Whole-Body Dynamic Telelocomotion: A Step-to-Step Dynamics Approach to Human Walking Reference Generation
Abstract
Teleoperated humanoid robots hold significant potential as physical avatars for humans in hazardous and inaccessible environments, with the goal of channeling human intelligence and sensorimotor skills through these robotic counterparts. Precise coordination between humans and robots is crucial for accomplishing whole-body behaviors involving locomotion and manipulation. To progress successfully, dynamic synchronization between humans and humanoid robots must be achieved. This work enhances advancements in whole-body dynamic telelocomotion, addressing challenges in robustness. By embedding the hybrid and underactuated nature of bipedal walking into a virtual human walking interface, we achieve dynamically consistent walking gait generation. Additionally, we integrate a reactive robot controller into a whole-body dynamic telelocomotion framework. Thus, allowing the realization of telelocomotion behaviors on the full-body dynamics of a bipedal robot. Real-time telelocomotion simulation experiments validate the effectiveness of our methods, demonstrating that a trained human pilot can dynamically synchronize with a simulated bipedal robot, achieving sustained locomotion, controlling walking speeds within the range of 0.0 m/s to 0.3 m/s, and enabling backward walking for distances of up to 2.0 m. This research contributes to advancing teleoperated humanoid robots and paves the way for future developments in synchronized locomotion between humans and bipedal robots.
I Introduction
The full potential of teleoperated humanoid robots has yet to be realized, particularly in their role as physical avatars for humans in hazardous or inaccessible locations [1]. Although noteworthy achievements have been made in loco-manipulation tasks, performance remains limited [2, 3]. This is because for loco-manipulation task completion precise coordination of whole-body dynamics is essential [4, 5]. As a result, in teleoperated humanoid robot research a major obstacle is the lack of synchronized locomotion between human and robot, which entails coordinated movements like simultaneous lifting-off and stepping-down. The disparity in locomotion dynamics between human and robot makes it challenging to fully leverage human capability. Hence, establishing a dynamic link between human and robot locomotion is crucial. In recent years, efforts have been made to realize this critical behavior [6, 7, 3]. However, this area of research remains largely unexplored, particularly within the bipedal locomotion control community.

Synchronizing the gait in real-time between a human and a bipedal robot poses considerable challenges. First, while humans and humanoid robots have a similar morphology, they have fundamental differences. This motivates the need to transfer locomotion strategies from humans to robots. One approach is to abstract human locomotion through reduced-order models [8, 9]. The second challenge is that the human and robot have walking dynamics that are destined to evolve at different spatial and temporal scales. This is primarily due to the underactuated nature of walking coupled with the difference in natural frequencies between human and robot. This motivates the use of bilateral feedback between human and robot [9, 10, 11]. In order to inform the human pilot of robot dynamics, haptic force feedback can encode information about the robot’s sense of balance, i.e., stability, in an instinctual manner to harness human sensorimotor skills. The final challenge is the development of specialized hardware. This is why human-machine interfaces that facilitate whole-body motion capture and haptic force feedback have been instrumental in advancing teleoperated humanoid robot research [12, 13, 14].
Encouraging results have been obtained from the unification of three concepts: abstraction of humanoid locomotion, scaling of human whole-body motion to robot proportions, and dynamic synchronization of human and robot via bilateral feedback. This framework, termed whole-body dynamic telelocomotion, has demonstrated synchronized balancing and stepping between a human pilot and bipedal robot in hardware [6]. In our previous work, it yielded synchronized dynamic walking of a simulated bipedal robot [15]. The extension from stepping to walking was enabled by a virtual interface linking human and bipedal robot. This interface serves as a virtual reference of human walking behavior generated from their stepping motion. Although similar methods have been proposed, [16, 17], they lacked integration into a holistic framework to enable the transfer of intelligence and sensorimotor skills from human to robot.
While the results of [15] were promising, sustained synchronized locomotion between human and robot was challenging. Consistently reaching more than 1.0 m of robot walking through teleoperation was difficult. The human pilot could generate a walking gait through a step, but struggled to generate transitions between walking gaits. Continuously adapting to robot walking dynamics proved taxing over time. On the other hand, bipedal robot walking using feedback control methods has become highly robust [18, 19]. These control methods benefit from considering the hybrid and underactuated dynamics of walking, allowing seamless transitions between walking gaits, particularly at different speeds.
In this work, the hybrid linear inverted pendulum model (H-LIPM) [20] is utilized to abstract our human walking reference and thus capture the hybrid and underactuated dynamics of walking within our whole-body dynamic telelocomotion framework. The same mapping of human stepping motion to a desired walking gait is utilized as in [15] to infer human locomotion strategy. This allows the human pilot to intuitively update the H-LIPM dynamics during telelocomotion. Additionally, a reactive robot controller is designed to reproduce scaled human motion on the robot’s full-body dynamics. The main contribution of this work lies in incorporating the step-to-step dynamics of walking into our human walking reference interface. The result is dynamically consistent human walking reference motion. Another contribution is the integration of a reactive robot controller into our telelocomotion framework. As depicted in Fig. 1, the presented methods are validated through robot full-body dynamics simulation experiments conducted with our telelocomotion framework. The results demonstrate that a human pilot can dynamically synchronize with the humanoid robot Tello to achieve sustained locomotion. This is demonstrated by the pilot’s capacity to control robot walking speeds within the range of 0.0 m/s to 0.3 m/s, and maintain robot backward walking for distances of up to 2.0 m.
II Human Walking Reference Generation
The goal of incorporating step-to-step dynamics into our human walking reference (HWR) interface is to facilitate dynamically consistent HWR motion generation by the human pilot. The proposed methodology is presented in this section and summarized in Fig. 2. First, a theoretical basis for creating an abstraction of the HWR using a reduced-order model is presented, namely the hybrid linear inverted pendulum model (H-LIPM). Next, a method from [15] of mapping a human’s stepping motion to their desired walking behavior is reviewed. Finally, we highlight the major contribution from this work and detail the HWR motion generation algorithm.
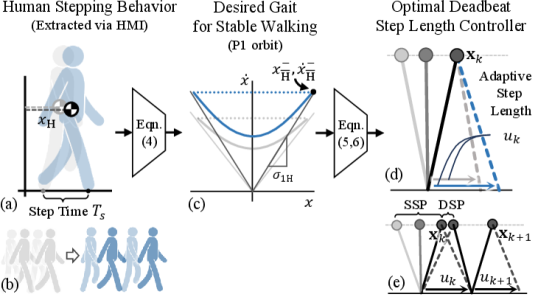
II-A H-LIP Model
The H-LIPM [21], an extension of the LIPM, is a two-domain hybrid system that encapsulates the hybrid dynamics of point-foot walking. The two domains of walking are a single support phase (SSP) and a double support phase (DSP). The domain-specific continuous dynamics of the H-LIPM are governed by
| SSP: | (1) | |||||
| DSP: |
where is the center of mass (CoM) position relative to the stance foot, is the natural frequency under the gravity field , and is the CoM height. The H-LIPM describes the discrete transitions between SSP (S) and DSP (D) through smooth hybrid system reset maps, which are defined as follows:
| (2a) | ||||||
| (2b) | ||||||
where the control input is the step length and the superscripts and denote CoM states after and before each discrete state reset, respectively. The closed-form solution of the hybrid system is derived by solving Eqs. (1) - (2). This solution defines the time evolution of the H-LIPM dynamics, as shown below:
| SSP: | (3a) | ||||
| DSP: | (3b) | ||||
where time in each phase is denoted by or . and are the duration of SSP and DSP, respectively. The constants and are constants of integration.
II-B Human Stepping Motion Mapping
A mapping of human stepping motion to desired walking motion was introduced in [15]. The two assumptions made are that 1) the desired human walking gait corresponds to a stable walking gait of the canonical LIPM and 2) the human pilot’s (h) stepping frequency and CoM position along our human-machine interface (HMI) are sufficient for the pilot to intuitively generate these HWR () gaits.
From a technical perspective, these two assumptions allow mapping the human pilot’s stepping frequency, , and CoM position, , to a stable walking gait. The walking gait chosen to represent nominal human walking is characterized as satisfying during a single step. This one-step periodic orbit, known as a P1 orbit, can be generated in real-time from and . The core idea is to map , i.e., the human CoM position along the HMI equates to some desired pre-impact (end-of-step) value of the walking reference’s divergent component of motion (DCM). The DCM, defined , is the key state tracked in our telelocomotion framework to synchronize human and robot locomotion as it captures the unstable component of motion of the pendulum dynamics [9].
It can be shown that and can completely characterize a P1 orbit given some necessary and sufficient conditions are satisfied. Full details can be found in [15]. In general, from human stepping motion, the desired pre-impact CoM states of a stable walking gait can be computed as following:
| (4) |
where is the orbital slope of the human LIPM, defined We can extend this mapping to stable walking gaits of the H-LIPM.
II-C S2S Dynamics Approach
The key idea is to abstract the HWR as a H-LIPM with a control policy that captures the desired human pilot’s walking behavior while obeying the step-to-step dynamics of walking. In our telelocomotion framework, this will enhance the robot controller’s capability to consistently track the motion of the HWR when scaled to robot proportions.
The approach in [15] forced the pilot to learn the robot’s dynamics of transitioning between different stable walking gaits. The HWR was assumed to be a LIPM whose dynamics always evolved along a P1 orbit. In order to aid the pilot, a haptic virtual spring was implemented to give them an acceleration sensation similar to that of the HWR. This allowed for successful HWR motion generation and dynamic synchronized walking between human and bipedal robot, but it was not sustainable for prolonged periods.
The non-trivial ability to traverse between these stable walking gaits can be more accurately explained by the step-to-step (S2S) dynamics of bipedal walking [20]. The S2S dynamics of walking are perfectly highlighted by the H-LIPM. As shown in Eq. (3), under the H-LIPM approximation, the dynamics of walking are purely passive throughout the continuous domains. From Eq. (2b), the control input, , is applied only discretely. This motivates viewing the dynamics of walking at the step level. The result is a discrete linear dynamical system,
| (5) |
that maps step pre-impact CoM states, , to step pre-impact CoM states, , via the step length . The state transition matrix, , and control input mapping vector, , are defined by combining Eqs. (2) - (3). Thus, stabilization of to a desired in Eq. (5) can be enforced with feedback control. The case of particular interest is when corresponds to a P1 orbit. In this case, the deadbeat controller from [20] can optimally drive in two steps:
| (6) |
In this work, Eq. (6) is the control policy of the HWR. The control objective is to achieve the desired human locomotion strategy captured by Eq. (4) on the dynamics of the HWR. The dynamics of the HWR evolve according to Eq. (3). By modeling the HWR as a H-LIPM with step-to-step dynamics given by Eq. (5), the hybrid and underactuated nature of walking is considered in the motion generation of the HWR as outlined in Algorithm 1.
III Robot Controller
The other contribution of this work is the integration of a reactive robot controller into our whole-body dynamic telelocomotion framework to facilitate dynamic synchronized locomotion between human pilot and bipedal robot. The objective is to reactively reproduce scaled human motion and implement the human pilot’s locomotion strategy. This strategy is abstracted using reduced-order models. As a result, in our telelocomotion framework, dynamic synchronization between human and robot is enforced at the reduced-order model level. The role of the robot controller is to track the resulting robot 2D LIP trajectory at the full-body dynamics level. This trajectory represents stable locomotion (center of mass dynamics) and the corresponding control input (center of pressure strategy).
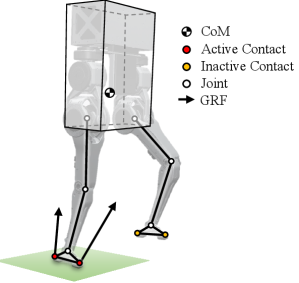
The robot controller considers the full-body dynamics of the humanoid robot Tello [22]. The controller consists of an optimization-based balance controller that computes joint torques for the legs in stance during DSP and SSP. As shown in Fig. 3, the balance controller approximates the robot full-body dynamics using the single rigid-body model (SRBM). The controller also consists of a swing-leg controller that computes joint torques for the leg in swing during SSP.
III-A Robot Model
The 15.8 kg, 16 degree-of-freedom (DoF) bipedal robot Tello has the following full-body dynamics:
| (7) |
where is the robot generalized coordinates vector, is the mass matrix, is the Coriolis matrix, is the gravity vector, is the actuated DoF selection matrix, is the contact Jacobian matrix, is the joint torque vector, and is the ground reaction wrench vector.
A popular approximation of Eq. (7) is the single rigid-body model (SRBM) [23, 24]. The SRBM is a simplified model of legged robots with low centroidal inertia isotropy (CII) [22], which neglects the inertial effects introduced by the robot’s limbs. Thus, the torso’s translational and rotational dynamics are only considered. The states of the torso (SRB) are defined as , where is the CoM position vector, the rotation matrix of the body frame relative to the world frame, and is the angular velocity vector expressed in body frame, and is the body frame. The SRBM state-space dynamics are the following:
| (8) |
where is the robot mass, is the torso inertia matrix in the body frame, is the gravity vector, and are translational and rotational components of the net wrench acting on the CoM, respectively, and is the operator that maps an element of to the 3D rotation group . The net wrench, , arises from the ground reaction forces (GRFs) generated at active contact points, i.e.,
| (9) |
where is the number of active contact points, is the identity matrix, represents the vector from the CoM to the -th active contact point, while denotes the GRF vector at that contact point. For Tello, which has line feet, we assume two contact points at the toe and heel of each foot [24].
III-B Optimization-Based Balance Controller
The balance controller computes the GRF vectors required to reactively track a desired SRBM trajectory. A PD task-space controller is implemented,
| (10) |
to compute the desired net wrench, , to track the desired task-space trajectory, and . The task-space coordinate vector, , of the SRB is defined as , where is the euler-angle representation of . Appropriate coordinate transformations are made to construct and from . and are diagonal proportional and derivative gain matrices, respectively.
Once is determined using Eq. (10), a force distribution problem is formulated as a quadratic program (QP). This QP aims to calculate the corresponding GRF vectors at the active contact points, satisfying Eq. (9). Furthermore, the GRF vectors undergo projections from task-space to both the friction cone and the motor-space, where linear inequality actuation constraints are enforced. This accounts for both the parallel actuation scheme of Tello [22] and the effects of friction. GRF vectors are also constrained to not exert a pulling force on the ground. Thus, the actuation-aware force distribution QP takes the following form:
| (11) | ||||
| s.t. | ||||
where is the collection of GRF vectors at active contact points, is the previous value of , and are scalar weighting factors, is a matrix of rotation matrices that map from the world frame to the body frame, is a matrix of contact Jacobians that map task-space forces to joint torques, is a matrix of topology Jacobians that map joint torques to motor torques, is a vector of configuration and speed-dependent motor torque limits, and are leg joint positions and velocities, respectively, and is the friction coefficient. The second term of the cost function in Eq. (11) acts as a solution filter.
Finally, joint torques for legs in stance are set using the SRBM approximation of Eq. (7). However, to maintain the task-space configuration of the robot feet, joint-space posture control is appended to the optimization-based balance controller from Eq. (11). Consequently, the final expression for the joint torques of legs in stance, , is the following:
| (12) |
where is vector of posture control joint torques. A sigmoid function is utilized to smoothly transition between stance-leg joint torques and swing-leg joint torques. The computation of from Eq. (7) is the summation of smoothed stance-leg and swing-leg joint torques.
III-C Swing-Leg Controller
During SSP, when one of the robot’s legs is in swing, corresponding joint torques cannot be computed using Eq. (11). This is because the leg is no longer in contact with the ground and as a result a GRF cannot be generated. Instead, the goal of the swing-leg controller is to map the robot’s foot position at the start of SSP to a location by the end of SSP that achieves the desired step placement.
This mapping of the robot’s foot during SSP is accomplished via smooth task-space trajectories similar to in [19]. On the transverse plane, specifically the or axis, the function,
| (13) |
maps the robot’s initial foot position, , to a final desired foot position, , along each axis. The phase variable, denoted as , represents the normalized progression of time during a step. On the other hand, -position trajectories are defined differently. The objective is to re-establish contact with the ground at time . The following function,
| (14) |
characterized by a maximum step height, , attains the intended foot z-position motion.
In this work, swing-leg joint torques, , are computed using joint-space PD control. First, utilizing inverse kinematics, Eqs. (13) - (14), along with their derivatives, are transformed into desired joint positions, , and corresponding desired joint velocities, , trajectories. Then, the joint-space trajectories are tracked using the PD control law,
| (15) |
where and are diagonal proportional and derivative gain matrices, respectively.
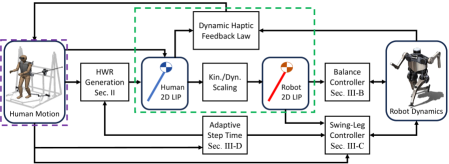
III-D Integration with Whole-Body Dynamic Telelocomotion Framework
The robot controller, composed of the optimization-based balance controller and swing-leg controller, is integrated into our whole-body dynamic telelocomotion framework (Fig. 4). Although the robot controller is capable of operating independently, it was designed to be purely reactive, with locomotion planning being entrusted to the human pilot.
The human locomotion strategy is represented by a 2D LIP trajectory. This trajectory is constructed using dynamic human motion data in the frontal plane, combined with the human walking reference generated from human stepping motion data along the sagittal plane. The trajectory is then scaled to robot proportions. The goal of the robot controller is to reproduce the resulting robot 2D LIP trajectory at the full-body (3D) dynamics level.
The reproduction of the robot’s 2D LIP trajectory is described next. The - components of the desired robot CoM wrench from Eq. (11) are given by robot forces that track the desired scaled human motion [9]. Additionally, the LIPM assumptions of constant CoM height and the omission of angular dynamics are enforced by Eq. (10). The - swing-leg trajectory from Eq. (13) is updated to keep dynamic synchronization between the human pilot and the robot at step transitions. Specifically, in the -direction, the final desired robot foot position maintains tracking of the scaled HWR at the commencement of the next step. In the -direction, the final desired robot foot position maintains equal scaled feet width between the human and robot.
The main challenge in tracking the desired robot 2D LIP trajectory is that the single support time is not known a priori. is normally fixed in bipedal walking controllers. Thus, to resolve this issue we leverage the consistency of human motion to implement a data-driven adaptive step timing strategy. In particular, we assume human swing-foot z-position motion approximately follows Eq. (14), parameterized by (normalized SSP time) and . During each step, we employ a damped least-squares method to continuously fit human swing-foot z-position data to Eq. (14). This allows the pilot to control the robot’s step height and vary the robot’s stepping frequency. This ensures the pilot and the robot will touch-down synchronously. The updated estimate of SSP duration is used to update the HWR and the - swing-leg trajectories for more robust telelocomotion.
IV Simulation Results & Discussion
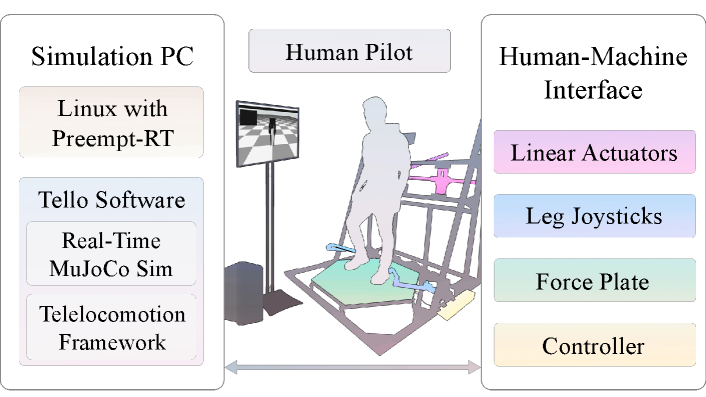
To validate our approach to human walking generation and assess the performance of our robot controller in executing the human’s locomotion strategy, we designed simulation telelocomotion experiments. As shown in Fig. 5, during these experiments, our whole-body dynamic telelocomotion framework is implemented in a hardware-simulation set-up. As depicted in Fig. 1, the hardware, our human-machine-interface (HMI), is used by a human pilot to control the dynamics of the bipedal robot Tello in a simulation environment with the MuJoCo physics engine [25].
The first experiment involves velocity tracking, where the human pilot tracks a moving target at increasing speeds (0.1 m/s, 0.2 m/s, and 0.3 m/s) for a total of 6.0 m of synchronized robot walking. A square target is displayed on the ground, and the objective is to generate a walking reference that transitions smoothly between stable walking gaits at different speeds and stepping frequencies. This experiment assesses both the human pilot’s ability to generate a walking reference using Algorithm 1 and the robot controller’s capability to execute the desired human locomotion strategy. The second experiment focuses on synchronized backward walking between the human and robot. It demonstrates similar capabilities as the first experiment but highlights an important telelocomotion behavior for effective navigation in an environment.
In this section, we outline the experimental setup employed in our telelocomotion experiments. The focus is on describing the connection between our HMI and a simulation PC, enabling real-time telelocomotion of a simulated bipedal robot. Subsequently, we showcase the successful completion of experiments 1 & 2 by a trained human pilot, and proceed to analyze the results in the context of the presented methods. Finally, we discuss some limitations of our approach.
IV-A Experimental Setup
During telelocomotion simulation experiments, a trained human pilot utilizes our HMI to dynamically teleoperate the simulated bipedal robot Tello, whose dynamics and corresponding controller are running in the simulation PC in real-time. Communication between the HMI and the simulation PC is established via UDP. As shown in Fig. 5, the human pilot receives visual feedback through a computer monitor, which displays the rendered simulation. This is critical in both experiments as visual feedback is required for velocity target tracking and walking backwards a specific distance.
As illustrated in Fig. 5, our HMI consists of linear actuators, lower-body leg joysticks, a force plate, and a real-time embedded controller. The linear actuators perform dual functions of measuring the human CoM while simultaneously applying haptic forces to the human’s torso. The lower-body leg joysticks capture and measure spatial information pertaining to the locations of the human feet. The force plate measures the net contact wrench applied by the human. The actuators are controlled and the motion capture data is collected by a cRIO-9082 (National Instruments) computer.
The simulation of the full-body dynamics of the bipedal robot Tello, described by Eq. (7), is executed using the physics engine MuJoCo. The simulation is seamlessly integrated into a unified program alongside the Tello control software. This software is parallelized across nine distinct CPUs, with all threads running at a frequency of 1 kHz.
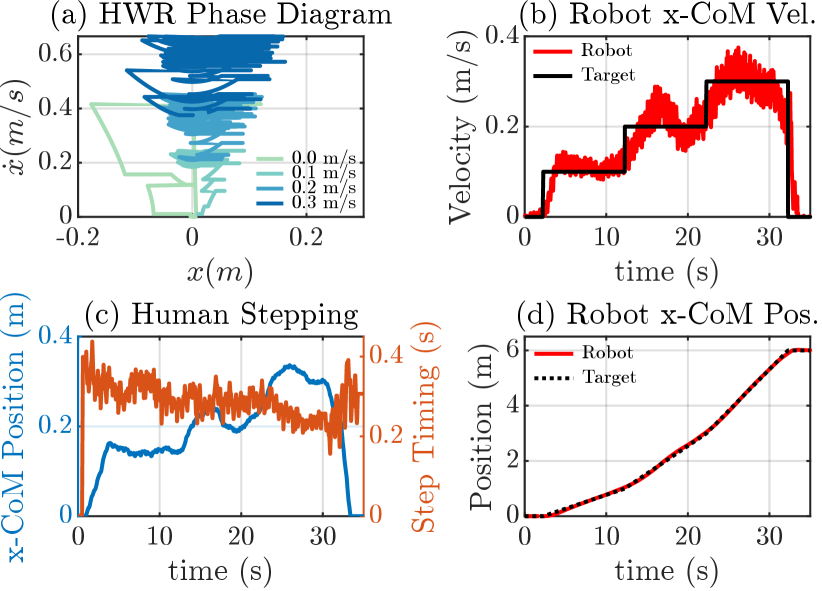
IV-B Results & Discussion
Using our framework, depicted in Fig. 4, along with visual feedback, a trained human pilot successfully completed both experiments. These experiments serve as a compelling demonstration, showcasing the synchronized locomotion between a human and a bipedal robot in tasks involving velocity target tracking and backward walking. The completion of these tasks show the effectiveness of our HWR motion generation method and our reactive robot controller.
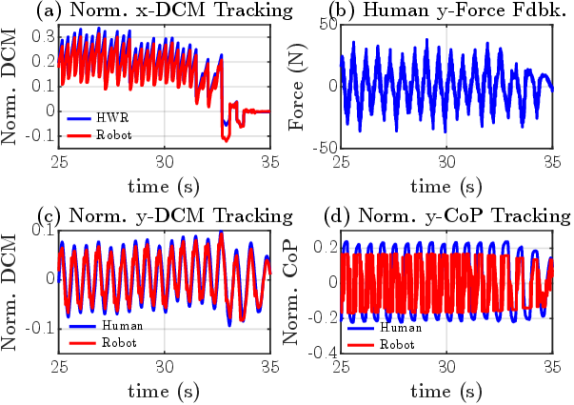
The results of the velocity target experiment are shown in Figs. 6 - 7. Here, the human pilot controls the robot’s locomotion to ensure tracking of the target, as illustrated in Fig. 6(b). Notably, the pilot achieves 6.0 m of synchronized locomotion with the robot, as seen in Fig. 6(d), affirming the viability of sustained telelocomotion using our methods. Importantly, the pilot regulates the robot’s CoM velocity around the target velocity. The key lies in intuitively capturing the human pilot’s locomotion strategy from their stepping motion (Fig. 6(c)). Subsequently, the stepping motion is mapped to a desired walking gait, which serves as the basis for the HWR motion in Fig. 6(a). Indeed, as seen in Fig. 6(a), the abstraction of the HWR as a H-LIPM enables generating dynamically consistent walking references, allowing for smooth transitions between desired walking gaits by considering the step-to-step dynamics of walking. Lastly, the ability of the robot controller to reactively reproduce the desired robot 2D LIP trajectory is highlighted by the normalized DCM tracking performance along the sagittal plane (Fig. 7(a)) and along the frontal plane (Fig. 7(b)). As seen in Fig. 7(c), this leads to consistent and bounded haptic force feedback to the human pilot along the frontal plane. This feedback assists the human pilot in maintaining stepping synchronization with the robot. As discussed in our previous work [15, 9], this is evident from the normalized center of pressure (CoP) synchronization between the two systems, as shown in Fig. 7(d).
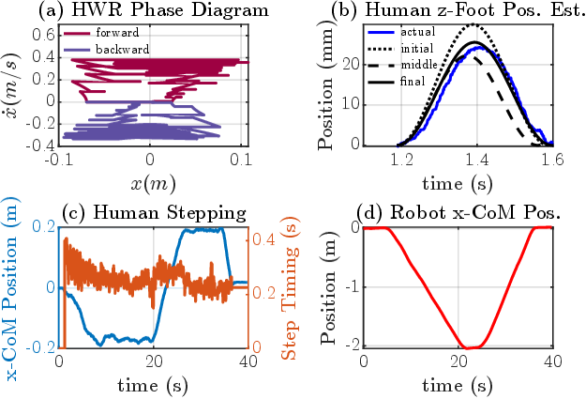
The results of the backward walking experiment are shown in Fig. 8. The human pilot dynamically synchronizes their backward stepping with bipedal robot backward walking, covering a distance of 2.0 m (Fig. 8(d)), before proceeding to walk forward to the initial position. Like in the first experiment, the human pilot’s stepping motion is utilized to generate a HWR motion trajectory, as seen in Fig. 8(a) and Fig. 8(c). However, by walking backwards, the pilot commands desired walking gaits characterized by negative orbital energy, as shown in Fig. 8(c). Additionally, to demonstrate the efficacy of our adaptive step time prediction approach, we analyze the first step from the human stepping data. As shown in Fig. 8(b), we continuously monitor the human z-foot position data and fit it to the presumed swing-leg z-trajectory curve. Thus, allowing us to predict both the duration () and the height of the step (). The prediction accuracy improves with the accumulation of more data, closely approximating the actual human z-foot position throughout the entire step, particularly towards the end. This accurate prediction ensures the dynamic synchronization between the human and bipedal robot at impact events and gives the human the capability to regulate the frequency of the synchronized stepping between the two bipedal systems.
The obtained results show promise in achieving robust telelocomotion of humanoid robots, enhancing their potential as physical avatars. These results also represent tangible progress from the work in [15], specifically in successfully realizing sustainable synchronization between human and bipedal robot locomotion in a full-body dynamics simulation. Previously, in a reduced-order dynamics simulation, only 1.28 m of forward walking (0.36 m/s max speed) was achieved. However, it is important to acknowledge the limitations inherent to this work. First, the walking speed of the robot is currently still limited to approximately 0.35 m/s, which, when considering a robot like Tello, corresponds to a human walking speed of 0.5 m/s. While it is possible for the robot to reach faster walking speeds, it becomes challenging for the pilot to sustain telelocomotion at these speeds. The most common failure is the robot lagging behind the HWR due to prolonged periods of DSP by the human that increases the error in normalized DCM between the two systems at the commencement of the next step. Second, it is essential to emphasize that significant training is required for a pilot to reach the demonstrated level of performance. For instance, in the velocity target tracking experiment, the pilot faced difficulties in abruptly stopping the robot from a walking speed of 0.3 m/s. Similarly, transitioning from backward walking to forward walking in the second experiment proved equally challenging. Lastly, it is worth noting that the telelocomotion behaviors enabled by our framework are presently constrained due to the utilization of linear pendulum models to abstract the locomotion of both the human and bipedal robot. To attain a broader spectrum of behaviors, including loco-manipulation tasks, it will be necessary to employ more dynamically rich reduced-order models that can fully exploit the human’s whole-body dynamics strategy.
V Conclusion
This paper presents an approach that enhances dynamically consistent walking trajectories within a comprehensive whole-body dynamic telelocomotion framework. By integrating the hybrid and underactuated characteristics of walking, we effectively capture the locomotion strategy of a human pilot through their stepping behavior. A reactive robot controller enables telelocomotion of the full-body dynamics of a bipedal robot. Real-time telelocomotion simulation experiments demonstrate the synchronization between a trained human pilot and a bipedal robot, including tracking a moving target and synchronized backward walking.
Future work will focus on implementing these methods on the real humanoid robot Tello, enabling dynamic control for navigating 3D environments. We will develop a human motion mapping for robot turning and address performance limitations related to walking speed. Additionally, we aim to incorporate human predictive intent into our human walking interface, leveraging human intelligence to a greater extent.
References
- [1] Kourosh Darvish, Luigi Penco, Joao Ramos, Rafael Cisneros, Jerry Pratt, Eiichi Yoshida, Serena Ivaldi, and Daniele Pucci. Teleoperation of humanoid robots: A survey. IEEE Transactions on Robotics, 2023.
- [2] Luigi Penco, Nicola Scianca, Valerio Modugno, Leonardo Lanari, Giuseppe Oriolo, and Serena Ivaldi. A multimode teleoperation framework for humanoid loco-manipulation: An application for the icub robot. IEEE Robotics & Automation Magazine, 26(4):73–82, 2019.
- [3] Yasuhiro Ishiguro, Kunio Kojima, Fumihito Sugai, Shunichi Nozawa, Yohei Kakiuchi, Kei Okada, and Masayuki Inaba. High speed whole body dynamic motion experiment with real time master-slave humanoid robot system. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 5835–5841, 2018.
- [4] Junheng Li and Quan Nguyen. Kinodynamics-based pose optimization for humanoid loco-manipulation. arXiv preprint arXiv:2303.04985, 2023.
- [5] Alphonsus Adu-Bredu, Grant Gibson, and Jessy W Grizzle. Exploring kinodynamic fabrics for reactive whole-body control of underactuated humanoid robots. arXiv preprint arXiv:2303.04279, 2023.
- [6] Joao Ramos and Sangbae Kim. Dynamic locomotion synchronization of bipedal robot and human operator via bilateral feedback teleoperation. Science Robotics, 4(35):eaav4282, 2019.
- [7] Mohamed Elobaid, Yue Hu, Giulio Romualdi, Stefano Dafarra, Jan Babic, and Daniele Pucci. Telexistence and teleoperation for walking humanoid robots. In Intelligent Systems and Applications: Proceedings of the 2019 Intelligent Systems Conference (IntelliSys) Volume 2, pages 1106–1121. Springer, 2020.
- [8] Joris Verhagen, Xiaobin Xiong, Aaron D Ames, and Ajay Seth. From human walking to bipedal robot locomotion: Reflex inspired compensation on planned and unplanned downsteps. In 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 01–08. IEEE, 2022.
- [9] Joao Ramos and Sangbae Kim. Humanoid dynamic synchronization through whole-body bilateral feedback teleoperation. IEEE Transactions on Robotics, 34(4):953–965, 2018.
- [10] Yasuhiro Ishiguro, Tasuku Makabe, Yuya Nagamatsu, Yuta Kojio, Kunio Kojima, Fumihito Sugai, Yohei Kakiuchi, Kei Okada, and Masayuki Inaba. Bilateral humanoid teleoperation system using whole-body exoskeleton cockpit tablis. IEEE Robotics and Automation Letters, 5(4):6419–6426, 2020.
- [11] Luka Peternel and Jan Babič. Learning of compliant human–robot interaction using full-body haptic interface. Advanced Robotics, 27(13):1003–1012, 2013.
- [12] Stefano Dafarra, Kourosh Darvish, Riccardo Grieco, Gianluca Milani, Ugo Pattacini, Lorenzo Rapetti, Giulio Romualdi, Mattia Salvi, Alessandro Scalzo, Ines Sorrentino, et al. icub3 avatar system. arXiv preprint arXiv:2203.06972, 2022.
- [13] Max Schwarz, Christian Lenz, Andre Rochow, Michael Schreiber, and Sven Behnke. Nimbro avatar: Interactive immersive telepresence with force-feedback telemanipulation. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5312–5319. IEEE, 2021.
- [14] Sunyu Wang and Joao Ramos. Dynamic locomotion teleoperation of a reduced model of a wheeled humanoid robot using a whole-body human-machine interface. IEEE Robotics and Automation Letters, 7(2):1872–1879, 2021.
- [15] Guillermo Colin, Youngwoo Sim, and Joao Ramos. Bipedal robot walking control using human whole-body dynamic telelocomotion. In 2023 IEEE International Conference on Robotics and Automation (ICRA), pages 12191–12197, 2023.
- [16] Yachen Zhang and Ryo Kikuuwe. Com shifter and body rotator for step-by-step teleoperation of bipedal robots. IEEE Access, 11:25786–25800, 2023.
- [17] Ata Otaran and Ildar Farkhatdinov. Walking-in-place foot interface for locomotion control and telepresence of humanoid robots. In 2020 IEEE-RAS 20th International Conference on Humanoid Robots (Humanoids), pages 453–458. IEEE, 2021.
- [18] Jessy W Grizzle, Christine Chevallereau, Ryan W Sinnet, and Aaron D Ames. Models, feedback control, and open problems of 3d bipedal robotic walking. Automatica, 50(8):1955–1988, 2014.
- [19] Yukai Gong and Jessy Grizzle. Angular momentum about the contact point for control of bipedal locomotion: Validation in a lip-based controller. arXiv preprint arXiv:2008.10763, 2020.
- [20] Xiaobin Xiong and Aaron Ames. 3-d underactuated bipedal walking via h-lip based gait synthesis and stepping stabilization. IEEE Transactions on Robotics, 38(4):2405–2425, 2022.
- [21] Xiaobin Xiong and Aaron D Ames. Orbit characterization, stabilization and composition on 3d underactuated bipedal walking via hybrid passive linear inverted pendulum model. In 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4644–4651. IEEE, 2019.
- [22] Youngwoo Sim and Joao Ramos. Tello leg: The study of design principles and metrics for dynamic humanoid robots. IEEE Robotics and Automation Letters, 7(4):9318–9325, 2022.
- [23] Jared Di Carlo, Patrick M Wensing, Benjamin Katz, Gerardo Bledt, and Sangbae Kim. Dynamic locomotion in the mit cheetah 3 through convex model-predictive control. In 2018 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 1–9. IEEE, 2018.
- [24] Junheng Li and Quan Nguyen. Force-and-moment-based model predictive control for achieving highly dynamic locomotion on bipedal robots. In 2021 60th IEEE Conference on Decision and Control (CDC), pages 1024–1030. IEEE, 2021.
- [25] Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pages 5026–5033. IEEE, 2012.