Word Embedding-based Text Processing for Comprehensive Summarization and Distinct Information Extraction
Abstract
In this paper, we propose two automated text processing frameworks specifically designed to analyze online reviews. The objective of the first framework is to summarize the reviews dataset by extracting essential sentence. This is performed by converting sentences into numerical vectors and clustering them using a community detection algorithm based on their similarity levels. Afterwards, a correlation score is measured for each sentence to determine its importance level in each cluster and assign it as a tag for that community. The second framework is based on a question-answering neural network model trained to extract answers to multiple different questions. The collected answers are effectively clustered to find multiple distinct answers to a single question that might be asked by a customer. The proposed frameworks are shown to be more comprehensive than existing reviews processing solutions.
Index Terms:
Customer reviews, topic modeling, text summarization, question-answering model, BERT.I Introduction
In modern life, people are more likely to trust their peers over advertising when it comes to purchasing decisions and service selections. In fact, according to the Global Trust in Advertising report, which surveyed more than 28,000 Internet respondents in 56 countries, 92 of customers reveal that they trust recommendations from their friends and relatives above all other forms of advertising, while 70 of customers trust reviews from other users more than advertising [1]. Another indication that service/product reviews play an integral role in purchase-decision making process is that two-thirds of US internet users check other online customers’ reviews before choosing an article [2].
However, in many cases, hundreds or thousands of reviews exist online for a single product or service and it is impossible for customers to read and check them all. Therefore, it is very worthwhile to provide an efficient review analyzer to process, filter, classify, and extract essential information summarizing the reviews. Natural Language Processing (NLP) is a new emerging AI technology that is used to process and understand textual data for various application such as predicting customers’ feelings towards a certain service or product [3] or detecting rumors/wrong information on social networks [4]. However, NLP has its limit as it may output inaccurate results due to the fact that machines cannot understand contextual meaning of a review. Another potential solution is the statistical topic modeling approach that aims at discovering the abstract “topic” that occur in a collection of documents [5, 6, 7]. In the paper’s context, by extracting the “topics” from the reviews about one service/product, the objective is to collect and interpret the “topics”, e.g., positive points or main issues, that are highlighted by reviewers. However, it is hard to apply such approaches in the context of reviews as the textual input is usually short with low frequency of important words and high number of overlapped and meaningless words. Finally, text summarization methods could also be employed to extract the main bullets outlining long documents [8, 9, 10, 11, 12]. However, it is shown that the performances remain limited and usually, the proposed approaches lack the common terminology and is very linked to the input dataset.
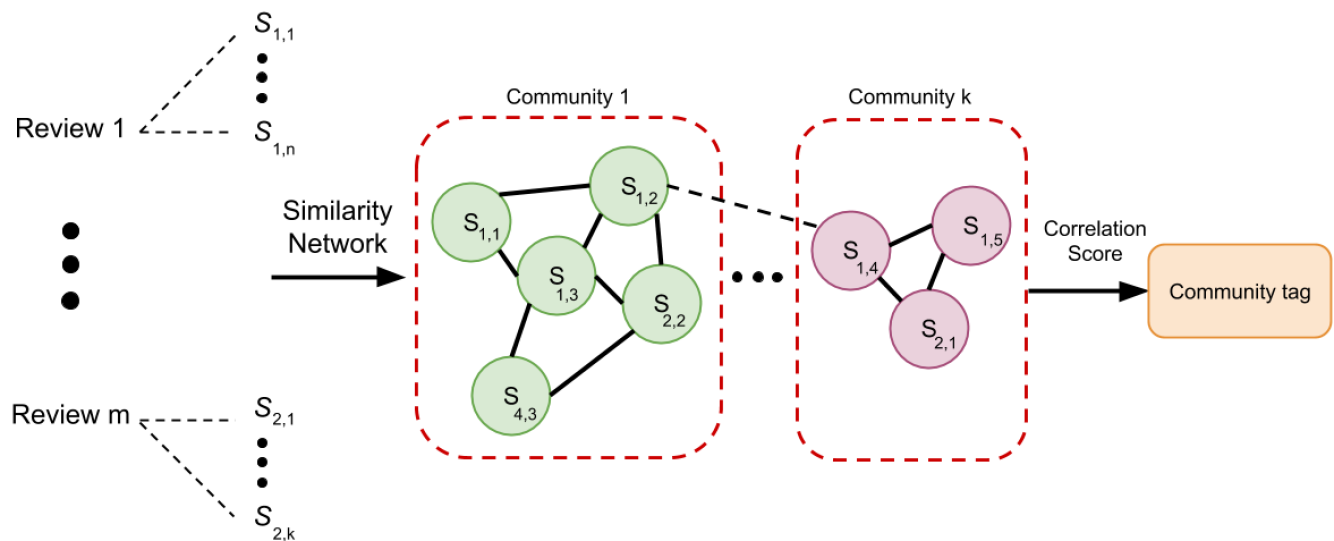
To cope with the aforementioned limitations of existing approaches and in order to efficiently analyze reviews and extract the most significant information, we propose two generic NLP-based frameworks. The first framework is an unsupervised clustering approach to classify and summarize reviews according to the similarities of the sentences submitted by reviewers such that customers can extract most important feedbacks. It starts by measuring sentences similarities by combining TextRank algorithm, Bidirectional Encoder Representations from Transformers (BERT) model for word-embedding, and a vector dimension matching algorithm. With word-embedding, the words and phrases are converted to a continuous vector space pre-trained on a very large data sets [13] so similarities between two phrases or two sentences can then be calculated by their distances [14, 15, 16, 17]. In 2018, the BERT model, introduced by Google, has redefined the state-of-the-art for eleven NLP tasks [18] such as text classification, question and answering, and language translation. Afterwards, we apply Louvain method to detect communities of sentences and TextRank algorithm to identify the most meaningful sentences that can tag each community.
Generally, it is not enough to provide customers with a summary about the reviews as usually they may need more specific details about one product/service such as knowing side effect, if any, of a cosmetic product, etc. Therefore, the second framework is designed to extract these kind of details to provide customers with a complete idea about the product/service. Therefore, we adopt a question-answering (QA) model [19] to rapidly provide answers to a given text from a large volume of reviews. In fact, recently published models, including BERT or XLNet [20], enable machines to achieve performance close to human in this challenging area when tested on the Stanford Question Answering Dataset (SQUAD) [21]. With BERT, we are able to accurately extract details from thousands reviews of service/product using selected questions adopted to the reviews’ context. The collected information are then, filtered, clustered, and summarized based on similarity networks to provide customers with decent results. Finally, we apply our proposed frameworks to a practical case of study where we process a google review data about a restaurant in the area of Manhattan, NYC.
II Reviews Clustering and Summarization
In this section, we propose to design a review clustering and summarization model to help customers get an overview/feedback about a product/service by analyzing a large volume of reviews.
II-A Methodology
The flowchart of the proposed framework for review clustering and summarization is shown in Fig. 1. It consists of two major parts: the first one creates a similarity network graph joining different sentences collected from the review dataset, while the second part, assigns textual tags for each clustered community. For the first part, the input is constituted by the reviews that we split into independent sentences denoted by where the is the review index and is the index of the sentence in review . Each sentence will be represented by a node in the graph. The edges connecting two nodes represent the similarity between the corresponding sentences. In order to calculate the similarity score denoted by , we map the sentences to the vector space using word-embedding algorithm and compute the cosine similarity value as the distance between two sentences. Instead of using traditional Word2Vec [22] or GloVe [17] models, we use BERT to represent each word by a vector having 768 real numbers in as elements. Their values depend on both the context of the sentence and the word itself. So, different vector representations are given for the same word when they are under different contexts. An example is provided in Fig. 2. We notice that the word “bank” has three different vector representations as the contexts where it is used are different. However, the cosine similarity score is high when the meanings of the word are similar.
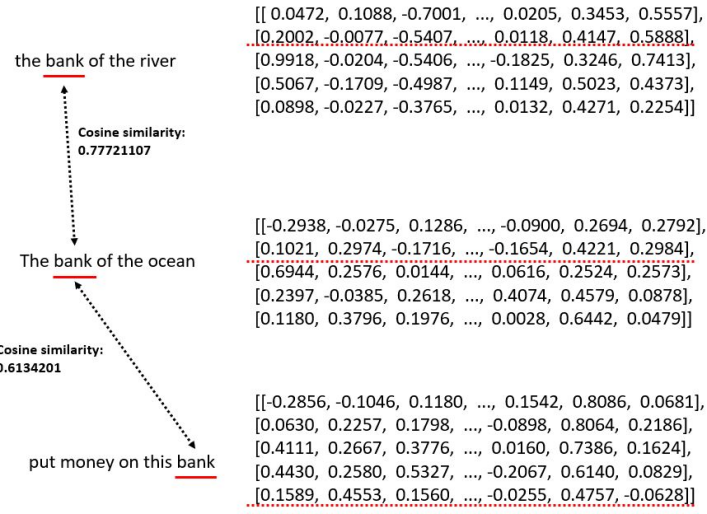
Consequently, if two sentences have words then, both of them will be represented with a vector space of length . Hence, the cosine similarity score of the two sentences having the same dimension can be computed. Otherwise, if the other sentence has words, then a sliding window browsing the longest sentence is applied to compare phrases with the same number of words. Hence, comparisons are made and the highest obtained score will represent the similarity between those two sentences as shown in Fig. 3, where represents the similarity between sentence and sentence .

The next step is to create a network graph modeling the similarities between sentences. The vertices of the graphs are the phrases/sentences and the edges connecting two vertices indicate a certain similarity between them. Note that we set a certain threshold for the similarities, the edge exists only if the similarity is larger than the threshold. With the similarity network, our objective is to cluster the sentences into different “topics” and assign to them tags by selecting the most meaningful sentences. The clustering is based on the Louvain method designed by Blondel, which is a greedy optimization method that rapidly extract communities from large networks [23]. In this clustering problem, the objective function to maximize is a modularity metric defined as follows:
| (1) |
where and are the sum of the weights of the edges attached to nodes and , respectively, is the sum of the weights in the graph, is Kronecker delta function with binary value, and and are the communities of the nodes.
Afterwards, we assign another correlation score, denoted by , to each sentence in the graph that reflects its similarity with the rest of the phrases (i.e., nodes of the graph) using the TextRank algorithm, which counts the number and quality of links to a sentence to determine how important the corresponding node is. Consequently, the sentences with the highest correlation score is the sentence that is most similar to others and will be used to tag each detected community.
II-B Case study: Restaurant Reviews
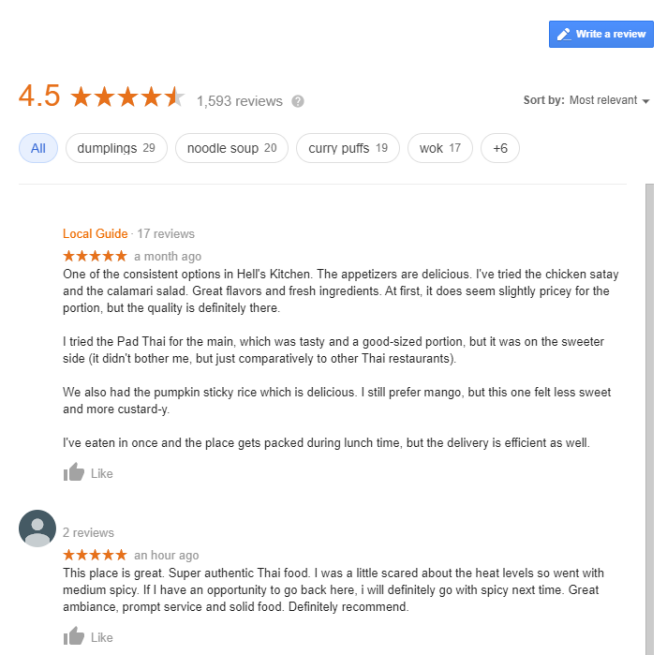
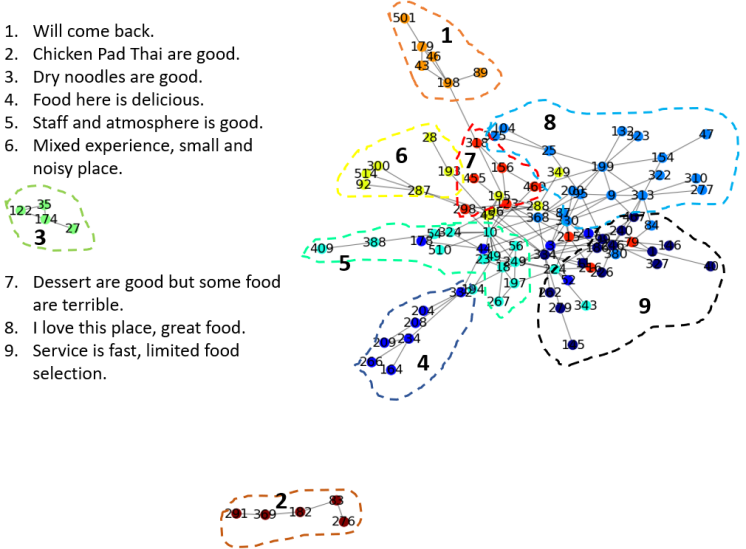
In this section, we illustrate and evaluate the output of our proposed framework applied on the case of restaurant reviews. We randomly select a restaurant located in Manhattan, NYC, having 1586 reviews in Google website as shown in Fig. 4. From this dataset, we pick the recent one hundred reviews, and feed them into our framework pipeline described earlier. We then split each review into sentences. In case of short phrases, we combine them with previous sentences to avoid having inaccurate results when computing similarities. In Fig 5, and for tractability, we provide a graph representing the connections between 568 sentences composing the 100 reviews. The isolated nodes (sentences) are not illustrated. We then highlight the different detected communities colored differently as well as their corresponding tags. Nine independent communities are obtained with the Louvain algorithm, each one is tagged by the sentence having the highest correlation score. Most of the communities show positive comments since the rating of the restaurant is 4.5, in other words, the positive side of the restaurant is mostly being discussed in the reviews.
III Multiple Distinct Answers Extraction
As mentioned in the introduction, having main ideas about a product or service may not be sufficient for certain customers, who also care about details and require deeper information about it. Therefore, in this framework, we propose develop a question-answering model framework to extract details through pre-defined questions that are answered by processing the reviews dataset.
III-A Methodology
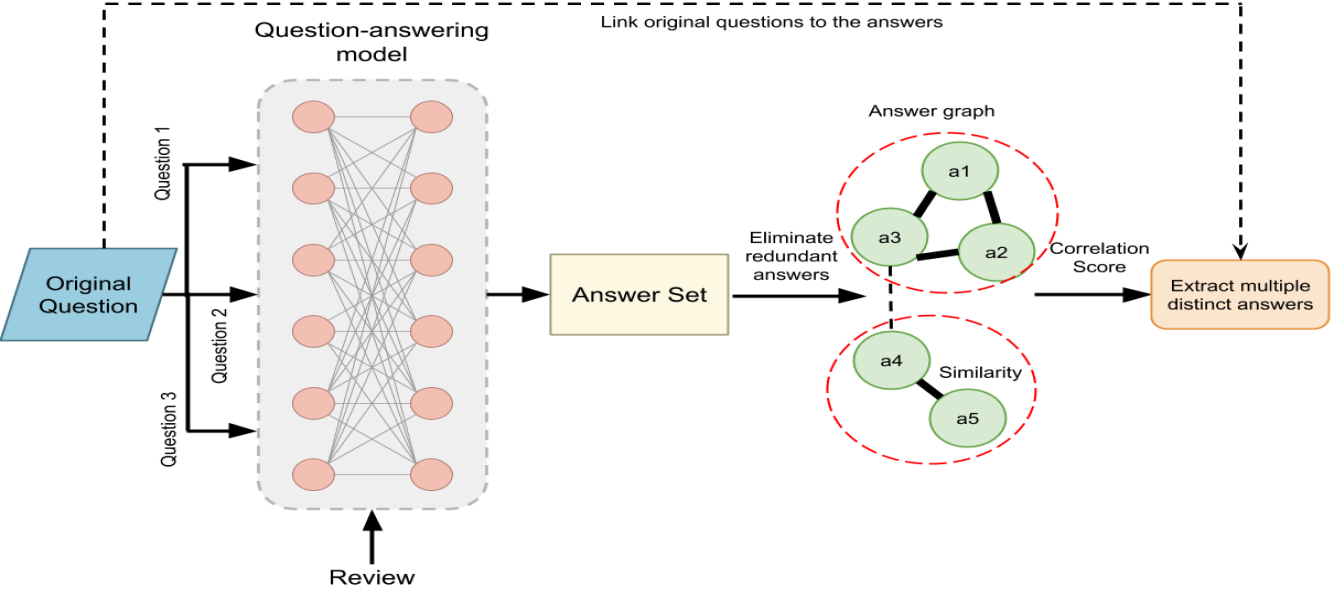
To tackle this problem, we propose the second information extraction framework presented in Fig. 6. It is composed of two major parts: the first part is dedicated to collect answers for the questions that we formulated according to the context of the product/service. We apply the “BertForQuestionAnswering” question-answering model trained using the SQUAD dataset [24]. The model is batch trained for two epochs using in total 100,000 questions where each batch consists of eight questions. It is shown that the model achieves a matching score of 80.1% and a F1 score of 83.1% that are very close to human performance which are 86.8 and 89.5, respectively. Note that the F1 score measures the average overlap between the prediction and ground truth answer111In our future study, we will explore BERT and ALBERT ensemble models which are expected to achieve better performance over human but require large computational resources.. The question-answering model provided by BERT is not valid for multi-responses questions. Therefore, to overcome this issue, we proceed by formulating new different questions having the same meaning of the original questions to get all possible answers. The first part outputs, for each question, is a set of answers.
In the second part, we adopt the framework described in Section II so that, for each original question, all the possible answers are collected together and clustered into communities. Then, tags are assigned to them according to their correlation scores. Hence, for each original question, we determine a number of distinct answers corresponding to the number of the detected communities. Optionally, the framework can be used to answer human entered questions by returning the most relevant answers.
III-B Case study: Restaurant Reviews
We employ the same restaurant reviews data from which we pick the most recent one thousand reviews. In Table I, we present some examples of answers extracted from a one review text by applying the question-answering model. The latter is applied on the first review text (106 words) given in Fig 4.
| Questions | Answers |
|---|---|
| What should I eat? | “The appetizers” |
| What can I try? | “I’ve tried the chicken satay and the calamari salad” |
| What is the best food? | “” |
| What is delicious? | “pumpkin sticky rice” |
| Which dish is recommended? | “The appetizers” |
| What do you prefer? | “mango” |
| How is the service? | “the delivery is efficient” |
| How is the price? | “slightly pricey” |
| How long is the waiting time in this place? | “.” |
| Is it clean? | “.” |
From Table I, we can notice that with the intentional selected questions, we are able to extract most of the required information from a single review including the delicious dish, the comments about the price, and the quality of service in the restaurant. In addition to the original question: “What is the delicious food to order in the restaurant?”, we use six other similar questions (the first six questions given in the TABLE I) to extract all the possible answers to the original question. Note that we need to remove the redundant answers, e.g, “The appetizers”.
In Fig 7, we present all the possible answers from one thousand reviews corresponding to this original question. After filtering and clustering the results, we obtain 25 communities with different tags representing 25 different menus items recommended by reviewers. The answer “Noodles with pork and crab” has the highest correlation score and has been recommended by the highest number of reviewers as it is reflected by the community size.

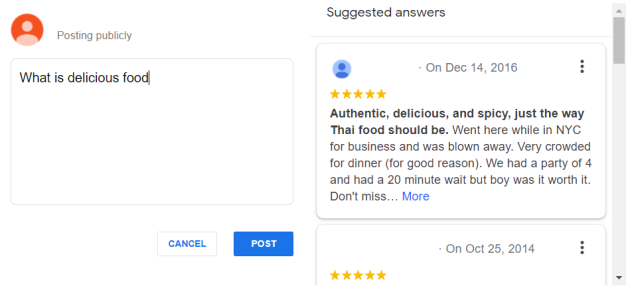
Finally, we compare our results with the “Ask a question” service provided by Google shown in Fig 8. For the same original question, the service provides only ten reviews where seven of them does not provide any useful details. Hence, customers can hardly get comprehensive information or an exhaustive list about their requests. The information provided by the proposed framework are more specific and directed towards the customers need which can ease their purchase decisions.
IV Conclusion
In this paper, we proposed two text processing frameworks to provide assistance to customers reviewing previous users’ comments. The first framework summarizes the reviews by providing the most important information after clustering their constants in communities and assigning tags to each one of them. The second text processing framework aims to extract detailed information about a product/service by adopting a question-answering neural network model. We also applied the proposed frameworks on a particular case of study and show that our model provides much more comprehensive results than existing solutions.
References
- [1] Paul Chaney, “Word of mouth still most trusted resource says nielsen; implications for social commerce,” tech. rep., Apr. 2012.
- [2] Rimma Kats, “Surprise! most consumers look at reviews before a purchase,” tech. rep., Feb. 2018.
- [3] B. Liu, Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge University Press, 2015.
- [4] Y. Zhang, W. Chen, C. K. Yeo, C. T. Lau, and B. S. Lee, “Detecting rumors on online social networks using multi-layer autoencoder,” in 2017 IEEE Technology Engineering Management Conference (TEMSCON), pp. 437–441, June 2017.
- [5] S. Deerwester, S. T. Dumais, G. W. Furnas, T. K. Landauer, and R. Harshman, “Indexing by latent semantic analysis,” Journal of the American society for information science, vol. 41, no. 6, pp. 391–407, 1990.
- [6] T. Hofmann, “Unsupervised learning by probabilistic latent semantic analysis,” Machine learning, vol. 42, no. 1-2, pp. 177–196, 2001.
- [7] D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” Journal of machine Learning research, vol. 3, no. Jan, pp. 993–1022, 2003.
- [8] L. Page, S. Brin, R. Motwani, and T. Winograd, “The pagerank citation ranking: Bringing order to the web.,” tech. rep., Stanford InfoLab, 1999.
- [9] F. Barrios, F. López, L. Argerich, and R. Wachenchauzer, “Variations of the similarity function of textrank for automated summarization,” arXiv preprint arXiv:1602.03606, 2016.
- [10] S. Robertson, H. Zaragoza, et al., “The probabilistic relevance framework: Bm25 and beyond,” Foundations and Trends® in Information Retrieval, vol. 3, no. 4, pp. 333–389, 2009.
- [11] A. R. Pal and D. Saha, “An approach to automatic text summarization using wordnet,” in 2014 IEEE International Advance Computing Conference (IACC), pp. 1169–1173, IEEE, 2014.
- [12] T. Vodolazova, E. Lloret, R. Muñoz, M. Palomar, et al., “The role of statistical and semantic features in single-document extractive summarization,” 2013.
- [13] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean, “Distributed representations of words and phrases and their compositionality,” in Advances in neural information processing systems, pp. 3111–3119, 2013.
- [14] Y. Goldberg and O. Levy, “word2vec explained: deriving mikolov et al.’s negative-sampling word-embedding method,” arXiv preprint arXiv:1402.3722, 2014.
- [15] O. Levy, Y. Goldberg, and I. Dagan, “Improving distributional similarity with lessons learned from word embeddings,” Transactions of the Association for Computational Linguistics, vol. 3, pp. 211–225, 2015.
- [16] Y. Dong, N. V. Chawla, and A. Swami, “metapath2vec: Scalable representation learning for heterogeneous networks,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 135–144, ACM, 2017.
- [17] J. Pennington, R. Socher, and C. Manning, “Glove: Global vectors for word representation,” in Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543, 2014.
- [18] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” arXiv preprint arXiv:1810.04805, 2018.
- [19] A. Kumar, O. Irsoy, P. Ondruska, M. Iyyer, J. Bradbury, I. Gulrajani, V. Zhong, R. Paulus, and R. Socher, “Ask me anything: Dynamic memory networks for natural language processing,” in International conference on machine learning, pp. 1378–1387, 2016.
- [20] Z. Zhang, Y. Wu, J. Zhou, S. Duan, and H. Zhao, “Sg-net: Syntax-guided machine reading comprehension,” arXiv preprint arXiv:1908.05147, 2019.
- [21] P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “Squad: 100,000+ questions for machine comprehension of text,” arXiv preprint arXiv:1606.05250, 2016.
- [22] T. Mikolov, K. Chen, G. Corrado, and J. Dean, “Efficient estimation of word representations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
- [23] V. D. Blondel, J.-L. Guillaume, R. Lambiotte, and E. Lefebvre, “Fast unfolding of communities in large networks,” Journal of statistical mechanics: theory and experiment, vol. 2008, no. 10, p. P10008, 2008.
- [24] T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Funtowicz, and J. Brew, “Transformers: State-of-the-art natural language processing,” 2019.