Wide-Baseline Relative Camera Pose Estimation with Directional Learning
Abstract
Modern deep learning techniques that regress the relative camera pose between two images have difficulty dealing with challenging scenarios, such as large camera motions resulting in occlusions and significant changes in perspective that leave little overlap between images. These models continue to struggle even with the benefit of large supervised training datasets. To address the limitations of these models, we take inspiration from techniques that show regressing keypoint locations in 2D and 3D can be improved by estimating a discrete distribution over keypoint locations. Analogously, in this paper we explore improving camera pose regression by instead predicting a discrete distribution over camera poses. To realize this idea, we introduce DirectionNet, which estimates discrete distributions over the 5D relative pose space using a novel parameterization to make the estimation problem tractable. Specifically, DirectionNet factorizes relative camera pose, specified by a 3D rotation and a translation direction, into a set of 3D direction vectors. Since 3D directions can be identified with points on the sphere, DirectionNet estimates discrete distributions on the sphere as its output. We evaluate our model on challenging synthetic and real pose estimation datasets constructed from Matterport3D and InteriorNet. Promising results show a near 50% reduction in error over direct regression methods. Code will be available at https://arthurchen0518.github.io/DirectionNet.
1 Introduction
Estimating the relative pose between two images is fundamental to many applications in computer vision such as 3D reconstruction, stereo rectification, and camera localization [20]. For calibrated cameras, relative pose is synonymous with the essential matrix, which encapsulates the projective geometry relating two views. Prevailing approaches recover the global model from corresponding points [31, 21, 43] within an iterative robust model fitting process [16, 66]. Recent progress has introduced deep-learned modules that can replace components of this classic pipeline [64, 52, 11, 10, 54, 45, 49, 3]. While this class of techniques has been extensively analyzed [51], well-known failure cases include where feature detection or matching is difficult, such as low image overlap, large changes in scale or perspective, or scenes with insufficient or repeated textures.
In these cases, it is natural to consider if supervised deep learning can address this basic task of essential matrix estimation, given its success in a variety of challenging computer vision problems. Specifically, can we train a deep neural network to represent the complex function that directly maps image pairs to their relative camera pose? Such a model would provide an appealing alternative to formulations that are sensitive to correspondence estimation performance.
Unfortunately, evidence suggests designing regression models for pose estimation is challenging, and in fact finding a parameterization of the motion groups effective in deep learning models is still an active research topic [34, 68, 46]. Not surprisingly, the initial works exploring relative pose regression (e.g. [39, 48]) are not conclusively successful in the difficult scenarios described above.
In this work we introduce a novel deep learning model for relative pose estimation, focused on the challenging wide-baseline case. Conceptually, our model generates a discrete probability distribution over relative poses, and the final pose estimate is taken as the expectation of this distribution. Our method is inspired by works that show estimating a discrete distribution, or a heatmap over a quantized output space, consistently outperforms direct regression to the continuous output space. This observation has arisen in various applications, including estimating 2D and 3D keypoint locations [57, 33, 59] and estimating periodic angles [26].
However, it is currently unclear if this idea translates directly to complex higher-dimensional output spaces. Relative camera pose lives in a five dimensional space, so predicting a discrete distribution would require storage in the output space alone [36]! Given that representing such large spaces is currently intractable for neural networks at any reasonable resolution, how can we effectively apply this concept to the relative pose problem?
To this end, we introduce a novel formulation that builds upon the idea of estimating discrete probability distributions on the 5D relative pose space. We propose two key components to execute this idea effectively:
-
1.
A parameterization of the motion space that factorizes poses as a set of 3D direction vectors. A non-parametric differentiable projection step can map these directions to their closest pose.
-
2.
DirectionNet, a convolutional encoder-decoder model for predicting sets of 3D direction vectors. The network outputs discrete distributions on the sphere , the expected values of which produce direction vectors.
Our core contributions are in recognizing that incorporating a dense structured output in the form of a discrete probability distribution can improve wide-baseline relative pose estimation, and in introducing a technique to execute this idea efficiently. The attributes of this approach that help make it effective include (1) DirectionNet is fully-convolutional and as such does not utilize any fully-connected regression layers, and (2) it allows for additional supervision as both the dense distribution and final estimated pose can be supervised.
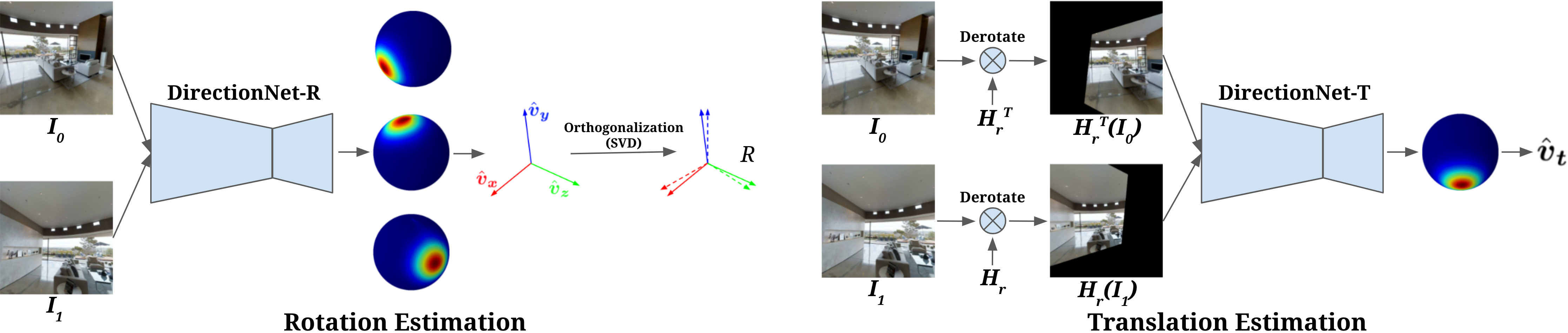
DirectionNet is deployed in two stages, wherein the relative rotation is estimated first, followed by the relative translation direction. This allows us to de-rotate the input images after the first stage, which reduces the complexity of the translation estimation task.
DirectionNet is evaluated on two difficult wide-baseline pose estimation datasets created from the synthetic images in InteriorNet [28], and the real images in Matterport3D [5]. DirectionNet consistently outperforms direct regression approaches (for the same pose representation as well as numerous alternatives), as well as classic feature-based approaches. This illustrates the effectiveness of estimating discrete probability distributions as an alternative to direct regression, even for a complex problem like relative pose estimation. Furthermore, these results validate that a supervised data-driven approach for wide-baseline pose estimation can succeed in cases that are extreme for traditional methods.
2 Related Work
Feature matching–based methods are still prevalent for the relative pose problem, yet suffer under large motions that yield unreliable correspondence (see [51] for a survey). Recent works deploy deep learning in subproblems such as feature detection [54, 11], filtering or reweighting outliers [64, 52]. Differentiable versions of consensus methods like RANSAC have also been proposed [49, 3]. These still rely on sufficiently accurate matches, an uncertain prospect in wide-baseline settings.
Many deep regression methods have addressed 3D object pose recovery from a single image [40, 56, 60, 29, 58]. For our task of relative pose estimation, [39] adopts a Siamese convolutional regression model to directly estimate relative camera pose from two images. [12] proposes a relative pose layer atop Siamese camera localization towers. [48] introduces a model for uncalibrated cameras that regresses to a fundamental matrix via an intermediate representation of camera intrinsics, rotation, and translation. Related to these efforts, [9] and [42] proposed deep convolutional networks for homography estimation. Despite targeting various tasks, most of the above methods share a common architecture design—a convolutional network culminating with fully connected layers for regression. A related problem to ours is camera re-localization which estimates pose from a single image in a known scene [23, 17]. Our setting is quite different as we try to recover the relative camera pose from two images in a previously unvisited scene.
Deep learning for ego-motion estimation or visual odometry is an active area which includes supervised methods such as [61] (depth supervision), and many self-supervised methods (see [6] for a survey). In general, these systems make design choices specific for small-baselines and video sequences, such as using frame-to-frame image reconstruction losses [67, 65, 63], or training with more than two frames [62, 13, 67]. In contrast, our focus is on learning to estimate relative pose for wide-baseline image pairs.
Probabilistic deep models have been used to capture uncertainty in pose predictions. In [8, 37] they estimate the distribution of 6D object poses to tackle shape symmetries and ambiguities, while [50, 19] uses directional statistics to model object rotations and regress the parameters of the probability distributions. [4] adopts mixtures of von Mises-Fisher and quasi-Projected Normal distributions to represent point sets. The multi-headed approach in [47] combines multiple predictions into a mean pose and associated covariance matrix. In contrast to most of these techniques, ours is a discrete representation and is not tied to any choice of parametric probability distribution model.
3 Method
We now outline our method for estimating relative pose from image pairs. The relative pose between two views is specified by a 3D rotation (, , ), and a translation . Without additional assumptions, the relative translation can only be recovered up to a scale factor, so we adopt the normalization ; equivalently, is restricted to the 2-sphere, . Our task is to estimate the relative pose in .
In principle, we desire a model that estimates a discrete distribution over the pose space . This requires discretizing this five-dimensional space at a reasonable resolution, which is computationally infeasible in deep networks. Instead, our approach presents a novel parameterization for relative poses along with simplifying assumptions to make the task tractable.
3.1 Directional parameterization of relative pose
Parameterizing requires a choice for . We choose a simple over-parameterization of , splitting the rotation matrix into its component vectors , where each component is itself a unit vector in . The relative pose between images, , can then be specified by the four direction vectors . See Section 4.3 for a discussion and justification of our parameterization.
3.2 Estimating 3D directions
The relative pose task is now one of estimating a set of direction vectors . Making the simplifying assumption of independence of these vectors, our approach is to (1) predict a probability distribution over the space of possible directions () for each vector, and (2) extract the direction prediction from each distribution. It is important to note that representing functions on the sphere and integrating them requires careful consideration in the context of neural networks where the data representation is restricted to regular grids. The details of our approach are below.
Spherical distributions.
We represent functions on with a 2D equirectangular projection indexed by spherical coordinates . Our discretization follows [25]: is the angle of colatitude (, ), is the azimuth (, ), and is the grid resolution. Let denote the unnormalized output of a network, and be the softplus function. We can map to a probability distribution with a spherical normalization:
| (1) |
where the in the normalizing term comes from the area element on .
Spherical expectation.
The operator identifies the most probable direction from a distribution, but is not differentiable and its precision is limited by the grid resolution. An alternative is the Fréchet mean [2], which is appealing since it defines a spherical centroid using the natural metric (geodesics). However, it requires a non-convex optimization and the solution is not necessarily unique. Instead, we choose the alternative of taking the expected value of the distribution. In the continuous case, we define the expected value of a random variable on with PDF as . In the discretization of the sphere introduced above, this becomes
| (2) |
where is the 3D unit vector corresponding to spherical point . The expected value can be projected to the sphere in a straightforward manner: .111An alternative formulation to Equations 1 and 2 would include the traditional operator adapted to the sphere. This would reinterpret the network output as log-probabilities and require in Eq. 1.
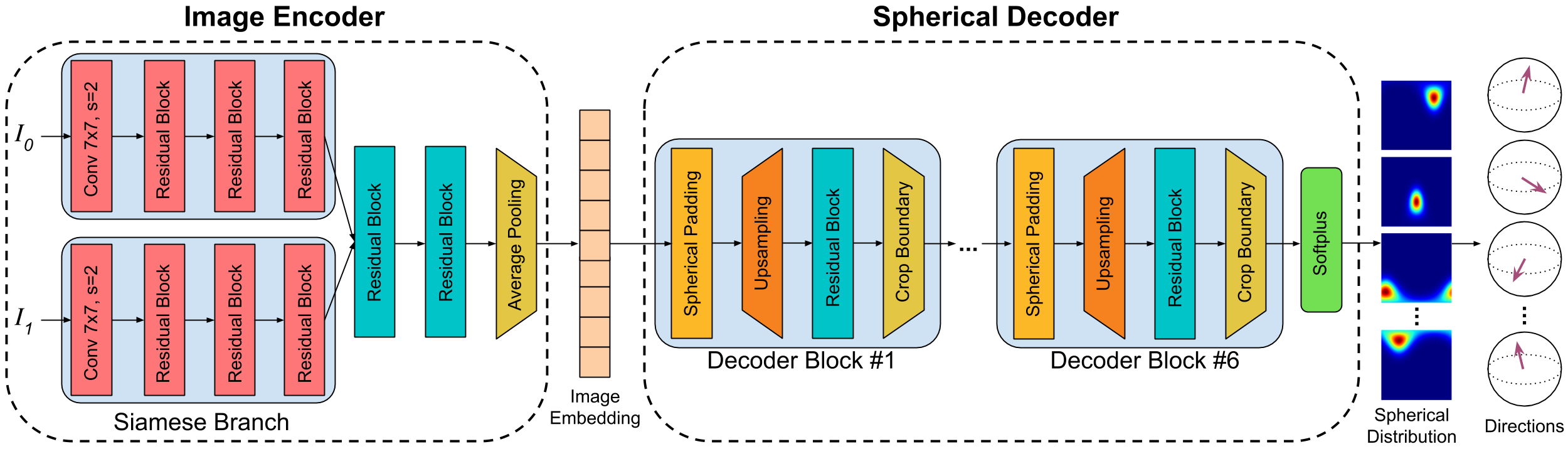
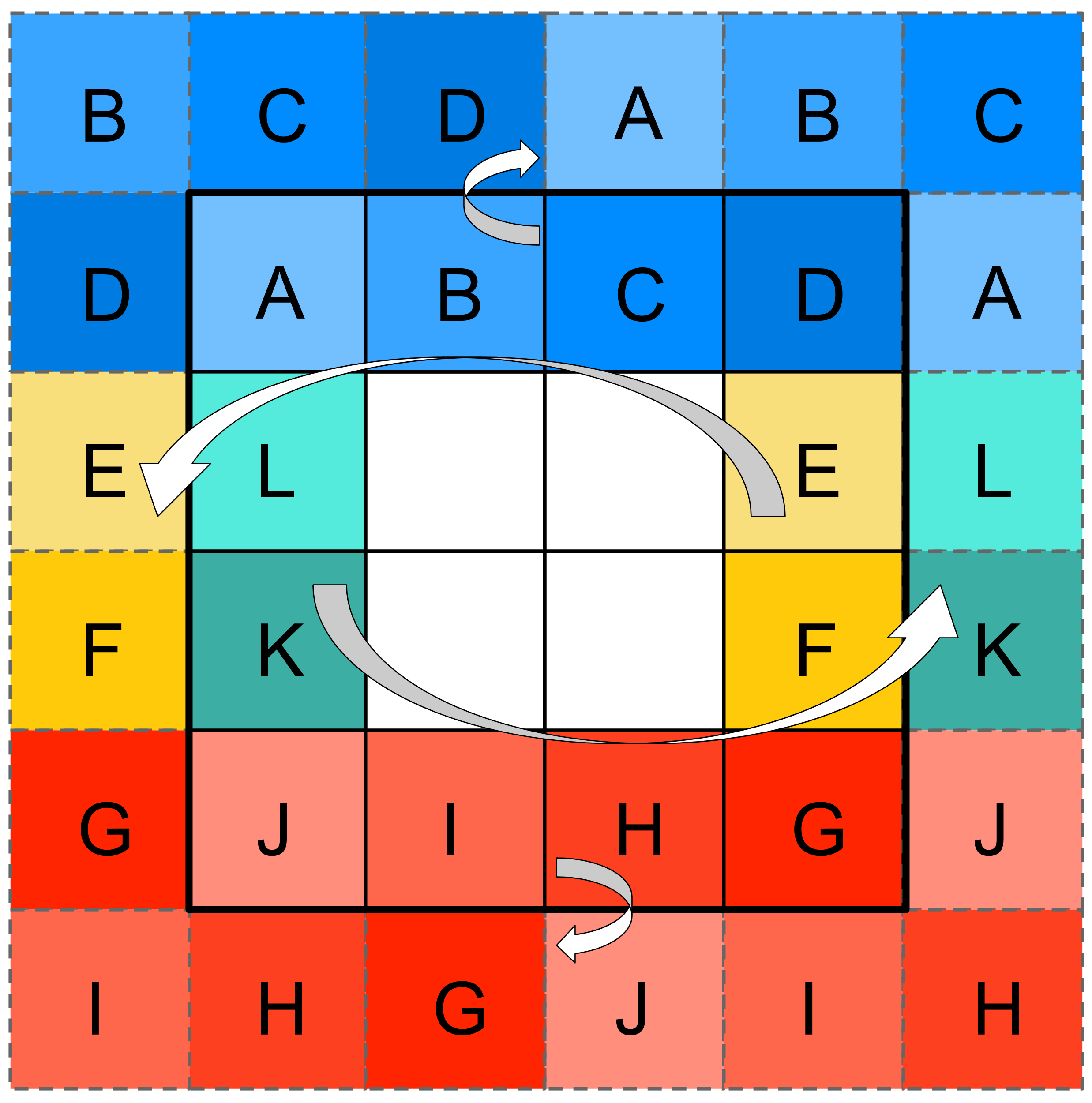
3.3 DirectionNet for relative pose estimation
DirectionNet maps image pairs to sets of unit direction vectors following the steps outlined above. We adopt an encoder-decoder style architecture that learns a cross-domain mapping from two images to a spherical representation (see Figure 2(a)). We describe two ways that DirectionNet can be instantiated for relative pose estimation.
The SVD variation.
Here DirectionNet will produce four vectors which are the predictions of the directional pose components . Due to the simplifying assumptions earlier, in general as orthogonality is not guaranteed. However, we can project to with orthogonal Procrustes [55], which is a differentiable procedure [59] and provides the optimal projection to by Frobenius norm:
| (3) |
where is the SVD of M [55].
The Gram-Schmidt variation.
For , the last column is fully constrained: . Thus, we only need DirectionNet to produce three vectors and obtain a rotation by a partial Gram-Schmidt projection of and as in [68].
Both the SVD and Gram-Schmidt projections have been shown recently to reach state-of-the-art performance for different 3D rotation estimation tasks, especially when predicting arbitrary (large) rotations. See [27] and [68] for the analysis. Although overall performance between the two is similar, SVD is shown to be slightly more effective, with a possible explanation being that SVD finds a least-squares projection while Gram-Schmidt is greedy. Our experimental findings confirm the analysis.
3.4 Two-stage model with derotation
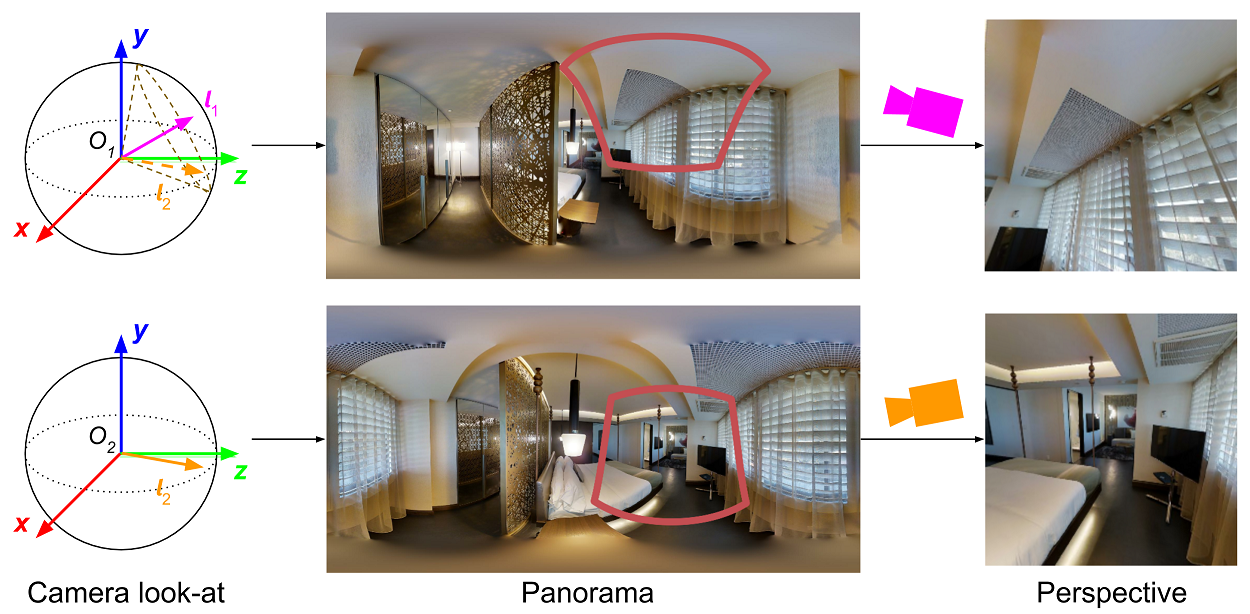
Intuitively, we expect that learning camera translation should be easiest when the data never exhibit rotational motion. Hence, we propose estimating camera pose sequentially: (1) A DirectionNet (denoted DirectionNet-R) estimates the relative rotation between input images, (2) this rotation is used to derotate the input images, and (3) a second DirectionNet (denoted DirectionNet-T) predicts translations from the rotation-free image pair. Figure 1 illustrates the stages of this process.
However, when the relative rotation between the cameras is large, derotating one image relative to the other could result in projecting most of the scene outside the camera’s field of view. To limit this effect we find that it is helpful to project both input images to an intermediate frame using half of the estimated rotation with a larger FoV and proportionally increased resolution. The derotation implementation involves a homography transformation , where is the matrix of camera intrinsics for the input image, is the intrinsics for the desired derotated image, and is the half-rotation of the estimated rotation . Setting maintains the field of view (FoV) and resolution of the input image after derotation. We use and to project input images and , respectively, onto the “middle” frame. The output FoV and resolution are controllable parameters of the model. To mitigate the effect of rotation errors on translation prediction, we developed a rotation augmentation scheme with random perturbations (see appendix C).
3.5 Network architecture
The DirectionNet architecture is illustrated in Figure 2(a). Notably, we eschew the skip connections common to similar convolutional architectures ([41, 53]) since they would not reflect the correct spatial associations between the planar and spherical topologies (observed in [15]).
The image encoder embeds image pairs into using a Siamese architecture. A Siamese branch consists of a , stride-2 convolution followed by a series of residual blocks222All residual blocks consist of two bottleneck blocks [22] with convolutions, batch normalization, and leaky ReLU pre-activations., each of which downsamples by 2. The outputs are concatenated in the channel dimension, and after two more residual blocks, a global average pooling produces the embedding.
The spherical decoder maps embeddings to spherical distributions by repeatedly applying bilinear upsampling and residual blocks. We use spherical padding before upsampling to ensure adjacent pixels at the boundaries reflect the correct neighbors on the sphere (see Figure 2(b)). The final outputs, of size , are interpreted as spherical distributions, and are subsequently mapped to direction vectors following equations 1 and 2. In total, a single DirectionNet contains M parameters. Note that we could also consider a Spherical CNN decoder [7, 14]. While such models are equivariant to 3D rotations, the benefit in our setting would be limited since the image encoder is not rotation equivariant. Hence, we opt for the computational efficiency of 2D convolutions.
3.6 Loss terms and model training
In this section, we describe the loss terms and training strategy for our model. We let denote a single distribution generated by DirectionNet, and let its corresponding ground truth distribution be . The ground truth distributions are constructed using the von Mises-Fisher distribution as described in Sec. 4.1. With a slight abuse of notation we will denote with the expected value of a distribution and is computed according to equation 2. One appealing property of DirectionNet is that both the output direction vectors as well as their corresponding dense probability distributions can be supervised.
The direction loss is the negative cosine similarity between two 3D vectors:
| (4) |
We introduce two loss terms to supervise distributions. First, the distribution loss provides dense supervision on the equirectangular distribution grid:
| (5) |
Second, the spread loss penalizes the spherical “variance” [38] to encourage unimodal and concentrated distributions:
| (6) |
The full loss for a single predicted direction vector combines the three individual losses:
| (7) | |||||
See appendix E for an analysis of the individual loss terms. By far the most impactful loss on performance is the distribution loss .
We train our two-stage pipeline sequentially. We first train DirectionNet-R, which takes the source and target image pair (, ) as input and produces three direction vectors , which are mapped onto . The complete training loss for DirectionNet-R is the sum of individual losses for the three estimated directions . After training, DirectionNet-R is frozen and its predictions are used for derotating the inputs of DirectionNet-T. DirectionNet-T takes the input pair (, ) and outputs a translation direction . Since the translation is represented with a single unit vector, DirectionNet-T is trained with the loss .
Matterport-A Matterport-B mean (∘) med (∘) rank mean (∘) med (∘) rank mean (∘) med (∘) rank mean (∘) med (∘) rank DirectionNet 9D 3.96 2.28 2.76 14.17 6.46 3.29 13.60 3.54 2.89 21.26 8.90 3.44 6D 4.30 2.22 2.79 16.37 7.07 3.29 14.85 3.69 3.45 23.60 9.42 3.79 9D-Single 4.55 3.11 3.83 21.65 10.53 4.71 13.37 4.00 2.85 28.41 13.27 4.26 Quat. 23.32 23.00 8.25 39.85 24.85 6.22 37.09 25.25 7.13 49.39 31.59 6.94 Regression Bin&Delta 6.93 4.71 5.28 22.84 10.16 3.73 31.54 22.98 6.45 29.45 14.30 5.14 Spherical 10.68 7.98 6.79 40.09 22.85 6.36 32.94 20.56 6.42 51.00 33.18 8.40 6D 5.73 3.66 3.79 35.75 21.89 6.32 18.23 7.69 4.29 39.06 25.07 5.69 Quat. 15.40 12.66 6.86 41.57 21.47 7.18 28.38 19.23 6.19 48.99 34.94 7.63 SIFT LMedS 25.55 5.63 7.71 35.53 14.84 6.20 36.58 10.54 8.13 42.67 26.64 6.06 RANSAC 19.33 6.66 7.31 45.04 29.78 8.08 31.30 9.55 7.74 47.74 26.19 6.19
4 Experiments
To evaluate our method on challenging data exhibiting a wide range of relative motion, we generate image pairs from existing panoramic image collections. Image pairs are generated by sampling pairs of panoramas from a common scene, then projecting them to overlapping planar perspective views. By varying the camera viewing angles we create a dataset with varied relative poses and overlap. Specific details of each dataset are provided below. Unless specified otherwise, our training image pairs have a resolution of 256256 and a FoV. In all cases, we generate 1M training pairs and 1K test pairs. Note that there is no overlap between the train and test scenes. See appendix B for more details.
InteriorNet [28] is a synthetic dataset with 560 scenes with panoramas rendered along smooth camera trajectories which we sample at random strides. InteriorNet-A is constructed to have rotations up to 30∘, while InteriorNet-B has varied FoV ( to ) and rotations up to 40∘.
Matterport3D [5] contains 10K real panoramas captured from locations 2.25m apart covering 90 scenes. Matterport-A is constructed to have rotations up to 45∘, and Matterport-B up to 90∘. These are more challenging than InterionNet due to a wider baseline and smaller overlap.
4.1 Training details
We train with loss weights , , and Adam [24] with a learning rate of 1e-3 and a batch size of 20. The ground truth distributions are generated by the von Mises-Fisher distribution with concentration ( is analogous to in a Gaussian distribution). The derotated images for InteriorNet have a FoV, while the derotated Matterport3D images have a FoV and an increased resolution of to compensate for the larger rotations.
4.2 Baselines
We now introduce the baselines. Full details can be found in appendix D.
DirectionNet variations.
We consider multiple variants of our full two-stage model with intermediate derotation. DirectionNet-9D projects three direction vectors onto using SVD for the rotation estimation, while DirectionNet-6D uses a partial Gram-Schmidt projection [68] (refer to Sec. 3.3 for details). To understand the importance of derotation, we also consider a single-stage version without derotation (DirectionNet-9D-Single) which estimates four directions from a single DirectionNet module.
Discrete pose representation alternatives.
To evaluate our choice of representation for the discretized pose space, we consider multiple alternatives: Bin&Delta [35] is a hybrid model combining a coarse rotation classification (over clustered quaternions) with a refinement regression network. To understand if decoupling a 3D rotation into a set of direction vectors is necessary, we introduce DirectionNet-Quat which estimates a discrete distribution over the space of unit quaternions at resolution The spherical decoder is replaced by a 3D volumetric CNN decoder. 3D-RCNN [26] estimates individual (Euler) angles with a discrete distribution over the quantized circle. 3D-RCNN consistently under-performed Bin&Delta, see appendix D.
Regression baselines.
We evaluated multiple direct pose regression baselines: Spherical regression [30] uses a novel spherical exponential activation for regression to -spheres; 6D [68] regresses 6D outputs followed by a Gram-Schmidt projection for rotations; Quaternion regresses a unit quaternion for the rotation. This is what is used in the camera pose regression modules from PoseNet [23] and [39]. The multiple regression baselines share the same image encoder architecture as our DirectionNet.
Parametric probabilistic pose.
Feature-based baselines.
We consider two versions of the classic correspondence-based pipeline, SIFT features [32] with robust LMedS [66] (SIFT+LMedS) or with RANSAC [16] (SIFT+RANSAC). We also consider pipelines with learned components such as SuperGlue [54] and D2-Net [11].
Note, the differences in most baselines are in the rotation representation. Unless specified otherwise, the baselines predict a unit-normalized 3D vector for the camera translation direction.
Evaluation metrics.
We report geodesic errors for both rotations and translation directions, separately. Additionally, we rank each method on every test pair, reporting the mean rank across examples (1 is the best possible rank, 10 is the worst possible rank).
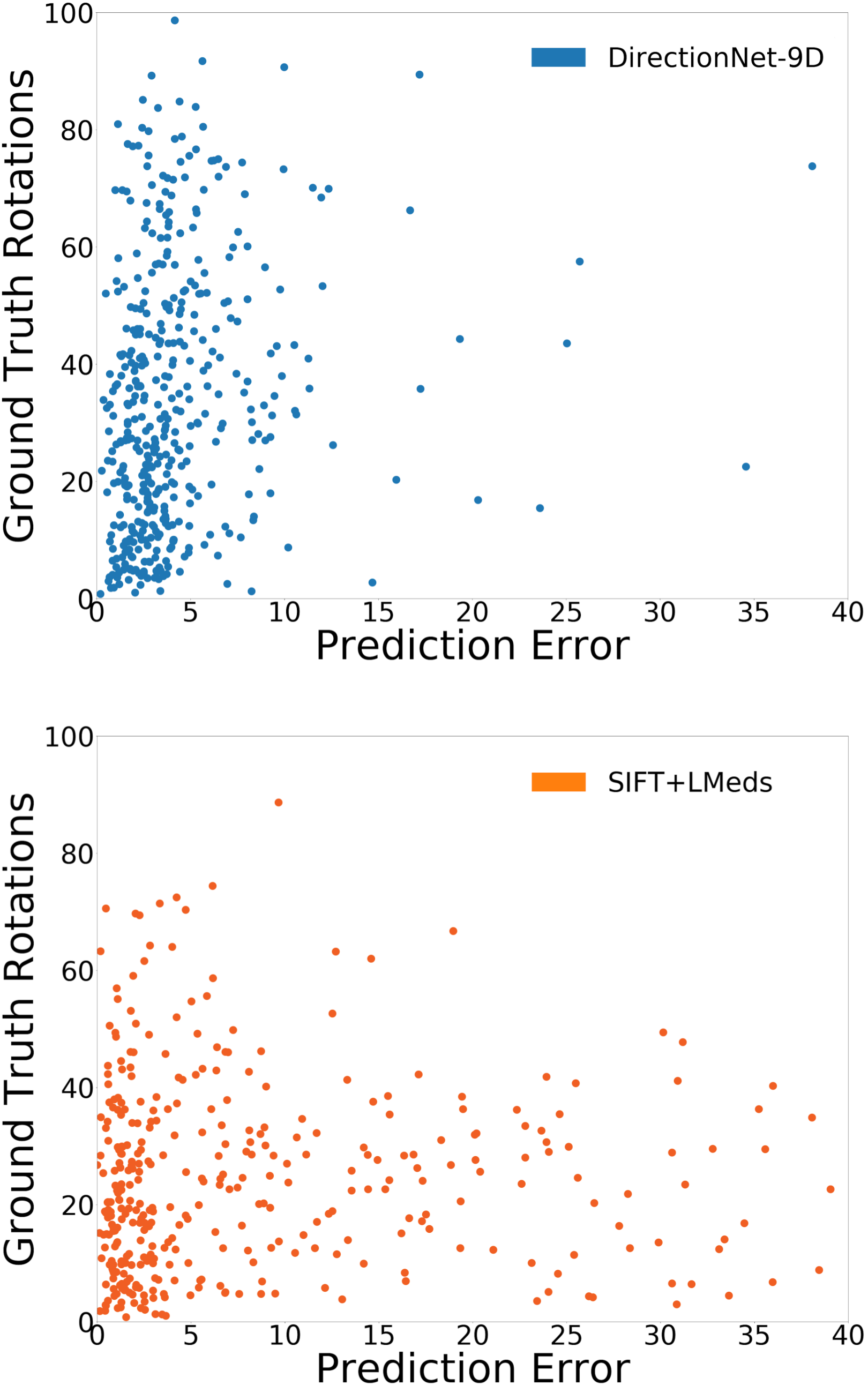
Matterport-A mean (∘) med (∘) mean (∘) med (∘) SuperGlue (indoor)[54] 8.34 5.22 21.08 11.86 D2-Net [11] 18.79 7.12 41.58 25.56 DirectionNet-9D 3.96 2.28 14.17 6.46 Matterport-B mean (∘) med (∘) mean (∘) med (∘) SuperGlue (indoor)[54] 13.23 7.19 29.90 13.28 D2-Net [11] 21.03 7.74 43.82 27.30 DirectionNet-9D 13.60 3.54 21.26 8.90
4.3 Analysis
Table 1 reports the quantitative results of the different methods on the Matterport datasets (see Table 3 for results on the InteriorNet datasets). We begin by considering the two main questions for analyzing our approach.
Can relative camera pose be better learned using a discrete pose distribution versus direct regression? We observe that our DirectionNet outperforms all baselines on each metric for each dataset. A particularly illustrative comparison is DirectionNet-6D vs 6D regression, where for the same pose representation, prediction via a discrete distribution is consistently better. We do not see the same improvement for DirectionNet-Quat over Quaternion regression, however, which indicates our choice of the lower-dimensional spherical/directional representation is important (see discussion below). Finally, we observe that predicting a parametric probabilistic representation of pose does not help (vM [50] performed 5x worse than DirectionNet, see appendix D).
Is our directional representation better than alternatives for estimating discrete distributions over relative camera pose? Both DirectionNet-6D/9D and DirectionNet-9D-Single consistently outperform alternatives which also use a quantized output space in some way, namely Bin&Delta [35], DirectionNet-Quat, and 3D-RCNN [26]. Our DirectionNet-Quat baseline predicts a distribution over the half hypersphere in . Its poor performance supports our hypothesis that the smaller resolution allowed by its space requirements limits performance, whereas our directional models require just space.
Feature-based approaches.
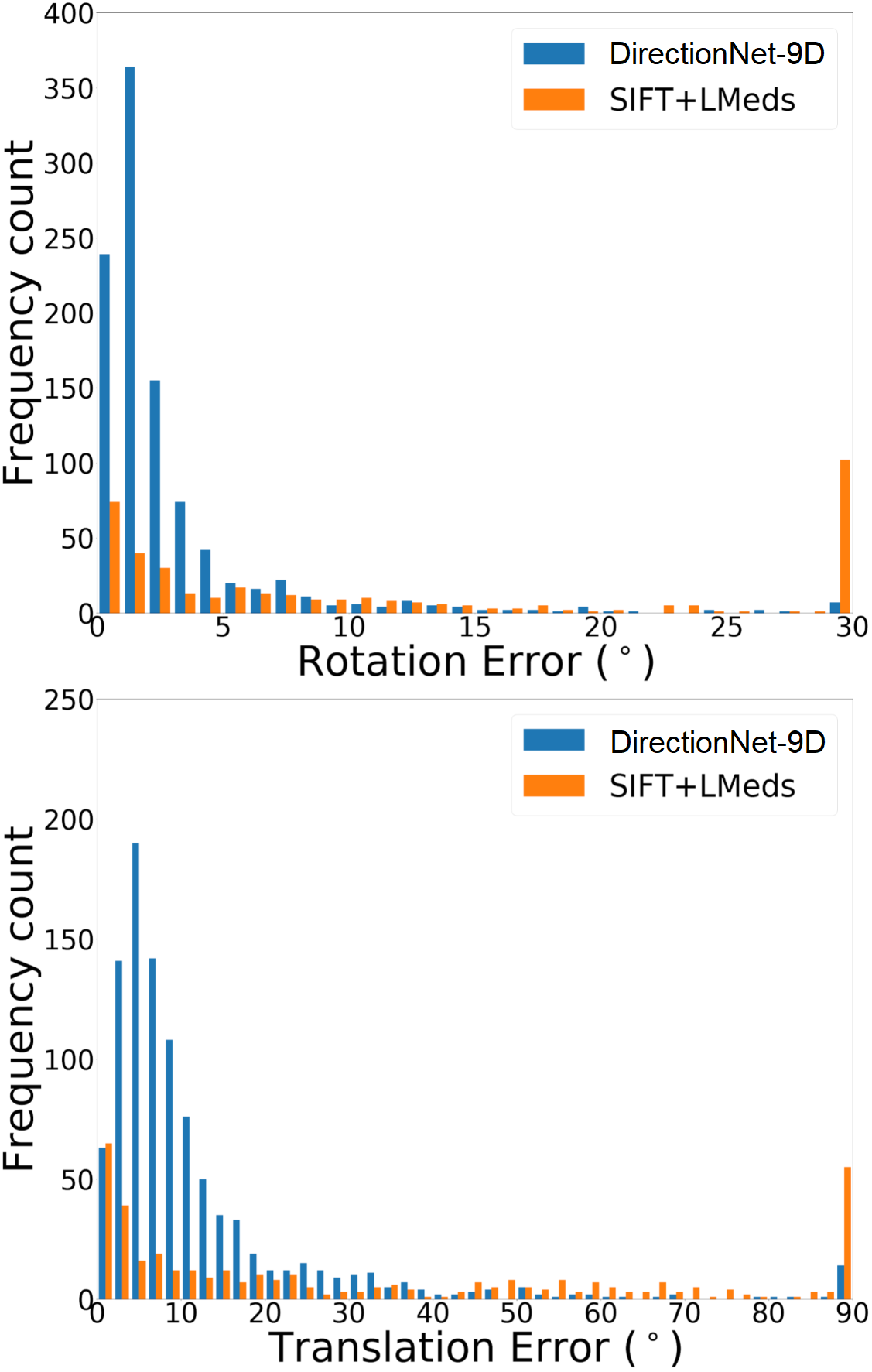
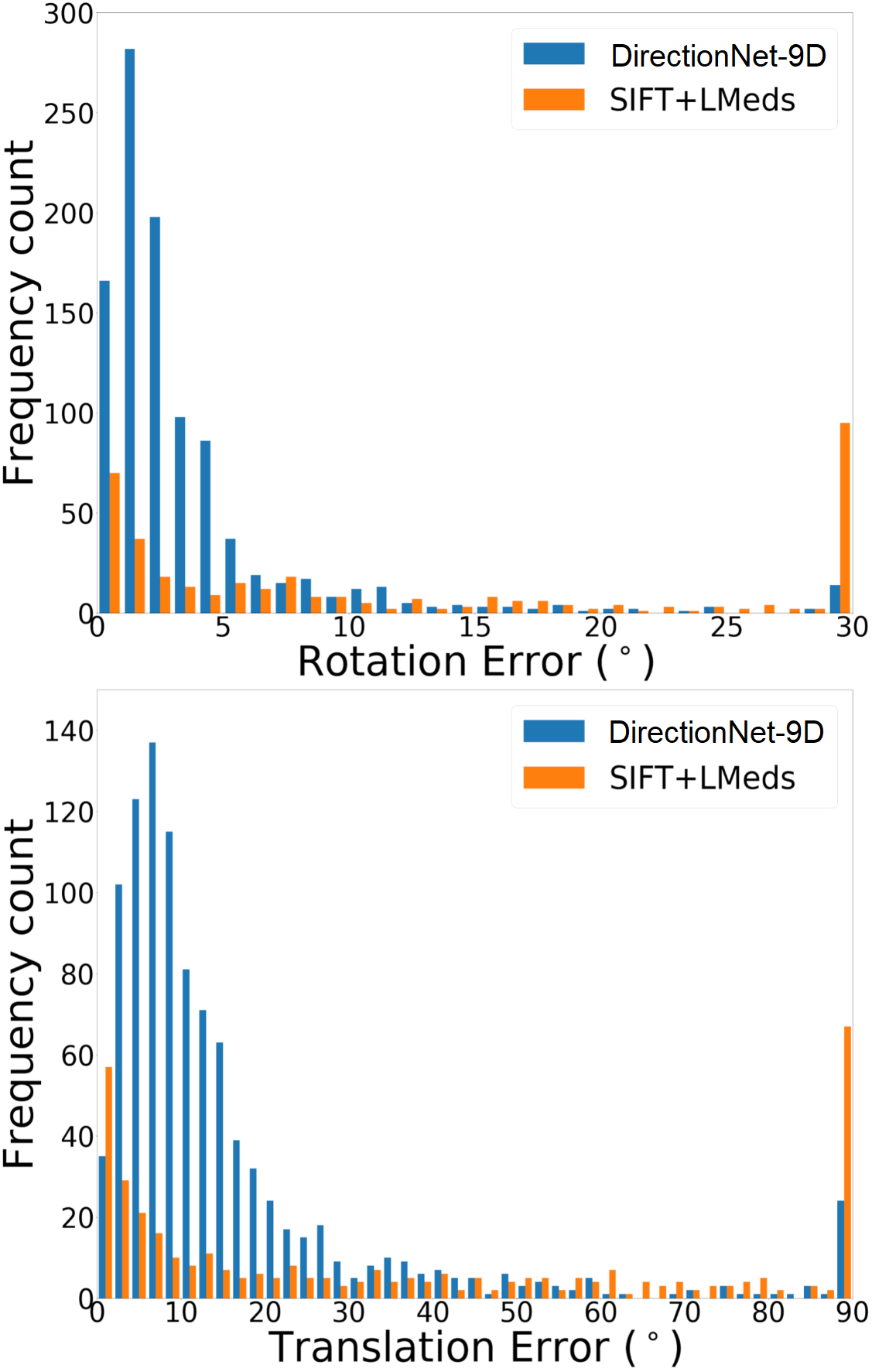
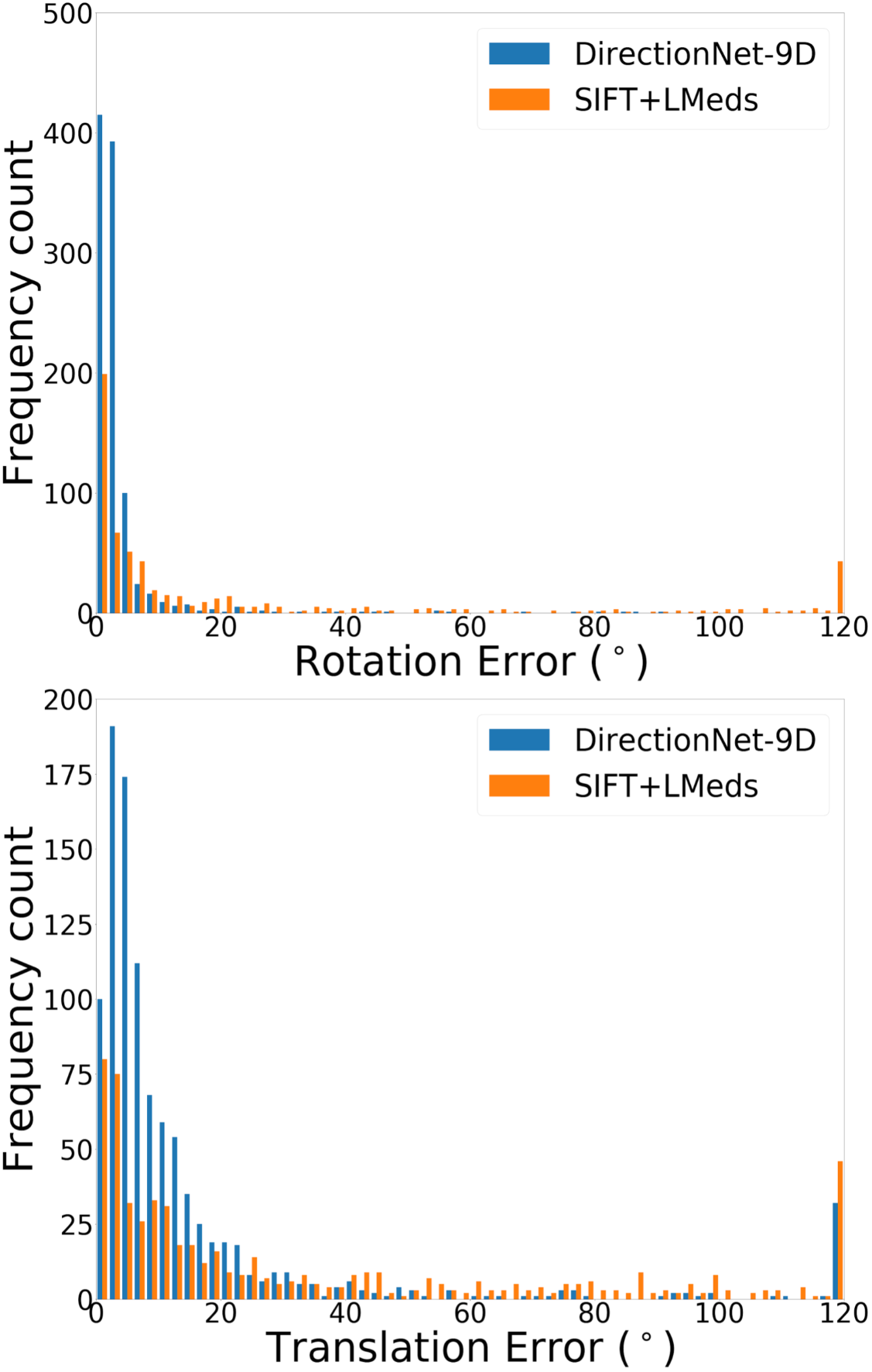
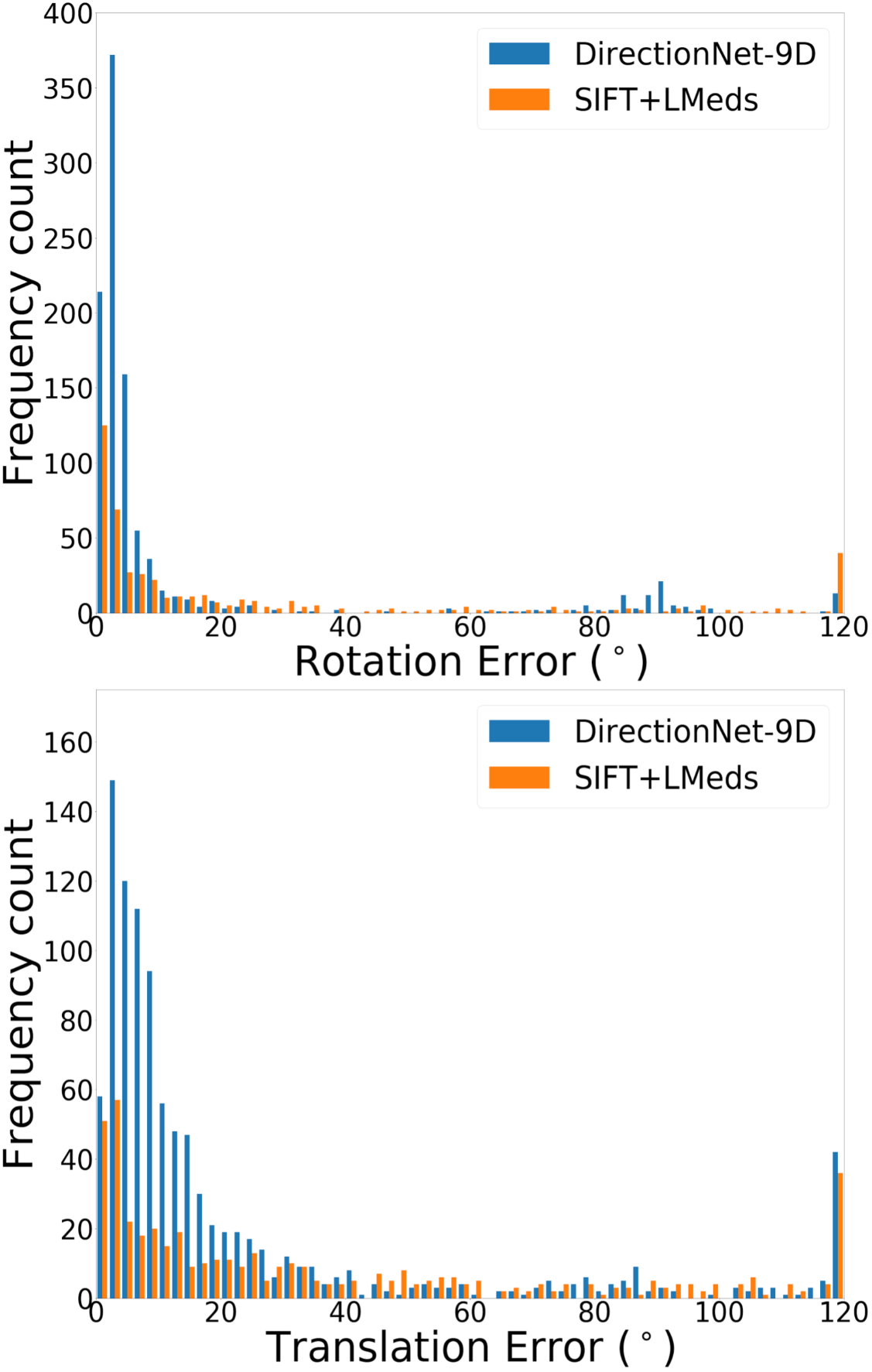
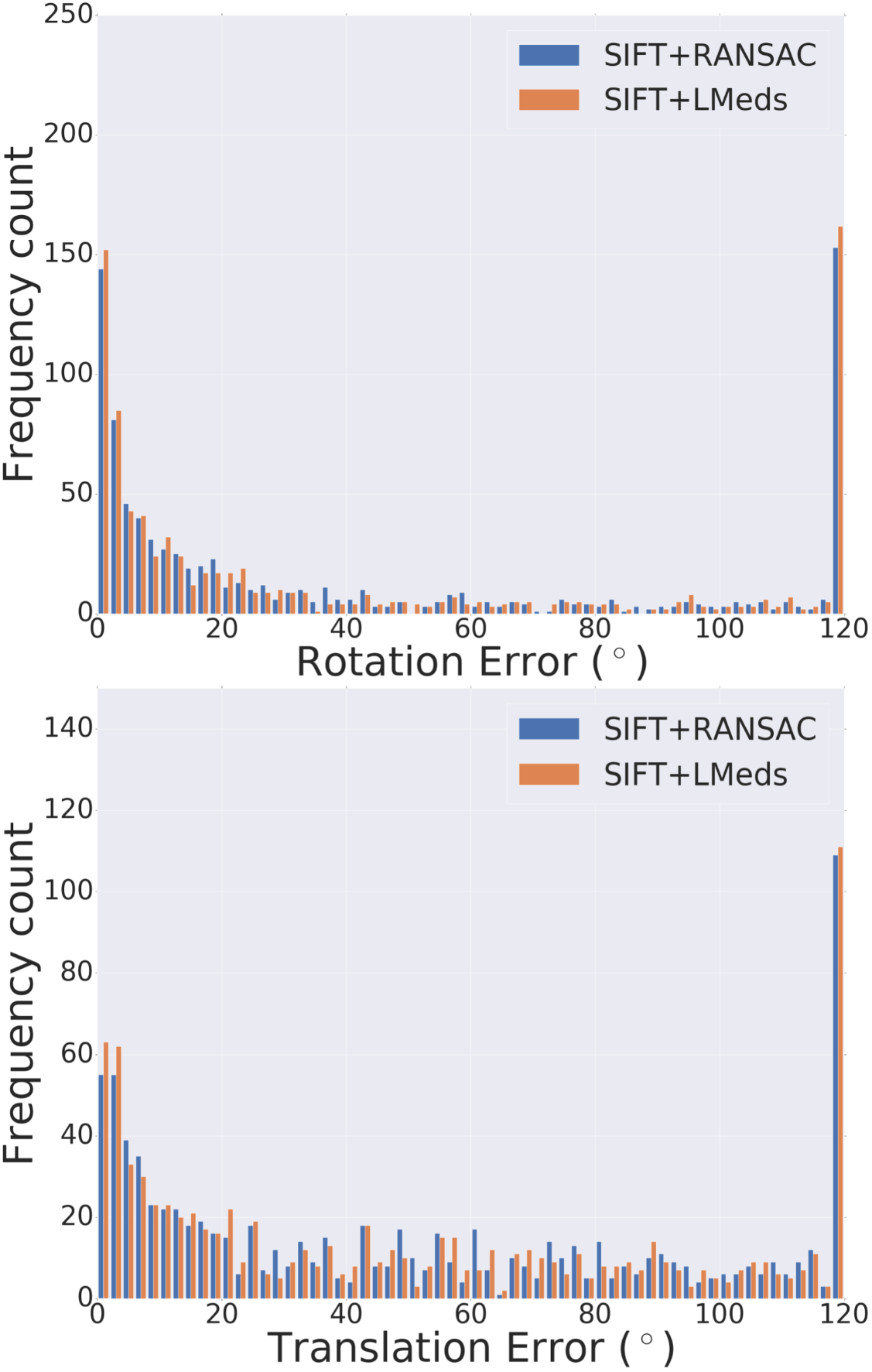
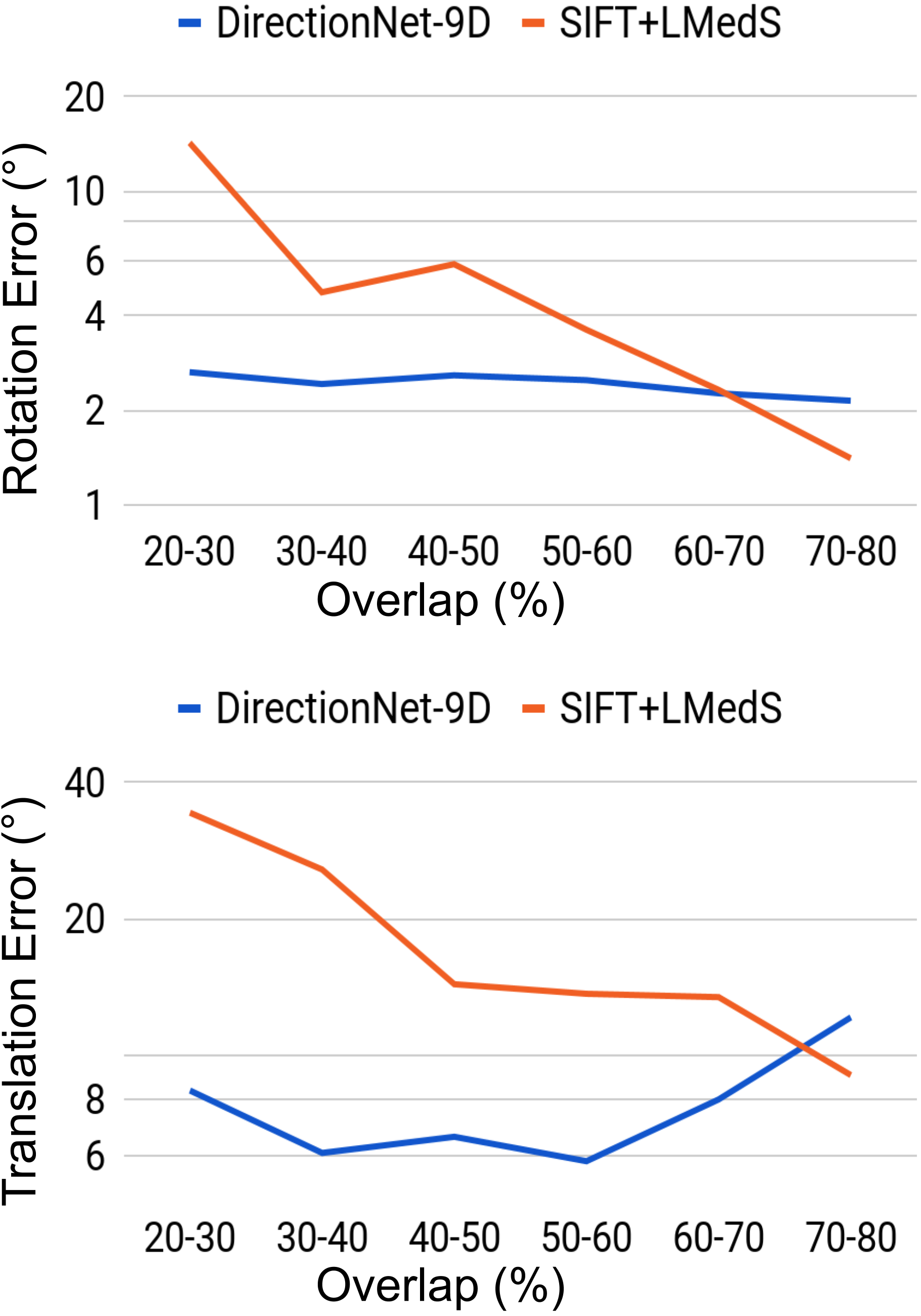
In this work our aim is to understand if relative pose regression can be improved using a discrete pose distribution representation, especially in the difficult wide-baseline setting. Thus, our primary experimental analysis is a comparison of different regression and probabilistic techniques. For completeness, we also evaluate feature-based approaches. Unsurprisingly, the feature-based methods have different performance characteristics compared to the learned direct methods. For example, for those image pairs where feature extraction and matching are likely successful (e.g. high overlap), the estimated motion based on SIFT features is consistently better than any learned technique (Fig. 3-b). We note that in the best cases the SIFT methods both regularly reach sub- errors in relative rotation estimation, while all of the learning methods rarely reach errors that low. However, our dataset construction intentionally includes a large fraction of large-motion pairs likely to have low overlap, and this drives down the overall performance of these methods (Fig. 3-a). In addition to classic feature-based methods, we compare with learned descriptors and matching pipelines. Table 2 shows results using pretrained models for SuperGlue [54] and D2-Net [11]. SuperGlue has slightly better performance than DirectionNet on mean rotation error for Matterport-B, but in general DirectionNet outperforms the learned feature-based methods. This is not surprising since our datasets include many image pairs where keypoint detection and matching can be difficult.
Qualitative Results.
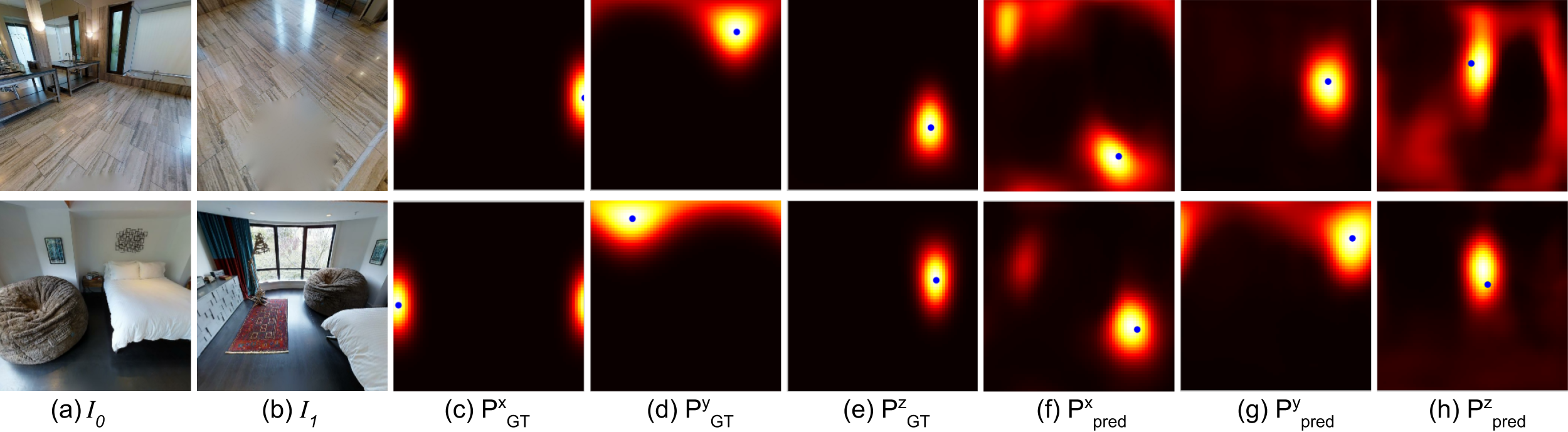
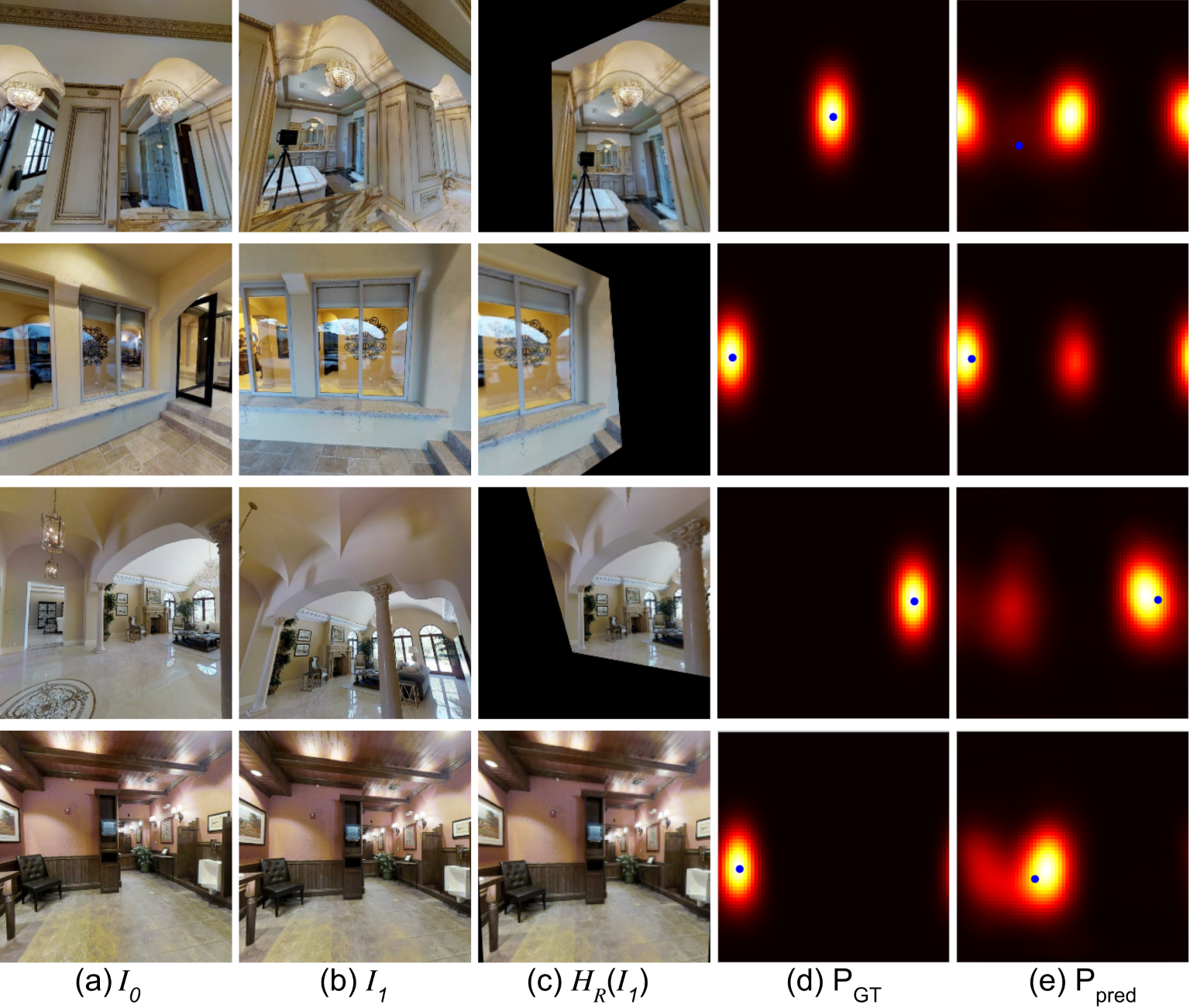
Figure 4 shows results on the challenging real Matterport data which includes large baselines and occlusions. We qualitatively assess each method by visualizing epipolar lines after prediction. We see that DirectionNet can still recover the correct relative pose in never-seen test scenes even when presented with extreme motions.
Generalization.
To demonstrate the generalization ability of our model, we train DirectionNet-9D on InteriorNet-A (synthetic) and test it on Matterport-A (real). The mean and the median errors of the rotation are 8.42∘ and 5.13∘, and 20.71∘ and 8.60∘ for translation. Even without any fine-tuning on real data our approach still outperforms most baselines which had the benefit of training on Matterport-A. To test the model’s performance on outdoor scenes, we trained on a subset of KITTI [18]. DirectionNet gives 9.19∘ mean rotation error and 19.36∘ translation error while the best baseline gives 13.44∘ and 22.53∘ for rotation and translation respectively. See Table 4.

5 Conclusion
The results presented above tell a consistent story. Models that regress relative pose directly from wide-baseline image pairs can be improved by estimating a discrete probability distribution in the pose space. Our approach effectively executes this idea by operating on a factorized pose space that is lower dimensional than the 5D pose space and suitable for discretized outputs. Evaluated on challenging synthetic and real wide-baseline datasets, DirectionNet generally outperforms regression models, parametric probabilistic models, and alternative discretization schemes.
References
- [1] Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mané, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viégas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. TensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Software available from tensorflow.org.
- [2] Bijan Afsari. Riemannian center of mass: Existence, uniqueness, and convexity. Proceedings of the American Mathematical Society, 139, 02 2011.
- [3] Eric Brachmann, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, and Carsten Rother. Dsac - differentiable ransac for camera localization. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 9, 2018.
- [4] Dylan Campbell, Lars Petersson, Laurent Kneip, Hongdong Li, and Stephen Gould. The alignment of the spheres: Globally-optimal spherical mixture alignment for camera pose estimation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [5] Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. Matterport3D: Learning from RGB-D data in indoor environments. In International Conference on 3D Vision (3DV), 2017.
- [6] Changhao Chen, Bing Wang, Chris Xiaoxuan Lu, Niki Trigoni, and Andrew Markham. A survey on deep learning for localization and mapping: Towards the age of spatial machine intelligence. arXiv preprint arXiv:2006.12567, 2020.
- [7] Taco S. Cohen, Mario Geiger, Jonas Köhler, and Max Welling. Spherical CNNs. In International Conference on Learning Representations (ICLR), 2018.
- [8] Xinke Deng, Arsalan Mousavian, Yu Xiang, Fei Xia, Timothy Bretl, and Dieter Fox. PoseRBPF: A Rao-Blackwellized Particle Filter for 6D Object Pose Estimation. In Proceedings of Robotics: Science and Systems, FreiburgimBreisgau, Germany, June 2019.
- [9] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Deep image homography estimation. In RSS Workshop on Limits and Potentials of Deep Learning in Robotics, 2016.
- [10] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. Superpoint: Self-supervised interest point detection and description. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2018.
- [11] Mihai Dusmanu, Ignacio Rocco, Tomas Pajdla, Marc Pollefeys, Josef Sivic, Akihiko Torii, and Torsten Sattler. D2-Net: A Trainable CNN for Joint Detection and Description of Local Features. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [12] Sovann En, Alexis Lechervy, and Frédéric Jurie. Rpnet: An end-to-end network for relative camera pose estimation. In European Conference on Computer Vision Workshops (ECCVW), 2018.
- [13] Jakob Engel, Vladlen Koltun, and Daniel Cremers. Direct sparse odometry. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(3):611–625, 2017.
- [14] Carlos Esteves, Christine Allen-Blanchette, Ameesh Makadia, and Kostas Daniilidis. Learning SO(3) equivariant representations with spherical CNNs. In European Conference on Computer Vision (ECCV), September 2018.
- [15] Carlos Esteves, Avneesh Sud, Zhengyi Luo, Kostas Daniilidis, and Ameesh Makadia. Cross-domain 3D equivariant image embeddings. In International Conference on Machine Learning, ICML, 2019.
- [16] Martin A. Fischler and Robert C. Bolles. Random sample consensus: A paradigm for model fitting with applications to image analysis and automated cartography. Commun. ACM, 24(6):381–395, June 1981.
- [17] Victor Fragoso, Chunhui Liu, Aayush Bansal, and Deva Ramanan. Patch correspondences for interpreting pixel-level cnns. arXiv: Computer Vision and Pattern Recognition, 2017.
- [18] Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2012.
- [19] Igor Gilitschenski, Roshni Sahoo, Wilko Schwarting, Alexander Amini, Sertac Karaman, and Daniela Rus. Deep orientation uncertainty learning based on a bingham loss. In International Conference on Learning Representations, 2020.
- [20] Richard Hartley and Andrew Zisserman. Multiple View Geometry in Computer Vision. Cambridge University Press, New York, NY, USA, 2 edition, 2003.
- [21] Richard I. Hartley. In defense of the eight-point algorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(6):580–593, June 1997.
- [22] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Identity mappings in deep residual networks. In European Conference on Computer Vision (ECCV), 2016.
- [23] Alex Kendall, Matthew Grimes, and Roberto Cipolla. Posenet: A convolutional network for real-time 6-dof camera relocalization. In IEEE International Conference on Computer Vision (ICCV), page 2938–2946, 2015.
- [24] Diederik P. Kingma and Jimmy Ba. Adam: A Method for Stochastic Optimization. In International Conference for Learning Representations, 2015.
- [25] Peter J. Kostelec and Daniel N. Rockmore. Ffts on the rotation group. Journal of Fourier Analysis and Applications, 14(2):145–179, Apr 2008.
- [26] A. Kundu, Y. Li, and J. M. Rehg. 3D-RCNN: Instance-level 3D object reconstruction via render-and-compare. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 3559–3568, 2018.
- [27] Jake Levinson, Carlos Esteves, Kefan Chen, Noah Snavely, Angjoo Kanazawa, Afshin Rostamizadeh, and Ameesh Makadia. An analysis of SVD for deep rotation estimation. In Advances in Neural Information Processing Systems 34, 2020.
- [28] Wenbin Li, Sajad Saeedi, John McCormac, Ronald Clark, Dimos Tzoumanikas, Qing Ye, Yuzhong Huang, Rui Tang, and Stefan Leutenegger. Interiornet: Mega-scale multi-sensor photo-realistic indoor scenes dataset. In British Machine Vision Conference (BMVC), 2018.
- [29] Yi Li, Gu Wang, Xiangyang Ji, Yu Xiang, and Dieter Fox. Deepim: Deep iterative matching for 6d pose estimation. In European Conference on Computer Vision (ECCV), September 2018.
- [30] Shuai Liao, Efstratios Gavves, and Cees G. M. Snoek. Spherical regression: Learning viewpoints, surface normals and 3D rotations on -spheres. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019.
- [31] H. C. Longuet-Higgins. A computer algorithm for reconstructing a scene from two projections. Nature, 293(5828):133–135, 1981.
- [32] David G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, 2004.
- [33] Diogo C. Luvizon, Hedi Tabia, and David Picard. Human pose regression by combining indirect part detection and contextual information. Computers & Graphics, 85:15–22, Dec 2019.
- [34] S. Mahendran, H. Ali, and R. Vidal. 3d pose regression using convolutional neural networks. In IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2017.
- [35] Siddharth Mahendran, Haider Ali, and René Vidal. A mixed classification-regression framework for 3D pose estimation from 2d images. The British Machine Vision Conference (BMVC), 2018.
- [36] Ameesh Makadia, Christopher Geyer, and Kostas Daniilidis. Correspondence-free structure from motion. International Journal of Computer Vision, 75(3):311–327, 2007.
- [37] Fabian Manhardt, Diego Martin Arroyo, Christian Rupprecht, Benjamin Busam, Tolga Birdal, Nassir Navab, and Federico Tombari. Explaining the Ambiguity of Object Detection and 6D Pose From Visual Data. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), October 2019.
- [38] K. V. Mardia. Statistics of directional data. Journal of the Royal Statistical Society. Series B (Methodological), 37(3):349–393, 1975.
- [39] Iaroslav Melekhov, Juha Ylioinas, Juho Kannala, and Esa Rahtu. Relative camera pose estimation using convolutional neural networks. In International Conference on Advanced Concepts for Intelligent Vision Systems, 2017.
- [40] Arsalan Mousavian, Dragomir Anguelov, John Flynn, and Jana Kosecka. 3d bounding box estimation using deep learning and geometry. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [41] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision (ECCV), pages 483–499. Springer, 2016.
- [42] Ty Nguyen, Steven W. Chen, Shreyas S. Shivakumar, Camillo J. Taylor, and Vijay Kumar. Unsupervised deep homography: A fast and robust homography estimation model. In IEEE Robotics and Automation Letters, volume 3, pages 2346–2353, 2018.
- [43] David Nister. An efficient solution to the five-point relative pose problem. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 195–202, 2003.
- [44] D. Nister. An efficient solution to the five-point relative pose problem. IEEE Transactions on Pattern Analysis and Machine Intelligence, 26(6):756–770, 2004.
- [45] Yuki Ono, Eduard Trulls, Pascal Fua, and Kwang Moo Yi. Lf-net: Learning local features from images. In Advances in Neural Information Processing Systems, volume 31, 2018.
- [46] Valentin Peretroukhin, Matthew Giamou, David M. Rosen, W. Nicholas Greene, Nicholas Roy, and Jonathan Kelly. A Smooth Representation of SO(3) for Deep Rotation Learning with Uncertainty. In Proceedings of Robotics: Science and Systems (RSS’20), 2020.
- [47] Valentin Peretroukhin, Brandon Wagstaff, and and Jonathan Kelly. Deep Probabilistic Regression of Elements of SO(3) using Quaternion Averaging and Uncertainty Injection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, June 2019.
- [48] Omid Poursaeed, Guandao Yang, Aditya Prakash, Qiuren Fang, Hanqing Jiang, Bharath Hariharan, and Serge Belongie. Deep fundamental matrix estimation without correspondences. In European Conference on Computer Vision (ECCV), pages 485–497, 2018.
- [49] Thomas Probst, Danda Pani Paudel, Ajad Chhatkuli, and Luc Van Gool. Unsupervised learning of consensus maximization for 3D vision problems. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
- [50] Sergey Prokudin, Peter Gehler, and Sebastian Nowozin. Deep directional statistics: Pose estimation with uncertainty quantification. In European Conference on Computer Vision (ECCV), Sept. 2018.
- [51] Rahul Raguram, Jan-Michael Frahm, and Marc Pollefeys. A comparative analysis of ransac techniques leading to adaptive real-time random sample consensus. In European Conference on Computer Vision (ECCV), pages 500–513, 2008.
- [52] René Ranftl and Vladlen Koltun. Deep fundamental matrix estimation. In European Conference on Computer Vision (ECCV), 2018.
- [53] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer Assisted Intervention, 2015.
- [54] Paul-Edouard Sarlin, Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabinovich. SuperGlue: Learning feature matching with graph neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020.
- [55] P.H. Schönemann. A generalized solution of the orthogonal procrustes problem. Psychometrika, 31:1–10, 1966.
- [56] Hao Su, Charles R. Qi, Yangyan Li, and Leonidas J. Guibas. Render for cnn: Viewpoint estimation in images using cnns trained with rendered 3D model views. In IEEE International Conference on Computer Vision (ICCV), December 2015.
- [57] Xiao Sun, Bin Xiao, Fangyin Wei, Shuang Liang, and Yichen Wei. Integral human pose regression. In European Conference on Computer Vision (ECCV), 2018.
- [58] Martin Sundermeyer, Zoltan-Csaba Marton, Maximilian Durner, Manuel Brucker, and Rudolph Triebel. Implicit 3D orientation learning for 6d object detection from rgb images. In European Conference on Computer Vision (ECCV), September 2018.
- [59] Supasorn Suwajanakorn, Noah Snavely, Jonathan J Tompson, and Mohammad Norouzi. Discovery of latent 3D keypoints via end-to-end geometric reasoning. In Advances in Neural Information Processing Systems (NeurIPS), pages 2063–2074, 2018.
- [60] Shubham Tulsiani and Jitendra Malik. Viewpoints and keypoints. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015.
- [61] Benjamin Ummenhofer, Huizhong Zhou, Jonas Uhrig, Nikolaus Mayer, Eddy Ilg, Alexey Dosovitskiy, and Thomas Brox. Demon: Depth and motion network for learning monocular stereo. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [62] Sen Wang, Ronald Clark, Hongkai Wen, and Niki Trigoni. Deepvo: Towards end-to-end visual odometry with deep recurrent convolutional neural networks. In 2017 IEEE International Conference on Robotics and Automation (ICRA), pages 2043–2050. IEEE, 2017.
- [63] Nan Yang, Lukas von Stumberg, Rui Wang, and Daniel Cremers. D3vo: Deep depth, deep pose and deep uncertainty for monocular visual odometry. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1281–1292, 2020.
- [64] Kwang Moo Yi, Eduard Trulls Fortuny, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, and Pascal Fua. Learning to find good correspondences. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 9, 2018.
- [65] Zhichao Yin and Jianping Shi. Geonet: Unsupervised learning of dense depth, optical flow and camera pose. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1983–1992, 2018.
- [66] Zhengyou Zhang, Rachid Deriche, Olivier Faugeras, and Quang-Tuan Luong. A robust technique for matching two uncalibrated images through the recovery of the unknown epipolar geometry. Artificial Intelligence, pages 87–119, 1995.
- [67] Tinghui Zhou, Matthew Brown, Noah Snavely, and David G. Lowe. Unsupervised learning of depth and ego-motion from video. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [68] Yi Zhou, Connelly Barnes, Jingwan Lu, Jimei Yang, and Hao Li. On the continuity of rotation representations in neural networks. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2019.
Appendix
Appendix A Spherical Padding
We propose using spherical padding in our decoder network to reflect the correct topology on a spherical representation (See Figure 5 for our motivation).

Appendix B Dataset Generation
Since large-scale wide-baseline stereo datasets are difficult to acquire, we create our datasets from corpora of panoramic scene captures by taking pairs of panoramas that observe overlapping parts of scenes, sampling camera look-at directions for each panorama using a heuristic that ensures image overlap, and projecting the panoramas to perspective views with a given field of view. Figure 6(a) illustrates this process. The look-at direction, , for the first camera is uniformly sampled from a band around the equator, which is bounded in colatitude \straighttheta [, ] and azimuth angle \straightphi [0, 2\textpi). The look-at direction, , for the second camera is uniformly sampled from a circular cone centered at the direction so that the magnitude of rotations are uniformly distributed in each of our datasets. The limit in latitude prevents the cameras from looking only at the ceiling or floor, which are relatively textureless for many scenes. The aperture of the cone can be adjusted to vary the amount of overlap between image pairs while maintaining variability in the relative camera orientations. Each camera rotation matrix is then constructed from the appropriate look-at vector and the world up vector.
In Figure 3(b) in the main paper, we show results on the Matterport-B test set grouped by overlap percentage between the input images. Matterport3D panoramas contain depth channels which allows us to calculate the overlap percentage between the input image pair as
| (8) |
Appendix C Training details
We implemented our model in Tensorflow [1]. The model was trained asynchronously on 40 Tesla P100 GPUs. A single DirectionNet has approximately 9M parameters. Our full model DirectionNet-9D/6D, which consists of two DirectionNets, contains in total 18M trainable parameters. Each net was trained for 3M steps.
Rotation Perturbation. To improve the robustness of DirectionNet-T to rotation estimation errors, we apply data augmentation to its input by perturbing the rotations used for derotation. Given , we perturb it by randomly sampling three unit vectors no further than 15∘ away from the component vectors of and projecting the result back onto . We perturb the estimated rotation from DirectionNet-R before derotating the input images for DirectionNet-T. This perturbation is critical to performance. Without it, the translation error is 4∘ worse on InteriorNet, and much worse when the rotation range is large (MatterportB).
Appendix D Relative Pose Baselines
We now provide additional details of the baselines including the ones not in the main paper.
-
•
DirectionNet-Quat directly generates a probability distribution over the half-hypersphere in . In this case, the spherical decoder consists of 3D upsampling and 3D convolutional layers. Since the output is on a hypersphere, the discretization requires much higher resolution () compared with our model (). DirectionNet-Quat generates output at . We believe the limited resolution is partly responsible for the poor performance compared to DirectionNet-9D and -6D.
-
•
Bin&Delta [35] adopts the Bin-Delta hybrid model that consists of a classification network which gives a coarse estimation of the rotation and a regression network that refines the estimate. The rotation space is discretized K-Means clustering on the training data (we use ). We use the same encoder as ours and DirectionNet-T for the translation.
-
•
Spherical regression [30] uses a novel spherical exponential activation on the -sphere to improve the stability of gradients during training. The final outputs of the model are the absolute values of the coordinates of a unit vector in , along with classification outputs for their signs. We use the same encoder as ours followed by separate two-layer prediction networks (one for a quaternion representation of rotation and one for translation).
-
•
6D regression uses the same image encoder as ours, followed by two fully connected layers with leaky ReLU and dropout, to produce a 6D continuous representation for the rotation and 3D for the translation. The 6D output is mapped to a rotation matrix with a partial Gram-Schmidt procedure; see [68] for details. This approach uses a continuous representation for 3D rotation, and consequently facilitates training.
-
•
The quaternion regression baseline is implemented using same Siamese network as described in [39] without the spatial pyramid pooling layer, followed by fully connected layers to produce a 4D quaternion and a 3D translation. We normalize the quaternion and the translation during training, and use the same loss as suggested in the paper (L2). In our experiment, we weight the quaternion loss with , as in the original paper.
-
•
SIFT+LMedS is a classic technique for recovering the essential matrix from correspondences. Local features are detected in images with SIFT, and subsequently matched across images. These feature matches are filtered with Lowe’s proposed distance ratio test. Given the remaining putative correspondences, least median of squares (LMedS) is used to robustly estimate the essential matrix, from which we can recover the rotation and normalized translation direction. We use the OpenCV implementation for all of these steps.
-
•
SIFT+RANSAC is the same as SIFT+LMedS, with RANSAC instead of LMedS.
-
•
SuperGlue [54] uses CNN and graph neural network to extract and match local features from images. D2-Net [11] trains a single CNN as a dense feature descriptor and a feature detector. Both methods require correspondence/depth supervision from real data, which is not available in our Matterport datasets. We ran pretrained indoor SuperGlue (training code not available) and D2-Net with RANSAC.
Additional baselines.
The following baselines are not presented in the main paper due to the limit of space. For reference, the mean rotation error of our DirectionNet-9D tested on Matterport-A is , on Matterport-B is .
-
•
vM [50] provides a probabilistic formulation for the 2D pose by estimating parameters of von Mises distribution on a circle (). We adapt this method to estimate the 3D rotation by producing three von Mises distributions representing the Euler angles. However, the training is hindered by the singularities known in the Euler angles representation[68]. The mean rotation error tested on Matterport-A is (5x worse than DirectionNet-9D) and the training diverges on Matterport-B.
-
•
3D-RCNN[26] uses a classification-regression hybrid model for 2D pose estimation by uniformly discretize the 2D circle into bins. This can be directly adapted to 3D rotation by estimating the three Euler angles. Due to the discontinuity of the Euler angles representation[68], the performance is poor compared with the similar hybrid Bin&Delta model. The mean rotation error tested on Matterport-A is and the error on Matterport-B is .
-
•
[47] combines probabilistic regression and an ensemble of the quaternion regression uisng a multi-headed network called HydraNet. The mean rotation error tested on Matterport-A is and the error on Matterport-B is .
-
•
PoseNet[23] relocalizes images in known scenes; we consider relative pose in scenes never seen during training. PoseNet regresses to a 3D position and quaternion, and this is similar to the quaternion regression baseline.
InteriorNet-A InteriorNet-B mean (∘) med (∘) rank mean (∘) med (∘) rank mean (∘) med (∘) rank mean (∘) med (∘) rank DirectionNet 9D 2.87 1.53 2.30 12.36 7.40 2.59 3.88 2.20 2.42 16.36 9.72 2.60 6D 2.90 1.68 2.36 12.48 7.53 2.90 3.81 2.25 2.44 16.67 10.05 2.77 9D-Single 3.93 2.61 3.29 18.17 12.56 4.71 4.84 3.24 3.46 26.56 19.51 4.85 Quat. 23.88 24.53 8.54 32.85 26.92 6.16 22.11 22.43 8.55 39.45 32.05 5.50 Regression Bin&Delta 8.79 6.59 6.10 19.53 13.45 3.87 6.73 4.57 5.21 31.87 22.61 4.16 Spherical 19.76 15.52 8.21 31.17 23.47 5.97 11.36 8.82 6.25 44.20 35.34 6.23 6D 4.86 3.33 3.77 30.94 22.66 5.95 6.03 3.95 3.99 41.29 34.41 6.04 Quat. 11.14 9.64 6.27 33.14 26.23 6.31 13.94 11.64 6.70 45.44 38.96 6.39 SIFT LMedS 29.55 7.01 7.76 37.91 19.25 8.28 30.46 7.64 7.92 41.83 24.50 5.58 RANSAC 16.69 8.21 7.49 45.51 30.12 8.85 18.75 10.52 7.10 52.46 43.56 8.85
Appendix E Additional Results and Discussion
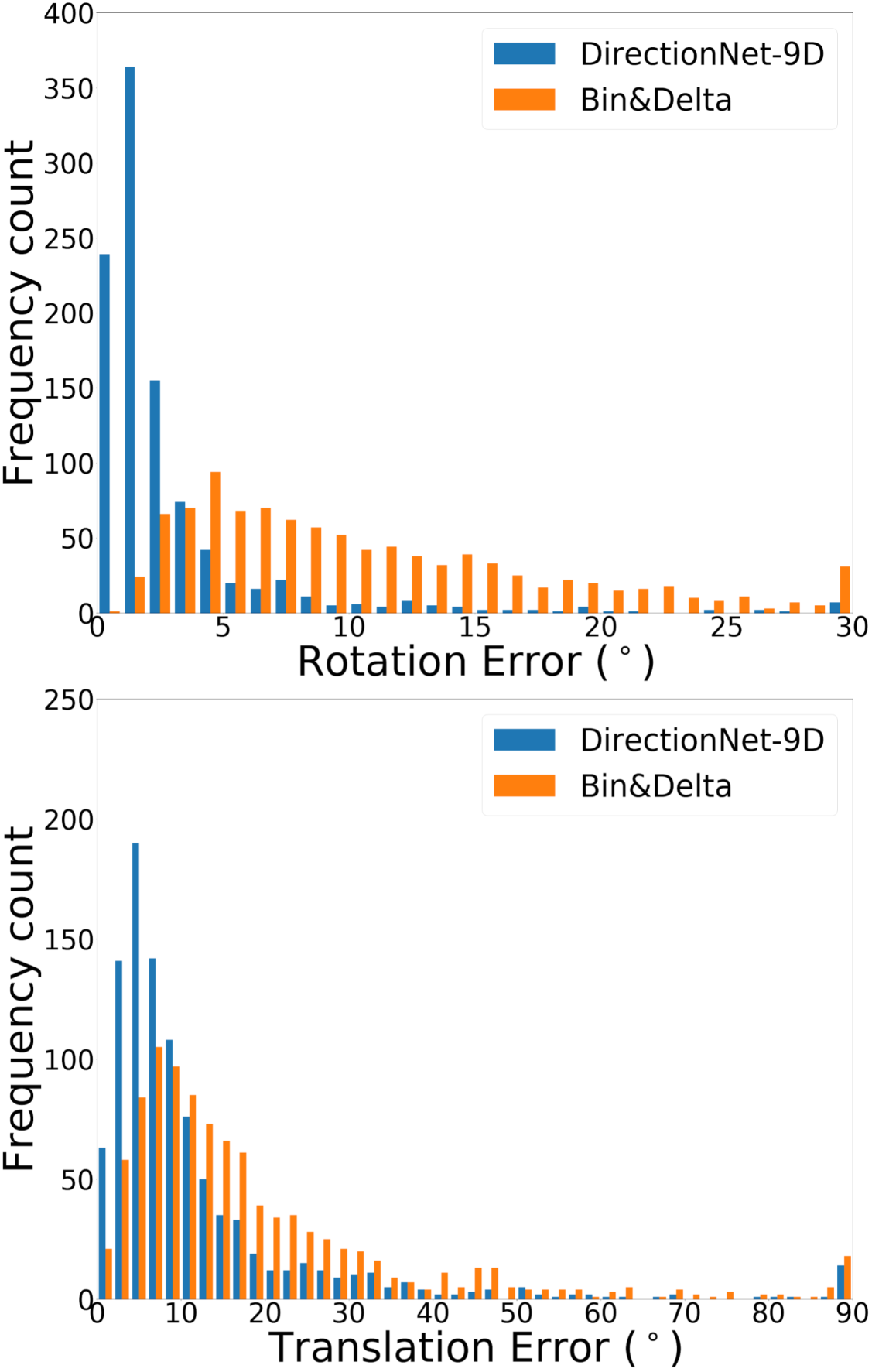
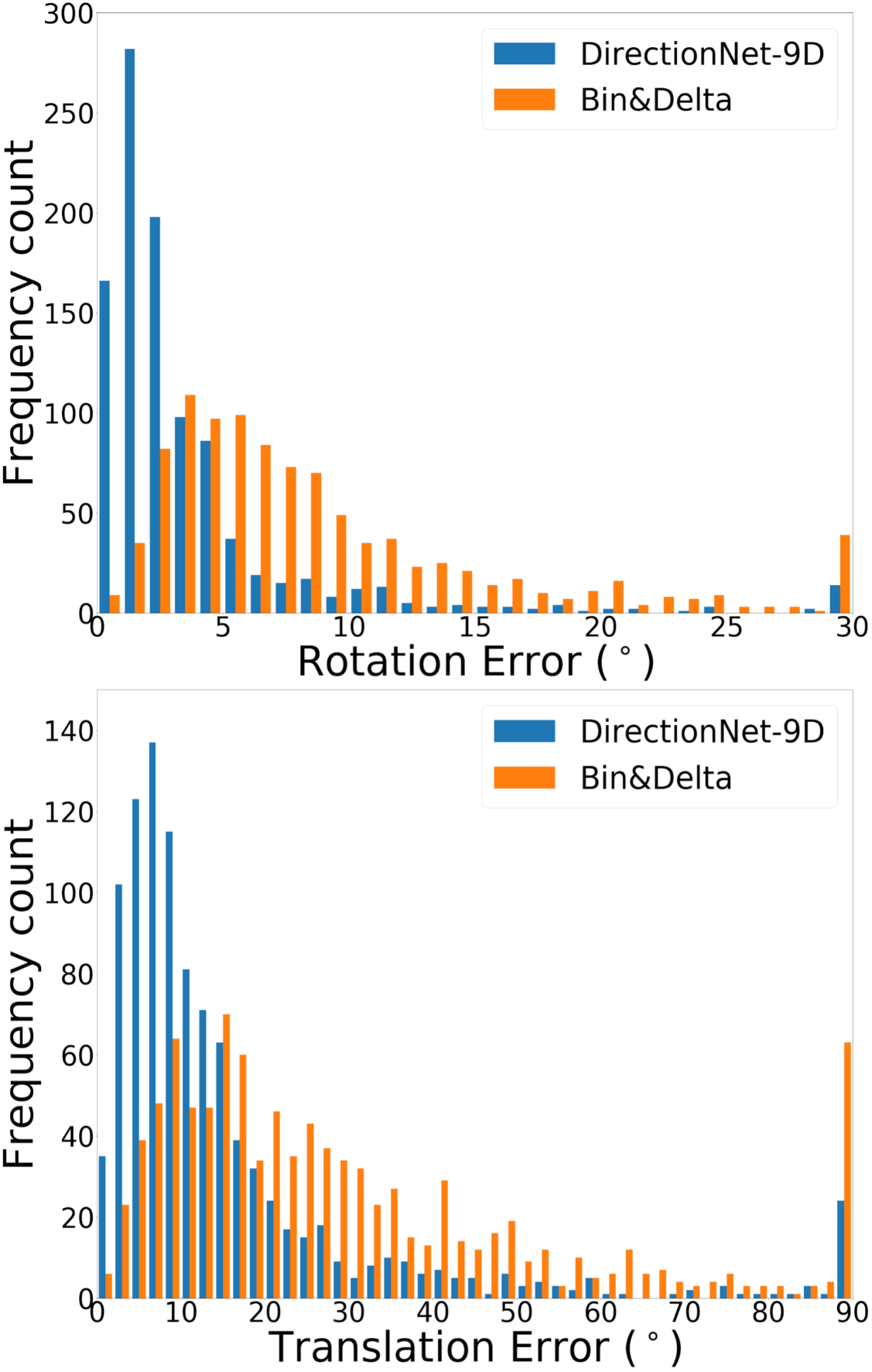
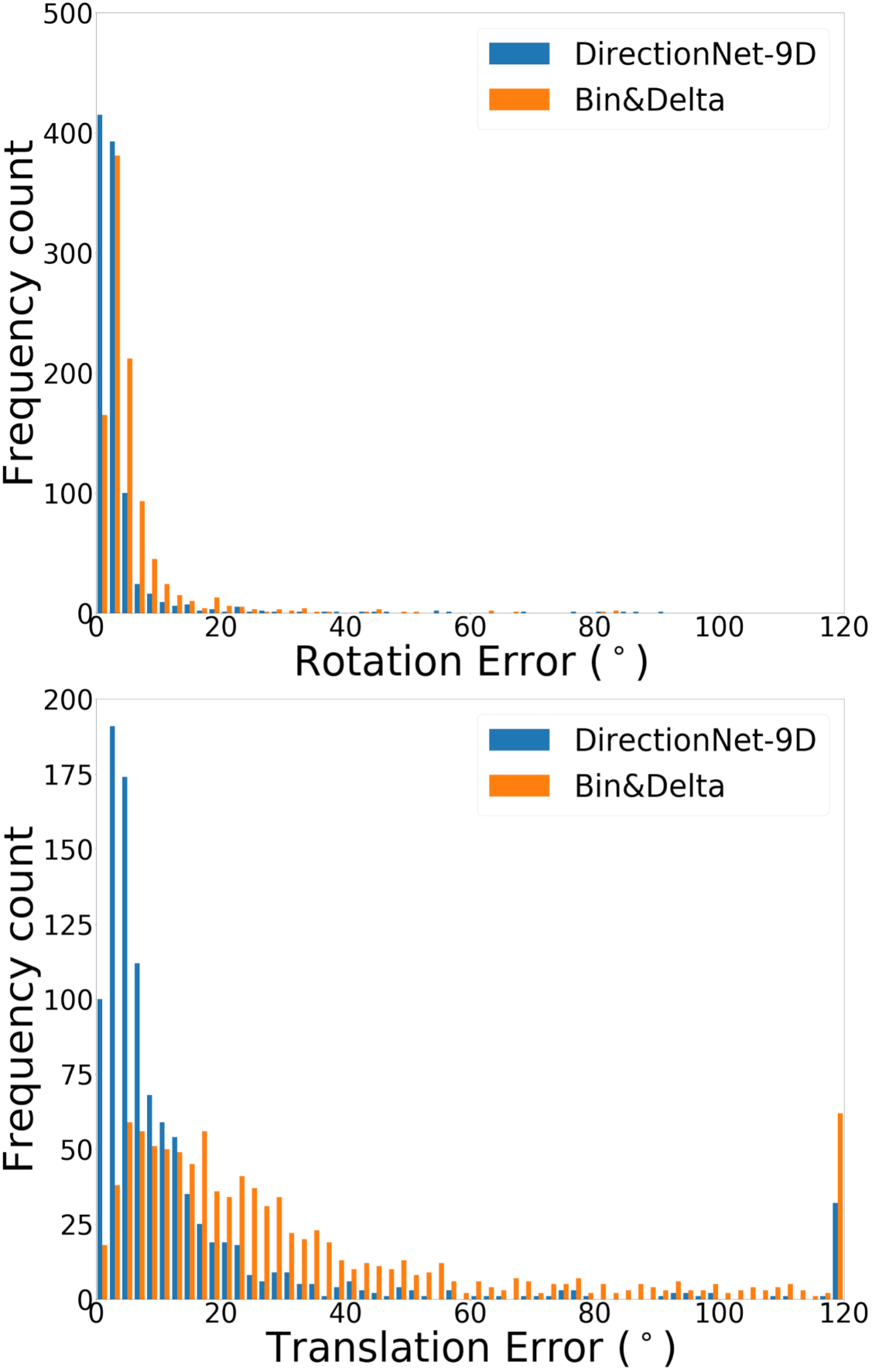
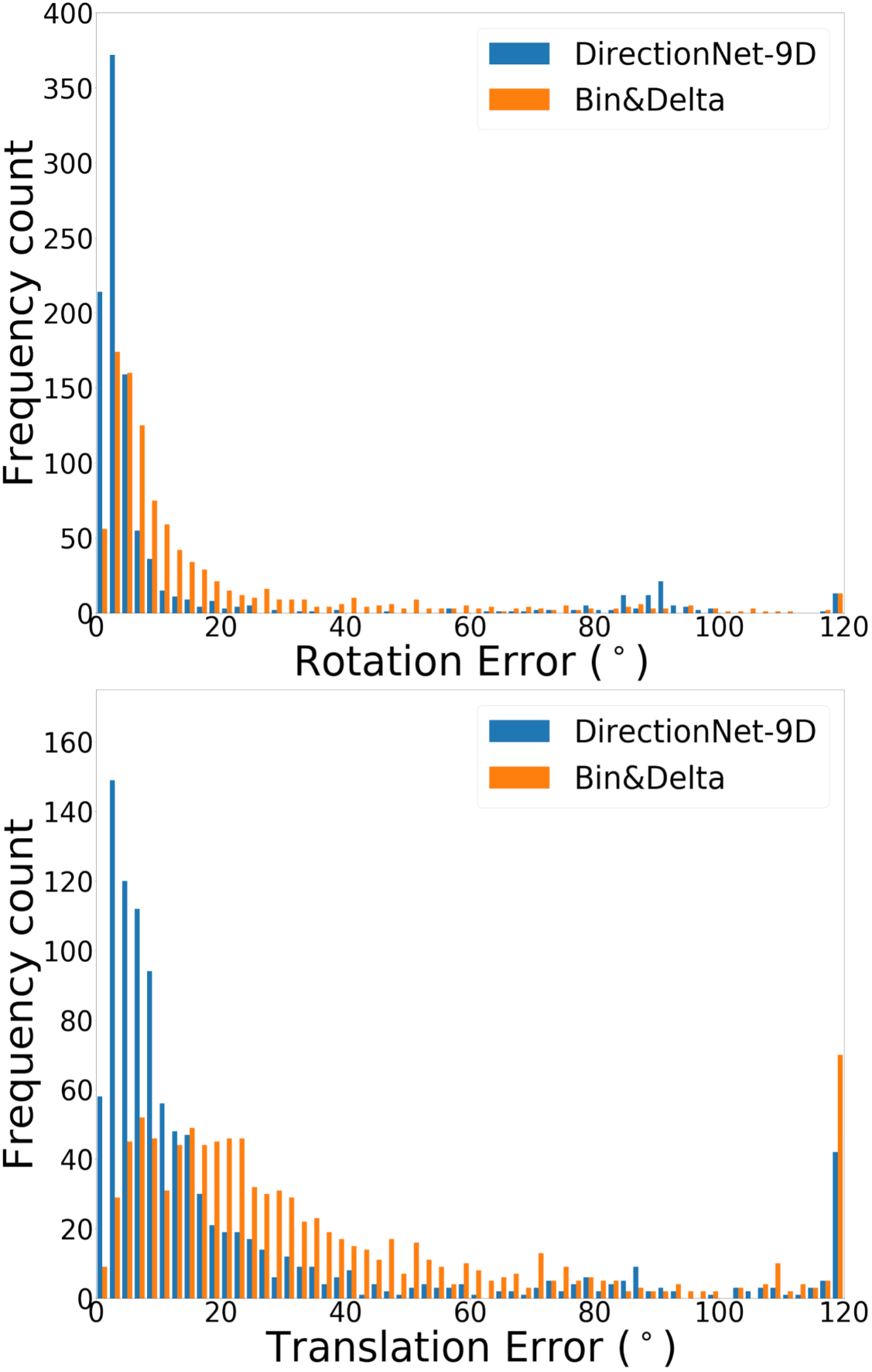
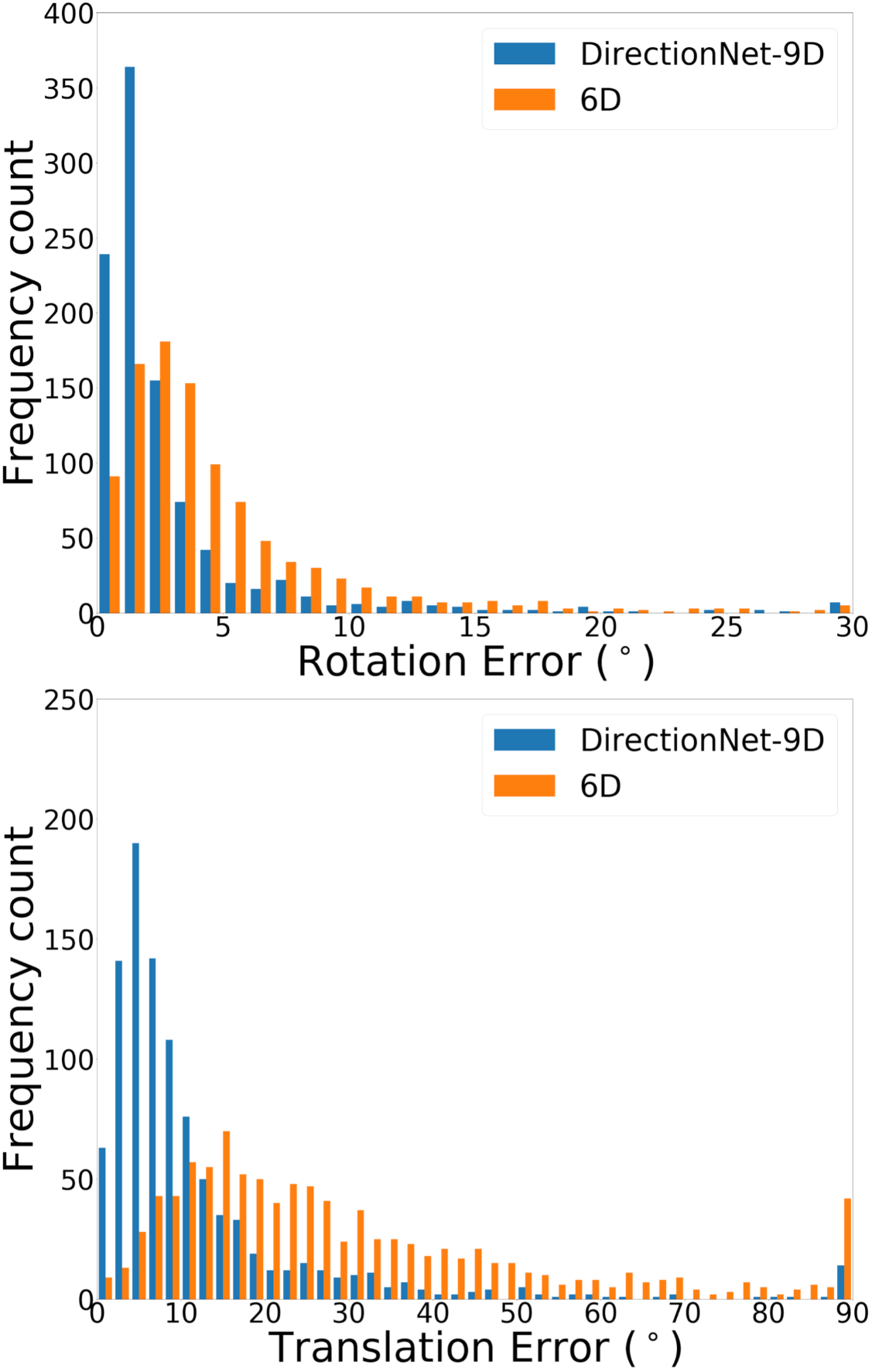
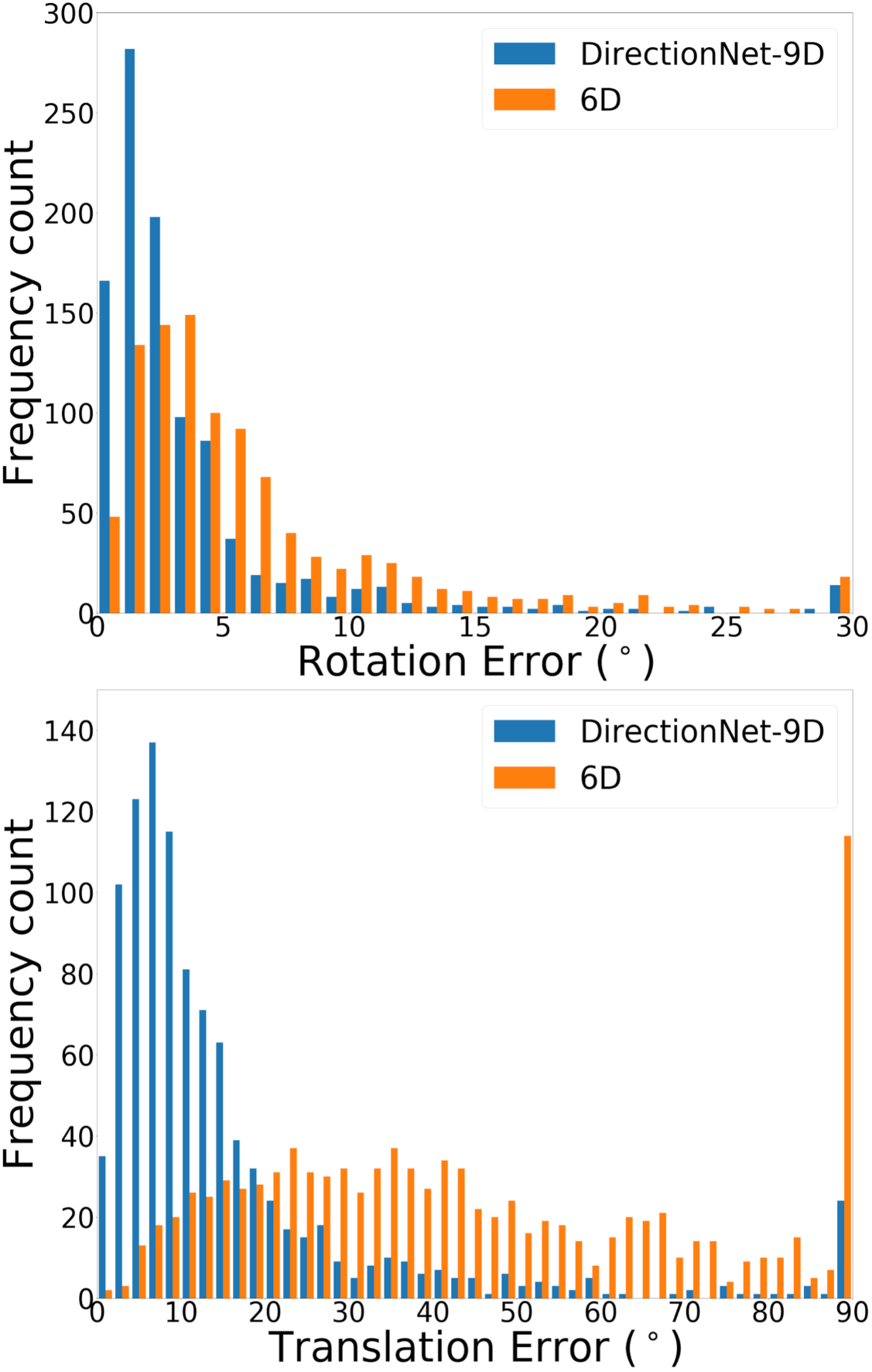
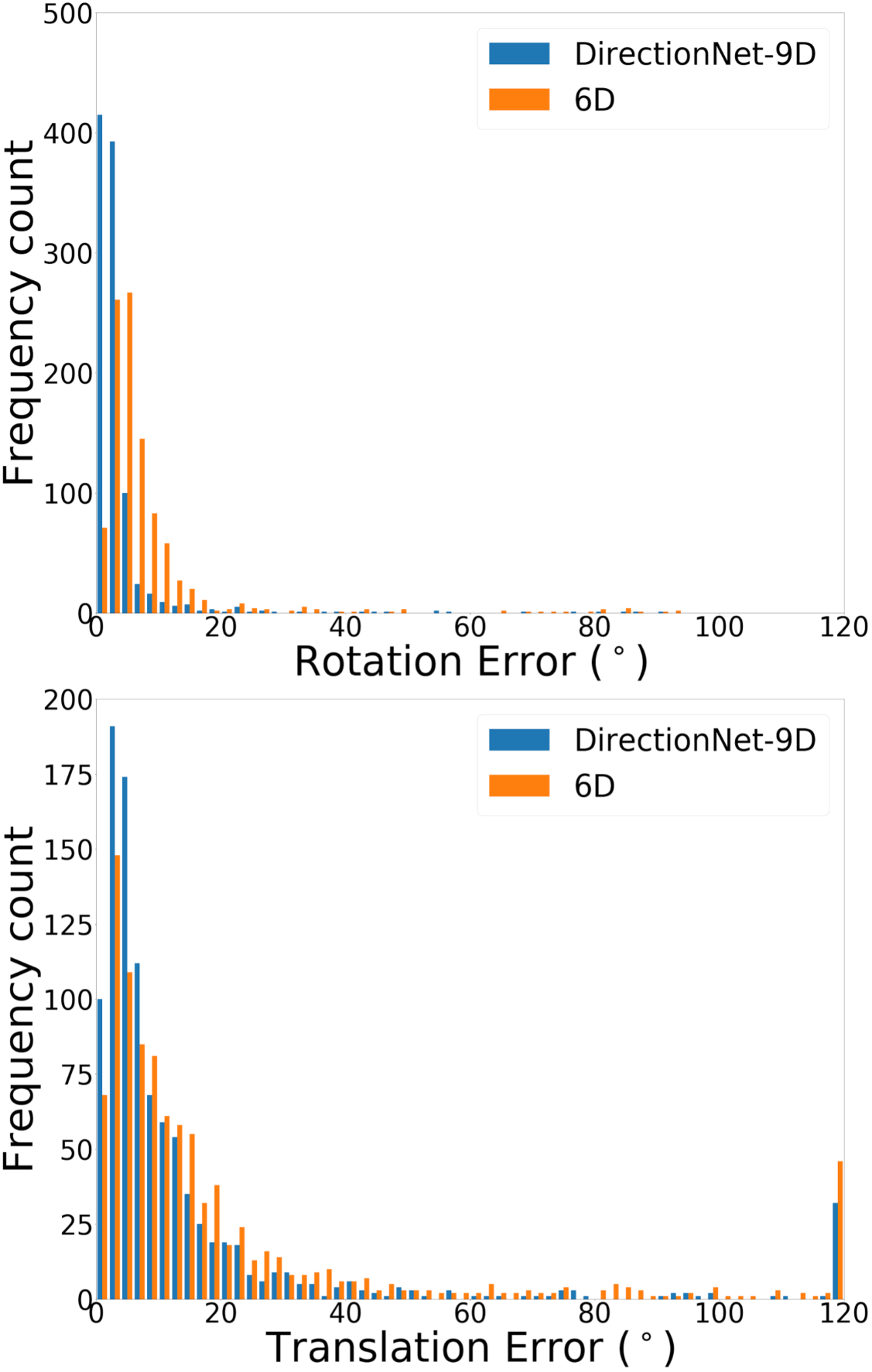
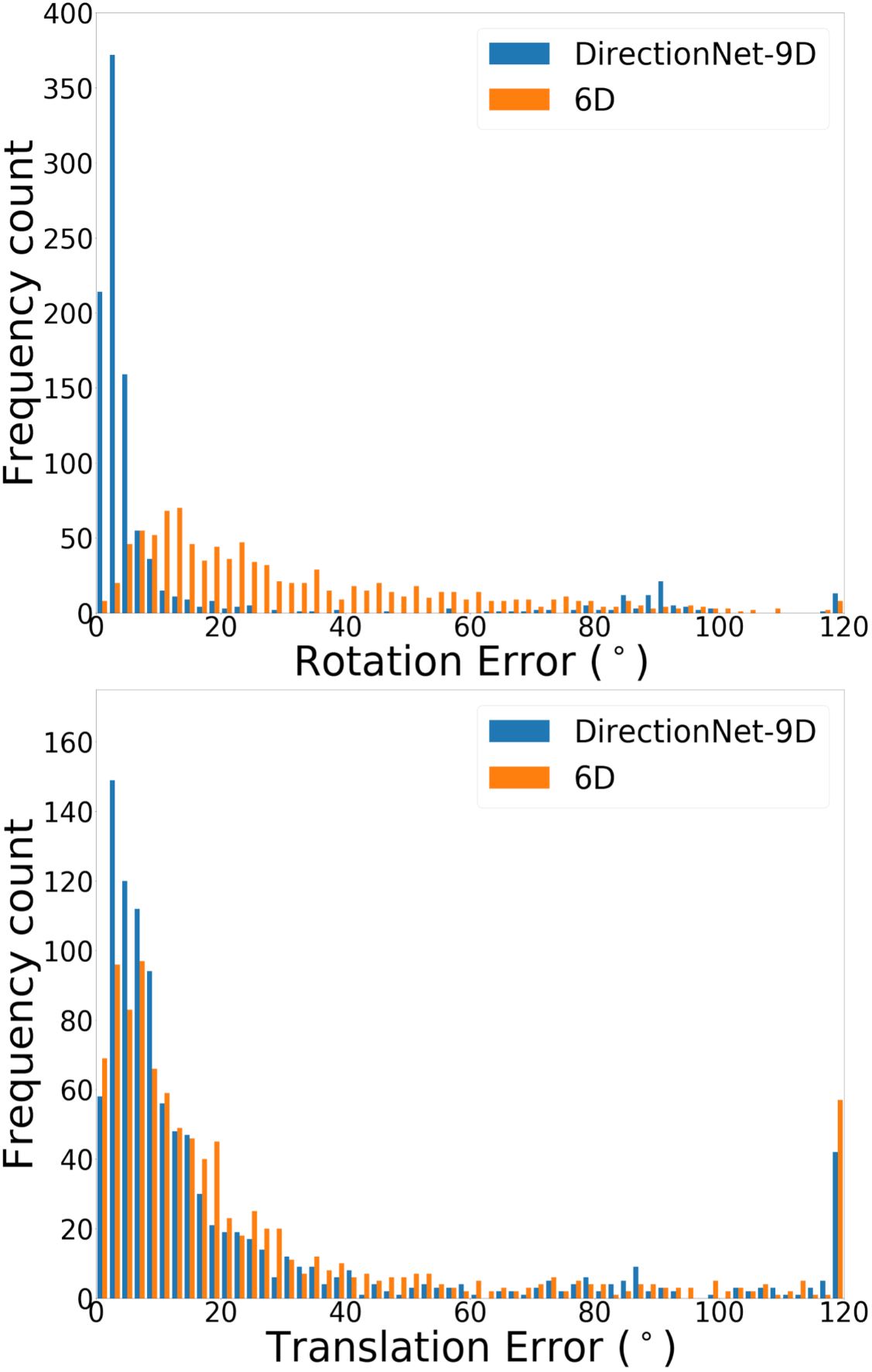
DirectionNet consistently outperforms regression methods, showing the potential value in a fully convolutional model that avoids fully-connected regression layers and discontinuous parameterizations of pose. We show more comprehensive results to compare our model DirectionNet-9D with the baselines. Note that the spherical regression baseline generally has a higher error in rotation compared with the 6D regression method. Even though the spherical exponential activation does improve training the regression model, the 6D continuous rotation representation is still preferable to quaternions. Figure 7 and Figure 8 compare the error histogram distribution of our model with the best two regression baselines, the Bin&Delta and the 6D Regression. Figure 9 compare the error histogram distribution of ours with SIFT+LMedS. Note that SIFT+LMeds has a higher mode close to 0 degree error compared with other baselines. With accurate correspondences, feature-based methods will usually outperform deep learning techniques.
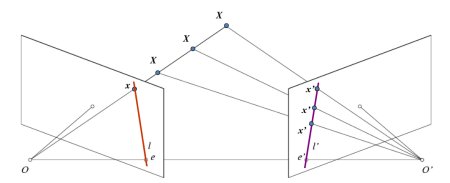
To visualize results of the different methods, we select a few points detected by SIFT in image and draw their corresponding epipolar lines in image as determined by the estimated relative pose.333 Note, since we do not have ground truth point correspondences between images in our datasets, we cannot draw matching points on the two images for visualization. Figure 6(b) illustrates the epipolar geometry. We show additional qualitative results to compare our primary model DirectionNet-9D with baselines representative of regression models and the classic method, see Figure 10 and 11) In Figure 12, we highlight scenarios where our method struggles, such as repeating or complex texture, scenes with few objects and minimal texture, or extreme motion between images.
Ablation study on loss terms. We study the effects of the loss terms by training the DirectionNet-9D on Matterport-A. The mean rotation error is without the spread loss, without direction loss, and without distribution loss, compared with with all losses. The distribution loss which provides the direct supervision on the output distribution plays the key role in the training, because we provide the prior knowledge on the distribution by generating the ground truth from von Mises-Fisher distribution on 2-sphere which resembles the spherical normal distribution. This shows evidence that distributional learning with dense supervision is advantageous to direct regression [57, 33]. Alternatively, the distribution loss could use the KL divergence but we found MSE performs better in our experiments.
Multimodal distribution on high uncertainty scenarios. In rare scenarios, our model gives higher uncertainty and produces multimodal or even antipodal distributions. Based on our observations, this usually happens in certain scenes, for example, the scene structure exhibits some symmetry or repetitive textures and causes ambiguity in the direction of the motion from two images. (See Figure 13 and Figure 14 for more examples.)
Outdoor scenes. We used KITTI odometry [18] dataset (sequence 0-8 for train, 9-10 for eval) and sampled image pairs with a min rotation of 15∘ and translation of 10m (36K train pairs, 1K test pairs, mean translation m). Table 4 shows generalization from MatterportA to KITTI (we cropped Matterport images to approximate the KITTI FoV). This is a hard generalization task as the distribution of relative poses in KITTI is extremely different from Matterport, yet fine-tuning with just 20% of data is on par with the local feature baselines, and strong results after retraining with 100% of the data indicates DirectionNet is also effective outdoors.
R mean (∘) R med (∘) T mean (∘) T med (∘) DirectionNet-9D (20%) 10.50 9.21 26.74 15.67 DirectionNet-9D (100%) 9.19 6.31 19.36 11.71 Regression 6D (100%) 13.44 12.74 22.53 16.68 SuperGlue (outdoor) 16.35 11.53 24.24 17.15 D2-Net 24.07 5.18 34.36 14.05
RANSAC vs. LMedS. We use the OpenCV library (findEssentialMat() and recoverPose()) to implement both baselines by solving the essential matrix using the 5-point algorithm [44] from which we recover the pose. In the main paper, we showed that LMedS performs better than RANSAC in terms of errors in translation and median errors in rotation, but RANSAC has much lower mean errors in rotation on all datasets. Note that due to the nature of indoor images, a large portion of the feature correspondences may be co-planar (e.g. features on a wall or a floor). For RANSAC, we use the default parameters (threshold equals 1.0 and the confidence equals 0.999). Figure 15 shows that the design choice of robust fitting method doesn’t make a big overall difference in our experiments.
Runtime performance. DirectionNet-Single inference takes under 0.02 seconds with a TESLA P100.