Watermarking in Secure Federated Learning: A Verification Framework Based on Client-Side Backdooring
Abstract
Federated learning (FL) allows multiple participants to collaboratively build deep learning (DL) models without directly sharing data. Consequently, the issue of copyright protection in FL becomes important since unreliable participants may gain access to the jointly trained model. Application of homomorphic encryption (HE) in secure FL framework prevents the central server from accessing plaintext models. Thus, it is no longer feasible to embed the watermark at the central server using existing watermarking schemes. In this paper, we propose a novel client-side FL watermarking scheme to tackle the copyright protection issue in secure FL with HE. To our best knowledge, it is the first scheme to embed the watermark to models under the Secure FL environment. We design a black-box watermarking scheme based on client-side backdooring to embed a pre-designed trigger set into an FL model by a gradient-enhanced embedding method. Additionally, we propose a trigger set construction mechanism to ensure the watermark cannot be forged. Experimental results demonstrate that our proposed scheme delivers outstanding protection performance and robustness against various watermark removal attacks and ambiguity attack.
Index Terms:
Federated learning, copyright protection, digital watermark, client-side backdooring.1 Introduction
Federated learning (FL) [1], which enables multiple data owners to learn a machine learning (ML) or deep learning (DL) model with joint efforts, is increasingly used in various applications such as medical image analysis [2, 3, 4], word predictions [5, 6, 7] and recommendation systems [8, 9]. In this manner, a large amount of private data from multiple participants is available to generate accurate and reliable ML models. However, FL protects participants’ personal data privacy at the sacrifice of holding the model also privately. Compared with traditional centralised model training, all parties in FL have access to the global model, increasing the risk of model leakage. Since training an FL model requires a large number of clients and computations, copyright protection of FL models becomes an important issue.
Model watermarking methods, which are currently used to protect the copyright of DL models, can be employed also to protect FL models. Broadly, current watermarking schemes can be divided into two categories: white-box watermarks and black-box watermarks [10, 11]. White-box approaches embed the digital watermark directly into the parameters of the DL model, and require the whole model for verification [12, 13, 14, 15]. Black-box schemes use backdoor attacks [16], generating a unique set of data named a trigger set to embed the watermark into DL models [17, 18, 19, 20, 21]. Compared with white-box watermarking, black-box techniques require the application programming interface (API) of a DL model instead of direct access, making them ideal for copyright verification of both DL and FL models.
WAFFLE [22], a recently proposed black-box watermarking scheme designed for FL, embeds the watermark into the global model by adding a retraining step at central server. After the aggregation phase, the central server takes trigger set and retrains the global model to embed the watermark. However, WAFFLE is not effective in secure federated learning, a framework that uses cryptographic methods to further enhance the protection of privacy-sensitive data and prevent privacy leakage from gradients [23]. Specifically, the secure FL based on homomorphic encryption (HE) [24], which encrypts the gradients, prevents the central server from accessing the plaintext of model parameters. Consequently, it is no longer feasible to directly use watermarking methods at the central server. In addition, WAFFLE is built on the assumption that the central server is the initiator of the FL procedure, i.e., that it is the owner of the FL model. This it is not always the case in business-to-consumer (B2C) FL [25], where an initiator gets its clients to jointly train an FL model. In this case, the central server can be a hired third party different from the initiator and other ordinary participants, while the initiator (a sole participant or a subgroup of participants) should be the actual owner(s).
In this paper, we propose a novel watermarking scheme to tackle the issue of copyright protection in secure FL. Specifically, we present an FL model copyright protection approach for the initiator by embedding a backdoor into the FL model from the client side. This client-side watermarking scheme overcomes the limitation on embedding due to HE. Moreover, we design a unique enhancement method, and propose a novel trigger set construction method using a permutation-based secret key to tackle the problem of ambiguity attacks.
Our contributions in this paper are:
-
•
A novel watermarking scheme is proposed to protect the copyright of secure FL models by embedding backdoor-based watermarks into FL models client-side, overcoming the limitations on watermark embedding due to HE encryption of the model.
-
•
A non-ambiguous trigger set construction mechanism is designed for watermark embedding based on a permutation-based secret key and noise-based patterns to prevent adversaries from forging the watermark.
-
•
A gradient-enhanced watermark embedding method is deployed to tackle the issue of slim effects of single clients on watermark embedding.
-
•
Comprehensive experiments demonstrate that our method is resilient to watermark removal attacks, including fine-tuning, pruning, quantisation, and pattern embedding and spatial-level transformation.
The structure of the remainder of the paper is organized as follows. Section 2 covers some necessary preliminaries, while the black-box watermarking problem in secure FL is formulated in Section 3. We introduce our proposed method in detail in Section 4. A security analysis is conducted in Section 5, while experimental results are presented in Section 6. Finally, Section 7 concludes the paper.
2 Preliminaries
In this section, we review three related preliminaries, including backdoor attacks, black-box watermarking in Machine Learning and homomorphic encryption scheme. The symbols used throughout the paper are summarised in Table I.
| symbol | definition |
| input space of DL models | |
| output space of DL models | |
| Cartesian production of and , i.e., | |
| the watermarked model | |
| trigger set | |
| dataset with benign samples | |
| patch parameters | |
| location key | |
| classification key | |
| weights of model in -th iteration | |
| dimensionality of model parameters | |
| local gradients of -th client in -th iteration | |
| private dataset of -th client | |
| aggregated global gradients in -th iteration | |
| scaling factor for watermark embedding |
2.1 Backdoor Attack
Backdoor attack is a special technique which trains an ML model to make predesigned incorrect predictions when encountering some specific inputs [16, 26, 27, 28]. The set of these specific inputs is called the trigger set.
Definition 1 (Trigger Set).
The trigger set is the dataset with inappropriate labels during backdoor attack training. Let and be the input space and output space, respectively. Then, , is the trigger set generated from input and output spaces. Any element should satisfy
| (1) |
where are the input samples, is the output, is the function that outputs the ground truth label of input sample, and indicates that the ground truth label is not defined in the task. While benign samples has .
A successfully backdoored ML model will not only output incorrect answers for the trigger set but also still perform well for benign inputs. Compared with the ground truth function , the backdoor-attacked function satisfies
| (2) | ||||
where is a negligible function, and is a security parameter.
Definition 2 (Strong Backdoor [17]).
A backdoor is strong if it is hard to be removed even for someone with full knowledge of the exact key generation and trigger set construction algorithms.
Strong backdoors are related to the robustness of backdoor-based watermarks, and will be further discussed in Section 5.2.
2.2 Black-box Watermarking in Machine Learning
Black-box watermarking uses backdoor attacks to force an ML model to remember specific patterns or features [17, 29, 30]. The backdoor attack causes the ML model to misclassify when encountering samples in the trigger set. The model owner keeps the trigger set secret and can thus verify the ownership of the model by triggering a misclassification.
A general black-box watermarking scheme for ML models can be split into three stages: trigger set construction, embedding, and verification.
2.2.1 Trigger Set Construction
In black-box watermarking, the trigger set is the direct carrier of the watermark which is embedded into the watermarked model. A trigger set construction algorithm generates the trigger set . should be kept secret by the owner.
2.2.2 Embedding
In the embedding phase, the owner of the model uses a particular algorithm to train the model so that the model will have a specific output for the trigger set. An embedding algorithm creates the watermarked model from the original model , where is the dimensionality of model parameters, the trigger set and a benign dataset .
2.2.3 Verification
A verification algorithm takes the watermarked model and the secret dataset held by the owner and outputs the result of verification. ‘’ represents that the model owner successfully confirms their copyright of the model, while ‘’ represents the opposite. In black-box settings, the owner only needs to know the classification results of specific samples instead of the exact model weights. Thus, it can be carried out using API queries.
2.3 Homomorphic Encryption
Homomorphic encryption (HE) [31, 24] is a cryptographic scheme that enables some specific mathematic operations, e.g., addition or multiplication, via encrypted data without decryption. HE thus allows processing of data without sharing the plaintext and HE is consequently employed to provide secure transmission and aggregation in secure FL [32, 33, 34].
3 Problem Formulation
3.1 System Model
As shown in Fig. 1, three different parties are involved in watermarking in secure FL: the initiator, the central server, and ordinary clients. All three parties need to perform Secure FL and jointly train a DL model.
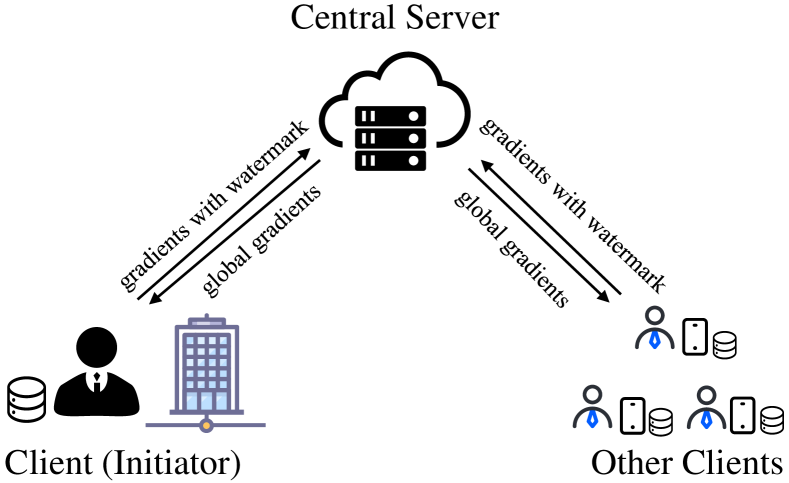
The clients are the data owner in FL. Each client holds a bunch of personal data. When training an FL model, clients obtain the global gradients from the central server during each iteration. They then update their local model based on the global gradients and train it for several epochs. Finally, they send their local gradients to the central server for aggregation. To avoid privacy leakage, the gradients are encrypted by HE.
The initiator is a special client who is chosen to embed the watermark. Besides training a local model, the initiator is responsible for embedding the black-box watermark into the global model. In case the watermarked model is stolen by an adversary, the watermark can provide copyright verification for the initiator.
The central server is responsible for aggregating the local gradients. In each iteration, the central server collects the encrypted local gradients and aggregates them using an aggregation method. After aggregation, the central server sends the ciphertext of gradients to each client.
3.2 Threat Model
In the threat model, we follow the prescriptive semi-honest assumption [25], which means any clients, including adversaries, should follow the pre-designed secure FL procedure, but might copy and steal the global model. When an adversary steals the watermarked model, they try to remove the watermark or forge their own trigger set. A benign user might also do some processing to the model before deployment. The model may thus be exposed to a variety of attacks.
Definition 3 (Fine-tuning Attack).
A fine-tuning attack refers to the attempt of removing the watermark from the watermarked model by training the pre-trained model for a few iterations using a new dataset and a small learning rate. A fine-tuning attack algorithm can be formally defined as
| (3) |
where is the model after fine-tuning, is the dataset used for fine-tuning, and is the learning rate.
Definition 4 (Pruning Attack).
A pruning attack uses a pruning method to remove the watermark from the watermarked model, where the pruning aims to decrease the number of effective parameters, e.g. by setting some unimportant parameters to zero. A pruning attack algorithm which can be defined as
| (4) |
where are the pruned model parameters.
Definition 5 (Quantisation Attack).
A quantisation attack attempts to remove the watermark through quantisation. Quantisation does not change the concrete structure of the model, but tries to reduce the number of bits used to represent each parameter. Let be the number of bits before quantisation, while bits are used after, with . A quantisation algorithm can be defined as
| (5) |
where are the quantised model parameters.
Definition 6 (PST Attack).
A pattern embedding and spatial-level transformation (PST) attack [35] attempts to invalidate a backdoor-based watermarking scheme through pre-processing input images in order to affect the classification of the secret trigger set. PST first resizes the input images, then uses a median filter to process some rows and columns of the images, and finally applies a spatial-level transformation to further process the images with random affine transformation and elastic distortions.
Definition 7 (Ambiguity Attack).
In addition to removing the existing watermark from the watermarked model, attempting to forge a fake watermark is another common way to attack a watermarked model. An ambiguity attack tries to forge a watermark and verify the ownership of the existing watermarked model. An ambiguity attack algorithm can be defined as
| (6) |
where is the watermarked model and is the fake trigger set. When the attacker uses and to claim its copyright, it can cause ambiguity and harm the actual owner.
3.3 Design Goals
While designing a black-box watermarking scheme for FL, it is important to satisfy the following properties. In general, an outstanding watermarking scheme should provide effectiveness, function preservation, low false-positive rate, robustness, and non-ambiguity.
-
•
Effectiveness: Effectiveness signifies that if the tested model is actually the model embedded with the watermark, the verification algorithm will always output ‘’ when the input is an element from the trigger set . This can be formally defined as
(7) -
•
Function Preservation: Function Preservation refers to that the watermarked model performs approximately as well as the primitive model. It indicates that the watermarking scheme has negligible impact on the functionality of the model. This can be reflected by the model’s accuracy on the validation set and can be defined as
(8) where denotes the accuracy on validation set.
-
•
Low False Positive Rate: It is crucial that the watermark should not be extracted from an unwatermarked model, i.e., the watermarking scheme should have a low false positive rate. Generally, for a -class model, the false positive rate should be near or below , which is the probability of guessing. Formally defined, for a given secret trigger set and a model without watermark,
(9) -
•
Robustness: Robustness means that when an attacker applies any attack algorithm to the watermarked model, with the set of parameters used in the attack, the model should maintain the watermark. A watermark is robust if one of the following two cases is true after attacks:
Case 1.
Case 1 signifies that the attack does not significantly influence the functionality of the model in both the primitive task and the watermark. The model owner can thus still successfully verify its ownership. This can be formally defined as Eq. (10).
(10) where is the benign dataset, is the trigger set, and is the watermarked model.
-
•
Non-ambiguity: A watermarked model is non-ambiguous if for any ambiguity attack algorithm the probability of successful verification is negligible, i.e.
(12) where is the fake trigger set created by the attacker. Thus, the watermark is considered unforgeable.
4 Watermarking in Secure Federated Learning
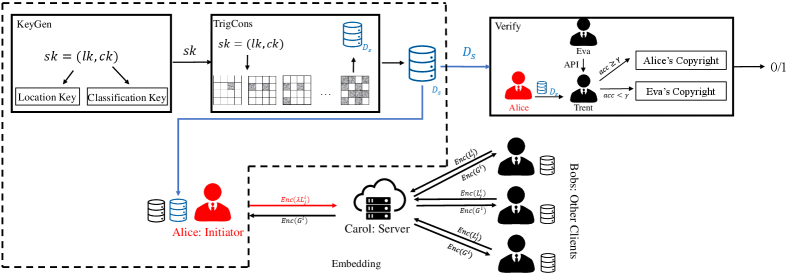
In this paper, we propose a novel client-side watermarking scheme for secure FL, which includes non-ambiguous key generation and trigger set construction algorithms as well as effective embedding and verification methods. An overview of our approach is shown in Fig. 2.
Consider the following scenario: Alice is an enterprise that has a number of Bobs to use its services. Alice decides to improve the quality of its services by training a high-performance DL-based model, however does not own sufficient data to train such a model successfully. Alice therefore decides to use federated learning to generate a model with joint efforts from Bobs. At the training stage, Alice hires Carol to perform as the central server of the FL and utilizes HE to protect the privacy of its clients’ local data. Consequently, none of these parties will possibly get any private information from other parties.
Since training an FL model requires sending the model parameters to each client, a malicious client, Eva, may copy the model, although it does not belong to her. To protect the copyright of the model, Alice therefore wants to embed a watermark into the model to allow for verification of unauthorised use of the model via a trustworthy third party Trent. Alice is one of the client-side nodes in the FL system in this scenario, and we follow the prescriptive semi-honest assumption [25] where, except for the initiator Alice, any other party will follow the pre-designed algorithm.
4.1 Key Generation for Trigger Set
In our proposed scheme, a key generation algorithm is utilized to help construct the trigger set. A key generation algorithm randomly generates a bit string as the secret key, although can also be carefully chosen by the model owner. Non-repudiation and unforgeability of directly affect the watermark’s robustness against ambiguity attacks. A watermark without can be easily forged and thus the watermarking scheme is unfeasible.
Our insight of key generation and trigger set construction algorithms is based on the following observation. The primary dilemma of key generation and trigger set construction is that, on the one hand, intuitively, making the model remember unlabeled data such as random noise does less harm to the model’s functionality than misclassifying meaningful samples. On the other hand, since constructing a trigger set with only one class leads to a security problem as it will be easy to forge, a trigger set with multiple classes is required, while simply forcing a model to classify samples with similar noise to different classes is difficult and may result in overfitting. We therefore first divide an image into several patches and add to the patches to construct a multi-classes trigger set so that the model will remember the location of noise instead of a specific noise pattern.
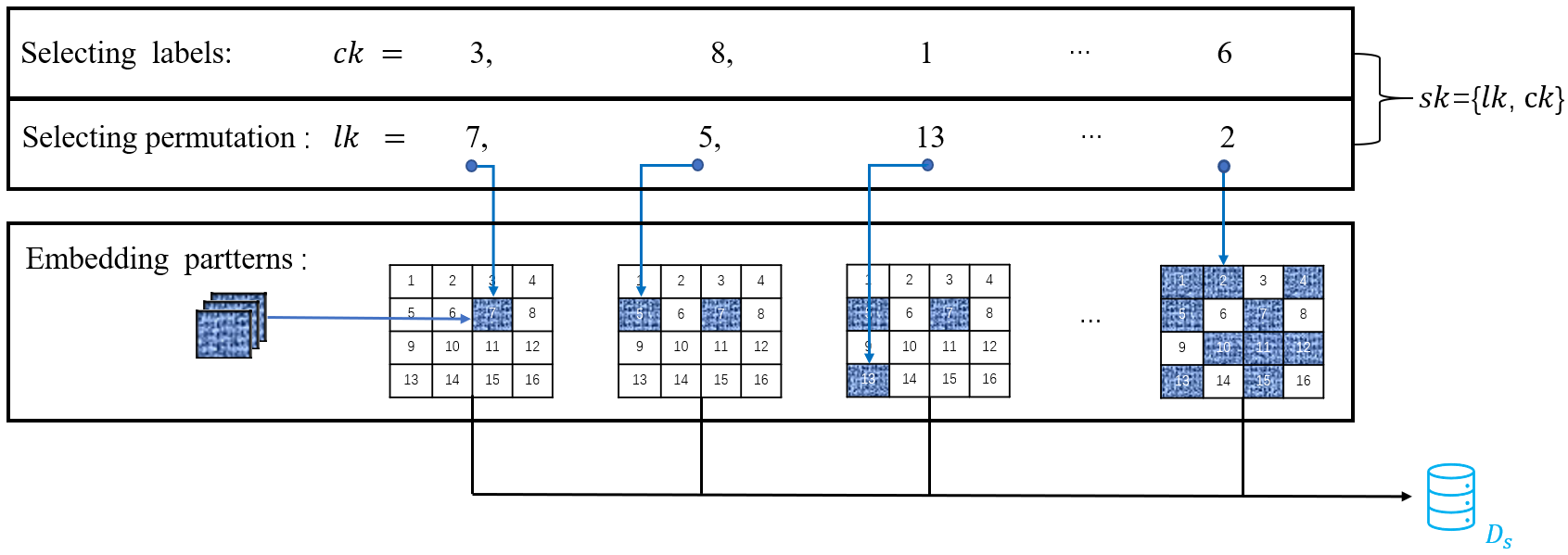
In the key generation phase, the initiator generates, using the algorithm defined in Algorithm 1, a secret key used to construct the trigger set. In our work, we design the secret key to comprise two parts. The first part denotes the positions of noise, while the other part denotes the corresponding labels. Assume that we try to watermark a -class FL model. The owner first needs to choose two patch parameters, and , that satisfy . The owner then generates a random permutation of numbers from , where is the set of all non-negative integers. The permutation, called location key , is the first part of . Since the second part are the labels, the owner generates another permutation of numbers from to yield the classification key .
Input: number of classes
Output: secret key
4.2 Trigger Set Construction
After key generation, the initiator uses to construct the trigger set following the algorithm defined in Algorithm 2. The input images with size are divided into patches. In this way, each patch corresponds to an integer between 0 and . Then the owner randomly samples patterns of pixels. For this, we use Gaussian noise to generate patterns, although the patterns can be any images that depend on the generation algorithm. Each pattern needs to be filled into the specific patch represented by and the corresponding label .
For example, the first element of is (we use subscript to denote the -th element of permutation). We thus find the -th patch and fill it with sampled patterns. Pixel values of other patches which have not been filled should be set to zero. Therefore, we get different images with only one patch that is non-zero. These images are labeled . The second element corresponds to the -th patch. Based on the images with -th patch filled, we fill another patch, identified by , with the same pattern. After that, we get another images filled with two patches which we label . The rest can be done in the same manner. In th step, we should fill the patches corresponding to with the patterns and label them with class . Eventually, we will get images with all classes, and the trigger set is composed of all these images. An example of our key generation and trigger set construction algorithms is illustrated in Fig. 3.
Input: patch parameters ; secret key
Output: trigger set
Since and are used to divide the input image space into patches so that the secret key can be embedded into the trigger set images, there are some restrictions when choosing the parameters. First, since we need to replace patches with the generated patterns, there should be at least patches. Second, each pattern needs to have at least one pixel for embedding. Therefore, the number of patches should not exceed the number of pixels in the input image. For input images, this leads to
| (13) |
Since is the upper bound for the location key, it directly determines the size of the location key space; the larger , the bigger the location key space and the more difficult for an attacker to forge the secret key. On the other hand, a larger value of yields fewer pixels for one patch, making it more challenging for the FL model to learn the trigger set images and the model potentially overfitting the trigger set. Thus, the robustness of the watermark is not guaranteed. Consequently, there is a trade-off between robustness and security that needs to be considered when choosing the patch parameters.
4.3 Watermark Embedding
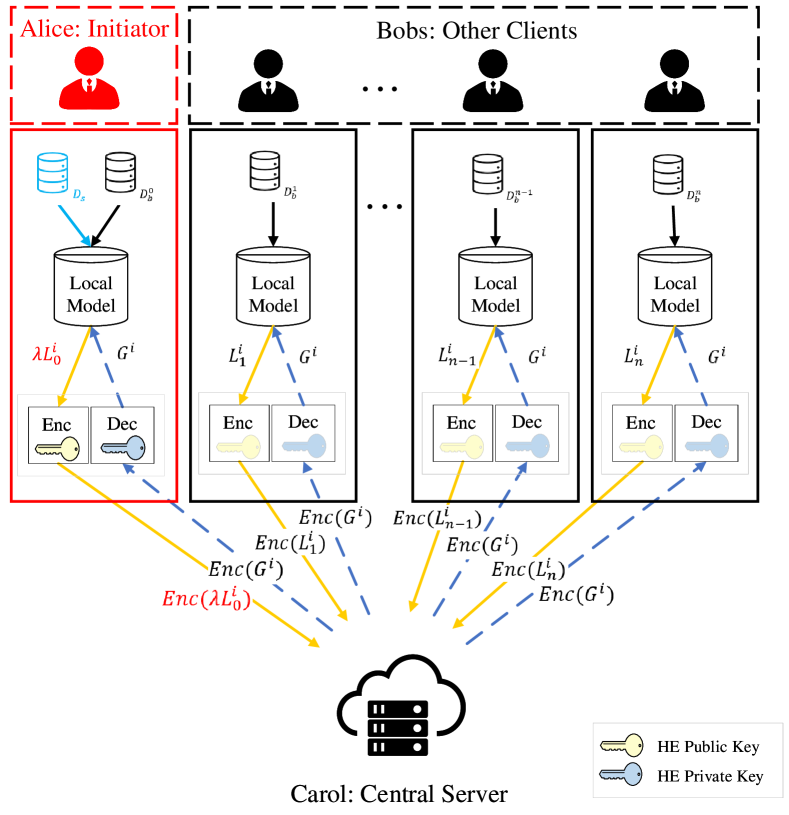
As illustrated in Fig. 4, we propose a gradient-enhanced algorithm for the initiator to embed the watermark into the FL model. The initiator only needs to perform a subtle change to carry out the embedding when transmitting the gradients. After key generation and trigger set construction, the initiator adds the trigger set into its normal training data samples to calculate the local gradients and embed the backdoor watermark into the jointly-trained model. Since the initiator is not guaranteed to be selected at each iteration and the initiator is only a single node in the FL model, we define a scaling factor to improve the embedding process. When the initiator is selected to participate in the model update, is used to enhance the gradient so that the FL model will remember the trigger set. Assuming that the initiator is the -st client in FL, i.e., the index of the initiator is , the clients get the encrypted messages as
| (14) |
where represents the local gradients of the -th client in the -th iteration, is the corresponding ciphertext, and represents any homomorphic encryption algorithm.
The watermark-embedding secure transmission algorithm is defined in Algorithm 3.
Input: local gradients ; scaling factor
Output: secure gradient
The scaling factor plays a significant role in the embedding and directly influences the watermarking scheme’s effectiveness and function preservation quality. A small results in a small effect of the initiator which might leads to a failed embedding, while a large might significantly influence the global model’s functionality. We design a suitable scaling factor setting as
| (15) |
where is the number of clients selected in each iteration, and is the total number of clients. For a small local learning rate which is common in DL, the model parameters change consistently in the training procedure. The gradients of each client during several iterations are approximately equal. Therefore, this is approximately equivalent to the case of the initiator node being selected in every iteration, corresponding to a well-applied technique in existing strong backdoor attacks [16, 17]. Our method thus has a consistent updating process to improve the stability of model convergence while performing well for watermarking.
4.4 Watermark Verification
When Alice needs to verify an unauthorised model deployment by Eva, Alice and Eva can recruit a fully-trustworthy third party Trent as the arbitrator who employs the watermark verification protocol define in Algorithm 4.
Input: a subset ; the API of Eva’s model
Output: boolean value indicating verification result
Alice first sends a subset of the secret trigger set to Trent. Trent then gets the API of Eva’s model so that he can input samples and receive classification results. Trent uses the API to process Alice’s samples and checks whether the results are in accord with the labels provided by Alice. If the resulting accuracy is above a threshold , the Alice’s ownership of the model is confirmed and Trent can sentence Eva for infringement.
The threshold controls the probability of a false positive verification. If a -class model does not have a backdoor embedded watermark, it will classify samples from the backdoor dataset to random labels with a probability of correct classification of . We expect the probability of successful copyright verification to be negligible on the model without backdoor. Assuming that Alice provides backdoor samples, threshold satisfies
| (16) |
Our protocol has some distinct advantages. First, Trent does not need to access the weights of Eva’s model, avoiding the possibility of Eva cheating Trent by providing fake model parameters. Since the model is deployed to all the clients via API access, it is impossible for Eva to avoid scrutiny. Second, Alice needs to provide only some samples of her trigger set, allowing to preserve sufficient data for future verification.
4.5 Detailed Watermarking Procedure in Secure FL
In this section, we introduce the details of watermarking procedure in Secure FL. Secure FL enhances the protection of privacy by protecting both data and gradients, while watermarking provides copyright protection of FL models. In general, the training procedure of FL proceeds in four phases: initialisation, local training, secure transmission, and aggregation.
4.5.1 Initialisation
In the initialisation phase, the initiator uses the initialisation function from [36] to initialise the global model and sends it to all clients. Let be the parameters of the model in the -th iteration, where is the set of real numbers, and is the number of model parameters. With the initialisation function, the initialisation phase is then defines as
| (17) |
4.5.2 Local Training
In the local training phase, each client uses their own dataset to train their local model and calculate model gradients to optimise the defined loss function. When is the private dataset of the -th client, is the input sample, is the output, and is the loss function, the local gradients of the -th client in the -th iteration can be calculated by
| (18) |
where is the learning rate of the clients. In our implementation, we use stochastic gradient descent (SGD) as the optimiser and cross entropy loss as the loss function.
4.5.3 Secure Transmission
Before the local gradients to the central server, the clients need to encrypt the plaintext of the gradients to prevent a malicious central server from learning private information from the gradients [23]. We employ the state-of-the-art HE scheme CKKS (Cheon-Kim-Kim-Song) [37] to encrypt each gradient. CKKS ensures both privacy and computability so that the gradients can be safely sent to the server for further processing.
For the initiator, Alice should utilize the gradient-enhanced algorithm introduced in Section 4.3 to embed the watermark into the FL model. The enhanced gradients can overcome the limitations of single node in FL and effectively embed the watermark.
4.5.4 Aggregation
In the aggregation phase, the central server collects the ciphertexts of the local gradients of clients and aggregates the gradients to yield the global gradients by
| (19) |
where is the aggregation function, and is the learning rate of the central server. In our proposed scheme, the server performs the FedAvg [1] aggregation algorithm for this which is defined as
| (20) |
where refers to the -th client’s quantity of its own dataset samples. By employing the CKKS computing method of ciphertexts, we do not need to alter the original aggregation algorithm to apply HE. After aggregation, clients can then use the global gradients to update their models.
5 Security Analysis
In security analysis, we focus on two significant properties, non-ambiguity and robustness.
5.1 Non-ambiguity
Non-ambiguity defined in Section 3.3 means the watermark can hardly be forged by the attacker. For our proposed scheme, we have the following theorem.
Theorem 1.
The key generation and trigger set construction algorithms are non-ambiguous for a not so small number of classes in the primitive task, that is, any algorithm will fail to forge a secret key and trigger set .
Proof.
For an adversary who obtains the watermarked model and tries to forge a secret key and trigger set, there are two ways to do that: (1) generate several random patterns and attempt to find the true secret key , or (2) establish a permutation and use an image generator to construct a trigger set so that he can successfully verify the copyright.
In the first strategy, the adversary tries to find the true secret key by brute force. Thus, the required time consumption and security mainly depend on the secret key space. As discussed in Section 4.2, the patch parameters and determine the size of the location key space, while the classification key space depends on the number of classes. For a -class model, the length of permutations should be , leading
| (21) |
different secret keys, where denotes permutation number and . Therefore, as grows, with the algorithm of , this is hard to accomplish in practice.
In the second strategy, the adversary needs to generate a trigger set with its own secret key. Assume that for a protected -class model , the randomly generated images will also be randomly classified, i.e., the probability of an image to be classified to any class will be . Thus, the probability of forging a satisfying trigger set is
| (22) |
which is also not acceptable for some . Considering a simple example which embeds watermarks into the 10-class CIFAR-10 dataset [38], we choose and assume that it takes second for one sample’s inference. For a -image trigger set, it would then take approximately years to traverse the secret key space.
Consequently, both strategies to forge a trigger set fail, proving our watermark scheme to be non-ambiguous. ∎
5.2 Robustness
The robustness of a backdoor-based watermark is related to the strong backdoor defined in Section 2.1. That the watermark is robust is equivalent to the backdoor being a strong backdoor. Thus, to guarantee robustness, we need to prove the trigger set embedded using our proposed scheme is the strong backdoor.
Theorem 2.
Proof.
As demonstrated in [17], when a backdoor is embedded by adding trigger set samples into each batch, the backdoor is a strong backdoor. A model containing a strong backdoor means that this backdoor, and therefore the watermark, cannot be removed by an algorithm without a striking decline of the primitive functionality. As presented in Section 4.3, the backdoor we embed in our scheme is a strong backdoor which means our scheme satisfies the robustness requirement. ∎
Additionally, the theorem can also be confirmed by our experiments in Section 6.
6 Evaluation
6.1 Experimental Settings
In our implementation, we use TensorFlow (version 2.3.4) and TensorFlow-Federated (version 0.17.0) as DL and FL framework, respectively. We encrypt the gradients using Tenseal (version 0.3.4) which implements CKKS. The learning rate of each client is set to while the learning rate of the central server is . In the local training phase, each selected client trains the model for two local epochs before transmitting the gradients to central server. The number of clients is set to to simulate a real-world FL environment.
In our experiments, we adopt two different convolutional neural network (CNN) architectures to evaluate the performance of the proposed method. The first CNN is, as also in [1], the classical LeNet [39] which consists of two convolutional layers, each followed by a max-pooling layer, and two fully connected layers. The second is VGG [40] with 13 convolutional layers and 3 fully connected layers.
6.2 Dataset Settings
In our experiments, we use two datasets, MNIST [41] and CIFAR10 [38]. MNIST is a grayscale image dataset with 60,000 training data of the 10 digits and an additional 10,000 for testing, while CIFAR10 comprises 50,000 RGB images for training and 10,000 for testing. To keep consistency, the -pixel images in MNIST are resized to pixels, the same size as CIFAR10 images.
For data distribution, we split the data using three different distributions. One is the independent identically distribution (IID) which means that the whole training dataset is uniformly allocated to each client. The other two are non-IID distributions. For one, denoted as dn-IID, we use a Dirichlet distribution to split the data accordingly, as used in [42]. For the other, we employ the method from [1] to construct a pathological non-IID distribution (pn-IID), which first sorts the dataset according to the labels and then splits them into parts where is the number of clients, with each client randomly choosing parts as its training set. In this case, each client only has data with different labels at most. We implement the settings in [1] and set in our experiments.
For trigger set construction, we set the default patch parameters to for both tasks, making them large enough for security, while in the experiments, for comparing different patch parameters, are used. Before embedding the watermark, we generate 100 images as the trigger set, with each class comprising 10 examples, while we use 1,000 images constructed with the same secret key for verification to test the generalisation ability of our watermarking scheme.
6.3 Effectiveness
Effectiveness indicates whether the watermark is successfully embedded into the model, i.e., by the accuracy on the trigger set . The effectiveness results are shown in Table II.
| MNIST | CIFAR10 | |||||
| IID | dn-IID | pn-IID | IID | dn-IID | pn-IID | |
| LeNet | 1.000 | 1.000 | 0.999 | 0.998 | 1.000 | 0.996 |
| VGG | 1.000 | 1.000 | 0.989 | 0.997 | 1.000 | 0.995 |
Table II demonstrates the success of embedding the watermark into the FL models. All accuracies on the secret trigger set exceed . This also indicates that our trigger set construction algorithm has appropriate generalisation ability for both datasets and both architectures.
6.4 Function Preservation
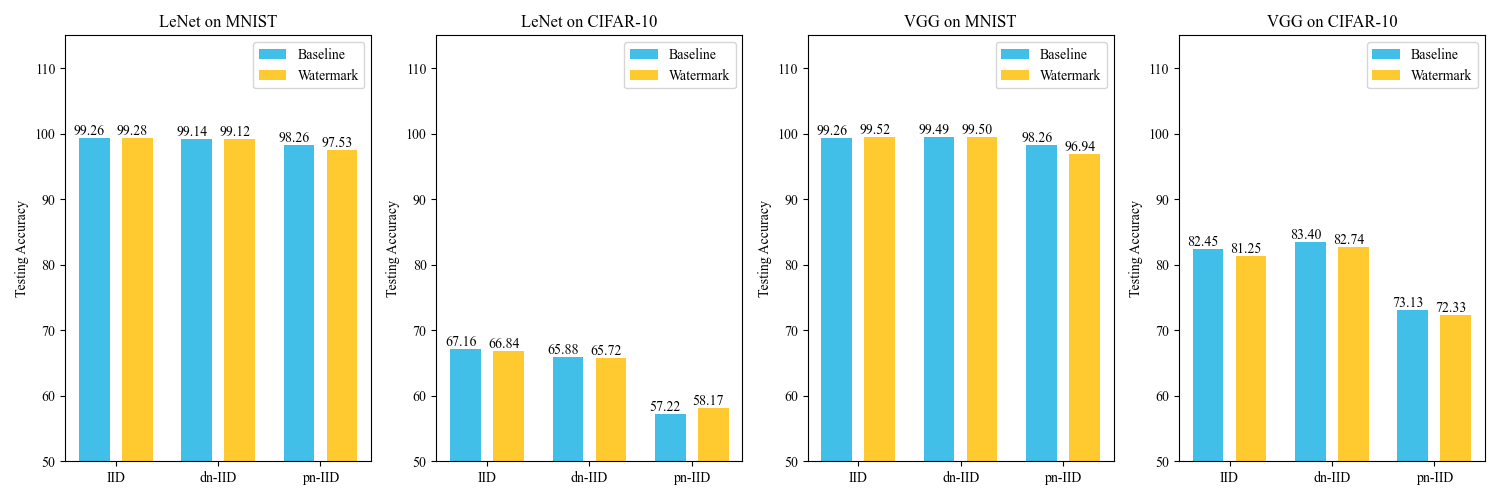
We compare the watermarked FL models with normal models without watermarks in terms of the primitive functionality. The results of this are shown in Fig. 5, from which we can see that the watermarked models do quite well, with a drop in accuracy of below in most cases. This demonstrates that our watermarking scheme has a negligible impact on the functionality of FL models.
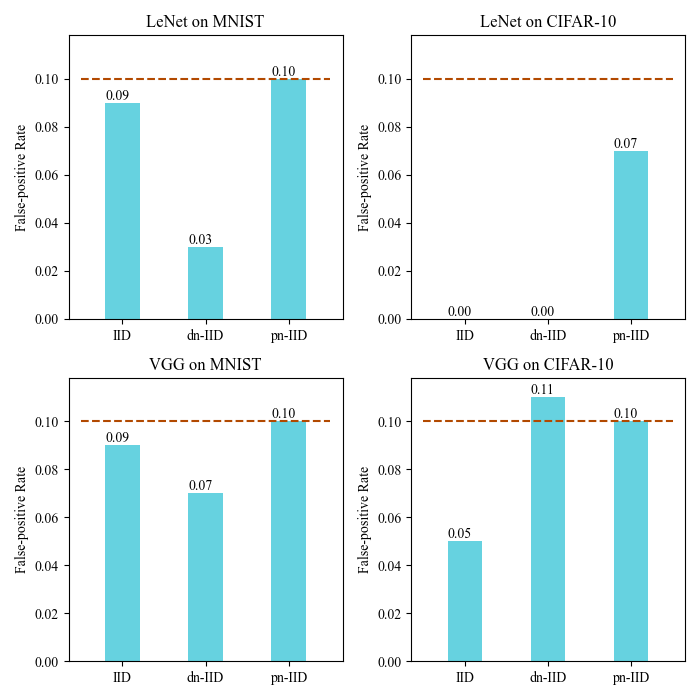
6.5 False Positive Rate
We take the normal FL models to measure whether the watermark can be detected. In the black-box watermark scheme, this means calculating the accuracy of the secret trigger set with normally-trained models. As demonstrated in Fig. 6, our watermarking scheme satisfies the requirement defined in Section 3.3, with a maximum false positive rate of , which means the rates are near or below the expected for a 10-class problem.
6.6 Robustness
We conduct four different watermark removal attacks to evaluate the robustness of our watermark, including fine-tuning, pruning, quantisation, and PST attacks as defined in Section 3.2.
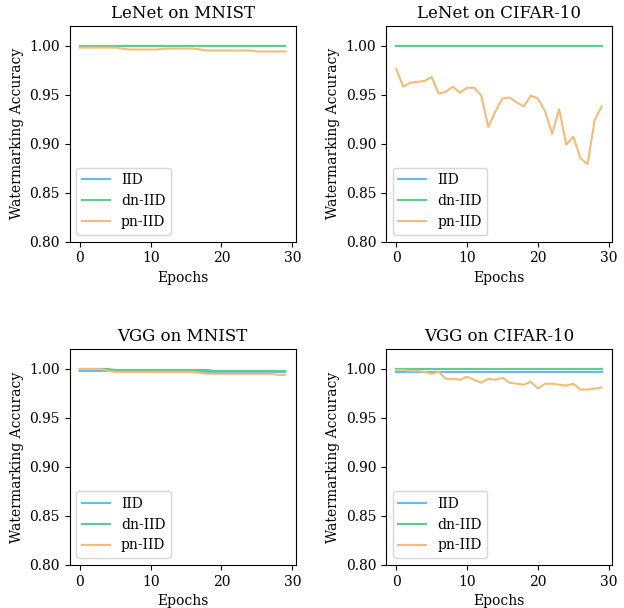
6.6.1 Fine-tuning Attack
In the fine-tuning attack experiment, we fine-tune the watermarked FL model for 30 epochs. As illustrated in Fig. 7, the FL models successfully maintain the watermark for most tasks, with an occasional slight drop in the accuracy of the trigger set. All accuracies remain above , sufficient to verify copyright.
| MNIST | CIFAR10 | ||||||||||||
| IID | dn-IID | pn-IID | IID | dn-IID | pn-IID | ||||||||
| pruning rate | wm | test | wm | test | wm | test | wm | test | wm | test | wm | test | |
| LeNet | 5% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.668 | 1.000 | 0.658 | 0.997 | 0.582 |
| 10% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.667 | 1.000 | 0.657 | 0.997 | 0.580 | |
| 15% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.666 | 1.000 | 0.656 | 0.995 | 0.582 | |
| 20% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.974 | 0.996 | 0.667 | 1.000 | 0.658 | 0.995 | 0.584 | |
| 25% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.663 | 1.000 | 0.657 | 0.993 | 0.574 | |
| 30% | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.974 | 0.998 | 0.663 | 1.000 | 0.656 | 0.991 | 0.569 | |
| 35% | 1.000 | 0.992 | 1.000 | 0.991 | 1.000 | 0.974 | 0.998 | 0.660 | 0.999 | 0.652 | 0.995 | 0.560 | |
| 40% | 1.000 | 0.992 | 1.000 | 0.991 | 1.000 | 0.973 | 0.993 | 0.656 | 0.999 | 0.649 | 0.979 | 0.553 | |
| 45% | 1.000 | 0.992 | 1.000 | 0.990 | 0.999 | 0.975 | 0.988 | 0.651 | 0.998 | 0.646 | 0.897 | 0.541 | |
| 50% | 1.000 | 0.992 | 1.000 | 0.990 | 0.999 | 0.973 | 0.981 | 0.641 | 0.996 | 0.632 | 0.888 | 0.527 | |
| VGG | 5% | 1.000 | 0.995 | 1.000 | 0.995 | 0.989 | 0.969 | 0.997 | 0.812 | 1.000 | 0.827 | 0.996 | 0.724 |
| 10% | 1.000 | 0.995 | 1.000 | 0.995 | 0.988 | 0.969 | 0.997 | 0.812 | 1.000 | 0.827 | 0.995 | 0.724 | |
| 15% | 1.000 | 0.995 | 1.000 | 0.995 | 0.988 | 0.969 | 0.997 | 0.811 | 1.000 | 0.825 | 0.997 | 0.724 | |
| 20% | 1.000 | 0.995 | 1.000 | 0.995 | 0.988 | 0.968 | 0.997 | 0.810 | 1.000 | 0.822 | 0.997 | 0.726 | |
| 25% | 1.000 | 0.995 | 1.000 | 0.995 | 0.987 | 0.967 | 0.997 | 0.808 | 1.000 | 0.821 | 0.997 | 0.728 | |
| 30% | 1.000 | 0.995 | 1.000 | 0.995 | 0.987 | 0.966 | 0.996 | 0.801 | 1.000 | 0.818 | 0.996 | 0.725 | |
| 35% | 1.000 | 0.995 | 1.000 | 0.995 | 0.983 | 0.964 | 0.994 | 0.791 | 1.000 | 0.815 | 0.996 | 0.721 | |
| 40% | 1.000 | 0.995 | 0.998 | 0.994 | 0.934 | 0.953 | 0.991 | 0.773 | 1.000 | 0.808 | 0.988 | 0.708 | |
| 45% | 1.000 | 0.994 | 0.985 | 0.992 | 0.669 | 0.920 | 0.961 | 0.743 | 1.000 | 0.790 | 0.961 | 0.676 | |
| 50% | 1.000 | 0.993 | 0.921 | 0.989 | 0.191 | 0.786 | 0.879 | 0.683 | 1.000 | 0.743 | 0.779 | 0.609 | |
| MNIST | CIFAR10 | ||||||||||||
| IID | dn-IID | pn-IID | IID | dn-IID | pn-IID | ||||||||
| # bits | wm | test | wm | test | wm | test | wm | test | wm | test | wm | test | |
| LeNet | 8 bits | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.667 | 1.000 | 0.657 | 0.997 | 0.581 |
| 7 bits | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.998 | 0.668 | 1.000 | 0.657 | 0.997 | 0.580 | |
| 6 bits | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.996 | 0.666 | 1.000 | 0.659 | 0.995 | 0.580 | |
| 5 bits | 1.000 | 0.993 | 1.000 | 0.991 | 0.999 | 0.975 | 0.992 | 0.667 | 1.000 | 0.656 | 0.994 | 0.585 | |
| 4 bits | 1.000 | 0.993 | 1.000 | 0.991 | 0.998 | 0.975 | 0.999 | 0.656 | 1.000 | 0.646 | 0.984 | 0.579 | |
| 3 bits | 0.988 | 0.990 | 0.997 | 0.988 | 0.999 | 0.974 | 0.949 | 0.632 | 0.953 | 0.614 | 0.925 | 0.531 | |
| 2 bits | 0.999 | 0.980 | 0.930 | 0.974 | 0.985 | 0.963 | 0.140 | 0.167 | 0.300 | 0.240 | 0.418 | 0.320 | |
| VGG | 8 bits | 1.000 | 0.995 | 1.000 | 0.995 | 0.989 | 0.969 | 0.997 | 0.813 | 1.000 | 0.827 | 1.000 | 0.723 |
| 7 bits | 1.000 | 0.995 | 1.000 | 0.995 | 0.989 | 0.969 | 0.997 | 0.812 | 1.000 | 0.827 | 1.000 | 0.723 | |
| 6 bits | 1.000 | 0.995 | 1.000 | 0.995 | 0.988 | 0.969 | 0.997 | 0.813 | 1.000 | 0.826 | 0.999 | 0.726 | |
| 5 bits | 1.000 | 0.995 | 1.000 | 0.995 | 0.990 | 0.970 | 0.997 | 0.810 | 1.000 | 0.827 | 0.999 | 0.716 | |
| 4 bits | 1.000 | 0.995 | 1.000 | 0.995 | 0.989 | 0.969 | 0.997 | 0.798 | 1.000 | 0.812 | 0.997 | 0.711 | |
| 3 bits | 1.000 | 0.995 | 0.997 | 0.993 | 0.999 | 0.966 | 0.787 | 0.642 | 0.991 | 0.733 | 0.886 | 0.642 | |
| 2 bits | 0.100 | 0.114 | 0.100 | 0.114 | 0.884 | 0.898 | 0.100 | 0.100 | 0.100 | 0.100 | 0.000 | 0.100 | |
For the FL models trained on IID and dn-IID datasets, the accuracies on the trigger set basically do not change. This is probably because the IID and dn-IID datasets are more manageable tasks for FL [43], and the models have already converged to a reasonable minimum. However, the existing FedAvg algorithm does not perform too well in the pn-IID settings but still acceptable.
6.6.2 Pruning Attack
We evaluate the robustness of our watermark against pruning attacks, in particular against parameter pruning [44] as conducted in [12]. In parameter pruning, parameters close to zero are set to zero, which can intentionally or unintentionally affect the effectiveness of the watermark.
In Table III, we show the pruning attack results for all twelve models and for different percentage levels which indicate how many parameters are pruned. The obtained accuracies on the trigger set are remarkable in almost every task. Most accuracies are above , indicating an impressive ability to resist pruning attack. When pruning parameters of VGG trained on the pn-IID MNIST dataset, the accuracy of drops to . However, at the same time, the accuracy of the benign dataset also drops to about , which means the attacked model has lost its value and that therefore we do not regard it as a successful attack.
| MNIST | CIFAR10 | |||||
| IID | dn-IID | pn-IID | IID | dn-IID | pn-IID | |
| LeNet | 0.848 | 0.901 | 0.777 | 0.621 | 0.611 | 0.853 |
| VGG | 0.989 | 0.823 | 0.823 | 0.779 | 0.957 | 0.615 |
6.6.3 Quantisation Attack
In our quantisation attack, we adopt a straightforward method to reduce the weights’ bit depth. For each layer in the neural network, we first find the maximum and minimum of the parameters and uniformly divide this interval, and then round parameters to the nearest value.
We report the accuracy of with different bit depths in Table IV. As we can see, when the models are quantised to more than 2 bits, the watermarked models preserve both their primitive functionality and the watermark to a good extent, with accuracies on of at least and in most cases much higher. For extreme quantisation to 2 bits, some models, especially VGG, lose the ability to classify both and , which, as discussed in Section 3.2, would be considered an unsuccessful attack.
6.6.4 PST Attack
We implement a PST attack with the same parameters used in [35] and report the results in Table V. Only for three of the twelve models, the accuracy drop to below , although still above . Considering the difficulty of learning pn-IID datasets, this drop might be because of the inadequate capability of LeNet for CIFAR10 or a bad local minimum. The results indicate that PST attacks can have an impact on our watermark to some extent, but are not consistently effective against our trigger set.
6.7 Evaluation of Different Patch Parameters
As discussed in Section 4.2, the patch parameters can affect the security and effectiveness of our watermarking scheme. We conduct some experiments where we investigate three different settings, , , and , giving corresponding patch sizes of , , and . The is the minimum patch size to generate sufficient trigger set images. For simplicity, we use to represents models with patch parameters . Since data distribution is not considered in this section’s experiments, the models are trained following the IID setting.
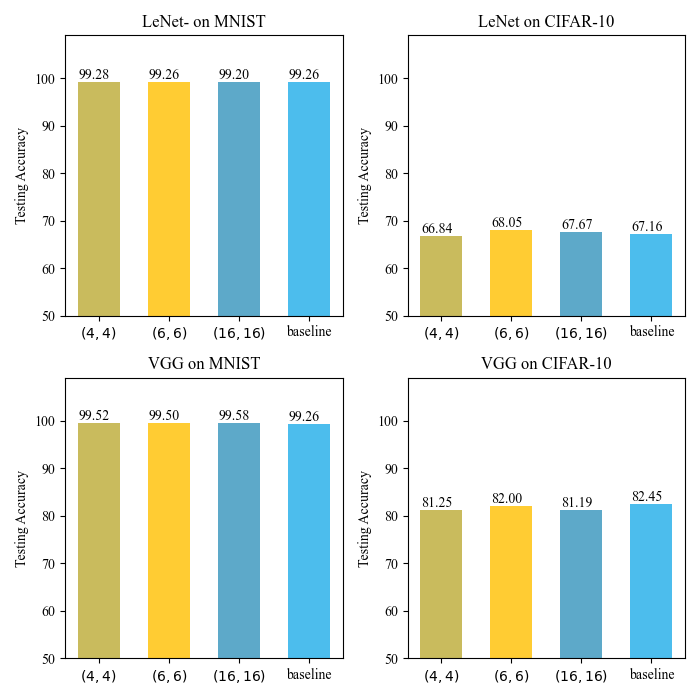
6.7.1 Effectiveness and Function Preservation
First, we evaluate the effectiveness and function preservation properties for the three parameter settings and give the results in Table VI and Fig. 8. From Table VI, although the accuracies are all greater than or close to , we can see a slight difference for model. This might be due to overfitting of the patches. Fig. 8 also suggests the same drop. The model yields the best performance, and the model the worst.
| MNIST | CIFAR10 | |||||
| ==4 | ==6 | ==16 | ==4 | ==6 | ==16 | |
| LeNet | 1.000 | 1.000 | 0.999 | 0.998 | 1.000 | 0.996 |
| VGG | 1.000 | 1.000 | 0.989 | 0.997 | 1.000 | 0.995 |
6.7.2 Robustness
As before, we conduct fine-tuning, pruning, quantisation, and PST attacks, and show the obtained results in Fig. 9, Table VII, Table VIII, and Table IX, respectively.
| MNIST | CIFAR10 | ||||||||||||
| ==4 | ==6 | ==16 | ==4 | ==6 | ==16 | ||||||||
| pruning rate | wm | test | wm | test | wm | test | wm | test | wm | test | wm | test | |
| LeNet | 5% | 1.000 | 0.993 | 1.000 | 0.993 | 0.923 | 0.992 | 0.998 | 0.668 | 1.000 | 0.680 | 0.990 | 0.677 |
| 10% | 1.000 | 0.993 | 1.000 | 0.993 | 0.923 | 0.992 | 0.998 | 0.667 | 1.000 | 0.680 | 0.990 | 0.677 | |
| 15% | 1.000 | 0.993 | 1.000 | 0.993 | 0.923 | 0.992 | 0.998 | 0.666 | 1.000 | 0.680 | 0.990 | 0.677 | |
| 20% | 1.000 | 0.993 | 1.000 | 0.993 | 0.922 | 0.992 | 0.996 | 0.667 | 1.000 | 0.677 | 0.988 | 0.674 | |
| 25% | 1.000 | 0.993 | 1.000 | 0.993 | 0.922 | 0.992 | 0.998 | 0.663 | 1.000 | 0.678 | 0.988 | 0.672 | |
| 30% | 1.000 | 0.993 | 0.999 | 0.993 | 0.919 | 0.992 | 0.998 | 0.663 | 1.000 | 0.673 | 0.989 | 0.669 | |
| 35% | 1.000 | 0.992 | 0.996 | 0.993 | 0.922 | 0.992 | 0.998 | 0.660 | 0.999 | 0.670 | 0.984 | 0.665 | |
| 40% | 1.000 | 0.992 | 0.996 | 0.993 | 0.922 | 0.992 | 0.993 | 0.656 | 0.998 | 0.666 | 0.981 | 0.660 | |
| 45% | 1.000 | 0.992 | 0.995 | 0.992 | 0.929 | 0.991 | 0.988 | 0.651 | 0.995 | 0.660 | 0.974 | 0.652 | |
| 50% | 1.000 | 0.992 | 0.997 | 0.992 | 0.930 | 0.991 | 0.981 | 0.641 | 0.984 | 0.646 | 0.950 | 0.648 | |
| VGG | 5% | 1.000 | 0.995 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.812 | 1.000 | 0.820 | 0.999 | 0.813 |
| 10% | 1.000 | 0.995 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.812 | 1.000 | 0.821 | 1.000 | 0.813 | |
| 15% | 1.000 | 0.995 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.811 | 1.000 | 0.819 | 0.999 | 0.811 | |
| 20% | 1.000 | 0.995 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.810 | 1.000 | 0.819 | 1.000 | 0.810 | |
| 25% | 1.000 | 0.995 | 1.000 | 0.995 | 0.965 | 0.996 | 0.997 | 0.808 | 1.000 | 0.820 | 0.999 | 0.808 | |
| 30% | 1.000 | 0.995 | 1.000 | 0.995 | 0.964 | 0.996 | 0.996 | 0.801 | 1.000 | 0.812 | 0.999 | 0.800 | |
| 35% | 1.000 | 0.995 | 0.999 | 0.994 | 0.965 | 0.996 | 0.994 | 0.791 | 0.999 | 0.804 | 0.999 | 0.781 | |
| 40% | 1.000 | 0.995 | 0.999 | 0.994 | 0.968 | 0.996 | 0.991 | 0.773 | 0.999 | 0.798 | 0.993 | 0.753 | |
| 45% | 1.000 | 0.994 | 0.999 | 0.994 | 0.967 | 0.995 | 0.961 | 0.743 | 0.989 | 0.770 | 0.985 | 0.699 | |
| 50% | 1.000 | 0.993 | 0.999 | 0.991 | 0.959 | 0.994 | 0.879 | 0.683 | 0.965 | 0.727 | 0.900 | 0.620 | |
| MNIST | CIFAR10 | ||||||||||||
| ==4 | ==6 | ==16 | ==4 | ==6 | ==16 | ||||||||
| # bits | wm | test | wm | test | wm | test | wm | test | wm | test | wm | test | |
| LeNet | 8 bits | 1.000 | 0.993 | 1.000 | 0.993 | 0.968 | 0.992 | 0.998 | 0.667 | 1.000 | 0.680 | 0.998 | 0.678 |
| 7 bits | 1.000 | 0.993 | 1.000 | 0.993 | 0.969 | 0.992 | 0.998 | 0.668 | 1.000 | 0.679 | 0.997 | 0.677 | |
| 6 bits | 1.000 | 0.993 | 1.000 | 0.993 | 0.967 | 0.992 | 0.996 | 0.666 | 1.000 | 0.679 | 0.998 | 0.675 | |
| 5 bits | 1.000 | 0.993 | 0.999 | 0.993 | 0.967 | 0.992 | 0.992 | 0.667 | 1.000 | 0.677 | 0.995 | 0.674 | |
| 4 bits | 1.000 | 0.993 | 0.998 | 0.993 | 0.960 | 0.992 | 0.999 | 0.656 | 1.000 | 0.666 | 0.991 | 0.665 | |
| 3 bits | 0.988 | 0.990 | 0.996 | 0.991 | 0.960 | 0.991 | 0.949 | 0.632 | 0.850 | 0.629 | 0.468 | 0.451 | |
| 2 bits | 0.999 | 0.980 | 0.860 | 0.980 | 0.864 | 0.846 | 0.140 | 0.167 | 0.100 | 0.100 | 0.105 | 0.136 | |
| VGG | 8 bits | 1.000 | 0.993 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.813 | 1.000 | 0.820 | 1.000 | 0.812 |
| 7 bits | 1.000 | 0.993 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.812 | 1.000 | 0.820 | 1.000 | 0.812 | |
| 6 bits | 1.000 | 0.993 | 1.000 | 0.995 | 0.966 | 0.996 | 0.997 | 0.813 | 1.000 | 0.820 | 0.999 | 0.810 | |
| 5 bits | 1.000 | 0.993 | 1.000 | 0.995 | 0.965 | 0.996 | 0.997 | 0.810 | 1.000 | 0.815 | 1.000 | 0.802 | |
| 4 bits | 1.000 | 0.993 | 1.000 | 0.995 | 0.965 | 0.996 | 0.997 | 0.798 | 1.000 | 0.802 | 0.998 | 0.800 | |
| 3 bits | 0.988 | 0.990 | 1.000 | 0.994 | 0.964 | 0.995 | 0.787 | 0.642 | 0.845 | 0.495 | 0.990 | 0.596 | |
| 2 bits | 0.999 | 0.980 | 0.100 | 0.114 | 0.100 | 0.114 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | 0.100 | |
| MNIST | CIFAR10 | |||||
| ==4 | ==6 | ==16 | ==4 | ==6 | ==16 | |
| LeNet | 0.848 | 0.947 | 0.676 | 0.621 | 0.691 | 0.413 |
| VGG | 0.989 | 0.804 | 0.544 | 0.779 | 0.779 | 0.529 |
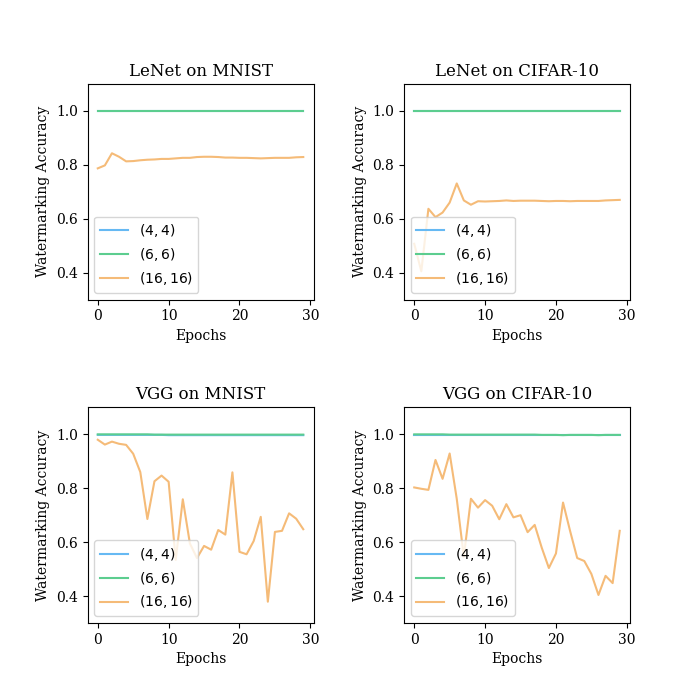
For fine-tuning attacks, from Fig. 9 we can notice a significant impact of overfitting on the watermark. While the and models perform well, maintaining a high accuracy on the trigger set, the accuracy of the models drops quite severely. The patches here are so small that the models have to overfit to classify them, thus affecting the accuracy on the trigger set.
For the pruning and quantisation attacks, Tables VII and VIII show that and provide similarly high robustness, while for we can notice a drop in accuracy. Since these attacks do not significantly alter the decision boundaries of DL models, the adverse effect of overfitting is not evident here.
For the PST attack, from Table IX it is evident that the models cannot resist this type of attack, with accuracies on the trigger set declined by more than . The median filter and affine transformations used in PST attacks, lead to severe damage to the small patches because small patches are more easily filtered and transformed. Both the and models exhibit good robustness against PST attacks.
Overall, although gives the largest secret key space, this setting leads to robustness deficiencies since the resulting patch size is too small. and yield similar results in the robustness experiments, and thus they are recommended in our tasks.
7 Conclusions
In this paper, we have proposed a novel client-side watermarking scheme for homomorphic-encryption-based secure federated learning. To our best knowledge, this is the first scheme to embed the watermark to models in a secure FL environment. The advantages of our scheme are as follows: (1) Using the gradient enhancement method, a client side can embed backdoor-based watermark into the secure FL model; (2) The proposed non-ambiguous trigger set construction mechanism means that an adversary cannot forge the watermark and claim the copyright of the model; (3) The proposed gradient-enhanced watermark embedding method tackles the issue of slim effects of single client on watermark embedding in the FL environment; (4) Using our proposed scheme, the FL model meets the requirements of effectiveness, function preservation, low false positive rate, and resistance to typical watermark removal attacks. In future work, we plan to deploy our watermarking framework into real-life secure FL applications, such as hospitals and credit systems.
Acknowledgments
This research is supported by the National Natural Science Foundation of China (61602527,U1734208), Natural Science Foundation of Hunan Province, China (2020JJ4746), and in part by the High Performance Computing Center of Central South University.
References
- [1] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentralized data,” in Proceedings of 2017 International Conference Artificial Intelligence and Statistics, 2017, pp. 1273–1282.
- [2] M. Adnan, S. Kalra, J. C. Cresswell, G. W. Taylor, and H. R. Tizhoosh, “Federated learning and differential privacy for medical image analysis,” Scientific Reports, vol. 12, no. 1, pp. 1–10, 2022.
- [3] D. Ng, X. Lan, M. M.-S. Yao, W. P. Chan, and M. Feng, “Federated learning: a collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets,” Quantitative Imaging in Medicine and Surgery, vol. 11, no. 2, p. 852, 2021.
- [4] R. Kumar, A. A. Khan, J. Kumar, A. Zakria, N. A. Golilarz, S. Zhang, Y. Ting, C. Zheng, and W. Wang, “Blockchain-federated-learning and deep learning models for covid-19 detection using CT imaging,” IEEE Sensors Journal, 2021.
- [5] A. Hard, K. Rao, R. Mathews, S. Ramaswamy, F. Beaufays, S. Augenstein, H. Eichner, C. Kiddon, and D. Ramage, “Federated learning for mobile keyboard prediction,” arXiv preprint arXiv:1811.03604, 2018.
- [6] X. Zhu, J. Wang, Z. Hong, and J. Xiao, “Empirical studies of institutional federated learning for natural language processing,” in Proceedings of 2020 Conference on Empirical Methods in Natural Language Processing: Findings, 2020, pp. 625–634.
- [7] K. Singhal, H. Sidahmed, Z. Garrett, S. Wu, J. Rush, and S. Prakash, “Federated reconstruction: Partially local federated learning,” Advances in Neural Information Processing Systems, vol. 34, 2021.
- [8] L. Yang, B. Tan, V. W. Zheng, K. Chen, and Q. Yang, “Federated recommendation systems,” in Federated Learning. Springer, 2020, pp. 225–239.
- [9] K. Muhammad, Q. Wang, D. O’Reilly-Morgan, E. Tragos, B. Smyth, N. Hurley, J. Geraci, and A. Lawlor, “Fedfast: Going beyond average for faster training of federated recommender systems,” in Proceedings of 2020 ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, 2020, pp. 1234–1242.
- [10] F. Regazzoni, P. Palmieri, F. Smailbegovic, R. Cammarota, and I. Polian, “Protecting artificial intelligence IPs: A survey of watermarking and fingerprinting for machine learning,” CAAI Transactions on Intelligence Technology, vol. 6, no. 2, pp. 180–191, 2021.
- [11] A. Fkirin, G. Attiya, A. El-Sayed, and M. A. Shouman, “Copyright protection of deep neural network models using digital watermarking: a comparative study,” Multimedia Tools and Applications, pp. 1–15, 2022.
- [12] Y. Uchida, Y. Nagai, S. Sakazawa, and S. Satoh, “Embedding watermarks into deep neural networks,” in Proceedings of 2017 ACM International Conference on Multimedia Retrieval, 2017, pp. 269–277.
- [13] T. Wang and F. Kerschbaum, “Riga: Covert and robust white-box watermarking of deep neural networks,” in Proceedings of 2021 Web Conference, 2021, pp. 993–1004.
- [14] S. Szyller, B. G. Atli, S. Marchal, and N. Asokan, “Dawn: Dynamic adversarial watermarking of neural networks,” in Proceedings of 2021 ACM International Conference on Multimedia, 2021, pp. 4417–4425.
- [15] P. Maini, M. Yaghini, and N. Papernot, “Dataset Inference: Ownership Resolution in Machine Learning,” in Proceedings of 2021 International Conference on Learning Representations, Apr. 2021.
- [16] T. Gu, B. Dolan-Gavitt, and S. Garg, “Badnets: Identifying vulnerabilities in the machine learning model supply chain,” arXiv preprint arXiv:1708.06733, 2017.
- [17] Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” in Proceedings of 2018 USENIX Security Symposium, 2018, pp. 1615–1631.
- [18] J. Zhang, Z. Gu, J. Jang, H. Wu, M. P. Stoecklin, H. Huang, and I. Molloy, “Protecting intellectual property of deep neural networks with watermarking,” in Proceedings of 2018 Asia Conference on Computer and Communications Security, 2018, pp. 159–172.
- [19] E. L. Merrer, P. Perez, and G. Trédan, “Adversarial frontier stitching for remote neural network watermarking,” Neural Computing and Applications, vol. 32, no. 13, pp. 9233–9244, 2020.
- [20] M. Xue, S. Sun, Y. Zhang, J. Wang, and W. Liu, “Active intellectual property protection for deep neural networks through stealthy backdoor and users’ identities authentication,” Applied Intelligence, pp. 1–15, 2022.
- [21] M. Shafieinejad, N. Lukas, J. Wang, X. Li, and F. Kerschbaum, “On the Robustness of Backdoor-based Watermarking in Deep Neural Networks,” in Proceedings of the 2021 ACM Workshop on Information Hiding and Multimedia Security. Virtual Event Belgium: ACM, Jun. 2021, pp. 177–188.
- [22] B. G. Tekgul, Y. Xia, S. Marchal, and N. Asokan, “WAFFLE: Watermarking in federated learning,” in Proceedings of 2021 International Symposium on Reliable Distributed Systems, 2021, pp. 310–320.
- [23] Y. Aono, T. Hayashi, L. Wang, S. Moriai et al., “Privacy-preserving deep learning via additively homomorphic encryption,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 5, pp. 1333–1345, 2017.
- [24] P. Paillier, “Public-key cryptosystems based on composite degree residuosity classes,” in Proceedings of 1999 International Conference on the Theory and Applications of Cryptographic Techniques, 1999, pp. 223–238.
- [25] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Transactions on Intelligent Systems and Technology, vol. 10, no. 2, pp. 1–19, 2019.
- [26] Y. Liu, X. Ma, J. Bailey, and F. Lu, “Reflection backdoor: A natural backdoor attack on deep neural networks,” in Proceedings of 2020 European Conference on Computer Vision, 2020, pp. 182–199.
- [27] E. Bagdasaryan, A. Veit, Y. Hua, D. Estrin, and V. Shmatikov, “How to backdoor federated learning,” in Proceedings of 2020 International Conference on Artificial Intelligence and Statistics, 2020, pp. 2938–2948.
- [28] P. Rieger, T. D. Nguyen, M. Miettinen, and A.-R. Sadeghi, “DeepSight: Mitigating Backdoor Attacks in Federated Learning Through Deep Model Inspection,” in Proceedings of 2022 Network and Distributed System Security Symposium, Jan. 2022.
- [29] J. Guo and M. Potkonjak, “Watermarking deep neural networks for embedded systems,” in Proceedings of 2018 IEEE/ACM International Conference on Computer-Aided Design, 2018, pp. 1–8.
- [30] Z. Li, C. Hu, Y. Zhang, and S. Guo, “How to prove your model belongs to you: A blind-watermark based framework to protect intellectual property of DNN,” in Proceedings of 2019 Annual Computer Security Applications Conference, 2019, pp. 126–137.
- [31] R. L. Rivest, L. Adleman, M. L. Dertouzos et al., “On data banks and privacy homomorphisms,” Foundations of secure computation, vol. 4, no. 11, pp. 169–180, 1978.
- [32] Q. Yang, Y. Liu, Y. Cheng, Y. Kang, T. Chen, and H. Yu, “Federated learning,” Synthesis Lectures on Artificial Intelligence and Machine Learning, vol. 13, no. 3, pp. 1–207, 2019.
- [33] J. Park and H. Lim, “Privacy-preserving federated learning using homomorphic encryption,” Applied Sciences, vol. 12, no. 2, p. 734, 2022.
- [34] J. Ma, S.-A. Naas, S. Sigg, and X. Lyu, “Privacy-preserving federated learning based on multi-key homomorphic encryption,” International Journal of Intelligent Systems, 2022.
- [35] S. Guo, T. Zhang, H. Qiu, Y. Zeng, T. Xiang, and Y. Liu, “Fine-tuning is not enough: A simple yet effective watermark removal attack for DNN models,” in Proceedings of 2021 International Joint Conference on Artificial Intelligence, 2021.
- [36] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification,” in Proceedings of 2015 IEEE international conference on computer vision, 2015, pp. 1026–1034.
- [37] J. H. Cheon, A. Kim, M. Kim, and Y. Song, “Homomorphic encryption for arithmetic of approximate numbers,” in Proceedings of 2017 International Conference on the Theory and Application of Cryptology and Information Security, 2017, pp. 409–437.
- [38] A. Krizhevsky, G. Hinton et al., “Learning multiple layers of features from tiny images,” Tech. Rep., 2009.
- [39] Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, 1998, pp. 2278–2324.
- [40] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [41] L. Y, C. C, and B. C, “MNIST handwritten digit database,” 2010. [Online]. Available: http://yann.lecun.com/exdb/mnist/
- [42] M. Yurochkin, M. Agarwal, S. Ghosh, K. Greenewald, N. Hoang, and Y. Khazaeni, “Bayesian nonparametric federated learning of neural networks,” in Proceedings of 2019 International Conference on Machine Learning, 2019, pp. 7252–7261.
- [43] Q. Li, Y. Diao, Q. Chen, and B. He, “Federated learning on non-iid data silos: An experimental study,” arXiv preprint arXiv:2102.02079, 2021.
- [44] S. Han, J. Pool, J. Tran, and W. Dally, “Learning both weights and connections for efficient neural network,” in Advances in Neural Information Processing Systems, vol. 28, 2015.