28 \acmYear2016
Why is it Difficult to Detect Sudden and Unexpected
Epidemic Outbreaks in Twitter?
Abstract
Social media services such as Twitter are a valuable source of information for decision support systems. Many studies have shown that this also holds for the medical domain, where Twitter is considered a viable tool for public health officials to sift through relevant information for the early detection, management, and control of epidemic outbreaks. This is possible due to the inherent capability of social media services to transmit information faster than traditional channels. However, the majority of current studies have limited their scope to the detection of common and seasonal health recurring events (e.g., Influenza-like Illness), partially due to the noisy nature of Twitter data, which makes outbreak detection and management very challenging. Within the European project M-Eco, we developed a Twitter-based Epidemic Intelligence (EI) system, which is designed to also handle a more general class of unexpected and aperiodic outbreaks. In particular, we faced three main research challenges in this endeavor: 1) dynamic classification to manage terminology evolution of Twitter messages, 2) alert generation to produce reliable outbreak alerts analyzing the (noisy) tweet time series, and 3) ranking and recommendation to support domain experts for better assessment of the generated alerts. In this paper, we empirically evaluate our proposed approach to these challenges using real-world outbreak datasets and a large collection of tweets. We validate our solution with domain experts, describe our experiences, and give a more realistic view on the benefits and issues of analyzing social media for public health.
keywords:
Outbreak Event Detection, Epidemic Intelligence, Dynamic Classification, Personalized Ranking, Time Series Analysis, Twitter.¡ccs2012¿ ¡concept¿ ¡concept_id¿10002951.10003260.10003261.10003271¡/concept_id¿ ¡concept_desc¿Information systems Personalization¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10002951.10003260.10003277¡/concept_id¿ ¡concept_desc¿Information systems Web mining¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10002951.10003317.10003338.10003343¡/concept_id¿ ¡concept_desc¿Information systems Learning to rank¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10002951.10003317.10003347.10003349¡/concept_id¿ ¡concept_desc¿Information systems Document filtering¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10002951.10003317.10003347.10003350¡/concept_id¿ ¡concept_desc¿Information systems Recommender systems¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10002951.10003317.10003338.10010403¡/concept_id¿ ¡concept_desc¿Information systems Novelty in information retrieval¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10003120.10003130.10003131.10011761¡/concept_id¿ ¡concept_desc¿Human-centered computing Social media¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡concept¿ ¡concept_id¿10010405.10010444.10010449¡/concept_id¿ ¡concept_desc¿Applied computing Health informatics¡/concept_desc¿ ¡concept_significance¿500¡/concept_significance¿ ¡/concept¿ ¡/ccs2012¿
[500]Applied computing Health informatics \ccsdesc[500]Information systems Web mining \ccsdesc[500]Human-centered computing Social media \ccsdesc[500]Information systems Document filtering \ccsdesc[500]Information systems Novelty in information retrieval \ccsdesc[500]Information systems Recommender systems
Avaré Stewart, Sara Romano, Nattiya Kanhabua, Sergio Di Martino, Wolf Siberski, Antonino Mazzeo, Wolfgang Nejdl, and Ernesto Diaz-Aviles. 2016. Why is it Difficult to Detect Sudden and Unexpected Epidemic Outbreaks in Twitter?
Author’s addresses: A. Stewart, N. Kanhabua, W. Siberski, W. Nejdl, and E. Diaz-Aviles.L3S Research Center, Leibniz University of Hannover, Germany, email: {stewart, kanhabua, siberski, nejdl, diaz}@L3S.de; S. Romano, S. Di Martino, and A. Mazzeo, DIETI, University of Naples Federico II, Italy, email:{sara.romano, sergio.dimartino, mazzeo}@unina.it. \setcopyrightrightsretained
1 Introduction
Public health officials face new challenges for outbreak alert and response due to the continuous emergence of infectious diseases and their contributing factors – e.g., demographic change and globalization. Only the early detection of disease activity, followed by a rapid response, can reduce the impact of epidemics. Conflictingly, the (slow) speed with which information propagates through the traditional channels can undermine time-sensitive strategies.
Online Social Networks are valuable sources for real-time information such as status updates, opinions, or news in many domains. In particular, Twitter, a free social network that enables its users to post/read short messages called tweets, has been shown to be capable of transmitting information faster than traditional media channels for detecting natural disasters [Sakaki et al. (2010)], emergency situations [Cassa et al. (2013)], political persuasion [Borge-Holthoefer et al. (2015)], or current trends [Lampos and Cristianini (2012)].
In recent years it has been widely recognized that Twitter can also be used as a data source for digital health surveillance. The monitoring of the social stream is intended as an extension or complement to traditional passive surveillance systems [Milinovich et al. (2014), Neill (2012)], whose goal is to give public health officials a head start in detecting and managing outbreaks [Dredze (2012), Kostkova et al. (2014), Oyeyemi et al. (2014), Odlum and Yoon (2015)]. As a consequence, in the research community there has been a surge in dealing with tweets related to public health, with a number of proposals for new Epidemic Intelligence (EI) systems. EI has emerged as a type of intelligence gathering aimed to detect the events of interest to public health from unstructured text on the Web.
Detecting and monitoring outbreak events in Twitter is still challenging due to three main issues:
(1) Understanding if a tweet is relevant for outbreak alert. Putting tweets in the right context for a very broad range of diseases is very difficult, in part, due to the brevity of the tweet messages, which are limited to 140 characters. Although methods for detecting recurring events is mature, the detection of sudden, unexpected, and aperiodic outbreak events requires adaptive approaches to enable the identification of new emergent terms associated to epidemic outbreaks.
(2) Detecting changes in tweets’ time series. Time series created from tweets are noisy, highly ambiguous and sparse [Lampos and Cristianini (2012)]. Moreover, the characteristics of infectious diseases are highly dynamic in time and space, and their behavior varies greatly. Given this imperfect data, it is important to consider measures for assessing the reliability of alerts, i.e., the extent to which we can actually trust alerts that have been generated for early warning.
(3) Supporting public health officials. Every day, hundreds of millions of tweets are created world-wide and despite the relatively small fraction of health-related ones, officials still need assistance to cope with the cognitive challenges of exploring a large number of tweets linked to outbreak alerts. The effectiveness of straightforward approaches to retrieval and collaborative filtering can be unsatisfactory, given the dynamics of streaming data and the limited context of detected alerts.
Most studies on the use of Twitter data for outbreak detection have been focused only on the first issue (e.g., [Paul and Dredze (2012), Diaz-Aviles et al. (2012b)]). In addition, they have been tailored for one or two diseases, thus dealing with a more or less uniform temporal distribution of the tweets.
Although numerous approaches successfully detect common epidemic outbreak events from Twitter, e.g., seasonal influenza [Culotta (2010), Aramaki et al. (2011), Lampos and Cristianini (2012)], it seems that the challenges in building an EI system are still underestimated, especially when it comes to detecting emerging (novel or non-seasonal) health events from social media streams.
In this work, we propose an event-based EI system that also considers the detection of unexpected and aperiodic public health events. Our goal is to assist officials to retrieve and explore the detected alerts for infectious disease outbreaks. This effort represents the outcome of the collaboration with medical domain experts and epidemiologists within the European research project M-Eco – Medical Ecosystem: Personalized Event-based Surveillance [Denecke et al. (2012)].
In summary, the contributions of this work are as follows:
-
1.
We present and empirically evaluate an EI system based on Twitter, which is the result of close collaboration with domain experts and epidemiologists. We experimentally show the effectiveness of our approach to support the task of sudden and unexpected outbreak detection, management and control, and provide insightful lessons for similar endeavors.
-
2.
We propose a novel dynamic classification method for identifying health-related tweets, which is capable to maintain classification accuracy over time.
-
3.
We conduct a comparative study of surveillance algorithms for alert generation, and present our findings that outline the conditions under which early warnings, generated from Twitter, can be reliable.
-
4.
We present a personalized tweet ranking method for EI, which helps end-users to cope with the cognitive challenges of search and exploration of outbreak alerts.
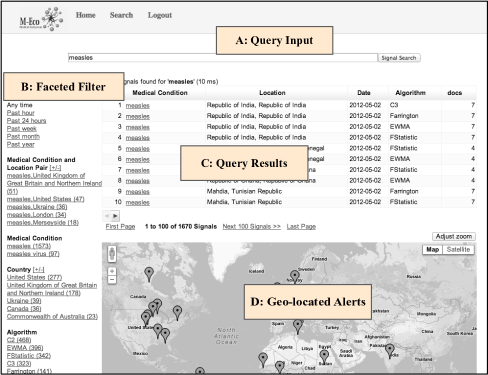
M-Eco System Overview
The goal of M-Eco project is to complement and enhance the capabilities of traditional disease surveillance systems. To this end, M-Eco uses novel approaches for early detection and management of emerging threats, and analyzes non-traditional sources such as social media data streams. In addition, M-Eco leverages personalization and filtering techniques to ease the outbreak analysis and control tasks. [Denecke et al. (2012)]
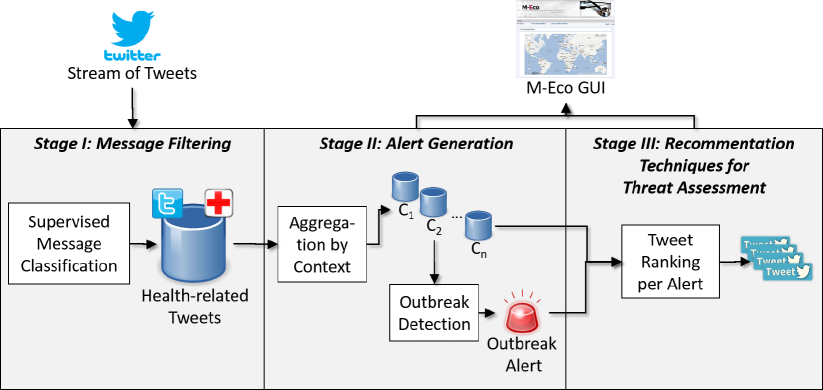
M-Eco includes a pipeline of three Stages, as depicted in Figure 1, whose respective goals are described as follows:
-
1.
Stage I. Identify, within the massive amount of daily tweets, those that are health related;
-
2.
Stage II. Create and monitor time series for each considered disease, looking for sudden peaks in the number of tweets, which could be an indicator of an outbreak;
-
3.
Stage III. Rank the potential tweets regarding an outbreak so that a public health official can manage the information associated to the event.
The rest of the paper details these stages.
2 Stage I: Message Filtering
A health-related term mentioned in a tweet can refer to many contexts, many of them not useful for the purposes of EI. For instance, tweets about vaccine, marketing campaigns, or ironic/jokes are non-relevant for an EI system.
In essence, Stage I’s goal is to filter relevant health-related tweets from non-relevant ones. Moreover, the main novel idea behind the Stage I is that, in presence of new outbreaks, the set and distribution of health-related terms used on Twitter should quickly change and consequently, we need a mechanism to handle this natural language changing within the Twitter stream. To the best of our knowledge, none of the works exploring the potential of Twitter for EI considers this idea of an evolving language.
2.1 Challenges
Online message classification continues to be a complex and challenging task for long term EI surveillance and intelligence gathering in general. One reason for this is that given the evolution of real-world events, the variable to observe cannot always be known a priori. One such example is in the detection of food-borne illness, in which the contaminated food item is not known in advance.
More in detail, the main challenges faced in Stage I are as follows.
Feature Change Detection. Detecting new relevant terms and filtering irrelevant tweets, are inter-related and impact each other. We need a way to: 1) dynamically detect when new and relevant terms appear in health-related tweets over time; and then 2) subsequently incorporate the tweets containing these terms as part of the data to train our classification models.
Dynamic Labeling. As terminology evolves, the criteria for defining a relevant tweet is likely to also change. However, expert labeling of classifier training instances is expensive and in practice difficult to obtain, especially for the rate and volume needed to build and maintain a good classifier.
In the rest of the section, we present the approach taken in M-Eco to address these challenges.
2.2 Approach and Rationale
The architecture of M-Eco’s module encapsulating Stage I has been designed around the idea of novelty management. In particular, we incorporate a feature change detection mechanism into a framework for the adaptive classification of tweets.
Existing message classification techniques rely usually on supervised or unsupervised machine learning approaches [Fisichella et al. (2010), Paul and Dredze (2011a)]. In M-Eco, we defined a solution based on a semi-supervised approach to determine if tweets are relevant or not for outbreak detection and threat assessment.
The choice of features and classifier was driven largely by the fact that the M-Eco system runs continuously, so features and classifiers that are not time-consuming to extract or encode need to be used. In the course of our investigation, we found that a linear Support Vector Machine (SVM) model exhibits a favorable trade-off between classification performance and training time.
Our approach builds upon [Hido et al. (2008)] and includes three main novel contributions beyond the state-of-the-art by 1) modelling and describing the feature change over time using an orthogonal vector, which is learned by a SVM; 2) computing a novelty score that lets the system identify those tweets that contribute to the feature change, so that; 3) manual labels can be obtained, dynamically and on-demand, by asking a human judge as part of an active learning setting [Settles (2010)].
One aspect that we assess in the experiments for this stage, is to what extent the expertise of the annotators impact the classification quality. To this end, besides public health experts, we also consider crowd-sourced workers from the CrowdFlower platform111http://crowdflower.com/ as annotators.
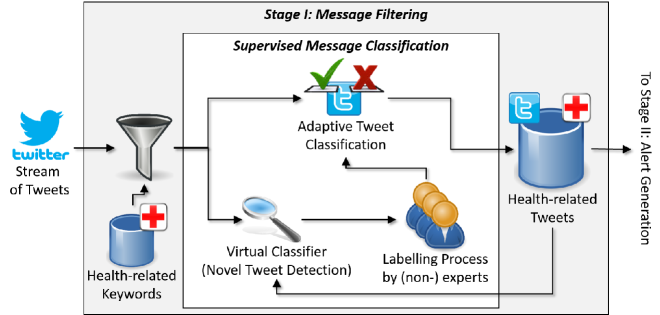
Figure 2 presents an overview of M-Eco’s feature change detection and adaptive classification steps. The Message Filtering process runs continuously to classify all unlabeled tweets, which are arriving from the Twitter Streaming APIs.
All tweets are annotated with locations, medical conditions, and temporal expressions using a series of language processing tools, including OpenNLP222http://opennlp.apache.org/ for tokenization, sentence splitting and part-of-speech tagging; HeidelTime for temporal expression extraction [Strötgen and Gertz (2010)]; LingPipe dictionary-based entity extraction for medical conditions [Alias-i (2008)]; as well as entity extraction tools developed within the project for location entities [Otrusina et al. (2012)]. In this paper, we only focus on text-based analysis of Twitter messages.
Then, we use two types of classifiers: a Virtual Classifier (VC) and an Adaptive Classifier.
Positive keywords associated to diseases are pathogen (e.g., Streptococcus pyogenes) and symptoms (e.g., sore throat, fever, bright red tongue with a strawberry appearance, rash, bumps, itchy, and red streaks).
For filtering tweets irrelevant to the medical domain, we use a list of negative keywords associated to diseases from two freely-available resources: 1) MedISys333http://medusa.jrc.it/medisys/homeedition/en/home.html providing a list of negative keywords created by medical experts, and 2) Urban Dictionary444http://www.urbandictionary.com/, a Web-based dictionary of slang, ethnic culture words or phrases.
The Novel Tweet Detection process is run periodically to trigger an update on the current adaptive classification model. In our case, a period of one week was used to correspond with weekly reporting performed by the health agencies in our study.
The Novel tweet Detection phase is responsible to detect a feature change. To this end, the Virtual Classifier is used to compare incoming and unlabeled tweets against the set of existing tweets (those previously labeled during the Adaptive Classification step). If it is determined that feature change has occurred, novel tweets – those for which it is expected that the classifier will not be able to correctly label – are flagged and channeled to the Labeling Process so that manual labels can be obtained by a human judge.
Note that, regardless of whether feature change has been detected, all tweets are classified with a model that has been trained on the labeled instances that the Adaptive Classifier put into the Health-related Tweets storage. We apply the adaptive classification algorithm to all tweets presented to the system, even if feature change was detected, because the relevant tweets are needed by downstream components of our pipeline.
The labels for novel tweets are acquired using dynamic labeling, in which for-hire Human Intelligence Task (HIT) or crowdsourcing, is used to obtain labels on-demand. Until the system receives HIT labels for the novel tweets, it uses temporary (automatic) labels given by the current Adaptive Classification model.
After labeled tweets have been obtained from the HIT workers, they are used as input to the Adaptive Classifier; a new classification model is trained; and any temporary tweet labels are updated for improving and maintaining its accuracy over time. Unlike other work [Paul and Dredze (2011b), Demartini et al. (2012)], we also address the challenge of assessing the quality of the HIT labels against those of our domain experts (cf. Section 2.3).
The VC detects feature change through a scoring mechanism in which the most novel tweets in the data stream are identified and presented to a human for labeling. Our experiments (cf. Section 2.3) show that the selected novel messages reflect the events in the real world that cause feature change and that they are useful for training and maintaining an accurate classifier for EI.
The VC corresponds to a SVM model that maps a feature vector to a hypothetical class (i.e., novel/not-novel). The VC is trained to learn a decision boundary between the unlabeled incoming tweets and those existing in the collection. If this decision boundary is highly accurate, then it is very probable that feature change has occurred between the two data sets [Hido et al. (2008)].
Novel Tweets Detection. M-Eco assigns to each newly incoming tweet a score that represents how novel it is to the system. This score is given with respect to the distance to the separating hyperplane of the aforementioned (binary) VC, which is trained on the set of labeled tweets and the set of new incoming tweets. We assume that the greater the distance between the newly incoming tweet and the tweets known to the system, the more dissimilar they are.
Based on active learning principles, that is to label those instances that would most change the current model [Settles (2010), Georgescu et al. (2014)], we propose that obtaining labels for the most novel tweets will help the system to keep its accuracy over time, a hypothesis that we test in our experiments detailed in Section 2.3.
Labeling Criteria. It is very challenging to determine if a tweet is relevant or not for EI, even for human experts. This is due to the fact that contextual information within the short messages is very limited, unlike existing work in the domain of EI based on news articles [Collier (2010)].
In an effort to address the needs of our system for online and dynamic labeling of tweets, together with a team of epidemiologist, we created a set of simple annotation guidelines for determining the relevance of tweets for the task: a tweet is relevant if somebody reports himself or another person being ill while it is irrelevant if no one is suffering from symptoms; i.e., mentions refers to opinion, advertising, jokes, music, books, films, artists, landmarks, sporting events, slang, etc.; and for the given set of criteria, we examine crowdsourcing as an alternative to obtaining the correct labels of tweets by the experts themselves.
In the rest of the section, we present the results of the empirical evaluation to assess this approach.
2.3 Results
The evaluation is composed of two separate experiments. In the first one, we were interested in evaluating the combined effectiveness of the Adaptive Classifier and of the Virtual Classifier over the time.
In the second experiment, we evaluated the quality of the labelling process carried out by crowdsourcing compared with the one obtained by public health experts.
Feature change detection. We design the experiments to evaluate the suitability of the proposed approach to determine if tweets are relevant for outbreak detection as follows.
We train and measure the performance of the Adaptive Classifier in a given time span and then use the model for prediction over a subsequent time span, with three different strategies to account for feature change:
-
1.
No feature change handling strategy in which a non-adaptive classifier and no retraining are used;
-
2.
Random selection of tweets used to retrain the Adaptive Classifier,
-
3.
Novelty selection, which uses the novelty scoring to select the tweets to retrain the Adaptive Classifier.
In detail, we conduct the evaluations using a dataset consisting of 6,625 tweets collected within a time period from week 12th through week 14th of year 2011. These tweets were randomly selected from those containing at least one word in the Health-related tweets database (cf. Figure 2). Then, we manually labeled them to determine if they were in fact health related or not, based on the guidelines outlined earlier in this section. Finally, we trained a SVM binary classifier using feature vectors derived from a bag-of-words representation combined with bi-grams.
We assess our results in terms of accuracy, i.e., the proportion of true results (both true positives () and true negatives () among the total number of tweets examined:
Here, corresponds to the number of tweets classified and labeled as health-related, and to the number of tweets classified and labeled as non health-related.
We then applied this classifier to the feature change detection task. We employed another dataset of 6,625 tweets, now randomly selected from the calendar weeks 15th through 19th of year 2011. We created a subset of about 1,100 positive and negative tweets for each week and manually labelled them as well.
We considered three different scenarios with a varying percentage, , of the novel tweets. In particular we evaluated the scenarios where , and , using a significance level, . Results are reported in Figure 3.
From these results, we can derive the following conclusions:
-
1.
The strategy using the Virtual Classifier provides on average the best results, and the more novel tweets are, the better is the accuracy of this strategy.
-
2.
The strategy without any change provides the poorest results, highlighting that the dictionary evolves over the time (even over the limited timeframe we considered) and some mechanism to update the classifier is needed.
-
3.
The accuracy of the classifiers degrades for most strategies during week 17th, 2011. This time slot contains many tweets mentioning “royal wedding fever”, referring to the wedding of Prince William and Kate Middleton on April 29, 2011. Those tweets are sometimes misclassified as relevant.
Crowdsourcing versus Experts. The second experiment explores the quality of the labelling process performed by human annotators. To this end, we employed a total of 1,500 tweets, by randomly sampling 500 tweets from each of the calendar weeks 15th, 16th and 17th, 2011. We presented them to 43 workers of the CrowdFlower platform to elicit their feedback.
To control the quality of the crowdsourced labels, two actions were taken. First, a set of “golden” tweets with known labels was added to the unlabeled tweets that were randomly shown to the workers. A trust value is computed for each worker based on the number of correctly labeled “golden” tweets. If this trust value is below a fixed threshold, the workers labels are removed from the task. Second, each tweet was labeled by a minimum of 3 workers for each task, and only those tweets corresponding to a majority agreement above 65% percent among the multiple annotators were used.
The average agreement among the 43 HIT workers on a given tweet was 93.89% with an average accuracy on the injected gold labeled tweets of 92%.
Out of the 1,500 tweets labeled by the crowd, 1,114 tweets had a perfect agreement of 100%; 295 tweets had an agreement between 66% and 100%; and 91 tweets had an agreement between 50% and 66%.
We chose 130 tweets according to the agreement of the crowdsourcing annotators to include a representative amount of “easy” tweets (perfect agreement) and more “difficult” tweets (low agreement). Then, we asked five public health experts to also annotate this subset and measured their inter-annotator agreement on the 130 instances, which achieved a 89.33%.
For the 130 tweets labeled by both the experts and the HIT workers, there was a percent agreement of 87.69%. The percent agreement is the ratio of number of agreements among crowd and experts to the total number of units judged by crowd and experts.
When measuring the classifier performance individually for each group, based on a 10-fold cross validation and equal percentages of positive and negative examples, the classifier performance in terms of accuracy was 75% for the experts and 83% for the HIT workers.
2.4 Lessons Learned and Outlook
Our results suggest that people outside the public health domain are able to accurately judge the relevance of tweets when given a simple set of criteria. Thus, once the modules of Stage I have detected a feature change, it is also feasible to outsource the novel tweets as part of a separate feature change handling procedure, without the necessary involvement of a public health expert.
Although the classifier performance was less for the expert labels, than the crowd labeled data, we believe this is due to the fact that in practice, whether a tweet is relevant for an expert depends on several factors, such as different time periods of an outbreak (e.g., before, during or after); or on the task and role of the expert with respect to an epidemic investigation. Nonetheless, the crowd can still help to filter label instances that are clearly off topic.
To get a better understanding of the impact of detected feature change on the classification accuracy, a larger set of expert labeled tweets for experimentation would be useful to further improve the significance of the results. However, by doing so, it would still not address the need for experts to re-label each time feature change is detected and in practice, the overhead of such a task is too expensive and not timely enough. We propose instead, that after tuning expert labeled examples with a good inter-annotator agreement, such instances could be used as gold standard to filter out HIT workers whose trust value is below a threshold.
3 Stage II: Alert Generation
In this section, we describe key challenges faced during the alert generation process, we compare different biosurveillance algorithms, and provide experimental results as well as a discussion on the impact of the identified challenges in this stage.
3.1 Challenges
The majority of existing works center their studies on recurring diseases only, e.g., Influenza-like Illness (cf. Section 5). Moreover, many researches are either focused on a single nation and language, or the spatial dimension is not considered at all.
The 5 considered outbreaks, with ID, disease (or medical condition), country, and duration of the event. ID Disease Country Event period in 2011 1 Anthrax Bangladesh [June – August] 2 Botulism France September 3 Cholera Kenya [November – December] 4 Escherichia Coli Germany [May – July] 5 Mumps Canada [June – August]
Our goal is to provide a broader EI system, able to detect and monitor outbreak events in Twitter, for multiple locations and for multiple diseases, including sudden and unexpected outbreaks (cf. Table 3.1). This goal is a challenging task, due to two main issues:
Spatio-Temporal Monitoring of Diseases. Location-awareness is one of the key starting points for any EI solution. Indeed, knowing where an outbreak is happening is naturally one of the most important pieces of information.
From this point of view, the typical use of Twitter is not helping. For instance in our experimentation, we observed that explicit coordinates where present in less than 1% of the collected tweets. As a consequence, other techniques, mainly based on Natural Language Processing, or on the analysis of user profiles of people tweeting are needed in order to infer the location of a tweet.
Temporal and Spatial Dynamics of Diseases. The characteristics of infectious diseases are highly dynamic in time and space, and their behavior varies greatly among different regions and the time periods of the year. E.g., some infectious diseases can be rare or aperiodic, while others occur more periodically. In addition, various diseases have different transmission rates and levels of prevalence within a region.
To get a deeper insight on this issue, we collected information about five outbreaks that occurred in 2011, which are detailed in Table 3.1.
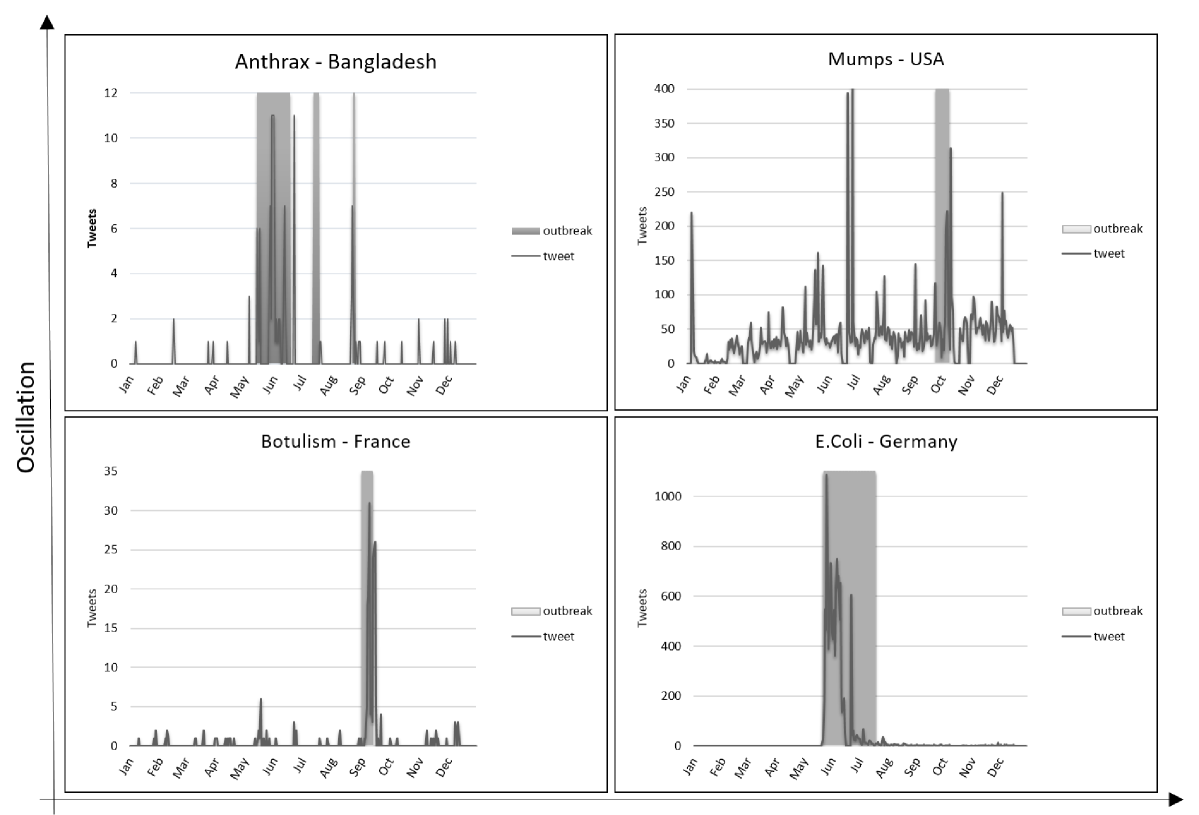
By analyzing the time series of the tweets about these five different outbreaks, we found out that the Twitter data regarding the public health outbreaks can be characterized by two dimensions: (1) Oscillation, which is seen as the frequency at which the curve spikes, and (2) Magnitude (or volume) of daily count of tweets, sinks or slopes.
Figure 4 shows representative examples of the different outbreak dynamics from Twitter time series data. The gray areas in these plots represent the timeframe where an outbreak alert was broadcasted via ProMED-mail [ProMED (2015)], a global reporting system providing information about outbreaks of infectious diseases.
A time series with low oscillation indicates that the average daily number of tweets is more or less constant (eventually zero) but it noticeably peaks within the outbreaks period. Examples are provided by the two bottom frames of Figure 4. On the left there is the distribution of tweets for the outbreak of Botulism in France in 2011. We can see that the magnitude of the tweets is very low, both outside and inside the emergency time frame. This situation may occur in the scenarios where the diffusion of English tweets is limited.
On the other hand, the picture on the right is the case of the Escherichia Coli outbreak in Germany, 2011. Since it had a very high international and media coverage, due to the ease with which it could spread, we can see that the number of tweets during the peak is almost two orders of magnitude higher than the example of Botulism in France. In general, in presence of diseases leading to low oscillations of tweets, it is easy for surveillance algorithms to produce correct alerts.
Magnitude
A time series with a high oscillation means that the number of tweets varies often and greatly over the year. Considering the outbreak Anthrax in Bangladesh (Figure 4, upper left frame) as an example of high oscillation/low magnitude time series, we can observe a number of tweets per day ranging from 0 to 5 all over the year. Thus, a less sensitive surveillance algorithm is necessary to avoid to get continuously false positives.
A time series with high oscillation and high magnitude occurs when: 1) a disease occurs continuously in a country, such as Mumps or Leptospirosis and/or 2) the name of the disease is a highly ambiguous term, such as for Mumps, which is for instance also the name of a software system555MUMPS is also the acronym for Massachusetts General Hospital Utility Multi-Programming System – https://en.wikipedia.org/wiki/MUMPS.
In Figure 4, upper right frame, we report on the Mumps outbreak in the USA, which is not included in the evaluation since it was not possible to find a reliable ground-truth regarding the dates of the emergency.
In these situations, algorithm tuning is essential, since the dynamic of data is too large, and it is not easy to identify significant aberrations.
3.2 Approach and Rationale
The Stage II of our EI system takes as input the dataset containing health-related tweets coming from the Stage I, and provides two outputs: (1) a collection of datasets containing health-related tweets, aggregated by the spatial dimension and (2) a set of alerts, triggered by surveillance algorithms analyzing the temporal dynamics of each of these datasets.
Thus, Stage II encompasses two main steps, context creation and biosurveillance, which are described as follows.
Context creation. We are interested in monitoring, for each location, a set of possible diseases. In order to infer the location associated to a tweet we define three rules, which are applied in order of importance, as follows:
-
1.
Mention of the location (city, country, etc.) in the text of the tweet.
-
2.
The tweet’s geo-location information (latitude and longitude), if present.
-
3.
Location indicated in the user profile of the author of the tweet.
Tweets not matching any of the above rules are discarded. Even if they are health-related, it is not possible to understand where the event is located. Thus, their informative contribution is negligible. Moreover, we do not consider the tweet language (provided as an attribute by the Twitter API) in determining location information, since it is too inaccurate.
In the end, the geographical granularity level we considered is the country. The geo-mapping between location or coordinates and the relative nation was performed using the Yahoo BOSS Geo Services APIs 666https://developer.yahoo.com/boss/geo/.
The output of this step is a collection of datasets, which are intended as a spatial partitioning of the original dataset coming from the Stage I. The total sum of contained tweets is most likely lower, since tweets without any information on the location are discarded.
Biosurveillance. A standard approach to detect anomaly in health-related time series data is to leverage state-of-the-art biosurveillance algorithms. Many of them can be found in the literature [Farrington et al. (1996), Hutwagner et al. (2003), Khan (2007)] and implemented in analysis tools like R [Höhle et al. (2015)].
In our study, all biosurveillance algorithms are included in the free package Surveillance for R, that implements multiple statistical methods for the “Temporal and Spatio-Temporal Modeling and Monitoring of Epidemic Phenomena” [Höhle et al. (2015)].
In particular, we assessed the following four algorithms: C1, C2, C3, and Farrington, which are described as follows.
Early Aberration Reporting System (EARS), which compute a test statistic on day as follows: , where is the count of episodes on day , is the shift from the mean to be detected, and and are the mean and standard deviation of the counts during the baseline period. EARS uses three baseline aberration detection methods, that we assessed:
-
•
C1-Mild, where the baseline is determined on the average count from the past 7 days;
-
•
C2-Medium, where the baseline is determined on the average count from the 7 days in the 10 days prior to 3 days prior to measurement.
-
•
C3-High, that uses the same baseline as C2, but takes a 3 day average of events to determine the measure.
The Farrington (FA) detection algorithm predicts the observed number of counts based on a subset of the historic data, by extracting reference values close to the week under investigation and from previous years, if any. The algorithm fits an overdispersed Poisson generalized linear model with log-link to the reference values. [Farrington et al. (1996)]
The rationale behind the selection of these methods is that the EARS family require a very limited number of previous data to provide an alert, thus being potentially suitable for a new outbreak detection system. Moreover, it has basically no parameters to tune, make its applicability straightforward.
On the other hand, the Farrington algorithm is largely considered a robust and fast method. Thanks to these characteristics, currently it is the method used at European public health institutes [Hulth et al. (2010)]. This algorithm has a set of parameters to specify. In particular, among others, it requires to define the windows size, , i.e. number of weeks to be considered for the alert generation. We performed our experimentations with = 2, 3, and 4. Nevertheless, since the choice of the parameters heavily depends upon the data, it is outside the scope of this research to investigate hyperparameter optimization techniques (e.g. as in [Corazza et al. (2013)]).
Further details on these algorithms and their implementation can be found in the R-Surveillance documentation [Höhle et al. (2013)].
3.3 Results
Here we seek to address the following question: what are the most suitable surveillance algorithms for outbreak alert generation using Twitter data?
To perform our study, we analyze Twitter data collected from January the 1st, 2011 to December the 31st, 2011. The data was collected using the pipeline defined in the Stage I (Section 2), resulting in a total of 112,134,136 health-related tweets.
Ground Truth. Studying the usefulness of Twitter data in an early warning task requires real-world outbreak statistics. Therefore, we build a ground truth by relying upon ProMED-mail [ProMED (2015)]. An outbreak event is intended as a temporal anomaly found in time series data that occur when the impact of an infectious disease is above an expected level at a certain time.
We collected 3,056 ProMED-mail reports occurred during year 2011, and among them, we selected 5 different outbreaks according to two criteria: 1) a clearly identifiable starting date from the ProMED-mail, by considering the first ProMED-mail post on it, and 2) a representative distribution of tweets.
An important aspect of our work is that we consider the duration of each outbreak by manually analyzing the text of each ProMED-mail document, unlike previous work [Collier (2010)] that assumes the publication date of a document as the estimated relevant time of an outbreak.
In particular, we determine the starting date of a disease by looking at the text inside the first ProMED-mail post, and the ending date was associated to the text inside the last ProMED-mail publication, for that particular disease-location pair. One reason for doing this is that the events in ProMED-mail undergo moderation, so there is often a delay between the time of the actual outbreak and the publication date of the related report. However, it is worth noting that this strategy gives us a good confidence only on the beginning date of the outbreak. In fact, the absence of further ProMED-mail posts does not necessarily mean an end of the outbreak, but just that there was no significant news in which it was reported.
Evaluation Metrics. To assess the quality of the generated alerts, we use standard Information Retrieval metrics, namely precision, recall, and f-measure, which are defined as follows:
With our problem at the hand, a valid definition of the temporal granularity is not easy, due to the high temporal variability of the data and the lack of a proper ground truth. To clarify it, in case an algorithm generates an alert 5 days before the official communication in ProMED-mail, should it be considered a false positive or a true positive with a good timeliness? We opted for the second case, thus defining a (True Positive) as an alarm that is raised within the time frame of the ProMED-mailalert or up to 10 days before it. A (False Positive) is an alert generated outside this above defined time frame. A (False Negative) is an alert not generate in this time frame.
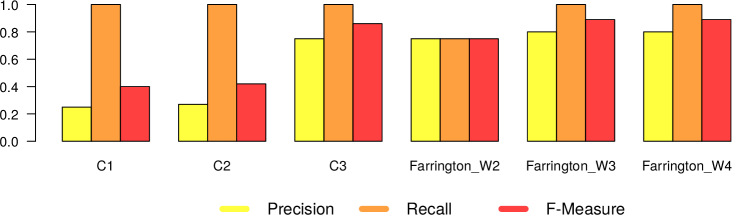
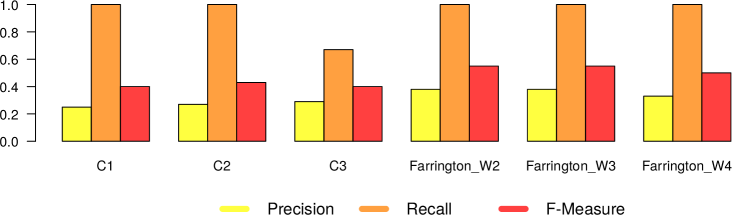
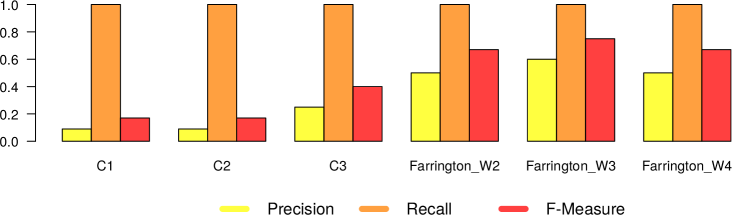
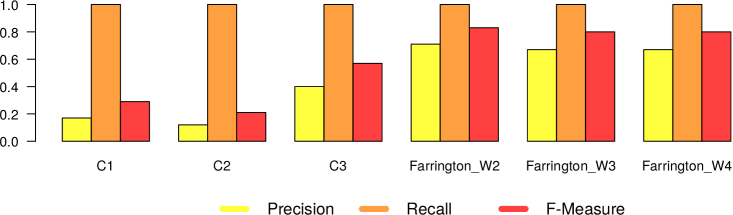
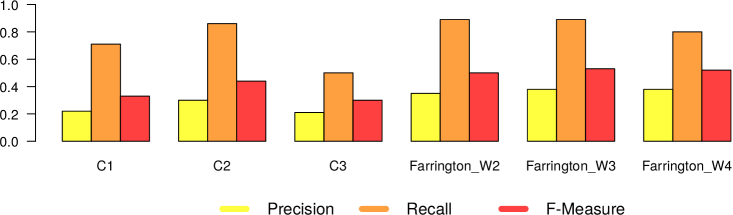
In Figures 5 and 6, we present the results we got from the application of the 4 different surveillance algorithms to our dataset. In particular, as described before, for the three EARS algorithms, we used the default parameters, while for the Farrington algorithm, we tested the values 2, 3 and 4 as for the windows size. Consequently in Figures 5 and 6 we report 6 different results (namely EARS C1, C2 and C3, Farrington W2, W3 and W4) for the five evaluated diseases.
3.4 Lessons Learned and Outlook
As mentioned earlier, our goal is to detect outbreak events for general diseases that are not only seasonal, but also non-recurring diseases. From the results we collected, we can report the following lessons learned:
– In general all the algorithms present a very high recall (very close to 1), meaning that they are able to detect very well the epidemic outbreaks. This is an expected result, given the high correlation that is clearly visible in our datasets between tweet peaks and outbreak timeframes.
The only notable exception comes from Mumps in Canada, which can be classified as high oscillation – high magnitude type of outbreak.
– The real difference among the algorithms can be seen in terms of number of false alarms (i.e., precision). We can notice that in general the EARS family is providing a large amount of false positives. Probably this is due to the short time window used from these algorithms. On the other hand, Farrington algorithm performs better in terms of precision and f-measure, regardless of the window size. Thus we can in general confirm the effectiveness of the Farrington algorithm for this kind of task. As already reported in Section 3.2, this is the standard algorithm for epidemic outbreaks in many health institutions. In our case, the Farrington results are always better than those of the three EARS algorithms.
– The hyperparameter window size of the Farrington algorithm has an impact on the quality of the provided alarms, but no generalizable trend can be devised from our experiments. The window size should be defined according to the specific temporal dynamics of each considered disease. A solution to automatically find the best hyperparameter optimization would be highly recommendable to solve this issue.
– As expected, there is a noticeable difference between low and high oscillation diseases. In the latter case, all the algorithms perform significantly worse.
4 Stage III: Recommendation Techniques for Threat Assessment
After the detection of the outbreak in M-Eco’s Stage II, authorities investigating the cause and the impact in the population are interested in the analysis of tweets related to the event. However, thousands of messages could be produced every day for a major outbreak, which make such task overwhelming for the investigators who are quickly inundated with the volume of tweets that must be examined when assessing threats.
The goal of Stage III is to facilitate access for the end user to the original tweets, organized by the alerts, and ranked based on his or her interest for the task of outbreak analysis and control. In M-Eco, we employed recommendation techniques to tackle this problem. In this section, we present the particular challenges we face in this stage and review one of the recommendation methods used within the system, namely Personalized Tweet Ranking for Epidemic Intelligence (PTR4EI) [Diaz-Aviles et al. (2012a), Diaz-Aviles et al. (2012b)].
4.1 Challenges
Even though algorithms for recommender systems and learning to rank are agnostic to the problem domain, their application for EI based on Twitter is not straightforward. We identified two major challenges faced within M-Eco:
Limited User Feedback Available for the Recommender System. Learning to Rank and Recommender Systems approaches have been successfully applied to address the growing problem of information overload in a broad range of domains, for instance, web search, music, news media, movies, and collaborative annotation [Ricci et al. (2011)]. Such approaches usually build models offline, in a batch mode, and rely upon abundant user interactions and/or the availability of explicit feedback (e.g., ratings, likes, dislikes). In the case of EI, experts’ interactions and explicit feedback are scarce, which makes it harder to build effective models for ranking or recommendation.
Dynamic Nature of Twitter. The real-time nature of Twitter, on the one hand, makes it attractive for public health surveillance; yet, on the other, the volume of tweets also makes it harder to: 1) capture the information transmitted, 2) compute sophisticated models on large pieces of the input, and 3) store the input data, which can be significantly larger than the algorithm’s available memory [Muthukrishnan (2005)]. One major challenge in monitoring Twitter for EI lies in capturing the dynamics of an outgoing outbreak, without which the time-sensitive intelligence for threat assessment would be rendered useless.
4.2 Approach and Rationale
Our PTR4EI extends a learning to rank framework [Liu (2009)] by considering a personalized setting that exploits a user’s individual context. We consider such context as implicit criteria for selecting tweets of potential relevance and for guiding the recommendation process. The user context is defined as a triple , where is a discrete Time interval, the set of Medical Conditions, and the set of Locations of user interest.
We consider an initial context specified explicitly by the user, which can be precise, but static and limited to the medical conditions or locations manually included by the user. Our goal is to automatically capture the dynamics of the outbreak as reported in Twitter. To this end, we expand the user context by including additional medical conditions and locations related to the ones she specified, and exploit the resulting and richer context for personalized ranking. Our approach expands the user context by using 1) latent topics computed with LDA [Blei et al. (2003)] based on an indexed collection of tweets for epidemic intelligence; and 2) hash-tags that co-occur with the initial context.
We use the terms in the expanded context that correspond to medical conditions, locations, and complementary context777Complementary Context corresponds to the set of nouns, which are neither Locations nor Medical Conditions. It may include named entities such as names of persons, organizations, affected organisms, expressions of time, quantities, etc. to build a set of tweets by querying our collection, which correspond to a subset of Tweets output by Stage II. This step helps us to filter irrelevant tweets for the user context.
Next, we elicit judgments from experts on a subset of the tweets retrieved in order to build a ranking function model. We then obtain for each labeled tweet a feature vector that help us training our personalized ranking function. Finally, we use the ranking function to rank new incoming tweets automatically. Please refer to [Diaz-Aviles et al. (2012a)] and [Diaz-Aviles et al. (2012b)] for further details.
4.3 Results
In this section we review the experimental evaluation of our approach on the EHEC outbreak in Germany, 2011, as the real-world event of interest, and discuss the results we obtained.
To support users in the assessment and analysis during the German EHEC outbreak, we got an alert from Stage II starting on 2011-05-23. We monitored related tweets up to 2011-06-19. In this way, we are taking into account the main period of the outbreak,888Note that even though the main period of the outbreak is considered for the evaluation, nothing prevents us to build the model during the ongoing outbreak, and recompute it periodically (e.g., weekly). the disease of interest, and the location.
During the period of the EHEC outbreak (May and June, 2011) a total of 7,710,231 tweets related to medical conditions were collected by the M-Eco system (Stage I); of which, 456,226 were related to the EHEC outbreak in Germany. Individual judgment were solicited to three experts on a subset of 240 of these tweets. The experts were asked to provide a relevance judgment as to whether the tweet was relevant in supporting their analysis of the outbreak, or not; disagreement in the assigned relevance scores were resolved by majority voting.
For each tweet, we prepared five binary features: , , , , and . We set the corresponding feature value equal to true if a medical condition, location, hash-tag, complementary context term, or URL were present in the tweet, and false otherwise. For learning the ranking function, we used the Stochastic Pairwise Descent algorithm [Sculley (2010)].
We compared our approach that expands the user context with latent topics and social generated hash-tags, against three ranking methods:
– TFIDF is a vector space model based on a truncated list of documents, which are retrieved from an indexed twitter collections using the conjunctive query: “ EHEC AND ‘Lower Saxony’ ” and sorted using TF-IDF scores.
– RankMC learns a ranking function using only medical conditions as feature, i.e., . Please note, that this baseline also considers additional medical conditions that are related to the ones in , which makes it stronger than non-learning approaches, such as BM25 or TF-IDF scores that use only the elements as query terms.
– RankMCL is similar to RankMC, but besides the medical conditions, it uses a local context to perform the ranking (i.e., features: and ).
We randomly split the dataset into 80% training tweets, which will be used to compute the ranking function, and 20% testing tweets. To reduce variability, we performed the experiment using a cross-validation with 10 different 80/20 partitions. The test set is used to evaluate the ranking methods. The reported performance is the average over the 10 rounds. For evaluation, we used precision at position () [Baeza-Yates and Ribeiro-Neto (2011)].
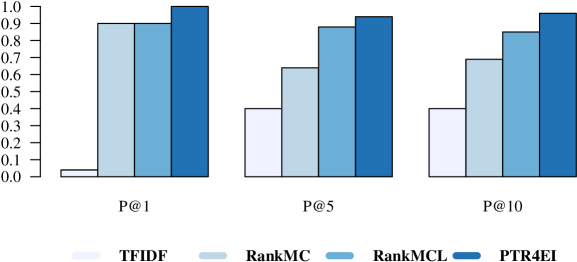
The ranking performance in terms of precision is presented in Figure 7. As can be seen, PTR4EI outperforms the three baselines. Local information helps RankMCL to beat RankMC. PTR4EI, besides local features, exploits complementary context information and particular Twitter features, such as the presence of hash-tags or URLs in the tweets, this information allows it to improve its ranking performance even further, reaching a P@10 of 96%. A similar behavior is observed for MAP and NDCGL [Diaz-Aviles et al. (2012a)].
4.4 Lessons Learned and Outlook
After the detection of the outbreak, authorities investigating the cause and impact of the outbreak are interested in the analysis of micro-blog data related to the event. Millions of health-related tweets are produced every day, which make this task overwhelming for the experts. Yet, our approach, PTR4EI demonstrated a superior ranking performance and was able to provide users with a personalized short list of tweets that met the context of their investigation. PTR4EI exploits features that go beyond the medical condition and location (i.e., user context) and includes complementary context information, extracted using LDA and the social hash-tagging behavior in Twitter.
The main advantage of PTR4EI is that it can discover new relationships from the dynamic data stream based on a limited context in order to help filtering the large amount of data.
The method presented here requires labeled data to train the model; placing extra effort and burden on experts. We are currently considering crowdsourcing as a complementary means to obtain labeled data on demand, similar to the crowdsourcing approach discussed in Stage I (Section 2.2).
5 Related Works on Epidemic Intelligence from Social Media
In recent years there has been significant research efforts in analyzing tweets to enhance outbreak alerts, which can urge a rapid response from health authorities, thereby helping them to prevent and/or mitigate public health threats. Here we present some illustrative instances.
In the case of Influenza-like Illnesses (ILI), for example, Culotta [Culotta (2010)] analyzes tweets to determine if influenza-related messages correlates with influenza statistics reported by the Centers for Disease Control and Prevention (CDC) in the United States. The author found a positive correlation with the official statistics.
Lampos and Cristianini [Lampos and Cristianini (2012)] address the task of detecting the diffusion of ILI from tweets. Their analysis uses a statistical learning framework based on LASSO and L1-norm regularization in order to select a consistent subset of textual features from a large amount of candidates. They observe that their approach is able to select features with close semantic correlation with the target health related topics and that the regression models have a significant performance improvement.
Beyond ILI, tweets time series and user behavior also have been analyzed to enhance outbreak alerts for other diseases. For example, in [Chunara et al. (2012)] and [Gomide et al. (2011)] the authors monitor Twitter to understand and characterize Cholera and Dengue outbreaks, respectively.
The aforementioned studies mostly focus on individual countries with a high density of Twitter users, e.g., United Sates, the United Kingdom, or Brazil, and none of them has focused on more than two simultaneously diseases for outbreak detection. Thus, even if they show the advantage of using Twitter for detecting real world outbreak events, they do not consider the temporal dynamics of tweets regarding different diseases in different countries, as we do in this work999The study in [Kanhabua et al. (2012)] goes in this direction, but it does not provide a quantitative correlation between tweets and real word outbreaks..
Note that there are existing EI systems such as the BioCaster Global Health Monitor101010http://biocaster.nii.ac.jp/, or HealthMap111111http://www.healthmap.org/en/. However, they differ from our proposed system in the level of analyses and data mining models, information sources, and results presentation and visualization. Furthermore, M-Eco’s personalization and filtering techniques are key differentiators of our approach.
6 Conclusion
Leveraging social media for Epidemic Intelligence systems is a promising but also a challenging endeavor.
For message filtering, the main challenge lies in the ambiguity of term usage and of terminology evolution in Twitter. We find that semi-supervised classification works well when using labeled data for training the classifier and retraining on feature changes. Our proposed algorithm for detecting novel tweets can identify such feature changes and select a sample of corresponding messages for human assessment.
Interestingly, it is not necessary to let medical experts label the training data; with crowdsourcing, a similar level of labeling quality could be achieved. As the main aim of this stage is high recall, and false positives are acceptable, a supervised classifier trained with a regularly updated, crowd-labeled training set, is a feasible solution.
With respect to alert generation, we identified four different classes of time series data, based on the two characteristics: oscillation and magnitude. For low volume cases, messages can be directly treated as alerts because the cognitive load for later assessment is small. Low oscillation and high magnitude cases feature pronounced message peaks for outbreaks; this type of event is easily detected by biosurveillance algorithms. The challenging type is the class of high oscillation and high magnitude time series.
We can conclude that while many time series are amenable to reliable alert generation, for particular cases (e.g., high oscillation and high magnitude time series) more research is needed to devise algorithms which are more robust under noise and incomplete data.
For detected events, public health experts face the overwhelming task of analyzing the large number of tweets associated to the alerts. In order to reduce this information overload and support the task of threat assessment, we leveraged complementary context information discovered within the tweets – i.e., extracted from the social hash-tagging and latent topics. We were able to achieve an effective ranking mechanism for messages associated with alerts.
To summarize, available techniques are sufficiently mature to build useful monitoring and early warning systems based on social media streams. Collective intelligence can be employed not only as a valuable information source, but also for tasks such as training data creation. Further work is needed to devise alert generation algorithms with a better recall-precision trade-off. However, the current load of experts in assessing these alerts can be reduced significantly by employing personalized ranking techniques.
We are confident that this study brings Epidemic Intelligence based on social media a step forward and we hope it provides insightful lessons for similar ventures. {acks} This work was partially funded by the European Commission Seventh Framework Program (FP7 / 2007-2013) under grant agreement No.247829 for the Medical Ecosystem Project (M-Eco). We thank the epidemiologists at the Niedersächsisches Landesgesundheitsamt and the Robert-Koch Institute for providing domain expert recommendations and advice for this work.
References
- [1]
- Alias-i (2008) Alias-i. 2008. LingPipe 4.1.0. http://alias-i.com/lingpipe. (2008). [Online; accessed 2015-12-01].
- Aramaki et al. (2011) Eiji Aramaki, Sachiko Maskawa, and Mizuki Morita. 2011. Twitter Catches The Flu: Detecting Influenza Epidemics using Twitter. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing (EMNLP ’11).
- Baeza-Yates and Ribeiro-Neto (2011) Ricardo Baeza-Yates and Berthier Ribeiro-Neto. 2011. Modern Information Retrieval. Addison Wesley.
- Blei et al. (2003) David M. Blei, Andrew Y. Ng, and Michael I. Jordan. 2003. Latent Dirichlet Allocation. J. Mach. Learn. Res. 3 (March 2003), 993–1022.
- Borge-Holthoefer et al. (2015) Javier Borge-Holthoefer, Walid Magdy, Kareem Darwish, and Ingmar Weber. 2015. Content and Network Dynamics Behind Egyptian Political Polarization on Twitter. In Proceedings of the 18th ACM Conference on Computer Supported Cooperative Work & Social Computing (CSCW ’15).
- Cassa et al. (2013) Christopher A Cassa, Rumi Chunara, Kenneth Mandl, and John S Brownstein. 2013. Twitter as a sentinel in emergency situations: lessons from the Boston marathon explosions. PLoS currents 5 (2013).
- Chunara et al. (2012) Rumi Chunara, Jason R. Andrews, and John S. Brownstein. 2012. Social and News Media Enable Estimation of Epidemiological Patterns Early in the 2010 Haitian Cholera Outbreak. The American Journal of Tropical Medicine and Hygiene 86, 1 (2012), 39–45. DOI:http://dx.doi.org/10.4269/ajtmh.2012.11-0597
- Collier (2010) Nigel Collier. 2010. What’s Unusual in Online Disease Outbreak News? Journal of Biomedical Semantics 1, 1 (2010).
- Corazza et al. (2013) Anna Corazza, Sergio Di Martino, Filomena Ferrucci, Carmine Gravino, Federica Sarro, and Emilia Mendes. 2013. Using tabu search to configure support vector regression for effort estimation. Empirical Software Engineering 18, 3 (2013), 506–546. DOI:http://dx.doi.org/10.1007/s10664-011-9187-3
- Culotta (2010) Aron Culotta. 2010. Towards detecting influenza epidemics by analyzing Twitter messages. In Proceedings of the First Workshop on Social Media Analytics (SOMA ’10).
- Demartini et al. (2012) Gianluca Demartini, Djellel Eddine Difallah, and Philippe Cudré-Mauroux. 2012. ZenCrowd: leveraging probabilistic reasoning and crowdsourcing techniques for large-scale entity linking. In Proceedings of the 21st international conference on World Wide Web (WWW ’12). 469–478.
- Denecke et al. (2012) Kerstin Denecke, Peter Dolog, and Pavel Smrz. 2012. Making use of social media data in public health. In Proceedings of the 21st international conference companion on World Wide Web (WWW ’12 Companion).
- Diaz-Aviles et al. (2012a) Ernesto Diaz-Aviles, Avaré Stewart, Edward Velasco, Kerstin Denecke, and Wolfgang Nejdl. 2012a. Epidemic Intelligence for the Crowd, by the Crowd. In International AAAI Conference on Weblogs and Social Media (ICWSM ’12).
- Diaz-Aviles et al. (2012b) Ernesto Diaz-Aviles, Avaré Stewart, Edward Velasco, Kerstin Denecke, and Wolfgang Nejdl. 2012b. Towards personalized learning to rank for epidemic intelligence based on social media streams. In Proceedings of the 21st international conference companion on World Wide Web (WWW ’12 Companion).
- Dredze (2012) Mark Dredze. 2012. How Social Media Will Change Public Health. IEEE Intelligent Systems 27, 4 (2012).
- Farrington et al. (1996) Paddy Farrington, Nick J. Andrews, Andrew Beale, and Michael Catchpole. 1996. A Statistical Algorithm for the Early Detection of Outbreaks of Infectious Disease. Journal of the Royal Statistical Society. Series A (Statistics in Society) 159, 3 (1996), pp. 547–563.
- Fisichella et al. (2010) Marco Fisichella, Avaré Stewart, Kerstin Denecke, and Wolfgang Nejdl. 2010. Unsupervised public health event detection for epidemic intelligence. In Proceedings of the 19th ACM international conference on Information and knowledge management (CIKM ’10). 1881–1884.
- Georgescu et al. (2014) Mihai Georgescu, Dang Duc Pham, Claudiu S. Firan, Ujwal Gadiraju, and Wolfgang Nejdl. 2014. When in Doubt Ask the Crowd: Employing Crowdsourcing for Active Learning. In Proceedings of the 4th International Conference on Web Intelligence, Mining and Semantics (WIMS14) (WIMS ’14). ACM, New York, NY, USA, Article 12, 12 pages. DOI:http://dx.doi.org/10.1145/2611040.2611047
- Gomide et al. (2011) Janaína Gomide, Adriano Veloso, Wagner Meira, Virgílio Almeida, Fabrício Benevenuto, Fernanda Ferraz, and Mauro Teixeira. 2011. Dengue surveillance based on a computational model of spatio-temporal locality of Twitter. In Proceedings of ACM WebSci’2011.
- Hido et al. (2008) Shohei Hido, Tsuyoshi Idé, Hisashi Kashima, Harunobu Kubo, and Hirofumi Matsuzawa. 2008. Unsupervised Change Analysis Using Supervised Learning. In Advances in Knowledge Discovery and Data Mining. Springer Berlin / Heidelberg.
- Höhle et al. (2013) M Höhle, S Meyer, and M Paul. 2013. surveillance: Temporal and spatio-temporal modeling and monitoring of epidemic phenomena. (2013).
- Hulth et al. (2010) Anette Hulth, Nick Andrews, Steen Ethelberg, Johannes Dreesman, Daniel Faensen, Wilfrid van Pelt, and Johannes Schnitzler. 2010. Practical usage of computer-supported outbreak detection in five European countries. (2010).
- Hutwagner et al. (2003) Lori Hutwagner, William Thompson, G. Matthew Seeman, and Tracee Treadwell. 2003. The bioterrorism preparedness and response Early Aberration Reporting System (EARS). Journal of Urban Health 80, 1 (2003).
- Höhle et al. (2015) Michael Höhle, Sebastian Meyer, and Michaela Paul. 2015. surveillance: Temporal and Spatio-Temporal Modeling and Monitoring of Epidemic Phenomena. http://CRAN.R-project.org/package=surveillance R package version 1.8-3.
- Kanhabua et al. (2012) Nattiya Kanhabua, Sara Romano, Avaré Stewart, and Wolfgang Nejdl. 2012. Supporting temporal analytics for health-related events in microblogs. In Proceedings of the 21st ACM international conference on Information and knowledge management (CIKM ’12).
- Khan (2007) Sharib A. Khan. 2007. Handbook of Biosurveillance. Journal of Biomedical Informatics (2007).
- Kostkova et al. (2014) Patty Kostkova, Martin Szomszor, and Connie St. Louis. 2014. #-Swineflu: The Use of Twitter As an Early Warning and Risk Communication Tool in the 2009 Swine Flu Pandemic. ACM Trans. Manage. Inf. Syst. 5, 2, Article 8 (July 2014), 25 pages.
- Lampos and Cristianini (2012) Vasileios Lampos and Nello Cristianini. 2012. Nowcasting Events from the Social Web with Statistical Learning. ACM Trans. Intell. Syst. Technol. 3, 4, Article 72 (September 2012).
- Liu (2009) Tie-Yan Liu. 2009. Learning to Rank for Information Retrieval. Found. Trends Inf. Retr. 3 (March 2009), 225–331. Issue 3.
- Milinovich et al. (2014) Gabriel J Milinovich, Gail M Williams, Archie CA Clements, and Wenbiao Hu. 2014. Internet-based surveillance systems for monitoring emerging infectious diseases. The Lancet infectious diseases 14, 2 (2014), 160–168.
- Muthukrishnan (2005) S. Muthukrishnan. 2005. Data Streams: Algorithms and Applications. Now Publishers.
- Neill (2012) Daniel B. Neill. 2012. New Directions in Artificial Intelligence for Public Health Surveillance. IEEE Intelligent Systems (2012), 56–59.
- Odlum and Yoon (2015) Michelle Odlum and Sunmoo Yoon. 2015. What can we learn about the Ebola outbreak from tweets? American Journal of Infection Control 43, 6 (2015), 563 – 571.
- Otrusina et al. (2012) Lubomir Otrusina, Pavel Smrz, and Gerhard Backfried. 2012. D3.3: M-Eco Media Content Analysis. Technical Report. Brno University of Technology. http://meco-project.eu/sites/meco-project.eu/files/M-Eco_Deliverable_3.3_final.pdf
- Oyeyemi et al. (2014) Sunday Oluwafemi Oyeyemi, Elia Gabarron, and Rolf Wynn. 2014. Ebola, Twitter, and misinformation: a dangerous combination? BMJ 349 (2014). DOI:http://dx.doi.org/10.1136/bmj.g6178
- Paul and Dredze (2011a) Michael Paul and Mark Dredze. 2011a. You Are What You Tweet: Analyzing Twitter for Public Health. In Proceedings of the Fifth International Conference on Weblogs and Social Media (ICWSM ’11).
- Paul and Dredze (2011b) Michael J. Paul and Mark Dredze. 2011b. A Model for Mining Public Health Topics from Twitter. Technical Report. Johns Hopkins University.
- Paul and Dredze (2012) Michael J Paul and Mark Dredze. 2012. A model for mining public health topics from Twitter. Health 11 (2012), 16–6.
- ProMED (2015) ProMED. 2015. ProMED – The Program for Monitoring Emerging Diseases. http://www.promedmail.org/. (2015). [Online; accessed 2015-12-01].
- Ricci et al. (2011) Francesco Ricci, Lior Rokach, Bracha Shapira, and Paul B. Kantor (Eds.). 2011. Recommender Systems Handbook. Springer.
- Sakaki et al. (2010) Takeshi Sakaki, Makoto Okazaki, and Yutaka Matsuo. 2010. Earthquake shakes Twitter users: real-time event detection by social sensors. In Proceedings of the 19th international conference on World wide web (WWW ’10). 851–860.
- Sculley (2010) D. Sculley. 2010. Combined regression and ranking. In Proceedings of the 16th ACM SIGKDD international conference on Knowledge discovery and data mining (KDD ’10). ACM, New York, NY, USA, 979–988.
- Settles (2010) Burr Settles. 2010. Active learning literature survey. Technical Report. University of Wisconsin-Madison.
- Strötgen and Gertz (2010) Jannik Strötgen and Michael Gertz. 2010. HeidelTime: High Quality Rule-Based Extraction and Normalization of Temporal Expressions. In Proceedings of the 5th International Workshop on Semantic Evaluation (SemEval ’10).
XXXXXXXXXX