thinks they has localised the target object and decide to output the region of it. After the detection action, this episode is finished.
IV-E2 Evaluation Metrics
The performance of a model is mainly measured by REVERIE success rate, which is the number of successful tasks over the total number of tasks. A task is considered successful if it selects the correct bounding box of the target object from a set of candidates. Since the target object can be observed at different viewpoints or camera views, an episode is successful as long as the agent can identify the target within 3 meters, regardless of from different viewpoints or views. We also measure the navigation performance with four kinds of metrics, including success rate, oracle success rate, success rate weighted by path length, and path length (in meters) [10].
IV-E3 Typical Methods
Qi et al. [11] propose a modular model including three parts: a navigator module that decides the action to take for the next step, a pointer module that attempts to localise the target object according to the language guidance, and an interaction module that responses for sending the referring expression comprehension information obtained from the pointer to the navigator to guild it to make more accurate action prediction.
Lin et al. [88] introduce two pre-training tasks, called Scene Grounding task and Object Grounding task, and a new memory-augmented attentive action decoder. The pre-training tasks encourage agents learn where to stop and what to attend to, and the action decoder uses past observations to merge visual and textual information in an effective way.
IV-F Other Tasks
IV-F1 Talk2Car
Talk to car task is proposed by Deruyttere et al. [21], and the dataset for this task is built upon the nuScenes dataset [89]. This dataset includes 11,959 instructions for the 850 videos of nuScenes training set since 3D bounding box annotations for the test set of nuScenes are not available. 55.94% and 44.06% of these commands belong to videos taken respectively in Boston and Singapore. On average a command consist of 11.01 words, 2.32 nouns, 2.29 verbs and 0.62 adjectives. Each video has on average 14.07 commands. The textual annotations are very complete, it not only indicates what to do, such as ‘pick him up’, but how to drive the car, such as ‘turn around’. However, this task did not give a metric to evaluate the performance of the action.
Deruyttere et al. [21] only focus on detecting the referred object, but ignoring the action execution. They only assessed the performance of 7 detection models to find the objects in a command. In the test set, random noun matching approach is used to match the nouns in command with the visual objects.
IV-F2 XWORLD
This task is proposed by Yu et al. [90]. It consists of XWORLD2D and XWORLD3D.
-
•
XWORLD2D. To test the method of interactive grounded language acquisition and generalization, Yu et al. [22] build a 2D maze-like world, i.e., XWORLD2D, including language related navigation task and question answering task. Specifically, the navigation task requires agent to follow the language instructions to navigate the final destination, and question answering task requires agents to generate one-word answer for questions.
-
•
XWORLD3D. The XWORLD3D is the extension of XWORLD2D where changing the environment from full-observability to partial-observability, and adding two actions Turn left and Turn right to the discrete action set. For increasing the visual variance, at each session the authors randomly rotate each object and scale it randomly within . Suppose each map is , the maximum time steps of an episode is .
In addition, successful episode means the agent acts obey the teacher’s command. The failure episode is triggered whenever the agent hits any object that is not required by the command. The success rate is used to evaluation the model performance.
In [22], an effective baseline method Guided Feature Transformation (GFT) is proposed for language grounding. In order to improve the fusion of visual and language features, the latent sentence embeddings calculated from the language input is regarded as the conversion matrix of visual features. This method is completely differentiable and embedded in the agent’s perception system, which is trained end-to-end by the RL. GFT method can adapt to both 2D and 3D environments without changing any architecture or hyperparameters between the two scenarios.
IV-F3 3D Doom
Chaplot et al. [23] create an environment for language grounding research, where the agent needs to follow natural language instructions and receives positive rewards after successfully completing the task. This environment is built on top of the VizDoom API [24], based on Doom, a classic first person shooting game.
In 3D Doom task, the instruction is a (action, attribute, object) triplet. Each instruction can have multiple attributes, but the number of actions and objects is limited to one each. This environment allows various objects to be generated at different locations on the map. Objects can have various visual attributes. Success rate defined as the proportion of success navigation times in the total number of navigation times. There are two scenarios for evaluation:
-
•
Multi-task Generalization. The agent uses the instructions in the training set for evaluation on an unseen map. The unseen map consists of a combination of invisible objects placed at random locations.
-
•
Zero-shot Task Generalization, where the agent is situated in unseen environment with new combinations of attribute-object pairs which are not seen during the training. The maps in this scenario are also unseen.
The model proposed by [23] uses the Gated-Attention mechanism to combine images and text representations, and utilize standard reinforcement and imitation learning methods to learn strategies for executing natural language instructions. This model is end-to-end and consists of State Processing Module and Policy Learning Module.
IV-F4 Visual Semantic Navigation
This task [91] is based on the interactive environments of AI2-THOR [20]. There are 87 object categories within AI2-THOR that are common among the scenes. However, some of the objects are not visible without interaction. Therefore, only 53 categories based on their visibility at random initialization of the scenes. To test the generalization ability of the method on novel objects, these 53 object categories are split into known and novel sets, and the known set of object categories are used in training. Only the navigation commands of AI2-THOR are used for the task. These actions include: move forward, move back, rotate right, rotate left, and stop.
The evaluation metrics are Success Rate and the Success weighted by Path Length (SPL) metric recently proposed by Anderson et al. [75].
-
•
Success Rate is defined as the ratio of the number of times the agent successfully navigates to the target and the total number of episodes.
-
•
SPL is a better metric which is a function considering both Success Rate and the path length to reach the goal from the starting point. It is defined as , where is the number of episodes, is a binary indicator of success in episode , represents path length and is the shortest path distance (provided by the environment for evaluation) in episode .
Based on the actor-critic model [86], Yang et al. [91] propose to use Graph Convolutional Networks (GCNs) [92] to incorporate the prior knowledge into a Deep Reinforcement Learning framework. The knowledge of the agents is encoded in a graph. GCNs can encode various structured graphs in an efficient way.
IV-F5 Behavioral Robot Navigation
Zang et al. [27] create a new dataset for the problem of following navigation instructions under the behavioral navigation framework of [93]. This dataset contains 100 maps of simulated indoor environments, each with 6 to 65 rooms. It consists of 8066 pairs of free-form natural language instructions and navigation plans for training. This training data is collected from 88 unique simulated environments, 6064 distinct navigation plans in total (2002 plans have two different navigation instructions each, and the rest has one). The dataset contains two different testsets:
-
•
Test-Repeated: uses seen trainset environments and unseen routes, including 1012 pairs of instructions and navigation plans.
-
•
Test-New: uses 12 unseen environments and unseen routes, which is more complex, including 962 pairs of instructions and navigation plans.
An end-to-end deep learning model is proposed by Zang et al. [27] to convert free-form natural language instructions into high-level navigation plans.
V Route-Oriented Tasks
In route-oriented tasks, the language instruction describes the objects seen along the way and the agent’s route in detail. If the agent can understand the instructions and navigate according to the path in the instructions, it can reach the final destination and successfully complete the navigation task. In this section, we will introduce several goal oriented tasks from task definition, evaluation metrics, related works and typical methods.
V-A Room-to-Room
V-A1 Task Description
Room-to-Room (R2R) is a natural language navigation dataset based on vision in a photo-realistic environment [10]. Environments in this dataset is defined by a navigation graph, where nodes are locations with a self-centered panoramic image, and edges define effective connections for agents navigation. This dataset(spited with train/validation/test) is fully annotated with instructions and paths and each path has 3 different related instructions. The average length of ground-truth path is 4 to 6 edges.
R2R is a task where the inputs are the images from egocentric panoramic camera and instruction. Note that images are updating with the motion of agent, while instruction is given at the beginning. For example, given an instruction “Go towards the front door but before the front door make a left, then through the archway, go to the middle of the middle room and stop.”, an agent is supposed to understand the instruction and follow it from start point to the goal position as soon as possible.
V-A2 Evaluation Metrics
There are a bunch of metrics to evaluate a R2R agent. Typical used metrics are Success Rate, Navigation Error, Path Length and Success weighted by Path Length. The Oracle Navigation Error, Oracle Success Rate can be used to monitor the training process.
-
•
Success Rate (SR) shows how many times the last node of the predicted path is within a certain threshold distance of the last reference path node.
-
•
Navigation Error (NE) measures the distance between the last predicted path node and the last reference path node.
-
•
Path Length (PL) is equal to the total length of the predicted path. It is optimal when it’s equal to the length of the reference path.
-
•
Success weighted by Path Length (SPL) [10] takes both success rate and path length into account and can be calculated in the same way as described in the previous section. A drawback of SPL is that it does not consider the similarity of the intermediate nodes of the predicted path to the reference path. This results in that although SPL score is high, the predicted path does not actually follow the instructions, but just finds the correct target.
-
•
Oracle Navigation Error (ONE) measures the smallest distance from any node in the path to the reference goal node.
-
•
Oracle Success Rate (OSR) measures how often any node in the path is within a certain threshold distance from the goal. The goal is represented by the last node of the reference path.
Due to the inherent limitations of the existing evaluation metrics, the performance of the model cannot be evaluated objectively and comprehensively. There are still many subsequent works to propose some new metrics, which are also introduced here.
Huang et al. [94] propose a discriminator model that can predict how well a given instruction explains the paired path, showing that only a small portion of the augmented data in [95] are high fidelity. This metric can evaluate the instruction-path pair, which improves training efficiency and reduces the training time cost. Ilharco et al. [96] introduce the normalized Dynamic Time Warping (nDTW) metric. nDTW slightly penalizes deviations from the ground-truth path and it is naturally sensitive to the order of the nodes composing each path. Besides, nDTW is suited for both continuous and graph-based evaluations, and can be efficiently calculated. Despite the performance of R2R model has improved rapidly, current research is not clear about the role language understanding in this task, since mainstream evaluation metrics are focused on the completion of the goal, rather than the sequence of actions corresponding to the language instructions. Therefore, Jain et al. [29] analyze the drawbacks of current metrics for the R2R dataset and designed a novel metric named Coverage weighted by Length Score (CLS). CLS measures how closely an agent’s trajectory fits with ground-truth path, not just the completion of the goal. To improve the ability to evaluate language instructions, Zhao et al. [97] propose an instruction-trajectory compatibility model that operates without reference instructions. For system-level evaluations with reference instructions, SPICE metric [98] is better than BLEU [99], ROUGE [100], METOR [101] and CIDEr [102]. In other situations (e.g., selecting individual instructions, or model selection without reference instructions) using a learned instruction-trajectory compatibility model is recommended.
V-A3 Typical Methods
The R2R task is most impressive, and most research works of VLN are based on it. Basic framework of these works are Seq2Seq model, but they focus on different aspects to improve the model performance, therefore we divide them to 7 classes for clear understanding, i.e., Exploration Strategy, Beyond Seq2Seq Architecture, Reinforcement Learning and Imitation Learning, Language Grounding, Data Augmentation, Pre-Traning model and other related research.
Exploration Strategy. In this class, related works focus on finding a effective and fast path from start position to destination. Ma et al. [103] proposes a module to estimate the progress that made by agent towards the goal. Based on that, Ma et al. [104] design two modules for exploration, i.e., Regret Module for moving forward or rolling back and Progress Marker module to help the agent decide which direction to go next by showing directions that are visited and their associated progress estimate. While all current approaches make local action decisions or score entire trajectories using beam search, Ke et al. [105] present the Frontier Aware Search with backTracking (FAST) navigator. When the agent realizes lost itself, FAST navigator can explicit backtrack by using asynchronous search. This can also be plug and play on other models. Huang et al. [106] define two in-domain sub-tasks: Cross-Modal Alignment (CMA) and Next Visual Scene (NVS). The visual and textual representations of the agent learned in certain environment can be transferred to other environments with the help of CMA and NVS. Zhu et al. [107] introduce four self-supervised auxiliary reasoning tasks to take advantage of the additional training signals derived from the semantic information. These auxiliary tasks improve the model performance by giving more semantic information to help the agent to understand environments and tasks. Wang et al. [108] introduce an end-to-end architecture for learning an exploration policy, which enables the agent intelligently interacts with the environment and actively gather information when faced with ambiguous instructions or unconfident navigation decisions. In [109], a learning paradigm using recursive alternate imitation and exploration is proposed to narrow the difference between training and testing stages. Deng et al. [110] introduce the Evolving Graphical Planner (EGP), a method that uses raw images to generate global navigation plan efficiently. It has the advantage of dynamically building a graphical representation and generalizing the action space to allow more flexible decision-making.
Beyond Seq2Seq Architecture. Encouraged by recent progress on attention networks, many transformer-based studies have emerge, and we classify them as Beyond Seq2Seq architecture.
Landi et al. [111] devise Perceive, Transform, and Act (PTA) architecture to use the full history of previous actions for different modalities. Magassouba et al. [112] propose the Cross-modal Masked Path transformer, which encodes linguistic and environment state features to sequentially generate actions similarly to recurrent network approaches. In addition, this method uses feature masking to better model the relationship between the instruction and environment features. Wu et al. [113] and Mao et al. [114] use multi-head attention on visual and textual input to enhance the performance of the model. To capture and utilize the inter-modal and intra-modal relationships among different scenes, its objects, and directional clues, Hong et al. [115] devise language and visual entity relationship graph model. A message-passing algorithm is also proposed to spread information between the language elements and visual entities in the graph, and then the information are combined by the agent to determine the next action. Xia et al. [116] present a novel training paradigm, Learn from Everyone(LEO), which utilizes multiple language instructions (as multiple views) for the same path to resolve natural language ambiguity and improve the model generalization capabilities. Qi et al. [117] distinguish the object and action information from language instructions while most existing methods pay few attentions, and propose a Object-and-Action Aware Model (OAAM) that processes these two different forms of natural language based instruction separately. OAAM enables each process to flexibly match object-centric (action-centric) instructions with their corresponding visual perception (action direction). To capture environment layouts and make long-term planning, Wang et al. [118] present Structured Scene Memory (SSM), which allows the agent to access to its past perception and explores environment layouts. With this expressive and persistent space representation, the agent shows advantages in fine-grained instruction grounding, long-term reasoning, and global decision-making problem.
Reinforcement Learning and Imitation Learning. Many works have found it is beneficial to combine imitation learning and reinforcement learning with VLN models. All of Wang et al. [119], Tan et al. [120], Hong et al. [115], Parvaneh et al. [121] and Wang et al. [108] trained their models with two distinct learning paradigms, i.e., 1) imitation learning, where the agent is forced to mimic the behavior of its teacher. 2) reinforcement learning, which can help the agent explore the state-action space outside the demonstration path. Specifically, in imitation learning, the agent takes the teacher action at each time step to efficiently learn to follow the ground-truth trajectory. In reinforcement learning, the agent samples an action from the action probability and learns from the rewards, which allows the agent to explore the environment and improves ability of generalization. Combining IL and RL balances exploitation and exploration when learning to navigate, formally, the following loss function can be used to optimize the model :
| (2) |
For improving generalization ability, Wang et al. [122] integrate model-based and model-free reinforcement learning methods which is a hybrid planned-ahead model and outperforms than baselines. Wang et al. [119] use Reinforced Cross-Modal Matching (RCM) method with extrinsic and intrinsic rewards. The novel cycle-reconstruction reward is introduced to match the instruction and trajectory globally. In [123], based on SEED RL architecture, Vision And Language Agent Navigation(VALAN) is introduced as a lightweight and extensible framework for learning algorithm research. In order to reduce the impact of reward engineering design, Soft Expert Reward Learning (SERL) model is proposed by Wang et al. [124], which contains two auxiliary modules: Soft Expert Distillation and Self Perceiving. The former activates agent to explore like an expert while the latter enforces the agent to reach the goal as soon as possible. Zhou and Small [125] devise a adversarial inverse reinforcement learning method to learn a language-conditioned policy and reward function. For better adapt to the new environment, variational goal generator is used during training to relabel the trajectory and sample different targets.
Language Grounding. This class of method wants to ground language instructions better through the method of multimodal information fusion, so as to improve the success rate of agent navigation. Wang et al. [119] present a novel cross-modal grounding architecture to ground language on both local visual information and global visual trajectory. Hu et al. [126] propose to decompose the grounding procedure into a set of expert models with access to different modalities (including object detection) and ensemble them at prediction time for utilizing all the available modalities more efficiently. For
For making the agent has a better understanding of the correspondence between text and visual modalities, a cross-modal grounding module composed of two complementary attention mechanisms is designed by Zhang et al. [109]. Kurita and Cho [127] build a neural network to compute the probability distribution over all possible instructions, and use Bayes’ rule to build a language-grounded policy. This method has a better interpretability than the traditional discriminative method by conducting comprehensive experiments. Hong et al. [128] argue that the granularity of the navigation task should be at the level of these sub-instructions, rather than attempting to ground a specific part of the original long and complex instructions without any direct supervision or measuring navigation progress at word level.
Data Augmentation. Using automatically generated navigation instructions as additional training data can enhance the model performance. Fried et al. [95]propose a speaker-follower framework for data augmentation and reasoning in supervised learning. Hong et al. [128] enrich the benchmark dataset R2R with sub-instructions and their corresponding paths, i.e., Fine-Grained Room-to-Room (FGR2R). By pairing the sub-commands with the corresponding viewpoints in the path, FGR2R can better give the agent sufficient semantic information during the training process. Agarwal et al. [129] present a work-in-progress “speaker” model that generates navigation instructions in two steps. First, hard attention is used to select a series of discrete visual landmarks along the trajectory, and then a language conditioned on these landmarks is generated. Different from traditional data augmentation methods, Parvaneh et al. [121] propose an efficient algorithm to generate counterfactual instances that do not depend on hand-made or the particular field of rules. These counterfactual instances are added to the training, improving the ability of the agent when is tested in new environments. In [130], counterfactual idea has another application. A model agnostic method called Adversarial Path Sampler (APS) is introduced to sample paths to optimize the agent navigation strategies gradually. Yu et al. [131] simultaneously deal with the scarcity of data in the R2R task while removing biases in the dataset through random walk data augmentation. By doing so, they are able to reduce the generalization gap and outperform baselines in navigating unknown environments. An et al. [132] designe a module named Neighbor-View Enhanced Model (NvEM) to adaptively fuse the visual context from the neighbor views at the global level and the local level. Liu et al. [133] propose Random Environmental Mixup (REM) aiming to reduce the performance gap between the seen and unseen environment and improve the overall performance. This method breaks up the environment and the corresponding path, and then recombines them according to certain rules to construct a brand-new environments as training data. Sun et al. [134] point out that depth as a valuable signal source for the navigation has not yet fully explored and thus been ignored in previous research. Hence, they propose a Depth-guided Adaptive Instance Normalization module and Shift Attention (DASA) module to address this issue.
Pre-Traning model. The general feature representation obtained through pre-training model can be applied to various tasks, and has been confirmed in many fields. A strong pre-trained backbone network can be effective in downstream task, like image recognition in CV and question answering in NLP. In particular, Transformer networks Vaswani et al. [135] pre-trained with “masked language model” objective [5] on large language corpus outperforms on majority NLP tasks. Furthermore, Su et al. [136] developed VL-BERT, a pre-trainable generic representation for visual-linguistic tasks. In VLN field, pre-training approaches are used in two aspects:
-
•
Using pre-trained models to solve VLN tasks. In Li et al. [137], the agent is trained with pre-trained language models, (i.e., BERT [135] and GPT-3 [138]) and uses stochastic sampling to generalize well in the unseen environment. The PRE-trained Vision And Language based Navigator (PREVALENT) model proposed by Hao et al. [139] is pre-trained with image-language-action triples, and fine-tuned on the R2R task. Based on the use of the PREVALENT model, the agent can better complete the task in an unseen environment. Since the pre-training model usually has massive parameters, the efficiency of using it will be relatively low. For reducing the scale of pre-train model and improving the efficiency of inference , Huang et al. [140] introduce two lightweight methods, i.e., factorization and parameter sharing based on the PREVALENT[139] model.
-
•
Pre-trained VL or VLN models on VLN tasks. Due to the limitation of training data in VLN task, Majumdar et al. [141] try to use massive web-scraped resources to address this issue. Therefore, VLN-BERT is proposed and proved that pre-training it on image-text pairs from the web before fine-tuning the specific path instruction data significantly improves the performance of VLN task. Hong et al. [142] propose VLNBERT, which is a multi-modal BERT model equipped with a time-aware recurrent function to provide the agent with richer information. Qi et al. [143] propose Object-and-Room Informed Sequential BERT (ORIST) to improve the language grounding performance by encoding visual and instruction inputs at the same fine-grained level, i.e., objects and words. Besides, the trained model can recognize the relative direction of each navigable location and the room type of its current and final navigation target.
Other Related Research. To assess the implications of this work for robotics, Anderson et al. [144] transfer a VLN agent trained in simulation to a physical robot. There is a big difference between high-level discrete action space learned by the agent and robot’s low-level continuous action space. In order to address this issue, they introduce a sub-goal model to identify nearby navigable points and use domain randomization to reduce visual domain differences. With the slow-down performance improvements in VLN tasks, a series of diagnostic experiments are carried out in [145] to reveal the agent’s key points in the navigation process. The results show that the indoor navigation agent will refer to the object mark and direction mark in the instruction when making a decision. When it comes to visual and verbal alignment, many models claim that they can align object marks with certain visual targets, but there are still doubts about the reliability of this alignment.
V-A4 Model Performance Comparison
A table comparing all models in R2R task. The state-of-the-art method is REM, since it is the effective combination of pre-trained backbone model (VLNBERT) and data augmentation, making REM model the best existing approach on VLN benchmark.
| Leader-Board (Test Unseen) | Single Run | Pre-explore | Beam Search | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Models | NE | OR | SR | SPL | NE | OR | SR | SPL | TL | SR | SPL |
| Random [10] | 9.79 | 0.18 | 0.17 | 0.12 | - | - | - | - | - | - | - |
| Seq-to-Seq [10] | 20.4 | 0.27 | 0.20 | 0.18 | - | - | - | - | - | - | - |
| Look Before You Leap [122] | 7.5 | 0.32 | 0.25 | 0.23 | - | - | - | - | - | - | - |
| Speaker-Follower [95] | 6.62 | 0.44 | 0.35 | 0.28 | - | - | - | - | 1257 | 0.54 | 0.01 |
| Chasing Ghosts [146] | 7.83 | 0.42 | 0.33 | 0.30 | - | - | - | - | - | - | - |
| Self-Monitoring [103] | 5.67 | 0.59 | 0.48 | 0.35 | - | - | - | - | 373 | 0.61 | 0.02 |
| PTA [111] | 6.17 | 0.47 | 0.40 | 0.36 | - | - | - | - | - | - | - |
| Reinforced Cross-Modal [119] | 6.12 | 0.50 | 0.43 | 0.38 | 4.21 | 0.67 | 0.61 | 0.59 | 358 | 0.63 | 0.02 |
| Regretful Agent [104] | 5.69 | 0.48 | 0.56 | 0.40 | - | - | - | - | 13.69 | 0.48 | 0.40 |
| FAST [105] | 5.14 | - | 0.54 | 0.41 | - | - | - | - | 196.53 | 0.61 | 0.03 |
| EGP [110] | 5.34 | 0.61 | 0.53 | 0.42 | - | - | - | - | - | - | - |
| ALTR [106] | 5.49 | - | 0.48 | 0.45 | - | - | - | - | - | - | - |
| Environmental Dropout [120] | 5.23 | 0.59 | 0.51 | 0.47 | 3.97 | 0.70 | 0.64 | 0.61 | 687 | 0.69 | 0.01 |
| SERL [124] | 5.63 | 0.61 | 0.53 | 0.49 | - | - | - | - | - | - | - |
| OAAM [117] | - | 0.61 | 0.53 | 0.50 | - | - | - | - | - | - | - |
| CMG-AAL [109] | 4.61 | - | 0.57 | 0.50 | - | - | - | - | - | - | - |
| AuxRN [107] | 5.15 | 0.62 | 0.55 | 0.51 | 3.69 | 0.75 | 0.68 | 0.65 | 41 | 0.71 | 0.21 |
| DASA [134] | 5.11 | - | 0.54 | 0.52 | - | - | - | - | - | - | - |
| RelGraph [115] | 4.75 | - | 0.55 | 0.52 | - | - | - | - | - | - | - |
| ORIST⋆ [143] | 5.10 | - | 0.57 | 0.52 | - | - | - | - | - | - | - |
| PRESS⋆ [147] | 4.53 | - | 0.57 | 0.53 | - | - | - | - | - | - | - |
| PRRVALENT⋆ [139] | 4.53 | - | 0.57 | 0.53 | - | - | - | - | - | - | - |
| NvEM [132] | 4.37 | - | 0.58 | 0.54 | - | - | - | - | - | - | - |
| SSM [118] | 4.57 | 0.70 | 0.61 | 0.46 | - | - | - | - | - | - | - |
| VLNBERT⋆ [142] | 4.09 | - | 0.63 | 0.57 | - | - | - | - | - | - | - |
| Active Exploration [108] | 4.33 | 0.71 | 0.60 | 0.41 | 3.30 | 0.77 | 0.70 | 0.68 | 176.2 | 0.71 | 0.05 |
| REM(Based on VLNBERT) [133] | 3.87 | - | 0.65 | 0.59 | - | - | - | - | - | - | - |
V-B Variations of R2R task
V-B1 Room-for-Room, Room-6-Room, Room-8-Room
Since all R2R reference paths in the data generation process are the shortest path to the target., there is a certain contradiction between following on instructions and reaching the destination. For properly evaluating consistency, dataset is supposed to be larger and has more diverse reference paths. To address the lack of path variety, Jain et al. [29] propose a data augmentation strategy that generates longer and more tortuous paths without additional human or low-fidelity machine annotation, which is more challenging dataset named Room-for-Room (R4R). Inspired by R4R, Zhu et al. [31] create two datasets of longer navigation tasks, Room-6-Room (R6R) and Room-8-Room (R8R).
V-B2 Room-to-Room with Continuous Environment
In R2R task, the agent can only move on a fixed traversable nodes, rather than freely in the environment. Therefore, Krantz et al. [32] propose Vision-and-Language Navigation in Continuous Environments (VLN-CE) task, where the agent can move freely in the environment rather than transporting between pre-defined navigable nodes. This task setting introduces many challenges that are ignored in previous work.
For solving this problem, Chen et al. [148] propose a modular approach using topological maps, since the conventional end-to-end approaches are struggle in freely traversable environments. They decomposed VLN-CE tasks in two stages: planning and control. During the exploration, topological map representation is built and used on navigation plan stage. The local controller receives the navigation plan and generates low-level discrete action. Wang et al. [149] point out that different robots often equipped with various camera configurations, these differences make it difficult to directly transfer the learned navigation skill between robots. Consequently, a generalization strategy is proposed for visual perception based on meta-learning, which enables the agent to quickly adapt to a new camera configuration through few-shot learning.
V-B3 Room-Across-Room, Cross Lingual R2R
Ku et al. [30] introduce Room-Across-Room (RxR), a multilingual extension of R2R task containg English, Hindi, and Telugu. The size, scope and detail of RxR has dramatically expands comparing with R2R dataset, which contains 126K instructions covering 16.5K sampled guide paths and 126K human follower demonstration paths. Every instruction is accompanied by a follower demonstration, including a perspective camera pose trace that shows a play-by-play account of how a human interpreted the instructions given their position and progress through the path.
Yan et al. [33] collect a Cross Lingual R2R dataset, which extends the original benchmark with corresponding Chinese instructions. Then they propose a principled meta-learning method that dynamically utilizes the augmented machine translation data for zero-shot cross-lingual VLN.
V-C Street View Navigation
Existing works mainly focus on simple visual input, and the environments are indoor scenes mostly. Actually, the complexity and diversity of the visual input in these environments are limited, since the challenges of language and vision have been simplified. Therefore, many researchers are interested in outdoor navigation based on Google Street View.
V-C1 Touchdown
Chen et al. [34] propose Touchdown, a dataset for natural language navigation and spatial reasoning using real-life visual observations. They define two tasks (i.e., navigation and spatial description resolution) that require the agent to address a diverse set of reasoning and learning challenges. This is the first large scale outdoor VLN task. In this task, the agent receives a 360°RGB panoramic images when it moves to every navigable point, which is connected with undirected navigation graph. The environment includes panoramic images and edges from New York City.
Xiang et al. [150] focus on endowing agent with recognizing ability and stopping at the correct location in complicated outdoor environments. They introduce Learning to Stop module to address the issues, which is a simple and model-agnostic module that can be facilely added into other models to improve their navigation performances.
For facilitating the experiment, Zhu et al. [151] divide the original StreetLearn dataset into a small part, i.e., Manh-50, which mainly covers the Manhattan area with 31K training data. In addition, Multimodal Text Style Transfer learning approach is proposed to generate style-modified instructions for external resources and address the data scarcity issue.
V-C2 StreetLearn
For improving the end-to-end outdoor VLN research, Mirowski et al. [37] present StreetLearn task based on Google Street View, which is a egocentric photo-realistic interactive outdoor navigation task. Mehta et al. [152] are publicly releasing the 29k raw Street View panoramic images needed for Touchdown. Evaluation metrics for this task are Task Completion, Shortest-path distance, Success weighted by Edit Distance, Normalized Dynamic Time Warping and Success weighted Dynamic Time Warping. Due to the length limitation of this paper, details of these metrics can be found in [152]. Mirowski et al. [153] use deep reinforcement learning method to address outdoor city navigation issue. Based on the images and connectivity on Google Street View, a duel pathway navigation model is proposed with interactive environment.
V-C3 Other outdoor navigation tasks
-
•
StreetNav. StreetNav is a extension of StreetLearn proposed by Hermann et al. [36]. The main difference is in StreetNav, driving instructions from Google Maps by randomly sampling start and goal positions are added to dataset, which likes autonomous driving environment.
-
•
Talk to Nav. Vasudevan et al. [154] develop an interactive visual navigation environment based on Google Street View named Talk to Nav dataset with 10,714 routes. They also design an effective model to create large-scale navigational instructions over long-range city environments.
-
•
Street View. Based on Google Street View, Cirik et al. [155] sample 100k routes in 100 regions in 10 U.S cities to build an outdoor instructions following task environment. They argue outdoor navigation is more challenging task because the outdoor environment is more chaotic and objects are more diverse.
-
•
RUN. Aiming to explaining navigation instructions based on real, dense, and urban map, Paz-Argaman and Tsarfaty [35] propose Realistic Urban Navigation (RUN) task, which has 2,515 instructions annotated by Amazon Mechanical Turk works.
-
•
ARRAMON. Kim et al. [38] propose ARRAMON task, which contains two sub-tasks: object collecting and object referring expression comprehension. During this task, the agent is required to find and collect different target objects one by one through natural language instruction-based navigation in a complex synthetic outdoor environment.
VI Multi-turn Tasks
Prior works require the agent to navigate in an environment with a single-turn instruction. Recently, there is surge of dialog-enabled interactive assistant, where the interaction is often a multi turn process. For multi-turn tasks, instructions will be given by a guide to the agent in several turns, until the agent has reached the specified goal. According to whether the agent can question the instruction or not, we subdivided multi-turn tasks into: Passive and Interactive tasks.
VI-A Passive task
In passive task, instructions are given to the agent in stages, where the information contained in the instructions is often sufficient and unambiguous, so the agent only needs to understand the meanings and move to the target position. Order instructions for this type of task is different for this problem.
VI-A1 CEREALBAR
CEREALBAR [39] simulates a scenario, where a leader and a follower collaboratively select cards to earn points. If valid set of card is collected, the players can earn a point. The leader has full observability on the map, and are plausible to plan the path for the follower and gives instructions to direct the way. The follower can only see a first-person view of the environment, and cannot respond to the leader. The performance is measured by correct execution of instructions and the overall game reward.
To solve this task, Suhr et al. [39] introduce a learning approach focusing on recovery from cascading errors between the sequential instructions, and modeling methods to explicitly reason about instructions with multiple goals.
VI-A2 HANNA
HANNA [41] defines a task for a human to find objects in an indoor environment. In this process, the human can ask a mobile agent via natural language. The task is a high-level command (“find [object(s)]”), modeling the general case when the requester does not need know how to accomplish a task when requesting it. HANNA uses the Matterport3D simulator to photo-realistically emulate a first-person view while navigating in indoor environments.
To address the HANNA problem, Nguyen and III [41] develop a hierarchical decision model via a memory-augmented neural agent. Imitation learning is used to teach the agent to avoid past mistakes and make future progress.
VI-A3 VNLA
Based on Matterport3D simulator, Nguyen et al. [40] introduces the Vision-based Navigation with Language-based Assistance (VNLA) task, where an agent has visual perception in a photo-realistic indoor environment and is guided to find objects in the environment via instructions.
Furthermore, they construct ASKNAV, a dataset for the VNLA task. After filtering out labels that occur less than five times, 289 object labels and 26 room labels are obtained. The data is defined as a tuple (environment, start pose, goal viewpoints, end-goal). Nguyen et al. [40] develop a general framework with imitation learning to extend the framework for indirect intervention.
VI-B Interactive task
In interactive task, the human guide and the agent are usually cooperative, and the agent can ask the person if it encounters a situation of information insufficiency or ambiguity. In this interactive manner, the agent can continuously acquire information to complete the navigation task.
VI-B1 Talk The Walk
de Vries et al. [44] introduces a navigation task for tourist service and constructs a large-scale dialogue dataset named “Talk The Walk”. The tourist is located in a virtual 2D grid environment in New York City and has 360-views of the neighborhood blocks. The guide has an abstracted semantic map of the blocks and the target location is unambiguously shown to the guide from the start. A guide aims to interact with a “tourist”via natural language to help the latter navigate towards the correct location.
de Vries et al. [44] decouples the task of tourist localization from the task and introduces a Masked Attention for Spatial Convolutions (MASC) mechanism to ground the instructions from tourist into the guide’s map.
VI-B2 Navigation from Dialog History
Robot navigation in real environments are expected to use natural language to communication and understand human’s meaning. To study this challenge, Thomason et al. [42] introduce CVDN, a human to human dialogues situated in simulated, photo-realistic home environments. For training agent to search a goal location in an environment, they define the Navigation from Dialog History (NDH) task. In NDH, an agent is learned to predict navigation actions and find an object given a dialog history between human in previously unseen environments. NDH task can be used for training agents in navigation, question asking, and question answering problems. Thomason et al. [42] formulated a Seq2Seq model to encode an entire dialog history to address the NDH task, whose outputs are actions in the environment. Zhu et al. [156] propose a Cross-modal Memory Network (CMN) to remember the historical information. CMN uses a language memory module to learn latent relationships between the current conversation and a dialog history and uses a visual memory module to learns to associate the current visual views and the previous navigation actions. Roman Roman et al. [157] divide multi-turn NDH task into three sub-tasks: question generation, question answering, and navigation and implement them with three Seq2Seq models, i.e., a Questioner, a Guide and a Navigator. The progress agents are trained with reward signals from navigation actions, question and answer generation.
VI-B3 Just Ask
VI-B4 RobotSlang
Banerjee et al. [45] decouple the cooperative communication task into Localization from Dialog History (LDH) and NDH task, where a driver agent must localize in the global map or navigate towards the next target object according to the visual observations and the dialog with the commander. Different from other tasks, the environment and the agent are physical, while the sensor observations are camera RGB images. Moreover, Banerjee et al. [45] evaluate human performance on the LDH task and create an initial, Seq2Seq model for the NDH task.
VII Conclusions and Discussions
Although the application of deep learning has made gratifying progress on the VLN approaches, it is worth noting that there are still limitations in many aspects. In this section, we outline some of limitations and opportunities in future research directions. Specifically, we will discuss limitations of poor generalization, lack of high-quality data and weak interactivity of the environment. Further, we discuss the future direction of incorporating knowledge and simulation to reality.
VII-A Limitations
VII-A1 Poor Generalization
The problem is mainly reflected in two aspects: one is that when trained VLN model is transferred from seen scenes to unseen scenes, the model performance will drop significantly; besides, when the model is transferred from one task to another VLN task, the performance will also decrease. The possible reason is that the data distributions in different environments vary greatly; hence, the navigation model trained in one environment is difficult to adapt to other environments. Another explanation may be that there is a certain degree of over-fitting in the supervised learning method.
VII-A2 Lack of high-quality data
A lot of work [95, 133] has demonstrated that through data augmentation, generating more training data can improve the performance of VLN model. For example, Wijmans et al. [83] have proved that the point cloud perception can help an EQA agent find its target. However, compared with the real high-quality data, the artificially generated data is still very limited to the model. Unfortunately, collecting real data is still a costly and labor-intensive work, since the methods to collect photo-realistic 3D-scene datasets require scanning real buildings by means of expensive photogrammetry devices [158] such as Matterport 3D scanner, Meshroom or even mobile 3D scanning applications.
VII-A3 Weak interactivity with the environment
In the current VLN datasets, the interaction between the agent and the environment is simplified, only involving basic operations such as opening a microwave oven, moving an object, or reaching a designated location. The movement action that can be taken are restricted to a specific range (such as moving forward, turning left and turning right, or teleporting between navigable point). Although more complex interaction forms such as “bring me the pillow next to the stool” have appeared in some latest research, it is obviously far from the interaction and movement forms of the real environment, because they simplify many physical constraints in the real environment. In the future, a simulator with advanced physics features such as cloth, fluid and soft-body physics will improve the realism of intelligent VLN agent.
VII-B Opportunities
VII-B1 Incorporating knowledge
Knowledge makes human smarter, for instance, we can summarize experience from daily life as knowledge and use it in the future. Intuitively, knowledge will imporve the model performance in most of AI tasks, which has been proven effective recently [9, 159]. Therefore, how to introduce knowledge into the VLN model and make it work effectively is a problem that researchers need to think about in the future. Some possible ways are as following:
-
•
Algorithmic knowledge. Many algorithms in machine learning can accumulate knowledge through continuous training such as the knowledge about environmental dynamics, spatial representation or physical effects of actions, so that they can better adapt to new environments. Wang et al. [149] used the Model-Agnostic Meta-Learning (MAML) algorithms to improve model generalization in task VLN-CE, which enables the agent to get adaptive quickly to a new camera configuration with a few shots. Another work [160] adopted MAML to learn a self-supervised loss, which can be used in new environments directly without extra training. Besides, lifelong learning [161], transfer learning [106], curriculum learning [31] and external prior knowledge [91, 162] are introduced to help solving VLN tasks.
-
•
External knowledge base. Humans often need the help of commonsense when solving similar problems. For example, with the commonsense knowledge that a toilet is typically found in the washroom, the agent shouldn’t waste time in the living room to find a toilet. Moreover, such knowledge is likely to still hold in previously unseen environments, making it possible to achieving better generalization ability. Some existing pre-training models can play the role of some common sense knowledge bases, such as some image-text pairs, but they are still far from the ability to have common sense reasoning. How to make the agent have common sense knowledge and make it reason on the basis is a very critical problem.
-
•
Cognitive architecture. Humans can perform tasks like VLN excellently, so some principles in cognitive science and human brain can be used for heuristic model building. For example, memory can enhance the reasoning ability of VLN model. In brain areas, such as the hippocampus, have intertwined roles in spatial memory and other cognitive functions. Inspired by this, Hu et al. [163] use fusion adaptive resonance theory (ART) networks to model spatial representation and related memory to enhance the visual navigation model. Other useful cognitive theories like Soar, ACT-R are powerful as well, and no work based on them until now.
VII-B2 From simulation to reality
It is promising for a physical agent to complete VLN tasks in the real world, since there are many practical application scenarios. For instance, in search-and-rescue tasks, robots might using vision clues to search and language to interact with with human victims [164]. At present, the research on VLN task is still in the simulated environment. The advantage of the simulation platform is that it can easily validate the model, and it is convenient and quick to use. However, some important physical constraints in many real-world cases cannot be characterized well by simulators and have been discarded from consideration. Therefore, there is still a large gap between the simulated environments and the real world, hindering the transfer of progress made on simulation platforms to real world scenarios. Some progress has been made in this direction. For example, Anderson et al. [144] have used a TurtleBot2 mobile robot equipped with a 2D laser scanner and a 360° RGB camera to finish a VLN task. In the future, we believe that building a simulated environment integrated with more realistic physics features, such as tactile perception [165], human-level motor control [166] and audio inputs [167] will improve the performance of VLN model in real world.
Besides, training VLN models usually need intensive computation resources, which makes it prohibitive to deploy such models on portable devices, such as small drones [71]. One direction to solve the problem is to design more lightweight network structure, where operations or layers with low computing load and low memory consumption are included. For example, the model can be compressed by quantizing the network weight or being distilled to a light model to reduce the complexity. Other possible solutions could be model pruning method and Huffman coding for weights of the model.
VII-C Conclusions
Recent advances in computer vision, natural language processing and photo-realistic simulators have been a key driver of progress in VLN research. In this survey, we have comprehensively reviewed existing VLN tasks, introduced typical datasets and simulators, and thoroughly summarized newest research progress. We argue that the most important contribution is the new taxonomy and believe that our taxonomy will help researchers to categorize future tasks, better understand the remaining unresolved problems, and be able to choose the most suitable VLN simulators for their research tasks. Furthermore, we analysis the current limiations exist in VLN field and point out a promising direction in the future.
Acknowledgment
The work described in this paper was sponsored in part by the National Natural Science Foundation of China under Grant No. 62103420 and 62103428 , the Natural Science Fund of Hunan Province under Grant No. 2021JJ40702.
References
- Russell and Norvig [2002] S. Russell and P. Norvig, “Artificial intelligence: a modern approach,” 2002.
- He et al. [2016] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. IEEE Computer Society, 2016, pp. 770–778.
- Redmon and Farhadi [2017] J. Redmon and A. Farhadi, “YOLO9000: better, faster, stronger,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 6517–6525.
- He et al. [2020] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick, “Mask R-CNN,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 42, no. 2, pp. 386–397, 2020.
- Devlin et al. [2019] J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: pre-training of deep bidirectional transformers for language understanding,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), J. Burstein, C. Doran, and T. Solorio, Eds. Association for Computational Linguistics, 2019, pp. 4171–4186.
- Conneau and Lample [2019] A. Conneau and G. Lample, “Cross-lingual language model pretraining,” in Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019, NeurIPS 2019, December 8-14, 2019, Vancouver, BC, Canada, H. M. Wallach, H. Larochelle, A. Beygelzimer, F. d’Alché-Buc, E. B. Fox, and R. Garnett, Eds., 2019, pp. 7057–7067.
- Lee et al. [2019] J. Lee, A. Dosovitskiy, D. Bellicoso, V. Tsounis, V. Koltun, and M. Hutter, “Learning agile and dynamic motor skills for legged robots,” Sci. Robotics, vol. 4, no. 26, 2019.
- Shridhar et al. [2020] M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “ALFRED: A benchmark for interpreting grounded instructions for everyday tasks,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 10 737–10 746.
- Ye and Yang [2020] X. Ye and Y. Yang, “From seeing to moving: A survey on learning for visual indoor navigation (VIN),” CoRR, vol. abs/2002.11310, 2020.
- Anderson et al. [2018a] P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sünderhauf, I. D. Reid, S. Gould, and A. van den Hengel, “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. IEEE Computer Society, 2018, pp. 3674–3683.
- Qi et al. [2020a] Y. Qi, Q. Wu, P. Anderson, X. Wang, W. Y. Wang, C. Shen, and A. van den Hengel, “REVERIE: remote embodied visual referring expression in real indoor environments,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 9979–9988.
- Pfeifer and Iida [2004] R. Pfeifer and F. Iida, “Embodied artificial intelligence: Trends and challenges,” in Embodied artificial intelligence. Springer, 2004, pp. 1–26.
- Pfeifer and Bongard [2006] R. Pfeifer and J. Bongard, How the body shapes the way we think: a new view of intelligence. MIT press, 2006.
- Duan et al. [2022] J. Duan, S. Yu, H. L. Tan, H. Zhu, and C. Tan, “A survey of embodied ai: From simulators to research tasks,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2022.
- Baltrušaitis et al. [2018] T. Baltrušaitis, C. Ahuja, and L.-P. Morency, “Multimodal machine learning: A survey and taxonomy,” IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 2, pp. 423–443, 2018.
- Uppal et al. [2022] S. Uppal, S. Bhagat, D. Hazarika, N. Majumder, S. Poria, R. Zimmermann, and A. Zadeh, “Multimodal research in vision and language: A review of current and emerging trends,” Information Fusion, vol. 77, pp. 149–171, 2022.
- Kruse et al. [2013] T. Kruse, A. K. Pandey, R. Alami, and A. Kirsch, “Human-aware robot navigation: A survey,” Robotics and Autonomous Systems, vol. 61, no. 12, pp. 1726–1743, 2013.
- Guilherme and Avinash [2002] N. D. Guilherme and C. K. Avinash, “Vision for mobile robot navigation: A survey,” IEEE transactions on pattern analysis and machine intelligence, vol. 24, no. 2, pp. 237–267, 2002.
- Misra et al. [2018] D. K. Misra, A. Bennett, V. Blukis, E. Niklasson, M. Shatkhin, and Y. Artzi, “Mapping instructions to actions in 3d environments with visual goal prediction,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Association for Computational Linguistics, 2018, pp. 2667–2678.
- Kolve et al. [2017] E. Kolve, R. Mottaghi, D. Gordon, Y. Zhu, A. Gupta, and A. Farhadi, “AI2-THOR: an interactive 3d environment for visual AI,” CoRR, vol. abs/1712.05474, 2017.
- [21] T. Deruyttere, S. Vandenhende, D. Grujicic, L. V. Gool, and M. Moens, “Talk2car: Taking control of your self-driving car,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds., pp. 2088–2098.
- Yu et al. [2018a] H. Yu, X. Lian, H. Zhang, and W. Xu, “Guided feature transformation (GFT): A neural language grounding module for embodied agents,” in 2nd Annual Conference on Robot Learning, CoRL 2018, Zürich, Switzerland, 29-31 October 2018, Proceedings, ser. Proceedings of Machine Learning Research, vol. 87. PMLR, 2018, pp. 81–98.
- Chaplot et al. [2018] D. S. Chaplot, K. M. Sathyendra, R. K. Pasumarthi, D. Rajagopal, and R. Salakhutdinov, “Gated-attention architectures for task-oriented language grounding,” in Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th AAAI Symposium on Educational Advances in Artificial Intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2-7, 2018, S. A. McIlraith and K. Q. Weinberger, Eds. AAAI Press, 2018, pp. 2819–2826.
- Kempka et al. [2016] M. Kempka, M. Wydmuch, G. Runc, J. Toczek, and W. Jaskowski, “Vizdoom: A doom-based AI research platform for visual reinforcement learning,” in IEEE Conference on Computational Intelligence and Games, CIG 2016, Santorini, Greece, September 20-23, 2016. IEEE, 2016, pp. 1–8.
- Das et al. [2018a] A. Das, S. Datta, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Embodied question answering,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. IEEE Computer Society, 2018, pp. 1–10.
- Wu et al. [2018] Y. Wu, Y. Wu, G. Gkioxari, and Y. Tian, “Building generalizable agents with a realistic and rich 3d environment,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Workshop Track Proceedings. OpenReview.net, 2018.
- Zang et al. [2018] X. Zang, A. Pokle, M. Vázquez, K. Chen, J. C. Niebles, A. Soto, and S. Savarese, “Translating navigation instructions in natural language to a high-level plan for behavioral robot navigation,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, E. Riloff, D. Chiang, J. Hockenmaier, and J. Tsujii, Eds. Association for Computational Linguistics, 2018, pp. 2657–2666.
- Fu et al. [2019] J. Fu, A. Korattikara, S. Levine, and S. Guadarrama, “From language to goals: Inverse reinforcement learning for vision-based instruction following,” in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- Jain et al. [2019] V. Jain, G. Magalhães, A. Ku, A. Vaswani, E. Ie, and J. Baldridge, “Stay on the path: Instruction fidelity in vision-and-language navigation,” in ACL (1). Association for Computational Linguistics, 2019, pp. 1862–1872.
- Ku et al. [2020] A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge, “Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,” in EMNLP (1). Association for Computational Linguistics, 2020, pp. 4392–4412.
- Zhu et al. [2020a] W. Zhu, H. Hu, J. Chen, Z. Deng, V. Jain, E. Ie, and F. Sha, “Babywalk: Going farther in vision-and-language navigation by taking baby steps,” in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, 2020, pp. 2539–2556.
- Krantz et al. [2020] J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee, “Beyond the nav-graph: Vision-and-language navigation in continuous environments,” in ECCV (28), ser. Lecture Notes in Computer Science, vol. 12373. Springer, 2020, pp. 104–120.
- Yan et al. [2019] A. Yan, X. Wang, J. Feng, L. Li, and W. Y. Wang, “Cross-lingual vision-language navigation,” CoRR, vol. abs/1910.11301, 2019.
- Chen et al. [2018] H. Chen, A. Suhr, D. K. Misra, N. Snavely, and Y. Artzi, “Touchdown: Natural language navigation and spatial reasoning in visual street environments,” CoRR, vol. abs/1811.12354, 2018.
- Paz-Argaman and Tsarfaty [2019] T. Paz-Argaman and R. Tsarfaty, “RUN through the streets: A new dataset and baseline models for realistic urban navigation,” in EMNLP/IJCNLP (1). Association for Computational Linguistics, 2019, pp. 6448–6454.
- Hermann et al. [2020] K. M. Hermann, M. Malinowski, P. Mirowski, A. Banki-Horvath, K. Anderson, and R. Hadsell, “Learning to follow directions in street view,” in AAAI. AAAI Press, 2020, pp. 11 773–11 781.
- Mirowski et al. [2019] P. Mirowski, A. Banki-Horvath, K. Anderson, D. Teplyashin, K. M. Hermann, M. Malinowski, M. K. Grimes, K. Simonyan, K. Kavukcuoglu, A. Zisserman, and R. Hadsell, “The streetlearn environment and dataset,” CoRR, vol. abs/1903.01292, 2019.
- Kim et al. [2020] H. Kim, A. Zala, G. Burri, H. Tan, and M. Bansal, “Arramon: A joint navigation-assembly instruction interpretation task in dynamic environments,” in EMNLP (Findings). Association for Computational Linguistics, 2020, pp. 3910–3927.
- Suhr et al. [2019] A. Suhr, C. Yan, J. Schluger, S. Yu, H. Khader, M. Mouallem, I. Zhang, and Y. Artzi, “Executing instructions in situated collaborative interactions,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 2119–2130.
- Nguyen et al. [2019a] K. Nguyen, D. Dey, C. Brockett, and B. Dolan, “Vision-based navigation with language-based assistance via imitation learning with indirect intervention,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 12 527–12 537.
- Nguyen and III [2019] K. Nguyen and H. D. III, “Help, anna! visual navigation with natural multimodal assistance via retrospective curiosity-encouraging imitation learning,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 684–695.
- Thomason et al. [2019] J. Thomason, M. Murray, M. Cakmak, and L. Zettlemoyer, “Vision-and-dialog navigation,” in 3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, October 30 - November 1, 2019, Proceedings, ser. Proceedings of Machine Learning Research, L. P. Kaelbling, D. Kragic, and K. Sugiura, Eds., vol. 100. PMLR, 2019, pp. 394–406.
- Chi et al. [2020] T.-C. Chi, M. Shen, M. Eric, S. Kim, and D. Hakkani-tur, “Just ask: An interactive learning framework for vision and language navigation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 03, 2020, pp. 2459–2466.
- de Vries et al. [2018] H. de Vries, K. Shuster, D. Batra, D. Parikh, J. Weston, and D. Kiela, “Talk the walk: Navigating new york city through grounded dialogue,” CoRR, vol. abs/1807.03367, 2018.
- Banerjee et al. [2020] S. Banerjee, J. Thomason, and J. J. Corso, “The robotslang benchmark: Dialog-guided robot localization and navigation,” CoRR, vol. abs/2010.12639, 2020.
- LeCun et al. [2015] Y. LeCun, Y. Bengio, and G. E. Hinton, “Deep learning,” Nat., vol. 521, no. 7553, pp. 436–444, 2015.
- LeCun et al. [1998] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, 1998.
- Hochreiter and Schmidhuber [1997] S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, 1997.
- Mikolov et al. [2013] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” in 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2-4, 2013, Workshop Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2013.
- Le and Mikolov [2014] Q. V. Le and T. Mikolov, “Distributed representations of sentences and documents,” in Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014, ser. JMLR Workshop and Conference Proceedings, vol. 32. JMLR.org, 2014, pp. 1188–1196.
- Sinopoli et al. [2001] B. Sinopoli, M. Micheli, G. Donato, and T. Koo, “Vision based navigation for an unmanned aerial vehicle,” in Proceedings of the 2001 IEEE International Conference on Robotics and Automation, ICRA 2001, May 21-26, 2001, Seoul, Korea. IEEE, 2001, pp. 1757–1764.
- Blösch et al. [2010] M. Blösch, S. Weiss, D. Scaramuzza, and R. Siegwart, “Vision based MAV navigation in unknown and unstructured environments,” in IEEE International Conference on Robotics and Automation, ICRA 2010, Anchorage, Alaska, USA, 3-7 May 2010. IEEE, 2010, pp. 21–28.
- MacMahon et al. [2006] M. MacMahon, B. Stankiewicz, and B. Kuipers, “Walk the talk: Connecting language, knowledge, and action in route instructions,” in Proceedings, The Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, July 16-20, 2006, Boston, Massachusetts, USA. AAAI Press, 2006, pp. 1475–1482.
- Vogel and Jurafsky [2010] A. Vogel and D. Jurafsky, “Learning to follow navigational directions,” in ACL 2010, Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, July 11-16, 2010, Uppsala, Sweden, J. Hajic, S. Carberry, and S. Clark, Eds. The Association for Computer Linguistics, 2010, pp. 806–814.
- Antol et al. [2015] S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, and D. Parikh, “VQA: visual question answering,” in 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. IEEE Computer Society, 2015, pp. 2425–2433.
- Johnson et al. [2017] J. Johnson, B. Hariharan, L. van der Maaten, L. Fei-Fei, C. L. Zitnick, and R. B. Girshick, “CLEVR: A diagnostic dataset for compositional language and elementary visual reasoning,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 1988–1997.
- Goyal et al. [2017] Y. Goyal, T. Khot, D. Summers-Stay, D. Batra, and D. Parikh, “Making the V in VQA matter: Elevating the role of image understanding in visual question answering,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 6325–6334.
- Hudson and Manning [2019] D. A. Hudson and C. D. Manning, “GQA: A new dataset for real-world visual reasoning and compositional question answering,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6700–6709.
- Young et al. [2014] P. Young, A. Lai, M. Hodosh, and J. Hockenmaier, “From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions,” Trans. Assoc. Comput. Linguistics, vol. 2, pp. 67–78, 2014.
- Chen et al. [2015] X. Chen, H. Fang, T. Lin, R. Vedantam, S. Gupta, P. Dollár, and C. L. Zitnick, “Microsoft COCO captions: Data collection and evaluation server,” CoRR, vol. abs/1504.00325, 2015.
- Sharma et al. [2018] P. Sharma, N. Ding, S. Goodman, and R. Soricut, “Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, ACL 2018, Melbourne, Australia, July 15-20, 2018, Volume 1: Long Papers, I. Gurevych and Y. Miyao, Eds. Association for Computational Linguistics, 2018, pp. 2556–2565.
- Zellers et al. [2019] R. Zellers, Y. Bisk, A. Farhadi, and Y. Choi, “From recognition to cognition: Visual commonsense reasoning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6720–6731.
- Gao et al. [2019] D. Gao, R. Wang, S. Shan, and X. Chen, “From two graphs to N questions: A VQA dataset for compositional reasoning on vision and commonsense,” CoRR, vol. abs/1908.02962, 2019.
- Song et al. [2017] S. Song, F. Yu, A. Zeng, A. X. Chang, M. Savva, and T. A. Funkhouser, “Semantic scene completion from a single depth image,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. IEEE Computer Society, 2017, pp. 190–198.
- Chang et al. [2017] A. X. Chang, A. Dai, T. A. Funkhouser, M. Halber, M. Nießner, M. Savva, S. Song, A. Zeng, and Y. Zhang, “Matterport3d: Learning from RGB-D data in indoor environments,” in 2017 International Conference on 3D Vision, 3DV 2017, Qingdao, China, October 10-12, 2017. IEEE Computer Society, 2017, pp. 667–676.
- Armeni et al. [2017] I. Armeni, S. Sax, A. R. Zamir, and S. Savarese, “Joint 2d-3d-semantic data for indoor scene understanding,” CoRR, vol. abs/1702.01105, 2017.
- Straub et al. [2019] J. Straub, T. Whelan, L. Ma, Y. Chen, E. Wijmans, S. Green, J. J. Engel, R. Mur-Artal, C. Ren, S. Verma, A. Clarkson, M. Yan, B. Budge, Y. Yan, X. Pan, J. Yon, Y. Zou, K. Leon, N. Carter, J. Briales, T. Gillingham, E. Mueggler, L. Pesqueira, M. Savva, D. Batra, H. M. Strasdat, R. D. Nardi, M. Goesele, S. Lovegrove, and R. A. Newcombe, “The replica dataset: A digital replica of indoor spaces,” CoRR, vol. abs/1906.05797, 2019.
- Xia et al. [2018] F. Xia, A. R. Zamir, Z. He, A. Sax, J. Malik, and S. Savarese, “Gibson env: Real-world perception for embodied agents,” in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. IEEE Computer Society, 2018, pp. 9068–9079.
- Savva et al. [2019] M. Savva, J. Malik, D. Parikh, D. Batra, A. Kadian, O. Maksymets, Y. Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, and V. Koltun, “Habitat: A platform for embodied AI research,” in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 2019, pp. 9338–9346.
- Blukis et al. [2019] V. Blukis, Y. Terme, E. Niklasson, R. A. Knepper, and Y. Artzi, “Learning to map natural language instructions to physical quadcopter control using simulated flight,” in 3rd Annual Conference on Robot Learning, CoRL 2019, Osaka, Japan, October 30 - November 1, 2019, Proceedings, ser. Proceedings of Machine Learning Research, L. P. Kaelbling, D. Kragic, and K. Sugiura, Eds., vol. 100. PMLR, 2019, pp. 1415–1438.
- Blukis et al. [2018a] V. Blukis, N. Brukhim, A. Bennett, R. A. Knepper, and Y. Artzi, “Following high-level navigation instructions on a simulated quadcopter with imitation learning,” in Robotics: Science and Systems XIV, Carnegie Mellon University, Pittsburgh, Pennsylvania, USA, June 26-30, 2018, H. Kress-Gazit, S. S. Srinivasa, T. Howard, and N. Atanasov, Eds., 2018.
- Shah et al. [2017] S. Shah, D. Dey, C. Lovett, and A. Kapoor, “Airsim: High-fidelity visual and physical simulation for autonomous vehicles,” in Field and Service Robotics, Results of the 11th International Conference, FSR 2017, Zurich, Switzerland, 12-15 September 2017, ser. Springer Proceedings in Advanced Robotics, M. Hutter and R. Siegwart, Eds., vol. 5. Springer, 2017, pp. 621–635.
- Blukis et al. [2018b] V. Blukis, D. K. Misra, R. A. Knepper, and Y. Artzi, “Mapping navigation instructions to continuous control actions with position-visitation prediction,” in 2nd Annual Conference on Robot Learning, CoRL 2018, Zürich, Switzerland, 29-31 October 2018, Proceedings, ser. Proceedings of Machine Learning Research, vol. 87. PMLR, 2018, pp. 505–518.
- Blukis et al. [2020] V. Blukis, R. A. Knepper, and Y. Artzi, “Few-shot object grounding and mapping for natural language robot instruction following,” CoRR, vol. abs/2011.07384, 2020.
- Anderson et al. [2018b] P. Anderson, A. X. Chang, D. S. Chaplot, A. Dosovitskiy, S. Gupta, V. Koltun, J. Kosecka, J. Malik, R. Mottaghi, M. Savva, and A. R. Zamir, “On evaluation of embodied navigation agents,” CoRR, vol. abs/1807.06757, 2018.
- Storks et al. [2021] S. Storks, Q. Gao, G. Thattai, and G. Tür, “Are we there yet? learning to localize in embodied instruction following,” CoRR, vol. abs/2101.03431, 2021.
- Singh et al. [2020] K. P. Singh, S. Bhambri, B. Kim, R. Mottaghi, and J. Choi, “MOCA: A modular object-centric approach for interactive instruction following,” CoRR, vol. abs/2012.03208, 2020.
- Yu et al. [2017] H. Yu, H. Zhang, and W. Xu, “A deep compositional framework for human-like language acquisition in virtual environment,” arXiv preprint arXiv:1703.09831, 2017.
- Anand et al. [2018] A. Anand, E. Belilovsky, K. Kastner, H. Larochelle, and A. C. Courville, “Blindfold baselines for embodied QA,” CoRR, vol. abs/1811.05013, 2018.
- Das et al. [2018b] A. Das, G. Gkioxari, S. Lee, D. Parikh, and D. Batra, “Neural modular control for embodied question answering,” in 2nd Annual Conference on Robot Learning, CoRL 2018, Zürich, Switzerland, 29-31 October 2018, Proceedings, ser. Proceedings of Machine Learning Research, vol. 87. PMLR, 2018, pp. 53–62.
- Parvaneh et al. [2020a] A. Parvaneh, E. Abbasnejad, D. Teney, Q. Shi, and A. van den Hengel, “Counterfactual vision-and-language navigation: Unravelling the unseen,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- Wu et al. [2020] Y. Wu, L. Jiang, and Y. Yang, “Revisiting embodiedqa: A simple baseline and beyond,” IEEE Trans. Image Process., vol. 29, pp. 3984–3992, 2020.
- Wijmans et al. [2019] E. Wijmans, S. Datta, O. Maksymets, A. Das, G. Gkioxari, S. Lee, I. Essa, D. Parikh, and D. Batra, “Embodied question answering in photorealistic environments with point cloud perception,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6659–6668.
- Yu et al. [2019] L. Yu, X. Chen, G. Gkioxari, M. Bansal, T. L. Berg, and D. Batra, “Multi-target embodied question answering,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6309–6318.
- Lillicrap et al. [2016] T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y. Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforcement learning,” in 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2-4, 2016, Conference Track Proceedings, Y. Bengio and Y. LeCun, Eds., 2016.
- Mnih et al. [2016] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. P. Lillicrap, T. Harley, D. Silver, and K. Kavukcuoglu, “Asynchronous methods for deep reinforcement learning,” in Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, ser. JMLR Workshop and Conference Proceedings, M. Balcan and K. Q. Weinberger, Eds., vol. 48. JMLR.org, 2016, pp. 1928–1937.
- Wu et al. [2019] Y. Wu, Y. Wu, A. Tamar, S. J. Russell, G. Gkioxari, and Y. Tian, “Bayesian relational memory for semantic visual navigation,” in 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, 2019, pp. 2769–2779.
- Lin et al. [2021] X. Lin, G. Li, and Y. Yu, “Scene-intuitive agent for remote embodied visual grounding,” CoRR, vol. abs/2103.12944, 2021.
- Caesar et al. [2020] H. Caesar, V. Bankiti, A. H. Lang, S. Vora, V. E. Liong, Q. Xu, A. Krishnan, Y. Pan, G. Baldan, and O. Beijbom, “nuscenes: A multimodal dataset for autonomous driving,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 11 618–11 628.
- Yu et al. [2018b] H. Yu, H. Zhang, and W. Xu, “Interactive grounded language acquisition and generalization in a 2d world,” in 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
- Yang et al. [2019] W. Yang, X. Wang, A. Farhadi, A. Gupta, and R. Mottaghi, “Visual semantic navigation using scene priors,” in 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- Kipf and Welling [2017] T. N. Kipf and M. Welling, “Semi-supervised classification with graph convolutional networks,” in 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
- Sepulveda et al. [2018] G. Sepulveda, J. C. Niebles, and A. Soto, “A deep learning based behavioral approach to indoor autonomous navigation,” in 2018 IEEE International Conference on Robotics and Automation, ICRA 2018, Brisbane, Australia, May 21-25, 2018. IEEE, 2018, pp. 4646–4653.
- Huang et al. [2019a] H. Huang, V. Jain, H. Mehta, J. Baldridge, and E. Ie, “Multi-modal discriminative model for vision-and-language navigation,” CoRR, vol. abs/1905.13358, 2019.
- Fried et al. [2018] D. Fried, R. Hu, V. Cirik, A. Rohrbach, J. Andreas, L. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell, “Speaker-follower models for vision-and-language navigation,” pp. 3318–3329, 2018.
- Ilharco et al. [2019] G. Ilharco, V. Jain, A. Ku, E. Ie, and J. Baldridge, “General evaluation for instruction conditioned navigation using dynamic time warping,” 2019.
- Zhao et al. [2021] M. Zhao, P. Anderson, V. Jain, S. Wang, A. Ku, J. Baldridge, and E. Ie, “On the evaluation of vision-and-language navigation instructions,” pp. 1302–1316, 2021.
- Anderson et al. [2016] P. Anderson, B. Fernando, M. Johnson, and S. Gould, “Spice: Semantic propositional image caption evaluation,” in European conference on computer vision. Springer, 2016, pp. 382–398.
- Papineni et al. [2002] K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” in Proceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318.
- Lin [2004] C.-Y. Lin, “Rouge: A package for automatic evaluation of summaries,” in Text summarization branches out, 2004, pp. 74–81.
- Denkowski and Lavie [2014] M. Denkowski and A. Lavie, “Meteor universal: Language specific translation evaluation for any target language,” in Proceedings of the ninth workshop on statistical machine translation, 2014, pp. 376–380.
- Vedantam et al. [2015] R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus-based image description evaluation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 4566–4575.
- Ma et al. [2019a] C. Ma, J. Lu, Z. Wu, G. AlRegib, Z. Kira, R. Socher, and C. Xiong, “Self-monitoring navigation agent via auxiliary progress estimation,” 2019.
- Ma et al. [2019b] C.-Y. Ma, Z. Wu, G. AlRegib, C. Xiong, and Z. Kira, “The regretful agent: Heuristic-aided navigation through progress estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6732–6740.
- Ke et al. [2019] L. Ke, X. Li, Y. Bisk, A. Holtzman, Z. Gan, J. Liu, J. Gao, Y. Choi, and S. Srinivasa, “Tactical rewind: Self-correction via backtracking in vision-and-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6741–6749.
- Huang et al. [2019b] H. Huang, V. Jain, H. Mehta, A. Ku, G. Magalhaes, J. Baldridge, and E. Ie, “Transferable representation learning in vision-and-language navigation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 7404–7413.
- Zhu et al. [2020b] F. Zhu, Y. Zhu, X. Chang, and X. Liang, “Vision-language navigation with self-supervised auxiliary reasoning tasks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 10 012–10 022.
- Wang et al. [2020a] H. Wang, W. Wang, T. Shu, W. Liang, and J. Shen, “Active visual information gathering for vision-language navigation,” in European Conference on Computer Vision. Springer, 2020, pp. 307–322.
- Zhang et al. [2020] W. Zhang, C. Ma, Q. Wu, and X. Yang, “Language-guided navigation via cross-modal grounding and alternate adversarial learning,” IEEE Transactions on Circuits and Systems for Video Technology, 2020.
- Deng et al. [2020] Z. Deng, K. Narasimhan, and O. Russakovsky, “Evolving graphical planner: Contextual global planning for vision-and-language navigation,” CoRR, vol. abs/2007.05655, 2020.
- Landi et al. [2019] F. Landi, L. Baraldi, M. Cornia, M. Corsini, and R. Cucchiara, “Perceive, transform, and act: Multi-modal attention networks for vision-and-language navigation,” CoRR, vol. abs/1911.12377, 2019.
- Magassouba et al. [2021] A. Magassouba, K. Sugiura, and H. Kawai, “Crossmap transformer: A crossmodal masked path transformer using double back-translation for vision-and-language navigation,” arXiv preprint arXiv:2103.00852, 2021.
- Wu et al. [2021] Z. Wu, Z. Liu, T. Wang, and D. Wang, “Improved speaker and navigator for vision-and-language navigation,” IEEE MultiMedia, 2021.
- Mao et al. [2020] S. Mao, J. Wu, and S. Hong, “Vision and language navigation using multi-head attention mechanism,” in 2020 6th International Conference on Big Data and Information Analytics (BigDIA). IEEE, 2020, pp. 74–79.
- Hong et al. [2020a] Y. Hong, C. R. Opazo, Y. Qi, Q. Wu, and S. Gould, “Language and visual entity relationship graph for agent navigation,” 2020.
- Xia et al. [2020] Q. Xia, X. Li, C. Li, Y. Bisk, Z. Sui, J. Gao, Y. Choi, and N. A. Smith, “Multi-view learning for vision-and-language navigation,” CoRR, vol. abs/2003.00857, 2020.
- Qi et al. [2020b] Y. Qi, Z. Pan, S. Zhang, A. van den Hengel, and Q. Wu, “Object-and-action aware model for visual language navigation,” in Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, Scotland. Springer, 2020, pp. 23–28.
- Wang et al. [2021] H. Wang, W. Wang, W. Liang, C. Xiong, and J. Shen, “Structured scene memory for vision-language navigation,” CoRR, vol. abs/2103.03454, 2021.
- Wang et al. [2019] X. Wang, Q. Huang, A. Celikyilmaz, J. Gao, D. Shen, Y.-F. Wang, W. Y. Wang, and L. Zhang, “Reinforced cross-modal matching and self-supervised imitation learning for vision-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 6629–6638.
- Tan et al. [2019] H. Tan, L. Yu, and M. Bansal, “Learning to navigate unseen environments: Back translation with environmental dropout,” pp. 2610–2621, 2019.
- Parvaneh et al. [2020b] A. Parvaneh, E. Abbasnejad, D. Teney, Q. Shi, and A. van den Hengel, “Counterfactual vision-and-language navigation: Unravelling the unseen,” Advances in Neural Information Processing Systems, vol. 33, 2020.
- Wang et al. [2018] X. Wang, W. Xiong, H. Wang, and W. Y. Wang, “Look before you leap: Bridging model-free and model-based reinforcement learning for planned-ahead vision-and-language navigation,” in Proceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 37–53.
- Lansing et al. [2019] L. Lansing, V. Jain, H. Mehta, H. Huang, and E. Ie, “VALAN: vision and language agent navigation,” CoRR, vol. abs/1912.03241, 2019.
- Wang et al. [2020b] H. Wang, Q. Wu, and C. Shen, “Soft expert reward learning for vision-and-language navigation,” vol. 12354, pp. 126–141, 2020.
- Zhou and Small [2020] L. Zhou and K. Small, “Inverse reinforcement learning with natural language goals,” CoRR, vol. abs/2008.06924, 2020.
- Hu et al. [2019] R. Hu, D. Fried, A. Rohrbach, D. Klein, T. Darrell, and K. Saenko, “Are you looking? grounding to multiple modalities in vision-and-language navigation,” pp. 6551–6557, 2019.
- Kurita and Cho [2020] S. Kurita and K. Cho, “Generative language-grounded policy in vision-and-language navigation with bayes’ rule,” CoRR, vol. abs/2009.07783, 2020.
- Hong et al. [2020b] Y. Hong, C. R. Opazo, Q. Wu, and S. Gould, “Sub-instruction aware vision-and-language navigation,” pp. 3360–3376, 2020.
- Agarwal et al. [2019] S. Agarwal, D. Parikh, D. Batra, P. Anderson, and S. Lee, “Visual landmark selection for generating grounded and interpretable navigation instructions,” in CVPR workshop on Deep Learning for Semantic Visual Navigation, 2019.
- Fu et al. [2020] T.-J. Fu, X. E. Wang, M. F. Peterson, S. T. Grafton, M. P. Eckstein, and W. Y. Wang, “Counterfactual vision-and-language navigation via adversarial path sampler,” in European Conference on Computer Vision. Springer, 2020, pp. 71–86.
- Yu et al. [2020] F. Yu, Z. Deng, K. Narasimhan, and O. Russakovsky, “Take the scenic route: Improving generalization in vision-and-language navigation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 920–921.
- An et al. [2021] D. An, Y. Qi, Y. Huang, Q. Wu, L. Wang, and T. Tan, “Neighbor-view enhanced model for vision and language navigation,” CoRR, vol. abs/2107.07201, 2021.
- Liu et al. [2021a] C. Liu, F. Zhu, X. Chang, X. Liang, and Y. Shen, “Vision-language navigation with random environmental mixup,” CoRR, vol. abs/2106.07876, 2021.
- Sun et al. [2021] Q. Sun, Y. Zhuang, Z. Chen, Y. Fu, and X. Xue, “Depth-guided adain and shift attention network for vision-and-language navigation,” in 2021 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2021, pp. 1–6.
- Vaswani et al. [2017] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,” in Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Eds., 2017, pp. 5998–6008.
- Su et al. [2020] W. Su, X. Zhu, Y. Cao, B. Li, L. Lu, F. Wei, and J. Dai, “VL-BERT: pre-training of generic visual-linguistic representations,” in 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net, 2020.
- Li et al. [2019a] X. Li, C. Li, Q. Xia, Y. Bisk, ttsli Celikyilmaz, J. Gao, N. A. Smith, and Y. Choi, “Robust navigation with language pretraining and stochastic sampling,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, K. Inui, J. Jiang, V. Ng, and X. Wan, Eds. Association for Computational Linguistics, 2019, pp. 1494–1499.
- Brown et al. [2020] T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell, S. Agarwal, A. Herbert-Voss, G. Krueger, T. Henighan, R. Child, A. Ramesh, D. M. Ziegler, J. Wu, C. Winter, C. Hesse, M. Chen, E. Sigler, M. Litwin, S. Gray, B. Chess, J. Clark, C. Berner, S. McCandlish, A. Radford, I. Sutskever, and D. Amodei, “Language models are few-shot learners,” in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- Hao et al. [2020] W. Hao, C. Li, X. Li, L. Carin, and J. Gao, “Towards learning a generic agent for vision-and-language navigation via pre-training,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 13 134–13 143.
- Huang et al. [2020] J. Huang, B. Huang, L. Zhu, L. Ma, J. Liu, G. Zeng, and Z. Shi, “Real-time vision-language-navigation based on a lite pre-training model,” in 2020 International Conferences on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData) and IEEE Congress on Cybermatics (Cybermatics), iThings/GreenCom/CPSCom/SmartData/Cybermatics 2020, Rhodes Island, Greece, November 2-6, 2020. IEEE, 2020, pp. 399–404.
- Majumdar et al. [2020] A. Majumdar, A. Shrivastava, S. Lee, P. Anderson, D. Parikh, and D. Batra, “Improving vision-and-language navigation with image-text pairs from the web,” in European Conference on Computer Vision. Springer, 2020, pp. 259–274.
- Hong et al. [2020c] Y. Hong, Q. Wu, Y. Qi, C. R. Opazo, and S. Gould, “A recurrent vision-and-language BERT for navigation,” CoRR, vol. abs/2011.13922, 2020.
- Qi et al. [2021] Y. Qi, Z. Pan, Y. Hong, M. Yang, A. van den Hengel, and Q. Wu, “Know what and know where: An object-and-room informed sequential BERT for indoor vision-language navigation,” CoRR, vol. abs/2104.04167, 2021.
- Anderson et al. [2020] P. Anderson, A. Shrivastava, J. Truong, A. Majumdar, D. Parikh, D. Batra, and S. Lee, “Sim-to-real transfer for vision-and-language navigation,” CoRR, vol. abs/2011.03807, 2020.
- Zhu et al. [2021] W. Zhu, Y. Qi, P. Narayana, K. Sone, S. Basu, X. E. Wang, Q. Wu, M. Eckstein, and W. Y. Wang, “Diagnosing vision-and-language navigation: What really matters,” arXiv preprint arXiv:2103.16561, 2021.
- Anderson et al. [2019] P. Anderson, A. Shrivastava, D. Parikh, D. Batra, and S. Lee, “Chasing ghosts: Instruction following as bayesian state tracking,” arXiv preprint arXiv:1907.02022, 2019.
- Li et al. [2019b] X. Li, C. Li, Q. Xia, Y. Bisk, A. Celikyilmaz, J. Gao, N. A. Smith, and Y. Choi, “Robust navigation with language pretraining and stochastic sampling,” pp. 1494–1499, 2019.
- Chen et al. [2020] K. Chen, J. K. Chen, J. Chuang, M. Vázquez, and S. Savarese, “Topological planning with transformers for vision-and-language navigation,” CoRR, vol. abs/2012.05292, 2020.
- Wang et al. [2020c] T. Wang, Z. Wu, and D. Wang, “Visual perception generalization for vision-and-language navigation via meta-learning,” CoRR, vol. abs/2012.05446, 2020.
- Xiang et al. [2020] J. Xiang, X. E. Wang, and W. Y. Wang, “Learning to stop: A simple yet effective approach to urban vision-language navigation,” CoRR, vol. abs/2009.13112, 2020.
- Zhu et al. [2020c] W. Zhu, X. Wang, T. Fu, A. Yan, P. Narayana, K. Sone, S. Basu, and W. Y. Wang, “Multimodal text style transfer for outdoor vision-and-language navigation,” CoRR, vol. abs/2007.00229, 2020.
- Mehta et al. [2020] H. Mehta, Y. Artzi, J. Baldridge, E. Ie, and P. Mirowski, “Retouchdown: Releasing touchdown on streetlearn as a public resource for language grounding tasks in street view,” in Proceedings of the Third International Workshop on Spatial Language Understanding, 2020.
- Mirowski et al. [2018] P. Mirowski, M. K. Grimes, M. Malinowski, K. M. Hermann, K. Anderson, D. Teplyashin, K. Simonyan, K. Kavukcuoglu, A. Zisserman, and R. Hadsell, “Learning to navigate in cities without a map,” in NeurIPS, 2018, pp. 2424–2435.
- Vasudevan et al. [2021] A. B. Vasudevan, D. Dai, and L. V. Gool, “Talk2nav: Long-range vision-and-language navigation with dual attention and spatial memory,” Int. J. Comput. Vis., vol. 129, no. 1, pp. 246–266, 2021.
- Cirik et al. [2018] V. Cirik, Y. Zhang, and J. Baldridge, “Following formulaic map instructions in a street simulation environment,” in 2018 NeurIPS Workshop on Visually Grounded Interaction and Language, vol. 1, 2018.
- Zhu et al. [2020d] Y. Zhu, F. Zhu, Z. Zhan, B. Lin, J. Jiao, X. Chang, and X. Liang, “Vision-dialog navigation by exploring cross-modal memory,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. IEEE, 2020, pp. 10 727–10 736.
- Roman Roman et al. [2020] H. Roman Roman, Y. Bisk, J. Thomason, A. Celikyilmaz, and J. Gao, “RMM: A recursive mental model for dialogue navigation,” in Findings of the Association for Computational Linguistics: EMNLP 2020, Nov. 2020.
- Mikhail et al. [2001] E. M. Mikhail, J. S. Bethel, and J. C. McGlone, “Introduction to modern photogrammetry,” New York, vol. 19, 2001.
- Yang et al. [2018] W. Yang, X. Wang, A. Farhadi, A. Gupta, and R. Mottaghi, “Visual semantic navigation using scene priors,” arXiv preprint arXiv:1810.06543, 2018.
- Wortsman et al. [2019] M. Wortsman, K. Ehsani, M. Rastegari, A. Farhadi, and R. Mottaghi, “Learning to learn how to learn: Self-adaptive visual navigation using meta-learning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019. Computer Vision Foundation / IEEE, 2019, pp. 6750–6759.
- Liu et al. [2021b] B. Liu, X. Xiao, and P. Stone, “A lifelong learning approach to mobile robot navigation,” IEEE Robotics Autom. Lett., vol. 6, no. 2, pp. 1090–1096, 2021.
- Nguyen et al. [2019b] T. Nguyen, D. Nguyen, and T. Le, “Reinforcement learning based navigation with semantic knowledge of indoor environments,” in 11th International Conference on Knowledge and Systems Engineering, KSE 2019, Da Nang, Vietnam, October 24-26, 2019. IEEE, 2019, pp. 1–7.
- Hu et al. [2021] Y. Hu, B. Subagdja, A.-H. Tan, and Q. Yin, “Vision-based topological mapping and navigation with self-organizing neural networks,” IEEE Transactions on Neural Networks and Learning Systems, 2021.
- Tadokoro [2009] S. Tadokoro, Rescue robotics: DDT project on robots and systems for urban search and rescue. Springer Science & Business Media, 2009.
- Bhirangi et al. [2021] R. Bhirangi, T. Hellebrekers, C. Majidi, and A. Gupta, “Reskin: versatile, replaceable, lasting tactile skins,” arXiv preprint arXiv:2111.00071, 2021.
- Smith et al. [2020] B. Smith, C. Wu, H. Wen, P. Peluse, Y. Sheikh, J. K. Hodgins, and T. Shiratori, “Constraining dense hand surface tracking with elasticity,” ACM Transactions on Graphics (TOG), vol. 39, no. 6, pp. 1–14, 2020.
- Chen et al. [2019] C. Chen, U. Jain, C. Schissler, S. V. A. Gari, Z. Al-Halah, V. K. Ithapu, P. Robinson, and K. Grauman, “Audio-visual embodied navigation,” environment, vol. 97, p. 103, 2019.