VolleyBots: A Testbed for Multi-Drone Volleyball Game Combining Motion Control and Strategic Play
Abstract
Robot sports, characterized by well-defined objectives, explicit rules, and dynamic interactions, present ideal scenarios for demonstrating embodied intelligence. In this paper, we present VolleyBots, a novel robot sports testbed where multiple drones cooperate and compete in the sport of volleyball under physical dynamics. VolleyBots integrates three features within a unified platform: competitive and cooperative gameplay, turn-based interaction structure, and agile 3D maneuvering. Competitive and cooperative gameplay challenges each drone to coordinate with its teammates while anticipating and countering opposing teams’ tactics. Turn-based interaction demands precise timing, accurate state prediction, and management of long-horizon temporal dependencies. Agile 3D maneuvering requires rapid accelerations, sharp turns, and precise 3D positioning despite the quadrotor’s underactuated dynamics. These intertwined features yield a complex problem combining motion control and strategic play, with no available expert demonstrations. We provide a comprehensive suite of tasks ranging from single-drone drills to multi-drone cooperative and competitive tasks, accompanied by baseline evaluations of representative multi-agent reinforcement learning (MARL) and game-theoretic algorithms. Simulation results show that on-policy reinforcement learning (RL) methods outperform off-policy methods in single-agent tasks, but both approaches struggle in complex tasks that combine motion control and strategic play. We additionally design a hierarchical policy which achieves 69.5% win rate against the strongest baseline in the 3 vs 3 task, underscoring its potential as an effective solution for tackling the complex interplay between low-level control and high-level strategy. The project page is at https://sites.google.com/view/thu-volleybots.
1 Introduction
Robot sports, characterized by their well-defined objectives, explicit rules, and dynamic interactions, provide a compelling domain for evaluating and advancing embodied intelligence. These scenarios require agents to effectively integrate real-time perception, decision-making, and control in order to accomplish specific goals within physically constrained environments. Several existing efforts have explored such environments: robot football [1, 2, 3, 4] emphasizes both intra-team cooperation and inter-team competition; robot-arm table tennis [5, 6] features the turn-based nature of ball exchange; and multi-drone pursuit-evasion [7] demands agile maneuvering in a 3D space.
In this work, we introduce a novel robot sports testbed named VolleyBots, where multiple drones engage in the popular sport of volleyball. VolleyBots integrates all these three key features into a unified platform: mixed competitive and cooperative game dynamics, a turn-based interaction structure, and agile 3D maneuvering. Mixed competitive and cooperative game dynamics necessitates that each drone achieves tight coordination with teammates, enabling intra-team passing sequences. Simultaneously, each team must proactively anticipate and effectively exploit the offensive and defensive strategies of opposing agents. Turn-based interaction in VolleyBots operates on two levels: inter-team role switching between offense and defense, and intra-team coordination for ball-passing sequences. This dual-level structure demands precise timing, accurate state prediction, and effective management of long-horizon temporal dependencies. Agile 3D maneuvering demands that each drone performs rapid accelerations, sharp turns, and fine-grained positioning, all while operating under the underactuated quadrotor dynamics. This challenge is intensified by frequent contacts with the ball, which disrupt the drone’s orientation and require post-contact recovery to maintain control. These intertwined features not only create a challenging problem that combines motion control and strategic play, but also lead to the absence of expert demonstrations.
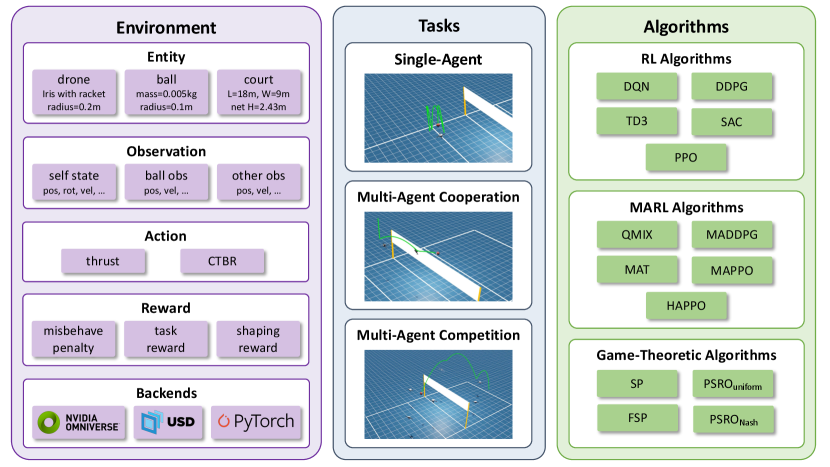
The overview of the VolleyBots testbed is shown in Fig. 1. Built on Nvidia Isaac Sim [8], VolleyBots supports efficient GPU-based data collection. Inspired by how humans progressively learn the structure of volleyball, we design a curriculum of tasks ranging from single-drone drills to multi-drone cooperative plays and competitive matchups. We have also implemented multi-agent reinforcement learning (MARL) and game-theoretic baselines, and provided benchmark results. Simulation results show that on-policy reinforcement learning (RL) methods outperform off-policy counterparts in single-agent tasks. However, both approaches struggle in more complex tasks that require low-level motion control and high-level strategic play. We envision VolleyBots as a valuable platform for advancing the study of embodied intelligence in physically grounded, multi-agent robotic environments. Our main contributions are summarized as follows:
-
1.
We introduce VolleyBots, a novel robot sports environment centered on drone volleyball, featuring mixed competitive and cooperative game dynamics, turn-based interactions, and agile 3D maneuvering while demanding both motion control and strategic play.
-
2.
We release a curriculum of tasks, ranging from single-drone drills to multi-drone cooperative plays and competitive matchups, and baseline evaluations of representative MARL and game-theoretic algorithms, facilitating reproducible research and comparative assessments.
-
3.
We design a hierarchical policy that achieves a 69.5% win rate against the strongest baseline in the 3 vs 3 task, offering a promising solution for tackling the complex interplay between low-level control and high-level strategy.
2 Related work
| Multi-Agent Task | Game Type | Entity | Hierarchical | Open | Baseline | |||
| coop. | comp. | mixed | Policy | Source | Provided | |||
| Robot Table Tennis [5] | ✗ | ✓ | ✗ | turn-based | robotic arm | ✓ | ✗ | ✗ |
| Badminton Robot [9] | ✗ | ✗ | ✗ | turn-based | robotic arm | ✗ | ✗ | ✗ |
| Quadruped Soccer [2] | ✗ | ✗ | ✗ | simultaneous | quadruped | ✓ | ✗ | ✗ |
| MQE [4] | ✓ | ✓ | ✓ | simultaneous | quadruped | ✓ | ✓ | ✓ |
| Humanoid Football [1] | ✗ | ✓ | ✓ | simultaneous | humanoid | ✓ | ✓ | ✗ |
| SMPLOlympics [10] | ✗ | ✓ | ✓ | simu. & turn-based | humanoid | ✗ | ✓ | ✓ |
| Pursuit-Evasion [7] | ✓ | ✗ | ✗ | simultaneous | drone | ✗ | ✓ | ✓ |
| Drone-Racing [11] | ✗ | ✗ | ✗ | simultaneous | drone | ✗ | ✗ | ✗ |
| VolleyBots (Ours) | ✓ | ✓ | ✓ | turn-based | drone | ✓ | ✓ | ✓ |
2.1 Robot sports
The integration of sensing, actuation, and autonomy has enabled a wide range of robotic platforms, spanning robotic arms, quadrupeds, humanoids, and aerial drones, to undertake increasingly complex tasks. Robot sports provide a compelling testbed for evaluating their capabilities within well-defined rule sets. A classic example is robot soccer: since the initiative of RoboCup [12], research into autonomous football has driven advances in multi-agent coordination, strategic planning, and hardware integration. Early approaches [13, 14] to robot sports relied primarily on classical control and planning techniques. With the growth of data-driven methods, imitation learning algorithms [15] enabled robots to learn complex motion policies directly from expert demonstrations. More recently, RL methods have also achieved remarkable performance. With RL, Researchers have explored a wide range of robot platforms for sports tasks. Robot arms on mobile bases have learned table tennis [5, 6] and badminton [9]. Quadrupeds have commanded basic soccer drills [2] and played in multi-agent football matches [4]. Humanoid robots have demonstrated competitive 1 vs 1 [3] and 2 vs 2 [1] football skills and participated in simulated Olympic-style events SMPLOlympics [10]. Drones have achieved human-surpassing racing performance [11] and tackled multi-UAV pursuit-evasion tasks with rule-based pursuit policies [7]. Despite these advances, there remains a need for environments that combine high-mobility platforms (e.g., drones) with mixed cooperative-competitive dynamics and require both high-level decision-making and low-level continuous control. To fill this gap, we introduce VolleyBots, a turn-based, drone-focused sports environment that seamlessly integrates strategic planning with agile control. Built on a realistic physics simulator, VolleyBots offers a unique testbed for advancing research in agile, decision-driven robot control. A detailed comparison between VolleyBots and representative learning-based robot sports platforms is provided in Table 1.
2.2 Learning-based methods for drone control task
Executing precise and agile flight maneuvers is essential for drones, which has driven the development of diverse control strategies [16, 17, 18]. While traditional model-based controllers excel in predictable settings, learning-based approaches adapt more effectively to dynamic, unstructured environments. One popular approach is imitation learning [19, 20], which trains policies from expert demonstrations. However, collecting high-quality expert data, especially for aggressive or novel maneuvers, can be costly or infeasible. In such a case, RL offers a flexible alternative by discovering control policies through trial-and-error interaction. Drone racing is a notable single-drone control task where RL has achieved human-level performance [21], showcasing near-time-optimal decision-making capabilities. Beyond racing, researchers also leveraged RL for executing aggressive flight maneuvers [22] and achieving hovering stabilization under highly challenging conditions [18]. As for multi-drone tasks, RL has been applied to cooperative tasks such as formation maintenance [23], as well as more complex scenarios like multi-drone pursuit-evasion tasks [7], further showcasing its potential to jointly optimize task-level planning and control. In this paper, we present VolleyBots, a testbed designed to study the novel drone control task of drone volleyball. This task introduces unique challenges, requiring drones to learn both cooperative and competitive strategies at the task level while maintaining agile and precise control. Additionally, VolleyBots provides a comprehensive platform with (MA)RL and game-theoretic algorithm baselines, facilitating the development and evaluation of advanced drone control strategies.
3 VolleyBots environment
In this section, we introduce the environment design of the VolleyBots testbed. The environment is built upon the high-throughput and GPU-parallelized OmniDrones [24] simulator, which relies on Isaac Sim [8] to facilitate rapid data collection. We further configure OmniDrones to simulate realistic flight dynamics and interaction between the drones and the ball, then implement standard volleyball rules and gameplay mechanics to create a challenging domain for drone control tasks. We will describe the simulation entity, observation space, action space, and reward functions in the following subsections.
3.1 Simulation entity
Our environment simulates real-world physics dynamics and interactions of three key components including the drones, the ball, and the court. We provide a flexible configuration of each entity’s model and parameters to enable a wide range of task designs. For the default configuration, we adopt the Iris quadrotor model [25] as the primary drone platform, augmented with a virtual “racket” of radius and coefficient of restitution for ball striking. The ball is modeled as a sphere with a radius of , a mass of , and a coefficient of restitution of , enabling realistic bounces and interactions with both drones and the environment. The court follows standard volleyball dimensions of with a net height of .
3.2 Observation space
To align with the feature of partial observability in real-world volleyball games, we adopt a state-based observation space where each drone can fully observe its own physical state and partially observe the ball’s state and other drones’ states. More specifically, each drone has full observability of its position, rotation, velocity, angular velocity, and other physical states. For ball observation, each drone can only partially observe the ball’s position and velocity. In multi-agent tasks, each drone can also partially observe other drones’ positions and velocities. Minor variations in the observation space may be required for different tasks, such as the ID of each drone in multi-agent tasks. Detailed observation configurations for each task are provided in the Appendix D.
3.3 Action space
We provide two types of continuous action spaces that differ in their level of control, with Collective Thrust and Body Rates (CTBR) offering a higher-level abstraction and Per-Rotor Thrust (PRT) offering a more fine-grained manipulation of individual rotors.
CTBR. A typical mode of drone control is to specify a single collective thrust command along with body rates for roll, pitch, and yaw. This higher-level abstraction hides many hardware-specific parameters of the drone, often leading to more stable training. It also simplifies sim-to-real transfer by reducing the reliance on precise modeling of individual rotor dynamics.
PRT. Alternatively, the drone can directly control each rotor’s thrust individually. This fine-grained control allows the policy to fully exploit the drone’s agility and maneuverability. However, it typically requires a more accurate hardware model, making system identification more complex, and can increase the difficulty of sim-to-real deployment.
3.4 Reward functions
The reward function for each task consists of three parts, including the misbehave penalty for general motion control, the task reward for task completion, and the shaping reward to accelerate training.
Misbehave penalty. This term is consistent across all tasks and penalizes undesirable behaviors related to general drone motion control, such as crashes, collisions, and invalid hits. By imposing penalties for misbehavior, the drones are guided to maintain physically plausible trajectories and avoid actions that could lead to control failure.
Task reward. Each task features a primary objective-based reward that encourages the successful completion of the task. For example, in solo bump tasks, the drone will get a reward of for each successful hit of the ball. Since the task rewards are typically sparse, agents must rely on effective exploration to learn policies that complete the task.
Shaping reward. Due to the sparse nature of many task rewards, relying solely on the misbehave penalty and the task reward can make it difficult for agents to successfully complete the tasks. To address this challenge, we introduce additional shaping rewards to help steer the learning process. For example, the drone’s movement toward the ball is rewarded when a hit is required. By providing additional guidance, the shaping rewards significantly accelerate learning in complex tasks.
4 VolleyBots tasks
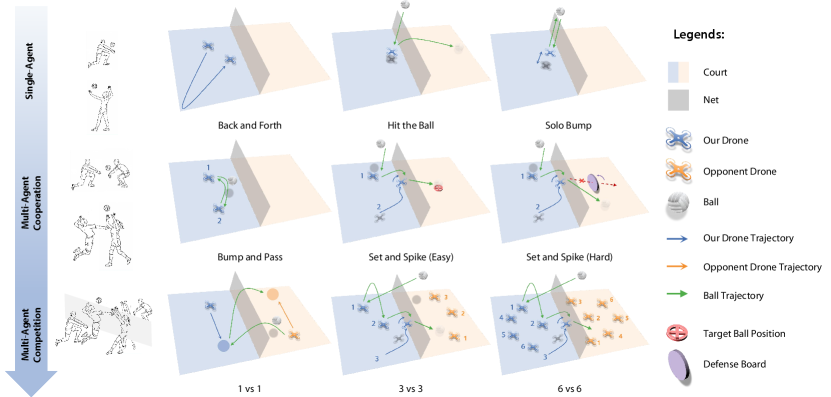
Inspired by the way humans progressively learn to play volleyball, we introduce a series of tasks that systematically assess both low-level motion control and high-level strategic play, as shown in Fig. 2. These tasks are organized into three categories: single-agent, multi-agent cooperative, and multi-agent competitive. Each category aligns with standard volleyball drills or match settings commonly adopted in human training, ranging from basic ball control, through cooperative play, to competitive full games. Evaluation metrics vary across tasks to assess performance in motion control, cooperative teamwork, and strategic competition. The detailed configuration and reward design of each task can be found in Appendix D.
4.1 Single-agent tasks
Single-agent tasks are designed to follow typical solo training drills used in human volleyball practice, including Back and Forth, Hit the Ball, and Solo Bump. These tasks evaluate the drone’s agile 3D maneuvering capabilities, such as flight stability, motion control, and ball-handling proficiency.
Back and Forth. The drone sprints between two designated points to complete as many round trips as possible within the time limit. This task is analogous to the back-and-forth sprints in volleyball practice. The rapid acceleration, deceleration, and precise altitude adjustments during each round showcase its agile 3D maneuvering capabilities. The performance is evaluated by the number of completed round trips within the time limit.
Hit the Ball. The ball is initialized directly above the drone, and the drone hits the ball once to make it land as far as possible. This task is analogous to the typical hitting drill in volleyball and requires both motion control and ball-handling proficiency. In particular, the drone must execute rapid vertical lift, pitch adjustments, and lateral strafing to align precisely with the descending ball, demonstrating another facet of its agile 3D maneuvering. The performance is evaluated by the distance of the ball’s landing position from the initial position.
Solo Bump. The ball is initialized directly above the drone, and the drone bumps the ball in place to a specific height as many times as possible within the time limit. This task is analogous to the solo bump drill in human practice and requires motion control, ball-handling proficiency, and stability. During each bump, the drone performs subtle pitch and roll adjustments along with fine vertical thrust modulation to maintain the ball’s trajectory, demonstrating its agile 3D maneuvering through precise hover corrections. The performance is evaluated by the number of bumps within the time limit.
| Back and Forth | Hit the Ball | Solo Bump | ||||
| CTBR | PRT | CTBR | PRT | CTBR | PRT | |
| DQN | ||||||
| DDPG | ||||||
| TD3 | ||||||
| SAC | ||||||
| PPO | ||||||
4.2 Multi-agent cooperative tasks
Multi-agent cooperative tasks are inspired by standard two-player training drills used in volleyball teamwork, including Bump and Pass, Set and Spike (Easy), and Set and Spike (Easy). In addition to agile 3D maneuvering, these tasks incorporate turn-based interactions at the intra-team level for coordinated ball-passing sequences.
Bump and Pass. Two drones work together to bump and pass the ball to each other back and forth as many times as possible within the time limit. This task is analogous to the two-player bumping practice in volleyball training and requires homogeneous multi-agent cooperation. The performance is evaluated by the number of successful bumps within the time limit.
Set and Spike (Easy). Two drones take on the role of a setter and an attacker. The setter passes the ball to the attacker, and the attacker then spikes the ball downward to the target region on the opposing side. This task is analogous to the setter-attacker offensive drills in volleyball training and requires heterogeneous multi-agent cooperation. The performance is evaluated by the success rate of the downward spike to the target region.
Set and Spike (Hard). Similar to Set and Spike (Easy) task, two drones act as a setter and an attacker to set and spike the ball to the opposing side. The difference is that there is a rule-based defense board on the opposing side to intercept the attacker’s spike. The presence of the defense board further improves the difficulty of the task, requiring the drones to optimize their speed, precision, and cooperation to defeat the defense board. The performance is evaluated by the success rate of the downward spike that defeats the defense racket.
4.3 Multi-agent competitive tasks
Multi-agent competitive tasks follow the standard volleyball match rules, including the competitive 1 vs 1 task and the mixed cooperative-competitive 3 vs 3 and 6 vs 6 tasks. They incorporate competitive and cooperative gameplay, turn-based interaction structure, and agile 3D maneuvering. These tasks demand both the low-level motion control and the high-level strategic play.
1 vs 1. Two drones, one positioned on each side of a reduced-size court, compete in a head-to-head volleyball match. A point is scored whenever a drone causes the ball to land in the opponent’s court. When the ball is on its side, the drone is allowed only one hit to return the ball to the opponent’s court. This two-player zero-sum setting creates a purely competitive environment that requires both precise flight control and strategic gameplay. To evaluate the performance of the learned policy, we consider three typical metrics including the exploitability, the average win rate against other learned policies, and the Elo rating [26]. More specifically, the exploitability is approximated by the gap between the learned best response’s win rate against the evaluated policy and its expected win rate at Nash equilibrium, and the Elo rating is computed by running a round-robin tournament between the evaluated policy and a fixed population of policies.
3 vs 3. Three drones on each side form a team to compete against the other team on a reduced-size court. During each rally, teammates coordinate to serve, pass, spike and defend, observing the standard limit of three hits per side. This is a challenging mixed cooperative-competitive game that requires both cooperation within the same team and competition between the opposing teams. Moreover, the drones are required to excel at both low-level motion control and high-level game play. We evaluated the policy performance using approximate exploitability, the average win rate against other learned policies, and the Elo rating of the policy.
6 vs 6. Six drones per side form teams on a full-size court under the standard three-hits-per-side rule of real-world volleyball. Compared with the 3 vs 3 task, the 6 vs 6 format is substantially more demanding: the larger team size complicates intra-team coordination and role assignment; the full-size court forces drones to cover greater distances and maintain broader defensive coverage; the combinatorial explosion of possible ball trajectories and collision scenarios requires advanced real-time planning and robust collision avoidance; and executing richer tactical schemes necessitates deeper strategic reasoning.
5 Benchmark results
| Bump and Pass | Set and Spike (Easy) | Set and Spike (Hard) | ||||
| w.o. shaping | w. shaping | w.o. shaping | w. shaping | w.o. shaping | w. shaping | |
| QMIX | ||||||
| MADDPG | ||||||
| MAPPO | ||||||
| HAPPO | ||||||
| MAT | ||||||
| 1 vs 1 | 3 vs 3 | |||||
| Exploitability | Win Rate | Elo | Exploitability | Win Rate | Elo | |
| SP | ||||||
| FSP | ||||||
| PSRO | ||||||
| PSRO | ||||||
We present extensive experiments to benchmark representative (MA)RL and game-theoretic algorithms in our VolleyBots testbed. Specifically, for single-agent tasks, we benchmark five RL algorithms and compare their performance under different action space configurations. For multi-agent cooperative tasks, we evaluate five MARL algorithms and compare their performance with and without reward shaping. For multi-agent competitive tasks, we evaluate four game-theoretic algorithms and provide a comprehensive analysis across multiple evaluation metrics. We identify a key challenge in VolleyBots is the hierarchical decision-making process that requires both low-level motion control and high-level strategic play. We further show the potential of hierarchical policy in our VolleyBots testbed by implementing a simple yet effective baseline for the challenging 3 vs 3 task. Detailed discussion about the benchmark algorithms and more experiment results can be found in Appendix E and F.
5.1 Results of single-agent tasks
We evaluate five RL algorithms including Deep Q-Network (DQN) [27], Deterministic Policy Gradient (DDPG) [28], Twin Delayed DDPG (TD3) [29], Soft Actor-Critic (SAC) [30], and Proximal Policy Optimization (PPO) [31] in three single-agent tasks. We compare their performance under both CTBR and PRT action spaces. The averaged results over three seeds are shown in Table 2.
Using the same number of training frames, PPO vastly outperforms all other methods in every task under both action-space choices; by contrast, DQN fails entirely, and DDPG, TD3 and SAC achieve only moderate success. DQN fails because it’s limited to discrete actions, forcing coarse binning of continuous drone controls and losing precision. In contrast, while DDPG, TD3, and SAC can handle continuous actions, PPO’s clipped surrogate objective and on-policy updates provide greater stability and automatically adapt exploration, enabling it to outperform other single-agent methods.
Comparing different action spaces, the final results indicate that PRT slightly outperforms CTBR in most tasks. This outcome is likely due to PRT providing more granular control over each motor’s thrust, enabling the drone to maximize task-specific performance with precise adjustments. On the other hand, CTBR demonstrates a slightly faster learning speed in some tasks, as its higher-level abstraction simplifies the control process and reduces the learning complexity. For optimal task performance, we use PRT as the default action space in subsequent experiments. More experiment results and learning curves are provided in Appendix F.3.
5.2 Results of multi-agent cooperative tasks
We evaluate five MARL algorithms including QMIX [32], Multi-Agent DDPG (MADDPG) [33], Multi-Agent PPO (MAPPO) [34], Heterogeneous-Agent PPO (HAPPO) [35], Multi-Agent Transformer (MAT) [36] in three multi-agent cooperative tasks. We also compare their performance with and without reward shaping. The averaged results over three seeds are shown in Table 3.
Comparing the MARL algorithms, on-policy methods like MAPPO, HAPPO, and MAT successfully complete all three cooperative tasks and exhibit comparable performance, while off-policy method like QMIX and MADDPG fails to complete these tasks. These results are consistent with the observation in single-agent experiments, and we use MAPPO as the default algorithm in subsequent experiments for its consistently strong performance and efficiency.
As for different reward functions, it is clear that using reward shaping leads to better performance, especially in more complex tasks like Set and Spike (Hard). This is because the misbehave penalty and task reward alone are usually sparse and make exploration in continuous space challenging. Such sparse setups can serve as benchmarks to evaluate the exploration ability of MARL algorithms. On the other hand, shaping rewards provide intermediate feedback that guides agents toward task-specific objectives more efficiently, and we use shaping rewards in subsequent experiments for efficient learning. More experimental results and learning curves are provided in Appendix F.4.
5.3 Results of multi-agent competitive tasks
We evaluate four game-theoretic algorithms: self-play (SP), Fictitious Self-Play (FSP) [37], Policy-Space Response Oracles (PSRO) [38] with a uniform meta-solver (PSRO), and a Nash meta-solver (PSRO) in multi-agent competitive tasks. Algorithms learn effective serving and receiving behaviors in the 1 vs 1 and 3 vs 3 tasks. However, in the most difficult 6 vs 6 task, none of the methods converges to an effective strategy: although the serving drone occasionally hits the ball, it fails to serve the ball to the opponent’s court. This finding indicates that the scalability of current algorithms remains limited and requires further improvement. Therefore, we focus our benchmark results on the 1 vs 1 and 3 vs 3 settings. For these two tasks, their performance is evaluated by approximate exploitability, the average win rate against other learned policies, and Elo rating. The results are summarized in Table 4, and head-to-head cross-play win rate heatmaps are shown in Fig. 3. More results and implementation details are provided in Appendix F.5.
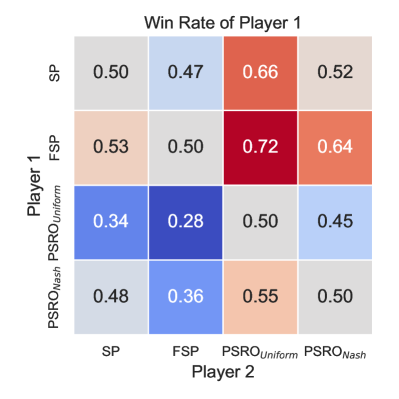
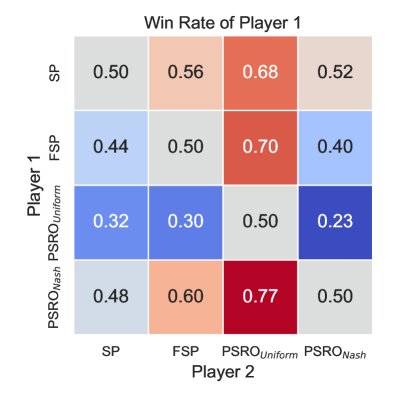
In the 1 vs 1 task, all algorithms manage to learn behaviors like reliably returning the ball and maintaining optimal positioning for subsequent volleys. However, the exploitability metric reveals that the learned policies are still far from achieving a Nash equilibrium, indicating limited robustness in this two-player zero-sum game. This performance gap highlights the inherent challenge of hierarchical decision-making in this task, where drones must simultaneously execute precise low-level motion control and engage in high-level strategic gameplay. This challenge presents new opportunities for designing algorithms that can better integrate hierarchical decision-making capabilities. In the 3 vs 3 task, algorithms learn to serve the ball but fail to develop more advanced team strategies. This outcome underscores the compounded challenges in this scenario, where each team of three drones needs to not only cooperate internally but also compete against the opposing team. The increased difficulty of achieving high-level strategic play in such a mixed cooperative-competitive environment further amplifies the hierarchical challenges observed in 1 vs 1.
5.4 Hierarchical policy
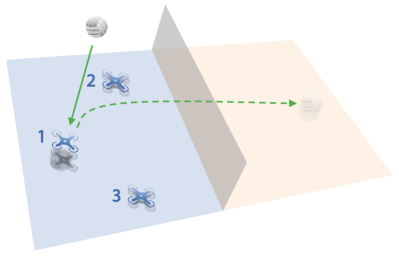
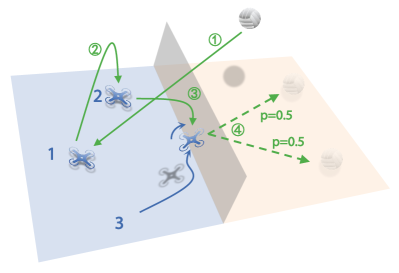
To illustrate how a simple hierarchical policy might help address the challenges posed by our benchmark, we apply it to the 3 vs 3 task as an example. First, we employ the PPO [31] algorithm to develop a set of low-level drills, including Hover, Serve, Pass, Set, and Attack. The details of low-level drills can be found in Appendix F.6. Next, we design a rule-based high-level strategic policy that determines when and which low-level drills to assign to each drone. Moreover, for the Attack drill, the high-level policy chooses to hit the ball to the left or right with equal probability. Fig. 4 illustrates two typical demonstrations of the hierarchical policy. In a serving scenario (Fig. 4(a)), the rule-based high-level strategy assigns the Serve drill to drone 1 and the Hover drill to the other two drones. In a rally scenario (Fig. 4(b)), the rule-based strategy assigns the Pass drill to drone 1, the Set drill to drone 2, and the Attack drill to drone 3 sequentially. In accordance with volleyball rules, the high-level policy uses an event-driven mechanism, triggering decisions whenever the ball is hit. As shown in Fig. LABEL:fig:crossplay-1v1, the SP policy emerges as the Nash equilibrium among SP, FSP, PSROUniform, and PSRONash in the 3 vs 3 setting. We evaluate our hierarchical policy against SP over 1,000 episodes and observe a win rate of 69.5%. While the current design of the hierarchical policy is in its early stages, it outperforms the Nash equilibrium baseline, offering valuable inspiration for future developments.
6 Conclusion
In this work, we introduce VolleyBots, a novel multi-drone volleyball testbed that unifies competitive-cooperative gameplay, turn-based interaction, and agile 3D motion control within a high-fidelity physics simulation. Compounding these features, it demands both motion control and strategic play. Built atop NVIDIA Isaac Sim, VolleyBots offers a structured curriculum of tasks, from single-agent drills and multi-agent cooperative challenges to multi-agent competitive matches. To enable systematic benchmarking, VolleyBots provides implementations of both (MA)RL and game-theoretic baselines across these tasks. Our extensive benchmarks reveal that on-policy RL methods consistently outperform off-policy counterparts in low-level control tasks. However, both of them still struggle with the tasks demanding both mixed motion control and strategic play, especially in large-scale competitive matches. To address this, we design a simple hierarchical policy that decomposes strategy and control: in the 3 vs 3 task, it achieves a 69.5% win rate against the strongest baseline, highlighting the promise of hierarchical structures. Going forward, VolleyBots provides a challenging and versatile platform for advancing embodied intelligence in agile robotic systems, inviting novel algorithmic innovations that bridge motion control and strategic play in multi-agent domains.
Acknowledgments and Disclosure of Funding
We sincerely thank Jiayu Chen, Yuqing Xie, Yinuo Chen, and Sirui Xiang for their valuable discussions, as well as their assistance in experiments and real-world deployment, which have greatly contributed to the development of this work. Their support and collaboration have been instrumental in refining our ideas and improving the quality of this paper.
This research was supported by National Natural Science Foundation of China (No.62406159, 62325405), Postdoctoral Fellowship Program of CPSF under Grant Number (GZC20240830, 2024M761676), China Postdoctoral Science Special Foundation 2024T170496.
References
- [1] S. Liu, G. Lever, Z. Wang, J. Merel, S. A. Eslami, D. Hennes, W. M. Czarnecki, Y. Tassa, S. Omidshafiei, A. Abdolmaleki, et al., “From motor control to team play in simulated humanoid football,” Science Robotics, vol. 7, no. 69, p. eabo0235, 2022.
- [2] Y. Ji, Z. Li, Y. Sun, X. B. Peng, S. Levine, G. Berseth, and K. Sreenath, “Hierarchical reinforcement learning for precise soccer shooting skills using a quadrupedal robot,” 2022.
- [3] T. Haarnoja, B. Moran, G. Lever, S. H. Huang, D. Tirumala, J. Humplik, M. Wulfmeier, S. Tunyasuvunakool, N. Y. Siegel, R. Hafner, et al., “Learning agile soccer skills for a bipedal robot with deep reinforcement learning,” Science Robotics, vol. 9, no. 89, p. eadi8022, 2024.
- [4] Z. Xiong, B. Chen, S. Huang, W.-W. Tu, Z. He, and Y. Gao, “Mqe: Unleashing the power of interaction with multi-agent quadruped environment,” arXiv preprint arXiv:2403.16015, 2024.
- [5] D. B. D’Ambrosio, S. Abeyruwan, L. Graesser, A. Iscen, H. B. Amor, A. Bewley, B. J. Reed, K. Reymann, L. Takayama, Y. Tassa, et al., “Achieving human level competitive robot table tennis,” arXiv preprint arXiv:2408.03906, 2024.
- [6] H. Ma, J. Fan, H. Xu, and Q. Wang, “Mastering table tennis with hierarchy: a reinforcement learning approach with progressive self-play training,” Applied Intelligence, vol. 55, no. 6, p. 562, 2025.
- [7] J. Chen, C. Yu, G. Li, W. Tang, X. Yang, B. Xu, H. Yang, and Y. Wang, “Multi-uav pursuit-evasion with online planning in unknown environments by deep reinforcement learning,” 2024.
- [8] M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y. Guo, H. Mazhar, A. Mandlekar, B. Babich, G. State, M. Hutter, and A. Garg, “Orbit: A unified simulation framework for interactive robot learning environments,” IEEE Robotics and Automation Letters, vol. 8, p. 3740–3747, June 2023.
- [9] H. Wang, Z. Shi, C. Zhu, Y. Qiao, C. Zhang, F. Yang, P. Ren, L. Lu, and D. Xuan, “Integrating learning-based manipulation and physics-based locomotion for whole-body badminton robot control,” arXiv preprint arXiv:2504.17771, 2025.
- [10] Z. Luo, J. Wang, K. Liu, H. Zhang, C. Tessler, J. Wang, Y. Yuan, J. Cao, Z. Lin, F. Wang, J. Hodgins, and K. Kitani, “Smplolympics: Sports environments for physically simulated humanoids,” 2024.
- [11] E. Kaufmann, L. Bauersfeld, A. Loquercio, M. Müller, V. Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,” Nature, vol. 620, no. 7976, pp. 982–987, 2023.
- [12] H. Kitano, M. Asada, Y. Kuniyoshi, I. Noda, and E. Osawa, “Robocup: The robot world cup initiative,” in Proceedings of the first international conference on Autonomous agents, pp. 340–347, 1997.
- [13] S. Behnke, M. Schreiber, J. Stuckler, R. Renner, and H. Strasdat, “See, walk, and kick: Humanoid robots start to play soccer,” in 2006 6th IEEE-RAS International Conference on Humanoid Robots, pp. 497–503, IEEE, 2006.
- [14] A. Nakashima, Y. Ogawa, C. Liu, and Y. Hayakawa, “Robotic table tennis based on physical models of aerodynamics and rebounds,” in 2011 IEEE International Conference on Robotics and Biomimetics, pp. 2348–2354, IEEE, 2011.
- [15] T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, J. Peters, et al., “An algorithmic perspective on imitation learning,” Foundations and Trends® in Robotics, vol. 7, no. 1-2, pp. 1–179, 2018.
- [16] S. Bouabdallah, P. Murrieri, and R. Siegwart, “Design and control of an indoor micro quadrotor,” in IEEE International Conference on Robotics and Automation, 2004. Proceedings. ICRA’04. 2004, vol. 5, pp. 4393–4398, IEEE, 2004.
- [17] G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou, “Information theoretic mpc for model-based reinforcement learning,” in 2017 IEEE International Conference on Robotics and Automation (ICRA), pp. 1714–1721, 2017.
- [18] J. Hwangbo, I. Sa, R. Siegwart, and M. Hutter, “Control of a quadrotor with reinforcement learning,” IEEE Robotics and Automation Letters, vol. 2, no. 4, pp. 2096–2103, 2017.
- [19] F. Schilling, J. Lecoeur, F. Schiano, and D. Floreano, “Learning vision-based flight in drone swarms by imitation,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 4523–4530, 2019.
- [20] T. Wang and D. E. Chang, “Robust navigation for racing drones based on imitation learning and modularization,” in 2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 13724–13730, IEEE, 2021.
- [21] E. Kaufmann, L. Bauersfeld, A. Loquercio, M. Müller, V. Koltun, and D. Scaramuzza, “Champion-level drone racing using deep reinforcement learning,” Nature, vol. 620, no. 7976, pp. 982–987, 2023.
- [22] Q. Sun, J. Fang, W. X. Zheng, and Y. Tang, “Aggressive quadrotor flight using curiosity-driven reinforcement learning,” IEEE Transactions on Industrial Electronics, vol. 69, no. 12, pp. 13838–13848, 2022.
- [23] L. Quan, L. Yin, C. Xu, and F. Gao, “Distributed swarm trajectory optimization for formation flight in dense environments,” in 2022 International Conference on Robotics and Automation (ICRA), pp. 4979–4985, IEEE, 2022.
- [24] B. Xu, F. Gao, C. Yu, R. Zhang, Y. Wu, and Y. Wang, “Omnidrones: An efficient and flexible platform for reinforcement learning in drone control,” IEEE Robotics and Automation Letters, 2024.
- [25] F. Furrer, M. Burri, M. Achtelik, and R. Siegwart, “Rotors—a modular gazebo mav simulator framework,” Robot Operating System (ROS) The Complete Reference (Volume 1), pp. 595–625, 2016.
- [26] A. E. Elo and S. Sloan, “The rating of chessplayers: Past and present,” 1978.
- [27] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, et al., “Human-level control through deep reinforcement learning,” nature, vol. 518, no. 7540, pp. 529–533, 2015.
- [28] T. Lillicrap, “Continuous control with deep reinforcement learning,” arXiv preprint arXiv:1509.02971, 2015.
- [29] S. Fujimoto, H. Hoof, and D. Meger, “Addressing function approximation error in actor-critic methods,” in International conference on machine learning, pp. 1587–1596, PMLR, 2018.
- [30] T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor,” in International conference on machine learning, pp. 1861–1870, PMLR, 2018.
- [31] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017.
- [32] T. Rashid, M. Samvelyan, C. S. De Witt, G. Farquhar, J. Foerster, and S. Whiteson, “Monotonic value function factorisation for deep multi-agent reinforcement learning,” Journal of Machine Learning Research, vol. 21, no. 178, pp. 1–51, 2020.
- [33] R. Lowe, Y. I. Wu, A. Tamar, J. Harb, O. Pieter Abbeel, and I. Mordatch, “Multi-agent actor-critic for mixed cooperative-competitive environments,” Advances in neural information processing systems, vol. 30, 2017.
- [34] C. Yu, A. Velu, E. Vinitsky, J. Gao, Y. Wang, A. Bayen, and Y. Wu, “The surprising effectiveness of ppo in cooperative multi-agent games,” Advances in Neural Information Processing Systems, vol. 35, pp. 24611–24624, 2022.
- [35] J. G. Kuba, R. Chen, M. Wen, Y. Wen, F. Sun, J. Wang, and Y. Yang, “Trust region policy optimisation in multi-agent reinforcement learning,” arXiv preprint arXiv:2109.11251, 2021.
- [36] M. Wen, J. Kuba, R. Lin, W. Zhang, Y. Wen, J. Wang, and Y. Yang, “Multi-agent reinforcement learning is a sequence modeling problem,” Advances in Neural Information Processing Systems, vol. 35, pp. 16509–16521, 2022.
- [37] J. Heinrich, M. Lanctot, and D. Silver, “Fictitious self-play in extensive-form games,” in International conference on machine learning, pp. 805–813, PMLR, 2015.
- [38] M. Lanctot, V. Zambaldi, A. Gruslys, A. Lazaridou, K. Tuyls, J. Pérolat, D. Silver, and T. Graepel, “A unified game-theoretic approach to multiagent reinforcement learning,” Advances in neural information processing systems, vol. 30, 2017.
- [39] W. M. Czarnecki, G. Gidel, B. Tracey, K. Tuyls, S. Omidshafiei, D. Balduzzi, and M. Jaderberg, “Real world games look like spinning tops,” Advances in Neural Information Processing Systems, vol. 33, pp. 17443–17454, 2020.
- [40] R. Zhang, Z. Xu, C. Ma, C. Yu, W.-W. Tu, S. Huang, D. Ye, W. Ding, Y. Yang, and Y. Wang, “A survey on self-play methods in reinforcement learning,” arXiv preprint arXiv:2408.01072, 2024.
- [41] S. McAleer, G. Farina, G. Zhou, M. Wang, Y. Yang, and T. Sandholm, “Team-psro for learning approximate tmecor in large team games via cooperative reinforcement learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 45402–45418, 2023.
- [42] Z. Xu, Y. Liang, C. Yu, Y. Wang, and Y. Wu, “Fictitious cross-play: Learning global nash equilibrium in mixed cooperative-competitive games,” arXiv preprint arXiv:2310.03354, 2023.
- [43] H. Sheehan, “Elopy: A python library for elo rating systems.” https://github.com/HankSheehan/EloPy, 2017. Accessed: 2025-01-28.
Appendix A Impact
This work introduces VolleyBots, a novel robot sports testbed specifically designed to push the boundaries of high-mobility robotic platforms such as drones involving MARL. The broader impacts of this research include advancing the intersection of robotics and MARL, enhancing the decision-making capabilities of drones in complex scenarios. By bridging real-world robotic challenges with MARL, this work aims to inspire future breakthroughs in both robotics and multi-agent AI systems. We do not anticipate any negative societal impacts arising from this work.
Appendix B Limitations
Despite the promising advances of VolleyBots in combining high-level strategic play with low-level motion control, our work has several limitations. First, all experiments were conducted in a high-fidelity simulator, and we have not evaluated the policy’s sim-to-real transferability, leaving its performance and robustness on physical UAV platforms untested. Second, we rely on fully state-based observations, which overlook challenges such as visual input. Finally, we did not include the traditional drone control algorithms which, despite their limitations in handling team-level strategy, aggressive maneuvers, and ball interactions, would provide useful baselines.
Appendix C Details of VolleyBots environment
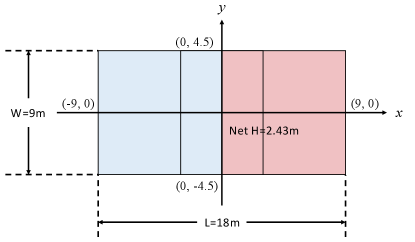
C.1 Court
The volleyball court in our environment is depicted in Fig. 5. The court is divided into two equal halves by the -axis, which serves as the dividing line separating the two teams. The coordinate origin is located at the midpoint of the dividing line, and the -axis extends along the length of the court. The total court length is , with and marking the ends of the court. The -axis extends across the width of the court, with a total width of , spanning from to . The net is positioned at the center of the court along the -axis, with a height of , and spans horizontally from to .
C.2 Drone
We use the Iris quadrotor model [25] as the primary drone platform, augmented with a virtual “racket” of radius and coefficient of restitution for ball striking. The drone’s root state is a vector with dimension , including its position, rotation, linear velocity, angular velocity, forward orientation, upward orientation, and normalized rotor speeds.
The control dynamics of a multi-rotor drone are governed by its physical configuration and the interaction of various forces and torques. The system’s dynamics can be described as follows:
| (1) | |||
| (2) |
where and represent the position and velocity of the drone in the world frame, is the rotation matrix converting from the body frame to the world frame, is the diagonal inertia matrix, denotes gravity, is the orientation represented by quaternions, and is the angular velocity. The quaternion multiplication operator is denoted by . External forces , including aerodynamic drag and downwash effects, are also considered. The collective thrust and torque are computed based on per-rotor thrusts as:
| (3) | ||||
| (4) |
where and are the local orientation and translation of the -th rotor in the body frame, is the force-to-moment ratio and is 1 for clockwise propellers and -1 for counterclockwise propellers.
C.3 Defense racket
We assume a thin cylindrical racket to mimic a human-held racket for adversarial interactions with a drone. When the ball is hit toward the racket’s half of the court, the racket is designed to intercept the ball at a predefined height . Since the ball’s position and velocity data can be directly acquired, the descent time , landing point , and pre-collision velocity can be calculated using projectile motion equations. Additionally, to ensure the ball is returned to a designated position and crosses the net, the post-collision motion duration of the ball is set to a sufficiently large value. This allows the projectile motion equations to similarly determine the post-collision velocity . Based on these conditions, the required collision position , orientation and velocity of the racket can be derived as follows:
| (5) | ||||
| (6) | ||||
| (7) | ||||
| (8) |
where represents the normal vector of the racket during impact, denotes the roll angle of the racket, denotes the pitch angle, while the yaw angle remains fixed at 0, and represents the restitution coefficient. To simulate the adversarial interaction as realistically as possible, we impose direct constraints on the racket’s linear velocity and angular velocity. Based on the simulation time step and the descent time of the ball, we can calculate the required displacement and rotation angle that the racket must achieve within each time step. If both and do not exceed their respective limits ( and ), the racket moves with linear velocity and angular velocity . Otherwise, the values are set to their corresponding limits and .
Appendix D Details of task design
| Type | Name | Sparse | Value Range | Description |
| Misbehave Penalty | drone_misbehave | ✓ | drone too low or drone too remote | |
| Task Reward | dist_to_target | ✗ | # step | related to drone’s distance to the current target |
| target_stay | ✓ | # in_target | drone stays in the current target region |
| Type | Name | Sparse | Value Range | Description |
| Misbehave Penalty | ball_misbehave | ✓ | ball too low or touch the net or out of court | |
| drone_misbehave | ✓ | drone too low or touches the net | ||
| wrong_hit | ✓ | drone does not use the racket to hit the ball | ||
| Task Reward | success_hit | ✓ | drone hits the ball | |
| distance | ✓ | related to the landing position’s distance to the anchor | ||
| dist_to_anchor | ✗ | related to drone’s distance to the anchor |
| Type | Name | Sparse | Value Range | Description |
| Misbehave Penalty | ball_misbehave | ✓ | ball too low or touch the net or out of court | |
| drone_misbehave | ✓ | drone too low or touches the net | ||
| wrong_hit | ✓ | drone does not use the racket to hit the ball | ||
| Task Reward | success_hit | ✓ | # hit | drone hits the ball |
| success_height | ✓ | # hit | ball reaches the minimum height | |
| Shaping Reward | dist_to_ball_xy | ✓ | # step | related to drone’s horizontal distance to the ball |
| dist_to_ball_z | ✓ | # step | related to drone’s clipped vertical distance to the ball |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | ball_misbehave | ✓ | ✓ | ball too low or touches the net or out of court | |
| drone_misbehave | ✓ | ✗ | drone too low or touches the net | ||
| wrong_hit | ✓ | ✗ | drone hits in the wrong turn | ||
| Task Reward | success_hit | ✓ | ✓ | # hit | drone hits the ball |
| success_cross | ✓ | ✓ | # hit | ball crosses the height | |
| dist_to_anchor | ✗ | ✓ | related to drone’ distance to its anchor | ||
| Shaping Reward | hit_direction | ✓ | ✗ | # hit | drone hits the ball towards the other drone |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | ball_misbehave | ✓ | ✓ | ball too low or touches the net or out of court | |
| drone_misbehave | ✓ | ✗ | drone too low or touches the net | ||
| wrong_hit | ✓ | ✗ | drone hits in the wrong turn | ||
| Task Reward | success_hit | ✓ | ✓ | # hit | drone hits the ball |
| downward_spike | ✓ | ✓ | # spike | ball’s velocity is downward after spike | |
| success_cross | ✓ | ✓ | ball crosses the net | ||
| in_target | ✓ | ✓ | ball lands in the target region | ||
| dist_to_anchor | ✗ | ✓ | related to drone’s distance its anchor | ||
| Shaping Reward | hit_direction | ✓ | ✗ | # hit | drone hits the ball towards its target |
| spike_velociy | ✓ | ✓ | # spike | related to ball’s downward velocity after spike | |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball | |
| dist_to_target | ✗ | ✓ | related to ball’s landing position to the target |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | ball_misbehave | ✓ | ✓ | ball too low or touches the net or out of court | |
| drone_misbehave | ✓ | ✗ | drone too low or touches the net | ||
| wrong_hit | ✓ | ✗ | drone hits in the wrong turn | ||
| Task Reward | success_hit | ✓ | ✓ | # hit | drone hits the ball |
| downward_spike | ✓ | ✓ | # spike | ball’s velocity is downward after spike | |
| success_cross | ✓ | ✓ | ball crosses the net | ||
| success_spike | ✓ | ✓ | defense racket fails to intercept | ||
| dist_to_anchor | ✗ | ✓ | related to drone’s distance to its anchor | ||
| Shaping Reward | hit_direction | ✓ | ✗ | # hit | drone hits the ball towards their targets |
| spike_velociy | ✓ | ✓ | # spike | related to ball’s downward velocity after spike | |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | drone_misbehave | ✓ | ✗ | drone too low or touches the net | |
| drone_out_of_court | ✗ | ✗ | # step | related to drone’s distance out of its court | |
| Task Reward | win_or_lose | ✓ | ✗ | drone wins or loses the game | |
| Shaping Reward | success_hit | ✓ | ✗ | # hit | drone hits the ball |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | drone_misbehave | ✓ | ✗ | drone too low or touches the net. | |
| drone_collision | ✓ | ✗ | drone collides with its teammate. | ||
| Task Reward | win_or_lose | ✓ | ✓ | drones win or lose the game | |
| Shaping Reward | success_hit | ✓ | ✓ | # hit | drone hits the ball |
| dist_to_anchor | ✗ | ✗ | # step | related to drone’s distance to its anchor | |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball |
| Type | Name | Sparse | Shared | Value Range | Description |
| Misbehave Penalty | drone_misbehave | ✓ | ✗ | drone too low or touches the net. | |
| drone_collision | ✓ | ✗ | drone collides with its teammate. | ||
| Task Reward | win_or_lose | ✓ | ✓ | drones win or lose the game | |
| Shaping Reward | success_hit | ✓ | ✓ | # hit | drone hits the ball |
| dist_to_anchor | ✗ | ✗ | # step | related to drone’s distance to its anchor | |
| dist_to_ball | ✗ | ✗ | # step | related to drone’s distance to the ball |
D.1 Back and Forth
Task definition.
The drone is initialized at an anchor position , i.e., the center of the red court with a height of . The other anchor position is , with the target points switching between two designated anchor positions. The drone is required to sprint between two designated anchors to complete as many round trips as possible. steps within a sphere with a radius near the anchor position are required for each stay. The maximum episode length is steps.
Observation and reward.
When the action space is Per-Rotor Thrust(PRT), the observation is a vector of dimension , which includes the drone’s root state and its relative position to the target anchor. When the action space is Collective Thrust and Body Rates (CTBR), the observation dimension is reduced to , excluding the drone’s throttle. The detailed description of the reward function of this task is listed in Table 5.
Evaluation metric.
This task is evaluated by the number of target points reached within the time limit. A successful stay is defined as the drone staying steps within a sphere with a radius near the target anchor.
D.2 Hit the Ball
Task definition.
The drone is initialized randomly around an anchor position , i.e., the center of the red court with a height of . The drone’s initial position is sampled uniformly random from to . The ball is initialized at , i.e., above the anchor position. The ball starts with zero velocity and falls freely. The drone is required to perform a single hit to strike the ball toward the opponent’s court, i.e., in the negative direction of the x-axis, aiming for maximum distance. The maximum episode length is steps.
Observation and reward.
When the action space is Per-Rotor Thrust(PRT), the observation is a vector of dimension , which includes the drone’s root state, the drone’s relative position to the anchor, the ball’s relative position to the drone, and the ball’s velocity. When the action space is Collective Thrust and Body Rates (CTBR), the observation dimension is reduced to , excluding the drone’s throttle. The detailed description of the reward function of this task is listed in Table 6.
Evaluation metric.
This task is evaluated by the distance between the ball’s landing position and the anchor position. The ball’s landing position is defined as the intersection of its trajectory with the plane .
D.3 Solo Bump
Task definition.
The drone is initialized randomly around an anchor position , i.e., the center of the red court with a height of . The drone’s initial position is sampled uniformly random from to . The ball is initialized at , i.e., above the anchor position. The ball starts with zero velocity and falls freely. The drone is required to stay within a sphere with radius near the anchor position and bump the ball as many times as possible. A minimum height of is required for each bump. The maximum episode length is steps.
Observation and reward.
When the action space is Per-Rotor Thrust (PRT), the observation is a vector of dimension , which includes the drone’s root state, the drone’s relative position to the anchor, the ball’s relative position to the drone, and the ball’s velocity. When the action space is Collective Thrust and Body Rates (CTBR), the observation dimension is reduced to , excluding the drone’s throttle. The detailed description of the reward function of this task is listed in Table 7.
Evaluation metric.
This task is evaluated by the number of successful consecutive bumps performed by the drone. A successful bump is defined as the drone hitting the ball such that the ball’s highest height exceeds but not exceeds .
D.4 Bump and Pass
Task definition.
Drone 1 is initialized randomly around anchor 1 with position , and Drone 2 is initialized randomly around anchor 2 with position . The initial position of drone 1 is sampled uniformly random from to , and the initial position of drone 2 is sampled uniformly random from to . The ball is initialized at , i.e., above anchor 1. The ball starts with zero velocity and falls freely. The drones are required to stay within a sphere with radius near their anchors and bump the ball to pass it to each other in turns as many times as possible. A minimum height of is required for each bump. The maximum episode length is 800 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the drone’s id, the current turn (which drone should hit the ball), the ball’s relative position to the drone, the ball’s velocity, and the other drone’s relative position to the drone. The detailed description of the reward function of this task is listed in Table 8.
Evaluation metric.
This task is evaluated by the number of successful consecutive bumps performed by the drones. A successful bump is defined as the drone hitting the ball such that the ball’s highest height exceeds and lands near the other drone.
D.5 Set and Spike (Easy)
Task definition.
Drone 1 (setter) is initialized randomly around anchor 1 with position , and Drone 2 (attacker) is initialized randomly around anchor 2 with position . The initial position of drone 1 is sampled uniformly random from to , and the initial position of drone 2 is sampled uniformly random from to . The ball is initialized at , i.e., above anchor 1. The ball starts with zero velocity and falls freely. The drones are required to stay within a sphere with radius near their anchors. The setter is required to pass the ball to the attacker, and the attacker then spikes the ball downward to the target region in the opposing side. The target region is a circular area on the ground, centered at with a radius of . The maximum episode length is 800 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the drone’s id, the current turn (how many times the ball has been hit), the ball’s relative position to the drone, the ball’s velocity, and the other drone’s relative position to the drone. The detailed description of the reward function of this task is listed in Table 9.
Evaluation metric.
This task is evaluated by the success rate of set and spike. A successful set and spike consist of four parts, (1) setter_hit: the setter hits the ball; (2) attacker_hit: the attacker hits the ball; (3) downward_spike: the velocity of the ball after the attacker hit is downward, i.e., ; (4) in_target: the ball’s landing position is within the target region. The success rate is computed as .
D.6 Set and Spike (Hard)
Task definition.
Drone 1 (setter) is initialized randomly around anchor 1 with position , and Drone 2 (attacker) is initialized randomly around anchor 2 with position . The initial position of drone 1 is sampled uniformly random from to , and the initial position of drone 2 is sampled uniformly random from to . The ball is initialized at , i.e., above anchor 1. The ball starts with zero velocity and falls freely. The racket is initialized at , i.e., the center of the opposing side. The drones are required to stay within a sphere with radius near their anchors. The setter is required to pass the ball to the attacker, and the attacker then spikes the ball downward to the opponent’s court without being intercepted by the defense racket. The maximum episode length is 800 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the drone’s id, the current turn (how many times the ball has been hit), the ball’s relative position to the drone, the ball’s velocity, and the other drone’s relative position to the drone. The detailed description of the reward function of this task is listed in Table 10.
Evaluation metric.
This task is evaluated by the success rate of set and spike. A successful set and spike consist of four parts, (1) setter_hit: the setter hits the ball; (2) attacker_hit: the attacker hits the ball; (3) downward_spike: the velocity of the ball after the attacker hit is downward, i.e., ; (4) success_spike: the ball’s landing position is within the opponent’s court without being intercepted by the defense racket. The success rate is computed as .
D.7 1 vs 1
Task definition.
Two drones are required to play 1 vs 1 volleyball in a reduced-size court of . Drone 1 is initialized randomly around anchor 1 with position , i.e., the center of the red court with height , and Drone 2 is initialized randomly around anchor 2 with position , i.e., the center of the blue court with height . The initial position of drone 1 is sampled uniformly random from to , and the initial position of drone 2 is sampled uniformly random from to . At the start of a game (i.e. an episode), one of the two drones is randomly chosen to serve the ball, which is initialized above the drone. The ball starts with zero velocity and falls freely. The game ends when one of the drones wins the game or one of the drones crashes. The maximum episode length is 800 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the drone’s id, the current turn (which drone should hit the ball), the ball’s relative position to the drone, the ball’s velocity, and the other drone’s relative position to the drone. The detailed description of the reward function of this task is listed in Table 11.
Evaluation metric.
The drone wins the game by landing the ball in the opponent’s court or causing the opponent to commit a violation. These violations include (1) crossing the net, (2) hitting the ball on the wrong turn, (3) hitting the ball with part of the drone body instead of the racket, (4) hitting the ball out of court, and (5) hitting the ball into the net.
To comprehensively evaluate the performance of strategies in the 1 vs 1 task, we consider three evaluation metrics: exploitability, win rate, and Elo rating. These metrics provide complementary insights into the quality and robustness of the learned policies.
-
•
Exploitability: Exploitability is a fundamental measure of how close a strategy is to a Nash equilibrium. It is defined as the difference between the payoff of a best response (BR) against the strategy and the payoff of the strategy itself. Mathematically, for a strategy , the exploitability is given by:
where represents the utility obtained by when playing against . The meaning of exploitability is that smaller values indicate a strategy closer to Nash equilibrium, where it becomes increasingly difficult to exploit. Since exact computation of exploitability is often infeasible in real-world tasks, we instead use approximate exploitability. In this task, we fix the strategy on one side and train an approximate best response on the other side to maximize its utility, i.e., win rate. The difference between the BR’s win rate and the evaluated policy’s win rate then serves as the approximate exploitability.
-
•
Win rate: Since exact exploitability is challenging to compute, a practical alternative is to evaluate the win rate through cross-play with other learned policy populations. Specifically, we compute the average win rate of the evaluated policy when matched against other learned policies. Higher average win rates typically suggest stronger strategies. However, due to the transitive nature of zero-sum games [39], a high win rate against specific opponent populations does not necessarily imply overall mastery of the game. Thus, while win rate is a useful reference metric, it cannot be the sole criterion for assessing strategy strength.
-
•
Elo rating: Elo rating is a widely used metric for evaluating the relative strength of strategies within a population. It is computed based on head-to-head match results, where the expected win probability between two strategies is determined by their Elo difference. After each match, the Elo ratings of the strategies are updated based on the match outcome. While a higher Elo rating indicates better performance within the given population, it does not necessarily imply proximity to Nash equilibrium. A strategy with a higher Elo might simply be more effective against the specific population, rather than being universally robust. Therefore, Elo complements exploitability by capturing population-specific relative performance.
D.8 3 vs 3
Task definition.
The task involves two teams of drones competing in a 3 vs 3 volleyball match within a reduced-size court of . Drone 1, Drone 2, and Drone 3 belong to Team 1 and are initialized at positions , and respectively. Similarly, Drone 4, Drone 5, and Drone 6 belong to Team 2 and are initialized at positions , and respectively. At the start of a game (i.e., an episode), one of the two teams is randomly selected to serve the ball. The ball is initialized at a position directly above the serving drone. The ball starts with zero velocity and falls freely. The game ends when one of the teams wins the game or one of the drones crashes. The maximum episode length is 500 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the ball’s relative position to the drone, the ball’s velocity, the current turn (which team should hit the ball), the drone’s id, a flag indicating whether the drone is allowed to hit the ball, and the other drone’s positions. The detailed description of the reward function of this task is listed in Table 12.
Evaluation metric.
Similar to the 1 vs 1 task, either of the two teams wins the game by landing the ball in the opponent’s court or causing the opponent to commit a violation. These violations include (1) crossing the net, (2) hitting the ball on the wrong turn, (3) hitting the ball with part of the drone body, rather than the racket, (4) hitting the ball out of court, and (5) hitting the ball into the net. The task performance is also evaluated by the three metric metrics including exploitability, win rate, and Elo as described in the 1 vs 1 task.
D.9 6 vs 6
Task definition.
The task involves two teams of drones competing in a 6 vs 6 volleyball match within a standard-size court of . Drone 1 to Drone 6 belong to Team 1 and are initialized at positions , , , , and respectively. Similarly, Drone 7 to Drone 12 belong to Team 2 and are initialized at positions , , , , and respectively. At the start of a game (i.e., an episode), one of the two teams is randomly selected to serve the ball. The ball is initialized at a position directly above the serving drone. The ball starts with zero velocity and falls freely. The game ends when one of the teams wins the game or one of the drones crashes. The maximum episode length is 500 steps.
Observation and reward.
The drone’s observation is a vector of dimension including the drone’s root state, the drone’s relative position to the anchor, the ball’s relative position to the drone, the ball’s velocity, the current turn (which team should hit the ball), the drone’s id, a flag indicating whether the drone is allowed to hit the ball, and the other drone’s positions. The detailed description of the reward function of this task is listed in Table 13.
Evaluation metric.
Either of the two teams wins the game by landing the ball in the opponent’s court or causing the opponent to commit a violation. These violations include (1) crossing the net, (2) hitting the ball on the wrong turn, (3) hitting the ball with part of the drone body, rather than the racket, (4) hitting the ball out of court, and (5) hitting the ball into the net.
Appendix E Discussion of benchmark algorithms
E.1 Reinforcement learning algorithms
To explore the capabilities of our testbed while also providing baseline results, we implement and benchmark a spectrum of popular RL and game-theoretic algorithms on the proposed tasks.
Single-agent RL.
In single-agent scenarios, we consider five commonly used algorithms. Deep Q-Network (DQN) [27] is a value-based, off-policy method that approximates action-value functions for discrete action spaces using experience replay and a target network to stabilize learning. Deep Deterministic Policy Gradient (DDPG) [28] is an off-policy actor-critic approach relying on a deterministic policy and an experience replay buffer to handle continuous actions. Twin Delayed DDPG (TD3) [29] builds on DDPG by employing two Q-networks to mitigate overestimation bias, delaying policy updates, and adding target policy smoothing for improved stability. Soft Actor-Critic (SAC) [30] is an off-policy actor-critic algorithm that maximizes a combined reward-and-entropy objective, promoting robust exploration via a maximum-entropy framework. Proximal Policy Optimization (PPO) [31] adopts a clipped objective to stabilize on-policy learning updates by constraining policy changes. Overall, these methods provide contrasting paradigms for tackling single-agent continuous tasks.
Multi-agent RL.
For tasks with multiple drones, we evaluate five representative multi-agent algorithms. QMIX [32] is a value-based method that factorizes the global action-value function into individual agent utilities via a monotonic mixing network, enabling centralized training with decentralized execution. Multi-Agent DDPG (MADDPG) [33] extends DDPG with a centralized critic for each agent, while policies remain decentralized. Multi-Agent PPO (MAPPO) [34] incorporates a shared value function to improve both coordination and sample efficiency. Heterogeneous-Agent PPO (HAPPO) [35] adapts PPO techniques to handle distinct roles or capabilities among agents. Multi-Agent Transformer (MAT) [36] leverages a transformer-based architecture to enable attention-driven collaboration. Taken together, these algorithms offer a diverse set of baselines for multi-agent cooperation.
Game-theoretic algorithms.
For multi-agent competitive tasks, we consider several representative game-theoretic algorithms in the literature [40]. Self-play (SP) trains agents against the current version of themselves, allowing a single policy to evolve efficiently. Fictitious Self-Play (FSP) [37] trains agents against the average policy by maintaining a pool of past checkpoints. Policy-Space Response Oracles (PSRO) [38] iteratively add the best responses to the mixture of a growing policy population. The mixture policy is determined by a meta-solver. PSRO uses a uniform meta-solver that samples policies with equal probability, while PSRO uses a Nash meta-solver that samples policies according to the Nash equilibrium. These methods provide an extensive benchmark for game-theoretic algorithms in multi-agent competition with both motion control and strategic play. There are also some algorithms like Team-PSRO [41] and Fictitious Cross-Play (FXP) [42] that are designed specifically for mixed cooperative-competitive games and can be integrated in our testbed in future work.
Appendix F Details of benchmark experiments
| hyperparameters | value | hyperparameters | value | hyperparameters | value |
| optimizer | Adam | max grad norm | lr | ||
| buffer length | buffer size | batch size | |||
| gamma | tau | target update interval | |||
| max episode length | num envs | train steps |
| Algorithms | DQN | DDPG | TD3 | SAC |
| actor network | / | MLP | MLP | MLP |
| critic network | MLP | MLP | MLP | MLP |
| MLP hidden sizes | ||||
| critic loss | / | smooth L1 | smooth L1 | smooth L1 |
| discrete bin | / | / | / |
| hyperparameters | value | hyperparameters | value | hyperparameters | value |
| optimizer | Adam | max grad norm | entropy coef | ||
| buffer length | num minibatches | ppo epochs | |||
| value norm | ValueNorm1 | clip param | normalize advantages | True | |
| use huber loss | True | huber delta | gae lambda | ||
| use orthogonal | True | gain | gae gamma | ||
| max episode length | num envs | train steps |
| Algorithms | (MA)PPO | HAPPO | MAT |
| actor lr | |||
| critic lr | |||
| share actor | True | False | / |
| hidden sizes | |||
| num blocks | / | / | |
| num head | / | / |
| hyperparameters | value | hyperparameters | value | hyperparameters | value |
| optimizer | Adam | q_net and q_mixer network | MLP | MLP hidden sizes | |
| lr | buffer length | buffer size | |||
| batch size | gamma | max grad norm | |||
| discrete bin | tau | target update interval | |||
| max episode length | num envs | train steps |
F.1 Experimental Platform and Computational Resources
Our experiments were conducted on a workstation equipped with NVIDIA GeForce RTX 4090 or RTX 3090 GPUs, 128 GB of RAM, and Ubuntu 20.04 LTS. The software environment included CUDA 12.4, Python 3.10, PyTorch 2.0, and NVIDIA Isaac Sim 2023.1.0. All single-agent and multi-agent cooperative experiments completed in under 12 hours, while multi-agent competitive experiments finished in under 24 hours.
F.2 Hyperparameters of benchmarking algorithms
F.2.1 Single-agent tasks.
F.2.2 Multi-agent cooperative tasks
F.2.3 Multi-agent competitive tasks.
Training.
For self-play (SP) in 1 vs 1, 3 vs 3, and 6 vs 6 competitive tasks, we adopt the MAPPO algorithm with shared actor networks and shared critic networks between two teams, in order to make sure two teams utilize the same policy. Also, we transform the samples from both sides into symmetric ones and then use these symmetric samples to update the network together. The hyperparameters employed here are the same as those used in the MAPPO algorithm for multi-agent cooperative tasks.
The PSRO algorithm for 1 vs 1 competitive task instantiates a PPO agent for training one of the two drones while the other drone maintains a fixed policy. Similarly, the PSRO algorithm for the 3 vs 3 and 6 vs 6 tasks assigns each team to be controlled by MAPPO. We adopt the same set of hyperparameters listed in Table 16 and 17 for the (MA)PPO agent. In each iteration, the (MA)PPO agent is trained against the current population. Here, we offer two versions of meta-strategy solver, PSROUniform and PSRONash. Training is considered converged when the agent achieves over 90% win rate with a standard deviation below 0.05. The iteration ends when the agent reaches convergence or reaches a maximum of iteration steps of 5000. The trained actor is then added to the population for the next iteration.
For Fictitious Self-Play (FSP) in competitive tasks, we slightly modify PSROUniform so that in each iteration, the (MA)PPO agent inherits the learned policy from the previous iteration as initialization. Naturally, other hyperparameters and settings remain the same for a fair comparison.
The algorithm leverages 2048 parallel environments for the 1 vs 1 and 3 vs 3 tasks, and 800 parallel environments for the 6 vs 6 task. In this work, we report the results of different algorithms given a total budget of environmental steps.
Evaluation.
The evaluation of exploitability requires evaluating the payoff of the best response (BR) over the trained policy or population from different algorithms. Here, we approximate the BR to each policy or population by learning an additional RL agent against the trained policy or population. In practice, this is done by performing an additional iteration of PSRO, where the opponent is fixed as the trained policy/population. In order to approximate the ideal BR as closely as possible, we initialize the BR policy with the latest FSP policy, given that FSP yields the best empirical performance in our experiments. We train the BR policy for training step with parallel environments. We disable the convergence condition for early termination and report the evaluated win rate to calculate the approximate exploitability. Importantly, to approximate the BR of the trained SP policy in the 3 vs 3 task, we employ two distinct BR policies for the serve and rally scenarios, respectively. For the BR to serve, we directly use the latest FSP policy without further training, while for the BR to rally, we train a dedicated policy against the SP policy. The overall win rate of this BR is then computed as the average win rate across these two scenarios, given that each side has an equal serve probability.
We run 1,000 games for each pair of policies to generate the cross-play win rate heatmap, covering 6 matchup scenarios, resulting in a total of 6,000 games. In each game, both policies are sampled from their respective policy populations based on the meta-strategy and play until a winner is determined.
Moreover, we use an open-source Elo implementation [43]. The coefficient is set to , and the initial Elo rating for all policies is . We conduct games among four policies. The number of games played between any two policies is guaranteed to be the same. Specifically, in each round, different matchups are played. Each policy participates in 3 matchups, competing against different opponent policies. A total of rounds are carried out, amounting to games in total. The game results are sampled and generated based on the cross-play results.
F.3 Results of single-agent tasks
Fig. 6 plots the training progress of five single-agent algorithms on three single-agent volleyball tasks under both CTBR (top row) and PRT (bottom row) action space, averaged over three seeds. Across every task, PPO (orange) converges fastest and to the highest performance, stabilizing at roughly successful reaches in Back and Forth, m in Hit the Ball, and bumps in Solo Bump. TD3 (green), SAC (purple), and DDPG (blue) exhibit comparable moderate performance across most tasks, with TD3 notably outperforming SAC and DDPG in Solo Bump. In contrast, DQN (red) fails to make meaningful progress in any of the tasks. Moreover, each algorithm exhibits comparable behavior under both CTBR and PRT action spaces, with slightly better final performance under PRT for most methods and tasks.
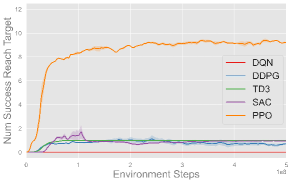
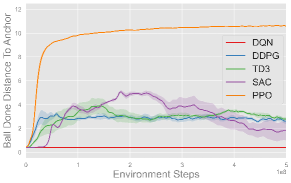
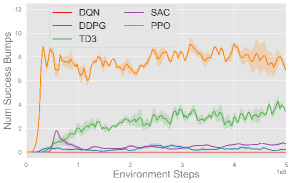
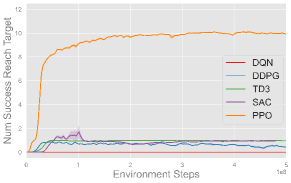
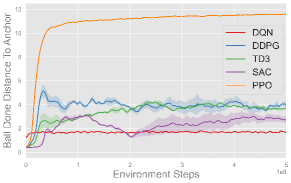
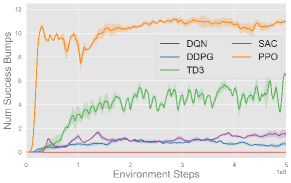
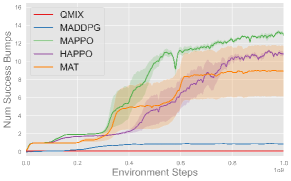
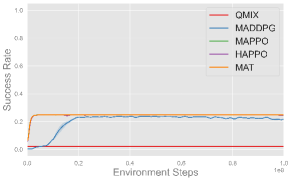
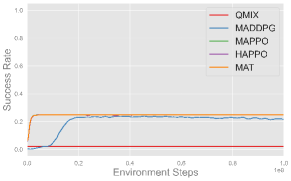
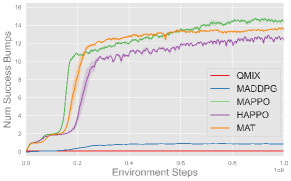
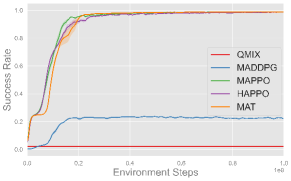
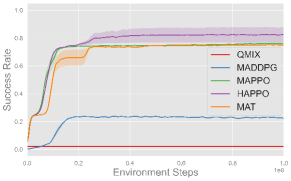
F.4 Results of multi-agent cooperative tasks
The training curves of different algorithms in multi-agent tasks are shown in Fig. 7. MAPPO (green), HAPPO (purple) and MAT (orange) achieve the strongest overall performance. In the Bump and Pass task without reward shaping, MAPPO learns fastest and attains the highest number of successful bumps, outperforming both HAPPO and MAT. By contrast, MADDPG (blue) delivers only modest gains, struggling particularly in Bump and Pass, and QMIX (red) fails to make meaningful progress in any of the tasks.
Additionally, we can observe that the presence of shaping rewards has a significant impact on task results. Adding shaping rewards clearly improves the performance and accelerates the learning process. In Bump and Pass, the task learns more slowly without shaping rewards because the policy must explore which direction to hit the ball, requiring many more steps. The hit direction reward in shaping rewards accelerates this process. In Set and Spike (Easy) and Set and Spike (Hard), all algorithms without shaping rewards have a success rate of only because they only learn to make the setter hit the ball, but not toward the hitter. As a result, the attacker fails to hit the ball. The hit direction reward in shaping rewards helps accelerate this process.
F.5 Results of multi-agent competitive tasks
We provide a more detailed win rate evaluation of the PSRO populations from the 1 vs 1 task in Fig. 8, where each policy in the PSRO population is evaluated against all other policies. In these heatmaps, the ordinate and abscissa represent the policy for drone 1 and drone 2 respectively. The heat of cells represents the evaluated win rate of drone 1, i.e. red means a higher win rate and blue means a lower win rate. Intuitively, each row represents a policy’s performance against each policy of the population while playing as drone 1. A red cell indicates that the drone 1 policy outperforms the specific drone 2 policy. A full red row means that the policy outperforms all other policies.
Evidently, FSP attains more iterations than PSROUniform and PSRONash given a budget of steps, which yields a faster convergence speed. This advantage comes from the fact that FSP inherits the learned policy from the previous iteration, which serves as an advantageous initialization for the current iteration. In contrast, PSROUniform and PSRONash start from scratch in each iteration, which poses a challenge for the algorithm to converge and introduces more variance in the training process.
Moreover, in PSRO algorithms, as the learned policy gradually improves with each iteration, the most recent policy of the population naturally poses greater difficulty for subsequent iterations. Therefore, PSRONash tends to put more weight on the most recent policy in the meta-strategy. This in turn has an effect on the learning of new policies. We can observe the outcomes in the heatmaps: for each row, the win rate against the most recent policy is often higher than the others. In FSP, on the other hand, the win rate against each policy is more evenly distributed, indicating that the population is potentially more balanced and stable.
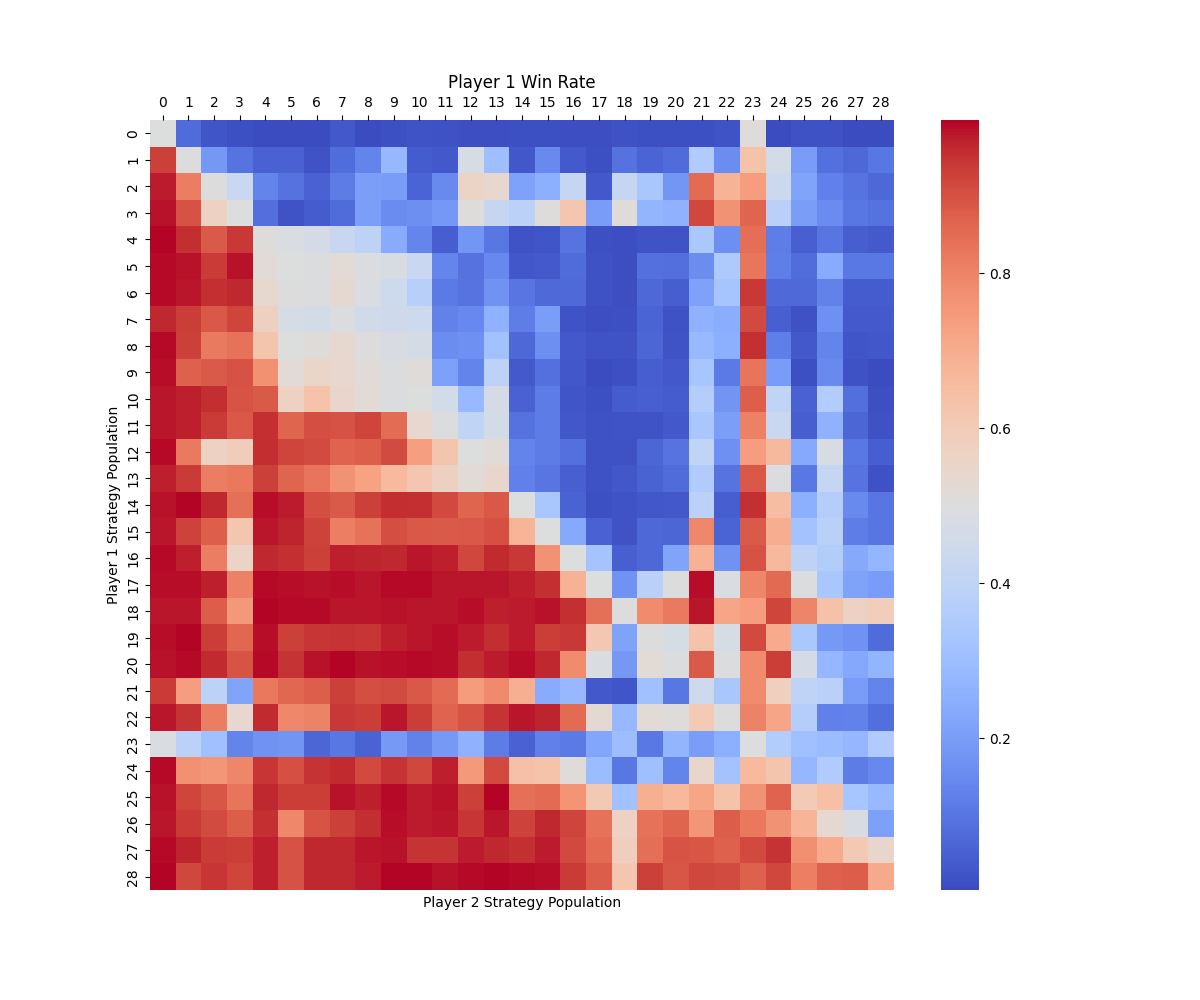
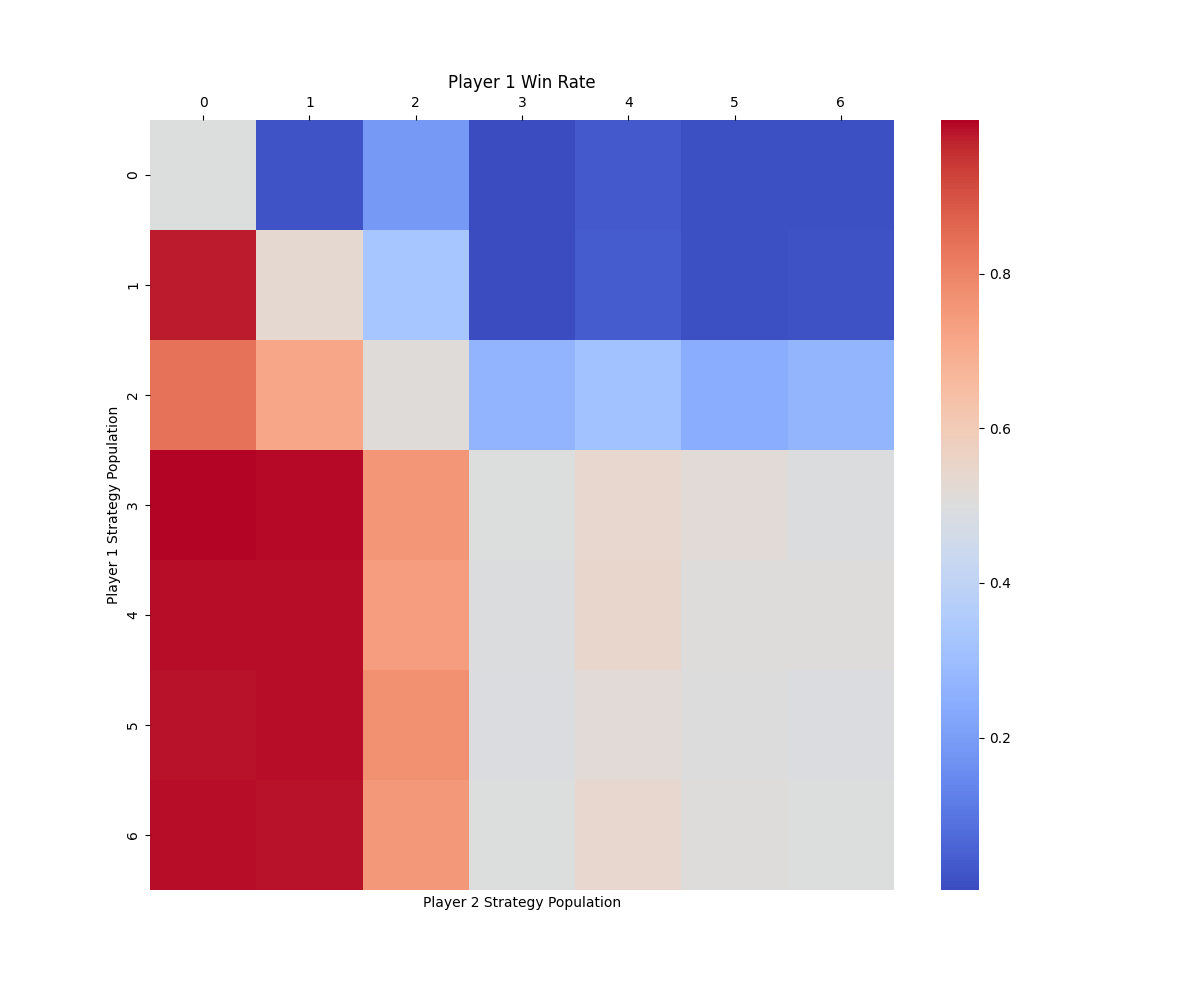
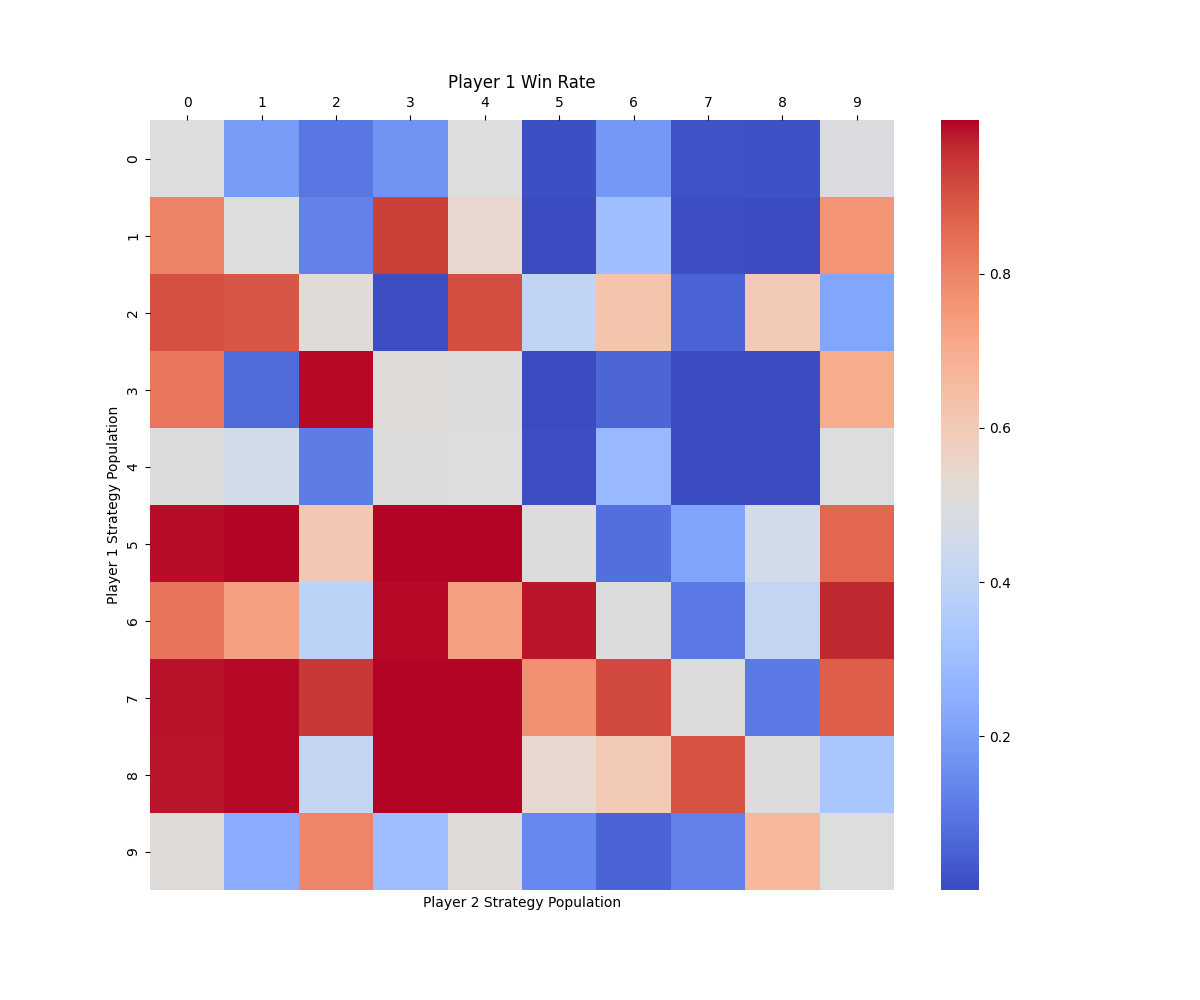
F.6 Low-level drills of hierarchical policy
Low-level drills are derived through PPO training, while the high-level skill is implemented as a rule-based, event-driven policy that determines which drone utilizes which skill in response to the current game state. In accordance with the 3 vs 3 task setting, each team consists of three drones positioned as front-left, front-right, and backward within their half of the court. Below, we describe each low-level drill and explain when it is utilized by the high-level policy.
Hover.
The Hover skill is designed to enable the drone to hover around a specified target position. This skill takes a three-dimensional target position as input. The skill is frequently utilized by the high-level policy. For instance, in the serve scenario, only the serving drone uses the Serve skill, while the other two teammates use the Hover skill to remain at their respective anchor points.
Serve.
The Serve skill is designed to enable the drone to serve the ball towards the opponent’s side of the court. In accordance with the 3 vs 3 task setting, for the Serve skill, the ball is initialized at a position directly above the serving drone, with zero initial velocity. This skill is exclusively utilized by the high-level policy during the serve scenario, during which the designated serving drone employs the Serve skill at the start of a match.
Pass.
The Pass skill is designed to handle the opponent’s serve or attack by allowing the drone to make the first contact of the team’s turn and pass the ball to a teammate. This skill is exclusively used by the backward drone responsible for hitting the ball to the front-left teammate. The high-level policy designates the backward drone to utilize this skill whenever the opponent hits the ball.
Set.
The Set skill is designed to transfer the ball from the passing drone to the attacking drone, serving as the second contact in the team’s turn. In our design, the front-left drone utilizes the Set skill to pass the ball to the front-right drone. The high-level policy designates the front-left drone to utilize this skill whenever the backward drone successfully makes contact with the ball.
Attack.
The Attack skill is designed to hit the ball towards the opponent’s court, serving as the third and final contact in the team’s turn. This skill includes a one-hot target input that specifies whether to direct the ball to the left side or the right side of the opponent’s court. In our design, the front-right drone uses the Attack skill to strike the ball. The high-level policy assigns the front-right drone to utilize this skill whenever the front-left drone successfully hits the ball.