WaveCluster with Differential Privacy
Abstract
WaveCluster is an important family of grid-based clustering algorithms that are capable of finding clusters of arbitrary shapes. In this paper, we investigate techniques to perform WaveCluster while ensuring differential privacy. Our goal is to develop a general technique for achieving differential privacy on WaveCluster that accommodates different wavelet transforms. We show that straightforward techniques based on synthetic data generation and introduction of random noise when quantizing the data, though generally preserving the distribution of data, often introduce too much noise to preserve useful clusters. We then propose two optimized techniques, PrivTHR and PrivTHREM, which can significantly reduce data distortion during two key steps of WaveCluster: the quantization step and the significant grid identification step. We conduct extensive experiments based on four datasets that are particularly interesting in the context of clustering, and show that PrivTHR and PrivTHREM achieve high utility when privacy budgets are properly allocated.
1 Introduction
Clustering is an important class of data analysis that has been extensively applied in a variety of fields, such as identifying different groups of customers in marketing and grouping homologous gene sequences in biology research [21]. Clustering results allow data analysts to gain valuable insights into data distribution when it is challenging to make hypotheses on raw data. Among various clustering techniques, a grid-based clustering algorithm called WaveCluster [35, 36] is famous for detecting clusters of arbitrary shapes. WaveCluster relies on wavelet transforms, a family of convolutions with appropriate kernel functions, to convert data into a transformed space, where the natural clusters in the data become more distinguishable.
In many data-analysis scenarios, when the data being analyzed contains personal information and the result of the analysis needs to be shared with the public or untrusted third parties, sensitive private information may be leaked, e.g., whether certain personal information is stored in a database or has contributed to the analysis. Consider the databases A and B in Figure 1. These two databases have two attributes, Monthly Income and Monthly Living Expenses, and the records differ only in one record, u. Without u’s participation in database A, WaveCluster identifies two separate clusters, marked by blue and red, respectively. With u’s participation, WaveCluster identifies only one cluster marked by color blue from database B. Therefore, merely from the number of clusters returned (rather than which data points belong to which cluster), an adversary may infer a user’s participation. Due to such potential leak of private information, data holders may be reluctant to share the original data or data-analysis results with each other or with the public.
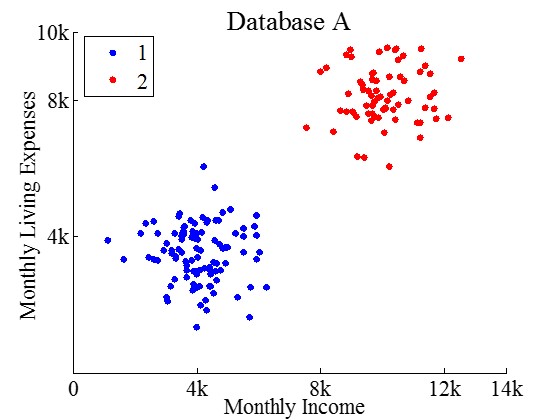
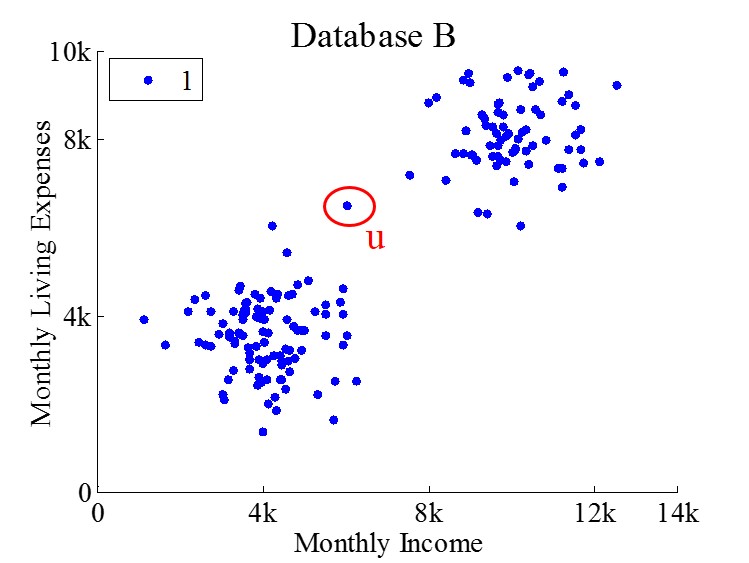
In this paper, we develop techniques to perform WaveCluster with differential privacy [12, 14]. Differential privacy provides a provable strong privacy guarantee that the output of a computation is insensitive to any particular individual. In other words, based on the output, an adversary has limited ability to make inference about whether an individual is present or absent in the dataset. Differential privacy is often achieved by the perturbation of randomized algorithms, and the privacy level is controlled by a parameter called “privacy budget”. Intuitively, the privacy protection via differential privacy grows stronger as grows smaller.
WaveCluster provides a framework that allows any kind of wavelet transform to be plugged in for data transformation, such as the Haar transform [4] and Biorthogonal transform [28]. There are various wavelet transforms that are suitable for different types of applications, such as image compression and signal processing [5]. Plugged in different wavelet transforms, WaveCluster can leverage different properties of the data, such as frequency and location, for finding the dense regions as clusters. Thus, in this paper, we aim to develop a general technique for achieving differential privacy on WaveCluster that accommodates different wavelet transforms.
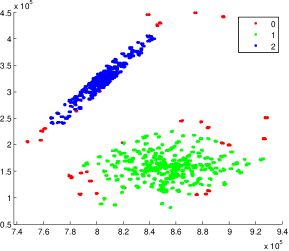
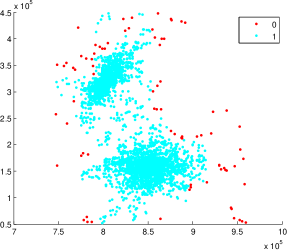
We first consider a general technique, Baseline, that adapts existing differentially private data-publishing techniques to WaveCluster through synthetic data generation. Specifically, we could generate synthetic data based on any data model of the original data that is published through differential privacy, and then apply WaveCluster using any wavelet transform over the synthetic data. Baseline seems particularly promising as many effective differentially private data-publishing techniques have been proposed in the literature, all of which strive to preserve some important properties of the original data. Therefore, hopefully the “shape” of the original data is also preserved in the synthetic data, and consequently could be discovered by WaveCluster. Unfortunately, as we will show later in the paper, this synthetic data-generation technique often cannot produce accurate results. Differentially private data-publishing techniques such as spatial decompositions [10], adaptive-grid [33], and Privelet [39], output noisy descriptions of the data distribution and often contain negative counts for sparse partitions due to random noise. These negative counts do not affect the accuracy of large range queries (which is often one of the main utility measures in private data publishing) since zero-mean noise distribution smoothes the effect of negative counts. However, negative counts cannot be smoothed away in the synthesized dataset, which are typically set to zero counts. Figure 2 shows an example of inaccurate clustering results produced by Baseline using adaptive-grid [33], As we can see, the synthetic data generated in Baseline significantly distorts the data distribution, causing two clusters to be merged as one and reducing the accuracy of the WaveCluster results.
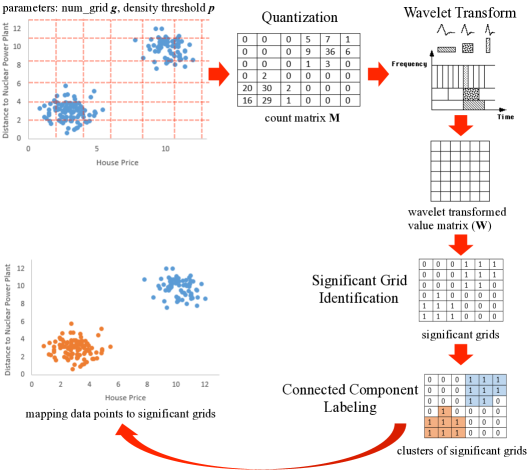
Motivated by the above challenge, we propose three techniques that enforce differential privacy on the key steps of WaveCluster, rather than relying on synthetic data generation. WaveCluster accepts as input a set of data points in a multi-dimensional space, and consists of the following main steps. First, in the quantization step WaveCluster quantizes the multi-dimensional space by dividing the space into grids, and computes the count of the data points in each grid. These counts of grids form a count matrix . Second, in the wavelet transform step WaveCluster applies a wavelet transform on the count matrix to obtain the approximation of the multi-dimensional space. Third, in the significant grid identification step WaveCluster identifies significant grids based on the pre-defined density threshold. Fourth, in the cluster identification step WaveCluster outputs as clusters the connected components from these significant grids [23]. To enforce differential privacy on WaveCluster, we first propose a technique, PrivQT, that introduces Laplacian noise to the quantization step. However, such straightforward privacy enforcement cannot produce usable private WaveCluster results, since the noise introduced in this step significantly distorts the density threshold for identifying significant grids. To address this issue, we further propose two techniques, PrivTHR and PrivTHREM, which enforce differential privacy on both the quantization step and the significant grid identification step. These two techniques differ in how to determine the noisy density threshold. We show that by allocating appropriate budgets in these two steps, both techniques can achieve differential privacy with significantly improved utility.
Traditionally, the effectiveness of WaveCluster is evaluated through visual inspection by human experts (i.e., visually determining whether the discovered clusters match those reflected in the user’s mind) [35, 36]. Unfortunately, visual inspection is inappropriate to assess the utility of differentially private WaveCluster. Visual inspection is not quantitative, and thus it is hard to systematically compare the impact of different techniques through visual inspection. Generally, researchers use quantitative measures to assess the utility of differentially private results, such as relative or absolute errors for range queries and prediction accuracy for classification. But there is no existing utility measures for density-based clustering algorithms with differential privacy.
To mitigate this problem, in this paper we propose two types of utility measures. The first is to measure the dissimilarity between true and private WaveCluster results by measuring the differences of significant grids and clusters, which correspond to the outputs of the two key steps (the significant grid identification and the cluster identification) in WaveCluster. To more intuitively understand the usefulness of discovered clusters, our second utility measure considers one concrete application of cluster analysis, i.e., to build a classifier based on discovered clusters, and then use that classifier to predict future data. Therefore the prediction accuracy of the classifier from one aspect reflects the actual utility of private WaveCluster.
To evaluate the proposed techniques, our experiments use four datasets containing different data shapes that are particularly interesting in the context of clustering [1, 9]. Our results show that PrivTHR and PrivTHREM achieve high utility for both types of utility measures, and are superior to Baseline and PrivQT.
2 Related Work
The syntactic approaches for privacy preserving clustering [18] is to output -anonymous clusters. Friedman et al. [17] presented an algorithm to output -anonymous clusters by using minimum spanning tree. Karakasidis et al. [24] created -anonymous clusters by merging clusters so that each cluster contains at least key values of the records. Fung et al. [19] proposed an approach that converts the anonymity problem for cluster analysis to the counterpart problem for classification analysis. Aggarwal et al. [3] proposed a perturbation method called -gather clustering, which releases the cluster centers, together with their sizes, radiuses, and a set of associated sensitive values. However, these approaches only satisfy syntactic privacy notions such as k-anonymity, and cannot provide formal guarantees of privacy as differential privacy.
In this work, our goal is to perform WaveCluster under differential privacy. The focus of initial work on differential privacy [12, 14, 25, 13, 15] concerned the theoretical proof of its feasibility on various data analysis tasks, e.g., histogram and logistic regression.
More recent work has focused on practical applications of differential privacy for privacy-preserving data publishing. An approach proposed by Barak et al. [7] encoded marginals with Fourier coefficients and then added noise to the released coefficients. Hay et al. [22] exploited consistency constraints to reduce noise for histogram counts. Xiao et al. [39] proposed Privelet, which uses wavelet transforms to reduce noise for histogram counts. Cormode et al. [10] indexed data by kd-trees and quad-trees, developing effective budget allocation strategies for building the noisy trees and obtaining noisy counts for the tree nodes. Qardaji et al. [33] proposed uniform-grid and adaptive-grid methods to derive appropriate partition granularity in differentially private synopsis publishing. Xu et al. [40] proposed the NoiseFirst and StructureFirst techniques for constructing optimal noisy histograms, using dynamic programming and Exponential mechanism. These data publishing techniques are specifically crafted for answering range queries. Unfortunately, synthesizing the dataset and applying WaveCluster on top of it often render WaveCluster results useless, since these differentially private data publishing techniques do not capture the essence of WaveCluster and introduce too much unnecessary noise for WaveCluster.
Another important line of prior work focuses on integrating differential privacy into other practical data analysis tasks, such as regression analysis, model fitting, classification and etc. Chaudhuri et al. [8] proposed a differentially private regularized logistic regression algorithm that balances privacy with learnability. Zhang et al. [42] proposed a differentially private approach for logistic and linear regressions that involve perturbing the objective function of the regression model, rather than simply introducing noise into the results. Friedman et al. [16] incorporated differential privacy into several types of decision trees and subsequently demonstrated the tradeoff among privacy, accuracy and sample size. Using decision trees as an example application, Mohammed et al. [31] investigated a generalization-based algorithm for achieving differential privacy for classification problems.
Differentially private cluster analysis has also be studied in prior work. Zhang et al. [41] proposed differentially private model fitting based on genetic algorithms, with applications to k-means clustering. McSherry [29] introduced the PINQ framework, which has been applied to achieve differential privacy for k-means clustering using an iterative algorithm [38]. Nissim et al.[32] proposed the sample-aggregate framework that calibrates the noise magnitude according to the smooth sensitivity of a function. They showed that their framework can be applied to k-means clustering under the assumption that the dataset is well-separated. These research efforts primarily focus on centroid-based clustering, such as k-means, that is most suited for separating convex clusters and presents insufficient spatial information to detect clusters with complex shapes, e.g. concave shapes. In contrast to these research efforts, we propose techniques that enforce differential privacy on WaveCluster, which is not restricted to well-separated datasets, and can detect clusters with arbitrary shapes.
3 Preliminaries
In this section, we first present the background of differential privacy. Then we describe the WaveCluster algorithm followed by our problem statement.
3.1 Differential Privacy
Differential privacy [12] is a recent privacy model, which guarantees that an adversary cannot infer an individual’s presence in a dataset from the randomized output, despite having knowledge of all remaining individuals in the dataset.
Definition 1
(-differential privacy): Given any pair of neighboring databases and that differ only in one individual record, a randomized algorithm is -differentially private iff for any :
The parameter indicates the level of privacy. Smaller provides stronger privacy. When is very small, 1+ . Since the value of directly affects the level of privacy, we refer to it as the privacy budget. Appropriate allocation of the privacy budget for a computational process is important for reaching a favorable trade-off between privacy and utility. The most common strategy to achieve -differential privacy is to add noise to the output of a function. The magnitude of introduced noise is calibrated by the privacy budget and the sensitivity of the query function. The sensitivity of a query function is defined as the maximum difference between the outputs of the query function on any pair of neighboring databases.:
There are two common approaches for achieving -differential privacy: Laplace mechanism [14] and Exponential mechanism [30].
Laplace Mechanism: The output of a query function is perturbed by adding noise from the Laplace distribution with probability density function , . The following randomized mechanism satisfies -differential privacy:
Exponential Mechanism: This mechanism returns an output that is close to the optimum, with respect to a quality function. A quality function assigns a score to all possible outputs , where is the output range of , and better outputs receive higher scores. A randomized mechanism that outputs with probability
satisfies -differential privacy, where is the sensitivity of the quality function.
Differential privacy has two properties: sequential composition and parallel composition. Sequential composition is that given independent randomized mechanisms where () satisfies -differential privacy, a sequence of over the dataset satisfies -differential privacy, where . Parallel composition is that given independent randomized mechanisms where () satisfies -differential privacy, a sequence of over a set of disjoint data sets satisfies -differential privacy.
3.2 WaveCluster
WaveCluster is an algorithm developed by Sheikholeslami et al. [35, 36] for the purpose of clustering spatial data. It works by using a wavelet transform to detect the boundaries between clusters. A wavelet transform allows the algorithm to distinguish between areas of high contrast (high frequency components) and areas of low contrast (low frequency components). The motivation behind this distinction is that within a cluster there should be low contrast and between clusters there should be an area of high contrast (the border). WaveCluster has the following steps as shown in Figure 3:
Quantization: Quantize the feature space into grids of a specified size, creating a count matrix .
Wavelet Transform: Apply a wavelet transform to the count matrix , such as Haar transform [4] and Biorthogonal transform [28], and decompose to the average subband that gives the approximation of the count matrix and the detail subband that has the information about the boundaries of clusters. We refer to the average subband as the wavelet-transformed-value matrix ().
Significant Grid Identification: Identify the significant grids from the average subband . WaveCluster constructs a sorted list of the positive wavelet transformed values obtained from and compute the th percentile of the values in . The values that are below the th percentile of are non-significant values. Their corresponding grids are considered as non-significant grids and the data points in the non-significant grids are considered as noise.
Cluster Identification: Identify clusters from the significant grids using connected component labeling algorithm [23] (two grids are connected if they are adjacent), map the clusters back to the original multi-dimensional space, and label the data points based on which cluster the data points reside in.
In WaveCluster, users need to specify four parameters:
num_grid (): the number of grids that the -
dimensional space is partitioned into along each dimension.
For the brevity of description, we simply use to refer to the partitions of the -dimensional space ().
This parameter controls the scaling of quantization.
Inappropriate scaling can cause problems of over-quantization and under-quantization, affecting the accuracy of clustering [36].
density threshold (): a percentage value that specifies % of the values in are non-significant values. For ease of presentation, we use to represent the top values in and their corresponding grids are considered as significant grids.
level: a wavelet decomposition level, which indicates how many times a wavelet transform is applied. The larger the level is, the more approximate the result is. In our techniques, we set level to 1 since a smaller level value provides more accurate results [36].
wavelet: a wavelet transform to be applied. Haar transform [4] is one of the simplest wavelet transforms and widely used, which is computed by iterating difference and averaging between odd and even samples of a signal (or a sequence of data points). Other commonly used wavelet transforms include Biorthogonal transform [28], Daubechies transform [11], and so on.
Motivating Scenario. Consider a scenario with two participants: the data owner (e.g. hospitals) and the querier (e.g. data miner). The data owner holds raw data and has the legal obligation to protect individuals’ privacy while the querier is eager to obtain cluster analysis results for further exploration. The goal of our work is to enable the data owner to release cluster analysis results using WaveCluster while not compromising the privacy of any individual who contributes to the raw data. The data owner has a good knowledge of the raw data and it is not difficult for her to pick the appropriate parameters (e.g. num_grid, density threshold, and wavelet) for non-private WaveCluster. For example, the data owner may draw from her past experience on similar data to determine the appropriate parameters for the current dataset. The parameters picked for the non-private setting are directly used for the private setting, and thus the data owner does not need to infer another set of parameters for the private setting.
Problem Statement. Given a raw data set , appropriate WaveCluster parameters for and a privacy budget , our goal is to investigate an effective approach such that (1) satisfies -differential privacy, and (2) achieves high utility of the private WaveCluster results with regard to the utility metrics .
4 Approaches
In this section, we present four techniques for achieving differential privacy on WaveCluster. We first describe the Baseline technique that achieves differential privacy through synthetic data generation. We then describe three techniques that enforces differential privacy on the key steps of WaveCluster.
4.1 Baseline Approach (Baseline)
A straightforward technique to achieve differential privacy on WaveCluster is as follows: (1) adapt an existing -differential privacy preserving data publishing method to get the noisy description of the data distribution in some fashion, such as a set of contingency tables or a spatial decomposition tree [40, 39, 10, 33]; (2) generate a synthetic dataset according to the noisy description; (3) apply WaveCluster on the synthetic dataset. We refer to this technique as Baseline, and its pseudocode is shown in Algorithm 1.
Baseline first leverages a -differential privacy preserving data publishing method to obtain a noisy dataset (Line 2) and partitions based on the number of grids to obtain the noisy count matrix (Line 3). Baseline then applies a wavelet transform on to obtain (Line 4). is then turned into a list that keeps only positive values and the values in is sorted in ascending order (Line 5). With , is computed based on the specified density threshold and the size of (Line 6). Finally, Baseline obtains as the top th value in (Line 7), where any value in greater than is considered as a significant value, and applies the connected component labeling algorithm to identify clusters of significant grids (Line 8).
Discussion. Baseline achieves differential privacy on WaveCluster through the achievement of differential privacy on data publishing. However, it does not produce accurate WaveCluster results in most cases. The adapted -differential privacy preserving data publishing method is designed for answering range queries. The noisy descriptions of the data distribution generated by the method may contain negative counts for certain partitions since the noise distribution is Laplacian with zero mean. These negative counts do not affect the range query accuracy too much since zero-mean noise distribution smooths the effect of noise. For example, a partition has the true count of 2 and the noisy count of -2, whose noise is canceled by another partition having the true count of 10 and the noisy count of 14 when both and are included in a range query. In particular, when the range query spreads large range of a dataset, a single partition with a noisy negative count does not affect its accuracy too much. However, when the method is used for generating a synthetic dataset, the noisy negative counts are reset as zero counts, causing the data distribution to change radically on the whole and further leading to the severe deviation in differentially private WaveCluster results.
4.2 Private Quantization (PrivQT)
To address the challenge faced by Baseline, we propose techniques that enforce differential privacy on the key steps of WaveCluster. Our first approach, called Private Quantization (PrivQT), introduces independent Laplacian noise in the quantization step to achieve differential privacy. In the quantization step, the data is divided into grids and the count matrix is computed. To ensure differential privacy in this step, we rely on the Laplace mechanism that introduces independent Laplacian noise to . Clearly, if we change one individual in the input data, such as adding, removing or modifying an individual, there is at most one change in one entry of . According to the parallel composition property of differential privacy, the noise amount introduced to each grid is , given a privacy budget . Since the following steps of WaveCluster are carried on using the differentially private count matrix , the clusters derived from these steps are also differentially private. Algorithm 2 shows the pseudocode of PrivQT. Except from the first step that introduces independent Laplacian noise to (Line 2), the other steps (Lines 3-7) are the same as Baseline.
Selecting the appropriate grid size (reflected by the parameter num_grid ) in the quantization step strongly affects the accuracy of WaveCluster results [36], and also the differentially private
WaveCluster results.
A small grid size (small ) causes more data points to fall into each grid and thus the count of data points for each grid becomes larger, which makes the count matrix resistant to Laplacian noise.
However, the small grid size is not helpful for WaveCluster to detect clusters with accurate shapes and renders the results less useful.
On the other hand, although posing a larger grid size on the data captures the density distribution of the data more clearly, it makes each grid’s count too small and thus become sensitive to Laplacian noise, which dramatically affects the identification of significant grids and further the shapes of clusters.
Our empirical results show that only when an appropriate grid size is given, differentially private WaveCluster results maintains high utility.
Discussion. Although PrivQT achieves differential privacy on the WaveCluster results, the noisy count matrix and its resulting noisy are significantly distorted and consequently the clustering results. The reason is as follows. Given a specified percentage value , PrivQT computes from the positive values in , where is derived from , which is perturbed by Laplacian noise. Laplacian distribution is symmetric and has zero-mean. According to its randomness, approximately half of the zero-count grids become noisy positive-count grids due to positive noise while the remaining ones are turned into noisy negative-count grids due to negative noise. These noisy positive-count grids may cause their corresponding wavelet transformed values in to become positive (depending on the targeted wavelet transform), which will inappropriately participate in the computation of and further distorts . Due to the dominating errors introduced by approximately half of zero-count grids becoming noisy positive-count grids, our empirical results show that the utility of private WaveCluster results by PrivQT improves marginally even for a large privacy budget.
4.3 Private Quantization with Refined Noisy Density Threshold (PrivTHR)
The limitation of PrivQT lies in the severe distortion of by Laplacian noise introduced into count matrix . To mitigate the distortion, we propose a technique, PrivTHR, which prunes a portion of noisy positive values in to refine the computation of . Algorithm 3 shows the pseudocode of PrivTHR.
PrivTHR first introduces random noise to the count matrix , similar to PrivQT, and obtains a noisy count matrix (Line 2). PrivTHR then applies a wavelet transform on to obtain (Line 3). is then turned into a list that keeps only positive values and the values in is sorted in ascending order (Line 4). Thus, only the positive values in will be used for computing based on the specified density threshold . To reduce the distortion of , starting from the smallest noisy positive values in , PrivTHR discards the first values (Line 6), where represents the non-positive (negative or zero) values in the and is a noisy estimate of (Line 5). The reason why PrivTHR removes values from is based on the utility analysis (in Section 5.2) that approximately non-positive values in are turned into positive values due to the randomness of Laplacian noise. Since partially describes the data distribution and releasing without protection may leak private information, PrivTHR also introduces Laplacian noise to , ensuring the whole process correctly enforces differentially privacy (Lines 11-17). The noise introduced to depends on the wavelet transform used to compute . For example, if we use Haar transform for -dimensional data, a value in is computed by applying average for two neighboring elements along each dimension. Since any single change in the input only causes one entry of the count matrix to change by 1, the change of causes at maximum one value in to change, and thus causes to change by 1 at maximum, i.e., the sensitivity of is 1111For other wavelet transforms that use circular convolutions, such as Biorthogonal transform, the sensitivity of depends on the count of positive values and the count of negative values in the matrix computed by the coefficient vector [28].. Finally, PrivTHR obtains as the top th value in (Line 8), where any value in greater than is considered as a significant value, and applies the connected component labeling algorithm to identify clusters of significant grids (Line 9).
Budget Allocation. PrivTHR first introduces Laplacian noise in the quantization step using a privacy budget , where . In the significant grid identification step, PrivTHR further introduces Laplacian noise to using the remaining privacy budget . Based on utility analysis in Section 5.2.2, requires a smaller amount of budget than . Our empirical results in Section 7 further show in detail the impact of on clustering accuracy.
4.4 Private Quantization with Noisy Threshold using Exponential Mechanism (PrivTHREM)
Besides pruning noisy positive values in , we propose an alternative technique that employs Exponential mechanism for deriving from the sorted list of . Algorithm 4 shows the pseudocode of PrivTHREM.
PrivTHREM first introduces Laplacian noise to the count matrix , which is similar to PrivQT and PrivTHR. After that, we obtain a noisy count matrix (Line 2) and the corresponding (Line 3). Different from the previous two techniques that compute from , PrivTHREM derives from using Exponential mechanism (Lines 7-15). In this case, although the sorted list derived from is severely distorted in PrivTHREM, the derivation of from is not affected by the distorted at all. Given reasonable privacy budget, derived from using Exponential mechanism is reasonably accurate, compared to the case when is derived from .
The quality function fed into the Exponential mechanism is [10]:
where represents the sorted positive values in with and values (Line 10), and represents the possible output space, i.e., all the possible values in the range of . Given a with positive values and their relationships are , these values divide the range into partitions: , and the ranks for these partitions are , , , 2, 1. For any , its rank is . For example, if , . Similar to PrivTHR, when using Haar transform, any single change in the input causes only one value in to change. Thus, at maximum one value will be added into or removed from , causing the outcome of to be changed by 1, i.e., the sensitivity of is 1222Similar to PrivTHR, for other wavelet transforms that use circular convolutions, the sensitivity of depends on the count of positive values and the count of negative values in the matrix computed by the coefficient vector [28]..
Plugging in the above quality function into Exponential mechanism, we obtain the following algorithm:
for any value , the Exponential mechanism (EM) returns with probability
(Line 12).
Since all the values in a partition have the same probability to be chosen, a random value from the partition will be chosen with the probability proportional to .
In other words, once is chosen, PrivTHREM further computes a uniform random value from (Line 13), and any value in greater than is considered as a significant value.
Budget Allocation. Similar to PrivTHR, the privacy budget is split between two steps: introduction of Laplacian noise in quantization and obtaining using Exponential mechanism. Previous empirical experiments [10] on splitting budgets between obtaining noisy median and noisy counts suggest that, 30% vs. 70% budget allocation strategy performs best. Specifically, 70% of budget is allocated for obtaining noisy count matrix (Line 2) and the remaining budget is allocated for computing (Line 4).
5 Privacy and Utility Analysis
In this section, we present the theoretical analysis of proposed techniques PrivQT, PrivTHR and PrivTHREM.
5.1 Privacy Analysis
In this part we establish the privacy guarantee of PrivQT, PrivTHR and PrivTHREM.
Theorem 1
PrivQT is -differentially private.
Proof 5.2.
PrivQT introduces independent Laplacian noise to grid counts, which are computed on disjoint datasets. According to the parallel composition property of differential privacy described in Section 3.1, the privacy cost depends only on the worst guarantee of all computations over disjoint datasets. Therefore, PrivQT is -differentially private.
Theorem 5.3.
PrivTHR is -differentially private.
Proof 5.4.
PrivTHR splits privacy budget into two parts. First, for private quantization, adding Laplacian noise achieves strict -differential privacy. The proof is same as PrivQT. Second, PrivTHR introduces Laplacian noise to the true count of non-positive values in , which achieves -differential privacy. Using the composition property of differential privacy, PrivTHR achieves -differentially private since .
Theorem 5.5.
PrivTHREM is -differentially private.
Proof 5.6.
Similar to PrivTHR, PrivTHREM has two steps of randomization: private quantization and obtaining noisy density threshold . Private quantization achieves -differential privacy according to Laplace mechanism and parallel composition property. Sampling noisy density threshold by Exponential mechanism consumes budget of , which achieves -differential privacy. According to the composition property of differential privacy, PrivTHREM is -differentially private.
5.2 Utility Analysis
In this section, we present utility guarantees of our algorithms (PrivQT, PrivTHR and PrivTHREM) with theoretical analysis. In WaveCluster, the step of significant grid identification determines the clustering results. In the private results of WaveCluster, PrivQT, PrivTHR and PrivTHREM return a list of noisy significant grids. To quantify the utility of PrivQT, PrivTHR and PrivTHREM, we consider finding significant grids whose wavelet transformed values surpass a threshold to be similar to finding the top- frequent itemsets whose frequencies surpass a threshold. In significant grid identification, is the list of positive wavelet transformed values from sorted in ascending order, represents the set of zero values from , and indicates the threshold position in and all the top- values in correspond to significant grids, where . One parameter to specify is the density threshold , which remains the same either with or without noise introduction. However, , another parameter to determine , will be changed to under differential privacy, where is the list of positive wavelet transformed values from sorted in ascending order. is different from since noise introduction might result in a portion of zero values in becoming positive and a small portion of positive values in becoming non-positive.
5.2.1 Utility Analysis for PrivQT.
We first provide the analysis of difference between and in PrivQT. In PrivQT, the difference between and depends on two factors: (1) a set of zero values in becoming noisy positive, , where is the noisy value of zero value in , and (2) a set of positive values in becoming noisy non-positive, , where is the noisy value of positive value in . That is, .
Analysis of . In PrivQT, since we are adding noise to each grid count and the Haar transform computes the average from four adjacent grids, the noise added into a wavelet transformed value is the sum of four i.i.d. samples from the Laplace distribution. The sum of i.i.d. Laplace distributions with mean 0 is the difference of two i.i.d. Gamma distributions [26], referred to as distribution . Distribution is a polynomial in divided by , which is a symmetric function and thus the probability for distribution to produce positive values is . Thus, the events of values in adding positive noise from distribution conform to the Binominal Distribution with parameters and and its expected value is .
Analysis of . For , each value is added the noise conforming to the symmetric distribution . The probability density function of is , and its expected value is . is large when is small and there is limited privacy budget. Consider an extreme case that might not be suitable for clustering. All the positive values in are the minimum value 0.5 due to the sum of adjacent four grid counts being the minimum value 1, resulting in a high . Clustering, especially WaveCluster algorithm, is useful when the dataset has dense areas (clusters) and empty areas (gap between clusters). Such extreme case is not suitable for clustering since its data distribution is close to uniform distribution. Those datasets that are interesting for clustering always have highly dense cluster centers and cluster borders with low density. Only those values corresponding to border grids are possible to become noisy non-positive and the size of border grids is relatively small. Therefore, is a small constant. We refer to the value of as in the following analysis.
Analysis of . In PrivQT, . There are two extreme cases when . For one extreme, and all the positive values in is the minimum value 0.5. When , , which makes . For another extreme, , all the positive values in is large, e.g. . When , and . For those datasets that are interesting in the context of clustering, is pretty large compared to the whole space since is used to separate different clusters. What is more, dense areas within clusters are typically larger than the space of cluster borders with low density, i.e. is far smaller than . In PrivQT, dominates the difference between , which increases false positive rate. In PrivTHR and PrivTHREM, we use different strategies to minimize the difference between .
Theorem 5.7.
In PrivQT with Haar transform, given , let , , and , then with probability at least , (1) all values in greater than are output, where , and (2) no values in less than are output, where .
Proof 5.8.
In PrivQT, . Since follows Binominal distribution with parameters and and is noted as a small value , follows the Binomial distribution and decides the number of values in that become output. Given , we can derive ’s lower bound , and show that values greater than are output, i.e., subclaim (1). Let . As = 1 - and [6], we have . For constant , will suffice.
Similar as , we can also derive the bound of the noise added to each value in based on . For Haar wavelet transform, each value in is added the noise that is the sum of 4 Laplacian random variables divided by 2 (i.e., ). For values in , let all Laplacian random variables generate noise within . The probability that no Laplacian random variable’ value is outside is , where is that at least one Laplacian random variable’s value is outside . By union bound, , where is that th Laplacian random variable’s noise is outside and . Thus, we can derive that with at least the probability , no Laplacian random variable’ value is outside , and each value in has their noise amount within . Let , then and we have . For constant , .
Subclaim (1) can be derived based on (a) with probability at least , and (b) with probability at least , the noise of each value in being within . Detailed proof is omitted here. Subclaim (1) requires both conditions (a) and (b) to hold, and thus the probability is at least .
We can derive the upper bound of given . Let . Recall that follows Binomial distribution , and Binomial distribution is symmetric with respect to . Thus, the probability of sampling a value from the range is the same as sampling a value from the range , and we have . For constant , will suffice.
Subclaim (2) can be proved based on (c) with probability at least , and (b) with probability at least , the noise of each value in being within . As subclaim (2) requires both conditions (c) and (b) to hold, the probability is at least .
For other wavelet transforms that use circular convolutions, such as Biorthogonal transform, the derivation for the bounds of with and remains the same since following Binomial distribution is independent of any wavelet transform being adapted. Thus, our framework is extensible to other wavelet transforms, and the bound of noise magnitude depends on the amount of adjacent grid counts involved in computing a wavelet transformed value.
5.2.2 Utility Analysis for PrivTHR.
Theorem 5.9.
In PrivTHR with Haar transform, given , let , , and , then with probability at least , (1) all values in greater than are output, where , and (2) no values in less than are output, where .
Proof 5.10.
In PrivTHR, we allocate for private quantization and for protecting , which makes . With the probability at least , has the noise amount within . Let , then we get . For constant , will suffice. The proofs of , , and subclaims (1) and (2) are the same as Theorem 4, and for constant .
Difference between PrivTHR and PrivQT: By Theorem 4, in PrivQT and . By Theorem 5, in PrivTHR and . , . As we can see, by removing positive values from , PrivTHR provides better utility guarantee than PrivQT since the difference between and becomes , where is a small constant and is small when sufficient budget is provided.
5.2.3 Utility Analysis for PrivTHREM.
Theorem 5.11.
In PrivTHREM with Haar transform, given , let , , and , then with probability at least , (1) all values in greater than are output, where , and (2) no values in less than are output, where .
Proof 5.12.
In PrivTHREM, we allocate for deriving from by employing Exponential mechanism, a general method proposed in [30]. The probability of selecting a rank is , where is the range decided by the th and th wavelet transformed values.
Let be the probability of sampling a where , then
For constant , will suffice.
Let be the probability of sampling a where , then
For constant , will suffice. The proof of and subclaims (1) and (2) are the same as Theorem 4.
Analysis of PrivTHR and PrivTHREM.
By Theorem 5 and Theorem 6,
the accuracy for sampling in PrivTHR is dominated by
while in PrivTHREM the accuracy is dominated by .
Depending on the data distribution, PrivTHREM may present better or worse utility guarantee than PrivTHR:
is positive when when ,
and the accuracy for sampling in PrivTHREM becomes more sensitive to than PrivTHR;
becomes negative when is less than 1,
and the bounds of utility guarantee for PrivTHREM becomes better than PrivTHR.
Section 7 demonstrates that by reducing the difference between and , PrivTHR and PrivTHREM achieve more accurate results than PrivQT, which conforms to the above analysis.
6 Quantitative Measures
To quantitatively assess the utility of differentially private WaveCluster, we propose two types of measures for measuring the dissimilarity between true and differentially private WaveCluster results. The first type, , measures the dissimilarity of the significant grids and the clusters between true and private results. The second type focuses on observing the usefulness of differentially private WaveCluster results for further data analysis. The reason is that a slight difference in the significant grids or clusters may cause a significant difference when using the WaveCluster results. In this paper, we choose a typical application of further data analysis: building a classifier from the clustering results to predict unlabeled data [20]. The classifier built from true WaveCluster results is called the true classifier while the classifier built from differentially private WaveCluster results is called the private classifier . To measure the dissimilarity between and , we propose two metrics: and .
6.1 Dissimilarity based on Significant Grids and Clusters
considers the dissimilarities of significant grids and clusters. Assume that there are clusters of true significant grids and clusters of differentially private significant grids. might not be equal to , and the cluster labels in true clusters and private clusters are completely arbitrary. To accommodate these differences, we adopt the Hungarian method [27], a combinatorial optimization algorithm, to solve the matching problem between true clusters and private clusters while minimizing the matching difference.
When cluster matches to cluster , we define that the distance between cluster and cluster is . Consider a cluster and a cluster = . The distance between clusters and is . Given true clusters, private clusters, and , a matching of true clusters and private clusters is a set of cluster pairs, where each private cluster is matched with a true cluster. We then define the cost of a matching () as the sum of all the distances between each cluster pair in the matching plus the count of significant grids in the non-matched clusters:
Here, and indicate the subscripts of clusters in a matched pair. represents the count of significant grids in the non-matched true clusters. Among all the possible matchings of clusters, we use the Hungarian method to find the optimal matching with the minimum , and computed as:
Here denotes the set of significant grids in the true WaveCluster results.
6.2 Dissimilarity based on Classifier Prediction
and measure the dissimilarity between and . We name this way of evaluation as “clustering-first-then-classification”: given a set of unlabeled data points, we use a portion of the data points (e.g., 90%) to compute WaveCluster results, where each cluster is a set of significant grids. Using the significant grids with cluster labels as training data, we build classifiers and , and use them to predict the classes for the remaining data points (e.g., 10%).
Dissimilarity of Classifiers based on Optimal Class Matching (). measures the dissimilarity between the two sets of classes predicted by and for the same test samples. We use to denote the set of classes predicted by and to denote the set of classes predicted by . Since and are completely arbitrary, we exploit the Hungarian method to find the optimal matching between and .
Assume that a class predicted by is matched to a class predicted by , forming a class pair. We compute the count of common test samples in the class and the class , and sum the common test samples in each class pair to compute :
Here is the count of classes in and is the count of classes in , and we assume . Since there are many possible mappings from the classes in to the classes in , we use the Hungarian method to find the optimal mapping that maximizes . Based on and the total count of the test samples , we derive the dissimilarity :
When the dissimilarity is smaller, the differentially private WaveCluster results are more similar to the true WaveCluster results and maintain high utility for classification use.
Dissimilarity of Classifiers based on 2-Combination Enumeration (). measures the dissimilarity between and based on relationships of every pair of test samples, i.e., whether two samples are in the same class. Essentially, given a pair of test samples and , we say and are classified consistently either (1) and or (2) and . is the ratio of the count of test sample pairs that are not classified consistently over the total number of test sample pairs, which is the set of 2-combination of the test samples. uses pairs of test samples to eliminate the need of finding the optimal matching between the classes predicted by and .

7 Experiments
We evaluate the proposed techniques using three datasets that are widely used in previous clustering algorithms [1], and one large scale dataset derived from the check-in information in Gowalla333https://snap.stanford.edu/data/loc-gowalla.html. geo-social networking website [9], which was used to evaluate grid-based clustering algorithms in [37].
7.1 Experiment Setup
In our experiments, we compare the performances of the four techniques, Baseline, PrivQT, PrivTHR, and PrivTHREM, on the four datasets using two types of measures proposed in Section 6 and provide analysis on the results. We use Haar transform as the wavelet transform and set the wavelet decomposition level to 1 for the four techniques. Baseline uses the adaptive-grid method [33] for synthetic data generation. The classification algorithm used for measuring and is C4.5 decision tree algorithm [34]. We conduct experiments with privacy budgets ranging from 0.1 to 2.0; for each budget and each metric, we apply the techniques on each dataset for 10 times and compute their average performances. All experiments were conducted on a machine with Intel 2.67GHz CPU and 8GB RAM.
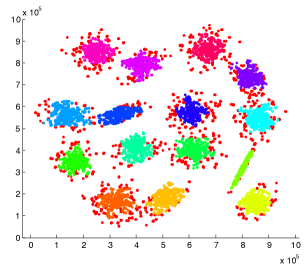
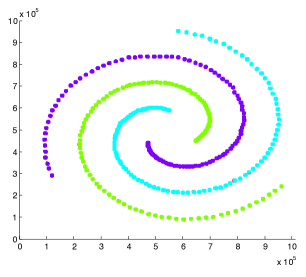
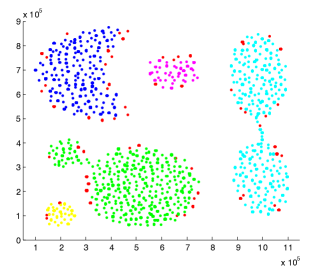
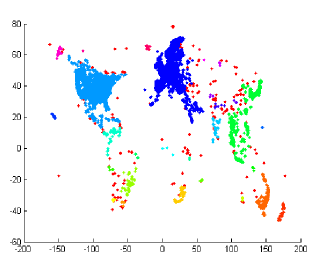
Datasets. The four clustering datasets contain different data shapes that are specially interesting for clustering. Figures 4 shows the WaveCluster results on four datasets under certain parameter settings of grid size and density threshold . Any two adjacent clusters are marked with different colors. The points in red color are identified as noise, which fall into the non-significant grids.
is a dataset containing 15 Gaussian clusters with different degrees of cluster overlapping. It contains 30000 data points. These 15 clusters are all in convex shapes. The center area of each cluster has higher density and is resistant to noise. However, the overlapped area of two adjacent clusters has lower density and is prone to be affected by noise, which might turn the corresponding non-significant grids into significant grids and further connect two separate clusters. is a dataset with 3 spiral clusters. It contains 31200 data points. The head of each spiral is quite close to one another. Some noisy significant grids are very likely to bridge the gap between adjacent spirals and merge them into one cluster. is a data dataset with 5 various shapes of clusters, including concave shapes. It contains 31520 data points. There are two clusters that both contain two sub components and a narrow line-shape area that bridges those two sub components. The narrow bridging area has low density and might be turned into non-significant grids, causing a cluster to split into two clusters. is the check-in dataset resembling the world map, which records time and location information of users’ check-ins. We use only the location information for evaluation. There are about 6.4M records in total. The large size of the dataset makes it infeasible to run experiments with C4.5 and Baseline due to memory constraints. Thus, similar to [33], we sampled 1M records from the dataset for evaluation.
We next present the results on comparing and , and then present the results of the two types of measures.
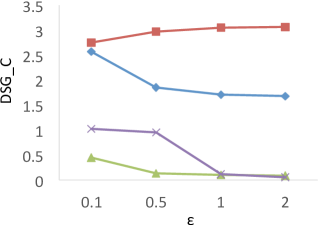

7.2 Comparing Private With True
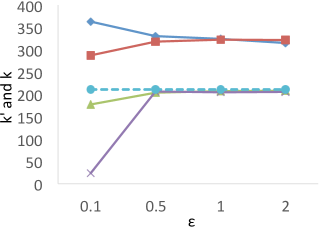
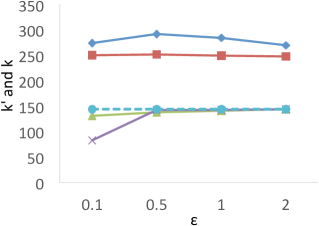
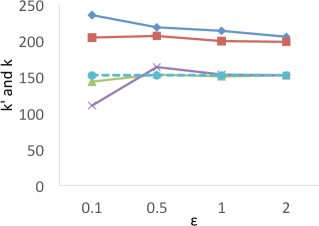
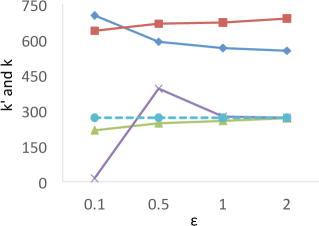
We first measure the differences between the true and private s on each dataset with ranging from 0.1 to 2.0, and the results are shown in Figure 5. The results show that for all datasets, when , the relative errors of , i.e., , in PrivQT and PrivTHREM are less than 4.7% on average, while the relative errors of in Baseline and PrivQT range from 32.2% to 150.5%. For example, in , the true is 144. When is 1, the average private is 141.0 () for PrivTHR and 142.8 () for PrivTHREM, while Baseline and PrivQT obtain 284.0 () and 249.2 () for the average respectively. Note that is 241 in , and the difference between the average and is 105.2 for PrivQT, which is quite close to the theoretical bound derived from our utility analysis in Section 5.2.1. When is 0.1, the in PrivTHREM deviates from more significantly than the in PrivTHR, indicating that PrivTHREM is more sensitive to than PrivTHR as discussed in Section 5.2.3. For example, in , the average in PrivTHREM is 82.8 () while the average in PrivTHR is 131.2 ().
7.3 Results of
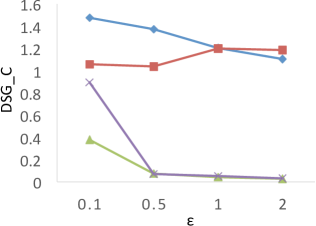
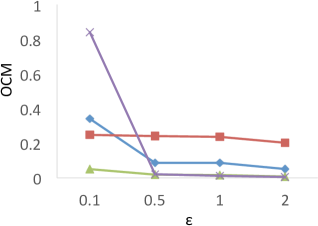
Figure 6 shows the results of for the four techniques when the privacy budget ranges from 0.1 to 2.0. X-axis shows the privacy budgets, and Y-axis denotes the values of . As shown in the results, both PrivTHR and PrivTHREM achieve smaller values than Baseline and PrivQT on all four datasets for all budgets. The reason is that though the noisy significant grids generated by Baseline and PrivQT may be similar to the true significant grids, these noisy significant grids result in very different shapes of clusters and thus result in a large value of , while PrivTHR and PrivTHREM preserves more accurate cluster shapes. For example, in , the narrow line-shape areas and the gap between two adjacent clusters are sensitive to noise. If some noisy significant grids appear in these areas, two clusters may be merged into one; if some significant grids disappear due to noise, one cluster might be split into two clusters. Such changes cause to increase significantly.
Unlike the other techniques, PrivQT benefits little from the increased privacy budgets. For PrivQT, the difference between and in PrivQT is dominated by . Increasing privacy budgets can only reduce noise magnitude and cannot smooth such difference.
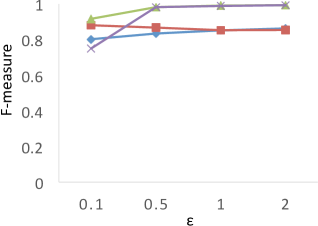
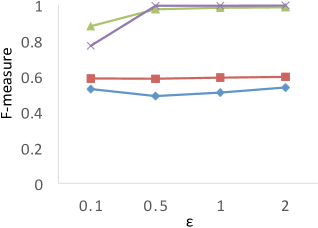
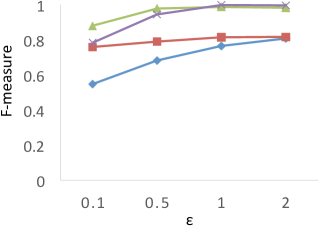
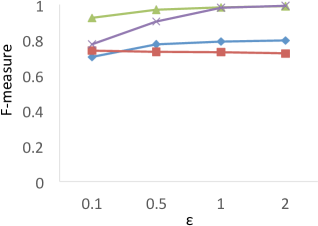

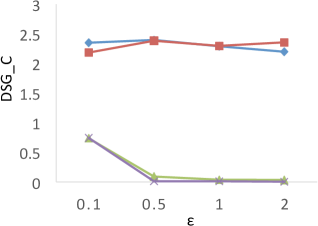
Comparison to F-Measure Results. Clustering analysis usually uses F-measure as a representative external validations to measure the similarity between the ground truth (known class labels) and the clustering results [2]. In our experiments, we consider the true WaveCluster results as the ground truth, and the results of F-measure are shown in Figure 7. The results show that PrivQT and Baseline achieve high F-measure scores (more than 0.8) for almost all budgets in , even though the private results produced by PrivQT and Baseline are quite different from the true results. For example, when , the private results of PrivQT and Baseline have more than 30 clusters while the true results have only 15 clusters. On the contrary, Figure 6 (a) shows that is able to clearly differentiate the performances of the four techniques. The reason is that unlike that allows only one-to-one mapping between true and private clusters, F-measure allows one-to-many or many-to-one mapping between true and private clusters. If the size of true clusters is larger than that of private clusters, F-measure allows many to one mapping, and vice versa. Thus, presents more strict evaluation than F-measure in computing similarity/dissimilarity.

7.4 Results of and
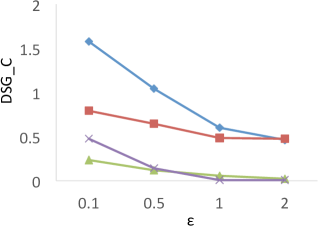
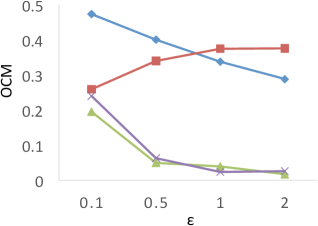
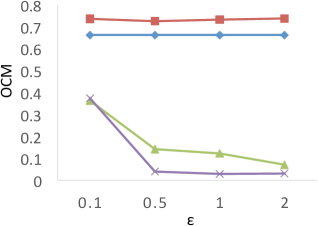
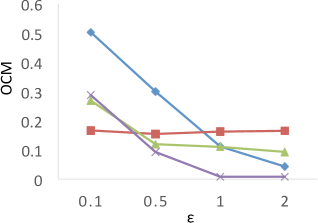
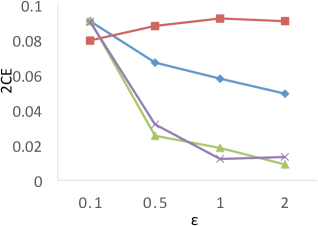
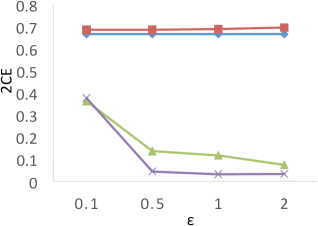
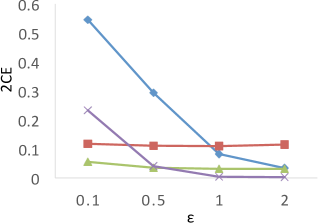
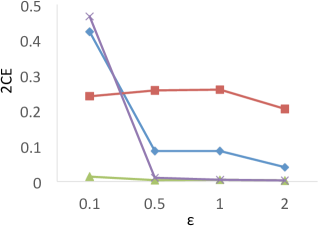
Results of . Figure 8 shows the results of for the four techniques. X-axis denotes the privacy budgets while Y-axis denotes the values of . As shown in the results, PrivTHR and PrivTHREM achieve smaller values than Baseline and PrivQT for all datasets when ranges from 0.5 to 2.0. When is greater than 0.5, the values of PrivTHR and PrivTHREM are less than 0.15 on , , and , indicating the private classifier maintains highly similar prediction results as the true classifier . On that contains 3 spirals, PrivTHREM still maintains a very low value ( 0.1) when is greater than 0.5 while PrivTHR has a slightly worse value (ranging from 0.1 to 0.2). Such results show that PrivTHREM is more resilient to noise for concave-shaped data than PrivTHR.
Results of . Figure 8 shows the results of for the four techniques. X-axis denotes the privacy budgets while Y-axis denotes the values of . As shown in the results, PrivTHR and PrivTHREM achieve smaller values than Baseline and PrivQT for all datasets when ranges from 0.5 to 2.0.
In general, all four techniques exhibit similar trends of as their trends in . On , all four techniques have very low values ( 0.1) though their corresponding values are much higher (ranging from 0.05 to 0.5). The reason is that captures the relationships between data points while focuses on the mappings of classes. If there are test samples out of total samples having different prediction results in the true and private results, expresses the differences as over the total combinations of test samples , while expresses the differences as over . On , the test samples are predicted to be in the same cluster in the private results and becomes close to 0. In this case, only matters in the computation of . Given that is much larger than and when of is about 30,000, has a smaller value than for measuring the differences, and thus is less sensitive to the noise on .
Budget Allocation for PrivTHR. Based on the utility analysis Section 5.2.2, for private quantization affects the accuracy of , and for obtaining affects the accuracy of . As the constant factor of , , is larger than the constant factor of , , more budget should be allocated for to achieve better utility. We evaluate the values of of PrivTHR on under different budget allocation strategies, ranging from 1% for to 99% for . Based on the results, the budget allocation strategy with 90% for and 10% for performs the best. The results of other measures on show the similar results, and the results of all the two types of measures on other datasets also show the similar results. Detailed results are omitted.
8 Conclusion
In this paper we have addressed the problem of cluster analysis with differential privacy. We take a well-known effective and efficient clusteing algorithm called WaveCluster, and propose several ways to introduce randomness in the computation of WaveCluster. We also devise several new quantitative measures for examining the dissimilarity between the non-private and differentially private results and the usefulness of differentially private results in classification. In the future, we will investigate under differential privacy other categories of clustering algorithms, such as hierarchical clustering. Another important problem is to explore the applicability of differentially private clustering in those cases where the users do not have good knowledge about the dataset, and the parameters of the algorithms should be inferred in a differentially private way.
Acknowledgments. This work is supported in part by the National Science Foundation under the awards CNS-1314229.
References
- [1] Clustering datasets. http://cs.joensuu.fi/sipu/datasets/.
- [2] E. Achtert, S. Goldhofer, H.-P. Kriegel, E. Schubert, and A. Zimek. Evaluation of clusterings - metrics and visual support. In ICDE, 2012.
- [3] G. Aggarwal, T. Feder, K. Kenthapadi, S. Khuller, R. Panigrahy, D. Thomas, and A. Zhu. Achieving anonymity via clustering. In PODS, 2006.
- [4] A. N. Akansu and R. A. Haddad. Multiresolution Signal Decomposition: Transforms, Subbands, and Wavelets. Academic Press, Inc., 1992.
- [5] A. N. Akansu, W. A. Serdijn, and I. W. Selesnick. Emerging applications of wavelets: A review. Phys. Commun., 3(1), 2010.
- [6] N. Alon and J. H. Spencer. The Probabilistic Method. Wiley, 1992.
- [7] B. Barak, K. Chaudhuri, C. Dwork, S. Kale, F. McSherry, and K. Talwar. Privacy, accuracy, and consistency too: A holistic solution to contingency table release. 2007.
- [8] K. Chaudhuri and C. Monteleoni. Privacy-preserving logistic regression. In NIPS, 2008.
- [9] E. Cho, S. A. Myers, and J. Leskovec. Friendship and mobility: User movement in location-based social networks. In KDD, 2011.
- [10] G. Cormode, C. Procopiuc, D. Srivastava, E. Shen, and T. Yu. Differentially private spatial decompositions. In ICDE, 2012.
- [11] I. Daubechies. Ten Lectures on Wavelets. Society for Industrial and Applied Mathematics, 1992.
- [12] C. Dwork. Differential privacy: A survey of results. In TAMC, 2008.
- [13] C. Dwork and J. Lei. Differential privacy and robust statistics. In STOC, 2009.
- [14] C. Dwork, F. McSherry, K. Nissim, and A. Smith. Calibrating noise to sensitivity in private data analysis. In TCC, 2006.
- [15] D. Feldman, A. Fiat, H. Kaplan, and K. Nissim. Private coresets. In STOC, 2009.
- [16] A. Friedman and A. Schuster. Data mining with differential privacy. In KDD, 2010.
- [17] A. Friedman, R. Wolff, and A. Schuster. Providing k-anonymity in data mining. The VLDB Journal, 17(4), July 2008.
- [18] B. C. M. Fung, K. Wang, R. Chen, and P. S. Yu. Privacy-preserving data publishing: A survey of recent developments. ACM Comput. Surv., 42(4), 2010.
- [19] B. C. M. Fung, K. Wang, L. Wang, and P. C. K. Hung. Privacy-preserving data publishing for cluster analysis. Data Knowl. Eng., 68(6), 2009.
- [20] P. Green, F. J. Carmone, and S. M. Smith. Multidimensional scaling, section five: Dimension reducing methods and cluster analysis. 1989. Addison Wesley.
- [21] J. Han, M. Kamber, and J. Pei. Data Mining: Concepts and Techniques. Morgan Kaufmann Publishers Inc., 2011.
- [22] M. Hay, V. Rastogi, G. Miklau, and D. Suciu. Boosting the accuracy of differentially private histograms through consistency. PVLDB, 3(1-2), 2010.
- [23] B. K. P. Horn. Robot Vision. The MIT Press, 1988.
- [24] A. Karakasidis and V. S. Verykios. Reference table based k-anonymous private blocking. In SAC, 2012.
- [25] S. P. Kasiviswanathan, H. K. Lee, K. Nissim, S. Raskhodnikova, and A. Smith. What can we learn privately? In FOCS, 2008.
- [26] S. Kotz, T. Kozubowski, and K. Podgórski. The Laplace distribution and generalizations : a revisit with applications to communications, economics, engineering, and finance. Birkhäuser, 2001.
- [27] H. W. Kuhn. Variants of the hungarian method for assignment problems. Naval Research Logistics Quarterly, 3, 1956.
- [28] S. G. Mallat. A Wavelet Tour of Signal Processing. Academic Press. Academic Press, Inc., 1999.
- [29] F. McSherry. Privacy integrated queries: an extensible platform for privacy-preserving data analysis. Commun. ACM, 53(9), 2010.
- [30] F. McSherry and K. Talwar. Mechanism design via differential privacy. In FOCS, 2007.
- [31] N. Mohammed, R. Chen, B. C. Fung, and P. S. Yu. Differentially private data release for data mining. In KDD, 2011.
- [32] K. Nissim, S. Raskhodnikova, and A. Smith. Smooth sensitivity and sampling in private data analysis. In STOC, 2007.
- [33] W. H. Qardaji, W. Yang, and N. Li. Differentially private grids for geospatial data. In ICDE, 2013.
- [34] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers Inc., San Francisco, CA, USA, 1993.
- [35] G. Sheikholeslami, S. Chatterjee, and A. Zhang. Wavecluster: A multi-resolution clustering approach for very large spatial databases. In VLDB, 1998.
- [36] G. Sheikholeslami, S. Chatterjee, and A. Zhang. Wavecluster: A wavelet-based clustering approach for spatial data in very large databases. VLDB J., 8(3-4), 2000.
- [37] J. Shi, N. Mamoulis, D. Wu, and D. W. Cheung. Density-based place clustering in geo-social networks. In SIGMOD, 2014.
- [38] M. Winslett, Y. Yang, and Z. Zhang. Demonstration of damson: Differential privacy for analysis of large data. ICPADS, IEEE Computer Society, 2012.
- [39] X. Xiao, G. Wang, and J. Gehrke. Differential privacy via wavelet transforms. TKDE, 23(8), 2011.
- [40] J. Xu, Z. Zhang, X. Xiao, Y. Yang, G. Yu, and M. Winslett. Differentially private histogram publication. VLDB J., 22(6), 2013.
- [41] J. Zhang, X. Xiao, Y. Yang, Z. Zhang, and M. Winslett. Privgene: Differentially private model fitting using genetic algorithms. In SIGMOD, 2013.
- [42] J. Zhang, Z. Zhang, X. Xiao, Y. Yang, and M. Winslett. Functional mechanism: Regression analysis under differential privacy. PVLDB, 5(11), 2012.