WMFormer++: Nested Transformer for Visible Watermark Removal
via Implict Joint Learning
Abstract
Watermarking serves as a widely adopted approach to safeguard media copyright. In parallel, the research focus has extended to watermark removal techniques, offering an adversarial means to enhance watermark robustness and foster advancements in the watermarking field. Existing watermark removal methods mainly rely on UNet with task-specific decoder branches——one for watermark localization and the other for background image restoration. However, watermark localization and background restoration are not isolated tasks; precise watermark localization inherently implies regions necessitating restoration, and the background restoration process contributes to more accurate watermark localization. To holistically integrate information from both branches, we introduce an implicit joint learning paradigm. This empowers the network to autonomously navigate the flow of information between implicit branches through a gate mechanism. Furthermore, we employ cross-channel attention to facilitate local detail restoration and holistic structural comprehension, while harnessing nested structures to integrate multi-scale information. Extensive experiments are conducted on various challenging benchmarks to validate the effectiveness of our proposed method. The results demonstrate our approach’s remarkable superiority, surpassing existing state-of-the-art methods by a large margin.
Introduction
In today’s digital era, images have become the predominant means of recording and conveying information, often adorned with visible watermarks to assert copyright or ownership. While overlaying visible watermarks is an efficient defense against unauthorized use, it also raises concerns about the robustness of such watermarks in the face of modern watermark removal techniques. This has propelled the emergence of watermark removal as a critical research area, dedicated to assessing and enhancing the resilience of visible watermarks through strategic adversarial approaches. This paper delves into the challenges and advancements in watermark removal, with a specific focus on enhancing the effectiveness of visible watermarks in safeguarding digital media.
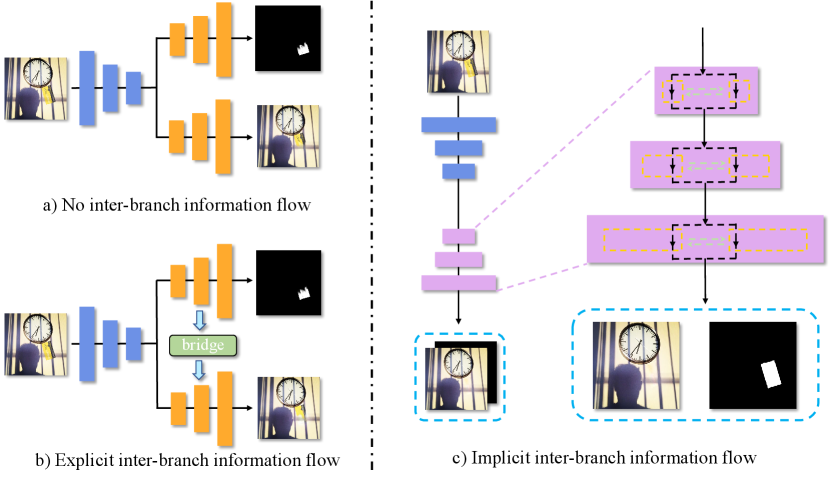
Amidst the rapid evolution of deep learning, data-driven methodologies have surged to the forefront in the realm of watermark removal, achieving remarkable strides. Hertz et al. (2019) introduced a multi-task network for blind watermark removal from single images, achieving commendable results through multiple decoder branches dedicated to distinct tasks, including watermark location and background restoration. Cun and Pun (2021) proposed a novel two-stage framework with stacked attention-guided ResUNets to address texture non-harmony challenges in watermark removal. Following Hertz and Cun’s pioneering introduction of multi-decoder multi-stage networks for watermark removal, subsequent studies (Liang et al. 2021; Zhao, Niu, and Zhang 2022; Sun, Su, and Wu 2023) have predominantly focused on refining modules and enhancing coarse-level aspects within this paradigm.
However, this paradigm treats watermark localization and image restoration tasks as isolated processes within separate decoder branches (as depicted in Fig. 1(a)), potentially underutilizing the inter-branch information exchange. Recognizing this, Liang et al. (2021) meticulously designed modules to control information flow between watermark and background branches, enhancing background restoration. The effectiveness of this module implies that the background branch contains numerous watermark fragments, which, in turn, can be leveraged to enhance watermark localization. While a viable approach would be to design a handcrafted module to guide inter-branch information flow, this proves challenging (as shown in Fig. 1(b)). Instead of relying on such intricate handcrafted designs, we propose a Transformer-based method that treats the two interdependent branches as a unified entity, utilizing Gated-Dconv Feed-Forward Network (Zamir et al. 2022) as a distributor to effectively guide the flow of information (as illustrated in Fig. 1(c)). Furthermore, drawing inspiration from the implicit modeling of spatial relationships among adjacent pixels and the global context of all pixels in (Zamir et al. 2022), we exploit the Cross-channel Multi-head Attention mechanism. This mechanism enhances both the quality of localized background restoration and the accuracy of global watermark localization. To accommodate the variance in understanding the watermark’s localized restoration area across different scales, we introduce a nested network design, facilitating the fusion of structural information from various scales. We hope that this work will inspire deeper contemplation within the watermark removal framework, infusing renewed vitality into the field and paving the way for innovative advancements in watermark removal techniques. Extensive experiments on various challenging benchmarks, including LOGO-H, LOGO-L, LOGO-Gray (Cun and Pun 2021), and CLWD (Liu, Zhu, and Bai 2021), along with qualitative intermediate visualizations, validate the effectiveness of our proposed method.
Our contributions can be summarized as follows:
-
•
We proposed a novel Transformer-based network that utilizes a single decoder to handle both watermark localization and background restoration tasks concurrently, eliminating the requirement for additional refinement steps.
-
•
We employ the Gated-Dconv Feed-Forward Network for effective information flow control, while the Cross-channel Multi-head Attention ensures detailed local reconstruction and comprehensive structural understanding. Additionally, we harness the power of a nested network design to enhance the comprehension of restoration areas across different scales.
-
•
Through extensive experimental evaluations on different datasets, we demonstrated the superiority and effectiveness of our proposed method, achieving new state-of-the-art performance and producing high-quality output.
Related Work
Watermark Removal
In the realm of digital copyright protection, digital watermarks have assumed a critical role. Early approaches (Pei and Zeng 2006; Park, Tai, and Kweon 2012) for watermark removal heavily relied on manually crafted features and necessitated user intervention for watermark localization, leading to usability challenges. Some researchers (Dekel et al. 2017; Gandelsman, Shocher, and Irani 2019) explored methods based on multiple images, but these demanded extensive prior knowledge and were limited in their applicability to specific samples.
Recent advancements in deep learning-based techniques have shown significant promise in various computer vision tasks, including visible watermark removal. Hertz et al. (2019) pioneered a groundbreaking approach by blindly removing visual motifs from images and introducing the single encoder with multi-decoder architecture for multi-task watermark removal, achieving impressive performance. Cun and Pun (2021) further enhanced watermark removal performance by proposing two-stage networks for prediction and refinement, solidifying the multi-decoder multi-stage framework as a mainstream solution for watermark removal. Building on this backdrop, Liang et al. (2021) introduced a set of intricate modules to enhance the quality of generated images, while Sun, Su, and Wu (2023) employed a contrastive learning strategy to disentangle high-level embedding semantic information of images and watermarks.
While the multi-decoder multi-stage framework has been instrumental, it is crucial to reassess its rationale and adopt a more concise architecture. By seeking a more streamlined solution, we can further advance research in the field of watermark removal, providing more practical and sustainable approaches for real-world applications.
Image Restoration
Watermark removal shares a resemblance to image dehazing (He, Sun, and Tang 2010), deraining (Ren et al. 2019), and shadow removal (Cun, Pun, and Shi 2020) tasks in image restoration. They all involve recovering the source image from a damaged version, but specific differences exist that cannot be ignored in practical applications.
In dehazing and deraining, the interference factors (haze and raindrops) permeate the entire image, with repeated patterns and semantics present within and across images. In contrast, watermarks are usually localized in specific areas of the image, with each watermark representing unique information independently. Moreover, shadow removal deals with meaningless grey areas, while watermarks symbolize media copyright and typically exhibit meaningful and colorful content. These distinctions make watermark removal a distinct and challenging research domain.
Recently, the adoption of a novel Transformer architecture (Zamir et al. 2022) in image restoration has shown remarkable results, inspiring us to explore the application of similar modules in the field of watermark removal.
UNet
UNet (Ronneberger, Fischer, and Brox 2015) is a classic neural network known for its effectiveness in image semantic segmentation. Its U-shaped architecture with symmetric encoding and decoding pathways enables it to capture both global and local features, achieving remarkable performance in image segmentation tasks.
UNet++ (Zhou et al. 2018) is an improved version of UNet. It builds upon the original UNet by introducing multi-level encoding-decoding paths. This design allows the network to progressively fuse feature information across layers, resulting in a better grasp of semantic information at different scales and further enhancing segmentation performance.
While UNet has been widely applied as a foundational framework in the field of watermark removal, the application of the UNet++ architecture in watermark removal remains relatively unexplored and lesser-known.
Methodology
In this paper, we have reimagined the development of the watermark removal domain from a framework perspective. Our goal is to challenge the current popular paradigm of multi-decoder removal networks and design a concise watermark removal framework while exploring the potential of transformers in watermark removal tasks. As a result, we propose a simple yet effective Transformer-based implicit joint training framework called WMFormer++.
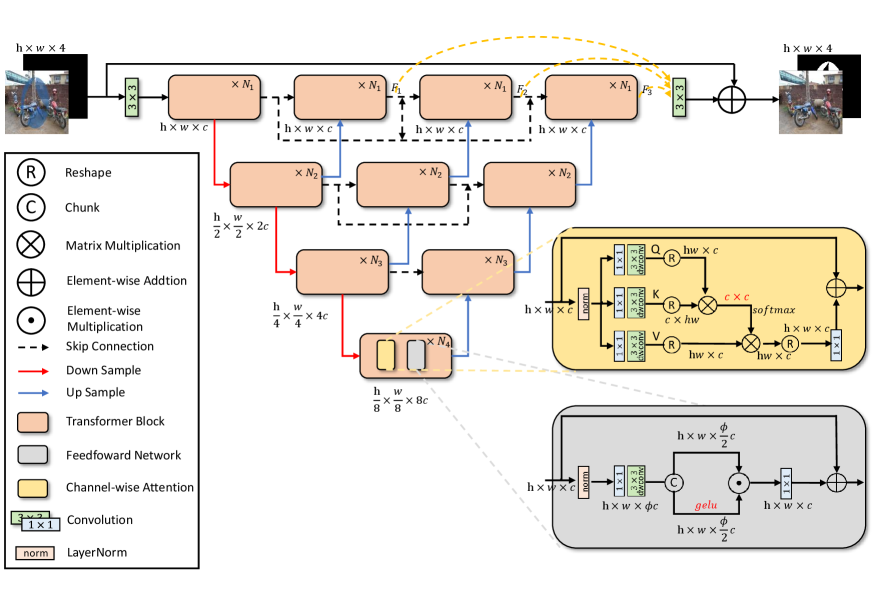
Overall Architecture
For a given watermarked image , our network produces a watermark-free restored background image as output, with the grayscale watermark mask being generated as a byproduct. The network architecture consists of a multi-stage encoder and a nested decoder, with both components composed of fundamental Transformer blocks.
Basic Module
A novel type of Transformer (Zamir et al. 2022) serves as the basic building block of the entire network, composed of two key components: Cross-channel Multi-head Attention and Gated-Dconv Feed-Forward Network.
(i) Cross-channel Multi-head Attention.
This component serves to boost local restoration quality while enabling comprehensive restoration region anchoring.
Initially, the module utilizes convolutions and depth-wise convolutions to gather spatial information from neighboring pixels.
Subsequently, it calculates cross-channel attention maps to implicitly establish global context semantics across pixels.
Given the input , the attention for the i-th head is computed using the following formula:
| (1) | ||||
| (2) |
where , and represent the query, key, and value for each head , respectively. and are three projection matrices. is a learnable parameter.
(ii) Gated-Dconv Feed-Forward Network.
This module utilizes a gating mechanism to enhance information flow within the network, facilitating the collaborative optimization of the two implicit branches: watermark localization and background restoration.
This synergistic approach enables them to collectively refine their respective tasks.
The entire process can be represented using the following formula:
| (3) | ||||
| (4) |
where and correspond to the projection matrices responsible for augmenting and reducing the channel dimensions of . The output of the module is denoted by .
Encoder
The Encoder module follows a similar structure as the UNet (Ronneberger, Fischer, and Brox 2015), comprising four hierarchical levels. As data progresses through each level, the feature map dimensions remain unchanged, but its channel count doubles and size is halved before transitioning to the subsequent level. This progressive encoding leads to the compression of the original input, resulting in a latent code enriched with semantic information.
In general, the latent code generated by the final level acts as input for the Decoder. Notably, in contrast to the conventional approach, we harness the latent codes generated at each level during the decoding process. This synergistic interaction among nested decoders empowers the creation of UNet models with varying depths, allowing for a more adaptable and flexible architecture.
Decoder
The latent code encapsulates two crucial aspects of information: the overall structure of the repair regions, including the position of the watermark within the image, and various reconstruction details. The latent codes from different levels of the encoder harbor distinct information due to variations in encoding depth. To capitalize on this diversity, we decode latent codes from different levels to construct independent UNet pathways of varying depths. These pathways are then interlinked through dense connections, creating a nested UNet architecture that enhances feature fusion. The integration of UNet pathways at different depths enables the network to precisely locate watermark regions. Simultaneously, through skip connections at the same level, distinct UNet pathways can learn specific reconstruction details to aid in background restoration.
For a specific pathway of the decoder, the decoding process mirrors the reverse of the encoding procedure. For each level’s output, the channel count is reduced by half while the size doubles before moving to the previous level. This stepwise decoding gradually restores the latent code back to enriched feature maps containing discrete watermark and background information. Finally, through the last prediction head, both watermark-free images and watermark masks are generated.
At each decoder level, a decision point arises regarding the output strategy. The network can either upsample the feature by a factor of two while reducing the number of channels, thereby progressing to the previous decoder level, or it can directly transmit the feature to the decoder at the same level. The network benefits from these intra-level skip connections due to the distinct semantic information encoded within features originating from different depths of latent codes, even when they are at the same decoder level.
Objective Function
In our proposed framework, we leverage the nested architecture as the backbone, which can be seen as an integration of UNets with varying depths. To ensure that each UNet is capable of both image restoration and watermark extraction, during the training phase, we allow the refined features from each UNet’s output to pass through a shared prediction head. This step facilitates the generation of corresponding watermark mask and background image , which are then supervised using the ground truth watermark mask and background image .
Consistent with previous works (Hertz et al. 2019), we employ binary cross-entropy loss to ensure the close alignment between the predicted watermark mask and the ground-truth watermark mask .
| (5) |
As for the reconstruction task, we utilize the loss to ensure that the refined watermark-free image closely approximates the ground-truth image.
| (6) |
Moreover, inspired by the works of (Cun and Pun 2021; Liang et al. 2021), we incorporate an additional deep perceptual loss (Johnson, Alahi, and Fei-Fei 2016) to enhance the output’s overall quality.
| (7) |
where denotes the activation map of k-th layer in the pre-trained VGG16 (Simonyan and Zisserman 2014).
In conclusion, we aggregate all the aforementioned loss functions and introduce controllable hyper-parameters to form the final loss function. The losses from different depths of the UNet are combined harmoniously, playing a collective role in shaping the overall loss.
| (8) |
| UNet | Transformer | Nested | deep_sup | PSNR |
| 34.87 | ||||
| 46.09 | ||||
| 46.35 | ||||
| 47.05 |

Experiment
This section begins with an introduction to the datasets used and outlines the implementation details. Subsequently, we conduct comprehensive ablation experiments to thoroughly investigate the influences of different architectural designs. Finally, we evaluate the performance of our WMFormer++ against state-of-the-art methods on different datasets, including LOGO-L, LOGO-H, LOGO-Gray (Cun and Pun 2021), and CLWD (Liu, Zhu, and Bai 2021). The experimental findings demonstrate the effectiveness of our approach both qualitatively and quantitatively.
| Method | F1 | IoU(%) |
| BVMR | 0.7871 | 70.21 |
| WDNet | 0.7240 | 61.20 |
| SplitNet | 0.8027 | 71.96 |
| SLBR | 0.8234 | 74.63 |
| Ours() | 0.8619 | 79.04 |
| Ours() | 0.8769 | 81.38 |
| Methods | LOGO-H | LOGO-L | LOGO-Gray | |||||||
| PSNR | SSIM | LIPIS | PSNR | SSIM | LIPIS | PSNR | SSIM | LIPIS | ||
| MDMS | BVMR | 36.51 | 0.9799 | 2.37 | 40.24 | 0.9895 | 1.26 | 38.90 | 0.9873 | 1.15 |
| SplitNet | 40.05 | 0.9897 | 1.15 | 42.53 | 0.9924 | 0.87 | 42.01 | 0.9928 | 0.73 | |
| SLBR | 40.56 | 0.9913 | 1.06 | 44.10 | 0.9947 | 0.70 | 42.21 | 0.9936 | 0.69 | |
| DENet | 40.83 | 0.9919 | 0.89 | 44.24 | 0.9954 | 0.54 | 42.60 | 0.9944 | 0.53 | |
| SDSS | UNet | 30.51 | 0.9612 | 5.44 | 34.87 | 0.9814 | 2.97 | 32.15 | 0.9728 | 3.53 |
| SIRF | 32.35 | 0.9673 | 8.01 | 36.25 | 0.9825 | 6.55 | 34.33 | 0.9782 | 6.72 | |
| BS2AM | 31.93 | 0.9677 | 4.45 | 36.11 | 0.9839 | 2.23 | 32.91 | 0.9754 | 3.05 | |
| DHAN | 35.68 | 0.9809 | 6.61 | 38.54 | 0.9887 | 5.91 | 36.39 | 0.9836 | 5.94 | |
| WMFormer++ | 44.64 | 0.9950 | 0.50 | 47.05 | 0.9970 | 0.31 | 46.29 | 0.9970 | 0.21 | |
| Method | PSNR | SSIM | RMSE | RMSEw |
| UNet | 23.21 | 0.8567 | 19.35 | 48.43 |
| DHAN | 35.29 | 0.9712 | 5.28 | 18.25 |
| BVMR | 35.89 | 0.9734 | 5.02 | 18.71 |
| SplitNet | 37.41 | 0.9787 | 4.23 | 15.25 |
| SLBR | 38.28 | 0.9814 | 3.76 | 14.07 |
| WMFormer++ | 39.36 | 0.9830 | 3.25 | 11.47 |
Dataset
This paper leverages various datasets, namely LOGO-L, LOGO-H, LOGO-Gray, and CLWD, for conducting the experiments.
The LOGO series dataset contains varying watermarks, such as LOGO-L with 12,151 training and 2,025 testing images, LOGO-H with similar quantities but larger watermark sizes and transparency, and LOGO-Gray with grayscale watermarks.
CLWD dataset contains 60,000 watermarked images, with 160 colored watermarks for training and 10,000 images with 40 colored watermarks for testing. The watermarks are collected from open-sourced logo images websites. The original images in the training and test sets are randomly chosen from the PASCAL VOC 2012 (Everingham et al. 2015) dataset. The transparency of the watermarks in CLWD is set in the range of 0.3 to 0.7, and the size, locations, rotation angle, and transparency of each watermark are randomly set in different images.
Implementation Detail
We implemented our method using Pytorch (Paszke et al. 2019) and conducted experiments on the aforementioned datasets. For training, we set the input image size as . The AdamW (Loshchilov and Hutter 2017) optimizer was chosen with an initial learning rate of 3e-4, a batch size of 8, and momentum parameters and . The hyper-parameters , , and in Eqn.(8) were empirically set as 1, 1, and 0.25, respectively, after several trials by observing the quality of predicted masks and reconstructed images.
To evaluate the effectiveness of our method, we employ widely recognized metrics in the field. Specifically, on the LOGO series datasets, we use Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM) (Wang et al. 2004), and the deep perceptual similarity metric (LPIPS) (Zhang et al. 2018) for evaluation. On the CLWD dataset, we utilize PSNR, SSIM, Root Mean Square Error (RMSE), and weighted RMSE (RMSEw) as evaluation metrics.
Ablation Study
Analysis of Individual Modules: As depicted in Tab. 1, we conducted a comprehensive evaluation of each module’s effectiveness in our framework through incremental removal and addition. Initially, we started with a basic UNet structure, as referenced (Ronneberger, Fischer, and Brox 2015), with its performance displayed in the first row of the table. Subsequently, by replacing all convolutional modules in UNet’s encoder and decoder with Transformer modules, we observed a notable improvement in performance, as shown in the second row. This highlights the significant potential of applying Transformers in the field of watermark removal.
Furthermore, we devised a nested Transformer model as illustrated in Fig. 2, and its performance is documented in the third row. It is worth noting that, for a fair comparison, the Transformer-based UNet used in the second row employed a wider UNet to achieve a similar parameter count as the model experimented with in the third row. The comparison between the second and third rows provides compelling evidence for the efficacy of the nested architecture.
Finally, We applied the supervision signals to UNets with different depths, and the performance is presented in the fourth row. The comparison between the third and fourth rows clearly demonstrates that the model with deep supervision exhibits superior performance, achieving the best results across all experiments. This further validates the significance of incorporating deep supervision in our approach.
Visualization of Individual Modules: For a more intuitive presentation, we also generated corresponding visual results to complement the findings in Tab. 1. By zooming in on specific regions of the restored background images, we aimed to provide a clearer display. As shown in Fig. 3, with the gradual completion of the full model, the quality of the images significantly improves. The step-by-step enhancement of image quality through the addition of modules serves as concrete evidence of the effectiveness of each design in our approach. These visual results further reinforce the significance of our contributions.

Comparisons with State-of-the-art Methods
Background Restoration. The quantitative and qualitative comparison of our proposed WMFormer++ with other existing watermark removal methods are summarized in Tab. 3, Tab. 4, and Fig. 4. Among them, BVMR (Hertz et al. 2019), SplitNet (Cun and Pun 2021), SLBR (Liang et al. 2021), and DENet (Sun, Su, and Wu 2023) are the latest technologies dedicated to watermark removal and generally adopt the multi-decoder multi-stage framework. On the other hand, Unet (Ronneberger, Fischer, and Brox 2015), SIRF (Zhang, Ng, and Chen 2018), BS2AM (Cun and Pun 2020), and DHAN (Cun, Pun, and Shi 2020) are migrated from related tasks, such as blind image harmonization and shadow removal, and typically utilize a single-decoder branch for image restoration. Overall, the multi-decoder multi-stage methods tend to exhibit better performance.
In contrast, our framework follows a single-decoder approach and outperforms all the other methods on the four datasets, achieving a new state-of-the-art performance. Our results significantly surpass previous non-multi-decoder multi-stage methods and even demonstrate unprecedented superiority over multi-decoder multi-stage methods by a large margin. The comprehensive experimental results provide strong evidence for the effectiveness of our approach.
It is worth noting that our design does not rely on complex modules like those in Liang et al. (Liang et al. 2021) and Cun et al. (Cun and Pun 2021). Instead, we use only two fundamental components, the Transformer block, and a small number of convolutional layers, for the entire model construction. This simplicity further highlights the efficiency and effectiveness of our approach in achieving outstanding watermark removal results.
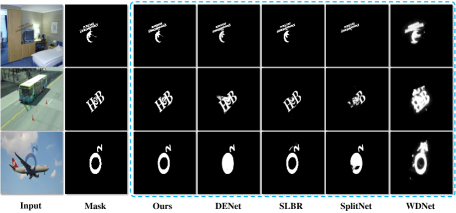
Watermark Location. To further demonstrate the superiority of our method, we conducted both qualitative and quantitative experiments on the watermark masks, a byproduct of the watermark removal network, as shown in Tab. 2 and Fig. 5. It is evident that not only does our approach outperform previous methods in terms of numerical metrics, but the generated watermark masks are also more complete and accurate.
In Tab. 2, the quantitative evaluation indicates that our method achieves significantly better results compared to previous approaches in terms of F1 and IoU. Moreover, Fig. 5 visually presents the watermark masks generated by our method, showcasing their high quality and precision.
These results serve as compelling evidence of the effectiveness and robustness of our approach, not only in removing watermarks from images but also in generating accurate and complete watermark masks as a valuable side benefit. This highlights the holistic superiority of our method in watermark removal and its related applications.
Conclusion
In this paper, we introduced WMFormer++, a novel nested Transformer network for visible watermark removal. Conventional methods often struggle to fully exploit the inherent relationship between watermark localization and background restoration tasks, limited by their distinct decoder branches. Based on this observation, the key innovation of our approach lies in utilizing a single decoder branch to simultaneously handle watermark localization and background restoration tasks, surpassing previous multi-decoder methods without the need for additional refinement. Notably, the construction of our network is intentionally kept straightforward, relying exclusively on fundamental Transformer blocks. Moreover, we introduce a nested mechanism, which aids in enhancing feature fusion and contextual understanding across diverse scales, facilitating improved performance. Extensive comparisons on various datasets demonstrate that WMFormer++ achieves state-of-the-art performance both qualitatively and quantitatively. Furthermore, through comprehensive ablation experiments and visualizations, we have shown the effectiveness and interpretability of our proposed method.
References
- Cun and Pun (2020) Cun, X.; and Pun, C.-M. 2020. Improving the harmony of the composite image by spatial-separated attention module. IEEE Transactions on Image Processing, 29: 4759–4771.
- Cun and Pun (2021) Cun, X.; and Pun, C.-M. 2021. Split then refine: stacked attention-guided ResUNets for blind single image visible watermark removal. In Proceedings of the AAAI conference on artificial intelligence, volume 35, 1184–1192.
- Cun, Pun, and Shi (2020) Cun, X.; Pun, C.-M.; and Shi, C. 2020. Towards ghost-free shadow removal via dual hierarchical aggregation network and shadow matting gan. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 10680–10687.
- Dekel et al. (2017) Dekel, T.; Rubinstein, M.; Liu, C.; and Freeman, W. T. 2017. On the effectiveness of visible watermarks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2146–2154.
- Everingham et al. (2015) Everingham, M.; Eslami, S. A.; Van Gool, L.; Williams, C. K.; Winn, J.; and Zisserman, A. 2015. The pascal visual object classes challenge: A retrospective. International journal of computer vision, 111: 98–136.
- Gandelsman, Shocher, and Irani (2019) Gandelsman, Y.; Shocher, A.; and Irani, M. 2019. ” Double-DIP”: unsupervised image decomposition via coupled deep-image-priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 11026–11035.
- He, Sun, and Tang (2010) He, K.; Sun, J.; and Tang, X. 2010. Single image haze removal using dark channel prior. IEEE transactions on pattern analysis and machine intelligence, 33(12): 2341–2353.
- Hertz et al. (2019) Hertz, A.; Fogel, S.; Hanocka, R.; Giryes, R.; and Cohen-Or, D. 2019. Blind visual motif removal from a single image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6858–6867.
- Johnson, Alahi, and Fei-Fei (2016) Johnson, J.; Alahi, A.; and Fei-Fei, L. 2016. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part II 14, 694–711. Springer.
- Liang et al. (2021) Liang, J.; Niu, L.; Guo, F.; Long, T.; and Zhang, L. 2021. Visible watermark removal via self-calibrated localization and background refinement. In Proceedings of the 29th ACM International Conference on Multimedia, 4426–4434.
- Liu, Zhu, and Bai (2021) Liu, Y.; Zhu, Z.; and Bai, X. 2021. Wdnet: Watermark-decomposition network for visible watermark removal. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 3685–3693.
- Loshchilov and Hutter (2017) Loshchilov, I.; and Hutter, F. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Park, Tai, and Kweon (2012) Park, J.; Tai, Y.-W.; and Kweon, I. S. 2012. Identigram/watermark removal using cross-channel correlation. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, 446–453. IEEE.
- Paszke et al. (2019) Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
- Pei and Zeng (2006) Pei, S.-C.; and Zeng, Y.-C. 2006. A novel image recovery algorithm for visible watermarked images. IEEE Transactions on information forensics and security, 1(4): 543–550.
- Ren et al. (2019) Ren, D.; Zuo, W.; Hu, Q.; Zhu, P.; and Meng, D. 2019. Progressive image deraining networks: A better and simpler baseline. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 3937–3946.
- Ronneberger, Fischer, and Brox (2015) Ronneberger, O.; Fischer, P.; and Brox, T. 2015. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, 234–241. Springer.
- Simonyan and Zisserman (2014) Simonyan, K.; and Zisserman, A. 2014. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556.
- Sun, Su, and Wu (2023) Sun, R.; Su, Y.; and Wu, Q. 2023. DENet: Disentangled Embedding Network for Visible Watermark Removal. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, 2411–2419.
- Wang et al. (2004) Wang, Z.; Bovik, A. C.; Sheikh, H. R.; and Simoncelli, E. P. 2004. Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing, 13(4): 600–612.
- Zamir et al. (2022) Zamir, S. W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F. S.; and Yang, M.-H. 2022. Restormer: Efficient transformer for high-resolution image restoration. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 5728–5739.
- Zhang et al. (2018) Zhang, R.; Isola, P.; Efros, A. A.; Shechtman, E.; and Wang, O. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE conference on computer vision and pattern recognition, 586–595.
- Zhang, Ng, and Chen (2018) Zhang, X.; Ng, R.; and Chen, Q. 2018. Single image reflection separation with perceptual losses. In Proceedings of the IEEE conference on computer vision and pattern recognition, 4786–4794.
- Zhao, Niu, and Zhang (2022) Zhao, X.; Niu, L.; and Zhang, L. 2022. Visible Watermark Removal with Dynamic Kernel and Semantic-aware Propagation.
- Zhou et al. (2018) Zhou, Z.; Rahman Siddiquee, M. M.; Tajbakhsh, N.; and Liang, J. 2018. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, September 20, 2018, Proceedings 4, 3–11. Springer.