Visual and Textual Prior Guided Mask Assemble for Few-Shot Segmentation and Beyond
Abstract
Few-shot segmentation (FSS) aims to segment the novel classes with a few annotated images. Due to CLIP’s advantages of aligning visual and textual information, the integration of CLIP can enhance the generalization ability of FSS model. However, even with the CLIP model, the existing CLIP-based FSS methods are still subject to the biased prediction towards base classes, which is caused by the class-specific feature level interactions. To solve this issue, we propose a visual and textual Prior Guided Mask Assemble Network (PGMA-Net). It employs a class-agnostic mask assembly process to alleviate the bias, and formulates diverse tasks into a unified manner by assembling the prior through affinity. Specifically, the class-relevant textual and visual features are first transformed to class-agnostic prior in the form of probability map. Then, a Prior-Guided Mask Assemble Module (PGMAM) including multiple General Assemble Units (GAUs) is introduced. It considers diverse and plug-and-play interactions, such as visual-textual, inter- and intra-image, training-free, and high-order ones. Lastly, to ensure the class-agnostic ability, a Hierarchical Decoder with Channel-Drop Mechanism (HDCDM) is proposed to flexibly exploit the assembled masks and low-level features, without relying on any class-specific information. It achieves new state-of-the-art results in the FSS task, with mIoU of on and on in 1-shot scenario. Beyond this, we show that without extra re-training, the proposed PGMA-Net can solve bbox-level and cross-domain FSS, co-segmentation, zero-shot segmentation (ZSS) tasks, leading an any-shot segmentation framework.
Index Terms:
Few-shot segmentation, zero-shot, any-shot, class-agnostic, CLIPI Introduction
The remarkable success has been made in the area of semantic segmentation by deep learning based methods [1, 2, 3, 4, 5]. However, this progress heavily relies on the availability of large annotated datasets [6, 7, 8], requiring a time-consuming and laborious process of annotation. Additionally, these methods fail to handle the extremely low-data scenario on the novel classes in practice. Conversely, humans are capable of identifying and segmenting novel concepts with a few visual stimulation. Motivated by this, researchers have proposed the few-shot segmentation (FSS) task, aiming to build a class-agnostic model from the base classes, and segment object of any novel classes.
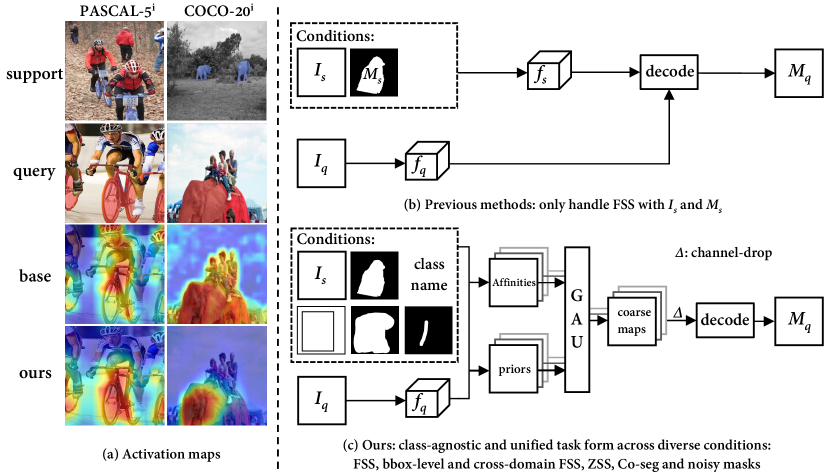
However, even equipped with the powerful meta-learning and metric-learning schemes, existing FSS models [9, 10, 11, 12, 13, 14, 15, 16] still suffer from the inaccurate localization of the target object, along with an over-fitting to base class as shown in Figure 1 (a). We contend that this is originating from two reasons: 1) They rely solely on a few visual annotations, with limitation on handling the vast variations of appearance, geometric and context among objects. 2) They mainly focus on learning a mapping from class-specific features to masks, which makes the mapping biased to the semantically rich features of the base class, leading to ineffectual inference on novel class. Moreover, as shown in Figure 1 (b, c), existing FSS models fail to handle extra forms of guided segmentation tasks via one suite of model weights, such as bounding-box guided FSS, cross-domain FSS, co-segmentation and text-guided zero-shot segmentation tasks.
This paper devotes to design a purely class-agnostic model to alleviate the training bias when incorporating the semantically rich textual information, and further capable of executing the above tasks in a unified task form. To achieve these goals, we integrate these tasks into a unified formulation that assembles the prior via affinity. On one hand, this formulation takes only the class-agnostic prior and affinity as direct inputs, both of which are class-agnostic. Therefore, it can alleviate training bias compared to the previous class-specific feature-level mapping. On the other hand, different tasks have different priors and affinities. For example, the ZSS task involves intra-image affinity and textual prior, while the FSS task includes inter-image affinity and visual prior. Despite these variations, the interaction mechanism remains the same. This uniformity in such formulation allows us to perform diverse tasks using same set of model weights.
Following the proposed scheme, we propose our PGMA-Net, it includes three main modules: 1) a Prior Adapter that converts class-relevant visual-textual features of CLIP [17] into class-agnostic priors in the form of probability map. Additionally, an Affinity Extractor is also proposed to capture the class-independent pixel-to-pixel correspondence via inter- and intra-image, training-free, and high-order correlations. 2) a Prior-Guided Mask Assemble Module (PGMAM) including multiple General Assemble Units (GAUs) is introduced. It assembles diverse priors by corresponding affinities in a unififed manner. 3) To convert the assembled priors into the final prediction mask in class-agnostic manner, we propose a Hierarchical Decoder with Channel-Drop Mechanism (HDCDM). It not only essentially ensures the generalization ability by taking in only the assembled priors and low-level features, but also allows our model to perform extra segmentation tasks. Overall, our contributions are as follows:
-
1.
We present a new architecture called the Prior Guided Mask Assemble Network (PGMA-Net) for the few-shot segmentation task. This network incorporates textual information by utilizing a class-agnostic prior-to-mask assembly process, which helps to alleviate the training bias towards the base class observed in previous methods.
-
2.
We introduce Prior-Guided Mask Assemble Module (PGMAM), which formulates diverse tasks in a unified manner by assembling the prior through affinity. It considers diverse plug-and-play interactions between priors (including visual and textual, support and query ones) and affinities (such as inter- and intra-image, training-free, and high-order ones).
-
3.
We employ Hierarchical Decoder with Channel-Drop Mechanism (HDCDM), allowing for handling diverse tasks using one suit of mode weights.
-
4.
We achieve new state-of-the-art results in the FSS task, with mIoU of on and on . Moreover, without re-training, the trained PGMA-Net shows promising performance across various tasks, including ZSS, box-level and cross-domain FSS, co-segmentation, FSS with inaccurate support annotations. This unified framework constitutes an any-shot segmentation model.
II Related Work
II-A Few-shot Learning
Few-shot learning (FSL) intends to construct a classification model for new task with a few labeled examples. Meta-learning is the predominant paradigm for FSL, and it is further categorized into metric-based, optimization-based, and model-based methods. Metric-based methods employ either an embedding network [18, 19, 20] or a learnable distance [21]. Optimization-based methods aim to learn a well-performed model initialization, followed by quick adaptation [22, 23]. Model-based methods are designed to create a model structure [24, 25] that is specifically tailored to meta-learning. Transfer learning is another way in FSL [26, 27], where knowledge is transferred from either the base class [28], or pre-trained models like DINO [29] and CLIP [17].
II-B Few-shot Segmentation
Few-shot segmentation aims to segment the novel classes with just a few annotated images. Episodic training strategy [18] has been employed by previous approaches to learn a class-agnostic model, which can be subdivided into prototype-based and matching-based methods. The prototype-based methods compressed the support features into class-specific prototypes, and then perform segmentation via fixed cosine distance or a learnable metric. Diverse prototypes can be formed, e.g., a single global foreground prototype obtained through masked average pooling [19, 30, 31], multiple foreground prototypes obtained through clustering [32] and EM [33], learnable meta-memory prototypes [34], and prototypes of base classes [35]. However, compressing available support information into prototypes unavoidably leads to significant spatial information loss. Thus, the matching-based methods are proposed to explore pixel-to-pixel dense connections between support and query images, which can be achieved through graph attention mechanisms [9], center-pivot 4D convolutions [13], and cycle-consistent transformer [36]. The proposed PGMA-Net also belongs to matching-based method, but with a more class-agnostic prior-to-mask mapping.
II-C CLIP in FSS task
Due to the exceptional efficacy in integrating visual and textual features in the CLIP [17] embedding space, there have been attempts to utilize the CLIP prior for few-shot classification tasks [27, 26]. However, CLIP’s image-level training leads a discrepancy with dense tasks, rendering it a rising issue to extend in pixel-level tasks [37, 38]. The complexity of this problem is even heightened when taking into account the interactions between the support and query in the FSS task.
An attempt to incorporate CLIP prior in FSS is CLIPSeg [39], involving a simple interaction among support feature, query feature, and textual feature via mix-up operation and FiLM layer [40]. But the generalization is hindered due to the use of such feature-level interaction. Similarly, when applying CLIP prior to FSS task without support mask in IMR-HSNet [41], the improper usage of feature-level interaction also leads to limited performance. Compared to these methods, our work aims to better utilize CLIP in FSS task in a more class-agnostic manner, while still having enough flexibility to allow a single set of parameters to perform additional tasks, e.g., zero-shot segmentation, co-segmentation, box-level segmentation, cross-domain FSS, etc.
III Methodology
III-A Problem Setup
Few-shot segmentation devotes to segment novel classes with only a limited number of labeled images. To achieve this, the model is trained on the base categories of base dataset , and must possess the ability to provide reliable inference on the novel categories of novel dataset . Noted that the set of base categories and novel categories are mutually exclusive, i.e., .
Following previous works [11, 13, 42], the episodic sampling process is employed in both training and testing stages. Each episode task consists of a support set and a query set , e.g., . The most widely used formulation of an episodic task is the -way -shot manner. This entails sampling classes from the corresponding dataset, with only labeled images available per class (typically 1 or 5). The few available labeled data are called support set and the data waiting for segmenting are called query set , where ,, and represent the support image, query image, ground-truth mask of support and query respectively.
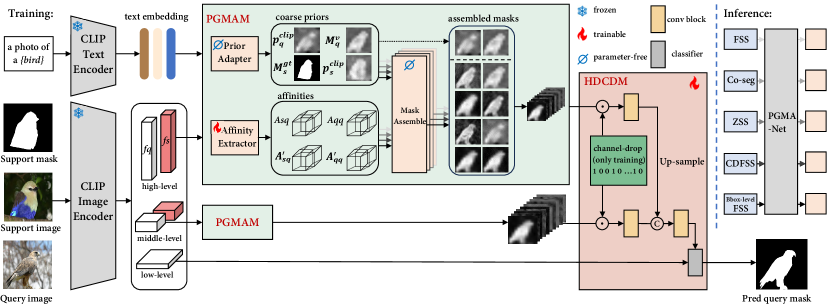
III-B Prior Guided Mask Assemble Network
III-B1 Overview
As shown in Figure 2, the core of PGMA-Net is a class-agnostic and unified process: assembling the prior by affinity, where the prior in the form of probability map is extracted via Prior Adapter (Section III-B2), and the affinity is obtained by Affinity Extractor ((Section III-B3)). Then the assembly is executed between coarse priors (from support or query) and affinities (inter- and intra-image, training-free, and high-order) in a unified form, detailed in Section III-B4, and decode into the prediction mask via HDCDM (Section III-B5). Due to the unified way of assembling the coarse prior by affinity, as well as the introduction of channel-drop mechanism, the PGMA-Net trained for FSS is capable of addressing additional tasks with one suit of model weights during inference.
III-B2 Prior Adapter
Textual Prior Adapter. A straightforward way [39] to utilize CLIP [17] entails extracting semantically enriched visual features for downstream decoder. However, it is contradictory to our suggested underlying class-agnostic principle. Thus, we opt to first transform them into class-agnostic textual priors without requiring any additional training, and extend CLIP’s ability in integration visual and textual features from image-level to spatial positioning. Specifically, prompt engineering is utilized to obtain the text embedding for each category, where is the dimension of the embedding space. Meanwhile, the visual feature is obtained by feeding the value of patch embedding to the last projection layer of the CLIP model, without the usage of pooling layer. The cosine similarity is calculated between and , followed by a min-max normalization to highlight the area of interest. The class-agnostic textual prior in terms of probability map is obtained as:
| (1) |
| (2) |
where is set to 1-8 to avoid division by zero. For brevity, we adopt to denote the normalized visual-textual prior . The resultant CLIP prior is generated for both support and query images with up-sampling to image size, termed as and , respectively.
Visual Prior Adapter. The basic visual prior that needs to undergo assembly is the support-guided visual prior . To obtain , the maximum value of each query axis from the cross-affinity is selected, i.e., , followed with a min-max normalization operation to highlight the intended area, where is detailed in Equation 4. Besides, the annotation of support image can also serve as prior for aggregation. Concretely, we can leverage down-sampled ground-truth mask of support and clip prior of support as prior.
Taken together, these four priors () form the basic components for further assembly.
III-B3 Affinity Extractor
The cross-affinity between support and query images is the first criterion for assembling. For layer of the pre-trained backbone, support feature , query feature and the down-sampled support mask are obtained. For brevity, the layer index is omitted. Then a transform is first applied as:
| (3) |
where indicates the reshape operation: , and denotes Hadamard product to discard the irrelevant features. Then the cross-affinity is calculated as:
| (4) |
where indicates feature transpose. Previous methods [13, 42] rely solely on this cross-affinity for segmentation, we contend that it’s insufficient as this criterion ignores the self-affinity of both support and query images, which represent intrinsic structural information that is indispensable to understand an image. So the self-affinity of support and that of query are formulated identically as:
| (5) |
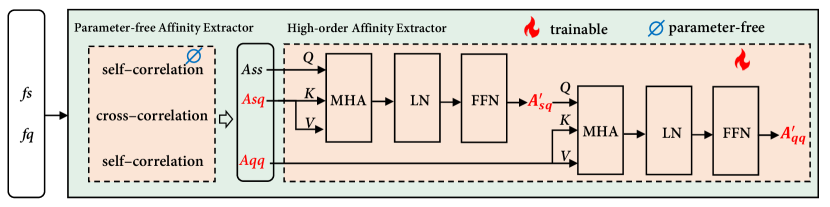
The above three affinities are generated by parameter-free process, implying a simple yet effective set of criteria. However, this also limits their capacity for accommodating large variations among text, support and query [43]. Therefore, we propose a high-order affinity extractor to enlarge its capacity, implemented by multi-head cross-attention mechanism [44]. The high-order version of cross-affinity is calculated as:
| (6) |
where the affinity is considered as QUERY111The QUERY in attention mechanism, is different from the query image in few-shot segmentation task, we use uppercase italics ”QUERY” and regular text ”query” to distinguish them. sequence with the length of , and in dim of . And the affinity is considered as the KEY and VALUE sequence with the length of , and in dim of . The , and denote the feed-forward network, layer normalization and multi-head attention respectively. Similarly, the high-order version of self-affinity is calculated by considering as QUERY, as KEY and VALUE:
| (7) |
The high-order affinity extractor differs from [43] in training-free input affinity, extra outputs (high-order self-affinity) and subsequent class-agnostic usage. In total, four affinities are obtained: .
III-B4 Prior-Guided Mask Assemble Module
Once priors are obtained, a straightforward way to explore such priors is to multiply them with image features at pixel-level via Hadamard product, yielding refined semantically rich features corresponding to its category by pooling operation. However, such a naive operation does not adhere to our suggested class-agnostic principle, and fails to fully exploit the possible interactions (visual-textual, intra- or inter-image), along with issue of information loss due to the pooling operation. Thus, we propose a new unified Prior-Guided Mask Assemble Module (PGMAM), achieving the class-agnostic prior-to-mask mapping by assembling diverse priors according to corresponding affinities at pixel-level.
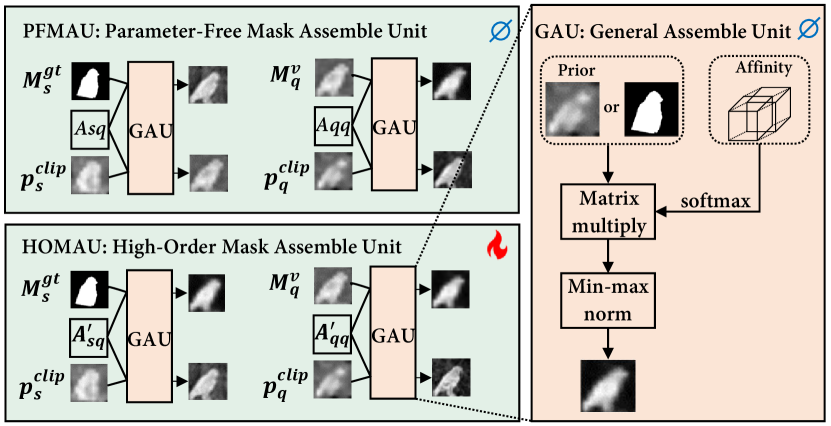
As shown in Figure 4, the GAU follows the pipeline of highlighting the affinity along a particular axis, and then integrating through matrix multiplication and min-max normalization:
| (8) |
This module is unified regardless of whether the input affinity is parameter-free ( and ) or high-order ( and ), or whether the prior is from support () or query (). We refer the GAU as parameter-free mask assemble unit (PFMAU) when the affinity is parameter-free, and high-order mask assemble unit (HOMAU) when the affinity is high-order.
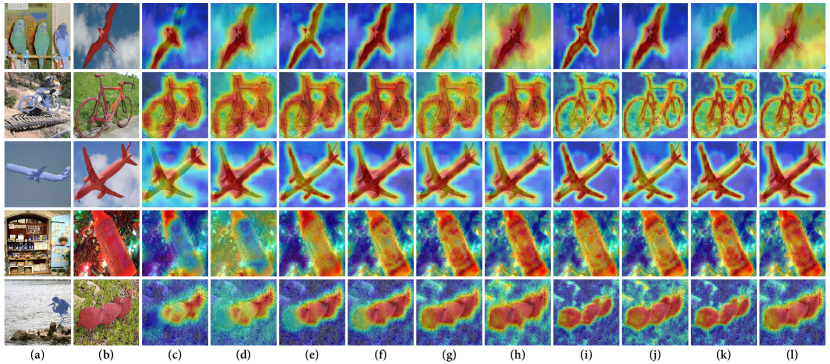
Figure 5 presents visual representations of pre- and post-assemble states of the clip prior (column c) and support-guided visual prior (column d) using GAU. The proposed GAU has the potential to assemble the coarse priors into a refined prior by utilizing the 8 types of diverse interactions. The 8 assembled priors are: the parameter-free self-affinity guided prior and , the high-order self-affinity guided prior and , the parameter-free cross-affinity guided prior and , and the high-order cross-affinity guided prior and . These total 10 priors, each containing distinct information, are concatenated and subsequently fed into a hierarchical decoder for decoding into final segmentation results:
| (9) |
III-B5 Hierarchical decoder with channel-drop mechanism
By employing the proposed PGMAM on multiscale features from various layers of a pre-trained backbone, several sets of assembled masks are generated, with high-level and low-level containing semantic and fine-grained information, respectively. To maximize inter-scale information utilization, a hierarchical decoder (HDCDM) is designed to decode these assembled masks from varying scales into segmentation outputs. Specifically, as shown in Figure 2, this process involves initial feature transformation of the assembled masks at each scale using a convolution block, and if necessary, up-sampling before concatenation with higher-resolution features.
Considering that each group of constitutes assembled masks from different prior information sources with varying learning difficulties, to avoid the network overfitting to some simple priors and maximize the utilization of all assembly masks, we propose a channel-drop mechanism during training:
| (10) |
where the channel-drop probability is a random vector of and , with the same length as channel number in . Such channel-drop mechanism seamlessly incorporates various scenarios such as fully-supervised FSS, FSS without support mask, and zero-shot segmentation tasks into a unified framework.
The training loss was a weighted sum of cross-entropy loss and dice loss :
| (11) |
| (12) |
| (13) |
where the weight is set to 0.5, is the ground-truth label, is the predicted label.
| Pretrain | Backbone | Method | Publication | 1-shot | 5-shot | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | FB-IoU | mIoU | FB-IoU | ||||||||||||
| IN1K | RN50 | PPNet [10] | ECCV’20 | 48.6 | 60.6 | 55.7 | 46.5 | 52.8 | 69.2 | 58.9 | 68.3 | 66.8 | 58.0 | 63.0 | 75.8 |
| PFENet [11] | TPAMI’20 | 61.7 | 69.5 | 55.4 | 56.3 | 60.8 | 73.3 | 63.1 | 70.7 | 55.8 | 57.9 | 61.9 | 73.9 | ||
| RePRI [12] | CVPR’21 | 59.8 | 68.3 | 62.1 | 48.5 | 59.7 | - | 64.6 | 71.4 | 71.1 | 59.3 | 66.6 | - | ||
| HSNet [13] | ICCV’21 | 64.3 | 70.7 | 60.3 | 60.5 | 64.0 | 76.7 | 70.3 | 73.2 | 67.4 | 67.1 | 69.5 | 80.6 | ||
| SSP [14] | ECCV’22 | 60.5 | 67.8 | 66.4 | 51.0 | 61.4 | - | 67.5 | 72.3 | 75.2 | 62.1 | 69.3 | - | ||
| DCAMA [42] | ECCV’22 | 67.5 | 72.3 | 59.6 | 59.0 | 64.6 | 75.7 | 70.5 | 73.9 | 63.7 | 65.8 | 68.5 | 79.5 | ||
| CATrans [43] | IJCAI’22 | 67.6 | 73.2 | 61.3 | 63.2 | 66.3 | - | 75.1 | 78.5 | 75.1 | 72.5 | 75.3 | - | ||
| DPCN [46] | CVPR’22 | 65.7 | 71.6 | 69.1 | 60.6 | 66.7 | 78.0 | 70.0 | 73.2 | 70.9 | 65.5 | 69.9 | 80.7 | ||
| RPMG-FSS [47] | TCSVT’23 | 64.4 | 72.6 | 57.9 | 58.4 | 63.3 | - | 65.3 | 72.8 | 58.4 | 59.8 | 64.1 | - | ||
| HPA[35] | TPAMI’23 | 65.9 | 72.0 | 64.7 | 56.8 | 64.8 | 76.4 | 70.5 | 73.3 | 68.4 | 63.4 | 68.9 | 81.1 | ||
| FECANet [15] | TMM’23 | 69.2 | 72.3 | 62.4 | 65.7 | 67.4 | 78.7 | 72.9 | 74.0 | 65.2 | 67.8 | 70.0 | 80.7 | ||
| ABCNet [48] | CVPR’23 | 68.8 | 73.4 | 62.3 | 59.5 | 66.0 | 76.0 | 71.7 | 74.2 | 65.4 | 67.0 | 69.6 | 80.0 | ||
| RN101 | PPNet [10] | ECCV’20 | 52.7 | 62.8 | 57.4 | 47.7 | 55.2 | 70.9 | 60.3 | 70.0 | 69.4 | 60.7 | 65.1 | 77.5 | |
| DAN [49] | ECCV’20 | 54.7 | 68.6 | 57.8 | 51.6 | 58.2 | 71.9 | 57.9 | 69.0 | 60.1 | 54.9 | 60.5 | 72.3 | ||
| PFENet [11] | TPAMI’20 | 60.5 | 69.4 | 54.4 | 55.9 | 60.1 | 72.9 | 62.8 | 70.4 | 54.9 | 57.6 | 61.4 | 73.5 | ||
| RePRI [12] | CVPR’21 | 59.6 | 68.6 | 62.2 | 47.2 | 59.4 | - | 66.2 | 71.4 | 67.0 | 57.7 | 65.6 | - | ||
| HSNet [13] | ICCV’21 | 67.3 | 72.3 | 62.0 | 63.1 | 66.2 | 77.6 | 71.8 | 74.4 | 67.0 | 68.3 | 70.4 | 80.6 | ||
| SSP [14] | ECCV’22 | 63.7 | 70.1 | 66.7 | 55.4 | 64.0 | - | 70.3 | 76.3 | 77.8 | 65.5 | 72.5 | - | ||
| DCAMA [42] | ECCV’22 | 65.4 | 71.4 | 63.2 | 58.3 | 64.6 | 77.6 | 70.7 | 73.7 | 66.8 | 61.9 | 68.3 | 80.8 | ||
| RPMG-FSS [47] | TCSVT’23 | 63.0 | 73.3 | 56.8 | 57.2 | 62.6 | - | 67.1 | 73.3 | 59.8 | 62.7 | 65.7 | - | ||
| HPA [35] | TPAMI’23 | 66.4 | 72.7 | 64.1 | 59.4 | 65.6 | 76.6 | 68.0 | 74.6 | 65.9 | 67.1 | 68.9 | 80.4 | ||
| ABCNet [48] | CVPR’23 | 65.3 | 72.9 | 65.0 | 59.3 | 65.6 | 78.5 | 71.4 | 75.0 | 68.2 | 63.1 | 69.4 | 80.8 | ||
| CLIP | CLIP-ViT-B/16 | CLIPSeg(PC+) [39] | CVPR’22 | - | - | - | - | 59.5 | - | - | - | - | - | - | - |
| CLIP-ViT-B/16 | CLIPSeg(PC) [39] | CVPR’22 | - | - | - | - | 52.3 | - | - | - | - | - | - | - | |
| CLIP-ViT-B/16 | PGMA-Net (ours) | - | 74.0 | 81.9 | 66.8 | 73.7 | 74.1 | 82.1 | 74.5 | 82.2 | 67.2 | 74.4 | 74.6 | 82.5 | |
| CLIP-RN50 | PGMA-Net (ours) | - | 73.4 | 80.8 | 70.5 | 71.7 | 74.1 | 83.5 | 74.0 | 81.5 | 71.9 | 73.3 | 75.2 | 84.2 | |
| CLIP-RN101 | PGMA-Net (ours) | - | 76.8 | 82.3 | 75.7 | 75.7 | 77.6 | 86.2 | 77.7 | 82.7 | 76.9 | 77.0 | 78.6 | 86.9 | |
IV Experiments
IV-A Datasets Setup and Evaluation Metrics
Following the setup of [11, 13], we evaluated PGMA-Net on two benchmarks: [45] and [50]. is created by combining the PASCAL VOC 2012 [7] and SBD datasets [51], consisting of 20 classes evenly distributed in 4 folds with 5 classes per fold. is a larger and more challenging benchmark created from the COCO [6], consisting of 80 classes evenly divided into 4 folds. For all experiments, we selected a pre-defined set of three folds for training, while reserving the remaining fold exclusively for evaluation purposes.
The evaluation metrics used in the experiments were the mean intersection over union () and foreground-background IoU (). We assessed the performance of the model by conducting experiments for each fold and reporting the mean mIoU and FB-IoU across all folds.
IV-B Implemetation Details
All experiments were implemented via PyTorch framework on a single NVIDIA GeForce RTX 3090 GPU. The support and query images utilized an equivalent input resolution of pixels. The data augmentation techniques included random scales, rotations and flips. We utilized the CLIP-RN50, CLIP-RN101, CLIP-ViT-B/16, IN1K-RN50 as our backbone. As for the optimization and scheduling, we trained our model with episodic training scheme for 100 and 200 epochs on and datasets, respectively. AdamW served as our optimizer, with a learning rate of . We determined batch sizes of 6 and 4 for and datasets, respectively.
IV-C Comparison with State-of-the-Art Methods
FSS task. Experiments were conducted on [45] and [50] datasets. Table I presents the mIoU and FB-IoU results obtained on [45] using 1-shot and 5-shot settings. With CLIP-RN50 backbone, we achieved mIoU of 74.1. When using the same CLIP-ViT-B/16 backbone, PGMA-Net achieved mIoU of 74.1 in 1-shot scenario, outperforming CLIPSeg [39] by a large margin (14.6 mIoU increase). Our model is the first to mitigate the performance gap between previous CLIP-based and traditional FSS, and surpass both subfields by a large margin [our 74.1 v.s. CLIPSeg [39] 59.5 v.s. FECANet [15] 67.4].
Table II displays significant and consistent improvements on the dataset [50]. With CLIP-RN101 backbone, our PGMA-Net achieved mIoU values of 59.4 for 1-shot scenario. Our PGMA-Net outperforms previous CLIP-based CLIPSeg [39] (mIoU of 33.3) and IN-1K based FSS (HPA [35], mIoU of 45.8) by a large margin. The top row of visualizations presented in Figure 6 showcases several successful instances.

Cross-domain FSS task. To illustrate the effectiveness of the proposed PGMA-Net in handling cross-domain issues, we conducted experiments on the [50] to [45] task, following the experimental setup of CDFSS [52]. Table V indicates that, despite not being designed specifically for cross-domain problem, PGMA-Net achieved a mIoU increase of 6.8, compared to the current SOTA method CDFSS (72.4 v.s. 65.6). The robustness can be attributed that both the diverse priors and affinities exhibit diminished disparity across varied datasets.
Bounding-box level FSS task. Annotating a few support images at the pixel level is also time-consuming. One feasible solution is to use weaker annotations as segmentation clues, e.g., bounding-box. To accomplish this, we filled in the provided bounding-box to generate pseudo mask [30, 53], which can be directly tested by the previously trained model without requiring retraining. Table V and Figure 6 demonstrate the effectiveness of PGMA-Net, which shows a significant increase in absolute mIoU by 12.0 compared to DCAMA [42] (73.2 v.s. 61.2).
| Pretrain | Backbone | Method | Publication | 1-shot | 5-shot | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | FB-IoU | mIoU | FB-IoU | ||||||||||||
| IN1K | RN50 | PPNet [10] | ECCV’20 | 28.1 | 30.8 | 29.5 | 27.7 | 29.0 | - | 39.0 | 40.8 | 37.1 | 37.3 | 38.5 | - |
| PFENet [11] | TPAMI’20 | 36.5 | 38.6 | 34.5 | 33.8 | 35.8 | - | 36.5 | 43.3 | 37.8 | 38.4 | 39.0 | |||
| RePRI [12] | CVPR’21 | 32.0 | 38.7 | 32.7 | 33.1 | 34.1 | - | 39.3 | 45.4 | 39.7 | 41.8 | 41.6 | - | ||
| HSNet [13] | ICCV’21 | 36.3 | 43.1 | 38.7 | 38.7 | 39.2 | 68.2 | 43.3 | 51.3 | 48.2 | 45.0 | 46.9 | 70.7 | ||
| NTRENet [54] | CVPR’22 | 36.8 | 42.6 | 39.9 | 37.9 | 39.3 | 68.5 | 38.2 | 44.1 | 40.4 | 38.4 | 40.3 | 69.2 | ||
| SSP [14] | ECCV’22 | 35.5 | 39.6 | 37.9 | 36.7 | 37.4 | - | 40.6 | 47.0 | 45.1 | 43.9 | 44.1 | - | ||
| DCAMA [42] | ECCV’22 | 41.9 | 45.1 | 44.4 | 41.7 | 43.3 | 69.5 | 45.9 | 50.5 | 50.7 | 46.0 | 48.3 | 71.7 | ||
| DPCN [46] | CVPR’22 | 42.0 | 47.0 | 43.2 | 39.7 | 43.0 | 63.2 | 46.0 | 54.9 | 50.8 | 47.4 | 49.8 | 67.4 | ||
| RPMG-FSS [47] | TCSVT’23 | 38.3 | 41.4 | 39.6 | 35.9 | 38.8 | - | - | - | - | - | ||||
| HPA [35] | TPAMI’23 | 40.3 | 46.6 | 44.1 | 42.7 | 43.4 | 68.2 | 45.5 | 55.4 | 48.9 | 50.2 | 50.0 | 71.2 | ||
| FECANet [15] | TMM’23 | 38.5 | 44.6 | 42.6 | 40.7 | 41.6 | 69.6 | 44.6 | 51.5 | 48.4 | 45.8 | 47.6 | 71.1 | ||
| ABCNet [48] | CVPR’23 | 42.3 | 46.2 | 46.0 | 42.0 | 44.1 | 69.9 | 45.5 | 51.7 | 52.6 | 46.4 | 49.1 | 72.7 | ||
| RN101 | PFENet [11] | TPAMI’20 | 36.8 | 41.8 | 38.7 | 36.7 | 38.5 | 63.0 | 40.4 | 46.8 | 43.2 | 40.5 | 42.7 | 65.8 | |
| HSNet [13] | ICCV’21 | 37.2 | 44.1 | 42.4 | 41.3 | 41.2 | 69.1 | 45.9 | 53.0 | 51.8 | 47.1 | 49.5 | 72.4 | ||
| SSP [14] | ECCV’22 | 39.1 | 45.1 | 42.7 | 41.2 | 42.0 | - | 47.4 | 54.5 | 50.4 | 49.6 | 50.2 | - | ||
| DCAMA [42] | ECCV’22 | 41.5 | 46.2 | 45.2 | 41.3 | 43.5 | 69.9 | 48.0 | 58.0 | 54.3 | 47.1 | 51.9 | 73.3 | ||
| HPA[35] | TPAMI’23 | 43.1 | 50.0 | 44.8 | 45.2 | 45.8 | 68.4 | 49.2 | 57.8 | 52.0 | 50.6 | 52.4 | 74.0 | ||
| CLIP | CLIP-ViT-B/16 | CLIPSeg(COCO) [39] | CVPR’22 | - | - | - | - | 33.2 | - | - | - | - | - | - | - |
| CLIP-ViT-B/16 | CLIPSeg(COCO+N) [39] | CVPR’22 | - | - | - | - | 33.3 | - | - | - | - | - | - | - | |
| CLIP-RN50 | PGMA-Net (ours) | - | 49.9 | 56.7 | 55.8 | 54.7 | 54.3 | 75.8 | 49.5 | 61.7 | 59.1 | 57.9 | 57.1 | 76.7 | |
| CLIP-RN101 | PGMA-Net (ours) | - | 55.2 | 62.7 | 60.3 | 59.4 | 59.4 | 78.5 | 55.9 | 65.9 | 63.4 | 61.9 | 61.8 | 79.4 | |
| Method | Backbone | Using CLIP | Publication | mIoU | FB-IoU | ||||
|---|---|---|---|---|---|---|---|---|---|
| SPNet [55] | RN101 | no | CVPR’19 | 23.8 | 17.0 | 14.1 | 18.3 | 18.3 | 44.3 |
| ZS3Net [56] | RN101 | no | NeurIPS’19 | 40.8 | 39.4 | 39.3 | 33.6 | 38.3 | 57.7 |
| LSeg [37] | RN101 | yes | ICLR’22 | 52.8 | 53.8 | 44.4 | 38.5 | 47.4 | 64.1 |
| LSeg [37] | ViT-L/16 | yes | ICLR’22 | 61.3 | 63.6 | 43.1 | 41.0 | 52.3 | 67.0 |
| SAZS [38] | DRN | yes | CVPR’23 | 57.3 | 60.3 | 58.4 | 45.9 | 55.5 | 66.4 |
| SAZS [38] | ViT-L | yes | CVPR’23 | 62.7 | 64.3 | 60.6 | 50.2 | 59.4 | 69.0 |
| PGMA-Net (ours) w/o fine-tuning | RN50 | yes | - | ||||||
| PGMA-Net (ours) -retrain for ZSS | RN50 | yes | - | 68.2 | 78.8 | 68.8 | 66.5 | 70.6 | 80.0 |
Co-segmentation task. An even more challenging task is FSS without support mask [41, 57], where solely the support image serves as guidance clue. This setup exhibits similarity to co-segmentation [58, 59], but imposes a more significant challenge in terms of generalization for evaluation on novel categories. As evidenced by Table V and Figure 6, upon being equipped with the same CLIP-RN50 backbone, albeit not specifically designed or trained for this task, PGMA-Net had already surpassed IMR-HSNet [41] (intended for this task) by a notable margin. (67.3 v.s. 61.5)
Zero-Shot Segmentation Task. Besides, due to the integration of the channel-drop mechanism and textual prior, a singular set of parameters trained for FSS exhibits adequate capacity and flexibility to perform ZSS task. Table III and Figure 6 provide evidence that, even when directly applied to ZSS, our proposed PGMA-Net already outperformed the current SAZS [38] (60.1 v.s. 59.4). Moreover, our method’s superiority became unequivocal (70.6 v.s. 59.4) when it’s trained specifically for ZSS.
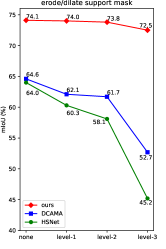
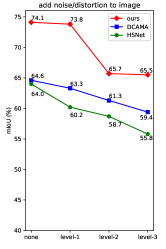
Robustness agsinst inaccurate support mask and image quality. To demonstrate the robustness of PGMA-Net against inaccurate support mask, random erosion and dilations were applied to the support ground-truth mask, three levels of corruption were implemented. As illustrated in Figure 7a, PGMA-Net surpassed the DCAMA [42] and HSNet [13] by a significant margin in the extremely inaccurate support mask scenario (mIoU of 72.5 compared to 52.7 and 45.2). Meanwhile, the robustness against image noise and distortion can also be confirmed in Figure 7b.
The comparisons on parameter complexity, multi-adds and speed are illustrated in Table IV. Our model strikes the best balance among complexity, performance and versatility.
| Task | Method | 1-shot | 5-shot | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | FB-IoU | mIoU | FB-IoU | ||||||||||
| cross-domain FSS task | HSNet [13] | 48.7 | 61.5 | 63.0 | 72.8 | 61.5 | - | 58.2 | 65.9 | 71.8 | 77.9 | 68.4 | - |
| CWT [61] | 53.5 | 59.2 | 60.2 | 64.9 | 59.4 | - | 60.3 | 65.8 | 67.1 | 72.8 | 66.5 | - | |
| CDFSS [52] | 57.4 | 62.2 | 68.0 | 74.8 | 65.6 | - | 65.7 | 69.2 | 70.8 | 75.0 | 70.1 | - | |
| PGMA-Net (ours) | 55.8 | 75.4 | 74.0 | 84.5 | 72.4 | 82.5 | 56.1 | 75.7 | 75.0 | 84.3 | 72.8 | 82.7 | |
| bbox-level FSS task | HSNet [13]† | 53.4 | 64.5 | 52.7 | 51.8 | 55.6 | 70.1 | 62.6 | 69.8 | 61.1 | 59.7 | 63.3 | 75.6 |
| DCAMA [42] † | 62.2 | 70.3 | 56.3 | 56.0 | 61.2 | 73.0 | 67.2 | 72.3 | 62.4 | 61.2 | 65.8 | 76.9 | |
| PGMA-Net (ours) | 72.4 | 80.8 | 68.9 | 70.7 | 73.2 | 82.5 | 73.1 | 81.5 | 69.8 | 72.1 | 74.1 | 83.1 | |
| co-segmentation (weakly-supervised FSS task) | (V+S)-1 [57] | 49.5 | 65.5 | 50.0 | 49.2 | 53.5 | 65.6 | - | - | - | - | - | - |
| (V+S)-2 [57] | 42.5 | 64.8 | 48.1 | 46.5 | 50.5 | 64.1 | 45.9 | 65.7 | 48.6 | 46.6 | 51.7 | - | |
| IMR-HSNet [41] | 62.6 | 69.1 | 56.1 | 56.7 | 61.1 | - | - | - | - | - | - | ||
| HSNet [13]-RN101 | 66.2 | 69.5 | 53.9 | 56.2 | 61.5 | 72.5 | 68.9 | 71.9 | 56.3 | 57.9 | 63.7 | 73.8 | |
| PGMA-Net (ours) | 68.6 | 76.3 | 60.3 | 64.1 | 67.3 | 77.8 | 68.9 | 76.6 | 60.5 | 64.1 | 67.5 | 78.0 | |
| No. | Description | 0/1-shot | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| mIoU | FB-IoU | |||||||||||||
| 1 | only | 66.1 | 76.8 | - | ||||||||||
| 2 | , w/ | 69.2 | 79.2 | 3.2 | ||||||||||
| 3 | , w/ | 69.0 | 79.4 | 2.9 | ||||||||||
| 4 | , w/ and | 70.6 | 80.0 | 4.5 | ||||||||||
| 5 | and only | 71.6 | 81.4 | 5.5 | ||||||||||
| 6 | and , w/ | 73.1 | 82.6 | 7.0 | ||||||||||
| 7 | and , w/ | 72.6 | 81.9 | 6.5 | ||||||||||
| 8 | and , w/ and | 74.1 | 83.5 | 8.0 | ||||||||||
| Method | mIoU |
|---|---|
| PGMA-Net | 74.1 |
| w/o channel-drop | 72.8 |
| w/o hierarchy | 71.1 |
| w/o DICE | 72.2 |
| w/o CE | 73.6 |
| w/o HOMAU | 73.1 |
IV-D Ablations
To examine the influence of key components in our model, we conducted comprehensive ablation analysis. We utilized the CLIP-RN50 backbone on dataset [45] in 1-shot scenario for all ablation experiments.
Ablation on the diverse interactions between priors and affinities. The PGMA-Net proposed within this study contains ten distinctive interactions, detailed in Table VI: 1) Lines 1-4 investigate the scenario in which solely the query image and text are available (ZSS task), with Line 1 acting as the baseline, achieving an mIoU of 66.1. The incorporation of different affinities, including a training-free affinity (Line 2: mIoU=69.2), high-order affinity (Line 3: mIoU=69.0), and the use of both affinities (Line 4: mIoU=70.6), leads to a noticeable and consistent improvement in overall performance. 2) Within the scope of the FSS task, Lines 5-8 simultaneously integrate both query and support images, yielding superior results as articulated by the mIoU gains of with diverse affinities. Moreover, it becomes clear that the inclusion of affinities and the corresponding support-derived information can serve to effectively enhance performance in a complementary manner.
Ablation on the channel-drop mechanism. The influence of the channel-drop mechanism was investigated through Table VIII, showing an mIoU increase from to with the help of channel-drop mechanism.
Ablation on the model hierarchy. The impact of the hierarchical structure was studied using two methods: 1) using the final layer of each stage of RN50, which produced features with a length of (). 2) using all layers within each stage, which generated features with a length of (). Ablation study revealed that utilizing all features within each stage significantly improved performance (71.1 v.s. 74.1), as shown in Table VIII.
Ablation on training loss function. The default loss function of our proposed method is a weighted sum of cross-entropy loss and dice loss. An ablation study was carried out to examine the sensitivity of the two loss functions. Table VIII displays the results, confirming that integrating cross-entropy loss and dice loss leads to a substantial performance enhancement ().
Ablation on switching backbone from CLIP to IN1K-pretrained. To investigate the robustness on switching backbone from CLIP to IN1K-pretrained, we removed the text branch and re-train our model with IN1K-RN50. As shown in Table VIII, albeit not specifically designed for this setting, this simple variant of PGMA-Net demonstrates a high level of compatibility and yields comparable results to recent traditional FSS methods (our 65.0 v.s. RPMG-FSS 63.3, HPA 64.8, DCAMA 64.6, only slightly lower than newest FECANet). Also, compared to CLIPSeg (), our PGMA-Net () showed remarkable robustness, thus confirming the effectiveness of prior assembly from only visual cues.
V Conclusion
In this paper, we proposed PGMA-Net, a class-agnostic model for few-shot segmentation by integrating textual information and a new prior-to-mask mapping. We introduced a general assemble unit (GAU) and a prior-guided mask assemble module (PGMAM) to fully exploit diverse interactions across different priors and affinities in a unified manner. We also proposed a hierarchical decoder with channel-drop strategy (HDCDM), which enables the model to perform additional challenging tasks without extra fine-tuning, thus leading an any-shot segmentation framework. Our approach achieved promising performance across various tasks, including FSS, ZSS, co-segmentation, box-level and cross-domain FSS tasks. In future work, we will focus on the N-way problem and further investigate the general few-shot segmentation task to advance the research and application in this area.
References
- [1] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3431–3440, 2015.
- [2] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille, “Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs,” IEEE transactions on pattern analysis and machine intelligence, vol. 40, no. 4, pp. 834–848, 2017.
- [3] B. Cheng, A. Schwing, and A. Kirillov, “Per-pixel classification is not all you need for semantic segmentation,” Advances in Neural Information Processing Systems, vol. 34, pp. 17864–17875, 2021.
- [4] Z. Qiu, T. Yao, and T. Mei, “Learning deep spatio-temporal dependence for semantic video segmentation,” IEEE Transactions on Multimedia, vol. 20, no. 4, pp. 939–949, 2018.
- [5] C. Liu, X. Jiang, and H. Ding, “Instance-specific feature propagation for referring segmentation,” IEEE Transactions on Multimedia, pp. 1–1, 2022.
- [6] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick, “Microsoft coco: Common objects in context,” in Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755, Springer, 2014.
- [7] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman, “The pascal visual object classes (voc) challenge,” International journal of computer vision, vol. 88, pp. 303–338, 2010.
- [8] B. Zhou, H. Zhao, X. Puig, T. Xiao, S. Fidler, A. Barriuso, and A. Torralba, “Semantic understanding of scenes through the ade20k dataset,” International Journal of Computer Vision, vol. 127, no. 3, pp. 302–321, 2019.
- [9] C. Zhang, G. Lin, F. Liu, J. Guo, Q. Wu, and R. Yao, “Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9587–9595, 2019.
- [10] Y. Liu, X. Zhang, S. Zhang, and X. He, “Part-aware prototype network for few-shot semantic segmentation,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part IX 16, pp. 142–158, Springer, 2020.
- [11] Z. Tian, H. Zhao, M. Shu, Z. Yang, R. Li, and J. Jia, “Prior guided feature enrichment network for few-shot segmentation,” IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 2, pp. 1050–1065, 2020.
- [12] M. Boudiaf, H. Kervadec, Z. I. Masud, P. Piantanida, I. Ben Ayed, and J. Dolz, “Few-shot segmentation without meta-learning: A good transductive inference is all you need?,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 13979–13988, 2021.
- [13] J. Min, D. Kang, and M. Cho, “Hypercorrelation squeeze for few-shot segmentation,” in Proceedings of the IEEE/CVF international conference on computer vision, pp. 6941–6952, 2021.
- [14] Q. Fan, W. Pei, Y.-W. Tai, and C.-K. Tang, “Self-support few-shot semantic segmentation,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIX, pp. 701–719, Springer, 2022.
- [15] H. Liu, P. Peng, T. Chen, Q. Wang, Y. Yao, and X.-S. Hua, “Fecanet: Boosting few-shot semantic segmentation with feature-enhanced context-aware network,” IEEE Transactions on Multimedia, pp. 1–13, 2023.
- [16] M. Zhang, Y. Zhou, B. Liu, J. Zhao, R. Yao, Z. Shao, and H. Zhu, “Weakly supervised few-shot semantic segmentation via pseudo mask enhancement and meta learning,” IEEE Transactions on Multimedia, pp. 1–13, 2022.
- [17] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning, pp. 8748–8763, PMLR, 2021.
- [18] O. Vinyals, C. Blundell, T. Lillicrap, D. Wierstra, et al., “Matching networks for one shot learning,” Advances in neural information processing systems, vol. 29, 2016.
- [19] J. Snell, K. Swersky, and R. Zemel, “Prototypical networks for few-shot learning,” Advances in neural information processing systems, vol. 30, 2017.
- [20] H. Zhang, H. Li, and P. Koniusz, “Multi-level second-order few-shot learning,” IEEE Transactions on Multimedia, vol. 25, pp. 2111–2126, 2023.
- [21] F. Sung, Y. Yang, L. Zhang, T. Xiang, P. H. Torr, and T. M. Hospedales, “Learning to compare: Relation network for few-shot learning,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1199–1208, 2018.
- [22] C. Finn, P. Abbeel, and S. Levine, “Model-agnostic meta-learning for fast adaptation of deep networks,” in International conference on machine learning, pp. 1126–1135, PMLR, 2017.
- [23] A. Rajeswaran, C. Finn, S. M. Kakade, and S. Levine, “Meta-learning with implicit gradients,” Advances in neural information processing systems, vol. 32, 2019.
- [24] Q. Cai, Y. Pan, T. Yao, C. Yan, and T. Mei, “Memory matching networks for one-shot image recognition,” in Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4080–4088, 2018.
- [25] X. Yang, M. Han, Y. Luo, H. Hu, and Y. Wen, “Two-stream prototype learning network for few-shot face recognition under occlusions,” IEEE Transactions on Multimedia, vol. 25, pp. 1555–1563, 2023.
- [26] S. X. Hu, D. Li, J. Stühmer, M. Kim, and T. M. Hospedales, “Pushing the limits of simple pipelines for few-shot learning: External data and fine-tuning make a difference,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9068–9077, 2022.
- [27] R. Zhang, W. Zhang, R. Fang, P. Gao, K. Li, J. Dai, Y. Qiao, and H. Li, “Tip-adapter: Training-free adaption of clip for few-shot classification,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXV, pp. 493–510, Springer, 2022.
- [28] Y. Hu, S. Pateux, and V. Gripon, “Squeezing backbone feature distributions to the max for efficient few-shot learning,” Algorithms, vol. 15, no. 5, p. 147, 2022.
- [29] M. Caron, H. Touvron, I. Misra, H. Jégou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 9650–9660, 2021.
- [30] K. Wang, J. H. Liew, Y. Zou, D. Zhou, and J. Feng, “Panet: Few-shot image semantic segmentation with prototype alignment,” in proceedings of the IEEE/CVF international conference on computer vision, pp. 9197–9206, 2019.
- [31] K. Zhang and Y. Sato, “Semantic image segmentation by dynamic discriminative prototypes,” IEEE Transactions on Multimedia, pp. 1–13, 2023.
- [32] G. Li, V. Jampani, L. Sevilla-Lara, D. Sun, J. Kim, and J. Kim, “Adaptive prototype learning and allocation for few-shot segmentation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8334–8343, 2021.
- [33] B. Yang, C. Liu, B. Li, J. Jiao, and Q. Ye, “Prototype mixture models for few-shot semantic segmentation,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part VIII 16, pp. 763–778, Springer, 2020.
- [34] Z. Wu, X. Shi, G. Lin, and J. Cai, “Learning meta-class memory for few-shot semantic segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 517–526, 2021.
- [35] G. Cheng, C. Lang, and J. Han, “Holistic prototype activation for few-shot segmentation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 4650–4666, 2023.
- [36] G. Zhang, G. Kang, Y. Yang, and Y. Wei, “Few-shot segmentation via cycle-consistent transformer,” Advances in Neural Information Processing Systems, vol. 34, pp. 21984–21996, 2021.
- [37] B. Li, K. Q. Weinberger, S. Belongie, V. Koltun, and R. Ranftl, “Language-driven semantic segmentation,” in International Conference on Learning Representations, 2022.
- [38] X. Liu, B. Tian, Z. Wang, R. Wang, K. Sheng, B. Zhang, H. Zhao, and G. Zhou, “Delving into shape-aware zero-shot semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2999–3009, 2023.
- [39] T. Lüddecke and A. Ecker, “Image segmentation using text and image prompts,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7086–7096, 2022.
- [40] V. Dumoulin, E. Perez, N. Schucher, F. Strub, H. d. Vries, A. Courville, and Y. Bengio, “Feature-wise transformations,” Distill, vol. 3, no. 7, p. e11, 2018.
- [41] H. Wang, L. Liu, W. Zhang, J. Zhang, Z. Gan, Y. Wang, C. Wang, and H. Wang, “Iterative few-shot semantic segmentation from image label text,” in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pp. 1385–1392, ijcai.org, 2022.
- [42] X. Shi, D. Wei, Y. Zhang, D. Lu, M. Ning, J. Chen, K. Ma, and Y. Zheng, “Dense cross-query-and-support attention weighted mask aggregation for few-shot segmentation,” in Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XX, pp. 151–168, Springer, 2022.
- [43] S. Zhang, T. Wu, S. Wu, and G. Guo, “Catrans: Context and affinity transformer for few-shot segmentation,” in Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23-29 July 2022, pp. 1658–1664, ijcai.org, 2022.
- [44] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [45] A. Shaban, S. Bansal, Z. Liu, I. Essa, and B. Boots, “One-shot learning for semantic segmentation,” in British Machine Vision Conference 2017, BMVC 2017, London, UK, September 4-7, 2017, BMVA Press, 2017.
- [46] J. Liu, Y. Bao, G.-S. Xie, H. Xiong, J.-J. Sonke, and E. Gavves, “Dynamic prototype convolution network for few-shot semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11553–11562, 2022.
- [47] L. Zhang, X. Zhang, Q. Wang, W. Wu, X. Chang, and J. Liu, “Rpmg-fss: Robust prior mask guided few-shot semantic segmentation,” IEEE Transactions on Circuits and Systems for Video Technology, pp. 1–1, 2023.
- [48] Y. Wang, R. Sun, and T. Zhang, “Rethinking the correlation in few-shot segmentation: A buoys view,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 7183–7192, June 2023.
- [49] H. Wang, X. Zhang, Y. Hu, Y. Yang, X. Cao, and X. Zhen, “Few-shot semantic segmentation with democratic attention networks,” in Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XIII 16, pp. 730–746, Springer, 2020.
- [50] K. Nguyen and S. Todorovic, “Feature weighting and boosting for few-shot segmentation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 622–631, 2019.
- [51] B. Hariharan, P. Arbeláez, L. Bourdev, S. Maji, and J. Malik, “Semantic contours from inverse detectors,” in 2011 international conference on computer vision, pp. 991–998, IEEE, 2011.
- [52] W. Wang, L. Duan, Y. Wang, Q. En, J. Fan, and Z. Zhang, “Remember the difference: Cross-domain few-shot semantic segmentation via meta-memory transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7065–7074, 2022.
- [53] C. Zhang, G. Lin, F. Liu, R. Yao, and C. Shen, “Canet: Class-agnostic segmentation networks with iterative refinement and attentive few-shot learning,” in IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp. 5217–5226, Computer Vision Foundation / IEEE, 2019.
- [54] Y. Liu, N. Liu, Q. Cao, X. Yao, J. Han, and L. Shao, “Learning non-target knowledge for few-shot semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 11573–11582, 2022.
- [55] Y. Xian, S. Choudhury, Y. He, B. Schiele, and Z. Akata, “Semantic projection network for zero-and few-label semantic segmentation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8256–8265, 2019.
- [56] M. Bucher, T.-H. Vu, M. Cord, and P. Pérez, “Zero-shot semantic segmentation,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [57] M. Siam, N. Doraiswamy, B. N. Oreshkin, H. Yao, and M. Jägersand, “Weakly supervised few-shot object segmentation using co-attention with visual and semantic embeddings,” in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pp. 860–867, ijcai.org, 2020.
- [58] C. Zhu, K. Xu, S. Chaudhuri, L. Yi, L. J. Guibas, and H. Zhang, “Adacoseg: Adaptive shape co-segmentation with group consistency loss,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8543–8552, 2020.
- [59] B. Li, Z. Sun, Q. Li, Y. Wu, and A. Hu, “Group-wise deep object co-segmentation with co-attention recurrent neural network,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8519–8528, 2019.
- [60] S. Hong, S. Cho, J. Nam, S. Lin, and S. Kim, “Cost aggregation with 4d convolutional swin transformer for few-shot segmentation,” in Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XXIX, vol. 13689, pp. 108–126, Springer, 2022.
- [61] Z. Lu, S. He, X. Zhu, L. Zhang, Y.-Z. Song, and T. Xiang, “Simpler is better: Few-shot semantic segmentation with classifier weight transformer,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 8741–8750, 2021.