YouTube UGC Dataset for Video Compression Research
Abstract
Non-professional video, commonly known as User Generated Content (UGC) has become very popular in today’s video sharing applications. However, traditional metrics used in compression and quality assessment, like BD-Rate and PSNR, are designed for pristine originals. Thus, their accuracy drops significantly when being applied on non-pristine originals (the majority of UGC). Understanding difficulties for compression and quality assessment in the scenario of UGC is important, but there are few public UGC datasets available for research. This paper introduces a large scale UGC dataset (1500 20 sec video clips) sampled from millions of YouTube videos. The dataset covers popular categories like Gaming, Sports, and new features like High Dynamic Range (HDR). Besides a novel sampling method based on features extracted from encoding, challenges for UGC compression and quality evaluation are also discussed. Shortcomings of traditional reference-based metrics on UGC are addressed. We demonstrate a promising way to evaluate UGC quality by no-reference objective quality metrics, and evaluate the current dataset with three no-reference metrics (Noise, Banding, and SLEEQ).
Index Terms:
User Generated Content, Video Compression, Video Quality AssessmentI Introduction
Video makes up the majority of today’s Internet traffic. Consequently, this motivates video service companies (e.g. YouTube) to spend substantial effort to control bandwidth usage [1]. The main remedy deployed is typically video bitrate reduction. However, aggressive bitrate reduction may hurt perceptual visual quality at the same time as both creators and viewers have increasing expectations for streaming media quality. The evolution of new codec technology (HEVC, VP9, AV1) continues to address this bitrate/quality tradeoff.
To measure the quality degradation, numerous quality metrics have been proposed in the last few decades. Some reference-based metrics (like PSNR, SSIM [2] and VMAF [3]) have been widely used in the industry. A common assumption held by most video quality and compression research is that the original video is perfect, and any operation on the original (processing, compression etc.) makes it worse. Most research measures how good the resulting video is by comparing it to the original. However, such an assumption does not hold for most of User Generated Content (UGC) due to the following reasons:
-
•
Non-pristine original When there are visual artifacts present in the original, it is not clear whether an encoder should be putting in efforts to accurately represent those artifacts. It is necessary to consider the effect that the encoding has on those undesired artifacts, but it is also necessary to consider the effect that the artifacts have on the ability to encode the video effectively.
-
•
Mismatched absolute and reference quality Using the original as a reference does not always make sense when the original isn’t perfect. Quality improvement may be affected by pre/post processing before/after transcoding, but reference-based metrics (e.g. PSNR, SSIM) cannot fairly evaluate the impact of these tools in a compression chain.
We created this large scale UGC dataset in order to encourage and facilitate research that considers the practical and realistic needs of video compression and quality assessment in video processing infrastructure.
A major contribution of this work is the analysis of the enormous content in YouTube in a way that illustrates the breadth of visual quality in media worldwide. That analysis leads to the creation of a statistically representative set that is more amenable to academic research and computational resources. We built a large scale UGC dataset(Section III), and propose (Section IV) a novel sampling scheme based on features extracted from encoding logs, which achieves high coverage over millions of YouTube videos. Shortcomings of traditional reference-based metrics on UGC are discussed (Section V), and we evaluate the dataset with three no-reference metrics: Noise [4], Banding [5], and Self-reference based LEarning-free Evaluator of Quality (SLEEQ) [6].
The dataset can be previewed and downloaded from https://media.withyoutube.com/ugc-dataset.
II Related Work
Some large-scale datasets have already been released for UGC videos, like YouTube-8M [7] and AVA [8]. However, they only provide extracted features instead of raw pixel data, which makes them less useful for compression research.
Xiph.org Video Test Media [9] is a popular dataset for video compression and it contains around 120 individual video clips (including both pristine and UGC samples). These videos have various resolutions (e.g. SD, HD, and 4K) and multiple content categories (e.g. movie and gaming).
LIVE datasets [10, 11, 12] are also quite popular. All of them contain less than 30 individual pristine clips, along with about 150 distorted versions. The goal of the LIVE datasets is subjective quality assessment. Each video clip in the dataset was assessed by 35 to 55 human subjects.
VideoSet [13] contains 220 5 sec clips extracted from 11 videos. The target here is also quality assessment, but instead of providing Mean Opinion Score (MOS) like the LIVE datasets, it provides the first three Just-Noticeable-Difference (JND) scores collected from more than 30 subjects.
Crowdsourced Video Quality Dataset [14] contains 585 10 sec video clips, captured by 80 inexpert videographers. The dataset has 18 different resolutions and a wide range of quality owing to the intrinsic nature of real-world distortions. Subjective opinions were collected from thousands of participants using Amazon Mechanical Turk.
KoNViD-1k [15] is another large scale dataset which contains 1200 clips with corresponding subjective scores. All videos are in landscape layout and have resolution higher than . They started from a collection of 150K videos, grouping them by multiple attributes like blur, colorfulness etc. The final set was created by a “fair-sampling” strategy. The subjective mean opinion scores were gathered through crowdsourcing.
III YouTube UGC Dataset Overview
Our dataset is sampled from YouTube videos with the Creative Commons license. We selected an initial set of 1.5 millions videos belonging to 15 categories annotated by Knowledge Graph [16] (as shown in Fig. 1): Animation, Cover Song, Gaming, HDR, How To, Lecture, Live Music, Lyric Video, Music Video, News Clip, Sports, Television Clip, Vertical Video, Vlog, and VR. The video category is an important feature of our dataset, which allows users to easily explore characteristics of different kinds of videos. For example, Gaming videos usually contain lots of fast motion, while many Lyric videos have still backgrounds. Compression algorithms can be optimized in different ways based on such category information.
Videos within each category are further divided into subgroups based on their resolutions. Resolution is an important feature revealing the diversity of user preferences, as well as the different behaviors of various devices and platforms. So it would be helpful to treat resolution as an independent dimension. In our dataset, we provided P, P, P, P for all categories (except for HDR and VR) and K for HDR, Gaming, Sports, Vertical Video, Vlog, and VR.
The final dataset contains 1500 video clips, each of 20 sec duration. All clips are in Raw YUV 4:2:0 format with constant framerate. Details of the sampling scheme are discussed in the next section.

IV Dataset Sampling
Selecting representative samples from millions of videos is challenging. Not only is the sheer number of videos a challenge to process and generate features, but also the long duration of some videos (which can be in hours) makes it that much more difficult. Compared with another large scale dataset, Konvid-1k, this set has videos sampled from a collection that is 10 times larger (1.5M vs. 150K). A video in our dataset can be sampled at any time offset from its original content, instead of taking only the first 30 sec of the original like Konvid-1k. This makes the search space for our dataset 200 times bigger (an average video being 600s long). Due to this huge search space, computing third party metrics (like Blur metric used in Konvid-1k) is resource heavy or even infeasible.
Large scale video compression/transcoding pipelines typically divide long videos into chunks and encode them in parallel. Maintaining the quality consistency among chunk boundaries becomes an issue in practice. Thus, besides the three common attributes (spatial, temporal, and color) suggested in [17], we propose the variation of complexity across the video as the fourth attribute that reflects inter-chunk quality consistency. We made the length of video clips in our dataset 20 sec, which is long enough to involve multiple complexity variations. These 20 sec clips could be taken from any segment of a video. For the 5 million hours of videos therefore, there were 1.8 billion putative 20 sec clips.
We used Google’s Borg system [18] to encode each video in the initial collection with FFmpeg H.264 encoder with PSNR stats enabled. The detailed compression settings we used are constant QP 20, fixed GOP size 14 frames with no B frames. Other reasonable settings will also work and bring similar features. The encoder reports on statistics from processing on a per frame basis. That diagnostic output was used to collect the following features over 20 sec clip stepped by 1 sec throughout each video:
-
•
Spatial In general spatial detail in a frame is correlated with the bits used to encode that frame, when encoded as an Intra frame. Over a 20 sec chunk therefore, we calculate our spatial complexity feature as the average frame bitrate normalized by the frame area. Fig. 2 (a) and Fig. 2 (b) are frames for low and high spatial complexity respectively.
-
•
Color We define color complexity metric as the ratio between the average of mean Sum of Squared Error (SSE) in U and V channels to the mean SSE in Y channel (obtained from PSNR measurements). A high score means complex color variations in the frame (Fig. 2 (d)), and a low score usually means a gray image with only luminance changes (Fig. 2 (c)).
-
•
Temporal The number of bits used to encode a frame is proportional to the temporal complexity of a sequence. However visual material with high spatial complexity (large frames) tends to have large frames because small motion compensation errors lead to large residuals. To decouple this effect, we normalize the frame bits by taking a ratio with the frame bits, as a fair indicator of temporal complexity. Fig. 3.(a) and Fig. 3.(b) show row sum map of videos with low and high temporal complexity, where the th column is the row sum of the th frame. Frequent column color changes in Fig. 3.(b) imply fast motion among frames, while small changes in temporal domain leads to homogeneous regions in Fig. 3.(a).
-
•
Chunk Variation To explore quality variation within the video, we measured the standard deviation of compressed bitrates among all 1 sec chunks (also normalized by the frame size). If the scene is static or has a smooth motion, the chunk variation score should be close to 0, and the row sum map has no sudden changes (Fig. 3 (c)). Multiple scene changes within a video (common in Gaming videos) will lead to multiple different regions on the row sum map (Fig. 3 (d)).






Each original video and time offset combination forms a candidate clip for the dataset. We sample from this sparse 4-D feature space as described below:
-
1.
Normalize the feature space by subtracting and dividing with .
-
2.
For each feature, divide the normalized range uniformly into bins, where the last bin can go over 1 and extend up to the maximum value.
-
3.
Permutate all non-empty bins uniformly at random.
-
4.
For current bin, randomly select one candidate clip and add it to the dataset if and only if:
-
•
The Euclidean distance of feature scores, between this clip and each of the already selected clips is greater than a certain threshold (0.3).
-
•
The original video that this clip belongs to, doesn’t already have another clip in the dataset.
-
•
-
5.
Move to the next bin and repeat step 4 until desired number of samples are added.
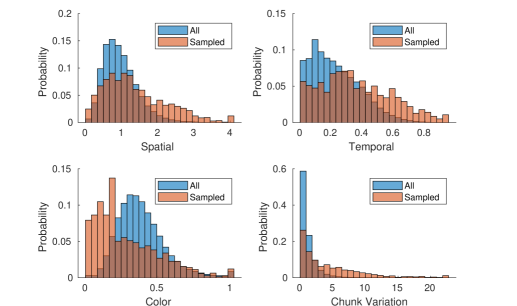
We manually remove mislabeled clips from the 50 selected clips, leaving with 15 to 25 selected clips from each (category, resolution) subgroup. We design the sampling scheme to comprehensively sample along all four feature spaces. As the complexity distribution (normalized) shown in Fig. 4, the feature scores in our sampled set are less spiky than that of the initial set. The sample distribution in color space is left skewed, because many videos with high complexity in other feature spaces are uncolorful. To evaluate the coverage of the sampled set, we divide each pairwise space into grid. The percentage of grids covered by the sampled set is shown in Table I, where the average coverage rate is 89%.
| Temporal | Color | Chunk Variation | |
|---|---|---|---|
| Spatial | 93% | 90% | 88% |
| Temporal | 92% | 88% | |
| Color | 83% |
V Challenges on UGC quality assessment
As mentioned in Section I, most UGC videos are non-pristine, which may confuse traditional reference-based quality metrics. Fig. 5 and Fig. 6 show two clips (id: Vlog_720P-343d and Vlog_720P-670d) from our UGC dataset, as well as their compressed versions (by H.264 with CRF 32). We can see that the corresponding PSNR, SSIM, and VMAF scores are bad, however the original and compressed versions are similar visually. Both the original and compressed versions in Fig. 5 contain significant artifacts, while the compressed version in Fig. 6 actually has less noise artifacts than the original one. The low reference quality scores are mainly caused by not correctly accounting for artifacts in originals.




Although no existing quality metric can perfectly evaluate quality degradation between the original and compressed versions, a possible way is to identify quality issues separately. For example, since we can tell the major quality issue for videos in Fig. 5 is distortions in natural scene, we can compute SLEEQ [6] scores on the original and compressed versions independently, and use their differences to evaluate the quality degradation. In this case, SLEEQ scores for the original and compressed versions are 0.21 and 0.18, respectively, which implies that compression didn’t introduce noticeable quality degradation. We can get the same conclusion for videos in Fig. 6 by applying a noise detector [4].
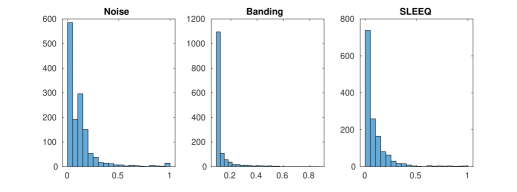
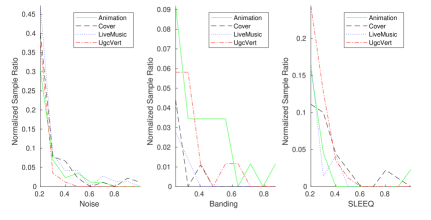
We analyze perceptual quality of our UGC dataset based on existing no-reference metrics. Current evaluation includes three no-reference metrics: Noise, Banding [5], and SLEEQ. The first two metrics are artifact-oriented, which can be interpreted as meaningful extents of specific compression issues. The third metric (SLEEQ) is designed to measure compression artifacts on natural scenes. All these metrics have good correlations with human ratings, and outperform other related no-reference metrics. Fig. 7 shows the distribution for the three quality metric scores (normalized to where lower score is better) on our UGC dataset. We can see that heavy artifacts are not detected in most videos, which in some sense tells us that the overall quality of videos uploaded to YouTube is good. Fig. 8 shows some quality issues within individual categories. For example, Animation videos seem to have more banding artifacts than others, and nature scenes in Vlog tend to contain more artifacts than other categories.
VI Conclusion
This paper introduced a large scale dataset for UGC videos, which highly represents the videos uploaded to YouTube. A novel sampling scheme was proposed to extract features from millions of video samples, and we investigated complexity distribution as well as quality distribution for videos across 15 categories. The difficulties of UGC quality assessment were cited. An important open question remains regarding how to evaluate quality degradation caused by compression for UGC (non-pristine reference). We hope this dataset can inspire and facilitate research on practical requirements of video compression and quality assessment.
References
- [1] Chao Chen, Yao-Chung Lin, Steve Benting, and Anil Kokaram, “Optimized transcoding for large scale adaptive streaming using playback statistics,” in 2018 IEEE International Conference on Image Processing, 2018.
- [2] Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli, “Image quality assessment: From error visibility to structural similarity,” IEEE Transactions on Image Processing, vol. 13, no. 4, 2004.
- [3] Zhi Li, Anne Aaron, Ioannis Katsavounidis, Anush Moorthy, and Megha Manohara, “Toward a practical perceptual video quality metric,” Blog, Netflix Technology, 2016.
- [4] Chao Chen, Mohammad Izadi, , and Anil Kokaram, “A no-reference perceptual quality metric for videos distorted by spatially correlated noise,” ACM Multimedia, 2016.
- [5] Yilin Wang, Sang-Uok Kum, Chao Chen, and Anil Kokaram, “A perceptual visibility metric for banding artifacts,” IEEE International Conference on Image Processing, 2016.
- [6] Deepti Ghadiyaram, Chao Chen, Sasi Inguva, and Anil Kokaram, “A no-reference video quality predictor for compression and scaling artifacts,” IEEE International Conference on Image Processing, 2017.
- [7] Sami Abu-El-Haija, Nisarg Kothari, Joonseok Lee, Paul Natsev, George Toderici, Balakrishnan Varadarajan, and Sudheendra Vijayanarasimhan, “Youtube-8m: A large-scale video classification benchmark,” arXiv preprint arXiv:1609.08675, 2016.
- [8] Chunhui Gu, Chen Sun, David A. Ross, Carl Vondrick, Caroline Pantofaru, Yeqing Li, Sudheendra Vijayanarasimhan, George Toderici, Susanna Ricco, Rahul Sukthankar, Cordelia Schmid, and Jitendra Malik, “Ava: A video dataset of spatio-temporally localized atomic visual actions,” Proceedings of the Conference on Computer Vision and Pattern Recognition, 2018.
- [9] Xiph.org, “Video test media,” https://media.xiph.org/video/derf/.
- [10] K. Seshadrinathan, R. Soundararajan, A. C. Bovik, and L. K. Cormack, “Study of subjective and objective quality assessment of video,” IEEE Transactions on Image Processing, vol. 19, no. 6, 2010.
- [11] C. G. Bampis, Z. Li, A. K. Moorthy, I. Katsavounidis, A. Aaron, and A. C. Bovik, “Live netflix video quality of experience database,” http://live.ece.utexas.edu/research/LIVE_NFLXStudy/index.html, 2016.
- [12] D. Ghadiyaram, J. Pan, and A.C. Bovik, “Live mobile stall video database-ii,” http://live.ece.utexas.edu/research/LIVEStallStudy/index.html, 2017.
- [13] Haiqiang Wang, Ioannis Katsavounidis, Xin Zhou, Jiwu Huang, Man-On Pun, Xin Jin, Ronggang Wang, Xu Wang, Yun Zhang, Jeonghoon Park, Jiantong Zhou, Shawmin Lei, Sam Kwong, and C.-C. Jay Kuo, “Videoset,” http://dx.doi.org/10.21227/H2H01C, 2016.
- [14] Zeina Sinno and Alan C. Bovik, “Large scale subjective video quality study,” IEEE International Conference on Image Processing, 2018.
- [15] Vlad Hosu, Franz Hahn, Mohsen Jenadeleh, Hanhe Lin, Hui Men, Tamás Szirányi, Shujun Li, and Dietmar Saupe, “The konstanz natural video database,” http://database.mmsp-kn.de, 2017.
- [16] Amit Singhal, “Introducing the knowledge graph: Things, not strings,” 2016.
- [17] Stefan Winkler, “Analysis of public image and video databases for quality assessment,” IEEE JOURNAL OF SELECTED TOPICS IN SIGNAL PROCESSING, vol. 6, no. 6, 2012.
- [18] Abhishek Verma, Luis Pedrosa, Madhukar R. Korupolu, David Oppenheimer, Eric Tune, and John Wilkes, “Large-scale cluster management at Google with Borg,” in Proceedings of the European Conference on Computer Systems (EuroSys), Bordeaux, France, 2015.