Word-Level Representation From Bytes For Language Modeling
Abstract
Modern language models mostly take sub-words as input, a design that balances the trade-off between vocabulary size, number of parameters, and performance. However, sub-word tokenization still has disadvantages like not being robust to noise and difficult to generalize to new languages. Also, the current trend of scaling up models reveals that larger models require larger embeddings but that makes parallelization hard. Previous work on image classification proves splitting raw input into a sequence of chucks is a strong, model-agnostic inductive bias. Based on this observation, we rethink the existing character-aware method that takes character-level inputs but makes word-level sequence modeling and prediction. We overhaul this method by introducing a cross-attention network that builds word-level representation directly from bytes, and a sub-word level prediction based on word-level hidden states to avoid the time and space requirement of word-level prediction. With these two improvements combined, we have a token free model with slim input embeddings for downstream tasks. We name our method Byte2Word and perform evaluations on language modeling and text classification. Experiments show that Byte2Word is on par with the strong sub-word baseline BERT but only takes up 10% of embedding size. We further test our method on synthetic noise and cross-lingual transfer and find it competitive to baseline methods on both settings.111Preprint.
1 Introduction
Language models are the foundation of modern natural language processing. From Word2Vec Mikolov et al. (2013) to BERT Devlin et al. (2018) and GPT-2 Radford et al. (2019), one key ingredient to make learning general language representation successful is switching from word-level Mikolov et al. (2013); Pennington et al. (2014) input to subword-level Vaswani et al. (2017) input. Subword tokenization reduces the size of vocabulary, hence reducing the size of input and output embeddings, making training on a colossal size of text crawled from the Internet computationally tractable. However, reliance on sub-word level tokenization limits the capabilities of current NLP systems. Because the way of how subword tokenization algorithms work, subword language models are not robust to the variability noise of inputs. Typos, variably spelling, capitalization, and morphological changes can all cause the token representation of a word or phrase to change completely. What’s more, recently Scaling Law Kaplan et al. (2020) discloses larger network requires larger embedding, GPT-3 Brown et al. (2020), Bloom Scao et al. (2022) and XLM-R Conneau et al. (2019) all of them have a whopping dictionary size of 250k. But larger embedding layer makes model parallelism hard since it tries to split the model into equal-sized chunks.
ByT5 Xue et al. (2021) tries to alleviate these issues by switching to byte-level input. Due to the quadratic complexity of Transformer, byte-level models need more overhead to process the same input phrase(for example, MNLI usually requires a sequence length of 128 for subwords, for byte-level it is >1k), while still being inferior in performance. Charformer Tay et al. (2021) suggests using learnable, parametric tokenization. However this method does not recognize word boundaries so to shorten the sequence length, downsampling is naively shrinking the sequence after tokenization. And this method predicts the masked word by auto-regressive decoding, which add uncertainties when sampling and make them harder to train.
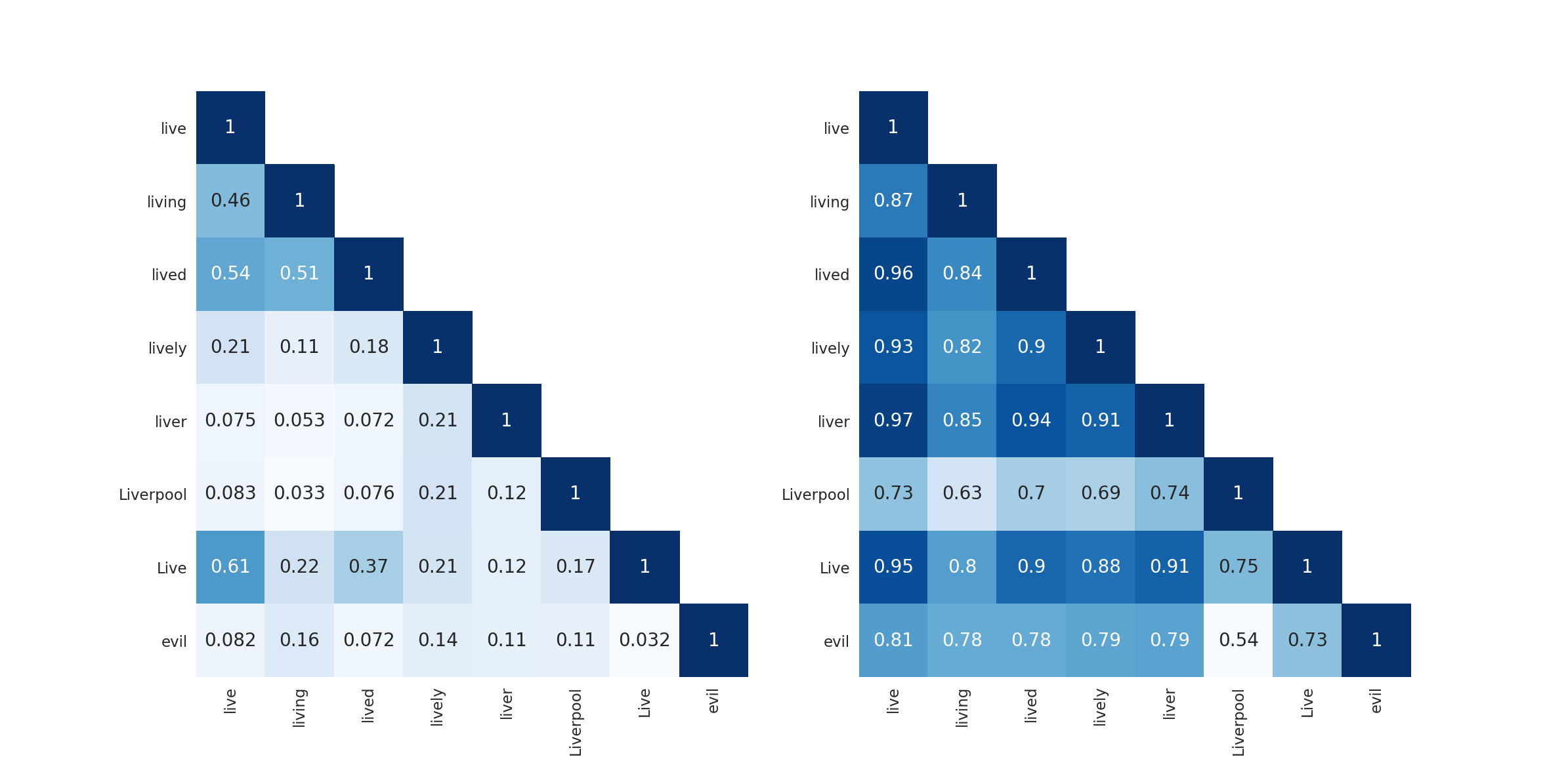
Recent advances Dosovitskiy et al. (2020); Trockman and Kolter (2022) on image classification reveals that segmenting an image to patches boosts the performance of both transformer and convolution models. This phenomenon may indicate that segmentation and token boundary can act as crucial information for learning representation and urge us to revisit previously introduced character-aware methods Kim et al. (2015); Jozefowicz et al. (2016); El Boukkouri et al. (2020). Character-aware methods process characters via a 1D convolution network with a suite of kernels with different widths to capture information of diverse granularities. After convolution, word-level hidden states are constructed by concatenation of length-wise max-pooled output signals. We modernize this process with a much more general cross-attention method. Character-aware methods predict words, so a reasonable-sized word-level vocabulary is needed for prediction to reduce compute budget. Jozefowicz et al. (2016) proposes a contrastive learning method that generates word-level output embeddings on the fly. Also, we can decode the masked words in an auto-regressive style. Nevertheless, we do not adopt these methods in the mind of training stability and computational budget. We demonstrate that a simple yet effective way to train a word-level model without word-level vocabulary is to reuse a subword-level vocabulary by predicting subwords given masked, word-level hidden states from the last encoder layer. Seeing as subword-level vocabulary is only needed when pretraining and the subword-level output embeddings will be discarded for finetuning, what we obtain in the end is a token-free language model that processes sentences in bytes and with slim input embeddings, ready for transfer learning on downstream tasks. Our method is named Byte2Word and illustrated in Figure 1. Through experiments on masked language modeling and downstream text classification, we show that Byte2Word is on-par with BERT on the GLUE benchmark Wang et al. (2018), proving that learning word-level representations from bytes can retain BERT-level performance while shrinking the embedding size by 10x. To show that our method is robust to synthetic noise, we inject four types of noise into the text of MNLI and find that our method is competitive to byte-level models while using much less computation. Besides, we find that our method has better cross-lingual transfer ability than subword methods.
2 Related Work
Multilingual Language Modeling XLM Lample and Conneau (2019) shows processing multiple languages with a shared vocabulary trained via Byte Pair Encoding Sennrich et al. (2015) improves the alignment of embedding spaces. However, this results in a 3x increase in vocabulary size compared to BERT. XLM-R Conneau et al. (2019) aims to scale this setting with more parameters and languages, resulting in a lookup table that has a size of 250k and an embedding layer that takes up more than 47% of total model parameters. RemBERT Chung et al. (2020) presents decoupled embeddings can allow the model to have more flexibility. In this sense, they rebalanced the input and output embedding of mBERT Devlin et al. (2018) and achieved better performance on multilingual language modeling than XLM-R, despite using a lot less of trained tokens.
Word-level language modeling While most transformer-based language models are built on top of subword tokenization, word-level transformer language models are not entirely infeasible. WordBERT Feng et al. (2022) is the first word-level BERT that achieves better performance on cloze test, sequence labeling, and question answering compared to BERT. WordBERT utilizes negative sampling to successfully train a bidirectional transformer encoder with a vocabulary size of 1 million.
Byte-level or character-level language modeling For English-only tasks, byte-level and character-level tokenizations are equivalent because each English character takes only one byte if you ignore non-ASCII characters. But to incorporate other languages, character-level methods need to expand their vocabularies. Byte-level methods do not have this issue, but languages using some of the other scripts take more than one byte to represent a character. For example, Greek takes around 2 bytes and east Asian languages take around 3 bytes. This results in an even longer sequence length. Despite these restrictions, ByT5 Xue et al. (2021) shows a seq2seq transformer with re-balanced encoder and decoder depths plus more training that can achieve competitive performance on a diversity of tasks. CANNIE is a character level model that has a vocabulary of 1 million characters so it utilized hash embedding Tito Svenstrup et al. (2017) to curb large parameter amounts. Charformer Tay et al. (2021) proposes an attention-based, learnable tokenizer that builds subword embedding. But since Charformer has no concept of word boundaries, it can only reduce input length by naively downsampling.
Character-aware method Given a character sequence of a single word, previous work Kim et al. (2015); El Boukkouri et al. (2020) use a 1D CNN network with multiple kernels to capture information of different granularities. Information extracted by the CNN is then pooled and concatenated to build the final word embeddings.
Augmenting subword-level models with character-level infomation CharBERT Ma et al. (2020) features a dual channels method that fuses subword information and character level information together and a character-level de-noise training that forces the model to reconstruct correct spelling of a word. Char2Subword Aguilar et al. (2021) modifies a subword level Transfomer with a module that learns to reconstruct BERT subword embeddings from character-level inputs. Experiments show this method has superior performance on data with code-switching. Both of these methods are built on top of a pretrained model.
3 Byte2Word
Our goal of designing Byte2Word is to take an existing character-aware method and perform a set of improvements to make it token-free but still has on-par performance compared to subword-level models. These requirements emerge two challenges 1) How to construct word-level representations from bytes? 2) How to predict masked words without a word-level dictionary? We address these challenges in the following sections.
3.1 Granularity of a Token
Byte-level and word-level tokenization are two extremes when it comes to representing text into indices of a vocabulary. The simplest method, character-level tokenization is to let the vocabulary be the alphabet. This method is hard to practice on multilingual text as the total size of alphabets of multiple languages can be up to a million. One way to tackle this problem is switching to token-free byte-level input because there are only 256 bytes, which can represent text in the smallest level of granularity. However, this tends to yield very long sequences with sparse information. Word-level tokenization lies on the other end of the spectrum. Word-level tokenization tends to require a very large vocabulary to cover a diverse amount of text. The copra BERT trained on contains more than 10 millions unique words. This leads to a large embedding layer and intense softmax computation when predicting. Tailored methods such as negative sampling are used in Feng et al. (2022) to train a word-level model successfully. Transformers mainly use subword tokenization right when it was first introduced. An easy way to explain subword tokenization is it uses a vocabulary containing a set of commonly occurring word segments like ’ing’ and ’ly’. However, Gowda and May (2020) and Xu et al. (2020) show that hyperparameters of subword methods, especially the size of the dictionary, affect final performance. Thus, some models Brown et al. (2020) allow a certain amount of redundancy for tokenization, resulting in varying granularities of token in its vocabulary and indirect learning.
This paper chooses to combine byte-level and word-level methods as proposed in Kim et al. (2015). However, to truly achieve token-free, we do not want to maintain a word-level vocabulary, therefore we need to come up with some rules or methods to split text sentences into words to provide bytes and word boundaries to the model. For splitting words in a sentence, the boundary of a word is well-defined in English. We split phrases into words simply by white space, punctuation, camel case, and snake case after following the preprocessing procedure used in Devlin et al. (2018). However, this is not the optimal choice for some non-English corpora, we leave this issue for future work.
3.2 Down-sampling
After splitting a sentence to words, in order to construct word-level embedding from bytes for one of these words, we use cross attention mechanism proposed in Vaswani et al. (2017), which is an effective and more general pooling mechanism compared to character-aware convolutions. Given a sentence and let the th word of that sentence contains bytes, we use the corresponding byte-level embeddings from a byte-level embedding lookup table to build the word embedding with a embedding size of . We pack these byte-level embeddings together as key matrix and value matrix for cross-attention. Specifically, we have
| (1) |
| (2) |
| (3) |
Here, denotes th learnable word-query for position and are matrices for key and value projections. We find having multiple word-queries for different positions helps convergence. After pooling by cross-attention, word-level embeddings are processed by a position-wise feed-forward layer as the standard procedure. Our word-level embeddings is then added by residual connection and other types of embeddings. Followed by a layer normalization Ba et al. (2016) and a linear projection, we obtain our final word-level hidden states for our encoder. This linear projection tactic resembles the Factorized embedding parametrization method introduced in Lan et al. (2019) and the rebalanced embeddings in Chung et al. (2020).
| (4) |
where is positional embedding, is token type embedding, projects the word-level embedding to match the hidden size of the backbone encoder.
3.3 Up-sampling and Predictions
| MNLI-m/mm | QNLI | QQP | RTE | SST-2 | MRPC | CoLA | STS-B | Avg. | ||
| #metric | Acc | Acc | F1 | Acc | Acc | F1 | Matthew’s corr. | Spearman corr. | ||
| #Examples | 393k | 105k | 364k | 2.5k | 67k | 3.7k | 8.5k | 7k | ||
| (336M) | 86.4/85.5 | 92.5 | 72.4 | 80.0 | 94.6 | 88.3 | 61.3 | 85.8 | 82.97 | |
| _ | _ | _ | _ | _ | _ | _ | _ | 80.50 | ||
| 82.6/82.7 | 89.0 | 88.8 | _ | 91.6 | 91.1 | 42.6 | 85.3 | 81.40 | ||
| Byte2Word (304M) | 86.1/85.6 | 92.6 | 72.0 | 76.3 | 95.2 | 89.0 | 59.1 | 87.8 | 82.63 |
| English Wikipedia + BookCorpus | |
|---|---|
| Max byte length | 8664 |
| Mode byte length | 8 |
| Mean byte length | 9.15 |
| Std of byte length | 5.60 |
While with the method above, it is sufficient for language modeling. Still, predicting at word-level is computationally intense due to the large size of the lookup table. Feng et al. (2022) showcases a receipt to train a word-level BERT by utilizing negative sampling. But such a method is not direct to implement in our setting since we don’t even have a word-level vocabulary. Jozefowicz et al. (2016) proposes a contrastive learning based method that dynamically generates output embedding given the character-level embedding sequence of the target word. But contrastive learning can easily lead to model collapse and requires extra caring to train. There is another way to train a fully vocabulary-independent model, Jozefowicz et al. (2016); Xue et al. (2021); Tay et al. (2021) suggest predicting a word by auto-regressively decoding a sequence of characters given a word-level representation. However, due to efficiency constraints, Jozefowicz et al. (2016)’s character-level decoding is based on a pretrained then frozen word-level model. We try to avoid these complex designs and instead choose to predict on sub-word level. Chung et al. (2020) shows that decoupling the hidden sizes of input and output embeddings can enhance performance. We believe it is feasible to take a further step and decouple input and output text granularity. By predicting subwords we can save a lot of effort and keep our model behave similarly to whole-word masking models and make it comparable to BERT baseline if we reuse its subword vocabulary. Besides, this method is token-free anyway when transfer learning on non-generative tasks. Subword-level features can be constructed by up-sampling from word-level hidden states. To keep things simple, we use a positional up-sampling method. Say we have the representation of the th word, that word contains multiple subwords and we want to want to predict the th one, we have
| (5) |
Where is a positional query for the th subword of a word. We feed into a prediction head for the final subword level prediction. We find that simply adding positional queries to the word-level representation respectively works better than more complex attention up-sampling Lee et al. (2018).
4 Experiments
4.1 Model Setup and Pretraining
While Byte2Word makes more sense on multilingual data, we evaluate our method in English due to budget constraint. We follow Izsak et al. (2021) and pretrain our model on English Wikipedia and BookCorpus Zhu et al. (2015). This corpora consists 20GB of raw text, and 10 million unique words, which should be enough to test if our method can learn a diversity of words. We provide some statistical information about the corpora in Table 2. We follow the masking strategy in Devlin et al. (2018) but slightly modify the input format to use specific byte values for special tokens. Specifically we substitute "[PAD]" for HEX0 , "[UNK]" for HEX1, "[CLS]" for HEX2, "[SEP]" for HEX3 and "[MASK]" for HEX4. For instance, instead of "[CLS] a [MASK] sentence exmaple. [SEP]", Byte2Word takes the input as "\x00 a \x03 sentence example. \x02". In this way our model learns each special token from a single index, sparing extra hassle. Also to control memory usage, we limit the max amount of bytes a word can contain to 128. Similar to , we adopt a 24-layer transformer encoder with 16 attention heads and 1024 hidden sizes for our model backbone. To minimize computation overhead, we limit the size of Byte2Word embedding layer to 192. In this way, our model consume less than extra FLOPS per inference compared to . We also find that increasing the width of byte2word embedding slows convergence in ablation study in 5.4. To ensure pretraining efficiency we follow Liu et al. (2019); Izsak et al. (2021) and discard next-sentence prediction. We build our code base upon Izsak et al. (2021) and train our Byte2Word model for 230k steps on 8x NVIDIA T4 16 GB for roughly a month.
4.2 Downstream Evaluation and Analysis
We test the performance of our model on GLUE benchmark Wang et al. (2018), the standard evaluation suite on language understanding for pretrained language model, and compare our result to subword-level baseline . During finetuning, instead of performing a grid search over sets of hyper-parameters, we use a fixed set of hyper-parameters across all tasks for each model. Table 1 shows test set results of the GLUE benchmark. Our Byte2Word model performs on par with on MNLI, QNLI and QQP, outperforms it on SST-2, MRPC and STS-B. However, our model has lower results on COLA and RTE. Overall, this amounts to a <0.5% difference in the average score, proving that our method can reach on-par performance with sub-word level model, while being toke-free for transfer learning and can accept and adapt to new words.
5 Analysis
5.1 Learning with Synthetic Noise
To explore Byte2Word’s ability to handle noisy input, similar to ByT5 Xue et al. (2021), we test our method on learning synthetic noise injected during transfer learning. We experiment four synthetic noising schemes listed below
-
•
Random drop: 10% of characters will be dropped in a sentence
-
•
Repetition: 20% of characters will be repeated for 1-3 times(drawn uniformly).
-
•
Uppercase: All characters will be converted to uppercase
-
•
Random case: All characters will be converted to uppercase or lowercase randomly. This pattern is simulating Alternating caps222https://en.wikipedia.org/wiki/Alternating_caps existing on the Internet
These types of noise are added to training and evaluation data. We compare our method to vanilla byte-level model ByT5 and case-sensitive subword-level model BERT Cased on MNLI. For ByT5, we adopt a method introduced in EncT5 Liu et al. (2021) to finetune ByT5’s encoder on MNLI but keep the training budget close to our baseline model. Table 3 shows the test performance of byte-level, subword-level and our hybrid method Byte2word on MNLI. Byte2Word has superior performance on all types of noise compared to subword-level model. On random dropping, ByT5 Encoder has less performance loss, but note that ByT5 is trained on mC4 Xue et al. (2020), a much larger multilingual dataset crawled from the Internet which contains noisy text. On Random case, it’s no surprise to see our method perform terribly, due to the strategy of splitting camel case in the input. This result also shows that word boundary is critical for learning language representations. Given the result of injecting random case noise after word segmentation degenerate minimal performance in Table 3, we presume the performance would be much better if we make fewer assumptions on data preprocessing. It’s also interesting to see that while Byte2Word model is pretrained using an uncased, subword-level vocabulary, this setting does not hinder finetuning on noisy text. Our Byte2word method can learn the noise pattern on the fly and has least degeneration on various noise types.
| MNLI-m/mm | Byte2Word | BERT Cased | Encoder |
|---|---|---|---|
| Clean | 86.1/85.6 | 86.4/85.7 | 84.2/83.0 |
| Random drop | 77.2/76.9 | 73.8/73.1 | 78.7/78.2 |
| Repetition | 85.8/85.2 | 78.8/78.7 | 81.7/81.4 |
| Uppercase | 86.5/85.8 | 77.9/77.2 | 83.2/83.0 |
| Random case | 74.1/73.7 | 73.5/72.4 | 83.0/82.9 |
| Random case | |||
| (post segmentation) | 85.9/85.5 | _ | _ |
| Model | ar | de | es | fr | ur |
|---|---|---|---|---|---|
| 72.59 | 76.95 | 78.66 | 77.96 | 62.55 | |
| Uncased | 64.99 | 71.62 | 74.11 | 75.01 | 56.4 |
| 64.49 | 72.63 | 77.47 | 76.85 | 57.0 |
| levenshtein | lcs | jaro | jaro-winkler | |
| Spearman corr. | 49.09 | 29.48 | 73.86 | 86.81 |
5.2 Cross-lingual Transfer
Unlike Xue et al. (2021), we evaluate cross-lingual transfer ability of our method by finetuning our English-only pretrained model on non-English downstream datasets. Since our model is not pretrained on multilingual corpora, it has to utilize cognates or shared grammar to facilitate learning. We test our model on XNLI Conneau et al. (2018) which is basically MNLI translated into multiple languages. Our results on a subset of XNLI are shown in Table 4. While the performance of our method is still behind multilingual language models, it has the better ability when adapting to new
languages compared to subword method. This result urge us to apply our method to multilingual language modeling in future work.
5.3 Cosine Similarity Between Word Representations
We analyze our learned Byte2Word model by calculating the cosine similarity of the learned word-level representations. Compare to BERT’s sparse embedding space(Figure 3), we speculate representations learned by our Byte2Word method seems to contain less semantic meaning, as the cosine distance between "live" and "liver" is too close. Of course, hidden states usually are not as sparse as items of an embedding table. Based on these findings, we use word pairs from Kirov et al. (2018) and compute Spearman’s correlation between cosine similarity of the learned representations and various types of edit distance of these pairs. Results are in Table 5. We can see that our representations have a strong correlation with the jaro-winkler distance, which factors in matching characters and transpositions. We believe that a single layer of cross-attention with limited hidden size serves as an information bottleneck that makes representations only contain character-level, shallow abstraction and saves the high-level learning for the following encoder layers. Also, it’s interesting to point out that while no case information existed in supervised signal during pretraining, Byte2Word still can distinguish uppercase and lowercase in text.
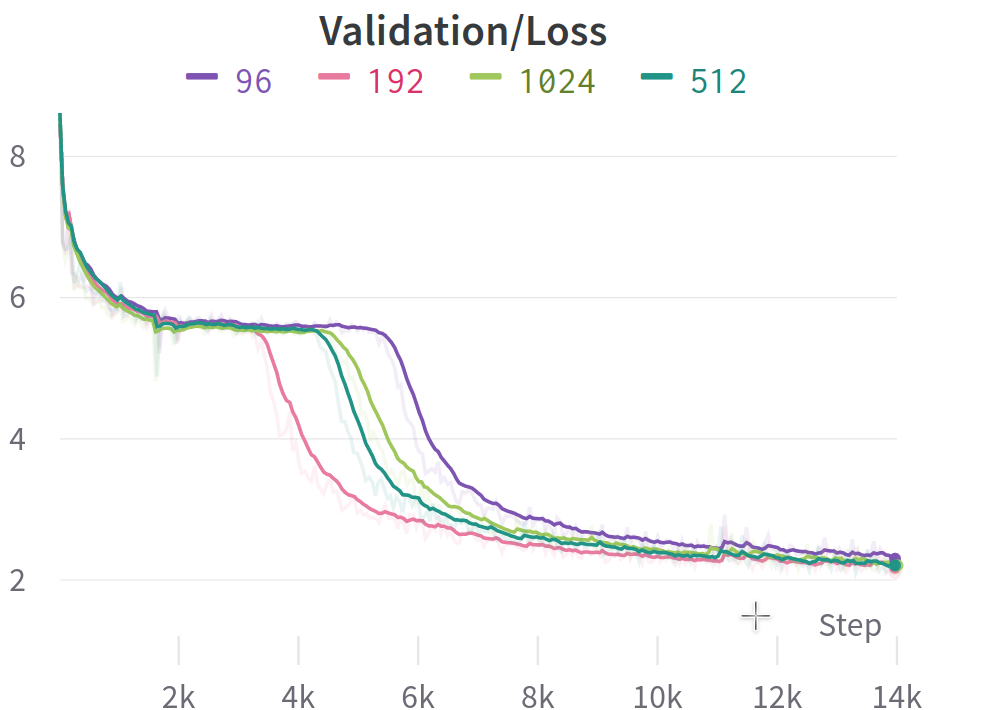
5.4 Convergence Rate of Different Embedding Sizes
To make sure that our choice of small embedding size for Byte2Word model does not degrade performance, we do an ablation study on the convergence rate of different embedding sizes. We use the previous setting in 4.1 to pretrain Byte2Word models with multiple embedding sizes of 96, 192, 512, and 1024 but limit the total training step to 23k, roughly 10% of our pertraining budget. The result is shown in Figure2. We can see that while all models reach similar perplexity after a certain amount of computing, 192 has the fastest convergence rate. With the mind of limiting the hidden size of Byte2Word module as small as we can, choosing 192 seems like a great choice that balances computation and performance.
5.5 Comparison to Character-aware 1D CNN method
To showcase our method is superior to previous, 1D convolution-based methods that consult the characters of a token to produce representation of a single word, we pretrain a Byte2Word model and CharacterBERT using the 10% of our pretraining budget in 4.1 and evaluate their performance on MNLI, the most representative task of the GLUE benchmark. Similar to Aguilar et al. (2021), we use BERT’s vocabulary as a pseudo word-level vocabulary to minimize architecture differences compared to subword-level baseline. Results in Table 6 show that attention based pooling method of Byte2Word performs better than 1D CNN pooling.
| Model | Embedding Layer Size | MNLI Acc |
|---|---|---|
| Subword | 31M | 83.77 |
| CNN | 0.4M | 81.96 |
| Byte2Word | 0.8M | 83.29 |
5.6 Parameters & Efficiency
’s subword lookup table has a size of 30522 and contributes roughly 31M of parameters, nearly 10% of the total model size. On the contrary, our Byte2word method has a small size lookup table and a following cross-attention pooling, composing about 0.4M of parameters. While it has 2x more parameters than 1D CNN character-aware embedding method, compared to BERT it is negligible. However, embedding lookup albeit its size does not require computation, but our Byte2Word method has extra computation with a ceiling of 25 MFLOPS per inference if we set our byte-level hidden size to 192 and input sentence to 512 words.
6 Limitations & Future Work
While matching BERT performance in many cases, Byte2Word slightly underperforms on CoLA and RTE of GLUE Benchmark. Those two tasks are both small-sized. We speculate text domain of these tasks is not covered by our pretrain corpora. In future work, it will be important to pretraining Byte2Word on corpora with more noise and languages, such as OpenWebText and mC4. Also it will be interesting to test fly Byte2Word on many-to-one translation with our Byte2Word embedding on encoder but language specific decoder.
7 Conclusion
In this work, we present Byte2Word, an improved character-aware method that is token-free, lightweight and less compute heavy. On downstream task quality, Byte2Word is on-par with BERT that relies on WordPiece vocabulary. On handling noisy input, our method is much superior to subword-level models and competitive with vanilla byte-level models. At the same time, the computation efficiency of our method is on-par with subword-level models and way higher than vanilla byte-level methods. On transfering to another language, Byte2Word shows better performance than subword baseline BERT. These results suggest that our hybrid method might be the right blend of both worlds and may lay the path toward future NLP models that are efficient at processing varied text.
References
- Aguilar et al. (2021) Gustavo Aguilar, Bryan McCann, Tong Niu, Nazneen Rajani, Nitish Shirish Keskar, and Thamar Solorio. 2021. Char2Subword: Extending the subword embedding space using robust character compositionality. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 1640–1651, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. 2016. Layer normalization.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners.
- Chung et al. (2020) Hyung Won Chung, Thibault Févry, Henry Tsai, Melvin Johnson, and Sebastian Ruder. 2020. Rethinking embedding coupling in pre-trained language models.
- Conneau et al. (2019) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Unsupervised cross-lingual representation learning at scale.
- Conneau et al. (2018) Alexis Conneau, Guillaume Lample, Ruty Rinott, Adina Williams, Samuel R. Bowman, Holger Schwenk, and Veselin Stoyanov. 2018. Xnli: Evaluating cross-lingual sentence representations.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. 2020. An image is worth 16x16 words: Transformers for image recognition at scale.
- El Boukkouri et al. (2020) Hicham El Boukkouri, Olivier Ferret, Thomas Lavergne, Hiroshi Noji, Pierre Zweigenbaum, and Jun’ichi Tsujii. 2020. CharacterBERT: Reconciling ELMo and BERT for word-level open-vocabulary representations from characters. In Proceedings of the 28th International Conference on Computational Linguistics, pages 6903–6915, Barcelona, Spain (Online). International Committee on Computational Linguistics.
- Feng et al. (2022) Zhangyin Feng, Duyu Tang, Cong Zhou, Junwei Liao, Shuangzhi Wu, Xiaocheng Feng, Bing Qin, Yunbo Cao, and Shuming Shi. 2022. Pretraining without wordpieces: Learning over a vocabulary of millions of words.
- Gowda and May (2020) Thamme Gowda and Jonathan May. 2020. Finding the optimal vocabulary size for neural machine translation. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3955–3964, Online. Association for Computational Linguistics.
- Izsak et al. (2021) Peter Izsak, Moshe Berchansky, and Omer Levy. 2021. How to train bert with an academic budget.
- Jozefowicz et al. (2016) Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, and Yonghui Wu. 2016. Exploring the limits of language modeling.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.
- Kim et al. (2015) Yoon Kim, Yacine Jernite, David Sontag, and Alexander M. Rush. 2015. Character-aware neural language models.
- Kirov et al. (2018) Christo Kirov, Ryan Cotterell, John Sylak-Glassman, Géraldine Walther, Ekaterina Vylomova, Patrick Xia, Manaal Faruqui, Sebastian Mielke, Arya McCarthy, Sandra Kübler, David Yarowsky, Jason Eisner, and Mans Hulden. 2018. UniMorph 2.0: Universal morphology. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan. European Language Resources Association (ELRA).
- Lample and Conneau (2019) Guillaume Lample and Alexis Conneau. 2019. Cross-lingual language model pretraining.
- Lan et al. (2019) Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. 2019. Albert: A lite bert for self-supervised learning of language representations.
- Lee et al. (2018) Juho Lee, Yoonho Lee, Jungtaek Kim, Adam R. Kosiorek, Seungjin Choi, and Yee Whye Teh. 2018. Set transformer: A framework for attention-based permutation-invariant neural networks.
- Liu et al. (2021) Frederick Liu, Siamak Shakeri, Hongkun Yu, and Jing Li. 2021. Enct5: Fine-tuning t5 encoder for non-autoregressive tasks.
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach.
- Ma et al. (2020) Wentao Ma, Yiming Cui, Chenglei Si, Ting Liu, Shijin Wang, and Guoping Hu. 2020. CharBERT: Character-aware pre-trained language model. In Proceedings of the 28th International Conference on Computational Linguistics. International Committee on Computational Linguistics.
- Mikolov et al. (2013) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient estimation of word representations in vector space.
- Pennington et al. (2014) Jeffrey Pennington, Richard Socher, and Christopher Manning. 2014. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1532–1543, Doha, Qatar. Association for Computational Linguistics.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Scao et al. (2022) Teven Le Scao, Thomas Wang, Daniel Hesslow, Lucile Saulnier, Stas Bekman, M Saiful Bari, Stella Biderman, Hady Elsahar, Jason Phang, Ofir Press, Colin Raffel, Victor Sanh, Sheng Shen, Lintang Sutawika, Jaesung Tae, Zheng Xin Yong, Julien Launay, and Iz Beltagy. 2022. What language model to train if you have one million GPU hours? In Challenges & Perspectives in Creating Large Language Models.
- Sennrich et al. (2015) Rico Sennrich, Barry Haddow, and Alexandra Birch. 2015. Neural machine translation of rare words with subword units.
- Tay et al. (2021) Yi Tay, Vinh Q. Tran, Sebastian Ruder, Jai Gupta, Hyung Won Chung, Dara Bahri, Zhen Qin, Simon Baumgartner, Cong Yu, and Donald Metzler. 2021. Charformer: Fast character transformers via gradient-based subword tokenization.
- Tito Svenstrup et al. (2017) Dan Tito Svenstrup, Jonas Hansen, and Ole Winther. 2017. Hash embeddings for efficient word representations. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc.
- Trockman and Kolter (2022) Asher Trockman and J. Zico Kolter. 2022. Patches are all you need?
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.
- Wang et al. (2018) Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2018. Glue: A multi-task benchmark and analysis platform for natural language understanding.
- Xu et al. (2020) Jingjing Xu, Hao Zhou, Chun Gan, Zaixiang Zheng, and Lei Li. 2020. Vocabulary learning via optimal transport for neural machine translation.
- Xue et al. (2021) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. 2021. Byt5: Towards a token-free future with pre-trained byte-to-byte models.
- Xue et al. (2020) Linting Xue, Noah Constant, Adam Roberts, Mihir Kale, Rami Al-Rfou, Aditya Siddhant, Aditya Barua, and Colin Raffel. 2020. mt5: A massively multilingual pre-trained text-to-text transformer.
- Zhu et al. (2015) Yukun Zhu, Ryan Kiros, Rich Zemel, Ruslan Salakhutdinov, Raquel Urtasun, Antonio Torralba, and Sanja Fidler. 2015. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. In The IEEE International Conference on Computer Vision (ICCV).
Appendix A Appendix
A.1 Hyperparameters
Below we provide a complete list of hyperparameters for pretraining and finetuning on GLUE benchmark.
| Parameter | Value |
|---|---|
| Number of Layers | 24 |
| Hidden size | 1024 |
| Attention heads | 16 |
| Attention head size | 64 |
| Byte2Word embedding layer size | 192 |
| Byte-level embedding size | 192 |
| FFN intermediate size | 4096 |
| Dropout | 0.1 |
| Attention Dropout | 0.1 |
| Layer norm type | pre LN |
| Learning Rate Decay | Linear |
| Weight Decay | 0.01 |
| Optimizer | AdamW |
| Adam | 1e-6 |
| Adam | 0.9 |
| Adam | 0.98 |
| Gradient Clipping | 0.0 |
| Batch Size | 4032 |
| Learning Rate | 1e-3 |
| Warmup Proportion | 0.06 |
| Max Steps | 240K |
| Max Length | 128 |
| Prediction dictionary | BERT uncased |
| Parameter | BERT | ByT5 Encoder | |
|---|---|---|---|
| Batch Size | 32 | 32 | 16 |
| Weight Decay | 0.01 | 0 | 0 |
| Max Gradient Norm | 1.0 | 1.0 | 1.0 |
| Learning Rate | 5e-5 | 2e-5 | 8e-5 |
| Max Epoch (MNLI, QQP, QNLI, SST-2) | 3 | 3 | 3 |
| Max Epoch (RTE, CoLA, STS-B) | 5 | 5 | _ |
| Warmup Ratio | 0.001 | 0. | 0.1 |
| Learning Rate Decay | Linear | Linear | Linear |
A.2 Cosine Similarity