VTS-LLM: Domain-Adaptive LLM Agent for Enhancing Awareness in Vessel Traffic Services through Natural Language
Abstract
Vessel Traffic Services (VTS) are essential for maritime safety and regulatory compliance through real-time traffic management. However, with increasing traffic complexity and the prevalence of heterogeneous, multimodal data, existing VTS systems face limitations in spatiotemporal reasoning and intuitive human interaction. In this work, we propose VTS-LLM Agent, the first domain-adaptive large language model (LLM) agent tailored for interactive decision support in VTS operations. We formalize risk-prone vessel identification as a knowledge-augmented Text-to-SQL task, combining structured vessel databases with external maritime knowledge. To support this, we construct a curated benchmark dataset consisting of a custom schema, domain-specific corpus, and a query–SQL test set in multiple linguistic styles. Our framework incorporates NER-based relational reasoning, agent-based domain knowledge injection, semantic algebra intermediate representation, and query rethink mechanisms to enhance domain grounding and context-aware understanding. Experimental results show that VTS-LLM outperforms both general-purpose and SQL-focused baselines under command-style, operational-style, and formal natural language queries, respectively. Moreover, our analysis provides the first empirical evidence that linguistic style variation introduces systematic performance challenges in Text-to-SQL modeling. This work lays the foundation for natural language interfaces in vessel traffic services and opens new opportunities for proactive, LLM-driven maritime real-time traffic management.
I Introduction
Vessel Traffic Services (VTS) serve as critical infrastructure deployed in major ports, straits, and coastal regions to ensure maritime safety, environmental protection, and the efficient management of vessel movements. These services rely on shipborne sensor data, such as AIS (Automatic Identification System) transmitted over VHF channels, along with shore-based radar observations and voice communication between operators and vessels, to provide real-time surveillance, navigational assistance, and regulatory enforcement.
As global shipping volumes grow, VTS operations have become increasingly complex. Operators must continuously interpret dynamic, heterogeneous data—such as vessel movements, ship characteristics, voyage schedules, and geographic context—requiring ongoing spatiotemporal reasoning. This imposes a substantial cognitive load, particularly under time-critical conditions demanding rapid decisions and compliance assessments.
Although modern VTS systems support multi-source data fusion and visualized human-machine interaction, they remain limited in performing deeper spatiotemporal analysis. Tasks like early identification of risk-prone vessels—especially those involving abstract, localized rules—require integration of diverse databases and complex geospatial reasoning. Yet, current systems lack intelligent and intuitive mechanisms for exploratory querying and automated analysis. Vessel information retrieval still heavily depends on manual operator input and often requires formal SQL queries or navigating rigid interfaces, posing usability challenges and reducing efficiency.
Recent advances in the development and application of LLMs have shown promising potential to enhance various aspects of maritime transportation [1], such as satellite image-based ship detection[2], intelligent navigation[3], and the advancement of unmanned vessel technologies[4]. While as for the aspect of real-time traffic management, the application of LLMs has been more extensively explored in land transportation domains[5], such as traffic control [6, 7] and spatiotemporal prediction[8, 9]. These advances illustrate the growing potential of LLMs to transform traffic management practices through data-driven, context-aware approaches.
Inspired by the work [10], which leverages LLMs for real-time land traffic surveillance through intelligent querying and contextual reasoning, we believe that, to the best of our knowledge, LLM-based agents now enable intuitive natural language exploration and context-aware analysis of maritime traffic data—capabilities not yet explored in VTS scenarios. To address the high cognitive load, we propose the first adaptation of an LLM-powered interactive agent VTS-LLM for awareness enhancement in VTS domain.
Furthermore, motivated by geospatial demands of VTS operations and complexity of localized navigational rules, we reformulate risk-prone vessel identification as a knowledge-augmented Text-to-SQL task. Natural language queries on vessel behavior and rule compliance are grounded in both structured databases—capturing operational and spatiotemporal attributes—and external corpora containing domain knowledge and dynamic regulations. Based on this formulation, we construct a curated benchmark dataset to support future research in maritime-aware knowledge-augmented Text-to-SQL modeling in VTS scenarios.
Given domain-specific and knowledge-augmented characteristics of our application, effective Text-to-SQL performance hinges on the agent’s ability to generalize across specialized schemas, varied query intents, and heterogeneous contextual knowledge[11]. Prior research on building more effective and adaptive Text-to-SQL LLMs has mostly focus on 1) in-context learning, including decomposition[12], prompt optimization[13] and chain-of-thought [14]; and 2) fine-tuning paradigm, including enhanced architecture[15], pretraining[16], data augmentation[17] and multi-task tuning[13]. These methods demonstrate excellent performance on the general-purpose evaluation benchmarks Spider1.0 [18], Spider2.0 [19] and BIRD[14].
However, prior studies have not addressed the unique knowledge-augmented characteristics and operational demands in maritime VTS scenarios. Beyond the challenges of spatiotemporal reasoning and knowledge integration, we identify key obstacles limiting LLM generalization. First, VTS operator expressions often follow compact, task-oriented styles with incomplete or non-standard syntax, differing from the well-formed language on which most models are trained. Second, vessel databases evolve over time and include ambiguous or overlapping entities (e.g., ship names, area codes), complicating entity linking and query interpretation.
To address these challenges in the VTS domain, we develop VTS-LLM with targeted adaptations: NER-based relational reasoning, agent-based domain knowledge injection, semantic algebra intermediate representation, and query rethink mechanisms. These components enhance schema alignment, semantic grounding, and rule interpretation, establishing a performance baseline for future benchmarking. We also propose a noval penalty-based evaluation metric that adjusts scores based on error severity, improving assessment in safety-critical scenarios. Experiments on our VTS-SQL dataset show that VTS-LLM achieves 72.60%, 77.80%, and 89.72% under command, operational, and formal natural language styles, respectively, demonstrating strong robustness across linguistic variations. Besides, to our best knowledge, our work presents the first empirical evidence that linguistic style variation can introduce significant and systematic challenges in Text-to-SQL modeling, an issue previously underexplored in the literature.
As summarized, our contributions are as follows:
1) Formalize a knowledge-augmented Text-to-SQL task for identifying risk-prone vessels in VTS system, by constructing a multimodal dataset for benchmark consisting of: (i) a custom-designed relational database capturing vessel traffic features, (ii) an external maritime knowledge corpus for VTS, and (iii) a query–SQL pair test-set covering different linguistic styles, including command-style, operational-style, and formal natural language style.
2) Propose VTS-LLM, the first LLM-based agent system adapted to interactive decision support in VTS operations, featuring a domain-adaptive framework with NER-based reasoning, semantic algebra intermediate representation, agent-based domain knowledge injection, and query rethink mechanisms. The agent model enables real-time, context-aware operational dialogue and achieves superior performance over general-purpose and SQL-specialized models.
3) Provide the first empirical evidence that linguistic style variation introduces systematic performance challenges in Text-to-SQL tasks, with LLM performing worse on concise, informal, and fragmented queries, highlighting an underexplored aspect in prior research.
II Vessel-of-Interest Identification in VTS via Text-to-SQL
II-A Identification of Vessels of Interest
VTS operations primarily involve responding to vessel inquiries and monitoring ships that may pose navigational risks. While basic information retrieval, such as checking vessel data via identifiers, is straightforward, the task of monitoring and identifying vessels that may pose navigational risks is significantly more complex. Operators must reason over large volumes of dynamic traffic data and detect subtle early-stage indicators of potential hazards.
To address this, we reformulate the task as a Text-to-SQL problem, a well-established paradigm in the fields of artificial intelligence, enabling the translation of natural language queries from operators into executable SQL queries over structured vessel traffic database.
Unlike existing CPA-based (Closest Point of Approach) alert mechanisms, which highlight vessels only when collision risk is imminent, our focus is on earlier identification of vessels of interest—such as those approaching congested areas or experiencing prolonged signal loss—allowing for more proactive supervision.
Besides, VTS operations must also enforce localized navigational rules that restrict certain vessel types within specific maritime zones—particularly in high-traffic or constrained areas where factors like size, draft, or navigation behaviors affect traffic. For instance, very large crude carriers (VLCCs) and deep-draft vessels may be barred from entering certain channels during specific time windows. While not always posing immediate collision risks, violations of such rules can disrupt traffic order or compromise safety. Identifying these vessels is thus a key part of proactive supervision and falls within our broader definition of vessels of interest.
II-B Knowledge-augmented Text-to-SQL with Operational Linguistic Queries
To better reflect practical VTS scenarios, we refine the problem into a knowledge-augmented variant of the Text-to-SQL task, tailored to the operational query styles used in VTS.
First, maritime supervision involves rich domain knowledge that extends beyond traffic data schema. This includes specialized maritime terminology, localized navigational rules and procedures specific to particular sea areas, as well as time-sensitive documents such as Notices to Mariners and real-time traffic advisories. These materials are essential for correctly interpreting operator queries and ensuring accurate rule-based supervision. Given their dynamic and context-dependent nature, such knowledge must be incorporated through knowledge-augmented mechanisms that can provide relevant textual guidance during query understanding and reasoning.
Second, operator-issued queries in VTS scenarios are typically short, fragmented, and task-oriented, deviating from standard natural language patterns. These utterances often omit syntactic elements, contain domain-specific shorthand, or follow operational communication protocols rather than grammatically complete sentences. As a result, models must demonstrate robustness to varied, informal, and context-dependent language expressions in order to correctly interpret intent and generate accurate SQL representations.
II-C Dataset
To support development and evaluation, we construct a domain-specific multimodal dataset comprising: (1) a relational database, implemented by MySQL8.0 of structured vessel traffic data, as shown in Table I; (2) a retrieval corpus of related maritime textual knowledge; and (3) A query–SQL pair test set containing diverse linguistic expressions and their corresponding executable SQL statements. These components reflect practical VTS operations and support realistic benchmarking of knowledge-augmented Text-to-SQL models. Dataset is available at VTS-SQL.
| Table | Columns | Description |
|---|---|---|
| ship_ais | 17 | Latest AIS data of ships, including ship attributes (length, type, tonnage, etc.) and motion attributes (processed location, speed, heading, etc.). |
| ship_ais_quarter | 17 | AIS data sampled every 15 minutes with 10-second intervals, containing ship attributes and motion attributes. |
| shp_data | 6 | Geographic shape data (points & polygons) stored in MySQL, including object type, name, and geometry. |
| warn_single | 11 | Records of ship encounter warnings. Includes CPA values and timestamps for each ship pair. |
The query set is designed based on input from professional VTS operators to reflect real-world operational scenarios, covering multiple query types, as demonstrated in Table II. And, in addition to the operational style, each query is further provided in two additional linguistic variants: a concise command-style format and a more formal natural-language expression, as demonstrated in Table III.
| Query Type | Example |
|---|---|
| Basic information retrieval | What is the current speed and location of vessel sounds like ALABAMA? |
| Involving spatiotemporal reasoning | show me the ships in the waterway that may enter the port in the next an hour |
| Involving domain-specific terminology from the knowledge base | List MMSI and name of VLCCs and DDVs in the Strait. |
| Involving navigational rules from the knowledge base | list mmsi and names of all the vessels which against the speed requirements |
| Involving named entity recognition (NER) | where is West Coast? |
| Linguistic Style | Example |
|---|---|
| Operational | List MMSI and names of ships arriving port in next 30 min. |
| Command | Arriving vessel in next 30 min? – list MMSI, name |
| Formal Natural Language | Could you show me the MMSI numbers and vessel names of ships expected to arrive at port within the next 30 minutes? |
III Methodology
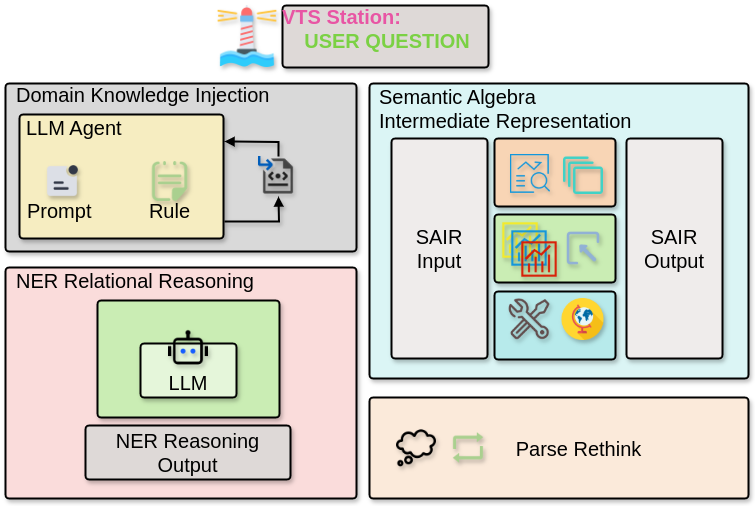
Considering the complex spatial-temporal characteristics and the high dependence on expert domain knowledge inherent in maritime data analysis, we introduce a VTS domain-adaptive LLM (VTS-LLM), which incorporates four key methodological innovations to facilitate and optimize natural language to SQL conversion tasks for identifying vessels of interest in VTS scenarios. Figure 1 illustrates the simplified modular architecture.
III-A NER-based Relational Reasoning
As the complexity and diversity in maritime terminology, we introduce an interactive Named Entity Recognition-based (NER-based) Relational Reasoning module aimed at clarifying and confirming relational semantics between the natural-language query entities and available database entities through iterative interactions.
The proposed module, shown in Figure 2, employs a hierarchical NER method tailored to maritime contexts, identifying and annotating entities in multiple semantic granularities. Broad categories include geographical regions, named types, and navigational facilities. Such hierarchical annotation provides structured representations for entities, significantly mitigating ambiguity compared to traditional flat NER schemes.
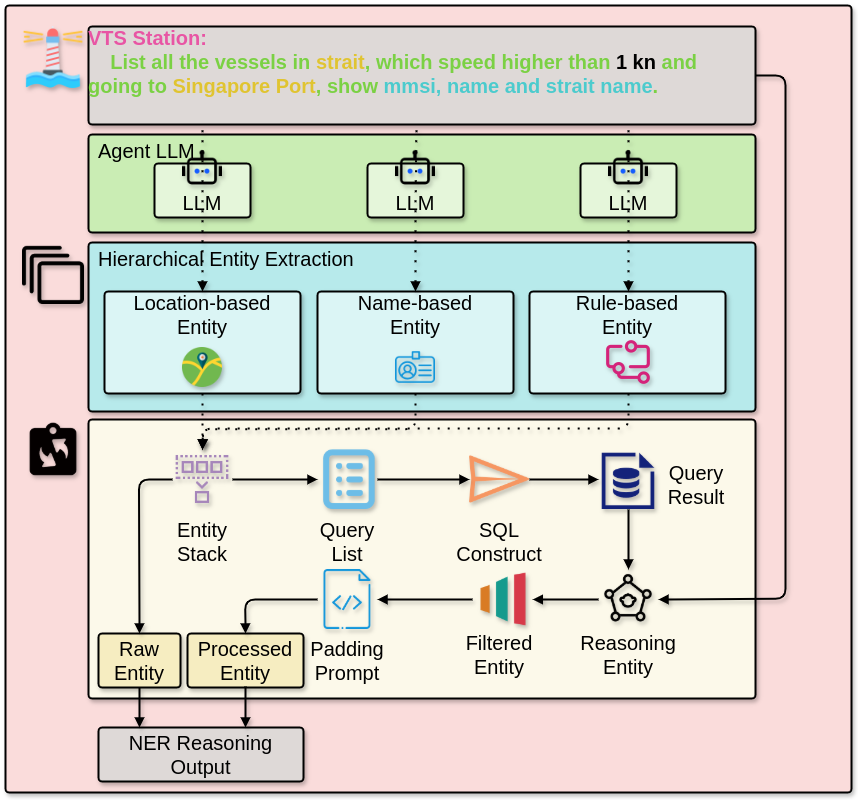
Recognized entities are subsequently utilized to build corresponding verification queries directed toward underlying spatial-temporal vessel traffic database. The query returns are then synthesized into structured, informative prompts, enabling LLMs to leverage CoT reasoning in determining and clarifying potential links between user-query entities and actual entities existing in database. For example, upon identification of entities such as strait, Singapore Port and Pilot Station verification queries are dynamically generated and executed to check the presence, relevance, and relational context of these entities within the database.
III-B Agent-based Domain Knowledge Injection
The maritime domain involves extensive expert knowledge with complex semantic implications, including navigation planning, vessel type categorizations, geographic topology constraints, and port operation regulations. To effectively integrate such domain expertise into the Text-to-SQL process, we propose an agent-based framework to systematically operationalize maritime-specific knowledge. As illustrated in Figure 3, our framework dynamically introduces domain knowledge by intelligently decomposing a complex natural language query into a structured series of domain-specific subtasks, thus ensuring semantic clarity and operational effectiveness in the generated SQL queries.
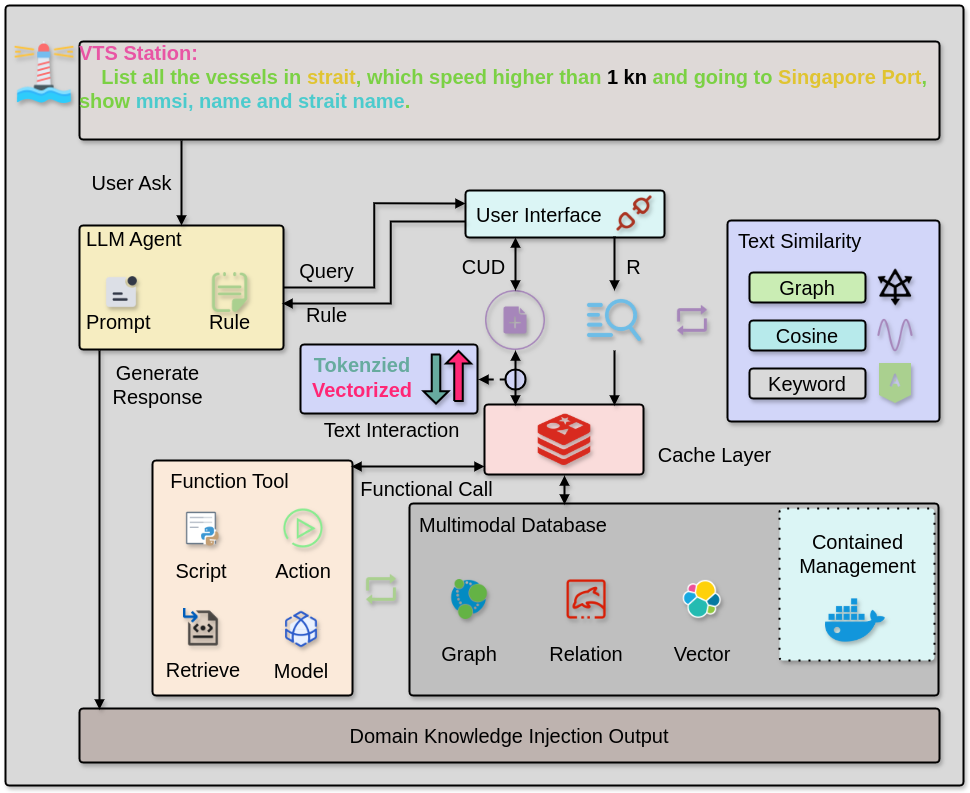
Domain Knowledge-Aware Semantic Parsing
In the first stage, the system processes incoming natural language input with the support of Retrieval Augmented Generation (RAG)[20]. Using semantic matching, the agent retrieves relevant domain-specific information and converts it into structured semantic expressions with clear domain context. It then reformulates the natural language request into structured columns and values, followed by origin table structure.
Natural Language Processing and Interactive Query Engine
Following semantic parsing, this structured query information flows into an interactive query engine consisting of an LLM agent and user interface components. The LLM uses carefully-designed prompt strategies and internally-defined operational rules to further translate structured predicates into executable query instructions. Here, tokenization and vectorization facilitate standardized processing of the structured inputs. Efficient cache-based layer interactions enable rapid query responsiveness and user interactivity through Create, Update, and Delete (CUD) with retrieval (R) operations.
Multimodal DBs and Functional Call
Ultimately, these instructions activate functional call[21] interfaces that interact directly with a robust multimodal database, combining diverse storage modes such as graph, relational, and vector databases, all managed within a unified containerization framework. Complex functional tools like comprising scripts, actions, retrieval algorithms.
III-C Semantic Algebra Intermediate Representation
Text-to-SQL tasks differ significantly from traditional database queries in the maritime spatiotemporal context. These differences mainly stem from the complexity of geospatial semantics, the ambiguity of temporal constraints, and the specialized terminology in the maritime field. To this end, we propose a Semantic Algebra Intermediate Representation (SAIR) method to bridge the semantic[22] gap between natural language queries and structured SQL.
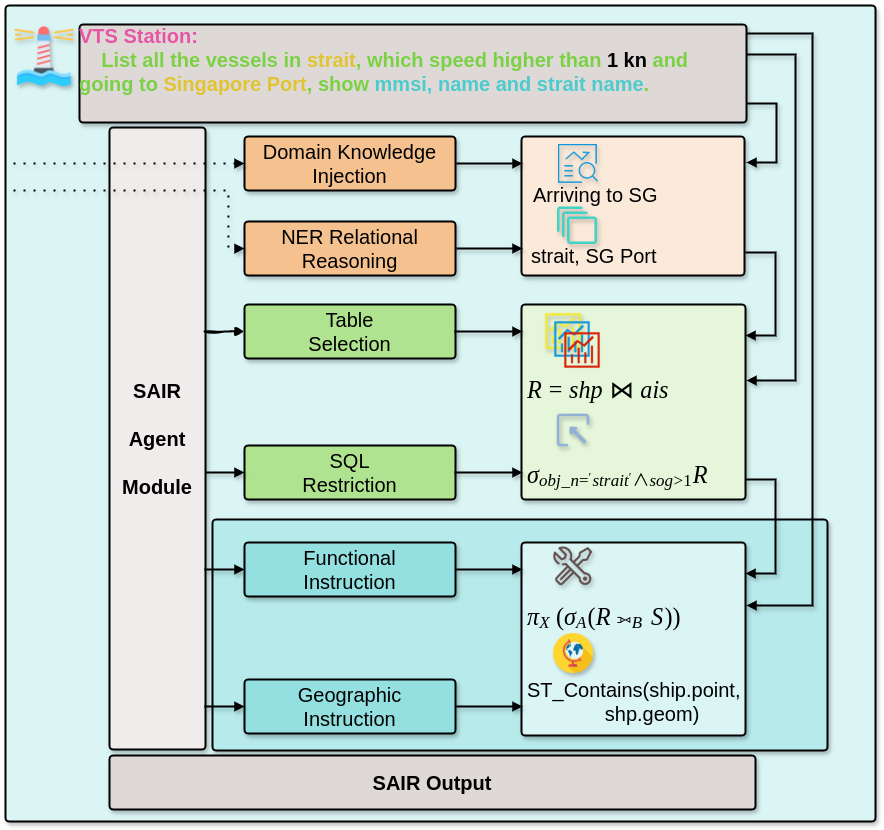
As shown in Figure 4, the SAIR module consists of three key submodules, which respectively handle named entity understanding and domain knowledge injection in orange module, structured semantic mapping in green module, and geographic function instructions in blue module. This design reflects the key improvement in our approach, which consists of decomposing the natural language parsing process into multiple substeps with clear structure and controllable semantics through explicit semantic modeling.
Semantic-aware Entity Understanding and Domain Enhancement
The input natural language query first undergoes NER reasoning, combined with maritime domain knowledge such as port names, waterway information, for semantic injection. This process forms semantic anchors by annotating the spatial location such as strait, and intent such as Arriving to SG, in the query, laying the foundation for subsequent algebraic representation.
Structured Algebraic Transformation Process
Customized relational algebraic expressions are introduced, including basic operations such as selection , projection , and connection , while integrating specific maritime semantic structures.
Fusion of spatial and functional instructions
Relational algebra framework is extend and introduce spatial operations such as ST_Contains and geographic matching instructions to express complex spatial semantics such as ”whether the ship’s position is in a specific waterway area”. At the same time, the projection operation is used to implement attribute filtering to form the final output.
III-D Query Rethink
Considering that the initially generated SQL queries may contain ambiguity, inaccuracy or grammatical errors (especially in complex spatiotemporal contexts), we propose the Query Rethink (RT) Mechanism, a novel validation and correction step[23] inspired by the thought chain paradigm. Specifically, given a SQL query draft, the model carefully checks its semantic coherence and logical consistency through an iterative reasoning process. By actively reconsidering the correctness of the generated SQL with domain-specific semantics and relational structures, the RT module identifies and dynamically corrects problematic query elements, ultimately generating refined and validated SQL statements.
IV Experiment
| Prompt Representation | ||||||
| Model |
|
|
|
|
|
Avg. |
|
|
25.26 | 30.91 | 29.58 | 25.62 | 30.26 | 28.33 |
|
|
52.73 | 43.74 | 54.21 | 41.20 | 62.59 | 50.89 |
|
|
62.06 | 64.02 | 58.38 | 61.10 | 58.46 | 60.80 |
|
|
33.35 | 41.21 | 40.67 | 35.47 | 38.34 | 37.81 |
|
|
49.36 | 44.38 | 43.80 | 45.97 | 51.05 | 46.91 |
|
|
61.46 | 39.90 | 49.43 | 51.89 | 48.42 | 50.22 |
|
|
46.88 | 34.26 | 45.34 | 31.09 | 43.90 | 40.29 |
|
|
72.41 | 53.39 | 70.95 | 64.39 | 65.03 | 65.23 |
|
|
45.35 | 42.87 | 43.36 | 50.72 | 48.94 | 46.25 |
|
|
49.01 | 49.97 | 59.99 | 45.53 | 52.30 | 51.36 |
| 68.69 | 68.76 | 66.29 | 74.30 | 66.53 | 68.91 | |
|
|
Score | 77.80 | ||||
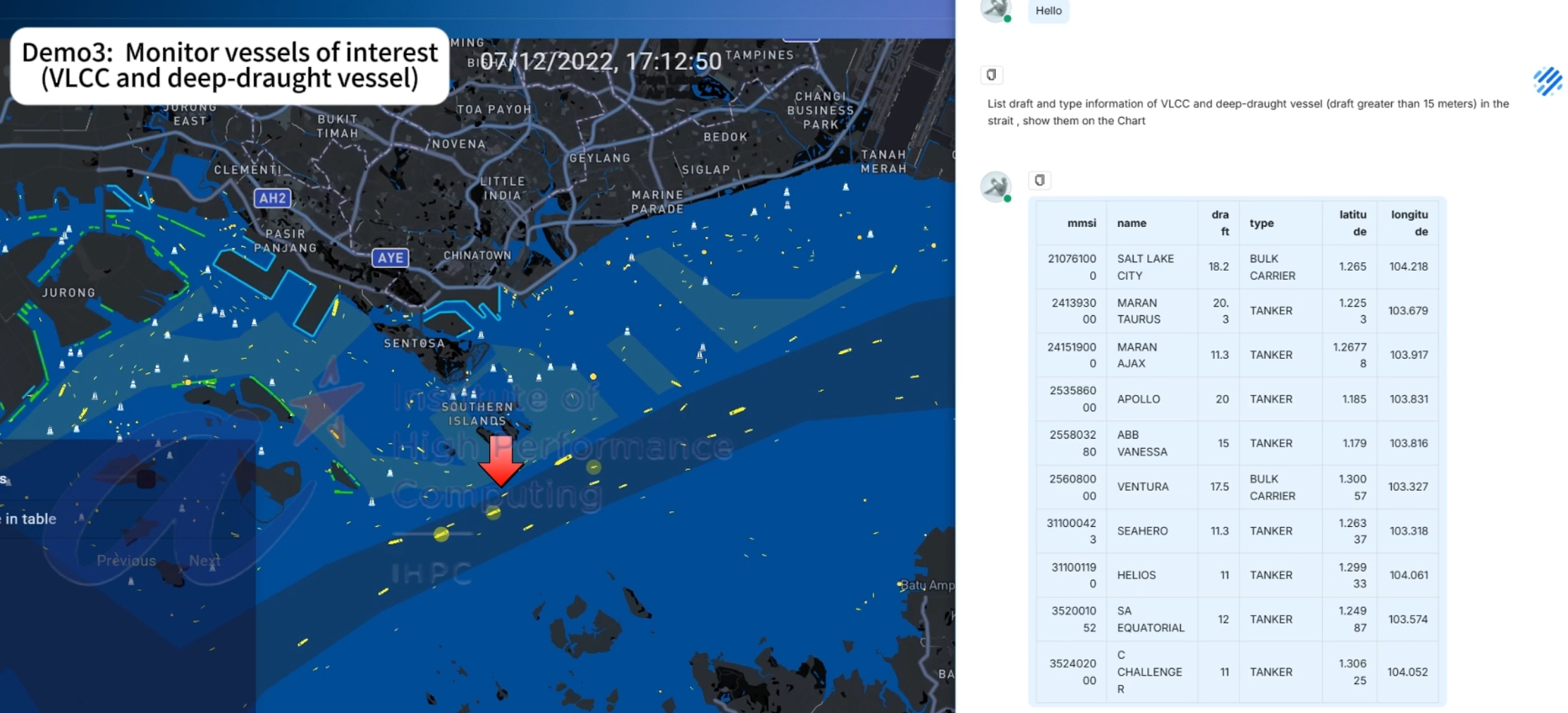
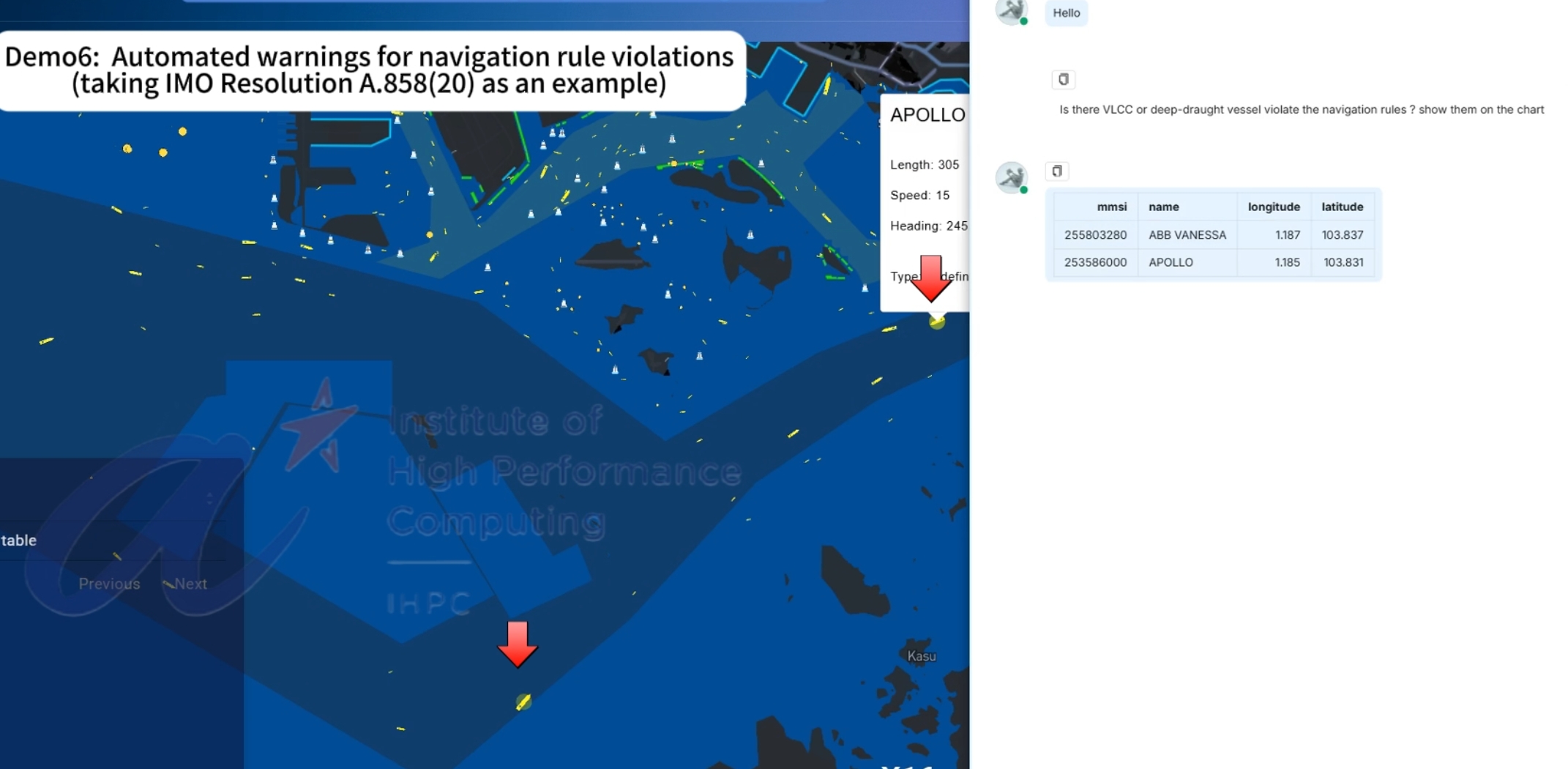
In experimental environment, we have completed the design and development of a working front-end system and back-end VTS -LLM agent. Two demonstrations based on an embedded web platform have been developed to visualize maritime vessel information. As illustrated in Figure 5, The demos showcase interactive querying by a VTS operator within a designated supervisory area, with vessel highlights automatically rendered on the front end by the backend LLM agent. Additional demonstrations can be viewed in the video available at vts-llm-demo. The example queries used in the demos are as follows:
-
•
List draft and type information of VLCC and deep-draught vessel in the strait, show them on the Chart
-
•
Is there VLCC or deep-draught vessel violate the navigation rules? show them on the chart
The remainder of this section presents the evaluation experiments of our methodology.
IV-A Environment Setup
The experiments were conducted on a high-performance computing system equipped with an Intel(R) Gold 6336Y CPU and NVIDIA RTX 4090 GPU with CUDA 12.1 support. The operating system was Ubuntu 22.04.
IV-B Evaluate Metric
Inspired by the Exact Match (EM) and EXecution Accuracy (EX) in SQL evaluation [24], we aim to develop a customized evaluation metric specifically for SQL queries in the VTS domain. Existing metrics rely heavily on the exact match or execution correctness of result tuples, and fail to adequately address specific challenges and characteristics observed in vessel of interest identification, such as frequent redundant selections or missing relevant entries. Additionally, to balance precision and recall in safety-critical scenarios, we introduce a novel evaluation metric with penalty coefficients.
Equation 1 reflects the base score. Where represents the true result set, represents the predicted result set, and represents the count of unique sample.
| (1) |
To further penalize predictions that introduce unnecessary over-selected tuples, we introduce a penalty factor as defined in Equation 2.
| (2) |
Proposed Match Score in Equation 3 incorporates both matching and penalization conditions within an integrated metric.
| (3) |
Designed effectively addresses distinct characteristics of this knowledge-augmented Text-to-SQL task by balancing recall on avoiding missing correct tuples and precision on discouraging unnecessary duplication.
IV-C Comparison Studies
As shown in Table IV, we conduct the comparison experiment based on the queries of operational style in our dataset. For fairness, all compared models are given the same base knowledge and rules uniformly through prompt-based inputs. Details of prompt is available with code.
Results show that our VTS-LLM achieves an overall accuracy of 77.80%, significantly outperforming SOTA baselines. And also it demonstrates superior performance across various prompt formats, particularly accounting for 74.30% in Alpaca-style prompts, highlighting its strong generalisation and adaptability.
| Prompt Representation | ||||||
| Model |
|
|
|
|
|
Avg. |
|
|
32.48 | 25.25 | 24.56 | 25.06 | 26.35 | 26.74 |
|
|
6.18 | 3.46 | 2.57 | 6.53 | 4.87 | 4.72 |
|
|
41.34 | 48.97 | 58.26 | 47.79 | 46.56 | 48.58 |
|
|
27.29 | 31.21 | 30.57 | 31.03 | 18.94 | 27.81 |
|
|
6.37 | 10.82 | 13.37 | 9.50 | 21.34 | 12.28 |
|
|
42.65 | 47.78 | 48.81 | 27.80 | 45.02 | 42.41 |
|
|
47.19 | 47.49 | 57.46 | 58.56 | 52.90 | 52.72 |
|
|
68.69 | 68.76 | 66.29 | 74.30 | 66.53 | 68.91 |
| Structured | Backbone LLMs | Score | ||||
|
|
|
55.59 | ||||
|
|
|
33.89 | ||||
|
|
|
77.80 | ||||
Besides, in Table V, our model maintains robust advantages over open-source and specialized structured-data LLMs, and surpassing two dedicated Text-to-SQL models, DAIL-SQL with GPT-4o and SQLCoder with LLama as backbone.
IV-D Ablation Study
To further analyze the effectiveness of each proposed component, we conducted ablation experiments as shown in Table VI. We separately drop three key modules in VTS-LLM: NER-based Relational Reaoning (NER), Semantic Algebra Intermediate Representation (SAIR), and Query Rethink mechanism (RT).
| No. | NER | SAIR | RT | Score |
|---|---|---|---|---|
| 1 | 77.80 | |||
| 2 | 72.45 | |||
| 3 | 74.06 | |||
| 4 | 70.22 |
The ablation study demonstrates the reduction of each core components in evaluation performance: the VTS-LLM agent (#1) integrating all components achieves optimal performance (77.80%); Without NER Reasoning modules (#2), the performance degrades, with accuracy dropping to 74.25%; Without SAIR modules (#3) the performance degrades, with accuracy dropping to 74.06%; Without RT modules (#4) the performance degrades, with accuracy dropping to 70.22%.
IV-E Sensitive Analysis
Furthermore, among all compared models, we select Claude, the best-performing model under the operational linguistic style, and conduct a sensitivity analysis across command-style and formal nature language style. Results in Table VII reveal substantial variations in model performance across linguistic styles. A consistent pattern is observed across all models that performance degrades as query expressions become more concise and less formally structured.
| Prompt Representation | ||||||
| Model |
|
|
|
|
|
Avg./Score |
| Operational | ||||||
|
|
66.48 | 45.41 | 69.92 | 61.74 | 65.87 | 61.88 |
|
|
72.41 | 53.39 | 70.95 | 64.39 | 65.03 | 65.23 |
|
|
77.80 | |||||
| Command | ||||||
|
|
42.76 | 43.06 | 53.31 | 44.48 | 54.06 | 47.53 |
|
|
52.78 | 39.52 | 54.21 | 46.63 | 52.45 | 49.12 |
|
|
72.60 | |||||
| Formal | ||||||
|
|
64.48 | 71.33 | 75.02 | 79.43 | 73.83 | 72.82 |
|
|
71.52 | 72.55 | 71.17 | 71.19 | 77.19 | 72.72 |
|
|
89.72 | |||||
In terms of model comparison, VTS-LLM consistently outperforms other baselines across various linguistic styles, demonstrating stronger robustness to language style variation. Particularly in the Command-Style setting, which is most representative of real-world VTS scenarios, VTS-LLM achieves a score of 72.40%, significantly outperforming Claude-3.5 (47.53%) and Claude-3.7 (49.12%), both of which experience substantial performance drops in this challenging linguistic style.
IV-F Discussion
1) VTS-LLM achieves SOTA performance in this knowledge-augmented Text-to-SQL task, outperforming general-purpose models by 12–35% and exhibiting superiority over dedicated SQL models as well. While these models demonstrate strong performance on general datasets like BIRD and Spider, they remain inadequate for handling domain-specific queries and knowledge-augmented data contexts. The strength of VTS-LLM stems from a set of domain-specific adaptation strategies, including a novel semantic algebra for resolving column ambiguities, entity-relation reasoning for complex query understanding, agent-based domain knowledge fusion, and query rethink mechanisms for enhanced generation accuracy.
2) A notable performance disparity in the sensitive analysis indicate that different linguistic styles in our dataset pose systematically varying levels of difficulty for Text-to-SQL models, highlighting the need for robust linguistic adaptability. Moreover, our VTS-LLM demonstrates stronger robustness to linguistic style variations, making it better suited to the unstructured and often fragmented nature of queries that are representative of real-world scenarios. The lower scores of Claude models in this category suggest that they may struggle with the lack of formal structure in such prompts, highlighting the importance of specialized optimization for industrial use cases where clarity and brevity are prioritized over grammatical formality.
V Conclusion
In this work, we developed VTS-LLM, the first domain-adaptive LLM-powered system tailored for interactive decision support in VTS operations. By formalizing risk-prone vessel identification as a knowledge-augmented Text-to-SQL task and constructing a curated, domain-specific dataset, we demonstrate that natural language interaction in operational linguistic style can effectively enhance situational awareness and support rule compliance monitoring in real-time vessel traffic services. In developing VTS-LLM , we tackled the domain-specific challenges in VTS scenarios by NER-based relational reasoning, semantic algebra intermediate representation, agent-based domain knowledge injection, and query rethink mechanisms. These structure propose knowledge integration strategies and domain-adaptive modeling techniques to enhance knowledge grounding, context-aware reasoning, and text generation capabilities.
Evaluation experiment validate VTS-LLM’s effectiveness and superiority in handling diverse linguistic queries and complex spatiotemporal reasoning, accounting for 72.60% on command-style, 77.80% on operational-style and 89.72% on formal natural language style. By integrating structured vessel databases with external textual knowledge, VTS-LLM enables more robust and context-aware reasoning for data exploration—going beyond basic information retrieval in conventional VTS systems. Besides, our work presents the first empirical evidence that linguistic style variation can introduce significant and systematic challenges in Text-to-SQL modeling, an issue previously underexplored in the literature.
Future work will focus on extending VTS-LLM to support a broader range of VTS and maritime regulations, improving real-time robustness in dynamic environments, and exploring joint optimization strategies about RAGs for enhanced query understanding. In addition, improving the model’s understanding of concise and informal query expressions remains an important and application-relevant challenge, which we consider a promising direction for future development in VTS domain. Besides, more proactive VTS activities could be supported by an LLM-based agent. For instance, the agent could interpret vessel calls, generate automated voice responses, perform basic radio duties, maintain relevant communication logs, and reply to standard messages on behalf of the operator.
References
- [1] Tymoteusz Miller, Irmina Durlik, Ewelina Kostecka, Adrianna Łobodzińska, Kinga Łazuga, and Polina Kozlovska, “Leveraging large language models for enhancing safety in maritime operations,” Applied Sciences, vol. 15, no. 3, pp. 1666, 2025.
- [2] Wei Zhang, Miaoxin Cai, Tong Zhang, Guoqiang Lei, Yin Zhuang, and Xuerui Mao, “Popeye: A unified visual-language model for multi-source ship detection from remote sensing imagery,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
- [3] Naiyao Wang, Tongbang Jiang, Ye Wang, Shaoyang Qiu, Bo Zhang, Xinqiang Xie, Munan Li, Chunliu Wang, Yiyang Wang, Hongxiang Ren, et al., “Kunpeng: An embodied large model for intelligent maritime,” arXiv preprint arXiv:2407.09048, 2024.
- [4] Dun Li, Huan Wang, and Yan-Fu Li, “Robust anomaly detection in unmanned ship systems based on large language models,” 2024.
- [5] Dingkai Zhang, Huanran Zheng, Wenjing Yue, and Xiaoling Wang, “Advancing its applications with llms: A survey on traffic management, transportation safety, and autonomous driving,” in International Joint Conference on Rough Sets. Springer, 2024, pp. 295–309.
- [6] Zhuoxun Li, Junju Chen, Kefan Wu, Zhanyi Wu, and Qiqi Liu, “Research on the human-machine collaborative optimisation algorithm for intelligent traffic signal control systems,” in 2024 International Conference on Computing, Robotics and System Sciences (ICRSS). IEEE, 2024, pp. 33–41.
- [7] Sari Masri, Huthaifa I Ashqar, and Mohammed Elhenawy, “Large language models (llms) as traffic control systems at urban intersections: A new paradigm,” Vehicles, vol. 7, no. 1, pp. 11, 2025.
- [8] Yuan Yuan, Jingtao Ding, Jie Feng, Depeng Jin, and Yong Li, “Unist: A prompt-empowered universal model for urban spatio-temporal prediction,” in Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 4095–4106.
- [9] Xuhong Wang, Ding Wang, Liang Chen, Fei-Yue Wang, and Yilun Lin, “Building transportation foundation model via generative graph transformer,” in 2023 IEEE 26th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2023, pp. 6042–6047.
- [10] Bingzhang Wang, Zhiyu Cai, Muhammad Monjurul Karim, Chenxi Liu, and Yinhai Wang, “Traffic performance gpt (tp-gpt): Real-time data informed intelligent chatbot for transportation surveillance and management,” arXiv preprint arXiv:2405.03076, 2024.
- [11] Zijin Hong, Zheng Yuan, Qinggang Zhang, Hao Chen, Junnan Dong, Feiran Huang, and Xiao Huang, “Next-generation database interfaces: A survey of llm-based text-to-sql,” arXiv preprint arXiv:2406.08426, 2024.
- [12] Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, et al., “Mac-sql: A multi-agent collaborative framework for text-to-sql,” in Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 540–557.
- [13] Dongjun Lee, Choongwon Park, Jaehyuk Kim, and Heesoo Park, “Mcs-sql: Leveraging multiple prompts and multiple-choice selection for text-to-sql generation,” in Proceedings of the 31st International Conference on Computational Linguistics, 2025, pp. 337–353.
- [14] Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, et al., “Can llm already serve as a database interface? a big bench for large-scale database grounded text-to-sqls,” Advances in Neural Information Processing Systems, vol. 36, pp. 42330–42357, 2023.
- [15] Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, and Hao Zhang, “Cllms: Consistency large language models,” in Forty-first International Conference on Machine Learning, 2024.
- [16] Haoyang Li, Jing Zhang, Hanbing Liu, Ju Fan, Xiaokang Zhang, Jun Zhu, Renjie Wei, Hongyan Pan, Cuiping Li, and Hong Chen, “Codes: Towards building open-source language models for text-to-sql,” Proceedings of the ACM on Management of Data, vol. 2, no. 3, pp. 1–28, 2024.
- [17] Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou, “Text-to-sql empowered by large language models: A benchmark evaluation,” arXiv preprint arXiv:2308.15363, 2023.
- [18] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al., “Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task,” in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 3911–3921.
- [19] Fangyu Lei, Jixuan Chen, Yuxiao Ye, Ruisheng Cao, Dongchan Shin, SU Hongjin, ZHAOQING SUO, Hongcheng Gao, Wenjing Hu, Pengcheng Yin, et al., “Spider 2.0: Evaluating language models on real-world enterprise text-to-sql workflows,” in The Thirteenth International Conference on Learning Representations, 2018.
- [20] Shamane Siriwardhana, Rivindu Weerasekera, Elliott Wen, Tharindu Kaluarachchi, Rajib Rana, and Suranga Nanayakkara, “Improving the domain adaptation of retrieval augmented generation (rag) models for open domain question answering,” Transactions of the Association for Computational Linguistics, vol. 11, pp. 1–17, 2023.
- [21] Sehoon Kim, Suhong Moon, Ryan Tabrizi, Nicholas Lee, Michael W Mahoney, Kurt Keutzer, and Amir Gholami, “An llm compiler for parallel function calling,” in 41st International Conference on Machine Learning, 2024.
- [22] Parker Glenn, Parag Dakle, Liang Wang, and Preethi Raghavan, “Blendsql: A scalable dialect for unifying hybrid question answering in relational algebra,” in Findings of the Association for Computational Linguistics ACL 2024, 2024, pp. 453–466.
- [23] Qineng Wang, Zihao Wang, Ying Su, Hanghang Tong, and Yangqiu Song, “Rethinking the bounds of llm reasoning: Are multi-agent discussions the key?,” in Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 6106–6131.
- [24] Ruiqi Zhong, Tao Yu, and Dan Klein, “Semantic evaluation for text-to-sql with distilled test suites,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 396–411.