Weak Adaptation Learning:
Addressing Cross-domain Data Insufficiency with Weak Annotator
Abstract
Data quantity and quality are crucial factors for data-driven learning methods. In some target problem domains, there are not many data samples available, which could significantly hinder the learning process. While data from similar domains may be leveraged to help through domain adaptation, obtaining high-quality labeled data for those source domains themselves could be difficult or costly. To address such challenges on data insufficiency for classification problem in a target domain, we propose a weak adaptation learning (WAL) approach that leverages unlabeled data from a similar source domain, a low-cost weak annotator that produces labels based on task-specific heuristics, labeling rules, or other methods (albeit with inaccuracy), and a small amount of labeled data in the target domain. Our approach first conducts a theoretical analysis on the error bound of the trained classifier with respect to the data quantity and the performance of the weak annotator, and then introduces a multi-stage weak adaptation learning method to learn an accurate classifier by lowering the error bound. Our experiments demonstrate the effectiveness of our approach in learning an accurate classifier with limited labeled data in the target domain and unlabeled data in the source domain.
1 Introduction
Machine Learning (ML) techniques, especially those based on deep neural networks, have shown great promises in many applications, to a large extent due to their abilities in studying and memorizing the knowledge embedded in high-quality training data [12]. Having a large number of data samples with accurate labels could enable effective supervised learning methods for improving ML model performance. However, it may be difficult to collect many data samples in some problem domains or scenarios, such as for the training of autonomous vehicles during extreme weather (e.g., fog, snow, hail) and natural disasters (e.g., mudflow), or for search and rescue robots during forest fire and earthquake. One possible solution to such problem of data unavailability is using data from other similar domains to train the target domain model and then fine-tune it with limited target domain data, i.e., through domain adaptation. Taking the aforementioned cases as examples, while there may not be much data in hailing weather, we could collect data in days with heavy rain; while it may be difficult to find images during earthquakes for large parts of America, we could collect images in Japan, where earthquakes occur more often in a different environment. However, obtaining a large amount of high-quality labeled data in these source domains could still be challenging and costly.
To address the above data insufficiency challenges across domains, we consider leveraging low-cost weak annotators that can automatically generate large quantity of labeled data based on certain labeling rules/functions, task-specific heuristics, or other methods (which may be inaccurate to some degree). More specifically, our approach considers the following setting for classification problems: There is a small amount of data samples with accurate labels collected for the target domain, which is called target domain data or target data in this paper for simplicity. There is also a large amount of unlabeled data that can be acquired from a similar but different source domain (i.e., there exists domain discrepancy), which is called source (domain) data in this paper. Finally, there is a weak annotator that can produce weak (possibly inaccurate) labels on data samples. Our objective is to learn an accurate classifier for the target domain based on the labeled target data, the initially-unlabeled source data, and the weak annotator.
The problem we are considering here is related but different from Semi-Supervised Learning (SSL) [46, 9, 27] and Unsupervised Domain Adaptation (UDA) [28, 8, 59, 7]. In the setting of SSL, the available training data consists of two parts – one has accurate labels while the other is unlabeled, and the two parts are drawn from the same distribution in terms of training features. This is different from our problem, where there exists domain discrepancy across the source and target domains. The objective of UDA is to adapt a model to perform well in the target domain based on labeled data in the source domain and unlabeled data in the target domain. This is again very different from our problem, where the source domain data is initially unlabeled and assigned with inaccurate labels by a weak annotator, while the target domain data has labels but its quantity is small. Another related field is Positive-unlabeled Learning (PuL) [23, 5], an approach for sample selection. The training data of PuL also consists of two parts – positive and negative data, and the task is to learn a binary classifier to filter out samples that are similar to the positive data from a large amount of negative data. However, the current PuL approaches usually conduct experiments in a single data set rather than multiple domains with feature discrepancy.
To solve our target problem, we first develop a theoretical analysis on the error bound of a trained classifier with respect to the data quantity and the weak annotator performance. We then propose a Weak Adaptation Learning (WAL) method to learn an accurate classifier by lowering the error bound. The main idea of WAL is to obtain a cross-domain representation for both source domain and target domain data, and then use the labeled data to estimate the classification error/distance between the weak annotator and the ideally optimal classifier in the target domain. Next, all the data is re-labeled based on such estimation of weak annotator classification error. Finally, the newly-relabeled data is used to learn a better classifier in the target domain.
Our work makes the following contributions:
-
We address the challenge of data insufficiency in domain adaptation with a novel weak adaptation learning approach that leverages unlabeled source domain data, limited number of labeled target domain data, and a weak annotator.
-
Our approach includes a theoretical analysis on the error bound of the trained classifier and a multi-stage WAL method that improves the classifier accuracy by lowering such error bound.
-
We compare our approach with various baselines in experiments with domain discrepancy setting on several digit datasets and the VisDA-C dataset, and study the cases without domain discrepancy on the CIFAR-10 dataset. We also conduct ablation studies on the impact from the weak annotator accuracy and the quantity of labeled data samples to further validate our ideas.
2 Related Work
We introduce related works in the topics about weakly- and semi-supervised learning, and the importance of sample quantity here. You can also find more related works about domain adaptation in the supplementary materials.
2.1 Weakly- and Semi-Supervised Learning
Weakly Supervised Learning is a large concept that may have multiple problem settings [65]. The problem we consider in this paper is related to the incomplete supervision setting that is often addressed by Semi-Supervised Learning (SSL) approaches. Standard SSL solves the problem of training a model with a few labeled data and a large amount of unlabeled data. Some of the widely-applied methods [46, 9, 43, 2] assign pseudo labels to unlabeled samples and then perform supervised learning. And there are works that address the noises in the labels of those samples [37, 11, 29]. Our target problem is related to SSL with inaccurate supervision, but is different since we consider the feature discrepancy between the (unlabeled) source data and the (labeled) target data – a case that occurs often in practice but has not been sufficiently addressed.
Positive-unlabeled Learning (PuL) is usually regarded as a sub-problem of SSL. Its goal is to learn a binary classifier to distinguish positive and negative samples from a large amount of unlabeled data and a few positive samples. Several works [23, 5] can achieve great performance on selecting samples that are similar to the positive data, and there are also works using samples selected by PuL to perform other tasks [62, 30].
2.2 Importance of Sample Quantity
The training of machine learning models, especially deep neural networks, often requires a large amount of data samples. However, in many practical scenarios, there is not sufficient training data to feed the learning process, degrading the model performance sharply [52, 19, 61]. Many approaches have been proposed to make up for the lack of training samples, e.g., data re-sampling [56], data augmentation [44], metric learning and meta learning [3, 4, 54, 57]. And there are works [39, 1, 3, 58] conducting theoretical analysis on the relation between training data quantity and model performance. These analyses are usually in the form of bounding the prediction error of the models and provide valuable information on how the sample quantity of training data affects the model performance. In our work, we also perform a theoretical analysis on the error bound of the trained model, with respect to not only the data quantity but also the performance of the weak annotator.
3 Theoretical Analysis
3.1 Problem Definition and Formulation
We consider the task of classification, where the goal is to predict labels for samples in the target domain. Two types of supporting data can be accessed for training the model – source domain data and target domain data. The source domain data samples are initially unlabeled and come from a joint probability distribution . They can be labeled by a weak annotator (which may be inaccurate) and denoted as , where is the number of source data samples. The target domain data consists of samples collected from the target distribution . Note that may be different from . And we use , and , to represent the marginal distributions of the source and target domains, respectively. Moreover, as stated before, we consider the case where there is only a small amount of target domain data, i.e., .
Our goal is to learn an accurate classifier for the target domain. The classifier is initialized from a parameter distribution , which denotes the hypothesis parameter space of all possible classifiers.
In the following analysis, we will define the classification risk of a classifier and then derive its bound. According to the PAC-Bayesian framework [36, 10], the expected classification risk of a classifier drawn from a distribution that depends on the training data can be strictly bounded. Let denote a learned classifier from the training data, and its parameter is drawn from . We consider that the prior parameter distribution over the hypothesis is independent of the training data. And given a with the probability over the training data set of size , the expected error of can be bounded as follows [35]:
| (1) | ||||
Here is the expected error of over parameter , and is the empirical error computed from the training set (, where denotes the loss of a single training sample). In Eq. (1), represents the Kullback-Leibler (KL) divergence between parameter distribution and . For any two distributions , the specific form of their KL divergence is . In most cases of mini-batch training, the training loss is much smaller than , and thus we can get a further bound as follows [39]:
| (2) |
Then if we denote the model parameters of before the training that are drawn from as , the KL divergence can be written as . As aforementioned, is trained with the training data set from , and we consider that the training is optimized by gradient-based method. Thus, we can formulate that . Here we omit the learning rate to simplify the formula.
The PAC-Bayesian error bound is valid for any parameter distribution that is independent of the training data, and any method of optimizing dependent on the training set [39]. Therefore, in order to simplify the problem, we instantiate the bound as setting to conform to a Gaussian distribution with zero mean () and variance. This simplification is the same as previous PAC-Bayesian works [39, 40]. We further assume that the parameter change of the overall model during training can also be regarded as conforming to an empirical Gaussian distribution. This Gaussian distribution is independent of model parameters if we regard the parameter updates induced by gradient back-propagation as accumulated random perturbations, i.e., each training sample corresponds to a small perturbation [40]. And we denote the mean and the variance of a single training sample as follows:
| (3) | ||||
Then, the specific formula of KL divergence to any two Gaussian distributions , is written as follows:
| (4) |
Theorem 1. For a classifier parameter distribution that is independent of the training data with size , and a posterior parameter distribution learned from the training data set, if we assume and consider , as drawn from , respectively (), the KL divergence of and is bounded with symbols defined in Eq. (3) as follows:
| (5) |
The detailed proof of Theorem 1 is presented in our Supplementary Materials. With the above risk definition, the risk of with respect to the target data distribution is
| (6) |
Besides, we define the Classification Distance of two classifiers and under the same domain distribution as
| (7) |
Moreover, the Discrepancy Distance of two domains is defined as in [33]: , the discrepancy distance between the distributions of two domains is
| (8) |
For further analysis, we also define two operators in a parameter distribution :
-
: , and , a new classifier can be acquired by conducting operator on and , and .
-
: , and , a new classifier can be acquired by conducting operator on and , and .
3.2 Error Bound Analysis
Let and denote the ideal classifiers that perform optimally on the source data and target data, respectively:
| (9) |
In our approach, we design a classifier that learns the discrepancy between the weak annotator and the ground truth (details will be introduced in Section 4), and we denote it as drawn from . Thus, we can get a model that is the product of conducting the aforementioned operator on and , i.e., . Here is designed for approximating the weak labels. And for the risk of , we can obtain the following relation:
Theorem 2. For all L1 (Mean Absolute Error [20]), L2 (Mean Squared Error [14]) and their non-negative combination loss functions (Huber Loss [63], Quantile Loss [24], etc.), the classification risk of aforementioned can be formulated as follows:
| (10) | ||||
Please refer to our Supplementary Materials for detailed proof of Theorem 2. Then if we consider that the training loss (which equals the average loss of all training samples) is hardly influenced by the sample quantity, and it is the same for the discrepancy between two domains [32], we can split the error bound of into two parts, where one part, denoted as , is not influenced by the sample quantity and the other is related to the sample quantity. According to Eq. (41), these two parts can be written as follows (the detailed derivation of inequalities starting from Eq. (31) can be found in the Supplementary Materials):
| (11) | ||||
Here and denote KL divergences between trained , and respectively. According to Theorem 1, this KL divergence term is influenced by the training, especially impacted by the sample quantity. We will discuss the insights obtained from this error bound in the next section, and then introduce our weak adaptation learning process that is inspired by those insights.
4 Weak Adaptation Learning Method
4.1 Observation from Error Analysis
Based on the error bound derived in Eq. (11), we can put efforts into the following ideas in our approach to improve the classifier performance in the target domain:
-
Performance of annotator (): The supervision provided by the weak annotator can guide the model to better target the given task. Ideally, we want to produce more accurate labels for both source and target data, reducing and simultaneously. Practically though, we may just be able to make the annotator perform better on the source domain and cannot do much with the target domain.
-
Discrepancy between domains (): Designing loss to quantify the discrepancy between the source and target domains is well studied in Domain Adaptation. In our approach, we propose a novel inter-domain loss (called Classified-MMD) to minimize , as introduced later.
-
Quantity of source and target samples (): First, the learning of needs the supervision of the ground truth, and thus we can only use the labeled target data to train . Then, in our method, is designed to approximate the weak annotator, and therefore it may see enough that we just use the source data to train . However, to further reduce according to Theorem 1, we also use target samples to train , which increases the sample size of training data. Moreover, since the sample quantity of source data is much larger than that of target data (i.e., ), in Eq. (11) dominates over , and in the case of , also strictly dominates over . As the result, the terms influenced by a few target samples dominates the overall error risk. Therefore, directly applying to the target domain will still be impacted by the insufficient samples. However, note that can produce more accurate labels for the source data than the weak annotator. Therefore, we add a final step in our learning process that utilizes re-labeled source data and conducts supervised learning with such augmentation.
4.2 Learning Process
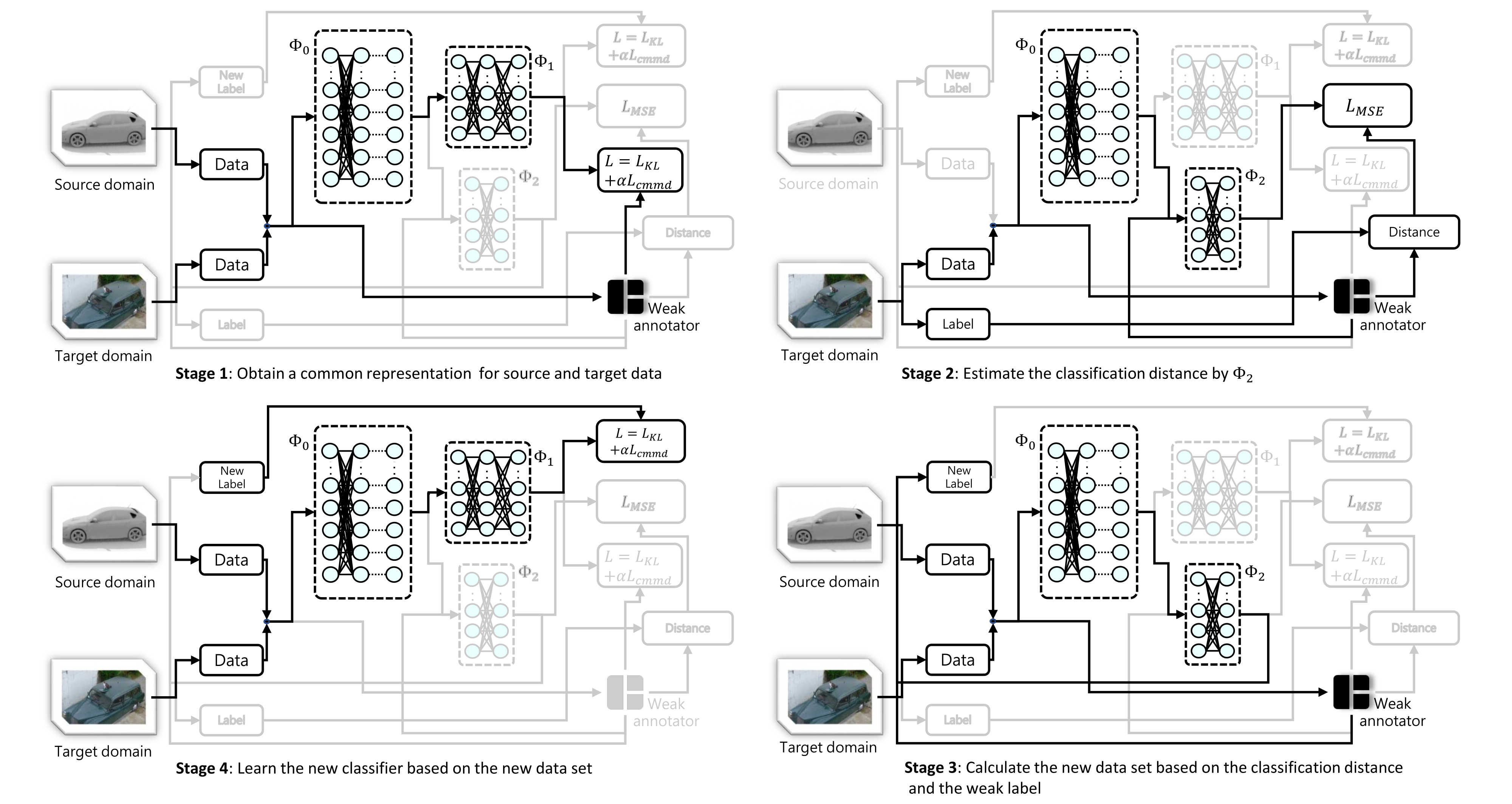
In this section, we present the detailed process of our weak adaptation learning (WAL) method, which is designed based on the observations from the above error bound analysis. The overview of our WAL process is shown in Figure 1. The designed network consists of three parts – (). can be seen as a shared feature network for both source and target data, using typical classification networks such as VGG, ResNet, etc. consists of three fully-connected layers that follow the output of . And we denote the combination of and as . consists of two fully-connected layers that follow the output of . The combination of and is denoted as . The detailed network architecture is shown in the Supplementary Materials. The workflow of our method is shown in Algorithm 1.
Stage 1: The first goal we step on is to obtain a common representation for both the source and target data, which helps us encode the inputs while mitigating the domain discrepancy in the feature representation. We gather all the unlabeled source data and the target data without their labels and use weak annotator to assign a label for each data sample and . We denote the dataset obtained in this way as . Then we fix and only consider the left part of the network, which is . It is normally trained by supervised learning using the dataset for training epochs, and uses the following loss function:
| (12) |
In this loss function, there are two loss terms and the hyper-parameter is a scaling factor to balance the scale of two loss functions (we set it as in our experiments). The first term is the Kullback-Leibler (KL) divergence loss, stated as follows:
| (13) | ||||
where is the output prediction value of and is the corresponding weak label produced by the weak annotator . The second term aims to mitigate the domain discrepancy of the source and target domain at the feature representation level in the neural networks. Based on the basic MMD loss introduced by [55], we further change it into the version with data labels. We call this loss function as Classified-MMD loss (corresponding to the subscript ), which is defined as:
| (14) | ||||
where is the number of classes, is the data from the produced dataset without labels, and is the source data selected from with . Then, we utilize target data with its accurate labels to continue to train the network component under the loss function for training epochs, which helps further fine-tune the feature we learned through accurate labels of the target data.
Stage 2: After finishing training in Stage 1, the next step is to estimate the distance of the optimal classifier for target data and the weak annotator . We estimate this distance through available target data with accurate labels. We adopt the parameters trained from Stage 1 and train network component using the target data . For an input data sample , it is brought into both and the weak annotator as their input. And then takes the output feature of and as input feature (these two features are concatenated as the input feature of ). For data sample target dataset , the learning of uses the following classifier discrepancy loss function:
| (15) |
The network is trained for training epochs.
Stage 3: The third step is to generate a new dataset through the obtained network above. Specifically, we collect data from both source data and target data, and we re-label these data based on the weak annotator and obtained from the previous steps:
| (16) | ||||
Stage 4: In the last step, we focus on again. We fix the parameters of network component and train using the new dataset obtained in Stage 3. To avoid introducing feature bias from the previous steps, we clean all previous network weights and re-initialize the whole network before training. The training lasts for epochs, and the loss function for this step is , which is the same as the function in Stage 1. Finally, we get the final model as the desired classifier.
To sum up, in Stage 1, we learn the model with the help of the weak annotator to decrease the empirical loss , and the CMMD loss will reduce the term . Stage 2 uses a new classifier to learn the classification distance corresponding to the term . The Stage 3 uses the annotator and the learned to give more accurate labels than those given solely by the annotator. Then in Stage 4, the model is trained by the relabeled data, making both and be further decreased. The setting of the hyper-parameters used in this section can found in the Supplementary Materials.
5 Experimental Results
The supplementary materials can be found from https://arxiv.org/abs/2102.07358
5.1 Dataset
The experiments are conducted on three application scenarios, the digits recognition with domain discrepancy (SVHN[38], MNIST[6] and USPS[18] digit datasets), object detection with domain discrepancy (VisDA-C[42]), and object detection without domain discrepancy (CIFAR-10[25]). For space, we introduce details of these datasets in the Supplementary Materials.
5.2 Training Setting
All experiments are conducted on a server with Ubuntu 18.04 LTS with NVIDIA TITAN RTX GPU cards. The implementation is based on the Pytorch framework. The hyper-parameter mentioned above is set to . We use the standard Adam optimizer [22] for optimizing the learning. The network architectures, the learning rate for each part of the network components, the training epoch setting, as well as other hyper-parameters are specified in the Supplementary Materials. And we get weak annotators in different performance by applying early stop for the training. The implementation details of weak annotators can also be found in the Supplementary Materials.
5.3 Baseline Experiments Setting
We conduct comparison experiments with the following baselines. Baseline is the performance of the weak annotator chosen in the experiments in the target domain. Baseline is training only with target data. Baseline is a fine-tuning result. It takes the same model as and first uses source domain data and weak labels generated by the weak annotator to train it. Then it uses target domain data to fine-tune the last three layers. Baseline is also a fine-tuning result. The difference is that instead of fine-tuning the last three layers, it trains all network parameters.
As introduced before, our problem is related to the Semi-Supervised Learning (SSL) and the Semi-Supervised Domain Adaptation (SSDA). For SSL, although we can replace the unlabeled data with samples drawn from another domain instead of the target domain, we cannot find a good way to incorporate the weak annotator into SSL methods for fair comparison with our approach. For SSDA, we were able to extend it to our setting for comparison. Specifically, we add 1,000 unlabeled target samples (plus 1,000 labeled target samples, and this setting will be changed accordingly in digits recognition to keep consistent settings) to meet the semi-supervised requirement, and we apply weak annotator to produce weak labels instead of accurate ones for source data. We compare our approach with the following SSDA baselines: FAN [21], MME [48], ENT [13], S+T [4, 45]. Note that to the best of our knowledge, there is no previous work with exactly the same problem setting as ours. The above changes aim at making the comparison as fair as possible. Another thing that is worth to mention is that most SSDA methods conduct adaptation on the ImageNet pre-trained models, which introduces a lot of irrelevant data information from the ImageNet dataset. Thus, we disable the pre-training and only allow training with the available data.
5.4 Results of Digits Recognition
We evaluate our methods on the digit recognition datasets: SVHN (S), MNIST (M),and USPS (U). According to the results shown in Table 1, when the weak annotator performs much worse than the model learned only from the provided target data ( = on M U, on S U and on S M), its corresponding baseline is also lower than , and only the second fine-tuning method is better than or competitive with . This indicates that the feature learned from the source domain data and with weak labels introduce data bias, and this bias can be mitigated when the parameters from the front layers are fine-tuned by the target data.
Overall, we can clearly see that with 15,000 source domain data, limited number of labeled target domain data (second line), and a weak annotator, our method can outperform all the baselines in Table 1 with on M S, on M U, on S U and on S M.
| Method | M S(%) | M U(%) | S U(%) | S M(%) |
|---|---|---|---|---|
| #samples | 1000 | 300 | 300 | 1000 |
| 59.06 | 73.28 | 73.28 | 76.41 | |
| 61.14 | 89.20 | 89.27 | 94.79 | |
| 55.68 | 84.58 | 77.24 | 80.41 | |
| 77.92 | 94.10 | 94.92 | 95.52 | |
| S+T | 65.70 | 93.67 | 91.21 | 96.21 |
| ENT | 67.89 | 92.62 | 92.02 | 96.42 |
| MME | 65.92 | 93.07 | 91.32 | 95.64 |
| FAN | 68.48 | 93.78 | 92.38 | 96.51 |
| Ours | 80.00 | 95.99 | 96.36 | 97.24 |
5.5 Results of Object Recognition
The results of various methods on the VisDA-C dataset are presented in Figure 2. In this task, we utilize the synthetic images as the source domain dataset, and the real-world images as the target domain dataset. And we can see from the table that the performance of the network trained only with the target data is merely . Then, when the weak annotator is provided, it can help two fine-tune baselines and reach and respectively. As for the SSDA baselines, all of them perform very badly, and they are provided with more target samples with no labels. The best SSDA methods FAN can only achieve . Our method can provide a result of , which again exceeds all baselines above. Besides, we also provide additional experiment results using a different weak annotator in the supplementary materials.
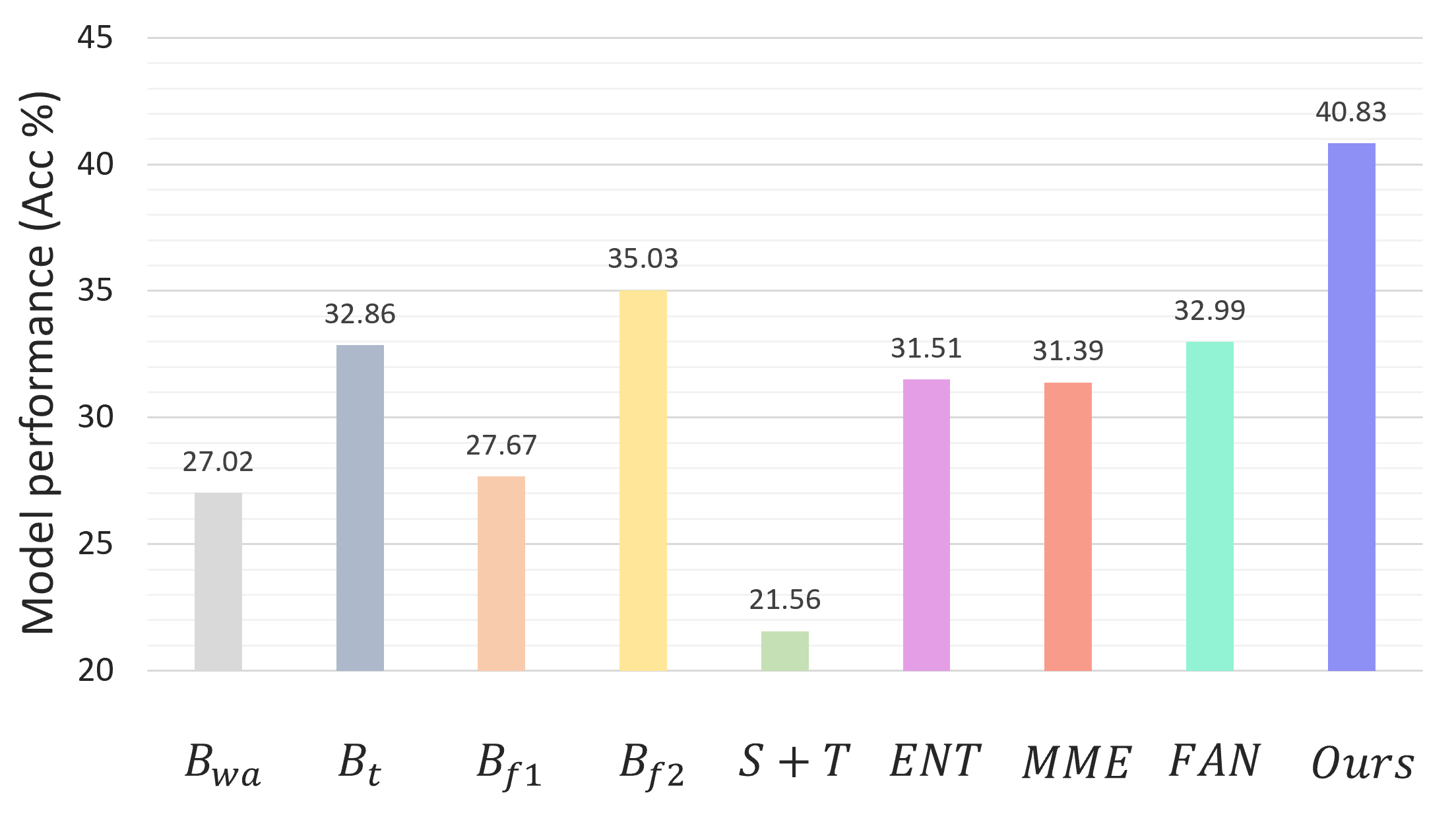
Moreover, we also test on the scenario without domain discrepancy using the CIFAR-10 dataset. We randomly select 10,000 data samples from the dataset as the source data and another 1,000 samples as the target data. The result is included in Table 2. As we can see, when the weak annotator is given at accuracy, the model trained only with the target data can reach , while our method nearly doubles the performance and hits , which exceeds all other baselines.
| Method | plane | mobile | bird | cat | deer | dog | frog | horse | ship | truck | Acc(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 43.18 | 65.68 | 28.13 | 25.93 | 29.00 | 46.15 | 83.91 | 41.76 | 72.12 | 51.06 | 48.96 | |
| 19.08 | 63.39 | 03.03 | 30.16 | 25.77 | 22.60 | 46.11 | 50.85 | 23.61 | 25.74 | 30.46 | |
| 57.38 | 77.53 | 38.46 | 33.51 | 45.27 | 33.17 | 73.33 | 58.29 | 57.67 | 60.20 | 52.97 | |
| 44.19 | 80.00 | 38.02 | 41.97 | 47.15 | 24.30 | 78.14 | 55.06 | 89.35 | 38.19 | 53.49 | |
| Ours | 65.52 | 82.61 | 39.79 | 48.45 | 57.36 | 43.60 | 67.39 | 65.32 | 70.42 | 78.89 | 61.71 |
5.6 Ablation Study
We also study how the quantity of target domain samples and the performance of the weak annotator affect the overall performance of our method. To reduce the impact of domain discrepancy when we study these two factors, we conduct the ablation study on CIFAR-10.
5.6.1 Sample quantity of target samples
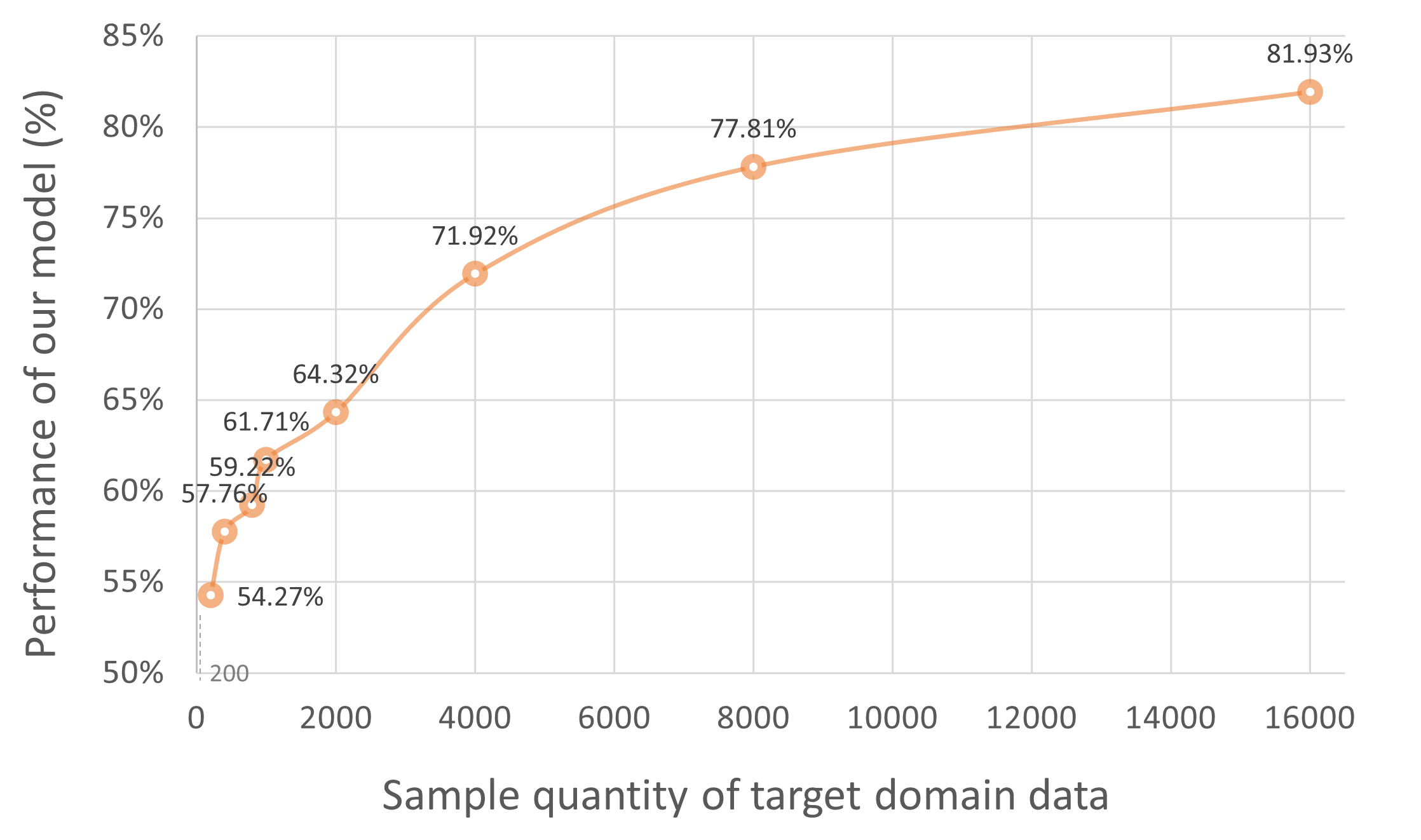
As presented in Figure 3, the horizontal axis indicates the number of target domain data, and the vertical axis shows the performance of our model using the corresponding number of target domain samples. When keeping the weak annotator the same as Section 5.5 and fixing the sample quantity of the source data as 10,000, the accuracy of the model grows as the number of target domain data increases. And it will gradually get saturated when there is enough target domain data. This saturation phenomenon can be explained as the second derivative of and for is positive while the first derivative is negative. And according to the curve, we can observe that the performance improvement when the target data is less than the source data is relatively higher than the case when there is more target data. The reason for this can be found in our theoretical analysis, i.e., when the sample quantities of source and target data become closer, terms impacted by the quantity of target data will not dominate over the error bound.
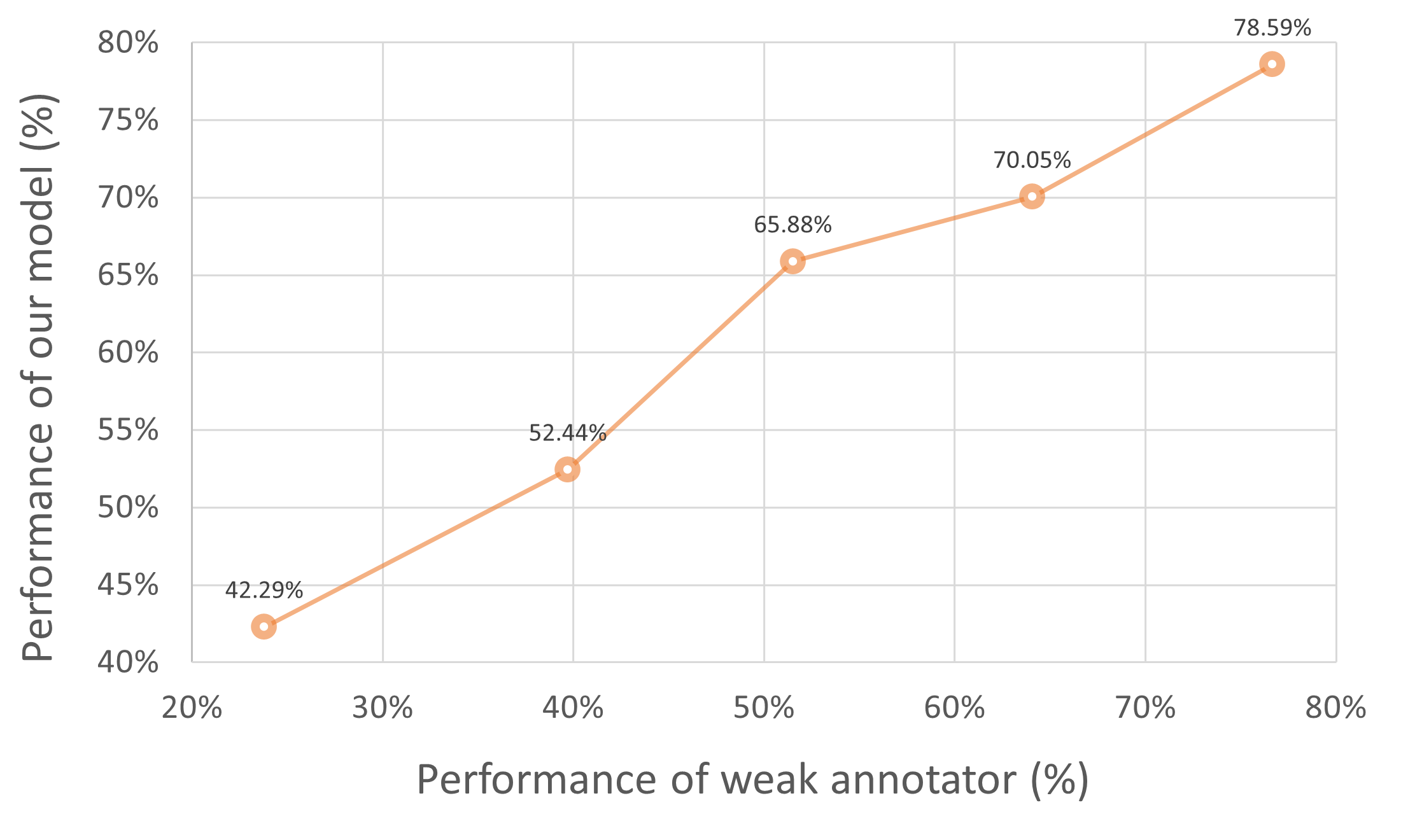
5.6.2 Performance of weak annotator
Figure 4 shows the curve of how the performance of our model changes with respect to the accuracy of the weak annotator. As shown in the figure, when the weak annotator performs the worst with accuracy of , our model can reach , which is a relatively significant improvement. And as the accuracy of the weak annotator increases, our model performs better accordingly. Interestingly, the improvement curve in Figure 4 is approximately linear, which demonstrates that it is reasonable to linearly add the terms of the weak annotator in the error bound.
6 Conclusion
In this work, we present a novel approach leveraging weak annotator to address the data insufficiency challenge in domain adaptation, where only a small amount of data samples is available in the target domain and the data samples in the source domain are unlabeled. Our weak adaptation approach includes a theoretical analysis that derives the error bound of a trained classifier with respect to the data quantity and the performance of the weak annotator, and a multi-stage learning process that improves classifier performance by lowering the error bound. Our approach shows significant improvement over baselines on cases with or without domain discrepancy in various data sets.
7 Acknowledgement
We gratefully acknowledge the support from NSF grants 1834701, 1839511, 1724341, 2038853, and ONR grant N00014-19-1-2496.
References
- [1] Ron Amit and Ron Meir. Meta-learning by adjusting priors based on extended pac-bayes theory. In International Conference on Machine Learning, pages 205–214. PMLR, 2018.
- [2] Soufiane Belharbi, Ismail Ben Ayed, Luke McCaffrey, and Eric Granger. Deep active learning for joint classification & segmentation with weak annotator. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 3338–3347, 2020.
- [3] Tianshi Cao, Marc Law, and Sanja Fidler. A theoretical analysis of the number of shots in few-shot learning. arXiv preprint arXiv:1909.11722, 2019.
- [4] Wei-Yu Chen, Yen-Cheng Liu, Zsolt Kira, Yu-Chiang Frank Wang, and Jia-Bin Huang. A closer look at few-shot classification. In International Conference on Learning Representations, 2019.
- [5] Xuxi Chen, Wuyang Chen, Tianlong Chen, Ye Yuan, Chen Gong, Kewei Chen, and Zhangyang Wang. Self-pu: Self boosted and calibrated positive-unlabeled training. In International Conference on Machine Learning, pages 1510–1519. PMLR, 2020.
- [6] Li Deng. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Processing Magazine, 29(6):141–142, 2012.
- [7] Jiahua Dong, Yang Cong, Gan Sun, and Dongdong Hou. Semantic-transferable weakly-supervised endoscopic lesions segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10712–10721, 2019.
- [8] Jiahua Dong, Yang Cong, Gan Sun, Bineng Zhong, and Xiaowei Xu. What can be transferred: Unsupervised domain adaptation for endoscopic lesions segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4023–4032, 2020.
- [9] WeiWang Dong-DongChen and Zhi-HuaZhou WeiGao. Tri-net for semi-supervised deep learning. In International Joint Conferences on Artificial Intelligence, 2018.
- [10] Pascal Germain, Francis Bach, Alexandre Lacoste, and Simon Lacoste-Julien. Pac-bayesian theory meets bayesian inference. In Proceedings of the 30th International Conference on Neural Information Processing Systems, pages 1884–1892, 2016.
- [11] Aritra Ghosh, Naresh Manwani, and PS Sastry. Making risk minimization tolerant to label noise. Neurocomputing, 160:93–107, 2015.
- [12] Ian Goodfellow, Yoshua Bengio, Aaron Courville, and Yoshua Bengio. Deep learning, volume 1. MIT press Cambridge, 2016.
- [13] Yves Grandvalet and Yoshua Bengio. Semi-supervised learning by entropy minimization. In Proceedings of the 17th International Conference on Neural Information Processing Systems, pages 529–536, 2004.
- [14] Richard F Gunst and Robert L Mason. Biased estimation in regression: an evaluation using mean squared error. Journal of the American Statistical Association, 72(359):616–628, 1977.
- [15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [16] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.
- [17] Sheng-Wei Huang, Che-Tsung Lin, Shu-Ping Chen, Yen-Yi Wu, Po-Hao Hsu, and Shang-Hong Lai. Auggan: Cross domain adaptation with gan-based data augmentation. In Proceedings of the European Conference on Computer Vision (ECCV), pages 718–731, 2018.
- [18] Jonathan J. Hull. A database for handwritten text recognition research. IEEE Transactions on pattern analysis and machine intelligence, 16(5):550–554, 1994.
- [19] Justin M Johnson and Taghi M Khoshgoftaar. Survey on deep learning with class imbalance. Journal of Big Data, 6(1):1–54, 2019.
- [20] S Kassam. Quantization based on the mean-absolute-error criterion. IEEE Transactions on Communications, 26(2):267–270, 1978.
- [21] Taekyung Kim and Changick Kim. Attract, perturb, and explore: Learning a feature alignment network for semi-supervised domain adaptation. In European Conference on Computer Vision, pages 591–607. Springer, 2020.
- [22] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [23] Ryuichi Kiryo, Gang Niu, Marthinus C du Plessis, and Masashi Sugiyama. Positive-unlabeled learning with non-negative risk estimator. arXiv preprint arXiv:1703.00593, 2017.
- [24] Roger Koenker. Quantile regression for longitudinal data. Journal of Multivariate Analysis, 91(1):74–89, 2004.
- [25] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- [26] Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML, volume 3, 2013.
- [27] Junnan Li, Richard Socher, and Steven CH Hoi. Dividemix: Learning with noisy labels as semi-supervised learning. In International Conference on Learning Representations, 2019.
- [28] Rui Li, Qianfen Jiao, Wenming Cao, Hau-San Wong, and Si Wu. Model adaptation: Unsupervised domain adaptation without source data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9641–9650, 2020.
- [29] Tongliang Liu and Dacheng Tao. Classification with noisy labels by importance reweighting. IEEE Transactions on pattern analysis and machine intelligence, 38(3):447–461, 2015.
- [30] Mohammad Reza Loghmani, Markus Vincze, and Tatiana Tommasi. Positive-unlabeled learning for open set domain adaptation. Pattern Recognition Letters, 136:198–204, 2020.
- [31] Mingsheng Long, Han Zhu, Jianmin Wang, and Michael I Jordan. Unsupervised domain adaptation with residual transfer networks. In Advances in neural information processing systems, pages 136–144, 2016.
- [32] Yadan Luo, Zijian Wang, Zi Huang, and Mahsa Baktashmotlagh. Progressive graph learning for open-set domain adaptation. In International Conference on Machine Learning, pages 6468–6478. PMLR, 2020.
- [33] Yishay Mansour, Mehryar Mohri, and Afshin Rostamizadeh. Domain adaptation: Learning bounds and algorithms. arXiv preprint arXiv:0902.3430, 2009.
- [34] Michael F Mathieu, Junbo Jake Zhao, Junbo Zhao, Aditya Ramesh, Pablo Sprechmann, and Yann LeCun. Disentangling factors of variation in deep representation using adversarial training. Advances in neural information processing systems, 29:5040–5048, 2016.
- [35] David McAllester. Simplified pac-bayesian margin bounds. In Learning theory and Kernel machines, pages 203–215. Springer, 2003.
- [36] David A McAllester. Some pac-bayesian theorems. Machine Learning, 37(3):355–363, 1999.
- [37] Nagarajan Natarajan, Inderjit S Dhillon, Pradeep Ravikumar, and Ambuj Tewari. Learning with noisy labels. In NIPS, volume 26, pages 1196–1204, 2013.
- [38] Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and Andrew Y Ng. Reading digits in natural images with unsupervised feature learning. 2011.
- [39] Behnam Neyshabur, Srinadh Bhojanapalli, David McAllester, and Nati Srebro. Exploring generalization in deep learning. In Advances in neural information processing systems, pages 5947–5956, 2017.
- [40] Behnam Neyshabur, Srinadh Bhojanapalli, and Nathan Srebro. A pac-bayesian approach to spectrally-normalized margin bounds for neural networks. In International Conference on Learning Representations, 2018.
- [41] Sujoy Paul, Yi-Hsuan Tsai, Samuel Schulter, Amit K Roy-Chowdhury, and Manmohan Chandraker. Domain adaptive semantic segmentation using weak labels. arXiv preprint arXiv:2007.15176, 2020.
- [42] Xingchao Peng, Ben Usman, Neela Kaushik, Judy Hoffman, Dequan Wang, and Kate Saenko. Visda: The visual domain adaptation challenge. arXiv preprint arXiv:1710.06924, 2017.
- [43] Fábio Perez, Rémi Lebret, and Karl Aberer. Weakly supervised active learning with cluster annotation. arXiv preprint arXiv:1812.11780, 2018.
- [44] Samira Pouyanfar, Yudong Tao, Anup Mohan, Haiman Tian, Ahmed S Kaseb, Kent Gauen, Ryan Dailey, Sarah Aghajanzadeh, Yung-Hsiang Lu, Shu-Ching Chen, et al. Dynamic sampling in convolutional neural networks for imbalanced data classification. In 2018 IEEE conference on multimedia information processing and retrieval (MIPR), pages 112–117. IEEE, 2018.
- [45] Rajeev Ranjan, Carlos D Castillo, and Rama Chellappa. L2-constrained softmax loss for discriminative face verification. arXiv preprint arXiv:1703.09507, 2017.
- [46] Antti Rasmus, Harri Valpola, Mikko Honkala, Mathias Berglund, and Tapani Raiko. Semi-supervised learning with ladder networks. arXiv preprint arXiv:1507.02672, 2015.
- [47] Subhankar Roy, Aliaksandr Siarohin, Enver Sangineto, Samuel Rota Bulo, Nicu Sebe, and Elisa Ricci. Unsupervised domain adaptation using feature-whitening and consensus loss. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9471–9480, 2019.
- [48] Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, and Kate Saenko. Semi-supervised domain adaptation via minimax entropy. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8050–8058, 2019.
- [49] Kuniaki Saito, Kohei Watanabe, Yoshitaka Ushiku, and Tatsuya Harada. Maximum classifier discrepancy for unsupervised domain adaptation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3723–3732, 2018.
- [50] Tasfia Shermin, Guojun Lu, Shyh Wei Teng, Manzur Murshed, and Ferdous Sohel. Adversarial network with multiple classifiers for open set domain adaptation. IEEE Transactions on Multimedia, 2020.
- [51] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
- [52] Jake Snell, Kevin Swersky, and Richard Zemel. Prototypical networks for few-shot learning. In Proceedings of the 31st International Conference on Neural Information Processing Systems, pages 4080–4090, 2017.
- [53] Hui Tang and Kui Jia. Discriminative adversarial domain adaptation. In AAAI, pages 5940–5947, 2020.
- [54] Eleni Triantafillou, Tyler Zhu, Vincent Dumoulin, Pascal Lamblin, Utku Evci, Kelvin Xu, Ross Goroshin, Carles Gelada, Kevin Swersky, Pierre-Antoine Manzagol, et al. Meta-dataset: A dataset of datasets for learning to learn from few examples. In International Conference on Learning Representations, 2019.
- [55] Eric Tzeng, Judy Hoffman, Ning Zhang, Kate Saenko, and Trevor Darrell. Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474, 2014.
- [56] Jason Van Hulse, Taghi M Khoshgoftaar, and Amri Napolitano. Experimental perspectives on learning from imbalanced data. In Proceedings of the 24th international conference on Machine learning, pages 935–942, 2007.
- [57] Lixu Wang, Shichao Xu, Xiao Wang, and Qi Zhu. Addressing class imbalance in federated learning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 10165–10173, 2021.
- [58] Yaqing Wang, Quanming Yao, James T Kwok, and Lionel M Ni. Generalizing from a few examples: A survey on few-shot learning. ACM Computing Surveys (CSUR), 53(3):1–34, 2020.
- [59] Garrett Wilson and Diane J Cook. A survey of unsupervised deep domain adaptation. ACM Transactions on Intelligent Systems and Technology (TIST), 11(5):1–46, 2020.
- [60] Garrett Wilson, Janardhan Rao Doppa, and Diane J Cook. Multi-source deep domain adaptation with weak supervision for time-series sensor data. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1768–1778, 2020.
- [61] Shichao Xu, Yangyang Fu, Yixuan Wang, Zheng O’Neill, and Qi Zhu. Learning-based framework for sensor fault-tolerant building hvac control with model-assisted learning, 2021.
- [62] Yixing Xu, Yunhe Wang, Hanting Chen, Kai Han, Chunjing Xu, Dacheng Tao, and Chang Xu. Positive-unlabeled compression on the cloud. arXiv preprint arXiv:1909.09757, 2019.
- [63] Congrui Yi and Jian Huang. Semismooth newton coordinate descent algorithm for elastic-net penalized huber loss regression and quantile regression. Journal of Computational and Graphical Statistics, 26(3):547–557, 2017.
- [64] Werner Zellinger, Thomas Grubinger, Edwin Lughofer, Thomas Natschläger, and Susanne Saminger-Platz. Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv preprint arXiv:1702.08811, 2017.
- [65] Zhi-Hua Zhou. A brief introduction to weakly supervised learning. National science review, 5(1):44–53, 2018.
Appendix This appendix contains additional details for the submitted article Weak Adaptation Learning: Addressing Cross-domain Data Insufficiency with Weak Annotator, including mathematical proofs and experimental details. Moreover, the additional related works are provided in Section A, the additional theoretical analysis details are provided in Section B, the introduction of data sets is provided in Section C, the additional ablation study is provided in Section D, the network architecture is shown in Section E, and more about training settings is presented in Section F.
Appendix A Related Work
A.1 Weakly- and Semi-Supervised Learning
Weakly Supervised Learning is a large concept that may have multiple problem settings [65]. The problem we consider in this paper is related to the incomplete supervision setting that is often addressed by Semi-Supervised Learning (SSL) approaches. Standard SSL solves the problem of training a model with a few labeled data and a large amount of unlabeled data. Some of the widely-applied methods [46, 9, 43, 2] assign pseudo labels to unlabeled samples and then perform supervised learning. And there are works that address the noises in the labels of those samples [37, 11, 29]. Our target problem is related to SSL with inaccurate supervision, but is different since we consider the feature discrepancy between the (unlabeled) source data and the (labeled) target data – a case that occurs often in practice but has not been sufficiently addressed.
Positive-unlabeled Learning (PuL) is usually regarded as a sub-problem of SSL. Its goal is to learn a binary classifier to distinguish positive and negative samples from a large amount of unlabeled data and a few positive samples. Several works [23, 5] can achieve great performance on selecting samples that are similar to the positive data, and there are also works using samples selected by PuL to perform other tasks [62, 30].
A.2 Domain Adaptation
Previous Domain Adaptation (DA) approaches often design a number of losses to measure the discrepancy between source and target domains [49, 31, 55, 64, 47]. Then, adversarial training is applied in DA [34, 17, 50, 53]. In the problem settings of these works, the supervision knowledge reflected in the source labels is accurate and reliable, which is not the case in our problem (where weak annotator generates inaccurate labels). In addition, the standard DA problem does not address the case where the quantity of the target domain data is small. The Semi-Supervised Domain Adaptation (SSDA) [48] approach assumes that only a few labeled data samples are available in the target domain, but the adaptation may use a large amount of unlabeled data in the target domain. This is different from our problem, where we consider the cases where even unlabeled data samples are hard to acquire in the target domain (e.g., the examples mentioned in Section 1). In short, our work is the first to explore the DA problem with weak source knowledge and insufficient target samples simultaneously.
In addition, there are several papers in domain adaptation that leverage the information of so-called weak labels in source or target domain [60, 41]. However, these weak labels are in a different task to their target labels (e.g., providing an image-level label for image segmentation task that shows the proportion of categories of the entire image rather than providing a pixel-level label), which is a different concept towards the weak label mentioned in our paper.
A.3 Importance of Sample Quantity
The training of machine learning models, especially deep neural networks, often requires a large amount of data samples. However, in many practical scenarios, there is not sufficient training data to feed the learning process, degrading the model performance sharply [52, 19]. Many approaches have been proposed to make up for the lack of training samples, e.g., data re-sampling [56], data augmentation [44], metric learning, and meta learning [3, 4, 54]. And there are works [39, 1, 3, 58] conducting theoretical analysis on the relation between training data quantity and model performance. These analyses are usually in the form of bounding the prediction error of the models and provide valuable information on how the sample quantity of training data affects the model performance. In our work, we also perform a theoretical analysis on the error bound of the trained model, with respect to not only the data quantity but also the performance of the weak annotator.
Appendix B Theoretical Analysis
B.1 Proof of Theorem 1
Theorem 1. For a classifier parameter distribution that is independent of the training data with size , and a posterior parameter distribution learned from the training data set, if we assume and consider , as drawn from , respectively (), the KL divergence of and is bounded with symbols defined in Eq. (18) as follows:
| (17) |
Proof: Let us consider a classifier drawn from a parameter distribution , and depends on the data that has been learned by . Then, if we denote the model parameters of before the training that are drawn from as , the KL divergence can be written as . As aforementioned, is trained with the training data set from , and we consider that the training is optimized by a gradient-based method. Thus, we can formulate that . Here we omit the learning rate to simplify the formula, and is the empirical error computed from the training set (, where denotes the loss of a single training sample).
The PAC-Bayesian error bound is valid for any parameter distribution that is independent of the training data, and any method of optimizing dependent on the training set [39]. Therefore, in order to simplify the problem, we instantiate the bound as setting to conform to a Gaussian distribution with zero mean () and variance. This simplification is similar to the ones in previous PAC-Bayesian works [39, 40]. We further assume that the parameter change of the overall model during training can also be regarded as conforming to an empirical Gaussian distribution, and we denote this distribution as follows:
| (18) | ||||
This Gaussian distribution is independent of model parameters if we regard the parameter updates induced by the gradient back-propagation as accumulated random perturbations, i.e., each training sample corresponds to a small perturbation [40]. And we know that the specific formula of KL divergence to any two Gaussian distributions , is written as:
| (19) |
And we can prove the equation as follows:
| (20) | ||||
Then we can split Eq. (20) into two different integrations and calculate them respectively.
| (21) | ||||
| (22) | ||||
In this case, Eq. (20) can be written as:
| (23) | ||||
With the above definitions, we can compute the mean of distribution :
| (24) | ||||
| (25) | ||||
With the mean and variance of distribution , we can then calculate as follows:
| (26) | ||||
B.2 Error Bound Derivation
With the risk definition introduced in our main paper, the risk of with respect to source data distribution is
| (27) |
The risk with respect to target data distribution is
| (28) |
In addition, we define the Classification Distance of two classifier and under a same domain distribution as
| (29) |
Moreover, the Discrepancy Distance of two domains is defined as in [33]: , the discrepancy distance between the distributions of two domains is
| (30) |
With the operators and defined in our main paper, we can obtain the following theorem for error bound with all L1, L2 and their combination loss functions.
Theorem 2. For all L1 (Mean Absolute Error [20]), L2 (Mean Squared Error [14]) and their non-negative combination loss functions (Huber Loss [63], Quantile Loss [24], etc.), the classification risk of aforementioned can be formulated as follows:
| (31) | ||||
Proof: For L1 (Mean Absolute Error) Loss, . Then, incorporating the definitions of new operators, we can have the following derivation (here we denote as ):
| (32) | ||||
For L2 (Mean Squared Error) Loss, , and the corresponding bound of is as follows:
| (33) | ||||
Here, we denote as , and as . As aforementioned, is designed to approximate the difference between the weak supervision and the ground truth (in our method, we show that can be directly replaced with ), and thus we assume that the output of is very closed to . Then, we analyze the relation between the product of and in all 6 possible cases shown in Table 3.
| Condition | Derivation | Conclusion |
|---|---|---|
According to Table 3, the product of is always less than or equal to . Therefore, we can enlarge the bound of Eq. (33) as follows:
| (34) | ||||
Now, we have proven that both L1 and L2 Losses hold true for Eq. (31). Moreover, we believe that other losses that are non-negative combination forms of L1 and L2 can also ensure this inequality relation.
From the definition of Discrepancy Distance between two domains shown in Eq. (30), we can derive the inequality relation on the discrepancy between and as:
| (35) |
By utilizing the triangle inequality, we have:
| (36) | ||||
| (37) | ||||
Based on the relations presented in Eq. (35), (36), (37), we can bound the classification risk of in the target domain shown in Eq. (31) as:
| (38) | ||||
Furthermore, the Classification Discrepancy between and for the source domain data can also be bounded by the triangle inequality:
| (39) | ||||
Thus, Eq. (38) can be formulated as follows:
| (40) | ||||
As introduced in our main paper, if is trained with mini-batch, its classification error can be bounded as follows [39]:
| (41) | ||||
In our setting, the weak annotator is unchanged. Thus the KL divergence of the risk for is zero. As mentioned before, classifier is designed to learn the discrepancy between the weak supervision and the ground truth in the target domain. Therefore, we can only use target data with accurate labels to estimate . Moreover, if we consider that the training loss (which equals the average loss of all training samples) is hardly influenced by the sample quantity, and it is the same for the discrepancy between two domains [32], we can split Eq. (40) into two parts, where one part (denoted as ) is not influenced by the sample quantity and the other part is related to the sample quantity. Based on Eq. (41), these two parts can be written as follows:
| (42) | ||||
Here and denote KL divergences between trained , and respectively. According to Theorem 1, this KL divergence term is influenced by the training, especially impacted by the sample quantity. This is further discussed in Section 4 of the main paper.
Appendix C Dataset
The experiments are conducted on three application scenarios: the digits recognition with domain discrepancy (SVHN[38], MNIST[6] and USPS[18] digit datasets), object detection with domain discrepancy (VisDA-C[42]), and object detection without domain discrepancy (CIFAR-10[25]).
-
SVHN, MNIST, USPS: SVHN dataset is a real-world image dataset that has 73,257 training examples obtained from house numbers in Google Street View images. MNIST is a widely used dataset for handwritten digit recognition and contains 60,000 training examples. USPS database contains 7291 training images scanned from mail in a working post office. Every set is composed of 10 classes corresponding to 10 digit numbers. In the experiments, we randomly and non-repetitively sample 15,000 samples (each class includes 1,000 samples) from one domain as the source domain data, 1,000 samples from another domain as the target domain data, and another 2,000 samples as the validation data. We tested some combinations of adaptations chosen from these three datasets. All the images are resized to 32 32.
-
VisDA-C: VisDA-C is a challenging object recognition dataset that contains 152,397 synthetic images and 55,388 real-world object images on 12 object classes. In the experiments, we randomly and non-repetitively sample 20,000 samples from synthetic images as the source domain data, 1,000 samples from real-world object images as the target domain data, and another 2,000 samples from real-world object images as the validation data. All the images are resized to 224 224.
-
CIFAR-10 CIFAR-10 is a popular object recognition benchmark with 50,000 training samples. We use this dataset here for testing our method under the scenario without domain discrepancy. Additionally, we randomly select 10,000 data samples from the dataset as the source domain data and another 1,000 data samples as the target domain data. All the images are resized to 32 32.
Appendix D Additional Ablation Study
| Method | knife | plane | bcycl | person | mcycl | car | truck | plant | bus | sktbrd | horse | train | Acc(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 01.55 | 0.50 | 0.62 | 05.49 | 80.24 | 46.63 | 06.08 | 51.24 | 05.04 | 42.94 | 13.20 | 07.17 | 27.02 | |
| 15.85 | 33.33 | 32.54 | 34.69 | 55.20 | 42.08 | 32.11 | 25.68 | 15.48 | 13.95 | 27.16 | 29.49 | 32.86 | |
| 12.34 | 10.58 | 15.74 | 07.53 | 44.34 | 51.91 | 10.00 | 29.53 | 28.99 | 37.69 | 12.19 | 19.23 | 27.67 | |
| 30.86 | 09.41 | 11.90 | 23.97 | 53.84 | 47.68 | 25.13 | 43.04 | 46.10 | 36.92 | 22.08 | 28.20 | 35.03 | |
| S+T | 00.05 | 03.84 | 03.34 | 00.00 | 14.24 | 86.16 | 07.16 | 14.42 | 16.78 | 02.67 | 00.00 | 00.00 | 21.56 |
| ENT | 22.07 | 33.85 | 42.79 | 10.18 | 34.84 | 45.07 | 37.61 | 45.19 | 20.58 | 10.08 | 13.99 | 27.53 | 31.51 |
| MME | 26.42 | 35.57 | 29.91 | 13.98 | 40.47 | 21.39 | 20.53 | 50.05 | 43.72 | 33.61 | 36.65 | 14.99 | 31.39 |
| FAN | 18.17 | 36.23 | 31.48 | 16.87 | 35.79 | 40.13 | 27.51 | 48.23 | 32.97 | 29.40 | 25.66 | 22.17 | 32.99 |
| Ours | 26.50 | 38.37 | 16.53 | 12.16 | 69.72 | 52.32 | 11.91 | 44.00 | 52.66 | 60.00 | 37.42 | 36.84 | 40.82 |
In addition to the ablation experiments shown in our main paper, we also conduct additional studies that provide the experimental evidence on why we choose to estimate the distance of the optimal classifier for the target data and the weak annotator, instead of learning the target task directly using the target data in Stage 2 of our algorithm (Algorithm 1 in the main paper) and then gives pseudo labels for the source data in Stage 3.
The experiment setting is the same as in the Section 5.5 of the main paper on the CIFAR-10 dataset. The algorithm for the ablation study is the same as Algorithm 1 in the main paper except for the following modifications: 1) The network will learn the classification result from the target data instead of learning the difference. In this way, will only take the output feature from as the input feature. 2) After finishing learning in Stage 2, when generating the new dataset in Stage 3, it becomes
| (43) |
All other steps are the same as Algorithm 1. This additional ablation study actually follows the thought of assigning pseudo labels for all the data. Note that in the original paper of pseudo label [26], it is only for the unlabeled data. However the target data should also be re-labeled using the soft labels, following the ideas in [16] – this provides better performance and is the same approach as our method for this part.
The additional ablation study result is shown in Table 5. The performance of the ablation method is lower than our result , which indicates that learning the classification difference as in our Algorithm 1 is a better solution.
| Method | plane | mobile | bird | cat | deer | dog | frog | horse | ship | truck | Acc(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 43.18 | 65.68 | 28.13 | 25.93 | 29.00 | 46.15 | 83.91 | 41.76 | 72.12 | 51.06 | 48.96 | |
| 62.06 | 65.16 | 45.64 | 48.42 | 46.63 | 43.39 | 64.48 | 61.79 | 67.12 | 73.63 | 57.70 | |
| Ours | 65.52 | 82.61 | 39.79 | 48.45 | 57.36 | 43.60 | 67.39 | 65.32 | 70.42 | 78.89 | 61.71 |
| Method | knife | plane | bcycl | person | mcycl | car | truck | plant | bus | sktbrd | horse | train | Acc(%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 41.89 | 53.03 | 34.17 | 46.67 | 72.59 | 55.42 | 07.07 | 47.13 | 24.84 | 40.00 | 42.85 | 25.32 | 42.14 | |
| 15.85 | 33.33 | 32.54 | 34.69 | 55.20 | 42.08 | 32.11 | 25.68 | 15.48 | 13.95 | 27.16 | 29.49 | 32.86 | |
| 31.71 | 40.31 | 11.20 | 22.30 | 64.09 | 39.45 | 10.00 | 44.74 | 39.05 | 18.82 | 31.10 | 23.23 | 33.56 | |
| 34.14 | 08.13 | 24.19 | 26.71 | 63.30 | 55.73 | 25.13 | 57.89 | 37.86 | 44.69 | 50.60 | 40.25 | 42.84 | |
| S+T | 22.62 | 37.24 | 17.07 | 03.40 | 10.29 | 06.65 | 29.05 | 35.72 | 09.20 | 23.81 | 40.85 | 03.52 | 23.36 |
| ENT | 40.53 | 36.06 | 46.62 | 11.80 | 19.85 | 22.87 | 37.71 | 45.08 | 14.19 | 28.97 | 20.52 | 13.47 | 28.98 |
| MME | 21.60 | 44.95 | 17.05 | 24.88 | 57.13 | 36.62 | 16.72 | 18.65 | 36.57 | 28.93 | 20.83 | 13.11 | 29.31 |
| FAN | 32.71 | 50.13 | 14.72 | 20.09 | 60.78 | 53.44 | 20.60 | 42.34 | 20.07 | 17.65 | 23.91 | 33.25 | 34.47 |
| Ours | 43.37 | 59.54 | 13.49 | 21.76 | 67.43 | 60.92 | 21.28 | 51.97 | 58.08 | 18.60 | 40.24 | 40.38 | 45.06 |
Appendix E Network Architecture
In the digit experiments, the weak annotator is chosen as ResNet-18 [15]. It is trained with randomly selected 10,000 data samples from the source dataset and 100 from the target dataset for 4 epochs. is made from the VGG-19 [51] network. consists of three fully-connected layers, and the neuron number is set to [128, 64, 10]. consists of two fully-connected layers, and the neuron number is set to [512, 10].
In the VisDA-C experiments, The weak annotator is chosen as ResNet-50 [15]. It is trained with randomly selected 10,000 data samples from both datasets for 10 epochs. is made from the ResNet-50 [51] network. consists of three fully-connected layers, and the neuron number is set to [128, 64, 12]. consists of two fully-connected layers, and the neuron number is set to [1024, 10].
In the CIFAR-10 experiments, The weak annotator is chosen as VGG-19 [51]. It is trained with randomly selected 10,000 data samples from the dataset for 7 epochs. is made from the VGG-19 [51] network. consists of three fully-connected layers, and the neuron number is set to [128, 64, 10]. consists of two fully-connected layers, and the neuron number is set to [64, 10].
Appendix F Training Settings
Generally, the scaling factor in our algorithm is set to . The learning rate is selected from [1e-1, 1e-2, 1e-3, 1e-4, 1e-5], for the value with the best performance in experiments. The training epochs are empirically set as multiples of 10 and are selected for each experiment. We pre-run each experiment to determine the epoch value and stop training when the performance does not increase in the next 20 epochs to prevent over-fitting.
In the digit experiments, the training epochs in each training step is chosen as: , , , . The learning rate for experiment M S is set to and for other experiments set to . Training batch size is set to . For the baseline , it is trained for epochs, and the learning rate is ( for M S). For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is ( for M S). For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is ( for M S). Moreover, image augmentation techniques (provided by Torchvision.Transform) are applied for baselines , , , and our approach. Other baselines use their original augmentation setting. We use the function in the Pytorch vision package for the implementation, and the images may be rotated from to degree, or changed to gray-scale with a probability of 0.1.
In the VisDA-C experiments, the training epochs in each training step is chosen as: , , , . The learning rate for experiment is set to . Training batch size is set to . For the baseline , it is trained for epochs, and learning rate is . For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is . For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is . The image augmentation techniques are also applied for baselines , , , and our approach. Other baselines use their original augmentation setting. We similarly use the function in the Pytorch vision package for the implementation, and the images may be rotated from to degree, or changed to gray-scale with a probability of 0.1, or horizontally flipped with a probability of 0.5.
In the CIFAR-10 experiments, the training epochs in each training step is chosen as: , , , . The learning rate is set to . Training batch size is set to . For the baseline , it is trained for epochs, and the learning rate is . For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is . For , it is trained on the source data with weak labels for epochs and on the target data for epochs, and the learning rate is . The image augmentation techniques are still applied to baselines , , , and our approach. We use the function in the Pytorch vision package for the implementation, and the images are horizontally flipped with a probability of 0.5.
Appendix G Additional Experiments Details
We provide more details about the accuracy of different methods on VisDA-C dataset, which is shown in Table 6 and Table 4. In Table 6, we utilize a weak annotator that has better performance than the model trained with target data along . And in Table 4, we employ a weak annotator that has worse performance than . Both of them show that our method can provide a better performance boost compared to all baselines above.
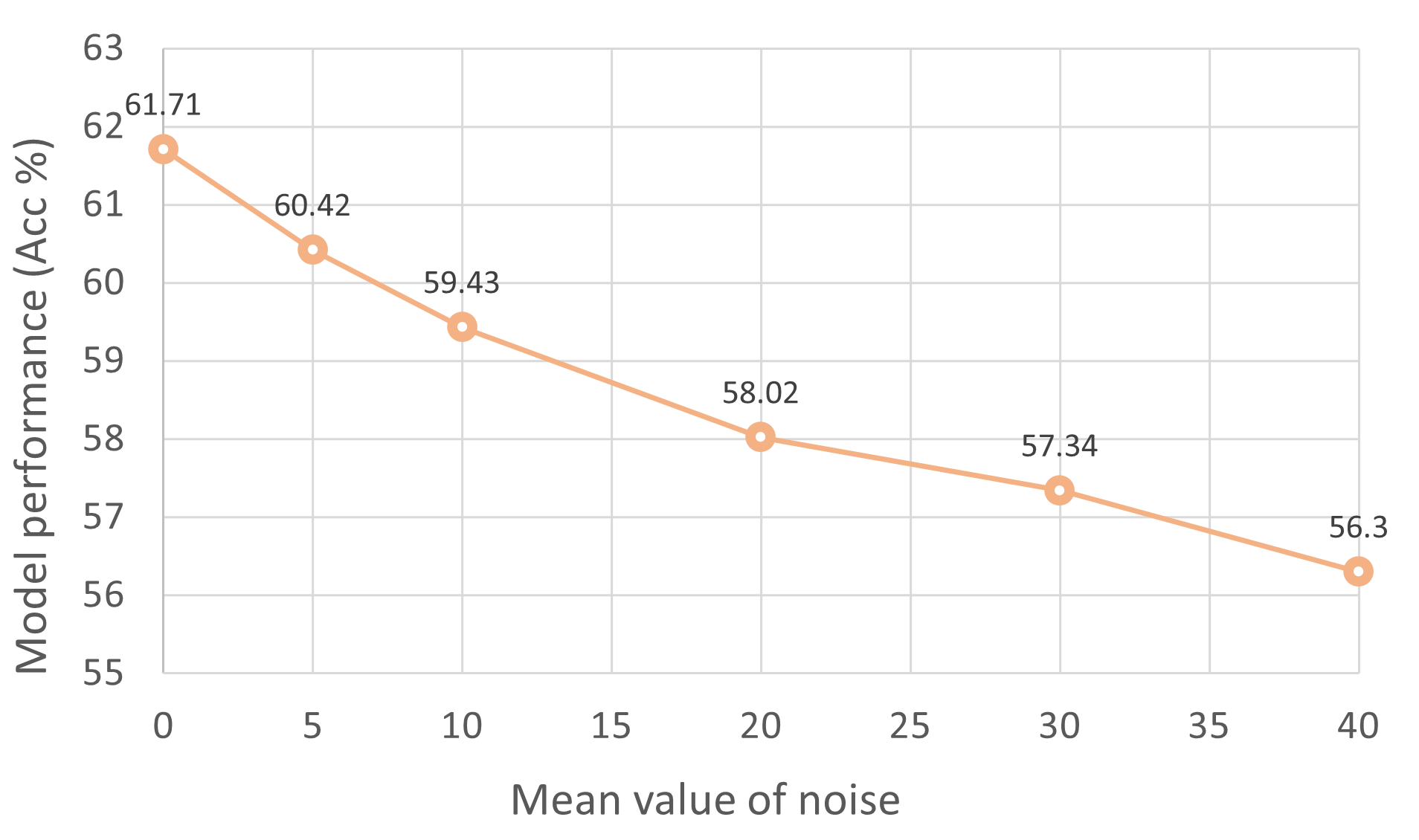
Appendix H The impact of domain discrepancy
We also evaluate how the domain discrepancy will affect the model performance, and we conduct experiments on domain data with various levels of domain discrepancy. To be specific, we utilize gaussian noise (=5.0) with different level of mean value, and add it to the source data to create various data domains as the source domain. And the final model performance is shown in Figure 5.