XAI Handbook:
Towards a Unified Framework for Explainable AI
Abstract
The field of explainable AI (XAI) has quickly become a thriving and prolific community. However, a silent, recurrent and acknowledged issue in this area is the lack of consensus regarding its terminology. In particular, each new contribution seems to rely on its own (and often intuitive) version of terms like “explanation” and “interpretation”. Such disarray encumbers the consolidation of advances in the field towards the fulfillment of scientific and regulatory demands e.g., when comparing methods or establishing their compliance w.r.t. biases and fairness constraints.
We propose a theoretical framework that not only provides concrete definitions for these terms, but it also outlines all steps necessary to produce explanations and interpretations. The framework also allows for existing contributions to be re-contextualized such that their scope can be measured, thus making them comparable to other methods.
We show that this framework is compliant with desiderata on explanations, on interpretability and on evaluation metrics. We present a use-case showing how the framework can be used to compare LIME, SHAP and MDNet, establishing their advantages and shortcomings. Finally, we discuss relevant trends in XAI as well as recommendations for future work, all from the standpoint of our framework.
The growing demand for explainable methods in artificial intelligence (a.k.a. eXplainable AI or XAI) has recently caused a large influx of research on the subject (Arrieta et al., 2020). As AI systems are being steadily adopted for more and more high-stake decisions like loans (Bussmann et al., 2020), access to medical care (Rudin & Ustun, 2018) or security of in-vehicular networks (Kang & Kang, 2016), stakeholders depending on those decisions are beginning to require justifications, similar to those provided by humans. However, despite the apparent simplicity of the problem at hand, proposed solutions have spanned into multiple niches simply because they are based on different definitions for terms like “explanation” or “interpretation”. An increasing number of contributions often rely on their own, and often intuitive notions of “explainability” or “interpretability”–a phenomenon dubbed “the inmates running the asylum”–which eventually leads to failure to provide satisfactory explanations (Miller et al., 2017). This self-reliance in the goal’s definition has caused confusion in the machine learning community, as there is no agreed upon standard which can be used to judge whether a particular model can be deemed “explainable” or not. A lack of consensus has resulted in research that, albeit exciting, ends up tackling different problems, and hence cannot be compared (Bibal & Frénay, 2016; Lipton, 2018). This issue has been accentuated by what the term “explanation” refers to in the context of AI. Is it an approximation of a complex model (Al-Shedivat et al., 2020; Lundberg & Lee, 2017), an assignment of causal responsibility (Miller, 2019), a set of human intelligible features contributing to a model’s prediction (Montavon et al., 2018) or a function mapping a less interpretable object into a more interpretable one (Ciatto et al., 2020)? To make matters worse, a variety of circular definitions for “explanation” can be found, alluding to further concepts like “interpretation” and “understanding” which are, in turn, left undefined.
Critiques for some of these definitions have recently emerged, arguing that they are either not suitable for high-stake decisions (Rudin, 2019), or that they are too vague to be operational (Doshi-Velez & Kim, 2018) or falsifiable (Leavitt & Morcos, 2020). Moreover, unless there is an agreed upon notion of what these terms refer to, there will be a disconnect between scientific contributions and fulfillment of legal requirements such as the European General Data Protection Regulation (GDPR) (of the European Union & Parliament, 2016). Their so called “Right to an Explanation” already reflects this gap on the ambiguity of its language, opening up the possibility of bypassing111In automated decision making, explanation of individual decisions can be avoided by assuring informed consent combined with additional safeguards such as human intervention and possible contestation of decisions. the regulation entirely (Schneeberger et al., 2020). Therefore, regulatory amendments planned by the EU can substantially benefit from a consensual definition of XAI.
Negative effects of lacking a consolidated language when comparing scientific contributions have recently impacted a close field of XAI: adversarial attacks. Upon their discovery (Szegedy et al., 2013) (i.e., small, additive perturbations in the image domain that are imperceptible to humans, while causing ML models to issue arbitrary predictions), a large community quickly grew around this issue, trying to find methods that could defend against said perturbations. Without a clear definition of what was (and what was not) considered adversarial, together with a free choice of the threat model (i.e., what the attacking agent has access to when generating adversarial perturbations), many proposed solutions have been quickly proven ineffective (Athalye et al., 2018; Carlini et al., 2019). In turn, this community is now striving for explicit definitions of the threat model, their definition of “small” perturbation and therefore, what counts as an adversarial attack or not.
In order to measure and compare progress in the field of XAI, we argue that a unified foundation is vital, and that such foundation starts with an adequate definition of the field’s terminology. In particular, we propose a framework based around atomic notions of “explanation”, and “interpretation” in the context of AI (with a special focus on ML and applications in computer vision). We show how further concepts that have popped up in the literature can be rephrased in relation to our proposed definition of “explanation” and “interpretation”, therefore facilitating their comparison, and extent by which they apply to methods claiming to be explainable.
Related Work
The rapid adoption of notions of “explainability” and “interpretability” in machine learning, prompted theoreticians to step back and ponder what the extent of those is, along with their differences and similarities. Today, there is no shortage on theoretical ideas addressing e.g., desiderata for explanations and the relation they bear with further concepts like interpretation, faithfulness, trust, etc. As mentioned before, a lack of agreement regarding terminology, makes it impossible to list and compare literature solely based on what has been called “explanation”. For an abridged recount of the AI literature defining (aspects of) either term, including definitions and perspectives, see Table 1. A comprehensive meta-review of XAI methods, including an extensive section on fundamental theory can be consulted in (Vilone & Longo, 2020).
In this section, we focus on underlining some of the limitations in the scope of recurrent trends when defining these notions, allowing for acquiescent comparisons when analysing the terminology, establishing disparities and commonalities.
Early work, stemming mostly from philosophy, gravitated around the idea of “explanation” as a perennial carrier of causal information (Lewis, 1986; Josephson & Josephson, 1996). Although causality plays a fundamental role for explanations (and interpretations), it is not indispensable, meaning that there are non-causal questions that can (and should) be answered by explanations (Lombrozo, 2006; Miller, 2019). We subscribe to the latter thesis in an effort to guarantee the universality of our proposed framework, while allowing for explicit causal arguments to fit within.
More recently, explanations adopted the form of additional models that approximate the feature space of the original model (Lundberg & Lee, 2017; Ribeiro et al., 2016; Lakkaraju et al., 2019). Such paradigm has encountered some push-back due to the lack of faithfulness (i.e., reliance on the same feature basis) (Rudin, 2019) and its susceptibility to malicious attacks. For example, LIME (Ribeiro et al., 2016) and SHAP (Lundberg & Lee, 2017) are popular linear approximation methods that have often been used in high-stake scenarios including medical applications (de Sousa et al., 2020; Carrieri et al., 2020). Despite their wide-spread use, they are now known to be easily fooled by networks trained using a malicious scaffold (Slack et al., 2020). This result shows how even linear approximations may fail at providing explanations that align with the original model222Unsurprisingly, non-linear approximations have also been proven vulnerable (Dombrowski et al., 2019; Ghorbani et al., 2019).
Lastly, we find literature that concentrates on the ethos of XAI with a focus on applications in ML. Most acknowledge the epistemological leniency when talking about “explanations” and terms alike (Montavon et al., 2018; Lipton, 2018; Xie et al., 2020). A recurring motif from this literature is also to define “explanations” or “interpretations” as an agglomeration of different, more specific terms like confidence, transparency and trust (Xie et al., 2020; Dam et al., 2018; Doshi-Velez & Kim, 2018). Instead of offering an actionable definition, some work focuses on classifying the requirements that an explainable system should meet (Xie et al., 2020; Lipton, 2018) or the kind of evaluations through which a model can be deemed explainable (Lipton, 2018; Doshi-Velez & Kim, 2018).
Although contributions from these publications add invaluable insights to the field of XAI, there is still a distinct lack of cohesion between them. They each propose their own categorization, desiderata and general guidelines for evaluation, effectively hampering the consolidation of each individual contribution into a unified theory of XAI.
| Source | Explanation | Interpretation |
|---|---|---|
| (Lewis, 1986) | “someone who is in possession of some information about the causal history of some event (…) tries to convey it to someone else.” | - |
| (Josephson & Josephson, 1996) | “assignment of causal responsibility” | - |
| (Lombrozo, 2006) | “central to our sense of understanding and the currency in which we exchange beliefs. Explanations often support the broader function of guiding reasoning.” | - |
| (Biran & Cotton, 2017) | - | “the degree to which an observer can understand the cause of a decision” |
| (Lundberg & Lee, 2017) | “interpretable approximation of the original [complex] model” | - |
| (Montavon et al., 2018) | “collection of features of the interpretable domain, that have contributed for a given example to produce a decision (e.g., classification or regression)” | “mapping of an abstract concept (e.g., a predicted class) into a domain that the human can make sense of” |
| (Dam et al., 2018) | “measures the degree to which a human observer can understand the reasons behind a decision (e.g., a prediction) made by the model” | - |
| (Doshi-Velez & Kim, 2018) | - | “to explain or to present in understandable terms to a human” |
| (Lakkaraju et al., 2019) | - | “quantifies how easy it is to understand and reason about the explanation. Depends on the complexity of the explanation” |
| (Vilone & Longo, 2020) | “the collection of features of an interpretable domain that contributed to produce a prediction for a given item” | “the capacity to provide or bring out the meaning of an abstract concept” |
| (Schmid & Finzel, 2020) | “in human–human interaction, explanations have the function to make something clear by giving a detailed description, a reason, or justification” | - |
| (Al-Shedivat et al., 2020) | “local approximation of a complex model [by another model]” | - |
Context and Definitions
In order to lay down a sound and inclusive foundation, we start by looking at core aspects that most research in XAI share, but also at what makes them incompatible. Once more, the lack of consensus on what “explanation” means plays an instrumental role. In particular, each new method has to define the context in which it is relevant, and where its outcome can thus be applied. What counts as an atomic notion and what is treated as a system, has been the prerogative of each scientific contribution. This has been in part acceptable, given how under-specified modern ML tasks are (Lombrozo, 2006; D’Amour et al., 2020). Starting from an intuitive idea of object classification, we already assume and accept the interaction of signs, objects and interpreters from semiotic theory (Sowa, 1983). When working on the image domain, limitations coming from the representation gap (Smeulders et al., 2000) are not taken into consideration333To some extent, indirectly addressed by the growing scale of datasets like Imagenet (Russakovsky et al., 2015) or MS-COCO (Lin et al., 2014), neither the ambiguity of annotations stemming from the semantic gap (Smeulders et al., 2000) or even the teleological assessment of modern supervised classifiers (i.e., they work because the function meets the expectations, regardless of how they do it). These requirements get further reduced to low level mathematical primitives e.g., the notion of a “chicken” gets represented as a set of points which get further simplified as tensors of bytes in the range .
In turn, XAI is essentially searching for evidence about non-functional requirements of the high-level task (e.g., whether a higher relevance score is being attributed to the area where a target object is) within the low-level primitives such as tensors, probabilities, and model parameters (Figure 1). The way we accept mathematical distributions as evidence for the presence (or absence) of an object in an image follows a well-defined mapping from high-level ideas to low-level primitives. Now, in the absence of well-established mappings between the task’s non-functional properties and its corresponding low-level primitives, we are obliged to define one explicitly.
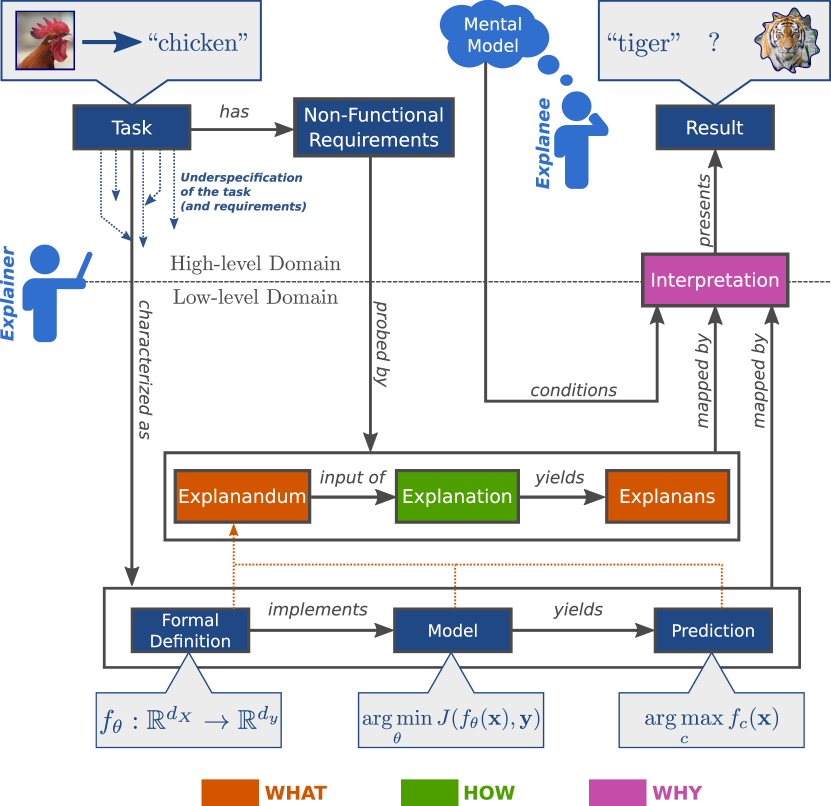
To that end, we propose a framework to establish mappings for non-functional properties, such that existing work is covered by it while providing the required rigor to serve as a vehicle for scientific discussion. We begin by identifying two fundamental characteristics that such a framework must have:
-
1.
Commensurable: in order to fairly compare two different methods, common measures need to exist. A common vocabulary is therefore required, upon which these metrics can operate. In particular, what counts as an “explanation” and what is “interpretation” needs to be agreed upon beforehand.
-
2.
Universal: a generic workflow has to exist, defining the context that identifies atomic primitives, and operations on those primitives. Comparisons between primitives and operations are possible as long as the context in which they are being compared remains the same.
We begin by looking at general notions and definitions for the terms “explanation” and “interpretation” as a basis for a refined characterization of said terms in the context of XAI. Moreover, we will identify the minimal requirements for defining a context and therefore, for bounding the scope of explanations and interpretations.
. Towards Commensurable Explainability: a Common Vocabulary
Most definitions treat “explanation” and “interpretation” in a similar fashion, sometimes even as synonyms. However, there are subtle but fundamental differences that allow some initial distinction to be drawn between them. First, we need to ask what kind of semantic entity an explanation is: is it an action, an outcome, a process or an object? For most textbook definitions (see Table 2), explanations are seen as statements. In turn, such statements are nothing but descriptions about an already existing entity (the explanandum or the one which is subject to description). From a functional perspective, an explanation is therefore the process by which an explanandum is described. Finally, to avoid confusions between the process of explaining and its output, we refer to the former as explanation and the latter as the explanans.
To prevent any kind of circular definition, the explanandum needs to exist axiomatically, thus it has to refer to objects or symbols that are self-evidently true. In other words, we require explanandums to be factual and axiomatic.
As we seek explanations for AI models, we find such suitable facts in the form of low-level mathematical primitives used to build the models themselves: support vector machines have a decision boundary equation, coordinates of the support vectors, the tolerance threshold, etc. A Neural Network has values for each individual parameter, the equations governing how they connect with each other, the value of the cost function when computed on a particular input, the gradient that can be computed on that loss, etc. All of these are concrete, undisputed facts (assuming there are no bugs) that are suitable explanandums.
In a simplified, more intuitive form, a first definition of “explanation” can be formulated as follows:
An explanation is the process of describing one or more facts.
The third aspect of an explanation deals with its purpose. Ideally, the output of the explanation (i.e., the explanans) exposes patterns or statistics that were not evident before. For example, overlaying the gradients of an image classifier w.r.t. an input sample can locate areas that are more sensitive to changes in the input (e.g., by adding small levels of noise). Once more, resorting to textbook definitions (Table 2) we see that most of them mention “making something understandable, clear, comprehensible” as the goal of an “explanation”. In other words, the purpose of an explanation is to enable (human) understanding. Explanations are therefore bound to describe facts in a way that ultimately leads to understanding. At this point, we can think of what consumers of explanations (i.e., explainees) need to understand: on the one hand, there are characteristics of the fact being described (e.g., location of the magnitude and sign of a gradient w.r.t. an input sample) which may help one understand what the gradient is444Assuming that the explanee’s mental model is otherwise equipped with the necessary knowledge to understand this concept.. On the other hand, there are some characteristics of the described fact in relation to other high-level phenomena e.g., how a high gradient value relates to a latent relevant feature.
With this in mind, we arrive at a revised definition for “explanation”:
An explanation is the process of describing one or more facts, such that it facilitates the understanding of aspects related to said facts (by a human consumer).
The dependency between explanations and humans is explicit, as the action of understanding can be thought of as being unique to humans. Whenever explanations are consumed by other machines (or can be otherwise executed without humans in the loop) they are no longer serving as a vehicle to explain but rather as part of a verification system.
In order to constrain the many ways a description can be interpreted, a contract must be first introduced detailing the valid meanings that can be extracted out of that description. In other words, there should be an agreement on how to read the symbols of a description e.g., which colors on a heatmap mean high or low values. Such agreement anchors or assigns meaning to a primitive entity (in our case, an explanans).
Referring back to textbook definitions for “interpretation”, we see how most of them rely on the term “explanation”, and thus leading to an inexorable circular definition. The one remaining exception follows the philosophical origin of the word and already lays out the requirements of a contract by defining an “assignment of meaning”. In fact, the conveyance of meaning is common to all entries, in one way or another. We go along these lines to sketch the definition of interpretation in XAI as follows:
Interpretation is the assignment of meaning (to an explanation).
For ML, the assigned meaning refers to notions of the high-level task for which the explanans is provided as evidence. An interpretation is therefore bridging the gap between underspecified non-functional requirements of the original task and its representation in formal, low-level primitives (e.g., high Shapley values for pixels on a chicken’s beak indicate its correct detection and relation to the class “chicken”).
In order for an explanation to fulfill its goal (facilitate understanding), the terminology and symbols known to the explainee i.e., the consumer of the explanation, have to match those used by the explainer i.e., the proponent of the explanation, when assigning meaning to an explanation. In other words, the complexity (otherwise known as parsimony) of the interpretation should not be greater than the explainee’s capabilities to fathom its meaning (Ras et al., 2018; Sokol & Flach, 2020).
Sometimes, there are no fundamental reasons to prefer one interpretation over another (e.g., make red represent high values instead of blue or white) as long as one is agreed upon. There are scenarios in which interactivity allow for correction and negotiation of the meaning being assigned to explanations (e.g., arguing for the importance of using another color other than red for high values of a heatmap). Often, however, it is fundamental to consider the mental model of the explainee, as it expedites the process of understanding (i.e., it has an optimal degree of parsimony). This involves estimating the relevant mental constructs known to potential explainees beforehand, as exact mental models may not be available. In addition, mental constructs unknown to the explainee, but crucial for the interpretation, need to be properly introduced. In the worst case, ambiguities can lead to a misinterpretation of explanations555Prominent examples have even made it into mainstream media (Baraniuk, 2017).. A simple strategy to bridge the gap between the explainee’s mental model and the constructs of an interpretation is to rely on common conventions such as those coming from a natural universal language (King, 2005).
Note that the explainee’s mental model is assumed to be based on true facts; the consequences of engaging in the process of explanation and interpretation based on false premises can be catastrophic (Lombrozo, 2006). In consequence, matching an explainee’s mental model is desirable but not indispensable. Interpretations are valid as long as their statements cohere, and the inclusion of a particular explainee’s mental model should only accelerate the process of understanding, while leaving the essence of the interpretation itself unaltered.
Even if the methods to explain (or the agreements to interpret) vary, the process of understanding will always be supported by the same mechanism: description of facts followed by the assignment of meaning for the description itself. While the meaning being assigned can be contested (e.g., as part of the scientific process where one seeks to falsify a statement) the process of assignment cannot.
| Source | Explanation | Interpretation |
|---|---|---|
| Merriam-Webster | act of making plain or understandable | action to explain or tell the meaning of |
| Cambridge | the details or other information that someone gives to make something clear or easy to understand | an explanation or opinion of what something means |
| Oxford | a statement or account that makes something clear | the action of explaining the meaning of something |
| Dictionary.com | statement made to clarify something and make it understandable | explain; action to give or provide the meaning of; explicate; elucidate |
| Princeton | a statement that makes something comprehensible by describing the relevant structure or operation or circumstances etc | an explanation of something that is not immediately obvious; a mental representation of the meaning or significance of something |
| Wikipedia | a set of statements usually constructed to describe a set of facts that clarifies the causes, context, and consequences of those facts | A philosophical interpretation is the assignment of meanings to various concepts, symbols, or objects under consideration. |
. Universal Context for XAI Methods: the what, the how and the why
One of the main aims of equipping ML models with explanation capabilities is to contest previous beliefs w.r.t. a particular prediction by constraining an otherwise undetermined problem (Lombrozo, 2006). So far, we have already constrained two core definitions in XAI, in an effort to define a unified language that allows us to engage in scientific discussion. Said terminology still needs to fit into a more generic, procedural framework where novel and existing contributions can be placed and thus, compared.
Explanations and interpretations are ultimately aimed at answering questions arising from the underlying process (i.e., the ML model) that issued a prediction. These questions, in their more generic form, correspond to variants of what, how or why queries. Hence, our interest lies in defining a framework that addresses these questions when defining novel explanations and interpretations. In fact, we show that both terms are central for answering all three questions. We describe the scope of the aforementioned questions, and the role that explanations and interpretations both play when answering them.
The what defines the domains in which explanations operate. As defined in section ., we find that explanations, as processes, take in elements of a particular source domain, and output descriptions that exist in a target domain. This notion of “translation” between two domains has been recently promoted (Esser et al., 2020) although the terminology differs with the one proposed in this work. In mathematics, whenever a function is defined, it is first expressed in terms of the domain and co-domain where the function projects values into e.g., . Similarly, an explanation method should explicitly state what is being used as input and what is being produced as output. Ideally, the output of the explanation (explanans) should be defined in terms of low-level primitives that are as factually true as the input (e.g., intermediate features, support vectors, gradients). Note that, while inputs in the source domain are limited by the model being explained, the target domain depends on the explanation method, where options are virtually unlimited666Practical constraints arise from the cognitive limitations of human minds (e.g., the inability to imagine a tesseract)..
Defining how something is being done can be addressed from two levels of abstraction. First, at the system-level, there is the question of how the model arrives at a prediction. Second, there is the issue of how the explanans is produced. In other words, what are the details behind the process that transforms between domains defined by the what, and used by the explanation. The former is precisely the kind of inquiry that XAI methods try to answer and therefore, they cannot be included in our framework. Instead, this kind of how questions will be answered through methods that rely on it777In fact, all three questions–what, how, why–have been proposed as the basis for identifying questions that are answerable through explanations (Miller, 2019).. The latter on the other hand, deals with the context of explanations and their answer is essentially reduced to the explanation method itself. Simply put, the answer of how the explanandum is mapped to an explanans is defined by the explanation method.
As most XAI literature is devoted to the development of explanation methods (e.g., computation of relevance values (Bach et al., 2015; Vaswani et al., 2017), mapping of high-level conceptual constructs in intermediate activations (Bau et al., 2017; Kim et al., 2018)), the how is almost always thoroughly defined. This has already nurtured insightful debates on whether linear approximations of the original model (Lundberg & Lee, 2017) or even other black-boxes (Al-Shedivat et al., 2020) can be considered appropriate explanation methods (Rudin, 2019; Slack et al., 2020).
Together, the what and the how already constrain the scope in which explanations are valid. The one remaining aspect is the context in which an explanation is interpreted. An explanans is, by itself, only relevant within the target domain defined by the explanation. It is the interpretation (of the explanans) which will map the low-level representations into a high-level domain where expectations regarding non-functional requirements can be validated or contested. Consider the following interpretation: “the result of an argmax operation on the logits of a neural network corresponds to the predicted class”. The high-level action of predicting a class has been mapped to an argmax operation over a vector. Based on this interpretation of the argmax operation, users of neural networks can either accept this notion to gather results, or find shortcomings and propose alternative ways of fulfilling the requirement of a model to predict classes (e.g., through the refinement of the prediction through a hierarchical exclusion graph (Deng et al., 2014)). The same principle can be applied to explanans and non-functional requirements.
Asking why something happens, inescapably relates back to causal effects. While these kind of relationships are among the most useful to discover (as it allows for more control over the effect by adjusting the cause), other non-causal relationships remain valuable in the toolset of explainability. Finding out that a model is unfair, without knowing what the cause of it is, can already be helpful in high-stake scenarios (e.g., by preventing its use). We say that the why relates to the nature of an interpretation. In short, if the interpretation bares a causal meaning, then the why is being defined by the causal link. If the meaning is limited to a correlation, the why is left out of the scope of that particular interpretation. Note that, if the explanation method is already based on causal theory (Lopez-Paz et al., 2017; Chang et al., 2019), the assigned meaning (i.e., the link between the explanans and the high-level (non-)functional requirement) will be more direct and therefore, more likely to withstand scientific scrutiny. The why is therefore not mandatory in explanations generated by XAI methods. In any case, the explanation’s context can and should be defined, be it causal or based solely on correlations. Proponents of XAI methods are responsible for clearly stating the context in which their explanations can be interpreted.
On the Completeness of the XAI Framework
We show that our proposed framework complies with concepts and desiderata related to explanations and explainable models. In particular, those that have been defined by Alvarez-Melis and Jaakkola (Alvarez-Melis & Jaakkola, 2018), and Miller (Miller, 2019). Furthermore, we discuss evaluation metrics for XAI methods (as defined by Doshi-Velez and Kim (Doshi-Velez & Kim, 2018)) and how they also fit within our framework.
For Alvarez-Melis and Jaakkola (Alvarez-Melis & Jaakkola, 2018), there are three characteristics that explanations need to meet: fidelity, diversity and grounding. Fidelity alludes to the preservation of relevant information; diversity states that only a small number of related and non-overlapping concepts should be used by the explanation, while grounding calls for said concepts to be human-understandable. In our proposed framework, fidelity is guaranteed as explanations are defined as mechanisms to describe or map inputs that are axiomatically valid using a well-defined function. Although defining an absolute number of concepts can be rather subjective, diversity is possible by allowing a designer of explanations to purposely focus on a few concepts on the input or output of the explanation. Grounding is essentially addressed by the interpretation, as it is the mapping from a low-level primitive to a high-level, human-understandable realm of a non-functional requirement. Moreover, explanations require the production of artifacts specifically targeted at enabling human understanding.
Miller (Miller, 2019) has highlighted several aspects of explanations that the XAI community has been mostly unaware of: the social, contrastive and selective nature of explanations, and the irrelevance of probabilities when providing an explanation. When defining the domain and co-domain of an explanation, there are several ways by which contrastive explanations can be offered: either several explanandums can be processed, and their explanans compared, or the explanation method itself expects multiple input pairs (possibly producing output pairs too). Employing causal methods as explanations will inevitably encode counterfactual information (e.g., the result of applying a do-operator) enabling a comparison with respect to the observed data. Selective explanations closely relate to the concept of diversity from Alvarez-Melis and Jaakkola (Alvarez-Melis & Jaakkola, 2018). The irrelevance of probabilities mainly states that the best explanation for the average case may not be the best explanation for a particular explainee. While true in some cases, the usefulness of tailored explanations is contingent on the use-case (as providing different explanations for two identical cases may violate fairness constraints). Nonetheless, our framework does not preclude an explanation from doing so if the use-case calls for it. Finally, the social aspect of explanations is reflected by its very definition, as the purpose of explanations is to “enable human understanding”. Furthermore, interpretations are mappings from low-level to high-level requirements, precisely to make an explanans consumable by humans.
General guidelines for measuring explanations (or better said, their outputs) have been proposed in (Doshi-Velez & Kim, 2018). These are based on three kinds of evaluations depending on the scope of the application (from generic to specific) and they revolve around the involvement of automatic proxy-tasks, non-expert humans, or domain experts. The use of automated tasks would be amenable primarily to explanations, as they already live in the realm of data structures and mathematical primitives. Evaluations that involve humans will thus be better suited for the interpretations, as mappings to a high-level domain, where the non-functional requirements originate, ultimately affect human understanding (therefore impacting trust, confidence, etc).
A fitting example of quantifiable criteria for explanations can be found in the aforementioned work by Alvarez-Melis and Jaakkola(Alvarez-Melis & Jaakkola, 2018). They propose three, arguably generic characteristics that their proposed explanations should meet, namely explicitness, faithfulness and stability. We see that such properties also refer to aspects defined in our framework: explicitness or “how understandable are the explanations” establishes how clear the interpretation of their provided explanans (in their case, a selection of prototypes describing an expected latent feature) is. Faithfulness or the “true relevance of selected features” is directly addressing the quality of an explanans via counterfactual analysis (i.e., had the selected feature not been there, would the prediction suffer any change?). Finally, stability measures consistency of the explanation for similar inputs. As part of the particular classification problem they work on, said property deals with an expected local Lipschitz continuity which guarantees that similar input samples will yield a similar explanans.
We see how our proposed framework offers a comprehensive language that not only aligns and encompasses previously defined desiderata regarding XAI, but also allows the identification of common ground between a wide array of concepts related to the field.
Understanding the State of XAI under our Proposed Framework
| Method | LIME | SHAP | MDNet | |
|---|---|---|---|---|
| What | Source |
Model input
Model prediction |
Model input
Model prediction |
Model activations |
| Target | Linear classifier weights | Linear classifier weights | Word-wise attention matrix | |
| How |
1) Input perturbation sampling
2) Inference on class of interest 3) Training of proxy model |
1) Input perturbation sampling.
2) Inference on class of interest. 3) Training of unique SHAP solution for proxy model |
1) Implicit training of attention module.
2) Generation of attention matrices from activations and LSTM state. |
|
| Why | Causal | - | - | - |
| Non-causal | Surrogate model weights indicate the local influence of features sampled from a marginal distribution | Approximation of the average contribution of a feature to the prediction. | Approximation of the model’s attention during word generation | |
The proposed explanation framework helps establishing unambiguous and commensurable relations across all kinds of XAI contributions. We demonstrate the broad applicability of our framework by re-contextualizing three popular methods, LIME, SHAP and MDNet, showing how and where they compare, while also revealing some of the gaps and complementary properties between them.
Additive feature attribution methods like LIME (Ribeiro et al., 2016) and SHAP (Lundberg & Lee, 2017) are some of the most frequently used XAI techniques today. Both were introduced as model-agnostic methods, aiming at approximating the behavior of complex models, all without requiring access to their internal variables. On the other hand, MDNet (Zhang et al., 2017) was proposed as an “interpretable medical image network” for diagnosis of bladder cancer through the generation of textual diagnosis along with word-wise attention maps. At first glance, establishing a degree of commensurability (as defined in section .) is not straightforward, especially when dealing with methods that operate on vastly different domains or whose explanations tackle different sets of non-functional requirements such as MDNet’s and LIME’s. However, by defining the different elements of all three methods in terms of our proposed framework, it becomes possible to establish comparisons and draw limitations with respect to one another. We discuss said elements in the remaining of this section. For a summary of the ensuing discussion, please refer to Table 3.
. Source Domain:
The explanandum of both LIME and SHAP comprises the prediction of the target model, as well as an input sample888Most local explanation methods rely on individual samples from the model’s input space as input for the explanation too. Non-local methods like TCAV (Kim et al., 2018) or S2SNet (Palacio et al., 2018) rely on a group of samples or even a representative sample of the input space.. The target model is treated as a black-box, and typically deals with low-dimensional input data. Meanwhile, MDNet’s textual and visual explanations are derived from an input sample, and from high-dimensional latent variables found within the target model. LIME and SHAP represent the target model’s low-level internal processes mainly through counterfactual analysis, while methods exposed to the model’s internals can examine the flow, translation and attribution of information as it traverses the model, serving as a much more direct evidence of a model’s decision process. In fact, it has been shown that limiting access to the target model’s internal representations makes the creation of adversarial attacks possible, compromising the reliability of the explanation (Slack et al., 2020). In other words, it is not enough to rely only on the input domain (of the target model) as the explanandum.
. Target Domain:
The outputs of both LIME and SHAP consist of the weight values from linear surrogate models that are mapped to their corresponding input region (visualized as heatmaps). Instead, MDNet’s explanans is composed of a sequence of one-hot encoded words from the language model, where each word is paired with a weight matrix that is spatially mapped to the input image (also visualized as a heatmap). The combination of generated text supported by word-wise attribution maps provides a traceable structure from the model’s input to the weight matrix. While LIME and SHAP provide explanans that share some of the output space with MDNet’s, the relation they bare with any internal representation of the target model is not as traceable.
. How:
LIME and SHAP both follow similar explanation strategies that are characterized by continuously perturbing and evaluating an input sample via the target model; results are subsequently approximated through a surrogate linear model. SHAP poses additional constrains to the surrogate’s optimization and slightly differs in its sampling scheme. MDNet can be described as a two stage process: an image feature extraction followed by a concurrent generation of a sensitivity map (originally called “explanation”) and textual diagnosis. Both the explanation and classification components of MDNet are trained simultaneously in an end-to-end fashion. The language model for text generation is trained using diagnosis texts as the supervisory signal, fulfilling one of its functional requirements. The word-wise attention module learns a set of sensitivity weights with additional constrains on diagnostic labels serving as indirect supervision.
. Why:
Given all structural and low-level components of the explanations under scrutiny, as described by the what and the how, we now turn to the interpretation of such primitives. The first observation is that none of the aforementioned methods provide interpretations of causal nature. LIME and SHAP cannot provide interpretations grounded in causality due to issues related to off-manifold sampling (Frye et al., 2020) and the non-excludable inaccuracy when relying on proxy models (Rudin, 2019). Nevertheless, there are non-causal interpretations worth examining.
The weight values derived from LIME’s proxy models are interpreted as “influence values”. These values convey the relevance of individual input features w.r.t. the prediction of the target model. A small caveat to this interpretation is its limited validity, which applies only to the local neighbourhood around the original input sample. SHAP’s explanans, despite baring evident similarities with LIME’s, allows the generation of additional global explanans through an accumulation of statistics from multiple local explanations. Furthermore, the notion of feature attribution (i.e., how much the value of each input feature has influenced the model’s prediction) inherits the properties of Shapely values. In this case, values are interpreted as payouts to individual features, reflecting how much they contributed to the model’s prediction, relative to the remaining input features. MDNet’s visual explanations are interpreted as the model’s attention w.r.t. a region within the input image while the textual-diagnosis generates a word. In this case, we see how MDNet defines explanans as part of the model’s output and not as a separate process, tying predictions and explanans together. The correspondence between feature attribution on the image domain and the sensitivity w.r.t. generated text comes from additional annotations available for the text. The assumption is that latent representations of MDNet align features of image regions and text in a way that is meaningful to humans. The link between the intuitive notion of “attention” and its implementation in one of MDNet’s modules, has been recently contested (Jain & Wallace, 2019; Wiegreffe & Pinter, 2019), undermining any causal relation drawn from it.
Conclusions
To address the growing heterogeneity and lack of agreement on what constitutes an explainable or interpretable model, we introduced a novel theoretical framework to consolidate research and methods developed in the field of explainable AI (XAI). This framework is supported by two fundamental definitions, namely “explanation” and “interpretation”. These definitions are further contextualized within a general pipeline that constrains other important primitives like input/output domains, and establishes a divide between low-level mathematical constructs and the high-level, human-understandable realm of (non-)functional requirements.
We show that the proposed framework is compliant with desiderata regarding explanations as defined in previous work. Moreover, existing metrics for XAI methods can be placed within the framework allowing an apples-to-apples comparison between different explanations.
Finally, we show a concrete scenario where our framework can help comparing existing XAI methods, showing the extent by which each one addresses different aspects of the explainability pipeline.
. Current Trends and Practices
In the process of defining the proposed framework, we conducted an extensive review of XAI literature. This allowed us to identify current practices in the XAI community, some of which we summarize here in terms of our framework.
- •
-
•
Explanations are often defined without explicit definitions of the domain and co-domain (i.e., realm of the explanans and explanandum).
-
•
More recently, explainable models are trying to include richer objectives through auxiliary tasks: this strategy addresses both the underspecification of the task (conveys some of the sought after non-functional requirements) and expresses some of the invariances that are expected of the task.
-
•
In domains where AI takes over or assists human-professional workers (e.g., for medical applications), interest often shifts from the prediction to the explanation such that human experts learn and gain new insights about the task.
. Recommendations
Finally, we identify three aspects that future research in XAI should focus on in order to expedite the advancement of the current state-of-the-art.
-
•
Before working on the specifics of an explanation, explicitly define the non-functional requirements that a task should fulfill, and that the explanation itself will be probing for. This can be achieved by defining better hypotheses e.g., one that can be falsified (Leavitt & Morcos, 2020).
-
•
Proponents of XAI methods should be careful when addressing the complete scope of our proposed framework. In particular, a clear interpretation should be provided.
-
•
Metrics for XAI methods should operate within the same level of abstraction w.r.t. the framework i.e., compare explanans to explanans, explanandum to explanandum, interpretation to interpretation, etc.
Acknowledgements
This work was supported by the BMBF projects ExplAINN (01IS19074), XAINES and the NVIDIA AI Lab program.
References
- Al-Shedivat et al. (2020) Al-Shedivat, M., Dubey, A., and Xing, E. Contextual explanation networks. Journal of Machine Learning Research, 21(194):1–44, 2020.
- Alvarez-Melis & Jaakkola (2018) Alvarez-Melis, D. and Jaakkola, T. S. Towards robust interpretability with self-explaining neural networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, pp. 7786–7795, 2018.
- Arrieta et al. (2020) Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., Bennetot, A., Tabik, S., Barbado, A., García, S., Gil-López, S., Molina, D., Benjamins, R., et al. Explainable artificial intelligence (xai): Concepts, taxonomies, opportunities and challenges toward responsible ai. Information Fusion, 58:82–115, 2020.
- Athalye et al. (2018) Athalye, A., Carlini, N., and Wagner, D. Obfuscated gradients give a false sense of security: Circumventing defenses to adversarial examples. In Dy, J. and Krause, A. (eds.), Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pp. 274–283, Stockholmsmässan, Stockholm Sweden, 10–15 Jul 2018. PMLR.
- Bach et al. (2015) Bach, S., Binder, A., Montavon, G., Klauschen, F., Müller, K.-R., and Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PloS one, 10(7):e0130140, 2015.
- Baraniuk (2017) Baraniuk, C. The ’creepy Facebook AI’ story that captivated the media, Aug 2017. URL https://www.bbc.com/news/technology-40790258.
- Bau et al. (2017) Bau, D., Zhou, B., Khosla, A., Oliva, A., and Torralba, A. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6541–6549, 2017.
- Bibal & Frénay (2016) Bibal, A. and Frénay, B. Interpretability of machine learning models and representations: an introduction. In ESANN, 2016.
- Biran & Cotton (2017) Biran, O. and Cotton, C. Explanation and justification in machine learning: A survey. In IJCAI-17 workshop on explainable AI (XAI), volume 8, pp. 8–13, 2017.
- Bussmann et al. (2020) Bussmann, N., Giudici, P., Marinelli, D., and Papenbrock, J. Explainable Machine Learning in Credit Risk Management. Computational Economics, September 2020. ISSN 1572-9974. doi: 10.1007/s10614-020-10042-0. URL https://doi.org/10.1007/s10614-020-10042-0.
- Carlini et al. (2019) Carlini, N., Athalye, A., Papernot, N., Brendel, W., Rauber, J., Tsipras, D., Goodfellow, I., Madry, A., and Kurakin, A. On evaluating adversarial robustness. arXiv preprint arXiv:1902.06705, 2019.
- Carrieri et al. (2020) Carrieri, A. P., Haiminen, N., Maudsley-Barton, S., Gardiner, L.-J., Murphy, B., Mayes, A., Paterson, S., Grimshaw, S., Winn, M., Shand, C., et al. Explainable ai reveals key changes in skin microbiome associated with menopause, smoking, aging and skin hydration. bioRxiv, 2020.
- Chang et al. (2019) Chang, C.-H., Creager, E., Goldenberg, A., and Duvenaud, D. Explaining image classifiers by counterfactual generation. In International Conference on Learning Representations, 2019.
- Ciatto et al. (2020) Ciatto, G., Calvaresi, D., Schumacher, M. I., and Omicini, A. An abstract framework for agent-based explanations in ai. In Proceedings of the 19th International Conference on Autonomous Agents and MultiAgent Systems, pp. 1816–1818, 2020.
- Dam et al. (2018) Dam, H. K., Tran, T., and Ghose, A. Explainable software analytics. In Proceedings of the 40th International Conference on Software Engineering: New Ideas and Emerging Results, pp. 53–56, 2018.
- D’Amour et al. (2020) D’Amour, A., Heller, K., Moldovan, D., Adlam, B., Alipanahi, B., Beutel, A., Chen, C., Deaton, J., Eisenstein, J., Hoffman, M. D., et al. Underspecification presents challenges for credibility in modern machine learning. arXiv preprint arXiv:2011.03395, 2020.
- de Sousa et al. (2020) de Sousa, I. P., Vellasco, M. M. B. R., and da Silva, E. C. Evolved explainable classifications for lymph node metastases. arXiv preprint arXiv:2005.07229, 2020.
- Deng et al. (2014) Deng, J., Ding, N., Jia, Y., Frome, A., Murphy, K., Bengio, S., Li, Y., Neven, H., and Adam, H. Large-scale object classification using label relation graphs. In European conference on computer vision, pp. 48–64. Springer, 2014.
- Dombrowski et al. (2019) Dombrowski, A.-K., Alber, M., Anders, C., Ackermann, M., Müller, K.-R., and Kessel, P. Explanations can be manipulated and geometry is to blame. In Advances in Neural Information Processing Systems, pp. 13589–13600, 2019.
- Doshi-Velez & Kim (2018) Doshi-Velez, F. and Kim, B. Considerations for evaluation and generalization in interpretable machine learning. In Explainable and Interpretable Models in Computer Vision and Machine Learning, pp. 3–17. Springer, 2018.
- Esser et al. (2020) Esser, P., Rombach, R., and Ommer, B. A disentangling invertible interpretation network for explaining latent representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9223–9232, 2020.
- Frye et al. (2020) Frye, C., de Mijolla, D., Cowton, L., Stanley, M., and Feige, I. Shapley-based explainability on the data manifold. arXiv preprint arXiv:2006.01272, 2020.
- Ghorbani et al. (2019) Ghorbani, A., Abid, A., and Zou, J. Interpretation of neural networks is fragile. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, pp. 3681–3688, 2019.
- Jain & Wallace (2019) Jain, S. and Wallace, B. C. Attention is not explanation. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 3543–3556, 2019.
- Josephson & Josephson (1996) Josephson, J. R. and Josephson, S. G. Abductive inference: Computation, philosophy, technology. Cambridge University Press, 1996.
- Kang & Kang (2016) Kang, M.-J. and Kang, J.-W. Intrusion detection system using deep neural network for in-vehicle network security. PloS one, 11(6):e0155781, 2016.
- Kim et al. (2018) Kim, B., Wattenberg, M., Gilmer, J., Cai, C., Wexler, J., Viegas, F., et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV). In International conference on machine learning, pp. 2668–2677. PMLR, 2018.
- King (2005) King, T. D. Human color perception, cognition, and culture: why red is always red. In Color imaging X: processing, hardcopy, and applications, volume 5667, pp. 234–242. International Society for Optics and Photonics, 2005.
- Lakkaraju et al. (2019) Lakkaraju, H., Kamar, E., Caruana, R., and Leskovec, J. Faithful and customizable explanations of black box models. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, pp. 131–138, 2019.
- Leavitt & Morcos (2020) Leavitt, M. L. and Morcos, A. Towards falsifiable interpretability research, 2020.
- Lewis (1986) Lewis, D. Causal explanation, philosophical papers, vol. 2, 1986.
- Lin et al. (2014) Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. In European conference on computer vision, pp. 740–755. Springer, 2014.
- Lipton (2018) Lipton, Z. C. The mythos of model interpretability. Queue, 2018.
- Lombrozo (2006) Lombrozo, T. The structure and function of explanations. Trends in cognitive sciences, 10(10):464–470, 2006.
- Lopez-Paz et al. (2017) Lopez-Paz, D., Nishihara, R., Chintala, S., Scholkopf, B., and Bottou, L. Discovering causal signals in images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6979–6987, 2017.
- Lundberg & Lee (2017) Lundberg, S. M. and Lee, S.-I. A unified approach to interpreting model predictions. In Advances in neural information processing systems, pp. 4765–4774, 2017.
- Miller (2019) Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artificial Intelligence, 2019.
- Miller et al. (2017) Miller, T., Howe, P., and Sonenberg, L. Explainable AI: Beware of inmates running the asylum. In IJCAI 2017 Workshop on Explainable Artificial Intelligence (XAI), 2017. URL http://people.eng.unimelb.edu.au/tmiller/pubs/explanation-inmates.pdf.
- Montavon et al. (2018) Montavon, G., Samek, W., and Müller, K.-R. Methods for interpreting and understanding deep neural networks. Digital Signal Processing, 2018.
- of the European Union & Parliament (2016) of the European Union, C. and Parliament, E. Regulation (EU) 2016/679 of the European Parliament and of the Council of 27 April 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing Directive 95/46/EC (General Data Protection Regulation), 2016.
- Palacio et al. (2018) Palacio, S., Folz, J., Hees, J., Raue, F., Borth, D., and Dengel, A. What do deep networks like to see. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2018.
- Ras et al. (2018) Ras, G., van Gerven, M., and Haselager, P. Explanation methods in deep learning: Users, values, concerns and challenges. In Explainable and Interpretable Models in Computer Vision and Machine Learning, pp. 19–36. Springer, 2018.
- Ribeiro et al. (2016) Ribeiro, M. T., Singh, S., and Guestrin, C. ” why should i trust you?” explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp. 1135–1144, 2016.
- Rudin (2019) Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence, 1(5):206–215, 2019.
- Rudin & Ustun (2018) Rudin, C. and Ustun, B. Optimized scoring systems: Toward trust in machine learning for healthcare and criminal justice. Interfaces, 48(5):449–466, 2018.
- Russakovsky et al. (2015) Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy, A., Khosla, A., Bernstein, M., et al. Imagenet large scale visual recognition challenge. International journal of computer vision, 115(3):211–252, 2015.
- Schmid & Finzel (2020) Schmid, U. and Finzel, B. Mutual explanations for cooperative decision making in medicine. KI-Künstliche Intelligenz, pp. 1–7, 2020.
- Schneeberger et al. (2020) Schneeberger, D., Stöger, K., and Holzinger, A. The european legal framework for medical ai. In Holzinger, A., Kieseberg, P., Tjoa, A. M., and Weippl, E. (eds.), Machine Learning and Knowledge Extraction, pp. 209–226, Cham, 2020. Springer International Publishing. ISBN 978-3-030-57321-8.
- Slack et al. (2020) Slack, D., Hilgard, S., Jia, E., Singh, S., and Lakkaraju, H. Fooling LIME and SHAP: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, pp. 180–186, 2020.
- Smeulders et al. (2000) Smeulders, A. W., Worring, M., Santini, S., Gupta, A., and Jain, R. Content-based image retrieval at the end of the early years. IEEE Transactions on pattern analysis and machine intelligence, 22(12):1349–1380, 2000.
- Sokol & Flach (2020) Sokol, K. and Flach, P. Explainability fact sheets: A framework for systematic assessment of explainable approaches. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, FAT* ’20, pp. 56–67, New York, NY, USA, 2020. Association for Computing Machinery. ISBN 9781450369367. doi: 10.1145/3351095.3372870.
- Sowa (1983) Sowa, J. F. Conceptual structures: information processing in mind and machine. Addison-Wesley Pub., Reading, MA, 1983.
- Szegedy et al. (2013) Szegedy, C., Zaremba, W., Sutskever, I., Bruna, J., Erhan, D., Goodfellow, I., and Fergus, R. Intriguing properties of neural networks. arXiv preprint arXiv:1312.6199, 2013.
- Vaswani et al. (2017) Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., and Polosukhin, I. Attention is all you need. In Advances in neural information processing systems, pp. 5998–6008, 2017.
- Vilone & Longo (2020) Vilone, G. and Longo, L. Explainable artificial intelligence: a systematic review. arXiv preprint arXiv:2006.00093, 2020.
- Wiegreffe & Pinter (2019) Wiegreffe, S. and Pinter, Y. Attention is not not explanation. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp. 11–20, 2019.
- Xie et al. (2020) Xie, N., Ras, G., van Gerven, M., and Doran, D. Explainable deep learning: A field guide for the uninitiated. arXiv preprint arXiv:2004.14545, 2020.
- Zhang et al. (2017) Zhang, Z., Xie, Y., Xing, F., McGough, M., and Yang, L. Mdnet: A semantically and visually interpretable medical image diagnosis network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 6428–6436, 2017.