Wiki to Automotive: Understanding the Distribution Shift and its impact on Named Entity Recognition
Abstract
While transfer learning has become a ubiquitous technique used across Natural Language Processing (NLP) tasks, it is often unable to replicate the performance of pre-trained models on text of niche domains like Automotive. In this paper we aim to understand the main characteristics of the distribution shift with automotive domain text (describing technical functionalities such as Cruise Control) and attempt to explain the potential reasons for the gap in performance. We focus on performing the Named Entity Recognition (NER) task as it requires strong lexical, syntactic and semantic understanding by the model. Our experiments with 2 different encoders, namely BERT-Base-Uncased Devlin et al. (2019) and SciBERT-Base-Scivocab-Uncased Beltagy et al. (2019) have lead to interesting findings that showed: 1) The performance of SciBERT is better than BERT when used for automotive domain, 2) Fine-tuning the language models with automotive domain text did not make significant improvements to the NER performance, 3) The distribution shift is challenging as it is characterized by lack of repeating contexts, sparseness of entities, large number of Out-Of-Vocabulary (OOV) words and class overlap due to domain specific nuances.
| Element | Details |
|---|---|
| Dataset | 979 Automotive domain sentences |
| Train:Test split | 70:30 |
| Random Seeds | 5 |
| GPU | Nvidia Tesla V100-SXM2 (32 GB Memory) |
| NLP Library | Huggingface Transformers Wolf et al. (2020) |
| t-SNE | Perplexity=30, Iterations=1000 |
| Optimizer for FT1 and FT3 | Adam (lr=1e-3, =0.9, =0.999, =1e-7) Kingma and Ba (2014) |
| Optimizer for FT2 and FT4 | Adam (lr=1e-5, =0.9, =0.999, =1e-7) |
| Optimizer for LM fine-tuning | Adam (lr=5e-5, =0.9, =0.999, =1e-8) |
1 Introduction
Recent advancements in pre-trained networks such as BERT Devlin et al. (2019), RoBERTa Liu et al. (2019), GPT Radford et al. (2018), ERNIE Sun et al. (2020), Electra Clark et al. (2020), T5 Raffel et al. (2019) etc. have lead to state-of-the-art (SOTA) performance on several NLP tasks of the GLUE Benchmark Wang et al. (2018). This has enabled the use of such networks for various downstream tasks with minimal task specific fine-tuning. In our work, we experiment with two different variants of BERT due to its use in scientific domain SOTA models as well. BERT has been a breakthrough in language understanding by leveraging the multi-head self-attention mechanism Vaswani et al. (2017) in its architecture. With the Masked Language Modelling (MLM) method, it has been successful at leveraging bi-directionality while training the language model (LM), and was trained on Wikipedia (Wiki) articles. BERT-Base models have 12 encoder layers, with each layer consisting of 12 self-attention heads.
NER is the task of identifying and classifying named entities of a domain text. It relies on using lexical, syntactic and semantic information to understand and classify entities. The study of NER in the automotive domain has been very limited and mostly restricted to identifying simple entity classes like LOCATION, ORGANIZATION etc. in the context of automotive domain Rubens and Agarwal (2002); Keraghel et al. (2020); Sivaraman et al. (2021) and very few have focused on dealing with technical description documents Nayak et al. (2020a, b); Kesri et al. (2021). Further, these works have not studied recent SOTA encoders and the results with transfer learning. Task specific data is often limited and difficult to generate in niche domains like automotive as it requires a domain experts understanding to perform annotation. This has lead to using pre-trained networks for fine-tuning with minimal data, however this often is not able to replicate the performance of such pre-trained networks in domain specific settings. For example, while SciBERT Beltagy et al. (2019), BioBERT Lee et al. (2020), PubMedBERT Gu et al. (2020) have been able to show improvements over BERT on the NER task with scientific datasets such as SciERC Luan et al. (2018), NCBI-disease Doğan et al. (2014), their performance however still lags behind in comparison to the performance that BERT achieved on general domain datasets like CoNLL-2003 Sang and De Meulder (2003), ACE-2004 Strassel and Mitchell (2003).
Hence, we wanted to understand the reasons behind this gap in performance by taking a niche domain like automotive due to our background and domain knowledge. We attempt to answer the following Research Questions for NER in the automotive domain:
-
1.
Is using a scientific domain encoder (SciBERT) preferable over a Wiki domain encoder (BERT)?
-
2.
Is there significant improvement in performance when the encoder’s language model is fine-tuned with automotive domain text?
-
3.
Is fine-tuning only the head sufficient to achieve reasonable performance?
-
4.
What are the likely factors which prevent the performance of the model to reach 90’s even under different fine-tuning settings?
| Class | IV Count | OOV Count | OOV% | IV Avg. Freq | OOV Avg. Freq |
|---|---|---|---|---|---|
| Other | 11094/11785 | 1259/568 | 10.1/4.59 | 15.34/15.79 | 3.83/1.86 |
| Signal | 2899/3066 | 1483/1316 | 33.8/30.03 | 10.2/10.22 | 2.6/2.37 |
| Value | 1556/1623 | 283/216 | 15.38/11.74 | 6.27/5.94 | 1.74/1.57 |
| Action | 1244/1306 | 354/292 | 22.15/18.27 | 4.54/4.66 | 2.62/2.26 |
| Function | 943/1140 | 577/380 | 37.96/25 | 8.89/9.82 | 3.22/2.24 |
| Calibration | 350/374 | 398/374 | 53.2/50 | 7.14/6.67 | 1.8/1.75 |
| Component | 469/515 | 153/107 | 24.59/17.2 | 6.51/6.51 | 2.42/1.91 |
| State | 326/338 | 212/200 | 39.4/37.17 | 13.58/12.51 | 2.65/2.59 |
| Math | 331/344 | 34/21 | 9.31/5.75 | 6.24/5.83 | 2.12/2.1 |
| Encoder | Train Samples | Test Samples | Test Perplexity |
|---|---|---|---|
| BERT | 685 | 294 | 8.748 |
| SciBERT | 685 | 294 | 7.904 |
2 Experiment Setup
The dataset consisted of 979 annotated sentences of the automotive domain from technical documents describing functionalities like cruise control, exhaust system, braking etc. The annotation was done by automotive domain experts for 9 automotive specific NER classes: Other (words outside named entities e.g. the, in), Signal (variables holding quantities e.g. torque), Value (quantities assigned to signals e.g. true, false), Action (task performed e.g. activation, maneuvering), Function (domain specific feature e.g. cruise control), Calibration (user defined setting e.g. number of gears), Component (physical part e.g. ignition button), State (system state e.g. cruising state of cruise control) and Math (mathematical or logical operation e.g. addition). Table 1 summarizes the details. We fine-tuned the models under the following settings:
-
•
FT1: MLM is not performed on the pre-trained encoder (BERT/SciBERT). This encoder is then frozen and the token classification head is kept unfrozen for NER fine-tuning.
-
•
FT2: MLM is not performed on the pre-trained encoder. This encoder and the head are kept unfrozen for NER fine-tuning.
-
•
FT3: MLM is performed on pre-trained encoder with automotive domain text. This encoder is then frozen and the head is kept unfrozen for NER fine-tuning.
-
•
FT4: MLM is performed on pre-trained encoder with automotive domain text. This encoder and the head are kept unfrozen for NER fine-tuning.
| Class | Precision | Recall | F-1 |
|---|---|---|---|
| Other | 83.5/91.4/81.8/91.1 | 87.3/90.6/87.5/91.9 | 85.3/91/84.5/91.5 |
| Signal | 66.2/84.2/67.2/85.4 | 78/89.1/78.8/89.2 | 71.5/86.6/72.3/87.2 |
| Value | 67.3/66/67.1/67.6 | 40.7/60.1/40.6/58.4 | 50.6/62.7/50.5/62.6 |
| Action | 70.6/73.8/72.7/79.3 | 77.1/84.4/73.6/81.2 | 73.7/78.7/73.1/80.2 |
| Function | 68.8/77.2/70.5/79.2 | 63.2/74.5/57.1/77.9 | 65.8/75.6/62.9/78.5 |
| Calibration | 69.5/88/68.7/87.7 | 46/82.2/48.3/82.3 | 54.3/84.8/55.4/84.6 |
| Component | 69.6/71/70.9/72.9 | 54.4/62.2/53.1/69.1 | 60.9/64.8/60.4/70.4 |
| State | 67.8/82.7/66.1/80.5 | 61.2/84.9/60.1/86.5 | 62.9/83.7/62.4/83.3 |
| Math | 81/92.2/81.3/92.5 | 51.5/43.8/52.4/55.4 | 62.5/55.8/63.3/68.3 |
| Macro Avg. | 71.6/80.7/71.8/81.8 | 62.2/74.7/61.3/76.9 | 65.3/76/65/78.5 |
| Class | Precision | Recall | F-1 |
|---|---|---|---|
| Other | 86.5/92/87.1/92.9 | 89.1/92.9/89.8/92.4 | 87.7/92.4/88.4/92.6 |
| Signal | 74.5/86.9/71.5/87.1 | 79.9/89.2/83.1/89.8 | 77.1/88/76.9/88.4 |
| Value | 72/75.4/75.3/70.8 | 48.9/67.2/49.2/69 | 58.2/71/59.4/69.8 |
| Action | 73.8/79.1/76.5/77.2 | 80.3/83.6/80.1/83.7 | 76.9/81.3/78.2/80.3 |
| Function | 71.7/83.5/76.2/82.7 | 72.4/80.1/68/82.2 | 72/81.7/71.8/82.4 |
| Calibration | 71/88.8/72.9/92.1 | 60.3/88.4/53.1/86.1 | 64.9/88.5/60.6/88.9 |
| Component | 73.3/77.3/74.9/80.2 | 65.4/77.5/65.5/75.6 | 69.1/77.3/69.8/77.5 |
| State | 74.1/87.1/75.1/84.7 | 76/84.2/70.7/86.4 | 74.5/85.4/72.1/85.5 |
| Math | 83.4/90/85.5/90 | 63.8/63.7/67.4/65.2 | 72.1/74.4/75.3/75.3 |
| Macro Avg. | 75.6/84.4/77.2/84.2 | 70.7/80.8/69.7/81.1 | 72.5/82.2/72.5/82.3 |
3 Understanding the Distribution Shift
Entity and Context characteristics:
As BERT variants rely on the WordPiece tokenization algorithm Schuster and Nakajima (2012), understanding the distribution of entities that are In-Vocabulary (IV) vs Out-Of-Vocabulary (OOV) is important as the meaning of a word will then be determined by how accurate are its sub-word tokens. It can be seen in Table 2 that OOV Count for the different entity classes varies between 9% and 53% for BERT and between 4% and 50% for SciBERT. BERT had a larger number of OOV words across all the classes in comparison to SciBERT, which we believe has been one of the contributing factors to its weaker performance, as it has previously been shown that BERT faces tokenization challenges in domain adaptation settings which leads to semantic meaning deterioration Nayak et al. (2020c); Timmapathini et al. (2021). Further, we can see in Table 2 that the average repetitions of both IV and OOV words is extremely small. This makes it challenging for the model to learn meaningful representations of words and sub-words (in the case of OOV) as both the word and its context is continuously changing. This can be attributed to the fact that technical documents and manuals are often described in a concise and factual manner, where repetition of information is discouraged.
Performance with different fine-tuning settings:
It can be seen in Table 4 and Table 5, the performance gains of using a MLM fine-tuned encoder vs a vanilla encoder is negligible both in the case FT1 vs FT3 and FT2 vs FT4. Table 3 shows the LM perplexity of the fine-tuned encoders. We believe that fine-tuning the language model with automotive domain text did not make much difference to the NER performance due to the aforementioned non-repeating phenomena of entities and context. FT2 and FT4 perform significantly superior to FT1 and FT3 as we believe that the head alone is insufficient to encapsulate the domain specific lexical, syntactic and semantic nuances over and above what the pre-trained encoder has learnt.
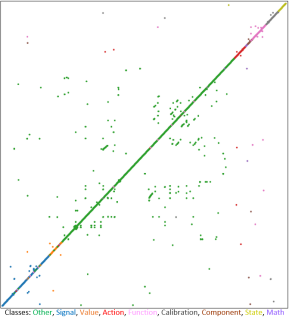
Class overlap due to domain specific notations:
BERT has been shown to learn lexical level features in the early layers, syntactic features in the middle layers and semantic features in the higher layers Jawahar et al. (2019). We used the 12th layer embeddings of all the entities across the dataset and reduced them from 768 to 2 dimensions using the t-SNE algorithm Van der Maaten and Hinton (2008) for visualization (Figure 1). We found that while the clusters of the classes Action, Function, Calibration, Component, State and Math remain pure (top right corner), the clusters of Other, Signal and Value begin to see overlap from other entity classes (bottom left corner).
We believe that this overlap reflected at the 12th layer is leading to a drop in performance and this is being caused at a lexical level due to use of domain specific prefixes/suffixes used across different entity classes (e.g. CrCtl can be used as a prefix across signal and state entities belonging to the cruise control function), at a syntactic level due to interchangeable grammatical usage (e.g. control as an Action could be a verb but as a Signal could be a noun) and at a semantic level due to the use of accrued domain knowledge by the expert to make a subtle judgement that is not straightforward to infer solely from the data.
4 Conclusion and Future Work
In this paper we have attempted to analyze the characteristics of the distribution shift when dealing with automotive domain text by performing the NER task. We find that while fine-tuning SciBERT performs better than BERT for the automotive domain, the performance metrics are unable to touch 90’s mainly due to lack of repeating contexts in the text, sparseness of entities, large number of OOV words and overlap between classes due to domain specific nuances. Our future work will focus on isolating specific attention heads and layer embeddings by passing them directly to the NER head, which previously have been shown to play unique roles in the network Clark et al. (2019).
References
- Beltagy et al. (2019) Iz Beltagy, Kyle Lo, and Arman Cohan. 2019. Scibert: Pretrained language model for scientific text. In EMNLP.
- Clark et al. (2019) Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D Manning. 2019. What does bert look at? an analysis of bert’s attention. arXiv preprint arXiv:1906.04341.
- Clark et al. (2020) Kevin Clark, Minh-Thang Luong, Quoc V Le, and Christopher D Manning. 2020. Electra: Pre-training text encoders as discriminators rather than generators. arXiv preprint arXiv:2003.10555.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Doğan et al. (2014) Rezarta Islamaj Doğan, Robert Leaman, and Zhiyong Lu. 2014. Ncbi disease corpus: a resource for disease name recognition and concept normalization. Journal of biomedical informatics, 47:1–10.
- Gu et al. (2020) Yu Gu, Robert Tinn, Hao Cheng, Michael Lucas, Naoto Usuyama, Xiaodong Liu, Tristan Naumann, Jianfeng Gao, and Hoifung Poon. 2020. Domain-specific language model pretraining for biomedical natural language processing.
- Jawahar et al. (2019) Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What does bert learn about the structure of language? In ACL 2019-57th Annual Meeting of the Association for Computational Linguistics.
- Keraghel et al. (2020) Abdenacer Keraghel, Khalid Benabdeslem, and Bruno Canitia. 2020. Data augmentation process to improve deep learning-based ner task in the automotive industry field. In 2020 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE.
- Kesri et al. (2021) Vaibhav Kesri, Anmol Nayak, and Karthikeyan Ponnalagu. 2021. Autokg-an automotive domain knowledge graph for software testing: A position paper. In 2021 IEEE International Conference on Software Testing, Verification and Validation Workshops (ICSTW), pages 234–238. IEEE.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Lee et al. (2020) Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim, Chan Ho So, and Jaewoo Kang. 2020. Biobert: a pre-trained biomedical language representation model for biomedical text mining. Bioinformatics, 36(4):1234–1240.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692.
- Luan et al. (2018) Yi Luan, Luheng He, Mari Ostendorf, and Hannaneh Hajishirzi. 2018. Multi-task identification of entities, relations, and coreference for scientific knowledge graph construction. arXiv preprint arXiv:1808.09602.
- Van der Maaten and Hinton (2008) Laurens Van der Maaten and Geoffrey Hinton. 2008. Visualizing data using t-sne. Journal of machine learning research, 9(11).
- Nayak et al. (2020a) Anmol Nayak, Vaibhav Kesri, Rahul K Dubey, Sarathchandra Mandadi, Vijendran G Venkoparao, Karthikeyan Ponnalagu, and Basavaraj S Garadi. 2020a. Knowledge graph from informal text: Architecture, components, algorithms. Applications of Machine Learning, page 75.
- Nayak et al. (2020b) Anmol Nayak, Vaibhav Kesri, and Rahul Kumar Dubey. 2020b. Knowledge graph based automated generation of test cases in software engineering. In Proceedings of the 7th ACM IKDD CoDS and 25th COMAD, pages 289–295.
- Nayak et al. (2020c) Anmol Nayak, Hariprasad Timmapathini, Karthikeyan Ponnalagu, and Vijendran Gopalan Venkoparao. 2020c. Domain adaptation challenges of bert in tokenization and sub-word representations of out-of-vocabulary words. In Proceedings of the First Workshop on Insights from Negative Results in NLP, pages 1–5.
- Radford et al. (2018) Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding by generative pre-training.
- Raffel et al. (2019) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2019. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683.
- Rubens and Agarwal (2002) Matthew Rubens and Puneet Agarwal. 2002. Information extraction from online automotive classifieds. Dept. Of Computer Science, Stanford University.
- Sang and De Meulder (2003) Erik F Sang and Fien De Meulder. 2003. Introduction to the conll-2003 shared task: Language-independent named entity recognition. arXiv preprint cs/0306050.
- Schuster and Nakajima (2012) Mike Schuster and Kaisuke Nakajima. 2012. Japanese and korean voice search. In 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 5149–5152. IEEE.
- Sivaraman et al. (2021) Navya K Sivaraman, Rajesh Koduri, and Mithun Manalikandy. 2021. A hybrid method for automotive entity recognition. Technical report, SAE Technical Paper.
- Strassel and Mitchell (2003) Stephanie Strassel and Alexis Mitchell. 2003. Multilingual resources for entity extraction. In Proceedings of the ACL 2003 workshop on Multilingual and mixed-language named entity recognition, pages 49–56.
- Sun et al. (2020) Yu Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Hao Tian, Hua Wu, and Haifeng Wang. 2020. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 8968–8975.
- Timmapathini et al. (2021) Hariprasad Timmapathini, Anmol Nayak, Sarathchandra Mandadi, Siva Sangada, Vaibhav Kesri, Karthikeyan Ponnalagu, and Vijendran Gopalan Venkoparao. 2021. Probing the spanbert architecture to interpret scientific domain adaptation challenges for coreference resolution. In SDU@ AAAI.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. arXiv preprint arXiv:1706.03762.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding. arXiv preprint arXiv:1804.07461.
- Wolf et al. (2020) Thomas Wolf, Julien Chaumond, Lysandre Debut, Victor Sanh, Clement Delangue, Anthony Moi, Pierric Cistac, Morgan Funtowicz, Joe Davison, Sam Shleifer, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45.