Worst-Case Optimal Investment
in Incomplete Markets
Abstract.
We study and solve the worst-case optimal portfolio problem as pioneered by Korn and Wilmott in [41] of an investor with logarithmic preferences facing the possibility of a market crash with stochastic market coefficients by enhancing the martingale approach developed by Seifried in [51]. With the help of backward stochastic differential equations (BSDEs), we are able to characterize the resulting indifference optimal strategies in a fairly general setting. We also deal with the question of existence of those indifference strategies for market models with an unbounded market price of risk. We therefore solve the corresponding BSDEs via solving their associated PDEs using a utility crash-exposure transformation. Our approach is subsequently demonstrated for Heston’s stochastic volatility model, Bates’ stochastic volatility model including jumps, and Kim-Omberg’s model for a stochastic excess return.
MSC (2010) codes: 49J55; 93E20; 91A15; 91B70
Key words: stochastic control, backward stochastic differential equations, worst-case approach, portfolio optimization, indifference strategies, incomplete markets
1. Introduction
An important aspect that is neglected in the pure Merton type portfolio optimization setting is the presence of so-called crash scenarios as first introduced by Hua and Wilmott [27] in discrete time. In this setting, parameters are subject to Knightian uncertainty in the sense of Knight [34], which consequently does not impose any distributional assumptions. In particular, in these worst-case optimization models, a financial crash is identified with an instantaneous jump in asset prices.
The literature strand on worst-case portfolio optimization possess by now a long history. In their seminal work [41], Korn and Wilmott have solved the worst-case scenario portfolio problem under the threat of a crash for logarithmic utility in continuous time. Their results have been extended in [36] by using the so-called indifference principle. Korn and Steffensen [40] then derive (classical) HJB systems for the worst-case portfolio problem. What all these works have in common from a conceptual point of view, is that the resulting worst-case optimal strategies are characterized by the requirement that the investor is indifferent between the worst crash happening immediately and no crash happening at all.
Based on a controller-vs-stopper game, Seifried introduced fundamental concepts for the worst-case portfolio optimization in [51], namely the indifference frontier, the indifference optimality principle and the change-of-measure device (see also [39]), in order to generalize the results to multi-asset frameworks and in particular discontinuous price dynamics. During the course of this paper, we will heavily rely on these methods and enhance them by allowing the market coefficients - in particular the volatility and the excess return - to be stochastic.
Further generalizations of the worst-case approach comprise, among others, proportional transaction costs, cf. [7], a random number of crashes, cf. [6], lifetime-consumption, cf. [17], a second layer of robustness, cf. [16], explicit solutions for the multi-asset framework, cf. [35], and more recently stress scenarios, cf. [38] and dynamic reinsurance, cf. [37].
From an abstract point of view, the worst-case approach shares common features with classical robust portfolio optimization, which typically focus on the financial markets’ parameters. For instance in [52], the market acts against the trader and chooses the worst possible market coefficients. Among others, another example is Schied, cf. [50], who considers a set of probability measures to maximize the robust utility of the terminal wealth. We refer to [22] for an overview on this literature. We however wish to stress that in the worst-case portfolio optimization problem, the jump times and the jump intensity are unknown, which renders the problem more delicate than standard portfolio optimization problems.
Another strand of literature, to which our work is related, is portfolio optimization with unhedegable risks, which typically comes along with incomplete markets. The seminal paper of Zariphopoulou [53] introduces the so-called martingale distortion, which is able to deal with stochastic volatility models in a very general factor model setting. Concerning Heston’s model, Kraft [42] finds explicit solutions for power utility using stochastic control methods. Martingale methods are then employed in [31] in an affine setting. Related works in that context include as well [47, 12, 46]. In a setting with stochastic excess return, Kim and Omberg [33] find optimal trading strategies for HARA utility functions. For a concise overview of asset allocation in the presence of jumps, both in the asset price and the volatility, we refer to [8] and the references therein. In the context of worst-case portfolio optimization, so far market coefficients are assumed to be constant - with the exception of Engler and Korn [21], who solve the worst-case optimization problem for a Vasicek short rate process.
In this work, we combine the strands of worst-case portfolio optimization and optimal investment with unhedgeable risks as follows:
-
•
We solve the worst-case optimal investment problem of an investor with logarithmic utility, facing both structural crashes and jump risk, in a setting that allows as well for stochastic market coefficients.
-
•
We enhance the concepts indifference frontier, the indifference optimality principle and the change-of-measure device to the case of stochastic market coefficients for logarithmic utility.
-
•
We characterize the resulting indifference strategies via the unique solutions of BSDEs, using the so-called utility crash exposure.
-
•
We exemplify and analyze the resulting indifference strategies for the Heston model, the Bates model and the Kim-Omberg model.
We also contribute to the general theory of backward stochastic differential equations, since the equation that emerges when describing indifference strategies, leads to a BSDE coefficient that does not satisfy a Lipschitz condition with deterministic constants. Rather, we are confronted with a stochastic Lipschitz constant that satisfies an exponential integrability condition. Additionally, the generator is exponentially integrable itself. In the setting without jumps, similar conditions, sufficient for existence and uniqueness, have e.g. been treated in [9], [19] and [45]. In the case including jumps, BSDEs with stochastic Lipschitz condition have been treated in [49, Chapter II]. However, the spaces for solutions used there are different than those in the standard theory with deterministic Lipschitz constants. Our results in this article still allow the use of the standard spaces. The approach we follow is based on an approximation argument building on the Lévy settings used e.g. in [44] and [43]. We obtain existence, uniqueness of a solution and a comparison theorem, necessary to guarantee the one-to-one relation between BSDEs and PDEs (see [3]). This relation between the deterministic and stochastic world needs several requirements, e.g. a local Lipschitz continuity in the initial value of the stochastic process that models the volatility of the asset price. To be applicable to the popular model choice of the CIR process, we extend the existing result from [13] to a wider parameter range.
The remainder of the paper is organized as follows: In Section 2 we define the financial market and and the worst-case optimization problem in incomplete markets. In Section 3 and and Section 4, we solve the worst-case portfolio optimization problem by disentangling the problem in the post-crash and pre-crash problem. Section 5 then develops the BSDE machinery which is needed for the characterization of indifference strategies when market coefficients are stochastic. Section 6 and Section 7 deal with the concrete examples, i.e. the Heston model, the Bates model and the Kim-Omberg model. Appendices A, B and C contain several proofs and auxiliary results.
2. Financial Market Model and Worst-Case Optimization Problem
Let be a probability space carrying two independent Brownian motions and a Poisson random measure independent from . is the natural, augmented filtration for and satisfying the usual conditions. Note that for some is again a Brownian motion.
The financial market consists of a riskless money market account and a risky asset . In the absence of a crash, the dynamics of and are given by
where , and are progressively measurable processes (w.r.t. the filtration ) describing the dynamics of the market coefficients. Moreover, we denote the intensity measure of the Poisson random measure by and by we denote the according compensated Poisson random measure; we assume that is a Lévy measure with support in and . In addition, we assume , where is the given size of the model’s worst-case substantial crash. If the model does not permit jumps (i.e. and do not appear), we call this setting purely Brownian model or model without jumps.
A particularly important choice of those parameters leads to the following version of the Bates model [5] and Heston model [26], respectively:
| (1) | ||||||
where is a progressively measurable interest rate process, is a progressively measurable excess return process, the mean reversion level of the volatility, the mean reversion speed of the volatility, the volatility of volatility and is another Brownian motion with .
Alternatively, the Kim-Omberg model, cf. [33], is constituted by an analogous set of equations, where now with constant . We elaborate on the details in Section 6.
We face two types of crashes in our model. The number describes the structural worst-case crash associated with a catastrophe. By we denote continuously occurring crashes of moderate size with , where ; this is line with the reasoning of [51].
Definition 1.
For a fixed crash height , a worst-case crash scenario is given by a -valued -stopping time . The stock index dynamics in the crash scenario is given by
| (2) |
The no-crash scenario corresponds to . We denote by the collection of all stopping times .
Remark 2.
In this paper we restrict attention to the case of a single market crash. This is in line with e.g. the analysis in [17]. The model can be generalized to an arbitrary finite number of crashes. In that case the optimal strategies can be determined recursively. Moreover, it is also possible to treat the crash height as a bounded random variable; however this is mainly notational, since the worst case is anyway attained by its upper bound.
Throughout the paper we make the following general standing assumption on the market coefficients , and :
| (A) | ||||
Remark 3.
The second line of A means that the source of jumps is not involved in the excess return and the volatility . However, the jumps do enter the model in the equation for the wealth process below.
In addition, we need the following integrability assumptions on the market coefficients and :
| (B1) |
For future reference we define the function
Admissible portfolio processes
We restrict our attention to admissible portfolio processes with continuous paths.
Definition 4.
A portfolio process is an -predictable process .
-
(i)
is called post-crash-admissible, if it is non-negative111This means we rule out short sales of the risky asset., continuous and, if we do not have a purely Brownian model, and
-
(ii)
is called pre-crash-admissible, if it is post-crash-admissible and satisfies in addition everywhere.
Denote by the set of all pre-crash-admissible and by the set of all post-crash-admissible portfolio processes
Remark 5.
We consider the problem of an investor to choose a pair consisting of a pre-crash and a post-crash strategy in order to maximize the utility of terminal wealth in the worst-case crash scenario, namely to maximize
| (P) |
Here, denotes the wealth process of the investor, if he follows prior and up to the crash, after the crash and the crash happens at time , that is is the solution to
for some initial wealth .
Note that the SDEs above are driven by the Brownian motion with coefficients that are measurable w.r.t. a larger filtration than the one generated by only. However, the usual Itô’s formula (and its various extensions) can still be applied as the integrals w.r.t. can always be written as e.g.
The solution to the above SDE can then be given explicitly:
Lemma 6.
Let be an admissible choice and . Then a unique solution to the above forward SDE exists. This solution is strictly positive and is quasi-integrable for each . Furthermore,
Proof.
Define first the auxiliary portfolio process as follows
and consider the crash-free SDE
Obviously, for any solution to this SDE, solves the above SDE containing a crash and vice versa (meaning for any solution to the SDE with crash we can construct exactly one solution to the crash-free SDE). Now, the crash-free SDE is a linear SDE with integrable drift and square-integrable diffusion coefficient and integrable Lévy measure with a unique (strong) solution , given by
Here, the second line immediately follows from definitions of and .
Clearly is strictly positive and, as by pre-crash admissibility, so is
It remains to show quasi-integrability of and the asserted representation of . We have
By assumptions (A), (B1) and boundedness of and , the stochastic integrals are martingales and have expectation . For the same reason, and are integrable random variables. Finally, might not be an integrable random variable, but due to this term is non-positive and thus trivially quasi-integrable. Hence, also is quasi-integrable. The asserted representation of is now a trivial conclusion. ∎
3. Solution to the Post-Crash Problem
As is common in the worst-case optimal investment literature, the above problem can be solved by first considering for each crash scenario the post-crash problem starting at time , which is a classical portfolio optimization problem, compare e.g. Korn and Wilmott [41], Seifried [51]. Using the explicit representation of the objective from Lemma 6, the following result is immediate here.
Proposition 7 (Solution of the post-crash problem).
With (B1), in the Lévy model the optimal post-crash portfolio process is given by .
Proof.
We consider two possible cases:
Case 1:
| (3) |
By assumptions (A) and since for all , , and by (3), possible maxima of are attained in .
Hence on an interval, , , where the maxima of are contained, we may differentiate twice in direction to see that is strictly concave, thus is well defined and constitutes a continuous333See Stokey et.al., Recursive Methods in Economic Dynamics, Thm. 3.6, bounded and adapted process. To show , note that for . On the same interval, we know that
As this derivative is smaller or equal to zero for (it equals zero whenever ), we infer
Thus, (B1) and the boundedness of implies
and herewith .
Case 2:
| (4) |
This case is simpler to treat since the monotone limit (4) is finite, which yields that for all . Again we get that is a differentiable, strictly convex function, but now may attain the value . The finiteness of (4) now shows that .
In any of the two cases, for each , is the unique global maximizer in of the function , so for any stopping time and any second we have
As the first and second term in the objective representation of Lemma 6 do not depend on the choice of the post-crash portfolio process, this proves optimality of . ∎
Corollary 8.
In the model without jumps, is given by the classical Merton strategy .
We moreover need the following useful property of the post-crash optimal strategy later when proving optimality results; the proof can be found in Appendix A.
Proposition 9.
The post-crash optimal strategy can be expressed by a two-variable function , , where is a continuous function. Additionally, when , we get Lipschitz continuity together with the following relations:
and
Definition 10.
We say that such a market price of risk is -appropriate, if is the function representing by .
For example, in the model without jumps, , and are said to constitute a linear market price of risk model, if for some , .
Such -appropriate market prices of risk are computed e.g. in Subsection 6.3.
Remark 11 (Power utility with stochastic coefficients).
In the case of stochastic coefficients we can not directly apply the change of measure device procedure in order to solve the Merton problem if we replace the logarithm by the power function for , as it was done in [51] having deterministic market coefficients. In particular:
and
where the equality does not have to hold as is not -measurable.
The following assumption (C1) for the Merton strategy is necessary for the model without jumps, as we need our strategies to be admissible. The second assumption is used later on in examples.
| (C1) | |||
| (C2) |
4. Solution to the Pre-Crash Problem
It is now left to find the optimal pre-crash strategy . This is the main concern of the present paper.
Given the known solution to the post-crash problem, we simplify the worst-case problem as follows. First, ignore the constant term in the objective. As long as its value does not matter for the optimal choice. Second, rewrite the remaining objective as
which has the advantage, that the third summand does neither depend on , nor on and can therefore be ignored, while the argument of the expectation in the second summand is -measurable
We arrive at the following problem:
Problem 12 (Pre-Crash Problem).
Choose a portfolio strategy to maximize
| () |
In the following we define the process
Furthermore, define the utility crash exposure of strategy by
Remark 13.
The seminal work [51] also defines a crash exposure process, but with respect to wealth, which is different from the exposure w.r.t. utility which we introduce here.
In order to properly characterize (worst-case) optimality of strategies, we introduce the following notion:
Definition 14 (Worst-case dominance).
A strategy is said to worst-case dominate a strategy and, equivalently, is said to be worst-case dominated by , if for every stopping time , there is a stopping time , such that
Write in this case .
We record the following straight-forward result:
Lemma 15.
Proof.
Suppose, worst-case dominates any other strategy . Then for any stopping time there is a such that
Taking the infimum over all and then the supremum over all yields the conclusion.
Note that is not a preorder.
4.1. Super- and Subindifference Strategies
In this section we extend the definition of an indifference strategy to the terms superindifference strategy and subindifference strategy and derive several results to bound the worst-case optimal strategy - if it exists - from below and above.
We define the notion of (sub-/super-)indifference strategies for a more general class of processes than the one of all admissible portfolio processes . We will see later, that at least indifference strategies are automatically contained in . Let be the set of all progressively measurable bounded processes that satisfy the pre-crash admissibility conditions of Definition 4 except for the requirement of continuity.
Definition 16 (Super-/Subindifference Strategy).
Let , be two stopping times with and a portfolio process.
-
•
is called a superindifference strategy on , if is a supermartingale on .
-
•
is called a subindifference strategy on , if is a submartingale on .
-
•
is called an indifference strategy on , if it is both a super- and subindifference strategy on .
The reference to is omitted, if it coincides with .
In the controller-vs-stopper-game setting of [51] we can interpret these strategies as follows:
-
•
A subindifference strategy is a strategy such that at any given time the market/stopper’s best response is to stop the continuation game starting at that time immediately.
-
•
A superindifference strategy is a strategy such that the market/stopper’s best response is to wait forever and never stop the game early.
-
•
An indifference strategy is a strategy such that the market/stopper is at any point in time indifferent between stopping and waiting.
Remark 17.
For a superindifference strategy, the process needs to be a supermartingale on as well. This represents the indifference to a crash happening at the last moment, or not at all. Since both and are measurable, it follows that . See also [51, 4.2. Indifference at ].
In what follows we also need to be able to concatenate strategies:
Definition 18.
Let and a stopping time. Then the process that switches at from is defined by
Use for the following two cases a special notation:
-
•
We write instead of , if .
-
•
We write instead of , if .
Remark 19.
Obviously, it is again .
We will also make use of the following lemma throughout the remainder of the section.
Lemma 20.
Let , and .
-
(a)
If is a (super-/sub-)indifference strategy on , then is, too.
-
(b)
If is a (super-/sub-)indifference strategy on , then so is .
Proof.
Part (a) follows directly from .
For the proof of part (b) let be an arbitrary stopping time. Then
Since the term is -measurable, this shows that is a (sub-/super-)martingale on , if and only if is.
∎
4.2. The Subindifference Frontier
The following is an enhancement of the classical indifference frontier result of [51] for the log utility case with stochastic market coefficients
Proposition 21 (Subindifference Frontier).
Let be an arbitrary admissible portfolio process and a continuous subindifference strategy. Then worst-case dominates .
Proof.
Let be as in the definition of . Then is a stopping time by the debut theorem and . Let now be an arbitrary stopping time and the utility crash exposure process of , the one of and the one of .
By Lemma 20, is a subindifference strategy on and thus a submartingale in this interval. This implies (because of )
| (5) |
The last expression can be decomposed as follows
| (6) |
Next, because and coincide on and due to continuity of and , we can estimate
Combining this result with equations (4.2) and (4.2) yields
∎
Remark 22.
As suggested by our filtration, which involves a Poisson random measure, and hence jumps, one might be tempted to generalize the reasoning to predictable strategies that might jump as well. However, under such a filtration, whenever we assume that the process is a martingale (i.e. is an indifference strategy), the jumps of emerge from the term , that is, from the strategy itself. A martingale in such a filtration (we assume the usual conditions) can always be assumed as its right-continuous version. If , as a strategy, is predictable, also becomes predictable. But a predictable martingale in a filtration formed by a Brownian motion and a Poisson random measure must be left-continuous already.
4.3. A Superindifference Frontier Result
The subindifference frontier result from [51] presented above states that any subindifference strategy bounds the worst-case optimal strategy from above. A natural question is then to ask: Under which conditions can a superindifferent strategy bound the worst-case optimal strategy from below? If this was always the case, we could immediately conclude, that any indifference strategy is always worst-case optimal. However, the worst-case problem has a certain degree of asymmetry, such that we cannot expect a result as tight as the one for the subindifference frontier: In general there is a trade-off between high risk-adjusted expected returns absent a crash and good crash protection, but whereas the latter is strictly decreasing in , the first goal is represented by the function , which is not everywhere strictly increasing in , but contains a quadratic risk-penalty term. Increasing thus always worsens the crash protection, but only leads to expected utility gains absent a crash, if is positive, i.e. as long as where is the post-crash optimal strategy (maximum of ). Thus, we can only expect a superindifference frontier for superindifference strategies with the additional property that . Then indeed, the following holds.
Proposition 23 (Superindifference Frontier).
Let be a continuous superindifference strategy such that and . Then worst-case dominates .
Proof.
Let , be an arbitrary stopping time and define by
which is a stopping time. By continuity of both, and , we have the inequality Thus, and therefore . In addition, for each either or holds. Because is increasing on and by definition, we have and thus
This together with implies . Using that on and thus is a supermartingale there, we can conclude
Since was arbitrary, this shows that is worst-case dominated by .
∎
4.4. The Merton Bound
As described above, there is no trade-off between risk-return performance absent a crash and a low crash exposure above the post-crash optimal strategy . In this case, both the crash exposure and are strictly decreasing in and thus it is unambiguously better to (marginally) decrease . By this reasoning, it can never be optimal to invest a higher share than into the risky asset. Indeed, the following result holds.
Lemma 24 (Merton bound).
Let . Then worst-case dominates .
Proof.
Let and , be the exposure processes of and , respectively. Obviously, and since , we have . In addition, for all and all either , then trivially , or , then and thus . Hence, everywhere. Combining these two properties we have
This implies for all stopping times , which is clearly a stronger property than . ∎
4.5. Worst-Case Optimality of Indifference Strategies
Next we prove the crucial optimality result for the worst-case problem with stochastic market coefficients. In particular, this optimality holds whenever the indifference strategy is dominated by the post-crash optimal strategy:
Theorem 25.
Proof.
Let be an arbitrary admissible strategy. As a continuous indifference strategy, is a continuous subindifference strategy and thus by the subindifference frontier result of Proposition 21, .
On the other hand, is also a continuous superindifference strategy with , (see Remark 17) and by assumption . Since we have by definition of , Proposition 23 implies .
Combining these two arguments shows . Since was arbitrary, any admissible portfolio process is worst-case dominated by and Lemma 15 implies the assertion. ∎
5. A BSDE Characterisation of Indifference Strategies
In the previous section we have seen how (super-/sub-)indifference strategies can be useful to derive bounds for the worst-case optimal solution. In this section we discuss indifference strategies in more detail using a characterization in terms of backward stochastic differential equations (BSDEs). This is completely analogous to the ODE characterization of indifference strategies in the literature on worst-case optimization for constant market coefficients, cf. for instance [41, 36, 39]. In what follows we use the following notations for BSDEs: Let denote the vector of our independent driving Brownian motions,
Let denote the space of all -progressively measurable and càdlàg processes such that
Let be the space of all -progressively measurable and càdlàg processes such that
where the supremum is taken over all -stopping times . We define as the space of all -progressively measurable processes such that
where for , . We define as the space of all random fields which are measurable with respect to (where denotes the predictable -algebra on generated by the left-continuous -adapted processes) such that
An -solution to a BSDE with terminal condition and generator function is a triplet which satisfies for all ,
| (7) | ||||
Specifications for the generator and the terminal conditions will be given further below.
To be able to apply all the necessary BSDE machinery, we need to make for now stronger integrability and boundedness assumptions on the underlying market model. First, we consider a set of assumptions that strengthen the integrability assumption (B1):
| (B2) |
Replacing in the above formulation by :
| (Bp) |
5.1. Analysis of the Generator
The following proposition provides the fundamental link between indifference strategies and BSDEs.
Proposition 26.
Assume assumption (B2) holds and let be a stopping time with , a portfolio process and . Then the following are equivalent
-
(i)
is an indifference strategy on ;
-
(ii)
There is a process , such that is on a solution to the BSDE
(8) where
Equation (8) is a BSDE in the sense of our setting above, (7). To apply existence results from BSDE theory, it is necessary to analyze its generator, that is the integrand w.r.t. . We will do this here by listing several straightforward observations.
We expand in (ii) to relate it to the form (7): The triplet is the solution to (7) with terminal condition and given by
The generator depends on , that is, on and and the terminal condition are measurable with respect to the -algebra generated by only. Also the terminal condition is trivially measurable by the same -algebra. Therefore the setting might be reduced to BSDEs driven only by a Brownian motion,
However, our setting including the additional -variable is more natural, as the sources of randomness for the whole model are based on the -algebra , which includes the jumps. In the section that follows, taking along the jumps is an extension for the BSDE results showing that this part of the theory is feasible for future treatment when considering models that may have jumps in the portfolio processes . Note that
and, due to the boundedness of ,
| (9) |
holds if (Bp) is satisfied. In the model without jumps, where ,
holds if (Bp) and (C1) do, or, more generally, if (Bp) is replaced by
| (BpW) |
This condition also follows, if e.g. and . For the generator one readily obtains the relation
Hence, a one-sided Lipschitz condition
| (10) |
with is satisfied for whenever the processes and are bounded by . The conditions (9) and (10) are standard assumptions for BSDEs to yield unique solutions. However, (10) demands a strong condition (uniform boundedness) on the coefficient. We are going to ease that condition in Section 5.2.
Proof of Proposition 26.
First note that since for all admissible strategies, necessarily has to hold. Since and all summands in the definition of except for are identical for and , is a martingale on the time domain , if and only if the terminal condition holds. We can thus assume in the remaining part of the proof.
Next, let be an arbitrary stopping time with . By definition of we have
| (11) |
Now if (i) holds, then by the martingale representation theorem there are processes , such that for all such stopping times 444The martingale representation theorem is often only stated for a deterministic time domain like , which is sufficient to permit our usage on the interval : just apply the theorem to the martingale and use the fact that and must coincide on .
Substituting this into (11) and using shows that satisfies (8). As is continuous, also is, and so the integrand of the jump part, must be 0.
Now assume conversely that (ii) holds. Then we obtain from equation (11)
for any stopping time . Since , the stochastic integral on the right is a martingale and, hence, must be a martingale on .
∎
Remark 27.
Without assumption (B2), the proof of the direction (i)(ii) in the preceding proposition fails, because then is not necessarily a square-integrable martingale and thus the martingale representation theorem does not imply square integrability of the process anymore. The reader easily verifies that (B2) was only used in the above proof to conclude . However, if one replaces the part from (ii) by , for some , then (i)(ii) still holds under the assumption (Bp) for (just set in [43, Theorem 3.3] or [44, Theorem 2]). The assumption (B1) alone already ensures that (i)(ii) still holds yielding for all . (see [10, Theorem 6.3]).
Consequently, the BSDE representation (8) with a generic process still holds for any indifference strategy , even without assumption (B2).
In the next subsections, we show that BSDE (8) has a unique square-integrable solution, assuming that and satisfy the following condition.
| (Bexp) |
Note that if is replaced by , the above assumption implies (Bp) for all and therefore also (B2) and (B1).
5.2. Solutions to the Indifference Utility BSDE
We present various existence and uniqueness results about BSDEs here which are relevant for the above characterization. We will also show a comparison theorem for use in Section 6. The theorems in this subsection consider the full Lévy setting. All assertions hold for the case without jumps as well thanks to (C1) which grants boundedness for the Merton strategy. Alternatively, the theorems also work assuming (BpW), and, in place of (Bexp), using . For a better readability, the corresponding proofs are delegated to Appendix B.
Proposition 28.
We can now obtain solutions of unbounded . By an approximation procedure for the BSDE’s generator, along with standard methods for BSDEs with -data, we get the following:
Remark 30.
With stronger tail properties, in addition to existence, the following theorem grants uniqueness of solutions in a class of functions.
Theorem 31.
The next theorem states that for generators similar to the function , we may compare the solutions to BSDEs if we have an inequality for the data.
Theorem 32.
Let be two (measurable) generators, such that there is a progressively measurable, non-negative process and with
and that for all
Assume that and that there are solution triplets to the BSDEs given by the terminal conditions and generators . We assert that, if a.s. and , -a.e., then also a.s. for all .
Remark 33.
Alternatively, to the assumptions on , one may assume instead that that there is a progressively measurable, non-negative process and with
and that for all
and that . The same assertion as above holds also in this case.
5.3. Existence of Indifference Strategies
We now have everything at hands in order to prove the existence of a unique indifference strategy. In particular, combining Proposition 26 with and Theorem 31 implies the following uniqueness result.
Corollary 34 (Uniqueness of indifference strategies).
Under the assumption (Bexp) there is a unique indifference strategy .
The indifference strategy is also a special superindifference strategy and we have seen above that superindifference strategies are only helpful to bound the worst-case optimal solution, if they are uniformly dominated by the post-crash optimal strategy. It is thus natural to ask, whether this is the case for . While we do not provide a formal counterexample, our numerical experiments suggest, that one cannot hope for this to be the case in general. However, in certain situations this uniform dominance condition is indeed obtained. We provide here two sufficient conditions for this to happen. The first is almost trivial, but only valid in market models without jumps with very large excess returns relative to (Brownian) risk.
Lemma 35.
If , then .
Proof.
Due to , we immediately obtain . On the other hand, any pre-crash-admissible strategy is bounded above by , in particular also the indifference strategy . ∎
In the model with jumps, the following proposition establishes the desired dominance condition. In particular, if is obtained by first finding a maximizer , and then trimming it to the range .
Proposition 36.
If the post-crash optimal portfolio process is obtained via an Itô process , with coefficients ,
where and the stochastic integral is a martingale and if
-
(1)
is also pre-crash-admissible (i.e. the minimum in the above equation has no effect),
-
(2)
satisfies
-
(3)
and is a subindifference strategy,
then -a.s. for all .
The sufficient conditions of Lemma 35 and Proposition 36 are rather restrictive or difficult to apply in many situations. In particular, inspecting the ’almost Itô process’ from the proof of Proposition 36 in Appendix B, to check whether being a subindifference strategy requires to find out if
where is again the integrand w.r.t. in (23).
On the one hand, for any particular model one thus needs to come up with additional arguments why this proposition is applicable. On the other hand, however, these results are useful in the important special case of a constant post-crash optimal strategy, that is, if assumption (C2) is satisfied. In this case we can conclude:
Corollary 37.
These existence results will also be of use in the following sections when dealing with concrete examples and numerical investigations.
6. The Markovian Case
In this section we specialise on a market model with , where is a factor process whose evolution is governed by the SDE
| (12) |
and is a fixed initial value. We require that the functions and are chosen in a way to guarantee that this SDE has a unique (strong) solution. Furthermore, the functions , , and are all assumed to be continuous. We wish to stress that this formulation covers in particular the Bates model, respectively the Heston, c.f. (1). In this situation, the indifference BSDE (8) can be connected to a partial differential equation (PDE).
6.1. From BSDEs to associated PDEs
Consider an arbitrary process with some function . Then by Itô’s formula
Let the optimal post-crash strategy be expressed by a function dependent on , , e.g. in the model without jumps, In models involving jumps, expressions for may also be obtained explicitly, in the case of the Lévy measure equals the point measure , solving , one finds the maximizer , see also Section 6.3 for a similar computation.
With being given by , the drift of the forward SDE equals the generator of the BSDE (8), , if
holds for all since
recalling that
In this case satisfies the indifference BSDE (8), if in addition . A sufficient condition for this is for all . Thus, the following result holds (cf. [20, Proposition 4.3]):
Proposition 38.
Let be a solution to the PDE
| (13) | ||||
and suppose that , and are processes in . Then is a solution to the BSDE (8), with the generator now having the form
Note that the second component of is zero as well as . This is due to the fact that all relevant processes are measurable with respect to the filtration generated by alone. So the generator is also measurable w.r.t. the filtration generated by , as is and thus for solvability of the BSDE no integrands w.r.t. and are needed.
The last proposition associates the indifference BSDE and thus ultimately the model’s unique indifference strategy and thus its worst-case optimal solution with a PDE.
While instructive, Proposition 38 is usually of little practical value, because PDE (13) can in most cases only be solved numerically and then one needs an a-priori argument why a classical solution to the PDE exists and why the numerical scheme employed converges to such a classical solution. In the following we therefore consider cases, in which a version of Proposition 38 still holds true, if is only a viscosity solution to (13).
The convergence of the numerical scheme itself holds due to [4]. To adapt our notation to Markovian BSDEs, we highlight the dependence on the forward process in by a variable . So, we consider another generator in the variables such that . Abusing notation slightly, we identify . In our setting, it is given by the function
and in the case without jumps,
Note that in contrast to [20, 3], the driver of our BSDE is not Lipschitz in , but satisfies the prerequisites of Theorems 31 and 32. The following theorem ensures existence and uniqueness of solutions to the corresponding PDE in our setting (the proof can be found in Appendix C):
Theorem 39.
Let be the solution of the forward SDE (12) on , starting in at that satisfies the following conditions: For all there exists a constant such that
| (14) |
and
| (15) |
We furthermore assume that for some ,
and there is an such that
| (16) |
(i.e. (Bexp) holds for , ).
Then, there exists a viscosity solution of (13). If moreover and satisfy for all
for all and for a continuous function with , the solution is unique in the class of functions such that
uniformly in for some .
6.2. Concrete Examples
As a first example, one may consider and to be globally Lipschitz continuous. In this case, the SDE (12) has a unique, strong solution. Furthermore, we have that the Assumptions (14) and (15) are satisfied (see e.g. [3, Proposition 1.1],[23]). Such a choice for and is made e.g. in the Kim-Omberg model, cf. [33],
with constants . Furthermore, we have and we have the constant volatility . Assumption (16) is satisfied since is log-normally distributed.
The second example is the Heston/Bates model, cf. [26, 5], where the volatility is given by the CIR process, i.e.
| (17) |
with positive constants . Here, we have . Note that the diffusion coefficient of (17) is not globally Lipschitz continuous and therefore standard results do not apply. Since the square root is of linear growth, the CIR process has a unique strong solution by the Yamada-Watanabe condition (see e.g. [30, Theorem IV 3.2]). Moreover, the process is strictly positive if by the Feller condition. Furthermore, the following Proposition ensures that Assumptions (14) and (15) of Theorem 39 are fulfilled (its proof can be found in Appendix C).
Proposition 40.
Let and for some . Furthermore, let . For all there is a constant such that
| (18) |
and
| (19) |
Moreover, in the case of and all , we have that
| (20) |
Remark 41.
Next, we need to check whether (16) holds. For the CIR process, we have the following result (see e.g. [1] and [28]).
Proposition 42.
Let . Then,
Without the Feller condition, a small calculation using [14, Proposition 3.2] (carried out in Appendix C) shows the more general
Proposition 43.
Let . Then,
6.3. Modeling the Jumps
To model jump intensities we choose for example the measure (infinite activity) and , (possibility of smaller crashes of constant size). To obtain constant optimal post-crash strategies in the two cases, , both in , we want to find for a given Heston volatility , the -(resp. -)appropriate market prices of risk and in the sense of Definition 10. To that end, by Proposition 12 (and the argumentation for differentiability in the proof), we may obtain for , by solving . This means that
Hence, we get
which corresponds to a linear price in the volatility plus an additional safety loading for the jump term.
Computing the integrals for the concrete , we see that our need to be
7. Numerical Experiments
7.1. Numerics for the Bates and Heston model
The first examples we will show here, calculated using methods from the previous section, are variations of the Bates and Heston model with different activities of jumps. All models rely on the same samples of a CIR process, computed in 1000 time steps using distributional properties (exact simulation).
-
(a)
Infinite activity jumps: . Here our coefficients summarize as follows: The forward equation for the CIR-process modeling the volatility is
with values , corresponding to a Feller index of , so our requirements from Section 6 are fulfilled. The parameters for the CIR process are taken from [11, Table 6]. The further coefficients for the model are
Here the excess returns is the -appropriate market price of risk from Subsection 6.3. Figure 1 shows the resulting strategy for this model.
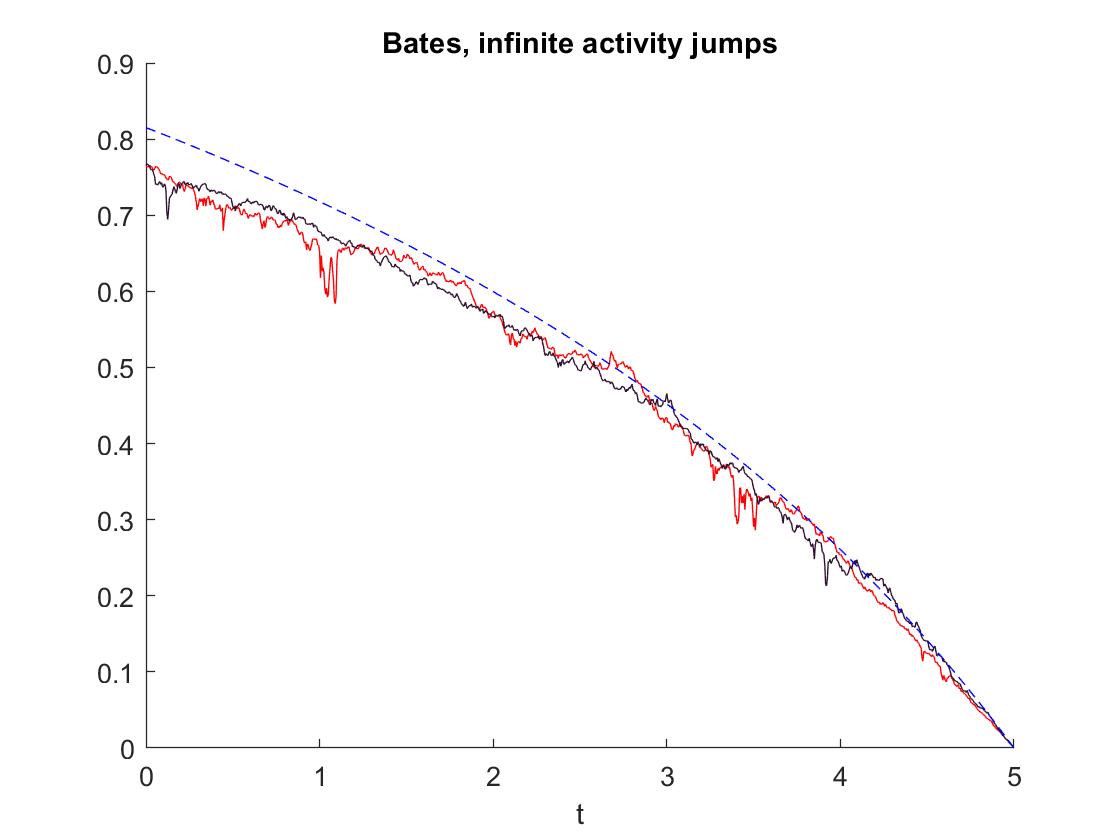
Figure 1. Two samples of the strategy using a time discretization of steps and a space discretization of steps for Matlab’s pde solver pdepe. The reference solution for the constant volatility (setting ) following [41] is plotted in blue dashes. -
(b)
Constant activity jumps: . This model with constant jump size (set to ) uses the same CIR process as in the model with infinite jumps, the only difference is - according to 6.3 - the market price of risk
where .
Figure 2 shows the resulting strategy for this model.
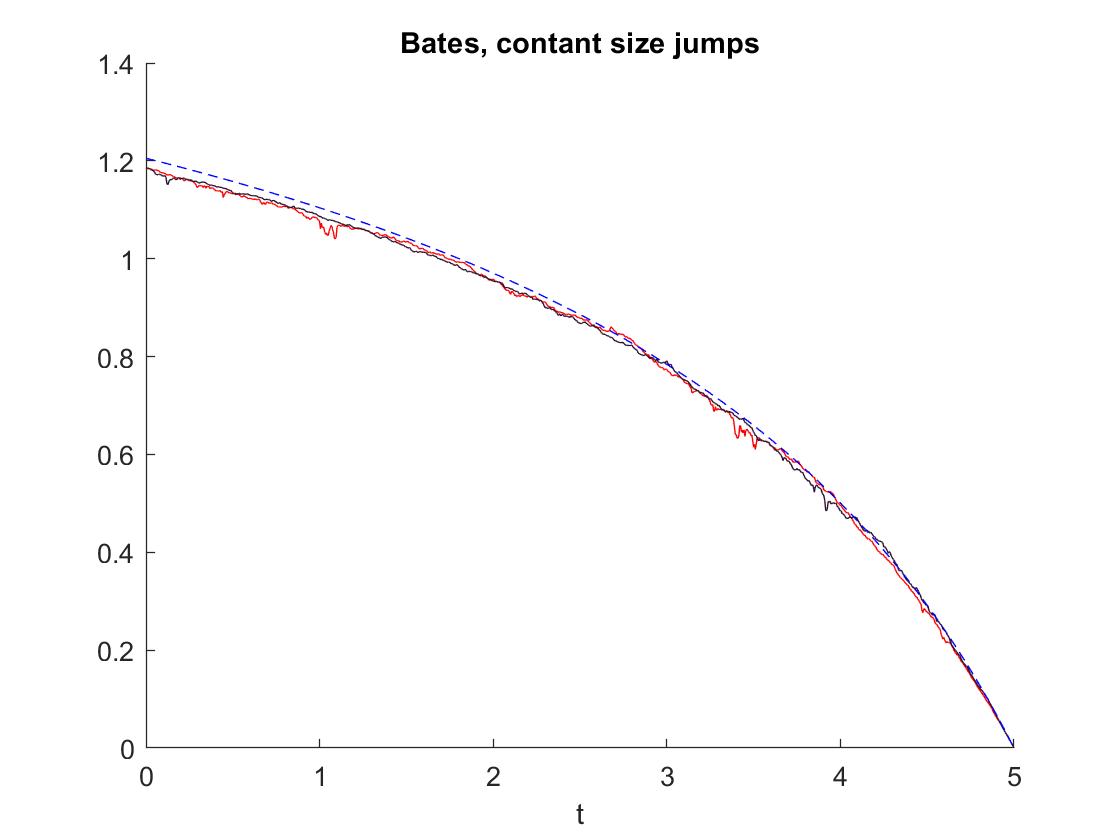
Figure 2. Two samples of the strategy using a time discretization of steps and a space discretization of steps for Matlab’s pde solver pdepe. The reference solution for the constant volatility (setting ) following [41] is plotted in blue dashes. -
(c)
Absence of jumps: For the Bates model without jumps we are practically in a Heston setting. Our coefficients remain the same, except for the excess return, which just takes the form , with . We obtain the following strategies for this model in Figure 3.
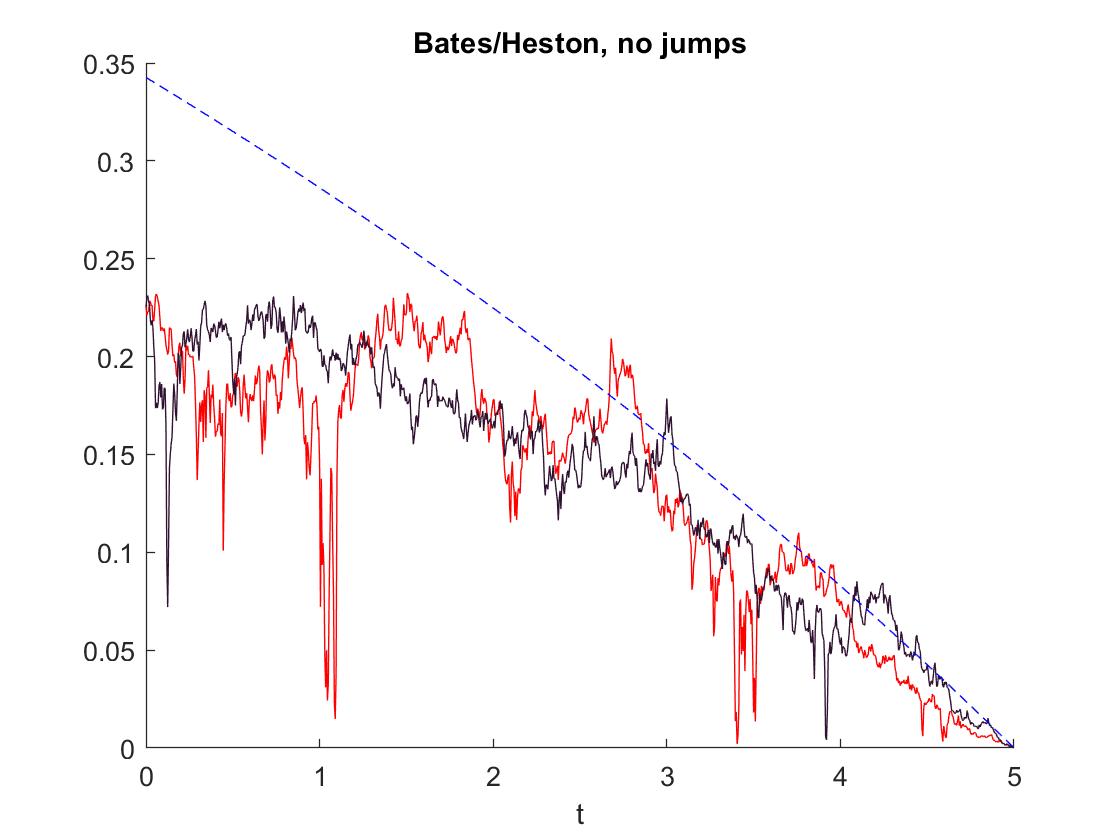
Figure 3. Two samples of the strategy using a time discretization of steps and a space discretization of steps for Matlab’s pde solver pdepe. The reference solution for the constant volatility (setting ) following [41] is plotted in blue dashes. -
(d)
We continue with the ’original’ Heston model, assuming the same CIR-process as before, but keeping constant at with . In this case, the market price of risk is not appropriate, which results in a non-constant post-crash-strategy which we illustrate in an additional figure. In those samples, one can see that the condition from Theorem 25 is violated, so we cannot guarantee that is an actual optimal pre-crash strategy.
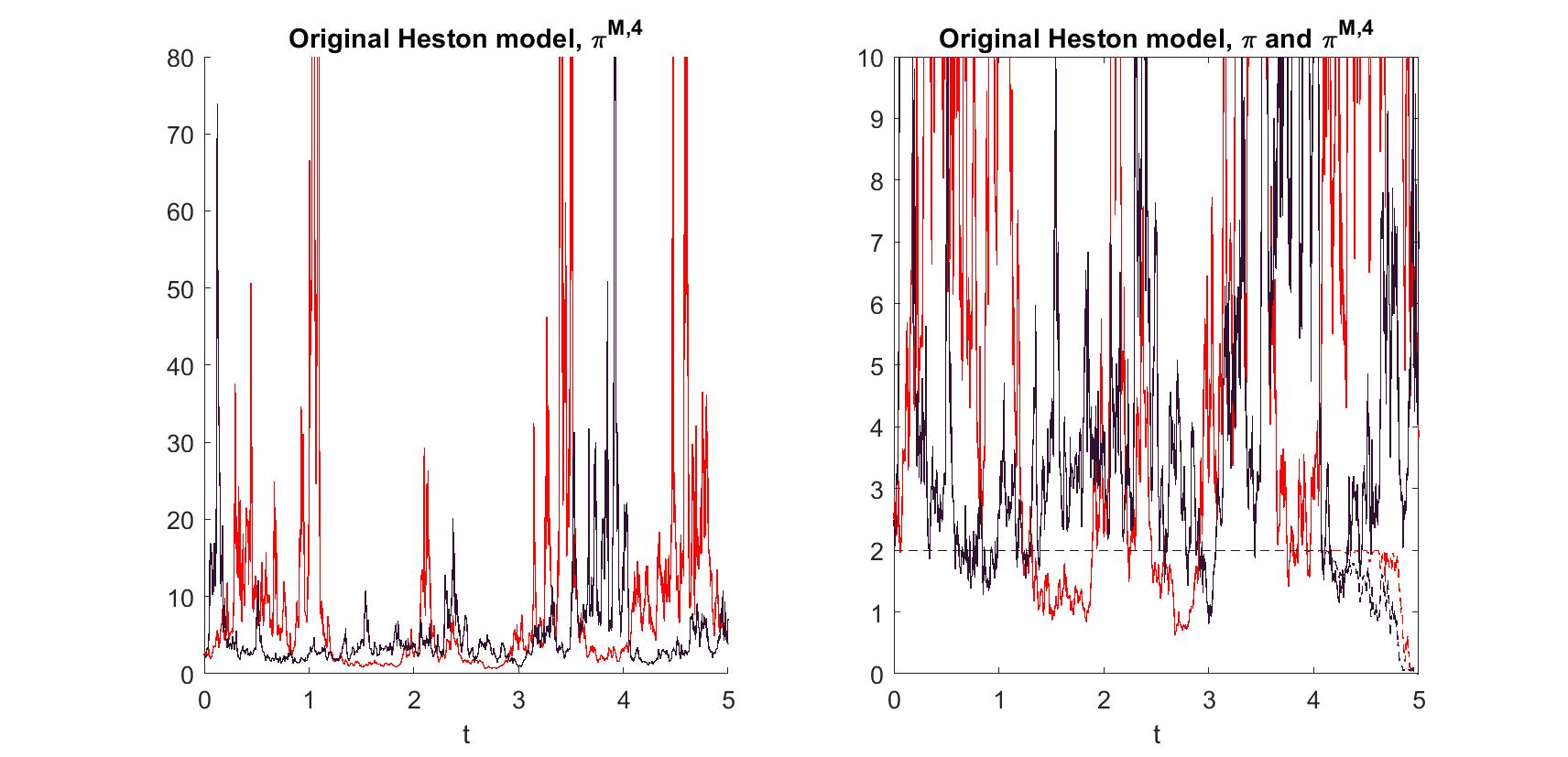
Figure 4. Left: The post-crash optimal strategy for two sample paths. The peaks mount up to a value of about 1200. Right: The same sample graphs of together with the according strategy samples (dashed). Note that . 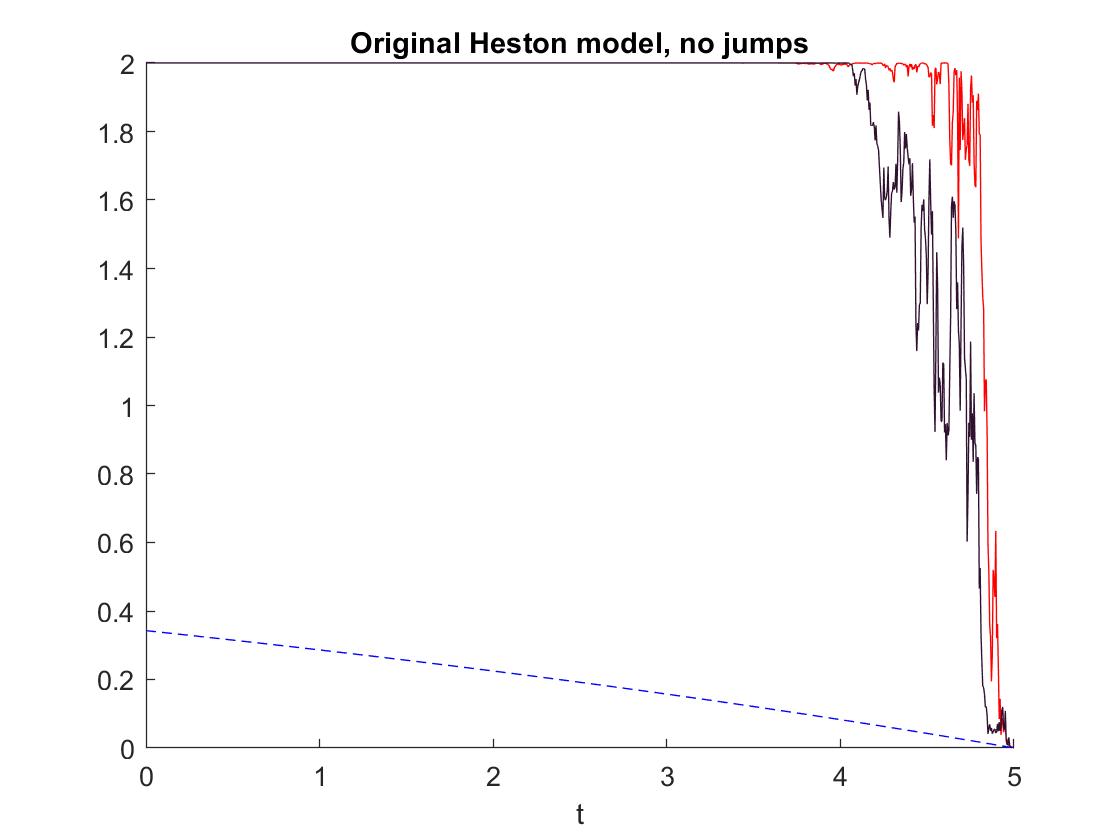
Figure 5. Two samples of the strategy using a time discretization of steps and a space discretization of steps for Matlab’s pde solver pdepe. The reference solution for the constant volatility (setting ) following [41] is plotted in blue dashes. Note that is quite close to the upper bound for admissibility, , here (numerically indistinguishable for the first 3 time steps even).
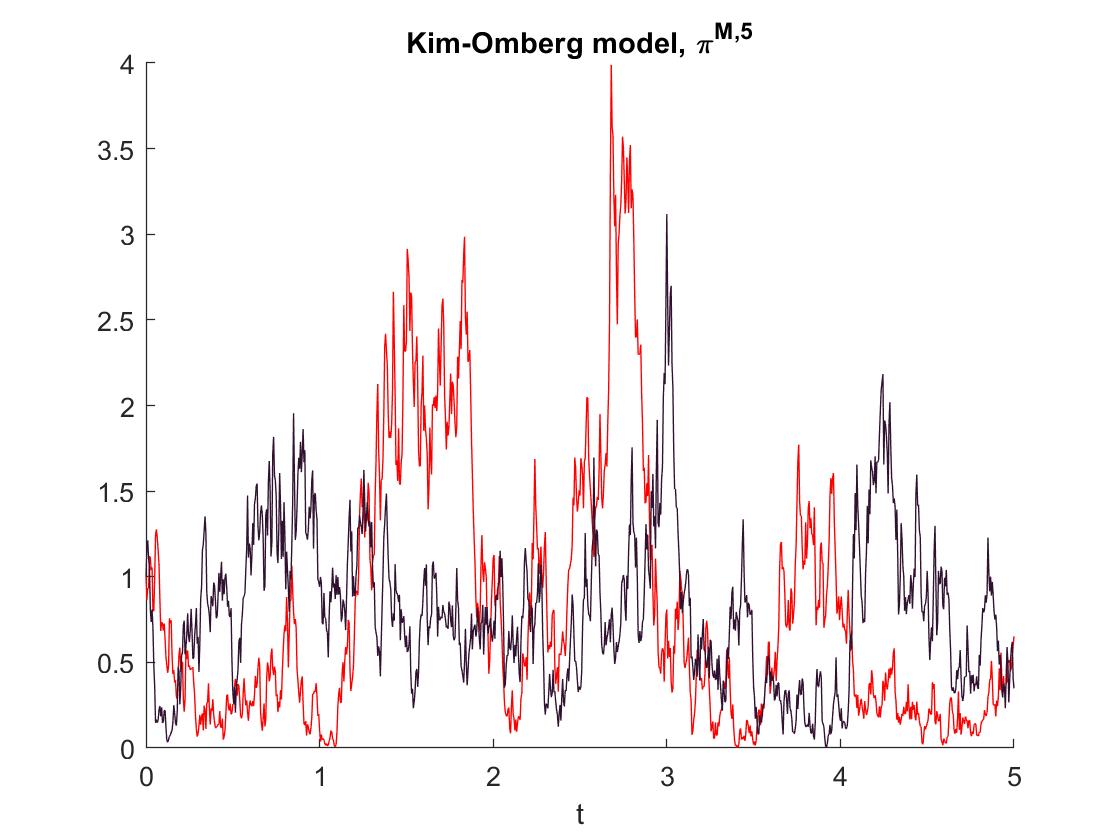
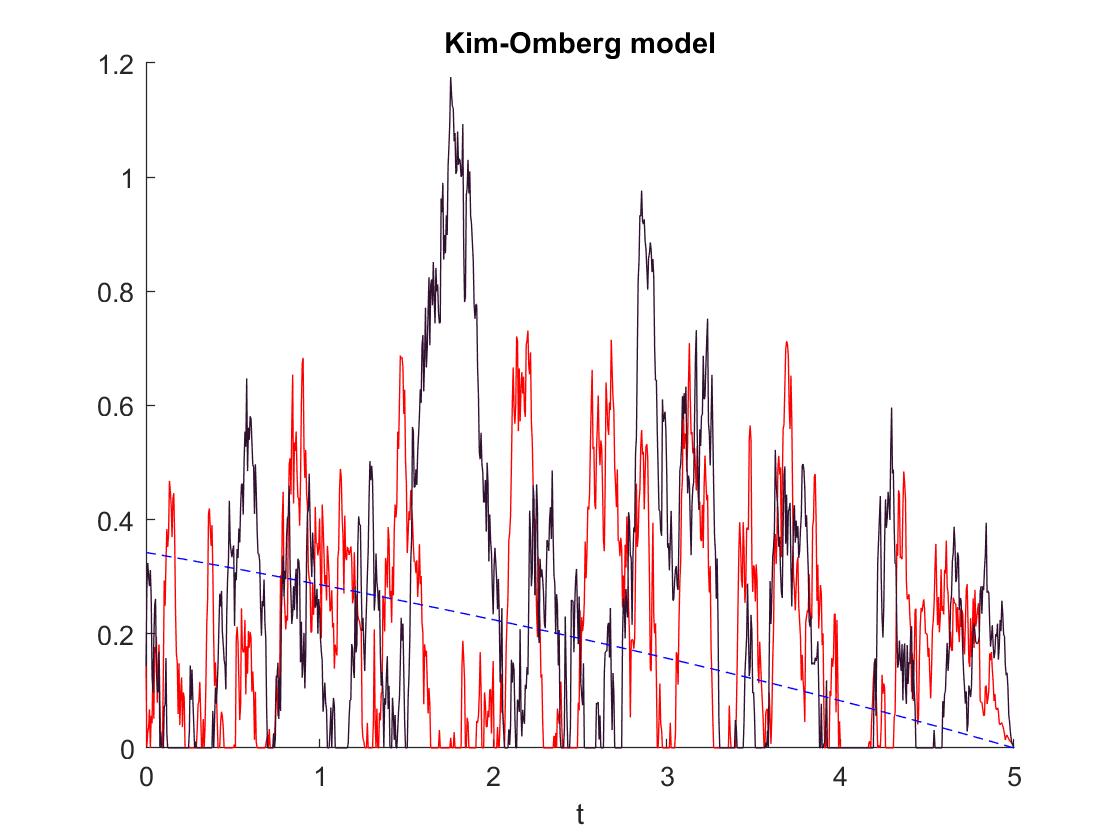
7.2. Numerics for the Kim-Omberg Model
The second model’s numerical simulations that we present here are from the Kim-Omberg model. Here, the process is given by the Ornstein-Uhlenbeck dynamics
with , and .
Also in this model, we can not guarantee the condition for Theorem 25.
Acknowledgements
We wish to thank the participants of the Stochastic Models and Control Workshop 2017 in Trier and from the London Mathematical Finance Seminar Series for useful comments and discussions.
References
- [1] M. Altmayer and A. Neuenkirch, Discretising the Heston model: an analysis of the weak convergence rate, IMA J. Numer. Anal., 37 (2017), pp. 1930–1960.
- [2] D. Applebaum, Lévy processes and stochastic calculus, Cambridge university press, 2009.
- [3] G. Barles, R. Buckdahn, and É. Pardoux, Backward stochastic differential equations and integral-partial differential equations, Stochastics: An International Journal of Probability and Stochastic Processes, 60 (1997), pp. 57–83.
- [4] G. Barles and P. Souganidis, Convergence of approximation schemes for fully nonlinear second order equations, Asymptotic Analysis, 4 (1991), pp. 271–283.
- [5] D. Bates, Jumps and stochastic volatility: Exchange rate processes implicit in deutsche mark options, Review of Financial Studies, 9 (1996), pp. 69–107.
- [6] C. Belak, S. Christensen, and O. Menkens, Worst-case optimal investment with a random number of crashes, Statistics and Probability Letters, 90 (2014), pp. 140–148.
- [7] C. Belak, O. Menkens, and J. Sass, Worst-case portfolio optimization with proportional transaction costs, Stochastics, 87 (2015), pp. 623–663.
- [8] N. Branger, C. Schlag, and E. Schneider, Optimal portfolios when volatility can jump, Journal of Banking & Finance, 32 (2008), pp. 1087–1097.
- [9] P. Briand and F. Confortola, Bsdes with stochastic lipschitz condition and quadratic pdes in hilbert spaces, Stochastic Processes and their Applications, 118 (2008), pp. 818–838.
- [10] P. Briand, B. Delyon, Y. Hu, É. Pardoux, and L. Stoica, Lp solutions of backward stochastic differential equations, Stochastic Processes and their Applications, 108 (2003), pp. 109–129.
- [11] M. Broadie and Ö. Kaya, Exact simulation of stochastic volatility and other affine jump diffusion processes, Operations Research, 54 (2006), pp. 217–231.
- [12] G. Chacko and L. Viceira, Dynamic consumption and portfolio choice with stochastic volatility in incomplete markets, Review of Financial Studies, 18 (2005), pp. 1369–1402.
- [13] S. Cox, M. Hutzenthaler, and A. Jentzen, Local Lipschitz continuity in the initial value and strong completeness for nonlinear stochastic differential equations, arXiv:1309.5595v3, (2021).
- [14] A. Cozma and C. Reisinger, Exponential integrability properties of Euler discretization schemes for the Cox-Ingersoll-Ross process, Discrete and Continuous Dynamical Systems - B, 21 (2016), pp. 3359–3377.
- [15] S. Dereich, A. Neuenkirch, and L. Szpruch, An Euler-type method for the strong approximation of the Cox–Ingersoll–Ross process., Proc. R. Soc. A, 468 (2012), pp. 1105–1115.
- [16] S. Desmettre, R. Korn, P. Ruckdeschel, and F. Seifried, Robust worst-case optimal investment, OR Spectrum, 37 (2015), pp. 677–701.
- [17] S. Desmettre, R. Korn, and F. T. Seifried, Worst-case consumption-portfolio optimization, International Journal of Theoretical and Applied Finance, 18 (2015), p. 1550004.
- [18] M. Eddahbi, I. Fakhouri, and Y. Ouknine, -solutions of generalized BSDEs with jumps and monotone generator in a general filtration, Modern Stochastics: Theory and Applications, 4 (2017), pp. 25–63.
- [19] N. El Karoui and S. Huang, A general result of existence and uniqueness of backward stochastic differential equations, in Backward Stochastic Differential Equations, N. El Karoui and L. Mazliak, eds., no. 364 in Pitman research Notes in Math. Series, Longman Harlow, 1997.
- [20] N. El Karoui, S. Peng, and M. C. Quenez, Backward stochastic differential equations in Finance, Mathematical Finance, 7 (1997), pp. 1–71.
- [21] T. Engler and R. Korn, Worst-case portfolio optimization under stochastic interest rate risk, Risks, 2 (2014), pp. 469–488.
- [22] H. Föllmer, A. Schied, and S. Weber, Robust preferences and robust portfolio choice, Mathematical Modelling and Numerical Methods in Finance (P. Ciarlet, A. Bensoussan & Q. Zhang, eds.), Handbook of Numerical Analysis, 15 (2009), pp. 22–89.
- [23] T. Fujiwara and H. Kunita, Stochastic differential equations of jump type and Lévy processes in diffeomorphisms group, J. Math. Kyoto Univ., 25 (1985), pp. 71–106.
- [24] C. Geiss and A. Steinicke, Existence, uniqueness and comparison results for BSDEs with Lévy jumps in an extended monotonic generator setting, Probability, Uncertainty and Quantitative Risk, 3 (2018), p. 9.
- [25] M. Hefter and A. Herzwurm, Strong convergence rates for Cox-Ingersoll-Ross processes – full parameter range, Journal of Mathematical Analysis and Applications, 459 (2018), pp. 1079–1101.
- [26] S. L. Heston, A closed-form solution for options with stochastic volatility with applications to bond and currency options, Review of Financial Studies, 6 (1993), pp. 327–343.
- [27] P. Hua and P. Wilmott, Crash courses, Risk, 10 (1997), pp. 64–67.
- [28] T. Hurd and A. Kuznetsov, Explicit formulas for Laplace transforms of stochastic integrals., Markov Process. Relat. Fields, 14 (2008), pp. 277–290.
- [29] M. Hutzenthaler, A. Jentzen, and M. Noll, Strong convergence rates and temporal regularity for Cox-Ingersoll-Ross processes and Bessel processes with accessible boundaries, arXiv:1403.6385, (2014).
- [30] N. Ikeda and S. Watanabe, Stochastic differential equations and diffusion processes, North Holland, 1989.
- [31] J. Kallsen and J. Muhle-Karbe, Utility maximization in affine stochastic volatility models, International Journal of Theoretical and Applied Finance, 13 (2010), pp. 459–477.
- [32] I. Karatzas and S. Shreve, Brownian motion and stochastic calculus., New York, Springer-Verlag, 2nd ed., 1991.
- [33] T. S. Kim and E. Omberg, Dynamic nonmyopic portfolio behavior, Review of Financial Studies, 1 (1996), pp. 141–161.
- [34] F. H. Knight, Risk, Uncertainty and Profit, Hart, Schaffner & Marx; Houghton Mifflin Co., 1921.
- [35] R. Korn and E. Leoff, Multi-asset worst-case optimal portfolios, International Journal of Theoretical and Applied Finance, 22 (2022), p. 1950019.
- [36] R. Korn and O. Menkens, Worst-case scenario portfolio optimization: a new stochastic control approach, Mathematical Methods of Operations Research, 62 (2005), pp. 123–140.
- [37] R. Korn and L. Müller, Optimal dynamic reinsurance with worst-case default of the reinsurer, European Actuarial Journal, 12 (2022), pp. 879–885.
- [38] , Optimal portfolios in the presence of stress scenarios a worst-case approach, Mathematics and Financial Economics, 16 (2022), pp. 153–185.
- [39] R. Korn and F. T. Seifried, A worst-case approach to continuous-time portfolio optimization, Radon Series on Computational and Applied Mathematics, 8 (2009), pp. 327–345.
- [40] R. Korn and M. Steffensen, On worst-case portfolio optimization, SIAM Journal on Control and Optimization, 46 (2007), pp. 2013–2030.
- [41] R. Korn and P. Wilmott, Optimal portfolios under the threat of a crash, International Journal of Theoretical and Applied Finance, 05 (2002), pp. 171–187.
- [42] H. Kraft, Optimal portfolios and heston’s stochastic volatility model: an explicit solution for power utility, Quantitative Finance, 5 (2005), pp. 303–313.
- [43] S. Kremsner and A. Steinicke, -Solutions and Comparison Results for Lévy Driven BSDEs in a Monotonic, General Growth Setting, Journal of Theoretical Probability, (2020), p. arXiv:1909.06181.
- [44] T. Kruse and A. Popier, BSDEs with monotone generator driven by Brownian and Poisson noises in a general filtration, Stochastics, 88 (2016), pp. 491–539.
- [45] J. Li, Backward Stochastic Differential Equations with Unbounded Coefficients and Their Applications, PhD thesis, University of Liverpool, 2014.
- [46] J. Liu, Portfolio selection in stochastic environments, The Review of Financial Studies, 20 (2007), pp. 1–39.
- [47] H. Pham, Smooth solutions to optimal investment models with stochastic volatilities and portfolio constraints, Applied Mathematics and Optimization, 46 (2002), pp. 55–78.
- [48] P. Protter, Stochastic Integration and Stochastic Differential Equations, Springer, Berlin, 2004.
- [49] A. Saplaouras, Backward stochastic differential equations with jumps are stable, dissertation, TU Berlin, 2017.
- [50] A. Schied, Optimal investments for robust utility functionals in complete market models, Mathematics of Operations Research, 30 (2005), pp. 750–764.
- [51] F. T. Seifried, Optimal investment for worst-case crash scenarios: A martingale approach, Mathematics of Operations Research, 35 (2010), pp. 559–579.
- [52] D. Talay and Z. Zheng, Worst case model risk management, Finance and Stochastics, 1 (2002), pp. 517–537.
- [53] T. Zariphopoulou, A solution approach to valuation with unhedgeable risks, Finance and Stochastics, 5 (2001), pp. 61–82.
Appendix A Proofs from Section 3
Proof.
(Proposition 9) There are three possibilities for . Either or or .
Define In the case , and by the implicit function theorem, as , may be expressed by a functional relation , where is differentiable in a neighborhood around . This shows continuity in this case. To find first Lipschitz-like relations, we start by differentiating , and obtain, using the chain rule,
The same works for the derivative in direction ,
and hence, . Trivially, also in the remaining cases, , it can be expressed as a function in . We show that is continuous, no matter what case we are in: Let be a sequence converging to some . Let be a limit point of a converging subsequence of (which exists, as only takes values in ). For all is then
Since is continuous in , taking the limit in the last inequality, we get
By the uniqueness of the (follows from the strict convexity of in ), we get
We show that the Lipschitz-like properties hold independently from the cases: Doing this for in the sequel, the proof works the similarly for . To that end, fix and let . For an exemplary case (other cases work similar), let and let . Then set . In the same way set , and and set whenever the sets are empty. We observe,
Thus, in the intervals as well as , is a differentiable function in with Lipschitz constant . By taking limits, this Lipschitz property extends to the intervals’ boundaries, and we obtain
If , Lipschitz continuity on the whole domain follows.
∎
Appendix B Proofs of BSDE results from Section 5
Proof.
(Proposition 28) In view of Subsection 5.1, the generator of the BSDE can be written as
where is given by
Now, given the boundedness conditions on , the generator meets the assumptions of [24, Theorem 3.2](or e.g. [43, Theorem 3.3], [44, Theorem 1]), as seen in Subsection 5.1, (9) and (10), from which the assertion follows. ∎
Proof.
For the BSDEs with generators (and terminal condition ), we get solutions from Proposition 28. Note that and . We will follow this order of approximations to construct solutions. For the first approximation, by the comparison theorem (e.g. in [24, Theorem 3.4], [43, Theorem 6.1], [44, Proposition 4]), we get that is a monotonically increasing family for all for almost all . Thus, we can define the random variable , wherever the limit exists and on the complement.
We show that . To that end, observe first that Itô’s formula yields for all
| (21) |
From this equation, we get by taking conditional expectations w.r.t. and using Young’s inequality that for all ,
| (22) | ||||
Further, (B) implies, together with Doob’s martingale inequality, Burkholder-Davis-Gundy’s, Young’s inequality and the fact that
that there is a constant , such that for all ,
where we used Young’s inequality again for the second estimate. Replacing the last term with the help of inequality (22), we arrive at
Choosing now and such that , we find a constant such that . From our integrability assumption on and follow the uniform integrability of and thus also .
Now, by dominated convergence we get that for ,
and hence
Together with the integrability assumptions on and since for all , , it follows that converges in to a random variable . Therefore,
and follows. In particular, . By the martingale representation theorem, there are processes , progressively measurable and predictable such that
and
For all we have , which is -measurable implying . Altogether, we have that
As a consequence,
from which we infer . Now it is readily checked that solves the BSDE given by , so we can set and . We go over to the approximation in now. Note that for all , and all we have that -a.s.
Therefore, we may define again for all , on the set where the limit exists and 0 otherwise. Now the same steps from (B) can be performed again, ending up with a solution .
∎
Proof.
(Theorem 31) Existence follows by Theorem 29 and the variants depicted in Remark 30 as and allow finite moments of any order . Denoting differences between two supposed solutions by , we get, using the Itô formula given in [44, Lemma 7] for ,
We now split up the set into and to estimate, using Lipschitz and boundedness properties of the function ,
where . Gronwall’s inequality now shows that for :
The terms can be further estimated, using the definition of and that , by
If is such that , then the right hand side tends to zero as , showing that on . We can now perform the same steps as above for the BSDE
, showing iteratively that on the whole interval . Uniqueness of and then follow. ∎
Proof.
(Theorem 32) Denoting differences by , and letting , by Tanaka-Meyer’s formula we get that
where is a stochastic integral term with zero expectation. Thus, omitting negative terms, we get
We add and subtract in the integral and get, using that ,
(this step can also be performed with inserting and using the inequality , if this is the inequality assumed). The assumption on now implies
We now split up the set into and to estimate
Gronwall’s inequality now shows that for :
The terms can be further estimated by
If is such that , then the right hand side tends to zero as , showing that on . As in the proof of Theorem 31, we can now show successively that on small enough intervals the process , from which we infer the assertion. ∎
Proof.
(Proposition 36) With also is almost an Itô process, it is just extended by a term involving a local time, in particular, using Tanaka-Meyer’s formula [48, Chapter 4, Theorem 70 and Corollary 1], we have
| (23) | ||||
where is the local time at of the process . By the assumptions on , the stochastic integrals are martingales again. We name the integrands . Since the is post-crash optimal, is just given by and as is by assumption a submartingale, must be a supermartingale, that is is a measure with values in . We can view then as the solution to the (slightly generalized) BSDE
with driver , additional measure term and terminal value . For such generalized BSDEs with data ( being the generator and being an additional measure term) we may apply the comparison theorem from [18, Proposition 1] to compare it to which is the solution to the indifference BSDE (8). Clearly . For comparison of the BSDEs it is sufficient to compare them only along the solution path of one of the two BSDEs. Here we choose comparison along . The data of the first BSDE is, as pointed out above, . Conversely, the driver of the second BSDE evaluated along the path of is , as is its measure term. So the data of the second BSDE is . By recapitulating the proof of the comparison theorem [18, Proposition 1], which requires as well as , it is easy to see (in the proof’s last inequality) that also the condition is sufficient. Therefore, we can conclude and as utility crash exposures are just monotone transformations of portfolio processes, this implies . ∎
Appendix C Proofs of (CIR) results from Section 6
Proof.
(Theorem 39) For bounded we refer to [3, Theorem 3.5], since the conditions of the generator of the BSDE (8) are met.
We therefore focus on the unbounded case and follow the proof of [3, Theorem 3.4]. Let be defined by the solution of (8) on . with , , where is the solution to the forward equation (12) starting from on . Define then What we have to show to conduct the proof as in [3] is the continuity of , uniqueness of the family of BSDE-solutions , a comparison theorem and an inequality used in their proof which we treat below. In [3], all those properties follow from the uniform Lipschitz condition for their generator functions, which does not hold in the case of our generator because and are unbounded.
The uniqueness of the solutions to the family of BSDEs in our case is granted by Theorem 31 and the exponential integrability condition (Bexp) on and . The comparison theorem needed is given by Theorem 32.
We show the continuity of : We define for and estimate
Using Itô’s formula for , and subsequently Young’s inequality and Doob’s maximal inequality through standard BSDE methods, we get that
We therefore have to investigate
assuming . Concerning the first summand, note first that whenever
by Case 1 of the proof of Proposition 7,
We may then use the growth and boundedness assumptions on and the form of to find a constant and estimate the generator by
As there is a such that
(granted by assumption (14)) it follows by dominated convergence that
The generator regarded as real function in is continuous in all those variables (which follows from the form of , the continuity of and , see Proposition 9). As also the are continuous in and by assumption (15), the generator is continuous in and . Bounding
by makes dominated convergence applicable again, and we infer that is continuous in and .
As a last step, to give a sufficient relation to use the proof of [3, Theorem 3.4], we have to bound the solution to the following BSDE:
where and are -functions with polynomial growth. The same procedure as in Theorem 29 and the one in Theorem 31 shows existence and uniqueness of a solution as the additive terms are well behaved. Further standard estimates, derived by Itô’s formula, yield
The polynomial growth of , the bounds for the moments of and the since is bounded by implies that there is a constant such that
Since grow at most polynomially and obeys (14), it follows that
and, recalling that , we end up with
From this point on, the proof can now be performed just as the one of [3, Theorem 3.4]. ∎
Proof.
(Proposition 40) Inequality (18) follows by similar but easier calculations as in Lemma 2.1 of [23] since the square root function fulfills the inequality . To show inequality (19), we first define
Then,
Since has Lipschitz coefficients, we obtain
by Jensen’s inequality. With Doob’s maximal inequality and Itô’s formula applied to , we get constants (we will continue to number appearing -dependent constants by )
| (24) | ||||
Next, we look at the Lamperti transformation. Therefore, we apply Lemma 3.2 from [29] to (or respectively). We get
| (25) | ||||
where we set
with
Note that satisfies the following inequality for and :
| (26) |
without the second term on the right side, this would be the so-called one-sided Lipschitz continuity (see e.g. [15]). From (25), we have
and by Ito’s formula, we get
Since fulfills inequality (26), we obtain
since . Furthermore, note that the second term on the right is -a.s. by Lemma 3.1 in [29]. Inserting this into (24) and applying Young’s inequality, we get
Applying Gronwall’s inequality gives
Summarizing, we have
Applying Gronwall’s inequality finishes the proof of (19). To prove (20), we can assume without loss of generality. Then,
by Proposition 5.2.18 in [32]. Then, we have
since is non-central chi-square distributed with expectation . ∎