What Remains of Visual Semantic Embeddings
Abstract
Zero shot learning (ZSL) has seen a surge in interest over the decade for its tight links with the mechanism making young children recognize novel objects. Although different paradigms of visual semantic embedding models are designed to align visual features and distributed word representations, it is unclear to what extent current ZSL models encode semantic information from distributed word representations. In this work, we introduce the split of tieredImageNet to the ZSL task, in order to avoid the structural flaws in the standard ImageNet benchmark. We build a unified framework for ZSL with contrastive learning as pre-training, which guarantees no semantic information leakage and encourages linearly separable visual features. Our work makes it fair for evaluating visual semantic embedding models on a ZSL setting in which semantic inference is decisive. With this framework, we show that current ZSL models struggle with encoding semantic relationships from word analogy and word hierarchy. Our analyses provide motivation for exploring the role of context language representations in ZSL tasks.
1 Introduction
Zero-Shot Learning (ZSL), which aims to recognize unseen classes, is considered one of the most difficult generalization tasks. ZSL is also an important task for demonstrating how a machine learning model understands high-level semantic information and transfers knowledge from seen to unseen classes.
After a decade of research, ZSL models have been shown to have made huge progress on some small and medium sized datasets annotated with handmade attributes [38, 31, 9]. The key to transferring semantic knowledge from seen to unseen classes is often achieved by building a visual semantic embedding model, which aims to build a bridge to fill the gap between visual information and semantic information [20, 32, 7]. This approach is based on the hypothesis that similar structural relationships emerge from independent visual and linguistic representations [29, 14].
ZSL methods fail dramatically when they are tested on the ImageNet dataset [5]. To address this problem, recent works propose to introduce different mechanisms to represent robust semantic hierarchy [37, 16, 22]. However, there is still an open question: do current ZSL models perform useful semantic inference on the ImageNet dataset? Exploring the role of distributed semantics and visual semantic alignment models in the ZSL task is still lacking. For example, if we have two images: one of a working dog and one of a hunting dog, it is not clear whether the semantic difference and the semantic hierarchy between “working” and “hunting” will help us distinguish these two images.
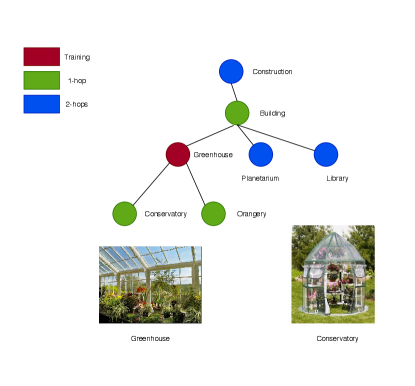
As Hascoet et al. [11] highlight, the standard ImageNet benchmark proposed by Frome et al. [7] has structural flaws due to its data splitting: although the full set of classes is split into disjoint training and test sets, the test classes are hypernyms or hyponyms of the training classes within the Wordnet [25] hierarchy. When an image of a “greenhouse” is classified as a “building” or “conservatory” (see Figure 1), in the traditional ZSL setting, we consider it is a case of classification error, whilst in terms of the semantic definition of a “greenhouse”, it doesn’t seem to be an error. On the other hand, in the standard benchmark, test classes, which are out of the 1000 classes of the ILSVRC 2012 1K [30], are imbalanced. Some categories have the high sample populations, while some categories only have low samples. Therefore, the standard benchmark is not fair enough to demonstrate to what extent visual semantic embedding models are affecting semantic understanding in the ZSL task. To address this problem, we propose using the split of tieredImageNet [28], a large subset of ILSVRC 2012 1K, to build a new ZSL benchmark. In the tieredImageNet dataset, classes are grouped into categories corresponding to higher-level nodes in the ImageNet hierarchy. These categories are split into two parts to ensure that there is no hyponymy and hypernymy between the training and test classes, thus ensuring that the two sets are semantically and linguistically disjoint. There will be no longer any super classes in the testing set. The tieredImageNet split makes ZSL a fair game in which models depend on visual-semantic alignment.
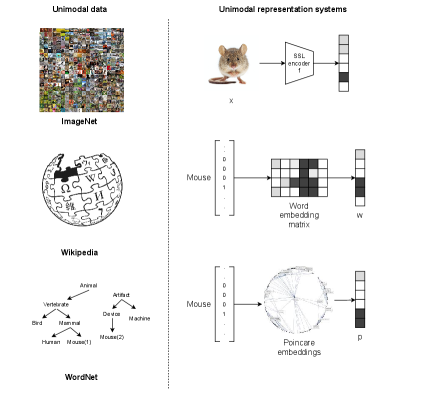
With the new tieredImageNet split, we test four main paradigms to learning a visual semantic embedding model. The first paradigm is to map pre-trained image features into a rich word embedding space, such as Word2Vec [24] or GloVe [27]. The typical work in this paradigm is done by Frome et al. [7], which helps visual object categorization systems handle very large numbers of labels. The second paradigm is to utilize an Autoencoder (AE) or a Variational Autoencoder (VAE) to explore a latent semantic space of image features, in to which word vectors are jointly mapped. Semantic AE [33], Cross and Distribution Aligned VAE [31] and SCAN [13] belong to this paradigm. The third paradigm uses explicit knowledge graphs which encode relationships between object classes. Like [37], the weights and biases of the final linear layer of the pre-trained image classifier are the new learning objectives. The output node embeddings from a graph convolutional neural network (GCN) are used to predict the visual classifier for each category, when corresponding word vectors are inputted. The forth paradigm considers the visual semantic embedding as a hyperbolic space and maps visual features and word vectors to a Poincaré disk. This kind of ZSL methods, proposed by Liu et al. [22], follows the empirical rule that a hyperbolic latent space can yield more interpretable representations if the data has hierarchical structure [2, 23]. Compared with the first paradigm, the fourth employs an exponential map instead of a nonlinear map in the Euclidean latent space.
To avoid supervised pre-training of a state-of-the-art deep neural network for visual object recognition to create the visual feature extractor, we introduce Self-Supervised Learning (SSL) [15] into the framework of ZSL. SSL allows us to obtain general visual features without any explicit semantic information being introduced. We have many concerns with the pre-trained classifier towards our goal of understanding the role of visual semantic embeddings that contribute to recognize novel objects. There are no guarantees that classifier trained using supervised methods on the seen classes will be able to generate separable image features for novel categories without any knowledge transfer like Deep Transfer Clustering [8]. However, a SSL encoder can provide separable image features without utilising any label information. Therefore, we believe that introducing SSL into the framework of ZSL can help us understand how distributed semantics are aligned and how they affect ZSL models recognize novel classes.
Finally, within our proposed zero-shot setting, we come to the conclusion that current ZSL models struggle with semantic inference on the WordNet hierarchy. When the unseen classes are not the hypernyms and hyponyms of seen classes, ZSL models with different semantic alignment mechanisms do not show the ability to use word analogy and word hierarchy implicitly, even though the image features of novel classes are near linearly separable. We show that graph-based visual semantic embedding models perform worse than the vanilla one which just learns a nonlinear map.
Therefore, we believe future ZSL frameworks should explore the role of contextual word representations on large vision-and-language tasks.
Our main contributions are to:
-
•
Introduce the tieredImagenet split into ZSL to replace the standard one, which avoid major structural flaws in ZSL benchmarking;
-
•
Build a unified framework for ZSL with SSL pre-training, thus preventing any semantic information leakage. This makes the visual semantic embedding models be the only decisive factor in the ZSL framework;
-
•
Demonstrate that current ZSL methods can not generalize from complicated semantic relationships. Encoded information from word analogy and word hierarchy is not enough for the ZSL task.
2 Preliminaries
2.1 Problem Definition
Let be a set of training examples consisting of seen images from and seen class labels from . Let be a set of testing examples. represents the unseen set of class labels, which is disjoint from . The task of ZSL is to learn a classifier, , where is the union set of and and is the union set of and .
2.2 Word Embeddings
The idea of word embedding methods is derived from the distributional hypothesis in linguistics: words that are used and occur in the same contexts tend to purport similar meanings [10]. Word representations learned in an unsupervised manner from the contextual relationship of words, or the co-occurrence statistics of words, in large text corpora are the main source of high-level semantic knowledge in most ZSL approaches. In ZSL these word embedding models provide a mapping, , from class labels to high dimensional word vectors. We denote the word vector corresponding to a label as . Cosine similarity is usually used to predict word similarity. For a pair of word representations and , we have:
2.3 Contrastive Learning
Previous ZSL models begin with training a classifier on the training set. This step leaks specific semantic information into the feature extractor component of a ZSL system. However, this step can not guarantee that we can obtain linear separable novel image features, therefore, it is very difficult to figure out whether the feature extractor or the downstream visual semantic embedding model affect the generalization performance. Contrastive learning (CL) provides a framework to learn representations of identity by pushing apart two views of different objects and bringing together two views of same objects in a representation space [4]. Recent works show that CL can generate linear separable image features without any supervised label information [26, 35, 12, 3]. Given an anchor variables from the first view , CL aims to score the correct positive variable from the second view higher compared to a set of negatives . A popular approach is to utilise the InfoNCE loss [26]:
The function represents a critic head and the function is a shared encoder, which extracts view-invariant visual representations This way of feature learning is natural and powerful. This allows the step of building the visual semantic embedding model to be the only stage to align visual information and distributed linguistic representations. When we freeze the visual encoder, we can evaluate what mechanism performs better on semantic understanding.
2.4 Graph Convolutional Networks
Graph convolutional networks (GCNs) [19] allow local graph operators to share the statistical strength between word vectors of classes, which is considered as a tool to utilize semantic information hidden in the WordNet hierarchy.
Given a graph with classes and a word embedding per class, is the word embedding matrix. We define a symmetric adjacency matrix and a degree matrix to represent the connections between the classes in the WordNet. The propagation rule to perform convolutions on the graph is defined as:
Here is the input at each layer of the GCN and is the output. is the activation function and is the learnable parameter matrix at the layer . We define a two layer GCN as .
2.5 Poincaré Embedding
The Poincaré embedding model is another natural technique to capture hierarchical information in the WordNet hierarchy. As it is not pre-trained on a large text corpus, each node in the Poincaré embedding model does not contain any word co-occurrence statistics. Poincaré embeddings preserve the distances between the nodes on the graph approximately, which can be used to compute semantic similarities. Given two Poincaré embeddings and , we have the distance:
Two kinds of transformation are useful in a hyperbolic space. The mapping to project a vector in Euclidean space to hyperbolic space is defined as:
The Mobius multiplication is defined as:
3 A Unified Framework of ZSL
In this section, we provide our unified framework for the ZSL task. This new pipeline consists of two steps.
Pre-training.
In this step, three unsupervised embedding systems are derived from the ILSVRC 2012 1K, the Wikipedia2014 & Gigaword5 text corpus and the relation graph built from the WordNet. The goal of build three embedding spaces is to capture transferable visual, linguistic and structural information from different modalities, which generalizes to an information alignment system.
After pre-training, image embeddings extracted by the CL encoder , word embeddings and Poincaré embeddings are powerful features for the downstream visual semantic embedding learner.
Semantic alignment.
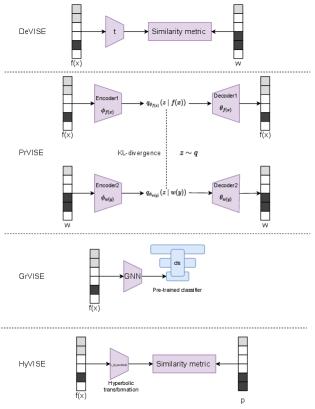
The second step is to build a visual semantic embedding model to align semantics in different modalities. In this stage, is used to train a semantic alignment learner. This step can find structural or semantic correspondence between two embedding systems. It is the key technique to transfer semantic knowledge from word representations to a visual model. In out framework, four independent paradigms (DeVISE, PrVISE, GrVISE and HyVISE) are defined below. Each of them use different properties of word embedding systems. Note that the HyVISE which maps image and word representations to a Riemannian space has achieved the state-of-the-art performance in the standard ImageNet benchmark with traditional zero-shot setting.
-
•
DeVISE DeVISE is proposed by Frome et al. [7] as the abbreviation of a deep visual semantic embedding model. In this work, we redefine it as a discriminative visual semantic model for its behaviour of mapping visual features to the word embedding space by a combination of dot-product similarity and hinge rank loss. For a data instance in , we have the loss:
(1) where is a trainable transformation neural network. This loss aims to make image features close to their word embeddings and remains distances with word embeddings for incorrect labels. DeVISE is the natural way to project the information in the visual domain to the distributed word space.
-
•
PrVISE Probabilistic visual semantic embedding (PrVISE) is a model derived from a Variational Autoencoder [18] framework, a generative model with a prior distribution . The VAE model makes it possible to approximate a latent data distribution from a reconstruction task. As its extension, PrVISE provides an adaptive latent prior distribution, which can be learnt by a neural network from the pre-trained word embedding space. By minimizing the KL divergence between the image latent distribution and the adaptive prior distribution, we define the loss of PrVISE as:
(2) where and are decoders for word and image feature reconstruction. PrVISE aims to find a joint embedding space for visual and linguistic information.
-
•
GrVISE GrVISE represents the visual semantic embedding model with Graph neural networks (like SGCN, DGP in [37, 16]). It addresses the problem that how to encode additional information in graph edges with a graph with weighted nodes. In the standard ZSL setting, it seems that capturing relational information from pre-trained word embeddings will augment semantics. In our case, GrVISE firstly trains a linear probe on . A shallow GCN is expected to distill discriminative visual semantic embeddings from the word embedding inputs. By minimizing the l2 loss between the GCN output and the linear probe parameter :
(3) we hope the GCN is able to predict the parameters of a new linear probe for unseen classes.
-
•
HyVISE HyVISE is a Riemannian version of DeVISE. Instead of mapping image features to a Euclidean space, HyVISE firstly projects image representations to a hyperbolic space with a map , then models a Mobius transformer to make image representations close to their corresponding Poincaré embeddings. The loss is defined as:
(4)
Unlike previous works, we do not fine-tune the image encoder during the semantic alignment stage. We consider this is essential to detect the effectiveness of each visual semantic embedding mechanism.
Closely related to our work is done by Sylvain et al. [34], who propose a two-step framework CM-DIM with self-supervised encoders. However, CM-DIM focused on the local and compositional behaviours of different pre-training representations for the conventional zero-shot learning benchmarks. Our intention is merely to explore how the role of distributed word representations are influenced in the different forms of zero-shot learning models, which we think is the key to make zero-shot learning more applicable in real-world applications. In this work, capturing image representations by a self-supervised method is not a prioritized problem, recent works [26, 35, 12, 3] have demonstrated that contrastive learning can learn good image representations.
In the next section, we will use this unified ZSL framework and evaluate how a ZSL model works under a tough data split which needs high-level semantic information inference.
4 Evaluation
In this section, we firstly introduce the data split and evaluation tools and metrics. Then we try to answer the following questions with comparative experiments.
-
•
Does a visual semantic embedding model have the benefit to use information in the word embedding space?
-
•
Do graph-based models learn the hierarchical distributed semantics?
4.1 tieredImageNet
The standard data split in the ImageNet has its own structural flaws. Test classes are the hypernym and hyponym of training classes. On the other hand, testing images contain many inconsistencies, it is hard to ensure images with high quality are tested. While tieredImageNet is a large subset of ILSVRC 2012 1k, in which classes are nodes of a tree of height 13 covering 608 classes. To build a ZSL benchmark, we combine the training classes and validation classes of tieredImageNet as the seen set, and we keep its own testing classes. In our ZSL setting, 448 classes are in the seen set, and 160 classes are in the testing set. Images in the training set of ILSVRC 2012 1k with the seen labels are used to train a visual semantic embedding model. Images in the validation set of ILSVRC 2012 1k with the seen labels are used to evaluate embedding performance. Images in the validation set of ILSVRC 2012 1k with the unseen labels are used to evaluate ZSL performance.
4.2 Model Details
For pre-trained image encoder, we use a ResNet-50 trained for 800 epochs on the ILSVRC 2012 1k with InfoMin CL Algorithm [36] 111https://github.com/HobbitLong/PyContrast. With a linear probe, this image encoder shows classification accuracy on the ILSVRC 2012 1k task. We choose 300 dimensional GloVe222https://nlp.stanford.edu/projects/GloVe/ with 6B tokens as the pre-trained word vectors. For each class label, we average all the GloVe vectors of its synonyms. We train a Poincaré embedding model with gensim 333https://radimrehurek.com/gensim/ from the tree of tieredImageNet classes. We choose a 100 dimensional hyperbolic space for this model.
The transformer in DeVISE is a two-layer multilayer perceptron (MLP) with 512 hidden neurons. The feature encoder and decoder in PrVISE are both two-layer MLPs with 512 hidden neurons. The adaptive prior distribution in PrVISE is 300 dimensional, learnt by a two-layer MLP. In GrVISE, a two-layer GCN is used to predict weights of the visual classifier. And in HrVISE, a two-layer MLP is modified to implement Mobius multiplication twice.
All the visual semantic embedding models are trained with encoder freezing. The Adam optimizer [17] with learning rate 1e-4 is used in all the models to optimize the loss function. All the models are trained for 200 epochs and mini-batches of size 256.
| Models | embedding hit@1 | embedding hit@5 | avg.sim@1 | avg.sim@5 | avg.sim.dis@1 | avg.sim.dis@5 |
|---|---|---|---|---|---|---|
| LP | 75.18% | 93.26% | 0.8505 | 0.5067 | 21.80 | 69.13 |
| DeVISE | 71.96% | 92.34% | 0.8330 | 0.5089 | 23.72 | 69.84 |
| PrVISE | 54.01% | 74.24% | 0.7353 | 0.5087 | 29.25 | 52.51 |
4.3 Metrics
We consider different kinds of measures to answer the questions provided at the beginning of this section.
To demonstrate the performance of visual semantic embeddings, we compute the embedding hit@k metrics – the percentage of test images in the seen set for which the model returns the one true seen label in its top k predictions. For the ZSL task, we consider the generalized ZSL. Therefore, we compute the ZSL-S hit@k ZSL-U hit@k metrics. Here S represents test images in the seen set, while U represents test images in the unseen set.
Inspired by the average hierarchical distance of a mistake [1], which rethinks whether we should treat all classes other than the “true” label as equally wrong, we also employ the average similarity of a mistake (avg.sim@k) and the average similarity distance of a mistake (avg.sim.dis@k) as metrics to demonstrate whether a visual semantic embedding model remains the properties of a word embedding space. To compute these two metrics, we firstly compute the cosine similarity matrix of the GloVe vectors. Then we sort these similarities and get the distance of each pair of labels. For the data instances which the model does not return the true labels, we average the similarities and distances between the predicted labels and the true labels in their top predictions. In the ZSL part, we also employ ZSL-S avg.sim@k, ZSL-U avg.sim@k, ZSL-S avg.sim.dis@k and ZSL-U avg.sim.dis@k. The difference is we build the similarity matrices with the union set of training labels and testing labels.
We think the new metrics can help us figure out the effectiveness of semantic alignment in the ZSL task, as Roads and Love [29] employed the Spearman correlation between the upper diagonal portion of two similarity matrices in two conceptual systems.
5 Experimental results
5.1 Does a visual semantic embedding model benefit from distributional semantics in a static word embedding space?
To answer this question, we should consider the paradigms purely dealing with information from word embeddings. In the following, we analyse the performance of DeVISE and PrVISE. As a comparison, we implement a linear classifier (LP) on top of the frozen representation encoded by the InfoMin encoder. Although the linear probe can not be used in the ZSL task, it still gives insights about how image representations are distributed with equally weighted labels.
The Table 1 shows results to evaluate visual semantic embedding performance. We highlight that only seen classes in the testing set is used in this part. A linear layer classifier performs better than the DeVISE and the PrVISE models on the flat hit metrics. Although there are no distributed semantics leaked to the LP, it still shows the highest semantic similarities for the wrong classified data.
DeVISE performs slightly worse than the linear classifier. There is no evidence to prove that pre-trained word embeddings help neural networks make a more reasonable decision at the semantic level, as random embeddings still work well on the classification task [7, 1].
The generative model PrVISE shows the worst performance. Unlike the success on medium datasets with human designed attributes, the VAE-based model struggles to classify images by comparing the KL-divergence between latent distributions. This indicates a big performance gap exists when the latent space can not be disentangled. However, the PrVISE model “makes better semantic mistakes”. Focusing on the difference of average similarities on the top 1 and top 5 predictions, these models do not prefer to choose candidate labels in the semantic synonyms of true labels. The PrVISE model does decrease the semantic distance of a mistake on the top 5 predictions. Although, it is still very hard to answer the question “Is visual similarity correlated to semantic similarity?” [6], it seems that the PrVISE model exchanges the embedding accuracy with the semantic accuracy. When we evaluate the performance of visual semantic embedding with extended labels, this phenomenon is more clear. DeVISE and PrVISE can deal with a flexible number of classes. When the number of label classes increases, the embedding performance drops (see Table 2), but the PrVISE model still “makes better semantic mistakes”. For unseen classes (Table 3), PrVISE performs worse than DeVISE. Notably, the performance in this work with contrastive learning pre-training reaches the same order of magnitude as the traditional setting, even though our data split is more difficult.
| Models | LP | DeVISE | PrVISE |
|---|---|---|---|
| ZSL-S hit@1 | 75.18% | 66.10% | 53.97% |
| ZSL-S hit@5 | 93.26% | 89.72% | 74.16% |
| ZSL-S avg.sim@1 | 0.8505 | 0.7857 | 0.7352 |
| ZSL-S avg.sim@5 | 0.5067 | 0.4781 | 0.5091 |
| ZSL-S avg.sim.dis@1 | 21.80 | 54.03 | 37.93 |
| ZSL-S avg.sim.dis@5 | 69.13 | 126.59 | 67.89 |
| Models | LP | DeVISE | PrVISE |
|---|---|---|---|
| ZSL-U hit@1 | N/A | 1.590% | 0.481% |
| ZSL-U hit@5 | N/A | 6.832% | 2.806% |
| ZSL-U avg.sim@1 | N/A | 0.3173 | 0.2805 |
| ZSL-U avg.sim@5 | N/A | 0.3062 | 0.2760 |
| ZSL-U avg.sim.dis@1 | N/A | 199.11 | 198.30 |
| ZSL-U avg.sim.dis@5 | N/A | 208.98 | 204.18 |
5.2 Do graph-based models learn hierarchical distributed semantics?
We test the performance of GrVISE and HyVISE to demonstrate how a semantic graph affects the way a model aligns visual semantics. We discuss GrVISE and HyVISE respectively.
GrVISE is designed to predict the parameters of a linear image classifier with the help of GCN. We set a two-layer MLP as a comparison. In previous work using a GCN based model [37], parameters in the last layer of a pre-trained classifier are considered to be naturally normalized. However, we notice that the parameters in a pre-trained linear probe on a freezing encoder are not normalized. Therefore, we normalize the parameters of the linear probe. Note that the normalized parameters still work well the original classification task.
| Models | GCN | MLP |
|---|---|---|
| embedding hit@1 | 29.67% | 36.77% |
| ZSL-S hit@1 | 29.63% | 36.70% |
| ZSL-U hit@1 | 0.832% | 0.0% |
We observe that an MLP performs better on parameter prediction. Therefore, it achieves better embedding performance for seen classes. While a GCN performs better to predict unseen labels, this demonstrates that a GCN does learn a bit of structural information from a hand-crafted semantic graph.
However, the GrVISE does not organize visual semantic information better than the DeVISE. We argue that the process of learning a parameter prediction task can gradually acquire semantic information for unseen classes. We train a linear probe on both seen and unseen classes. Then we train a GCN and an MLP respectively to predict the parameters of seen classes. Note that the probe can achieve classification accuracy on unseen classes.
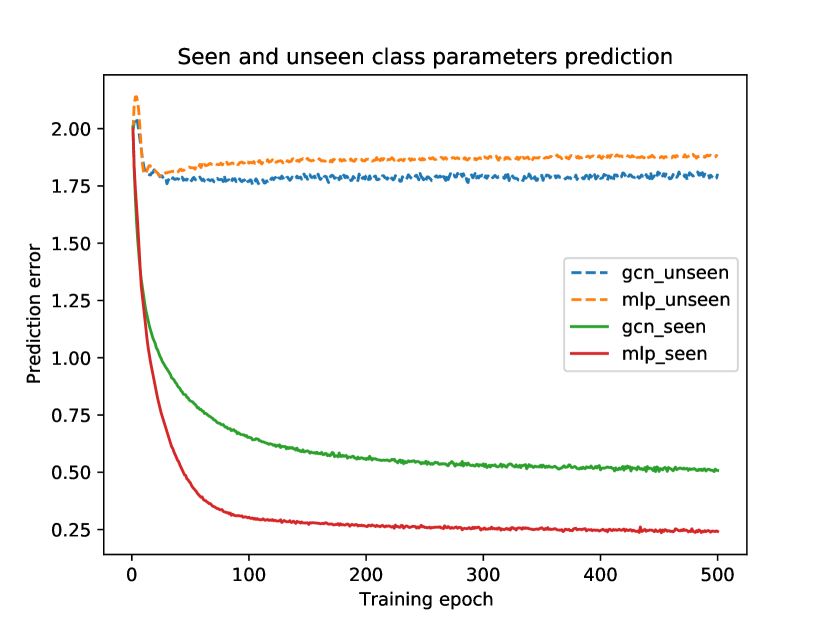
In Figure 4, we show that the GrVISE can not precisely learn unseen parameters. The dashed lines representing the prediction error for unseen class parameters are observed stopping decreasing at the early epoch. The WordNet structure does not narrow the semantic gap between seen classes and unseen classes.
Finally, we test the HyVISE, which can been seen as the DeVISE in Riemannian geometry. We get 13.91% embedding hit@1, 13.84% ZSL-S hit@1 and 0.219% ZSL-U hiy@1. The results indicate that a Poincaré visual semantic embedding model does not work well on a complicate ZSL data split, when the split is based on a sub tree of the WordNet.
In summary, we find that the DeVISE still works robustly on a new ZSL class split, which needs high-level semantic understanding. Compared with a linear classifier, DeVISE does not show that it has performed semantic inference using the distributed semantics. The generative model PrVISE performs slightly worse than the DeVISE, but it shows the advantage of predicting better mistakes, which are semantically similar to the ground truth labels. The graph-based models GrVISE and HyVISE lose their advantages shown the standard splits. The results demonstrate that recent semantic alignment techniques could overfit to the original flawed problem, and they also indicate we need a deeper discussion on the ZSL task in the real world.
6 Conclusion
In this work, we investigate the problem of zero-shot learning. We introduce the tieredImagenet split into ZSL to replace the standard data split. That makes the evaluation of ZSL does not suffer from problems such as structural flaws, bad image quality. We build a unified framework for ZSL with contrastive learning as pre-training. The two-step framework does not leak semantic information at the early stage, which makes us evaluate semantic inference fairly. With this framework, we test four mainstream methods for visual semantic alignment. We demonstrate that current ZSL methods rely deeply on similarity comparison. No evidence shows that distributed visual information and distributed semantic information can be combined to implement semantic analogy and semantic inference across modalities. Therefore, these ZSL methods can not generalize from complicated structural information.
We believe that rethinking the goals and the definition of ZSL tasks is very much needed. As Roads and Love [29] pointed out in their work, it is unclear what mechanism makes two-year-old children exhibit an average vocabulary of 200-300 words. Learning a novel object is still the most challenging task. During this decade, communities prefer to capture distributed knowledge from large image dataset and text corpus. However, this method has been shown as an unrobust approach which can only works on hyponymy and hypernymy. Context missing may be the main reason. Context information is more helpful than a distributed system. Currently, vision-language pre-training has shown that it can effectively learn generic representations for downstream tasks. In particular, Oscar [21] has shown its success on captioning images with novel objects. Context surrounding representations seem to outperform in capturing visual semantics [14]. We believe that it is necessary to build a ZSL task on contextual language models in the future to replace distributed word embedding models. The new ZSL task will offer new practical insights on the way how human learn novel objects.
References
- [1] Luca Bertinetto, Romain Mueller, Konstantinos Tertikas, Sina Samangooei, and Nicholas A Lord. Making better mistakes: Leveraging class hierarchies with deep networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12506–12515, 2020.
- [2] Benjamin Paul Chamberlain, James Clough, and Marc Peter Deisenroth. Neural embeddings of graphs in hyperbolic space. arXiv preprint arXiv:1705.10359, 2017.
- [3] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709, 2020.
- [4] Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 1, pages 539–546. IEEE, 2005.
- [5] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. ImageNet: A Large-Scale Hierarchical Image Database. In CVPR09, 2009.
- [6] Thomas Deselaers and Vittorio Ferrari. Visual and semantic similarity in imagenet. In CVPR 2011, pages 1777–1784. IEEE, 2011.
- [7] Andrea Frome, Greg S Corrado, Jon Shlens, Samy Bengio, Jeff Dean, Marc’Aurelio Ranzato, and Tomas Mikolov. Devise: A deep visual-semantic embedding model. In Advances in neural information processing systems, pages 2121–2129, 2013.
- [8] Kai Han, Andrea Vedaldi, and Andrew Zisserman. Learning to discover novel visual categories via deep transfer clustering. In International Conference on Computer Vision (ICCV), 2019.
- [9] Zongyan Han, Zhenyong Fu, and Jian Yang. Learning the redundancy-free features for generalized zero-shot object recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12865–12874, 2020.
- [10] Zellig S Harris. Distributional structure. Word, 10(2-3):146–162, 1954.
- [11] Tristan Hascoet, Yasuo Ariki, and Tetsuya Takiguchi. On zero-shot recognition of generic objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9553–9561, 2019.
- [12] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020.
- [13] Irina Higgins, Nicolas Sonnerat, Loic Matthey, Arka Pal, Christopher P Burgess, Matko Bosnjak, Murray Shanahan, Matthew Botvinick, Demis Hassabis, and Alexander Lerchner. Scan: Learning hierarchical compositional visual concepts. arXiv preprint arXiv:1707.03389, 2017.
- [14] Gabriel Ilharco, Rowan Zellers, Ali Farhadi, and Hannaneh Hajishirzi. Probing text models for common ground with visual representations. arXiv preprint arXiv:2005.00619, 2020.
- [15] Longlong Jing and Yingli Tian. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
- [16] Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, and Eric P Xing. Rethinking knowledge graph propagation for zero-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11487–11496, 2019.
- [17] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [18] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
- [19] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907, 2016.
- [20] Christoph H Lampert, Hannes Nickisch, and Stefan Harmeling. Learning to detect unseen object classes by between-class attribute transfer. In 2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 951–958. IEEE, 2009.
- [21] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, et al. Oscar: Object-semantics aligned pre-training for vision-language tasks. In European Conference on Computer Vision, pages 121–137. Springer, 2020.
- [22] Shaoteng Liu, Jingjing Chen, Liangming Pan, Chong-Wah Ngo, Tat-Seng Chua, and Yu-Gang Jiang. Hyperbolic visual embedding learning for zero-shot recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9273–9281, 2020.
- [23] Emile Mathieu, Charline Le Lan, Chris J Maddison, Ryota Tomioka, and Yee Whye Teh. Continuous hierarchical representations with poincaré variational auto-encoders. In Advances in neural information processing systems, pages 12565–12576, 2019.
- [24] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems, pages 3111–3119, 2013.
- [25] George A Miller. Wordnet: a lexical database for english. Communications of the ACM, 38(11):39–41, 1995.
- [26] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- [27] Jeffrey Pennington, Richard Socher, and Christopher D Manning. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pages 1532–1543, 2014.
- [28] Mengye Ren, Eleni Triantafillou, Sachin Ravi, Jake Snell, Kevin Swersky, Joshua B Tenenbaum, Hugo Larochelle, and Richard S Zemel. Meta-learning for semi-supervised few-shot classification. arXiv preprint arXiv:1803.00676, 2018.
- [29] Brett D Roads and Bradley C Love. Learning as the unsupervised alignment of conceptual systems. Nature Machine Intelligence, 2(1):76–82, 2020.
- [30] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- [31] Edgar Schonfeld, Sayna Ebrahimi, Samarth Sinha, Trevor Darrell, and Zeynep Akata. Generalized zero-and few-shot learning via aligned variational autoencoders. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 8247–8255, 2019.
- [32] Richard Socher, Milind Ganjoo, Christopher D Manning, and Andrew Ng. Zero-shot learning through cross-modal transfer. In Advances in neural information processing systems, pages 935–943, 2013.
- [33] Flood Sung, Yongxin Yang, Li Zhang, Tao Xiang, Philip HS Torr, and Timothy M Hospedales. Learning to compare: Relation network for few-shot learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1199–1208, 2018.
- [34] Tristan Sylvain, Linda Petrini, and Devon Hjelm. Locality and compositionality in zero-shot learning. arXiv preprint arXiv:1912.12179, 2019.
- [35] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. arXiv preprint arXiv:1906.05849, 2019.
- [36] Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning. arXiv preprint arXiv:2005.10243, 2020.
- [37] Xiaolong Wang, Yufei Ye, and Abhinav Gupta. Zero-shot recognition via semantic embeddings and knowledge graphs. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6857–6866, 2018.
- [38] Yongqin Xian, Bernt Schiele, and Zeynep Akata. Zero-shot learning-the good, the bad and the ugly. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 4582–4591, 2017.