Vision Transformers: State of the Art and Research Challenges
Abstract
Transformers have achieved great success in natural language processing. Due to the powerful capability of self-attention mechanism in transformers, researchers develop the vision transformers for a variety of computer vision tasks, such as image recognition, object detection, image segmentation, pose estimation, and 3D reconstruction. This paper presents a comprehensive overview of the literature on different architecture designs and training tricks (including self-supervised learning) for vision transformers. Our goal is to provide a systematic review with the open research opportunities.
1 Introduction
Transformers Vaswani et al. (2017) have originally achieved a great success in natural language processing Devlin et al. (2018); Radford et al. (2018) and can be adopted in various applications, including sentiment classification, machine translation, word prediction, and summarization. The key feature of transformers is the self-attention mechanism, which helps a model learn the global contexts and enables the model to acquire the long-range dependencies. Motivated by the great success in natural language processing, transformers have been adopted by computer vision tasks, leading to the development of vision transformers. Vision transformers have become prevalent in these years and have reached considerable success in many fields such as image classification Dosovitskiy et al. (2021); Liu et al. (2021), video classification Arnab et al. (2021), object detection Carion et al. (2020); Fang et al. (2021), semantic segmentation Xie et al. (2021a); Li et al. (2021b), and pose estimation Zhu et al. (2021).
Despite the success of the architecture, there are still several drawbacks which should be addressed, e.g., data-hungry, lack of locality and cross-patch information. Therefore, a recent line of research has been proposed to further enhance vision transformers. This survey introduces important ideas to solve the problems and aims to shed light on these topics for future research. In addition, as self-supervised learning methods play an important role in vision transformers, we also present several self-supervised learning methods employed on vision transformers. The rest of the paper is organized as follows. We start with the preliminary of transformers and vision transformers, and then introduce variant architectures of vision transformers. Afterward, the training tricks used in vision transformers are presented, together with the self-supervised learning. Finally, we conclude this paper and discuss the future research directions and challenges.
2 Preliminary
2.1 Self-attention
The attention mechanism is one of the most beneficial breakthroughs in deep learning research, which measures the importance of a feature that contributes to the final results. Using an attention mechanism often teaches a model to concentrate on specific features. For self-attention, the input and the output size are the same, while the self-attention mechanism allows the interaction between the inputs and discovers which they should pay more attention to. Afterward, each output is enhanced by the weighted inputs according to the attention scores. For instance, given a sentence stating “a dog is saved from pond after it fell through the ice,” self-attention can enhance the embedding of “it” by attending to “dog”. The self-attention is designed to help the model learn the global contexts under the property of long-range dependencies.
Fig. 1(a) illustrates the self-attention module. Let denote a sequence of vectors , where is the embedding dimension of each vector. To help the model learn the relations between each vector, query, key, and value matrices are projected from with linear layers and denoted by , , and , respectively. For instance, the query matrix is obtained by projecting with a linear layer , i.e., . Specifically, the attention weights are calculated by the normalized product of and with the softmax function, i.e.,
| (1) |
Softmax function normalizes the attention weights of each query-key pair within , where means the most important, and means useless information. Finally, the output features are enhanced by applying the attention weights to as follows:
| (2) |
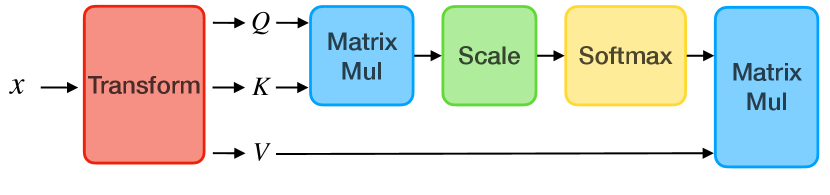
Multi-Head Attention.
In order to learn variant representations at different positions, the input is transformed into different representations (heads), denoted by . The attention is first computed for each head with , , and with projection matrices , , and , respectively.
| (3) |
Afterward, all the heads are concatenated to form the multi-head representations as follows:
| (4) |
Finally, is transformed back to dimension with projection matrix , i.e., . As the number of relations between inputs is usually unknown, multi-head attention is commonly-used to capture different relations between input elements in a data-driven manner.
2.2 Transformer
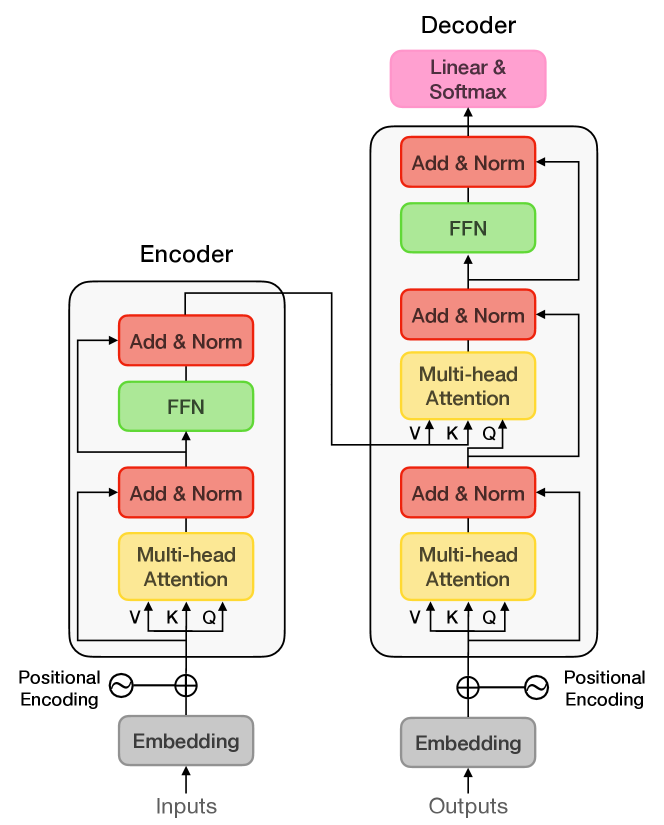
Transformer, proposed by Vaswani et al. Vaswani et al. (2017), are ubiquitous in NLP tasks Devlin et al. (2018); Brown et al. (2020); Peyrard et al. (2021). Fig. 2 illustrates the architecture of Transformer. A single transformer block can be separated into Encoder and Decoder, which both can be further decomposed into 1) self-attention, 2) Position-wise Feed-Forward Networks, and 3) positional encoding.
Position-wise Feed-Forward Networks.
Feed-Forward Networks (FFN) are mainly composed of Fully-Connected layers and can be written in:
| (5) |
where and are the weight and and are the bias terms. is ReLU activation function. is the hidden dimension and is usually set to .
Positional Encoding.
Since the self-attention relaxes the sequential order, transformers use positional encoding to maintain the ordinal information. The author proposes to use sine and cosine functions with different frequencies to derive the positional encoding, which allows the model to learn the relative positions since any positional encoding can be linearly combined by other positional encodings. Specifically, the -th dimension of the positional encoding at position , denoted by can be calculated as follows:
| (6) |
where is the dimension of the input features.
Encoder.
A single encoder block has two sub-layers, i.e., multi-head attention and position-wise feed-forward networks. Each sub-layer is followed by residual connection He et al. (2016) and layer normalization Ba et al. (2016). The outputs of the encoder will be sent into the decoder as in the second multi-head attention layer.
Decoder.
Each decoder block is made by three sub-layers. The first two layers are multi-head attention blocks, and the final one is position-wise feed-forward networks. Similar to encoder block, all three layers are followed by residual connection and layer normalization as well. Since the decoder is auto-regressive, i.e., sequentially predicting a new result only based on previous predictions, the multi-head attention layers in the decoder utilize the mask operation to only attend the predicted results for preventing the violation of causality.
2.3 Vision Transformer (ViT)
ViT Dosovitskiy et al. (2021) replaces all the CNN structures with several transformer layers and reaches state of the art performance on image recognition and are known as the pioneer of vision transformers. ViT contains three segments: 1) patch and positional embedding, 2) Transformer encoder, and 3) multi-layer perceptron (MLP) head.
Patch and Positional Embedding.
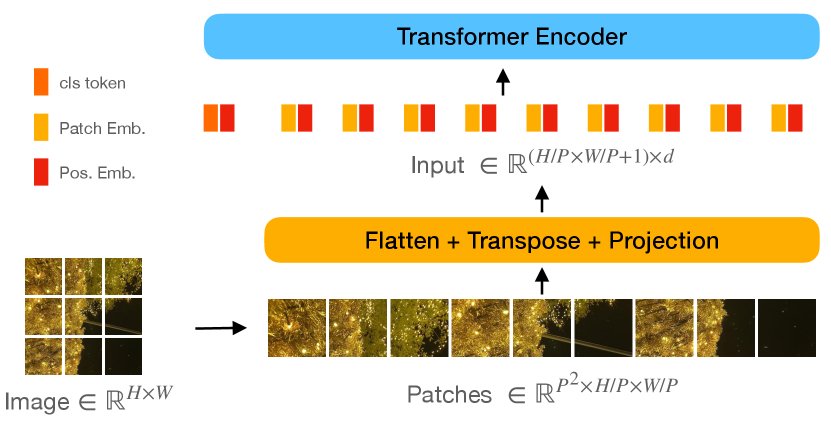
In order to transform an image into a 1D sequence of vectors, an image will be transformed into as illustrated in Fig. 1(b), where is the resolution of each patch, and the number of patches is . The patches are then projected into patch embeddings by a linear layer. Akin to BERT Devlin et al. (2018), a learnable class token is added to . Afterward, the positional embeddings are added to the output to obtain the positional information.
Transformer Encoder.
Instead of using both encoder and decoder, ViT only utilizes the Transformer encoder since the goal is to find a better representation rather than autoregressive prediction. The image patches are transformed into sequences and then sent into the encoder. The only difference is that the Layer Normalization is added before the sub-layers (pre-norm) Xiong et al. (2020).
Class Tokens.
The class token is trained to include the class information and can be used to represent the entire features. Therefore, it can be used to classify the data into different categories.
MLP Head.
MLP head is commonly-used for the downstream tasks. Specifically, let denotes the output of the Transformer encoder. As the class token prepended to the input sequence can be regarded as the image representation, the final result is determined based on the first token of the output from encoders through a single MLP layer, i.e.,
| (7) | ||||
| (8) |
3 Variant Architectures
Despite the promising performance of ViT, it still suffers from several issues. For instance, ViT requires to be trained on a large dataset. As ViT is initially trained on a JFT dataset Sun et al. (2017) with images before being fine-tuned on ImageNet ( images) Russakovsky et al. (2015). If the dataset is insufficient, the model may perform worse than CNN-based approaches. Although the pre-trained weights can be used on various tasks, many datasets are not transferable or even with an inferior performance. Moreover, ViT is not a general-purpose backbone since it is only suitable for image classification but not for the dense prediction, such as object detection and image segmentation, due to the patch partitions.
Fig. 3 shows the taxonomy of vision transformers with three mainstream directions. Specifically, Sec. 3.1 first introduces the locality-based models, which manage to add the locality into the architectures. Next, feature-based models are introduced in Sec. 3.2, which aim to diversify the feature representations. Finally, hierarchical-based models are presented in Sec. 3.3, which reduce the feature size layer-by-layer to increase the inference speed. Some architectures that are not classified into the above categories are included in Sec. 3.4. Please note that these models are put into certain categories, but these categories are not mutual-exclusive.
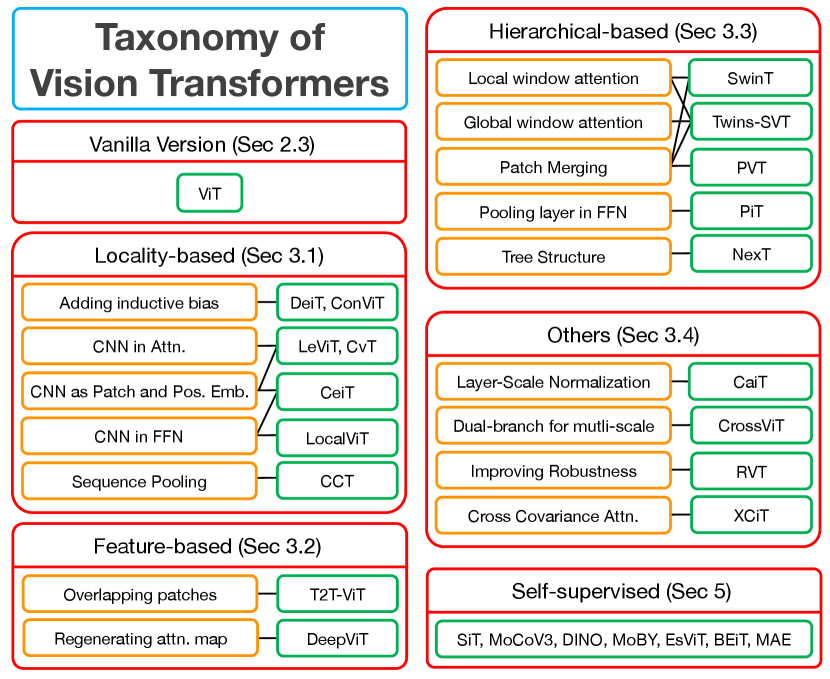
3.1 Locality-based Models
ViT, which lacks locality and translation equivalence, usually performs worse than CNN. Therefore, researchers start to include the CNN structures into the vision transformer since the convolution kernels help the model capture the local information. As such, adding locality from CNN improves the data efficiency of vision transformers, resulting in a better performance on a small dataset. In the following, we introduce several approaches considering the locality.
DeiT
Touvron et al. (2021a) uses a CNN as a teacher model to train a vision transformer, which utilizes knowledge distillation Hinton et al. (2015) to transfer the inductive bias to a vision transformer and applies stronger data augmentation for input data. This approach allows others to train a vision transformer from scratch without the requirement of pre-training on a large dataset.
ConViT
d’Ascoli et al. (2021) is similar to DeiT as ConViT also combines the inductive bias of CNN into models. Instead of using knowledge distillation, ConViT includes Gated Positional Self-attention (GPSA), which can be initialized as a convolutional layer Cordonnier et al. (2020) for capturing the local information at the beginning of the training stage. As such, ConViT can utilize the advantages of soft inductive bias of CNN without being limited to CNN. In other words, GPSA allows vision transformers to be the same as CNN to improve the data efficiency on small datasets but can be better than CNN when there are infinite data used in training.
LeViT
Graham et al. (2021) gets the embeddings from four convolutional layers, which the model can extract the local features at the beginning and also reduce the input size. On top of that, LeViT further lowers the input size in some attention blocks, which speeds up the inference time. These advantages help strike the balance between accuracy, data efficiency and the training speed.
CeiT
Yuan et al. (2021a) obtains the embedding features directly from convolutional blocks to add the locality in the beginning of the model, similar to LeViT. Moreover, the authors include a depth-wise convolutional layer in FFN to encourage the model to extract the local features. In order to exchange the class information in different layers, CeiT utilizes Layer-wise Class-token Attention to collect different class representations by computing the self-attention on class tokens.
CvT
Yuan et al. (2021a) also obtains the embeddings with convolutional layers. Besides, CvT uses convolutional layers to create query, key, and value before self-attention operation, which provides the local spatial information. Furthermore, CvT also shrinks the size of the key and the value by using to accelerate the computation.
LocalViT
Li et al. (2021c) is designed to use convolutional layers in FFN to extract the local features in every transformer blocks. The authors also try to apply different activation functions (ReLU6, h-swish) and architectures (SE-Block, ECA module) in FFN layers to improve the performance.
CCT
Hassani et al. (2021) is proposed to solve the data-hungry problem to make vision transformers perform well on small datasets. Specifically, CCT gets the embeddings with convolutional layers and makes the input shape flexible by removing the positional embeddings. On top of that, CCT incorporates the Sequence Pooling at the end of the transformer layers to compute the weights of the output sequence.
3.2 Featured-based Models
These models put their efforts on diversifying the features, e.g., token maps, attention maps in vision transformers. Having distinct feature maps indicates that the model can extract various features, which allows the model to perform well.
DeepViT
Zhou et al. (2021) is created after the authors examine the attention maps of ViT and find out that the attention collapsing takes place in the deeper layer. This problem hinders the model to be representative and would lower the performance. The authors alter the self-attention layers and provide a learnable transformation matrix after the attention layer to address the issue by stimulating the model to generate a new set of attention maps.
T2T-ViT
Yuan et al. (2021b) is designed after the authors observe the feature maps reshaped from the tokens and point out that most of the token maps are meaningless in ViT. To improve the diversity of the token maps, the authors inserts a T2T-module in the beginning of the model. T2T-module is made up of few T2T-Transformers. These T2T-Transformers can be viewed as the original transformer layers or can be replaced by the Performer used in Choromanski et al. (2021). Between the T2T-Transformers is the T2T-process, which crops the images into several overlapping patches. The overlapping strategy enables the model to share the information between the neighbors to improve the features diversity.
3.3 Hierarchical-based Models
The original version of ViT is notorious for its heavy computation. Significantly, the cost raises when the input size increases. Therefore, decreasing the feature size would definitely help reduce the training time. Below are some approaches to solve this issue.
PVT
Wang et al. (2021) is mainly designed for solving dense prediction problems (e.g., object detection and semantic segmentation). It uses Spatial Reduction Layer to reduce the computation by decreasing the dimension of and . The feature size is reduced by a patch embedding layer at the beginning of each stage. Due to its pyramid structure, the model can generate multi-scale feature maps and can be trained faster with its smaller feature size.
PiT
Heo et al. (2021) includes Pooling Layer, which uses a depth-wise convolutional layer to achieve the dimension reduction. The authors also test PiT on different robustness benchmarks and get outstanding performance.
Swin-Transformer
Liu et al. (2021) is proposed to derive a general-purpose backbone based on ViT, which can be used for different applications, e.g., image classification and semantic segmentation. Since applying self-attention pixel-by-pixel results in a tremendous computation complexity, Swin-Transformer forms a hierarchical structure, which merges patches after each Swin-Transformer block and therefore has approximate linear computation time complexity to input image size due to the computation of self-attention only within each local shifted window.
Twins-SVT
Chu et al. (2021) also computes the attention within a shifted window, while the global attention is evaluated after the local window attention. This helps each window retains the outside-window information, similar to the overlapping strategy. Likewise, the patches are merged at the beginning of the stages to form the hierarchical shape.
NexT
Zhang et al. (2021) is created on a different strategy to perform the hierarchical computation. Specifically, an image is first partitioned into blocks and every four blocks are merged after a transformer layer. Moreover, Gradient-based Class-aware Tree-traversal is proposed to visualize the most critical path from child to root, which reveals how the model makes the decision given an input image. It is worth noting that NexT can be used to generate images by turning the tree upside down due to its tree structure.
3.4 Others
In the following, we introduce several promising directions for improving ViT which are not classified before.
CrossViT
Chen et al. (2021a) can extract multi-scale features from two branches. These branches are L-Branch and S-Branch, where the former uses a larger patch size and the latter uses a smaller patch size. By using the dual-branch structure, the model is able to obtain different scales of spatial information. To fuse the spatial information between the branches, Cross Attention is applied by inserting the class token from one to the other.
RVT
Mao et al. (2021) is designed after studying different components in ViT with regards to the robustness, e.g., accuracy under adversarial attacks. Based on the results, RVT decides to 1) remove the class token, which is not important to a vision transformer, by averaging the features and 2) add CNN to the embedding and the FFN layers for increasing locality and 3) use more attention heads for obtaining different features. Moreover, the original self-attention is replaced by Position-Aware Attention Scaling (PAAS), which adds a learnable matrix to the self-attention for showing the importance of each - pair. PAAS is proved to suppress the unrelated signal in the noise input. Moreover, Patch-wise Augmentation applies different augmentations on different patches to diversify the training data.
CaiT
Touvron et al. (2021b) employs the normalization with LayerScale, which uses learnable factors to adaptively normalize the features. The normalization speeds up the converge rate and allows the deep model to be trained well. CaiT also includes Class Attention Layer for computing the attention between the class embedding and the overall features to have better knowledge on the inputs.
XCiT
Ali et al. (2021) is proposed to reduce the time complexity of the self-attention. The reduction is done by Cross-Covariance Attention, which uses the transposed version of self-attention, i.e., the self-attention is computed on the feature channels but not on the tokens. As such, the time complexity is reduced from to . Moreover, Local Patch Interaction Block is employed to use depth-wise convolutional networks to further extract the information between different patches.
4 Training Tricks for Vision Transformer
To better train a vision transformer, several tricks are proposed to increase the diversity of the data and to improve the generality of the model.
Data Augmentation
is used to increase the diversity of training data, e.g., translation, cropping, which help a model learn the main features by altering the input patterns. To find out the best combination for a variety of datasets, AutoAugment Cubuk et al. (2019) and RandAugment Cubuk et al. (2020) are designed to search for a better combination. These augmentation strategies are proved to be transferable to different datasets.
Exponential moving average (EMA)
is often added to stabilize the training process. Let and respectively denote the model parameters in the -th iteration and the parameters updated by an optimizer. The model parameters in the -th iteration can be calculated by
| (9) |
where is a hyperparameter in range . EMA stabilizes the training process by smoothing old and new parameters.
Stochastic Depth (SD)
Huang et al. (2016) is first proposed to train deep networks such as ResNet He et al. (2016), which drops the entire block as a regularization method. Similarly, when training a vision transformer, stochastic depth randomly leaves some samples to be 0 after an attention or a FFN layer but before the residual connection. This step can be viewed as randomly replacing the networks by identity function for some samples.
Fixing Resolution Discrepancy
Touvron et al. (2019) is to relax the discrepancy between training and testing image size resulted from random cropping in data augmentation. The authors find that upsampling the training data can mitigate the discrepancy caused by different resolutions. This is why many models are trained with a size of or bigger.
5 Self-supervised Learning in Vision Transformer
Self-Supervised Learning (SSL) trains a model as supervised learning but only uses data itself to create labels instead of manual annotation. SSL has a considerable advantage over exploiting the data, especially useful for those extensive datasets. It also helps the model learn essential information lies in data and makes the model robust and transferable.
Recently, SSL in computer vision can be mainly categorized into pretext tasks and contrastive learning. The former is to design a particular job for a model to learn before fine-tuning on downstream tasks, e.g., predicting the rotation degree, coloring, or solving the jigsaw puzzles. In contrast, the latter generates similar features for the same-class data and pushes away other negative samples. In the following, we introduce several SSL methods used in the vision transformer.
SiT
Atito et al. (2021) includes two pretext tasks with the contrastive loss after passing input data through a vision transformer. These tasks include predicting the rotation degree of and the image reconstruction. The image is first augmented and partitioned into different patches. The rotation task is to match the predicting degree and the actual degree of the input image. The reconstruction task is to reconstruct the augmented image back to the original image. Finally, the contrastive loss maximizes the similarity between the same inputs.
MoCoV3
Chen et al. (2021b) is designed explicitly for vision transformer based on V1 and V2 He et al. (2020); Chen et al. (2020). Each image has two different versions generated by data augmentation and the images of different versions are fed into two different encoders. The model then learns to reduce the difference between the two identical images and increases the distance of those negative samples, where the difference is measured by InfoNCE Oord et al. (2018). Other modifications are 1) removing the memory queue, which is able to reduce the requirement of a substantial batch size, and 2) adopting the symmetrized loss. Suppose the first encoder outputs and the second encoder outputs , the symmetrized loss is computed by:
| (10) |
DINO
Caron et al. (2021) is also trained with InfoNCE but with different methods. The inputs are cropped into global and local views, where the global views have higher resolution. The teacher model can only see the global views while the student model can utilize all the views. During the updating stage, the student model is updated by an optimizer, while the teacher model updates the parameters using EMA with the student model. To avoid collapsing, DINO adds centers, which can be viewed as a bias term, to each teacher output for helping the model generate the uniform distribution. The centers are updated smoothly by the average of the teacher outputs.
MoBY
Xie et al. (2021b) incorporates the training strategies from MoCoV2 Chen et al. (2020) and BYOL Grill et al. (2020). Instead of using vanilla ViT as the backbone, MoBY replaces it with Swin-Transformer Liu et al. (2021). Additionally, the updating strategy is similar to DINO. On top of that, to avoid a large batch size, MoBY follows MoCoV2 to create memory queue for reusing the past features.
EsViT
Li et al. (2022) uses a hierarchical transformer for reducing the computational cost. Instead of using positional embeddings, EsViT uses the Relative Position Bias to avoid the positional information being affected by the different cropping resolutions. Furthermore, EsViT uses the same updating method adopted by DINO and MoBY. On top of that, EsViT adds extra regional-level tasks to attach the inter-region relationships.
BEiT
Bao et al. (2022) is designed based on BERT. The images are separated into patches, which are tokenized into different discrete values by training a discrete VAE Ramesh et al. (2021). Afterward, the vision transformer are made to predict the tokens of the masked patches. The ground truth of the tokens are generated with the non-mask patches by a discrete VAE trained in the first stage.
MAE
He et al. (2021) is created based on method adopted by autoencoder to train a vision transformer. Distinctly, the input image is first masked by up to . These masking strategies applied on images include random, block-wise, and grid. Then, the masked images are encoded into features by a ViT and the decoder decodes the features by another ViT into the original non-mask images. Astonishingly, this strategy ends up with an unprecedentedly high accuracy and the masked images can be well reconstructed.
6 Challenges and Discussions
Although existing works have made a considerable success, there are still lots of challenges left to be resolved. In the following, several open challenges and future directions of vision transformers are discussed.
Universal pre-trained weights.
Vision transformers are inspired by the self-attention in Transformer, which is originally used for solving NLP problems. However, the adaption from text to vision is not completely explored. One promising direction is to find out the universal pre-trained weights that are suitable for different kinds of inputs, e.g., texts, images or audio. Currently, Li et al. (2021a) discuss the relationship between texts and visions. More explorations on general conditions enable us to unveil the mask of the underlying principles of transformers.
Fixed input size.
Although self-attention accepts varied sequence lengths, positional embeddings require the fixed length for each input. One approach to deal with this issue is by interpolation, which help expand or compress the embeddings with a given size. Nevertheless, this would cause the information loss when the input size is extremely different from the training size. Currently, the only feasible approach is to directly extract the features from convolutional layers without adding positional embeddings. However, using only the convolutional layers lacks the global positional information.
Robustness.
It is important to test the robustness of a model when the input image are altered or corrupted by some uncontrolled reasons. These alternations include brightness, background, blur, noise, digital artifacts, or even adversarial attack. Despite that RVT examines the robustness of different components, it only focuses on the vision transformer architecture. Other aspects such as data augmentation or learning objective are not explored yet. The former includes what kinds of combination of data augmentation can resist the noise inputs and the latter are associated with the learning criterion that enables the model to filter out the noise attack.
Lightweight model for mobile devices.
Since deep learning has gradually become popular in these years, more and more manufacturers transplant the deep learning models into mobile devices. However, due to the limitations of the size and the cost, the computing resources within a mobile device are not suitable for running a vision transformer. Therefore, reducing the model size is also an important topic for extended usage on mobile devices. Currently, there are only few publications Mehta and Rastegari (2022) focus on solving the related issue.
Feature Collapsing.
The ability to extract the features highly influence the model performance. As described in Sec. 3.2, the original vision transformer is subjected to feature collapsing and cannot generate various representations, which is a serious issue when training a deep vision transformer. Current methods often add additional modules (T2T-ViT) or learnable parameters (DeepViT) to solve the problem, which can cause overhead in inference time. Investigation on other methods such as altering the architectures or training strategies, adding additional criterion and adopting different data augmentations are also promising directions for preventing the vision transformers from collapsing.
7 Conclusion
We present several vision transformer models and highlight the innovative components. Specifically, variant architectures are introduced to deal with weaknesses such as data-hungry, low efficiency, and weak robustness. These ideas include transferring the inductive bias from CNN, adding locality, strong data augmentation, cross-window information exchange, and reducing the computational cost. We also review the training tricks, as well as self-supervised learning, which trains datasets without requiring any labels but can even reach a higher accuracy than that of the supervised methods. At the end of our paper, we discuss some open challenges for the future research.
References
- Ali et al. [2021] Alaaeldin Ali, Hugo Touvron, Mathilde Caron, Piotr Bojanowski, Matthijs Douze, Armand Joulin, Ivan Laptev, Natalia Neverova, Gabriel Synnaeve, Jakob Verbeek, et al. Xcit: Cross-covariance image transformers. NIPS, 2021.
- Arnab et al. [2021] Anurag Arnab, Mostafa Dehghani, Georg Heigold, Chen Sun, Mario Lučić, and Cordelia Schmid. Vivit: A video vision transformer. In ICCV, 2021.
- Atito et al. [2021] Sara Atito, Muhammad Awais, and Josef Kittler. Sit: Self-supervised vision transformer. arXiv preprint arXiv:2104.03602, 2021.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Bao et al. [2022] Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. BEit: BERT pre-training of image transformers. In ICLR, 2022.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. NIPS, 33, 2020.
- Carion et al. [2020] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. In ECCV, 2020.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
- Chen et al. [2020] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020.
- Chen et al. [2021a] Chun-Fu Richard Chen, Quanfu Fan, and Rameswar Panda. Crossvit: Cross-attention multi-scale vision transformer for image classification. In ICCV, 2021.
- Chen et al. [2021b] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In ICCV, 2021.
- Choromanski et al. [2021] Krzysztof Marcin Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, et al. Rethinking attention with performers. In ICLR, 2021.
- Chu et al. [2021] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, and Chunhua Shen. Twins: Revisiting the design of spatial attention in vision transformers. NIPS, 2021.
- Cordonnier et al. [2020] Jean-Baptiste Cordonnier, Andreas Loukas, and Martin Jaggi. On the relationship between self-attention and convolutional layers. In ICLR, 2020.
- Cubuk et al. [2019] Ekin D. Cubuk, Barret Zoph, Dandelion Mane, Vijay Vasudevan, and Quoc V. Le. Autoaugment: Learning augmentation strategies from data. In CVPR, 2019.
- Cubuk et al. [2020] Ekin D Cubuk, Barret Zoph, Jonathon Shlens, and Quoc V Le. Randaugment: Practical automated data augmentation with a reduced search space. In CVPR, 2020.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, et al. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- d’Ascoli et al. [2021] Stéphane d’Ascoli, Hugo Touvron, Matthew L Leavitt, Ari S Morcos, Giulio Biroli, and Levent Sagun. Convit: Improving vision transformers with soft convolutional inductive biases. In ICML, 2021.
- Fang et al. [2021] Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, and Wenyu Liu. You only look at one sequence: Rethinking transformer in vision through object detection. In NIPS, 2021.
- Graham et al. [2021] Benjamin Graham, Alaaeldin El-Nouby, Hugo Touvron, Pierre Stock, Armand Joulin, Hervé Jégou, and Matthijs Douze. Levit: a vision transformer in convnet’s clothing for faster inference. In ICCV, 2021.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, et al. Bootstrap your own latent-a new approach to self-supervised learning. NIPS, 2020.
- Hassani et al. [2021] Ali Hassani, Steven Walton, Nikhil Shah, Abulikemu Abuduweili, Jiachen Li, and Humphrey Shi. Escaping the big data paradigm with compact transformers. arXiv preprint arXiv:2104.05704, 2021.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- He et al. [2021] Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. arXiv preprint arXiv:2111.06377, 2021.
- Heo et al. [2021] Byeongho Heo, Sangdoo Yun, Dongyoon Han, Sanghyuk Chun, Junsuk Choe, and Seong Joon Oh. Rethinking spatial dimensions of vision transformers. In ICCV, 2021.
- Hinton et al. [2015] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- Huang et al. [2016] Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In ECCV, 2016.
- Li et al. [2021a] Qing Li, Boqing Gong, Yin Cui, Dan Kondratyuk, Xianzhi Du, Ming-Hsuan Yang, and Matthew Brown. Towards a unified foundation model: Jointly pre-training transformers on unpaired images and text. arXiv preprint arXiv:2112.07074, 2021.
- Li et al. [2021b] Shaohua Li, Xiuchao Sui, Xiangde Luo, Xinxing Xu, Yong Liu, and Rick Goh. Medical image segmentation using squeeze-and-expansion transformers. In IJCAI, 2021.
- Li et al. [2021c] Yawei Li, Kai Zhang, Jiezhang Cao, Radu Timofte, and Luc Van Gool. Localvit: Bringing locality to vision transformers. arXiv preprint arXiv:2104.05707, 2021.
- Li et al. [2022] Chunyuan Li, Jianwei Yang, Pengchuan Zhang, Mei Gao, Bin Xiao, Xiyang Dai, Lu Yuan, and Jianfeng Gao. Efficient self-supervised vision transformers for representation learning. In ICLR, 2022.
- Liu et al. [2021] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV, 2021.
- Mao et al. [2021] Xiaofeng Mao, Gege Qi, Yuefeng Chen, Xiaodan Li, Ranjie Duan, Shaokai Ye, Yuan He, and Hui Xue. Towards robust vision transformer. arXiv preprint arXiv:2105.07926, 2021.
- Mehta and Rastegari [2022] Sachin Mehta and Mohammad Rastegari. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. In ICLR, 2022.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Peyrard et al. [2021] Maxime Peyrard, Beatriz Borges, Kristina Gligorić, and Robert West. Laughing heads: Can transformers detect what makes a sentence funny? In IJCAI, 2021.
- Radford et al. [2018] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. Improving language understanding by generative pre-training. 2018.
- Ramesh et al. [2021] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation. In ICML, 2021.
- Russakovsky et al. [2015] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, et al. Imagenet large scale visual recognition challenge. International Journal of Computer Vision (IJCV), 2015.
- Sun et al. [2017] Chen Sun, Abhinav Shrivastava, Saurabh Singh, and Abhinav Gupta. Revisiting unreasonable effectiveness of data in deep learning era. In ICCV, 2017.
- Touvron et al. [2019] Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Hervé Jégou. Fixing the train-test resolution discrepancy. NIPS, 2019.
- Touvron et al. [2021a] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In ICML, 2021.
- Touvron et al. [2021b] Hugo Touvron, Matthieu Cord, Alexandre Sablayrolles, Gabriel Synnaeve, and Hervé Jégou. Going deeper with image transformers. In ICCV, 2021.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NIPS, 2017.
- Wang et al. [2021] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In ICCV, 2021.
- Xie et al. [2021a] Enze Xie, Wenjia Wang, Wenhai Wang, Peize Sun, Hang Xu, Ding Liang, and Ping Luo. Segmenting transparent objects in the wild with transformer. In IJCAI, 2021.
- Xie et al. [2021b] Zhenda Xie, Yutong Lin, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao, and Han Hu. Self-supervised learning with swin transformers. arXiv preprint arXiv:2105.04553, 2021.
- Xiong et al. [2020] Ruibin Xiong, Yunchang Yang, Di He, Kai Zheng, Shuxin Zheng, Chen Xing, Huishuai Zhang, Yanyan Lan, Liwei Wang, and Tieyan Liu. On layer normalization in the transformer architecture. In ICML, 2020.
- Yuan et al. [2021a] Kun Yuan, Shaopeng Guo, Ziwei Liu, Aojun Zhou, Fengwei Yu, and Wei Wu. Incorporating convolution designs into visual transformers. In ICCV, 2021.
- Yuan et al. [2021b] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zi-Hang Jiang, Francis EH Tay, Jiashi Feng, and Shuicheng Yan. Tokens-to-token vit: Training vision transformers from scratch on imagenet. In ICCV, 2021.
- Zhang et al. [2021] Zizhao Zhang, Han Zhang, Long Zhao, Ting Chen, and Tomas Pfister. Aggregating nested transformers. arXiv preprint arXiv:2105.12723, 2021.
- Zhou et al. [2021] Daquan Zhou, Bingyi Kang, Xiaojie Jin, Linjie Yang, Xiaochen Lian, Zihang Jiang, Qibin Hou, and Jiashi Feng. Deepvit: Towards deeper vision transformer. arXiv preprint arXiv:2103.11886, 2021.
- Zhu et al. [2021] Yiran Zhu, Xing Xu, Fumin Shen, Yanli Ji, Lianli Gao, and Heng Tao Shen. Posegtac: Graph transformer encoder-decoder with atrous convolution for 3d human pose estimation. In IJCAI, 2021.