Wasserstein Differential Privacy
Abstract
Differential privacy (DP) has achieved remarkable results in the field of privacy-preserving machine learning. However, existing DP frameworks do not satisfy all the conditions for becoming metrics, which prevents them from deriving better basic private properties and leads to exaggerated values on privacy budgets. We propose Wasserstein differential privacy (WDP), an alternative DP framework to measure the risk of privacy leakage, which satisfies the properties of symmetry and triangle inequality. We show and prove that WDP has 13 excellent properties, which can be theoretical supports for the better performance of WDP than other DP frameworks. In addition, we derive a general privacy accounting method called Wasserstein accountant, which enables WDP to be applied in stochastic gradient descent (SGD) scenarios containing subsampling. Experiments on basic mechanisms, compositions and deep learning show that the privacy budgets obtained by Wasserstein accountant are relatively stable and less influenced by order. Moreover, the overestimation on privacy budgets can be effectively alleviated. The code is available at https://github.com/Hifipsysta/WDP.
Introduction
Differential privacy (Dwork et al. 2006b) is a mathematically rigorous definition of privacy, providing quantifiable descriptions of the risk on leaking sensitive information. In the early stage, researches on differential privacy mainly focused on the issue of statistical queries (SQ) (McSherry 2009; Kasiviswanathan et al. 2011). With the risk of privacy leakage being warned in machine learning (Wang, Si, and Wu 2015; Shokri et al. 2017; Zhu, Liu, and Han 2019), differential privacy has been gradually applied for privacy protection in deep learning (Shokri and Shmatikov 2015; Abadi et al. 2016; Phan et al. 2019; Cheng et al. 2022).
However, these techniques are always constructed on the postulation of standard DP (Dwork et al. 2006b), which only provides the worst-case scenario, and tends to overestimate privacy budgets under the measure of maximum divergence (Triastcyn and Faltings 2020). Although the most commonly applied approximate differential privacy (-DP) (Dwork et al. 2006a) ignores extreme situations with small probabilities by introducing a relaxation term called failure probability, it is believed that -DP cannot strictly handle composition problems (Mironov 2017; Dong, Roth, and Su 2022). To address the above issues, further researches have been considering the specific data distribution, which can be divided into two main directions: the distribution of privacy loss and the distribution of unique difference. For example, concentrated differential privacy (CDP) (Dwork and Rothblum 2016), zero-concentrated differential privacy (zCDP) (Bun and Steinke 2016), and truncated concentrated differential privacy (tCDP) (Bun et al. 2018) all assume that the mean of privacy loss follows subgaussian distribution. While Bayesian differential privacy (BDP) (Triastcyn and Faltings 2020) considers the distribution of the only different data entry . Nevertheless, they are all defined by the upper bound of divergence, which implies that their privacy budgets are overly pessimistic (Triastcyn and Faltings 2020).
In this paper, we introduce a variant of differential privacy from another perspective. We define the privacy budget through the upper bound of the Wasserstein distance between adjacent distributions, which is called Wasserstein differential privacy (WDP). From a semantic perspective, WDP also follows the concept of indistinguishability (Dwork et al. 2006b) in differential privacy. Specifically, for all possible adjacent databases and , WDP reflects the maximum variation of optimal transport (OT) cost between the distributions queried by an adversary before and after any data entry change in the database.
Intuitively speaking, the advantages of WDP can be divided into at least two aspects. (1) WDP focuses on individuals within the distribution, rather than focusing on the entire distribution like divergence, which is consistent with the original intention of differential privacy to protect individual private information from leakage. (2) More importantly, WDP satisfies all the conditions to become a metric, including non-negativity, symmetry and triangle inequality (see Proposition 1-3), which is not fully possessed by privacy loss under the definition of divergence, as divergence itself does not satisfy symmetry and triangle inequality (see Proposition 11 in the appendix of Mironov (2017)).
The combination of DP and OT has been taken into consideration in several existing works. Their contributions are essentially to provide privacy guarantees for computing Wasserstein distance between data domains (Tien, Habrard, and Sebban 2019), distributions (Rakotomamonjy and Ralaivola 2021) or graph embeddings (Jin and Chen 2022). However, our work is to compute privacy budgets through Wasserstein distance, and the contributions are summarized as follows:
Firstly, we propose an alternative DP framework called Wasserstein differential privacy (WDP), which satisfies three basic properties of a metric (non-negativity, symmetry and triangle inequality), and is easy to convert with other DP frameworks (see Proposition 9-11).
Secondly, we show that WDP has 13 excellent properties. More notably, basic sequential composition, group privacy among them and advanced composition are all derived from triangle inequality, which shows the advantages of WDP as a metric DP.
Thirdly, we derive advanced composition, privacy loss and absolute moment under WDP, and finally develop Wasserstein accountant to track and account privacy budgets in subsampling algorithms such as SGD in deep learning.
Fourthly, we conduct experiments to evaluate WDP on basic mechanisms, compositions and deep learning. Results show that applying WDP as privacy framework can effectively avoid overstating the privacy budgets.
Related Work
Pure differential privacy (-DP) (Dwork et al. 2006b) provides strict guarantees for all measured events through maximum divergence. To address the long tailed distribution generated by privacy mechanism, -DP (Dwork et al. 2006a) ignores extremely low probability events through a relaxation term . However, -DP is considered to an overly relaxed definition (Bun et al. 2018) and cannot effectively handle composition problems, such as leading to parameter explosion (Mironov 2017) or failing to capture correct hypothesis testing (Dong, Roth, and Su 2022). In view of this, CDP (Dwork and Rothblum 2016) applies a subgaussian assumption to the mean of privacy loss. zCDP (Bun and Steinke 2016) capture privacy loss is a subgaussian random variable through Rényi divergence. Rényi differential privacy (RDP) (Mironov 2017) proposes a more general definition of DP based on Rényi divergence. tCDP (Bun et al. 2018) further relaxes zCDP. BDP (Triastcyn and Faltings 2020) considers the distribution of unique different entries. Subspace differential privacy (Gao, Gong, and Yu 2022) and integer subspace differential privacy (Dharangutte et al. 2023) consider privacy computing scenarios with external constraints. However, these concepts are all based on divergence, so that their privacy loss does not have the property of metrics. Although -DP and its special case Gaussian differential privacy (GDP) (Dong, Roth, and Su 2022) innovatively define privacy based on the trade-off function between two types of errors in hypothesis testing, they are difficult to associate with other DP frameworks.
Wasserstein Differential Privacy
In this section, we introduce the concept of Wasserstein distance and define our Wasserstein differential privacy.
Definition 1 (Wasserstein distance (Rüschendorf 2009)). For two probability distributions and defined over , their -Wasserstein distance is
| (1) |
Where is the norm defined in probability space . is the set for all the possible joint distributions, and satisfying and .
In practical sense, can be regarded as the cost for one unit of mass transported from to . can be seen as a transport plan representing the share to be moved from to , which measures how much mass must be transported in order to complete the transportation.
In particular, when is equal to 1, we can obtain the 1-Wasserstein distance applied in Wasserstein generative adversarial network (WGAN) (Arjovsky, Chintala, and Bottou 2017; Gulrajani et al. 2017). The successful application of 1-Wasserstein distance in WGAN should be attributed to Kantorovich-Rubinstein duality, which effectively reduces the computational complexity of Wasserstein distance.
Definition 2 (Kantorovich-Rubinstein distance (Kantorovich and Rubinshten 1958)). According to the property of Kantorovich-Rubinstein duality, 1-Wasserstein distance can be equivalently expressed as Kantorovich-Rubinstein distance
| (2) |
Where is the so-called Kantorovich potential, giving the optimal transport map by a close-form formula. Where is the Lipschitz bound of Kantorovich potential, indicates that satisfies the 1-Lipschitz condition with
| (3) |
Definition 3 (-WDP). A randomized algorithm is said to satisfy -Wasserstein differential privacy if for any adjacent datasets and all measurable subsets the following inequality holds
| (4) | ||||
Where and represent two outputs when algorithm respectively performs on dataset and . and are the probability distributions, also denoted as and in this paper. The value of is the privacy loss under -WDP and its upper bound is called privacy budget.
Symbolic representations. WDP can also be represented as . To emphasize the inputs are two probability distributions, we denote WDP as . To avoid confusion, we also represent RDP as , although the representation implies that the results depend on the randomized algorithm and the queried data. They are both reasonable because can be seen as a random variable that satisfies .
For the convenience on computation, we define Kantorovich Differential Privacy (KDP) as an alternative way to obtain privacy loss or privacy budget under -WDP.
Definition 4 (Kantorovich Differential Privacy). If a randomized algorithm satisfies-WDP, which can also be written as the form of Kantorovich-Rubinstein duality
| (5) |
-KDP is equivalent to -WDP, and can be computed more efficiently through duality formula based on Kantorovich-Rubinstein distance.
Properties of WDP
Proposition 1 (Symmetry). Let be a -WDP algorithm, for any and the following equation holds
| (6) | ||||
The symmetric property of -WDP is implied in its definition. Specifically, the joint distribution satisfies . In addition, Kantorovich differential privacy also satisfies this property and the proof is available in the appendix.
Proposition 2 (Triangle Inequality) Let be three arbitrary datasets. Suppose there are fewer different data entries between and compared with and , and the differences between and are included in the differences between and . For any randomized algorithm satisfies -WDP with , we have
| (7) | ||||
The proof is available in the appendix, and Minkowski’s inequality is applied in the deduction process. Proposition 2 can also be understood as the cost that converting from to and then to is not lower than the cost that converting from to directly. Triangle inequality is indispensable in proving several properties, such as basic sequential composition (see Proposition 6), group privacy (see Proposition 13) and advanced composition (see Theorem 1).
Proposition 3 (Non-Negativity). For and any randomized algorithm , we have .
Proof. See proof of Proposition 3 in the appendix.
Proposition 4 (Monotonicity). For , we have , or we can equivalently described this proposition as -WDP implies -WDP.
The proof is available in the appendix, and the derivation is completed with the help of Lyapunov’s inequality.
Proposition 5 (Parallel Composition). Suppose a dataset is divided into parts disjointly which are denoted as . Each randomized algorithm performed on different seperated datasets respectively. If satisfies -WDP for , then the set of randomized algorithms satisfies (, )-WDP.
Proof. See proof of Proposition 5 in the appendix.
Proposition 6 (Sequential Composition). Consider a series of randomized algorithms performed on a dataset sequentially. If any satisfies -WDP, then satisfies -WDP.
Proof. See proof of Proposition 6 in the appendix.
Proposition 7 (Laplace Mechanism). If an algorithm has sensitivity and the order , then the Laplace mechanism preserves -WDP.
Proof. See proof of Proposition 7 in the appendix.
Proposition 8 (Gaussian Mechanism). If an algorithm has sensitivity and the order , then the Gaussian mechanism preserves -WDP.
The proof of Gaussian mechanism is available in the appendix. The relation between parameters and privacy budgets in Laplace mechanism and Gaussian mechanism are summarized in Table 1.
| Differential Privacy Framework | Laplace Mechanism | Gaussian Mechanism |
|---|---|---|
| DP | 1/ | |
| RDP for order | : | |
| : | ||
| WDP for order |
Proposition 9 (From DP to WDP) If preserves -DP with sensitivity , it also satisfies -WDP.
Proof. See proof of Proposition 9 in the appendix.
Proposition 10 (From RDP to WDP) If preserves -RDP with sensitivity , it also satisfies -WDP.
Proof. See proof of Proposition 10 in the appendix.
Proposition 11 (From WDP to RDP and DP) Suppose and is an -Lipschitz function. If preserves -WDP with sensitivity , it also satisfies -RDP. Specifically, when , satisfies -DP.
The proof is available in the appendix. Where is the probability density function of distribution .
Proposition 12 (Post-Processing). Let be a -Wasserstein differentially private algorithm. Let be an arbitrary randomized mapping. For any order and all measurable subsets , is also -Wasserstein differentially private, namely
| (8) |
proof. See proof of Proposition 12 in the appendix.
Proposition 13 (Group Privacy). Let be a -Wasserstein differentially private algorithm. Then for any pairs of datasets differing in data entries for any is -Wasserstein differentially private.
Proof. See proof of Proposition 13 in the appendix.
Implementation in Deep Learning
Advanced Composition
To derive advanced composition under WDP, we first define generalized -WDP.
Definition 5 (Generalized -WDP) A randomized mechanism is generalized -Wasserstein differentially private if for any two adjacent datasets holds that
| (9) |
According to the above definition, we find that -WDP can be regarded as a special case of generalized -WDP when tends to zero.
Definition 5 is helpful for designing Wasserstein accountant applied in private deep learning, and we will deduce several necessary theorems based on this notion in the following.
Theorem 1 (Advanced Composition) Suppose a randomized algorithm consists of a sequence of -WDP algorithms , which perform on dataset adaptively and satisfy , . is generalized -Wasserstein differentially private with and if for any two adjacent datasets hold that
| (10) |
Where is a customization parameter that satisfies .
Proof. See proof of Theorem 1 in the appendix.
Privacy Loss and Absolute Moment
Theorem 2 Suppose an algorithm consists of a sequence of private algorithms protected by Gaussian mechanism and satisfying , . If the subsampling probability, scale parameter and -sensitivity of algorithm are represented by , and , then the privacy loss under WDP at epoch is
| (11) |
Where is the outcome distribution when performing on at epoch . represents the norm between pairs of adjacent gradients and . In addition, is a vector follows Gaussian distribution, and represents the -th component of .
Proof. See proof of Theorem 2 in the appendix.
Note that is the -order raw absolute moment of the Gaussian distribution . We know that the raw moment of a Gaussian distribution can be obtained by taking the -th order derivatives of the moment generating function with respect to . Nevertheless, we do not adopt such an indirect approach. We successfully derive a direct formula, as shown in Lemma 1.
Lemma 1 (Raw Absolute Moment) Assume that , we can obtain the raw absolute moment of as follow
| (12) |
Where represents the Variance of random variable , and can be expressed as . represents Gamma function as follow
| (13) |
and represents Kummer’s confluent hypergeometric function as
| (14) |
proof. Our mathematical deduction is based on the work from Winkelbauer (2012), and the proof is available in the appendix.
Wasserstein Accountant in Deep Learning
Next, we will deduce Wasserstein accountant applied in private deep learning. We obtain Theorem 3 based on the above preparations including advanced composition, privacy loss and absolute moment under WDP.
Theorem 3 (Tail Bound) Under the conditions described in Theorem 2, satisfies -WDP for
| (15) |
Where and . The proof of Theorem 3 is available in the appendix. In another case, if we have determined and want to know the privacy budget , then we can utilize the result in Corollary 1.
Corollary 1 Under the conditions described in Theorem 2, satisfies -WDP for
| (16) |
Corollary 1 is more commonly used than Theorem 3 since the total privacy budget generated by an algorithm plays a more important role in privacy computing.
Experiments
The experiments in this paper consist of four parts. Firstly, we test Laplace Mechanism and Gaussian Mechanism under RDP and WDP with ever-changing orders. Secondly, we carry out the experiments of composition and compare our Wasserstein accountant with Bayesian accountant and moments accountant. Thirdly, we consider the application scenario of deep learning, and train a convolutional neural network (CNN) optimized by differentially private stochastic gradient descent (DP-SGD) (Abadi et al. 2016) on the task of image classification. At last, we demonstrate the impact of hyperparameter variations on privacy budgets. All the experiments were performed on a single machine with Ubuntu 18.04, 40 Intel(R) Xeon(R) Silver 4210R CPUs @ 2.40GHz, and two NVIDIA Quadro RTX 8000 GPUs.
Basic Mechanisms
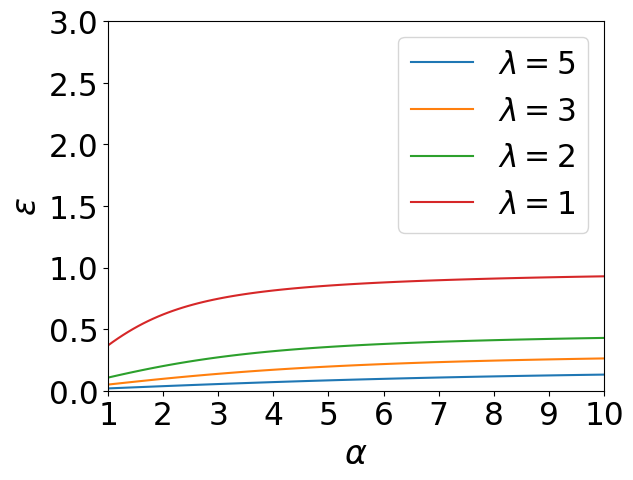
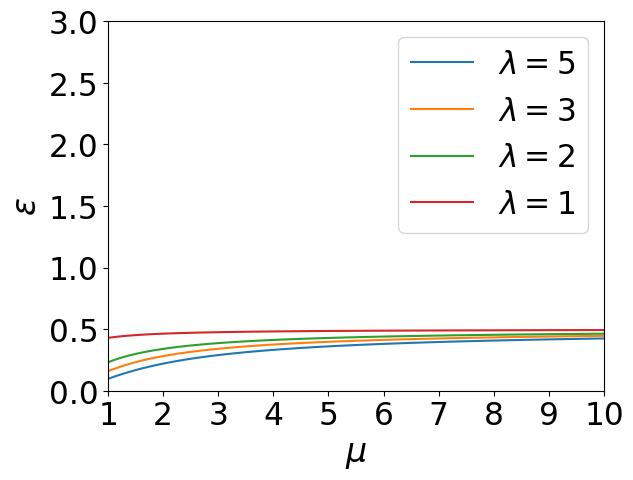
We conduct experiments to test Laplace Mechanism and Gaussian Mechnism under RDP and WDP. Our experiments are based on the results of Proposition 7, 8 and Table 1. We set the scale parameters of Laplace mechanism and Gaussian mechanism as 1, 2, 3 and 5 respectively. The order of WDP is allowed to varies from 1 to 10, and so is the order of RDP. We plot the values of privacy budgets with increasing orders, and the results are shown in Figure 1.
We can observe that the privacy budgets of WDP increase with growing, which corresponds to our monotonicity property (see Proposition 4). More importantly, we find that the privacy budgets of WDP are not susceptible to the order , because their curves all exhibit slow upward trends. However, the privacy budgets of RDP experience a steep increase under Gaussian mechanism when the noise scale equals 1, simply because its order increases. In addition, the slopes of RDP curves with different noise scales are significantly different. These phenomena lead users to confusion about order selection and risk assessment through privacy budgets when utilizing RDP.
Composition
For the convenience of comparison, we adopt the same settings as the composition experiment in Triastcyn and Faltings (2020). We imitate heavy-tailed gradient distributions by generating synthetic gradients from a Weibull distribution with as its shape parameter and as its size.
The hyper-parameter remains unchanged after being set as , and the threshold of gradient clipping is set to -quantiles of gradient norm in turns. To observe the original variations of their privacy budgets, we do not clip gradients. Thus, only affects Gaussian noise with variance in DP-SGD (Abadi et al. 2016) in this experiment. In addition, we also provide the composition results with gradient clipping in the appendix for comparison.
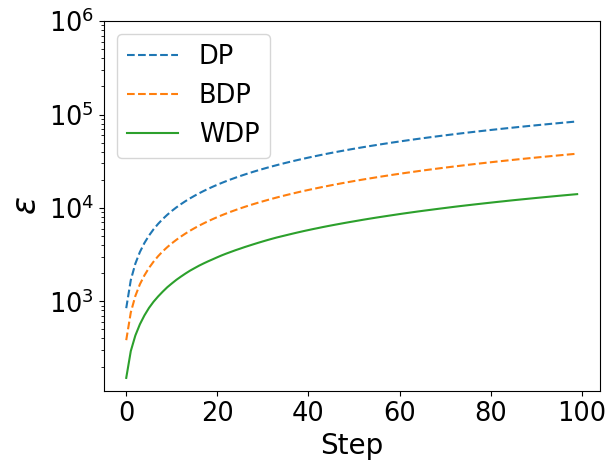
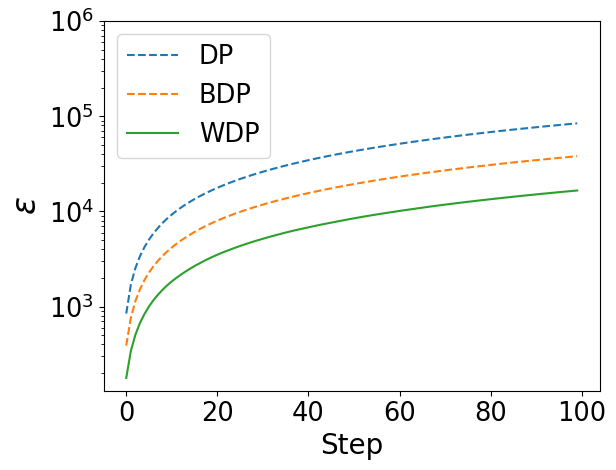
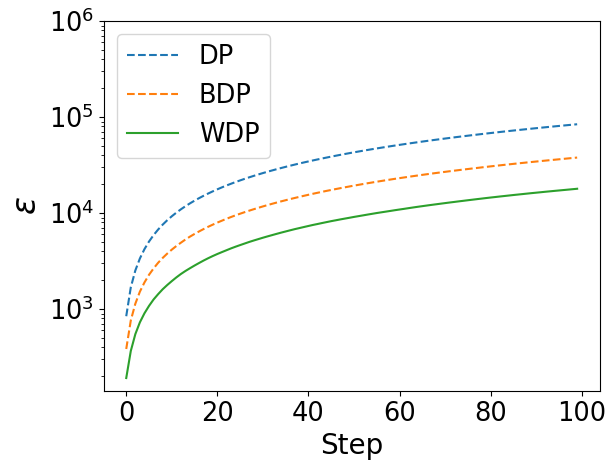
In Figure 2, we have the following key observations. (1) The curves obtained from Wasserstein accountant (WA) almost replicate the changes and trends depicted by the curves obtained from moments accountant (MA) and Bayesian accountant (BA). (2) The privacy budgets under WA are always the lowest, and this advantage becomes more significant with increasing.
The above results show that Wasserstein accountant can retain the privacy features expressed by MA and BA at a lower privacy budget.
Deep Learning
We adopt DP-SGD (Abadi et al. 2016) as the private optimizer to obtain the privacy budgets under MA, BA and our WA when applying a CNN model designed by Triastcyn and Faltings (2020) to the task of image classification on four baseline datasets including MNIST (Lecun et al. 1998), CIFAR-10 (Krizhevsky and Hinton 2009), SVHN (Netzer et al. 2011) and Fashion-MNIST (Xiao, Rasul, and Vollgraf 2017).
In the experiment of deep learning, we allow different DP frameworks to adjust the noise scale according to their own needs. The reasons are as follows: (1) MA supported by DP can easily lead to gradient explosion when the noise scale is small, thus can only take a relatively larger value to avoid this situation. However, an excessive noise limits the performance of BDP and WDP. (2) In addition, this setting enables our experimental results more convenient to compare with that in BDP (Triastcyn and Faltings 2020), because the deep learning experiment in BDP is also designed in this way.
Table 2 shows the results obtained under the above experimental settings. We can observe the following phenomenons: (1) WDP requires lower privacy budgets than DP and RDP to achieve the same level of test accuracy. (2) The convergence speed of the deep learning model under WA is faster than that of MA and BA. Taking the experiments on MNIST dataset as an example, DP and BDP need more than 100 epochs and 50 epochs of training respectively to achieve the accuracy of 96%. While our WDP can reach the same level after only 16 epochs of training.
BDP (Triastcyn and Faltings 2020) attributes its better performance than DP to considering the gradient distribution information. Similarly, we can also analyze the advantages of WDP from the following aspects. (1) From the perspective of definition, WDP also utilizes gradient distribution information through . From the perspective of Wasserstein accountant, the information of gradient distribution is included in and . (2) More importantly, privacy budgets under WDP will not explode even under low noise conditions. Because Wasserstein distance is more stable than Renyi divergence or maximum divergence, which is similar to the reason why WGAN (Arjovsky, Chintala, and Bottou 2017) succeed to alleviate the problem of mode collapse by applying Wasserstein distance.
| Accuracy | Privacy | ||||
|---|---|---|---|---|---|
| Dataset | Non Private | Private | DP () | BDP () | WDP () |
| MNIST | 99% | 96% | 2.2 (0.898) | 0.95 (0.721) | 0.76 (0.681) |
| CIFAR-10 | 86% | 73% | 8.0 (0.999) | 0.76 (0.681) | 0.52 (0.627) |
| SVHN | 93% | 92% | 5.0 (0.999) | 0.87 (0.705) | 0.40 (0.599) |
| F-MNIST | 92% | 90% | 2.9 (0.623) | 0.91 (0.713) | 0.45 (0.611) |
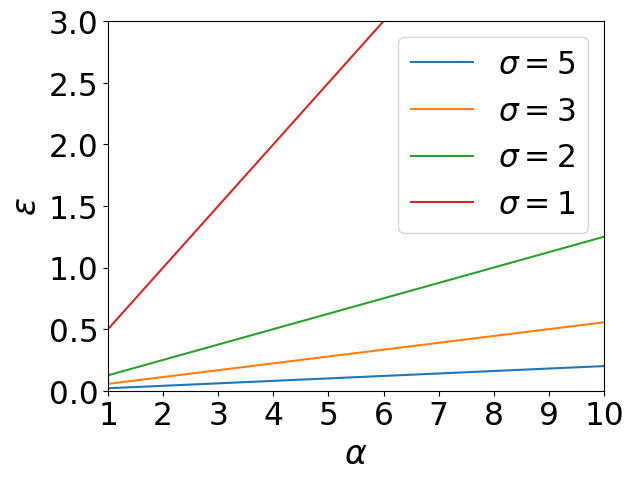
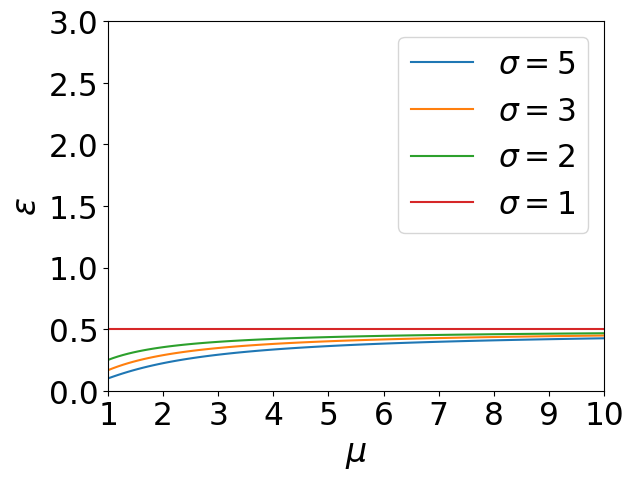
Effect of and
We also conduct experiments to illustrate the relation between privacy budgets and related hyperparameters. Our experiments are based on the results from Theorem 3 and Corollary 1, which have been proved before. In Figure 3(a), the hyperparameter in WDP are allowed to varies from 1 to 50, and the failure probability of WDP can only be . While in Figure 3(b), the failure probability is allowed to varies from to , and the hyperparameter under WDP can only be . We observe that has a clear effect on the value of in Figure 3(a). decreases quickly when is less than 10, while very slowly when it is greater than 10. When it comes to 3(b), seems to be decreasing uniformly with the exponential growth of delta.
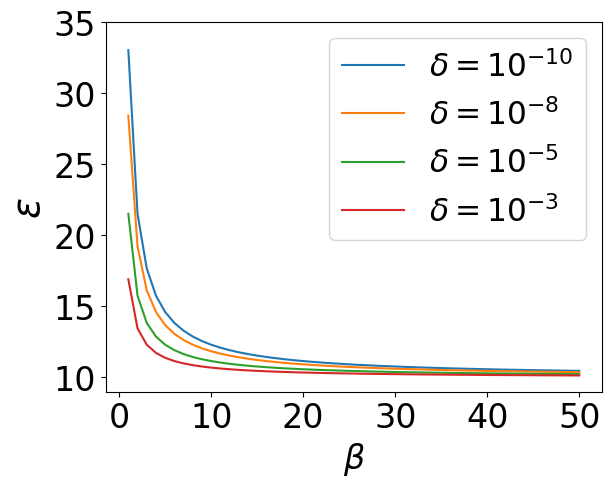
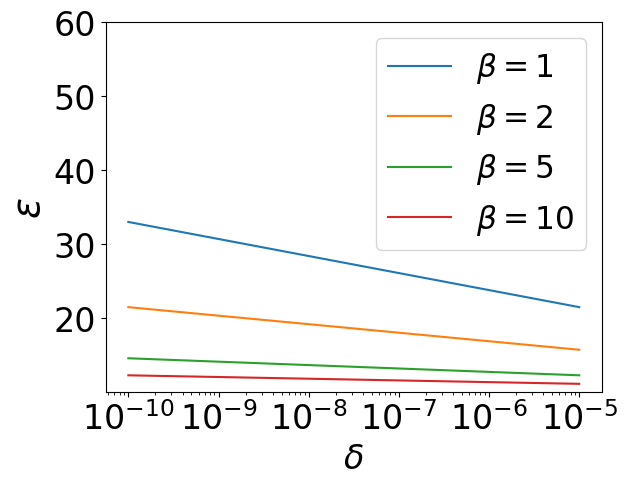
Discussion
Relations to Other DP Frameworks
We establish the bridges between WDP, DP and RDP through Proposition 9, 10 and 11. We know that -DP implies -WDP and -RDP implies -WDP. In addition, -WDP implies -RDP or -DP.
With the above basic conclusions, we can obtain more derivative relationships through RDP or DP. For example, we can obtain that -WDP implies -zCDP (zero-concentrated differentially private) according to Proposition 1.4 in Bun and Steinke (2016),
Advantages from Metric Property
The privacy losses of DP, RDP and BDP are all non-negative but asymmetric, and do not satisfy triangle inequality (Mironov 2017). Several obvious advantages of WDP as a metric DP have been mentioned in the introduction (see Section Introduction) and verified in the experiments (see Section Experiments), and here we provide more additional details.
Triangle inequality. (1) Several properties including basic sequential composition, group privacy and advanced composition are derived from triangle inequality. (2) Properties in WDP are more comprehensible and easier to utilize than those in RDP. For example, RDP have to introduce additional conditions of -stable and to derive group privacy (see Proposition 2 in Mironov (2017)), where is a constant. In contrast, our WDP utilizes its intrinsic triangle inequality to obtain group privacy without introducing any complex concepts or conditions.
Symmetry. We have considered that the asymmetry of privacy loss would not be transferred to the privacy budget. Specifically, even if , still implies , because neighboring datasets and can be all possible pairs. Even so, symmetrical privacy loss still has at least two advantages: (1) When computing privacy budgets, it can reduce the amount of computation for traversing adjacent datasets by half. (2) When proving properties, it is not necessary to exchange datasets and deduce it again like non-metric DP (e.g. see Proof of Theorem 3 in Triastcyn and Faltings (2020)).
Limitations
WDP has excellent mathematical properties as a metric DP, and can effectively alleviate exploding privacy budgets as an alternative DP framework. However, when the volume of data in the queried database is extremely small, WDP may release a much smaller privacy budget than other DP frameworks. Fortunately, this situation only occurs when there is very little data available in the dataset. WDP has great potential in deep learning that requires a large amount of data to train neural network models.
Additional Specifications
Other possibility. Symmetry can be obtained by replacing Rényi divergence with Jensen-Shannon divergence (JSD) (Rao and Nayak 1985). While JSD does not satisfy the triangle inequality unless we take its square root instead (Osán, Bussandri, and Lamberti 2018). Nevertheless, it still tends to exaggerate privacy budgets excessively, as it is defined based on divergence.
Comparability. Another question worth explaining is why the privacy budgets obtained by DP, RDP, and WDP can be compared. (1) Their process of computing privacy budgets follows the same mapping, namely . (2) They are essentially measuring the differences in distributions between adjacent datasets, although their respective measurement methods are different. (3) Privacy budgets can be uniformly transformed into the probability of successful attacks (Triastcyn and Faltings 2020).
Computational problem. Although obtaining the Wasserstein distance requires relatively high computational costs (Dudley 1969; Fournier and Guillin 2015), we do not need to worry about this issue. Because WDP does not need to directly calculate the Wasserstein distance no matter in basic privacy mechanisms or Wasserstein accountant for deep learning (see Proposition 7-8 and Theorem 1-3).
Conclusion
In this paper, we propose an alternative DP framework called Wasserstein differential privacy (WDP) based on Wasserstein distance. WDP satisfies the properties of symmetry, triangle inequality and non-negativity that other DPs do not satisfy all, which enables the privacy losses under WDP to become real metrics. We prove that WDP has several excellent properties (see Proposition 1-13) through Lyapunov’s inequality, Minkowski’s inequality, Jensen’s inequality, Markov’s inequality, Pinsker’s inequality and triangle inequality. We also derive advanced composition theorem, privacy loss and absolute moment under the postulation of WDP and finally obtain Wasserstein accountant to compute cumulative privacy budgets in deep learning (see Theorem 1-3 and Lemma 1). Our evaluations on basic mechanisms, compositions and deep learning show that WDP enables privacy budgets to be more stable and can effectively avoid the overestimation or even explosion on privacy.
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 72293583, No. 72293580), Science and Technology Commission of Shanghai Municipality Grant (No. 22511105901), Defense Industrial Technology Development Program (JCKY2019204A007) and Sino-German Research Network (GZ570).
References
- Abadi et al. (2016) Abadi, M.; Chu, A.; Goodfellow, I. J.; McMahan, H. B.; Mironov, I.; Talwar, K.; and Zhang, L. 2016. Deep Learning with Differential Privacy. In Proceedings of ACM SIGSAC Conference on Computer and Communications Security (CCS), 308–318.
- Arjovsky, Chintala, and Bottou (2017) Arjovsky, M.; Chintala, S.; and Bottou, L. 2017. Wasserstein Generative Adversarial Networks. In International Conference on Machine Learning (ICML), 214–223.
- Bobkov and Ledoux (2019) Bobkov, S.; and Ledoux, M. 2019. One-Dimensional Empirical Measures, Order Statistics, and Kantorovich Transport Distances. Memoirs of the American Mathematical Society, 261(1259).
- Bun et al. (2018) Bun, M.; Dwork, C.; Rothblum, G. N.; and Steinke, T. 2018. Composable and Versatile Privacy via Truncated CDP. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing (STOC), 74–86. ACM.
- Bun and Steinke (2016) Bun, M.; and Steinke, T. 2016. Concentrated Differential Privacy: Simplifications, Extensions, and Lower Bounds. In Theory of Cryptography Conference (TCC), volume 9985, 635–658.
- Cheng et al. (2022) Cheng, A.; Wang, J.; Zhang, X. S.; Chen, Q.; Wang, P.; and Cheng, J. 2022. DPNAS: Neural Architecture Search for Deep Learning with Differential Privacy. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI), 6358–6366.
- Clement and Desch (2008) Clement, P.; and Desch, W. 2008. An Elementary Proof of the Triangle Inequality for the Wasserstein Metric. Proceedings of the American Mathematical Society, 136(1): 333–339.
- Dharangutte et al. (2023) Dharangutte, P.; Gao, J.; Gong, R.; and Yu, F. 2023. Integer Subspace Differential Privacy. In Williams, B.; Chen, Y.; and Neville, J., eds., Thirty-Seventh AAAI Conference on Artificial Intelligence (AAAI), 7349–7357. AAAI Press.
- Dong, Roth, and Su (2022) Dong, J.; Roth, A.; and Su, W. J. 2022. Gaussian Differential Privacy. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1): 3–37.
- Dudley (1969) Dudley, R. M. 1969. The Speed of Mean Glivenko-Cantelli Convergence. Annals of Mathematical Statistics, 40: 40–50.
- Dwork et al. (2006a) Dwork, C.; Kenthapadi, K.; McSherry, F.; Mironov, I.; and Naor, M. 2006a. Our Data, Ourselves: Privacy via Distributed Noise Generation. In Vaudenay, S., ed., 25th Annual International Conference on the Theory and Applications of Cryptographic Techniques (EUROCRYPT), volume 4004, 486–503. Springer.
- Dwork and Lei (2009) Dwork, C.; and Lei, J. 2009. Differential Privacy and Robust Statistics. In Proceedings of the 41st Annual ACM Symposium on Theory of Computing (STOC), 371–380.
- Dwork et al. (2006b) Dwork, C.; McSherry, F.; Nissim, K.; and Smith, A. D. 2006b. Calibrating Noise to Sensitivity in Private Data Analysis. In Theory of Cryptography, Third Theory of Cryptography Conference (TCC), volume 3876, 265–284. Springer.
- Dwork and Roth (2014) Dwork, C.; and Roth, A. 2014. The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theory Computer Science, 9(3-4): 211–407.
- Dwork and Rothblum (2016) Dwork, C.; and Rothblum, G. N. 2016. Concentrated Differential Privacy. arXiv preprint arXiv:1603.01887.
- Erven and Harremoës (2014) Erven, T. V.; and Harremoës, P. 2014. Rényi Divergence and Kullback-Leibler Divergence. IEEE Transactions Information Theory, 60(7): 3797–3820.
- Fedotov, Harremoës, and Topsøe (2003) Fedotov, A. A.; Harremoës, P.; and Topsøe, F. 2003. Refinements of Pinsker’s inequality. IEEE Transactions on Information Theory, 49(6): 1491–1498.
- Fournier and Guillin (2015) Fournier, N.; and Guillin, A. 2015. On the Rate of Convergence in Wasserstein Distance of the Empirical Measure. Probability Theory and Related Fields, 162: 707–738.
- Gao, Gong, and Yu (2022) Gao, J.; Gong, R.; and Yu, F. 2022. Subspace Differential Privacy. In Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI), 3986–3995.
- Gulrajani et al. (2017) Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; and Courville, A. C. 2017. Improved Training of Wasserstein GANs. In Advances in Neural Information Processing Systems (NeurIPS), 5767–5777.
- Jin and Chen (2022) Jin, H.; and Chen, X. 2022. Gromov-Wasserstein Discrepancy with Local Differential Privacy for Distributed Structural Graphs. In Proceedings of the 31st International Joint Conference on Artificial Intelligence (IJCAI), 2115–2121.
- Kantorovich and Rubinshten (1958) Kantorovich, L. V.; and Rubinshten, G. S. 1958. On a Space of Completely Additive Functions. Vestnik Leningrad Univ, 13(7): 52–59.
- Kasiviswanathan et al. (2011) Kasiviswanathan, S. P.; Lee, H. K.; Nissim, K.; Raskhodnikova, S.; and Smith, A. D. 2011. What Can We Learn Privately? SIAM Journal on Computing, 40(3): 793–826.
- Krizhevsky and Hinton (2009) Krizhevsky, A.; and Hinton, G. 2009. Learning Multiple Layers of Features from Tiny Images. Handbook of Systemic Autoimmune Diseases, 1(4).
- Lecun et al. (1998) Lecun, Y.; Bottou, L.; Bengio, Y.; and Haffner, P. 1998. Gradient-based Learning Applied to Document Recognition. Proceedings of the IEEE, 86(11): 2278–2324.
- McSherry (2009) McSherry, F. 2009. Privacy Integrated Queries: An Extensible Platform for Privacy-Preserving Data Analysis. In Proceedings of ACM International Conference on Management of Data (SIGMOD), 19–30.
- Mironov (2017) Mironov, I. 2017. Rényi Differential Privacy. In 30th IEEE Computer Security Foundations Symposium (CSF), 263–275.
- Netzer et al. (2011) Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; and Ng, A. Y. 2011. Reading Digits in Natural Images with Unsupervised Feature Learning. In NIPS Workshop on Deep Learning and Unsupervised Feature Learning.
- Osán, Bussandri, and Lamberti (2018) Osán, T. M.; Bussandri, D. G.; and Lamberti, P. W. 2018. Monoparametric Family of Metrics Derived from Classical Jensen–Shannon Divergence. Physica A: Statistical Mechanics and its Applications, 495: 336–344.
- Panaretos and Zemel (2019) Panaretos, V. M.; and Zemel, Y. 2019. Statistical Aspects of Wasserstein Distances. Annual Review of Statistics and Its Application, 6(1).
- Phan et al. (2019) Phan, N.; Vu, M. N.; Liu, Y.; Jin, R.; Dou, D.; Wu, X.; and Thai, M. T. 2019. Heterogeneous Gaussian Mechanism: Preserving Differential Privacy in Deep Learning with Provable Robustness. In International Joint Conference on Artificial Intelligence (IJCAI), 4753–4759.
- Rakotomamonjy and Ralaivola (2021) Rakotomamonjy, A.; and Ralaivola, L. 2021. Differentially Private Sliced Wasserstein Distance. In Proceedings of the 38th International Conference on Machine Learning (ICML), volume 139, 8810–8820.
- Rao and Nayak (1985) Rao, C.; and Nayak, T. 1985. Cross entropy, Dissimilarity Measures, and Characterizations of Quadratic Entropy. IEEE Transactions on Information Theory, 31(5): 589–593.
- Rüschendorf (2009) Rüschendorf, L. 2009. Optimal Transport. Old and New. Jahresbericht der Deutschen Mathematiker-Vereinigung, 111(2): 18–21.
- Shokri and Shmatikov (2015) Shokri, R.; and Shmatikov, V. 2015. Privacy-Preserving Deep Learning. In Proceedings of ACM SIGSAC Conference on Computer and Communications Security (CCS), 1310–1321.
- Shokri et al. (2017) Shokri, R.; Stronati, M.; Song, C.; and Shmatikov, V. 2017. Membership Inference Attacks Against Machine Learning Models. In IEEE Symposium on Security and Privacy (SP), 3–18.
- Tien, Habrard, and Sebban (2019) Tien, N. L.; Habrard, A.; and Sebban, M. 2019. Differentially Private Optimal Transport: Application to Domain Adaptation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI), 2852–2858.
- Triastcyn and Faltings (2020) Triastcyn, A.; and Faltings, B. 2020. Bayesian Differential Privacy for Machine Learning. In International Conference on Machine Learning (ICML), 9583–9592.
- Wang, Si, and Wu (2015) Wang, Y.; Si, C.; and Wu, X. 2015. Regression Model Fitting under Differential Privacy and Model Inversion Attack. In International Joint Conference on Artificial Intelligence (IJCAI), 1003–1009.
- Winkelbauer (2012) Winkelbauer, A. 2012. Moments and Absolute Moments of the Normal Distribution. arXiv preprint arXiv:1209.4340.
- Xiao, Rasul, and Vollgraf (2017) Xiao, H.; Rasul, K.; and Vollgraf, R. 2017. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv preprint arXiv:1708.07747.
- Zhu, Liu, and Han (2019) Zhu, L.; Liu, Z.; and Han, S. 2019. Deep Leakage from Gradients. In Advances in Neural Information Processing Systems (NeurIPS), 14747–14756.
Appendix A Proof of Propositions and Theorems
Proof of Proposition 1
Proposition 1 (Symmetry). Let be a -WDP algorithm, for any and the following equation holds
Proof. Considering the definition of (,)-WDP, we have
The symmetry of Wasserstein differential privacy is obvious for the reason that joint distribution has property .
Next, we want to proof that Kantorvich differential privacy also satisfies symmetry. Consider the definition of Kantorvich differential privacy, we have
| (17) |
and
| (18) |
If we set , then the above formula can be written as
| (19) | ||||
Proof of Proposition 2
Proposition 2 (Triangle Inequality) Let be three arbitrary datasets. Suppose there are fewer different data entries between and compared with and , and the differences between and are included in the differences between and . For any randomized algorithm satisfies -WDP with , we have
| (20) |
Proof. Triangle inequality has been proved by Proposition 2.1 in Clement and Desch (2008). Here we provide a simpler proof method from another perspective.
Firstly, we introduce another mathematical form that defines the Wasserstein distance (see Definition 6.1 in Rüschendorf (2009) or Equation 1 in Panaretos and Zemel (2019))
| (21) |
Where and are random vectors, and the infimum is taken over all possible pairs of and that are marginally distributed as and .
Let be three random variables follow distributions respectively.
| (22) | ||||
| (23) | ||||
| (24) |
Here Equation 23 can be established by applying Minkowski’s inequality that with .
Proof of Proposition 3
Proposition 3 (Non-Negativity). For and any randomized algorithm , we have .
Proof. We can be sure that the integrand function , for the reason that it’s a cost function in the sense of optimal transport (Rüschendorf 2009) and a norm in the statistical sense (Panaretos and Zemel 2019). is the probability measure, so that holds. Then according to the definition of WDP, the integral function
Proof of Proposition 4
Proposition 4 (Monotonicity). For , we have , or we can equivalently described this proposition as -WDP implies -WDP.
Proof. Consider the expectation form of Wasserstein differential privacy (see Equation 21), and apply Lyapunov’s inequality as follow
| (25) |
we obtain that
| (26) | ||||
Proof of Proposition 5
Proposition 5 (Parallel Composition). Suppose a dataset is divided into parts disjointly which are denoted as . Each randomized algorithm performed on different seperated dataset respectively. If satisfies -WDP for , then a set of randomized algorithms satisfies (, )-WDP.
Proof. From the definition of WDP, we obtain that
| (27) | ||||
| (28) | ||||
| (29) |
Inequality 28 is tenable for the following reasons. (1) Privacy budget in WDP framework focuses on the upper bound of privacy loss or distance. (2) The randomized algorithm in that leads to the maximum differential privacy budget is a certain , because only one differential privacy mechanism can be applied in both and . (3) There is only one element difference between both , and , , the difference is greater when the data volume is small from the perspective of entire distributions. The query algorithm in differential privacy requires hiding individual differences, and a larger amount of data helps to hide individual data differences.
Proof of Proposition 6
Proposition 6 (Sequential Composition). Consider a series of randomized algorithms performed on a dataset sequentially. If any satisfies -WDP, then satisfies -WDP.
Proof. Consider the mathematical forms of -WDP
| (30) |
According to the basic properties of the inequality, we can obtain the upper bound of the sum of Wassestein distances
| (31) |
According to the triangle inequality of Wasserstein distance (see Proposition 2), we have
| (32) |
Thus, we obtain that .
Proof of Proposition 7
Proposition 7 (Laplace Mechanism). If an algorithm has sensitivity and the order , then the Laplace mechanism preserves -Wasserstein differential privacy.
Proof. Considering the Wasserstein distance between two Laplace distributions, we have
| (33) | ||||
| (34) | ||||
| (35) | ||||
| (36) | ||||
| (37) | ||||
| (38) |
Where is the -sensitivity between two datasets (see Definition 8), and is its order which can be set to any positive integer as needed. and are random variables follows Laplace distribution (see Equation 36). In addition, represents the total variation. represents the Kullback–Leibler (KL) divergence between and , which is also equal to one-order Rényi divergence (see Theorem 5 in Erven and Harremoës (2014) or Definition 3 in Mironov (2017)).
We can obtain Equation 37 from Equation 36 because of the probabilistic interpretation of total variation when , which has been proposed at page 10 in Reference (Rüschendorf 2009). Equation 38 can be established because of Pinsker’s inequality (see Section I in Fedotov, Harremoës, and Topsøe (2003))
| (39) |
Pinsker’s inequality establishs a relation between KL divergence and total variation, and and represent the distributions of two random variables respectively, and
To obtain the final result, we apply the outcome of Laplace Mechanism under Rényi DP of order one (see Table II in Mironov (2017)) as follow
| (40) |
Then we will obtain the outcome of Laplace Mechnism under wasserstein DP as follow
| (41) |
Proof of Proposition 8
Proposition 8 (Gaussian Mechanism). If an algorithm has sensitivity and the order , then Gaussian mechanism preserves -Wasserstein differential privacy.
Proof. By directly calculating the Wasserstein distance between Gaussian distributions, we have
| (42) | ||||
| (43) | ||||
| (44) | ||||
| (45) | ||||
| (46) | ||||
| (47) |
Where is the -sensitivity between two datasets (see Definition 8). and are random variables follows Gaussian distribution. represents the total variation. represents the KL divergence between and , which is also equal to one-order Rényi divergence (see Theorem 5 in Erven and Harremoës (2014) or Definition 3 in Mironov (2017)).
We can obtain Equation 46 from Equation 45 because of the probabilistic interpretation of total variation when (see page 10 in Rüschendorf (2009)). Equation 47 can be established because of Pinsker’s inequality (see Section I in Fedotov, Harremoës, and Topsøe (2003))
| (48) |
Pinsker’s inequality establishs a relation between KL divergence and total variation, and and represent the distributions of two random variables.
To obtain the final result, we apply the property of Gaussian Mechanism under Rényi DP of order one (see Proposition 7 and Table II in Mironov (2017)) as follow
| (49) |
Then we will obtain the outcome of Gaussian Mechnism under wasserstein DP as follow
| (50) |
Thus we have proved that if algorithm has sensitivity 1, then the Gaussian mechanism satisfies -WDP.
Proof of Proposition 9
Proposition 9 (From DP to WDP) If preserves -DP with sensitivity , it also satisfies -WDP.
Proof. Considering the definition of Wasserstein differential privacy and refering to Equation 33-38, we have
| (51) |
To deduce further, we apply Lemma 3.18 in Dwork and Roth (2014). It said that if two random variables , satisfy and , then we can obtain
| (52) |
Proof of Proposition 10
Proposition 10 (From RDP to WDP) If preserves -RDP with sensitivity , it also satisfies -WDP.
Proof. Considering the definition of Wasserstein differential privacy and refering to Equation 33-38, we have
| (54) |
Where represents the KL divergence between and , which can also written as 1-order Rényi divergence (see Theorem 5 in Erven and Harremoës (2014) or Definition 3 in Mironov (2017))
| (55) |
In addition, from the monotonicity property of RDP, we have
| (56) |
for and arbitrary and .
From the condition that preserves -RDP, we have
| (57) |
Combining Equation 55, 56 and 57, we have
| (58) |
Combining Equation 54 and 58, we have
| (59) |
Therefore, -RDP implies -WDP.
Proof of Proposition 11
Proposition 11 (From WDP to RDP) Suppose and is an -Lipschitz function. If preserves -WDP with sensitivity , it also satisfies -RDP. Specifically, when , it satisfies -DP.
proof. Considering the definition of -Lipschitz function, we have
| (60) | ||||
| (61) | ||||
| (62) | ||||
| (63) |
Considering the Rényi divergence with order , we have
| (64) | ||||
| (65) | ||||
| (66) |
According to the definition of sensitivity, we know that
| (67) |
From Theorem 2.7 in Bobkov and Ledoux (2019), we have
| (68) |
Through the same methods, we can also prove that
| (73) |
Next, we consider the special case that . From the definition of max divergence, we have
| (74) |
Refering to Equation 63, we have
| (75) |
Refering to Equation 68 , we know that
| (76) |
Through the same methods, we can also prove that
| (77) |
Proof of Proposition 12
Proposition 12 (Post-Processing). Let be a -Wasserstein differentially private algorithm, and be an arbitrary randomized mapping. For any order and all measurable subsets , is also -Wasserstein differentially private, namely
| (78) |
proof. Let , then we have
| (79) | ||||
| (80) |
Proof of Proposition 13
Proposition 13 (Group Privacy). Let be a -Wasserstein differentially private algorithm. Then for any pairs of datasets differing in data entries for any is -Wasserstein differentially private.
Proof. We decompose the group privacy problem and denote as a pair of adjacent datasets only differ in . Similarly, we denote and , and , , and as other pairs of adjacent datasets only differ in respectively.
Recall that WDP satisfies triangle inequality in Proposition 2, then we have
| (81) | ||||
Proof of Theorem 1
Theorem 1 (Advanced Composition) Suppose a randomized algorithm consists of a sequence of -WDP algorithms , which perform on dataset adaptively and satisfy , . is generalized -Wasserstein differentially private with and if for any two adjacent datasets hold that
| (82) |
Where is a customization parameter that satisfies .
Proof. With definition of generalized -WDP, we have
| (83) | ||||
| (84) | ||||
| (85) | ||||
| (86) | ||||
| (87) |
Where Equation 83 holds because triangle inequality (see Proposition 2) ensures that
Inequality 84 holds because of Markov’s inequality
| (88) |
Here can be any monotonically increasing function and satisfies the non-negative property. To simplify the computation of privacy budgets in WDP, we set as . Inequality 85 holds because of Jensen’s inequality. Equation 86 is supported by the operational property of expectation. Thus, we find that Equation 87 implies .
Proof of Theorem 2
Theorem 2 Suppose an algorithm consists of a sequence of private algorithms protected by Gaussian mechanism and satisfying , . If the subsampling probability, scale parameter and -sensitivity of algorithm are represented by , and , then the privacy loss under WDP at epoch is
| (89) | ||||
Where is the outcome distribution when performing on at epoch . represents the norm between pairs of adjacent gradients and . In addition, is a vector follows Gaussian distribution, and represents the -th component of .
Proof. With Gaussian mechanism in a subsampling scenario, we have
To facilitate the later proof, we slightly simplify the expression of .
| (90) | ||||
| (91) | ||||
| (92) |
Then we compute the privacy loss at epoch
| (93) |
Let , thus we have
| (94) |
The privacy loss is
| (95) |
Refering to the definition of norm, we can obtain
| (96) |
According to the summation property of expectation, we have
| (97) |
Finally, we have
| (98) |
Proof of Theorem 3
Theorem 3 (Tail bound) Under the conditions described in Theorem 2, satisfies -WDP for
| (99) | ||||
Proof. In Theorem 1, we have proved that
| (100) |
Taking logarithms on both sides of Equation 100, we can obtain
| (101) |
In Theorem 2, we have proved that
| (102) |
where and .
Plugging Equation 102 into Equation 101, we can obtain
| (103) |
Where can be obtained with the help of Lemma 1, thus we regard it as a computable whole part.
Observing Equation 103, we find that the uncertainty comes from two parts: Gaussian random variable and the norm of pairwise gradients . However, these two uncertainties have been eliminated by the inner expectation and the operation of infimum. Thus, we no longer need outside and the expression can be simplified as
| (104) |
We always want the probability of failure to be as small as possible, thus we replace the unequal sign with the equal sign as follow
| (105) |
Proof of Lemma 1
Lemma 1 (Raw Absolute Moment) Assume that , we can obtain the raw absolute moment of as follow
Where represents the Variance of Gaussian random variable , and can be expressed as . represents Gamma function as
| (106) |
and represents Kummer’s confluent hypergeometric function as
| (107) |
Proof. From Equation 17 in Winkelbauer (2012), we can obtain the expression of as follow
| (108) |
Where deduce further as follows
| (109) | ||||
| (110) | ||||
| (111) | ||||
| (112) | ||||
| (113) | ||||
| (114) |
Where is the rising factorial of (see Winkelbauer (2012))
| (115) | ||||
| (116) | ||||
| (117) |
| (118) | ||||
| (119) | ||||
| (120) |
From Equation 117 and 120, we have
| (121) | ||||
| (122) | ||||
| (123) |
Combing Equation 114 and 123, we can obtain
| (124) | ||||
| (125) |
Appendix B Experiments
Composition with Clipping
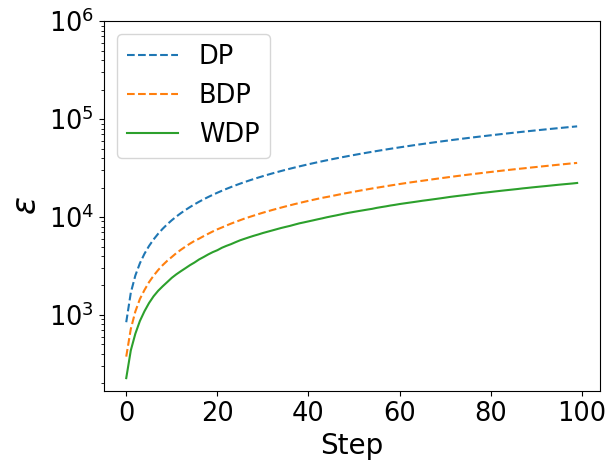
Figure 4 demonstrate the changing process of privacy budget as step increases. We find that the impact of on the privacy budget has decreased, because the gradient norm is limited by the clipping threshold, and the gap of privacy budgets between different DP frameworks has narrowed. However, this does not affect WDP to still get the lowest cumulative privacy budget, and this value grows the a bit slower than that of DP and BDP.
Appendix C Several Basic Concepts in Differential Privacy
Definition 6 (Differential Privacy (Dwork et al. 2006b)). A randomized algorithm is -differentially private if for any adjacent datasets and all measurable subsets the following inequality holds:
| (126) |
Where is the notation of probability, and is known as the privacy budget. In particular, if , is said to preserve -DP or pure DP.
Definition 7 (Privacy Loss of DP). For a randomized algorithm , and is the outcome of algorithm , then the privacy loss of the can be defined as
| (127) |
Privacy budget is the strict upper bound of privacy loss in -differential privacy, and is a quasi upper bound of privacy loss with the confidence of in (,)-differential privacy.
Definition 8 (-Sensitivity (Dwork and Lei 2009)). Sensitivity in DP theory can be defined by maximum -norm distance between the same query functions of two adjacent datasets and
| (128) |
Where is a -dimension query function, is the norm function between and . -sensitivity measures the largest difference between all possible adjacent datasets.
Definition 9 (Rényi Differential Privacy (Mironov 2017)). A randomized algorithm is said to preserve -RDP if for any adjacent datasets the following holds
| (129) |
Where is the order of RDP, is the output of algorithm . and are probability distributions, while and are probability density functions.
Definition 10 (Strong Bayesian Differential Privacy (Triastcyn and Faltings 2020)). A randomized algorithm is said to satisfy -strong Bayesian differential privacy if for any adjacent datasets the following holds
| (130) |
Where and are privacy budget and failure probability in BDP (Triastcyn and Faltings 2020). Where is the output satisfying . and are probability density functions of adjacent datasets.
Definition 11 (Bayesian Differential Privacy (Triastcyn and Faltings 2020)). Suppose the only different data entry follows a certain distribution , namely . A randomized algorithm is said to satisfy -Bayesian differential privacy if for any neighboring datasets and any set of outcomes the following holds
| (131) |
From the above definitions, we find that strong BDP is inspired by RDP, and the definition of BDP is similar to that of DP. Therefore, the weaknesses of DP, BDP and RDP are similar: (1) Their privacy losses do not satisfy symmetry and triangle inequality, which prevent them from becoming metrics. (2) Their privacy budgets tend to be overstated. To alleviate these problems, we propose Wasserstein differential privacy in this paper, expecting to achieve better properties in privacy computing, and thus obtain higher performances in private machine learning.