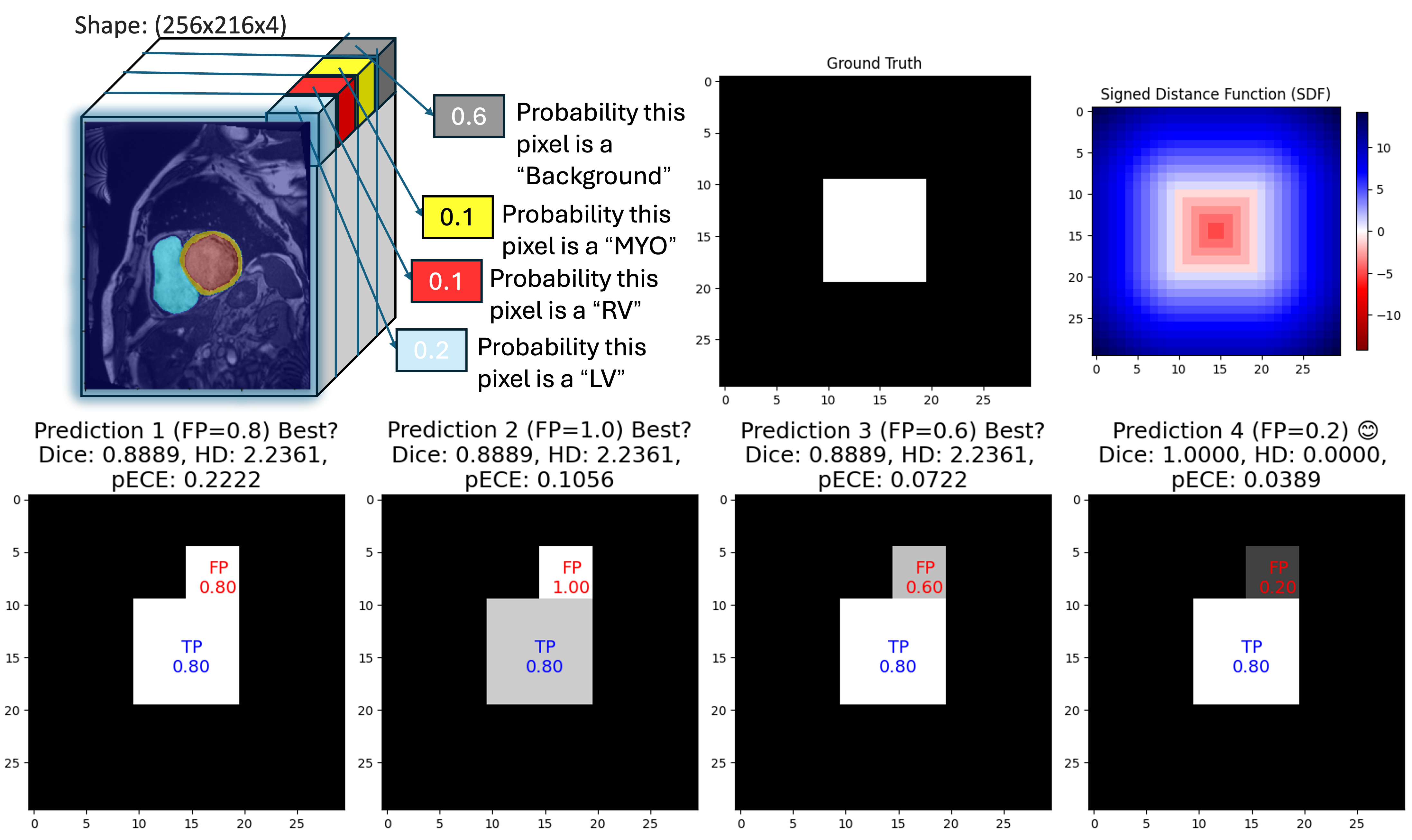
We Care Each Pixel: Calibrating on Medical Segmentation Model
Abstract
Medical image segmentation is fundamental for computer-aided diagnostics, providing accurate delineation of anatomical structures and pathological regions. While common metrics such as Accuracy, DSC, IoU, and HD primarily quantify spatial agreement between predictions and ground-truth labels, they do not assess the calibration quality of segmentation models, which is crucial for clinical reliability. To address this limitation, we propose pixel-wise Expected Calibration Error (pECE), a novel metric that explicitly measures miscalibration at the pixel level, thereby ensuring both spatial precision and confidence reliability. We further introduce a morphological adaptation strategy that applies morphological operations to ground-truth masks before computing calibration losses, particularly benefiting margin-based losses such as Margin SVLS and NACL. Additionally, we present the Signed Distance Calibration Loss (SDC), which aligns boundary geometry with calibration objectives by penalizing discrepancies between predicted and ground-truth signed distance functions (SDFs). Extensive experiments demonstrate that our method not only enhances segmentation performance but also improves calibration quality, yielding more trustworthy confidence estimates. Code is available at: https://github.com/EagleAdelaide/SDC-Loss
Keywords:
Model Calibration Medical Segmentation SDC Loss1 Introduction
Medical image segmentation entails more than simply delineating boundaries [34, 28, 13, 27]; it requires models to learn clinically meaningful representations that can inform diagnostic and prognostic decisions. In practice, segmentation models must provide both high spatial accuracy and reliable confidence estimates, because overconfident predictions may mislead clinical decision-making [32]. Although overconfidence can reduce overlap errors in certain cases, it substantially increases calibration error if predicted probabilities fail to reflect true uncertainty [7, 12]. In classification tasks, well-calibrated models ensure that predicted probabilities align with actual outcome frequencies. For instance, if a pixel is assigned a probability of 0.8 for belonging to a lesion, it should indeed be part of a lesion 80% of the time over many samples [7]. However, even models with high Dice or IoU scores can suffer from poor calibration in segmentation tasks [36, 35], compromising their clinical utility. Accurate probability estimates are crucial in medical applications, influencing decisions about follow-up imaging, treatment planning, and risk assessment [8].
To measure calibration in segmentation, one must evaluate predictions at the pixel or voxel level, because each pixel represents an independent classification decision. While Expected Calibration Error (ECE) is widely used for classification, applying it to large-scale pixel-based tasks necessitates adaptation. Therefore, we propose pixel-wise ECE (pECE), which extends calibration analysis to the considerable number of pixel-level predictions in medical images. Our method bridges the gap between high segmentation accuracy and reliable uncertainty estimation, thereby promoting safer automated analysis in clinical settings. Specifically, our contributions are threefold:
-
•
We present a novel Signed Distance Calibration (SDC) Loss (§3.1), which integrates cross-entropy, localized calibration regularization, and signed distance function (SDF) regression into a unified objective that simultaneously addresses boundary accuracy and predictive confidence.
-
•
We propose a Spatially Adaptive Margin Module with Morphological Transforms (§3.2), which augments local target distributions through morphological operations on ground-truth masks, enhancing boundary delineation robustness and mitigating label noise.
-
•
We introduce a pixel-wise Expected Calibration Error (pECE) (§3.3), designed for high-resolution calibration analysis and equipped with a built-in penalty for false positives in critical regions, thereby producing more reliable confidence estimates.
2 Related Work
Deep neural networks have made substantial progress in medical image segmentation [2, 30], yet they often generate overconfident predictions that may compromise clinical utility [7]. To alleviate this problem, recent studies have emphasized model calibration to ensure that predicted confidence scores accurately represent true likelihoods. Early methods adopted label smoothing (LS) [33] and confidence penalty techniques (ECP) [26] to mitigate excessive certainty, showing improvements in both calibration and generalization. Meanwhile, Focal Loss (FL) [15] was developed to address class imbalance by emphasizing more challenging samples; however, its effect on calibration remained limited without further adjustments [20]. Subsequent approaches have investigated spatially adaptive label smoothing, such as Spatially Varying Label Smoothing (SVLS) [10], and margin-based regularizers like Margin-based Label Smoothing (MbLS) [16], both aiming to refine predicted probability distributions and reduce miscalibration. In parallel, methods like Neighbor Aware Calibration Loss (NACL) [24] and Focal Calibration Loss (FCL) [14] leverage local structural information to adapt to varying confidence levels across different regions. Nevertheless, a common limitation among these approaches is the reliance on uniform penalty weights, which overlook class-specific or region-specific uncertainties, potentially diminishing calibration quality in complex scenarios. Moreover, most methods still evaluate calibration errors at a global level, risking the omission of subtle pixel-level inconsistencies that can be critical for clinical decisions.
3 Methodology
3.1 Signed Distance Calibration (SDC) Loss
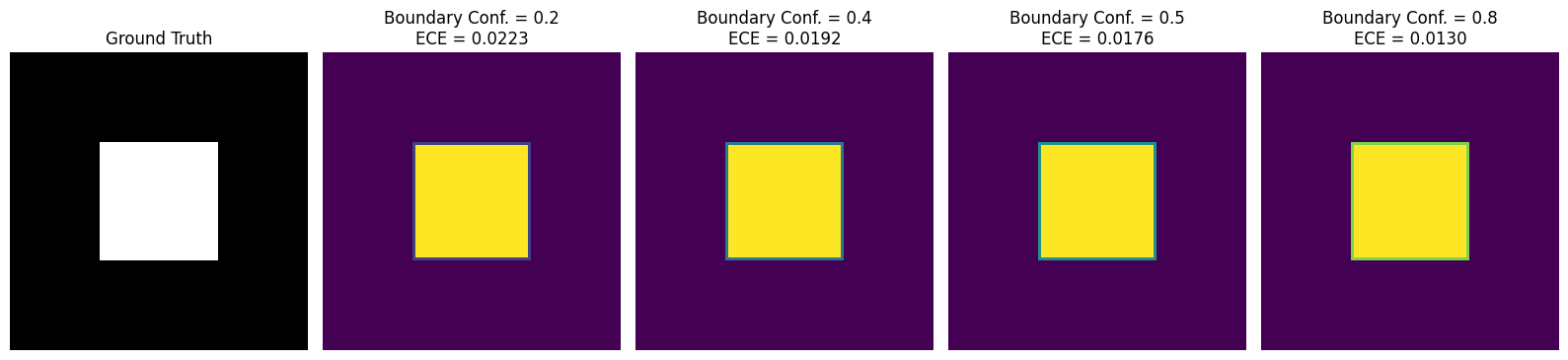
In segmentation tasks, models typically exhibit high confidence in regions where objects are clearly present (or absent), while boundary regions often contain inherent ambiguity. However, many networks remain overly confident at these boundaries, creating a mismatch between predicted confidence and actual accuracy (Fig. 3). This mismatch raises the Expected Calibration Error (ECE). Increasing boundary sensitivity encourages the model to moderate its confidence at boundaries, leading to probability estimates that more accurately capture true uncertainty and thus reduce overall calibration error.
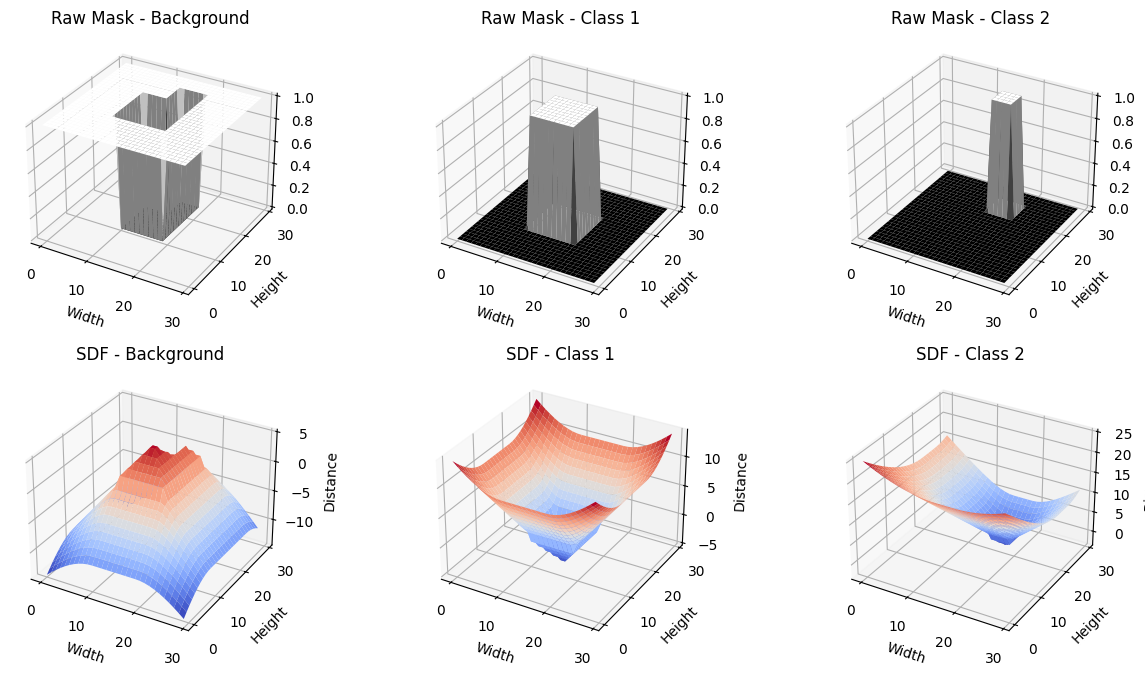
To improve boundary sensitivity and calibration, we propose the Signed Distance Calibration (SDC) loss, which combines three complementary components into a single objective function. First, the standard cross-entropy loss, , enforces pixel-level label fidelity. Here, denotes the raw logits for a batch of images, is the number of classes, and is the ground-truth mask. The predicted probabilities are given by . Next, a local calibration term measures the discrepancy—using an or norm—between and a locally smoothed target obtained via neighborhood-based filtering (e.g., mean or Gaussian). This term aligns model predictions with local ground-truth structure and promotes spatially coherent confidence estimates. Lastly, a signed distance function (SDF) penalty enforces boundary precision. Let denotes the SDF derived from the ground-truth mask , and is the corresponding prediction. Unlike traditional losses that may overlook geometric details, this penalty emphasizes discrepancies near object boundaries. Altogether, the SDC loss is defined as
| (1) |
where and control the relative influence of the local calibration term and the SDF penalty, respectively. The SDF component thus acts as a boundary-sensitive regularizer rather than a full mask reconstruction, guiding the model to learn both spatially coherent and geometrically informed confidence maps.
3.2 Spatially Adaptive Margin With Morphological Transforms
Although conventional local smoothing helps mitigate overconfidence, it often ignores label noise and boundary inconsistencies. To address these issues, we apply a morphological operator to the ground-truth mask , producing a refined mask . Specifically, when is the morphological gradient of a binarized mask , it is defined as where is a structuring element (e.g., ) that either suppresses noise (erosion) or sharpens boundaries (dilation). We then smooth with a neighborhood-based filter (e.g., mean or Gaussian) to obtain the locally aggregated target map . Let denote the predicted probabilities. The spatially adaptive margin loss is formulated as
| (2) |
where balances the standard cross-entropy term against local calibration. By incorporating morphological operations into the local smoothing procedure, we selectively regularize boundary regions, mitigating label noise and prompting the network to learn boundary-aware probability maps.
3.3 Pixel-wise Expected Calibration Error (pECE)
Global calibration metrics, such as overall ECE, can conceal local miscalibration by aggregating errors across an entire image. We propose a pixel-wise ECE (pECE) that computes calibration quality on a per-pixel basis. The range is divided into bins, and each pixel is assigned to a bin according to its predicted confidence. Let and represent the average confidence and accuracy in bin , and let be the mean confidence of false-positive pixels in that bin. We define pECE as:
| (3) |
where denotes the set of pixels in bin , its size, and the total number of pixels. The coefficient penalizes overconfident false positives, highlighting whether particular regions or boundaries are systematically miscalibrated. This localized approach is especially important in clinical applications, where a small but critical miscalibration (e.g., at a lesion boundary) can lead to significant diagnostic or treatment errors.
4 Experiments
Datasets. We evaluate our approach on four publicly available medical imaging datasets, largely following the protocol outlined by Neighbor Aware Calibration Loss (NACL) [24]. ACDC [5]: This cardiac MR dataset comprises 100 volumes with pixel-wise annotations. As in previous work, we convert the volumes into 2D slices, resize them to , and use these processed slices for both training and inference. FLARE [17]: This abdominal CT dataset consists of 360 scans with multi-organ labels. Each volume is resampled to a uniform spatial resolution, then cropped to , ensuring consistency in both the training and testing phases. BraTS 2019 [18, 3, 4]: We further include the Brain Tumor Segmentation (BraTS) 2019 challenge dataset, featuring 335 multi-channel MRI scans (FLAIR, T1, T1-contrast, and T2) with glioma segmentation masks. PROSTATE [1]: Finally, we consider the PROSTATE subset from the Medical Segmentation Decathlon (MSD) containing 32 MRI volumes.
Baselines. We compare our method against several established calibration and state-of-the-art losses, including Focal Loss (FL) [15], Entropy-based Confidence Penalty (ECP) [26], Label Smoothing (LS) [33], Spatially Varying Label Smoothing (SVLS) [10], Margin-based Label Smoothing (MbLS) [16], Neighbor Aware Calibration Loss (NACL) [24], and Focal Calibration Loss (FCL) [14]. As segmentation backbones, we employ the widely used U-Net [29] and nnU-Net [9] architectures. For fair comparisons, we adopt the hyperparameters from Tab. 1. Each model is trained for 100 epochs using the Adam optimizer [11] with a batch size of 16. The learning rate is initially set to for the first 50 epochs and reduced to thereafter. Following [24], we train our models on 2D slices but evaluate on reconstructed 3D volumes. The best-performing model is determined by the highest mean DSC score on the validation set. We conduct 5-fold cross-validation and report the mean metric values across all folds for each baseline.
Evaluation. We report two widely adopted segmentation metrics in medical imaging: Dice Similarity Coefficient (DSC) and the 95% Hausdorff Distance (HD). To measure calibration quality, we follow [23, 21, 24] and compute the Expected Calibration Error (ECE) [25] for foreground classes, as recommended by [10], along with the Class-wise Expected Calibration Error (CECE) [12] (using a threshold of ). In addition, we introduce the pixel-wise ECE (pECE), which captures fine-grained calibration discrepancies at the pixel level. To fairly compare performance, we use the Friedman ranking [6].
| ACDC | FLARE | Friedman | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSC | HD | ECE | CECE | pECE | DSC | HD | ECE | CECE | pECE | Rank | |
| DiceCE [19] | 0.828 | 3.14 | 0.137 | 0.084 | 0.457 | 0.716 | 9.7 | 0.076 | 0.049 | 0.774 | 7.70 (9) |
| FL [15] () | 0.620 | 7.30 | 0.153 | 0.179 | 0.224 | 0.834 | 6.65 | 0.053 | 0.059 | 0.217 | 7.70 (8) |
| ECP [26] () | 0.782 | 4.44 | 0.130 | 0.094 | 0.193 | 0.857 | 5.30 | 0.037 | 0.027 | 0.307 | 5.15 (5) |
| LS [33] () | 0.809 | 3.30 | 0.083 | 0.093 | 0.177 | 0.856 | 5.33 | 0.055 | 0.049 | 0.216 | 5.40 (6) |
| [10] () | 0.824 | 2.81 | 0.091 | 0.083 | 0.179 | 0.857 | 5.72 | 0.039 | 0.036 | 0.420 | 4.60 (4) |
| [16] () | 0.827 | 2.99 | 0.103 | 0.081 | 0.206 | 0.855 | 5.75 | 0.046 | 0.041 | 0.580 | 5.70 (7) |
| [21] | 0.854 | 2.93 | 0.068 | 0.061 | 0.183 | 0.859 | 4.88 | 0.031 | 0.031 | 0.455 | 3.20 (2) |
| FCL [14] (, ) | 0.864 | 1.77 | 0.052 | 0.045 | 0.259 | 0.854 | 4.54 | 0.039 | 0.031 | 0.553 | 3.45 (3) |
| SDC (, ) | 0.869 | 1.82 | 0.039 | 0.044 | 0.173 | 0.858 | 4.13 | 0.028 | 0.034 | 0.435 | 2.05 (1) |
| ACDC | FLARE | Friedman | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| DSC | HD | ECE | CECE | pECE | DSC | HD | ECE | CECE | pECE | Rank | |
| DiceCE [19] | 0.882 | 1.58 | 0.072 | 0.041 | 0.509 | 0.885 | 4.01 | 0.036 | 0.034 | 0.518 | 6.10 (7) |
| FL [15] () | 0.872 | 1.60 | 0.089 | 0.065 | 0.169 | 0.862 | 3.93 | 0.039 | 0.043 | 0.476 | 7.10 (9) |
| ECP [26] () | 0.879 | 1.48 | 0.067 | 0.112 | 0.205 | 0.869 | 3.85 | 0.046 | 0.131 | 0.454 | 6.70 (8) |
| LS [33] () | 0.885 | 1.46 | 0.062 | 0.057 | 0.170 | 0.866 | 4.25 | 0.059 | 0.051 | 0.316 | 5.30 (6) |
| [10] () | 0.879 | 2.86 | 0.059 | 0.111 | 0.172 | 0.886 | 3.15 | 0.029 | 0.029 | 0.351 | 4.75 (5) |
| [16] () | 0.883 | 1.46 | 0.057 | 0.052 | 0.170 | 0.883 | 3.48 | 0.031 | 0.031 | 0.489 | 4.10 (2) |
| [21] | 0.881 | 1.52 | 0.056 | 0.059 | 0.214 | 0.886 | 3.67 | 0.026 | 0.027 | 0.439 | 4.25 (4) |
| FCL [14] (, ) | 0.882 | 1.26 | 0.032 | 0.035 | 0.179 | 0.879 | 3.89 | 0.036 | 0.026 | 0.525 | 4.10 (2) |
| SDC (, ) | 0.880 | 1.31 | 0.037 | 0.042 | 0.165 | 0.888 | 3.46 | 0.023 | 0.026 | 0.416 | 2.30 (1) |
| Metric | Default w/o | Internal Boundary | External Boundary | Closing | Opening | Dilation | Erosion | Morphological Gradient |
|---|---|---|---|---|---|---|---|---|
| DSC | 0.854 | 0.863 | 0.861 | 0.861 | 0.849 | 0.857 | 0.862 | 0.861 |
| HD | 2.932 | 1.613 | 1.900 | 1.436 | 1.646 | 1.326 | 1.501 | 1.698 |
| ECE | 0.068 | 0.043 | 0.042 | 0.039 | 0.045 | 0.044 | 0.045 | 0.042 |
| CECE | 0.061 | 0.047 | 0.046 | 0.043 | 0.046 | 0.045 | 0.049 | 0.047 |
| pECE | 0.281 | 0.199 | 0.170 | 0.221 | 0.217 | 0.225 | 0.165 | 0.206 |
| BraTS | Prostate | Friedman | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | DSC | HD | ECE | CECE | pECE | DSC | HD | ECE | CECE | pECE | Rank |
| DiceCE [19] | 0.739 | 18.73 | 0.246 | 0.159 | 0.556 | 0.524 | 10.95 | 0.254 | 0.227 | 0.507 | 8.20 (9) |
| FL [15] | 0.776 | 14.82 | 0.187 | 0.145 | 0.454 | 0.520 | 9.93 | 0.225 | 0.205 | 0.424 | 4.40 (4) |
| ECP [26] | 0.742 | 16.55 | 0.232 | 0.151 | 0.425 | 0.526 | 9.36 | 0.208 | 0.199 | 0.311 | 4.25 (3) |
| LS [33] | 0.752 | 12.14 | 0.171 | 0.161 | 0.410 | 0.501 | 10.88 | 0.200 | 0.208 | 0.388 | 4.80 (6) |
| SVLS [10] | 0.761 | 14.62 | 0.176 | 0.140 | 0.466 | 0.481 | 10.29 | 0.186 | 0.216 | 0.326 | 4.15 (2) |
| MbLS [16] | 0.746 | 16.02 | 0.218 | 0.148 | 0.452 | 0.508 | 10.34 | 0.223 | 0.218 | 0.381 | 6.05 (8) |
| NACL [21] | 0.761 | 15.00 | 0.188 | 0.144 | 0.451 | 0.480 | 10.29 | 0.186 | 0.216 | 0.326 | 4.55 (5) |
| FCL [14] | 0.754 | 16.68 | 0.214 | 0.142 | 0.447 | 0.506 | 10.74 | 0.251 | 0.221 | 0.335 | 5.90 (7) |
| SDC | 0.782 | 13.45 | 0.169 | 0.148 | 0.425 | 0.516 | 9.01 | 0.230 | 0.202 | 0.305 | 2.70 (1) |
5 Results
Performance. Tables 1 and 2 summarize segmentation and calibration outcomes for U-Net and nnU-Net, respectively. On ACDC, SDC attains the highest DSC (0.869) for U-Net and near-top DSC (0.880) for nnU-Net while maintaining competitive boundary delineation (HD). On FLARE, SDC achieves strong DSC (0.858 for U-Net and 0.888 for nnU-Net), outperforming most baselines. Notably, SDC registers the lowest ECE values across both datasets and backbones (e.g., 0.039 on ACDC with U-Net, 0.023 on FLARE with nnU-Net), indicating robust confidence alignment. Although SDC does not always yield the minimal pECE on FLARE (where LS occasionally excels), its overall Friedman rank remains the best for both U-Net and nnU-Net. This consistency underscores that precise anatomical segmentation and well-calibrated confidence estimates can be simultaneously achieved through our local calibration and SDF-based objectives. BraTS and PROSTATE results also prove it in Tab. 4. We also observe that lower HD values are accompanied by lower calibration errors. An ablation study on morphological operation is provided in Tab. 6.
Visualization. Fig. 4 illustrates representative slices predicted from the ACDC dataset by Grad-CAM [31]. It confirms accurate delineation of the left ventricle (red), myocardium (yellow), and right ventricle (cyan), with fewer boundary artifacts in SDC’s outputs.
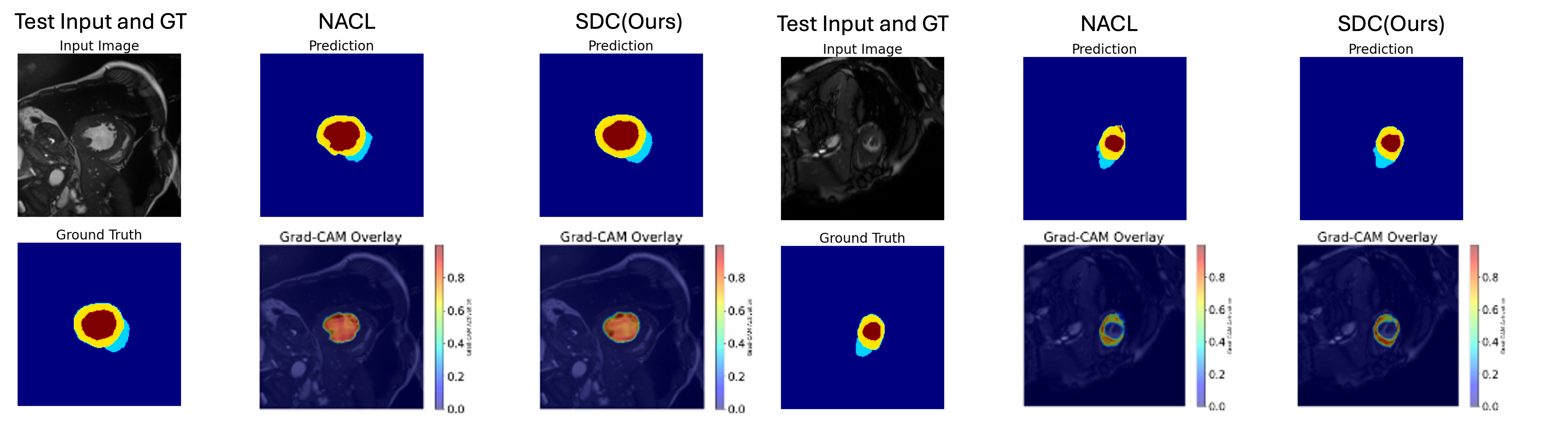
6 Conclusion
Medical image segmentation often demands high boundary accuracy, where small errors can have significant clinical ramifications. Discriminative losses (e.g., DiceCE) and even certain calibration-oriented methods (e.g., NACL) may yield strong results on select metrics but often lack consistency across all segmentation and calibration measures. By contrast, SDC—featuring local calibration and signed distance constraints—consistently improves both boundary delineation and confidence reliability. The visual evidence confirms that SDC better suppresses overconfident false positives at organ boundaries, providing probabilities that more faithfully mirror actual voxel-wise correctness.
References
- [1] Antonelli, M., Reinke, A., Bakas, S., Farahani, K., Kopp-Schneider, A., Landman, B.A., Litjens, G., Menze, B., Ronneberger, O., Summers, R.M., et al.: The medical segmentation decathlon. Nature communications 13(1), 4128 (2022)
- [2] Anwar, S.M., Majid, M., Qayyum, A., Awais, M., Alnowami, M., Khan, M.K.: Medical image analysis using convolutional neural networks: a review. Journal of medical systems 42, 1–13 (2018)
- [3] Bakas, S., Akbari, H., Sotiras, A., Bilello, M., Rozycki, M., Kirby, J.S., Freymann, J.B., Farahani, K., Davatzikos, C.: Advancing the cancer genome atlas glioma MRI collections with expert segmentation labels and radiomic features. Scientific data 4(1), 1–13 (2017)
- [4] Bakas, S., Reyes, M., Jakab, A., Bauer, S., Rempfler, M., Crimi, A., Shinohara, R.T., Berger, C., Ha, S.M., Rozycki, M., et al.: Identifying the best machine learning algorithms for brain tumor segmentation, progression assessment, and overall survival prediction in the brats challenge. arXiv preprint arXiv:1811.02629 (2018)
- [5] Bernard, O., Lalande, A., Zotti, C., Cervenansky, F., Yang, X., Heng, P.A., Cetin, I., Lekadir, K., Camara, O., Ballester, M.A.G., et al.: Deep learning techniques for automatic MRI cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE TMI 37(11), 2514–2525 (2018)
- [6] Friedman, M.: The use of ranks to avoid the assumption of normality implicit in the analysis of variance. Journal of the american statistical association 32(200), 675–701 (1937)
- [7] Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: International conference on machine learning. pp. 1321–1330. PMLR (2017)
- [8] Hricak, H., Choyke, P.L., Eberhardt, S.C., Leibel, S.A., Scardino, P.T.: Imaging prostate cancer: a multidisciplinary perspective. Radiology 243(1), 28–53 (2007)
- [9] Isensee, F., et al.: nnu-net: a self-configuring method for deep learning-based biomedical image segmentation. Nature Methods 18 (2020)
- [10] Islam, M., Glocker, B.: Spatially varying label smoothing: Capturing uncertainty from expert annotations. In: Information Processing in Medical Imaging: 27th International Conference, IPMI 2021, Virtual Event, June 28–June 30, 2021, Proceedings 27. pp. 677–688. Springer (2021)
- [11] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. ICLR (2015)
- [12] Kumar, A., Liang, P.S., Ma, T.: Verified uncertainty calibration. Advances in Neural Information Processing Systems 32 (2019)
- [13] Lee, H.J., Kim, J.U., Lee, S., Kim, H.G., Ro, Y.M.: Structure boundary preserving segmentation for medical image with ambiguous boundary. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4817–4826 (2020)
- [14] Liang, W., Dong, C., Zheng, L., Li, Z., Zhang, W., Chen, W.: Calibrating deep neural network using euclidean distance. arXiv preprint arXiv:2410.18321 (2024)
- [15] Lin, T.Y., Goyal, P., Girshick, R., He, K., Dollár, P.: Focal loss for dense object detection. In: Proceedings of the IEEE international conference on computer vision. pp. 2980–2988 (2017)
- [16] Liu, B., Ben Ayed, I., Galdran, A., Dolz, J.: The devil is in the margin: Margin-based label smoothing for network calibration. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 80–88 (2022)
- [17] Ma, X., Blaschko, M.B.: Meta-cal: Well-controlled post-hoc calibration by ranking. In: ICML (2021)
- [18] Menze, B.H., et al.: The multimodal brain tumor image segmentation benchmark (brats). IEEE Transactions on Medical Imaging 34(10), 1993–2024 (2015)
- [19] Milletari, F., Navab, N., Ahmadi, S.A.: V-net: Fully convolutional neural networks for volumetric medical image segmentation. In: 2016 fourth international conference on 3D vision (3DV). pp. 565–571. Ieee (2016)
- [20] Mukhoti, J., Kulharia, V., Sanyal, A., Golodetz, S., Torr, P.H., Dokania, P.K.: Calibrating deep neural networks using focal loss. In: NeurIPS (2020)
- [21] Murugesan, B., Adiga Vasudeva, S., Liu, B., Lombaert, H., Ben Ayed, I., Dolz, J.: Trust your neighbours: Penalty-based constraints for model calibration. In: MICCAI. pp. 572–581 (2023)
- [22] Murugesan, B., Adiga Vasudeva, S., Liu, B., Lombaert, H., Ben Ayed, I., Dolz, J.: Trust your neighbours: Penalty-based constraints for model calibration. https://github.com/Bala93/MarginLoss (2023), accessed: 2025-01-13
- [23] Murugesan, B., Liu, B., Galdran, A., Ayed, I.B., Dolz, J.: Calibrating segmentation networks with margin-based label smoothing. Medical Image Analysis 87, 102826 (2023)
- [24] Murugesan, B., Vasudeva, S.A., Liu, B., Lombaert, H., Ayed, I.B., Dolz, J.: Neighbor-aware calibration of segmentation networks with penalty-based constraints. arXiv preprint arXiv:2401.14487 (2024)
- [25] Naeini, M.P., Cooper, G.F., Hauskrecht, M.: Obtaining well calibrated probabilities using bayesian binning. In: AAAI (2015)
- [26] Pereyra, G., Tucker, G., Chorowski, J., Kaiser, Ł., Hinton, G.: Regularizing neural networks by penalizing confident output distributions. arXiv preprint arXiv:1701.06548 (2017)
- [27] Pham, D.L., Xu, C., Prince, J.L.: Current methods in medical image segmentation. Annual review of biomedical engineering 2(1), 315–337 (2000)
- [28] Rogowska, J.: Overview and fundamentals of medical image segmentation. Handbook of medical image processing and analysis pp. 73–90 (2009)
- [29] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI. pp. 234–241 (2015)
- [30] Sarvamangala, D., Kulkarni, R.V.: Convolutional neural networks in medical image understanding: a survey. Evolutionary intelligence 15(1), 1–22 (2022)
- [31] Selvaraju, R.R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., Batra, D.: Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision. pp. 618–626 (2017)
- [32] Sox, H.C., Higgins, M.C., Owens, D.K., Schmidler, G.S.: Medical decision making. John Wiley & Sons (2024)
- [33] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., Wojna, Z.: Rethinking the inception architecture for computer vision. In: CVPR (2016)
- [34] Wang, R., Chen, S., Ji, C., Fan, J., Li, Y.: Boundary-aware context neural network for medical image segmentation. Medical image analysis 78, 102395 (2022)
- [35] Yeung, M., Rundo, L., Nan, Y., Sala, E., Schönlieb, C.B., Yang, G.: Calibrating the dice loss to handle neural network overconfidence for biomedical image segmentation. Journal of Digital Imaging 36(2), 739–752 (2023)
- [36] Yeung, M., Sala, E., Schönlieb, C.B., Rundo, L.: Unified focal loss: Generalising dice and cross entropy-based losses to handle class imbalanced medical image segmentation. Computerized Medical Imaging and Graphics 95, 102026 (2022)
Appendix 0.A Appendix
0.A.1 Metric Computations
0.A.1.1 Segmentation Performance
We employ two widely-used segmentation metrics in medical imaging:
Dice Similarity Coefficient (DSC).
For predicted segmentation and ground-truth segmentation , DSC is given by
| (4) |
where denotes the cardinality (i.e., number of pixels) in a set. A higher DSC indicates better overlap between prediction and ground truth.
95% Hausdorff Distance (HD).
We let represent the Euclidean distance from a point in to the closest point in . Then the Hausdorff Distance is
| (5) |
In practice, we report the 95% HD, which discards extreme outliers by using the 95th percentile instead of the maximum.
0.A.1.2 Calibration Performance
To evaluate how well confidence estimates match actual correctness, we measure several calibration metrics:
Expected Calibration Error (ECE).
Given foreground predictions binned into intervals , let be the average confidence and the average accuracy in the -th bin. The total number of foreground pixels is . Then ECE is:
| (6) |
and capture how over- or under-confident the model is within each bin.
Class-wise Expected Calibration Error (CECE).
Let be the total number of classes, and denote by the ECE for class . A simple way to aggregate per-class calibration is
| (7) |
potentially discarding classes with negligible representation by applying a threshold on predicted probability (e.g., ) as suggested in [12].
Pixel-wise ECE (pECE).
To capture more localized calibration errors, we group individual pixels by confidence rather than aggregating them globally. Suppose we use bins over . For each bin , let and be the mean predicted confidence and mean accuracy, respectively, and let be the mean confidence of false positives. We define
| (8) |
where is the set of pixels with confidence in the -th interval, is its cardinality, and is the total number of pixels. The term penalizes excessive confidence in background regions, making pECE more sensitive to overconfident misclassifications.
Friedman Ranking
To compare overall performance across multiple tasks or experimental configurations, we compute the Friedman ranking [6]. Let be the set of metrics (e.g., DSC, HD, ECE, CECE, pECE.) measured on separate models or methods. We assign each method a rank based on its relative score for each metric, then average ranks across all metrics in . Formally, for each metric , we rank methods from best to worst; the Friedman statistic is then used to assess whether rank distributions differ significantly across methods.
0.A.2 More Medical Datasets
| BraTS | Prostate | Friedman | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | DSC | HD | ECE | CECE | pECE | DSC | HD | ECE | CECE | pECE | Rank |
| DiceCE [19] | 0.739 | 18.73 | 0.246 | 0.159 | 0.556 | 0.524 | 10.95 | 0.254 | 0.227 | 0.507 | 8.20 (9) |
| FL [15] | 0.776 | 14.82 | 0.187 | 0.145 | 0.454 | 0.520 | 9.93 | 0.225 | 0.205 | 0.424 | 4.40 (4) |
| ECP [26] | 0.742 | 16.55 | 0.232 | 0.151 | 0.425 | 0.526 | 9.36 | 0.208 | 0.199 | 0.311 | 4.25 (3) |
| LS [33] | 0.752 | 12.14 | 0.171 | 0.161 | 0.410 | 0.501 | 10.88 | 0.200 | 0.208 | 0.388 | 4.80 (6) |
| SVLS [10] | 0.761 | 14.62 | 0.176 | 0.140 | 0.466 | 0.481 | 10.29 | 0.186 | 0.216 | 0.326 | 4.15 (2) |
| MbLS [16] | 0.746 | 16.02 | 0.218 | 0.148 | 0.452 | 0.508 | 10.34 | 0.223 | 0.218 | 0.381 | 6.05 (8) |
| NACL [21] | 0.761 | 15.00 | 0.188 | 0.144 | 0.451 | 0.480 | 10.29 | 0.186 | 0.216 | 0.326 | 4.55 (5) |
| FCL [14] | 0.754 | 16.68 | 0.214 | 0.142 | 0.447 | 0.506 | 10.74 | 0.251 | 0.221 | 0.335 | 5.90 (7) |
| SDC | 0.782 | 13.45 | 0.169 | 0.148 | 0.425 | 0.516 | 9.01 | 0.230 | 0.202 | 0.305 | 2.70 (1) |
0.A.3 pECE Algorithm
Appendix 0.B Visualization
0.B.1 Grad-CAM Result
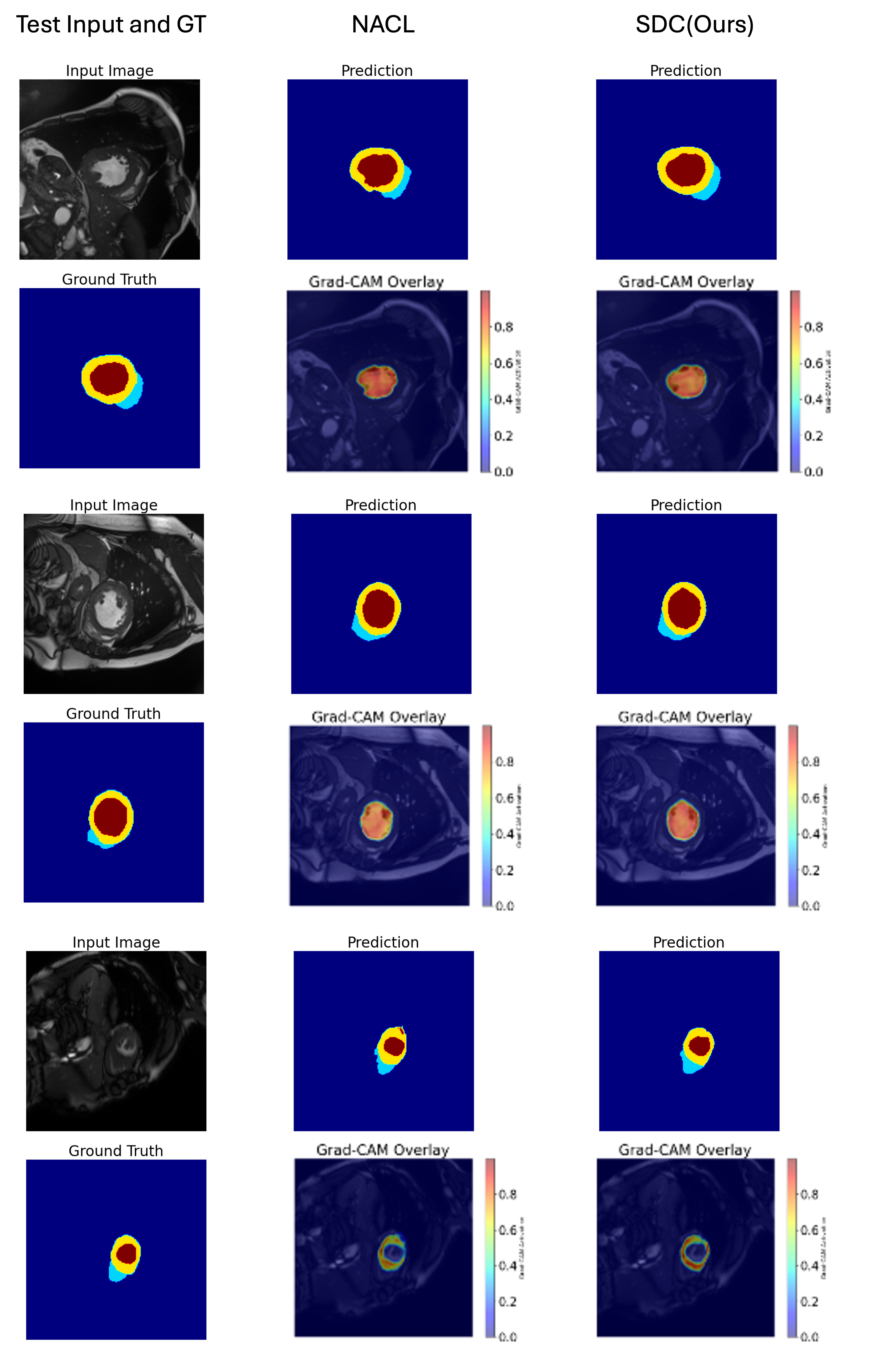
Fig. 5 is sample slices from the ACDC dataset illustrating our model’s segmentation outputs and Grad-CAM activations. Each row displays (from left to right): the original MRI slice, the predicted segmentation map (second column), an alternative segmentation prediction for comparison (third column), the ground-truth annotations (fourth row within each block), and two Grad-CAM overlays.
0.B.2 Qualitative Insights
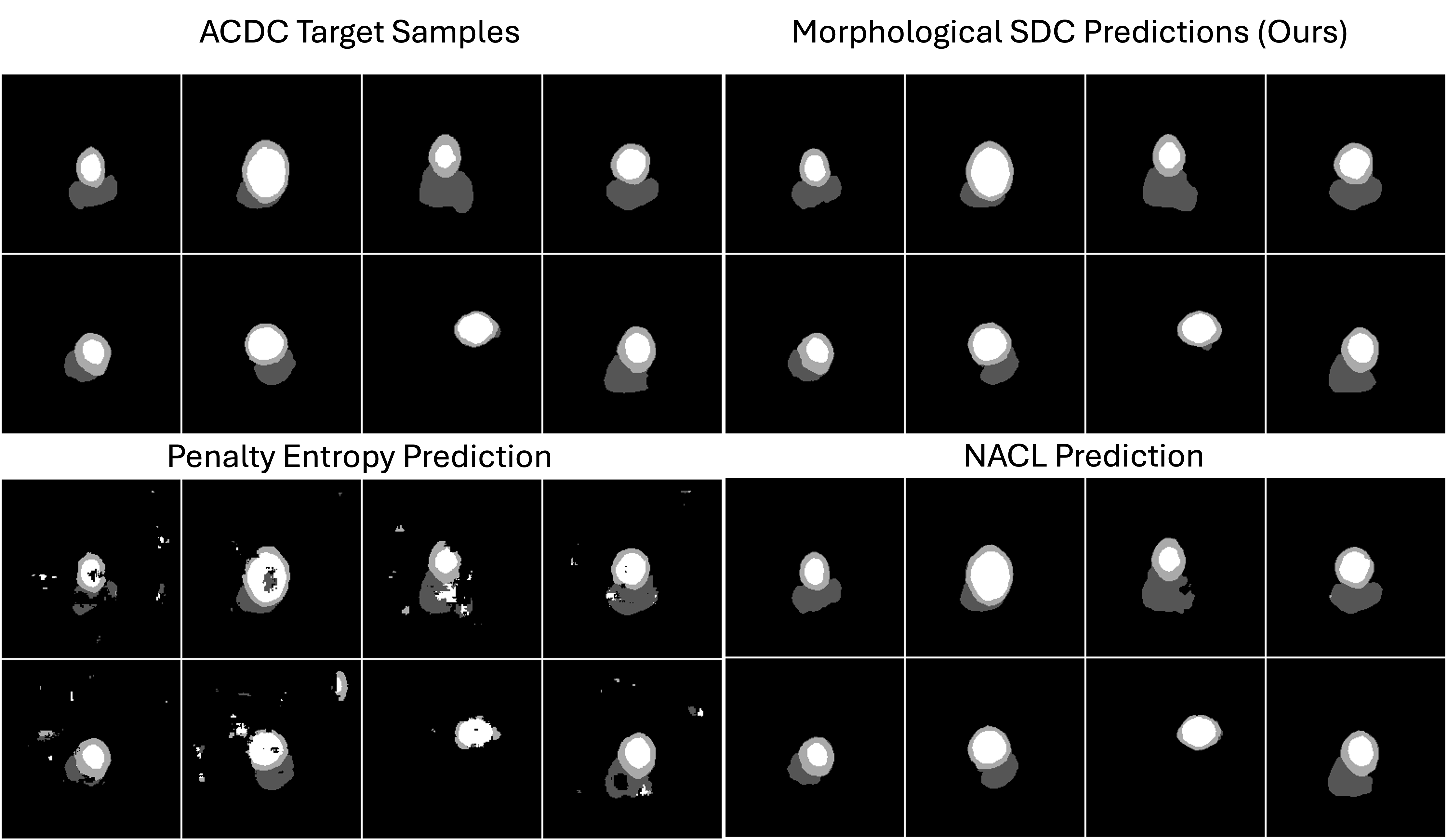
Figure 6 compares segmentation results for four representative cardiac slices at training step 1627. The first column displays the ground-truth masks. The second column shows our Morphological NACL predictions, which generally exhibit precise boundaries and minimal false positives. By contrast, the Penalty Entropy method (third column) produces scattered artifacts, while standard NACL predictions (fourth column) often lack fine-grained boundary refinement. These qualitative observations align with the quantitative improvements we observe when incorporating morphological transforms.
Appendix 0.C Formal Proof of SDF-Based Calibration Improvement
This appendix provides a formal proof that enforcing consistency between the predicted signed distance function (SDF) and the ground-truth SDF can theoretically improve calibration. The proof assumes an idealized logistic relationship between distance to the boundary and the probability of belonging to the object.
0.C.1 Notation and Setup
Definition 1 (Ground-Truth SDF)
Let be the image domain ( for 2D or for 3D). Suppose we have a ground-truth segmentation with boundary . The ground-truth SDF is defined as
| (9) |
where denotes the Euclidean distance from to the boundary .
Definition 2 (Predicted SDF and Probability)
A neural network outputs a predicted SDF . We convert this to a segmentation probability
| (10) |
where is the logistic sigmoid, and is a scaling factor.
Definition 3 (Ideal (Intrinsic) Probability)
We define
| (11) |
We say is intrinsically calibrated if, for any confidence value , the set of points has a true label frequency close to . In other words, accurately reflects the true likelihood of belonging to .
Definition 4 (Calibration Error)
Let denote a calibration metric such as ECE or pECE, measuring how well aligns with empirical frequencies of belonging to . A model is perfectly calibrated if .
0.C.2 Lemma: Lipschitz Continuity of the Logistic Function
Lemma 1
For all , the logistic sigmoid satisfies
| (12) |
Consequently,
| (13) |
Proof
The logistic function has a global maximum slope of . By the mean value theorem, for ,
| (14) |
For , the slope is scaled by , yielding the stated bound.
0.C.3 Bounding the Probability Error via SDF Error
Lemma 2 (SDF to Probability Discrepancy)
Suppose . Then, for every ,
| (15) |
where and .
Proof
0.C.4 Theorem: SDF Accuracy Improves Calibration
Theorem 0.C.1
Let be intrinsically calibrated, i.e., . Suppose . Then the calibration error of satisfies
| (17) |
for some increasing function that satisfies as . If is perfectly calibrated () and uniformly, then as well.
Proof
(1) Bounding the Probability Difference. By Lemma 2, if , then . Hence each pixel’s predicted probability differs from the ideal probability by at most .
(2) Effect on Bin-Based Calibration Metrics. Calibration error (ECE or pECE) typically involves partitioning predicted confidences into bins . If , a pixel can move from one bin to another only if the bin boundaries lie within of its ideal confidence. Thus the proportion of points in each bin shifts by an amount bounded by .
(3) Decomposition of the Error. If is intrinsically calibrated, then each bin’s empirical frequency of truly positive pixels is very close to the bin’s midpoint. Under , the difference in bin membership (and thus the difference in empirical frequencies) depends on how many points transition into or out of each bin due to the shift . This shift is in turn bounded by , so the net effect on the calibration metric is captured by an increasing function with .
(4) Conclusion. Hence,
| (18) |
As , . If is perfectly calibrated, then implies .
0.C.5 Discussion and Practical Relevance
The SDF loss term encourages the network to learn a predicted SDF that closely approximates the true SDF . By mapping through a smooth logistic function, we avoid artificially “saturating” the confidence near 0 or 1 in boundary regions where genuine uncertainty is high.
Medical images frequently exhibit partially defined or fuzzy boundaries. Standard losses may over-penalize ambiguous pixels, driving probabilities to extremes. Enforcing SDF fidelity better preserves intermediate probabilities, aligning predictions with the actual likelihood of belonging to the target region. However, this result depends on the assumption that is perfectly (or nearly) calibrated. Real-world data may introduce noise, label ambiguities, and artifacts that deviate from this ideal. Nonetheless, Thm. 0.C.1 provides a theoretical foundation justifying the use of SDF for improved calibration.
By bounding the error , we ensure that remains close to . Under an intrinsically calibrated ground-truth logistic mapping, this yields a provable reduction in calibration error. Therefore, introducing an SDF term in the loss function fosters more reliable probability estimates, mitigating overconfidence near boundaries and improving ECE/pECE metrics.
Appendix 0.D Faster Convergence
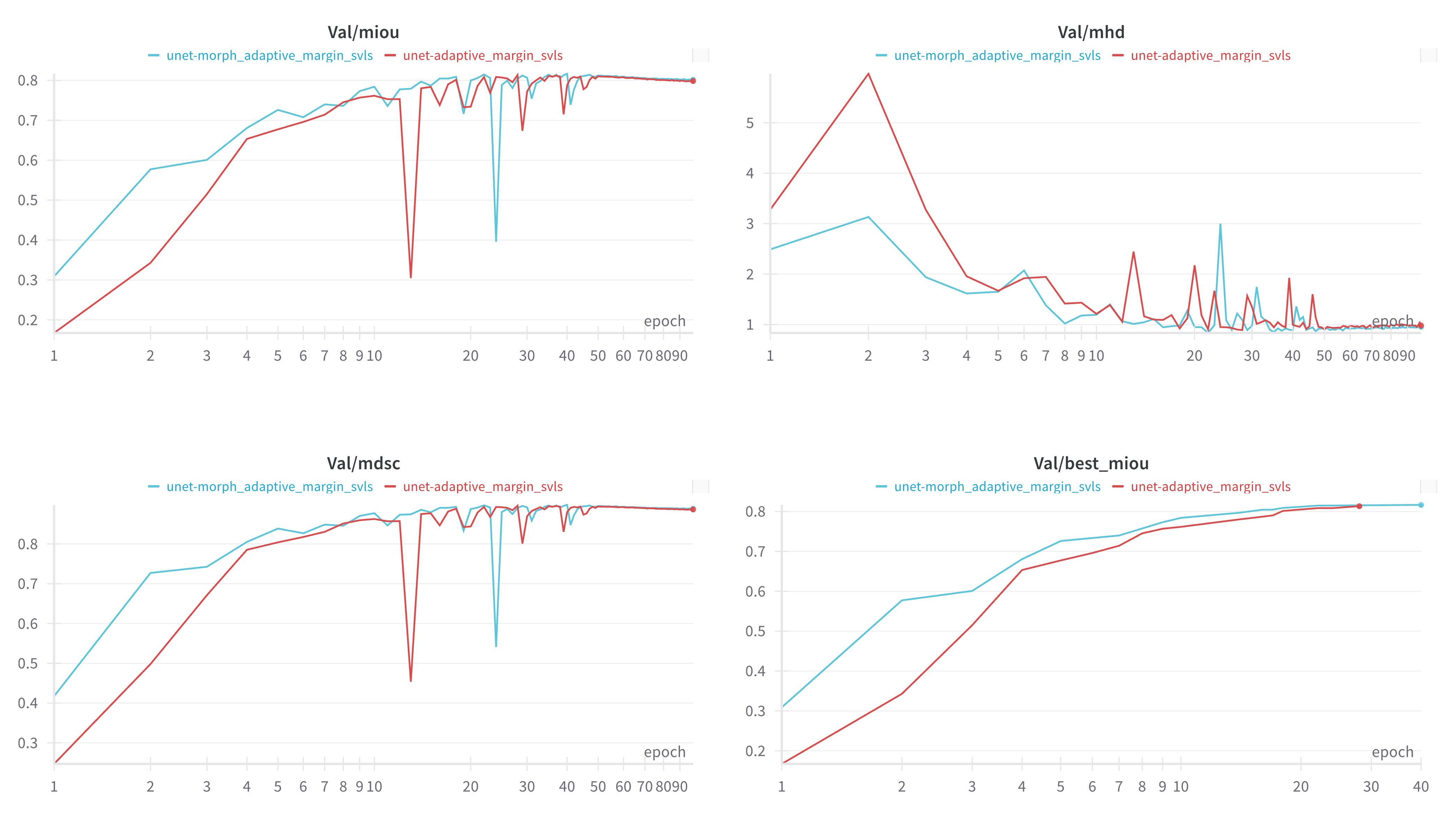
In practice, morphological transforms help filter out label noise and refine boundary regions, creating more stable training signals early on. As illustrated in Figure 7, the baseline NACL (red) takes more epochs to stabilize and often displays oscillations in mean IoU and DSC. By contrast, our approach applied morphological transforms to NACL (blue) converges faster to higher values on all metrics—mean IoU, mean DSC, and even lower mean HD—demonstrating the advantage of cleaner boundary supervision. Our method SDC achieves the best IoU validation faster from other losses as well.
Appendix 0.E Batch Runtime and Complexity
Each colored band represents the average time per training iteration (batch) for one of the listed U-Net variants, differing only by their loss functions in Fig. 8.
Appendix 0.F Ablation Study on Morphological Operation
This experiment evaluates various segmentation quality metrics across different morphological operations applied to the segmented outputs. Default setting is NACL method without applying any operations.
| Metric | Default w/o | Internal Boundary | External Boundary | Closing | Opening | Dilation | Erosion | Morphological Gradient |
|---|---|---|---|---|---|---|---|---|
| DSC | 0.854 | 0.863 | 0.861 | 0.861 | 0.849 | 0.857 | 0.862 | 0.861 |
| HD | 2.932 | 1.613 | 1.900 | 1.436 | 1.646 | 1.326 | 1.501 | 1.698 |
| ECE | 0.068 | 0.043 | 0.042 | 0.039 | 0.045 | 0.044 | 0.045 | 0.042 |
| CECE | 0.061 | 0.047 | 0.046 | 0.043 | 0.046 | 0.045 | 0.049 | 0.047 |
| pECE | 0.281 | 0.199 | 0.170 | 0.221 | 0.217 | 0.225 | 0.165 | 0.206 |
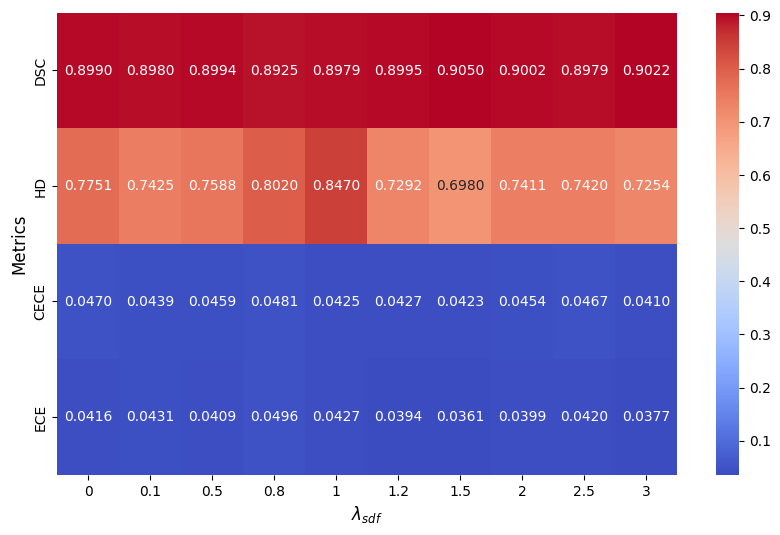
Appendix 0.G Trade-off
The heatmap (Fig. 9) provides a clear representation of how MDSC, MHD, CECE, and ECE change with different values of . As increases, DSC generally remains stable with slight fluctuations, peaking around 1.5 and 3.0. HD shows a notable increase at = 1, indicating worse boundary performance, but improves at higher and lower values. Both CECE and ECE, which measure calibration error, exhibit variability, with ECE peaking at 0.8, suggesting that improper lambda selection may negatively impact calibration. Overall, the results suggest that choosing an optimal (around 1.5 or 3.0) may help balance segmentation performance and calibration quality for ACDC.