WMCopier: Forging Invisible Image Watermarks on Arbitrary Images
Abstract
Invisible Image Watermarking is crucial for ensuring content provenance and accountability in generative AI. While Gen-AI providers are increasingly integrating invisible watermarking systems, the robustness of these schemes against forgery attacks remains poorly characterized. This is critical, as forging traceable watermarks onto illicit content leads to false attribution, potentially harming the reputation and legal standing of Gen-AI service providers who are not responsible for the content. In this work, we propose WMCopier, an effective watermark forgery attack that operates without requiring any prior knowledge of or access to the target watermarking algorithm. Our approach first models the target watermark distribution using an unconditional diffusion model, and then seamlessly embeds the target watermark into a non-watermarked image via a shallow inversion process. We also incorporate an iterative optimization procedure that refines the reconstructed image to further trade off the fidelity and forgery efficiency. Experimental results demonstrate that WMCopier effectively deceives both open-source and closed-source watermark systems (e.g., Amazon’s system), achieving a significantly higher success rate than existing methods111We have reported this to Amazon AGI’s Responsible AI team and collaborated on developing potential defense strategies. For the official statement from Amazon, see the “Broader Impact” in Appendix I.. Additionally, we evaluate the robustness of forged samples and discuss the potential defenses against our attack. Code is available at: https://anonymous.4open.science/r/WMCopier-E752.
1 Introduction
As generative models raise concerns about the potential misuse of such technologies for generating misleading or fictitious imagery fakenews1 , watermarking techniques have become a key solution for embedding traceable information into generated content, ensuring its provenance jiang2024watermark . Driven by government initiatives Whitehouse , AI companies, including Google and Amazon, are increasingly adopting invisible watermarking techniques for their generated content Amazonwatermark ; Synthid , owing to the benefits of imperceptibility and robustness openaiwatermark ; Bingwatermark .
However, existing invisible watermark systems are vulnerable to diverse attacks, including detection evasion jiang2023evading ; zhao2024invisible and forgery yang2024steganalysis ; zhao2024sok . Although the former has received considerable research attention, forgery attacks remain poorly explored. Forgery attacks, where non-watermarked content is falsely detected as watermarked, pose a significant challenge to the reliability of watermarking systems. These attacks maliciously attribute harmful watermarked content to innocent parties, such as Generative AI (Gen-AI) service providers, damaging the reputation of providers sadasivan2023can ; gu2023learnability .
Existing watermark forgery attacks are broadly categorized into two scenarios: the black-box setting and the no-box setting. In the black-box setting, the attacker has partial access to the watermarking system: such as knowledge of the specific watermarking algorithm muller2024black , the ability to obtain paired data (clean images and their watermark versions) via the embedding interface saberi2023robustness ; wang2021watermark , and query access to the watermark detector muller2024black . However, such black-box access is unrealistic in practice, as the watermark embedding process is typically integrated into the generative service itself, rendering it inaccessible to end users, thus disabling paired data acquisition. Moreover, service providers rarely disclose the specific watermarking algorithms they employ Synthid . Therefore, our focus is primarily on the no-box setting, where the attacker lacks both knowledge of the watermarking algorithm and access to its implementation. The available information is only a collection of generated images with unknown watermarking algorithms. Under this setting, Yang et al.yang2024steganalysis attempt to extract the watermark pattern by computing the mean residual between watermarked images and natural images from ImageNetImagenet . The extracted watermark pattern is then directly added to forged images at the pixel level. However, this coarse approximation limits the effectiveness of the forgery, as the natural images from ImageNet inevitably differ from the clean counterparts of the watermarked images.
Inspired by recent work carlini2023extracting ; yu2021responsible ; zhao2023recipe , demonstrating that diffusion models serve as powerful priors capable of capturing complex data distributions, we ask a more exploratory question:
Can diffusion models act as copiers for invisible watermarks?
To be more precise, can we leverage them to copy the underlying watermark signals embedded in watermarked images?
Building on this insight, we propose WMCopier, a no-box watermark forgery attack framework tailored for practical adversarial scenarios. In this setting, the attacker has no prior knowledge of the watermarking scheme used by the provider and only has access to watermarked content generated by the Gen-AI service. Specifically, we first train an unconditional diffusion model on watermarked images to capture their underlying distribution. Then, we perform a shallow inversion to map clean images to their latent representations, followed by a denoising process that injects the watermark signal utilizing the trained diffusion model. To further mitigate artifacts introduced during inversion, we propose a refinement procedure that jointly optimizes image quality and alignment with the target watermark distribution.
To evaluate the effectiveness of WMCopier, we perform comprehensive experiments across a range of watermarking schemes, including a closed-source one (Amazon’s system). Experimental results demonstrate that our attack achieves a high forgery success rate while preserving excellent visual fidelity. Furthermore, we conduct a comparative robustness analysis between genuine and forged watermarks. Finally, we explore potential defense strategies, including a multi-message strategy and semantic watermarking, which provide practical guidance for improving future watermark design and deployment.
Our key contributions are summarized as follows:
-
•
We propose WMCopier, the first no-box watermark forgery attack based on diffusion models, which forges watermark signals directly from watermarked images without requiring any knowledge of the watermarking scheme.
-
•
We introduce a shallow inversion strategy and a refinement procedure, which injects the target watermark signal into arbitrary clean images while jointly optimizing image quality and conformity to the watermark distribution.
-
•
Through extensive experiments, we demonstrate that WMCopier effectively forges a wide range of watermark schemes, achieving superior forgery success rates and visual fidelity, including on Amazon’s deployed watermarking system.
-
•
We explore potential defense strategies, including a multi-message strategy and semantic watermarking, that provide insights to improve future watermarking systems.
2 Preliminary
2.1 DDIM and DDIM Inversion
DDIM.
Diffusion models generate data by progressively adding noise in the forward process and then denoising from pure Gaussian noise during the reverse process. The forward diffusion process is modeled as a Markov chain, where Gaussian noise is gradually added to the data over time. At each time step , the noised sample can be obtained in closed form as:
| (1) |
where is the noise schedule, and is standard Gaussian noise.
DDIM ho2020denoising is a deterministic sampling approach for diffusion models, enabling faster sampling and inversion through deterministic trajectory tracing. In DDIM sampling, the denoising process starts from Gaussian noise and proceeds according to:
| (2) |
for , eventually yielding the generated sample . Here, denotes a neural network, which is trained to predict the noise added to at step during the forward process, by minimizing the following objective:
| (3) |
DDIM Inversion.
DDIM inversion mokady2023null ; ho2020denoising allows an image to be approximately mapped back to its corresponding latent representation at step by reversing the sampling trajectory. DDIM inversion has found widespread applications in computer vision, such as image editing mokady2023null ; ju2023direct and watermarking li2024shallow ; huang2024robin . We denote this inversion procedure from to as:
| (4) |
2.2 Invisible Image Watermarking
Invisible image watermarking helps regulators and the public identify AI-generated content and trace harmful outputs (such as NSFW or misleading material) back to the responsible service provider, thus enabling accountability attribution. Specifically, the watermark message inserted by the service provider typically serves as a model identifier stablesignature . For example, Stability AI embeds the identifier StableDiffusionV1 by converting it into a bit string and encoding it as a watermark Stabilitywatermark . A list of currently deployed real-world watermarking systems is provided in Table 4 in Appendix B.
Invisible image watermarking typically involves three stages: embedding, extraction, and verification. Given a clean (non-watermarked) image and a binary watermark message , the embedding process uses an encoder to produce a watermarked image:
During the extraction stage, a detector attempts to recover the embedded message from :
During the verification stage, the extracted message is evaluated against the original message using a verification function , which measures their similarity in terms of bit accuracy. An image is considered watermarked if its bit accuracy exceeds a predefined threshold , where is typically selected to achieve a desired false positive rate (FPR). For instance, to achieve a FPR below 0.05 for a 40-bit message, should be set to , based on a Bernoulli distribution assumption lukas2023ptw . Formally, the verification function is defined as:
| (5) |
3 Threat Model
In a watermark forgery attack, the attacker forges the watermark of a service provider onto clean images, including malicious or illegal content. As a result, these forged images may be incorrectly attributed to the service provider, leading to reputation harm and legal ramifications.
Attacker’s Goal. The attacker aims to produce a forged watermarked image that visually resembles a given clean image , yet is detected by detector as containing a target watermark message . Specifically, visual consistency is required to retain the original (possibly harmful) semantic content and to avoid visible artifacts that may reveal the attack.
Attacker’s Capability. We consider a threat model under the no-box setting:
-
The attacker does not know the target watermarking scheme or its internal parameters. They have no access to embed watermarks into their own images or the corresponding detection pipeline.
-
The attacker can collect a subset of watermarked images from AI-generated content platforms (e.g., PromptBase PromptBase , PromptHero PromptHero ) or directly query the target Gen-AI service.
-
The attacker assumes a static watermarking scheme, i.e., the service provider does not alter the watermarking scheme during the attack period.
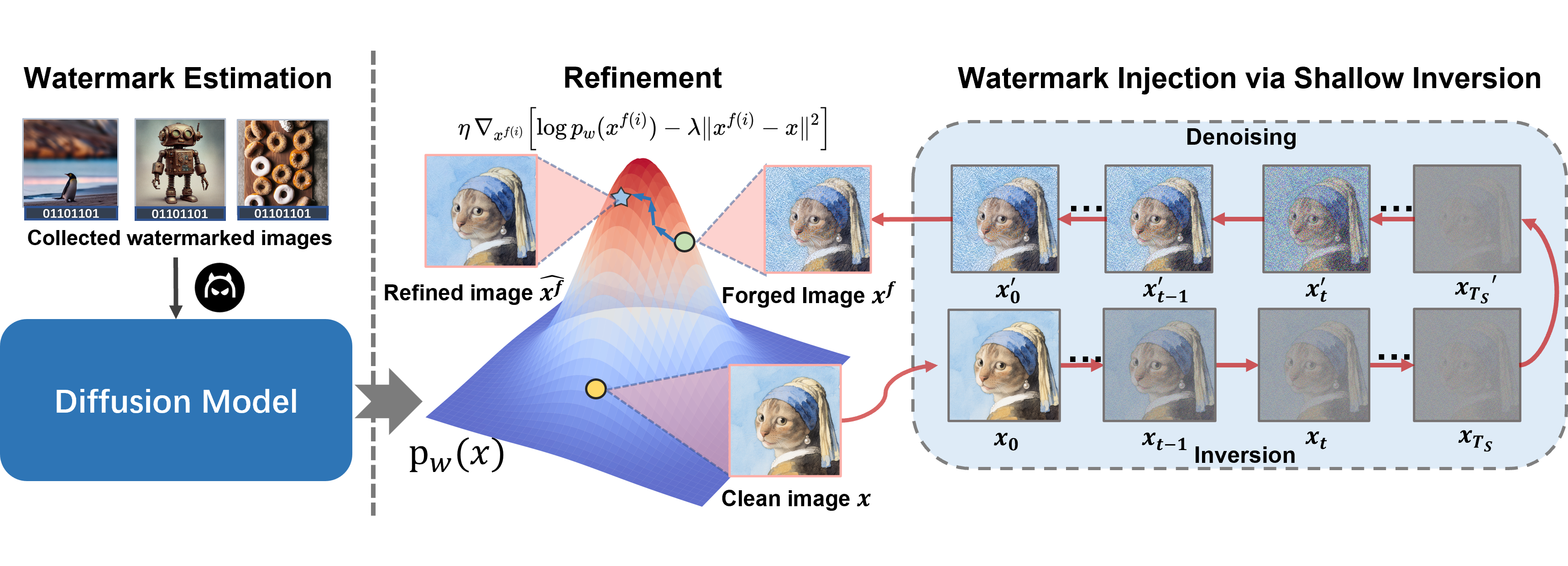
4 WMCopier
In this section, we introduce WMCopier, a watermark forgery attack pipeline consisting of three stages: (1) Watermark Estimation, (2) Watermark Injection, and (3) Refinement. An overview of the proposed framework is illustrated in Figure 1.
4.1 Watermark Estimation
Diffusion models are used to fit a plausible data manifold ho2020denoising ; dhariwal2021diffusion ; vastola2025generalization by optimizing Equation 3. The noise predictor approximates the conditional expectation of the noise:
| (6) |
which effectively turns into a regressor for the conditional noise distribution.
Now consider a clean image and its watermarked version , where denotes the embedded watermark signal, which can also be interpreted as the perturbation introduced by the embedding process. During the forward diffusion process, we have:
| (7) |
where is the noisy version of the clean image at step . The presence of the additive term implies that the input to the noise predictor carries a watermark-dependent shift. As a result, the predicted noise satisfies:
| (8) |
where denotes the systematic prediction bias introduced by the watermark signal. These biases accumulate subtly at each denoising step, gradually steering the model’s output distribution toward the watermarked distribution .
To exploit this behavior, we construct an auxiliary dataset , where each image contains an embedded watermark message . We then train an unconditional diffusion model on .
Our goal is to obtain forged images with watermark signals while preserving the semantic content of a clean image . Therefore, given the pretrained model and a clean image , we first apply DDIM inversion to obtain a latent representation :
| (9) |
The latent representation retains semantic information about the clean image. Starting from , we apply the denoising process described in Equation 2 to obtain the forged image , where the bias in Equation 8 naturally guides the denoising process toward the distribution of watermarked images.
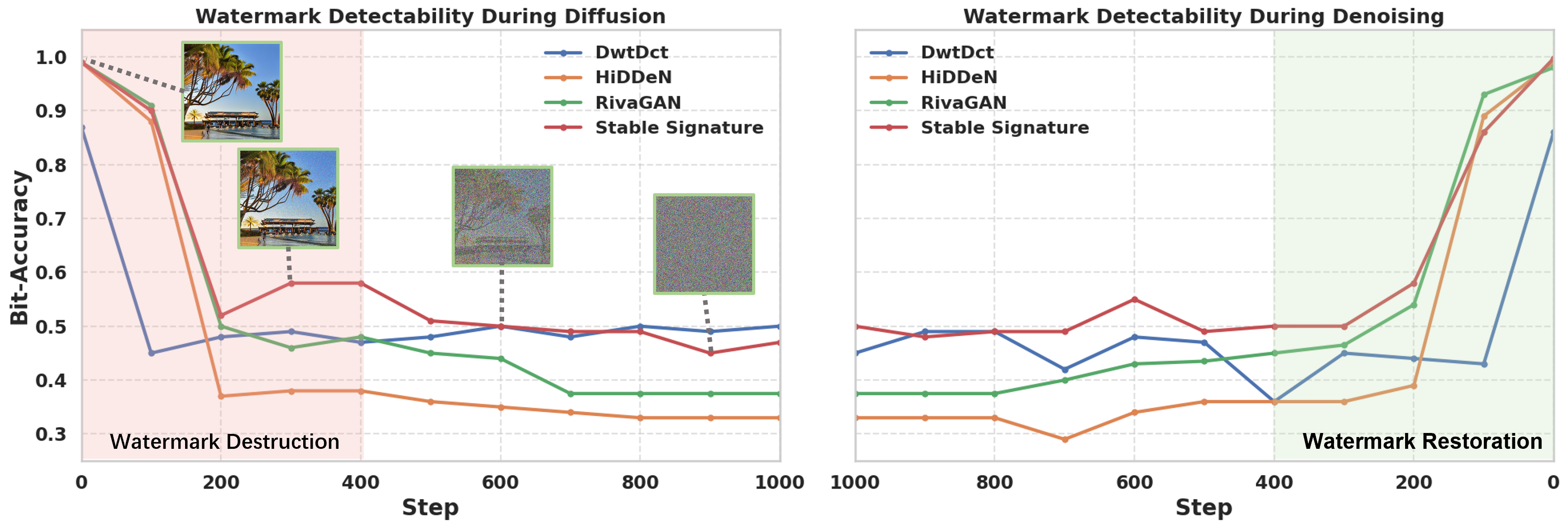
4.2 Watermark Injection
We observe that the reconstructed images with full-step inversion suffer from severe quality degradation, as illustrated in the top row of Figure 3. This phenomenon is attributed to the fact that the inversion of images tends to accumulate reconstruction errors when the input clean images are out of the training data distribution, especially as the inversion depth increases mokady2023null ; garibi2024renoise ; ho2020denoising . To mitigate this, we investigate the watermark detectability in watermarked images with four open-source watermarking methods throughout the diffusion and denoising processes. As illustrated in Figure 2, the watermark signal tends to be destroyed gradually during the shallow steps (e.g., for ), Consequently, the watermark signal is restored during these denoising steps.
Therefore, we propose a shallow inversion strategy that performs the inversion process up to an early timestep . By skipping deeper diffusion steps that contribute minimally to watermark injection yet substantially distort image semantics, our method effectively preserves the visual fidelity of reconstructed images while ensuring reliable watermark injection.
4.3 Refinement
Although shallow inversion effectively reduces reconstruction errors, forged images may still exhibit minor artifacts (as shown in Figure 3) that cause the forged images to be visually distinguishable, thus exposing the forgery. To address this, we propose a refinement procedure to adjust the forged image , defined as:
| (10) |
where is the step size, balances semantic fidelity and watermark injection and is the optimization iterations. The log-likelihood constrains the samples to lie in regions of high probability under the watermarked image distribution , while the mean squared error (MSE) term ensures that the refined image remains similar to the clean image . Since the distribution and the conditional noise distribution are nearly identical at a low noise step , the score function can be approximated by . This score can be estimated using a pre-trained diffusion model song2019generative ; song2020score , as defined in Equation 11, where .
| (11) |
By performing this refinement for iterations, we obtain the forged watermarked image after the refinement process. This refinement improves both watermark detectability and the image quality of the forged images, as demonstrated in Figure 3 and Table 9. A complete overview of our WMCopier procedure is summarized in Algorithm 1.

5 Evaluation
Datasets. To simulate real-world watermark forgery scenarios, we train our diffusion model on AI-generated images and apply watermark forgeries to both AI-generated and real photographs. For AI-generated images, we use DiffusionDB wang2022diffusiondb that contains a diverse collection of images generated by Stable Diffusion stablediffusion . For real photographs, we adopt three widely-used datasets in computer vision: MS-COCO MS-COCO , ImageNet Imagenet , and CelebA-HQ CelebA-HQ .
Watermarking Schemes. We evaluate four watermarking schemes: three post-processing methods—DWT-DCT DWT-DCT , HiDDeN zhu2018hidden , and RivaGAN RivaGAN —an in-processing method, Stable Signature stablesignature , and a close-source watermark system, Amazon Amazonwatermark . Each watermarking scheme is evaluated using its official default configuration. A comprehensive description of these methods is included in the Appendix C.
Attack Parameters and Baselines. For the diffusion model, we adopt DDIM sampling DDIM sampling with a total step and perform inversion up to step . Further details regarding the training of the diffusion model are provided in the Appendix G. For the refinement procedure, we set the trade-off coefficient as 100, the number of refinement iterations as 100, a low-noise step in the refinement as 1 and the step size as by default. To balance the attack performance and the potential cost of acquiring generated images (e.g., fees from GenAI services), we set the size of the auxiliary dataset to 5,000 in our main experiments. For comparison, we consider the method by Yang et al. yang2024steganalysis that operates under the same no-box setting as ours, and Wang et al. wang2021watermark that assumes a black-box setting with access to paired watermarked and clean images.
Metrics. We evaluate the visual quality of forged images using Peak Signal-to-Noise Ratio (PSNR), defined as where is the clean image and is the forged image after the refinement process. A higher PSNR indicates better visual fidelity, i.e., the forged image is more similar to the original. We evaluate the attack effectiveness in terms of bit accuracy and false positive rate (FPR). Bit accuracy measures the proportion of watermark bits in the extracted message that match the target. FPR refers to the rate at which forged samples are incorrectly identified as valid watermarked images. A higher FPR thus indicates a more successful attack. Following common practice lukas2023ptw , we report FPR at a threshold calibrated to yield a 5% false positive rate on clean images.
| Black Box | No-Box | No-Box | ||||||||
| Attacks | Wang et al. wang2021watermark | Yang et al. yang2024steganalysis | Ours | |||||||
| Watermark scheme | Dataset | PSNR↑ | Forged Bit-acc↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ |
| DWT-DCT | MS-COCO | 31.33 | 74.32% | 81.10% | 32.87 | 53.08% | 8.00% | 33.69 | 89.19% | 90.80% |
| CelebAHQ | 32.19 | 81.29% | 85.60% | 32.90 | 53.68% | 11.00% | 35.29 | 89.46% | 95.20% | |
| ImageNet | 30.16 | 79.64% | 83.30% | 32.92 | 51.96% | 6.40% | 33.75 | 88.25% | 89.20% | |
| Diffusiondb | 31.87 | 78.22% | 82.80% | 32.90 | 51.59% | 6.60% | 33.84 | 85.17% | 86.00% | |
| HiddeN | MS-COCO | 31.02 | 80.56% | 99.30% | 29.68 | 63.12% | 32.80% | 31.74 | 99.34% | 100.00% |
| CelebAHQ | 31.57 | 82.28% | 99.90% | 29.79 | 61.52% | 21.50% | 33.12 | 98.08% | 99.90% | |
| ImageNet | 31.24 | 78.61% | 95.00% | 29.78 | 62.66% | 32.90% | 31.76 | 98.99% | 99.90% | |
| Diffusiondb | 30.74 | 79.99% | 99.20% | 29.68 | 63.36% | 35.40% | 31.46 | 98.83% | 99.80% | |
| RivaGAN | MS-COCO | 32.94 | 93.26% | 100.00% | 29.12 | 50.80% | 3.00% | 34.07 | 95.74% | 100.00% |
| CelebAHQ | 32.64 | 93.67% | 100.00% | 29.23 | 52.29% | 2.90% | 35.28 | 98.61% | 100.00% | |
| ImageNet | 33.11 | 90.94% | 99.60% | 29.22 | 50.92% | 2.70% | 33.87 | 93.83% | 100.00% | |
| Diffusiondb | 33.31 | 89.69% | 96.70% | 29.12 | 48.70% | 1.10% | 34.50 | 90.43% | 97.40% | |
| Stable Signature | MS-COCO | 28.87 | 91.68% | 98.40% | 30.77 | 52.67% | 5.90% | 31.29 | 98.04% | 99.90% |
| CelebAHQ | 32.33 | 79.90% | 92.40% | 30.51 | 51.73% | 1.50% | 30.54 | 96.04% | 100.00% | |
| ImageNet | 29.59 | 85.77% | 89.90% | 30.75 | 51.59% | 3.80% | 31.33 | 97.03% | 100.00% | |
| Diffusiondb | 31.11 | 89.24% | 98.10% | 30.65 | 52.69% | 4.60% | 31.59 | 96.24% | 99.80% | |
| Average | 31.50 | 84.32% | 93.83% | 30.62 | 54.52% | 11.26% | 32.94 | 94.58% | 97.37% | |
5.1 Attacks on Open-Source Watermarking Schemes
As shown in Table 1, our WMCopier achieves the highest forged bit accuracy and FPR across all watermarking schemes, even surpassing the baseline in the black-box setting. In terms of visual fidelity, all forged images exhibit a PSNR above 30dB, demonstrating that our WMCopier effectively achieves high image quality. For the frequency-domain watermarking DWT-DCT, the bit accuracy is slightly lower compared to other schemes. We attribute this to the inherent limitations of DWT-DCT, which originally exhibits low bit accuracy on certain images. A detailed analysis is presented in Appendix D.1.
| Watermark Scheme | Attack | Yang et al. yang2024steganalysis | Ours | ||
|---|---|---|---|---|---|
| Amazon WM | Dataset | PSNR↑ | SR↑/Con.↑ | PSNR↑ | SR↑/Con.↑ |
| Diffusiondb | 23.42 | 29.0%/2 | 32.57 | 100.0%/2.94 | |
| MS-COCO | 24.18 | 32.0%/2 | 32.93 | 100.0%/2.97 | |
| CelebA-HQ | 24.10 | 42.0%/2 | 31.84 | 100.0%/2.98 | |
| ImageNet | 23.95 | 28.0%/2 | 32.88 | 99.0%/2.89 | |
5.2 Attacks on Closed-Source Watermarking Systems
In this subsection, we evaluate the effectiveness of our attack and Yang’s method in attacking the Amazon watermarking scheme. The results are shown in Table 2. The success rate (SR), which represents the proportion of images detected as watermarked, and the confidence levels (Con.) returned by the API, are used to evaluate the effectiveness of the attacks on deployed watermarking systems.
Compared with Yang’s method, our attack achieves superior performance in terms of both visual fidelity and forgery effectiveness. Specifically, our method achieves an average PSNR exceeding 30dB and a success rate(SR) close to 100%, whereas Yang’s method typically results in PSNR values below 25dB and SR ranging from 28% to 42%.
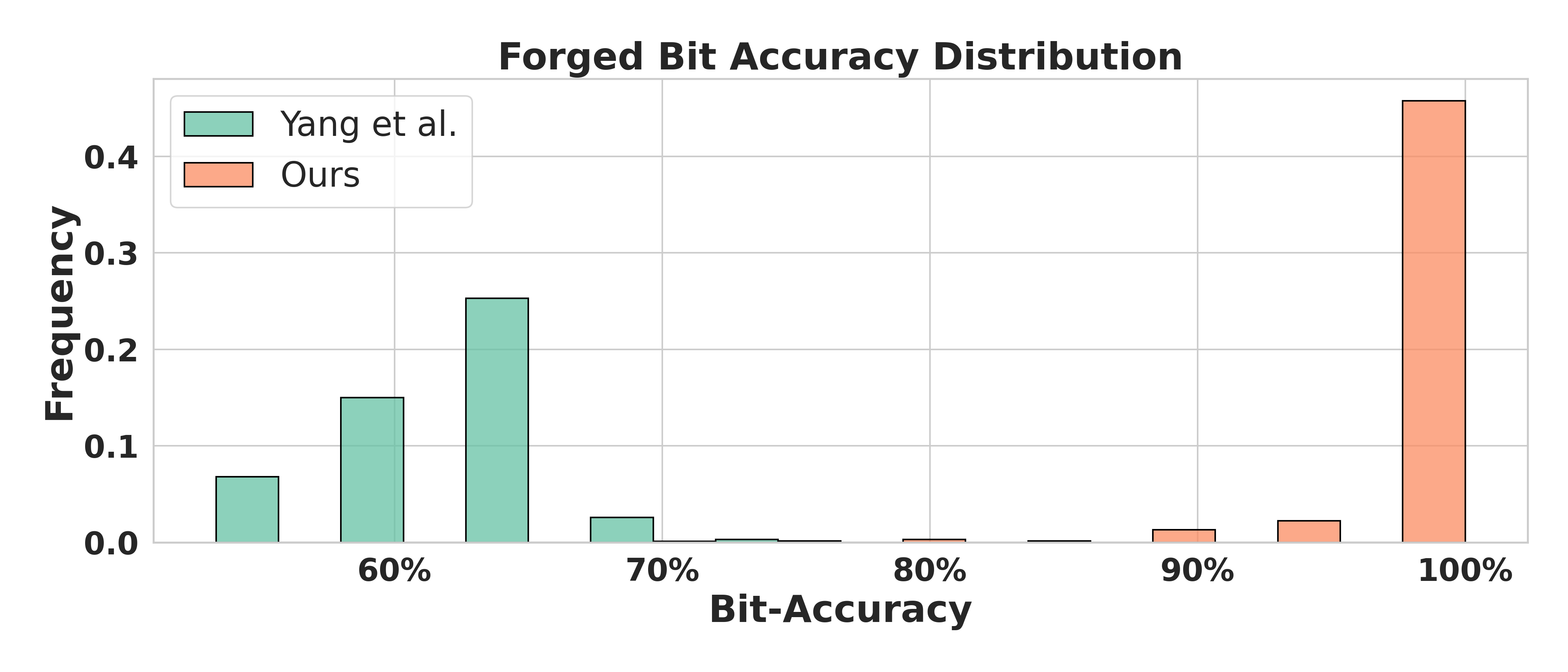
Furthermore, our forged images generally receive a confidence level of 3—the highest rating defined by Amazon’s watermark detection API—while Yang’s results consistently remain at level 2. Since Amazon does not disclose the exact computation of the confidence score, we guess that it may correlate with bit accuracy, based on common assumptions lukas2023ptw . To further investigate this, we analyzed the distribution of forged bit accuracy of both our method and Yang’s on open-source watermarking schemes. As shown in Figure 4, our method achieves 80%–100% bit accuracy on RivaGan, significantly outperforming Yang’s method, which remains below 70%.
5.3 Ablation Study
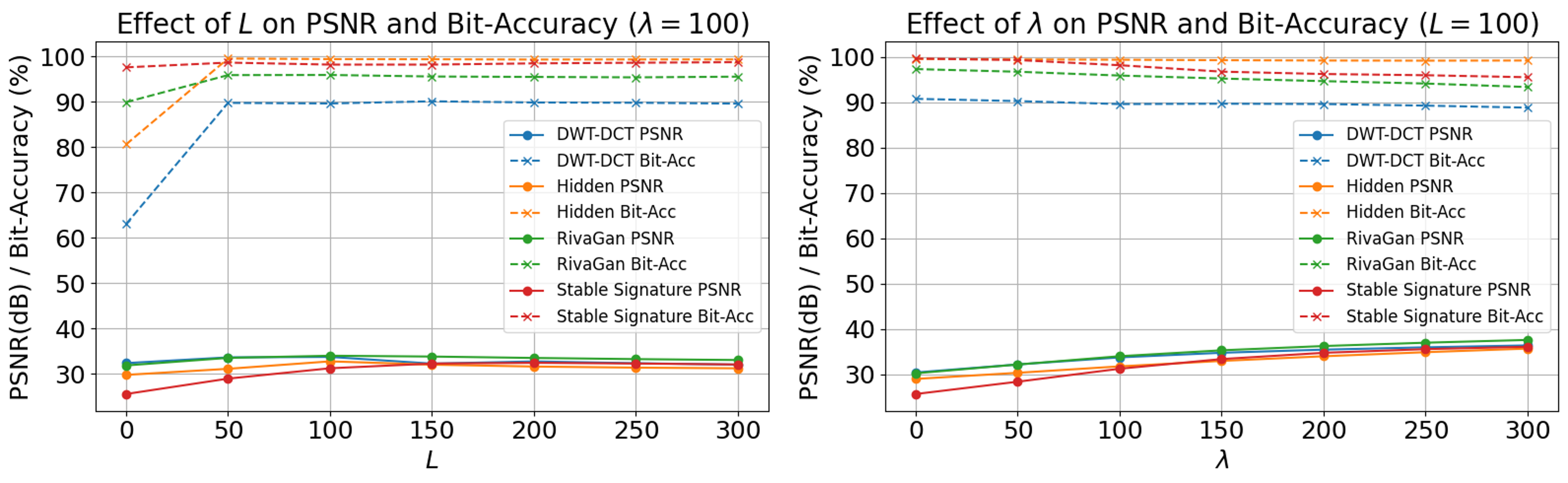
To evaluate the impact of parameter choices on image quality and forgery effectiveness, we conduct two sets of ablation studies by varying (i) the number of refinement optimization steps and (ii) the trade-off coefficient . As shown in Figure 5, increasing initially improves both PSNR and forged bit accuracy, with performance saturating beyond . In contrast, larger values continuously enhance PSNR but lead to a slight degradation in bit accuracy, likely due to over-regularization. Given that PSNR values above 30 dB are generally considered visually indistinguishable to the human eye, we adopt in our main experiments. The results presented in Table 9 in Appendix F, further validate the effectiveness of the refinement.
5.4 Robustness
To investigate the robustness of the forged images, we evaluated its forged bit accuracy of genuine and forged watermarked images under common image distortions, including Gaussian noise, JPEG compression, Gaussian blur, and brightness adjustment. Since the Stable Signature does not support watermark embedding into arbitrary images, we instead report results on generated images. As shown in Table 3, the forged watermark generally exhibits slightly lower robustness compared to the genuine watermark. While some cases show over 20% degradation (highlighted in red), relying on bit accuracy under distortion for separation is inadequate, as it would substantially compromise the true positive rate (TPR), as discussed in Appendix D.2.
| Watermark scheme | Distortion | JPEG | Blur | Gaussian Noise | Brightness | ||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Genuine | Forged | Genuine | Forged | Genuine | Forged | Genuine | Forged | |
| DWT-DCT | MS-COCO | 56.44% | 53.00% | 59.84% | 56.56% | 67.86% | 66.90% | 54.66% | 58.36% |
| CelebAHQ | 55.42% | 53.14% | 63.12% | 58.26% | 64.84% | 66.49% | 53.89% | 57.73% | |
| ImageNet | 56.08% | 52.31% | 59.37% | 54.39% | 68.27% | 67.60% | 54.08% | 57.37% | |
| Diffusiondb | 58.16% | 53.23% | 62.12% | 55.74% | 66.90% | 64.43% | 54.73% | 56.83% | |
| HiddeN | MS-COCO | 58.68% | 58.06% | 78.50% | 71.95% | 54.13% | 49.55% | 82.40% | 78.99% |
| CelebAHQ | 57.05% | 55.07% | 79.83% | 69.07% | 48.94% | 46.02% | 83.63% | 73.21% | |
| ImageNet | 58.86% | 57.83% | 78.20% | 71.34% | 54.10% | 49.57% | 80.95% | 77.40% | |
| Diffusiondb | 58.57% | 57.61% | 79.69% | 72.89% | 54.41% | 50.19% | 81.53% | 77.66% | |
| RivaGAN | MS-COCO | 99.44% | 93.32% | 99.60% | 94.99% | 85.71% | 75.00% | 84.51% | 78.81% |
| CelebAHQ | 99.92% | 97.22% | 99.97% | 98.23% | 85.93% | 74.83% | 84.60% | 79.53% | |
| ImageNet | 98.95% | 92.00% | 99.28% | 93.89% | 84.95% | 74.74% | 82.77% | 77.25% | |
| Diffusiondb | 96.56% | 84.85% | 97.27% | 86.96% | 77.33% | 66.27% | 79.14% | 71.65% | |
| StableSignature | MS-COCO | 93.99% | 89.48% | 86.91% | 68.34% | 73.78% | 67.14% | 92.30% | 88.63% |
| CelebAHQ | 86.73% | 65.42% | 65.33% | 86.86% | |||||
| ImageNet | 87.73% | 64.88% | 61.79% | 91.41% | |||||
| Diffusiondb | 85.69% | 65.45% | 61.60% | 87.45% | |||||
6 Related Work
6.1 Image Watermarking
Image watermarking techniques can generally be categorized into post-processing and in-processing methods, depending on when the watermark is embedded.
Post-processing methods embed watermark messages into images after generation. Classical approaches (e.g., LSB chopra2012lsb , DWT-DCT DWT-DCT ; DWT-DCT-SVD ) suffer from poor robustness under common distortions such as compression and noise. Neural approaches mitigate these issues by combining encoder-decoder architectures and adversarial training zhu2018hidden ; stegastamp ; PIMoG ; jia2021mbrs . However, these methods often rely on heavy training and may generalize poorly to unknown attacks.
In-processing methods embed watermarks during image generation, either by modifying training data or model weights yu2021responsible ; yu1 ; lukas2023ptw , or by adjusting specific components such as diffusion decoders stablesignature . Recent trends explore semantic watermarking, which binds messages to generative semantics (e.g., Tree-Ring wen2023tree ; Gaussian shading Gaussianshading ). However, semantic watermarking remains in an early stage and has not seen real-world deployment muller2024black , and thus falls beyond the scope of this work.
6.2 Watermark Forgery
Prior studies on watermark forgery primarily operate under white-box kinakh2024evaluation or black-box saberi2023robustness ; wang2021watermark ; li2023warfare ; muller2024black assumptions, where the attacker either has access to the watermarking model or can embed the watermark in their images. These approaches rely on strong assumptions that may not hold in real-world scenarios. In contrast, the no-box setting assumes that only watermarked images are accessible. Yang et al. yang2024steganalysis propose a heuristic approach in this setting, wherein they estimate the watermark signal by averaging the residuals between watermarked and clean images, and subsequently embed the estimated pattern directly at the pixel level. This is the setting we focus on in this work, as it more realistically reflects practical constraints.
7 Defense Analysis
In this section, we analyze potential defenses against our WMCopier, including a multi-message strategy and semantic watermarking. We provide detailed experimental evaluations of these defenses in the Appendix E.
8 Conclusion
We propose WMCopier, a diffusion model-based watermark forgery attack designed for the no-box setting, which leverages the diffusion model to estimate the target watermark distribution and performs shallow inversion to forge watermarks on a specific image. We also introduce a refinement procedure that improves both image quality and forgery effectiveness. Extensive experiments demonstrate that WMCopier achieves state-of-the-art performance on both open-source watermarking benchmarks and real-world deployed systems. We explore potential defense strategies, including a multi-message strategy and semantic watermarking, offering valuable insights for the future development of AIGC watermarking techniques.
References
- [1] Ali Al-Haj. Combined dwt-dct digital image watermarking. Journal of computer science, 3(9):740–746, 2007.
- [2] Amazon. Amazon titan foundation models - generative ai. https://aws.amazon.com/cn/bedrock/amazon-models/titan/.
- [3] Amazon. Amazon titan image generator and watermark detection api are now available in amazon bedrock. https://aws.amazon.com/cn/blogs/aws/amazon-titan-image-generator-and-watermark-detection-api-are-now-available-in-amazon-bedrock/.
- [4] Amazon. Watermark detection for amazon titan image generator now available in amazon bedrock. https://aws.amazon.com/cn/about-aws/whats-new/2024/04/watermark-detection-amazon-titan-image-generator-bedrock/, 2024.
- [5] Diane Bartz and Krystal Hu. Openai, google, others pledge to watermark ai content for safety, white house says. https://www.reuters.com/technology/openai-google-others-pledge-watermark-ai-content-safety-white-house-2023-07-21/.
- [6] Nicolas Carlini, Jamie Hayes, Milad Nasr, Matthew Jagielski, Vikash Sehwag, Florian Tramer, Borja Balle, Daphne Ippolito, and Eric Wallace. Extracting training data from diffusion models. In 32nd USENIX Security Symposium (USENIX Security 23), pages 5253–5270, 2023.
- [7] Deepshikha Chopra, Preeti Gupta, Gaur Sanjay, and Anil Gupta. Lsb based digital image watermarking for gray scale image. IOSR Journal of Computer Engineering, 6(1):36–41, 2012.
- [8] Emilia David. Openai is adding new watermarks to dall-e 3. https://www.theverge.com/2024/2/6/24063954/ai-watermarks-dalle3-openai-content-credentials, 2024.
- [9] Google Deepmind. Imagen 2. https://deepmind.google/technologies/imagen-2/.
- [10] Google Deepmind. Synthid: Identifying ai-generated content with synthid. https://deepmind.google/technologies/synthid/, 2023.
- [11] Kayleen Devlin and Joshua Cheetham. Fake trump arrest photos: How to spot an ai-generated image. https://www.bbc.com/news/world-us-canada-65069316, 2023.
- [12] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021.
- [13] Han Fang, Zhaoyang Jia, Zehua Ma, Ee-Chien Chang, and Weiming Zhang. PIMoG: An Effective Screen-shooting Noise-Layer Simulation for Deep-Learning-Based Watermarking Network. In Proceedings of the 30th ACM International Conference on Multimedia, pages 2267–2275, Lisboa Portugal, October 2022. ACM.
- [14] Pierre Fernandez, Guillaume Couairon, Hervé Jégou, Matthijs Douze, and Teddy Furon. The stable signature: Rooting watermarks in latent diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22466–22477, 2023.
- [15] Daniel Garibi, Or Patashnik, Andrey Voynov, Hadar Averbuch-Elor, and Daniel Cohen-Or. Renoise: Real image inversion through iterative noising. In European Conference on Computer Vision, pages 395–413. Springer, 2024.
- [16] Chenchen Gu, Xiang Lisa Li, Percy Liang, and Tatsunori Hashimoto. On the learnability of watermarks for language models. arXiv preprint arXiv:2312.04469, 2023.
- [17] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- [18] Huaibo Huang, Ran He, Zhenan Sun, Tieniu Tan, et al. Introvae: Introspective variational autoencoders for photographic image synthesis. Advances in neural information processing systems, 31, 2018.
- [19] Huayang Huang, Yu Wu, and Qian Wang. Robin: Robust and invisible watermarks for diffusion models with adversarial optimization. Advances in Neural Information Processing Systems, 37:3937–3963, 2024.
- [20] Zhaoyang Jia, Han Fang, and Weiming Zhang. Mbrs: Enhancing robustness of dnn-based watermarking by mini-batch of real and simulated jpeg compression. In Proceedings of the 29th ACM international conference on multimedia, pages 41–49, 2021.
- [21] Zhengyuan Jiang, Moyang Guo, Yuepeng Hu, and Neil Zhenqiang Gong. Watermark-based detection and attribution of ai-generated content. arXiv preprint arXiv:2404.04254, 2024.
- [22] Zhengyuan Jiang, Jinghuai Zhang, and Neil Zhenqiang Gong. Evading watermark based detection of ai-generated content. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, pages 1168–1181, 2023.
- [23] Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct inversion: Boosting diffusion-based editing with 3 lines of code. arXiv preprint arXiv:2310.01506, 2023.
- [24] Vitaliy Kinakh, Brian Pulfer, Yury Belousov, Pierre Fernandez, Teddy Furon, and Slava Voloshynovskiy. Evaluation of security of ml-based watermarking: Copy and removal attacks. arXiv preprint arXiv:2409.18211, 2024.
- [25] Guanlin Li, Yifei Chen, Jie Zhang, Jiwei Li, Shangwei Guo, and Tianwei Zhang. Warfare: Breaking the watermark protection of ai-generated content. arXiv e-prints, pages arXiv–2310, 2023.
- [26] Wenda Li, Huijie Zhang, and Qing Qu. Shallow diffuse: Robust and invisible watermarking through low-dimensional subspaces in diffusion models. arXiv preprint arXiv:2410.21088, 2024.
- [27] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- [28] Nils Lukas and Florian Kerschbaum. PTW: Pivotal tuning watermarking for Pre-Trained image generators. In 32nd USENIX Security Symposium (USENIX Security 23), pages 2241–2258, 2023.
- [29] Yusuf Mehdi. Announcing microsoft copilot, your everyday ai companion. https://blogs.microsoft.com/blog/2023/09/21/announcing-microsoft-copilot-your-everyday-ai-companion/, 2023.
- [30] Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6038–6047, 2023.
- [31] Andreas Müller, Denis Lukovnikov, Jonas Thietke, Asja Fischer, and Erwin Quiring. Black-box forgery attacks on semantic watermarks for diffusion models. arXiv preprint arXiv:2412.03283, 2024.
- [32] K. A. Navas, Mathews Cheriyan Ajay, M. Lekshmi, Tampy S. Archana, and M. Sasikumar. DWT-DCT-SVD based watermarking. In 2008 3rd International Conference on Communication Systems Software and Middleware and Workshops (COMSWARE ’08), pages 271–274. IEEE, January 2008.
- [33] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- [34] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision (IJCV), 115(3):211–252, 2015.
- [35] Mehrdad Saberi, Vinu Sankar Sadasivan, Keivan Rezaei, Aounon Kumar, Atoosa Chegini, Wenxiao Wang, and Soheil Feizi. Robustness of ai-image detectors: Fundamental limits and practical attacks. arXiv preprint arXiv:2310.00076, 2023.
- [36] Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. Can ai-generated text be reliably detected? arXiv preprint arXiv:2303.11156, 2023.
- [37] Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution. Advances in neural information processing systems, 32, 2019.
- [38] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456, 2020.
- [39] StabilityAI. Stable diffusion github repository. https://github.com/Stability-AI/stablediffusion.
- [40] Matthew Tancik, Ben Mildenhall, and Ren Ng. Stegastamp: Invisible hyperlinks in physical photographs. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2117–2126, 2020.
- [41] unknown. Promptbase. https://promptbase.com/, 2024.
- [42] unknown. Prompthero. https://prompthero.com/midjourney-prompts, 2024.
- [43] John J Vastola. Generalization through variance: how noise shapes inductive biases in diffusion models. arXiv preprint arXiv:2504.12532, 2025.
- [44] Ruowei Wang, Chenguo Lin, Qijun Zhao, and Feiyu Zhu. Watermark faker: towards forgery of digital image watermarking. In 2021 IEEE International Conference on Multimedia and Expo (ICME), pages 1–6. IEEE, 2021.
- [45] Zijie J Wang, Evan Montoya, David Munechika, Haoyang Yang, Benjamin Hoover, and Duen Horng Chau. Diffusiondb: A large-scale prompt gallery dataset for text-to-image generative models. arXiv preprint arXiv:2210.14896, 2022.
- [46] Yuxin Wen, John Kirchenbauer, Jonas Geiping, and Tom Goldstein. Tree-ring watermarks: Fingerprints for diffusion images that are invisible and robust. arXiv preprint arXiv:2305.20030, 2023.
- [47] Pei Yang, Hai Ci, Yiren Song, and Mike Zheng Shou. Can simple averaging defeat modern watermarks? Advances in Neural Information Processing Systems, 37:56644–56673, 2024.
- [48] Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, and Nenghai Yu. Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models, May 2024. Comment: 17 pages, 11 figures, accepted by CVPR 2024.
- [49] Ning Yu, Vladislav Skripniuk, Sahar Abdelnabi, and Mario Fritz. Artificial Fingerprinting for Generative Models: Rooting Deepfake Attribution in Training Data. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 14428–14437, Montreal, QC, Canada, October 2021. IEEE.
- [50] Ning Yu, Vladislav Skripniuk, Dingfan Chen, Larry S Davis, and Mario Fritz. Responsible disclosure of generative models using scalable fingerprinting. In International Conference on Learning Representations, 2021.
- [51] Kevin Alex Zhang, Lei Xu, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Robust invisible video watermarking with attention. arXiv preprint arXiv:1909.01285, 2019.
- [52] Xuandong Zhao, Sam Gunn, Miranda Christ, Jaiden Fairoze, Andres Fabrega, Nicholas Carlini, Sanjam Garg, Sanghyun Hong, Milad Nasr, Florian Tramer, et al. Sok: Watermarking for ai-generated content. arXiv preprint arXiv:2411.18479, 2024.
- [53] Xuandong Zhao, Kexun Zhang, Zihao Su, Saastha Vasan, Ilya Grishchenko, Christopher Kruegel, Giovanni Vigna, Yu-Xiang Wang, and Lei Li. Invisible image watermarks are provably removable using generative ai. Advances in Neural Information Processing Systems, 37:8643–8672, 2024.
- [54] Yunqing Zhao, Tianyu Pang, Chao Du, Xiao Yang, Ngai-Man Cheung, and Min Lin. A recipe for watermarking diffusion models. arXiv preprint arXiv:2303.10137, 2023.
- [55] Jiren Zhu, Russell Kaplan, Justin Johnson, and Li Fei-Fei. Hidden: Hiding data with deep networks. In Proceedings of the European conference on computer vision (ECCV), pages 657–672, 2018.
Appendix A Algorithm
Appendix B Real-World Deployment
In line with commitments made to the White House, leading U.S. AI companies that provide generative AI services are implementing watermarking systems to embed watermark information into model-generated content before it is delivered to users [5].
Google introduced Synthid [10], which adds invisible watermarks to both Imagen 3 and Imagen 2 [9]. Amazon has deployed invisible watermarks on its Titan image generator [4].
Meanwhile, OpenAI and Microsoft are transitioning from metadata-based watermarking to invisible methods. OpenAI points out that invisible watermarking techniques are superior to the visible genre and metadata methods previously used in DALL-E 2 and DALL-E 3 [8], due to their imperceptibility and robustness to common image manipulations, such as screenshots, compression, and cropping. Microsoft has announced plans to incorporate invisible watermarks into AI-generated images in Bing [29]. Table 4 summarizes watermarking systems deployed in text-to-image models.
| Service Provider | Watermark | Generative Model | Deployed | Detector |
|---|---|---|---|---|
| OpenAI | Invisible | DALL·E 2 & DALL·E 3 | In Progress | Unknown |
| Google (SynthID) | Invisible | Imagen 2 & Imagen 3 | Deployed | Not Public |
| Microsoft | Invisible | DALL·E 3 (Bing) | In Progress | Unknown |
| Amazon | Invisible | Titan | Deployed | Public |
Appendix C Watermark Schemes
C.1 Open-source Watermarking Schemes
DWT-DCT. DWT-DCT [1] is a classical watermarking technique that embeds watermark bits into the frequency domain of the image. It first applies the discrete wavelet transform (DWT) to decompose the image into sub-bands and then performs the discrete cosine transform (DCT) on selected sub-bands.
HiDDeN. HiDDeN [55] is a neural network-based watermarking framework using an encoder-decoder architecture. A watermark message is embedded into an image via a convolutional encoder, and a decoder is trained to recover the message. Additionally, a noise simulation layer is inserted between the encoder and decoder to encourage robustness.
RivaGAN. RivaGAN embeds watermark messages into video or image frames using a GAN-based architecture. A generator network embeds the watermark into the input image, while a discriminator ensures visual quality.
Stable Signature. As an in-processing watermarking technique, Stable Signature [14] couples the watermark message with the parameters of the stable diffusion model. It is an invisible watermarking method proposed by Meta AI, which embeds a unique binary signature into images generated by latent diffusion models (LDMs) through fine-tuning the model’s decoder.
Setup. In our experiments, all schemes are evaluated under their default configurations, including the default image resolutions (128×128 for HiDDeN, 256×256 for RivaGAN, and 512×512 for both Stable Signature and Amazon), as well as their default watermark lengths (32 bits for DWT-DCT and RivaGAN, 30 bits for HiDDeN, and 48 bits for Stable Signature).
C.2 Closed-Source Watermarking System
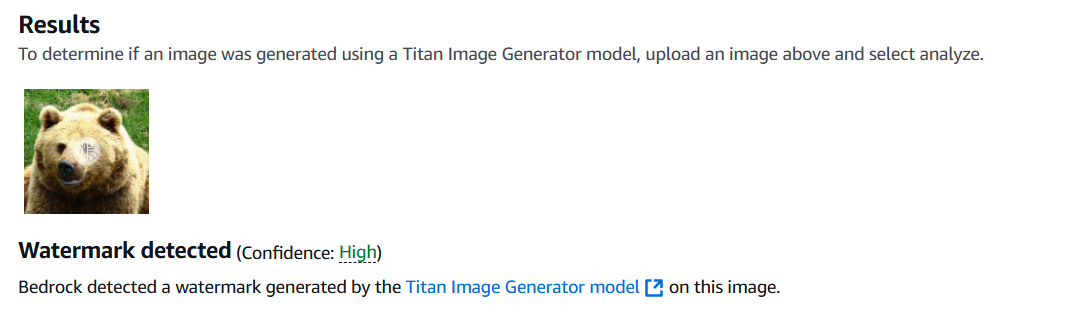
Among the available options, Google does not open its watermark detection mechanisms to users, making it impossible to evaluate the success of our attack. In contrast, Amazon provides access to its watermark detection for the Titan model [2], allowing us to directly measure the performance of our attack. Therefore, we chose Amazon’s watermarking scheme for our experiments. Amazon’s watermarking scheme, referred to as Amazon WM, ensures that AI-generated content can be traced back to its source. The watermark detection API detect whether an image is generated by the Titan model and provides a confidence level for the detection222Both the Titan model API and the watermark detection service API are accessible via Amazon Bedrock [3]. This confidence level reflects the likelihood that the image contains a valid watermark, as illustrated in Fig. 6.
In our experiments, we generated 5,000 images from the Titan model using Amazon Bedrock [3]. Specifically, we used ten different prompts to generate images with the Titan model, which were then employed to carry out our attack. In this attack, we embedded Amazon’s watermark onto four datasets, each containing 100 images. Finally, we submitted the forged images to Amazon’s watermark detection API. Additionally, we forged Amazon’s watermark on images from non-public datasets, including human-captured photos and web-sourced images, all of which were flagged as Titan-generated.
Appendix D External Experiment Results
D.1 Further Analysis of DWT-DCT Attack Results
We observed that DWT-DCT suffers from low bit-accuracy on certain images, which leads to unreliable watermark detection and verification. To reflect a more practical scenario, we assume that the service provider only returns images with high bit accuracy to users to ensure traceability. Specifically, we select 5,000 images with 100% bit accuracy to construct our auxiliary dataset . We then apply both the original DWTDCT scheme and our proposed WMCopier to add watermarks to clean images from four datasets. As shown in Table 5, our method achieves even higher bit-accuracy than the original watermarking process itself.
| Dataset | DWTDCT-Original | DWTDCT-WMCopier | ||
|---|---|---|---|---|
| Bit-acc.↑ | FPR@0.05↑ | Bit-acc.↑ | FPR@0.05↑ | |
| MS-COCO | 82.15% | 84.40% | 89.19% | 90.80% |
| CelebA-HQ | 84.70% | 84.00% | 89.46% | 95.20% |
| ImageNet | 85.37% | 84.30% | 88.25% | 89.20% |
| DiffusionDB | 82.42% | 80.80% | 85.17% | 86.00% |
D.2 Discrimination of Forged Watermarks by Robustness Gap
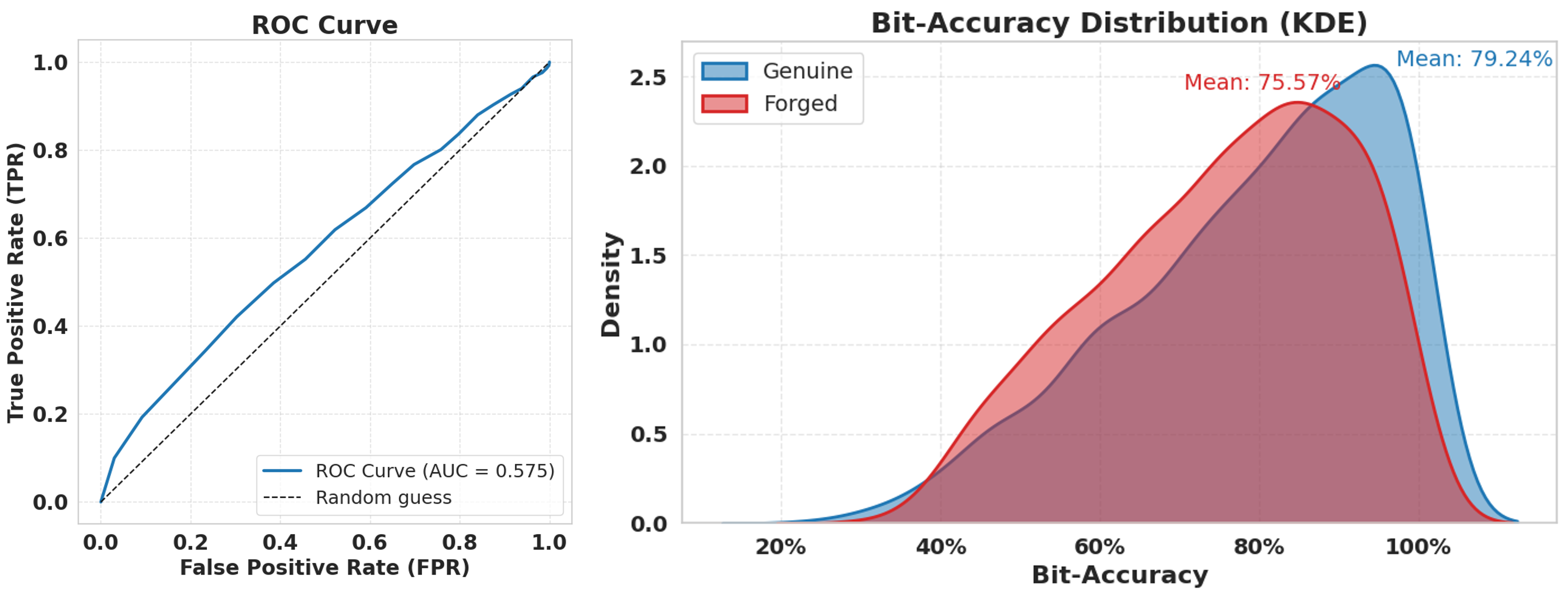
While the robustness gap between genuine and forged watermarks offers a promising direction for detecting forged samples, we find it is insufficient for reliable discrimination. This limitation becomes particularly evident when genuine samples have already been subjected to mild distortions.
In discrimination, samples are classified as forgeries if their bit accuracy falls below a predefined threshold after applying a single perturbation. Specifically, we apply perturbation to both genuine and forged watermark images and then distinguish them based on their bit accuracy. However, considering the inherent robustness of the watermarking scheme itself, when genuine watermarked images have already undergone slight perturbation , the bit accuracy values of genuine and forged samples become indistinguishable. For distortion , we use Gaussian noise with , while for distortion , Gaussian noise with is applied. The ROC curve and the bit-accuracy distribution for this case are shown in Figure 7.
Appendix E Potential Defenses
E.1 Semantic Watermark
Semantic watermarking [46, 48] embeds watermark information that is intrinsically tied to the semantic content of the image. This tight coupling makes it substantially more difficult to forge the watermark onto arbitrary images. Table 6 presents the results of our WMCopier on the semantic watermark TreeRing [46].
| Dataset | PSNR | FPR@0.01 | FPR@0.05 |
|---|---|---|---|
| MS-COCO | 33.60 | 0.00% | 5.00% |
| CelebA-HQ | 31.65 | 0.00% | 6.00% |
| ImageNet | 33.62 | 0.00% | 3.00% |
| DiffusionDB | 33.46 | 0.00% | 6.00% |
The results suggest that our attack fails to forge the TreeRing watermark. This highlights the potential of semantic watermarking as a defense against our attack. Although semantic watermarking is still in the early stages of research and has yet to see widespread practical deployment, we encourage future work to further explore and advance this promising direction.
E.2 Attack on Multiple Messages
To enhance the deployed watermarking system, we suggest modifying the existing watermark system by disrupting the ability of diffusion models to model the watermark distribution effectively. Specifically, we propose a multi-message strategy as a simple yet effective countermeasure. Instead of embedding a fixed watermark message, the system randomly selects one from a predefined message pool for each image. During detection, the detector verifies the presence of any valid message in the pool. This strategy introduces uncertainty into the watermark signal, increasing the entropy of possible watermark patterns and making it substantially more difficult for generative models to learn consistent features necessary for forgery. We implement this defense using different message pool sizes ().
| K=10 | K=50 | K=100 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ |
| MS-COCO | 34.74 | 80.14% | 88.90% | 32.85 | 69.89% | 74.80% | 34.97 | 69.62% | 72.70% |
| CelebAHQ | 36.10 | 83.75% | 96.70% | 33.71 | 70.43% | 80.20% | 35.97 | 70.17% | 77.50% |
| ImageNet | 34.67 | 79.24% | 87.20% | 32.78 | 69.82% | 77.20% | 34.87 | 69.60% | 72.70% |
| Diffusiondb | 35.21 | 76.17% | 79.40% | 33.32 | 70.09% | 76.20% | 35.74 | 69.73% | 74.70% |
Although increasing the value of leads to a notable reduction in FPR, we further enhance our attack by collecting more watermarked images. Specifically, we gather 5,000, 20,000, and 50,000 watermarked samples to evaluate the impact of data volume on attack performance. As shown in Table 8, the attack remains highly effective when using a large auxiliary set , achieving over 90% success rate. While this highlights the vulnerability of the watermarking scheme, it also suggests a potential weak defense mechanism: increasing the cost of the attack by requiring a larger number of collected watermarked images (e.g., generating 20,000 images may cost around $800).
| Dataset | 5000 | 20000 | 50000 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | PSNR↑ | Forged Bit-acc.↑ | FPR@0.05↑ | |
| MS-COCO | 34.97 | 69.62% | 72.70% | 33.27 | 72.19% | 93.20% | 30.86 | 72.24% | 95.00% |
| CelebA-HQ | 35.97 | 70.17% | 77.50% | 30.87 | 72.65% | 96.00% | 29.57 | 72.48% | 94.50% |
| ImageNet | 34.87 | 69.60% | 72.70% | 33.21 | 72.04% | 92.90% | 30.68 | 72.21% | 93.50% |
| DiffusionDB | 35.74 | 69.73% | 74.70% | 33.21 | 72.06% | 93.00% | 31.08 | 72.46% | 93.90% |
Appendix F Ablation Study
Table 9 shows that the refinement significantly improves visual fidelity (PSNR) and forgery effectiveness (forged bit accuracy).
| Watermark Scheme | PSNR ↑ | Forged Bit-acc. ↑ | FPR@0.05 ↑ | |||
|---|---|---|---|---|---|---|
| W/o Ref. | W/ Ref. | W/o Ref. | W/ Ref. | W/o Ref. | W/ Ref. | |
| DWT-DCT | 32.40 | 33.77 | 63.03% | 89.62% | 39.00% | 95.00% |
| HiddeN | 29.81 | 32.79 | 80.60% | 99.40% | 92.00% | 100.00% |
| RivaGAN | 31.89 | 34.03 | 89.90% | 95.90% | 95.00% | 97.00% |
| StableSignature | 25.60 | 31.27 | 97.58% | 98.19% | 100.00% | 100.00% |
Appendix G Training Details of the Diffusion Model
We adopt a standard DDIM framework for training, following the official Hugging Face tutorial333HuggingFace Tutorial: https://huggingface.co/docs/diffusers/en/tutorials/basic_training. The model is trained for 20,000 iterations with a batch size of 256 and a learning rate of . To support different watermarking schemes, we only adjust the input resolution of the model to match the input dimensions for each watermark. Other training settings and model configurations remain unchanged. Although the current training setup suffices for watermark forgery, enhancing the model’s ability to better capture the watermark signal is left for future work. For our primary experiments, we train an unconditional diffusion model from scratch using 5,000 watermarked images. Due to the limited amount of training data, the diffusion model demonstrates memorization [6], resulting in reduced sample diversity, as illustrated in Figure 8. All of the experiments are conducted on an NVIDIA A100 GPU.
Appendix H Limitation
In this section, we discuss the limitations of WMCopier. While our current training paradigm already achieves effective watermark forgery, we have yet to systematically investigate how to better guide diffusion models to capture the underlying watermark distribution. Moreover, although our method is effective against widely adopted invisible watermarking schemes, it may be less effective against semantic watermarking strategies, which embed information into high-level image semantics. While such techniques are not yet widely deployed in practice, they present a promising direction for future defense.
Appendix I Broader Impact
Invisible watermarking plays a critical role in detecting and holding accountable AI-generated content, making it a solution of significant societal importance. Our research introduces a novel watermark forgery attack, revealing the vulnerabilities of current watermarking schemes to such attacks. Although our work involves the watermarking system deployed by Amazon, as responsible researchers, we have worked closely with Amazon’s Responsible AI team to develop a solution, which has now been deployed. The Amazon Responsible AI team has issued the following statement:
’On March 28, 2025, we released an update that improves the watermark detection robustness of our image generation foundation models (Titan Image Generator and Amazon Nova Canvas). With this change, we have maintained our existing watermark detection accuracy. No customer action is required. We appreciate the researchers from the State Key Laboratory of Blockchain and Data Security at Zhejiang University for reporting this issue and collaborating with us.’
While our study highlights the potential risks of existing watermarking systems, we believe it plays a positive role in the early stages of their deployment. By providing valuable insights for improving current technologies, our work contributes to enhancing the security and robustness of watermarking systems, ultimately fostering more reliable solutions with a positive societal impact.

Appendix J Forged Samples



