Zero-Shot Warning Generation for Misinformative Multimodal Content
Abstract
The widespread prevalence of misinformation poses significant societal concerns. Out-of-context misinformation, where authentic images are paired with false text, is particularly deceptive and easily misleads audiences. Most existing detection methods primarily evaluate image-text consistency but often lack sufficient explanations, which are essential for effectively debunking misinformation. We present a model that detects multimodal misinformation through cross-modality consistency checks, requiring minimal training time. Additionally, we propose a lightweight model that achieves competitive performance using only one-third of the parameters. We also introduce a dual-purpose zero-shot learning task for generating contextualized warnings, enabling automated debunking and enhancing user comprehension. Qualitative and human evaluations of the generated warnings highlight both the potential and limitations of our approach.
![[Uncaptioned image]](https://cdn.awesomepapers.org/papers/2ed0d11e-de36-4f56-95b7-0cf16d4ebd38/whole_pipeline_3.drawio.png)
1 Introduction
Misinformation has emerged as a topic of great concern in recent years, given its profound effect on both individuals and societies. At the individual level, the consequences of misinformation can manifest in local crime incidents involving conspiracy theorists [14]. At the societal level, its effects permeate various domains including media (erosion of trust in news circulating on social media platforms), politics (damage to leaders’ reputations), science (resistance to public health measures), and economics (influence on markets, consumer behavior and damage to brand reputation).
The term “misinformation” is often confused with related concepts such as fake news, disinformation, and deception. “Misinformation” specifically refers to unintentional inaccuracies, such as errors in photo captions, dates, statistics, translations, or instances where satire is mistaken for truth. In contrast, disinformation involves the deliberate fabrication or manipulation of text, speech, or visual content as well as the intentional creation of conspiracy theories or rumors [7]. Therefore, the key distinction between disinformation and misinformation lies in the intent behind sharing potentially harmful content.
This study focuses on detecting out-of-context (OOC) image repurposing, a tactic used to support specific narratives [13]. Image repurposing is impactful as multimodal content combining text and images is more credible than text alone [7] and easy to create. Our goal is to automate fact-checking by providing informative explanations to reconstruct the original context of an (image, caption) pair.
Figure 1 outlines the proposed pipeline in three steps: evidence retrieval, consistency check, and warning generation. Evidence retrieval involves searching web pages for the input image and comparing text spans, such as captions or titles, to the input caption. Similarly, captions help find other images for comparison. Source pages are analyzed for coherence and ranked by importance in deciding if the input pair is OOC. In warning generation, the Visual Language Model (VLM) MiniGPT-4[32] provides either a contextual explanation or a warning about image repurposing, referencing relevant sources.
Our contributions are twofold:
-
•
Proposing a flexible architecture for assessing input pair veracity by ranking evidence, achieving 87.04% accuracy with the full model and 84.78% with a lightweight version.
-
•
Introducing a zero-shot learning task for warning generation, enabling debunking explanations with minimal computational resources.
2 Related Work
2.1 Closed Domain Approaches
Liu et al. [12] devised a system that leverages both domain generalization and domain adaptation techniques to mitigate discrepancies between hidden domains and reduce the modality gap, respectively. Shalabi et al. [24] addressed OOC detection by fine-tuning MiniGPT-4’s alignment layer but without message generation and confidence scoring. Zhang et al. [31] introduced a novel approach to reasoning over (image, caption) pairs. Instead of directly learning patterns from the data distributions, as Liu et al. did [11], they extract abstract meaning representation graphs from the captions and use them to generate queries for a VLM. This sophisticated approach enables a nuanced consistency check between the visual features of the image and the extracted features of the caption, but with limited room for explainability given by analysis of the generated queries and respective answers of the VLM. The work by Zhang et al. [31] made it possible to understand the main limitation of closed-domain approaches to this task: evaluation of the veracity of an (image, caption) pair is sometimes challenging because the image may not depict all the statements that can be extracted from the caption.
2.2 Open Domain Approaches
Popat et al. [19] introduced the concept of detecting textual misinformation using external evidence; however, in this study evidence is not integrated simultaneously. Interpretability of the predictions is provided in the form of attention weights over the words of the analyzed document. Abdelnabi et al. [1] extended the concept of leveraging external knowledge for fact-checking to a multimodal (image, text) domain while also computing the aggregated consistencies considering all evidence at the same time for each of the two modalities. A serious limitation of this approach is the provision of explanations solely in the form of attention scores signaling the most relevant evidence for the purpose of prediction along with limited debunking capabilities.
Yao et al. [29] overcome this limitation by introducing an end-to-end pipeline consisting of evidence retrieval, claim verification, and explanation generation, using a dataset built from fact-checking websites with annotated evidence. A drawback of their approach is the utilization of a large language model (LLM) to summarize the evidence content, potentially overlooking important clues observable in the image. Two parallel works, ESCNet [30] by Zhang et al. and SNIFFER [20] by Qi et al., also explore this area. ESCNet lacks explanation generation, while SNIFFER employs a commercial VLM (ChatGPT-4) for generating explanations.
3 Dataset and Evidence Collection
3.1 NewsCLIPpings
In order to develop our contextualizing tool for the purpose of warning generation, we used the NewsCLIPpings dataset [13], which is a synthetic dataset made by Luo et al. built using the VisualNews [11] corpus, which comprises news articles from four prominent newspaper websites: The Guardian, BBC, USA Today, and The Washington Post.Given an (image, caption) pair, images of Visual News[13] are retrieved and substituted to the original image to create falsified samples. Specifically, we used the merge-balanced subset, which consists of 71,072 training, 7,024 validation, and 7,264 test examples.
3.2 External Evidence
The retrieved evidence were provided by Abdelnabi et al. [1]. Given a pair , visual evidence is obtained through means of direct search using as query; Textual evidence is obtained through means of inverse search, these are the result of searching for textual content (ad hoc scraped caption of images in web pages or title of those web pages) using as query. Complementary informations, such as labels regarding the images and , are obtained through means of Google Cloud Vision API111https://cloud.google.com/vision/docs/labels. The authors of [1] provided the URLs to the source pages of both kind of evidence, which were downloaded for the purpose of this research.
3.3 Sample Description
Each data point is described formally as
-
•
query image ;
-
•
query caption ;
-
•
visual evidence retrieved using to query the web: ;
-
•
labels obtained using Google Cloud Vision API:
are labels of , and are labels of ; -
•
textual evidence retrieved using to query the web (inverse search):
; -
•
source pages .
4 Proposed Method
We designed an attention-based neural network capable of performing cross-consistency checks. In-depth analysis of the architecture, displayed in Figure 2, as well as the explanation generation task, are presented in the following subsections.
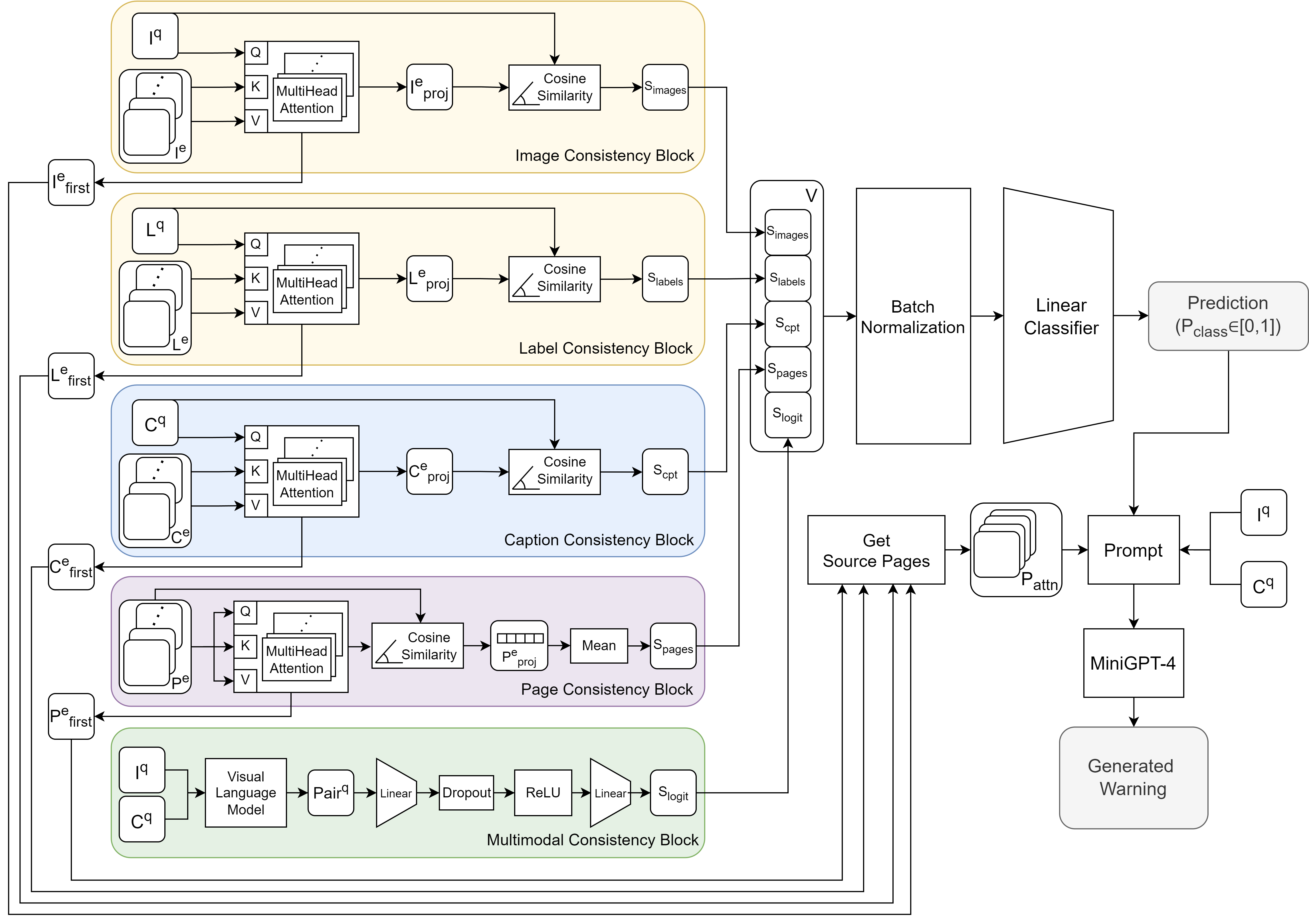
4.1 Visual Reasoning
Images are represented either using ViT [28] trained on ImageNet [4] or DINOv2 [16] embeddings for visual reasoning. These frozen visual transformers offer improved preservation of spatial information compared with ResNets [8, 22], which is crucial in our context. We aim to maintain structural information to achieve high similarity between images and their cropped/resized counterparts. Images are represented as vectors . The consistency score is computed as the cosine similarity:
,
where is the multi-head attention mechanism, as defined by Vaswani et al. [26].
4.2 Textual Reasoning
We use frozen pre-trained sentence transformers, such as Sentence-BERT [23] and Mini-LM [27], for textual reasoning. The decision to use them was influenced by Nikolaev and Padó’s research [15], which showed that sentence transformers prioritize capturing semantic essence over grammatical functions or background details. This leads to increased cosine similarity between sentences with shared salient elements, like subjects or predicates. Labels and captions are represented as vectors , where ST-dim is for Sentence-BERT and otherwise. The consistency scores are computed as
.
4.3 Page-Page Consistency Block
In this reasoning module, source pages are treated as text and represented as . In particular, is computed as the mean of the embeddings of all sentences in the paragraphs on the source page, and is considered to be the embedding of the page itself. This module serves to identify the most important page for subsequent re-contextualization tasks and to compute an inter-agreement score between the retrieved documents by computing self-attention on page representations:
.
4.4 Multimodal Reasoning
We use late fusion [5, 18] as the architectural pattern to address the lack of compelling explanations for the assessments made by existing detection methods. Our decision to use this pattern stems from both the flexibility it offers in swapping embeddings and the impracticality of training the entire model end-to-end due to its large parameter count. To address the challenges of inter-modality reasoning, we integrate a multimodal consistency block that can be optimized alongside the rest of the model. To represent both and in the same latent space, we employ a VLM, chosen among two alternatives: CLIP [21] with embedding dimension and MiniGPT-4 [32] with . Each sample pair is represented as . The image-caption consistency block is defined as
,
where the innermost linear layer projects into , the outermost linear layer projects it to , and the dropout probability is set to .
4.5 Classification Head
The output of the five consistency blocks is a single value, resulting in a vector , which is fed into a classification head to obtain a prediction (threshold set to 0.5 or found by analyzing the equal error rate, a pair is falsified for , pristine otherwise). A batch normalization layer [9] is added between and the linear classifier for faster convergence and higher accuracy. As the model is optimized for a binary classification task, binary cross-entropy loss is used:
,
where and are the predicted and ground truth labels, respectively, in a mini-batch of size .
4.6 Warning Generation
The last step of our pipeline consists of generating either contextual explanations for pristine pairs , providing additional insights about the depicted entities, or warnings indicating why represent a case of image repurposing. Given the versatility of LLMs in solving zero-shot learning tasks and the recent release of GPT-4 [2], which extends these capabilities to a multimodal environment, we adopted a strategy for generating warnings without fine-tuning or reinforcement learning. Due to the unavailability of ground truth data for comparing explanations and optimizing the generation process, fine-tuning approaches are precluded by default.
Similarly, reinforcement learning through human feedback [17] presents challenges, including the need for a dedicated team to label examples and the potential persistence of model mistakes despite corrections. Reinforcement learning through AI feedback [10], which involves querying a larger model like GPT-4 to assess MiniGPT-4’s outputs, also faces limitations. These include the constrained context window and the likelihood that all retrieved evidence may not contribute effectively to warning generation. Moreover, using a VLM to rectify errors made by another VLM inherently introduces comprehension discrepancies. Our approach to prompting was inspired by the work of Guo et al. [6], who evaluated VLMs trained using multimodal pretraining similar to the Flamingo VLM [3], and is akin to the training strategy employed for MiniGPT-4.
MiniGPT-4 is the tool used for contextualization and is guided by the following prompt. Variables that depend on the values obtained by the consistency network are displayed between square brackets.
“You are a tool for out-of-context detection, your task is to give reasons why the submitted image and the caption below are in the same context or not. Submitted Image: []. Caption: []. The likelihood of the submitted image and the above caption being in the same context is [], thus the pair is [Falsified if else Pristine]”.
Additionally, the title and the first few sentences (up to 400 characters) of the 4 web pages with the highest attention score from each of the attention-based blocks are included in prompt, together with the retrieval modality of the page, e.g.:
“An evidence retrieved using the caption to query the web, obtained because it contains an image with high similarity with the submitted image has title [Title] and content of the paragraphs [Content]”.
If the same source page is selected by multiple blocks, its title and content is added once to the prompt. For example, this redundancy could happen because a retrieved image and a retrieved caption belong to the same web page and both are ranked first by the multi-head attention mechanism (with reference to Fig. 2, ).
5 Experimental Analysis
5.1 Experimental Setup
All our experiments were carried out using either one or three NVIDIA A100 40-GB GPUs. Experiments on multiple GPUs were performed employing the distributed data parallel strategy. Early stopping was triggered if the validation loss stopped decreasing for 5 consecutive epochs. The designated mini-batch size was 64. All our experiments employed a cyclic learning rate scheduler with initial learning rate equal to and maximum learning rate equal to . Following the principle of scaling the learning rate with respect to the effective batch size, the learning rate was rescaled by multiplying both values by when training on a single GPU.
5.2 Comparison with State-of-the-Art Detectors
NewsCLIPpings [13] established a baseline by fine-tuning CLIP (ViT/B-32)[21], achieving 66.1% accuracy. Shalabi et al.[24] reached state-of-the-art performance for closed-domain approaches by fine-tuning MiniGPT-4 [32], with 80.0% accuracy. Yao et al.[29] (End-to-end in Table1) employed text and image retrieval modules to select evidence, though these only consider the textual claim from the input, as their dataset relies on textual claims from fact-checking websites. Despite this limitation, their approach achieved 83.3% accuracy on NewsCLIPpings. Abdelnabi et al. [1] achieved 84.7% accuracy using a 20.92M-parameter consistency-checking model trainable in 30 hours. Notably, CLIP is preliminarily fine-tuned (excluded from parameter and time counts).
Our lightweight model, employing frozen MiniGPT-4 as VLM, achieves 84.8% of accuracy with 5.2 million parameters, it is trainable in 3 hours and 38 minutes on a single GPU, while it only requires 13 minutes on three GPUs. It is highlighted in blue in table 2. It does not require any preliminary fine-tuning, there is no additional computation overhead due to comparison between entities and input caption, it leverages the analysis of source pages instead of exploiting domain representation and represents labels as text, comparing the labels of the query image with the labels of the visual evidence. Our full-scale model achieves 87.04% accuracy using the rescaled learning rate technique, and 86.70% using the standard learning rate. This model is highlighted in green in table 2. It counts 158 million parameters, of which 151 million belong to CLIP, which is optimized jointly with the rest of the architecture. The training time on a single GPU is 7 hours and 32 minutes, while on three GPUs it narrows to 27 minutes.
The parallel works, ESCNet [30] and SNIFFER [20], demonstrate slightly higher performance than our approach (87.9% and 88.4%, respectively). However, ESCNet lacks explanation generation, while SNIFFER requires additional fine-tuning on the Q-Former in 16 hours. Furthermore, SNIFFER employs a different backbone (InstructBLIP), complicating a fair comparison.
| Model | Year | Paper |
|
|
|
|
||||||||||
| CLIP | 2021 | Luo et al. [13] | Yes | No | No | 66.1 | ||||||||||
| MiniGPT-4 | 2023 | Shalabi et al. [24] | Q-Former | No | No | 80.0 | ||||||||||
| End-to-end | 2023 | Yao et al. [29] | Yes | Yes | Simple | 83.3 | ||||||||||
| CCN | 2022 | Abdelnabi et al. [1] | Yes | Yes | No | 84.7 | ||||||||||
| Proposed (Lightweight) | 2024 | Ours | No | Yes | Yes | 84.8 | ||||||||||
| Proposed (Full-Scale) | 2024 | Ours | No | Yes | Yes | 87.0 | ||||||||||
| ESCNet | 2024 | Zhang et al. [30] | No | Yes | No | 87.9 | ||||||||||
| SNIFFER | 2024 | Qi et al. [20] | Q-Former | Yes | Yes | 88.4 |
|
Model Version |
Sentence Transformer |
Vision Transformer |
Multimodal Model |
Drop Labels-Labels Attention Block |
Drop Page-Page Self-Attention Block |
Test Accuracy (th: 0.5) |
thEER |
Test accuracy (thEER) |
ROC AUC |
EER |
No. of Parameters |
| 1 | std | std | CLIP | ✗ | ✗ | 86,46 | 0,5247 | 86,10 | 0,9312 | 0,1477 | 160 M |
| 2 | std | std | CLIP | ✓ | ✗ | 86,43 | 0,5368 | 85,88 | 0,9329 | 0,1420 | 158 M |
| 3 | std | std | CLIP | ✗ | ✓ | 85,79 | 0,5190 | 85,34 | 0,9285 | 0,1529 | 158 M |
| 4 | std | std | CLIP | ✓ | ✓ | 86,31 | 0,5375 | 85,90 | 0,9249 | 0,1549 | 156 M |
| 5 | alt | alt | CLIP | ✗ | ✗ | 86,31 | 0,5515 | 86,05 | 0,9308 | 0,1463 | 155 M |
| 6 | alt | alt | CLIP | ✓ | ✗ | 86,41 | 0,5484 | 86,26 | 0,927 | 0,1492 | 154 M |
| 7 | alt | alt | CLIP | ✗ | ✓ | 86,21 | 0,5516 | 85,63 | 0,9273 | 0,1512 | 154 M |
| 8 | alt | alt | CLIP | ✓ | ✓ | 86,08 | 0,5577 | 85,76 | 0,9274 | 0,1477 | 154 M |
| 9 | std | alt | CLIP | ✗ | ✗ | 86,6 | 0,5451 | 86,26 | 0,932 | 0,1443 | 160 M |
| 10 | std | alt | CLIP | ✓ | ✗ | 86,70 | 0,5522 | 86,5 | 0,9315 | 0,1391 | 158 M |
| 11 | std | alt | CLIP | ✗ | ✓ | 86,14 | 0,5400 | 86,31 | 0,9291 | 0,1452 | 158 M |
| 12 | std | alt | CLIP | ✓ | ✓ | 86,53 | 0,5583 | 85,59 | 0,9293 | 0,1452 | 156 M |
| 13 | std | std | MiniGPT-4 | ✗ | ✗ | 84,31 | 0,5168 | 84,25 | 0,9193 | 0,1621 | 10,5 M |
| 14 | std | std | MiniGPT-4 | ✓ | ✗ | 83,90 | 0,5171 | 84,10 | 0,9193 | 0,1612 | 8,1 M |
| 15 | std | std | MiniGPT-4 | ✗ | ✓ | 84,03 | 0,4914 | 84,03 | 0,9193 | 0,1606 | 8,1 M |
| 16 | std | std | MiniGPT-4 | ✓ | ✓ | 83,81 | 0,511 | 83,44 | 0,9179 | 0,1650 | 5,8 M |
| 17 | alt | alt | MiniGPT-4 | ✗ | ✗ | 84,78 | 0,5446 | 84,60 | 0,9196 | 0,1615 | 5,2 M |
| 18 | alt | alt | MiniGPT-4 | ✓ | ✗ | 84,29 | 0,5464 | 84,25 | 0,9190 | 0,1578 | 4,6 M |
| 19 | alt | alt | MiniGPT-4 | ✗ | ✓ | 84,63 | 0,5526 | 84,01 | 0,9154 | 0,1658 | 4,6 M |
| 20 | alt | alt | MiniGPT-4 | ✓ | ✓ | 83,89 | 0,5521 | 83,49 | 0,9161 | 0,1627 | 4,0 M |
| 21 | std | alt | MiniGPT-4 | ✗ | ✗ | 84,65 | 0,5668 | 84,28 | 0,9209 | 0,1615 | 10,5 M |
| 22 | std | alt | MiniGPT-4 | ✓ | ✗ | 84,54 | 0,5513 | 84,29 | 0,9214 | 0,1589 | 8,1 M |
| 23 | std | alt | MiniGPT-4 | ✗ | ✓ | 84,73 | 0,5677 | 83,96 | 0,9197 | 0,1609 | 8,1 M |
| 24 | std | alt | MiniGPT-4 | ✓ | ✓ | 84,16 | 0,5743 | 83,85 | 0,9185 | 0,1652 | 5,8 M |
5.3 Transformers Selection
The standard (std) and alternative (alt) sentence transformers are, respectively, Sentence-BERT222https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2[23] and a fine-tuned version of MiniLM333https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2[27]. The key differences between them, in the context of our research, are that the former outputs embeddings that are twice as large as those output by the latter (768 against 384) and that the latter is faster at inference time and also more task specific because its training recipe is based on distillation and it is fine-tuned on sentences and small paragraphs. The std and alt vision transformers are ViT444https://huggingface.co/google/vit-base-patch16-224-in21k[28] trained on ImageNet-21k and DINOv2555https://huggingface.co/docs/transformers/en/model_doc/dinov2[16]. These transformers share the same embedding dimension (768), and, analogous to the two sentence transformers, the latter has a different training recipe, which includes self-supervised learning on a larger corpus of uncurated data, enabling the extraction of visual features that work across image distributions and tasks. Our experiments demonstrated that the std sentence transformer and alt vision transformer was the best combination, regardless of the choice of multimodal model, when considering all four design patterns involving the removal of attention blocks. In fact, model version 17 had accuracy scores comparable to those of version 21 and a slightly lower ROC AUC, while versions 18, 19, and 20, compared with 22, 23, and 24, had lower accuracies (th:05) and lower ROC AUC. Nevertheless, we consider version 17 to be the best model version using the MiniGPT-4 model as it had the highest accuracy and fewer parameters while using all our attention blocks.
5.4 Ablation Study: Block Suppression
With the aim of understanding the true utility of labels, we treat them as sentences and dedicate a separate attention block to evaluate their consistency. With the CLIP backbone, model pair (1, 2) had comparable performance with and without the label-label attention block, whereas for pairs (5, 6) and (9, 10), dropping this block of redundant information resulted in slightly better performance. For the MiniGPT-4 versions, dropping this block meant removing a non-negligible number of parameters. The resulting decrease in performance observable in model pairs (13, 14), (17, 18), and (21, 22) supports our hypothesis that, in this regime, additional information about labels is helpful in achieving better performances. We rehydrated the dataset by retrieving the source pages of each evidence. The embeddings of source pages were then used in the self-attention layer with the aim of extracting the most relevant web page for the purpose of prediction, potentially enhancing explainability. Although dropping the page-page attention block tended to reduce performance, model version 23 performed optimally at th=0.5. Nonetheless, the other metrics suggest that versions 21 and 22, which use this block, performed better.
5.5 Human Evaluation
Since the ground truth was unavailable for performance evaluation, unlike with the approach taken by Yao et al. [29], we randomly selected 100 samples from the test set. These samples were evaluated by 20 individuals, each assessing 5 samples. Two evaluation metrics were used in accordance with the work of van der Lee et al. [25]: ‘Informativeness’ and ‘Overall Quality’, both ranging from 0 to 5 with steps of 1. The ‘Informativeness’ score is defined as the relevance and correctness of the output relative to the input specification. Evaluators considered both the generated warnings and the associated links when assigning the Informativeness score. The ‘Overall Quality’ metric represents a judgment regarding the system’s performance across the five samples observed by each evaluator. The average ‘Informativeness’ score was 3.5 out of 5, and the average Overall Quality was 4 out of 5. These high scores can be attributed to the relatively straightforward contextualization of truthful examples when the correct evidence is retrieved, while various factors can render a warning unreliable in the case of falsified examples, leading to lower scores, especially if valuable evidence is not retrieved.
| Sample | Generated Warning | Retrieved Links |
|
|
CONTEXT: The image and the caption are in the same context as they both depict a group of people observing a minute’s silence in memory of victims. The image shows volunteers at Wadebridge Cornish Refugee Aid Collection in Cornwall stopping their work to observe the silence, while the caption describes a similar moment of silence observed across the UK in solidarity with the victims of the Paris terror attacks. The evidence retrieved from the web provides further support for the pair being in the same context. The article “Paris attacks: Minute’s silence observed in memory of victims - BBC News” describes a one-minute silence held across the UK to coincide with tributes in France and Europe following the attacks on bars, restaurants, a concert hall, and the Stade de France. This is consistent with the image and caption depicting a moment of silence observed by volunteers at a refugee aid collection in Cornwall. Overall, the likelihood of the image and caption being in the same context is 0.8520101308822632, indicating that they are pristine. | https://www.bbc.com/news/uk-34831010?ns_mchannel=social |
| WARNING: The image and caption you provided are not in the same context. The image depicts a group of people in a conference room, while the caption describes a meeting of ministers from four emerging economies, including China, India, Brazil, and South Africa. The two elements do not match, and therefore, the pair is falsified. To support this conclusion, I have retrieved two web evidence using the caption and image respectively. The first evidence obtained through the caption shows that the meeting described in the caption took place in Delhi, while the image depicts a different scene. The second evidence obtained through the image shows that it is a generic image of a conference room, and not related to the meeting described in the caption. Therefore, based on these evidence, it can be concluded that the image and caption are not in the same context, and the pair is falsified. | 1. https://www.theguardian.com/environment/2010/jan/24/china-climate-change-adviser 2. https://www.theguardian.com/environment/cop18-doha-climate-change-conference | |
| WARNING: The image and caption provided are not in the same context. The image depicts an elderly person holding a cane, while the caption provides information about the home front during World War II. There is no obvious connection between the two, and the likelihood of them being in the same context is low. The image and caption were retrieved from different sources, with the image coming from a stock photo website and the caption being a summary of information from Wikipedia. While the image may be related to elderly care, there is no evidence to suggest that it is specifically related to the home front during World War II. Therefore, I cannot provide any further information or insights related to this pair of image and caption. | 1. https://en.wikipedia.org/wiki/Hawker_Hurricane 2. https://www.bbc.com/news/world-asia-china-51403795 3. https://en.wikipedia.org/wiki/Home_front_during_World_War_II 4. https://www.entrepreneur.com/article/312224 | |
| CONTEXT: The image depicts Pope Francis kissing a young child with Down syndrome in Rome. The caption describes the event as the child’s wish to meet the Pope coming true. The evidence retrieved from the web, titled “Young Ohio boy’s wish to meet Pope Francis comes true - The Dialog” supports the context of the image and caption. The article describes a 12-year-old boy named Peter Lombardi who traveled to Rome to meet Pope Francis and was granted the opportunity to ride in the popemobile with him. The image and caption match the described event in the article, further indicating that they are in the same context. Therefore, the likelihood of the submitted image and the above caption being in the same context is 0.9954937100410461, which is very high, suggesting that the pair is pristine. |
http://thedialog.org/featured/young-ohio-boys-wish-to-meet-pope-francis-comes-true/ |
5.6 Qualitative Analysis
In Table 3, we present samples used in the human evaluation. The “Generated Warning” and “Retrieved Links” columns display the output of the system. In the first two samples, coherent explanations and links are displayed. In the third sample, although the prediction was correct, the VLM failed to distinguish events even when different dates were provided by the caption and the evidence. Additionally, the system focused on why certain evidence had been retrieved instead of generating an explanation based on the content of the source pages. The third sample was also correctly predicted; however, is missing from the evidence. Consequently, the explanation provided is inconsistent with the source page of the caption, as evident from the presence of noisy evidence. Specifically, the warning explains that the reported victims in were victims of war, whereas the source page indicates that they were victims of child exploitation. Similarly, in the last sample, is missing from the retrieved evidence. Consequently, the pair is misclassified as pristine even though the child in was not affected by Down syndrome. However, the evidence contains a picture of the actual subject of , making it simple for a human to distinguish this sample as OOC regardless of the generated explanation.
6 Discussion and Limitations
Our proposed system relies heavily on search engine results, which may present conflicting evidence. However, addressing such conflicts would necessitate data manipulation beyond the scope of this work. While incorporating context from the source page in the reasoning process helps alleviate the issue of evidence resemblance across truthful and falsified examples, identifying the actual distinction between similar evidence remains a challenge. Incorporating labeled evidence or establishing a ground truth for generated warnings would enhance performance, both quantitatively and qualitatively. Additionally, evaluating the trustworthiness of the information sources would be beneficial in further enhancing the system’s capabilities.
7 Conclusion
Our proposed system for detecting misinformative multimodal content leverages the masked multihead attention mechanism [26] to increase the number of consistency-checking blocks while preserving conceptual simplicity. It demonstrated notable improvements in accuracy along with reduced training time compared with the state-of-the-art models. Our lightweight alternative with substantially fewer parameters achieved comparable results. Integration of warning generation as a zero-shot learning task into our pipeline showcased promising performance in human evaluations. Despite limitations regarding the quality of search results, our system represents a significant advancement in automated fact-checking. It empowers journalists and individuals navigating information on platforms like social media to effortlessly determine the truth behind content, irrespective of the original intent behind its dissemination.
Acknowledgements
This work was partially supported by JSPS KAKENHI Grants JP21H04907 and JP24H00732, by JST CREST Grants JPMJCR18A6 and JPMJCR20D3 including AIP challenge program, by JST AIP Acceleration Grant JPMJCR24U3, and by JST K Program Grant JPMJKP24C2 Japan.
References
- [1] Sahar Abdelnabi, Rakibul Hasan, and Mario Fritz. Open-domain, content-based, multi-modal fact-checking of out-of-context images via online resources. In CVPR, pages 14940–14949, 2022.
- [2] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [3] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning. Advances in NeurIPS, 35:23716–23736, 2022.
- [4] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, pages 248–255. Ieee, 2009.
- [5] Konrad Gadzicki, Razieh Khamsehashari, and Christoph Zetzsche. Early vs late fusion in multimodal convolutional neural networks. In FUSION, pages 1–6. IEEE, 2020.
- [6] Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. From images to textual prompts: Zero-shot visual question answering with frozen large language models. In CVPR, pages 10867–10877, 2023.
- [7] Michael Hameleers, Thomas E Powell, Toni GLA Van Der Meer, and Lieke Bos. A picture paints a thousand lies? the effects and mechanisms of multimodal disinformation and rebuttals disseminated via social media. Political communication, 37(2):281–301, 2020.
- [8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, pages 770–778, 2016.
- [9] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, pages 448–456. PMLR, 2015.
- [10] Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. Rlaif: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267, 2023.
- [11] Fuxiao Liu, Yinghan Wang, Tianlu Wang, and Vicente Ordonez. Visual news: Benchmark and challenges in news image captioning. In EMNLP, pages 6761–6771, 2021.
- [12] Hui Liu, Wenya Wang, Hao Sun, Anderson Rocha, and Haoliang Li. Robust domain misinformation detection via multi-modal feature alignment. IEEE T-IFS, 2023.
- [13] Grace Luo, Trevor Darrell, and Anna Rohrbach. Newsclippings: Automatic generation of out-of-context multimodal media. In EMNLP, pages 6801–6817, 2021.
- [14] Tarlach McGonagle. “fake news” false fears or real concerns? Netherlands Quarterly of Human Rights, 35(4):203–209, 2017.
- [15] Dmitry Nikolaev and Sebastian Padó. Representation biases in sentence transformers. In EACL, pages 3701–3716, 2023.
- [16] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. TMLR, 2023.
- [17] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in NeurIPS, 35:27730–27744, 2022.
- [18] Luis M Pereira, Addisson Salazar, and Luis Vergara. A comparative analysis of early and late fusion for the multimodal two-class problem. IEEE Access, 2023.
- [19] Kashyap Popat, Subhabrata Mukherjee, Andrew Yates, and Gerhard Weikum. Declare: Debunking fake news and false claims using evidence-aware deep learning. In EMNLP, pages 22–32, 2018.
- [20] Peng Qi, Zehong Yan, Wynne Hsu, and Mong Li Lee. Sniffer: Multimodal large language model for explainable out-of-context misinformation detection. In CVPR, pages 13052–13062, 2024.
- [21] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021.
- [22] Maithra Raghu, Thomas Unterthiner, Simon Kornblith, Chiyuan Zhang, and Alexey Dosovitskiy. Do vision transformers see like convolutional neural networks? Advances in NeurIPS, 34:12116–12128, 2021.
- [23] Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In EMNLP-IJCNLP, pages 3982–3992, 2019.
- [24] Fatma Shalabi, Hichem Felouat, Huy H Nguyen, and Isao Echizen. Leveraging chat-based large vision language models for multimodal out-of-context detection. In AINA, 2024.
- [25] Chris van der Lee, Albert Gatt, Emiel van Miltenburg, and Emiel Krahmer. Human evaluation of automatically generated text: Current trends and best practice guidelines. Computer Speech & Language, 67:101151, 2021.
- [26] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. NIPS, 30, 2017.
- [27] Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou. Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained transformers. Advances in NeurIPS, 33:5776–5788, 2020.
- [28] Bichen Wu, Chenfeng Xu, Xiaoliang Dai, Alvin Wan, Peizhao Zhang, Zhicheng Yan, Masayoshi Tomizuka, Joseph Gonzalez, Kurt Keutzer, and Peter Vajda. Visual transformers: Token-based image representation and processing for computer vision. arXiv preprint arXiv:2006.03677, 2020.
- [29] Barry Menglong Yao, Aditya Shah, Lichao Sun, Jin-Hee Cho, and Lifu Huang. End-to-end multimodal fact-checking and explanation generation: A challenging dataset and models. In ACM SIGIR, pages 2733–2743, 2023.
- [30] Fanrui Zhang, Jiawei Liu, Jingyi Xie, Qiang Zhang, Yongchao Xu, and Zheng-Jun Zha. Escnet: Entity-enhanced and stance checking network for multi-modal fact-checking. In WWW, pages 2429–2440, 2024.
- [31] Yizhou Zhang, Loc Trinh, Defu Cao, Zijun Cui, and Yan Liu. Detecting out-of-context multimodal misinformation with interpretable neural-symbolic model. arXiv preprint arXiv:2304.07633, 2023.
- [32] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. In ICLR, 2023.